#fMRI
Note
Hi, I'm too nervous to put this on my account but wanted to share my feelings.
There's little scientific proof of non-traumagenic systems because they haven't been researched enough. This should not serve as a way to discredit someone who IDENTIFIES as plural. Expecting someone to prove their identity is wrong. Requiring someone to have a proven diagnosis of plurality is very prejudiced towards those who do not wish to seek a diagnosis and see plurality as their identity. Obtaining a diagnosis doesn't prove anything, because no one can see what is going on inside the human mind. All anyone can do is observe, hypothesize, experiment and make an estimated guess based on the results.
Demanding proof of plurality is ableist because it implies that only someone fitting a certain criteria can be studied and properly understood, and that the personal experiences and reports of patients should be ignored. It also suggests a lack of understanding what is defined as "proof."
Thank you for sharing! And this is so true!
I also have to say that, right now, actual scientific proof of your multiplicity, if it's even possible at all, is something most systems don't have and can't have. Many anti-endos don't see medical recognition as proof since it's just the opinion of your psychiatrist. But this can also go for diagnosis. What they seem to expect is brain scans.
And yet, a big reason we don't see a lot of universities jumping to use FMRIs on non-disordered systems is because it's so expensive.
I'm hopeful for the results for the Stanford Tulpa Study, but when you look at it, there's a very clear reason that these types of studies aren't common. The FMRI machines are limited, and time has to be rented out. The participants are all over the country, and their travel expenses and room and board have to be covered by the researchers. You're looking at an investment that's likely at least in the tens of thousands of dollars, if not more.
And even these FMRI studies still can't prove anything about internal experiences.
One concern I have is that when the Stanford Tulpa Study does come out, if it shows differences between tulpas and hosts fronting, the anti-endos will move the goalposts to claim these studies aren't enough because it doesn't show people's internal experiences. If this happens, they will also invalidate a lot of the studies into DID too.
#syscourse#endogenic#tulpa#tulpamancy#psychiatry#psychology#tulpa system#systems#system#fmri#multiplicity#plural#plurality#endogenic system#plural system
23 notes
·
View notes
Quote
Have you ever wondered what it’s like to participate in a functional Magnetic Resonance Imaging fMRI study? I participated in a few when I was completing my undergrad degree (all those years ago!) and they were among the most interesting studies I participated in.
#fMRI
6 notes
·
View notes
Quote
A lot of research labs will promote these via posters and social media to invite participants into the lab to participate. In my case, as a research assistant in various labs, I was actually invited to fill in last-minute no-show slots by other graduate students in the lab.
#fmri
7 notes
·
View notes
Text
She responded to her trauma script by going numb: Her mind went blank, and nearly every area of her brain showed markedly decreased activity.
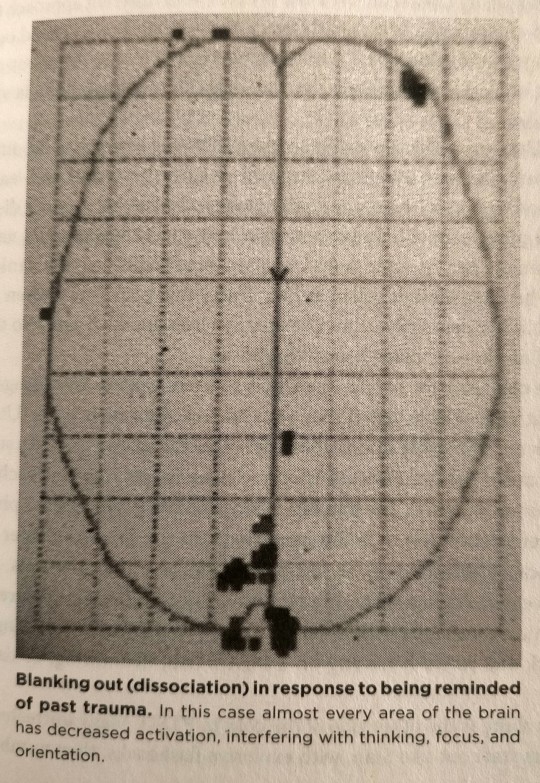
"The Body Keeps the Score: Mind, brain and body in the transformation of trauma" - Bessel van der Kolk
#book quotes#the body keeps the score#bessel van der kolk#nonfiction#trauma response#depersonalization#derealization#dissociation#flashbacks#trauma#ptsd#fmri#brain imaging
16 notes
·
View notes
Text
Analysis of: "From Brain to AI and Back" (academic lecture by Ambuj Singh)
youtube
The term "document" in the following text refers to the video's subtitles.
Here is a summary of the key discussions:
The document describes advances in using brain signal recordings (fMRI) and machine learning to reconstruct images viewed by subjects.
Challenges include sparseness of data due to difficulties and costs of collecting extensive neural recordings from many subjects.
Researchers are working to develop robust models that can generalize reconstruction capabilities to new subjects with less extensive training data.
Applications in medical diagnosis and lie detection are possibilities, but risks of misuse and overpromising on capabilities must be carefully considered.
The genre of the document is an academic lecture presenting cutting-edge neuroscience and AI research progress to an informed audience.
Technical content is clearly explained at an advanced level with representative examples and discussion of challenges.
Ethical implications around informed consent, privacy, and dual-use concerns are acknowledged without overstating current capabilities.
While more information is needed, the presentation style and framing of topics skews towards empirical science over opinion or fiction.
A wide range of stakeholders stand to be impacted, so responsible development and governance of emerging neural technologies should involve multidisciplinary input.
Advancing both basic scientific understanding and more human-like machine learning is a long-term motivation driving continued innovation in this important field.
Here is a summary of the key points from the document:
The speaker discusses advances in using brain signal recordings (fMRI) to reconstruct images that a person is viewing by training AI/machine learning models.
An example is shown where the top row is the actual image viewed and the bottom row is the image reconstructed from the person's brain signals.
Larger datasets with brain recordings from multiple subjects are allowing better models to be developed that may generalize to new subjects.
Challenges include the sparseness of brain signal data due to the difficulty and costs of collecting it from many subjects.
A model is presented that maps brain signals to a joint embedding space of images and text, allowing reconstruction of novel images from new brain signals.
Examples are shown where the reconstructed images match fairly well or not as well depending on image details and semantics.
Issues around ethics, risks of misuse, and questions of explaining and improving the models are discussed.
Ongoing work aims to address challenges around transferring models between subjects and measuring reconstruction performance.
Based on the content and style of the document, it appears to be an academic lecture or presentation.
Key evidence points include:
The document consists primarily of a speaker talking and presenting slides/examples to an audience, as indicated by phrases like "Let me just start with this" and an applause at the end.
Technical topics from neuroscience and machine learning/AI are discussed in detail, such as fMRI brain recordings, reconstructing images from brain signals, modeling approaches, dataset descriptions, and challenges/questions in the field.
Academic concepts like human subjects studies, building models, transferring learning, and measuring performance are referred to.
The presentation of information is intended to educate the audience on the state of the field and cuttting edge research, not just entertain.
There are no narratives, characters or creative storytelling elements - it adheres strictly to explaining complex technical content.
Therefore, based on the instructive/educational style and focus on explaining advanced technical research, I would classify the genre of this document as an academic lecture/presentation intended to inform an audience about progress in the domain of neuroscience and artificial intelligence.
Here are some of the key stakeholders that could be affected by the content and topics discussed in this document:
Neuroscience researchers - Directly interested and impacted by advances reported from their field of study. Progress informs future research directions.
AI/machine learning researchers - Models and challenges discussed could inspire new research at the intersection of AI and neuroscience. Transfer of model techniques.
Medical/clinical communities - Potential applications to diagnosis, personalized medicine if models can accurately reconstruct brain states. Raises ethical issues.
Government research agencies - Fund future related research based on understanding of opportunities and challenges conveyed. Evaluates societal impacts.
General public - Increased understanding of science helps engagement but topics like brain reading raise public concerns around privacy, consent if translated beyond research.
Research participants - Summary does not disclose identities but motivates others to contribute data for progress. Well-being depends on responsible use of data.
Technology companies - Commercial opportunities from real-world applications but also reputational risks if misused. Data ownership questions.
Academic institutions - Collaborations, education of next generations of researchers on cutting-edge topics is enabled through open dissemination of knowledge.
Overall the document provides value to a wide range of stakeholders by communicating the state and potential implications of this multidisciplinary area of neuroscience and AI research. Responsible stewardship is important given several ethical considerations.
Here is a summary of the key points about advances in using brain signal recordings from the document:
Researchers are using fMRI to record brain signals as people view images, in order to reconstruct the viewed images from the brain activity patterns alone.
Machine learning models, especially neural networks, are allowing researchers to train mappings from brain signals to representations of semantic content like images and text.
Examples show the capability of reconstructing fairly accurate images that a person viewed, based solely on their brain activity recordings during viewing.
Larger datasets with multiple subjects are important to develop models that may generalize beyond individual subjects. However, fMRI data is very difficult and expensive to collect at scale.
Advances now allow reconstruction of more complex stimuli like full stories a person reads, not just static images.
Ongoing work aims to better understand brain learning processes and apply those principles to more human-like machine learning architectures.
Analyzing brain recordings also has potential applications for medical diagnosis, lie detection, personalized medicine as models improve.
Ethics must be carefully considered to ensure technologies for reading neural signals are developed and applied responsibly and avoid misuse or privacy violations.
So in summary, the document outlines significant progress using machine learning on brain recordings to reconstruct sensory experiences, with applications and open questions that can further both neuroscience and AI.
Here is a summary of the key points about the sparseness of brain signal data:
Collecting fMRI brain signal recordings from large numbers of subjects is extremely challenging and costly due to the resources and time required.
Each recording session with a single subject takes considerable time, as the number of images/stimuli that can be presented is limited within a session.
Collecting data from a single subject sufficient for training complex models may require recording sessions over multiple days or weeks.
As a result, publicly available datasets typically contain recordings from only a small number of subjects, often under 10.
The sparseness of data makes it difficult to develop robust models that will generalize well to new subjects that lack extensive recordings.
Researchers aim to better leverage smaller datasets by training models that can reconstruct novel stimuli from just a subset of training data per subject.
If successful, this could enable more efficient data collection, such as obtaining usable models from a subject after a single shorter session rather than many long sessions.
However, overcoming the sparseness of brain signal data remains a major challenge holding back progress in the field. Larger collaborative datasets are needed.
So in summary, sparse data severely limits progress but also motivates techniques to optimize learning from limited samples per subject.
Here is a summary of key points regarding risks of misuse from the document:
Advances in reconstructing cognitive states like images viewed from brain recordings raise potential dual-use concerns if technologies are not regulated.
Applications in medical diagnosis and lie detection could help many, but lead to issues if used without consent or for non-medical surveillance.
Overly ambitious claims about capabilities need to be avoided to prevent misleading expectations that could fuel inappropriate usage assumptions.
Privacy and security of sensitive neural data must be prioritized to prevent potential misuse for profiling, identification or manipulation without oversight.
Commercial pressures may incentivize premature deployment before understanding implications, so continued research is important.
Public education about limitations and complexities involved can help curb fears that fuel misuse if capabilities are overestimated.
Multidisciplinary cooperation ensures societal and ethical issues are considered proactively rather than reactively addressed later.
Governance frameworks may be needed to steer applications toward public benefit rather individual or state abuse of personal mental information.
The speaker acknowledges misuse risks to inform discussion and underscore the importance of ongoing examination of new neural technologies through multidisciplinary lens including ethics.
Based on the content and style of presentation, my evaluation of the document status is:
Science vs Fiction: Clearly grounded in science as it discusses ongoing empirical research studies using neuroimaging and machine learning techniques. No fictional or hypothetical elements.
Empirical vs Anecdotal: Empirical in nature, rooted in dataset collection from human subjects and quantitative modeling/evaluation, not personal experience. While data quantities are limited, research follows scientific method.
Fact vs Opinion: Primarily presents technical details and research findings as established facts from the literature. Does not advance strong personal opinions beyond realistic discussion of challenges. Maintains an objective tone.
Objective vs Subjective: Remains objective in explaining research accomplishments and questions objectively without emotive language or bias. Any subjective experience like dataset limitations are clearly labeled as such. Presentation aims for factual information transfer.
In summary, while farther research is still ongoing, the document presents the current state of a scientific research domain factually based on empirical evidence and quantitative analysis published in the field. It does not intermingle non-factual elements or stray from an objective reporting of the topic at hand. The status therefore skews heavily toward science, empiricism, fact and objectivity.
I did not identify any logical fallacies in the content or arguments presented in this document.
The speaker objectively summarizes established research results and proposals, without making assertions that require logical scrutiny.
Some key reasons why logical fallacies are not present include:
No causal claims are made without proper evidence or empirical support from published studies. Progress is tied to concrete research efforts.
No arguments are constructed through flawed reasoning or non sequiturs. Concepts are explained clearly and build upon each other logically.
Comparisons to other approaches are fair without strawman misrepresentations of opposing ideas. Related work is acknowledged.
Limitations and open challenges are candidly outlined rather than ignored or obscured through fallacious defense.
No emotional, exaggerated or politically motivated language is used that could constitute emotional appeals. Tone remains factual.
No false dilemmas or false attributions of complexity are presented. Discussions appropriately scope multi-factor research questions.
No hasty generalizations are made from limited evidence. Data constraints are clearly communicated.
Overall, through objectively summarizing established neuroscience and AI research domains and techniques, without engaging in argument or debate, I did not find any logical fallacies employed in this academic information-sharing document. The focus appears to be factual reporting of progress and issues, avoiding fallacious reasoning.
Here is an evaluation of the ethics addressed and considered in the document:
Informed consent is implied but not explicitly discussed for research participants. Given the sensitivity of brain data, proper protocols were likely followed.
Privacy and anonymity of participants is a concern, but cannot be fully assessed without more details on the dataset and review process.
Potential dual-use issues around brain reading/reconstruction technologies are identifed by discussing applications but also worries about misuse or lack of oversight. This shows awareness of ethical implications.
Limitations and challenges and openly discussed, avoiding overpromising on capabilities. This establishes credibility and sets appropriate expectations.
Societal impacts and usage beyond research (e.g. diagnostics) are flagged as requiring careful consideration of risks like surveillance, discrimination if not regulated properly.
No claims are made without empirical evidence, showing results are driven by facts rather than desires which can bias judgment. Objectivity helps ethical analysis.
Multidisciplinary collaboration is emphasized , suggesting diverse viewpoints were incorporated into the research process.
Overall, while full review details are not provided, the document demonstrates an awareness of important ethical considerations around privacy, consent and responsible development for these sensitive types of neural data and technologies. A balanced assessment of opportunities and risks is conveyed.
Here are the usual evaluation criteria for an academic lecture/presentation genre and my evaluation of this document based on each criteria:
Clarity of explanation: The concepts and technical details are explained clearly without jargon. Examples enhance understanding. Overall the content is presented in a clear, logical manner.
Depth of technical knowledge: The speaker demonstrates thorough expertise and up-to-date knowledge of the neuroscience and AI topics discussed, including datasets, modeling approaches, challenges and future directions.
Organization of information: The presentation flows in a logical sequence, with intro/overview, detailed examples, related work, challenges/future work. Concepts build upon each other well.
Engagement of audience: While an oral delivery is missing, the document seeks to engage the audience through rhetorical questions, previews/reviews of upcoming points. Visuals would enhance engagement if available.
Persuasiveness of argument: A compelling case is made for the value and progress of this important multidisciplinary research area. Challenges are realistically discussed alongside accomplishments.
Timeliness and relevance: This is a cutting-edge topic at the forefront of neuroscience and AI. Advances have clear implications for the fields and wider society.
Overall, based on the evaluation criteria for an academic lecture, this document demonstrates strong technical expertise, clear explanations, logical organization and timely relevance to communicate progress in the domain effectively to an informed audience. Some engagement could be further enhanced with accompanying visual/oral presentation.
mjsMlb20fS2YW1b9lqnN
#Neuroscience#Brainimaging#Neurotechnology#FMRI#Neuroethics#BrainComputerInterfaces#AIethics#MachineLearning#NeuralNetworks#DeepLearning#DataPrivacy#InformationSecurity#DigitalHealth#MentalHealth#Diagnostics#PersonalizedMedicine#DualUseTech#ResearchEthics#ScienceCommunication#Interdisciplinary#Policymaking#Regulation#ResponsibleInnovation#Healthcare#Education#InformedConsent#Youtube
2 notes
·
View notes
Text
High-resolution image reconstruction with latent diffusion models from human brain activity
Machines/AI can now read images from our brains. The top row of images is what we see, the bottom row are those images as deciphered by a machine using fMRI data.

8 notes
·
View notes
Text
Transcript Episode 70: Language in the brain - Interview with Ev Fedorenko
This is a transcript for Lingthusiasm episode ‘Language in the brain - Interview with Ev Fedorenko’. It’s been lightly edited for readability. Listen to the episode here or wherever you get your podcasts. Links to studies mentioned and further reading can be found on the episode show notes page.
[Music]
Gretchen: Welcome to Lingthusiasm, a podcast that’s enthusiastic about linguistics! I’m Gretchen McCulloch. I’m here with Dr. Evelina Fedorenko who’s an Associate Professor at Massachusetts Institute of Technology (MIT), and we’re getting enthusiastic about how brains make language work. Hello, Ev!
Ev: Hi, Gretchen.
Gretchen: Hi, thank you so much for coming.
Ev: My pleasure. Thanks for having me.
Gretchen: We always start by asking our guests, “How did you get into linguistics?”
Ev: I liked learning languages when I was little. That was my schtick. I was in a school were English was started pretty early. Then my mom wanted me to be a citizen of the world, so at age 9 or 10, I started learning French. Eventually, we added Spanish and Polish because I had some Polish ancestry, German, a couple others. And so, I enjoyed that. I liked seeing patterns in languages.
Gretchen: This feels very relatable.
Ev: Yeah, but I didn’t really know what to do with that. I was growing up in Russia, I should say, and I knew that I wouldn’t stay there in the long run. But I couldn’t quite see yet how I could use all these languages in a professional way. I didn’t wanna be an interpreter. It just wasn’t really clear to me what else I could do. When I started my undergraduate degree, I took a class in linguistics, and then later in cognitive science, and learned that you can basically study language and how we process language for a living, and so that’s what I’ve been doing ever since.
Gretchen: Amazing. I think I went through that “Oh, I like learning languages.” “So, you’re gonna be a translator at the UN?” And I was like, “Uh, no, but what else is there?”
Ev: That’s right, yeah.
Gretchen: How did that get you into your current research topic?
Ev: Well, I started out as an undergrad researcher doing some behavioural experiments and then realised that I want to do this for a living, so I applied for graduate programs. I came to MIT. I was a grad student here as well. That was in 2002. I initially wasn’t sure exactly what kind of questions I wanna pursue. But then gradually I got really interested in the relationship between language and other cognitive capacities. So, questions like, “Do we use the same mechanisms, the same neural machinery, to understand language and to do math,” or to process structure in music, or something like that. For those kinds of questions, behavioural experiments just cannot directly answer them. The best tool that exists for answering these questions is functional MRI where you can directly have people do a language task and, say, a music task or a language task and some logical reasoning tasks and see if the same brain areas are activated. I started working with Nancy Kanwisher, first developing robust tools for finding language responsive areas in individual brains, and then over the next, I guess, 15 years or so, trying to understand what it is that these regions are doing and how they relate to other systems that we have in our brains.
Gretchen: Let’s say you’re trying to study this as a behavioural task, what does a behavioural task look like?
Ev: You mean trying to understand the relationship between language and other things?
Gretchen: Yeah, so if you’re trying to compare language and music or language and math or something, what would you be even trying to do?
Ev: There’s generally two behavioural approaches that you can use for these kinds of questions. One is called a dual task approach, so you’re trying to get people to do two things at once, and you’re trying to see whether the difficulty that you get when you’re doing these two things is above and beyond the additive difficulty of each of the tasks. Okay?
Gretchen: Okay. So, this is like rubbing your head and patting your stomach at the same time?
Ev: Exactly.
Gretchen: If this is hard, it’s because they’re both movement tasks, and they’re in different directions, but the idea is you’re trying to sing a song and also do some math problems at the same time. And if this is really hard then maybe that tells you something.
Ev: Exactly. You always would need control conditions and all sorts of things to make reasonable inferences. That’s one thing. Another thing you can do is relying on individual differences. You can look across a bunch of individuals and say, okay, are people who are good at math, as measured by some battery of tasks or whatever, are also good at music. Again, you’d wanna control for some basic general goodness of brains. People vary in how good their brains are, how quickly they work. But above and beyond some kind of general shared variance, is there a meaningful relationship between, say, how good your linguistic ability is and your musical ability – these kinds of things.
Gretchen: These feel kind of indirect.
Ev: Exactly. For individual differences, you just also need vast samples to draw meaningful inferences. It’s painstaking, and the tasks are sometimes tricky to get just the right difficulty so you can get some variability. Some people are better and worse.
Gretchen: Right. Because if everyone’s getting 100% on the task then that’s not gonna tell you anything about what some people are better at than others.
Ev: That’s right. Yeah.
Gretchen: This seems very complicated. So, instead, we stick them in the brain. We make them do some math. We make them listen to some language. We make them listen to some music or something. And then we see which bits light up.
Ev: That’s right.
Gretchen: There’s a couple different ways we could look at them in the brain. There’s different types of machines to do studies in. The two that I’m most familiar with are MRI and EEG. Can you tell us a little bit about what the difference is between those and why you pick MRI for your particular type of studies?
Ev: Sure. EEG is basically recordings of electrical activity from the scalp. It’s a signal that is very temporally precise. You know millisecond by millisecond how these very small voltage changes happen, but you don’t really know where the signal is coming from.
Gretchen: This is the one when you see picture of it, you see people with a sort of skull cap on their heads with all the little nodes and electrodes like you’re in a scientific experiment. Because your brain makes electricity as you’re thinking, if you contract that electricity, but very imprecisely because you’re doing it through your hair and your scalp and your skull and all of this layers of fluid and stuff, you kind of know it’s happening maybe in the left and the front.
Ev: Exactly. That’s the very coarse level. For questions like, “Do two abilities draw on the same resources,” this is just not good enough. Even though people have tried to use it in those ways, I think it’s limited. In fMRI, instead, we basically take images of the brain. We can take anatomical images, which are just static, detailed images of people’s anatomy and takes a few minutes. You can take a really good image. Of course, what’s more valuable to people who are interested in brain function are functional images. There, we can’t take very precise images because we’re trying to take them fast enough to measure changes over the course of seconds. That’s about as good as we can get in most circumstances with fMRI. We take a very coarse image every two seconds, typically, in most typical sequences. Then we try to look at, basically analyse, brightness levels which reflect changes in blood flow. Through this general approach we can, with very high precision, figure out where exactly in the brain are these changes happening. So, which are the bits of the brain that are working harder when you’re, say, solving a math problem or listening to a piece of music.
Gretchen: So, the MRI – it’s the same machine; it’s just how many pictures you’re taking, how quickly, between functional and the regular MRI.
Ev: It’s different sequences, that’s right.
Gretchen: You go into the massive tube, which is a big magnet, and the magnet is effectively measuring the iron in the blood in your brain that’s being used more in some areas than in others.
Ev: Exactly. When some brain area works, cells fire, and to fire, cells need glucose and oxygen. If some area is working hard, there’s gonna be an increase in blood flow to replenish the supplies that have been used up, and we’re detecting these changes.
Gretchen: Then you can see relatively fine-grained where the blood is going, so if you wanna see where stuff is in the brain, you wanna use an MRI.
Ev: Exactly, yeah.
Gretchen: The EEG gives you stuff down to the millisecond, but the MRI is like, “Okay, every two seconds, that’s as close as we can get,” because there’s always a trade off between how fine-grained a location you can figure out and how fine-grained a time thing you can figure out.
Ev: That’s exactly right.
Gretchen: Maybe someday we’ll come up with a technology that lets us do both, but that doesn’t exist right now.
Ev: Yeah. No, there are people who are combining EEG. They actually have people wear these caps and scan them at the same time. I have yet to see the use of this combined technology to answer some deep question. Mostly, it seems like a technical feat to deal with all the artefacts that you get from these channels. But I haven’t seen any really cool discoveries from the combination of the two methods. There is another method which is very limited in the population that we can test with it, but it’s intracranial recordings. Occasionally, when people undergo surgery, we can get access to the brain directly, and then we know exactly where we are, and we can get very fine time resolution.
Gretchen: But it’s a little bit harder to get people to undergo surgery just to do a study in your lab. [Laughs]
Ev: No, no, no, it’s only for people who clinically need this, which is either when they have drug-resistant epilepsy or when they have a tumour or when they need a deep stimulation device implanted as in cases of Parkinson’s disease or something like that.
Gretchen: So, if people are already having brain surgery for some other reason, then you can say, “Well, let’s figure out where your language centre is.”
Ev: Yeah, that’s right.
Gretchen: This brings us to this question of where your language centre is and what you normally find in people’s brains when it comes to where language is.
Ev: Sure. First, I think it’s sometimes helpful to just draw the distinction between speech and language because I don’t know if that often comes up in your podcast. I’ve heard some episodes, but not all of them. There is the acoustics of speech – or for sign languages, there’re some visual basic processing, or for reading, there’s also some perceptual, visual cortexes to recognise the letters. There’re specialised mechanisms for this perceptual analysis. Then after the information is analysed through these perceptual mechanisms, we have to interpret the signal. Basically, once we’ve extracted the sequence of words, we’re trying to understand what the meaning of the sequence of words is. That’s the system that we’ve primarily studied. This is a set of brain areas that, in most people, are in their left hemisphere. There’re some frontal components, so the front of the head and the side of the head and the temporal lobe. Those regions basically work whenever you understand language, regardless of whether you read it or heard it or if somebody signed to you if you’re a speaker of a sign language. It also works when you produce language – when you’re converting a thought into a sequence of words for somebody else to understand. It seems like the system is basically storing our knowledge of language, and so we can use it to convert from thoughts into messages or decode messages that we hear or read.
Gretchen: That’s really important because you don’t wanna be like, “Oh, we found language. It turns out it’s actually just the part that’s involved in processing the sound of the human voice, and we don’t use it at all for reading,” or signers don’t use it, but if you can find something that’s in common between all of these different formats, then it’s like, this is the bit that’s the core thing that we think is actually doing language irrespective of what modality it exists in.
Ev: That’s absolutely right.
Gretchen: You said that most people have the language processing bits on the left-hand side. I remember hearing about this when I was about 13, and I was newly getting into linguistics. I learned that it was basically all right-handed people that have their language hemisphere on the left side of their brain because when it comes to physical control of the body, the left side of the brain controls the right-hand side, and the right-hand side controls the left. Then still a lot of left-handed and ambidextrous people also have their language hemisphere on this left side. But then there’re a few of the left-handed and ambidextrous people who process their language on the right-hand side or on both sides. I’ve always wondered, hey, I’m left-handed – am I part of this anomaly group? When I was an undergrad, I did a lot of psych studies or whatever because they pay you $10.00, and it was a good deal, and I buy lunch.
Ev: Good stuff!
Gretchen: Yeah, yeah, yeah. [Laughs] But I always got excluded for the brain scan ones – the fMRI ones – because they were like, “Oh, we’re not doing left-handed people because you have this massive confound of you might have your language hemisphere on the wrong side.” It was like, “Yes, that’s what I wanna know!” I was really excited that you agreed to let me come into your MRI machine and find out, for once and for all, for no practical purpose, but like, I would like to know, and also then my data can be added to your studies, which side my language hemisphere is on. We have those results.
Ev: Yeah, we do. We have those results from when we scanned you.
Gretchen: Oh, so this is my brain?
Ev: This is your brain. Your language system is very left lateralised, as in most people.
Gretchen: So, I’m not a special person. I’m just like everyone else.
Ev: You’re a very special person. [Laughter] Just not for this reason.
Gretchen: Not for this reason. I’m seeing these black and white scans, and then some areas that are really lit up in red and yellow. The lit-up bits are in the left hemisphere mostly, and they’re in this V shape around the side where my ear would be.
Ev: That’s right.
Gretchen: Cool. And I mean, obviously the colours chosen are sort of arbitrary, but it’s something that’s lit up.
Ev: Of course, yeah. When we show people – like when we look at language system activations, this based on the contrast between people processing language. Sometimes we use auditory stimuli. Sometimes we use written stimuli. Like I said, the system doesn’t really seem to care one way or the other. Then we compare the response during the language condition to a control condition where, in terms of the perceptual properties, the stimulus is similar, but it doesn’t have any meaning or structure in it. For example, you did a task where you read sentences as opposed to sequences of non-words. You just kind of hear, “floor,” “blanket,” something. You can’t make sense of them, but they sound speech-like. We subtract that from the language responses, and then we get these regions that work more.
Gretchen: So, we don’t want it to have the bit that’s lit up when I am reading anything that looks like a shape on a white square or something like that.
Ev: That’s right.
Gretchen: I’m also seeing here that there are some bits in the right hemisphere that are lit up – not quite in this nice V shape, but there’re still some bits that are lit up. Can you tell me anything about that side?
Ev: Yes. In fact, in the majority of left-lateralised people, there is some response in the right hemisphere as well. There’s still a lot of debate about how exactly right hemisphere regions contribute to language processing. We’re trying to evaluate some of those ideas. In the vast majority of people, there’s some response – some nice, replicable response. It’s usually weaker. I also have a graph that shows you how much activity those different regions show. This is responses now to those two conditioned sentences and sequences of non-words. You can see that the dark bar, the sentence response, is much higher – like twice stronger – in the left hemisphere. But there’s still a response in the right hemisphere.
Gretchen: That’s still a stronger response than the right hemisphere compared to the non-words. Like, maybe twice as much a response to the non-words as to the words themselves. Obviously, I want to know this for personal gratification, but the finding that most people’s language is processed on the left is something that I read about when I was 13. It’s old news when it comes to, okay, which side is language on. What are you trying to study that’s a deeper version of that question now?
Ev: Well, there’s still a lot of interesting puzzles. One thing that we still don’t know as a field is whether having language be atypically lateralised – so right lateralised or bilateral, present in both hemispheres – whether that makes you in some way worse at language. We don’t know that. There’s mixed evidence so far, but I think also this question hasn’t been investigated in large enough populations and with sufficiently sensitive tests – both neural, in the brain, and behavioural tests. I think that question is still a little bit in the open. We’ve spent some time trying to develop tasks that would allow us to get variability in the neurotypical population in terms of their language skills because most tests that exist to assess people at the individual level come from either the developmental literature or the literature on individuals with language disorders like aphasia following a stroke or something like this. If we take those tests and administer them to college undergraduates, they’ll all perfectly accurate, like you were saying. Then we can’t get that variance. We’ve been trying to develop sensitive tests of language comprehension and production to try to see if we can then relate that variability to how lateralised their responses are. That’s all work in progress.
Gretchen: If I had turned out to have language on both sides or on the right-hand side then you’d be like, “Ah, and now we can use this to see what your responses are like to these kinds of things.”
Ev: Exactly. We now know – we as a field, and my lab specifically – we know that it doesn’t seem like you can’t have a perfectly functional language system on the right. So, at least in cases where you have extensive early damage in the left hemisphere – that happens sometimes when you have an early stroke as a child or even prenatally – these individuals will typically end up with a perfectly functional system in the right hemisphere. We’ve been working with this interesting individual who was born without her left temporal lobe. Her system is fully right lateralised. Her language is great. She even was like, all the most sensitive tests, we’ve tested, and she didn’t even know that she was missing her left temporal lobe until she was about 20-something.
Gretchen: Oh my gosh. So, she’s just missing this massive part of the front left above the ear of the brain and nobody noticed because the rest of her brain just took over.
Ev: Yeah. She has an advanced degree. She is very smart. We’re growing that line of work. That suggests that, from early on, the two hemispheres are – “equipotential” is sometimes a term that people will use – either can develop a language system. Now, for some reason, in most people it still ends up on the left. Something about that bias is making it advantageous to have it there.
Gretchen: This made sense to me when I was thinking about, okay, well, right-handed people, maybe it’s because they use the right-handed side more, and so something to do with maybe writing and language although, of course, there’s lots of language that isn’t writing as well, which made it fascinating for me from a left-handed perspective of like, “Okay, well, then logically I should be using the right hemisphere,” and yet, still most left-handed people have it on the left as well, which is the puzzle that I find interesting. Are you trying to scan a lot of left-handed people because the odds that they’re gonna have some other lateralisation things are higher?
Ev: Yeah. I mean, it’s something – we’re not exclusively doing this right now. There may be project that will start on that. But mostly we’ve been focusing on other kinds of questions like – yeah, there’s so many questions to ask. I usually try to keep my lab relatively small, so I can work closely with all the people in the lab as opposed to letting it become hierarchically structured, which is just inevitable if your lab grows enough. We’re focusing on other – yeah.
Gretchen: What kinds of questions are you trying to answer now?
Ev: One question that we’ve tackled among the first ones is the relationship between language and thought. We found across multiple approaches, but fMRI prominently, that the regions in your brain – so these regions you were just looking at in this graph that work really hard when you understand or produce language – they don’t work at all when you’re doing math or solve logical problems or think about other people’s mental states. The system is very, very strongly selective for processing linguistic information.
Gretchen: Even though you can use language when you’re doing math, or you could use language when you’re thinking about other people’s mental states? You could talk about other people’s mental states. Or you can talk about math. But that’s different.
Ev: That’s right. Language and thought have historically been conflated in all sorts of contexts because, of course, how people speak and what they say is our prime source of evidence for what’s going on in their mind. It’s a reflection. We can evaluate people how well they think by how they structure their linguistic utterances. But it turns out that the mechanisms that we use for those two things are completely non-overlapping. In fact, perhaps the most compelling evidence that’s complementary to fMRI comes from patients with what’s known as “global aphasia.” This is severe, severe damage to the language system, so typically due to a very large stroke that happens in this large artery that supplies this frontal and temporal cortex. These people basically can’t produce, can’t understand anything, and yet, they can do math and solve sudoku puzzles, and do all sorts of sophisticated reasoning. This is this centuries-old question about language and thought with a lot of theorising and a lot of strong claims about how you need language to think complex thoughts. It turns out that you really don’t. That’s one big thing we’ve figured out.
Gretchen: How would you go about studying that in an fMRI machine? Can you do a sudoku? They can’t really write.
Ev: Yeah, you can get them to do all sorts of – I mean, we haven’t looked at sudoku puzzles specifically, but basically, yeah, you put them in the scanner just like we did with you. We find their language regions, and then we also ask them to do non-language tasks like solve some math problems or do a hard-working memory task, like I think you did a spatial memory task as one of the tasks.
Gretchen: I did one where I looked at a bunch of blue squares. I guess this is also the point to say that I did another interview with Saima Malik-Moraleda, who was the PhD student and the technician who ran me through all of these tasks. We broke down all of the tasks in detail and sort of what I was looking for in each of the tasks and what I was looking at. That is a bonus episode, which you can get access to at patreon.com/lingthusiasm. You can see the details about what I did in the machine and what it was like in the machine there. Returning to this question of what are you trying to look at, how do you test people’s reasoning of other people’s mental states in a machine?
Ev: That’s a good question. There’s a number of paradigms that exist that one standard one is actually a verbal paradigm, but of course it’s verbal in both conditions. If you find a difference, it’s not due to language processing. But a common contrast that people use is processing little stories, little vignettes, about thinking about somebody else’s mental state, which is now incorrect. For example, “Gretchen thought that Ev had put her computer on this shelf,” or something like this, or “Gretchen saw Ev put this somewhere here, and then Gretchen went away, and then I moved it.”
Gretchen: And then I come back in – okay, yeah, I think I have encountered this as the Sally-Anne task or something which they do on children.
Ev: Exactly right. Then there’s a control version where there’s no mental states involved, but there’s still a difference between some representation of reality and reality. It’s known sometimes as the false photograph condition. For example, “I took a picture of Gretchen’s house when I was visiting her last year. Since then, she added a whole other level, and now the house is three stories tall” – my representation, my picture that I took, and reality, and they’re different. In terms of the structure of the task, it’s similar if you’re thinking about somebody else’s state, which differs from reality, but there’s no mental state as such. That contrast gives you so-called “theory of mind” regions. There’s a professor at MIT here in the same department, Rebecca Saxe, who has discovered this brain system and has been characterising it for the last couple decades, I guess.
Gretchen: In terms of what’s involved when you’re thinking about other people’s states of knowledge.
Ev: Yes. That system seems distinct from the language system quite strongly.
Gretchen: Right. Because I was thinking how are you going to try to tell people about people’s mental states without using language, but if you just use language in both conditions –
Ev: That’s right. Or you can also show people videos – you know, silent films. We make all sorts of rich inferences about what people are thinking from what they’re doing even if there’s no language at all. There is actually a version of this task that our lab and Rebecca Saxe’s lab has been using based on just watching silent animation films and then contrasting responses to when you have little clips, which invoke you thinking about other’s thoughts and beliefs and so on compared to some control clips where there’s maybe some social interaction, but there’s no real thinking of, you know, “What am I thinking that Gretchen is thinking right now?”
Gretchen: Right. Okay. And those don’t seem to involve a language part.
Ev: No, not at all.
Gretchen: Because I was thinking, okay, put me in the machine, tell me to think about some stuff, you know, okay, what do we know from this, but you have these very controlled environments where you’re like, okay, you’re figuring out what people are thinking and what the mental states are of the people in the video.
Ev: That’s right. That’s one thing we learned is that the language system is quite specialised for language processing. We’ve also been doing a bunch of stuff with diving into this system and trying to see do different parts of the that system – you saw that there’s quite a few regions, right, that are active when we process language. Do different regions process different aspects of language? Is there a region that maybe processes linguistic structure and some other region that processes words? That turns out not to be the case. From what we can tell from many dozens of experiments across our group and other groups, it seems that this distinction between word meanings and linguistic structure is not realised in terms of a spatial separation into distinct regions. It seems the very same regions that care about structure in language also deeply care about meaning, so individual words.
Gretchen: There’s a certain level of specialisation in terms of this area is used for visual language or this language is used for auditory language, but apart from when it comes to processing different types of meaning, are there any regions that do specialised things there? Or is it like, “Ugh, we just don’t know,” or there’s so much individual variability?
Ev: No, it’s a good question. I mean, the language system is specialised for language relative to all sorts of other things, right – non-linguistic things. But in terms of the divisions within the language system, it’s been hard to find those. People have made claims that some parts of the system do – you know, there is a very strong claim from a few groups over the years that some subset of the system is specialised for syntactic processing, structure processing, and language, so figuring out the dependencies between words, and is relatively insensitive to what “table” means. But it seems that, with robust enough methods, you find that that distinction is just not there. It looks like it’s a distributed processing of both syntactic components of language and word meanings.
Gretchen: Right. So, being able to pin down, okay, not only this is where the specific word “table” is stored, but like, this is my dictionary where all of the meanings are stored, and this is my grammar where all of the relationships of like, “Ah, here’s what verbs do, here’s what nouns do.”
Ev: That seems to be it.
Gretchen: Yeah, like, this is how linguists like to organise their writing, but it’s not necessarily what the brain is actually doing internally, which is sort of disappointing because it’d be nice if we’d stumble on the right thing the first time.
Ev: Yeah, that’s right. But I think in a lot of – as I’m sure you know – in a lot of linguistic traditions, the grammatical information is actually very deeply tied to meanings of particular words. It’s not this very abstract level where a sentence is made up of a noun and a verb, but instead there’s very particular combinatorial constraints of how each word combines with other kinds of words.
Gretchen: Maybe it’s something where, okay, so you need to know for the word “eat” specifically that you can say, “I eat,” and you can also say, “I eat a sandwich,” but for something like –
Ev: “Devour.”
Gretchen: “Devour” – “I devour a sandwich,” but “I devour” by itself doesn’t work even though “eat” and “devour” otherwise mean the same thing.
Ev: Very similar. That’s right.
Gretchen: You can’t just have one abstract thing. You have to be thinking about it at every individual word, “What does it do with relation to the grammar?”
Ev: Yeah, that’s right.
Gretchen: Cool. You’re also looking at stuff to do with multiple languages.
Ev: We are. We are very interested in how individuals who speak many languages – two or more languages – represent and process those languages. That, of course, has been a question of interest for many years. I got into this work originally through work on polyglots, so individuals who learn sometimes many dozens of languages. We had a project – this line of work that I kind of got involved in accidentally. I just had somebody contact me and say, “I have a teenage child who has learned 26 languages, and he keeps learning them, would you be interested in scanning them?” And I was like, “Yeah, yeah, we can look at that. That sounds interesting, yeah.” At that time, I didn’t really know if we were gonna just do this kind of as a one-off thing or really go into this line of work, especially because there’s not many polyglots. It’s a pretty rare population. But we brought him in, and we scanned him. One thing I noticed is that – so he’s a native English speaker. He’s American. When we looked at his responses during his native language processing, his language regions looked like they were not looking very hard. They looked smaller, and they weren’t very active. I was like, “Well, that’s interesting.”
Gretchen: Because you might think, “Oh, well, you’re using language regions a lot of the time. You’ve got this big, buff language region.” Like, if I used my shoulder muscles a lot, they get bigger, you know.
Ev: That’s absolutely right. So, I was like, “Oh, well, maybe just something” – I mean, we scanned him on a couple different sessions, and we saw that it’s a replicable thing. So, how big your language regions are is actually quite stable within people. But I didn’t really know what to make of it. Then I had a postdoc who is now faculty in Canada in Carleton, Olessia Jouravlev. When she was here, she was interested in multilingualism. She found a couple other polyglots and scanned them. Then she kept finding them, and we kept scanning them. And so eventually, we had a sample of, you know, on the order of 20 people. It turns out that this result – this smaller language region – is a real thing in polyglots compared to monolinguals and bilinguals. They have a smaller language system. The way that we interpreted this is as greater efficiency, like your language system doesn’t have to work as hard, perhaps because you’re training it so much by learning all these different languages. But we also don’t know. Maybe their language system is different from the start and without doing longitudinal work –
Gretchen: Ideally, you’d wanna study somebody who starts out speaking one or two languages, and then they keep acquiring more throughout their life, and see, like, do their language centres get smaller as they use them more, or do they already start out smaller, and this creates a predisposition to becoming a polyglot because they’re already more efficient at it.
Ev: That’s absolutely right.
Gretchen: Because anecdotally I feel like some people have an easier time in language classes, and I’ve never quite been sure why that’s the case.
Ev: That’s absolutely right. There’s definitely variability there, but it’s also like, people for whom it comes easy, they’re a pretty heterogeneous population. Different aspects of language seem to be easy for different people. Some people are really good imitators. You can tell them a sequence of sounds in any language totally unfamiliar to them, and they can repeat it beautifully. Some people are just really good at learning words. They hear a word; they just don’t forget it. Some people are really good at deciphering grammatical patterns like how words combine and how they agree and all that stuff. It would be really nice to try to unpack this and see if these different linguistic talents, if you wish, are actually meaningfully different. For now, all we have –
Gretchen: Earlier, we were like, “Oh, well, it doesn’t seem like there’s one area in the brain that does words and one area that does grammar.” But it does seem like there’re some people who are really good at words and some people who are really good at grammar, who are really good at sounds.
Ev: Yeah.
Gretchen: It’s hard to say what that is.
Ev: That’s right. It’s not incompatible with not having a spatial separation within the system. It could be like, you know, maybe your language system is more strongly tied to your memory mechanisms or something like that.
Gretchen: Right. Or like, these things are all working together in your brain to do X. And these things are all working together to do Y within that. I might venture to guess that there might be a higher proportion of Lingthusiasm listeners who might be polyglots. Are you still doing the study, if people are polyglots, and they’re in the Boston area?
Ev: That’d be great. We’ve been scanning people here in Boston.
Gretchen: If people wanna come in and get their brain scanned because you speak several languages, they can get in touch.
Ev: They should get in touch, yeah.
Gretchen: Great. We’ll link to that in the description. You guys tested me for English and French because those are the languages that I operate in the most – even though I have smatterings of linguistic knowledge of other things.
Ev: That’s right.
Gretchen: Can you tell me anything about what I’m doing for French?
Ev: Your language systems works when you process French. It actually works –
Gretchen: My neighbours in Montreal will be relieved to hear that.
Ev: That’s right. It actually works a little bit harder compared to English. In this graph I’m showing you here – this is how much it works when you process French. This is how much it works when you process English.
Gretchen: Okay, so those are big bar lines, and the English one’s halfway up, and the French one’s three quarters of the way up.
Ev: That’s right. Then there’s a couple of control conditions. If you may remember, you heard these things – we call them “quilted” or “textured” speech. I mean, it kind of sounds like speech, but you can’t really make sense of it. It’s really muffled and degraded. Then a couple of unfamiliar languages, which typically will elicit some response in people. So, this is Basque and Tamil, which I don’t think you have familiarity with.
Gretchen: Yeah, I don’t speak either of those, no.
Ev: Those are lower than either of the languages that you speak. There’s also interesting – so Saima Malik-Moraleda, who you talked to as well, she’s been noticing that in same bilingual and multilingual people, responses to unfamiliar languages seem stronger than in people who are monolingual.
Gretchen: So, you’re trying to parse them even though you don’t actually know what’s going on.
Ev: Exactly. So, you may have some kind of generally increased sensitivity to trying to decipher something from linguistic utterances if you’re linguistically attuned.
Gretchen: I noticed when they were playing for me the Basque and Tamil I was thinking, “Oh, how interesting. I don’t think I’ve heard a passage in either of these languages that’s this long before. I wonder if I can figure out what the phonology of them is; what sort of sounds they have in comparison to other languages I know.” I was kind of trying to go into language processing. I wonder if that’s something that you could train people to do with practice.
Ev: Perhaps, yeah. Don’t know. We haven’t tried. I’m not aware of anybody who had tried, but it’s possible, yeah.
Gretchen: I mean, what makes some people learn more languages than others, and also, could any of this help someone learn a language if they’re – because this is a difficult task for a lot of people trying to learn a language in adulthood. Is there anything that could make it easier for them to do it? Although, I guess that’s very early stages.
Ev: Right. I mean, so far, the best advice we can give is just do it earlier because it does help. [Laughter]
Gretchen: Go back in time and tell your parents.
Ev: Or do it for your kids or something.
Gretchen: Thank you so much for coming on the podcast. If you could leave people knowing one thing about linguistics, what would that thing be?
Ev: That’s a very good question. I mean, I think I would probably emphasise this result that I briefly talked about that language is not the same thing as thought even though sometimes intuitively it feels like we’re talking to ourselves all the time, it turns out that’s even not a universal. Some people don’t feel like they have a voice in their heads. Some people who do a lot of thinking about, for example, math, some professional mathematicians will say that when they get this voice, it interferes with their thinking. The thinking that happens in your brain doesn’t happen in the same system that you use to understand language and to produce language. I think that’s important to know. Even though people sometimes have very strong intuitions about language being really a key part of complex thinking, that just doesn’t seem to be empirically true.
Gretchen: That’s really interesting. Thank you so much.
[Music]
Gretchen: For more Lingthusiasm and links to all the things mentioned in this episode, go to lingthusiasm.com. You can listen to us on Apple Podcast, Google Podcast, Spotify, SoundCloud, YouTube, or wherever else you get your podcasts. You can follow @lingthusiasm on Twitter, Facebook, Instagram, and Tumblr. You can get IPA scarves, kiki bouba notebooks, and other Lingthusiasm merch at lingthusiasm.com/merch.
I can be found as @GretchenAMcC on Twitter, my blog is AllThingsLinguistic.com, and my book about internet language is called Because Internet. Lauren tweets and blogs as Superlinguo.
You can follow our guest, Ev Fedorenko, on Twitter @ev_fedorenko and her website is evlab.mit.edu.
Have you listened to all the Lingthusiasm episodes, and you wish there were more? You can get access to an extra Lingthusiasm episode to listen to every month plus our entire archive of bonus episodes to listen to right now at patreon.com/lingthusiasm or follow the links from our website.
Have you gotten really into linguistics, and you wish you had more people to talk with about it? Patrons can also get access to our Discord chatroom to talk with other linguistics fans. Plus, all patrons help keep the show ad-free. Recent bonus topics include a live Q&A episode about swearing, a chat about the many uses of “like,” and a behind the scenes look at what it was like in the MRI machine doing language studies.
Can’t afford to pledge? That’s okay, too. We also really appreciate it if you could recommend Lingthusiasm to anyone in your life who’s curious about language.
Lingthusiasm is created and produced by Gretchen McCulloch and Lauren Gawne. Our senior producer is Claire Gawne, our Editorial Producer is Sarah Dopierala, our Production Assistant is Martha Tsutsui-Billins, and our Production Manager is Liz McCullough. Our music is “Ancient City” by The Triangles.
Ev: Stay lingthusiastic!
[Music]

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
#language#linguistics#lingthusiasm#episode 70#podcasts#transcript#interiew#ev fedorenko#brain scan#mri#fmri#language in the brain
25 notes
·
View notes
Text
Researchers at Johns Hopkins University have documented changes in the brains of patients with post-treatment Lyme disease that may explain symptoms such as brain fog, memory loss and other cognitive issues. The finding could also have implications for patients with fibromyalgia, multiple sclerosis, chronic fatigue and other health conditions who have cognitive problems.
Lyme disease is a bacterial illness spread by ticks that causes a rash, flu-like aches and fever, joint pain and fatigue. Most patients fully recover when treated early with antibiotics, but up to 20% of those with post-treatment Lyme disease (PTLD) have long-term symptoms, including depression, insomnia and cognitive difficulties. There is usually no clinical or laboratory evidence to explain their ongoing issues.
“Objective biologic measures of post-treatment Lyme symptoms typically can’t be identified using regular MRIs, CT scans, or blood tests,” says John Aucott, MD., director of the Johns Hopkins Lyme Disease Clinical Research Center.
Aucott and his colleagues recruited 12 PTLD patients and 18 people without a history of Lyme to undergo functional MRI (fMRI) scans while performing a short-term memory task. The scans allow investigators to track blood flow and other changes in the brain in real time.
Their findings, published in the journal PLOS ONE, linked the cognitive difficulties in PTLD patients to functional and structural changes in the “white matter” of the brain, which is crucial for processing and relaying information. The imaging tests revealed unusual activity in the frontal lobe, an area of the brain responsible for memory recall and concentration. That finding correlated to patients with post-treatment Lyme needing longer periods of time to complete the memory task.
“We saw certain areas in the frontal lobe under-activating and others that were over-activating, which was somewhat expected,” said lead author Cherie Marvel, PhD, an associate professor of neurology at Johns Hopkins. “However, we didn’t see this same white matter activity in the group without post-treatment Lyme.” (Read more at link)
10 notes
·
View notes
Quote
A lot of research labs will promote these via posters and social media to invite participants into the lab to participate. In my case, as a research assistant in various labs, I was actually invited to fill in last-minute no-show slots by other graduate students in the lab.
#fmri
2 notes
·
View notes
Quote
For those who have never worn those weird hospital gowns before, it’s a colossal mess and I’m not sure how anyone ever puts one on themselves. It’s a flat piece of fabric that you wrap around the front of your body. There are strings that you tie around the back of your neck and the back of your waist.
#stories
3 notes
·
View notes
Quote
Then comes the time to robe up. Just like hospitals, for the research study, they have you robe up in one of those flimsy hospital gowns.
#stories
2 notes
·
View notes
Quote
... according to a new study, alcohol consumption even at levels most would consider modest—a few beers or glasses of wine a week—may also carry risks to the brain. An analysis of data from more than 36,000 adults, led by a team from the University of Pennsylvania, found that light-to-moderate alcohol consumption was associated with reductions in overall brain volume.
More Alcohol, Less Brain: Association Begins With an Average of Just One Drink a Day - Neuroscience News
0 notes
Text
I see what you did there…a (very) brief history of imaging the brain: blood, BOLD and fMRI
A little more #neuro #science #history
This time: functional magnetic resonance imaging #fMRI #BOLD
#scicomm #writing #blogging #neuroscience #brain
For many patients we can discover – or discount – physical causes of neurological problems ‘in real time’ with a range of imaging and other measurement techniques. Neuroimaging techniques are mainly children of the 20th century, and their development is ongoing in the 21st, but their roots stretch back through the 19th century. For example, photography and its ability to reproduce an enduring…
View On WordPress
#Angelo Mosso#CT#EEG#electrophysiology#epilepsy#fMRI#heamodynamics#Keith Thulborn#MEG#MRI#neuroimaging#neurology#neuroskeptic#neurovascular coupling#PET#Peter Bandettini#Seiji Ogawa#xkcd#Your Brain through...History
0 notes
Quote
Also, after such an extensive screening about not bringing metal in, I wasn’t so sure whether bras were okay to wear into the scanner. Is the "wiring" in my wire bras truly metal? Or is it actually plastic given how I buy the inexpensive bras?
#stories
0 notes
Text
Day 10 of trying to install AFNI and FSL on Ubuntu.
I've tried virtualizing with Wsl, with HyperV, with Virtual Box and I'm currently on VMware.
I've tried Ubuntu 20, then 18, and now 22.
Currently my issue is running FSL commands, which seem nowhere to be found even if they're set both in PATH and in .bashrc... but I know that, as soon as I'll solve this one, something else will pop out.
As always.
At least I can mantain hope that the platform I'm currently on will not have some structural issues that will force me to start again on something else.
I hate to be spending my august frustrated like this. I'm not an IT expert, I just want to see my fancy brains.
0 notes
Last Seen Blogs

sonicfan-78
odie

goldjewellerybuyer-blog
Gold Jewellery buyer

bonnetmagazine
Bonnet Magazine

jesterhoro
Horo's Art

acmarkz
Alphaverse