#3D objects
Photo

Polygonal Drip
Acrylic, ink, graphite, 3d objects on 12x18” watercolor paper
3 notes
·
View notes
Text
NVIDIA’s GTC in Four Headlines
New Post has been published on https://thedigitalinsider.com/nvidias-gtc-in-four-headlines/
NVIDIA’s GTC in Four Headlines
Impressive AI hardware innovations and interesting software moves.
Created Using DALL-E
Next Week in The Sequence:
Edge 381: We start a new series about autonomous agents! We introdice the main concepts in agents and review the AGENTS framework from ETH Zurich. Additionally, we provide an overview of BabyAGI.
Edge 382: We review PromptBreeder, Google Deemind’s self-improving prompt technique.
You can subscribe below:
heSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: NVIDIA’s GTC in Four Headlines
I tried to resist making this weekend’s editorial about NVIDIA because I think you might have been inundated with headlines from the GTC conference. Unable to resist, I instead decided to present the four most impactful announcements in terms of ambition and market impact. If I have to summarize two key takeaways from NVIDIA’s AI announcements this week, they would be these:
NVIDIA is not only outgrowing but also out-innovating everyone else in AI compute hardware by a large margin.
NVIDIA’s software ambitions should be taken seriously.
To put that in context, here are four key announcements from this week’s GTC:
Blackwell GPU Series: NVIDIA unveiled the Blackwell B200 GPU, optimized for trillion-parameter models. The chip can improve LLM inference by up to 30x, which is quite remarkable.
NIM Microservices: My favorite announcement of GTC was the NIM platform, which delivers models optimized for inference and packaged as containers. NIM speeds up inference by using the Triton Inference Server, TensorRT, and TensorRT-LLM.
Project GR00T: I think the coolest and most ambitious announcement was Project GR00T, which focuses on developing foundation models for humanoid robots. The stack is based on multimodal models for video, audio, and language.
Distribution: An overlooked announcement during GTC was the impressive list of strategic alliances with top software companies like Microsoft, Google, Amazon, Dell, Oracle, and many others. NVIDIA is simply everywhere.
There were many additional announcements at GTC, but the aforementioned four are incredibly impactful. NVIDIA’s AI hardware dominance is unquestionable, but it’s quickly making inroads in the software space.
🔎 ML Research
Chronos
Amazon Science published a paper introducing Chronos, a family of pretrained foundation models for time series forecasting. Chronos models time-series data using the same techniques used by LLMs —> Read more.
Moirai
Salesforce Research also got into time series forecasting with foundation models with the publication of a paper detailing Moirai. The new model follows the paradigm of a universal forecasting model that can issues predictions across many domains and time scales —> Read more.
TacticAI
Google DeepMind published a paper detailing TacticAI, a model that can provide technical insights in football( soccer) plays, particularly corner kicks. The model uses geometric deep learning by generating possible reflections of a game situation including the player’s relationships —> Read more.
RAFT
Researcers from UC Berkely published a paper introducing retrieval-augmented fine-tuning(RAFT), a training technique that improves the ability of models to answer questions based on external data. Given a question, RAFT ignores the documents that are not relevant to formulagte the answer leading to more accurate outputs —> Read more.
Evolutionary Optimization and FM Model Merging
Researchers from Sakana AI published a paper that uses evolutionary optimization to merge foundation models. The technique attempts to harness the collective intelligence of different models to create more powerful foundation models —> Read more.
SceneScript
Meta AI Research published a paper detailing SceneScript, a method for reconstructing layouts of physical spaces. The technique can have profound implications in augmented reality scenarios that merge physical and virtual spaces —> Read more.
🤖 Cool AI Tech Releases
NVIDIA NIM
NVIDIA announced NIM, its cloud microservices endpoints for pretrained foundation models —> Read more.
Grok
Elon Musk’s xAI open sourced a version of its marque model Grok —> Read more.
Stable Video 3D
Stability AI released Stable Video 3D, an improved model that can generate 3D objects from text descriptions —> Read more.
🛠 Real World ML
AI Training Logging at Meta
Meta discusses Logarithm, their solution for AI training logging —> Read more.
GNNs at Pinterest
Pinterest details their use of graph neural networks(GNNs) for content understanding —> Read more.
RL at Lyft
Lyft discusses the architecture powering their internal reinforcement learning workloads —> Read more.
Cloud Monitoring at Microsoft
Microsoft discusses the AI used to monitor its Azure cloud services —> Read more.
📡AI Radar
NVIDIA unveiled plenty of AI hardware and software innovations at its GTC conference.
Reddit had a strong IPO debut fueled by AI data demands.
Apple is reportedly in conversations with Google to power IPhone AI features using Gemini.
On a surprising move, Microsoft hired Inflection co-founder Mustafa Suleyman and part of his team to lead its Copilot efforts.
After loosing several key people, Inflection announced a pivot into AI for business.
NVIDIA announced a series of AI partnerships with the world’s largest tech companies.
Databricks announced the acquisition of Lilac to improves its unstructure data preparation and analysis capabilities.
Astera Labs shares popped 70% in its IPO pushed by the demand of its AI data transfer features.
Roblox introduced new AI features for Avatar creation and texturing.
Anthropic, AWS and Accenture announced a strategic alliance to bring generative AI to enterprises.
ServiceNow released a new version of its Now platform for AI workflow automation.
Amazon and Snowflake announced a partnership to modernize data streaming pipelines.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#3d#3d objects#accenture#ai#ai training#Amazon#Analysis#Announcements#anthropic#apple#architecture#audio#augmented reality#automation#avatar#AWS#azure#azure cloud#blackwell#Business#Cloud#cloud services#Collective#Companies#conference#Containers#content#data#data preparation#data streaming
0 notes
Text




some glassy-container adopts i made. Only the Sun is currently available for 65$ (+10$ for extra animation like the cat guy)
2K notes
·
View notes
Text





i was about to make a post asking if anyone had good refs of leshy's camera, but the artist Lumioze himself generously uploaded it in a neat little turnaround here!!!this is the remastered version he wanted to make that was added in Kaycee's mod!!!
i especially LOVE the little detail on the back of it showing what looks like a soul being captured by the camera!!!!!!

#GRAHAHH I LOVE INSCRYPTION I LOVE EVERY 3D MODEL ARTIST FOR THIS GAME WHY ARE THEY SO GOOD#THIS IS MY BREAD AND BUTTER#inscryption#leshy#this object is sexjual. to me
848 notes
·
View notes
Text

rainmaker
#this one uses two materials—one for the rainmaker's shiny body; and another for the goal + ranked logo sticker on the rm's body#since it's a gamemode objective i think it's a logical exception to the one-material-per-weapon rule#plus i originally didn't include the sticker; i added it only when i realised i could make the goal and sticker share a texture/material#splatoon#3d art#my art#lowpoly#splatoon 3
1K notes
·
View notes
Text

i feel room temperature about this news
#i made these in mspaint btw. i think the shittiness adds something to memes though#'hey we closed the eshop so buy our games again but on switch please'#anyway mod your DS systems which are the objectively better systems to play aa on#ace attorney#i will defend aai w my life btw thats the hill i will die on#edit in the tags: i didnt think AA would get trending over this and as always underestimate 1) how active this fandom gets when there's new#-things happening and 2) how much the fandom loves Apollo#(which is to say i do not by any means he's a bad character)#so anyway don't let my meme ruin your fun#(but do look into hacking ur 3ds <3
527 notes
·
View notes
Text
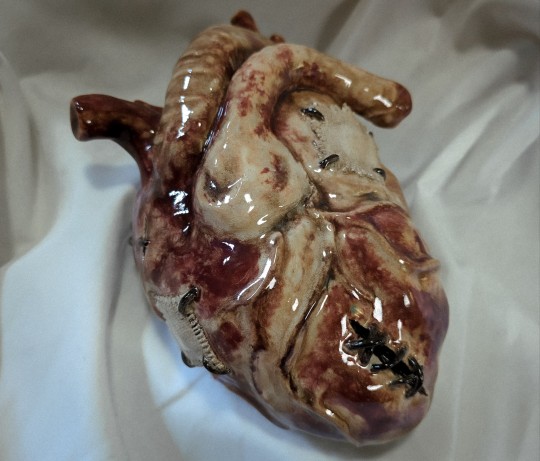

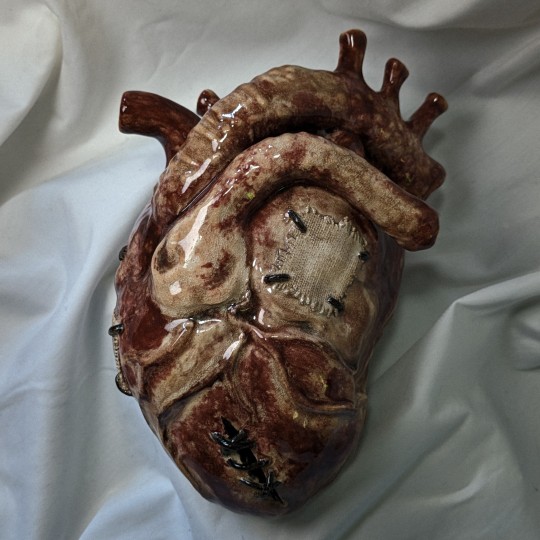
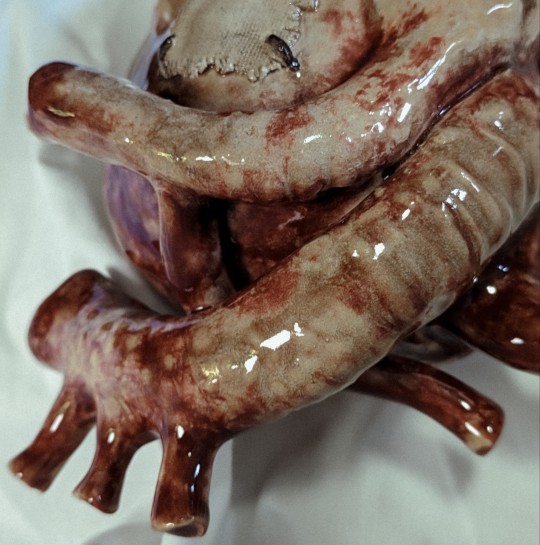
You must fix your heart and you must build an altar where it swells
#my art#my chemical romance#ceramics#3d art#anatomical heart#art#plastic#mcr#gerard way#foundations of decay#sharp objects#ethel cain#hannibal#bones and all
107 notes
·
View notes
Text
what happened to you four and x bfb?!






#bfb#bfdi#tpot#four bfb#x bfb#object shows#osc#osc art#3d modeling#cursed#cock and ball torture#i love gay men kissing
121 notes
·
View notes
Text

ELECTROBASIS is a 3d dialogue-driven game, sprinkled with platforming and puzzle quests. Meet a cast of heavenly hosts that come with a MYRIAD of issues, and help to fix (most of) them!
The casino yearns for a savior - she awaits a restoration.
Hundreds, if not THOUSANDS of years ago, a Biblical rapture fell upon the Earth, leading for angels to walk beside man, in effort to make humankind more holy living by example. Which, nowadays, isn’t all that sacred of a concept - angels are everywhere! THEY’ve integrated human characteristics into their own culture, rather than vice versa.
Made up of pure electricity, cherubs take up object heads to anthropomorphize their form. They own businesses, live in casinos, and are free to gamble their heart away. YOU, as a fallen angel, crashland SMACKdab in the center of a casino in Vegas - LITERALLY crashland. By playing this game you agree to clean-up duty*, fixing up the spark inside! Start with fixing up the casino herself by turning back on the power, and then expand into the happiness of the residents in the rooms upstairs.
INCLUDES:
A casino and hotel to explore!
Five different residents that have something wrong with them!
Exposition dump in text form for YOUR, yes your, eyeballs to scan over!
2010s dance party ending!
At least one rat
Music from famous musician REN! You know Ren, don’t you?
[ katabasis (n.)
a mytheme or trope in which the hero embarks on a journey to the underworld
any journey downwards or fall ]
*RatRoomGames cannot legally force players to improve the spark of the casino.
109 notes
·
View notes
Text
hiiii guys, new to the witch hat atelier fandom here, the fuck you mean you have this figurine

#i thought this was a 3d render when i saw it for the first time what the HELL#most beautiful physical object i've ever seen#witch hat atelier#wha#coco wha
78 notes
·
View notes
Photo

Dynamic-Compound
Acrylic, ink, graphite, markers, 3D objects - Mixed media on 12x18" watercolor paper
#art#artwork#mixed media art#abstract art#drawing#colorful#ink drawing#graphite#3d objects#acrylic painting#micron pens#artists on tumblr
1 note
·
View note
Text
MELON: Reconstructing 3D objects from images with unknown poses
New Post has been published on https://thedigitalinsider.com/melon-reconstructing-3d-objects-from-images-with-unknown-poses/
MELON: Reconstructing 3D objects from images with unknown poses
Posted by Mark Matthews, Senior Software Engineer, and Dmitry Lagun, Research Scientist, Google Research
A person’s prior experience and understanding of the world generally enables them to easily infer what an object looks like in whole, even if only looking at a few 2D pictures of it. Yet the capacity for a computer to reconstruct the shape of an object in 3D given only a few images has remained a difficult algorithmic problem for years. This fundamental computer vision task has applications ranging from the creation of e-commerce 3D models to autonomous vehicle navigation.
A key part of the problem is how to determine the exact positions from which images were taken, known as pose inference. If camera poses are known, a range of successful techniques — such as neural radiance fields (NeRF) or 3D Gaussian Splatting — can reconstruct an object in 3D. But if these poses are not available, then we face a difficult “chicken and egg” problem where we could determine the poses if we knew the 3D object, but we can’t reconstruct the 3D object until we know the camera poses. The problem is made harder by pseudo-symmetries — i.e., many objects look similar when viewed from different angles. For example, square objects like a chair tend to look similar every 90° rotation. Pseudo-symmetries of an object can be revealed by rendering it on a turntable from various angles and plotting its photometric self-similarity map.
Self-Similarity map of a toy truck model. Left: The model is rendered on a turntable from various azimuthal angles, θ. Right: The average L2 RGB similarity of a rendering from θ with that of θ*. The pseudo-similarities are indicated by the dashed red lines.
The diagram above only visualizes one dimension of rotation. It becomes even more complex (and difficult to visualize) when introducing more degrees of freedom. Pseudo-symmetries make the problem ill-posed, with naïve approaches often converging to local minima. In practice, such an approach might mistake the back view as the front view of an object, because they share a similar silhouette. Previous techniques (such as BARF or SAMURAI) side-step this problem by relying on an initial pose estimate that starts close to the global minima. But how can we approach this if those aren’t available?
Methods, such as GNeRF and VMRF leverage generative adversarial networks (GANs) to overcome the problem. These techniques have the ability to artificially “amplify” a limited number of training views, aiding reconstruction. GAN techniques, however, often have complex, sometimes unstable, training processes, making robust and reliable convergence difficult to achieve in practice. A range of other successful methods, such as SparsePose or RUST, can infer poses from a limited number views, but require pre-training on a large dataset of posed images, which aren’t always available, and can suffer from “domain-gap” issues when inferring poses for different types of images.
In “MELON: NeRF with Unposed Images in SO(3)”, spotlighted at 3DV 2024, we present a technique that can determine object-centric camera poses entirely from scratch while reconstructing the object in 3D. MELON (Modulo Equivalent Latent Optimization of NeRF) is one of the first techniques that can do this without initial pose camera estimates, complex training schemes or pre-training on labeled data. MELON is a relatively simple technique that can easily be integrated into existing NeRF methods. We demonstrate that MELON can reconstruct a NeRF from unposed images with state-of-the-art accuracy while requiring as few as 4–6 images of an object.
MELON
We leverage two key techniques to aid convergence of this ill-posed problem. The first is a very lightweight, dynamically trained convolutional neural network (CNN) encoder that regresses camera poses from training images. We pass a downscaled training image to a four layer CNN that infers the camera pose. This CNN is initialized from noise and requires no pre-training. Its capacity is so small that it forces similar looking images to similar poses, providing an implicit regularization greatly aiding convergence.
The second technique is a modulo loss that simultaneously considers pseudo symmetries of an object. We render the object from a fixed set of viewpoints for each training image, backpropagating the loss only through the view that best fits the training image. This effectively considers the plausibility of multiple views for each image. In practice, we find N=2 views (viewing an object from the other side) is all that’s required in most cases, but sometimes get better results with N=4 for square objects.
These two techniques are integrated into standard NeRF training, except that instead of fixed camera poses, poses are inferred by the CNN and duplicated by the modulo loss. Photometric gradients back-propagate through the best-fitting cameras into the CNN. We observe that cameras generally converge quickly to globally optimal poses (see animation below). After training of the neural field, MELON can synthesize novel views using standard NeRF rendering methods.
We simplify the problem by using the NeRF-Synthetic dataset, a popular benchmark for NeRF research and common in the pose-inference literature. This synthetic dataset has cameras at precisely fixed distances and a consistent “up” orientation, requiring us to infer only the polar coordinates of the camera. This is the same as an object at the center of a globe with a camera always pointing at it, moving along the surface. We then only need the latitude and longitude (2 degrees of freedom) to specify the camera pose.
MELON uses a dynamically trained lightweight CNN encoder that predicts a pose for each image. Predicted poses are replicated by the modulo loss, which only penalizes the smallest L2 distance from the ground truth color. At evaluation time, the neural field can be used to generate novel views.
Results
We compute two key metrics to evaluate MELON’s performance on the NeRF Synthetic dataset. The error in orientation between the ground truth and inferred poses can be quantified as a single angular error that we average across all training images, the pose error. We then test the accuracy of MELON’s rendered objects from novel views by measuring the peak signal-to-noise ratio (PSNR) against held out test views. We see that MELON quickly converges to the approximate poses of most cameras within the first 1,000 steps of training, and achieves a competitive PSNR of 27.5 dB after 50k steps.
Convergence of MELON on a toy truck model during optimization. Left: Rendering of the NeRF. Right: Polar plot of predicted (blue x), and ground truth (red dot) cameras.
MELON achieves similar results for other scenes in the NeRF Synthetic dataset.
Reconstruction quality comparison between ground-truth (GT) and MELON on NeRF-Synthetic scenes after 100k training steps.
Noisy images
MELON also works well when performing novel view synthesis from extremely noisy, unposed images. We add varying amounts, σ, of white Gaussian noise to the training images. For example, the object in σ=1.0 below is impossible to make out, yet MELON can determine the pose and generate novel views of the object.
Novel view synthesis from noisy unposed 128×128 images. Top: Example of noise level present in training views. Bottom: Reconstructed model from noisy training views and mean angular pose error.
This perhaps shouldn’t be too surprising, given that techniques like RawNeRF have demonstrated NeRF’s excellent de-noising capabilities with known camera poses. The fact that MELON works for noisy images of unknown camera poses so robustly was unexpected.
Conclusion
We present MELON, a technique that can determine object-centric camera poses to reconstruct objects in 3D without the need for approximate pose initializations, complex GAN training schemes or pre-training on labeled data. MELON is a relatively simple technique that can easily be integrated into existing NeRF methods. Though we only demonstrated MELON on synthetic images we are adapting our technique to work in real world conditions. See the paper and MELON site to learn more.
Acknowledgements
We would like to thank our paper co-authors Axel Levy, Matan Sela, and Gordon Wetzstein, as well as Florian Schroff and Hartwig Adam for continuous help in building this technology. We also thank Matthew Brown, Ricardo Martin-Brualla and Frederic Poitevin for their helpful feedback on the paper draft. We also acknowledge the use of the computational resources at the SLAC Shared Scientific Data Facility (SDF).
#000#2024#3d#3D object#3d objects#Angular#animation#applications#approach#Art#benchmark#Blue#Building#Cameras#chicken#CNN#Color#Commerce#comparison#computer#Computer vision#continuous#data#E-Commerce#Engineer#Fundamental#GAN#gap#generative#Global
0 notes
Text





Some 3d adopts i made that has been sold to their respective owners. As you can see i love using galaxy and glass shaders
1K notes
·
View notes
Text



KNIFE MAN
#el's art#digital sculpture#3d model#digital art#3d artwork#art#3d modeling#3d sculpture#3d art#knife man#ajj#ajjtheband#ajj band#knife#object head#from the tour shirt
361 notes
·
View notes
Text

lime lime lime lime lime (and his m34th weapon that can turn into many things)
#the cat witchs guild#the misc adventures of mochi and lime#tcwg#tmaomal#lime#mochi#limochi#art#ocs#original#weapons#LIME IN THE CORNER IS SO CUTE....HES SO HAPPY LOOK AT HIM#really i drew this to draw his weapon#the special m34th technology weapon that can combat magic and also turn into a lot of things#and can only be weilded by a black canvas (or super high res)#its actually hardly ever a gun but when it is its fucking cool and so hard to fight against#its usually a sword/dual swords/polearm/hammer/axe#thats not his blood#his shoulder hurts i think mochi should massage him#i got the gun from a clip studio 3d model that is not my design at all but i cannot draw inanimate objects#mochi praise is a drug and hes hooked
280 notes
·
View notes
Text


Queen Eclipse Staff!
First time making my own 3D object from one of my works :D!
Trying to learn more on 3D and had fun recreating the staff from my Queen Eclipse artwork with a couple of changes cause i thought it was cool lol!
reference image below :>!

124 notes
·
View notes
Last Seen Blogs

naritamarchaiswebsite
Naritaマルシェ

windeslat
Winny Desty Lathifah's

myungrock
rockjin's dance intro in kcon la 2017

aaniag
Aania (short hiatus)

socvault
SOCVault | Best Cybersecurity Company