#ComputeShader
Photo

Art by @dokodemo.works 02-02-2023 Cleaned up tons of compute shader stuff, testing throughput: simulating 10 million particles, spawning 1 million every frame. Stills from audioreactive test ProRes external recording, expecting uploaded video to suffer terribly from compression. #unity3D #madewithunity #shaders #computeshader #interactiveart #art #digitalart #proceduralart #generativeart #motion #newmediaart #code #particles #particlesimulation #gpu #kyoto #freelance #visualart #programming #3d #pointcloud #photgrametry #volumetric https://www.instagram.com/p/Cp_YRGEjeij/?igshid=NGJjMDIxMWI=
#unity3d#madewithunity#shaders#computeshader#interactiveart#art#digitalart#proceduralart#generativeart#motion#newmediaart#code#particles#particlesimulation#gpu#kyoto#freelance#visualart#programming#3d#pointcloud#photgrametry#volumetric
2 notes
·
View notes
Text
0 notes
Photo

Unity Volumetric Fire 3D
This is still under development. Inspired by Embergen.
https://github.com/supertask/UnityVolumetricFire3D
vimeo
Aiming to create following vfx video with AR in the future. And also
fire effect
smoke effect
youtube
0 notes
Text

Shared Memory를 활용한 향상된 GPGPU
GPGPU에 대한 학습은, 프로그래밍 뿐만 아니라 GPU Memory Architecture에 대한 학습을 함께 병행해야 더 깊어질 수 있다고 믿는다
다량의 객체로 구성된 Swarm System을 만든다 가정하자. System내의 객체는 주변 객체와의 거리를 확인하여 너무 멀면 응집하고, 너무 가까우면 서로를 밀어내는 등 정해진 알고리즘에 따라 창발적인 모양의 군집을 이룬다.
이와 같이 객체간의 인터랙션을 위해서 객체 각각마다 무리 내의 모든 객체의 정보를 한번씩 열람하여야 하는 경우 연산량은 객체의 갯수 n에 대하여 n^2의 비율로 증가한다.
이렇듯 생성한 GPU Buffer내의 모든 데이터를 전수조사 해야하는 경우가 발생할 때에, 이를 좀 더 신속하게 처리할 수 있는 방법에 대해 고민하였다.
동일 SM(Streaming Multiprocessor)에 속한 SP(Streaming Processor)는 Shared Memory를 공유한다. 단순 공유의 문제가 아니라, 동일 SM내에서의 접근이기 때문에 메모리 접근 속도도 상당히 빠르다.
Compute Shader기준 일반적으로 생성한 buffer는 GPU DRAM에 생성된다. 문제는 DRAM은 그다지 접근속도가 빠른 메모리가 아니라는 것이다. 따라서 하나의 Thread에서 DRAM에 생성된 모든 데이터에 접근하는 것은 Latency의 관점에서 상당히 효율적이지 못한 일이다.
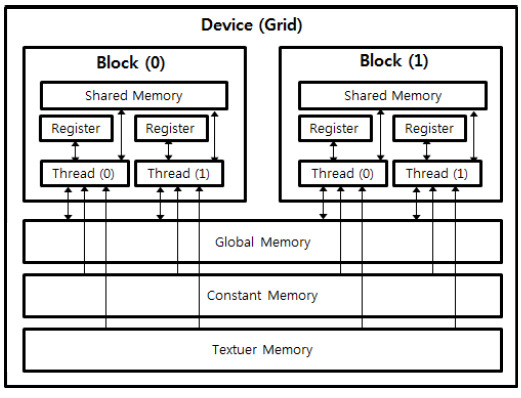
GPU Memory Architecture
이럴때 Shared Memory를 창의적으로 활용하면 Latency를 확 줄일 수 있게 된다. 대략적인 소스코드는 다음과 같다.
groupshared SharedBuffer;
void Kernel(int threadIdx){
float3 myData = buffer[threadIdx].data;
for(int blockIdx = 0; blockIdx < 총 생성된 객체량; blockIdx += 블락사이즈)
{
sharedBuffer[threadIdx] = buffer[blockIdx + threadIdx];
GroupMemoryBarrierWithGroupSync();
for(int idx = 0; i < 블락사이즈; ++i){
float3 yourData = sharedBuffer[idx];
// myData와 yourData간의 관계 알고리즘 작성
}
GroupMemoryBarrierWithGroupSync();
}
}
위와같은 방법을 사용함으로써, DRAM에 접근해야 하는 업무를 블락사이즈만큼 나누고(위 코드 7번째 줄에 해당), 대신 shared메모리를 통해 좀더 신속하게 데이터에 접근할 수 있게 된다.
0 notes
Text
Compute Shading
I compared CPU and GPU performances using compute shaders.
youtube
My GPU is not that good so try it yourself HERE.
You can also find the full dissertation I made in the same folder.
2 notes
·
View notes
Photo

Who wants to cultivate this tiny world? #madewithunity #unity3d #indiedev #gamedev #computeshaders #shaders https://t.co/lds1oZKgan – http://twitter.com/Lub_Blub/status/1239640741070045184 – @Lub_Blub
1 note
·
View note
Video
vimeo
Particle system with collision from Tim Gerritsen on Vimeo.
Updated compute particle system shader example for TouchDesigner.
Particles colliding with a heightmap.
Sourcecode available at derivative.ca/community-post/asset/compute-particle-system-v20
#yfxlab, #touchdesigner, #glsl, #particlesystem, #computeshader, #collision, #newton, #forces, #gravitation
0 notes
Text
0 notes
Video
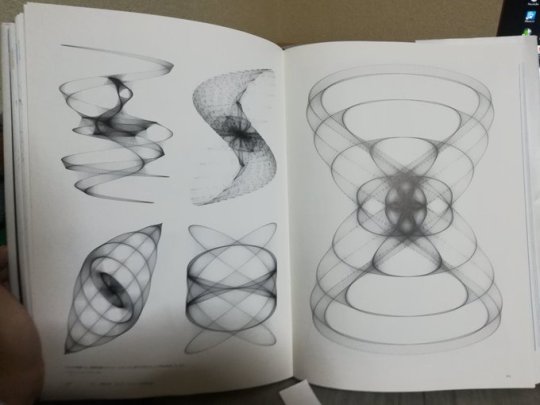
#Lissajous curve with VFX Graph
Referred from a book called Generative Design.
0 notes
Video
Compute shaders + Instanced Shaders =
0 notes
Text
[C/C++] Projekt: DX11 Engine raSystem
[C/C++] Projekt: DX11 Engine raSystem
Seit ich 14 Jahre alt bin Programmiere ich. Angefangen mit Visual Basic über PHP zu C/C++, ASM, Lua, sh-script, SQL, Python und C#.
Möchte ich meine bisherigen und noch kommenden Projekte vorstellen. Bin nicht gelernte Programmierrerin sondern rein aus Hobby.
Das erste Projekt das ich vorstelle ist mein erstes größeres Projekt, mit dem ich mir das Spiele Programmieren näher gebracht habe.…
View On WordPress
#Computeshader#Delegates#DirectX#Directx11#Engine#Programmieren#Properties#Rasystem#shader#si#Smartpointers#Tesselation
0 notes
Last Seen Blogs

brilliancetheory
Faerie W15B

nurtureify
Untitled

ratassium
Ratassium

bunnywr1tes
Bunny

idreamaboutlegs
I dream about legs