#Data protection
Text
psst, let me tell you a secret
are you listening?
ready?
Tumblr Blaze is the biggest fuck-you to Facebook, Twitter, Google, Amazon, and other advertising companies in basically ever
wanna know why?
On Facebook, I could show this post only to white, politically undecided, lesbian college students aged 18-21 who live in zip codes 75023, 75024, and 75025 (yes, even after the changes Facebook recently announced). Anyone who interacts with the post, therefore, is extremely likely to be a white, politically undecided, lesbian college student aged 18-21 who lives in Plano, Texas. If this post was an ad, and you clicked the ad and bought the thing it was advertising, then I’d also know your name, physical address, telephone number, email address, and approximate financial status.
You probably don’t want me to know all that about you, right?
Do you want your health insurer to know? What about your employer? If you’re queer and not out to your family and friends, would you want them to know? What if you’re a domestic violence survivor, hiding from your ex-spouse?
All they need to do to get all that information is buy a Facebook ad for under $5.
And before you say that you don’t share all that on Facebook: too bad! Even if you don’t, Facebook (along with pretty much every ad company out there) buys, sells, and/or trades the data it collects about you with other companies. Facebook collects data about you even if you don’t have a Facebook account.
Wanna know what’s scarier?
Bad guys can also buy targeted ads, and use them to convince you to do things like vote for a particular presidential candidate, or vote against unionizing Amazon workers. This is a very common tactic used by hostile foreign governments to foster extremism and isolate vulnerable minorities, and influence elections and other political and social events. Even the tech companies themselves can and do use this data to manipulate your emotions, making you happier or sadder according to their own whims.
(why do you know all this, Sanity? because I’ve worked in information security, fighting for data privacy and security, for over a decade)
Facebook, Google, Twitter, Amazon, and other advertisers claim that collecting all that data about you, and letting anyone target you with it, is absolutely, 100% necessary for the existence of the entire ad-funded Internet. They want you to believe that nothing bad could possibly come of it, despite proof to the contrary being in the news every other month. They want you to blindly continue letting them collect and use YOUR data to influence you to think, feel, and do what THEY want.
But.
BUT!!!
Enter Tumblr Blaze.

(from the Blaze FAQ)
Tumblr looked at advertising and said, you know what? we don’t need to target anyone. Targeted ads don’t actually work anyway. All that hyper-specific targeting is just an excuse for ad companies to raise prices and collect more data to use for their own purposes.
Tumblr said, we bet people will pay real-life dollars to share their posts with up to 50,000 people, whether or not those people will care.
Tumblr said, we’re going to blow up the entire online advertising industry.
That is fucking amazing, y'all.
#information technology#information security#data privacy#data protection#tumblr blaze#sanity talks a lot
15K notes
·
View notes
Text
reminder not to do what i almost did just now and tell tumblr what your high school mascot is/was just because someone made a fun poll about it, because that's a SECURITY QUESTION ON A BUNCH OF YOUR PASSWORD-PROTECTED PLATFORMS
227 notes
·
View notes
Text
It's concerning that this is now an LGB and women's issue now, but I really encourage people to begin purchasing USB drives or external hard drives and saving digital research on things such as gay & lesbian history, screenshots of tweets that might be important, homosexual and bisexual research, women's history, radical feminist books or PDFs, and really just anything that is at risk of being "corrected" by gender ideology or made inaccessible by academic publishers.
We need to save these things in a hard copy format as opposed to just using internet archive or taking Sci-hub for granted, because these organizations are experiencing heavy lawsuits. Additionally, it's becoming common for LGB and gender nonconformity history and research to be "rewritten" by gender ideologists. Actually, this is even true for past research and history on transvestism and transsexualism, too, in addition to things such as sex dysphoria, etc.
I bought three 64GB USBs for just $25. If you can't afford an external hardrive, buy some different colored USBs and start building your own library. We need to preserve this information and decentralize it as much as possible. It's worrisome enough that we rely on digital archives this much just generally, especially with the advent of AI and government and corporate attempts to eliminate data privacy and control.
This is a women's rights issue and an LGB issue now.
#human rights#LGB#LGBT#gay history#protect gay history#women's history#women's rights#LGBT history#gender critical#radical feminist#dataprotection#data protection#references#resources#activism#gay activism#lesbian culture#lesbian rights#lesbian history#gay rights#adult human female#feminism
994 notes
·
View notes
Text
If you've ever used 23andMe to learn more about your family ancestry, you could be eligible for compensation due to a class-action lawsuit against the company.
Law firms in Toronto and Vancouver launched a class-action lawsuit against 23andMe this week in response to a data breach that exposed users’ highly sensitive and valuable personal information earlier this year.
"The action alleges that contrary to their promises, statements and representations, as well as the privacy regulation and industry standards applicable to them, [23andMe] did not introduce, implement or maintain proper or adequate data retention and data protection practices," reads the lawsuit.
Full article
Tagging: @politicsofcanada
#cdnpoli#canada#canadian politics#canadian news#canadian#23andme#23 and me#class action#class action lawsuit#data protection#data security#privacy#data privacy
148 notes
·
View notes
Text


28.11.2023 | tuesday
going out to eat to recharge + some Data Protection studying
#studyblr#law studyblr#law student#studyspo#lawblr#study motivation#study#studying#student#uni studyblr#uniblr#uni#university#master's degree#data protection
99 notes
·
View notes
Text
Switching to Firefox

This post is to answer @leaveblackkbrosalone’s question on my post about me switching to Firefox!
I recently had an eye opener moment when researching about Google and how they collect data to alter the things they recommend you and other things. And it was astonishing how much data they collect on you and how they track you every movement whilst on Google/Chrome/Other Google services e.g. Google PlayStore.
I truly believe there are better alternatives out there than the default Google Chrome people tend to use. We now live in world of constant data breaches and online tracking, therefore protecting your online privacy and security has never been more important.
I’ve recently deleted Chrome from my phone and computer and switched to FireFox and I’ll explain why~!

What is Firefox?
Firefox is the famous fox web browser! It is a free and open-source that is developed by the Mozilla Foundation. It's designed to be fast, secure, and customizable, and is available for multiple operating systems, including Windows, Mac, and Linux.
Firefox includes a suite of built-in features, such as enhanced tracking protection, custom themes (so important obviously) and add-ons, and a flexible interface that can be tailored to the user's needs.
Why Firefox and not Google Chrome?
There are a bunch of reasons why I chose to delete Google Chrome and why I prefer FireFox now, let me list some:
Privacy
Firefox has a strong focus on privacy and security, with features like built-in tracking protection and a strict anti-tracking policy.
In contrast, Chrome is owned by Google, a company that relies heavily on data collection and advertising for its business model.
Customisation
Firefox has a much more flexible and customizable interface than Chrome, with a wide range of add-ons (equivalent to Chrome’s ‘extensions’ I believe) and themes available to personalize your browsing experience.
Open-source
Firefox is an open-source project, meaning that anyone can contribute to its development and review the code for security issues.
Chrome, on the other hand, is based on the Chromium project, which is also open-source but is controlled by Google.
Cross-platform compatibility
Firefox works on a wide range of devices and operating systems, including Windows, Mac, Linux, and mobile devices.
Chrome is also available on multiple platforms, but it's more heavily integrated with Google's services and ecosystem.
Performance
Firefox has made significant improvements in recent years and is now a competitive browser in terms of speed and efficiency.
Still, Chrome is known for its fast performance
Community-driven
Firefox is developed by the non-profit Mozilla Foundation, which has a strong focus on user empowerment and community involvement. This means that Firefox users have a voice in the development process and can contribute to the browser's future direction.
With all of that being said, there is one particular area that caught my eye that I mentioned briefly: the Privacy and Security.
Firefox’s Privacy and Security Advantages
Firefox definitely has advantages in these areas than Google Chrome surprisingly!
Enhanced Tracking Protection
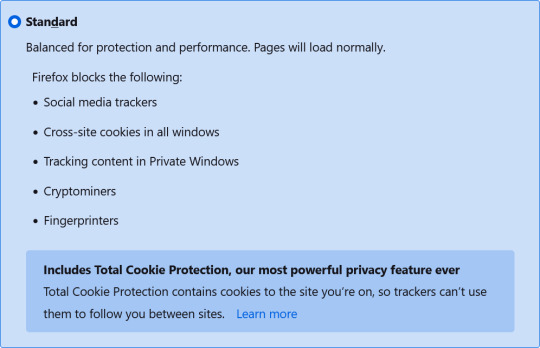
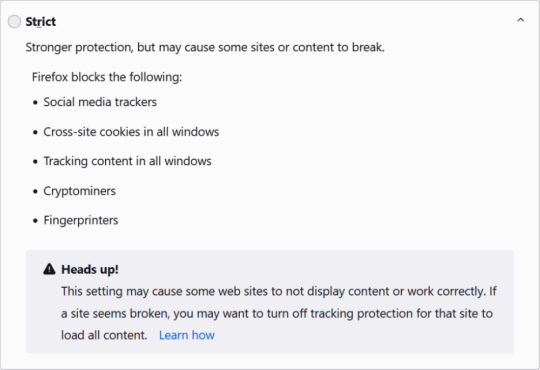
Firefox includes built-in tracking protection that blocks many common types of trackers by default, including
third-party cookies, cryptominers, and fingerprinters
This helps to protect your online privacy and reduce the amount of data that's collected about you. Below are the options for the 'Enhance Tracking Protection' in the settings:
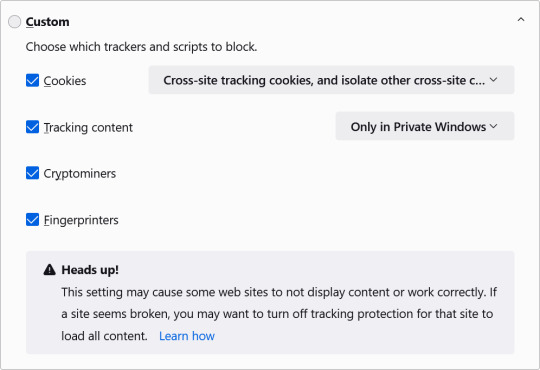
No Google Tracking
Oh boy, I like this one. So unlike Chrome, which is owned by Google and ties into its advertising and data collection ecosystem, Firefox is developed by the non-profit Mozilla Foundation and has no affiliation with Google or any other major tech company. This means that Firefox is less likely to collect and share your data with third parties.
No Sign-In Required
While Chrome requires you to sign in with a Google account to access certain features, Firefox does not require any sign-in at all. This means that you can still use Firefox without creating a user profile or linking your browsing activity to any personal information -
Don’t get me wrong, if you want to use the Google search engine WITHIN FireFox, it might still prompt you to sign in but you still don’t have to! Also, the choice is there to create an account just to sync bookmarks and tab from one device to another e.g. phone to laptop.
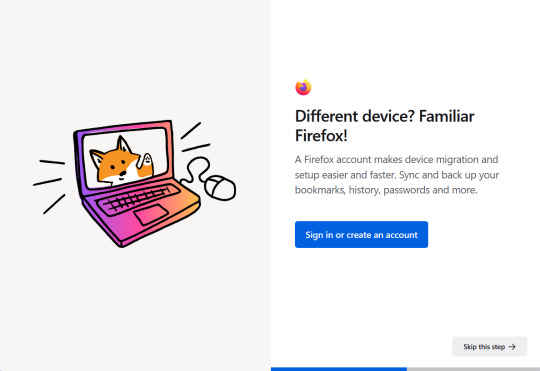
Private Browsing Mode
(Another very important part!) Firefox offers a Private Browsing mode that doesn't save your browsing history, cookies, or temporary files. This can be useful for browsing sensitive content or preventing others from seeing what you've been looking at.
Firefox's Private Browsing mode offers a more robust set of features for privacy and security than Google’s Incognito mode. Within the ‘Settings’, you can customise your privacy settings more extensively than Google Chrome. You can choose to block all third-party cookies, prevent websites from accessing your location data, and clear your browsing history and data automatically when you close the browser.
Google's Incognito mode does not block all cookies or prevent all forms of tracking.
Open-Source Security
Like I mentioned before, Firefox is an open-source project, meaning that anyone can review the code and contribute to its development. This helps to ensure that security vulnerabilities are identified and addressed quickly, and that the browser remains as secure as possible. You too can find something and report it to the repository via creating an issue!

To Conclude
Of course, these are just some general reasons why you might prefer Firefox over Chrome, and the choice ultimately comes down to personal preference and priorities. I know with developers, they would prefer Chrome for the dev tools and I think it’s almost a standard to use Chrome (though at my workplace we use Microsoft Edge), anyhoo Google is just a default for web browsing and search engine. I also know it’s hard if you have a whole Google ecosystem set up like Google docs to Sheet to Slides, emails, calendar etc, you can still use them but on a safer browser.
I would also recommend using ‘DuckDuckGo’ for a search engine as they too are really good with security and privacy but as a search engine (plus on their phone app they have a cool animation when you want to delete you browsing data from the tabs hehe)!
Links to interesting pages for more information on this topic:
YouTube videos: video 1 | video 2 | video 3 | video 4
Articles: article 1 | article 2 | article 3
I’d say give it a go, if you don’t like it I still recommend anything but Google Chrome! Well, that’s all and thank you for reading! 🥰👍🏾💗
#xc: programming blog post#programming#coding#studying#codeblr#progblr#studyblr#comp sci#computer science#firefox#google chrome#chrome#security and privacy#safer internet#security#privacy#data protection#user data
268 notes
·
View notes
Note
could you possibly make a shirt for the merch shop like the data protection one from this post? i would buy that so fast
Shifty version is available now!


199 notes
·
View notes
Text
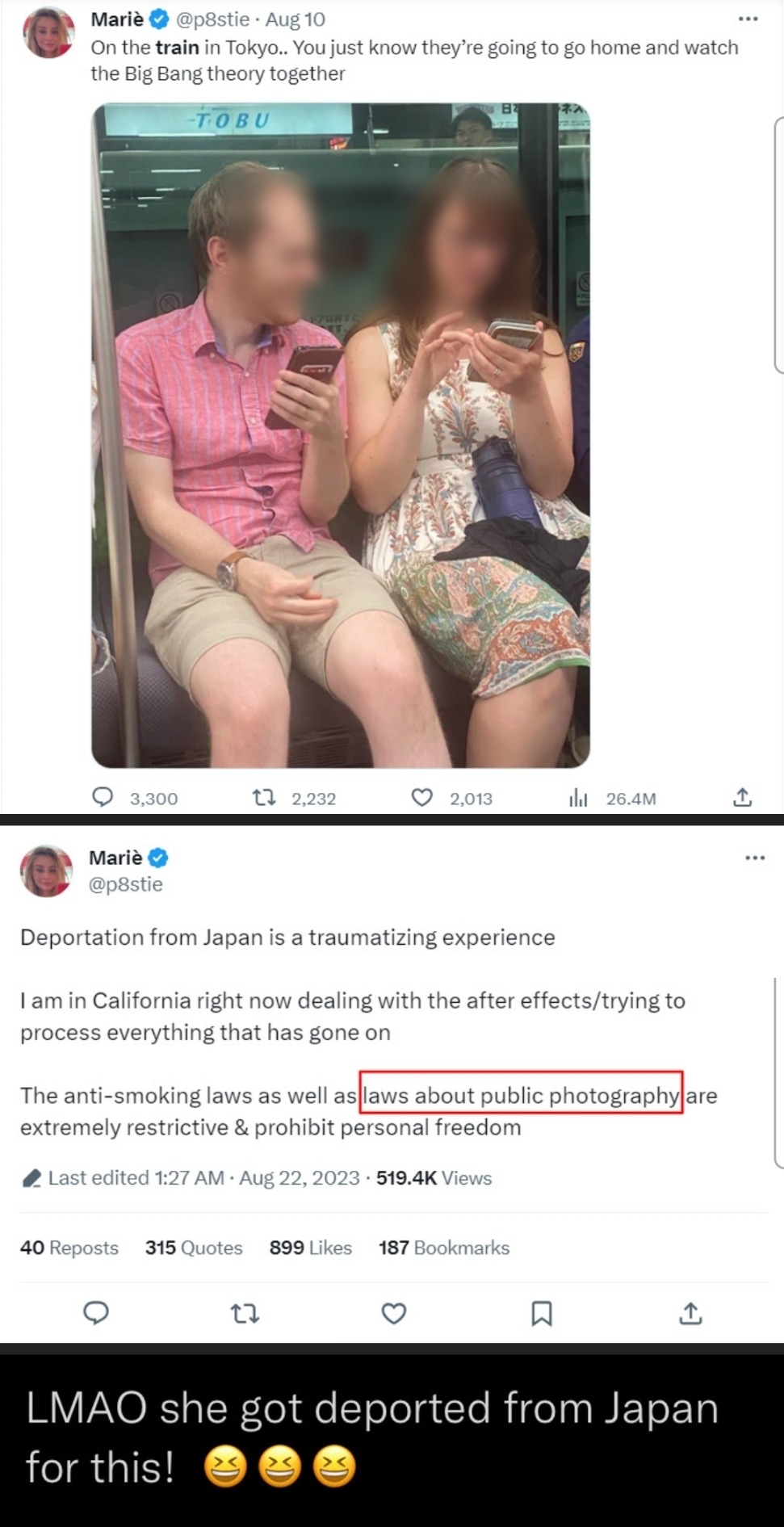
This is not from my post originally (it's a popular post from about 5 days ago and ironically spreads a picture taken without consent). I've censored the original picture because this is a jumping off point for what happened to me on Sunday while at work.
So I was at work on the shop floor when a man came in facetiming someone. He was picking up books and showing them to the lady he was facetiming, who told him that those books weren't the ones she was looking for. The man then turns to me (I was behind the tills) and asks I've I've heard of [book name]. I hadn't and explained that I'd been stocking the bookshelves earlier and hadn't come across it while doing that. He then flips his phone around so that the facetime camera is pointing at me. I freak out internally because what the hell?? I'm at work and you didn't ask me to talk to whoever it is you're talking to.
Man walks around the tills, comes up to the threshold of the till area and shoves the camera closer to my face. Because of where I was stood, I physically could not walk away from the tills because there is a wall of books in my way. I would have had to jump over the counter to leave. Honestly the whole thing made me really uncomfortable and I deeply resent people who think it's okay to take pictures of or record people in public. Ask for permission first. And if you can't, don't! Especially don't corner someone and force them to facetime a complete stranger. It's not okay, even if you think it's lighthearted.
#privacy#consent#data privacy#data protection#customer service#right to privacy#if you've also experienced something like this and feel comfortable sharing please do#I can't be the only person this has happened to
57 notes
·
View notes
Text
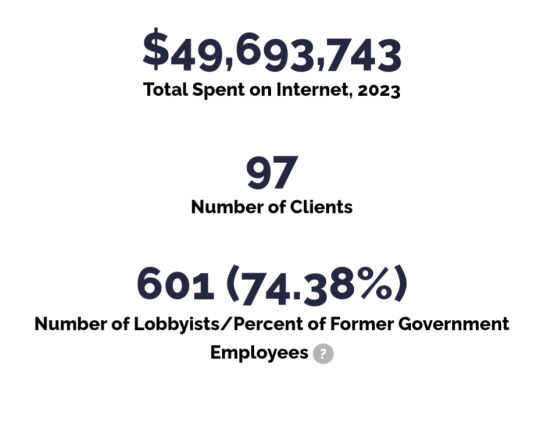
Y'all ever look at this?
I was doing some research about healthcare and stumbled into this lobbying tracker and I am...pissed off???
Free rage machine over at opensecrets

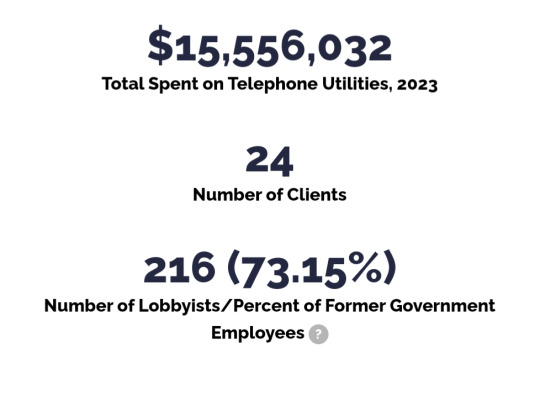

#politics#Lobbying#us politics#us government#congress#senate#oil#gas#clean energy#climate change#data protection#capitalism#healthcare#health insurance#oil company#gas company
64 notes
·
View notes
Text
Ireland's privacy regulator is a gamekeeper-turned-poacher

This Saturday (May 20), I’ll be at the GAITHERSBURG Book Festival with my novel Red Team Blues; then on May 22, I’m keynoting Public Knowledge’s Emerging Tech conference in DC.
On May 23, I’ll be in TORONTO for a book launch that’s part of WEPFest, a benefit for the West End Phoenix, onstage with Dave Bidini (The Rheostatics), Ron Diebert (Citizen Lab) and the whistleblower Dr Nancy Olivieri.

When the EU passed its landmark General Data Protection Regulation (GDPR), it seemed like a privacy miracle. Despite the most aggressive lobbying Europe had ever seen, 500 million Europeans were now guaranteed a digital private life. Could this really be?
If you’d like an essay-formatted version of this post to read or share, here’s a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
Well, yes…and no. Despite flaws (Right to Be Forgotten), the GDPR has strong, well-crafted, badly needed privacy protections. But to get those protections, Europeans need their privacy regulators to enforce the rules.
That’s where the GDPR miracle founders. Europe includes several tax-havens — Malta, Cyprus, the Netherlands, Luxembourg, Ireland — that compete to offer the most favorable terms to international corporations and other criminals. For these havens, paying little to no tax is just table-stakes. As these countries vie to sell themselves out to giant companies, they compete to offer a favorable regulatory environment, insulating companies from lawsuits over corruption, labor abuses and other crimes.
All of this is made possible — and even encouraged — by the design of European federalism, which lets companies easily shift which flag of convenience they fly. Once a company re-homes in a country, it can force Europeans across the union to seek justice in that country’s courts, under the looming threat that the company will up sticks for another haven if the law doesn’t bend over backwards to protect corporate citizens from the grievances of flesh-and-blood humans.
Big Tech’s most aggressive privacy invaders have long flown Irish flags. Ireland is “headquarters” to Google, Meta, Tinder, Apple, Airbnb, Yahoo and many other tech companies. In exchange for locating a handful of jobs to Ireland, these companies are allowed to maintain the pretense that their global earnings are afloat in the Irish Sea, in a state of perfect, untaxable grace.
That cozy relationship meant that the US tech giants were well-situated to sabotage Ireland’s privacy regulator, who would be the first port of call for Europeans whose privacy had been violated by American firms. For many years, it’s been obvious that the Irish Data Protection Commission was a sleeping watchdog, with infinite tolerance for the companies that pretend to make Ireland their homes. 87% of Irish data protection claims involve just eight giant US companies (that pretend to be Irish).
But among for hardened GDPR warriors, the real extent of the Data Protection Commissioner’s uselessness is genuinely shocking. A new report from the Irish Council for Civil Liberties reveals that the DPC isn’t merely tolerant of privacy crimes, they’re gamekeepers turned poachers, active collaborators in privacy abuse:
https://www.iccl.ie/wp-content/uploads/2023/05/5-years-GDPR-crisis.pdf
The report’s headline figure really tells the story: the European Data Protection Board — which oversees Ireland’s DPC — overturns the Irish regulator’s judgments 75% of the time. It’s actually worse than it appears: that figure only includes appeals of the DPC’s enforcement actions, where the DPC bestirred itself to put on trousers and show up for work to investigate a privacy claim, only to find that the corporation was utterly blameless.
But the DPC almost never takes enforcement actions. Instead, the regulator remains in its pajamas, watching cartoons and eating breakfast cereal, and offers an “amicable resolution” (that is, a settlement) to the accused company. 83% of the cases brought before the DPC are settled with an “amicable resolution.”
Corporations can bargain for multiple, consecutive amicable resolutions, allowing them to repeatedly break the law and treat the fines — which they negotiate themselves — as part of the price of doing business.
This is illegal. European law demands that cases that involve repeat offenders, or that are likely to affect many people, must be fully investigated.
Ireland’s government has stonewalled on calls for an independent review of the DPC. The DPC continues to abet lawlessness, allowing corporations to use privacy invasive techniques for surveillance, discrimination and manipulation. In 2022, the DPC concluded 64% of its cases with mere reprimands — not even a slap on the wrist.
Meanwhile, the DPC trails the EU in issuing “compliance orders” — which directly regulate the conduct of privacy-invading companies — only issuing 49 such orders in the past 4.5 years. The DPC has only issues 28 of the GDPR’s “one-stop-shop” fines.
The EU has 26 other national privacy regulators, but under the GDPR, they aren’t allowed to act until the DPC delivers its draft decisions. The DPC is lavishly funded, with a budget in the EU’s top five, but all that money gets pissed up against a wall, with inaction ruling the day.
Despite the collusion between the tech giants and the Irish state, time is running out for America’s surveillance-crazed tech monopolists. The GDPR does allow Europeans to challenge the DPR’s do-nothing rulings in European court, after a long, meandering process. That process is finally bearing fruit: in 2021, Johnny Ryan and the Irish Council for Civil Liberties brought a case in Germany against the ad-tech lobby group IAB:
https://pluralistic.net/2021/06/16/inside-the-clock-tower/#inference
And the activist Max Schrems and the group NOYB brought a case against Google in Austria:
https://pluralistic.net/2020/05/15/out-here-everything-hurts/#noyb
But Europeans should not have to drag tech giants out of Ireland to get justice. It’s long past time for the EU to force Ireland to clean up its act. The EU Commission is set to publish a proposal on how to reform Ireland’s DPA, but more muscular action is needed. In the new report, the Irish Council For Civil Liberties calls on the European Commissioner for Justice, Didier Reynders, to treat this issue with the urgency and seriousness that it warrants. As the ICCL says, “the EU can not be a regulatory superpower unless it enforces its own laws.”

Catch me on tour with Red Team Blues in Toronto, DC, Gaithersburg, Oxford, Hay, Manchester, Nottingham, London, and Berlin!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
[Image ID: A toddler playing with toy cars. The cars are Irish police cars. The toddler's head has been replaced with the menacing, glowing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The toddler's knit cap is decorated with the logos for Apple, Google, Facebook and Tinder.]
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#made towns#EDPB#gamekeeper turned poacher#ireland#alphabet#eire#erin go bragh#big tech#corruption#data protection#facebook#tax havens#google#meta#tiktok#microsoft#msft#micros~1#gdpr#privacy#european federalism#eu#european union#European Data Protection Board#airbnb#tinder#forum-shopping apple#federalism
58 notes
·
View notes
Text

How automakers make use of data collected by connected cars is coming under scrutiny in California. On Monday, the California Privacy Protection Agency announced that it will review the data privacy practices of connected vehicle manufacturers. The agency is empowered to do so thanks to a 2018 state law, the California Consumer Privacy Act.
"Modern vehicles are effectively connected computers on wheels. They're able to collect a wealth of information via built-in apps, sensors, and cameras, which can monitor people both inside and near the vehicle," said Ashkan Soltani, CPPA's executive director.
"Our Enforcement Division is making inquiries into the connected vehicle space to understand how these companies are complying with California law when they collect and use consumers' data," he said in a statement.
Connected cars are fast becoming ubiquitous—it may well be impossible to buy a new car, truck, or SUV in 2023 that doesn't have at least one embedded modem in it. In the mid-2010s, many OEMs saw dollar signs at the prospect of monetizing data collected by their deployed vehicle fleets, and unlike with cellphones, it can be hard or impossible to disable location tracking in one's car.
"Under the California Consumer Privacy Act, geolocation is considered personal information. People have the right to say no to being tracked in their cars, but it is unclear if car companies are providing this right," said Justin Kloczko, a privacy advocate at Consumer Watchdog. "These companies know more about us than we know about ourselves, and they’re the ones in control of our personal information, not us," Kloczko said.
(continue reading)
#politics#location tracking#smart cars#privacy rights#data mining#spyware#geolocation data#connected cars#data protection#data privacy#consumer protection#geolocation tracking
45 notes
·
View notes
Text

hello from Spot’s weird owner! If you’re like me and don’t want to license your cute cat photos/dank memes to weird AI companies, make sure to enable this toggle on each of your blogs! As an ex-staff member I’m disappointed that selling my data to third-party AI companies is opt-out and not opt-in and I really hope @staff reconsiders - lots of folks will miss this announcement and unknowingly have their stuff shared without them actually consenting, which sucks.
10 notes
·
View notes
Text
Making the AI crawling thing opt-out rather than opt-in is so vile. First of all, it causes unnecessary extra work from the users, who now have to go through all their blogs and opt-out manually. Second, people who deactivated blogs or are inactive will not be able to prevent the AI stealing their content. It's messed up and I'm honestly wondering how that's legal, especially considering European data privacy laws.
@staff are you actively trying to kill this site? make that stuff opt-in rather than opt-out, or you might find yourself in a legal battle one day
8 notes
·
View notes
Text
What's up with TikTok?
"What is the deal with this whole TikTok thing?"
Journalist Taylor Lorenz unpacks the reasons behind the movement to ban the popular app.
Listen to our full conversation on @spotify
4 notes
·
View notes
Text
Oh btw, if u wanna not have ads in ur mobile apps and you use Android you can get blockada which is an open source software that can block ads and other data collection sources on apps that you use or just in the background.
I would recommend going to the official site and downloading the version 5 APK because that one is entirely free as compared to the version on the app store which I believe at this time is 6 and is subscription based.
#privacy#adblock#cyber security#digital privacy#data protection#data privacy#data mining#ads#ad blocking#my stuff#my post#open source#phone apps#android#blockada#data tracking
20 notes
·
View notes
Text
Anticipating the future of malicious open-source packages: next gen insights
New Post has been published on https://thedigitalinsider.com/anticipating-the-future-of-malicious-open-source-packages-next-gen-insights/
Anticipating the future of malicious open-source packages: next gen insights

Ori Abramovsky is the Head of Data Science of the Developer-First group at Check Point, where he leads the development and application of machine learning models to the source code domain. With extensive experience in various machine learning types, Ori specializes in bringing AI applications to life. He is committed to bridging the gap between theory and real-world application and is passionate about harnessing the power of AI to solve complex business challenges.
In this thoughtful and incisive interview, Check Point’s Developer-First Head of Data Science, Ori Abramovsky discusses malicious open-source packages. While malicious open-source packages aren’t new, their popularity among hackers is increasing. Discover attack vectors, how malicious packages conceal their intent, and risk mitigation measures. The best prevention measure is…Read the interview to find out.
What kinds of trends are you seeing in relation to malicious open-source packages?
The main trend we’re seeing relates to the increasing sophistication and prevalence of malicious open-source packages. While registries are implementing stricter measures, such as PyPI’s recent mandate for users to adopt two-factor authentication, the advances of Large Language Models (LLMs) pose significant challenges to safeguarding against such threats. Previously, hackers needed substantial expertise in order to create malicious packages. Now, all they need is access to LLMs and to find the right prompts for them. The barriers to entry have significantly decreased.
While LLMs democratise knowledge, they also make it much easier to distribute malicious techniques. As a result, it’s fair to assume that we should anticipate an increasing volume of sophisticated attacks. Moreover, we’re already in the middle of that shift, seeing these attacks extending beyond traditional domains like NPM and PyPI, manifesting in various forms such as malicious VSCode extensions and compromised Hugging Face models. To sum it up, the accessibility of LLMs empowers malicious actors, indicating a need for heightened vigilance across all open-source domains. Exciting yet challenging times lie ahead, necessitating preparedness.
Are there specific attack types that are most popular among hackers, and if so, what are they?
Malicious open-source packages can be applied based on the stage of infection: install (as part of the install process), first use (once the package has been imported), and runtime (infection is hidden as part of some functionality and will be activated once the user will use that functionality). Install and first use attacks typically employ simpler techniques; prioritizing volume over complexity, aiming to remain undetected long enough to infect users (assuming that some users will mistakenly install them). In contrast, runtime attacks are typically more sophisticated, with hackers investing efforts in concealing their malicious intent. As a result, the attacks are harder to detect, but come with a pricier tag. They last longer and therefore have higher chances of becoming a zero-day affecting more users.
Malicious packages employ diverse methods to conceal their intent, ranging from manipulating package structures (the simpler ones will commonly include only the malicious code, the more sophisticated ones can even be an exact copy of a legit package), to employing various obfuscation techniques (from classic methods such as base64 encoding, to more advanced techniques, such as steganography). The downside of using such concealment methods can make them susceptible to detection, as many Yara detection rules specifically target these signs of obfuscation. Given the emergence of Large Language Models (LLMs), hackers have greater access to advanced techniques for hiding malicious intent and we should expect to see more sophisticated and innovative concealment methods in the future.
Hackers tend to exploit opportunities where hacking is easier or more likely, with studies indicating a preference for targeting dynamic installation flows in registries like PyPI and NPM due to their simplicity in generating attacks. While research suggests a higher prevalence of such attacks in source code languages with dynamic installation flows, the accessibility of LLMs facilitates the adaptation of these attacks to new platforms, potentially leading hackers to explore less visible domains for their malicious activities.
How can organisations mitigate the risk associated with malicious open-source packages? How can CISOs ensure protection/prevention?
The foremost strategy for organisations to mitigate the risk posed by malicious open-source packages is through education. One should not use open-source code without properly knowing its origins. Ignorance in this realm does not lead to bliss. Therefore, implementing practices such as double-checking the authenticity of packages before installation is crucial. Looking into aspects like the accuracy of package descriptions, their reputation, community engagement (such as stars and user feedback), the quality of documentation in the associated GitHub repository, and its track record of reliability is also critical. By paying attention to these details, organisations can significantly reduce the likelihood of falling victim to malicious packages.
The fundamental challenge lies in addressing the ignorance regarding the risks associated with open-source software. Many users fail to recognize the potential threats and consequently, are prone to exploring and installing new packages without adequate scrutiny. Therefore, it is incumbent upon Chief Information Security Officers (CISOs) to actively participate in the decision-making process regarding the selection and usage of open-source packages within their organisations.
Despite best efforts, mistakes can still occur. To bolster defences, organisations should implement complementary protection services designed to monitor and verify the integrity of packages being installed. These measures serve as an additional layer of defence, helping to detect and mitigate potential threats in real-time.
What role does threat intelligence play in identifying and mitigating risks related to open-source packages?
Traditionally, threat intelligence has played a crucial role in identifying and mitigating risks associated with open-source packages. Dark web forums and other underground channels were primary sources for discussing and sharing malicious code snippets. This allowed security professionals to monitor and defend against these snippets using straightforward Yara rules. Additionally, threat intelligence facilitated the identification of suspicious package owners and related GitHub repositories, aiding in the early detection of potential threats. While effective for simpler cases of malicious code, this approach may struggle to keep pace with the evolving sophistication of attacks, particularly in light of advancements like Large Language Models (LLMs).
These days, with the rise of LLMs, it’s reasonable to expect hackers to innovate new methods through which to conduct malicious activity, prioritizing novel techniques over rehashing old samples that are easily identifiable by Yara rules. Consequently, while threat intelligence remains valuable, it should be supplemented with more advanced analysis techniques to thoroughly assess the integrity of open-source packages. This combined approach ensures a comprehensive defence against emerging threats, especially within less-monitored ecosystems, where traditional threat intelligence may be less effective.
What to anticipate in the future?
The emergence of Large Language Models (LLMs) is revolutionising every aspect of the software world, including the malicious domain. From the perspective of hackers, this development’s immediate implication equates to more complicated malicious attacks, more diverse attacks and more attacks, in general (leveraging LLMs to optimise strategies). Looking forward, we should anticipate hackers trying to target the LLMs themselves, using techniques like prompt injection or by trying to attack the LLM agents. New types and domains of malicious attacks are probably about to emerge.
Looking at the malicious open-source packages domain in general, a place we should probably start watching is Github. Historically, malicious campaigns have targeted open-source registries such as PyPI and NPM, with auxiliary support from platforms like GitHub, Dropbox, and Pastebin for hosting malicious components or publishing exploited data pieces. However, as these registries adopt more stringent security measures and become increasingly monitored, hackers are likely to seek out new “dark spots” such as extensions, marketplaces, and GitHub itself. Consequently, malicious code has the potential to infiltrate EVERY open-source component we utilise, necessitating vigilance and proactive measures to safeguard against such threats.
#Accessibility#ai#Analysis#applications#approach#attention#authentication#Business#challenge#Check Point#CISOs#code#Community#complexity#comprehensive#Dark#Dark web#data#data privacy#data protection#data science#details#detection#Developer#development#documentation#domains#double#dropbox#Ecosystems
3 notes
·
View notes
Last Seen Blogs

osuj4p2vy
Untitled

melmonium
Are you ready for the fun times

harringroveera
Billy Hargrove Twin

candlewaxandp0lar0ids
Long live all the magic we made

birbardakyagmuur
birbardakyağmur