#archived data (source material)
Text
A writer’s guide to the historical method: how historians work with sources
In this post, I provide a brief overview of how historians engage with different types of sources, with a focus on the mindset of a historian. This insight could be valuable for anyone crafting a character whose profession revolves around history research. It may also prove useful for authors conducting research for their book.
Concept of historical source
The concept of historical source evolves over time.
Initially, the focus was mainly on written sources due to their obvious availability. However, as time has progressed, historians now consider a wide range of sources beyond just written records. These include material artifacts, intangible cultural elements, and even virtual data.
While "armchair historians" may rely on existing studies and secondary sources, true professional historians distinguish themselves by delving directly into primary sources. They engage in a nuanced examination of various sources, weaving together diverse perspectives. It's crucial to recognize the distinction between personal recollection or memory and the rigorous discipline of historical inquiry. A historical source provides information, but the truth must be carefully discerned through critical analysis and corroboration.
Here's a concise list of the types of sources historians utilize:
Notarial source
Epistolary source
Accountancy source
Epigraphic source
Chronicle source
Oratory and oral source
Iconographic source
Diary source
Electronic source
Example: a notarial source
These are documents drafted by a notary, a public official entrusted with providing legal certainty to facts and legal transactions. These documents can take various forms, such as deeds, lawsuits, wills, contracts, powers of attorney, inventories, and many others.
Here we are specifically discussing a lawsuit document from 1211 in Italy.
A medieval lawsuit document is highly valuable for understanding various aspects of daily life because in a dispute, one must argue a position. From lawsuits, we also understand how institutions truly operated.
Furthermore, in the Middle Ages, lawsuits mostly relied on witnesses as evidence, so we can access a direct and popular source of certain specific social situations.
Some insight into the methodology of analysis:
Formal examination: historians scrutinize the document's form, verifying its authenticity and integrity. Elements such as structure, writing style, language, signatures, and seals are analyzed. Indeed, a professional historian will rarely conduct research on a source published in a volume but will instead go directly to the archive to study its origin, to avoid transcription errors.
Content analysis: historians proceed to analyze the document's content, extracting useful information for their research. This may include data on individuals, places, events, economic activities, social relations, and much more. It's crucial to compile a list of witnesses in a case and identify them to understand why they speak or why they speak in a certain manner.
Cross-referencing with other sources: information derived from the notarial source is compared with that of other historical sources to obtain a more comprehensive and accurate view of the period under examination.
Documents of the episcopal archive of Ivrea
Let's take the example of a specific legal case, stemming from the documents of the episcopal archive of Ivrea. It's a case from 1211 in Italy involving the bishop of Ivrea in dispute with Bongiovanni d'Albiano over feudal obligations.
This case is significant because it allows us to understand how feudal society operated and how social status was determined.
The bishop's representative argues that Bongiovanni should provide a horse as a feudal service. Bongiovanni denies it, claiming to be a noble, not a serf. Both parties present witnesses and documents supporting their arguments.
Witnesses are asked whether the serf obligations had been endured for a long time. This helps us understand that in a society where "law" was based on customs, it was important to ascertain if an obligation had been endured for a long time because at that point it would no longer be contestable (it would have become customary).
The responses are confused and inconsistent, so witnesses are directly asked whether they consider Bongiovanni a serf or a noble. This is because (and it allows us to understand that) the division into "social classes" wasn't definable within concrete boundaries; it was more about the appearance of one's way of life. If a serf refused to fulfill his serf duties, he would easily be considered a noble by bystanders because he lived like one.
Ultimately, the analysis of the case leads us to determine that medieval justice wasn't conceived with the logic of our modern system, but was measured in oaths and witnesses as evidentiary means. And emerging from it with honor was much more important than fairly distributing blame and reason.
Other sources
Accounting source: it is very useful for measuring consumption and its variety in a particular historical period. To reconstruct past consumption, inventories post mortem are often used, which are lists of goods found in households, described and valued by notaries to facilitate distribution among heirs.
Alternatively, the recording of daily expenses, which in modern times were often very detailed, can lead to insights into complex family histories and their internal inequalities - for example, more money might be spent on one child than another corresponding to their planned future role in society.
Oral source: in relation to the political sphere, it is useful for representing that part of politics composed of direct sources, that is, where politics speaks of itself and how it presents itself to the public, such as a politician's public speech.
However, working with this type of source, a historian cannot avoid hermeneutic work, as through the speech, the politician aims to present himself to a certain audience, justify, persuade, construct his own image, and achieve results. This is the hidden agenda that also exists in the most obvious part of politics.
Iconographic source: it concerns art or other forms of "artistic" expression, such as in the case of an advertising poster. They become historical sources when it is the historian who, through analysis, confers upon them the status of a historical source. Essentially, the historian uses the source to understand aspects of the past otherwise inaccessible.
The first step in this direction is to recontextualize the source, returning it to its original context. Examining the history of the source represents the fundamental first step for historical analysis.
Diary source: diaries are a "subjective" source, a representation of one's self, often influenced by the thoughts of "others," who can be close or distant readers, interested or distracted, visible or invisible, whom every diary author can imagine and hope to see, sooner or later, reflected on the pages of their writing.
Furthermore, they are often subject to subsequent manipulations, and therefore should be treated by historians only in their critical edition; all other versions, whether old or new, foreign or not, are useful only as evidence of the changes and manipulations undergone over time by the original manuscripts.
Electronic source: historians use Wikipedia even if they often don't admit it out loud.
This blog is supported through tips here on Tumblr. If you’d like to support me, please consider giving a tip.
#writing advice#writing help#writing reference#writing tips#creative writing#fantasy worldbuilding#fantasy writing#worldbuilding#worldbuilding tips
295 notes
·
View notes
Note
You wouldn't happen to have an extensive layout dissection of the Jedi Temple on Coruscant? Or even a list of all notable and obscure sections of the Jedi Temple? OR or even labelled areas that are public and reserved for only temple residents. Both from canon and legends, please and thank you!!!
The best I managed to find comes from Star Wars Complete Locations - you may check out the whole archived version here. The “zoom in” option is pretty good for reading details. Below the pages (I suppose the best is to open them in new tab for better reading):

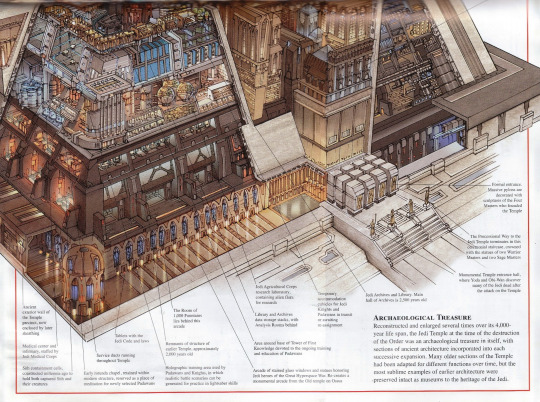


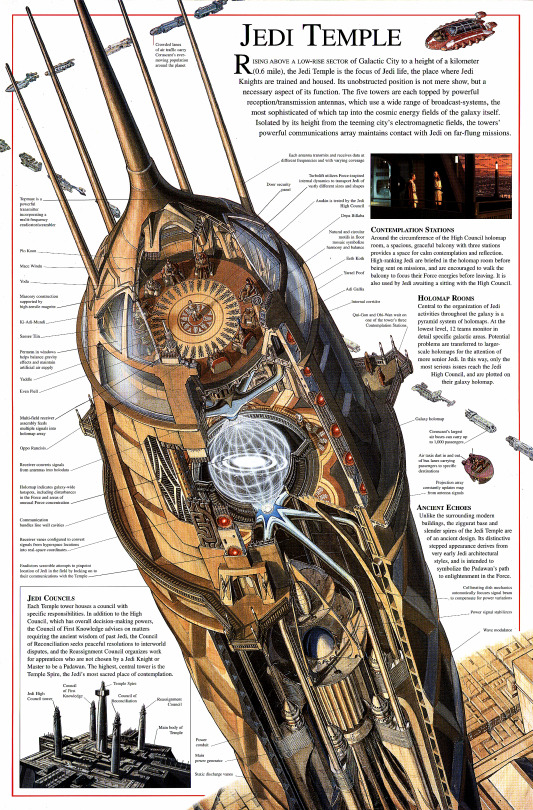
As for the list of locations, I recommend wookiepedia's list. Plenty of data, both for Legends and New Canon.
Additional sources worth to check out:
Jedi Temple Locations & Jedi Temple History - both published as official material on star wars.com in regard to prequels and New Canon sources. Pictures and references to various places inside Temple.
Star Wars.com's The Clone Wars episode guide + videoclips from the series, like
A) Jedi Archives Tour (the entrance to one of the most restricted areas of the temple: The Holocron Vault).
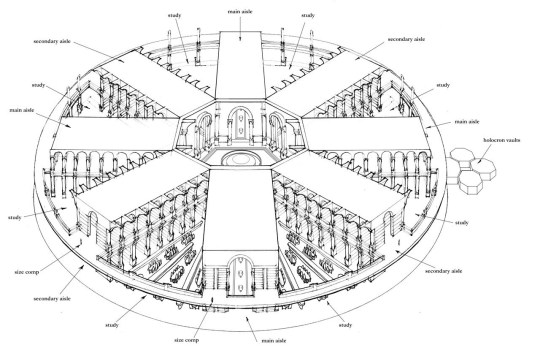
B) Layout of Jedi Temple Library (source)
C) Jedi Temple funeral room + environment illustration by Tara Rueping (source)


Old Data Bank for Jedi Temple
HoloNews mentioning "a mob of 20 university students attempted to infiltrate the Jedi Temple" and "managing to get as far as the Second Atrium Lobby"
Star Wars Battlefront (2) game wiki provides some map and location description
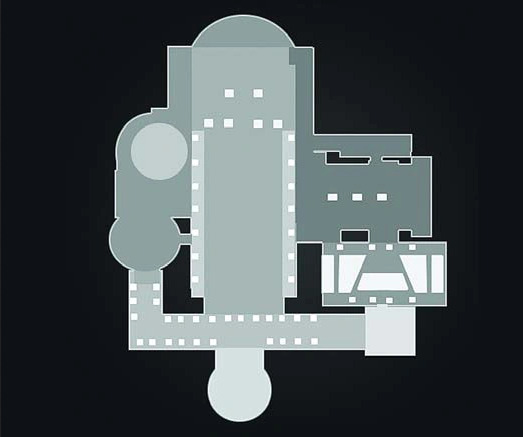
and if you have time (and patience) you can watch gameplay from 501st Legion's mission in Jedi Temple for reference, like this one
youtube
The wookiepedia's articles should give enough good idea of the rooms, their location and functions, but I'm adding a few source pages:
STAR WARS: FACT FILES #36 provides a lot informations what and where was inside the Temple and some general data about visitors, security, Grand Balcony, Grand Corridor & Towers. Not all is super specific, but worth checking out for sure.




The Complete Star Wars Encyclopedia mentions this:




and for Jedi Temple entry:

As for the named locations that are public or reserved for only temple residents, there is definitely a division like that, however I'm not sure if this issue was very well explained. The source gives us some ideas, like for example, Jedi Archives have data accessible only for Jedi with rank of Master or higher (thus most likely separated areas to study). At the same time, Fact Files #25 says that Jedi Archives offers an "excellent resources to researchers, including star-map hologram consoles", but also an access to entire scientific and historical knowledge of the Republic

so non-Jedi were allowed to use Jedi Library/Archives for their own research and work-related needs. We also must remember that the Jedi Order had various scientific branches, including archaeology, exploring unknown regions, and medicine, so logically thinking Jedi worked with other, non-Jedi specialists of many fields.
We also know from various sources, that politicians and important guests were invited for various occasions. We could see in Republic comics series that Bail Organa, Mon Mothma and senator Ask Aak were allowed to listen to Jedi reporting before High Council about his last battle

or attending Jedi Funeral like Duchess Satine and Padme Amidala did for the (fake) Obi-Wan's one or just visiting as a friend/comrade-in-arm

I would need to make more research about this issue as there is plenty tie-in material to Jedi Temple on Coruscant that would take a lot time to study, but at this moment, I think the best is assume how far a non-Jedi may walk into Temple will depend greatly who is that person and what is nature of their business with Jedi.
At the same time, Purge: Seconds to Die has this line "Clone Troopers? This deep in the Temple? Not permitted."

The Jedi was in Archives herself, so it is worth to take into account that clones could have more limited access to Temple than the average guest before war did. At the same time, clone troopers could make a report before Yoda and Mace Windu/High Council, as was presented by Star Wars Tales (Honor Bound):

so it is not like they were outright forbidden to enter the temple either.
Hope it will help!
#star wars#jedi temple#jedi culture#my replies#I'm pretty sure Star Wars Miniatures too had some maps for playing inside Jedi Temple#but sadly couldn't get any good images
339 notes
·
View notes
Text
The (open) web is good, actually

I'll be at the Studio City branch of the LA Public Library tonight (Monday, November 13) at 1830hPT to launch my new novel, The Lost Cause. There'll be a reading, a talk, a surprise guest (!!) and a signing, with books on sale. Tell your friends! Come on down!

The great irony of the platformization of the internet is that platforms are intermediaries, and the original promise of the internet that got so many of us excited about it was disintermediation – getting rid of the middlemen that act as gatekeepers between community members, creators and audiences, buyers and sellers, etc.
The platformized internet is ripe for rent seeking: where the platform captures an ever-larger share of the value generated by its users, making the service worst for both, while lock-in stops people from looking elsewhere. Every sector of the modern economy is less competitive, thanks to monopolistic tactics like mergers and acquisitions and predatory pricing. But with tech, the options for making things worse are infinitely divisible, thanks to the flexibility of digital systems, which means that product managers can keep subdividing the Jenga blocks they pulling out of the services we rely on. Combine platforms with monopolies with digital flexibility and you get enshittification:
https://pluralistic.net/2023/01/21/potemkin-ai/#hey-guys
An enshittified, platformized internet is bad for lots of reasons – it concentrates decisions about who may speak and what may be said into just a few hands; it creates a rich-get-richer dynamic that creates a new oligarchy, with all the corruption and instability that comes with elite capture; it makes life materially worse for workers, users, and communities.
But there are many other ways in which the enshitternet is worse than the old good internet. Today, I want to talk about how the enshitternet affects openness and all that entails. An open internet is one whose workings are transparent (think of "open source"), but it's also an internet founded on access – the ability to know what has gone before, to recall what has been said, and to revisit the context in which it was said.
At last week's Museum Computer Network conference, Aaron Straup Cope gave a talk on museums and technology called "Wishful Thinking – A critical discussion of 'extended reality' technologies in the cultural heritage sector" that beautifully addressed these questions of recall and revisiting:
https://www.aaronland.info/weblog/2023/11/11/therapy/#wishful
Cope is a museums technologist who's worked on lots of critical digital projects over the years, and in this talk, he addresses himself to the difference between the excitement of the galleries, libraries, archives and museums (GLAM) sector over the possibilities of the web, and why he doesn't feel the same excitement over the metaverse, and its various guises – XR, VR, MR and AR.
The biggest reason to be excited about the web was – and is – the openness of disintermediation. The internet was inspired by the end-to-end principle, the idea that the network's first duty was to transmit data from willing senders to willing receivers, as efficiently and reliably as possible. That principle made it possible for whole swathes of people to connect with one another. As Cope writes, openness "was not, and has never been, a guarantee of a receptive audience or even any audience at all." But because it was "easy and cheap enough to put something on the web," you could "leave it there long enough for others to find it."
That dynamic nurtured an environment where people could have "time to warm up to ideas." This is in sharp contrast to the social media world, where "[anything] not immediately successful or viral … was a waste of time and effort… not worth doing." The social media bias towards a river of content that can't be easily reversed is one in which the only ideas that get to spread are those the algorithm boosts.
This is an important way to understand the role of algorithms in the context of the spread of ideas – that without recall or revisiting, we just don't see stuff, including stuff that might challenge our thinking and change our minds. This is a much more materialistic and grounded way to talk about algorithms and ideas than the idea that Big Data and AI make algorithms so persuasive that they can control our minds:
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens
As bad as this is in the social media context, it's even worse in the context of apps, which can't be linked into, bookmarked, or archived. All of this made apps an ominous sign right from the beginning:
https://memex.craphound.com/2010/04/01/why-i-wont-buy-an-ipad-and-think-you-shouldnt-either/
Apps interact with law in precisely the way that web-pages don't. "An app is just a web-page wrapped in enough IP to make it a crime to defend yourself against corporate predation":
https://pluralistic.net/2023/08/27/an-audacious-plan-to-halt-the-internets-enshittification-and-throw-it-into-reverse/
Apps are "closed" in every sense. You can't see what's on an app without installing the app and "agreeing" to its terms of service. You can't reverse-engineer an app (to add a privacy blocker, or to change how it presents information) without risking criminal and civil liability. You can't bookmark anything the app won't let you bookmark, and you can't preserve anything the app won't let you preserve.
Despite being built on the same underlying open frameworks – HTTP, HTML, etc – as the web, apps have the opposite technological viewpoint to the web. Apps' technopolitics are at war with the web's technopolitics. The web is built around recall – the ability to see things, go back to things, save things. The web has the technopolitics of a museum:
https://www.aaronland.info/weblog/2014/09/11/brand/#dconstruct
By comparison, apps have the politics of a product, and most often, that product is a rent-seeking, lock-in-hunting product that wants to take you hostage by holding something you love hostage – your data, perhaps, or your friends:
https://www.eff.org/deeplinks/2021/08/facebooks-secret-war-switching-costs
When Anil Dash described "The Web We Lost" in 2012, he was describing a web with the technopolitics of a museum:
where tagging was combined with permissive licenses to make it easy for people to find and reuse each others' stuff;
where it was easy to find out who linked to you in realtime even though most of us were posting to our own sites, which they controlled;
where a link from one site to another meant one person found another person's contribution worthy;
where privacy-invasive bids to capture the web were greeted with outright hostility;
where every service that helped you post things that mattered to you was expected to make it easy for you take that data back if you changed services;
where inlining or referencing material from someone else's site meant following a technical standard, not inking a business-development deal;
https://www.anildash.com/2012/12/13/the_web_we_lost/
Ten years later, Dash's "broken tech/content culture cycle" described the web we live on now:
https://www.anildash.com/2022/02/09/the-stupid-tech-content-culture-cycle/
found your platform by promising to facilitate your users' growth;
order your technologists and designers to prioritize growth above all other factors and fire anyone who doesn't deliver;
grow without regard to the norms of your platform's users;
plaster over the growth-driven influx of abusive and vile material by assigning it to your "most marginalized, least resourced team";
deliver a half-assed moderation scheme that drives good users off the service and leaves no one behind but griefers, edgelords and trolls;
steadfastly refuse to contemplate why the marginalized users who made your platform attractive before being chased away have all left;
flail about in a panic over illegal content, do deals with large media brands, seize control over your most popular users' output;
"surface great content" by algorithmically promoting things that look like whatever's successful, guaranteeing that nothing new will take hold;
overpay your top performers for exclusivity deals, utterly neglect any pipeline for nurturing new performers;
abuse your creators the same ways that big media companies have for decades, but insist that it's different because you're a tech company;
ignore workers who warn that your product is a danger to society, dismiss them as "millennials" (defined as "anyone born after 1970 or who has a student loan")
when your platform is (inevitably) implicated in a murder, have a "town hall" overseen by a crisis communications firm;
pay the creator who inspired the murder to go exclusive on your platform;
dismiss the murder and fascist rhetoric as "growing pains";
when truly ghastly stuff happens on your platform, give your Trust and Safety team a 5% budget increase;
chase growth based on "emotionally engaging content" without specifying whether the emotions should be positive;
respond to ex-employees' call-outs with transient feelings of guilt followed by dismissals of "cancel culture":
fund your platforms' most toxic users and call it "free speech";
whenever anyone disagrees with any of your decisions, dismiss them as being "anti-free speech";
start increasing how much your platform takes out of your creators' paychecks;
force out internal dissenters, dismiss external critics as being in conspiracy with your corporate rivals;
once regulation becomes inevitable, form a cartel with the other large firms in your sector and insist that the problem is a "bad algorithm";
"claim full victim status," and quit your job, complaining about the toll that running a big platform took on your mental wellbeing.
https://pluralistic.net/2022/02/18/broken-records/#dashes
The web wasn't inevitable – indeed, it was wildly improbable. Tim Berners Lee's decision to make a new platform that was patent-free, open and transparent was a complete opposite approach to the strategy of the media companies of the day. They were building walled gardens and silos – the dialup equivalent to apps – organized as "branded communities." The way I experienced it, the web succeeded because it was so antithetical to the dominant vision for the future of the internet that the big companies couldn't even be bothered to try to kill it until it was too late.
Companies have been trying to correct that mistake ever since. After three or four attempts to replace the web with various garbage systems all called "MSN," Microsoft moved on to trying to lock the internet inside a proprietary browser. Years later, Facebook had far more success in an attempt to kill HTML with React. And of course, apps have gobbled up so much of the old, good internet.
Which brings us to Cope's views on museums and the metaverse. There's nothing intrinsically proprietary about virtual worlds and all their permutations. VRML is a quarter of a century old – just five years younger than Snow Crash:
https://en.wikipedia.org/wiki/VRML
But the current enthusiasm for virtual worlds isn't merely a function of the interesting, cool and fun experiences you can have in them. Rather, it's a bid to kill off whatever is left of the old, good web and put everything inside a walled garden. Facebook's metaverse "is more of the same but with a technical footprint so expensive and so demanding that it all but ensures it will only be within the means of a very few companies to operate."
Facebook's VR headsets have forward-facing cameras, turning every users into a walking surveillance camera. Facebook put those cameras there for "pass through" – so they can paint the screens inside the headset with the scene around you – but "who here believes that Facebook doesn't have other motives for enabling an always-on camera capturing the world around you?"
Apple's VisionPro VR headset is "a near-perfect surveillance device," and "the only thing to save this device is the trust that Apple has marketed its brand on over the last few years." Cope notes that "a brand promise is about as fleeting a guarantee as you can get." I'll go further: Apple is already a surveillance company:
https://pluralistic.net/2022/11/14/luxury-surveillance/#liar-liar
The technopolitics of the metaverse are the opposite of the technopolitics of the museum – even moreso than apps. Museums that shift their scarce technology budgets to virtual worlds stand a good chance of making something no one wants to use, and that's the best case scenario. The worst case is that museums make a successful project inside a walled garden, one where recall is subject to corporate whim, and help lure their patrons away from the recall-friendly internet to the captured, intermediated metaverse.
It's true that the early web benefited from a lot of hype, just as the metaverse is enjoying today. But the similarity ends there: the metaverse is designed for enclosure, the web for openness. Recall is a historical force for "the right to assembly… access to basic literacy… a public library." The web was "an unexpected gift with the ability to change the order of things; a gift that merits being protected, preserved and promoted both internally and externally." Museums were right to jump on the web bandwagon, because of its technopolitics. The metaverse, with its very different technopolitics, is hostile to the very idea of museums.
In joining forces with metaverse companies, museums strike a Faustian bargain, "because we believe that these places are where our audiences have gone."
The GLAM sector is devoted to access, to recall, and to revisiting. Unlike the self-style free speech warriors whom Dash calls out for self-serving neglect of their communities, the GLAM sector is about preservation and access, the true heart of free expression. When a handful of giant companies organize all our discourse, the ability to be heard is contingent on pleasing the ever-shifting tastes of the algorithm. This is the problem with the idea that "freedom of speech isn't freedom of reach" – if a platform won't let people who want to hear from you see what you have to say, they are indeed compromising freedom of speech:
https://pluralistic.net/2022/12/10/e2e/#the-censors-pen
Likewise, "censorship" is not limited to "things that governments do." As Ada Palmer so wonderfully describes it in her brilliant "Why We Censor: from the Inquisition to the Internet" speech, censorship is like arsenic, with trace elements of it all around us:
https://www.youtube.com/watch?v=uMMJb3AxA0s
A community's decision to ban certain offensive conduct or words on pain of expulsion or sanction is censorship – but not to the same degree that, say, a government ban on expressing certain points of view is. However, there are many kinds of private censorship that rise to the same level as state censorship in their impact on public discourse (think of Moms For Liberty and their book-bannings).
It's not a coincidence that Palmer – a historian – would have views on censorship and free speech that intersect with Cope, a museum worker. One of the most brilliant moments in Palmer's speech is where she describes how censorship under the Inquistion was not state censorship – the Inquisition was a multinational, nongovernmental body that was often in conflict with state power.
Not all intermediaries are bad for speech or access. The "disintermediation" that excited early web boosters was about escaping from otherwise inescapable middlemen – the people who figured out how to control and charge for the things we did with one another.
When I was a kid, I loved the writing of Crad Kilodney, a short story writer who sold his own self-published books on Toronto street-corners while wearing a sign that said "VERY FAMOUS CANADIAN AUTHOR, BUY MY BOOKS" (he also had a sign that read, simply, "MARGARET ATWOOD"). Kilodney was a force of nature, who wrote, edited, typeset, printed, bound, and sold his own books:
https://www.theglobeandmail.com/arts/books/article-late-street-poet-and-publishing-scourge-crad-kilodney-left-behind-a/
But there are plenty of writers out there that I want to hear from who lack the skill or the will to do all of that. Editors, publishers, distributors, booksellers – all the intermediaries who sit between a writer and their readers – are not bad. They're good, actually. The problem isn't intermediation – it's capture.
For generations, hucksters have conned would-be writers by telling them that publishing won't buy their books because "the gatekeepers" lack the discernment to publish "quality" work. Friends of mine in publishing laughed at the idea that they would deliberately sideline a book they could figure out how to sell – that's just not how it worked.
But today, monopolized film studios are literally annihilating beloved, high-priced, commercially viable works because they are worth slightly more as tax writeoffs than they are as movies:
https://deadline.com/2023/11/coyote-vs-acme-shelved-warner-bros-discovery-writeoff-david-zaslav-1235598676/
There's four giant studios and five giant publishers. Maybe "five" is the magic number and publishing isn't concentrated enough to drop whole novels down the memory hole for a tax deduction, but even so, publishing is trying like hell to shrink to four:
https://pluralistic.net/2022/11/07/random-penguins/#if-you-wanted-to-get-there-i-wouldnt-start-from-here
Even as the entertainment sector is working to both literally and figuratively destroy our libraries, the cultural heritage sector is grappling with preserving these libraries, with shrinking budgets and increased legal threats:
https://blog.archive.org/2023/03/25/the-fight-continues/
I keep meeting artists of all description who have been conditioned to be suspicious of anything with the word "open" in its name. One colleague has repeatedly told me that fighting for the "open internet" is a self-defeating rhetorical move that will scare off artists who hear "open" and think "Big Tech ripoff."
But "openness" is a necessary precondition for preservation and access, which are the necessary preconditions for recall and revisiting. Here on the last, melting fragment of the open internet, as tech- and entertainment-barons are seizing control over our attention and charging rent on our ability to talk and think together, openness is our best hope of a new, good internet. T
he cultural heritage sector wants to save our creative works. The entertainment and tech industry want to delete them and take a tax writeoff.
As a working artist, I know which side I'm on.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/13/this-is-for-everyone/#revisiting
Image:
Diego Delso (modified)
https://commons.wikimedia.org/wiki/File:Museo_Mimara,_Zagreb,_Croacia,_2014-04-20,_DD_01.JPG
CC BY-SA 4.0
https://creativecommons.org/licenses/by-sa/4.0/
#pluralistic#ar#xr#vr#augmented reality#extended reality#virtual reality#museums#cultural preservation#aaron cope#Museum Computer Network#cultural heritage#glam#access#open access#revisiting#mr#mixed reality#asynchronous#this is for everyone#freedom of reach#gatekeepers#metaverse#technofeudalism#privacy#brick on the face#rent-seeking
185 notes
·
View notes
Text
fanfic friday*: found media
*it's probably not friday
Going to bring rec lists back into Fashion!! Today's theme is: in-universe fanworks: aka: publications and materials that you might come across within the universe of The Murderbot Diaries.
^ This is a neocities website that reads like a sponsored infoarticle for different SecUnit brands. Resist your knee-jerk urge to close out the popup advertisement and enjoy it, it's part of the experience. It's a riot. You can also go here for the simplified version posted to AO3. Save it in your AO3 bookmarks and give the website creator their due accolades! Kudos and comment etc. If you want.
^ This one is an article by a Corporate Rim media critic who watched Dr. Bharadwaj's documentary about bot and construct rights. Reads in a painfully plausible way. The classic conundrum of: "Well why should I worry about the problems others face? Do they really have it as bad as the rest of us?"
^ The author apotropiacsymbol is a great writer with a distinct je ne sais quoi style and a knack for eerie worldbuilding that closes in around you. You should check out all their works tbh, their way with words is mesmerizing. This one is presented as an academic presentation about mysterious found data. Read between the lines of this fic to figure out what has been going on... Though the author also explains a bit in the comment section.
^ In the style of an academic article about the little-appreciated effects and casualties of the robot revolution in hindsight. Complete with Headers and Sources Cited.
^ Last but absolutely not least, this work was developed for pod-together, and comes with a full podfic with sound effects. It goes hard in the metatextuality of the Murderbot series and fandom. It's an absolute banger and I love it a lot. It envisions a future where there are constructs and bots who are created free.
The sound-artist/creator of the work is a Preservation-born SecUnit who was made without a governor module. It must find its way in the world and navigate the weight of the recent past — all the struggles for construct self-determination and the long shadows of those that came before it: Murderbot, Three, and a certain ComfortUnit...
This is a story about machine intelligences struggling to establish themselves in a human world, about how we can't possibly shake off the traumas that built our world, and about how to carry forth a legacy and heal wounds that you inherit, inherent to your creation. And it's so good. Also there's a whole very serious bit about a fart.
67 notes
·
View notes
Note
How do you find the time to read all your book recs?? Also would you mind talking about your process for researching specific topics :)
i generally only make rec lists for things i have enough familiarity with to navigate the literature so, you have to keep in mind those lists are sometimes literally a decade+ of cumulative reading on my end. i do also sometimes include texts i haven't read in their entirety, or occasionally even ones i've only come across in footnotes but still think are foundational or relevant enough to warrant a rec.
as to my research process: there's no single answer here because the sort of research i do will depend on what questions i'm trying to answer. usually if i'm starting to look at a topic completely from scratch, i'll ask someone who publishes in that area what the major recent works are, then scan a few of them. i might 'snowball' those texts (read the works they cite in their footnotes) but, that strategy has limited utility because it only goes backward in time and sometimes a recent or uncited text can be incredibly valuable. so there's a fair amount of bumbling around in the secondary literature at this point. some academic journals maintain bibliographies for their subfields, which are not comprehensive but can be useful; i usually also do a certain amount of keyword fuckery in my library's database. sometimes i waste a lot of time at this point chasing leads that turn out to be irrelevant, or i discover that a question i was chasing is really better tackled from an entirely different direction. shit happens.
at some point i usually reach a stage where i need to look at some primary sources, because i'm oriented enough in the major issues to identify spots where previous researchers haven't made full use of historical records, or may be interpreting them in a way i disagree with. so, what exactly i'm looking for now really varies. sometimes i just want to read the primary texts that another historian is commenting on: for example, the last few months i was trawling through the french national library's archives to see what people were saying in print about a specific historical figure between about 1778 and 1862. other times i might want population data or land records: births, deaths, cholera infections, records of church property sales, &c. depending on, again, what sorts of questions you're asking, anything might have useful information to you: postmortem personal auction catalogues have given me some mileage, along with wills and personal correspondance. i have a committee member who collects and analyses postcards often being sold for pennies at flea markets out of people's grandparents' attics, and another who has an ongoing project looking at a zillion editions of a specific children's book printed in the late 19th century. along the way, as i look at primary sources, i will typically go back and forth to more secondary literature, as i find new topics that might be relevant or help me contextualise what i'm looking at. i can't ever really plan these things out systematically; i just follow what looks promising and interesting and see where it leads me.
another thing to consider is that the primary sources sometimes tell me useful information directly in their capacity as material objects. what type of paper is used, what personal or library stamps appear on the cover, who's the publisher, how many editions did it go through, are the print and typeset jobs sloppy, where was this copy found or preserved? these sorts of details tell me about how people reacted to the text, its author, and the ideas within, which can be a valuable part of whatever investigation i'm trying to conduct. sometimes i end up chasing down information on a publisher or the owner whose personal library a book or piece of ephemera came out of; there are people who research processes of preservation, printing, &c in themselves, which has yielded some fascinating studies in recent decades.
at some point, if it's a research project i'm trying to communicate to other people, i will switch to writing mode, where i try to organise ^^ all of that in my head, and form a coherent narrative or argument that i think is worth making. this might be revisionist in nature ('people have argued before that such and such was x way or historical actors thought about it like y, but what i have here indicates we should actually understand it in the context of z') or it might be more like, "hey, i found this thing i don't think anyone knows about!" or anything else. again, the way you put together a research project will vary so widely depending on what you're researching, and why, and why you think it matters and to whom.
also, i should emphasise that what i've written here isn't necessarily something that happens on a strict or compressed timeline. i'm working on a dissertation, so for that topic, i do have reasons i want to complete parts at certain times, unfortunately. but i also have research projects that i just chip away at for fun, that i've had on various backburners for literally years, that i might sometimes write about (eg, on here) without necessarily ever planning to subject them to the hegemon of academic publishing. i think knowledge dissemination is great and to that end i love to talk to people about what i'm researching and hear about their stuff as well. but, i also think research projects can be fun / rewarding / &c when they're completely for your own purposes, untimed, unpublished, &c &c. i guess i'm just saying, publishing and research conventions and rules sometimes have purposes (like "make it possible to publish this as a book in the next 5 years") but don't get so hung up on those rules that they prevent you from just researching something for any number of other reasons. there are so many ways to skin a cat 📝
47 notes
·
View notes
Note
Please disregard if there's no way to answer this without it being invasive but... re: your recent post about your job supporting your fatigue and disabilities... would you mind saying what industry it is? I have a friend with disability/chronic debilitating illness who is trying to figure out how to envision a working life while managing ongoing pain, surgeries, fatigue, etc., and I think he despairs of any place ever being willing to accommodate him for a few hours a week. We google things plenty, but the difference between a helpful listicle and a real person's anecdote is everything.
sure. my job is kind of niche so I don’t know how easy it would be to go hunting for it specifically, and I do kinda worry about giving its title since afaict only one company uses it (though more than one does this same basic thing) and my job is very regional, but maybe describing it would help you somehow
basically I work for an archive / news service. technically, I’m a journalist, but realistically what I do is more akin to gophering and data entry. I work three days a week - two short days in my county and one long one in one of the neighboring counties. on days when I leave the county I get hours for my driving time and miles reimbursed.
I don’t get a lot of flexibility on how many days I work, but when I started the job I got to pick which three days I would work, so got to decide whether one long rest or two short rests would suit me better. On the days I work I have a deadline (5pm) but can work whenever I want to meet that deadline. Sometimes it’s 9am - 11am and other times it’s 1pm - 3pm. Sometimes there’s no new cases and work is 20 minutes from my couch.
And basically what I do is compile a list of potentially interesting lawsuits filed in the county, go to the relevant courthouse to read the actual legal complaint, summarize and log the ones that meet certain criteria in a simple sentence, and get scans of ones that meet even stricter criteria to upload to our archive, all of which gets sent out to our subscribers on mailing lists.
Then, journalists and lawyers pay to get these updates or access these databases for their own reporting or research. I often know local headlines a few days to a couple weeks early because I was the one reading the source material.
I work an average of 7 hours a week. My short days are usually an hour or two. My long day is 3-7 hours depending on which county I’m going to and how unique or complicated the filed cases are. It does not take long to do the actual work. Most of my hours come from driving rural highways and listening to podcasts.
It’s the kind of job there’s not a lot of. But while it’s the best I’ve found, I’ve found very part time work with lenient employers before. It is possible. You just gotta be specific about it.
I will say, while most jobs are not looking for employees that part time, those that are will thrilled to hear that’s enough hours for you. Employers who need one specific skilled task that only takes 7 hours a week often struggle with retention because, well, how many people are gonna take that as a stop gap until they get more full time work? And then all the rest are likely to be disabled people like me, who have retention issues for reasons of health. That being said I’ve worked this job for years now, and I’m not letting it go without, like, some other better guarantee. Because while I’m happy to provide hope that these jobs do exist, it is also true that they’re tough to find.
20 notes
·
View notes
Note
You are probably aware of this given your interest in the topic, but some other interesting things to look at for the fucked up fertility industry (and how they absolutely don't give a fuck about their patients/clients or the children they produce):
This piece from reveal specifically talks about how fertility clinics downplay something as basic and fundamental as the health risks of twins and triplets.
https://revealnews.org/podcast/misconceptions/
Sarah Zhang (excellent science writer) has written a lot (mostly for The Atlantic) about fertility ethics and legal issues. In this piece, she talks about a case where a clinic mix up led to a couple using the wrong samples to conceive, and that only coming to light years later, and the ensuing legal case
https://www.theatlantic.com/science/archive/2019/07/ivf-embryo-mix-up-parenthood/593725/
I think I've already seen you talk about The Retrievals, but good lord that's fucked up.
Yes I did listen to the The Retrievals!! I think last month or the month before. Really lays bare how medicine is not exempt from cultural beliefs, with the juxtaposition of real medical issues (pain from lack of anesthesia) and the constructed medical issue (you want to conceive a baby) - the patriarchal constructed idea taking precedence over real women's pain. Highly recommend any feminist listen to it.
It definitely should come to no surprise to any feminist that the for-profit fertility and adoption industries looooove to lie, much like any industry! It comes in the form of lobbying, creative marketing, and of course just straight up lying to your customers. The fertility industry and the plastic surgery industry in my mind are holding hands in this way, that recovery from any of these procedures is easy, no worries, like magic. And of course, the over reliance on detached clinical language when it suits them (like in ads to egg donors...a sort of "you aren't using them, who cares!") just to flip to over reliance on pathos when it suits them ("we understand your internal need to hold a baby in your arms, it's more powerful than science" sort of talk), when really neither the emotional nor physical repercussions should be taken lightly. It's easy to persuade a young 20 something who needs money that her genetic material totally has no emotional weight, dude. just like it's easy to rely on the magical thinking that already exists in the cultural conscience to persuade women that pregnancy is sort of a nebulous, a baby is just small and then it just gets big, who knows what goes on in there process, instead of a long set of very specific biological processes that require many of your resources. Like, it really is your blood and energy and hormones making this baby, not just your "womb" doing "magic".
One of the things I find alarming is if you search "risks of egg donation" is how the results from all sorts of different .coms and .orgs are all over the place, with few linked sources, and a general blase attitude of how there are few proven risks to date...but also the process requires you to give yourself hormonal injections every single day for minimum two weeks. I'm not saying you should start believing conspiracies and think "well definitely there are risks being ignored and hidden on purpose", I'm just saying it follows a pattern in women's health, where things are understudied and the more convenient narrative is believed over trying to get data. What do we actual know about injecting hormones every day for two weeks (at least) for the long term? I don't know!!! There doesn't seem to be any serious data anywhere. Could be low risk, could be high risk, who cares!!! Do it three or four or five times for $$$ and you can find out in 5 or 40 years, if you're even believed.
25 notes
·
View notes
Note
Hey Sol! I remember quite a while ago, someone asked you about how to get into archiving stuff and you answered with a little guide of sorts of useful programs/websites/etc.
Do you still have that guide up? Is there somewhere I can learn more in-depth about how to begin archiving too?
Tumblr search is failing me and I can't find that post now... So! I'll type it again. Lately I've been thinking about writing some kind of "archivist's manifesto" type thing for my Neocities in an effort to hype people up about archiving and to guide them on how to do it. When I write that up I'll post it here too.
Here's a big post I wrote on how to scan books and where to upload them (this is also linked in the big GG masterpost that's in my pinned): https://solradguy.tumblr.com/post/722512206034501632/sol-radguy-scanning-guide
That guide also has some tips on photo editing that may be useful for non-book scanning stuff, like some free program alternatives.
I've tried finding professional guides on how to archive media but most of them are written for people looking to archive family photos/things and not web media or physical books. None of them have been very helpful, honestly. One thing they recommend doing that I think IS helpful though is the rule of 3: Keep 3 copies of an archive somewhere. A physical hard drive, cloud storage, a second hard drive stored separately from the first (in case of accidents/hardware failure), uploaded to separate file hosts, and printing new physical copies are some. Doing any 3 of those is highly recommended. I do the two hard drives and cloud storage/file hosts ones. My hosts are generally Archive.org, Neocities, and Google Drive.
Be very careful about trusting image hosting sites with valuable scan data because they come and go like the wind. Photobucket, Tinypic, Imageshack... They're either dead or require a premium to host files now, which doesn't help hobby archivists at all. Imgur's demise is on the horizon. It's just the way it goes with these due to how expensive and space-consuming image hosting is.
Absolutely 1000% do not ever use just Discord for archiving/hosting things. Nothing on that platform can be backed up easily or with automation, and the guys that run it have already made weird choices the community didn't want while also putting more and more things behind the Nitro paywall. I suspect they're going to kneecap image and file hosting some day soon, too.
For archiving someone else's files, something that helps greatly (if it can be done) is either including the source of the file in the file's name or writing a separate document with the sources and whatever other additional information there is.
Here's a basic example of some Sol images from my Sol folder:

The first two are from the Counterside collab event and then the second two are official art but the file names are descriptive and it saves time sourcing them for things later. For archiving fan art/fiction, the filename is a good place to put the artist credit. Something like [Artwork Title]-[Artist Name]-[Original File Creation Date].format ("Sol Badguy Missing Link - Daisuke Ishiwatari - May 14 1998.jpg," or however you wanna organize the folder) works good.
Windows 11 didn't like working with Japanese text in file names for some of the Vastedge stuff I archived and I had to translate/romanize them. If you can't read Japanese/source's language, just do your best (number them instead?) and include the native language text in a .TXT file if possible.
A more complex example from the Vastedge .TXT doc:
The Vastedge materials archive is pretty dense and had a lot of contributors so the first half of the .TXT document's just credits for who did what. This is useful for if something gets lost because we'll know who to go bother about it. Among other things.
The next section is a long stack of details about the files themselves. I won't paste the whole thing here, it's pretty long. It covers how the archive came to be, issues with some of the files, how the files were obtained, and some other stuff:

The last half of the .TXT doc is a listing of the folder contents. I included this for quick reference and because sometimes archives get fractured by people only reuploading certain parts of it. Future archivists or anyone else going through this archive now have a list of what should be in there and will know if something is missing.
Archive.org/Wayback Machine has a browser extension for quickly archiving webpages. I have that and WebP / Avif Image Converter by Nullbrains (Chrome, might be on Firefox?) installed to quickly archive pages and convert image files as I save them.
In summary:
Upload/store things in multiple places
Include credits wherever you can, however is easiest for you
Try to keep files in the most widely compatible formats (jpg, gif, bmp, png, tiff, mp3, mp4, txt, pdf, flac, etc). Google's .DOC, Clip Studio Paint's .CLIP, and similar file formats meant for a specific piece of software may not be supported in the future.
A bad/incomplete archive is better than no archive at all. Consider how exciting Sappho poetry fragments are compared to what it would be like if we didn't have anything. Don't worry about making it "perfect."
Hope that helps some!! I'll try to write the manifesto for my NC soon
50 notes
·
View notes
Note
hey i say this out of concern is there any confirmation accountability archive is legit? i noticed on their forms they state theyre interested in *student records*, which kind of raised an alarm for me. their twitter account and website is SUPER vague, and there seem to be people who are palestinian (or at least have family who are) also asking who is running this. i’m not sure if sending identifying and personal information of individuals to an anonymous source is a good idea.
i first heard about accountability archive through various groups/orgs that i know vet their material when reposting and have seen the org itself seeking out university partners and journalists, which to me seems like a good sign. i have a strong amount of skepticism and don't like to reblog stuff blindly so when i did some digging based on their gofundme and their more explicit goals outlined over there (in which they give a broad explanation of their plans and methodology) they name that the archive "was co-founded by Dr. Philip Proudfoot, an anthropologist whose research focuses on economic inequality, forced migration, and humanitarianism, and Mahdi Zaidan, who has worked on similar data gathering projects centred on the Syrian civil war." it seems these two have been working together since at least 2019. in addition, the archive "has grown to a group of about a dozen researchers, activists, archivists, tech experts, translators, and lawyers. We are based in the UK but the group has representation from around the globe." i think people can consider how and if they want to share personal info, but there are real names attached to the project on the whole
13 notes
·
View notes
Photo

!NEW RELEASE!
Title: Sylvia Plath Day by Day, Volume 1: 1932-1955
Author: Carl Rollyson
Publication date: 15 August 2023
Pages: 400
Publisher: University Press of Mississippi (UPM)
Image source (cover & description): https://www.upress.state.ms.us
About the book:
“A fascinating investigation into the life and art of one of America’s greatest poets
Since Sylvia Plath’s death in 1963, she has become the subject of a constant stream of books, biographies, and articles. She has been hailed as a groundbreaking poet for her starkly beautiful poems in Ariel and as a brilliant forerunner of the feminist coming-of-age novel in her semiautobiographical The Bell Jar. Each new biography has offered insight and sources with which to measure Plath’s life and influence. Sylvia Plath Day by Day, a two-volume series, offers a distillation of this data without the inherent bias of a narrative.
Volume 1 commences with Plath’s birth in Boston in 1932, records her response to her elementary and high school years, her entry into Smith College, and her breakdown and suicide attempt, and ends on February 14, 1955, the day she wrote to Ruth Cohen, principal of Newnham College, Cambridge, to accept admission as an “affiliated student at Newnham College to read for the English Tripos.”
Sylvia Plath Day by Day is for readers of all kinds with a wide variety of interests in the woman and her work. The entries are suitable for dipping into and can be read in a minute or an hour. Ranging over several sources, including Plath’s diaries, journals, letters, stories, and other prose and poetry—including new material and archived material rarely seen by readers—a fresh kaleidoscopic view of the writer emerges.
Reviews
"The details in Rollyson’s Sylvia Plath Day by Day, Volume 1: 1932–1955 are a dream come true for the reader, fan, and scholar of Sylvia Plath. The seeds of so much of her creative writing are present, but Rollyson deftly does not foreshadow how events impact Plath’s life and when she transforms experiences from life to art. He lets each moment stand on its own importance."
"Sylvia Plath Day by Day, Volume 1: 1932–1955 is a must-have book for any reader interested in Plath. Detailed yet highly readable, it paints a portrait of a young woman who would become, as will be chronicled in volume 2, one of the seminal authors in the twentieth century."
"Sylvia Plath Day by Day, Volume 1: 1932–1955 fills the lacunae of existing biographies and uncovers new insights into its subject, as when Plath writes about her experiences at Smith, hearing ‘nasty little tag ends of conversation directed at you and around you, meant for you, to strangle you on the invisible noose of insinuation.’ Or her months in New York at Mademoiselle, which grow less mysterious here. Again, Carl Rollyson has provided us with an indispensable book on Sylvia Plath." “
You can order the book through their website or from other online shops.
#sylvia plath#new release#carl rollyson#sylvia plath day by day#sylviaplath#sylvia plath scholarship#university press of mississippi
28 notes
·
View notes
Text
Bellingcat: Two Years Since Russia's Full-Scale Invasion of Ukraine
Two years ago today, Russia unleashed its full-scale invasion of Ukraine. That move has caused widespread destruction, inflamed world tensions and as of last November killed at least 10,000 civilians, according to the UN.
Open source investigative techniques have allowed many to scrutinise this conflict from afar. On the first days of the invasion, we set up our Ukraine Civilian Harm Map, which features over 1,500 incidents verified by our team. Our colleagues in Bellingcat's Justice & Accountability Unit have also advocated for a greater role for open source materials in judicial proceedings.
Much has changed since those first days. The optimistic projections following Ukraine's successful counteroffensive in Kharkiv Region are a thing of the past. Following Russia's capture of Avdiivka this month and growing hurdles to US military support for Ukraine, Russian President Vladimir Putin reportedly has renewed hope for achieving his maximalist goals. This war may last well into 2024 — or more likely into 2025 or beyond.
Whatever happens, we'll continue to watch and investigate. In this newsletter, we'll share useful open source techniques from our work on Ukraine and offer examples of the finest open source investigations on Ukraine.
Top Five: Tools, Techniques and Tips
Over the years, Bellingcat's team has shared new tools and techniques with the help of the wider open source community. They've been invaluable in our investigations on Ukraine. Here are five particularly innovative examples:
It's all in the stitching. While camouflage patterns match, the way that camouflage fabric is cut, arranged and stitched can help identify specific uniforms. Bellingcat researcher Michael Sheldon used this technique to investigate a redacted photo of a man holding a severed head in Syria. The same uniform had been worn by a notorious Russian neo-Nazi who fought in eastern Ukraine.
Look at the smoke. NASA's FIRMS tool detects anomalous heat signatures, many of which can be caused by military activity. As Michael found in the same piece, a large smoke plume in an image can provide a clue as to when it was taken by searching the area on FIRMS.
Pierce through the clouds. When ships turn off their transponders and 'go dark', they disappear from online ship tracking websites. When it's cloudy, you may not see them on satellite imagery. So when tracking a Russian ship smuggling stolen Ukrainian grain which had disappeared in this way, we used Synthetic Aperture Radar (SAR). Much like a bat emits 'sonar' to detect images in its path, this satellite data can show the lay of the land even in the darkest moments.
Save often, save early. Useful footage online is often deleted. Sometimes it's the user, sometimes it's the platform, as such content violates standards on violent imagery. This is where our auto-archiver tool comes in, saving crucial imagery documenting civilian harm in Ukraine and other warzones worldwide.
Cut those corners. Geolocation is a game of patience, but the Open Street Map Search Tool by our colleague Logan Williams allows you to narrow down a search area by selecting visible features listed in Open Street Map. It's also been invaluable in our work on Ukraine and Russia.
Top Five: Open Source Investigations on Ukraine
Over the past two years, we've seen mainstream media increasingly use open source techniques in their reporting on Ukraine. As journalists increasingly adopt this craft, more specialist teams continue to develop new tools and techniques. Here are some of our staff's suggestions for the best open source investigations on Ukraine, in no particular order:
Olga Lubiv recommends Human Rights Watch (HRW)'s investigation into a Russian cluster munition attack on Kramatorsk railway station in April 2022, which claimed the lives of 63 civilians. It used extensive social media imagery and 3D modelling to piece together the incident.
Maxim Edwards recommends the work of Ukrainian investigative team Texty.UA, such as this satellite image survey of the drought caused upstream by the destruction of the Kakhovka Dam in June 2023.
Pooja Chaudhuri recommends one of Texty.UA's other notable pieces, a massive visual investigation showing that over 110,000 artefacts from Ukraine are held in two Russian museums.
Michael Sheldon recommends a Reuters investigation that reviewed thousands of documents left behind by Russia after its troops fled the town of Balakliia in September 2022. Further reporting last year revealed the horrifying story of a Russian military commandant who oversaw the unlawful detention of at least 200 civilians in the town, and whose men committed torture.
Charley Maher recommends RFE/RL's interactive map of Russian military bases and fortifications in occupied Crimea.
4 notes
·
View notes
Text
Mapping LGBTQ+ Spaces through the Years
by Chloe Foor, Student Historian 2022/2024
Hello everyone! Welcome to a little project update from your local Student Historian in Residence. The last two months have been filled with research, data collection, and learning new software programs. I’ve had a great time, and I can’t wait to share what I’ve been doing.
I spent the first few weeks of October doing more research, scouring both the Archives and the Internet to find more locations significant to LGBTQ+ Madisonians over the years. While in the Archives, I looked at the Lesbian, Gay, Bisexual, and Transgender (LGBT) Folder 1 Subject File, which has materials from the 1990s to the mid-2010s (see University of Wisconsin-Madison Subject Files collection. uac69, Box 75, Folder 10. University of Wisconsin-Madison Archives, Madison, WI.). The most interesting things to me was a document written by Joe Elder on Reflection on the LGBTQ movement on Campus, which he wrote in the aftermath of the 2016 Orlando Nightclub Shooting. It provided some really interesting perspectives on the LGBTQ+ Rights movement in Madison.
Online, my main source of information is the Wisconsin LGBTQ+ History Project, which I wrote more about in my last blog post. I didn’t realize that they had digitized copies of old guides that listed LGBTQ+ friendly businesses as far back as 1963. It was fascinating to go through those and find the locations that queer people frequented in the past. The most interesting place that I found that was listed was called Apple Island, which I have seen before in archival research, but I didn't know it was in Madison. Apple Island was a community organization created to promote women's culture, and it was reported that 90% of the clientele were lesbians. My favorite part of the research project is finding these lesser-known spaces, and I can’t wait for more people to be able to easily access them through my project!
Outside of finding new “spaces,” I spent some time filling in the spreadsheet I use to keep track of each location. For each space, I list the title, address, significance, and years it was active, but sometimes it's hard to find all of that information on the first pass through. Sometimes, I'll just write the title and a short description, and then I can go back through later and fill in the rest. Now, all 165 entries are fully fleshed out!
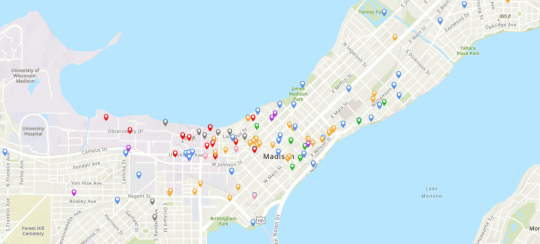
With the spreadsheet being fully populated, I was ready to import it into ArcGIS, a digital mapping software. It was able to read the spreadsheet into different categories and add every space to a map! In the above image, all of the gray makers are for “Purge,” the blue markers are for “Community,” the orange markers are for “Commercial Area,” the purple markers are for “Healthcare,” the pink markers are for “Media,” the green markers are for “Politics,” and the red markers are for “UW”! If you click on a marker, a pop-up window will display with information about the location, including beginning and end dates as well as a short description.
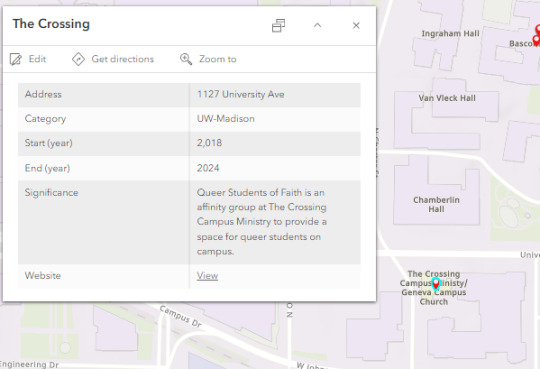
Here is the pop-up for The Crossing:
In the coming months, I will be working on making a public website to share my research! I also want to host an outreach event in collaboration with the Gender and Sexuality Campus Center and Phi Alpha Theta, the History Honors Society. I’m sure more meetings on the topic will come up in the coming months, and I will make sure to keep you posted! For now, though, that’s all from me!
7 notes
·
View notes
Text
Looking for input for archival purposes.
Hey all sorry for the silence again but I’m hoping to ask for a little bit of input here.
I’ve been thinking over how to present certain things I’ve been discovering. Especially given tumblr is heavily limited on picture posting and had to consider if I would end up creating more then one post about things and just figuring out a way to keep all the data together.
After some discussion, I am considering making a text list of all the people Ugigiugi copied because based on what me and a few people have found. This list would be divided into brackets for the sake of organization and keeping updates.
Here’s what I’m thinking of as a breakdown of the list.
Twist Fan artist Ugigiugi has copied (Eastern and western artists)
Other Artist who Ugigiugi has traced. (People who are not part of Twst community who have their work stolen ei: Oc’s, tracing from other fandom’s fanart.)
Open resources that Ugigiugi has copied/not given credit to (These are the “anime” or “Pose” bases as well as patreon reward bases Ugi has taken)
A small section for Twst Game animation/resources along with Disney related things. (While JP disney/Aniplex and the other studios involved have copyright protection, this is still a part of the issues of tracing so I’ll address this section.
Other copyrighted material. (Aka Manga, other published and officially licensed comic or manga series. Again copyright protection is still in place for these but this part will need to be addressed.
I feel like this format will at help list things down for people. I have a private list myself but I figure perhaps releasing something equivalent can help organize findings since a number of people have stuff on one side or another.
Plus? After everything I’ve been combing through? It’s just a rabbit hole at this point because I’ve been just finding more things going through older content I enjoyed and now all I see is just where tracing happened.
I can update the text list with names of artists as more things come up. Also If anyone else wants to add names, all they have to do is message me with proof of the copy/original source and name of the artist to help credit stuff. At least that's my idea on the matter. (Tho i will need to go backlog in the #tag because i know i have missed peoples previous posts due to my busy schedule, my apologies on that one!)
People are free to leave comments on this post for input. I’m just generally trying to see if a list would be a good idea for archival purposes as well as just adding all the numbers to a tally.
-TwstedPomeTea
19 notes
·
View notes
Text
Linguistic Jobs: Interview with a Data Manager & Digital Archivist
This month’s interview is with Julia Miller, a Data Manager and Digital Archivist who uses their Linguistics background to archive high-quality endangered language materials. As a recent PhD graduate, I greatly appreciated Julia’s validating advice that the absence of a tenure-track position or a position in the tech industry does not qualify as “failing”. This message is on-brand for this series, as one of the intentions behind these interviews is to demonstrate that Linguistics training is applicable to lots of jobs, not just the academic ones. Additionally, this interview contains some refreshing and practical advice regarding postdoc and PhD management.
You can follow Julia on Twitter @Spectregraph.

What did you study at university?
I began my undergrad studies in Portland, focusing on art (printmaking) and languages (Russian, French, German, later adding Arabic and Latin). I loved languages and exploring the patterns; at this point I didn’t know about Linguistics. After a short break from school and a bit of reflection, I moved to Seattle, enrolled at the University of Washington, switched my area of study to Linguistics and ended up getting the hat-trick of degrees in Linguistics all from UW: BA (1998), MA (2003), and PhD (2013). My research focused on acoustic phonetics and sociolinguistics; my PhD project explored acoustic properties of lexical tone in two dialects of the Dene language Dane-zaa, spoken in NE British Columbia. During my MA and PhD studies, I was fortunate to have been part of the DOBES Documentation of Endangered Languages program, working on a collaborative documentation project of the Dane-zaa (Beaver) language, which offered funding for tuition and fieldwork, as well as providing me with training in field methods, language documentation & description, and archiving. When I was in the final stages of writing my PhD thesis, I relocated to Australia and began working with PARADISEC, based at their node at the Australian National University (ANU), in order to expand what I knew about digital language archives, building upon what I learned working with the Language Archive for the Beaver DOBES project. I then received a Postdoctoral fellowship at the ANU**, working on another DOBES-funded collaborative documentation project, working with the languages of the Morehead District, Nen, Komnzo, Idi, Nmbo, spoken in the Western Province in Papua New Guinea. The postdoc work included phonetic analyses, sociolinguistic interviews, mapping projects, as well data management and archiving. Despite my love of phonetic description and social network analysis, by the time I submitted my PhD thesis, it was clear that I was more interested in data management and archiving than in linguistic analyses. This was a difficult, yet freeing revelation.
**I do NOT suggest starting a postdoc when you are still writing your completely unrelated PhD thesis! I submitted my thesis in between field trips to PNG.
What is your job?
I am the senior data manager for the ARC Centre of Excellence for the Dynamics of Language (CoEDL) as well as a digital archivist for the Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC). I facilitate the archiving of indigenous and minority language digital material collected by CoEDL members and affiliates from the region, as well as other PARADISEC depositors world-wide. I offer training for researchers, students, and anyone interested in data management and archiving procedures. I liaise with other archives, cultural institutions, and language centres for collaboration. Despite not holding an academic position, teaching is still a large part of my daily work; I offer guest lectures in Field Methods and Digital Humanities courses and run intensive training sessions in digital archiving and data management for university researchers and job placement participants. I have developed curricula, technical workflows and archiving best-practice advice for audiences with different skillsets and goals. I also manage audio and manuscript digitising studios, where we digitise audio cassettes, reel-to-reel tapes, and field notebooks, etc. and I maintain a lending library of field equipment and offer training and advice.
How does your linguistics training help you in your job?
It would appear that my entire PhD path has prepared me for my current job. All the training I received in fieldwork, collaborative research, language documentation & description, and archiving allows me to understand the work our depositors are carrying out. I can offer informed advice and try to anticipate issues they may face in the field regarding data management, equipment failures, etc. And having archived my own materials in multiple archives, I can offer commiseration (and advice) as someone who has had to create metadata databases, follow strict formatting guidelines for A/V files, and adhere to deadlines based on funding agreements.
What was the transition from university to work like for you?
I am still working at a university, but the transition from an academic role to what is considered a non-academic role has been a bit of a challenge. I find I still do a lot of research for my work, and then try to pass on what I have learned in training modules and technical writing projects. I am fortunate to be in an environment that allows me to carry out what could be considered ‘supplemental’ work. Knowing that teaching and outreach are very important to me will help me on my career path as it evolves.
Do you have any advice you wish someone had given to you about linguistics/careers/university?
As a MA/PhD student, I would have loved to have been told of career options outside of Academia (or Big Tech), or even just been reassured that it is a valid option to not pursue tenure track jobs. I think many of my cohorts and I felt as if we failed or let down our professors by not getting a tenure track position in Linguistics. I’m glad to see that the culture of academia is changing and that there is support and advice made more available to students now.
Related interviews:
Interview with a Metadata Specialist and Genealogist
Interview with a Data Scientist
Interview with a Museum Curator
Interview with a Librarian
Interview with a Computational Linguist
Recent interviews:
Interview with a Natural Language Annotation Lead
Interview with an EMLS/Linguistics instructor & mother of four
Interview with a Performing Artiste and Freelance Editor
Interview with a Hawaiian and Tahitian language Instructor, Translator & Radio Host
Interview with a Customer Success Manager
Resources:
The full Linguist Jobs Interview List
The Linguist Jobs tag for the most recent interviews
The Linguistics Jobs slide deck (overview, resources and activities)
The Linguistics Jobs Interview series is edited by Martha Tsutsui Billins. Martha is a linguist whose research focuses on the Ryukyuan language Amami Oshima, specifically honourifics and politeness strategies in the context of language endangerment. Martha runs Field Notes, a podcast about linguistic fieldwork.
#data management#digital archivist#digital archiving#language archiving#endangered language archiving#ling jobs#linguist#language#linguistics#linguistics jobs#archiving
103 notes
·
View notes
Text
DATA TODAY WITH DAN KLEIN EPISODE 9
Data and Digital Archiving with John Sheridan
We can use archives to unlock our past. But how can these vast analogue data sets utilise technology and still retain their value?
Today’s guest is John Sheridan, Digital Director at The National Archives. In his role, John looks after all things digital. He shapes the strategy and direction of its numerous digital services including the vast and extensive National Archive website.
We discuss the power of being able to easily access archival material, the increasing quality of document digitisation, and why archives are critical to the retention of primary sources.
3 notes
·
View notes
Text
Archive Your Shit Please
TL;DR: Users of user-created custom TF2 gamemode create custom maps for 6 years. everything during the first and second years is lost due to no archival practices, and the rest of the content since then has had poor survival chances due to bad practices from uploaders. present day, attempts to enforce archival practices are met with pushback from other staff and weird half-hearted efforts at archiving future content. as a result, i give up, as archival is not something you do halfway. if the veterans themselves do not care about the history, then i as a relatively new player should not care either.
rant below
i'm involved with a niche community scene for a video game and i recently was invited to be a part of the administration team to help oversee the Discord and weigh in on gamemode/administrative/competitive issues.
this niche community i speak of is involved with a custom gamemode and has evolved via custom maps, plugins, and configurations over the course of 6-7 years!!
and despite them carving out this gamemode through hard work and effort over the course of years by testing and trying, there exists no real archival process for all this custom material. for example, the original map that the gamemode used before it was overhauled only has ONE version currently known to be available to play out of the original dozens that have been lost to time. yeah, it's that bad.
i originally tried to make some strides towards better version control and archiving by recently pushing for maps to be uploaded to tf2maps.net, a website which hosts custom tf2 maps and is an important hub for them. this caught on exactly once and then stopped immediately after as mappers were not forced to upload their maps there. it is admittedly easier to upload the map to discord or to a google drive rather than to put in the effort of going onto the website, but this is horrible for archival since Discord could collapse at basically any minute due to lack of funding and people often blindly delete old Drive/mediafire/MEGA links to make space for more data.
so today i tried pushing harder for some enforcement regarding proper archival methods. i collected all the old versions i could from sources available to me including contacting various veteran users, and compiled a map archive. i proposed my idea of requiring all maps that will be played in the Discord-hosted pick-up games to be uploaded to tf2maps, and for all older versions to be uploaded to tf2maps as well. this idea was not received well as other staff members viewed it as too restrictive; a fair point, but considering a staff member thought that Discord was an acceptable archival space ever, it was clear to me that being restrictive was the way. the effort of uploading a map is extremely minimal, especially compared to how much work a mapper has to put in to create new versions of maps. in my view, this change would not ultimately cause any issues, but other staff disagreed.
as an attempt at compromise, they have adopted a policy of "Archival From Here On Out", where slight restrictions have been applied, but the restrictions are so vague that they may as well not exist. as a result, i've just given up on the whole process. mind you: i was not here 6 years ago to see the custom content be created. i only started actively participating in this environment 5 months ago. i was willing to put in that effort for history that wasn't even mine, because i think it's important
all i can realistically hope is that one day the other staff members look back and regret their decision to make half-hearted attempts at archival, as years of important history is potentially permanently lost due to fears of pushback from users.
please please PLEASE archive the things you make. take care of it. these things are important, and could become even more incredibly important in the future.
#tw vent#vent post#personal rant#tw rant#data archiving#archival#data preservation#game preservation#tf2#team fortress 2
4 notes
·
View notes
Last Seen Blogs

companyformationscanada
Company Formations Blog

stonecoldspaghetti
Uh oh

drc8mer
hlvrai

senator-dveri-blog
Без названия

naeworm
eva