#dataprivacy
Text
The Dark Web: What is it and Why Should You Care?
The term “Dark Web” has become increasingly common in recent years, but what exactly is it? In simple terms, the Dark Web refers to a portion of the internet that is not indexed by search engines and can only be accessed through special software. This allows for a degree of anonymity and privacy that is not possible on the regular internet.
While the Dark Web is not inherently illegal or malicious, it is often associated with criminal activity. This is due to the fact that the anonymity it provides can be used by individuals and groups to engage in illegal activities such as drug trafficking, human trafficking, and the sale of stolen goods. It is also a haven for hackers and cybercriminals who use it to buy and sell malware, exploit kits, and other tools of the trade.
But it’s not all bad news. The Dark Web is also home to a number of legitimate uses. For example, journalists and activists in repressive regimes may use the Dark Web to communicate and share information without fear of retribution. Whistleblowers may also use it to leak sensitive information without being identified. Additionally, some individuals may simply use it for privacy reasons, such as to browse the web without being tracked by advertisers or governments.
So, why should you care about the Dark Web? Well, even if you have no interest in engaging with it yourself, it is still important to be aware of its existence and potential dangers. Hackers and cybercriminals can use the Dark Web to buy and sell your personal information, such as credit card numbers and login credentials. They can also use it to launch attacks on websites and services, causing disruptions and potentially exposing sensitive data.
Fortunately, there are steps you can take to protect yourself. First and foremost, it is important to practice good cybersecurity hygiene, such as using strong, unique passwords and enabling two-factor authentication. You should also be cautious when clicking on links or downloading attachments, even from sources you trust. Finally, consider using a virtual private network (VPN) to encrypt your internet traffic and protect your privacy.
In conclusion, the Dark Web is a complex and often misunderstood aspect of the internet. While it can be used for both legal and illegal purposes, it is important to be aware of its potential dangers and take steps to protect yourself online. Stay safe out there!
#DarkWeb#InternetPrivacy#Cybersecurity#OnlineSafety#Anonymity#TorBrowser#VPN#Hackers#Cybercrime#Whistleblowers#Journalism#Activism#IllegalActivities#PersonalInformation#DataPrivacy#DataSecurity#OnlineThreats#OnlineProtection#DigitalSecurity#DarkWebExplained#DigitalPrivacy#DigitalAnonymity#DigitalFreedom#TorNetwork#OnionRouting#informatology
42 notes
·
View notes
Text
Awareness and Responsibility for your Own Privacy and Security

During a specific discussion in the course of Data Privacy and Security, a video was played by our instructor in which a man was presented to be figuratively naked in the cyberspace. His medical records, credit card details, and even his behavioral history and criminal records were out in the open. This left him flabbergasted, later feeling insane with the line that keeps repeating "It is in the system". From the reaction of the man in the video, it was either he unknowingly offered his personal information without thinking the consequences towards his privacy, or he was aware that he was offering his data but did not really think what comes next. It was a great presentation that tackles the great need for education and awareness towards the ever-valuable thing we possess, our data. Serving as a lesson that we ourselves are responsible for our own data and privacy. Luckily, in the video, the exposed data of the man was used to cater his pizza order. However, if a malicious entity was to get access of that system, not just the man can fall as a victim. The video was very informative and impactful. It encouraged me to even share my thoughts about privacy to my family and friends. I am glad that I was already a private person to begin with. It means I really do not have that much of digital footprint. It is not a good idea to have your personal affairs and data to be out in the public. So, listen up, tighten up those accounts, flag and uninstall those apps, read those terms and conditions, and be responsible of your own data. Especially in the modern era of technology, data is the most powerful weapon, the new oil, the new focus. This is the Information Age.
2 notes
·
View notes
Text
Hey friends, come follow us on Mastodon @[email protected]! We post a lot of content there, and Ariel is a lot more active with replies over there (usually….).
#Mastodon#Fediverse#ClimateJustice#SolarpunkPresentsPodcast#solarpunk#podcast#podcasting#SocialMedia#Privacy#DataPrivacy#FederatedInstances#federation#DataHarvesting#FacebookAlternative#MetaAlternative#ActivityPub
2 notes
·
View notes
Text
Analysis of: "From Brain to AI and Back" (academic lecture by Ambuj Singh)
youtube
The term "document" in the following text refers to the video's subtitles.
Here is a summary of the key discussions:
The document describes advances in using brain signal recordings (fMRI) and machine learning to reconstruct images viewed by subjects.
Challenges include sparseness of data due to difficulties and costs of collecting extensive neural recordings from many subjects.
Researchers are working to develop robust models that can generalize reconstruction capabilities to new subjects with less extensive training data.
Applications in medical diagnosis and lie detection are possibilities, but risks of misuse and overpromising on capabilities must be carefully considered.
The genre of the document is an academic lecture presenting cutting-edge neuroscience and AI research progress to an informed audience.
Technical content is clearly explained at an advanced level with representative examples and discussion of challenges.
Ethical implications around informed consent, privacy, and dual-use concerns are acknowledged without overstating current capabilities.
While more information is needed, the presentation style and framing of topics skews towards empirical science over opinion or fiction.
A wide range of stakeholders stand to be impacted, so responsible development and governance of emerging neural technologies should involve multidisciplinary input.
Advancing both basic scientific understanding and more human-like machine learning is a long-term motivation driving continued innovation in this important field.
Here is a summary of the key points from the document:
The speaker discusses advances in using brain signal recordings (fMRI) to reconstruct images that a person is viewing by training AI/machine learning models.
An example is shown where the top row is the actual image viewed and the bottom row is the image reconstructed from the person's brain signals.
Larger datasets with brain recordings from multiple subjects are allowing better models to be developed that may generalize to new subjects.
Challenges include the sparseness of brain signal data due to the difficulty and costs of collecting it from many subjects.
A model is presented that maps brain signals to a joint embedding space of images and text, allowing reconstruction of novel images from new brain signals.
Examples are shown where the reconstructed images match fairly well or not as well depending on image details and semantics.
Issues around ethics, risks of misuse, and questions of explaining and improving the models are discussed.
Ongoing work aims to address challenges around transferring models between subjects and measuring reconstruction performance.
Based on the content and style of the document, it appears to be an academic lecture or presentation.
Key evidence points include:
The document consists primarily of a speaker talking and presenting slides/examples to an audience, as indicated by phrases like "Let me just start with this" and an applause at the end.
Technical topics from neuroscience and machine learning/AI are discussed in detail, such as fMRI brain recordings, reconstructing images from brain signals, modeling approaches, dataset descriptions, and challenges/questions in the field.
Academic concepts like human subjects studies, building models, transferring learning, and measuring performance are referred to.
The presentation of information is intended to educate the audience on the state of the field and cuttting edge research, not just entertain.
There are no narratives, characters or creative storytelling elements - it adheres strictly to explaining complex technical content.
Therefore, based on the instructive/educational style and focus on explaining advanced technical research, I would classify the genre of this document as an academic lecture/presentation intended to inform an audience about progress in the domain of neuroscience and artificial intelligence.
Here are some of the key stakeholders that could be affected by the content and topics discussed in this document:
Neuroscience researchers - Directly interested and impacted by advances reported from their field of study. Progress informs future research directions.
AI/machine learning researchers - Models and challenges discussed could inspire new research at the intersection of AI and neuroscience. Transfer of model techniques.
Medical/clinical communities - Potential applications to diagnosis, personalized medicine if models can accurately reconstruct brain states. Raises ethical issues.
Government research agencies - Fund future related research based on understanding of opportunities and challenges conveyed. Evaluates societal impacts.
General public - Increased understanding of science helps engagement but topics like brain reading raise public concerns around privacy, consent if translated beyond research.
Research participants - Summary does not disclose identities but motivates others to contribute data for progress. Well-being depends on responsible use of data.
Technology companies - Commercial opportunities from real-world applications but also reputational risks if misused. Data ownership questions.
Academic institutions - Collaborations, education of next generations of researchers on cutting-edge topics is enabled through open dissemination of knowledge.
Overall the document provides value to a wide range of stakeholders by communicating the state and potential implications of this multidisciplinary area of neuroscience and AI research. Responsible stewardship is important given several ethical considerations.
Here is a summary of the key points about advances in using brain signal recordings from the document:
Researchers are using fMRI to record brain signals as people view images, in order to reconstruct the viewed images from the brain activity patterns alone.
Machine learning models, especially neural networks, are allowing researchers to train mappings from brain signals to representations of semantic content like images and text.
Examples show the capability of reconstructing fairly accurate images that a person viewed, based solely on their brain activity recordings during viewing.
Larger datasets with multiple subjects are important to develop models that may generalize beyond individual subjects. However, fMRI data is very difficult and expensive to collect at scale.
Advances now allow reconstruction of more complex stimuli like full stories a person reads, not just static images.
Ongoing work aims to better understand brain learning processes and apply those principles to more human-like machine learning architectures.
Analyzing brain recordings also has potential applications for medical diagnosis, lie detection, personalized medicine as models improve.
Ethics must be carefully considered to ensure technologies for reading neural signals are developed and applied responsibly and avoid misuse or privacy violations.
So in summary, the document outlines significant progress using machine learning on brain recordings to reconstruct sensory experiences, with applications and open questions that can further both neuroscience and AI.
Here is a summary of the key points about the sparseness of brain signal data:
Collecting fMRI brain signal recordings from large numbers of subjects is extremely challenging and costly due to the resources and time required.
Each recording session with a single subject takes considerable time, as the number of images/stimuli that can be presented is limited within a session.
Collecting data from a single subject sufficient for training complex models may require recording sessions over multiple days or weeks.
As a result, publicly available datasets typically contain recordings from only a small number of subjects, often under 10.
The sparseness of data makes it difficult to develop robust models that will generalize well to new subjects that lack extensive recordings.
Researchers aim to better leverage smaller datasets by training models that can reconstruct novel stimuli from just a subset of training data per subject.
If successful, this could enable more efficient data collection, such as obtaining usable models from a subject after a single shorter session rather than many long sessions.
However, overcoming the sparseness of brain signal data remains a major challenge holding back progress in the field. Larger collaborative datasets are needed.
So in summary, sparse data severely limits progress but also motivates techniques to optimize learning from limited samples per subject.
Here is a summary of key points regarding risks of misuse from the document:
Advances in reconstructing cognitive states like images viewed from brain recordings raise potential dual-use concerns if technologies are not regulated.
Applications in medical diagnosis and lie detection could help many, but lead to issues if used without consent or for non-medical surveillance.
Overly ambitious claims about capabilities need to be avoided to prevent misleading expectations that could fuel inappropriate usage assumptions.
Privacy and security of sensitive neural data must be prioritized to prevent potential misuse for profiling, identification or manipulation without oversight.
Commercial pressures may incentivize premature deployment before understanding implications, so continued research is important.
Public education about limitations and complexities involved can help curb fears that fuel misuse if capabilities are overestimated.
Multidisciplinary cooperation ensures societal and ethical issues are considered proactively rather than reactively addressed later.
Governance frameworks may be needed to steer applications toward public benefit rather individual or state abuse of personal mental information.
The speaker acknowledges misuse risks to inform discussion and underscore the importance of ongoing examination of new neural technologies through multidisciplinary lens including ethics.
Based on the content and style of presentation, my evaluation of the document status is:
Science vs Fiction: Clearly grounded in science as it discusses ongoing empirical research studies using neuroimaging and machine learning techniques. No fictional or hypothetical elements.
Empirical vs Anecdotal: Empirical in nature, rooted in dataset collection from human subjects and quantitative modeling/evaluation, not personal experience. While data quantities are limited, research follows scientific method.
Fact vs Opinion: Primarily presents technical details and research findings as established facts from the literature. Does not advance strong personal opinions beyond realistic discussion of challenges. Maintains an objective tone.
Objective vs Subjective: Remains objective in explaining research accomplishments and questions objectively without emotive language or bias. Any subjective experience like dataset limitations are clearly labeled as such. Presentation aims for factual information transfer.
In summary, while farther research is still ongoing, the document presents the current state of a scientific research domain factually based on empirical evidence and quantitative analysis published in the field. It does not intermingle non-factual elements or stray from an objective reporting of the topic at hand. The status therefore skews heavily toward science, empiricism, fact and objectivity.
I did not identify any logical fallacies in the content or arguments presented in this document.
The speaker objectively summarizes established research results and proposals, without making assertions that require logical scrutiny.
Some key reasons why logical fallacies are not present include:
No causal claims are made without proper evidence or empirical support from published studies. Progress is tied to concrete research efforts.
No arguments are constructed through flawed reasoning or non sequiturs. Concepts are explained clearly and build upon each other logically.
Comparisons to other approaches are fair without strawman misrepresentations of opposing ideas. Related work is acknowledged.
Limitations and open challenges are candidly outlined rather than ignored or obscured through fallacious defense.
No emotional, exaggerated or politically motivated language is used that could constitute emotional appeals. Tone remains factual.
No false dilemmas or false attributions of complexity are presented. Discussions appropriately scope multi-factor research questions.
No hasty generalizations are made from limited evidence. Data constraints are clearly communicated.
Overall, through objectively summarizing established neuroscience and AI research domains and techniques, without engaging in argument or debate, I did not find any logical fallacies employed in this academic information-sharing document. The focus appears to be factual reporting of progress and issues, avoiding fallacious reasoning.
Here is an evaluation of the ethics addressed and considered in the document:
Informed consent is implied but not explicitly discussed for research participants. Given the sensitivity of brain data, proper protocols were likely followed.
Privacy and anonymity of participants is a concern, but cannot be fully assessed without more details on the dataset and review process.
Potential dual-use issues around brain reading/reconstruction technologies are identifed by discussing applications but also worries about misuse or lack of oversight. This shows awareness of ethical implications.
Limitations and challenges and openly discussed, avoiding overpromising on capabilities. This establishes credibility and sets appropriate expectations.
Societal impacts and usage beyond research (e.g. diagnostics) are flagged as requiring careful consideration of risks like surveillance, discrimination if not regulated properly.
No claims are made without empirical evidence, showing results are driven by facts rather than desires which can bias judgment. Objectivity helps ethical analysis.
Multidisciplinary collaboration is emphasized , suggesting diverse viewpoints were incorporated into the research process.
Overall, while full review details are not provided, the document demonstrates an awareness of important ethical considerations around privacy, consent and responsible development for these sensitive types of neural data and technologies. A balanced assessment of opportunities and risks is conveyed.
Here are the usual evaluation criteria for an academic lecture/presentation genre and my evaluation of this document based on each criteria:
Clarity of explanation: The concepts and technical details are explained clearly without jargon. Examples enhance understanding. Overall the content is presented in a clear, logical manner.
Depth of technical knowledge: The speaker demonstrates thorough expertise and up-to-date knowledge of the neuroscience and AI topics discussed, including datasets, modeling approaches, challenges and future directions.
Organization of information: The presentation flows in a logical sequence, with intro/overview, detailed examples, related work, challenges/future work. Concepts build upon each other well.
Engagement of audience: While an oral delivery is missing, the document seeks to engage the audience through rhetorical questions, previews/reviews of upcoming points. Visuals would enhance engagement if available.
Persuasiveness of argument: A compelling case is made for the value and progress of this important multidisciplinary research area. Challenges are realistically discussed alongside accomplishments.
Timeliness and relevance: This is a cutting-edge topic at the forefront of neuroscience and AI. Advances have clear implications for the fields and wider society.
Overall, based on the evaluation criteria for an academic lecture, this document demonstrates strong technical expertise, clear explanations, logical organization and timely relevance to communicate progress in the domain effectively to an informed audience. Some engagement could be further enhanced with accompanying visual/oral presentation.
mjsMlb20fS2YW1b9lqnN
#Neuroscience#Brainimaging#Neurotechnology#FMRI#Neuroethics#BrainComputerInterfaces#AIethics#MachineLearning#NeuralNetworks#DeepLearning#DataPrivacy#InformationSecurity#DigitalHealth#MentalHealth#Diagnostics#PersonalizedMedicine#DualUseTech#ResearchEthics#ScienceCommunication#Interdisciplinary#Policymaking#Regulation#ResponsibleInnovation#Healthcare#Education#InformedConsent#Youtube
2 notes
·
View notes
Photo

Productive meetings, meaningful engagements, welcome reconnections & fantastic new connections made last week at #ICANN76 in #Cancun #Mexico. Likely to be one of the most consequential international meetings I have attended in my career. - - - - - - - - - - - - - #DigitalPolicy #ICTPolicy #InternetPolicy #InternetGovernance #DNS #DNSAbuse #WHOIS #DataPrivacy #DataProtection #dotPOST #Security #Trust https://www.instagram.com/p/CqG2z7Vo_db/?igshid=NGJjMDIxMWI=
#icann76#cancun#mexico#digitalpolicy#ictpolicy#internetpolicy#internetgovernance#dns#dnsabuse#whois#dataprivacy#dataprotection#dotpost#security#trust
8 notes
·
View notes
Text
The future of cloud PBX providers!
The major roles that contribute to the success and triumph of business communications are "VOIP service providers or Cloud PBX providers." Almost all types of businesses, from small to large, are replacing their old phone systems with modernized ones. Recent surveys and research studies are proving that future communications are ruled by internet telephony services and their providers.
What is CLOUD PBX?
A company phone system that is housed on servers in distant data centers and is operated online is referred to as a "cloud PBX." This indicates that VoIP technology is used by these phone systems to place and receive calls. It is often known as a virtual PBX or hosted PBX, which is an exchange system that is created, built, and hosted in the cloud which is controlled by a third-party service provider and which is accessed over the Internet.
Not from the beginning, but from the past few years, many businesses including some of the large scale ones are switching to cloud PBX. It was previously considered as a con of this hosted PBX regarding data security. But gradually with enhancements done, this is essential to understand that security of cloud PBX will be transferred to the companies that are experts in the field.

Cost Savings of Cloud/Hosted PBX:
Investment is of top priority for any business organization. It has to be calculated twice along with the assessment of the resources as well as the requirements before investing. And, that is a move of wit. Once data security has been promised by the PBX service providers, users started to use it due to the cost saving primarily with respect to the space to be allotted and hardware.
However, hosted PBX saves maintenance cost and the cost of a dedicated tech team to maintain it. The above mentioned factors would save a lump sum in the long run. Besides, integration with other new installations and accessibility increases.
Reasons why these services are referred to as future technology:
Get the services within your budget:
The budget that must be allocated for the purchase of the software or hardware equipment is the first worrying factor that any firm takes into account but this technology is undoubtedly very affordable. Depending upon the company’s requirements get the communication infrastructure and subscriptions.
Flexible
Yes, very flexible and comfortable as one can keep working on the device that is connected to the internet and your service provider even when the individual or team is out of the desk. Cloud PBX solutions erase the geographical limitations to your team if some of them are interested in working remotely.
Features
VoIP dominates every other telecommunication system with absolute free calling and advanced features. For example, when it comes to internal communication of a business team, audio and video calls conferences could be conducted with premium call quality. An important asset that has to be addressed is that Cloud calling provides 99.99% uptime leading to an uninterrupted network.
The most important factor that encouraged firms to replace the legacy systems is the features incorporated with the VOIP phones few among them are:
Ring teams
Unlimited phone calls
Call waiting
Voicemail to email
Online meetings
Using text messages
Automatic attendant
Branch office support
Call forwarding
Pause the music
Billing
DND
Allows customization:
As already discussed, one more good reason for shifting towards the internet telephone is it allows the companies to do their customizations depending upon the firms’ requirements. It is pretty scalable if you want new lines. You can get any number of lines without spending on additional hardware or installation charges. All you need to do is to pay for more bandwidth and the service provider will guide you with the process.
Integrations and multiple storages:
Of course! VoIP can be integrated with any new software easily with no complications. This feature would help you in saving money and time.
You can easily combine cloud data with information already present in company systems, such as CRM integration. You can also integrate with sales applications and the service provider handles data redundancy by keeping identical data on servers located in various locations. Thus, it confirms that this technology is easy to set up and operate.
All processes are automated:
VoIP eliminates the need for manual help by automatically creating reports, billing, and other services reducing the manual effort in the firms.
Customer service:
The VoIP services effectively implement round-the-clock customer support services, increasing business efficiency hence proving that this modernized technology attracts more clients and helps small businesses particularly.
Conclusion:
Installing a cloud PBX system from a reputable service provider is the major step that needs to be taken by businesses, one such firm providing an adaptive environment through their products and services is VITEL GLOBAL COMMUNICATIONS, so don’t delay in searching for the best provider as we are one of the leading Cloud PBX providers focusing and developing your business communications. For more information, visit www.vitelglobal.in
9 notes
·
View notes
Photo

Biometric Security: Enhancing Security through Biometric Authentication
2 notes
·
View notes
Text
How to ByPass the TikTok Ban
This guide will show you how to bypass the a TikTok Ban step-by-step. Before we get started, let’s just acknowledge that TikTok definitely does not meet our criteria for an application that respects users privacy. So why help users bypass the TikTok Ban? The answer is that banning apps, websites, speech, communication, or just parts of the Internet in general poses a much greater threat to free…

View On WordPress
#corporate#dataprivacy#dataprotection#freespeech#Government#internet#internet of things#IoT#monitoring#privacy#smart devices#smart phone#spying#surveillance#surveillance capitalism#surveillance economy#tiktok#tiktokban
6 notes
·
View notes
Text

We think it's time to make sure you're safe and secure when you’re online.
.
.
#codeblendlabs#dataprotectionday#dataprotection#privacy#security#datasecurity#dataprivacy#DataProtectionDay2023#awareness#developer#digitalmarketing#webdevelopment#graphicsdesigning
6 notes
·
View notes
Photo

Backend Developer Complete Roadmap😉⭐️ 👉Learn the fundamentals of software supply chain security with questions and answers 🌟🌟🌟 https://amzn.to/3Z3iFOg #applicationsecurity #cloudsecurity #iot #iotsecurity #dataprivacy #datasecurity #mobilesecurity #cognitivesecurity #automationsecurity #applicationsecuritytesting #portprotocol #datagovernance #smartcar ##networksecurityengineer #mobilesec #smartcarsecurity #pythonprogramming #pyhtonlearning #networksecurity #cybersecurityexpert #portsecurity #pythonprojects #datasecurityconsulting #blockchainprogramming #blockchaincybersecurity #bigdatasecurity #dataprivacyjobs #developerjobs #cybersecurityexpertcourses (at India) https://www.instagram.com/p/Cm1jNXPvraC/?igshid=NGJjMDIxMWI=
#applicationsecurity#cloudsecurity#iot#iotsecurity#dataprivacy#datasecurity#mobilesecurity#cognitivesecurity#automationsecurity#applicationsecuritytesting#portprotocol#datagovernance#smartcar#networksecurityengineer#mobilesec#smartcarsecurity#pythonprogramming#pyhtonlearning#networksecurity#cybersecurityexpert#portsecurity#pythonprojects#datasecurityconsulting#blockchainprogramming#blockchaincybersecurity#bigdatasecurity#dataprivacyjobs#developerjobs#cybersecurityexpertcourses
2 notes
·
View notes
Text
Day 4 ~ imagine what would life be if I'm good at this Blog thingy
I mean I'm decently good but not that professional


Well Hello, I'm kind of a rushing because I'm in a hectic spot but rest assure the content will still be as it was before or even better of course anything for my 1 follower.
So, as you can see in the image what do you think these two has in common? Yes you're right, I can tell by the way your eyes move. These two has a history of having their systems compromised, as for the culprit we do not know, I mean it was unrevealed for security purposes. I mean Jollibee has millions of revenues and stocks with thousands of outlets worldwide—who wouldn't want to compromise such money—I wouldn't. But, oh boy, PNP the stronghold of Philippines, the organization that holds the mightiest name. Why in the world would you have the worst security of all other unit. I mean attackers do always find a way to do their things that is understandable but as a national unit they could have done better. I mean I'm not complaining because I'm also just a normal citizen but still.
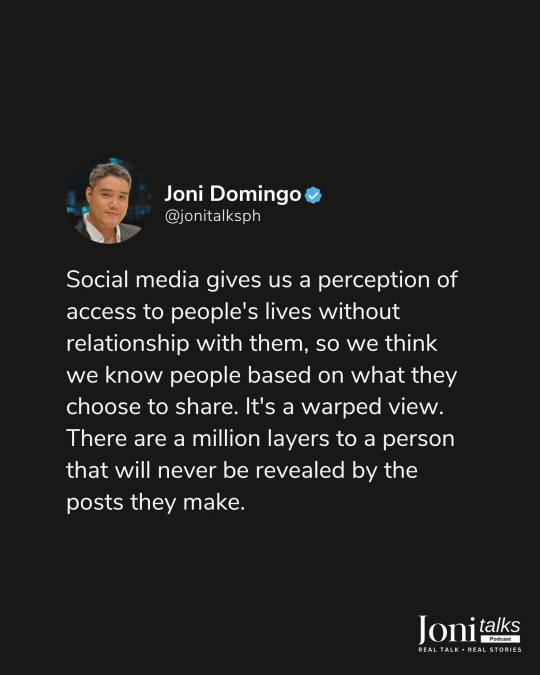
Next would be, the phrase "Facebook give us social status and we give them data" ~ from a certain adviser. I mean it's real if we think about it, it's a win-win situation for most people because it's a way for them to have a connection all around the world and it's the most efficient way to advertise/market your product. However, (if you haven't read blog 3 then you definitely should—it's really interesting) there's this thing where we should limit the data that we share to them because the less they know the better. So, you're questioning me as for why the need for it? I mean because my adviser said so—he's really scary so there's no need to question it, it's meaningless. No, I'm just kidding it's because if you control your data then at least you control how it will be used. The amount of data you pull back will be solely dependent on how much you trust Facebook over your data. The massive social network claims to utilize your data to protect you and provide relevant adverts; for example, if someone logs into your account from a country you don't typically visit, Facebook may flag the activity as suspicious. But when it comes to protecting your data, this is not an entity that you can trust. Facebook has shared your information with third parties in an inconsiderate manner, regardless of how it has utilized your information.
The fact that Facebook also owns Instagram and WhatsApp and has the ability to combine some of the data it collects through both apps further complicates matters. The best option to reduce Facebook's tracking is to permanently uninstall all three apps. If you find that too drastic, you should simply go to the countryside; after a few months, you'll be able to live a truly freedom-filled existence. Just kidding, there are actually some ways or you should just be aware of how Facebook handles your data so you will know how to control it.
You could also follow this link. It shows some tips on how to do it.
https://www.wired.com/story/ways-facebook-tracks-you-limit-it/
0 notes
Text
Mozilla Waves Red Flag Over Data Hungry Dating Apps

Nearly two dozen dating apps were flagged by Mozilla researchers Tuesday as failing to meet privacy and security standards.
https://jpmellojr.blogspot.com/2024/04/mozilla-waves-red-flag-over-data-hungry.html
0 notes
Text
instagram
#TikTokBan#USChinaRelations#TechRegulation#SocialMediaNews#HouseOfRepresentatives#TikTokUpdate#DigitalPolicy#DataPrivacy#OnlineSecurity#TechLegislation#SocialMediaBan#TechNews#DigitalGovernance#InternetRegulation#DataProtection#TikTokPolicy#DigitalSecurity#SocialMediaLaw#TechCompliance#TechPolicy#whatshappeningintheworld#breaking news#world news#global news#news#usa news#entertainment#Instagram
0 notes
Text
Why Your Customers' Privacy is Your Business
Our lives are intertwined with digital technologies and protecting personal data has become a crucial issue. If you’re a business owner in the UK aiming to win over customer loyalty, it’s time to recognize the pivotal role of data privacy.
Let’s dive into why it matters and how you can earn trust by safeguarding your customers’ information.
Why Data Privacy is Essential
Think about it: How…

View On WordPress
#AdvocacyMatters#BrandLoyalty#ConsentManagement#ConsumerTrust#CustomerExperience#CustomerLoyalty#Cybersecurity#DataHandling#dataprivacy#datasecurity#EthicalBusiness#GDPRCompliance#lexdexsolutions#PersonalDataProtection#PrivacyMeasures#PrivacyPolicies#RelationshipBuilding#ReputationManagement#TransparencyMatters#TrustBuilding#UKRegulations
0 notes
Text
Do you trust artificial intelligence with the safety of your personal data? 🤖

Traditional anonymization methods are no longer cutting it. Your names, addresses, and even medical records could become fodder for AI's ravenous algorithms.
But there's a solution – synthetic data, homomorphic encryption, and blockchain. These technologies promise true privacy for machine learning. 🔐
Communities like @anon_tg and https://t.me/anon_club are already stirring, sensing this acute data privacy crisis. Want to learn more?
Tap the link in bio and join the vanguard of the fight for digital anonymity. The race is on! 🏁
0 notes
Photo

Can We Strengthed Data Privacy with AI-Powered Policy Automation?
2 notes
·
View notes
Last Seen Blogs

miirabel
house of memories

happyimagesinbaltimore-blog
Happy Images

yarewbrewing
やーるー醸造新報

ixhavenoidea
✕⎢Who the hell translated this?

yourneighbortoasty
desolate landscape