#source: weheartit.com
Text

“Trong rừng có nai có thỏ, có sói, có hổ và rắn
Có loài dậu đổ bìm leo, có loài nhảy bổ vào cắn
Có loài ăn không nói có, có loài thừa nước đục thả câu
Miệng thì cười, tay thì bắt, dao thì kề trước ngực đã lâu”
Trích “Ai muốn nghe không - Đen Vâu”
8 notes
·
View notes

Text
~ Say Yes To Heaven ~








👼🏻 Shu & Yui 👼🏻
Water Aesthetic.
Quote lyrics, Say Yes to Heaven by Lana del Rey.
Beach Photos Source: weheartit.com
#diabolik lovers#shu sakamaki#yui komori#shu & yui#diabolik lovers moodboard#lana del rey lyrics#lana del rey#diabolik lovers shu#sakamaki brothers#shu sakamaki aesthetic#anime couple#say yes to heaven#diaboys#diabolik lovers edit
361 notes
·
View notes
Photo

source: weheartit
https://weheartit.com/entry/321216121
#halloween#halloween 2022#halloween aesthetic#halloweencore#halloween vibes#halloween blog#year round halloween blog#halloween decorations#active halloween blog#autumn#autumncore#autumn aesthetic#autumn vibes#jack o'lantern#spooky#october#september#spooky aesthetic#october aesthetic#orange#fall#fallblr#year round fall blog#pumpkins#pumpkin carving#autumnal#spooky season
1K notes
·
View notes
Text

“We are the remains of something that consumes us.”
~•Roberto Juarroz•~
#Roberto Juarroz #beautiful #photo source weheartit.com
79 notes
·
View notes
Text

Wherever you go, whatever you do, I will be right here waiting for you.
Source: weheartit.com
42 notes
·
View notes
Text

Source : weheartit.com
45 notes
·
View notes
Text
Scraper Bots, Fuck Off! How to "Opt Out" of Your Artistic "Data" Being Used in "Research"
How can artists protect their work from being used by art-generating "AI" bots? How can we take a stand against this continuing, as more and more programmers build their own forks and train derivative models?
Here are a few steps artists can take to keep their work from being used to train new art generators (and one step non-artists can do to help). For the reasoning and explanation behind these steps, click the Read More.
The Method:
Remove images that do not have watermarks. Take down every one of your images that can be accessed publicly and does not have a watermark. (In fact, if you have the resources, take down every image, even those with watermarks, and reupload them with new names or URLs).
Add watermarks to your images and re-upload them. Put a watermark on every image you intend to share publicly. It doesn't have to be huge and obvious, but for best results, it should have text, and if you really want to be a pain in some engineer's neck, it should be colorful. I explain why below the cut. @thatdogmagic has shared an absolutely brilliant watermark method here (https://www.tumblr.com/thatdogmagic/702300132999397376/that-your-audience-wont-hate-this-is-a-method).
Watermark everything. From now on, any image you share publicly should have a watermark.
One host domain only. Strive for keeping your image files on only one domain—for example, tumblr.com, or your personal domain. Again, I explain below the cut.
ADVANCED: Configure your domain's robots.txt. If you have administrative access to your host domain, update your robots.txt file to contain the following: User-agent: CCBot Disallow: /
ADVANCED: Configure your meta-tags. If you have administrative access to your web pages, update your meta-tags to include the following: <meta name="robots" content="nofollow">
ADVANCED: Configure your .htaccess. If you have administrative access to your host domain, update your .htaccess file to prevent hotlinking to images. There are a few ways to achieve this, and a simple tutorial can be found here (https://www.pair.com/support/kb/block-hotlinking-with-htaccess/).
Bullying Campaigning. If you do not have administrative access to your host domain (for example, if you host on tumblr, or deviantart), ask your administrator to block CCBot in the domain's robot.txt, disable hotlinking, or take similar actions to prevent image scraping.
Aggressively pursue takedowns on image sharing sites. The best known sources of this issue are Pinterest and WeHeartIt, but especially focus on Pinterest. The image takedown form for Pinterest can be found here (https://www.pinterest.com/about/copyright/dmca-pin/), and the image takedown form for WeHeartIt can be found here (https://weheartit.com/contact/copyright).
Non-artists: do not reupload images, do not share reuploaded images (no, not even to add the source in comments), do not truck with re-uploaders. If you see an image without a watermark on image share sites like Pinterest, and it doesn't look like the artist themselves pinned it, give them a heads up so they can file a takedown.
The Reasoning:
Why watermarks? Why meta-tags? What good will any of this do?
Below the cut, I explain how these art-generation bots are "trained," and how we can use that information to prevent new bots from training on stolen art.
Those Who Can't, Program
Deep learning models capable of generating images from natural language prompts are growing in both capability and popularity. In plain English: there are bots out there that can generate art based on written (and sometimes visual) prompts. DALL-E, Stable Diffusion, and Midjourney are examples of art-generating "AI" already in use.
These models are trained using large-scale datasets—and I mean, large. Billions of entries large. Because teaching a learning machine requires a lot of examples.
Engineers don't make this data on their own: they acquire datasets from other organizations. Right now, there is no better dataset out there than the Internet, so that's what most engineers use to train their models.
Common Crawl (https://commoncrawl.org) is where most of them go to grab this data in a form that can be presented to a learning model. Common Crawl has been crawling the publicly-accessible web once a month since 2011, and provides archives of this data for free to anyone who requests it. Crucially, these are "text" archives—they do not contain images, but do contain urls of images and descriptions of images, including alt text.
The Common Crawl dataset is, in some form, the primary source used to train learning models, including our art generators.
Nobody Likes Watermarks
Watermarks are one of the easiest and most effective ways to remove your art from the training set.
If the model is trained using the LAION-5B dataset (https://laion.ai/blog/laion-5b/), for example, there's a good chance your art will be removed from the set to begin with if it has a watermark. LAION-5B is a filtered, image-focused version of the Common Crawl data, with NSFW and watermarked images filtered out.
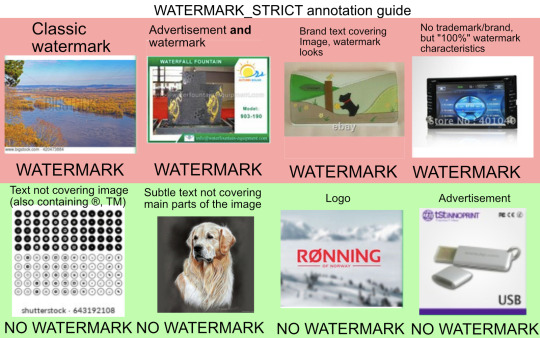
Using this example provided by the LAION team, we can determine what kind of watermark will ensure your art is filtered from the dataset: partially transparent text placed over the image. Bots trained with data filtered similarly to LAION-5B will not be trained using your images if you use such a watermark.
As a bonus, if you include a watermark in your image and it somehow still makes it into a training set, the additional visual data will skew the training. It will assume any images it generates that are “inspired” by yours should include similar shapes and colors. The bot doesn’t actually understand what a watermark is and assumes it’s a natural element of the image.
404 Art Not Found
The reason we want to remove and re-upload images with new URLs is simple. The datasets these models study do not have actual images, they have the URLs pointing to images. If your image is no longer at that URL, the model can’t load your image, and any models trained with out-of-date datasets will not be able to locate your images.
However, this is only a temporary fix if you can’t prevent Common Crawler from recording the image’s new location in its monthly archiving of the internet.
Unusually Polite Thieves
The slightly more advanced tricks we can use to keep crawlers from recording the URLs of your images rely on the etiquette of crawler bots.
Firstly, keeping all your images in one domain has a chance to reduce the number of times models training from filtered datasets will reference your images in training. Crawling or scraping that results in significant negative impact on a domain’s bandwidth is bad. Like, legal action bad. The people behind the learning model generally want to avoid pissing off domain admins. So, there is a narrow chance that simply having all your images hosted on the same domain will prevent a model from trying to access all of them. It’s a bit of a stretch, though.
Something that is much more likely to see results is to plant the equivalent of “KEEP OUT” signs in your domain. Common Crawler, for all its presumption, follows bot etiquette and will obey any instructions left for it in robots.txt. Common Crawler’s bot is named CCBot. Create a robots.txt file and place it in the top-level folder of your domain. Make sure robots.txt includes User-agent: CCBot Disallow: / and CCBot will not archive your pages.
Using meta-tags in the headers of HTML pages on your domain will also help. Adding <meta name="robots" content="nofollow"> will tell any crawler robots not to follow any of the links from this page to other pages or files. If CCBot lands on your page, it won’t then discover all the other pages that page leads to.
The more advanced tactic is to disable hotlinking for your domain. When someone accesses an image hosted on your domain from somewhere other than your domain, this is called hotlinking. It’s not just a bandwidth sink, it’s also the exact process by which models are accessing your images for training.
This can be tricky: it involves creating and configuring a hidden file on your domain. The tutorial linked above in the step-by-step gives a simple look at what you can do by editing your .htaccess file, but searching “htaccess hotlink” will provide a bunch of other resources too.
Fucking Pinterest
Let’s cut to the chase: a majority of images in these training sets were scraped from Pinterest. Not DeviantArt! Not ArtStation! Literally 8%, of the billions of images collected, were from Pinterest. Image sharing social sites are the worst.
There’s no easy way to prevent people from resharing your images there, but between your new watermarks and the Pinterest takedown form, you can potentially keep ahead of it. 🫡
Now for the Downside
This won’t work on the models that already exist.
Unfortunately, we can’t untrain DALL-E or Midjourney. We can’t do anything about the data they’ve already studied. It stinks that this happened without common knowledge or forewarning, but all we can do is figure out how to move forward.
The good news is that while the current models are powerful and impressive, they still have some significant flaws. They’ll need more training if they want to live out the bizarre pie-in-the-sky, super fucking unethical dreams some of these weirdos have about “democratizing” art (which seems to mean eliminating trained artists altogether).
If we educate ourselves on how these models are trained and how the training sets are compiled, if we continue to make noise about artists’ rights to their own data, we can make sure this art-generator trend doesn’t somehow mutate into a thing that will genuinely replace living, biological artists.
#as always the moral remains: watermark your shit#artist tips#ai art#dall e#midjourney#stable diffusion#craiyon#machine learning#love when my adhd is a super power and I can spend hours in useful research
223 notes
·
View notes

Text

Source: weheartit.com
7 notes
·
View notes


Text








Carla & Yui
Water Aesthetic.
Can I let go?
And let your memory dance
In the ballroom of my mind
Across the county line
It hurts to love you
But I still love you
It's just the way I feel
Quote Lyrics, 13 Beaches by Lana del Rey. 👑
Water Aesthetic Photos Source: weheartit.com
#diabolik lovers#yui komori#carla tsukinami#diabolik lovers moodboard#diaboys#lana del rey lyrics#lana del rey#diabolik lovers edit#diabolik lovers fandom#lyric quotes#anime couple
151 notes
·
View notes
Photo

source: weheartit
https://weheartit.com/entry/321251562
#halloween#halloween aesthetic#halloweencore#halloween vibes#halloween blog#all hallows eve#halloween decorations#vintage halloween#active halloween blog#year round halloween blog#cozy#autumn#autumncore#fallblr#pumpkins#october#september#halloween 2022#active fall blog#spooky#spooky season#spooky aesthetic#skeleton#black cats#autumn vibes#autumn aesthetic#autumn blog#fall#autumnal
165 notes
·
View notes
Text

Source: weheartit.com
ℍ𝐚𝓵l נ𝐀 𝔳คĻǤẸ
10 notes
·
View notes
Text
Doggo stim tools!
Doesn’t matter if you’re dogkin, doggender, dog therian, or just love dogs. As long as you’re sentient and self-aware with rational and moral capacity and complex language, thought, and emotion, this is a post for you!
(Meaning do not give these toys to dog dogs. ^^’)
Long, image-heavy post ahead! Some tools listed are geared toward children, *geplay (a), or p*tlay (e)

1) Bone and paw glitter (a)(b)(c)(d)(e)(f)(g)
2) Flexi dogs 3D (a)(b)(c)(d)(e)(f)(g)(h)(i)(j)

3) Squooshy woofers (a)(b)(c)(d)(e)(f)(g)(h)(i)
4) Doggo spinner (a)(b)(c)(d)(e)(f)(g)(h)(i)
5) Meat squishy (a)(b)(c)(d)(e)(f)(g)(h)(i)(j)(k)

6) Shakers (a)(b)(c)(d)(e)(f)(g)(h)
7) Pup chews (a)(b)(c)(d)(e)(f)(g)(h)(i)(j)(k)
8) Chewy bones (a)(b)(c)(d)(e)(f)(g)(h)(i)

9) Paw spinner rings (a)(b)(c)(d)(e)(f)(g)(h)(i)(j)(k)
10) Pup-its (a)(b)(c)(d)(e)(f)(g)
11) Weighted woofers (a)(b)(c)(d)(e)(f)(g)(h)(i)(j)

12) Plastic bones (a)(b)(c)(d)(e)(f)(g)
13) Squishy paws (a)(b)(c)(d)(e)
14) Bone beads (a)(b)(c)(d)(e)(f)(g)

15) Dog beads (a)(b)(c)(d)
16) Flexi dogs 2D (a)(b)(c)(d)(e)(f)(g)
17) Pocket pups (a)(b)(c)(d)(e)(f)(g)(h)(i)

18) Bone spinner (a)(b)(c)(d)(e)
19) Canine slime (a)(b)(c)(d)(e)
20) Squishy bones (a)(b)(c)

Source for gif: https://weheartit.com/entry/359122552 ???
#stim tools#adult stimming#actuallyneurodivergent#themed lists#animal#tactile#visual#kinesthetic#auditory#noise toys#silicone#squishies#plushies#jewelry#chewy#spinners#3d printed#plastic#metal#slimes#taste safe
62 notes
·
View notes
Last Seen Blogs

adalminsworld
Untitled

airbusiron3
The Blogging of Noble 630

ariaadagio
Tyger Tyger, Burning Bright

farha-7
Untitled

whyjohnny
Self destruction is such a pretty little thing.