#the habsburgs
Text
Reading about Habsburg emperors makes me laugh like nothing else
This is Ferdinand I The Benevolent. I am dying

19K notes
·
View notes
Text
The Coprophagic AI crisis

I'm on tour with my new, nationally bestselling novel The Bezzle! Catch me in TORONTO on Mar 22, then with LAURA POITRAS in NYC on Mar 24, then Anaheim, and more!

A key requirement for being a science fiction writer without losing your mind is the ability to distinguish between science fiction (futuristic thought experiments) and predictions. SF writers who lack this trait come to fancy themselves fortune-tellers who SEE! THE! FUTURE!
The thing is, sf writers cheat. We palm cards in order to set up pulp adventure stories that let us indulge our thought experiments. These palmed cards – say, faster-than-light drives or time-machines – are narrative devices, not scientifically grounded proposals.
Historically, the fact that some people – both writers and readers – couldn't tell the difference wasn't all that important, because people who fell prey to the sf-as-prophecy delusion didn't have the power to re-orient our society around their mistaken beliefs. But with the rise and rise of sf-obsessed tech billionaires who keep trying to invent the torment nexus, sf writers are starting to be more vocal about distinguishing between our made-up funny stories and predictions (AKA "cyberpunk is a warning, not a suggestion"):
https://www.antipope.org/charlie/blog-static/2023/11/dont-create-the-torment-nexus.html
In that spirit, I'd like to point to how one of sf's most frequently palmed cards has become a commonplace of the AI crowd. That sleight of hand is: "add enough compute and the computer will wake up." This is a shopworn cliche of sf, the idea that once a computer matches the human brain for "complexity" or "power" (or some other simple-seeming but profoundly nebulous metric), the computer will become conscious. Think of "Mike" in Heinlein's *The Moon Is a Harsh Mistress":
https://en.wikipedia.org/wiki/The_Moon_Is_a_Harsh_Mistress#Plot
For people inflating the current AI hype bubble, this idea that making the AI "more powerful" will correct its defects is key. Whenever an AI "hallucinates" in a way that seems to disqualify it from the high-value applications that justify the torrent of investment in the field, boosters say, "Sure, the AI isn't good enough…yet. But once we shovel an order of magnitude more training data into the hopper, we'll solve that, because (as everyone knows) making the computer 'more powerful' solves the AI problem":
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
As the lawyers say, this "cites facts not in evidence." But let's stipulate that it's true for a moment. If all we need to make the AI better is more training data, is that something we can count on? Consider the problem of "botshit," Andre Spicer and co's very useful coinage describing "inaccurate or fabricated content" shat out at scale by AIs:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4678265
"Botshit" was coined last December, but the internet is already drowning in it. Desperate people, confronted with an economy modeled on a high-speed game of musical chairs in which the opportunities for a decent livelihood grow ever scarcer, are being scammed into generating mountains of botshit in the hopes of securing the elusive "passive income":
https://pluralistic.net/2024/01/15/passive-income-brainworms/#four-hour-work-week
Botshit can be produced at a scale and velocity that beggars the imagination. Consider that Amazon has had to cap the number of self-published "books" an author can submit to a mere three books per day:
https://www.theguardian.com/books/2023/sep/20/amazon-restricts-authors-from-self-publishing-more-than-three-books-a-day-after-ai-concerns
As the web becomes an anaerobic lagoon for botshit, the quantum of human-generated "content" in any internet core sample is dwindling to homeopathic levels. Even sources considered to be nominally high-quality, from Cnet articles to legal briefs, are contaminated with botshit:
https://theconversation.com/ai-is-creating-fake-legal-cases-and-making-its-way-into-real-courtrooms-with-disastrous-results-225080
Ironically, AI companies are setting themselves up for this problem. Google and Microsoft's full-court press for "AI powered search" imagines a future for the web in which search-engines stop returning links to web-pages, and instead summarize their content. The question is, why the fuck would anyone write the web if the only "person" who can find what they write is an AI's crawler, which ingests the writing for its own training, but has no interest in steering readers to see what you've written? If AI search ever becomes a thing, the open web will become an AI CAFO and search crawlers will increasingly end up imbibing the contents of its manure lagoon.
This problem has been a long time coming. Just over a year ago, Jathan Sadowski coined the term "Habsburg AI" to describe a model trained on the output of another model:
https://twitter.com/jathansadowski/status/1625245803211272194
There's a certain intuitive case for this being a bad idea, akin to feeding cows a slurry made of the diseased brains of other cows:
https://www.cdc.gov/prions/bse/index.html
But "The Curse of Recursion: Training on Generated Data Makes Models Forget," a recent paper, goes beyond the ick factor of AI that is fed on botshit and delves into the mathematical consequences of AI coprophagia:
https://arxiv.org/abs/2305.17493
Co-author Ross Anderson summarizes the finding neatly: "using model-generated content in training causes irreversible defects":
https://www.lightbluetouchpaper.org/2023/06/06/will-gpt-models-choke-on-their-own-exhaust/
Which is all to say: even if you accept the mystical proposition that more training data "solves" the AI problems that constitute total unsuitability for high-value applications that justify the trillions in valuation analysts are touting, that training data is going to be ever-more elusive.
What's more, while the proposition that "more training data will linearly improve the quality of AI predictions" is a mere article of faith, "training an AI on the output of another AI makes it exponentially worse" is a matter of fact.

Name your price for 18 of my DRM-free ebooks and support the Electronic Frontier Foundation with the Humble Cory Doctorow Bundle.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/03/14/14/inhuman-centipede#enshittibottification
Image:
Plamenart (modified)
https://commons.wikimedia.org/wiki/File:Double_Mobius_Strip.JPG
CC BY-SA 4.0
https://creativecommons.org/licenses/by-sa/4.0/deed.en
#pluralistic#ai#generative ai#André Spicer#botshit#habsburg ai#jathan sadowski#ross anderson#inhuman centipede#science fiction#mysticism
548 notes
·
View notes
Photo
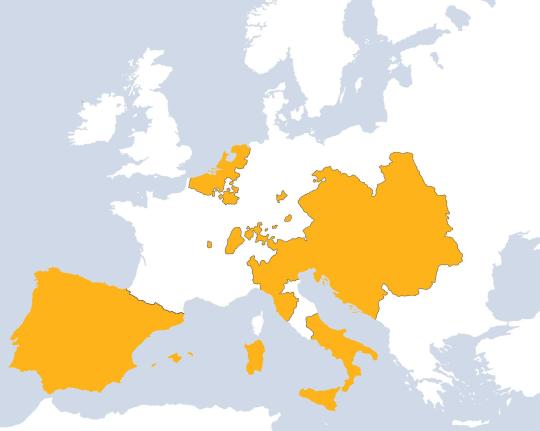
All lands the Habsburgs ever controlled in Europe.
207 notes
·
View notes
Text


Gown and train of Marie Louise of Austria, second wife of Napoleon Bonaparte
(Bust of Napoleon and painting of Marie Louise in the background)
Museo Glauco Lombardi
#this dress looks way better here than in the painting for some reason lol#Museo Glauco Lombardi#dress#gown#1800s#19th century fashion#train#ball gown#Parma#Italy#Marie Louise#marie-louise#Marie Louise of Austria#napoleonic#Austria#Habsburg#habsburgs#history of fashion#fashion history#historical fashion
311 notes
·
View notes
Text

Prison of Francis I by Giovanni Migliara
#francis i#prison#prisoner#spain#art#giovanni migliara#architecture#king#france#french#king of france#history#europe#european#françois i#habsburg#spanish#charles v#battle of pavia#medieval#middle ages#renaissance#royalty#royals#royal#nobility
199 notes
·
View notes
Note
would the dog royal families be like pugs because of all the inbreeding? would love to see your take on a dog form of the Hapsburgs lol
Probably nowhere near as extreme as modern pugs and other hyper exaggerated breeds today, but to some degree certainly.
#royals and nobles were very inbred folk it's bound to create some hereditary health issues#Habsburgs spread so far and wide in European upper class circles they eventually had to start marrying each other#and are infamous for their protruding lower jaws#I think I'd have to come up with a specific Habsburg breed or something#because sometimes you see brachycephalic dogs with really truly bad underbites#but I believe most of those breeds emerged in the 1800s and looked much more moderate back then#answered#anonymous
251 notes
·
View notes
Note
King and Queen looking through a window at a boy and a girl in love with each other.
King: Oh, what a wonderful sight to see young love.
Queen: Honey, that's our children!
Ancient Egypt be like
102 notes
·
View notes
Text

TIARA ALERT: Archduchess Ildikó of Habsburg-Lorraine wore Princess Louise of Bourbon-Two Sicilies' Diamond Tiara for Le Bal des Débutantes at the Shangri La Hotel in Paris on 25 November 2023.
#Tiara Alert#Archduchess Ildiko#Habsburg#Austrian Royal Family#Austria#Hungary#tiara#diamond#diadem#royal jewels#royaltyedit#Orleans#Bourbon Two Sicilies#Le Bal des Debutantes
177 notes
·
View notes
Text
Alpine has confirmed their 2024 line-up. It confirms Mick Schumacher but also Ferdinand Habsburg, Charles Milesi and Paul-Loup Chatin

#and a huge amount of the rumours were trie#racing#wec#mick schumacher#ferdinand habsburg#nicolas lapierre#matthieu vaxivierre#charles milesi
153 notes
·
View notes
Text


Napoleon II, Duke of Reichstadt
His mother's son (at least for the purposes of this bracket)
Philip II, King of Spain, King of Portugal, reigned 1556-1598
Instant discourse, just say the word 'armada'
242 notes
·
View notes
Text



ISABELLA OF PORTUGAL by Titian, 1548
JOANNA OF AUSTRIA by Sánchez Coello, 1557
ANNA OF AUSTRIA by Bartolomé González y Serrano, 1570
#historyedit#isabella of portugal#joanna of austria#juana of austria#anna of austria#queen of portugal#queen of spain#princess of portugal#history#women in history#house of aviz#house of habsburg#titian#alonso sanchez coello#bartolome gonzalez y serrano#art#renaissance art#gramma isabella#joanna was isabella's daughter#and anna was joanna's niece#thus isabella's granddaughter#edit#x#i just love how anna looked more like her aunt than her own mom 🥹#and both joanna and anna looked like their grandma
383 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
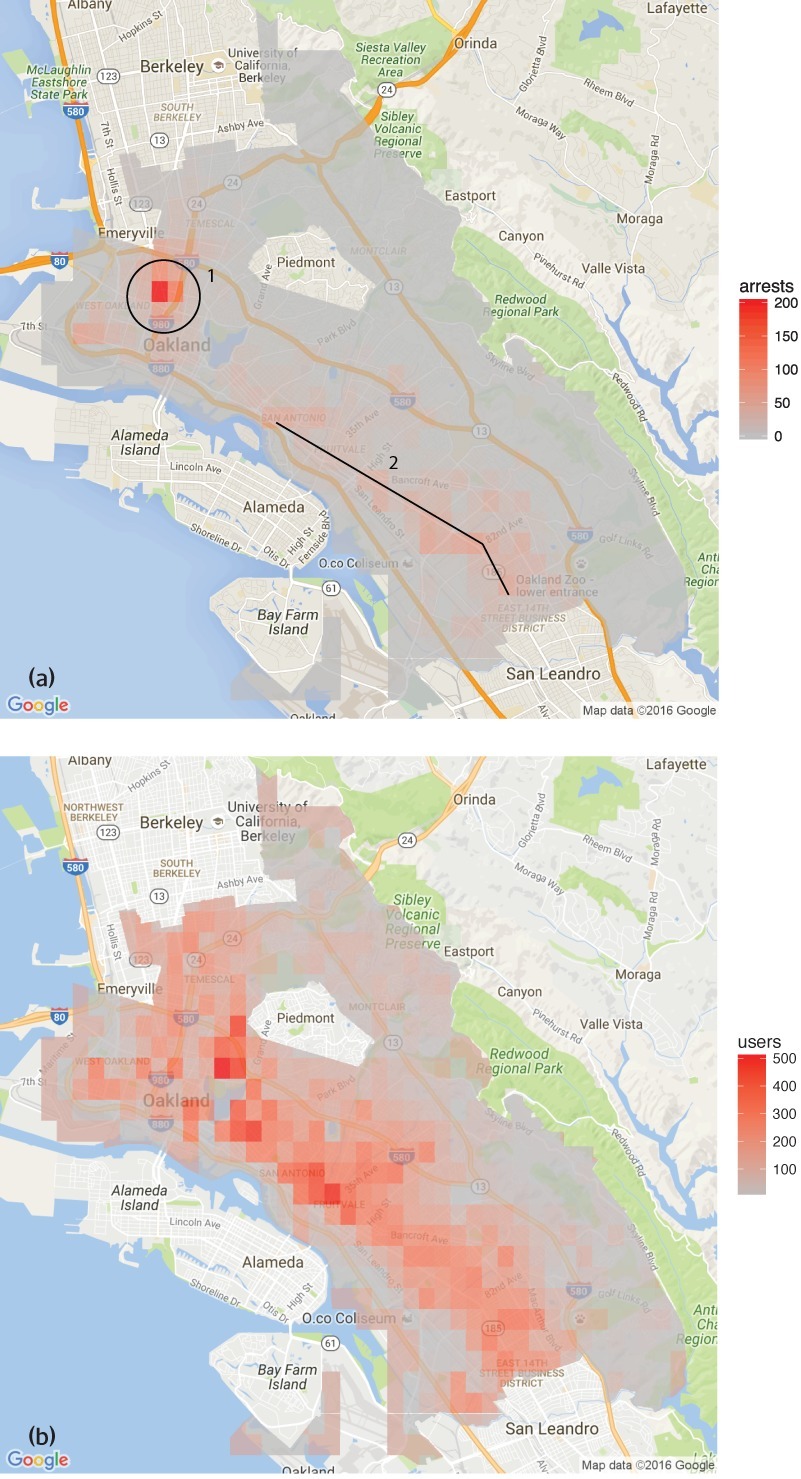
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified)
https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0
https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified)
https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified)
https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0
https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
825 notes
·
View notes
Text
considering the historical influences in the fashion of Dishonored (and the extent of nsfw fanfiction this fandom has) I’ve been thinking about the layers that would be, realistically, part of the daily dress
which means: dishonored seems to honour the importance of a vest in a properly dressed gentleman’s or lady’s wardrobe
vests were, and I cannot stress this enough, a mandatory part of an outfit, to the point of men wearing only vests if they could not afford a fully tailored suit (trousers + vest + jacket) and a new shirt and opting to only wear a fake collar under the vest for the illusion of a full outfit
shirts were underwear, so to speak. there were no occasions in ‘polite society‘ where one could only wear a shirt without a vest on top.
this is something we see mirrored in both dishonored games, though the style of the vests and clothing have somewhat changed, they still follow the same rules of vests worn with every outfit, as far as we can tell. (we could argue that Jessamine is not wearing one, or that some higher class women aren’t wearing vests under their buttoned up jackets, but since we don’t really see underneath we can’t judge.)
we see the vests be worn even by the Whalers in the first game (which in itself brings up many questions. are whalers, the actual whalers that capture and kill whales, held in high enough regard by the society that they made a vest part of their uniform? or is it merely something that is worn by all? something that every citizen of sound mind would don, were they to leave their house?)
there are a few exceptions to this, of course, but this whole thing came to be by asking a simple question
does the Outsider wear a vest under his leather jacket?
now, in the first game, his jacket is unbuttoned just enough for us to get a good enough peek at what lies beneath. which is to say: there is no hint of a vest underneath. judging by the vests in the first game, the fashion was that the vest would go up high, often covering collarbones or even having a standing collar. what we see on the Outsider is just... an unbuttoned shirt
it’s much the same in the second game, even if we examine his final concept art, his outfit consists of a shirt (more or less underwear) with most of the top buttons unbuttoned, and a jacket on top. no hint of a vest underneath
what I’m trying to say is that the Outsider is a slut
#dh#dishonored#the outsider#I got hyperfixated on fashion of the belle epoque (the inspiration for dh fashion) so most of this information in regards to history#should be accurate#mind you the books I read had a heavy focus on habsburg monarchy fashion so it might be slightly different to say the US or france etc etc#but that should be right#if anyone has stuff from the games to disprove the vest in higher classes statement bring it on#I doubt the artists would do such a great transgression against polite manners though /j#but yeah tl;dr the outsider wears the equivalent of a blazer on top of a bra#I have so many thoughts and feelings about the fashion in these games I could go on for Ages#this all started when I was thinking about human outsider being taken in by corvo and emily and as he takes his clothes off for a bath#a maid is absolutely scandalized by his lack of a vest underneath#I do want to acknowledge that there is concept art of outsider in dh2 that DOES have a vest under the jacket but that one went unused#the pattern on it kinda reminds me of the pattern on corvo's and emily's clothing tho that might be a reach. or just a pattern thats popular#i firmly stand by my headcanon that the outsider tries to imitate the fashion of the real world in the void with a bit of his own Void spin
284 notes
·
View notes
Photo

The Habsburg Empire, 16th-17th centuries
« Atlas historique », Nathan, 1982
by cartesdhistoire
In 1519, Charles Quint found himself virtually the master of Europe. However, instead of viewing his role as a spiritual mission, he felt a deep sense of duty to his lineage. This obligation drove him to perpetuate, and if possible, enhance, what he had inherited for his successors. This principle, deeply ingrained in the tradition of the House of Burgundy, became a cornerstone of Habsburg governance, with each possession managed as if he were the sole monarch of each one.
In 1556, Philippe II inherited the ancient estates of Burgundy, the Spanish Monarchy (including its Italian dependencies), and the Duchy of Milan. Throughout his foreign policy, the sense of dynasty always took precedence: the Dutch were treated more as rebels than heretics; the incorporation of Portugal in 1580 was driven by the defense of succession rights rather than expansionism. Similarly, interventions in the French civil war and the Armada against England in 1588 aimed more at defending the integrity of heritage than pursuing a crusade.
Under Philippe III (1598-1621), signs of decline began to emerge within the Hispanic monarchy. The reign of Philippe IV (1621-1665) was marked by continual unrest, with no respite for a year of peace. Involvement in the Thirty Years War strained the Castilian Treasury, leading to economic crises in the 1630s and subsequent anti-tax revolts. The dissatisfaction of peripheral elites culminated in secessionist revolts in Catalonia and Portugal in 1640, while nobles conspired against the Crown. In Italy, revolts in Naples and Sicily in 1647 further exacerbated the crisis. Amid internal opposition, economic depression, and military setbacks, the Hispanic Monarchy struggled for survival, with only the Portuguese secession achieving success.
92 notes
·
View notes
Text
I’m crying, this author was UNHINGED 😂😂






#kutuzov#tsar Alexander I#francis ii#napoleonic era#napoleonic wars#napoleonic#Austria#hre#habsburgs#Habsburg#romanovs#general kutuzov#first french empire#19th century#1800s#french revolution#Austerlitz#battle of austerlitz#napoleon#napoleon bonaparte#history#book pic
212 notes
·
View notes
Text

The Battle of Pavia by Karl Ludwig Hassmann
#battle of pavia#art#karl ludwig hassmann#pavia#italian wars#holy roman empire#france#habsburg#history#medieval#renaissance#middle ages#knights#knight#armour#soldiers#landsknecht#europe#european#italy#northern italy#cavalry#habsburg empire#battlefield
343 notes
·
View notes
Last Seen Blogs

saka-sakis
i am not fond of natsume sakasaki

john-welch
Untitled

rainbowslicknightmare
What lurks in darkness

graysglass
Gray's Glass

up-stone-onbir
UP STONE onbir