
Last Seen Blogs

onethousandonefaces
1001faces.org

kathakacademy-blog
Kathak Academy

glass-moth
glassmoth

kepamount
simi 🤍

julianroman
Untitled
Link
Keepalived is a Linux implementation of VRRP. The usual role of VRRP is to share a virtual IP across a set of routers. For each VRRP instance, a leader is elected and gets to serve the IP address, ensuring the high availability of the attached service. Keepalived can also be used for a generic leader election, thanks to its ability to use scripts for healthchecking and run commands on state change.
A simple configuration looks like this:
vrrp_instance gateway1 { state BACKUP # ❶ interface eth0 # ❷ virtual_router_id 12 # ❸ priority 101 # ❹ virtual_ipaddress { 2001:db8:ff/64 } }
The state keyword in ❶ instructs Keepalived to not take the leader role when starting. Otherwise, incoming nodes create a temporary disruption by taking over the IP address until the election settles. The interface keyword in ❷ defines the interface for sending and receiving VRRP packets. It is also the default interface to configure the virtual IP address. The virtual_router_id directive in ❸ is common to all nodes sharing the virtual IP. The priority keyword in ❹ helps choosing which router will be elected as leader. If you need more information around Keepalived, be sure to check the documentation.
VRRP design is tied to Ethernet networks and requires a multicast-enabled network for communication between nodes. In some environments, notably public clouds, multicast is unavailable. In this case, Keepalived can send VRRP packets using unicast:
vrrp_instance gateway1 { state BACKUP interface eth0 virtual_router_id 12 priority 101 unicast_peer { 2001:db8::11 2001:db8::12 } virtual_ipaddress { 2001:db8:ff/64 dev lo } }
Another process, like a BGP daemon, should advertise the virtual IP address to the “network”. If needed, Keepalived can trigger whatever action is needed for this by using notify_* scripts.
Until version 2.21 (not released yet), the interface directive is mandatory and Keepalived will transmit and receive VRRP packets on this interface only. If peers are reachable through several interfaces, like on a BGP on the host setup, you need a workaround. A simple one is to use a VXLAN interface:
$ ip -6 link add keepalived6 type vxlan id 6 dstport 4789 local 2001:db8::10 nolearning $ bridge fdb append 00:00:00:00:00:00 dev keepalived6 dst 2001:db8::11 $ bridge fdb append 00:00:00:00:00:00 dev keepalived6 dst 2001:db8::12 $ ip link set up dev keepalived6
Learning of MAC addresses is disabled and one generic entry for each peer is added in the forwarding database: transmitted packets are broadcasted to all peers, notably VRRP packets. Have a look at “VXLAN & Linux” for additional details.
vrrp_instance gateway1 { state BACKUP interface keepalived6 mcast_src_ip 2001:db8::10 virtual_router_id 12 priority 101 virtual_ipaddress { 2001:db8:ff/64 dev lo } }
Starting from Keepalived 2.21, unicast_peer can be used without the interface directive. I think using VXLAN is still a neat trick applicable to other situations where communication using broadcast or multicast is needed, while the underlying network provide no support for this.
via Planet Debian
0 notes
Link
Now that GitHub released v1.0 of the gh cli tool, and this is all over HN, it might make sense to write a note about my clumsy aliases and shell functions I cobbled together in the past month. Background story is that my dayjob moved to GitHub coming from Bitbucket. From my point of view the WebUI for Bitbucket is mediocre, but the one at GitHub is just awful and painful to use, especially for PR processing. So I longed for the terminal and ended up with gh and wtfutil as a dashboard.
The setup we have is painful on its own, with several orgs and repos which are more like monorepos covering several corners of infrastructure, and some which are very focused on a single component. All workflows are anti GitHub workflows, so you must have permission on the repo, create a branch in that repo as a feature branch, and open a PR for the merge back into master.
gh functions and aliases
# setup a token with perms to everything, dealing with SAML is a PITA export GITHUB_TOKEN="c0ffee4711" # I use a light theme on my terminal, so adjust the gh theme export GLAMOUR_STYLE="light" #simple aliases to poke at a PR alias gha="gh pr review --approve" alias ghv="gh pr view" alias ghd="gh pr diff" ### github support functions, most invoked with a PR ID as $1 #primary function to review PRs function ghs { gh pr view ${1} gh pr checks ${1} gh pr diff ${1} } # very custom PR create function relying on ORG and TEAM settings hard coded # main idea is to create the PR with my team directly assigned as reviewer function ghc { if git status | grep -q 'Untracked'; then echo "ERROR: untracked files in branch" git status return 1 fi git push --set-upstream origin HEAD gh pr create -f -r "$(git remote -v | grep push | grep -oE 'myorg-[a-z]+')/myteam" } # merge a PR and update master if we're not in a different branch function ghm { gh pr merge -d -r ${1} if [[ "$(git rev-parse --abbrev-ref HEAD)" == "master" ]]; then git pull fi } # get an overview over the files changed in a PR function ghf { gh pr diff ${1} | diffstat -l } # generate a link to a commit in the WebUI to pass on to someone else # input is a git commit hash function ghlink { local repo="$(git remote -v | grep -E "github.+push" | cut -d':' -f 2 | cut -d'.' -f 1)" echo "https://github.com/${repo}/commit/${1}" }
wtfutil
I have a terminal covering half my screensize with small dashboards listing PRs for the repos I care about. For other repos I reverted back to mail notifications which get sorted and processed from time to time. A sample dashboard config looks like this:
github_admin: apiKey: "c0ffee4711" baseURL: "" customQueries: othersPRs: title: "Pull Requests" filter: "is:open is:pr -author:hoexter -label:dependencies" enabled: true enableStatus: true showOpenReviewRequests: false showStats: false position: top: 0 left: 0 height: 3 width: 1 refreshInterval: 30 repositories: - "myorg/admin" uploadURL: "" username: "hoexter" type: github
The -label:dependencies is used here to filter out dependabot PRs in the dashboard.
Workflow
Look at a PR with ghv $ID, if it's ok ACK it with gha $ID. Create a PR from a feature branch with ghc and later on merge it with ghm $ID. The $ID is retrieved from looking at my wtfutil based dashboard.
Security Considerations
The world is full of bad jokes. For the WebUI access I've the full array of pain with SAML auth, which expires too often, and 2nd factor verification for my account backed by a Yubikey. But to work with the CLI you basically need an API token with full access, everything else drives you insane. So I gave in and generated exactly that. End result is that I now have an API token - which is basically a password - which has full power, and is stored in config files and environment variables. So the security features created around the login are all void now. Was that the aim of it after all?
via Planet Debian
0 notes
Link
Four years ago somebody posted a comment-thread describing how you could start writing a little reverse-polish calculator, in C, and slowly improve it until you had written a minimal FORTH-like system:
At the time I read that comment I'd just hacked up a simple FORTH REPL of my own, in Perl, and I said "thanks for posting". I was recently reminded of this discussion, and decided to work through the process.
Using only minimal outside resources the recipe worked as expected!
The end-result is I have a working FORTH-lite, or FORTH-like, interpreter written in around 2000 lines of golang! Features include:
Reverse-Polish mathematical operations.
Comments between ( and ) are ignored, as expected.
Single-line comments \ to the end of the line are also supported.
Support for floating-point numbers (anything that will fit inside a float64).
Support for printing the top-most stack element (., or print).
Support for outputting ASCII characters (emit).
Support for outputting strings (." Hello, World ").
Support for basic stack operations (drop, dup, over, swap)
Support for loops, via do/loop.
Support for conditional-execution, via if, else, and then.
Load any files specified on the command-line
If no arguments are included run the REPL
A standard library is loaded, from the present directory, if it is present.
To give a flavour here we define a word called star which just outputs a single start-character:
: star 42 emit ;
Now we can call that (NOTE: We didn't add a newline here, so the REPL prompt follows it, that's expected):
> star *>
To make it more useful we define the word "stars" which shows N stars:
> : stars dup 0 > if 0 do star loop else drop then ; > 0 stars > 1 stars *> 2 stars **> 10 stars
This example uses both if to test that the parameter on the stack was greater than zero, as well as using do/loop to handle the repetition.
Finally we use that to draw a box:
> : squares 0 do over stars cr loop ; > 4 squares **** **** **** **** > 10 squares ********** ********** ********** ********** ********** ********** ********** ********** ********** **********
Anyway if that is at all interesting feel free to take a peak. There's a bit of hackery there to avoid the use of return-stacks, etc. Compared to gforth this is actually more featureful in some areas:
I allow you to use conditionals in the REPL - outside a word-definition.
I allow you to use loops in the REPL - outside a word-definition.
Find the code here:
Tags: forth, github, go, golang, hackernews |
via Planet Debian
0 notes
Link
A few weeks ago I configured a road warrior VPN setup. The remote end is on a VPS running OpenBSD and OpenIKED, the VPN is an IKEv2 VPN using x509 authentication, and the local end is StrongSwan. I also configured an IKEv2 VPN between my VPSs. Here are the notes for how to do so.
In all cases, to use x509 authentication, you will need to generate a bunch of certificates and keys:
a CA certificate
a key/certificate pair for each client
Fortunately, OpenIKED provides the ikectl utility to help you do so. Before going any further, you might find it useful to edit /etc/ssl/ikeca.cnf to set some reasonable defaults for your certificates.
Begin by creating and installing a CA certificate:
# ikectl ca vpn create # ikectl ca vpn install
For simplicity, I am going to assume that the you are managing your CA on the same host as one of the hosts that you want to configure for the VPN. If not, see the bit about exporting certificates at the beginning of the section on persistent host-host VPNs.
Create and install a key/certificate pair for your server. Suppose for example your first server is called server1.example.org:
# ikectl ca vpn certificate server1.example.org create # ikectl ca vpn certificate server1.example.org install
Persistent host-host VPNs
For each other server that you want to use, you need to also create a key/certificate pair on the same host as the CA certificate, and then copy them over to the other server. Assuming the other server is called server2.example.org:
# ikectl ca vpn certificate server2.example.org create # ikectl ca vpn certificate server2.example.org export
This last command will produce a tarball server2.example.org.tgz. Copy it over to server2.example.org and install it:
# tar -C /etc/iked -xzpvf server2.example.org.tgz
Next, it is time to configure iked. To do so, you will need to find some information about the certificates you just generated. On the host with the CA, run
$ cat /etc/ssl/vpn/index.txt V 210825142056Z 01 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/[email protected] V 210825142208Z 02 unknown /C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/[email protected]
Pick one of the two hosts to play the âactiveâ role (in this case, server1.example.org). Using the information you gleaned from index.txt, add the following to /etc/iked.conf, filling in the srcid and dstid fields appropriately.
ikev2 'server1_server2_active' active esp from server1.example.org to server2.example.org \ local server1.example.org peer server2.example.org \ srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/[email protected]' \ dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/[email protected]'
On the other host, add the following to /etc/iked.conf
ikev2 'server2_server1_passive' passive esp from server2.example.org to server1.example.org \ local server2.example.org peer server1.example.org \ srcid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server2.example.org/[email protected]' \ dstid '/C=US/ST=Pennsylvania/L=Pittsburgh/CN=server1.example.org/[email protected]'
Note that the names 'server1_server2_active' and 'server2_server1_passive' in the two stanzas do not matter and can be omitted. Reload iked on both hosts:
# ikectl reload
If everything worked out, you should see the negotiated security associations (SAs) in the output of
# ikectl show sa
On OpenBSD, you should also see some output on success or errors in the file /var/log/daemon.
For a road warrior
Add the following to /etc/iked.conf on the remote end:
ikev2 'responder_x509' passive esp \ from 0.0.0.0/0 to 10.0.1.0/24 \ local server1.example.org peer any \ srcid server1.example.org \ config address 10.0.1.0/24 \ config name-server 10.0.1.1 \ tag "ROADW"
Configure or omit the address range and the name-server configurations to suit your needs. See iked.conf(5) for details. Reload iked:
# ikectl reload
If you are on OpenBSD and want the remote end to have an IP address, add the following to /etc/hostname.vether0, again configuring the address to suit your needs:
inet 10.0.1.1 255.255.255.0
Put the interface up:
# ifconfig vether0 up
Now create a client certificate for authentication. In my case, my road-warrior client was client.example.org:
# ikectl ca vpn certificate client.example.org create # ikectl ca vpn certificate client.example.org export
Copy client.example.org.tgz to client and run
# tar -C /etc/ipsec.d/ -xzf client.example.org.tgz -- \ ./private/client.example.org.key \ ./certs/client.example.org.crt ./ca/ca.crt
Install StrongSwan and add the following to /etc/ipsec.conf, configuring appropriately:
ca example.org cacert=ca.crt auto=add conn server1 keyexchange=ikev2 right=server1.example.org rightid=%server1.example.org rightsubnet=0.0.0.0/0 rightauth=pubkey leftsourceip=%config leftauth=pubkey leftcert=client.example.org.crt auto=route
Add the following to /etc/ipsec.secrets:
# space is important server1.example.org : RSA client.example.org.key
Restart StrongSwan, put the connection up, and check its status:
# ipsec restart # ipsec up server1 # ipsec status
That should be it.
Sources:
https://wiki.strongswan.org/projects/strongswan/wiki/IKEv2ClientConfig
https://www.openbsd.org/faq/faq17.html
ikectl(8)
iked.conf(5)
via Planet Debian
0 notes
Link

Speaking of Spamhaus, this just popped up in my RSS feed reader. It looks like Spamhaus is going to take a harder stance against users who query their blacklists via open or public DNS systems (such as Google Public DNS or Cloudflare's 1.1.1.1 Service). They're going to respond to all queries from public/open DNS systems with a new 127.255.255.254 answer code, and respond to excessive queries from other sources with a new 127.255.255.255 response code. The net here is that if you query Spamhaus a lot, and aren't a registered, paying user, or if you use public DNS services for even your small hobbyist server, you're going to get cut off.
And based on the way this is implemented, it's possible that a bunch of legitimate mail will start bouncing before all Spamhaus users figure it out.
Even on my own hobbyist Linux box, I'm likely to run afoul of it. Instead of running my own DNS server, I just use Google's public DNS, and I use Spamhaus's "Zen" blacklist in my Postfix email server. Or at least I did, until I removed it from the configuration just now.
Stay tuned. I bet we're going to start seeing people popping up to ask why they're suddenly not receiving any more inbound mail.
Click here to head on over to Spamhaus to read the announcement.
This post first appeared on Al Iverson's Spam Resource.
via Al Iverson's Spam Resource
0 notes
Link
You hear stories sometimes. About how when a deliverability person warns sales that they shouldn't sign that client, but the client comes aboard anyway. "If they do bad things, so what? It shouldn't impact other clients. We'll give them their own domain, their own IPs, and it'll be fine."
Are you sure?
Too many times now, I've seen blacklists like SORBS or Spamhaus blacklist whole ESPs or whole large blocks of IP addresses at an ESP. I bet it's not fun explaining to client #2 that their bounce rate jumped to 50%+ because of the bad acts of client #1.
And this isn't just something that happened in the past. Just about two weeks ago I saw Spamhaus blacklist 255 IP addresses at a particular email service provider due to the actions of a single client. (The listing is since removed, so I can't link to it. And my goal isn't to name-and-shame, so I'm not mentioning which ESP it is. If you're smart, maybe you can figure it out.)
You might argue that Spamhaus appled too broad a stick and perhaps they shouldn't have done that. You might be right. Complain all you want, though, but you can't control Spamhaus, and neither can I, and neither can that ESP. But that ESP can control what clients they allow to use their services, so I would argue that they did have a way that they could have prevented this.
Assuming that one client's bad practices won't affect other clients is a risky proposition.
And I'm not even touching on what this kind of thing does to an ESP's reputation. If you want to be a member of M3AAWG, or if you want ISP people to respond to you favorably when you sometimes ask for help out of band, you need to not have the reputation that your platform will take any client, even ones with bad practices.
This post first appeared on Al Iverson's Spam Resource.
via Al Iverson's Spam Resource
0 notes
Link
Is buying an email list a good idea? Let's ask around.
Hubspot's got the best quick summary, in my opinion. They say buying an email is a bad idea because:
Reputable email marketing services don't let you send emails to lists you've bought.
Good email address lists aren't for sale.
People on a purchased or rented list don't actually know you.
You'll harm your email deliverability and IP reputation.
You can come across as annoying.
Your email service provider can penalize you.
Don't believe them? Ask Campaign Monitor.
Don't believe Campaign Monitor? Ask Constant Contact.
Don't believe Constant Contact? Ask Godaddy.
Don't believe Godaddy? Ask HostGator.
Don't believe HostGator? Ask SparkPost.
Don't believe SparkPost? Ask GetResponse.
Don't believe GetResponse? Ask Vertical Response.
Don't believe Vertical Response? Ask WhatCounts.
I could keep going...but you get the idea.
This post first appeared on Al Iverson's Spam Resource.
via Al Iverson's Spam Resource
0 notes
Link
These are really nice power supply modules from Pololu..
They run from anything up to 36V and regulate down to a nice 3.3V. They cope if I reverse the polarity. They are tiny (0.4″ × 0.5″). They just work.
They cost a few dollars, and actually cost more than the ESP32-WROOM-32 (at current pre-brexit style exchange rates), but they really just work, and I am using them everywhere.
What I did not work out, when ordering a 100 of them, is that they are so recyclable! I am changing controllers from ESP8266 to ESP32, but the power modules can be easily desoldered and re-used. I have so many I am thinking of listing them on Amazon.
I whole heartedly recommend them, very nice, work well, don't get fried when you cock up. via www.me.uk RevK's rants
0 notes
Link
If you have ever used aptitude a bit more extensively on the command-line, you’ll probably have come across its patterns. This week I spent some time implementing (some) patterns for apt, so you do not need aptitude for that, and I want to let you in on the details of this merge request !74.
so, what are patterns?
Patterns allow you to specify complex search queries to select the packages you want to install/show. For example, the pattern ?garbage can be used to find all packages that have been automatically installed but are no longer depended upon by manually installed packages. Or the pattern ?automatic allows you find all automatically installed packages.
You can combine patterns into more complex ones; for example, ?and(?automatic,?obsolete) matches all automatically installed packages that do not exist any longer in a repository.
There are also explicit targets, so you can perform queries like ?for x: ?depends(?recommends(x)): Find all packages x that depend on another package that recommends x. I do not fully comprehend those yet - I did not manage to create a pattern that matches all manually installed packages that a meta-package depends upon. I am not sure it is possible.
reducing pattern syntax
aptitude’s syntax for patterns is quite context-sensitive. If you have a pattern ?foo(?bar) it can have two possible meanings:
If ?foo takes arguments (like ?depends did), then ?bar is the argument.
Otherwise, ?foo(?bar) is equivalent to ?foo?bar which is short for ?and(?foo,?bar)
I find that very confusing. So, when looking at implementing patterns in APT, I went for a different approach. I first parse the pattern into a generic parse tree, without knowing anything about the semantics, and then I convert the parse tree into a APT::CacheFilter::Matcher, an object that can match against packages.
This is useful, because the syntactic structure of the pattern can be seen, without having to know which patterns have arguments and which do not - basically, for the parser ?foo and ?foo() are the same thing. That said, the second pass knows whether a pattern accepts arguments or not and insists on you adding them if required and not having them if it does not accept any, to prevent you from confusing yourself.
aptitude also supports shortcuts. For example, you could write ~c instead of config-files, or ~m for automatic; then combine them like ~m~c instead of using ?and. I have not implemented these short patterns for now, focusing instead on getting the basic functionality working.
So in our example ?foo(?bar) above, we can immediately dismiss parsing that as ?foo?bar:
we do not support concatenation instead of ?and.
we automatically parse ( as the argument list, no matter whether ?foo supports arguments or not
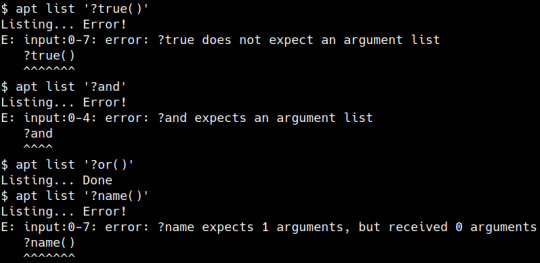
apt not understanding invalid patterns
Supported syntax
At the moment, APT supports two kinds of patterns: Basic logic ones like ?and, and patterns that apply to an entire package as opposed to a specific version. This was done as a starting point for the merge, patterns for versions will come in the next round.
We also do not have any support for explicit search targets such as ?for x: ... yet - as explained, I do not yet fully understand them, and hence do not want to commit on them.
The full list of the first round of patterns is below, helpfully converted from the apt-patterns(7) docbook to markdown by pandoc.
logic patterns
These patterns provide the basic means to combine other patterns into more complex expressions, as well as ?true and ?false patterns.
?and(PATTERN, PATTERN, ...)
Selects objects where all specified patterns match.
?false
Selects nothing.
?not(PATTERN)
Selects objects where PATTERN does not match.
?or(PATTERN, PATTERN, ...)
Selects objects where at least one of the specified patterns match.
?true
Selects all objects.
package patterns
These patterns select specific packages.
?architecture(WILDCARD)
Selects packages matching the specified architecture, which may contain wildcards using any.
?automatic
Selects packages that were installed automatically.
?broken
Selects packages that have broken dependencies.
?config-files
Selects packages that are not fully installed, but have solely residual configuration files left.
?essential
Selects packages that have Essential: yes set in their control file.
?exact-name(NAME)
Selects packages with the exact specified name.
?garbage
Selects packages that can be removed automatically.
?installed
Selects packages that are currently installed.
?name(REGEX)
Selects packages where the name matches the given regular expression.
?obsolete
Selects packages that no longer exist in repositories.
?upgradable
Selects packages that can be upgraded (have a newer candidate).
?virtual
Selects all virtual packages; that is packages without a version. These exist when they are referenced somewhere in the archive, for example because something depends on that name.
examples
apt remove ?garbage
Remove all packages that are automatically installed and no longer needed - same as apt autoremove
apt purge ?config-files
Purge all packages that only have configuration files left
oddities
Some things are not yet where I want them:
?architecture does not support all, native, or same
?installed should match only the installed version of the package, not the entire package (that is what aptitude does, and it’s a bit surprising that ?installed implies a version and ?upgradable does not)
the future
Of course, I do want to add support for the missing version patterns and explicit search patterns. I might even add support for some of the short patterns, but no promises. Some of those explicit search patterns might have slightly different syntax, e.g. ?for(x, y) instead of ?for x: y in order to make the language more uniform and easier to parse.
Another thing I want to do ASAP is to disable fallback to regular expressions when specifying package names on the command-line: apt install g++ should always look for a package called g++, and not for any package containing g (g++ being a valid regex) when there is no g++ package. I think continuing to allow regular expressions if they start with ^ or end with $ is fine - that prevents any overlap with package names, and would avoid breaking most stuff.
There also is the fallback to fnmatch(): Currently, if apt cannot find a package with the specified name using the exact name or the regex, it would fall back to interpreting the argument as a glob(7) pattern. For example, apt install apt* would fallback to installing every package starting with apt if there is no package matching that as a regular expression. We can actually keep those in place, as the glob(7) syntax does not overlap with valid package names.
Maybe I should allow using [] instead of () so larger patterns become more readable, and/or some support for comments.
There are also plans for AppStream based patterns. This would allow you to use apt install ?provides-mimetype(text/xml) or apt install ?provides-lib(libfoo.so.2). It’s not entirely clear how to package this though, we probably don’t want to have libapt-pkg depend directly on libappstream.
feedback
Talk to me on IRC, comment on the Mastodon thread, or send me an email if there’s anything you think I’m missing or should be looking at.
via Planet Debian
0 notes
Link
I could not find much information on the interwebs how many containers you can run per host. So here are mine and the issues we ran into along the way.
The Beginning
In the beginning there were virtual machines running with 8 vCPUs and 60GB of RAM. They started to serve around 30 containers per VM. Later on we managed to squeeze around 50 containers per VM.
Initial orchestration was done with swarm, later on we moved to nomad. Access was initially fronted by nginx with consul-template generating the config. When it did not scale anymore nginx was replaced by Traefik. Service discovery is managed by consul. Log shipping was initially handled by logspout in a container, later on we switched to filebeat. Log transformation is handled by logstash. All of this is running on Debian GNU/Linux with docker-ce.
At some point it did not make sense anymore to use VMs. We've no state inside the containerized applications anyway. So we decided to move to dedicated hardware for our production setup. We settled with HPe DL360G10 with 24 physical cores and 128GB of RAM.
THP and Defragmentation
When we moved to the dedicated bare metal hosts we were running Debian/stretch + Linux from stretch-backports. At that time Linux 4.17. These machnes were sized to run 95+ containers. Once we were above 55 containers we started to see occasional hiccups. First occurences lasted only for 20s, then 2min, and suddenly some lasted for around 20min. Our system metrics, as collected by prometheus-node-exporter, could only provide vague hints. The metric export did work, so processes were executed. But the CPU usage and subsequently the network throughput went down to close to zero.
I've seen similar hiccups in the past with Postgresql running on a host with THP (Transparent Huge Pages) enabled. So a good bet was to look into that area. By default /sys/kernel/mm/transparent_hugepage/enabled is set to always, so THP are enabled. We stick to that, but changed the defrag mode /sys/kernel/mm/transparent_hugepage/defrag (since Linux 4.12) from the default madavise to defer+madvise.
This moves page reclaims and compaction for pages which were not allocated with madvise to the background, which was enough to get rid of those hiccups. See also the upstream documentation. Since there is no sysctl like facility to adjust sysfs values, we're using the sysfsutils package to adjust this setting after every reboot.
Conntrack Table
Since the default docker networking setup involves a shitload of NAT, it shouldn't be surprising that nf_conntrack will start to drop packets at some point. We're currently fine with setting the sysctl tunable
net.netfilter.nf_conntrack_max = 524288
but that's very much up to your network setup and traffic characteristics.
Inotify Watches and Cadvisor
Along the way cadvisor refused to start at one point. Turned out that the default settings (again sysctl tunables) for
fs.inotify.max_user_instances = 128 fs.inotify.max_user_watches = 8192
are too low. We increased to
fs.inotify.max_user_instances = 4096 fs.inotify.max_user_watches = 32768
Ephemeral Ports
We didn't ran into an issue with running out of ephemeral ports directly, but dockerd has a constant issue of keeping track of ports in use and we already see collisions to appear regularly. Very unscientifically we set the sysctl
net.ipv4.ip_local_port_range = 11000 60999
NOFILE limits and Nomad
Initially we restricted nomad (via systemd) with
LimitNOFILE=65536
which apparently is not enough for our setup once we were crossing the 100 container per host limit. Though the error message we saw was hard to understand:
[ERROR] client.alloc_runner.task_runner: prestart failed: alloc_id=93c6b94b-e122-30ba-7250-1050e0107f4d task=mycontainer error="prestart hook "logmon" failed: Unrecognized remote plugin message:
This was solved by following the official recommendation and setting
LimitNOFILE=infinity LimitNPROC=infinity TasksMax=infinity
The main lead here was looking into the "hashicorp/go-plugin" library source, and understanding that they try to read the stdout of some other process, which sounded roughly like someone would have to open at some point a file.
Running out of PIDs
Once we were close to 200 containers per host (test environment with 256GB RAM per host), we started to experience failures of all kinds because processes could no longer be forked. Since that was also true for completely fresh user sessions, it was clear that we're hitting some global limitation and nothing bound to session via a pam module.
It's important to understand that most of our workloads are written in Java, and a lot of the other software we use is written in go. So we've a lot of Threads, which in Linux are presented as "Lightweight Process" (LWP). So every LWP still exists with a distinct PID out of the global PID space.
With /proc/sys/kernel/pid_max defaulting to 32768 we actually ran out of PIDs. We increased that limit vastly, probably way beyond what we currently need, to 500000. Actuall limit on 64bit systems is 222 according to man 5 proc.
via Planet Debian
0 notes
Link
An increasingly popular design for a datacenter network is BGP on the host: each host ships with a BGP daemon to advertise the IPs it handles and receives the routes to its fellow servers. Compared to a L2-based design, it is very scalable, resilient, cross-vendor and safe to operate.1 Take a look at “L3 routing to the hypervisor with BGP” for a usage example.
BGP on the host with a spine-leaf IP fabric. A BGP session is established over each link and each host advertises its own IP prefixes.
While routing on the host eliminates the security problems related to Ethernet networks, a server may announce any IP prefix. In the above picture, two of them are announcing 2001:db8:cc::/64. This could be a legit use of anycast or a prefix hijack. BGP offers several solutions to improve this aspect and one of them is to reuse the features around the RPKI.
Short introduction to the RPKI
On the Internet, BGP is mostly relying on trust. This contributes to various incidents due to operator errors, like the one that affected Cloudflare a few months ago, or to malicious attackers, like the hijack of Amazon DNS to steal cryptocurrency wallets. RFC 7454 explains the best practices to avoid such issues.
IP addresses are allocated by five Regional Internet Registries (RIR). Each of them maintains a database of the assigned Internet resources, notably the IP addresses and the associated AS numbers. These databases may not be totally reliable but are widely used to build ACLs to ensure peers only announce the prefixes they are expected to. Here is an example of ACLs generated by bgpq3 when peering directly with Apple:2
$ bgpq3 -l v6-IMPORT-APPLE -6 -R 48 -m 48 -A -J -E AS-APPLE policy-options { policy-statement v6-IMPORT-APPLE { replace: from { route-filter 2403:300::/32 upto /48; route-filter 2620:0:1b00::/47 prefix-length-range /48-/48; route-filter 2620:0:1b02::/48 exact; route-filter 2620:0:1b04::/47 prefix-length-range /48-/48; route-filter 2620:149::/32 upto /48; route-filter 2a01:b740::/32 upto /48; route-filter 2a01:b747::/32 upto /48; } } }
The RPKI (RFC 6480) adds public-key cryptography on top of it to sign the authorization for an AS to be the origin of an IP prefix. Such record is a Route Origination Authorization (ROA). You can browse the databases of these ROAs through the RIPE’s RPKI Validator instance:
RPKI validator shows one ROA for 85.190.88.0/21
BGP daemons do not have to download the databases or to check digital signatures to validate the received prefixes. Instead, they offload these tasks to a local RPKI validator implementing the “RPKI-to-Router Protocol” (RTR, RFC 6810).
For more details, have a look at “RPKI and BGP: our path to securing Internet Routing.”
Using origin validation in the datacenter
While it is possible to create our own RPKI for use inside the datacenter, we can take a shortcut and use a validator implementing RTR, like GoRTR, and accepting another source of truth. Let’s work on the following topology:
BGP on the host with prefix validation using RTR. Each server has its own AS number. The leaf routers establish RTR sessions to the validators.
You assume we have a place to maintain a mapping between the private AS numbers used by each host and the allowed prefixes:3
ASN Allowed prefixes AS 65005 2001:db8:aa::/64 AS 65006 2001:db8:bb::/64,
2001:db8:11::/64 AS 65007 2001:db8:cc::/64 AS 65008 2001:db8:dd::/64 AS 65009 2001:db8:ee::/64,
2001:db8:11::/64 AS 65010 2001:db8:ff::/64
From this table, we build a JSON file for GoRTR, assuming each host can announce the provided prefixes or longer ones (like 2001:db8:aa::42:d9ff:fefc:287a/128 for AS 65005):
{ "roas": [ { "prefix": "2001:db8:aa::/64", "maxLength": 128, "asn": "AS65005" }, { "…": "…" }, { "prefix": "2001:db8:ff::/64", "maxLength": 128, "asn": "AS65010" }, { "prefix": "2001:db8:11::/64", "maxLength": 128, "asn": "AS65006" }, { "prefix": "2001:db8:11::/64", "maxLength": 128, "asn": "AS65009" } ] }
This file is deployed to all validators and served by a web server. GoRTR is configured to fetch it and update it every 10 minutes:
$ gortr -refresh=600 \ -verify=false -checktime=false \ -cache=http://127.0.0.1/rpki.json INFO[0000] New update (7 uniques, 8 total prefixes). 0 bytes. Updating sha256 hash -> 68a1d3b52db8d654bd8263788319f08e3f5384ae54064a7034e9dbaee236ce96 INFO[0000] Updated added, new serial 1
The refresh time could be lowered but GoRTR can be notified of an update using the SIGHUP signal. Clients are immediately notified of the change.
The next step is to configure the leaf routers to validate the received prefixes using the farm of validators. Most vendors support RTR:
Platform Over TCP? Over SSH? Juniper JunOS ✔️ ❌ Cisco IOS XR ✔️ ✔️ Cisco IOS XE ✔️ ❌ Cisco IOS ✔️ ❌ Arista EOS ❌ ❌ BIRD ✔️ ✔️ FRR ✔️ ✔️ GoBGP ✔️ ❌
Configuring JunOS
JunOS only supports plain-text TCP. First, let’s configure the connections to the validation servers:
routing-options { validation { group RPKI { session validator1 { hold-time 60; # session is considered down after 1 minute record-lifetime 3600; # cache is kept for 1 hour refresh-time 30; # cache is refreshed every 30 seconds port 8282; } session validator2 { /* OMITTED */ } session validator3 { /* OMITTED */ } } } }
By default, at most two sessions are randomly established at the same time. This provides a good way to load-balance them among the validators while maintaining good availability. The second step is to define the policy for route validation:
policy-options { policy-statement ACCEPT-VALID { term valid { from { protocol bgp; validation-database valid; } then { validation-state valid; accept; } } term invalid { from { protocol bgp; validation-database invalid; } then { validation-state invalid; reject; } } } policy-statement REJECT-ALL { then reject; } }
The policy statement ACCEPT-VALID turns the validation state of a prefix from unknown to valid if the ROA database says it is valid. It also accepts the route. If the prefix is invalid, the prefix is marked as such and rejected. We have also prepared a REJECT-ALL statement to reject everything else, notably unknown prefixes.
A ROA only certifies the origin of a prefix. A malicious actor can therefore prepend the expected AS number to the AS path to circumvent the validation. For example, AS 65007 could annonce 2001:db8:dd::/64, a prefix allocated to AS 65006, by advertising it with the AS path 65007 65006. To avoid that, we define an additional policy statement to reject AS paths with more than one AS:
policy-options { as-path EXACTLY-ONE-ASN "^.$"; policy-statement ONLY-DIRECTLY-CONNECTED { term exactly-one-asn { from { protocol bgp; as-path EXACTLY-ONE-ASN; } then next policy; } then reject; } }
The last step is to configure the BGP sessions:
protocols { bgp { group HOSTS { local-as 65100; type external; # export [ … ]; import [ ONLY-DIRECTLY-CONNECTED ACCEPT-VALID REJECT-ALL ]; enforce-first-as; neighbor 2001:db8:42::a10 { peer-as 65005; } neighbor 2001:db8:42::a12 { peer-as 65006; } neighbor 2001:db8:42::a14 { peer-as 65007; } } } }
The import policy rejects any AS path longer than one AS, accepts any validated prefix and rejects everything else. The enforce-first-as directive is also pretty important: it ensures the first (and, here, only) AS in the AS path matches the peer AS. Without it, a malicious neighbor could inject a prefix using an AS different than its own, defeating our purpose.4
Let’s check the state of the RTR sessions and the database:
> show validation session Session State Flaps Uptime #IPv4/IPv6 records 2001:db8:4242::10 Up 0 00:16:09 0/9 2001:db8:4242::11 Up 0 00:16:07 0/9 2001:db8:4242::12 Connect 0 0/0 > show validation database RV database for instance master Prefix Origin-AS Session State Mismatch 2001:db8:11::/64-128 65006 2001:db8:4242::10 valid 2001:db8:11::/64-128 65006 2001:db8:4242::11 valid 2001:db8:11::/64-128 65009 2001:db8:4242::10 valid 2001:db8:11::/64-128 65009 2001:db8:4242::11 valid 2001:db8:aa::/64-128 65005 2001:db8:4242::10 valid 2001:db8:aa::/64-128 65005 2001:db8:4242::11 valid 2001:db8:bb::/64-128 65006 2001:db8:4242::10 valid 2001:db8:bb::/64-128 65006 2001:db8:4242::11 valid 2001:db8:cc::/64-128 65007 2001:db8:4242::10 valid 2001:db8:cc::/64-128 65007 2001:db8:4242::11 valid 2001:db8:dd::/64-128 65008 2001:db8:4242::10 valid 2001:db8:dd::/64-128 65008 2001:db8:4242::11 valid 2001:db8:ee::/64-128 65009 2001:db8:4242::10 valid 2001:db8:ee::/64-128 65009 2001:db8:4242::11 valid 2001:db8:ff::/64-128 65010 2001:db8:4242::10 valid 2001:db8:ff::/64-128 65010 2001:db8:4242::11 valid IPv4 records: 0 IPv6 records: 18
Here is an example of accepted route:
> show route protocol bgp table inet6 extensive all inet6.0: 11 destinations, 11 routes (8 active, 0 holddown, 3 hidden) 2001:db8:bb::42/128 (1 entry, 0 announced) *BGP Preference: 170/-101 Next hop type: Router, Next hop index: 0 Address: 0xd050470 Next-hop reference count: 4 Source: 2001:db8:42::a12 Next hop: 2001:db8:42::a12 via em1.0, selected Session Id: 0x0 State: <Active NotInstall Ext> Local AS: 65006 Peer AS: 65000 Age: 12:11 Validation State: valid Task: BGP_65000.2001:db8:42::a12+179 AS path: 65006 I Accepted Localpref: 100 Router ID: 1.1.1.1
A rejected route would be similar with the reason “rejected by import policy” shown in the details and the validation state would be invalid.
Configuring BIRD
BIRD supports both plain-text TCP and SSH. Let’s configure it to use SSH. We need to generate keypairs for both the leaf router and the validators (they can all share the same keypair). We also have to create a known_hosts file for BIRD:
(validatorX)$ ssh-keygen -qN "" -t rsa -f /etc/gortr/ssh_key (validatorX)$ echo -n "validatorX:8283 " ; \ cat /etc/bird/ssh_key_rtr.pub validatorX:8283 ssh-rsa AAAAB3[…]Rk5TW0= (leaf1)$ ssh-keygen -qN "" -t rsa -f /etc/bird/ssh_key (leaf1)$ echo 'validator1:8283 ssh-rsa AAAAB3[…]Rk5TW0=' >> /etc/bird/known_hosts (leaf1)$ echo 'validator2:8283 ssh-rsa AAAAB3[…]Rk5TW0=' >> /etc/bird/known_hosts (leaf1)$ cat /etc/bird/ssh_key.pub ssh-rsa AAAAB3[…]byQ7s= (validatorX)$ echo 'ssh-rsa AAAAB3[…]byQ7s=' >> /etc/gortr/authorized_keys
GoRTR needs additional flags to allow connections over SSH:
$ gortr -refresh=600 -verify=false -checktime=false \ -cache=http://127.0.0.1/rpki.json \ -ssh.bind=:8283 \ -ssh.key=/etc/gortr/ssh_key \ -ssh.method.key=true \ -ssh.auth.user=rpki \ -ssh.auth.key.file=/etc/gortr/authorized_keys INFO[0000] Enabling ssh with the following authentications: password=false, key=true INFO[0000] New update (7 uniques, 8 total prefixes). 0 bytes. Updating sha256 hash -> 68a1d3b52db8d654bd8263788319f08e3f5384ae54064a7034e9dbaee236ce96 INFO[0000] Updated added, new serial 1
Then, we can configure BIRD to use these RTR servers:
roa6 table ROA6; template rpki VALIDATOR { roa6 { table ROA6; }; transport ssh { user "rpki"; remote public key "/etc/bird/known_hosts"; bird private key "/etc/bird/ssh_key"; }; refresh keep 30; retry keep 30; expire keep 3600; } protocol rpki VALIDATOR1 from VALIDATOR { remote validator1 port 8283; } protocol rpki VALIDATOR2 from VALIDATOR { remote validator2 port 8283; }
Unlike JunOS, BIRD doesn’t have a feature to only use a subset of validators. Therefore, we only configure two of them. As a safety measure, if both connections become unavailable, BIRD will keep the ROAs for one hour.
We can query the state of the RTR sessions and the database:
> show protocols all VALIDATOR1 Name Proto Table State Since Info VALIDATOR1 RPKI --- up 17:28:56.321 Established Cache server: rpki@validator1:8283 Status: Established Transport: SSHv2 Protocol version: 1 Session ID: 0 Serial number: 1 Last update: before 25.212 s Refresh timer : 4.787/30 Retry timer : --- Expire timer : 3574.787/3600 No roa4 channel Channel roa6 State: UP Table: ROA6 Preference: 100 Input filter: ACCEPT Output filter: REJECT Routes: 9 imported, 0 exported, 9 preferred Route change stats: received rejected filtered ignored accepted Import updates: 9 0 0 0 9 Import withdraws: 0 0 --- 0 0 Export updates: 0 0 0 --- 0 Export withdraws: 0 --- --- --- 0 > show route table ROA6 Table ROA6: 2001:db8:11::/64-128 AS65006 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:11::/64-128 AS65009 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:aa::/64-128 AS65005 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:bb::/64-128 AS65006 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:cc::/64-128 AS65007 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:dd::/64-128 AS65008 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:ee::/64-128 AS65009 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100) 2001:db8:ff::/64-128 AS65010 [VALIDATOR1 17:28:56.333] * (100) [VALIDATOR2 17:28:56.414] (100)
Like for the JunOS case, a malicious actor could try to workaround the validation by building an AS path where the last AS number is the legitimate one. BIRD is flexible enough to allow us to use any AS to check the IP prefix. Instead of checking the origin AS, we ask it to check the peer AS with this function, without looking at the AS path:
function validated(int peeras) { if (roa_check(ROA6, net, peeras) != ROA_VALID) then { print "Ignore invalid ROA ", net, " for ASN ", peeras; reject; } accept; }
The BGP instance is then configured to use the above function as the import policy:
protocol bgp PEER1 { local as 65100; neighbor 2001:db8:42::a10 as 65005; ipv6 { import keep filtered; import where validated(65005); # export …; }; }
You can view the rejected routes with show route filtered, but BIRD does not store information about the validation state in the routes. You can also watch the logs:
2019-07-31 17:29:08.491 <INFO> Ignore invalid ROA 2001:db8:bb::40:/126 for ASN 65005
Currently, BIRD does not reevaluate the prefixes when the ROAs are updated. There is work in progress to fix this. If this feature is important to you, have a look at FRR instead: it also supports the RTR protocol and triggers a soft reconfiguration of the BGP sessions when ROAs are updated.
Notably, the data flow and the control plane are separated. A node can remove itself by notifying its peers without losing a single packet. ↩︎
People often use AS sets, like AS-APPLE in this example, as they are convenient if you have multiple AS numbers or customers. However, there is currently nothing preventing a rogue actor to add arbitrary AS numbers to their AS set. ↩︎
We are using 16-bit AS numbers for readability. Because we need to assign a different AS number for each host in the datacenter, in an actual deployment, we would use 32-bit AS numbers. ↩︎
Cisco routers and FRR enforce the first AS by default. It is a tunable value to allow the use of route servers: they distribute prefixes on behalf of other routers. ↩︎
via Planet Debian
0 notes
Link
Over in The PGP Problem, there’s an extended critique of PGP (and also specifics of the GnuPG implementation) in a modern context. Robert J. Hansen, one of the core GnuPG developers, has an interesting response:
First, RFC4880bis06 (the latest version) does a pretty good job of bringing the crypto angle to a more modern level. There’s a massive installed base of clients that aren’t aware of bis06, and if you have to interoperate with them you’re kind of screwed: but there’s also absolutely nothing prohibiting you from saying “I’m going to only implement a subset of bis06, the good modern subset, and if you need older stuff then I’m just not going to comply.” Sequoia is more or less taking this route — more power to them.
Second, the author makes a couple of mistakes about the default ciphers. GnuPG has defaulted to AES for many years now: CAST5 is supported for legacy reasons (and I’d like to see it dropped entirely: see above, etc.).
Third, a couple of times the author conflates what the OpenPGP spec requires with what it permits, and with how GnuPG implements it. Cleaner delineation would’ve made the criticisms better, I think.
But all in all? It’s a good criticism.
The problem is, where does that leave us? I found the suggestions in the original author’s article (mainly around using IM apps such as Signal) to be unworkable in a number of situations.
The Problems With PGP
Before moving on, let’s tackle some of the problems identified.
The first is an assertion that email is inherently insecure and can’t be made secure. There are some fairly convincing arguments to be made on that score; as it currently stands, there is little ability to hide metadata from prying eyes. And any format that is capable of talking on the network — as HTML is — is just begging for vulnerabilities like EFAIL.
But PGP isn’t used just for this. In fact, one could argue that sending a binary PGP message as an attachment gets around a lot of that email clunkiness — and would be right, at the expense of potentially more clunkiness (and forgetfulness).
What about the web-of-trust issues? I’m in agreement. I have never really used WoT to authenticate a key, only in rare instances trusting an introducer I know personally and from personal experience understand how stringent they are in signing keys. But this is hardly a problem for PGP alone. Every encryption tool mentioned has the problem of validating keys. The author suggests Signal. Signal has some very strong encryption, but you have to have a phone number and a smartphone to use it. Signal’s strength when setting up a remote contact is as strong as SMS. Let that disheartening reality sink in for a bit. (A little social engineering could probably get many contacts to accept a hijacked SIM in Signal as well.)
How about forward secrecy? This is protection against a private key that gets compromised in the future, because an ephemeral session key (or more than one) is negotiated on each communication, and the secret key is never stored. This is a great plan, but it really requires synchronous communication (or something approaching it) between the sender and the recipient. It can’t be used if I want to, for instance, burn a backup onto a Bluray and give it to a friend for offsite storage without giving the friend access to its contents. There are many, many situations where synchronous key negotiation is impossible, so although forward secrecy is great and a nice enhancement, we should assume it to be always applicable.
The saltpack folks have a more targeted list of PGP message format problems. Both they, and the article I link above, complain about the gpg implementation of PGP. There is no doubt truth to these. Among them is a complaint that gpg can emit unverified data. Well sure, because it has a streaming mode. It exits with a proper error code and warnings if a verification fails at the end — just as gzcat does. This is a part of the API that the caller needs to be aware of. It sounds like some callers weren’t handling this properly, but it’s just a function of a streaming tool.
Suggested Solutions
The Signal suggestion is perfectly reasonable in a lot of cases. But the suggestion to use WhatsApp — a proprietary application from a corporation known to brazenly lie about privacy — is suspect. It may have great crypto, but if it uploads your address book to a suspicious company, is it a great app?
Magic Wormhole is a pretty neat program I hadn’t heard of before. But it should be noted it’s written in Python, so it’s probably unlikely to be using locked memory.
How about backup encryption? Backups are a lot more than just filesystem; maybe somebody has a 100GB MySQL or zfs send stream. How should this be encrypted?
My current estimate is that there’s no magic solution right now. The Sequoia PGP folks seem to have a good thing going, as does Saltpack. Both projects are early in development, so as a privacy-concerned person, should you trust them more than GPG with appropriate options? That’s really hard to say.
Additional Discussions
reddit netsec
Hacker News
reddit crypto
reddit crypto 2
via Planet Debian
0 notes
Link
#!/bin/bash remote=$1 cmd=$2 if [[ ! "${remote}" ]]; then echo No remote given, aborting, try username@host exit 1 fi if [[ ! "${cmd}" ]]; then echo No command given, aborting, try switch or nop exit 1 fi python=/usr/bin/python3.5 commit=$(git rev-parse HEAD) date=$(date +%Y%m%d_%H%M%S) name="${date}_${commit}" src="${name}/git" settings="${src}/src/conf/settings/" venv="${name}/virtualenv" archive="${name}.tar.gz" previous="previous" latest="latest" set -e echo "Transfer archive..." git archive --format tar.gz -o "${archive}" "${commit}" scp "${archive}" ${remote}: rm -f "${archive}" echo "Set up remote host..." ssh "${remote}" mkdir -p "${src}" ssh "${remote}" tar xzf "${archive}" -C "${src}" ssh "${remote}" virtualenv --quiet "${venv}" -p ${python} ssh "${remote}" "${venv}/bin/pip" install --quiet --upgrade pip setuptools ssh "${remote}" "${venv}/bin/pip" install --quiet -r "${src}/requirements.txt" echo "Set up django..." ssh "${remote}" "${venv}/bin/python ${src}/src/manage.py check" ssh "${remote}" "${venv}/bin/python ${src}/src/manage.py migrate --noinput" ssh "${remote}" "${venv}/bin/python ${src}/src/manage.py collectstatic --noinput" if [[ "$cmd" == "switch" ]]; then echo "Switching to new install..." ssh "${remote}" rm -f "${previous}" ssh "${remote}" mv "${latest}" "${previous}" ssh "${remote}" ln -s ${name} "${latest}" ssh "${remote}" 'kill -15 $(cat previous/git/src/gunicorn.pid)' echo "Deleting obsolete deploys" ssh "${remote}" /usr/bin/find . -maxdepth 1 -type d -name "2*" \ grep -v $(basename $(readlink latest)) | \ grep -v $(basename $(readlink previous )) \ | /usr/bin/xargs /bin/rm -rfv fi echo "Cleaning up..." ssh "${remote}" rm -f "${archive}" rm -f "${archive}" set +e
via The Django community aggregator
0 notes
Link
I've been tinkering with hardware for a couple of years now, most of this is trivial stuff if I'm honest, for example:
Wiring a display to a WiFi-enabled ESP8266 device.
Making it fetch data over the internet and display it.
Hooking up a temperature/humidity sensor to a device.
Submit readings to an MQ bus.
Off-hand I think the most complex projects I've built have been complex in terms of software. For example I recently hooked up a 933Mhz radio-receiver to an ESP8266 device, then had to reverse engineer the protocol of the device I wanted to listen for. I recorded a radio-burst using an SDR dongle on my laptop, broke the transmission into 1 and 0 manually, worked out the payload and then ported that code to the ESP8266 device.
Anyway I've decided I should do something more complex, I should build "a computer". Going old-school I'm going to stick to what I know best the Z80 microprocessor. I started programming as a child with a ZX Spectrum which is built around a Z80.
Initially I started with BASIC, later I moved on to assembly language mostly because I wanted to hack games for infinite lives. I suspect the reason I don't play video-games so often these days is because I'm just not very good without cheating ;)
Anyway the Z80 is a reasonably simple processor, available in a 40PIN DIP format. There are the obvious connectors for power, ground, and a clock-source to make the thing tick. After that there are pins for the address-bus, and pins for the data-bus. Wiring up a standalone Z80 seems to be pretty trivial.
Of course making the processor "go" doesn't really give you much. You can wire it up, turn on the power, and barring explosions what do you have? A processor executing NOP instructions with no way to prove it is alive.
So to make a computer I need to interface with it. There are two obvious things that are required:
The ability to get your code on the thing.
i.e. It needs to read from memory.
The ability to read/write externally.
i.e. Light an LED, or scan for keyboard input.
I'm going to keep things basic at the moment, no pun intended. Because I have no RAM, because I have no ROM, because I have no keyboard I'm going to .. fake it.
The Z80 has 40 pins, of which I reckon we need to cable up over half. Only the arduino mega has enough pins for that, but I think if I use a Mega I can wire it to the Z80 then use the Arduino to drive it:
That means the Arduino will generate a clock-signal to make the Z80 tick.
The arduino will monitor the address-bus
When the Z80 makes a request to read the RAM at address 0x0000 it will return something from its memory.
When the Z80 makes a request to write to the RAM at address 0xffff it will store it away in its memory.
Similarly I can monitor for requests for I/O and fake that.
In short the Arduino will run a sketch with a 1024 byte array, which the Z80 will believe is its memory. Via the serial console I can read/write to that RAM, or have the contents hardcoded.
I thought I was being creative with this approach, but it seems like it has been done before, numerous times. For example:
https://ift.tt/30qOzVG
https://ift.tt/2JtepCJ
https://ift.tt/30t3hLL
Anyway I've ordered a bunch of Z80 chips, and an Arduino mega (since I own only one Arduino, I moved on to ESP8266 devices pretty quickly), so once it arrives I'll document the process further.
Once it works I'll need to slowly remove the arduino stuff - I guess I'll start by trying to build an external RAM/ROM interface, or an external I/O circuit. But basically:
Hook the Z80 up to the Arduino such that I can run my own code.
Then replace the arduino over time with standalone stuff.
The end result? I guess I have no illusions I can connect a full-sized keyboard to the chip, and drive a TV. But I bet I could wire up four buttons and an LCD panel. That should be enough to program a game of Tetris in Z80 assembly, and declare success. Something like that anyway :)
Expect part two to appear after my order of parts arrives from China.
via Planet Debian
0 notes
Link
People keep asking me which smart bulbs they should buy. It's a great question! As someone who has, for some reason, ended up spending a bunch of time reverse engineering various types of lightbulb, I'm probably a reasonable person to ask. So. There are four primary communications mechanisms for bulbs: wifi, bluetooth, zigbee and zwave. There's basically zero compelling reasons to care about zwave, so I'm not going to.
Wifi
Advantages: Doesn't need an additional hub - you can just put the bulbs wherever. The bulbs can connect out to a cloud service, so you can control them even if you're not on the same network.
Disadvantages: Only works if you have wifi coverage, each bulb has to have wifi hardware and be configured appropriately.
Which should you get: If you search Amazon for "wifi bulb" you'll get a whole bunch of cheap bulbs. Don't buy any of them. They're mostly based on a custom protocol from Zengge and they're shit. Colour reproduction is bad, there's no good way to use the colour LEDs and the white LEDs simultaneously, and if you use any of the vendor apps they'll proxy your device control through a remote server with terrible authentication mechanisms. Just don't. The ones that aren't Zengge are generally based on the Tuya platform, whose security model is to have keys embedded in some incredibly obfuscated code and hope that nobody can find them. TP-Link make some reasonably competent bulbs but also use a weird custom protocol with hand-rolled security. Eufy are fine but again there's weird custom security. Lifx are the best bulbs, but have zero security on the local network - anyone on your wifi can control the bulbs. If that's something you care about then they're a bad choice, but also if that's something you care about maybe just don't let people you don't trust use your wifi.
Conclusion: If you have to use wifi, go with lifx. Their security is not meaningfully worse than anything else on the market (and they're better than many), and they're better bulbs. But you probably shouldn't go with wifi.
Bluetooth
Advantages: Doesn't need an additional hub. Doesn't need wifi coverage. Doesn't connect to the internet, so remote attack is unlikely.
Disadvantages: Only one control device at a time can connect to a bulb, so harder to share. Control device needs to be in Bluetooth range of the bulb. Doesn't connect to the internet, so you can't control your bulbs remotely.
Which should you get: Again, most Bluetooth bulbs you'll find on Amazon are shit. There's a whole bunch of weird custom protocols and the quality of the bulbs is just bad. If you're going to go with anything, go with the C by GE bulbs. Their protocol is still some AES-encrypted custom binary thing, but they use a Bluetooth controller from Telink that supports a mesh network protocol. This means that you can talk to any bulb in your network and still send commands to other bulbs - the dual advantages here are that you can communicate with bulbs that are outside the range of your control device and also that you can have as many control devices as you have bulbs. If you've bought into the Google Home ecosystem, you can associate them directly with a Home and use Google Assistant to control them remotely. GE also sell a wifi bridge - I have one, but haven't had time to review it yet, so make no assertions around its competence. The colour bulbs are also disappointing, with much dimmer colour output than white output.
Zigbee
Advantages: Zigbee is a mesh protocol, so bulbs can forward messages to each other. The bulbs are also pretty cheap. Zigbee is a standard, so you can obtain bulbs from several vendors that will then interoperate - unfortunately there are actually two separate standards for Zigbee bulbs, and you'll sometimes find yourself with incompatibility issues there.
Disadvantages: Your phone doesn't have a Zigbee radio, so you can't communicate with the bulbs directly. You'll need a hub of some sort to bridge between IP and Zigbee. The ecosystem is kind of a mess, and you may have weird incompatibilities.
Which should you get: Pretty much every vendor that produces Zigbee bulbs also produces a hub for them. Don't get the Sengled hub - anyone on the local network can perform arbitrary unauthenticated command execution on it. I've previously recommended the Ikea Tradfri, which at the time only had local control. They've since added remote control support, and I haven't investigated that in detail. But overall, I'd go with the Philips Hue. Their colour bulbs are simply the best on the market, and their security story seems solid - performing a factory reset on the hub generates a new keypair, and adding local control users requires a physical button press on the hub to allow pairing. Using the Philips hub doesn't tie you into only using Philips bulbs, but right now the Philips bulbs tend to be as cheap (or cheaper) than anything else.
But what about
If you're into tying together all kinds of home automation stuff, then either go with Smartthings or roll your own with Home Assistant. Both are definitely more effort if you only want lighting.
My priority is software freedom
Excellent! There are various bulbs that can run the Espurna or AiLight firmwares, but you'll have to deal with flashing them yourself. You can tie that into Home Assistant and have a completely free stack. If you're ok with your bulbs being proprietary, Home Assistant can speak to most types of bulb without an additional hub (you'll need a supported Zigbee USB stick to control Zigbee bulbs), and will support the C by GE ones as soon as I figure out why my Bluetooth transmissions stop working every so often.
Conclusion
Outside niche cases, just buy a Hue. Philips have done a genuinely good job. Don't buy cheap wifi bulbs. Don't buy a Sengled hub.
(Disclaimer: I mentioned a Google product above. I am a Google employee, but do not work on anything related to Home.)
comments via Planet Debian
0 notes
Link
Review: Finnish Nightmares, by Karoliina Korhonen
Publisher: Atena Copyright: 2018 ISBN: 952-300-222-8 Format: Hardcover Pages: 87
Meet Matti. A typical Finn who appreciates peace, quiet and personal space. If you feel somewhat uncomfortable when reading this book, you just might have a tiny Matti living in you.
Finnish Nightmares is a hardcover collection of mostly single-panel strips from the on-line comic of the same name. They're simple line drawings, mostly in black and white with small, strategic use of color, portraying various situations that make Matti, a stereotypical Finn, uncomfortable (and a few at the end, in the Finnish Daydreams chapter, that make him happy).
This is partly about Finnish culture and a lot about introversion and shyness. Many of these cartoons will be ruefully familiar to those of us who are made uncomfortable by social interactions with strangers. A few made me curious enough about Finnish customs to do a bit of Google research, particularly the heippalappu, an anonymous note left in an apartment hallway for the neighbors, which has no name in English and is generally decried as "passive aggressive." A Google search for heippalappu returns tons of photographs of notes, all in Finnish that I can't read, and now I'm fascinated.
I have seen US jokes and cartoons along similar lines, but in US culture I think it's more common for those to either poke some fun at the introverted person or to represent introverted people trying to navigate a world that's not designed for them. Finnish Nightmares instead presents the introverted position as the social norm that other people may be violating, which is a subtle but important shift. Matti's feelings are supported and shown as typical, and the things that make him uncomfortable are things that maybe the other person should not be doing. Speaking as someone who likes lots of quiet and personal space, it makes Finland seem very attractive.
I am very much the target audience for this book. "When you want to leave your apartment but your neighbor is in the hallway" is something I have actually done, but I've never heard anyone else mention. Likewise "when the weather is horrible, but the only shelter is occupied" (and I appreciated the long list of public transport awkwardness). I think my favorite in the whole book is "when someone's doing something 'wrong' and staring at them intensely won't make them stop."
This was a gift from a friend (who, yes, is a Finn), so I read the English version published in Finland. That edition doesn't appear to be available at the moment from US Amazon, but it looks like it will be coming out in both hardcover and Kindle in August of 2019 from Ten Speed Press. It's a thin and short collection, just an hour or two of browsing at most, but it put a smile on my face and was an excellent gift.
Rating: 7 out of 10
via Planet Debian
0 notes
Link
The next release of Debian OS (codename "Buster") is due very soon. It's currently in deep freeze, with no new package updates permitted unless they fix Release Critical (RC) bugs. The RC bug count is at 123 at the time of writing: this is towards the low end of the scale, consistent with being at a late stage of the freeze.
As things currently stand, the default graphical desktop in Buster will be GNOME, using the Wayland desktop technology. This will be the first time that Debian has defaulted to Wayland, rather than Xorg.
For major technology switches like this, Debian has traditionally taken a very conservative approach to adoption, with a lot of reasoned debate by lots of developers. The switch to systemd by default is an example of this (and here's one good example of LWN coverage of the process we went through for that decision).
Switching to Wayland, however, has not gone through a process like this. In fact it's happened as a result of two entirely separate decisions:
The decision that the default desktop environment for Debian should be GNOME (here's some notes on this decision being re-evaluated for Jessie, demonstrating how rigorous this was)
The GNOME team's decision that the default GNOME session should be Wayland, not Xorg, consistent with upstream GNOME.
In isolation, decision #2 can be justified in a number of ways: within the limited scope of the GNOME desktop environment, Wayland works well; the GNOME stack has been thoroughly tested, it's the default now upstream.
But in a wider context than just the GNOME community, there are still problems to be worked out. This all came to my attention because for a while the popular Synaptic package manager was to be ejected from Debian for not working under Wayland. That bug has now been worked around to prevent removal (although it's still not functional in a Wayland environment). Tilda was also at risk of removal under the same rationale, and there may be more such packages that I am not aware of.
In the last couple of weeks I switched my desktop over to Wayland in order to get a better idea of how well it worked. It's been a mostly pleasant experience: things are generally very good, and I'm quite excited about some of innovative things that are available in the Wayland ecosystem, such as the Sway compositor/window manager and interesting experiments like a re-implementation of Plan 9's rio called wio. However, in this short time I have hit a few fairly serious bugs, including #928030 (desktop and session manager lock up immediately if the root disk fills and #928002 (Drag and Drop from Firefox to the file manager locks up all X-based desktop applications) that have led me to believe that things are not well integrated enough — yet — to be the default desktop technology in Debian. I believe that a key feature of Debian is that we incorporate tools and technologies from a very wide set of communities, and you can expect to mix and match GNOME apps with KDE ones or esoteric X-based applications, old or new, or terminal-based apps, etc., to get things done. That's at least how I work, and one of the major attractions of Debian as a desktop distribution. I argue this case in #927667.
I think we should default to GNOME/Xorg for Buster, and push to default to Wayland for the next release. If we are clear that this a release goal, hopefully we can get wider project engagement and testing and ensure that the whole Debian ecosystem is more tightly integrated and a solid experience.
If you are running a Buster-based desktop now, please consider trying GNOME/Wayland and seeing whether the things you care about work well in that environment. If you find any problems, please file bugs, so we can improve the experience, no matter the outcome for Buster.
via Planet Debian
0 notes