
porchdog
From the Porch
by David Levy: (Fake) Brooklyn Nets CEO, astronomer, chess player, politician and all other things that having a relatively common name afford me. (See here.) (Real) former Startup Lead at Stripe, Venture Partner at ER Accelerator, Startup BD at Amazon, former EIR at Comcast Ventures, former EIR at Broadway Video Ventures, founder of a few companies (Tigerbow and Philo), and seller of one. Also advising, investing in, and playing with new ideas. Prior, spent a decade or so on Wall Street covering, investing in, and advising growth and technology companies. Investor: Mailchain Wagon Analytics (acquired by Box) Hopscotch Chromatik (acquired by TakeLessons) Panna Cooking (acquired by Discovery) Factorial CapitalENIAC Ventures Advisor: Figure1 eduClipper (acquired by Participate) MyPerfectColor Email me at dslevy [at] gmail [dot] com. All opinions/etc. are my own.
45 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

aberamagold
no wager today

tokyo--doll
「 Conjure up my missing self 」

blog-sweety
pro-shipper

bisexualericandre
Gotta Be Fresh

Text
Next Gen SEO (SEaLLMO?)
In my last screed, I foretold a scenario where ChatGPT et al share subscription, advertising, and other revenue with content creators (kinda like a Spotify) in exchange for access to their content for LLM training. So here’s what happens next…. AI companies figure out LLM attribution and begin paying / sharing revenue with content creators whose content is used to train their models. Then, all of the content creators start begging to be included in chatbot LLMs rather than suing or blocking them - asking: “How do I get my content included and referenced by LLMs?” Because they’ll get paid every time LLMs cough up new content generated from their original content - i.e., they’ll get paid not just when that model is trained, but also anytime it is determined that new content generated from their original content has been delivered.
Sound familiar? It should. This is (sort of) how the search engine optimization (SEO) business came to be. Remember when I said here that “...all Web1/2 companies / concepts will be rebuilt for Web3 [i.e., GPU-accelerated compute] to leverage the economic and practical opportunities unlocked (much like every sector was rebuilt for web and for social and for mobile and for cloud and so on)...”? This is one of those concepts.

Today, the SEO industry is about $80B annually growing somewhere around 20% per year (according to some Googling, because ChatGPT, that little minx, refused to give me a straight answer). So it shouldn’t necessitate Jobsian creative forethought to imagine that spending shifts rapidly to content optimization for LLMs. (SEO for LLMs? Hmm, too long. LLM Optimization? Nah, that’s taken. Search Engine and Large Language Model Optimization (SEaLLMO)? Sure, that’s catchy...)
Already, SEO experts are weighing in on optimizing content for LLM ingestion (and egestion <- it’s actually a word, I looked it up). E.g., a quick Google search yields this digital agency piece that helps you unlock the power of SEO, LLMs, and Knowledge Graphs (according to the blog’s headline). And ChatGPT itself told me what language, prompts, formatting, data sets, etc. to use to optimize content for LLMs.

Perhaps the biggest challenge, however, comes not in trying to figure out how to increase your chances of an LLM using your content, but in how we determine that the *new* content the model generates is based on your content that participated in training said model; i.e., with Google et al, search output is the actual content from (and links to) the referenced page; by contrast, with LLMs, the output is newly generated content that the model created based on how it was trained. So how can we tell that the brand spankin’ new itinerary ChatGPT planned for my family trip to Italy next summer is based on content scraped from Fodors.com, TripAdvisor.com, and nomadicmatt.com? Or, more importantly, how do Fodors, TripAdvisor, and Nomadic Matt know that their content was used to create my itinerary?
Answer: I don’t know.
But I bet ChatGPT does. And I suspect the longer answer to how to track content through ingestion / training and then to creation / delivery of novel content involves blockchain. Why? Because it requires an impenetrably secure and neutral third party with an immutable ledger that catalogs the cascading tree of relationships and engagement with content to accurately and appropriately compensate contributors fairly. (Mouthful, eh?)

So we’ve got the content, the LLM that ingests it all and creates new content, the revenue share model, and now the tagging / tracking mechanism. Perhaps there’s a business in here for automating this all for content creators. Or an exchange of sorts that matches LLMs with content. Or maybe it’s worth investigating: (1) buying (a ton of) content (on the cheap), (2) optimizing the acquired content for LLM ingestion / training / generation, and (3) tagging and tracking that content’s usage and influence as it makes its way through the interconnected world of LLMs. Regardless, we’re amidst a tectonic shift in not just how content and information are discovered and how the creators of that content are compensated, but also in the tooling and structure of how content is created.
0 notes
Text
For AI / Web3: Think Spotify, Not Google / Facebook (/ Yahoo)
There are any number of obvious ways companies will make money via AI (and blockchain and metaverse and….) But the business model(s) that fund the most basic online activity - finding information - are likely to look more like Spotify than Google or Facebook. Lemme ‘splain; but first, a(nother) walk down memory lane….

Web1. This may sound crazy a quarter century after Google was founded, but among the early criticism of the company (and there was a lot of criticism) was that rather than keeping users *on* site like Yahoo and the other portals (yes, I said portals), Google seemed to want to get people *off* of its site as quickly as humanly (and algorithmically) possible. Remember, in the early(er) days of content, the goal was to keep people staring at, listening to, watching, or otherwise engaging with *your* content on *your* media property so that you could show them ads the brands paid you to show them. Google didn’t do that; “worse,” Google didn’t even have banner ads to monetize the large but ephemeral traffic they were getting. We all know what happened though. In short: Google adopted (some say borrowed and some say stole) sponsored search results (AdWords) and got paid a ton for traffic origination and got over a trillion dollars in market cap.
Web2. In 2012 I wrote about how the early criticism of Facebook (and there was a *lot* of criticism) was analogous to my Google example in that (1) Facebook was originating an increasingly large percentage of Web traffic and (2) Facebook was not using a standard monetization strategy like (its brief flirtation with) banner ads or sponsored search results (which I wrote about here <- but please don’t read because I got it at least half wrong). Facebook compounded the “problem” by cleverly convincing the world to move to mobile (jk) where they had even less of a semblance of a revenue model until they introduced sponsored posts and became a nearly trillion dollar company.

Web3. And here we are again. (Yahoo ->) Google -> Facebook -> ChatGPT.
The prediction (for lack of a better crystal ball) is that in 5-10 years our primary source of finding information will shift from Google search and Facebook feeds to bots like ChatGPT and Bard and whatever’s next. To compare, we won’t have good measures like percentage of traffic originating from Google or Facebook or ChatGPT or… and we won’t have measures like time-on-site or clicks or taps that correlate well. And this also throws a curve ball to the model we once didn’t understand (“no banners?!”) and then hated (“sponsorships ruin the integrity of search / feeds!) and then fell in love with (ooh… money money money)… because this isn’t originating traffic. And it’s not necessarily keeping traffic on-site to get ad views. So what is it? Short answer: dunno. BUT… (and, to quote the late Paul “Pee Wee Herman” Reubens, “everybody… has a big but(t)…”) This isn’t going away. Generative AI is here to stay. For better or worse.
What’s happening now?
ChatGPT and others are ingesting (some say scraping and some say stealing) as much available content as humanly (and algorithmically) possible and unleashing hoards of tireless GPUs to make sense of its booty before puking it out in (very) nicely packaged CliffsNotes that, when they finally put voice to ChatGPT’s text, will sound either like Kubrick and Clarke’s gratuitously polite HAL 9000 or like Cameron and Schwarzenegger’s genocidal SkyNet. (Salient side note: both tried to murder their creators.)

Meanwhile, content creators (like Sarah Silverman, love her) are suing OpenAI and its contemporaries for the aforementioned ingestion, transformation, and regurgitation of their content because they’re not getting paid on it. (Fair complaint.) And OpenAI released GPTbot to crawl the web and ingest more content to train its models and / but simultaneously shared how to block said bot from sucking the lifeblood from said content creators.
And, well, users are doing what they do: opting for the most effective ways of getting the content they want; i.e., increasingly opting for ChatGPT. So what’s going to happen? Should we look to Google or Facebook for what model will solve this? After all, both companies got content creators very excited for mechanisms to surface content and bring traffic so content creators could make money. Nah. Look to Spotify.
A brief history of time music streaming.
June 1999: The Fannings and Sean Parker start Napster and we all start downloading all of the music we can get our hands on because we know there’s no way this party will last. Key point: this was not just a cheaper (free) way to get music, but a faster / better / more enjoyable way to get music.

December 1999: The Recording Industry Association of America (RIAA) sues Napster because it was facilitating music theft. Nobody stops using Napster. The RIAA would later sue college students too, which was stupid.
2000: Dotcom bubble party! 🎶
March 2001: RIAA wins legal battle and Napster becomes “illegal.” (The party - and the dotcom bubble - are over.)
July 2001: Napster shuts down. (For the time being.) And then nobody listens to music for five years. (Ok that part isn’t true.)
April 2006: Daniel Ek and Martin Lorentzon start Spotify… in Sweden. They convince artists and labels to put music on the service in exchange for sharing ad and subscription revenue. Now everybody is happy and the world is in harmony again.

I may have taken a few liberties with that walk down memory lane (is Apple in the music business?) But the point is: Napster created a new way for people to listen to music that wasn’t only free but better. Turns out people were willing to pay for that or put up with ads. And turns out that it was a really nice way to get money from music consumers to labels and artists.
So wtf does that have to do with ChatGPT? Easy…. Analogous to Napster (and Spotify), ChatGPT created a new way to consume content that users love. But now content creators need to find a way to get excited to have their content used to train these AI models. ChatGPT (et al) will still crawl and scrape and ingest all the content it can, but could pay for access to some content <- that GPTbot could be a nice way to figure out who needs to get paid. Consumers will “pay” for varying levels of access to AI generated content. That $20/mo for ChatGPT seems like a nice start, but I suspect there is a lot more coming to that rather than just better GPT models and more features. Everybody is happy and the world is in harmony again.
(NB: See here for some thoughts on how we’ll track all that content churning and transforming through LLMs and such.)
(Also: pardon my hyperbole above; it’s entirely possible and likely, well, likely that the GenAI chatbots also find revenue models in sponsored content / results, traffic origination <- e,g, “To learn more, see source here….” etc. Just thought this was a good way to look at it too. Carry on….)
0 notes
Text
Connective Tissue
I’ve been trying to articulate how AI, blockchain, and metaverse (gaming / etc.) are intricately connected by forces other than (all) being (technologically and economically) enabled by GPU (and other HPC) silicon. And perhaps I’m trying too hard. (Spoiler alert: I’m not.) After socializing my last three posts and talking to every founder and investor I can get my hands on (who have been pro and con and everything in between re each of these three technologies), my most current convergence thesis has evolved to these three points (because it’s always three points….)

(1) AI is terrific and its authenticity and (content) ownership issues may be mitigated by blockchain technology.
(2) Social media is broken with even Facebook conceding that the fediverse is the future, but IMO it’s likely the fediverse evolves into a truly decentralized and interconnected (social) network of identities underpinned by blockchain technology.
(3) Digital (e.g., crypto) currencies currently only have utility for “everyday” use in “currency challenged” countries (don’t cry for me, Argentina), in the US (etc.) for buying drugs, and (most importantly) in gaming platforms where kids will accumulate digital currency value, grow up, go to college, and use their V-bucks and Robux to buy tacos.
Let me 'splain....

ONE: Love / Hate Blockchain <;> AI.
Everybody had a crush on blockchain (yay!) and now everybody hates it (*sniffle*). Now everybody is smitten with AI (yay!) And the big headline issues with AI (aside from Skynet *sniffle*) are things like authenticity - e.g., how do we know things are real; and copyright implications - e.g., LLMs trained on content, but creators getting no credit or payment (see: Sarah Silverman, *sniffle again*). And all the people that were hot on blockchain before dumping it for AI are clutching their pearls: “Oh heavens how are we going to solve these AI authenticity and copyright issues!” The three options (there’s that three again) are: (1) stop it entirely via legislation and policing - see how that worked for music; (2) do nothing - ummmm; or (3) implement models and technology to appropriately track content, move money, and compensate creators. The way to do option 3 is, karmically, blockchain. (“Baby come back!”) No idea how that will work in practice, but I think it’s the solution to a lot of it. There are plenty of non blockchain solutions; e.g., MIT’s Photoguard “poisons” pixels to make photos un-Photoshop-able. But approaches like this still won’t track things in an easy, immutable, secure way, which is what I think will be required assuming it can be cheap enough.
TLDR: in the future all content etc. will be on chain (in some way shape or form) to facilitate authenticity, flow of information, and flow of money to appropriate creators, distributors, etc.

TWO: Social media broke.
It was hacked in 2016 (MAGA!) and Elon Musk sealed its inevitable fate by doing a National Enquirer-esque catch and kill (buy and murder?) with Twitter during an ongoing (and fittingly) tabloid-esque soap opera. Well done, sir. Meanwhile, Facebook’s Threads announcement included a bit about a forthcoming fediverse feature (fedi what? <- TLDR: interconnected social networks). This is basically Zuckerberg saying hey Facebook etc. are broken and eventually it’ll all be replaced by some sort of open thing so we’re gonna back that. Kinda like when he pivoted the company to mobile in 2012, see here, and made what I still think will be a good bet on VR two years later when he bought Oculus - see here. (Creative destruction FTW!) Fediverse isn’t blockchain, but it’s half way to a real open / user-owned content, etc. platform. (Except the user ownership thing doesn’t happen in fediverse because of course.)
This will morph to something on-chain because it’ll be better for users and faster and neater and better and…. On-chain user-owned identities and content interacting with each other without a closed system containing it all (i.e., a social network) will be the direction. (Think: AOL -> web.) Advertising, targeting, etc. will still happen, but the facilitator won’t be a closed social network. It’ll be something else. Honestly not sure what that looks like (tokenized Mastodon? Second Life reincarnated?) But, for sure, it will be cheaper, nay, more effective (i.e., higher ROI) for advertisers and brands and whatever to reach users so things will move that way. Eventually. The place where this sort of exists now is games. Not exactly, but sort of; and, also, saying that it sort of exists in games now helps my final point….

THREE: It's raining tacos.
Crypto is currently useless (for consumers) in the US aside from currency speculation (bro) and buying drugs (and prostitutes). Its best consumer use is for people in non Western countries like Argentina and Nigeria for storing value because of their own currencies’ hyper inflation / volatility. So *they* do need to onboard to crypto (to get money into a stable coin digital format) and off board crypto (to buy stuff). So that’s one way crypto will proliferate and accumulate in people’s “wallets”; i.e., the rest of the world slowly growing (crypto) assets to be used to buy stuff here and elsewhere such that stores etc. here will need to take it (or have an easy way to convert to fiat).
The only place that some sort of stored value digital currency will accumulate for Americans is kids playing video games. That market will get stupidly large(r) and eventually all of these kids will grow up and want to spend that digital “money” on stuff like tacos at college. (We used our student IDs to buy tacos at Penn, which went on our bursar bill - thanks, Mom and Dad!) So they’ll need a way to convert their V-bucks and Robux to money to buy tacos. That’s the off-board. Oh and games is also metaverse and AI and blockchain as per above and here, here, and here.
So there you have it: blockchain is the connective tissue linking AI, gaming / metaverse, and the rest of the web together. I think.
0 notes
Text
GPU = Gpu Percentage going… Up
Here are some numbers that justify my “web3” thesis. First, recall that I use “web3” to include blockchain, AI, metaverse, etc. - because I can; see here. Second, these numbers work because I cherry picked them to prove my point; i.e., they may be wrong and naively thrown together, but it all makes sense directionally. So, without further ado….
40M GPUs / 400M CPUs = 10%; and that’s going… up.
The global market for CPUs is somewhere around 400M units per year. The global market for GPUs is somewhere around 40M units per year. So assuming these figures are accurate (they’re not), then the “attach rate” of GPUs to CPUs is about 10% because every GPU requires a CPU to function. Does this mean that the attach rate will approach 100% and the GPU market will increase tenfold? Probably not, but maybe. Regardless, it will be multiples larger than it is today; i.e., that 10% figure is going… up (a lot) because AI, blockchain, metaverse etc. require GPU compute power and every device, application, tool, etc. will be adding AI, blockchain, metaverse, etc. capability.

Obligatory history lessons (and gratuitous victory laps).
The sector call I made in 1997 was that effectively 100% of US homes had computers, but only 20% were connected to the Internet. And 100% of new computers sold were connected to the Internet so that gap between 20% and 100% would close to zero (spoiler alert: it did); TLDR: buy ISP stocks (and everything Internet, for that matter). It was the right call in terms of what happened to the percentage of computers connected to the Internet and it was the right stock call for a few years (before it was a very wrong call, but let’s gloss over that for now).

And in 2011, I wrote here that there were ~240 million cell phone accounts in the US, of which only ~30% were smart phones, but soon everyone would have a smart phone with a data plan. So if 80% of the 70% that didn’t have data plans got plans (spoiler alert: they did, and then some), then >130 million new data plans would be created at ~$30/month for almost $50 billion in incremental annual revenue to the carriers, roughly half of which is incremental free cash flow.
And when I joined AWS in 2014, <10% of total IT spend was cloud, but effectively 100% of startups were using cloud. (Reference point: AWS 2014 revenue turned out to be around $4.6B.) Would that mean that IT spend allocation to cloud would go to 100%? Had no idea; but figured it would go… up. (Update: AWS did $80B+ in 2022 - right again!)
What’s under the headline numbers?
All of those calls or even this (GPU attach rate) call are reasonably obvious; they’re big numbers and the (ISP, mobile, cloud, GPU chip) companies have been direct beneficiaries, but it’s also the implications for nearly every sector of society and the economy that can warp your brain. E.g., in the smart / cellphone example from 2011, someone had to build equipment, buy equipment, install boxes, climb cell towers, administrate, manage, market, support, etc., which goosed both white collar and blue collar labor, and created new jobs categories like social media marketer, influencer and manager. And then the productivity gains from mobile (and social and cloud) computing ensued.
So what now?
I don’t think it’s difficult to see the productivity gains to come from AI. (Blockchain and metaverse take a little more squinting, but they’re there - e.g., financial transaction cost reduction, healthcare processing efficiency, communications optimization, advertising economics.) And I appreciate the anxiety that AI in particular creates over (likely tectonic) employment dislocations. But creating, building, and managing all of this infrastructure requires participation from existing (e.g., engineering, hardware assembly, creative design, etc.) and emerging (e.g., prompt engineering) vocations.

Right now (mostly) Nvidia (and a few other companies) can’t come close to building enough chips to meet demand; Nvidia already raised its revenue forecast by 50% after reporting blowout earnings. While the large cloud providers plead for (compute) power from Nvidia and its brethren, those same companies are designing their own chips (like Google’s TPU) or cutting deals with other providers (e.g., Microsoft / Coreweave, which, entirely not ironically enough, lists Nvidia as an investor) to gain GPU access. And, as per BI, VCs, worried about limited access to GPUs for their portfolio companies, started buying GPUs directly(!)

At Computex this year, Nvidia’s CEO predicted an accelerated computing data center of the future powered by GPUs that has a 20-40x cost advantage over today’s CPU-based data centers; specifically, one LLM would cost $10M for 960 CPU-based servers that would require 11 GW of power, whereas the same $10M would buy 48 GPU-based servers that could train 44 LLMs using one-third the energy. Blockchain enthusiasts, meanwhile, are looking to FPGAs as an alternative to GPUs for their high performance compute needs. To wit, Intel’s perennial arch enemy AMD bought Nvidia’s perennial arch (Canadian) enemy ATI in 2006 (smart), and last year the chip company completed its acquisition of Xilinx, one of the premier FPGA designers (smart again).
So the GPU market should increase 5-10x; big range, but there’s just no way the GPU:CPU “attach rate” remains at ~10%. For (at best) tangential context, as per above, the cloud computing’s share of total IT spend increased >5x (and total revenue increased even more than that). To build those GPUs requires semiconductor capital equipment, which may explain the US warships circling Taiwan (and, specifically, TSMC); it requires semiconductor design software, engineers, developers, etc. It also requires (peace?)ships to get products around the world and into data centers; as well as people to assemble, deliver, install, configure, code, and maintain servers.
The infrastructure rebuild also requires new software and tooling to make use of GPU technology, which is teaching a new generation of developers to build and use new products that every existing developer will use to build AI, blockchain, and metaverse applications. Nvidia’s CUDA has been around since 2006, but was mostly relegated to gaming and other niche market enthusiasts before every AI researcher on earth cut their teeth on the platform. And devs accustomed to Github, Python, and AWS will have to learn to spin up nodes and code in Solidity.

Beyond that, every application we know will be rewritten, updated, patched, glued, spackled, and painted to integrate these new technologies. Microsoft is already adding AI to all of its products in the form of Clippy Copilot. Adding Copilot to Word is a no-brainer, but what if Word didn’t exist and someone were to build a document creation application from scratch today (similar to how Google built Googledocs natively for cloud a decade ago)? Or a spreadsheet? Or a decentralized blockchain-based CRM platform?
Even with ubiquitous, cheap(er) high performance compute, we won’t see all applications move on-chain, but they will adopt blockchain for parts of their infrastructure to gain unique improvements in identity portability, security and authenticity, and efficiency. Most people won’t “see” the infrastructure changes, much like my mother-in-law has never waxed poetic to me about Netflix’s wonderful cloud infrastructure; she just likes that she can stream eclectic, tawdry, foreign-language TV shows on demand. (See Nick Ducoff’s piece “It’s Going to Be Blockchain, Not Crypto” for more.) Similarly, I don’t think we’ll see a Ready Player One-like version of Microsoft Word, but we’re already seeing attempts at decentralized social networking like Bluesky Social (without blockchain) and a ton more (using blockchain).

What will this all look like once AI, blockchain, and metaverse are ubiquitous? Just ask ChatGPT. TLDR: “...it's not hard to imagine a future where your AI assistant helps you manage your day, your finances are entirely handled by blockchain-based applications, and you spend a significant portion of your day in the metaverse, working in a virtual office, hanging out with friends who live thousands of miles away, or exploring entirely new virtual worlds…. Privacy concerns, digital divide, mental health issues, cyber threats, job displacement due to automation, regulatory hurdles, and ethical implications are some of the potential issues…. The transition to this future will likely be gradual and require significant technological, societal, and regulatory adaptations….” I’d argue it will be gradual until it’s not.
Footnote: yes AI is hot; no metaverse is not dead (see here); yes blockchain is real and it's not (just) crypto; FPGAs could be the next GPUs; and everything starts in gaming (or pornography).
2 notes
·
View notes
Text
Defining Web3 (Without Self Mutilation)
When I wrote in my last note that Web3 is blockchain + metaverse + AI, the two most common feedback threads were: (1) what are the real use cases for Web3 - specifically, blockchain (e.g., “This is a solution looking for a problem…”); and (2) what is the definition of Web3 - specifically, should it really include AI and metaverse? I had promised to answer the first question and I will - I promise; just want to get some definitions down first. The answer to the second question - specifically around Web3 being inclusive of AI and metaverse (as well as blockchain) is, frankly: I can call it whatever the hell I want. Just ask Dr. W. C. Minor. He was one of the most prolific contributors to the Oxford English Dictionary, whilst committed to a British psychiatric hospital after killing an innocent man in a paranoid rage and before he cut off his own penis. (You can read about his autopenectomy in this book, if you dare.)

A little (more) history....
Most definitions of Web2 refer to social media; specifically going from read (only) Web(1) to read / write Web(2). But I submit that it’s myopic to discuss the move to Web2 / social media without the context of moves from desktop to mobile and local to cloud computing. (I did that here a dozen years ago, kind of by accident.) Wikipedia defined Web2 here and even noted that: “Some scholars argue that cloud computing is an example of Web 2.0 because it is simply an implication of computing on the Internet.” Point is, social media (and the more standard definition of Web2) may not *require* cloud or mobile computing, but none of the big moves were really possible without those catalysts. Sure, Facebook built and managed its own data centers, but the mushroom cloud (see what I did there?) of new companies that came after wouldn’t have been possible without the adoption of cloud computing that lowered the cost of starting a business by (let’s call it) 95%. And the move from desktop to mobile that many concluded an existential threat to Facebook (see here), instead turned out to be the dopamine that lubricated our location- and friend-tagged Instagram (and later Tik Tok etc.) compulsions. Also, everything comes in threes. (It’s the magic number… yes it is.)

So how does that apply to Web3? Well, Wikipedia defines it this way; tldr: decentralization, blockchain, and tokenomics. Do you see AI / metaverse in there? Me neither. Forbes took it a step further here, not only excluding AI but specifically noting that Web3 “...is not synonymous with the [m]etaverse, which is an equally open-source environment for virtual reality.” So am I wrong? Nah. Just ask Dr. Minor (again). But then how does one or more of my three Web3 components facilitate the adoption of the others? For the answer to that I did three(!) things: (1) I asked myself that question, (2) I asked my developer friends that question, and (3) I asked ChatGPT that question (uh huh).
Self: “This means something….”
Everything always starts in gaming and my crush on (what I’m calling) Web3 is no different. I was watching my (then) eight year old son play Roblox and beneath each game tile were numbers like: 455k, 108k, 429, 1.1k, 9.9k, 400, 56…. “What are those?” He told me they were player counts. “Ah total users signed up…” “No, dad, that's how many are playing right now.” “Holy shit.” “What?” “Nothing. Shh.” Thousands of concurrent users playing games created by a fragmented collection of independent amateur game designers. Felt like a YouTube MCN-like opportunity (and probably still is - see Infinite Canvas et al). But I also marveled at how the platform managed thousands of concurrent users in (relatively) graphics intensive environments, which must have required massive amounts of compute. At the same time (concurrently, if you will), developer friends tinkering with blockchain projects mused about the massive compute required to power the embedded cryptography. And it was no secret that AI / ML required massive compute, especially to someone employed by the world’s largest cloud computing company for the majority of the last decade.

Three seemingly unrelated trends with one common thread: massive compute requirements. I concluded (with zero hard data to support my hypothesis) that we’d hit a tipping point in cost / performance for compute that enabled these three things to happen at the same time (dare I say… concurrently). That was also the day I bought NVDA. (Disclosure: I’m long NVDA; RBLX too.) My first stab at weaving them together: games (and metaverse(s)) would require blockchain to make their assets and characters (and avatars and identities) interoperable, portable, and valuable. And, well, some form of AI has been integrated into gaming for as long there were single player games. This means something….
Nerds: Rabbits and Sheep. (But good sheep.)
Next I went to my propellerheads. "I like the re-rendering of Web3 as broader to include AI..." said the first. Ok - confirmation bias. (To be fair: I was selective in my question targets.) But one of my most cynical and favorite tin hat wearing engineering crazies, who hates every new technology I’ve ever shown him (ironic though I suppose healthy for an engineer focused on startups), shared that “...Web3 [i.e., blockchain] is amazingly lacking in AI. That’s the next gen. Right now it’s pure plumbing….” [Eyebrow rises - especially because that lovable kook runs solutions architecture at a very large crypto company - also, he’s smart AF.]

And one of my newest friendly rabbits furthest down the hole suggested that generative AI (check) could radically decrease the cost of decentralized compute (check) and vice versa (bingo). This was getting interesting. Finally, one of the people running Techstar’s Crypto program up here in Beantown (I get to call it that) wrote this re generative AI *needing* blockchain; tldr: “…as the generative AI industry grows, there are critical questions that need to be addressed, such as how data for these models is acquired and tracked, and how value flows down to the original IP owners…. [He] proposes that a blockchain-based system could underpin the AI ecosystem and allow every participant to benefit from the upside….” Note: ChatGPT summarized his post for me - automagically. Neat.
ChatGPT: Our forthcoming digital overlords agree with me.
Given I used generative AI to summarize that Techstars post, it was only natural that I asked ChatGPT directly: “How are blockchain, metaverse, and (generative) AI related?” Lightly edited answers below. TLDR: of course they’re related. (Note: ChatGPT is very agreeable.)

“[B]lockchain, metaverse, and generative AI… can intersect and complement one another, driving innovation and enabling new possibilities across various industries. [E.g….]
In the metaverse, users can own, trade, and create digital assets like virtual land, clothing, or collectibles. Blockchain technology can be used to establish ownership and provenance of these digital assets by creating… NFTs that are unique, indivisible, and verifiable.
Blockchain can enable the formation of decentralized organizations (DAOs) in the metaverse, where decision-making is based on token holders' votes, and governance rules are enforced through smart contracts.
Generative AI can be used to create unique and customizable assets, like clothing, artwork, or even entire virtual environments within the metaverse. These assets can then be tokenized and traded using blockchain technology.
AI can help users discover and engage with relevant content, services, or experiences within the metaverse. Blockchain can be used to enable secure and transparent transactions in these AI-driven marketplaces….
AI can be used to enhance blockchain's efficiency and scalability, while blockchain can be employed to enable secure and transparent AI data-sharing, model training, and deployment.”
So there you have it. Web3 expanded and defined, without the antiquarian books and leaving all of your body parts attached to where they started.
3 notes
·
View notes
Text
Ah Sh*t, Here We Go Again….
About a dozen years ago I wrote about Web2 powering (1) a tectonic technological infrasTructure shift (there was no synonym for infrastructure that started with the letter “T”), (2) consequent robust job creation, (3) a ~2x increase in the Nasdaq, and (4) consumer spending increases to power the virtuous (dare I say) flywheel. Fast forward: lots of that happened, but now comes the hangover.... Massive startup valuation deflation, financing doors slam shut, (pseudo) hyper inflation and skyrocketing interest rates, consumers cut spending, housing market imploding, Big tech laying off thousands of people, war in Ukraine, high energy prices, pandemics, tripledemics, Chinese balloon invasions, and the four horsepeople of the apocalypse are saddling up.
So what now?
Ah Sh*t, here we go again…. In 1995, J. Neil Weintrout from my then future employer Hambrecht & Quist (the tech boutique investment bank of tech boutique investment banks that took Apple public a decade and a half prior) said: “The Internet changes everything.” (Or something like that.) And it did. (Duh.) Newspapers no longer needed paper distribution, retail didn’t need physical locations, banks didn’t need branches, and so on and so forth. It was an easy call in retrospect; nearly all US homes had computers, but only ~20% were connected to the Internet so the gap was destined to close. (I know because I wrote that in an equity research report I wrote a couple of years later. [Taps self on back.]) Valuations went bonkers (tell me about a bubble when splits pop stocks again), Buy.com spent a trillion dollars on a blank black screen Super Bowl commercial; and then everything blew up. In the aftermath, Google and everything else happened. Yes, I know Google was founded before that, but it went public at $23B and, as per my trader at my first hedge fund, there was “a line around the corner to short it.”

It was a once in a generation tectonic shift, only it happened again not a decade later when social, mobile, and cloud computing entered the vernacular. We called it Web 2.0 (I know because I have a t-shirt), but we really didn’t call it that until now. And it changed everything (again). Maybe it wasn’t quite the apparent boom bust (boom) cycle given it was obfuscated by a Great Recession, but new leadership emerged; Facebook and Twitter (and MySpace and Friendster) took on Google, AWS emerged in the cloud from a boring online bookstore (with Microsoft / Oracle / Dell / EMC caught flat footed), and we started streaming movies to our iPads via Netflix. In retrospect, like the dotcom bubble before it, it seems like it was a straight line up and to the right. It wasn’t. A bunch of companies went public, but then Facebook broke issue (and the valuation halved from ~$100B at IPO) and the party was over. Only it wasn’t. Love it or hate it, Facebook quadrupled its IPO valuation (and octupled its low), half of IT spend is now for cloud infrastructure (from <10% ten years ago), and last month I watched the Super Bowl on Youtube TV.
So what now? (Didn’t I just say that?)
First, the parallels. Bitcoin went over $60K, Nvidia GPUs got sizzling hot (see what I did there?), Roblox and Fortnite pulled our kids into Ready Player One, Coinbase bought a gazillion dollar Super Bowl ad with a broken QR code, Square changed its name to Block, and ChatGPT got $400M from Microsoft to make Google prematurely ejaculate Bard; and then everything blew up. Again. (Recap of very recent history: crypto currencies are down 50%+ from their highs, the Ethereum Merge turned Nvidia GPUs into paperweights, RBLX sits at half its IPO price, and the fruit fly attention span of the peanut gallery dumped crypto to fall in love with generative AI.)

Buuuuut, like Web1 and Web2 after their respective (generously described) downturns, what didn’t change is the fundamental impact of these platform shifts on technology and society - infrastructure change is real, new, novel, and profoundly impactful.
Put another way: “The Internet Web3 changes everything [again (again)].”
Web3 is the intersection of blockchain, metaverse, and artificial intelligence - three fundamental technologies that are only now feasible because of the availability of increasingly high performance compute at increasingly lower cost. Web1 was “read” (e.g., static web pages) and Web2 brought “read / write” (e.g., social media) based on distributed client server models (e.g., cloud computing). Web3 introduces “read / write / own” in which users create, consume, and own the upside of their work via tokens. It is built on peer-to-peer networks that interact without middlemen. This means that all Web1/2 companies / concepts will be rebuilt for Web3 to leverage the economic and practical opportunities unlocked (much like every sector was rebuilt for web and for social and for mobile and for cloud and so on).
What are all of those things that need to be rebuilt and what are those unique and novel things we’ll be able to do? I.e., what are the killer apps for Web3? Read my next installment to find out. (Spoiler alert: I don’t really know, but we’re gonna figure it out together.)
[Disclosure: at any given time I may be long AMZN, COIN, NVDA, FB, etc.; i.e., nearly any public (or private) company mentioned above.]
1 note
·
View note
Text
Tell me about a time when you hired a nanny...?
The most important lesson I learned from my 4+ years at Amazon was how to hire. I’d been on both sides of the process in different industries in different roles (including CEO) over 20+ years, but Amazon's remarkably structured, consistent, objective, and largely dispassionate approach to hiring is a skill I'll take with me for the rest of my career. So when did this come in handy most? Hiring our nanny.
TLDR: we adapted the Amazon Leadership Principles for our family (here) and instituted a modified version of Amazon’s interviewing approach. The result: we have the world’s best nanny. You could ask our kids, but they’re probably busy with her making banana bread from scratch.

Context:
Earlier this year, our nanny of five years left with two weeks notice and we were stuck. (Thanks Papa Fred and Grandma June for filling in for a while!) We scrambled to find a replacement, asking everyone we knew for candidates. Trying to do my part (my wife had done the lion's share of the sourcing etc., naturally), I decided I could do vetting and reference checks. I honestly had no idea what to ask despite being the second best parent in our household, so I fell back on what I knew: Amazon.
Amazon’s interview process:
You can learn about Amazon's interview process by reading The Everything Store or checking out sites like this or this. But, here are the highlights:
You’ll do two phone screens that will be more casual, review background, feel out fit and excitement etc. If you make it through the phone screens you’ll be invited to do a formal interview loop.
A loop is roughly half a dozen back-to-back behavioral interviews testing on Amazon’s Leadership Principles (LPs). I cannot stress enough how critical Amazon’s LPs are for interviewing (and thriving) at Amazon.
Behavioral interview questions won’t ask: “Tell me about a time you were Customer Obsessed...” (which is Amazon’s first LP). Rather, you’ll be asked something like: “Tell me about a time when a customer wanted one thing and you thought they needed another....”
The interviewers will be people from the group that is hiring as well as a “Bar Raiser.” A bar raiser theoretically makes sure new hires are “better” than half the people at Amazon, thus “raising the bar.” But the best explanation of a bar raiser that I’ve heard is a specially trained employee that is not emotionally invested in filling the role. For every bad hire I’ve ever made (and there have been plenty), I can think back to what I saw during the interview, but overlooked because I was excited to hire someone. This is the proverbial friend that meets your new significant other and tells you: “Hey I know Lorena is cute, but that scissor obsession of hers gives me pause.”
Interviewers will submit their vote (yay or nay) and feedback (before being able to see anybody else’s vote / feedback). Everybody on the loop will review votes and feedback and the bar raiser will organize and host a debrief to review and make a decision as a group.

But for a nanny?
Of course. Choosing someone to care for children is a bit more important than any other hire. That said, we had to make a few adjustments to the Amazon LPs (and interview questions) to accommodate our family. For example, “Customer Obsession” became “Children / Family Obsession” and “Hire and Develop the Best” became “Finding and Friending the Best Nannies.” But ironically many of other LPs transitioned just fine as written (e.g., “Are Right, A Lot, “Bias for Action,” and “Disagree and Commit.”)
A complete list of our Nanny Principles is here.
What happened....
We phone screened and / or interviewed a dozen or more candidates - taking notes and sharing feedback.
"Tell me about a time when a child or parent wanted one thing, but you felt that needed something else..."
"Give me an example of a childcare situation where you wish you had done better...."
"Tell me about a time when you had an idea for the parents that was strongly opposed.... How did you handle negative feedback...."
We narrowed it down to two candidates for whom we did 2-3 reference checks each - relying in large part again on the Amazon interview approach (consistently probing for specific examples). We made a decision. We made an offer. And we hired our nanny.
(We're still deciding on which one of us was the bar raiser.)
1 note
·
View note
Text
Onward Startup Soldiers!
Last month, after completing a year+ at Stripe, I announced my decision to leave. My group at Stripe built a platform to engage and track impact on startups from top tier accelerators and venture capitalists. I'm proud to have been part of the effort and look forward to watching Stripe continue to dazzle and delight users, arm the upstarts, and increase the GDP of the Internet.

Before I talk about what’s next, I wanted to share how I got to this post - realizing I haven’t updated this blog about my career since I was at Comcast Ventures....

In 2014, while EIR’ing at Comcast Ventures, the fund’s CFO suggested I talk to her friend Dave Schappell (not that Dave Chappelle) at AWS re their startup BD group. “Hosting sales?!” I (foolishly) sneered. “Um, I don’t think that’s what Dave does...” she (not foolishly) replied. That was an understatement. Dave recruited me into a group that was roughly twenty people globally at the time (half US and half of that early stage). The group was, without exception, ex founders and / or ex venture capitalists. Over the next 4+ years, I was fortunate to help build that platform to the preeminent startup engagement group in the world. In fact, given the backgrounds of the team members and the data and wherewithal of Amazon, I believe there isn’t a group in the world with a more comprehensive and discerning view of early stage companies and startup and venture ecosystems. By the time I left, the group had grown by ~7x and managed relationships with over 4,000 accelerator / venture / angel / etc. partners and over 40,000 startups. (And AWS revenue increased to >$25 billion in 2018 from ~$4 billion in 2014 when I joined while Amazon’s stock had surpassed $1,500/share from ~$370/share. 🙏🤦♂️ Naturally, I take nearly all of the credit... for being at the right place at the right time 😉)

So why did I leave? I didn’t want to. I really enjoyed my time at Amazon. But Stripe was another “foundational” platform and critical component of a company’s tech stack with analogous developer and startup focused DNA and early success. They were looking for someone to help build a comparable group from scratch and the opportunity was too good to pass up. The company, its products, and its prospects are mind-bogglingly amazing, but unfortunately the role wasn’t what I expected so I parted ways after putting in place the infrastructure to set the startup group up for continued success. (To that point, the data structure, metrics and forecasting system, and playbook I instituted increased Stripe startup penetration at engaged portfolios by 4x organic penetration growth.)

What’s next? I’m still a venture partner at ERA, as I’ve been for most of the last decade, as well as a mentor at Techstars and elsewhere. I’ll continue mentoring companies from those and other accelerator and venture portfolios as well as founders and companies I meet along the way where I can be helpful. And I’ll have some news soon about my next adventure. In the meantime, I plan on sharing a few of the lessons and anecdotes I’ve learned over the last 5+ years on the “corporate” side (and, well, the last 20+ years all over the place).
Ahhhhh. It’s nice to have my voice back :) Stay tuned....
1 note
·
View note
Text
Haaaaaave you met...?
I’ve had this on my todo list since I read my old colleague’s "how to get/make intros" post three years ago. Given his (old) role at Amazon (before he retired) and his mind blowing network, he (still) gets asked for intros more than frequently so he’s become a seasoned pro. He also suggests a few other approaches (here) and I have a different style so I wanted to share this.

But first, why does this matter?
Two reasons. (1) Part of my role at Amazon includes helping startups in any way possible including making introductions to potential investors and partners and different people and groups within Amazon. So I do this a lot and this is the format I’ve learned works most effectively. And (2) I’ve been burned before! More on that later.
Without further ado, here is my process:
Send me a (single) clean / new email thread. Do not reply to our existing email thread that contains our prior conversation. Do not send me a single email or multiple emails tailored to specific people. I’ll handle that. Just start a new email.
The subject should be brief / generic. E.g., “Follow-up re MyCompany chat at ThisAccelerator….” (Unless otherwise noted or appropriate.)
The body of the email should be super duper uber brief. It should (1) identify what the company does and (2) highlight a traction point. E.g., “Hey David – great catching up during office hours at ThisAccelerator. As discussed, MyCompany is [one sentence]. We’ve [one note about traction and / or how badass you guys are]. Look forward to seeing you around ThisAccelerator….”
The one sentence about your company should be just that - one very simple sentence. Not a paragraph about what you do. Nobody will read that. (You should be able to describe your company in one short sentence anyway - no need to puke up everything there is to know about your company - the idea is to get people interested enough to ask you more questions.) Examples here:
“…MyCompany translates online recipes into product SKUs.”
“…MyCompany facilitates programmatic native advertising.”
“…MyCompany lets people print PCBs on demand.”
“…MyCompany lets people spin up cloud desktops for ML.”
The note about traction should be just that (as well) - one very simple sentence (as well). Not a paragraph about all of your awards and blog posts. Nobody will read that. This is what will quickly demonstrate that your company is “real.” Examples here (and related to the above company description examples):
“…We’ve had tens of thousand of users convert recipes to SKUs given our partnership with Food & Wine.”
“…We’ve delivered millions of impressions for top brands like Gap and Coca Cola.”
“…We’ve accelerated our PCB production and we’re now delivering over a dozen boards per week.”
“…We’ve raised $10M from NEA and others.”
I will use your email to forward to the appropriate contact and tailor as necessary. If the person is interested in connecting, I will add you back to the thread with a short note. Please make sure to get back to that person within 24hrs and BCC me unless I’ve specifically requested to remain on the thread.
Voila. If and when you do connect, please follow-up with me to let me know if anything developed.
So, now some history on how I learned the hard way to do this….
Five years ago I asked a well-connected friend for an introduction to a prominent venture capitalist. He was happy to oblige, but insisted I follow an intro format that he himself described as “baroque.” His (literally) twelve step program is below. (And, fwiw, this is another approach you or others may use, just isn’t what I do….)
Baroque Intro Process:
If you haven't already done so, make sure to customize your LinkedIn URL.
Research the hell out of whomever you are looking to speak with, as this makes the conversation much better.
Send me an email in the following format on SUNDAY evening for each of the people that we discussed.
Subj Line: “Intro to <name>”; Body: "Dear [friend], Thank you for the offer to introduce me to <name>. Historically, I have done XXXXXX. Here is my background: <link to your LinkedIn profile> I would like have a short (<30m) informational talk with <name> about YYYYY as it relates to <whatever you are trying to do>. Regards, <your name>”
I send it on MONDAY morning, Eastern time, as that has generated the best open rates, historically.
I put you on bcc:. DO NOT CONTACT THE PERSON. The bcc: is so that you know that the note went out.
When/if I hear from the other party, I will introduce you two in a new thread.
Put me on bcc: on the FIRST REPLY only. This lets me know that you have responded.
Don't delay, respond that day.
Let me know after the meeting happened that the meeting was worthwhile or not.
Send a "thank you" note to the person you spoke with.
Voila.
I, in turn, obliged. I, in turn, also thought he was nuts.
Fast forward a couple of years and I was on the receiving end of an intro request to a (different) prominent venture capitalist. Prior to making the introduction we jumped on the phone and I explained to this entrepreneur that under no circumstances should he try and pitch him, that he hears pitches all day and night and will just tune out, that he should just share what he’s working on and ask for advice, that he should share common experiences, etc. I made the intro by email, the entrepreneur replied (all) with a grandiose and lengthy pitch about changing the world, and I got an email from the venture capitalist later that day saying, “I’m telling you this because you’re my friend. Please don’t ever do that again.”
I reached back out to the friend w the self described baroque intro approach and told him that I understood why he does what he does. “You got burned, eh? ;-)”
0 notes
Text
Leapfrog - $FB $GOOG #in
When Google acquired Android and word got out that it was building a mobile operating system and possibly a phone, the general consensus was that the company had gone looney. Another silly project from a giant company with fat margins and tons of cash that was akin to building space ships and flying (self driving?) cars. Turns out it was a good move considering the whole world moved to mobile and mobile devices outnumber desktop by an order of magnitude.

Microsoft and other tech giants followed suit launching their own phones, mobile operating systems, etc. But Facebook didn't, despite persistent rumors they would. Separately, the company spent $2B to buy Oculus, which makes a virtual reality mask that you attach to your face. Looney? Maybe. But perhaps Facebook is looking past mobile to a world of that moves to wearables and "things" with Internet that outnumber mobile phones by orders magnitude.
2 notes
·
View notes
Text
Traffic from Messaging - $FB $GOOG $TWTR
Traffic origination is shifting to messaging. Once upon a time, traffic to websites originated from search. And Google put a toll on it by selling sponsored results. Now Google is worth >$350B. Then, social media went from driving 5% of traffic to >25% and probably a bunch more. Now Facebook and Twitter are worth >$150B and ~$20B. Now this....
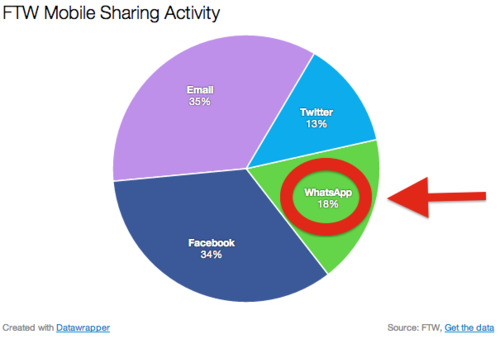
According to Digiday, 18% of sharing actvity on FTW (USA Today's viral sports site) comes from the WhatsApp share button. (Same post notes similar WhatsApp sharing craziness on Buzzfeed, Shazam, and Aviary). This is a really big deal and may finally explain why Facebook laid out $19B for WhatsApp and why Evan Spiegel negged Facebook's $3B Snapchat indication of interest.

Point is, when applications:
(1) have tons of users (duh), and
(2) originate traffic to publishers, other apps, and the like (ok); they
(3) can make lots of money (how?)
Here we go again....
Google once had tons of traffic and had no revenue. The fledgling search company was all but laughed at for not doing banner advertising (see here) and everyone cried when it 'destroyed the integrity of search' by allowing companies to pay to sponsor search. People may not remember, but it happened.
Facebook and Twitter once had tons of traffic and minimal revenue. Facebook did a little (>$4B?) of display, but now generates most of its revenue from mobile / sponsored feed posts. And Twitter makes its money similarly. Everyone cried when both 'destroyed the integrity of the feed' by cluttering it with ads (and some are still crying), but by and large nobody cares, the ads work (uh huh), and the companies are making money (yuh huh). See here, here, and here re sponsored posts, Facebook's business model, and paying for downloads (i.e., app traffic).
So, um, messaging?
The early complaint re Google and ad revenue was that people used Google to go elsewhere (i.e., users didn't stay at Google like they did with Yahoo and other portals - they searched and bounced elsewhere). And the complaints re Facebook and Twitter are that people don't use them with purchase intent like they do Google. (I'll throw out that people once didn't use Google with purchase and intent, but whatever.)
Similarly but differently, naysayers re messaging note that messaging is private and peer-to-peer (i.e., not as viral) and therefore ads won't work. First, USA Today/FTW's robust sharing traffic from WhatsApp would suggest otherwise re the latter. And re 'ads' we need to think about what that unit will be. With Google it wasn't display and in social it wasn't paid search. So to look at messaging and expect an exact replica of an existing ad unit would be naive. Will it be stickers or sponsored apps or some sort of paid functionality or something entirely different, I don't really know. But considering the enormous and growing user bases and even more enormously and faster growing activity via messaging, it seems clear that the revenue potential is real (again).
0 notes
Text
(Re)inventing Television - A Brief History of the Brief History of Philo
In 2010 I conceived, built, financed, and launched a social television platform called Philo. It let TV viewers use their mobile phones and laptops to connect and interact with programming and other viewers. Philo and its brethren kicked-off the social TV revolution. Ultimately, the original product failed and I pivoted and sold the company, but not before the television viewing experience was forever changed.

I waited almost three years to finally put some thoughts down on this experience so forgive me if the facts are a little fuzzy. Sometimes it’s best to get your thoughts down right away. And sometimes it’s better to put some space in between the experience and the post mortem. In the case of both of my first two startups, I needed time to recuperate. Rested, recovered, and reflective… here goes….
“Check-in for TV?” was the subject of the email I sent to my CTO-to-be on December 13, 2009. I was watching Animal House for the millionth time and after the “Otis” allusion in the email’s first line, I continued.... “TV check-in.... I’d like that.... Lots of bizdev opps.... This could replace Nielsen.” And thus the seed for Philo was planted. For most of the three years prior I had been slogging away on my first startup, a gifting company called Tigerbow. It had become clear that Tigerbow was going nowhere with customers and investors and I needed a new idea. Philo was it. It blended my passion for digital media and television and it was clear to me that the nearly $200 billion global television industry was on the cusp of radical transformation.

To vet the idea I did a high-level search for comparable digital products. After all, people were already using social media to talk about television in real-time, but the process was cumbersome and consequently added limited value to the viewer’s experience. The search yielded little so even if there were available platforms, they had not gone mainstream thus the opportunity persisted.
Next, I lobbied my dearest friend from college, who had emerged as one of Hollywood’s most prolific reality TV show producers. He understood the television business better than anyone I knew and had close relationships with all of the television networks and production companies. He soon quit his lucrative TV production job and my CTO quit his comfortable software development position to join me in creating Philo (named, appropriately, after Philo Farnsworth, who is credited with inventing the television in the early 20th century).
There was little to build from (other than check-in apps in other verticals like Foursquare in location) as social TV was barely a term let alone an industry. And I had never really built my own digital product from scratch so had zero experience with writing a product specification for developers. As a result, I spent the next several days (and nights) meticulously drawing out by hand each screen of Philo’s mobile application and fitting together the puzzle of how the user experience would flow. While my CTO holed up and coded our application to that specification, I began to woo investors, many of whom I had grown to know during my previous startup. Within a few months we had investors committed and a working prototype. We launched Philo to the public in May 2010.
“[Re]inventing Television.”
Watching television is an inherently social activity, making it the subject of much of office water cooler conversation. So we set out to build a dead simple application that would unleash and encourage that activity by helping viewers find something to watch, share and invite friends to watch together, and interact with other viewers and programming. We built Philo to cater to every viewer’s needs. Philo’s mobile application featured a complete television schedule, recommendations for popular and trending shows, and chatrooms for every show on air. We mitigated the “empty room” dilemma by partnering with networks and production companies to throw virtual viewing parties, often with the participation of celebrity talent on Philo’s platform. We were striving to make watching television without Philo comparable to watching television with the sound off. We were striving to make Philo an indispensable component of the television viewing experience.

Initially, the television networks were supportive. After all, among their biggest issues was the erosion of live viewership (where networks earn the bulk of their revenue) resulting from DVR and over-the-top television. Turning each viewer into a promotional vehicle for their shows by encouraging them to share what they were watching via Facebook and Twitter (with the help of Philo) was a no cost, viral, and effective marketing strategy. Empirical evidence was already beginning to show a correlation between social media activity and ratings. In theory, networks later would gain the ability to pay Philo to promote relevant shows to relevant viewers via sponsored recommendations. Considering networks spend more money promoting shows than creating shows, a Philo success story would make for a network television promotional bonanza.
But Philo Failed.
Philo did not succeed for three reasons. First, our execution was sloppy. In attempting to deliver to the user everything we believed the viewer wanted, we made a critical error in product development by trying to pack in too many features. The product just was not simple or elegant enough. As CEO, the product was a direct reflection of my vision and my product vision was flawed. (In contrast, one of our competitor’s products began with only a single function: share what you are watching.)
Second, we did not have the right team in place. After launch, it became evident that our technology team was not the right one to build the platform we needed to support a large viewing audience. Worse, I felt like our technical leadership did not take ownership of the product, company, successes, or failures. But as CEO, my job was to rectify that immediately. Eventually I replaced our entire tech team with a top notch group - a process that included bringing one fleeting CTO who, in effect, fired our original tech team only to quit days before he was to start in the office (which made for one helluva weekend and board meeting and one helluva story for another post). But I had waited too long to make the changes, which had significant negative impacts on team morale, product, and overall execution.
Third, and finally, it turns out that viewers did not need a separate application for blending social media and television. Facebook and, especially, Twitter were more than enough to satisfy viewers’ needs. And with installed bases of hundreds of millions or more, not only were the social media giants more important to television networks, but the user experience itself was remarkably enhanced by the participation of so many people. Philo, and ultimately its competitors, could not effectively compete.
#SocialTVToday
Roughly half a year after Philo’s launch and after the realization that television viewers were content to use Facebook and Twitter to interact with programming, I made the difficult decision to scrap Philo’s consumer product and focus my newly hired tech team on using parts of our platform to build a product to help networks reach out to viewers with content and offers. Before we completed that product, I orchestrated the sale of Philo to a social advertising platform, which gave my team a new home and our investors some skin in the game in the form of stock in a new company.

Philo itself did not become the indispensable companion to television viewing that I had hoped. But Philo’s social television experiment was part of a much bigger movement that persists #today.
4 notes
·
View notes
Text
"Could it be... Education?"
In honor of SXSWedu, which regrettably I am not attending, I thought it would be fun to put down a few thoughts about edtech, which I love - because, well, who wouldn’t? It’s one of the few trillion (with a ’t’) dollar markets (aside from healthcare and financial services?), it’s technology, it’s about education, and I’ve got a kid.

First, a ‘market’ look at the education sector. These numbers are wrong - as usual - but the orders of magnitude should be sorta right and illustrative….
Today, education represents around 10-20% of the economy (or some double digit percentage at least), but probably less than 1% of market capitalization. So it seems clear to me that the potential for education to represent a larger component of market cap is obvious - with room to grow by as much or more than an order of magnitude. Those types of opportunities are a bit harder to screw up as an investor, entrepreneur, etc.
Economics + Delivery System + Product
Comparing healthcare and education provides another useful point. With healthcare, it is clear that (1) there is a financial imperative for change; i.e., the current state of the healthcare system in the country is unsustainable from an economic point of view, and (2) there is a severe problem with the delivery of healthcare services, regardless of which side of the political spectrum you lean. That said, the actual healthcare products (e.g., medical procedures, medication, and other medical service) are effective. Maybe not as effective as we’d like, but they ‘work.’
I recently met Don Burton, managing director of the Techstars Kaplan EdTech Accelerator, who educated me on the contrast between these three factors as they relate to healthcare and education: (1) economics, (2) delivery methods, and (3) the product itself. Don previously worked at Goldman Sachs and McKinsey and ran business development at Disney before founding and running several successful education companies including Parent Partners (sold to the Washington Post), Global Education Network, Aha Learning Partners, eebee’s Adventures, and Learning Edge Labs. I.e., Don knows the education space cold.

As in healthcare, it is clear that there is an economic imperative to reform or completely replace our education system. And it should also be clear that the delivery mechanisms are not serving large portions of the population sufficiently. But: does the product work? Does the curriculum-based system for teaching children, young adults, and adults most effectively prepare the country’s population? Believers in progressive education would say no. That is, they would say the product is broken as well.
So therein lie the opportunities. A broken product, a broken delivery system, and an economic imperative to catalyze change in both. Let’s hope it works.
[Disclosure: I have a handful of relationships in the edtech space including but not limited to the following.... I am an advisor to Admittedly (through the Entrepreneurs Roundtable Accelerator), eduClipper, and Figure 1; and I am an investor in Chromatik.]
1 note
·
View note
Text
All #in.
Hedge fund managers and startup CEOs may appear to come from opposite worlds - the former numbers-obsessed nutjobs hiding behind dozens of screens, the latter product-obsessed nutjobs hiding behind dozen of bowls of ramen - but having masqueraded as both nutjobs I’ve noticed one unique quality ever present in the best of both: they know how to go all in.

What I mean by knowing how to go all in is that not only do they have the balls to do it, but they are experts about knowing where and when to go all in.
When you own a bunch of stocks in your portfolio and one starts working, it may feel intuitive to take a little off and book some profits. “Nobody ever lost money taking a profit.” And often it’s the right move. But the best folks I’ve seen are keenly aware of that moment when it’s time to back up the truck. They nail the breakout and ride it out.
Startup(ies?)
Every startup advisor I’ve ever worked with has told me to find that one simple thing the company does really well and focus all energy and resources on only that. It sounds amazingly obvious, but when you’re in the trenches it’s not that simple. You’re a young, nimble company struggling to find the right product / market fit and the thought of cutting off potential areas of development, sacrificing features existing customers use, or not appealing to all of your users is terrifying. Diversification may feel like a better strategy - you never know what will hit and you certainly don’t want to piss off or lose existing users. But it’s the wrong strategy. (You can do it later when you’re Google.) When that one thing works (product, feature, market, demo, etc.) the rest doesn’t matter. That’s when it’s time to go all in.
2 notes
·
View notes
Text
Ready? Set? Code....
Alexandra Jordan and Super Fun Kid Time finally got me to put some thoughts down re coding and its impact on youth culture. Who is Alex Jordan? She's the nine year old fourth grader that dreamed up, designed, and pitched her playdate app at Techcrunch Disrupt the other day. Her (adorable) presentation and an interview are here. According to Techcrunch, she's learning to code in Ruby and HTML with help from her father and Codecademy.
The bigger takeaway here is, as Mashable put it:
"Coding is 21st century literacy."
And it is permeating youth culture in a profound way. It is mainstream. It is cool. It is hip. And it is a really big deal.

Stories like Alex Jordan's are becoming more and more common. A HuffPo article earlier this year examined a teenaged girl's fickle taste in iPhone apps. But the most striking sentence to me was the following:
"Casey is a novice programmer and has customized the code on her Tumblr blog so it displays how many people are viewing it at one time."
Casey certainly isn't a hardcore computer science engineer. Nor is she a nerdy hacker. She's a 14 year old girl from Millburn, NJ. A digital native. A novice programmer. And an otherwise normal eighth grader. She and Alexandra are becoming the norm.
My good friend Jeff Novich, himself a computer science degree holder, serial entrepreneur, serial hackathon winner, and product guy, predicted suggested that teaching computer science would be a prerequisite to high school graduation. He wrote the following in 1998.

15 years later he may finally be right. In Massachusetts, Google, Microsoft, Intel, and Oracle are backing MassCAN to push the state to require schools to offer computer science classes as early as eighth grade and introduce computing standards and course work to state high schools. And I swear I read an article about one Massachusetts high school requiring coding skills to graduate. Maybe I was dreaming, but it will happen. [Update: I wasn't dreaming. Beaver Country Day School outside Boston just made coding lessons a requirement. Thanks for the find, David Kern.]
And if it doesn't, there are already plenty of private companies jumping into the mix to train kids and adults to code. Places like General Assembly and The Flatiron School offer complete beginners and seasoned veterans classes to learn expert coding. And web-based platforms like Codecademy and One Month Rails make it easy for anyone to learn from the comfort of their own home. Applications targeting kids specifically are popping up as well. CodeHS targets high school kids and teachers (in school or at home). And Hopscotch appeals to even younger kids around 8 or 10 years old.
I suppose coding doesn't really break into pop culture until there's a reality TV show (and Startups: Silicon Valley et al don't count)! Can't you see it now? American Coder. Project Hackathon. America's Next Top Developer...
"Ready? Set? Code...."
PS - I may or may not be an investor in one of the private companies mentioned. Hit me privately for details.
PPS - I reserve all rights to the "Ready? Set? Code...." competition elimination reality show.
10 notes
·
View notes
Text
Meet the new EIR @ Comcast Ventures: Me.
I'm excited to announce that last month I joined Comcast Ventures for a stint as Entrepreneur-in-Residence. EIR roles have many definitions, but for this one I'll be sourcing and vetting deals, particularly in early stage digital, social, and mobile media companies in New York City.

A little bit about Comcast Ventures and Comcast Corporation....
Comcast Corporation (Nasdaq: CMCSA, CMCSK) is a global media and technology company with two primary businesses, Comcast Cable and NBCUniversal. Comcast Cable is the nation's largest video, high-speed Internet and phone provider to residential customers under the XFINITY brand and also provides these services to businesses. NBCUniversal operates 30 news, entertainment and sports cable networks, the NBC and Telemundo broadcast networks, television production operations, television station groups, Universal Pictures and Universal Parks and Resorts. Visit www.comcastcorporation.com for more information.
And now a little bit about me....
For those of you that don't know me, I've spent the last 17 years financing, investing in, advising, and building companies in growth and technology - particularly in the digital media and infrastructure sectors. I built the Internet research and investment banking practice at Furman Selz (which later became ING Barings) before joining the Internet team at Hambrecht & Quist (which ultimately became JPMorgan). This was during the dotcom bubble, which was awesome. Like all bubbles, however, the dotcom bubble burst (which wasn't awesome) and I ended up moving to the buyside to invest in growth and technology companies - first as a partner at MLH Capital (the hedge fund group run by former Furman Selz Chairman and CEO Ed Hajim) and then up to Connecticut to pick tech stocks for Phil Hempleman and Andrea Dotter at Ardsley Partners.

<- (that's me.)
But by the end of 2005 I'd had enough of Wall Street (and Wall Street may have had enough of me!) Moreover, I smelled a similar setup to what preceded the dotcom bubble and hypothesized that another set of paradigm shifts was underway. During the dotcom bubble we moved from desktop to web computing, from narrowband to broadband, and so on. This time, we were moving from web to social computing, from narrowband to broadband (smartphone) mobile, from local to cloud storage, and so on. (I wrote more about the parallels starting here.) So I decided to start my own company. My first one was a real gifting platform called Tigerbow. I worked at it for several years before, sadly, I wound it down (post mortem here). But it set me up nicely to start my second company with the help of financing from North Bridge Venture Partners, DFJ Gotham, and other investors. It was a social TV platform called Philo, which I sold to LocalResponse in 2011. Since then, I've been an advisor to a number of startups, a venture partner at the Entrepreneur's Roundtable Accelerator, and an investor in a handful of companies. (The rest of my details can be found here.)
So what am I doing at Comcast Ventures? Well, I love new companies, new technologies, new platforms, new businesses, and really anything that will change the way we interact with the world in the future. Having financed, invested in, advised, and built growth and technology companies, I came to Comcast Ventures to spend the balance of this year finding companies for Comcast Ventures in New York City that will change the way we interact with the world. So if you've got one of those companies, feel free to find me at dslevy [at] gmail [dot] com and lets talk about the future. Because it's still early.
2 notes
·
View notes
Text
From Web Traffic to App Traffic ($GOOG $FB $AAPL $TWIT)
Google directs traffic to websites and that has made the company the most powerful on the web. In social and mobile, the power will reside with companies that direct traffic to mobile apps.

Right now, those companies include Facebook, Twitter, Apple, and (well) Google. And right now, the methods of directing traffic to mobile apps are via app stores and native / in-stream advertising (e.g., sponsored posts and promoted tweets) like this one:

Consider these points:
Mobile users will eclipse desktop users by 2014 (if they haven't already) according to Morgan Stanley.
Mobile traffic will eclipse desktop traffic (if it hasn't already). This already happened in India.
According to Business Insider, "Time spent on apps dwarfs time spent on the mobile Web, and smartphone owners now spend 127 minutes per day in mobile apps."
So mobile users/traffic will be greater than fixed users/traffic and on mobile platforms the users/traffic and time spent will be on apps. Sounds obvious, but consider the implications. Budget to drive downloads and usage should go where the users are; that is, apps.
Driving users to download apps is the more obvious component (especially as app downloads become more seamless), but I believe where it starts to get even more interesting is using platforms like Facebook (via sponsored stories) and Twitter (via promoted tweets and new/forthcoming functionality on cards) to drive (existing) app usage. Already, the percentage of (all) traffic to publishers from social media has increased to >25% from 5% just a few years ago. It seems natural that social media platforms will drive more and more traffic to mobile web and apps as well. Some examples....
Note that in each of the screenshots above, app activity posts (GetGlue on the left and Instagram on the right) allow users to tap over to the apps that generated that activity post. And not only to the app but to specific "places" in the apps (the mobile equivalent of clicking over to a specific story at CNN.com rather than just CNN's home page). Neither of these posts is sponsored, but they could be. Going a step further, what if the producer of the movie "Stand Up Guys" (in the case of the GetGlue post) wanted to promote that content? Or a local restaurant wanted to sponsor similar content in someone's foursquare activity post? Starts to get a bit more interesting. And Facebook and Twitter and other mobile platforms won't be the only beneficiaries. Plenty of room out there for companies like YieldMo, which delivers app download ad units to mobile web content, and other ad tech companies.
Great post from a partner at Greylock here re mobile monetizing better than desktop. I wholeheartedly agree. Point is, believing mobile is not (as) monetizable as the web is as naive as believing the web wasn't (as) monetizable as other media. And believe me, people did believe that at one point.
(Disclosure: I'm a pinch long Facebook and supposedly own some shares in Twitter via a secondary market transaction. Oh and I know a guy or two at YieldMo.)
2 notes
·
View notes