
Last Seen Blogs


masttapa
المصطبة

galaxycryptidart
doodles n stuff

kawin-snapstock-blog
Untitled
galaxycryptidart
doodles n stuff
Text
hpssacli, command line에서 HP Smart Array 관리하기
단순 작업 기록.
기존 논리 드라이브를 날리기 위해 지우는 명령 먼저
[root@server ~]# hpssacli ctrl slot=1 logicaldrive 4 delete forced Warning: Deleting an array can cause other array letters to become renamed. E.g. Deleting array A from arrays A,B,C will result in two remaining arrays A,B ... not B,C [root@server ~]#
그리고 1~11번 디스크를 사용해서 RAID5 형식의 논리 드라이브 만들기
[root@server ~]# hpssacli ctrl slot=1 create type=ld drives=1I:1:1-1I:1:11 raid=5
이렇게 만들어진 논리 드라이브에 디스크 고장을 대비한 여분 디스크 할당.
[root@server ~]# hpssacli ctrl slot=1 logicaldrive 2 add spares=1I:1:12
어떻게 되었을까?
[root@server ~]# hpssacli ctrl all show config Smart Array P410 in Slot 1 (sn: PACCRID112607F6) ... array B (SAS, Unused Space: 0 MB) logicaldrive 2 (18.2 TB, RAID 5, OK) physicaldrive 1I:1:1 (port 1I:box 1:bay 1, SAS, 2 TB, OK) physicaldrive 1I:1:2 (port 1I:box 1:bay 2, SAS, 2 TB, OK) physicaldrive 1I:1:3 (port 1I:box 1:bay 3, SAS, 2 TB, OK) physicaldrive 1I:1:4 (port 1I:box 1:bay 4, SAS, 2 TB, OK) physicaldrive 1I:1:5 (port 1I:box 1:bay 5, SAS, 2 TB, OK) physicaldrive 1I:1:6 (port 1I:box 1:bay 6, SAS, 2 TB, OK) physicaldrive 1I:1:7 (port 1I:box 1:bay 7, SAS, 2 TB, OK) physicaldrive 1I:1:8 (port 1I:box 1:bay 8, SAS, 2 TB, OK) physicaldrive 1I:1:9 (port 1I:box 1:bay 9, SAS, 2 TB, OK) physicaldrive 1I:1:10 (port 1I:box 1:bay 10, SAS, 2 TB, OK) physicaldrive 1I:1:11 (port 1I:box 1:bay 11, SAS, 2 TB, OK) physicaldrive 1I:1:12 (port 1I:box 1:bay 12, SAS, 2 TB, OK, spare) Enclosure SEP (Vendor ID HP, Model DL18xG6BP) 248 (WWID: 5001438013CA9903, Port: 1I, Box: 1) Expander 250 (WWID: 5001438013CA98F0, Port: 1I, Box: 1) SEP (Vendor ID PMCSIERA, Model SRC 8x6G) 249 (WWID: 500143801687647F) [root@server ~]#
0 notes
Text
리눅스 브릿지 구성, vBridge
가상화 환경에서 제공하는 여러 잇점 중 하나가 기존 환경에서는 물리적으로 존재하여 건드리기 조금 HARD 했던 것을 가상화를 통해 보다 SOFT하게, VIRTUAL하게 건드릴 수 있다는 점일 것 같다.
그 중에서, 서버 관리자의 영역에 들어있는 듯, 벗어난 듯 애매하면서 (기술적으로든 R&R 때문이든) 건드리기 어려웠던 또는 한정지어졌던 네트워크에 대한 상세한 모니터링을 단일 지점에서 하고싶었다. (물론, pcap/tcpdump/winpcap 등을 이용하여 서버 안에서도 트래픽을 볼 수 있지만, 서버 내부의 영향을 잊고 있는 그대로의 틍신을 보기 위해서, 대상이 되는 서버 밖에서 모니터링을 하고 싶었다.)
그래서 바로 Linux 기반 Virtual Bridge!
준비물
VMware vSphere Server
Linux! Linux! Linux!
구성하기
리눅스 커널에는 가상의 bridge device를 만들 수 있는 기능이 들어있고, 이것을 제어하기 위한 bridge-utils 라는 패키지가 있다.
구성 자체는 어렵지 않으니, 일단은 생략.
구성이 완료된 모습은 아래와 같다.
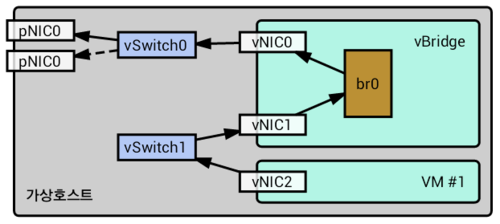
기호설명영역 pNIC0네트워크에 연결된 물리 NIC, 인터넷 연결 통로H/W pNIC1네트워크에 연결된 물리 NIC, Stand-byH/W vSwitch0외부 연결용 가상 스위치, 물리 NIC 등록vSphere vSwitch1VM 연결용 가상 스위치, NIC 없음vSphere VM #1실 서비스용 VMvSphere vBridge리눅스로 구성한 가상 브릿지Linux vNIC0eth0, 외부 가상 스위치에 연결된 NICLinux vNIC1eth1, 내부 가상 스위치에 연결된 NICLinux br0br0, 두 vNIC를 Port로 거느린 리눅스 bridge 디바이스Linux
장벽을 넘어
Linux 기반의 가상 bridge 구성을 간단히 마쳤으나 동작하지 않았다. 원인을 알 수 없다. 구성을 잘못한 것인지, 환경에 문제가 있는지...
처음 시도한 관통시험은 내부의 VM에서 GW에 ping을 던지는 단순한 동작이었는데, 응답을 받을 수 없었다. bridge VM 내부에서 tcpdump를 사용하여 확인한 결과, ICMP 패킷을 던지기 전에 상대방의 MAC을 확인하기 위한 ARP 호출이 발생하는데, Request 자체는 br0, eth0, eth1에서 동일하게 발견되지만 이에 대한 response 가 eth1에서는 발견되지 않는 현상이 발생했다.
열심의 Googling과 ServerFault를 뒤졌고, 관련되었을만한 여러 설정을 바꿔보았지만 답을 얻을 수 없었다. 그리고, 최종적으로 다음 URL의 글을 찾을 수 있었다.
VMware Community에서 발견한 동일한 상황의 질문
질문했던 사람이 작성한 원인분석
다른 사람이 작성한 우회 방법
결론부터 말하면, 문제의 원인은 vSphere의 vSwitch가 갖는 한계라고 한다. vSwitch에 둘 이상의 NIC가 연결되어 있다면(나의 경우 역시 회선 장애를 대비한 이중화 구성이 되어 있었다.) 그 NIC가 Active 상태이든 Standby 상태이든, ARP Requst를 복재하게 된다고 한다. (복재된 그것이 왜 다시 안으로 들어오는지? 그 부분은 좀 의문) 그 과정에서, 중복된 Request의 출발지를 근거로 작성된 bridge 내부의 Port-MAC 매핑 테이블의 혼돈으로 인하여, 정작 Response는 실제로 전달해야 할 Port에 전달하지 않는 것.
문제를 피해가는 방법은,
btctl setageing br0 0
명령을 이용하여, bridge로 하여금 MAC 정보 학습을 금하고 bridge에 도달하는 모든 패킷을 전체 Port에 복사하도록 하는 것. (쉽게 말하면 Dummy Hub로 동작하도록 하는 것)
일단, 나의 환경에서 위의 내용들을 시험해봤을 때, 문제상황의 재현도, 단일 물리 NIC를 사용하는 경우도, Dummy Hub로 만드는 방법도 모두 "그렇게", 될 것과 안될 것이 구분되어 확인이 가능했다.
아무튼, 이제 네트워크 모니터링 환경 구비 완료!
0 notes