#datascientist
Text
#AIart#art#machinelearning#deeplearning#artificialintelligence#datascience#iiot#data#MLsoGood#code#python#bigdata#MLart#algorithm#chatGPT#openAI#programmer#pytorch#DataScientist#Analytics#AI#VR#iot#TechCult#Digitalart#DigitalArtMarket#generativeai#ArtMarket#DataArt#GAN
484 notes
·
View notes
Text
Predicting Alzheimer's With Machine Learning
Alzheimer's disease is a progressive neurodegenerative disorder that affects millions of people worldwide. Early diagnosis is crucial for managing the disease and potentially slowing its progression. My interest in this area is deeply personal. My great grandmother, Bonnie, passed away from Alzheimer's in 2000, and my grandmother, Jonette, who is Bonnie's daughter, is currently exhibiting symptoms of the disease. This personal connection has motivated me to apply my skills as a data scientist to contribute to the ongoing research in Alzheimer's disease.
Model Creation
The first step in creating the model was to identify relevant features that could potentially influence the onset of Alzheimer's disease. After careful consideration, I chose the following features: Mini-Mental State Examination (MMSE), Clinical Dementia Rating (CDR), Socioeconomic Status (SES), and Normalized Whole Brain Volume (nWBV).
MMSE: This is a commonly used test for cognitive function and mental status. Lower scores on the MMSE can indicate severe cognitive impairment, a common symptom of Alzheimer's.
CDR: This is a numeric scale used to quantify the severity of symptoms of dementia. A higher CDR score can indicate more severe dementia.
SES: Socioeconomic status has been found to influence health outcomes, including cognitive function and dementia.
nWBV: This represents the volume of the brain, adjusted for head size. A decrease in nWBV can be indicative of brain atrophy, a common symptom of Alzheimer's.
After selecting these features, I used a combination of Logistic Regression and Random Forest Classifier models in a Stacking Classifier to predict the onset of Alzheimer's disease. The model was trained on a dataset with these selected features and then tested on a separate dataset to evaluate its performance.
Model Performance
To validate the model's performance, I used a ROC curve plot (below), as well as a cross-validation accuracy scoring mechanism.
The ROC curve (Receiver Operating Characteristic curve) is a plot that illustrates the diagnostic ability of a model as its discrimination threshold is varied. It is great for visualizing the accuracy of binary classification models. The curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings.
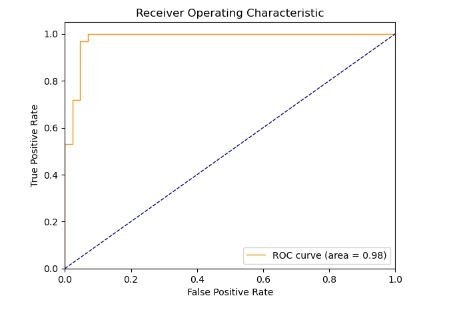
The area under the ROC curve, often referred to as the AUC (Area Under the Curve), provides a measure of the model's ability to distinguish between positive and negative classes. The AUC can be interpreted as the probability that the model will rank a randomly chosen positive instance higher than a randomly chosen negative one.
The AUC value ranges from 0 to 1. An AUC of 0.5 suggests no discrimination (i.e., the model has no ability to distinguish between positive and negative classes), 1 represents perfect discrimination (i.e., the model has perfect ability to distinguish between positive and negative classes), and 0 represents total misclassification.
The model's score of an AUC of 0.98 is excellent. It suggests that the model has a very high ability to distinguish between positive and negative classes.
The model also performed extremely well in another test, which showed the model has a final cross-validation score of 0.953. This high score indicates that the model was able to accurately predict the onset of Alzheimer's disease based on the selected features.
However, it's important to note that while this model can be a useful tool for predicting Alzheimer's disease, it should not be the sole basis for a diagnosis. Doctors should consider all aspects of diagnostic information when making a diagnosis.
Conclusion
The development and application of machine learning models like this one are revolutionizing the medical field. They offer the potential for early diagnosis of neurodegenerative diseases like Alzheimer's, which can significantly improve patient outcomes. However, these models are tools to assist healthcare professionals, not replace them. The human element in medicine, including a comprehensive understanding of the patient's health history and symptoms, remains crucial.
Despite the challenges, the potential of machine learning models in improving early diagnosis leaves me and my family hopeful. As we continue to advance in technology and research, we move closer to a world where diseases like Alzheimer's can be effectively managed, and hopefully, one day, cured.
#alzheimersresearch#alzheimersdisease#dementia#neurology#machinelearning#ai#artificialintelligence#aicommunity#datascience#datascientist#healthcare#medicalresearch#programming#python programming#python#python 3
56 notes
·
View notes

Text
Top Data Science Courses With Certificate ⬇️
1-IBM Data Science Professional Certificate
https://imp.i384100.net/YgYndj
2-Google Data Analytics Professional Certificate
https://imp.i384100.net/x9jAxk
3-Google Data Analytics Professional Certificate
https://imp.i384100.net/x9jAxk
4-Introduction to Data Science Specialization
https://imp.i384100.net/Ryqyry
5-Applied Data Science with Python Specialization
https://imp.i384100.net/GjkEPn
6-Google Advanced Data Analytics Professional Certificate
https://imp.i384100.net/1r5E3B
7-What is Data Science?
https://imp.i384100.net/JzmRaN
8-Data Science Specialization
https://imp.i384100.net/BX9BmB
9-Python for Data Science, AI & Development
https://imp.i384100.net/g1ARWv
10-Foundations of Data Science
https://imp.i384100.net/nL2Wza
11-IBM Data Analyst Professional Certificate
https://imp.i384100.net/jWGKxa
12-Machine Learning Specialization
https://imp.i384100.net/k0gLAV

#courses#coursera#google#data analytics#jobs#dataanalytics#dataanalysis#data science#data analyst jobs#data analysis#datascientist#machine learning#free courses#courses with certification#online courses
13 notes
·
View notes
Photo

It happens 💬 😂😂😂😂😂😂😂😂 Follow @openprogrammer Data +Science +ML +Python / R+Deep Learning + Neutral Network + AI #data #science #datascienceforindia #datascientist #datascience #machinelearning #ml #python #sql #ai #artificialintelligenceai #deeplearning #neuralnetworks #maths #bigdata #techno #technology #dataanalysis #hadoop #java #coderforlife #codinglife #coding#ruby #javascript #scala #perl #go #swift #java https://www.instagram.com/p/Cnlygopv-4l/?igshid=NGJjMDIxMWI=
#data#science#datascienceforindia#datascientist#datascience#machinelearning#ml#python#sql#ai#artificialintelligenceai#deeplearning#neuralnetworks#maths#bigdata#techno#technology#dataanalysis#hadoop#java#coderforlife#codinglife#coding#ruby#javascript#scala#perl#go#swift
30 notes
·
View notes
Text
#excel#excel formulas#excel training#microsoft excel#formula#google sheets#tips and tricks#follow#trending#corporate#analytics#subscribe#dataanalysis#datascientist#data strategy#data synchronization
9 notes
·
View notes
Text
Data Engineer vs. Data Scientist The Battle for Data Supremacy
In the rapidly evolving landscape of technology, two professions have emerged as the architects of the data-driven world: Data Engineers and Data Scientists. In this comparative study, we will dive deep into the worlds of these two roles, exploring their unique responsibilities, salary prospects, and essential skills that make them indispensable in the realm of Big Data and Artificial Intelligence.
The world of data is boundless, and the roles of Data Engineers and Data Scientists are indispensable in harnessing its true potential. Whether you are a visionary Data Engineer or a curious Data Scientist, your journey into the realm of Big Data and AI is filled with infinite possibilities. Enroll in the School of Core AI’s Data Science course to day and embrace the future of technology with open arms.
2 notes
·
View notes
Text
Why NumPy?
So in data science what is the thing we deal with?
Data, right?
Yes, and how do we store the data?
Array? List? Dictionary?
Right.. Now think here we’re dealing with tons and tons of data and the data where we’re storing is super slow. What is gonna be the experience?
Terrible.
Absolutely, and that is why we use NumPy. In data science NumPy is the fundamental package to perform high-level mathematical computations on multi-dimensional arrays.
So we store the data in NumPy arrays, and use NumPy to perform those computations.
.
.
.
#numpy#datascientist#dataanalyst#pythonprogramming#codingdays#techbloggerlife#codingbook#womanegineer#freedatasciencebook#datascience#fyp#techinterview#learntocode#algorithms#softwarengineer#developer#yazilim#bilgisayarmuhendisligi
9 notes
·
View notes
Link
✔️ AI And ML Trends That Will Transform The Way People Work And Live ✔️
Artificial Intelligence (AI) and Machine Learning (ML) have already started to revolutionize the way people work and live, and the next decade will witness even more transformative advancements. Here are some AI and ML trends that will reshape various aspects of our lives.
Read Here 🌐 - https://bit.ly/3qgKndw
#machinelearning#artificialintelligence#ai#datascience#python#technology#programming#deep learning#coding#bigdata#computerscience#tech#data#iot#software#dataanalytics#pythonprogramming#developer#datascientist#javascript
2 notes
·
View notes
Text
#AIart#art#machinelearning#deeplearning#artificialintelligence#datascience#iiot#data#MLsoGood#code#python#bigdata#MLart#algorithm#programmer#pytorch#DataScientist#Analytics#AI#VR#iot#TechCult#Digitalart#DigitalArtMarket#ArtMarket#DataArt#GAN#GANart#arttech#ai art
11 notes
·
View notes
Text
#AIart#art#machinelearning#deeplearning#artificialintelligence#datascience#iiot#data#MLsoGood#code#python#bigdata#MLart#algorithm#chatGPT#openAI#programmer#pytorch#DataScientist#Analytics#AI#VR#iot#TechCult#Digitalart#DigitalArtMarket#generativeai#ArtMarket#DataArt#GAN
13 notes
·
View notes
Video
BRING DATA FROM THE WEB INTO EXCEL!
2 notes
·
View notes
Text
Become Coding Expert with Data Structure Training Institute

Are you looking to take your programming skills to the next level?
Master the foundations of computer science with our comprehensive data structures and algorithms training!
Why Data Structures Matter: Data structures form the backbone of efficient and organized programming. Understanding how to manipulate and utilize data is crucial for solving complex problems and creating optimized algorithms. Whether you're a beginner or an experienced coder, diving deep into data structures is a game-changer for your coding journey.
At Kochiva, the premier Data Structure Training Institute in India, we provide in-depth training on essential data structures like arrays, linked lists, stacks, queues, trees, graphs, and more. Our expert instructors with years of industry experience will help you truly understand how these data structures work and how to implement them efficiently in any programming language. You’ll gain hands-on experience with coding challenges and projects designed to hone your skills.
Don't just learn data structures; become a coding maestro! 🎓 Enroll in Kochiva now and sculpt your coding prowess with the best in the industry.
Your coding adventure awaits! 🚀💻
#kochivamarketing#kochivalearning#online courses#kochivacourses#onlineclasses#data strategy#datascientist#data structures#instituteinindia
6 notes
·
View notes
Text
WHAT IS THE PURPOSE OF DATA SCIENCE?

Data Science's main aim is to identify trends inside data. In order to Analyze and draw lessons from the results, it utilizes different statistical techniques. A Data Scientist should carefully scrutinize the information from data acquisition, wrangling and pre-processing. Then, from the details, he has the duty to make predictions. To read more visit: https://www.rangtech.com/blog/data-science/what-is-the-purpose-of-data-science
1 note
·
View note
Text
Best Data Scientist Course | Salary | Fees in 2023
Data science has made technology even simpler and easier. With the advance of data science, machine learning has also become quite simple. Do you also want to make a career in data science and want to know how to become a data scientist and how to achieve success in this field? Come, let us know in detail in this blog how to become a data scientist.
Read More About Data Science and how to Become

2 notes
·
View notes
Text
Data Science Modeling
The process of outlining the connections between various types of information that will be kept in a database is known as data modeling. One goal of data modeling is to determine the most efficient way to store data while yet allowing for full access and reporting.

What is Data Science?
In order to extract significant insights from data, the field of study known as "data science" combines subject-matter expertise, programming prowess, and proficiency in math and statistics.
Data scientists develop artificial intelligence (AI) systems that can perform tasks that frequently need human intellect by employing machine learning algorithms on a variety of data types, including numbers, text, pictures, videos, and audio. Analysts and business users can then translate the insights these technologies produce into actual economic value.
Why Data Science is important?
Data science, artificial intelligence, and machine learning are becoming more and more important to businesses. Businesses of any size or sector must act swiftly to develop and implement data science capabilities if they are to remain competitive in the big data era.
Key Skills required in Data Science
According to data science firms, the ideal person must have a particular set of skills before beginning data science modeling. To execute data science modeling, the following skills are necessary:
Probability and Statistics
Programming abilities
Skills in Data Visualization
Machine Learning and Deep Learning
Communication Skills
1) Probability and statistics
Probability and statistics provide the basis of data science. Making forecasts benefits from understanding probability theory. Estimations and projections are essential in data science. Statistical techniques are used by data scientists to estimate the outcomes of upcoming study. The application of probability theory in statistical procedures is very widespread. The basis of all statistics and probability is data.
2) Programming abilities
Python is the most popular programming language used in data science, but other languages including R, Perl, C/C++, SQL, and Java are also utilised. Data scientists can use these programming languages to organise collections of unstructured data.
3) Skills in Data Visualization
Sketches are primarily read, whereas the most important newspaper stories are only skimmed and disregarded. Humans believe that when they see something, it is registered in their minds. The entire dataset, which could have hundreds of pages, can be turned into two or three graphs or plots. You must first view the Data Patterns in order to create a graph.
4) Machine Learning and Deep Learning
Machine learning expertise is a requirement for any data scientist. Predictive models are created using machine learning. For instance, if you want to forecast how many clients you'll have in the following month based on the data from the previous month, you'll need to employ Machine Learning techniques. Machine learning and deep learning algorithms are the basis of data science modeling.
5) Communication Skills
Senior Management or a group of Team Members must hear your results. By employing communication, we can get beyond the issues that everyone is fighting for. You can convey ideas more clearly and identify inconsistencies in data if you have good communication skills. Presentation skills are crucial for displaying Data Discoveries and creating future strategies in a project.
Procedures for Data Science Modeling
The following are the main steps in data science modeling:
Step 1: Understanding the Problem
Step 2: Data Extraction
Step 3: Data Cleaning
Step 4: Exploratory Data Analysis
Step 5: Feature Selection
Step 6: Incorporating Machine Learning Algorithms
Step 7: Testing the Models
Step 8: Deploying the Model
Step 1: Understanding the Problem
The first stage in the Data Science Modeling process is to understand the problem. A data scientist listens for keywords and phrases when chatting with a line-of-business specialist about a business scenario. The Data Scientist deconstructs the problem into a procedural flow that always includes a thorough understanding of the business challenge, the Data that must be collected, and the Artificial Intelligence and Data Science approaches that can be used to solve the problem.
Step 2: Data Extraction
The next stage of data science modeling is data extraction. The bits of unstructured data you collect that are relevant to the business problem you're trying to solve, not just any data. Data is gathered from a number of different websites, surveys, and pre-existing datasets.
Step 3: Data Cleaning
Since you must sanitise data as you collect it, data cleaning is beneficial. The following list includes some of the most typical causes of data discrepancies and errors:
Duplicate items are eliminated from various databases.
Input with precision-related inaccuracy data
Changes, updates, and deletions are made to the Data entries.
Variables in several databases lack values.
Step 4: Exploratory Data Analysis
A trusted technique for getting comfortable with data and extracting insightful information is exploratory data analysis (EDA). Data scientists sift through unstructured data to look for patterns and infer relationships between different data points. Data scientists use statistics and visualisation tools to summarise Central Measurements and variability for EDA.
Step 5: Feature Selection
Identifying and selecting the attributes that have the greatest impact on the output or forecast variable that interests you can be done manually or automatically.
Your model may become less accurate and train using irrelevant features if your data contains irrelevant characteristics. In other words, if the traits are strong enough, the machine learning algorithm will provide outstanding outcomes.
Step 6: Incorporating Machine Learning Algorithms
One of the most crucial tasks in data science modeling is the creation of a functional data model, which the machine learning algorithm aids in doing. There are numerous algorithms available, and the model selected depends on the problem.
Step 7: Testing the Models
This is the stage where we must ensure that our Data Science Modeling efforts are up to par. The Data Model is used to the Test Data in order to determine its accuracy and the presence of all desired characteristics. To detect any adjustments that might be required to boost performance and achieve the desired results, you can run additional tests on your data model. In the event that the required precision is not attained, you can go back to Step 5 (Machine Learning Algorithms), choose a different data model, and test the model once more.
Step 8: Deploying the Model
The model that provides the best output is finalised and deployed in the production environment once the desired outcome has been achieved through suitable testing in accordance with business goals.
Conclusion
The steps for performing data science modeling are covered in this post. Integrating data from diverse sources is the initial step in putting any Data Science algorithm into effect.
#datascience#machinelearning#python#artificialintelligence#ai#data#dataanalytics#bigdata#programming#coding#datascientist#technology#deeplearning#computerscience#datavisualization#analytics#pythonprogramming#tech#iot#dataanalysis#java#developer#programmer#business#ml#database#software#javascript#statistics#innovation
6 notes
·
View notes
Last Seen Blogs

e--mail
angel from space

fanofseabassanddorito
Can I Keep Them?

italyarts
➳Abelyana➳

fitmithund
Fit mit Hund

largando
Untitled