
mediba-ce
mediba Creator × Engineer Blog
mediba クリエイターとエンジニアの技術ブログ
165 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

chasejordashian-blog
Chase Jordashian

keep-your-nightvision-on
Waylon Park did nothing wrong

legendofzelda4life
Immasimplol

cheikosairin
CHEIKO SAIRIN PHOTOGRAPHY

czalasek97-blog
Laska
Text
人魚ラプソディ(mermaid入門)

View on Twitter
長男が藤本タツキの短編にハマっていて喜んでいいのかわかりません。
本稿は、藤本タツキ論ではなく、図解ツール mermaidをauウェルネス開発チームで利用した際のtipsです。
mermaidとは
JavaScriptベースの図解ツールです。
ライブエディタも提供されています。
プラットフォームは、開発に欠かせない各種SaaSでのサポートも進んでおり、notionを導入している弊チームもそのメリットを享受することが出来ております。
その話は、また後日に。
入門
弊チームでは、事ある毎に図表を残すようにしています。
現状もmermaidを利用を強制することはしておりませんが、PlantUMLで各種図表を作成してきました。
mermaidの文法は、PlantUMLを利用されたことがあれば、直感的にわかるでしょう。
サンプルのリンクを貼っておきますので、気になる方はどうぞ。
シーケンス図
フローチャート
ER図
tips
オンラインのコミュニケーションが定着している弊チームですが、ご多分に漏れず情報共有のあり方には課題がありました。
特に設計フェーズにおいては、図解して概要や意図を伝える(書き残す)ことが習慣化出来ていたものの、PlantUMLではその成果物の管理に一手間あり、チームの負担にもなっていました。
notionを導入している弊チームからするとmermaidは、PlantUMLに比べて成果物をリアルタイムで共有、手軽に管理出来ることにメリットがあります。
今後は、変更管理の課題に取り組んでいきたいと思います。
おわりに
mermaidは、それ単体でも十二分に有用なツールですが、JavaScriptベースであることを活かして各種SaaSやプラットフォームと組み合わせ利用できることに強みがあります。
皆さんの図解ライフに本稿が少しでも貢献出来れば幸いです。
ではまた。
0 notes
Text
中途入社エンジニア向けのオンボーディングプログラムを始めました
こんにちは、テクノロジーセンターオンボーディングチームメンバーです。
皆さんの会社では、オンボーディングプログラムをどのように運営していますか?
medibaでは、テクノロジーセンターに入った従業員向けの教育プログラム『中途社員向けオンボーディング』を実施しています。
今回は、テクノロジーセンターの有志のメンバーが教育プログラムを構築し、実施し改善した活動についてお話しようと思います。社歴が長い人も入社したての人も、異なる職種のメンバーが集まり、限られた短い時間の中で取り組みました。
エンジニア向けにオンボーディングを構築する上で少しでもご参考になれば幸いです。
なぜオンボーディングプログラムを作ったのか

数年前から、全社の組織構造が事業型からマトリクス型へ変わりました。現在は、エンジニアが所属するテクノロジーセンターと、プロダクトごとのプロダクトチームが交差する組織構造となっています。
これまではテクノロジーセンターでのオンボーディングがなく、以下のような課題がありました。
情報が足りていない、まとまっていない、検索しにくい
入社者は、何からはじめたらよいかわからない
プロジェクトに入ればプロダクトのオンボーディングがあるが、人となりや保有技術がわからず誰に聞いたらいいかわからない
担当によって教えることにばらつきがあり、OJT担当者に負荷がかかっている
オンボーディングプログラムの目指すべき姿
そこで、オンボーディングプログラムがどうあるべきなのか、ヒアリングを実施し、下記を目指すことにしました。
中途入社の方が即戦力として活躍できる環境を作る
活躍できない、既存メンバーに負荷がかかるなどの理由での退職を防ぐ
プロジェクトや人に依存しない仕組みを作る
課題解決のために何をやったか
上記の課題を解決するために、オンボーディングプログラムとして、入社時に知っておくと良いリンク集「まとめページ」を作成しました。入社者には「まとめページ」にそって自習していただき「チェックシート」で各項目が把握できたかを記載し共有します。分からないことは「よろず相談」へ問い合わせてもらいます。そして、下記のようなタスクを作り、半年間運営してみました。
入社時に知っておくと良いリンク集「まとめページ」と入社者用「チェックシート」の作成
入社翌日に30分ほど説明会と、オンボーディングメンバーの紹介
問い合わせ場所「よろず相談」で分からないこと・ご意見お伺い
入社者向けアンケート自動化
入社者の質問に伴い「まとめページ」を随時更新し継続的改善
上長、OJT担当向けにヒアリング
テクノロジーセンター向けアンケートでオンボーディング活動の価値をお伺い
来期活動の課題を抽出
人事と連携して入社情報をキャッチアップ
実は、進める上で苦労したこと
知ってもらいたい情報量が多すぎて、スコープが決まらず、情報の重要度と粒度を決めるのが大変でした。そこで、半年でプログラムの実施及び検証を前提に開始予定日を決め、「中途エンジニアが組織で活躍するために必要な情報」として、エンジニアがオンボーディングで触れておきたい項目を下記の3つに絞って整理することにしました。
知っていないと業務開始できない・・・開発に関する知識
業務が深くなったり領域が広がった時知らないと困る・・・センターに関する情報
長く会社にいると必要になってくる・・・会社全体の情報

結果はどうだったか
半年で「まとめページ」の作成、半年でオンボーディングプログラムの運営を行ってみての結果は、アンケートやヒアリング結果を分析したところ、当初課題の6割がたは解決できました。また、今回の活動の内容をより多くの人に知ってもらうために、社内報告会を行いました。
それぞれいただいた意見は下記のような内容でした。
<ポジティブな意見>
入社者が感じる「情報が足りていない」「何からはじめたらよいかわからない」は解決できた
オンボーディングプログラムによる受入部門の負担は減った
入社者からの質問は、まとめページの改善につながる
<まだまだ改善が必要な点>
人
先輩との交流の機会をもっとつくってもらえないか
もっと「人」がわかる仕組みが欲しい
情報
まとめページのブラッシュアップ
情報メンテナンスの文化をつくってもらいたい
フォロー体制
目標や評価は自分で読んで理解するには限界あり
「開発に関する知識」の情報は見ていただいているが、「会社全体の情報」は見られていない傾向にある
最後に
まだ課題は残っているのですが、今回のオンボーディングプログラムを実施した方からは好意的なご意見をもらえました。 受け入れるプロダクトの方の負担も減り、オンボーディングの活動自体に価値を感じました。 これからも活動を継続して残っている課題を解決していき、今後入社される方の助けになることができればと思います。
テクノロジーセンターでは、いろんな視点のいろんな職種のメンバがアイディアを出し合って、「いいものを作り続ける」マインドでオンボーディングプログラムを運営しています。
現在medibaではメンバーを大募集しています。
募集・応募ページ
medibaってどんな会社だろうと、興味を持っていただいた方は、カジュアル面談もやっておりますので、お気軽にお申込み頂ければと思います。
カジュアル面談
0 notes
Text
Reactコンポネートーー制御か非制御か
こんにちは。mediba でテクノロジー2G にてFEをしております、楊です。
最近のPJ開発中にあったことで、Reactコンポネートの制御か非制御か当時綺麗に解決できなかったので、 振り返って、色々調べた上にまとめたメモです。
コンポネートの制御と非制御
React公式の説明
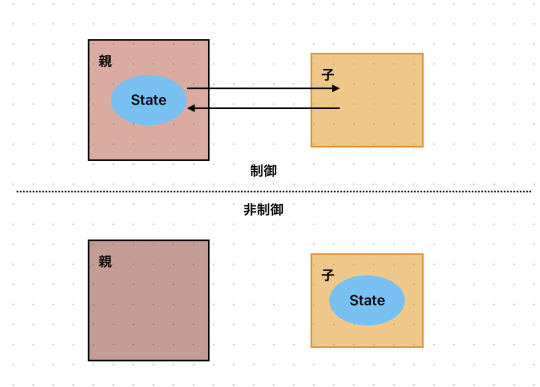
下手な絵で簡単に説明すると↓
ではどうすれば、非制御であり制御コンポネートでもあるコンポネートを作れるでしょう
最も簡単なやり方ーー内外のStateを持ちながら同期させる
まずは子コンポネート内でStateを持たせて、どんな状態(制御モード・非制御モード)でも自分のStateを使うようにする。 次は制御モードにおいて、内部StateをPropsと同期させれば、問題なさそう!
const Input: FC<{ value?: string; onChange?: (value: string) => void; }> = (props) => { const isControlled = props.value !== undefined; const [value, setValue] = useState(props.value); const handleOnChange = (e) => { if (isControlled) { setValue(e.target.value); props.onChange(e.target.value); } } useEffect(() => { if (isControlled) { setValue(props.value); } },[props.value]); return ( <input value={value} onChange={handleOnChange}/> ); };
よくみてみると、制御モードでは気になるところも出てきたね
子コンポネート内のState更新はParentより遅い
パフォマンス的によくない、useEffect内でのsetStateの使いなので、余計な再描画が発生してしまう
解決できそうかな、試してみよう
子コンポネート内のState更新はParentより遅い
これだと簡単に解決できそう、制御モードにおいてPropsから渡してきた値そのまま使えばいい。
const finalVal = isControlled ? props.value : value const handleOnChange = (e) => { if (isControlled) { setValue(e.target.value); props.onChange(e.target.value); } } return ( <input value={finalVal} onChange={handleOnChange}/> );
こうすれば、同期は一歩遅くても、子コンポネートに使ってもらうStateは必ず最新であることを担保できる。
パフォマンス的によくない、useEffect内でのsetStateの使いなので、余計なレンダリングが発生してしまう
useEffect内でのState同期なので、再描画を防げなくて、簡単なコンポネートであれば、パフォマンスの影響は少ないが、コンプレックスなコンポネートには、問題である
ポイントは同期させるタイミングだね、ならどうしよう、、、、
Stateでvalue保存には、setterで同期させた直後に再描画が始まる、もし再描画が制御可能になったら問題ないでしょう。 保存にはRefを使って、強制再描画には 仮のstateを作って
const [_, setObj] = useState({}) function triggerRendering(){ setObj({}) }
を使う。そうしたら全体は↓
const Input: FC<{ value?: string; onChange?: (value: string) => void; }> = (props) => { const isControlled = props.value !== undefined; const stateRef = useRef(props.value); if (isControlled) { stateRef.current = props.value; } const [_, setObj] = useState({}); function triggerRendering() { setObj({}); } const handleOnChange = (e: React.ChangeEvent) => { stateRef.current = e.target.value; triggerRendering(); props.onChange(e.target.value); }; return <input value={stateRef.current} onChange={handleOnChange}/>; };
こうしたことで値の同期による再描画がなくなり、制御同時に非制御のコンポネートが出来上がった。 refとhandleOnChangeの部分を取り出し、hooksにすることで、他のコンポネートに適用することもできるでしょう。
現在medibaではメンバーを大募集しています。
募集・応募ページ
medibaってどんな会社だろうと、興味を持っていただいた方は、カジュアル面談もやっておりますので、お気軽にお申込み頂ければと思います。
カジュアル面談
0 notes
Text
エンジニア採用課題を現場で考えてみた
こんにちは。mediba でテクノロジー統合Unit にてマネージャをしております、長根と申します。
エンジニア業界の市況は、各社熾烈なエンジニアの取り合いといった状況となって久しい今日この頃いかがお過ごしでしょうか。
さて、こと弊社においてもエンジニア採用は、重要テーマかつ永遠のテーマでもあります。 これまでもエンジニア組織と、人事部門が連携して課題に取り組んでおりましたが、一昨年から、「(組織課題解決の)民主化」と称して、現場を主体で課題を解決していく取り組みを行っております。
今回はその活動における取り組みの紹介を通したいと思います。medibaのことに少しでも興味を持って頂けたり、同じような課題を持つ方への参考の一助となれば幸いです。
組織課題の民主化とは?
これまで組織課題の解決において、マネージャを中心として進めていくことが多くありましたが、以下のような課題がありました。
プロセスが不透明とみられることが多い。健全性の担保に難がある。
マネージャ主体では、現場での課題から遠いケースがある。
これらの課題から、「役職関係なくエンジニアの誰もが参加可能で、現場のエンジニアがより良い課題解決を行う」ことができるよう民主化の取り組みが開始されました。
好きなフルーツを決めよう!
課題の民主化の取り組みにおいて、上司から指示を参加を強制されることはありません。 参加するもしないも自分次第です。
課題弊社VPoEの下地から、メンバーに向けて取り組みたい課題をフルーツに例え参加表明をしていくカジュアルな感じでメンバーが募られていきます。
見て頂くとわかるように、民主化の取り組みにおいては、採用活動以外にも、色々なチームがあります。
何をどのように取り組んでいったのか。
採用チームとして、適切な組織維持のために継続的な採用を行う必要がありますが、そもそ��の面談/面接の母数を増やさない事には、採りたいエンジニアの方を獲得することは難しいです。
そのため、まずは面談/面接回数を向上するといったKPIを掲げ、その中で適切なスキルセットやマインドを持つ方にアプローチや、情報が届けられるよう、様々な観点から施策を行っていきました。
個々詳細の施策内容は割愛しますが、以下のような取り組みを行っていきました。
採用チャネル別の見直し
採用エージェント
市場感の把握、求職者視点で知りたい情報が伝えられているか
エージェントさん向けの個別資料(組織、カルチャー等)の作成・提供
リファラル採用
リファラル採用施策の改善(運用、インセンティブ見直し)
カジュアル面談
カジュアル面談の応募ページの作成、導線作成
ダイレクトリクルーティング
新規ダイレクトリクルーティングツールの利用開始
新卒採用
新卒カジュアル面談の運用・改善(多人数での面談が可能な体制へ変更)
採用ページ改善
求職者が求める情報(現場課題、制度、カルチャー、記載できていない福利厚生等)を拡充
視認性向上
これらの施策をエンジニアだけで行うことは限界があるので、人事部門との週次の定期ミーティングを通して課題解決に向けて、それぞれの部門でのタスクを分担して進めていきました。
結果と感想
上期のKPIは無事達成することができました。 取り組み前に比べ、格段に面談数が多い状況となりました。 下期状況はまだ未確定ですが、良い数字が出ている状況です。
面談/面接数のKPIは、目標指数として分かりやすい反面、転職市況やその他外的要因から大きく影響を受けるため、施策がダイレクトに繋がったかどうかの評価が難しい点もありますが、なるべく定量的に評価できるように計測や振り返りが必要と感じています。
今回の民主化活動を通じ、未来の仲間を増やしていくため、様々な観点から採用課題に取り組むことで、見えてくることも多く、これは大きな発見であったと感じます。
今後も未来のmedibaを担うメンバーと巡り合えるように積極的に活動をしていきたいと思います。
現在medibaではメンバーを大募集しています。
募集・応募ページ
medibaってどんな会社だろうと、興味を持っていただいた方は、カジュアル面談もやっておりますので、お気軽にお申込み頂ければと思います。
カジュアル面談
0 notes
Text
サッカーとエンジニア組織について
初めに
こんにちは、バックエンドエンジニアの山口です。
W 杯での三苫選手を筆頭とした日本代表チームの躍進、アルゼンチン vs フランスの決勝を見て、これまでサッカーを見てなかったけど abemaTV などで海外サッカーを見るようになった!という方も多いのではないでしょうか。
今回の記事では主観満載でサッカークラブを考察して、エンジニア組織、開発チームの運営について自分なりに考えてみたいと思います。
それぞれに関わっているメンバーをざっくりと
エンジニア組織
VPoE
マネージャー
エンジニア
サッカーチーム
監督
コーチ(フィジカル,戦術,セットプレーなどなど)
選手
チームについて
サッカークラブを語るにあたって切り離せないのが監督と選手です。
今、欧州で最も成績を残しているチームはマンチェスター・シティ, レアル・マドリードだと思います。(僕はクレですが。)
この 2 チームを戦術•監督•選手•試合内容の観点で単純比較すると以下のようになります。

どちらのチームも欧州で最高レベルの成績を近年残し続けているクラブなので、どちらが良い悪いの話ではありませんが、チーム作りに違いがあります。
レアル・マドリードのようなチームはエンジニア組織に例えると、尖ったエンジニア達(I 型人材)を政治力•マネジメント力の強いマネージャーがまとめ上げているイメージでしょうか。逆にマンチェスターシティは T 型人材を上手く配置し、組織内で適切にアロケーションし組織運営しているイメージです。
では、エンジニア組織•開発チームを運営するにあたってどちらのクラブチームを参考にするのが良いか考えていきたいと思います。
レアル・マドリード
レアル・マドリードはチャンピオンズリーグ優勝回数が欧州で最多のチームです。 なので、1 発勝負の重要な大会やここ一番という試合展開では絶対的な強さを発揮します。この点においてはヨーロッパ1と言って良いでしょう。レアル・マドリードの強さの第 1 は選手のタレント力ですが、臨機応変さも大きな強みです。試合中に核となる選手達が試合状況・展開を俯瞰し、どこで点を取りに行くか、ボールキープをするか、誰にボールを渡せば一番効果的かということを現場レベルで臨機応変に対応できています。現在であればモドリッチ、クロース、ダビドアラバ、ベンゼマなどの選手達です。このような核となる選手を揃えることで、監督のマネジメントが届きにくい試合中であっても現場レベルで問題を解決し、圧倒的な強さを発揮できるのかなと考えます。
このようなチームが向いているフェーズとしては以下のようなフェーズでしょうか。スピーディーかつ高可用性が求められる開発フェーズですかね。まだまだプロダクト運営のルールが決まりきっていない 0->1 のフェーズの開発力でも強さを発揮しそうです。また、中小企業で 1 つのサービスに注力しているな企業の開発にも向いているように感じます。
ベンチャー初期フェーズ
プロジェクト立ち上げ時の開発チーム
中小企業での注力サービスの開発•運用
マンチェスター・シティ
マンチェスター・シティは世界最高峰のプレミアリーグでここ 5 年間で 4 度の優勝をしています。チャンピオンズリーグと違い、試合回数•対戦相手も多く安定した戦いをすることが求められます。デブライネのような核となる選手は存在しますがレアル・マドリードほど個人に依存することはなく、ローテーションしつつどんなメンバーで試合に出ても一定以上の成績を収めており、ゲームプラン通りに試合展開を進めることを得意とし磐石に勝利するイメージです。一方で、ここ一番での破壊力や試合展開に逆らわず強弱をつけるような試合展開は得意な方ではないです。臨機応変さが少し足りないですね。
このようなチームが向いているフェーズとしては以下のようなフェーズでしょうか。 ルールが整備されてきているプロダクトでのグロースや機能追加、事前のプラン通りにアクションプランを立てていくことが望ましいサービス成長期などで力を発揮しそうです。
サービスグロース期
サービス成長期及び組織拡大時期
上記以外にもそれぞれ向いているフェーズや役割がしっかりありそうだと僕は思います。
個人について
ここからは選手個人にフォーカスを当てたいと思います。
今季からマンチェスター・シティに点を取ることに特化した 22 歳のハーランドというバケモノ選手が移籍してきました。この選手はタイプで言えばレアル・マドリードタイプの選手といえると思います。確かに個人成績は素晴らしい反面、リーグ戦でのチーム成績は思ったよりも伸びておらず現在 2 位です。圧倒的な個性を持った選手(I 型の選手)がチームバランスを壊すというのはサッカー界ではあるあるです。(それでも強いですが。)最近移籍したクリスティアーノロナウドも晩年のマンチェスターユナイテッドではこのような立ち位置でした。この事象はイケイケの強強エンジニアをアサインした際にそのエンジニアのパフォーマンスは期待通りだが、他メンバーのパフォーマンスが落ちてしまう現象に近いです。
それでは I 型の選手はなかなかビッグクラブで活躍するのは難しいのかということを考えていきたいと思います。サッカー界で神と呼ばれるイブラヒモビッチはグアルディオラ(マンチェスター・シティの監督)に対して次のようにコメントを残しており、尖���まくっていて、扱いづらいように感じます。
自伝『ADRENALINA』より
「現在のマンチェスター・シティのボスは、マンツーマンのスキルが欠けていると今でも思っている。"哲学者"は、言い返さずに従う選手を好むんだ」 「俺を買うということは、フェラーリを買うということだ」
ただ、このイブラヒモビッチは昨シーズンに長年リーグ優勝から遠ざかっていた AC ミランをベテランかつ精神的支柱としてリーグ優勝に導いています。 サッカーでは若い頃に尖っていた選手が円熟味を増す晩年期にチームの支柱として成績を残すというのはよくあります。今回の W 杯のアルゼンチン優勝のメッシにも似たような臭いを感じます(メッシはそれほど尖ってはいませんが)。ちなみにメッシ、イブラヒモビッチ共にチーム最高齢でした。強烈な個性を持った選手はそれだけカリスマ性も高く、若い選手からもリスペクトされる傾向が強いのでキャリア晩年には若手の牽引や経験からくる試合中の読みでチームを勝たせているイメージがあります。 強強エンジニアは若手時代に同じような強強エンジニアを手本に、ベテラン・シニア時には若い強強エンジニアの個性を殺さずに見守るのが良いのでしょうか。(メッシがロナウジーニョの背中を見ていたように。)
ハーランドにはイブラヒモビッチの弟子になってほしいと思いますね。
まとめ
エンジニアはスキルがあればという意見が強いですが、自分のパーソナリティに合う環境、一緒に働くメンバーも同じくらい重要な要素です。 レアル・マドリードのような会社であれば技術的なパーソナリティを強くしスペシャリストのような役割を。 マンチェスター・シティのような会社だと技術的強みを生かしつつ多少オールラウンダーな振る舞いが必要そうです。 弊社はどちらかというとマンチェスター・シティ寄りでしょうか。レアル・マドリード的な風土も取り入れて強固な組織にしていきたいですね。
個人的には今回のブログはキャリアを考える良い材料になりました。
最後に
面談でサッカー談義がしたいと思われた方がいらっしゃいましたら、ご応募お待ちしておりますのでよろしくお願いします。
PS: 次は技術ブログを書きます。
ありがとうございました。
2 notes
·
View notes
Text
社内でLTワークショップを開催したら大盛況だったので紹介する
はじめに
皆様、こんにちはこんばんは、SREの北浦(@kitta0108)です。
今回はmedibaの取り組みでLTワークショップを開いたら、 思いのほか大盛況だったため、その取り組みを紹介します。
読者想定
こんな方におすすめの記事にしていくモチベーションで書いています。
medibaの風土が知りたい。
mediba社内LTの発表資料が見たい。
エンジニアの発信力強化を目的とした他社の取り組みを知りたい。
なぜLTワークショップを開こうと思ったのか
エンジニア採用事情の課題解決、技術力向上、エンゲージメント向上…などなど、 さまざまな課題からエンジニア自身の発信力につながるような文化を醸成していきたいという気持ちがありました。
出発地点が文化醸成という事から、 大枠として以下の要素を満たすような企画をしたいと考えました。
参入障壁が低いこと
興味関心を引くようなコンテンツであること
実際に体験できるコンテンツであること
まず、体験するものに関しては、 エンジニアのアウトプットとしても比較的、参入障壁が低いLTにしました。
また、全員が初めてのLTという前提で、 発表の企画から資料作りまでを1から一緒に作っていくようなワークショップ形式にすることにより、 発表内容のイメージが湧かないような人でも参加しやすいものにしました。
いざ参加者を募集
というように企画案が固まったところで、参加者の募集文を考えるに至ります。
たかが募集文、されど募集文。
ここで人が集まらないとなってしまうと、文化醸成も甚だしく、企画倒れになってしまいます。
なので、ここはおふざけ一切なし、僕らの真剣な想いが伝わる文を投下しました。
僕のアウトプットパワーが最強かどうかはさておき、 想いのある漢達が真面目に考えた甲斐もあって、 17名の参加応募をいただきました。
それにしても、思い返してみれば、仮に参加応募0人だったら僕はどんな心境になったんでしょうね。
きっと3ヶ月くらいの休職期間を必要としたに違いありません。
そう考えたなら、救ってくれた参加者の皆様には感謝しかありません。
ワークショップ1日目
1日目は主にアウトプットを行うことによるリターンはどのようなものがあるのかということと、 プロット作成について話してみました。
これは持論なのですが、LTのようなラフなアウトプットでも、資料作りに打ち込んだり、 当日は緊張しながら発表したりと、それなりに負荷があるものだと思っています。
やりとげた達成感や、その他のメリットをしっかり享受できたら良いのですが、 そのメリットは例えばどんなものがあるのか、それはどうやったら享受できる可能性が上がるのかという話をしました。
あとは発表内容の企画においては、プロットを作成しておくと、 後の工程がグッと楽になるTipsを紹介しました。
資料はこちらです。
ワークショップ2日目
2日目はアジェンダ(というよりストーリー構成)と資料作りの細かいTipsをメインに話しました。
ここのレイヤーは僕自身があまり熱を入れないところなので、 あくまで最低限、発表できるレベルになるまでに知っておくとためになることの詰め合わせのような発表になりました。
(むしろ教わりたいくらいなので、社内で得意な人が突如現れて次回のワークショップ開催されるイベントが期待されますw)
資料はこちらです。
ワークショップ3日目
3日目は、みんなでLT大会するという内容にしまして、 以下のルールを設けました。
1人5分を意識すること(止めないけど)
発表資料はWebにアップロードすること
必ず1つの発表に対して、1人1コメント、ポジティブな内容でチャットに投稿すること
特に3番目のルールは、アンケート結果や参加者のフィードバックとして、
「聴講する側としてもコメントしようと意識して聞くことによって学びが得られた」
「発表したときに周りがコメントしてくれるのが嬉しかった」 という声をいただけたので、設けて正解だったのかなという所感でした。
記述量少ないですが資料はこちらです。
みんなの発表資料
ブログ記事で公開OKいただいた方の資料を掲載します。
発表者 タイトル 資料URL 板谷 誰でも簡単 実質30分でできるYoutubeLive配信のすすめ 資料 retch 闇の魔術に対する防衛術 競技プログラミング編 資料 永原 英語を勉強してみて 資料 井上 不要になったAWSリソースを削除してサービス障害起こした話 資料 下地 良いフィードバックとは 資料 山本(翔) フロントエンドの フレームワーク事情2022 資料 吉澤 VSCode+Vim 資料 kamaboko フロントエンド採用における面接の課題について 資料 堀 バックエンドからフロントエンドにジョブチェンジした話 資料 菅原 新しいNISAざっくり解説 資料 馬淵 Slackでスタンプを押すとBackLogに起票する仕組みを作る 資料
アンケート結果
後の活動に生かすため、アンケートをとっていました。
あくまでmediba内の活動としての回答結果ではありますが、 参考になるようなことがあればと思い、質問事項や実際の回答からの所感も合わせて知見として共有してみます。
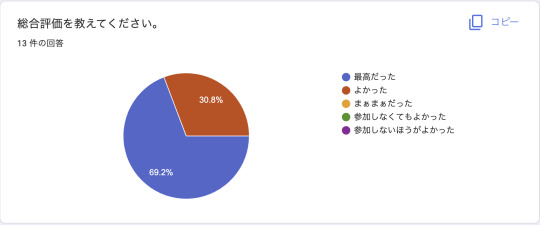
主に僕の振り返りをするために設けた項目ですが、 ポジティブ寄りの結果になり、嬉しいですね。
企画自体がよかったのと、発表時に設けたルールによって、 場の雰囲気を和気藹々とできたことが主な勝因だったかなという所感です。

これは新しい発見でした。 次回の機会があるならば、なぜ発信力をあげたいのかという一つ深ぼった話も聞いてみたいものです。
数ある項目の中で、ソフトスキル面の向上というベクトルの意識が高いのは、 同じエンジニアとしても誇らしい限りです。
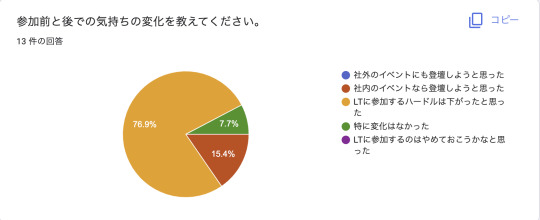
この取り組みにおける僕と参加者のゴールは、LTに参加する敷居を下げるという点においていたので、 目的は達成できたように感じます。
社内のイベントには登壇していこうかなって意識が芽生えたという意見も嬉しいですね。
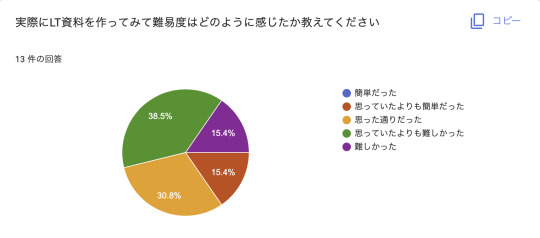
難しいヨネー、未だにここの難易度がイージーになるという未来は僕も見えませんw
それ相応の負荷を乗り越えて発表してくれているんだというコンテキストを尊重しあっていきたいものです。

勉強になること、フィードバックをもらえること、この2点が良い体験になったようです。 この結果を次回の企画に反映していきたいところです。

意識が高い...! この経験から活動領域が増えるキッカケになったのであれば嬉しいですね。

この4択であれば、資料や内容の支援が必要とされているようです。
発表する内容の正当さが不安要素が障壁として大きく感じているという結果な気がします。 ここは上司ぴにも相談して、会社としての取り組みとして検討してもらうことにしましょう。
さいごに
LTワークショップの取り組みについて紹介しましたが、いかがでしたでしょうか。 medibaの和気藹々とした雰囲気が伝わったり、発表資料の内容や取り組みについて何か持ち帰るものがあったなら幸いです。
0 notes
Text
sGTMを試してみた【後編】
こんにちは、データアナリストの左海です。
昨日16日に引き続き、mediba Advent カレンダー 17日目は私からサーバーサイドGTM(以下sGTM)を試してみたお話の続きとなります。
前編でsGTMの導入が完了したので、後編ではSafariのITP制限がGoogle Analytics4(以下GA4)のログにどう影響しているのか観察していきます。
SafariのITP制限によるGA4ログへの影響とsGTM
まずは、前編の重要な部分を簡単に振り返ります。
SafariのITP制限は主にCookieに対して制限をかけており、JavaScriptで設定された1st Party Cookieの有効期限は7日間となります。
そのため、アクセス解析においては8日以上の間隔を空けて再訪問したユーザーは新規ユーザー扱いとなり、同一ユーザーとしてカウントされません。
上記問題を緩和するのがsGTMで、サーバーサイドでCookieを発行するため、GA4のCookieの有効期限はデフォルトの有効期限に緩和することが可能でした。
観察したいこと
前述の通り、ITP制限のアクセス解析への影響は、8日以上の間隔を空けて再訪問したユーザーは新規ユーザー扱いとなることです。
ゆえに、sGTMを利用した場合、GA4では8日以上の間隔を空けて再訪問したユーザーは同一ユーザーとして計測されるのか観察していきます。
おそらく、同一ユーザーと判定されるため、GA4のデータ探索でユーザー数1と表示されるはずです。
観察方法
それでは、観察していきます。観察は以下の手順で行いました。
2022/12/7 13:00ごろSafariで初���訪問し、page_viewイベントを発生させる
2022/12/14 14:00以降にSafariで再訪問し、page_viewイベントを発生させる(8日以上の間隔を空けて再訪問)
GA4のデータ探索でユーザー数を確認する
観察結果
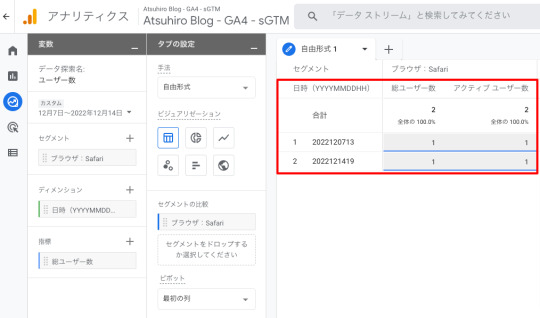
GA4のデータ探索で確認したところ、想定していた結果とは異なり、総ユーザー数/アクティブユーザー数には2と表示されていました。新規ユーザーとして扱われていることになります。
ユーザー数(想定) ユーザー数(結果) sGTMを利用 1 2
データ探索の設定は、ユーザーセグメントでブラウザをSafariに絞って総ユーザー数/アクティブユーザー数を取得しています。
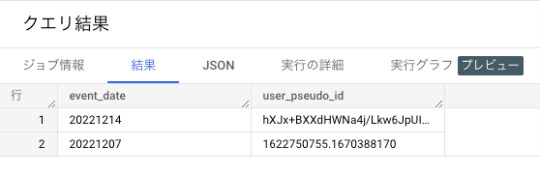
BigQueryで以下クエリを実行して日付ごとに訪問ユーザーのuidを確認してみました。
SELECT DISTINCT(event_date) ,user_pseudo_id FROM `projectName.datasetName.events_*` WHERE _TABLE_SUFFIX BETWEEN '20221207' AND '20221214' AND device.mobile_model_name = 'Safari' ;
7日と14日で全く別の値が入っているので別ユーザーとしてカウントされています。
考察
観察した結果、当初想定していた同一ユーザーとしてはカウントされず、新規ユーザーとしてカウントされてしまいました。
今回調査に十分な時間を確保できなかったのですが、Webkitの「IPアドレス判定でのCookie制限」が既に適用されているかもしれません。
WebKit will start limiting the lifetime of cookies to 7 days when set via "third-party" IP addresses. Third-partiness determined by whether the first half of the request's IP address matches the first half of the first-party IP address.
参考 - Steven Englehardt氏
おわりに
今回、sGTMを試してみてCookieへの理解、sGTMやDNSの設定方法など新たに多くのことを知ることができました。
中でもCookieはデータアナリストとして業務を行う上でプライバシー保護の取り組みと併せて最新の情報を理解しておく必要があると感じました。
最後に、今回の観察結果の���察が正しければ、やはりITPがプライバシーを守る取り組みである以上、sGTMでCookie制限を恒久的に回避するのは難しいかもしれません。
どなたかの参考になれば、幸いです。
0 notes
Text
sGTMを試してみた【前編】
こんにちは、データアナリストの左海です。
mediba Adventカレンダー16日目ということで、私からはサーバーサイドGTM(以下sGTM)を試してみたお話についてです。
はじめに
私自身、過去にsGTMを利用したことがなく、理解を深めるためにプライベート環境へ導入してみることにしました。
sGTMに触れる上で切り離せない話題としてApple社のSafariのITP制限が挙げられます。
そのため、今回はsGTMの導入だけでなく、ITP制限がGoogle Analytics4(以下GA4)のログにどう影響しているのかまで観察していきます。
※本投稿は「sGTMを導入したお話」と「ITP制限のGA4ログへの影響を観察したお話」(明日17日投稿予定)の2部構成となっています。
sGTMとは
初めに、sGTMとはGoogle Tag Manager(以下GTM)のコンテナ種別の「Server」のことを指します。
従来のGTMはタグの処理をクライアント(ブラウザ)側で処理していたのに対し、sGTMを利用することでWebサイト管理者が管理するサーバー上で処理することが可能になります。
今回、タグを処理するためのサーバーはGoogle Cloud Platform(以下GCP)のApp Engineで設置します。

sGTMとApple社のSafariのITP制限の関係
ITPとは、Apple社がSafariに搭載したユーザーの行動データの収集を規制するための機能です。2022/12/11時点でSafariでは主にCookieに対して以下の制限が設けられています。
Cookie 制限内容 1st Party Cookie document.cookieで設定されたCookieの場合
・Webサイト上でユーザーの操作がない状態でブラウザが7日間使用されると削除される
参照元ドメインが既知のトラッカーである場合
・URL装飾(クエリパラメータやフラグメント)があるページでは有効期限が24時間に設定される 3rd Party Cookie Storage Access APIを除いてすべてのアクセスを制限
参考 - Cookie Status
GA4のCookie(_ga)はJavaScriptで設定された1st Party Cookieとなるため、Cookieの有効期限は7日となります。
(ここでは、参照元URLに、Appleが定義したトラッカーのURLパラメータが含まれる場合は触れません。)
そのため、アクセス解析においては8日以上の間隔を空けて再訪問したユーザーは新規ユーザー扱いとなり、同一ユーザーとしてカウントされません。
上記問題を緩和するのがsGTMで、サーバーサイドでCookieを発行するため、GA4のCookieの有効期限はデフォルトの有効期限に緩和することが可能です。
ただ、ITPがプライバシー守るという取り組みであるのでこの方法を継続的に利用するのは難しいかもしれません。現にWebKitは、 「サードパーティ」と判定したIPアドレス経由で設定されたクッキーの有効期間を7日間に制限するようです。
参考 - Steven Englehardt氏
sGTM導入手順
それでは早速、私の個人ブログにsGTMを導入していきます。導入手順は以下の通りです。
サーバーコンテナの作成
GCP(App Engine)とのプロビショニングとカスタムドメイン設定(GTM/GCP/DNS)
ウェブ用コンテナ側でのトランスポートURL設定(GTM)
サーバー用コンテナ側での初期タグ設定(GTM)
参考 - サーバー用GTMコンテナの初期導入方法まとめ | アユダンテ株式会社
サーバーコンテナの作成(GTM)
GTMのコンテナ一覧画面 > コンテナを作成する > Serverでサーバー用コンテナの作成を行います。
なお、通常のウェブ用コンテナも必要ですので準備しておきます。

GCP(App Engine)とのプロビショニングとカスタムドメイン設定(GTM/GCP/DNS)
次にサーバー用コンテナを動かすためのサーバーを準備し、サーバー側のエンドポイントのURLに対してカスタムドメイン設定を行います。
本工程はアユダンテさんのコラムに分かりやすく記載されているので参考にしてみてください。
なお、プロビショニングは設定内容を確認したく「手動設定」で行いました。
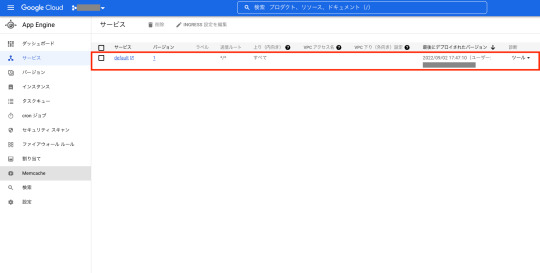
添付画像の通り、無事にサーバのデプロイが完了しました。
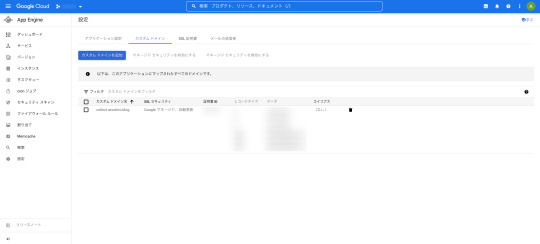
カスタムドメインの設定も完了しました。
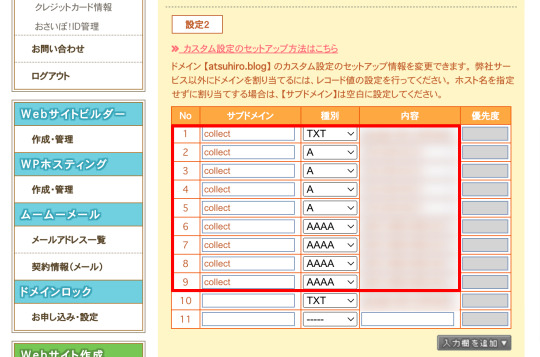
補足ですが、カスタムドメインの設定では、私のサイトドメインを管理しているレジストラの管理画面で「ドメインの所有権の証明」と「サブドメインのDNS設定」の際にDNSのレコード登録が必要になりました。
��はムームーDNSを利用していたのでコントロールパネル > ドメイン管理 > ドメイン操作 > ムームーDNSから設定しました。
ウェブ用コンテナ側でのトランスポートURL設定(GTM)
事前に準備したウェブ用コンテナで計測に必要なタグの作成を行います。今回はGA4のpage_viewイベントを計測することにします。
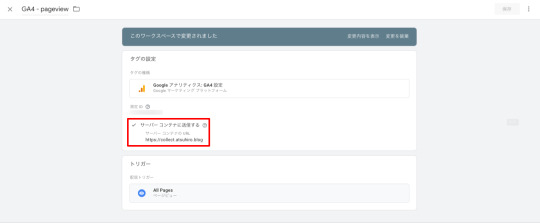
添付画像の通りにGA4設定タグを作成し、All Pagesトリガーを紐付けます。
sGTMを利用する場合、赤枠箇所の「サーバーコンテナに送信」にチェックを入れ、サーバー側のエンドポイントのURLを入力します。
すると、GA4ログの送り先はデフォルトのGAサーバではなく、指定のサーバーに変更されます。
サーバー用コンテナ側での初期タグ設定(GTM)
サーバー用コンテナでは、ウェブ用コンテナから受信したデータを本来送信すべきツールサーバー(GA)へ飛ばすための設定を行います。
具体的にはウェブ用コンテナに「対応するクライアントが登録されているかの確認」/「対応するGA計測タグの登録」の2つです。
私の場合、対応するクライアントが登録されていなかったので新規作成しました。
詳細設定の「Cookieとクライアントの識別」ではサーバー用コンテナでのGA4計測タグのクライアントIDの保存場所を指定します。サーバー用コンテナが発行するCookieを使用したいため、サーバー管理を選択します。
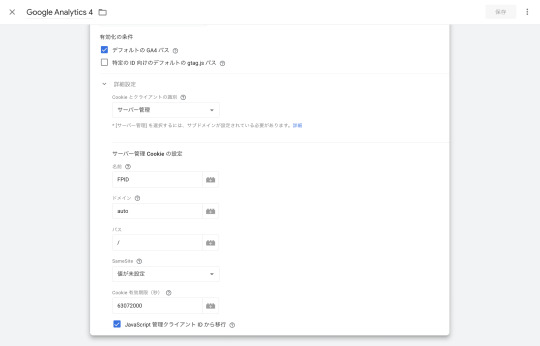
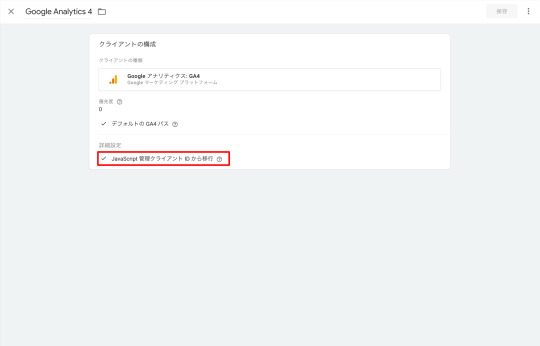
「JavaScript 管理クライアント IDから移行」にもチェックを入れます。チェックを入れないと、ページ側でJavaScript管理のCookie(_ga)を保持していたとしても、特に気にせず、サーバー管理CookieではクライアントIDが生成されるようです。
次に、サーバー用コンテナでもウェブ用コンテナ同様にGA4のpage_viewイベントタグを作成します。
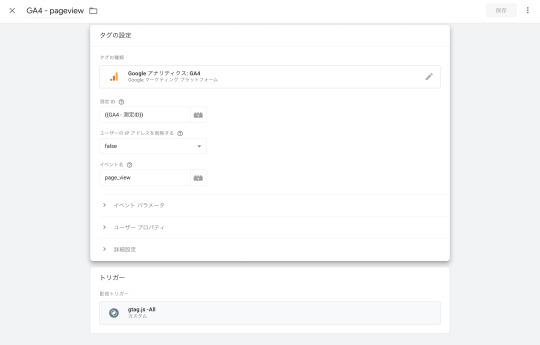
トリガーはウェブ用コンテナとは異なり、カスタムトリガーでトリガーの発生場所を先ほど作成したクライアントを設定するため、Clinent NameがGoogle Analytics 4に等しいを選択します。

以上の設定が完了すれば、ウェブ用コンテナからのデータ受信後、サーバー用コンテナで登録されたクライアントが反応してGA4イベントタグが発火され、GA4のログが送信できるようになります。
GA4ログの確認
ウェブ/サーバー用の両コンテナを公開後、想定通りにGA4のpage_viewイベントが飛んでいるのが確認できました。

これでsGTMの導入は完了です。明日17日も引き続き私からITP制限のGA4ログへの影響を観察したお話についてです。
ぜひご覧ください。
0 notes
Text
auスマートパスBFFチームでのモブワークについて
こんにちは。本格的に今年の終わりが見えてきましたが、みなさまいかがお過ごしでしょうか。私は最近毎日ふるさと納税で頂いたツナ缶を食べて過ごしています。マグロの油は頭が良くなるそうなのでしっかり油まで食べてます。
medibaフロントエンドエンジニアでBFFチーム所属兼auスマートパスTCLの 山本(@yamam00s)です。
この投稿はmediba Advent Calendar 2022の20日目の記事です。
この記事では今期取り組んでいる、auスマートパスでのBFFチームのモブワークについてお話させていただきます。
BFFとは?という方については、去年の私のアドベントカレンダーの記事をご参考いただければと思います。
BFFチームの選定技術
auスマートパスのBFFではTypeScriptを採用しています。
現在はフロントエンドとチームを分けていますが、将来的にフロントエンドとBFFの垣根を無くすことで、疎結合なアプリケーションの機能実装の一連の流れを1つのチームで完結できようになることを見越しての選定となっております。
フロントエンドはAPIも、BFFチームはViewの構築もできるようになる為の、最初の1歩として言語を揃えて開発していこうという試みです。
BFFチームメンバーと課題について
今までのauスマートパスはバックエンドとフロントエンドでしっかりきっちりチームを分けていたため、 BFFチームを結成した際は下記のような課題を持ったメンバー構成となりました。
私のようなバックエンド開発経験のないフロントエンドエンジニア
TypeScript経験があまりないバックエンドエンジニア
auスマートパスのドメイン知識が薄いエンジニア
※ あえて課題をメインに書かせていただいています。
BFFという特性上、他チームと比較して特に個人の持つ技術スタックがバラつきやすいのかなと感じました。
モブワークについて
BFFチームでは上記で説明した課題を解消するため、1日の半分をモブワークで過ごしています。
基本的にリモートで作業しており、Gather.Townを使用しています。 全員がオンラインで通話をつなぎコミュニケーションを取り、時には今日の晩ごはんの話をしながら、みんなで1つの機能を実装しています。

とても楽しそうですね
モブワークで進める1日の流れ
基本的な1日の流れは下記になります。
10:00~10:30 プロダクト全体の朝会
11:00~12:00 別チームとの共有(トピックのある日のみ)
13:30~16:30 BFFモブワーク

水曜日は燃えるゴミの日だそうです
medibaでのモブプロラグラミングへの取り組みについてはモブプログラミングはじめましたを一読いただければよりイメージがつかみやすいかと思います。
モブワークでのルール
モブワークで進めるにあたって、下記のようなルールで進行しています。
意思決定は基本的に全員同意
モブプロのドライバーはメンバーが均等に担当する
実装の方針や機能作成時の一連の流れはモブワークで進める
ソロタスク含めPRのMergeもモブワークで進める
わからないことは何でも正直に聞く
逆にソロタスクを割り振るようなものは、実装方針をモブで決めたものに絞っています。
モブワークで嬉しかったこと
嬉しいことがたくさんありました。
mainブランチの内容をメンバーが把握している状態を維持できる
メンバーごとのコードの品質の差を抑えることができる
メンバー全員がプロダクトに詳しくなる
1人では得られない量のナレッジを得ることができる
1人での作業に詰まる孤独から開放される
モブワークで作業を進めることで上記のメリットがある他、長い時間をメンバーと過ごすため関係性も深まり、互いにリスペクトも生まれ良い体制だなと個人的に思っています。
今回のチームではリーダーを務めさせていただていますが、他プロダクトを任せていただくときにも同じようなチーム作りができればと考えています。
(もちろんプロダクトの特性によって向き不向きがあるので一概には言えませんが…)
最後に
auスマートパスをはじめとするmedibaの様々なプロダクトでは、共に働くエンジニアを募集しています!
現在、medibaの募集求人ページから応募され入社が決定すると、お祝い金として30万円をプレゼントするキャンペーンを実施中です!! リモート環境を充実するためディスプレイやマイクを買いそろえるも良し。スキル習熟のために自己研鑽に使うも良し。使途は完全自由です。
いきなり応募だとちょっとハードルが高い・・でも興味がある方は、カジュアル面談も行っていますので、まずはお話してみませんか?
※お祝い金は、試用期間(3か月)を経て、雇用が継続した場合に支給させて頂きます。また、お祝い金は予告なく終了する場合があります。
ご応募お待ちしております!!!
0 notes
Text
JAWSとNRUGのSRE支部を設立した思い出
mediba Advent Calendar 2022と SRE Advent Calendar 2022の15日目の記事です。
はじめに
medibaでSREをしている北浦(@kitta0108)です。
今回は、JAWS-UG SRE支部やNRUG SRE支部の設立に至るまでの裏側の話を雑に語っていこうと思います。
先にお断りしておくと、何かしらの知見を得られるようなものにはなっていない気がしていましてw
ユーザーコミュニティの立ち上がりってどんな感じなのかというベクトルから、 読み物としてお楽しみいただくようなコンテンツになるよう意識しています。
なんなら、これをきっかけにエンジニア界隈のユーザーコミュニティ活動に 興味をもってくれるような人が出てきたら、この上なく嬉しい気持ちになる気がします。
そんなモチベーションで頑張って書いていきます。
JAWS-UG SRE支部設立のきっかけ
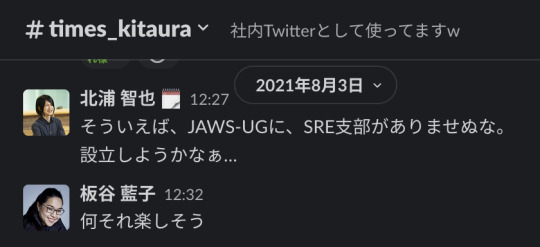
ことの発端は、弊社にはslackにtimesチャンネルを作る文化があるのですが、 その場でJAWS-UGにSRE支部あったらいいのになーとぼやき始めたところになります。
この時点では95%くらいの冗談寄りで設立しちゃおっかなみたいなことを言っていますね。
元々、弊社の課題感として、 AWSの各リソースを使ってSREのプラクティスを実践していくという事の関心や、 社外の方との意見交換を欲していたこともあり、そのせいもあってか、 社内からは設立に関しては後押しされる声をいただきました。
追い風のように、社外の親しくさせていただいているエンジニアや、 1on1にお付き合いいただいているメンターからも、ポジティブな声をいただくなどして、 いよいよもってして、本当に設立しちゃおっかなという気持ちの昂りがあったことを今でも覚えています。
設立の決断
この時点で、設立に関して、かなり前向きになっている状態なので、 日頃の発言も設立に関することが多くなっていたような気がします。
そんなこともあってか、弊社の板谷さん(@mary_tuba)が ホントにやるなら手伝うよと声をあげてくれたり、
当時、New Relicの技術コンサルとして支援いただいていた瀬戸島さん(@tossi_104)との雑談から あんどぅさん(@integrated1453)を紹介いただいたり、
元、弊社でSREチームのマネージャーをしていた沼沢さん(Twitterやってないヨ)にも手伝ってもらうことになったり、
あれよあれよと運営メンバーが集まることになりました。
幸いにも、日頃からJAWS-UGの出入りが多かったメンツだったこともあり、 設立の手筈なども、もたつくことなくコミュニケーションがとれ、そして設立宣言に至ります。

緊張の第一回目開催
非常に嬉しい誤算なのですが、 当時、参加者数50人集まったらいいよねみたいな話をしていた矢先、 まさかの430人集まるという事態になりました。
やっぱりみんな、SRE支部欲しかったんだなと改めて感じたのと本当に設立してよかったと思う瞬間でした。
話はじめてしまえばどうということはないのですが、 開始10分前とかは、緊張しすぎて小鹿のように足を震わせてた思い出ですw
そんな第一回目は以下からアーカイブ視聴が可能なので、よかったらみてやってください。
SRE支部第一回目アーカイブ
反響もよく、アンケート結果はもちろん、 個人としても、他のSRE界隈のコミュニティでもSRE支部で取り上げた内容の参照がされていたり、 有意義なコンテンツを提供できた手応えを感じました。
余談ですけど、いただいたアンケートは穴が開くほどよくみているので、 勉強会に参加された方でアンケート求められたら、運営している方のためと思って協力してあげてください。 泣いて喜ぶことになるでしょうw
そして、運営メンバーもこのタイミングで4名追加になって一気に華やかになりました。
ユーザーコミュニティというと、勉強会の開催をメインにやっていく集まりのように見えるかもしれませんが、 割と普段から技術面の意見交換だったり、時には恋バナ?wなどでも盛り上がれる最高のメンバーで構成されてます。
ちょうど昨日、SRE支部運営メンバーで今年の成果報告会やろうぜなどといって、 お互い発表しあって楽しい時を過ごすなどをしましたw
今のメンバーと取り組みはこんな感じです。

NRUG SRE支部設立のきっかけ
JAWS-UG SRE支部設立から時は経ち、 一方で、SRE業務の関心軸として、開発者体験の向上やサイト信頼性向上といった文脈から、 o11y導入のモチベーションが高まっていました。
そんな中、NRUG Vol.0の懇親会にお邪魔した際に、 清水さん(@photographed)からNRUGでもSRE支部設立どおっすか?と お声かけいただく機会がありました。
その後、NRUG Vol.1に登壇させていただき、その際の資料にNRUG SRE支部一緒に設立したい人募集!と軽い気持ちで一文書いておいたところ、 Tocyukiさん(@Tocyuki)とkazumaxさん(@kazumax55)が 手をあげてくださり、その場でのいきおいwで設立することになりました。
ドキドキの第一回目
JAWS-UGのときもそうだったのですが、第一回目の開催前は、 コミュニティの意義、参加想定者、僕らは何に貢献していくのか、などを整理していく過程を踏んでいくことになります。
その整理にいたっては、 運営3名 + New Relicさん側から、大平さん(@joe_yuzupi)と清水さんのサポートがあり、 手前味噌ながら、高い完成度の指針を作り込めた気がします。
そんな中で迎えた第一回目のテーマは「俺たちのNew RelicとSRE」です。 参加者数も192名と、当初想定のおおよそ4倍近い方々からの参加をいただきました。 SNS上の拡散などで応援してくれた方々も多かったので、その点は大変に感謝です。
そんな皆様のご支援もあってか、JAWS-UGと同様、参加者は思ってた以上に集まり、ォィォィZoomの参加可能枠超えちまうよみたいな謎テンションの心配事をした記憶がありますw
運営3名がちょうどSREのフェーズ感が違っていたというのと、 それぞれが発表できそうなネタがあるということで運営3名が登壇したのですが、 こちらもアンケート結果や当日のTwitterの賑わいなどからも、手応えとしてグッとくるものがありました。
NRUG SRE支部 Vol.1アーカイブ
o11yとSREは親和性の高さを感じるものがあり、 今後も継続して良質なコンテンツを提供できるように頑張っていきたいものです。
まとめと所感
思ってた以上に、自分ごとを書き連ねてしまった反省はあるのですが、 いかがでしたでしょうか。
思い返してみれば、コロナ禍という向かい風があった中でしたが、 たくさんの人に支えあって、やりとげられたことのような気しかしません。 運に極振りしたような人生ですねw
色々と書きましたが、「ユーザーコミュニティは参加するのも運営するのもいいゾォォ。」 こんな雰囲気が伝わったならいいかなと思います。
ちょっとだけ宣伝
各ユーザーコミュニティのリンクです。 興味ある方は是非Watchいただけると嬉しく思います。
JAWS-UG SRE支部は次回1月開催 NRUG SRE支部は次回2月開催・・・ができたらいいなという温度感で取り組んでいます。
JAWS-UG SRE支部
NRUG SRE支部
本件とは別のコミュニティですが、北浦個人として以下のコミュニティ運営も携わらせていただいてます。
JAWS-UG コンテナ支部
Tech-on
2022/12/20はコンテナ支部#22 re:Cap会やります! リモート参加もOKですし、現地ではBeer Bashをやります。飲もうぜ!!
JAWS-UGコンテナ支部 #22 re:Cap
0 notes
Text
E2EテストをNew Relicで実装してみたら簡単だったので紹介したい
New Relic Advent Calendar 2022の12日目の記事となります。
はじめに
どうも、こんにちはこんばんは、SREの北浦(@kitta0108)です。
今回はNew RelicのSynthetics機能を使ってE2Eテストを実装したら思いの他、 簡単且つ、痒いところによく手が届く印象でしたので、 その知見を共有します。
この記事を読んだら、E2Eテストを実装したくなっちゃうに違いない!? そんな熱量でお届けしていきます。
読者想定
こんな方におすすめの記事にしていくモチベーションでおります。
外形監視の実装方法の選択肢を広げたい
ブラウザベースのE2Eテストの実装方法を知りたい。
より一層New Relicに魂を売りたい。
対象の機能
New Relicのマネジメントコンソール上では、以下からアクセスできる機能です。

お題
解説の便宜上、以下のようなログイン画面の例を使っていきます。
■実装したいシナリオ
ログイン画面にアクセスする。
ユーザーIDを入力する。
「次へ」ボタンをクリックする。
パスワードを入力する。
「Log In」ボタンをクリックする。

ログインユーザー名の表示が指定の文字列であることを確認する。
実装方法
まずはSynthetics画面からCreate monitorをクリックします。

monitor typeの選択画面に遷移するので、今回は「User step execution」を選択します。 Zero code monitor buildingって書いてありますね。フレーズが素敵ですw

Creater monitor画面に遷移します。 なんのテストなのか、名付けしたり、実行間隔の設定をします。
後述しますが、「Enable screenshot on failure and in script」にはチェックを入れておくと、後々捗ります。

お次はSelect locationsの設定です。 外形監視として、どこのLocationからの疎通をTryするのかという設定ですね。

今回は日本国内からの疎通が取れればOKというアプリケーション要件なので、Tokyo、JPだけにチェックを入れます。
ここからが主題の設定です。 以下がお題の完成形でして、画面右部の1 ~ 6のStepで処理が実行されます。

詳細は別���クションで解説します。
Define stepsの各種設定項目
Navigate
どこのURLへアクセスしにいくのか設定します。
Advanced OptionsによってUser-Agentの指定も可能です。
Type Text
要素をXPathで指定し、入力する文字列を設定します。
Click Element
要素をXPathで指定し、画面上でクリックさせる��定をします。
Secure Credential
要素をXPathで指定し、機密情報を入力する設定をします。
New Relic上で機密情報を扱う際には、Secure Credentialという機能を使って、情報を保存します。
基本的なところではありますが、機密情報の扱いはベタのTextベースで扱わないように日々気をつけていきましょう!
Assert Text
要素をXPathで指定し、表示されているTextが指定の文字列と一致しているか確認します。
Equals以外にも以下の選択肢があります。これだけ揃っていれば不便な思いはしないで済みそうですね。

各種Tips
XPathの取得方法
Google ChromeのDeveloper Toolを使ってCopyが可能です。
Fail時のScreenShot機能

Results画面に遷移すると以下のように疎通結果ログの回覧が可能です。
その中で結果がFailであったものの詳細をドリルダウンしていくと、疎通時の描画状態をScreenShotとして回覧が可能です。 これは超絶便利ですよね。 以下はAssert Checkでわざと違う値を設定した例です。Assert結果が違うって指摘もちゃんと出てますね。(ぼかしが多くてスミマセン!)
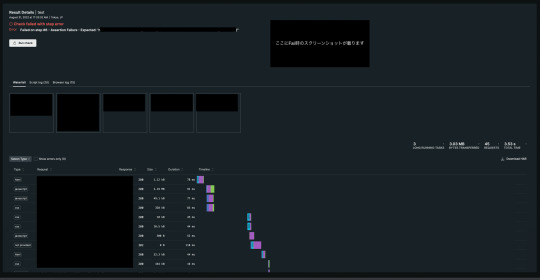
おわりに
New RelicというとAPMのイメージが強いかと思いますが、今回は毛色を変えてSynthetics機能を紹介してみました。 E2Eテストしてみたい!もっと品質良く、且つ高速なフィードバックによる開発体験の向上したい!などの文脈で取り組んでみてはいかがでしょうか。
0 notes
Text
時系列データベース InfluxDBを使ってみた
この記事はmediba Advent Calendar 2022の12日目にエントリーされた記事です。
はじめに
株式会社medibaの@zuuundayoと申します。テクノロジー統合UNIT内のSREチームのメンバーです。 Advent Calendar向けの良いネタがあまり思いつかなかったので 個人で時系列データベースを触ったことを共有します(ちょっと今更感ありますが)。
時系列データベースとは
雑に説明すると時間と値の組み合わせデータ(時系列データ)を対象としたデータベースです。 リレーショナルデータベースなどもこのようなデータの取り扱いが可能ですが、 特化したデータベースが作られているのには理由があります。 IoT製品のセンサーから観測されたデータなどはリアルタイムに利用されたりするので絶え間なくデータが送り続けられて来たりします。 このような状態で取りこぼさずにデータを格納したり、時間や値を元にデータを素早く引っ張り出す機能にニーズがあるためです。
IoTが幅広く普及してきた近年では、Amazon Timestreamなどのマネージドな時系列データベースも登場したりしています。
なんで触ろうと考えたのか
個人でリアルタイムに投票するシステムを作ろうと考えました。 RDBを採用すると汎用的な用途ゆえ機能が多すぎてオーバースペックな気がするし、 シンプルな形でデータを簡単かつ高速に集計する仕組みが良かったので時系列データベースを採用してみることにしました。
InfluxDBとは
InfluxDB https://www.influxdata.com はオープンソースな時系列データベースです。 いろいろな方が性能や使い勝手を比較されていますが それらを参考にお手軽に利用できそうだなと判断して採用しました。
他の時系列データベースはRDBの拡張モジュールだったり、有料だったりしたので お手軽感のあるこちらを選んでます。
InfluxDBにはマネージド版のInfluxDB Cloudが存在しており、なおかつFreeプランが存在しているため 個人での利用に嬉しいメリットがあります。今回はマネージド版のFreeプランを使ってます。
セットアップ
InfluxDBのサイトからInfluxDB Cloudの会員登録を行います。登録すると管理コンソールにアクセスできます。
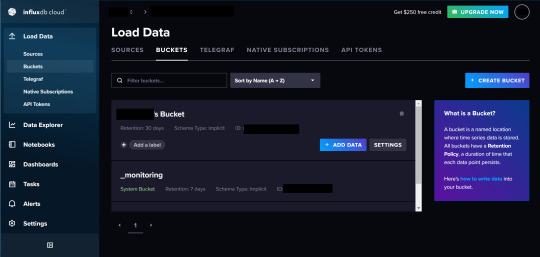
まず最初にBucketsメニューでBucketを作成します。BucketとはRDBのテーブルみたいなものでデータを放り込む場所になります。
Create Bucketボタンを押すとメニューが出てくるので名前とデータの有効期限を設定します。
Advanced ConfigurationではBucket Schema Typeを選べます。今回はImplicitを選びます。
Implicitを選ぶとSchemaが暗黙的となりSchemaが強制されません。
Explicitを選ぶとSchemaが強制されるので形式があっていないデータは格納できなくなります。
ただし、一度スキーマを設定するとあとからカラムを変更できず新規追加しかできないそうなのでご注意を。

利用方法(簡易的に試す方法)
結構親切に体験する方法を教えてくれるのであまり書くことないですが、注意事項等書いておきます。
バケットが作成できるとバケットの一覧から作成したバケットの欄のADD DATAボタンをクリックします。
クリックするとメニューパネルが出てくるのでClient Libraryをクリックします。CSV Uploadなどのボタンもあるのでからもデータをインポートできるようです。
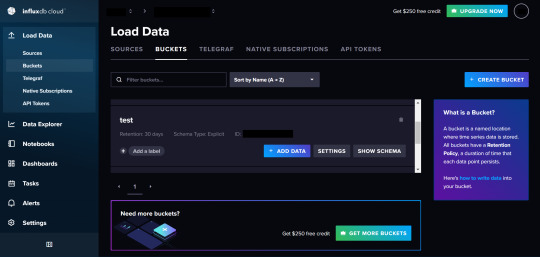
Client Libraryをクリックすると様々な言語が出てくるのでお好きな言語をクリック。ここではPythonを選びます。

ページを移動すると親切にウィザード形式でセットアップ方法を指示してくれます。
まずはローカルにクライアントモジュールをインストールします。
pip3 install influxdb-client
次にトークンを発行し環境変数に追加するよう指示されます。
ウィザードで自動的に発行されたトークンはすべての権限が付与されたものになるので非推奨であるそうです。実際に利用する際はAPI Tokensのメニューから特定のバケット等に権限を絞ったトークンを発行して利用しましょう。
クライアントの初期コードが出てくるので指示通り、Pythonのインタプリタにコードを入力する。
続いて今回作成したバケットにデータを送信するコードが出てきます。今回作成したバケットを選択するとコードも自動的に修正してくれます。
ここでのコードは0から4までの値を1秒おきに送信するコードです。
下の欄にデータが取得されたかを確認するボタンがあるので、確認してみてください。うまく行ってると"Connection Found!"と表示されます。
次の画面では送信したデータをFlux Queryで確認する方法が表示されます。管理画面のData Explorer上でもクエリ叩けますがPython上で叩くコードも表示されます。
うまく行ってると下記のように時系列データが表示されます。Data Explorerで表示させると画像みたいな感じです。
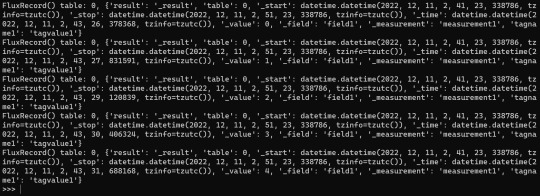

利用してみての感想
Cloud版はマネージドなだけあってセットアップを簡単に行うこともできましたし、 APIのリファレンスなどのドキュメントも分かりやすい方なので使い勝手は良いです。 何よりシンプルな設定でサクッと時系列データをとりあえず保管して可視化するには便利なので皆さんも利用してみてはいかがでしょうか。 現在はそこまで大きなワークロードで活用し��いるわけではないのでデメリットは使っているうちに見えてくると思います。 ここには書いていませんがFlux Queryは監視ツールなどによくある時系列データに対する様々な集計関数があったりするので使ってみると面白いですよ。
終わりに
個人的な試行をAdvent Calenderにしてしまいましたが、決して会社の中で何もやっていないわけではないですという言い訳をしておきます(汗)。
微妙にネタかぶりしてしまったんです。はい。 今弊社のSREチームでは、絶賛メンバーを募集しております。 チームメンバーには業務だけでなくプライベートでも様々な活動されている方々もいらっしゃるので雰囲気を知りたい方はお気軽にお問い合わせください ( https://hrmos.co/pages/mediba/jobs/1100000001 )。 最近はフルリモート勤務での採用も開始してます!
0 notes
Text
New Relicのアラート作成で時間を指定する設定5つについて解説してみる
はじめに
mediba Advent Calendar 2022 と、
New Relic Advent Calendar 2022の8日目の記事となります。
みなさんNew Relicでアラート設定していますか?
おはこんハロチャオ!medibaでSREをしている北浦(@kitta0108)です。
今回はNew Relicでオンコール対応を初めとした通知機能を運用に実装しようとした際に、
お世話になるであろうAlert機能の中で、時間にまつわる設定値の話をつらつらと書いていきます。
弊社の中でも、この設定値は1つずつ紐解いていくのが困難でわからないという声が多��あがっていたので、筆をとってみました。
というわけで、この”時間”を指定する設定について、
- なぜ必要なのか
- どんな時にチューニングするのか
- 一旦は何も考えずに設定したいときはどうしたらいいのか
を紹介していきます。
読者想定
こんな方々へ何かしらの貢献ができる記事になるよう意識しています。
New Relicでアラート設定をしたいモチベーションがある
メトリクスの扱いに自信がない
今までなんとなくアラート設定していたので理解を深めたい
問題の設定値
時間を設定する値って5つもあるんですよねー。 今回は以下を解説していきます。
Condition thresholds
Signal loss expiration time
Window Duration
Slide by Interval
Event flowのDelayまたは、Event TimerのTimer

お題
解説の便宜上、以下、2つの例を使っていきます。
- 例A(ALBのHealthy Host Countが0になったらアラートする)
SELECT max(aws.applicationelb.HealthyHostCount) FROM Metric FACET aws.applicationelb.LoadBalancer
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
SELECT sum(aws.applicationelb.HTTPCode_Target_5XX_Count) FROM Metric FACET aws.applicationelb.LoadBalancer
1.Condition thresholds
アラートの閾値としての時間指定です。
例えば、above or equals 2 at least once in 1 minutesと指定した場合は、
少なくとも1分間に指定のメトリクスが2以上に上がった時、
アラート判定とする設定です。
アラートとして、メトリクスを見にいく頻度(回数)という見方もできます。
この時間は、短くすればするほど、
こまめにメトリクスが上がってないか見てくれるので、
解像度を高めることができます。
- 例A(ALBのHealthy Host Countが0になったらアラートする)
equals 0 at least once in 1 minutes
0になったらアラートなので、equals 0と指定します。
頻度に関しては、0となった時にすぐ連絡が欲しいので、1分間毎にします。
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
above or equals 10 at least once in 5 minutes
10以上になったらアラートなので、above or equals 10と指定します。
頻度に関しては、5分間の総量を判定させたいので、5分毎にします。
2.Signal loss expiration time
メトリクスがNew Relicで受信できなかったときに、
Signal lossと判定させるまでの時間です。
- 例A(ALBのHealthy Host Countが0になったらアラートする)
ALBのHealtyHostCountメトリクスは
1分間に1回の頻度で集計されるメトリクスなので、
AWSからNew Relicに対しては、以下のように1分間に1回のペースでメトリクスデータが送られます。

しかし、このメトリクスデータがネットワークの揺らぎなどの原因により、
New Relicに3分間届かなかったとします。
このようなケースにおいて、アラートとしてどのような振る舞いをするべきか、
厳密な設定が可能です。
HealtyHostCountのケースでは生存確認の意を含んだアラートになる為、
3分間データが届かなかった場合は、
メトリクスデータが届いていないというアラートを起票するようにしたいです。
そのためsignal lost after 3 minutesでOpen New “lost signal” violationにチェックを入れます。
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
HealtyHostCountは定期的に集計されて送られてくる継続データでしたが、
一方で以下のように、とあるイベントが発生したときだけ、
送るといった不定期なデータも存在します。
※画面例は4XXエラーです。5XXエラーはなかなか画面ショットを撮りたい時に発生してくれないものでしてあしからず。

このような不定期データをアラートとして扱う場合、
以下で説明するEvent Timer設定により詳細なコントロールが可能であるため、
無効化しておくことが個人的なおすすめです。
3.Window Duration
いつのメトリクスデータを評価するのかという枠の指定です。
1分間の合計を評価するのか、あるいは5分間の合計を評価するのか。
評価するための時間枠はここで設定します。
- 例A(ALBのHealthy Host Countが0になったらアラートする)
HealtyHostCountの場合、一度でも0だった場合、
不健全とみなし、アラート発報させたいので
可能な限り頻度の高い設定値にします。
このメトリクスデータは1分間集計なので、
Window Durationは1分間という枠にします。
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
HTTPCode_Target_5XX_Countは5分間の合計値を1分間の頻度で確認したいため、
Window Durationは5分間に設定します。
4.Slide by Interval
Window Durationで指定した枠を、どのくらいスライドして評価させるかという指定です。
弊社でも多くの人の理解を挫折に導いた設定値ですが、
適切なアラートをさせるために重要な設定でもあります。
- 例A(ALBのHealthy Host Countが0になったらアラートする)
このケースでは使いません。
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
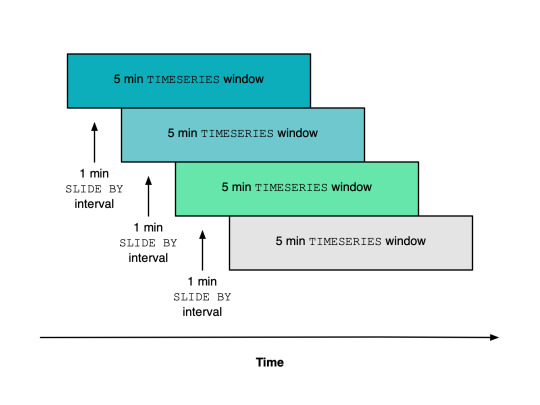
Window Durationを5分間に設定した場合、このSlide by Intervalの設定をしないと、 5分間に1回の評価しかできません。
5分間の集計を1分間の頻度で評価をするためには、 5分間集計を1分間毎にスライドさせて評価する必要があります。
これを実現させるために、このケースではSlide by Intervalの設定を1分間に設定します。
参考イメージ<https://docs.newrelic.com/docs/query-your-data/nrql-new-relic-query-language/nrql-query-tutorials/create-smoother-charts-sliding-windows>
5.Event flowのDelay または、Event TimerのTimer
Streaming Methodによって、より確実に集計するための設定です。
メトリクスデータが継続的なものか、不定期なものかによって、
Event Flowを使うか、Event Timerを使うか変わってきます。
Cadenceという設定もあるのですが、
現在では非推奨設定なので、選択肢からは除外してよいでしょう。
例A(ALBのHealthy Host Countが0になったらアラートする)
HealtyHostCountは継続データなので、Event Flowを使います。
結論から伝えると2分間のDelayを設けます。
この設定を入れることにより、現在の時刻が12:02だった場合、11:59 ~ 12:00のメトリクスデータを評価するようになります。
Signal lossの箇所でも解説した通り、
メトリクスデータはリアルタイムで届かない可能性があり、
その考慮がないと適切な評価ができず、
閾値を超えているのにアラート判定がされない…という状況が起きかねません。
2分間のDelayを設けることにより、
メトリクスデータが到着している可能性を高めることができます。
ここは確実性と検知スピードのトレードオフになるので、
適切なチューニングが必要とされます。
まぁ、2分間も設けておけば、検知スピードとして問題となるケースも少ないでしょう。
- 例B (ALBのHTTPCode_Target_5XX_Countが10以上になったらアラートする)
HTTPCode_Target_5XX_Countは不定期データなので、
Event Timerを使います。 結論から伝えると5分間のTimerを設けます。
この設定をいれることにより、
12:00に初回のメトリクスデータが到着した場合、
その時点から5分間のタイマーがセットされます。
その後、12:03に2回目のメトリクスデータが到着した場合、
その時点から追加で5分間のタイマーがセットされ、
12:08に12:00 ~ 12:05のメトリクスデータが評価されます。
このTimerは仕組み上、
Window Durationよりも少ない時間を指定することがは非推奨なので、
その点は注意しましょう。
おわりに
ざざっと該当項目に関して解説してみましたがいかがでしょうか。
例などを出してわかりやすくしたつもりではありますが、
改めて見返しても、 必要となる前提知識や背景などの情報量の多さ故に腰を据えてみていかないと理解が難しい側面はあるかもしれません。
何かしらアラート設定でつまづいた時にでも、
こんなこと書いてたやつがいたなーと思い出してもらえたら幸いです。
ちょっとだけ宣伝
NRUG(New Relic User Group):通称ぬるぐ というユーザーグループがあります。
弊社でも板谷(@mary_tuba)がNRUGの運営、
僕がNRUG SRE支部の運営を勤めておりまして、直近の予定は以下になります。
12/14(水) NRUG Vol.5 Day1 1周年だよ!全員集合!! https://nrug.connpass.com/event/265357/ 12/15(木) NRUG Vol.5 Day2 交流会 https://nrug.connpass.com/event/266747/
?/? NRUG SRE支部 Vol.3 来年春頃まで必ずやりたい…!!
気になる方は是非チェックしてみてください!
0 notes
Text
New Relic Alert Condition設定におけるチームでの基本指針を策定した
はじめに
※この記事は mediba Advent Calendar 2022 の5日目の記事です。
株式会社mediba バックエンドエンジニアの@hrktcyです。社会人2年目になりました。 みなさまの運用するサービスには監視SaaSを導入していますか。弊社では1日目の記事でもお伝えしている通り、近年New Relicによるサービス監視が主流となっています。現在私が参加している、ポイントリワードサービスにおけるポイント付与機構の開発プロジェクトにも導入する運びとなりました。本記事では題目の通り、New Relic Alert Condition設定におけるチームでの基本指針を策定したのでその内容を共有したいと思います。
アプリケーション側のコードの見直し
まずはConditionの設定をする前に、アプリケーション側のコードの見直しを行うことにしました。コーディングしていた時期から結構期間が空いていたので、記憶から抜けていた部分を埋めていきながら、「適切なエラーハンドリングができているか」「使用しているカスタムログのログレベルが正しいか」の2点を重点的にチェックしました。
ログレベル
値 内容 Info 実行状態を把握するために出力する Warn 致命的ではないが想定外の挙動をしたときに出力する Error 予期しないエラーでサービス及びシステムに影響があり調査及び復旧が必要な時に出力する
ポリシーを分ける
ポリシーとは、1つ以上のコンディションのグループを指します。今回、ポリシーは以下の2つに分けることにしました。
オンコールポリシー
Slack通知ポリシー
オンコールポリシー
検知された場合、インシデントとなり得る事案のため至急対応が必要なものをオンコールポリシーに割り当てます。ログレベルで言うとErrorレベルのものを指します。具体的には、
バッチが多重起動している
AWSサービスのクライアント読込、アクセスに失敗している
外部サービスへのアクセス、SFTP経由でのダウンロードに失敗している
といったものになります。 ポイント誤課金事故を防ぐためにもこのようなインシデントに対しては早急に調査・復旧対応する必要があるので、ローンチ段階ではNRQLの条件を厳しめに設定し、Slack通知+Twilioで業務端末へ架電するように設定しました。しかし条件が厳しいほど、アラートによる疲弊問題にも向き合う必要があり、インシデント対応プロセスでケアレスミスやコミュニケーションミスに繋がりやすくなるので、架電対象者はランダム(不在時は別の対象者に架電)にして、NRQL条件については保守運用が安定してきたら少しずつ緩和していきたいと考えています。
Slack通知ポリシー
検知された場合、想定外のエラーでサービス及びシステムに影響があるが、調査及び復旧が至急ではないものをSlack通知ポリシーに割り当てます。ログレベルで言うとWarnレベルのものを指します。具体的には、
ポイント付与に失敗している
CPU/メモリ/DB使用率が一定期間n%を超えている
DBコネクション数が一定期間n件以上
といったものになります。 「ポイント付与に失敗している」については、リカバリーを考慮した設計になっているため、基本的には楽観視しても良いのですが、断続的に失敗している際は調査が必要になります。また、インフラのパフォーマンス監視についてもワーニングポリシーに割り当てておき、検知がされたタイミングで高負荷となっている要因の調査が必要になります。こちらのポリシーについてはSlack通知のみ行うように設定しました。
コンディションの管理について
TerraformによるIaC化を行い、ポリシーに紐づくコンディションを一元管理しました。terraform applyで素早くAlert Conditionを設定できるようになるため、将来顧客が増えた場合のインフラ環境の増築に対しても即対応が可能になります。
実際どうだったか
ローンチから1ヶ月ほど経ちましたが、至急対応が必要な事案は現状1件、検知によって迅速な復旧作業を行うことができました。また、ローンチ後にはAlert Conditionに加えてAPMによるHTTPトランザクションや、関数・クエリ単位での計装を実装することができ、サービスの信頼性維持の体制が整ってきていると感じます。
終わりに
特にオリジナリティのある指針ではないかもしれませんが、私はAlert Condition設定をしている際に、いろいろと考え過ぎてしまい沼にはまることが度々ありました。チームメンバー間の認識を合わせるためにも一度言語化しておくと困った時に立ち返ることができるかと思います。また今後の新規開発の際には、予め監視対象やAlert Condition設定を意識しながらコーディングできるように心がけていきたいです。
宣伝
KDDIグループ企業各社のDeveloperが集い、「エンジニアが楽しめる」イベントを提供するコミュニティKDDI Group Developer Community(KGDC)の運営スタッフとして活動しています。来年も引き続き開催していきますので、ぜひConnpassよりメンバーになっていただき、次回のイベントに参加していただけると嬉しいです!
0 notes
Text
Charlesを活用してCSPにGA4のディレクティブを追加してみた
こんにちは、データアナリストの左海です。
今回はパケットキャプチャツールCharlesを活用してレスポンスヘッダーのContent-Security-PolicyフィールドにGA4のディレクティブを追加したお話について書いていきます。
課題と背景
Universal Analyticsのサポート終了発表に伴い、弊社でも対象のサービスサイトにてGA4の導入を進めていたのですが、CSP(Contents Security Policy)関連でエラーが発生しGA4ログの疎通が確認できませんでした。
Google Chromeのデベロッパーツールで調査すると、サイトのCSPにGA4のオリジンが宣言されておらず、リソースがブロックされていたため、ログが飛んでいないことが判明しました。

加えて、対象のサービスサイトは外部の会社が運用しており、私自身の環境でデバックする必要があったため、Charlesを活用することにしました。
方策
Google ChromeのConsoleでエラーログを確認すると、有難いことにエラーの解決方法まで記載されています。
A site's Content Security Policy is set either as via an HTTP header (recommended), or via a meta HTML tag.
HTTP ヘッダーまたはHTMLのメタタグに以下の通りにGA4のディレクティブを宣言すれば解決できるようです。
script-src: https://www.google-analytics.com https://ssl.google-analytics.com img-src: https://www.google-analytics.com connect-src: https://www.google-analytics.com
では、実際にCharlesのRewriteという機能を使用してレスポンスヘッダーのContent-Security-PolicyフィールドにGA4のディレクティブを追加しデバックしてみることにします。
CSP(Contents Security Policy)とは
Charlesでデバックする前にCSPについて解説します。CSPについてMDNには以下のように記載されています。
HTTP の Content-Security-Policy レスポンスヘッダーは、ウェブサイト管理者が、あるページにユーザーエージェントが読み込みを許可されたリソースを管理できるようにします。いくつかの例外を��いて、大半のポリシーにはサーバーオリジンとスクリプトエンドポイントの指定を含んでいます。これはクロスサイトスクリプティング攻撃 (クロスサイトスクリプティング) を防ぐのに役立ちます。 https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Content-Security-Policy
レスポンスヘッダーのContent-Security-Policyフィールドにてサイトに必要なリソースを宣言することでリソースの管理が行えます。CSPに宣言されていないリソースは読み込まれないため、悪意のあるリソースの読み込みを回避しクロスサイトスクリプティング攻撃(XSS攻撃)を防ぐことにつながるようです。
Charlesでデバックする
CharlesのRewriteという機能を使用すればHTTPリクエスト/レスポンスの内容を書き換えることが可能です。早速、レスポンスヘッダーのContent-Security-PolicyフィールドにGA4のディレクティブを追加していきます。
1.Charlesを選択した状態でアプリケーションメニュー > Tools > Rewriteを選択する
Charlesを起動してアプリケーションメニュー > Tools > Rewriteの順序で添付画像のRewriteを選択します。

2.Enable Rewriteのチェックボックスにチェックを入れ、Rewrite Settingsを追加する
Rewrite SettingsでEnable Rewriteを有効にし、Rewriteの設定を新規作成するのでAddを選択します。設定の名前はmodify cspとしました。

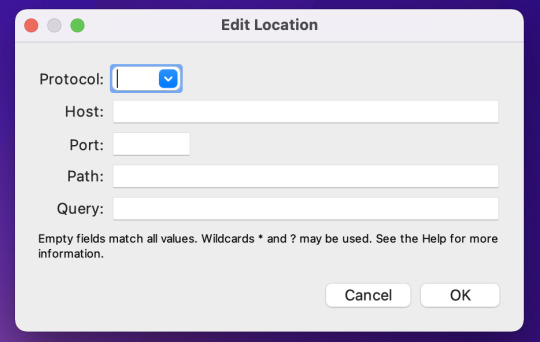
次に、Rewriteの対象となる該当のURIを添付画像の赤枠箇所のAddから設定していきます。

URIをProtocol、Host、Port、Path、Queryに分けて記載することで、Locationの設定は完了です。
最後に、Rewrite RuleにてレスポンスヘッダーのContent-Security-Policyフィールドの修正を設定していきます。赤枠箇所のAddからURIの設定の際と同じようにRewrite Ruleの新規作成を行います。
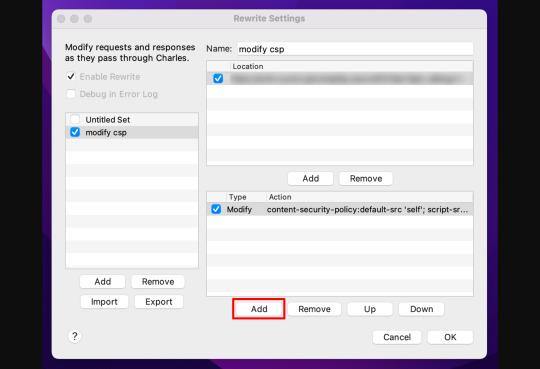
設定項目について順番に解説します。
Type
実行するRewriteのタイプを指定します。今回はレスポンスヘッダーを修正するのでModify Headerを選択しましょう。
Where
Rewriteを適用する場所を選択します。レスポンスヘッダーを修正するのでResponseにチェックを入れましょう。
Match
修正するヘッダー名とその値を指定します。値は空白にし、どんな値でも置換されるように、Match whole valueにチェックを入れます。大文字と小文字を区別したい場合はCase sensitiveに、正規表現を使用したい場合はRegexにチェックを入れます。
Replace
修正後のContent-Security-Policyフィールドの値を設定します。値にGA4のディレクティブを追加します。値はすべて書き換えるので、Replace Allにチェックを入れます。

以上でRewriteの設定は完了です。
3.該当のサイトにてGA4ログが正しく飛んでいるか確認する
添付画像の通り、意図した通りにGA4ログを確認することができました。
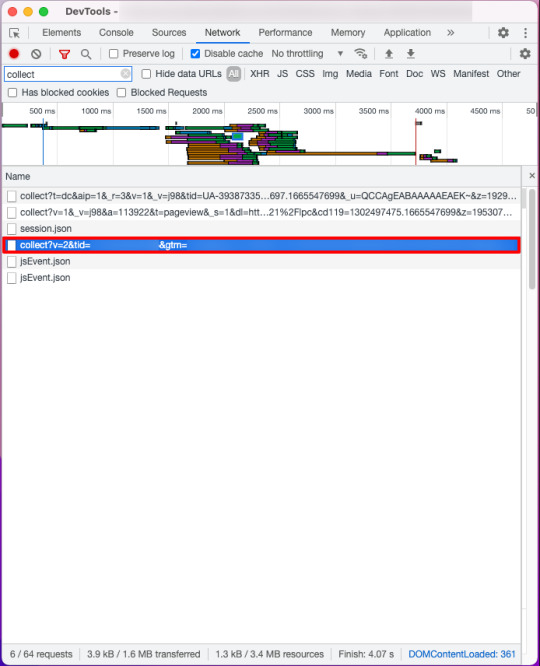
おわりに
CharlesのRewriteは、実際にサーバーの設定を変更することなく私自身の環境でデバックすることが可能です、かなり便利ですね。
今回の私のケースのように、外部の会社にサイトの運用を依頼している場合は原因調査に時間とコストがかかると思いますのでCharlesの利用をぜひ検討してみてはいかがでしょうか。
どなたかの参考になれば、幸いです。
0 notes
Text
GitHub Actions で開発リードタイムとデプロイ数を計測してダッシュボードを作っている話
はじめに
こんにちは。エンジニアの中畑(@yn2011)です。
今年の4 月から現在のチームでテックリードの役割を担うようになり、開発チームのパフォーマンスに関心を持つようになりました。開発チームのパフォーマンスという漠然としたテーマを前に、自分は何をするべきなのだろうか?と悩みながら情報収集をしていたのですが、texta.fm #5 Accelerate で Four Keys と呼ばれる開発組織のパフォーマンス指標(と書籍「Lean と DevOps の科学」)について知り、「これは良さそう」と思い開発チームに導入してみることにしました。
今回は開発チームが Four Keys 運用の最初の一歩として、どのような技術を利用して計測と可視化を実現したかご紹介させて頂きます。
なぜやるか
Four Keys は既にユーザに対してプロダクトを公開し、継続的なリリースを行っているチームを前提としていると認識していますが、 私のチームでは新規開発を行っていて、まだプロダクトを公開していません。 とはいえ、新規開発においても開発の生産性や健全性に関心を持つことは重要だと考えています。開発チームのパフォーマンスを定量で語れる状況を作ることで、解くべき課題を明らかにし、チームが行った改善の結果を正しく認識することができます。
Four Keys をツールとして捉えれば、新規開発を行っているチームにおいても有用なのではないかという仮説の元、 本質を見失わない程度に Four Keys の定義をチームに合うように変更することで、新規開発においても開発チームのパフォーマンスを定量化できるはず、と考え導入の検討を始めました。
何から始めるか
まずは、現在のチームの Four Keys を計測し可視化する仕組みが必要です。Four Keys の運用は私やチームにとって初めての試みなので、最初から大掛かりな計測と可視化の仕組み(システム)を構築するのではなく、できるだけ小さく始めようと計画しました。
そこで、Four Keys のうち開発リードタイムとデプロイ数の 2 つの指標に絞ることにしました。変更障害率とサービス復元時間は取得が難しいことと、プロダクトを公開していないのでそもそも定義できないというのが理由です。システムのアーキテクチャも GitHub Actions と GitHub Pages を使った簡易的な構成から始めてみようと考え、開発を開始しました。
対象とする指標については、新規開発であることを考慮して以下の定義としました。
開発リードタイム: コミットしてから main ブランチにマージされるまで
デプロイ数: main ブランチにマージした回数(main ブランチにマージすると開発環境向けのビルドとデプロイを行うため)
システム構築
今回は以下の機能を持つシステムを構築しました。
スケジュール実行できる
対象のリポジトリから開発リードタイムとデプロイ頻度を収集する
収集したデータを元に指標をダッシュボードとして Web に公開する(ただし社内メンバーのみアクセス可能)
ダッシュボードの更新を Slack 通知する
以下にシステム概要図を示します。
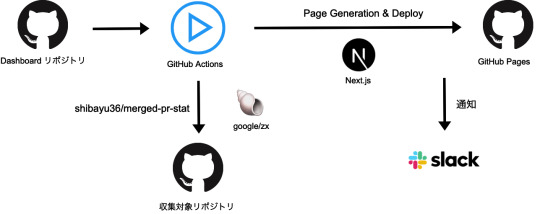
それでは、システム概要図を元に詳細についてご紹介します。
リポジトリ
データ収集対象のリポジトリとは別に、Dashboard 用リポジトリを新たに作成しました。Dashboard 用リポジトリでは、GitHub Actions を利用して以下を行っています。
リポジトリからのデータ収集
Dashboard 作成
GitHub Actions でスケジュール実行する
指標は 1週間の中央値や平均値で算出したいので、データの収集と Dashboard の更新は週に 1 度だけ実行します。
例えば、毎週月曜日の日本時間 9 時に実行する場合は以下のように記述します。スケジュール実行に加えて、手動で実行したい場合のために workflow_dispatch: も含めておくと便利です。
// actions.yaml on: schedule: - cron: '0 0 * * 1' workflow_dispatch:
収集する
shibayu36/merged-pr-stat を利用して、開発リードタイム(コミットから main ブランチマージまでの日数)とデプロイ頻度(PR のマージ数)を取得します。(main ブランチにマージした際にビルドとデプロイを実行しているのでデプロイ数は PR 数と同等と見なしています)
後続のダッシュボード生成で利用するため、取得した結果は JSON ファイルとして出力します。
今回は「小さく始める」というコンセプトで開発しているので、 1 度取得したデータを永続化せず、GitHub Actions を実行する度に全てのデータを再取得することにしました。当然時間の経過と共に GitHub API のリクエスト数は増えてしまいますが、まだプロジェクトの開始から3ヶ月程度しか経過していないのでしばらくは大きな問題にはならないだろうという判断です(とはいえそのうち何とかしたい)
ちなみに、基準日から 7 日間毎のデータを繰り返し取得するため、zx でスクリプトを書いて merged-pr-stat を実行しています。
実装イメージ
while (startDate.add(7, "day").isBefore(now)) { // ...省略 await $`GITHUB_TOKEN=${process.env.GITHUB_TOKEN} yarn merged-pr-stat --start=${isoStartDateTime} --end=${isoEndDateTime} --query="repo:mediba/repo-name"`.pipe($`tail -n +2`); }
※補足ですが、コミット日時がコマンド引数に与えた対象期間外でも PR マージが対象期間に含まれていれば計測対象になります。
zx を使うことで、JavaScript から直感的に分かりやすくシェルスクリプトを実行し、その結果を利用することができます。また、ESM に対応しているため top level await が使える点も便利です。今回は利用していませんが、Promise.all でコマンド実行を並列化することで処理速度を上げることもできそうです。
可視化する
出力した JSON ファイルを元にグラフを描いて Next.js で SSG します。react-chartjs-2 を利用して以下のようなグラフを作成しました。
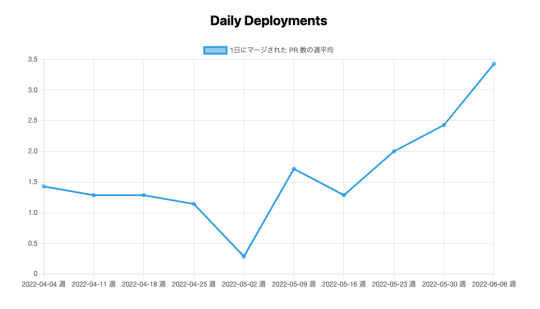
参考用に実装例を掲載します。
PR 数のグラフの場合は、以下のようにオプション(軸ラベル)とデータセットを定義し
// 軸の設定 const prOptions = { ...options, scales: { x: { title: { text: "週", display: true, }, }, y: { title: { text: "PR数", display: true, }, }, }, }; // x 軸の目盛りラベル const labels = json.map((d) => `${d.startDate} 週`); // データセット const prs = { labels, datasets: [ { label: "1日にマージされた PR 数の週平均", data: json.map((d) => d.count / 7), borderColor: "rgb(53, 162, 235)", backgroundColor: "rgba(53, 162, 235, 0.5)", }, ], };
Line コンポーネントに受け渡せば OK です。
<Line options={prOptions} data={prs} />
GitHub Pages にデプロイする
peaceiris/actions-gh-pages を利用して、生成したダッシュボードを GitHub Pages にデプロイします。GitHub Actions は main ブランチで実行し、SSG で生成したディレクトリを gh-pages ブランチにコミットします。
通知する
最後にダッシュボードの更新を Slack に通知します。今回は使い慣れていたので rtCamp/action-slack-notify@v2 を利用しました。
継続的にチームメンバーへ共有することで Four Keys に対する意識が高まっていきそうです。
まとめ
GitHub Actions と GitHub Pages を利用して、定期的に開発リードタイムとデプロイ頻度を収集し可視化する仕組みを作ることができました。
今回は Four Keys に対する取り組みの技術面をご紹介しましたが、今後は新規開発チームで Four Keys を計測・可視化する仕組みを導入した結果、どのようなメリットやデメリットがあったのか等開発プロセスとの関わりについてもご紹介できればと思います。
最後までお読み頂きありがとうございました。
0 notes
Text
2年間育てあげたブランチ戦略を人類のために公開する。
はじめに
こんにちは、SRE Unitの北浦(@kitta0108)です。
皆様、今日も元気にブランチを切っていますか?
僕は今まで、脳死でDevelopブランチを切っては、 ただただ空を見つめる・・・そんな人生を送っていました。
そんな僕にも救いの光が差し込みまして、 とても上手に運用しているなと思うチームから、 運用論や具体的な方法を聞くことができました。今回はその内容をご紹介したいと思います。
※ 社内では発案者である下地さん(@primunu)のお名前をお借りして「shimoji-flow」と呼ばれているそうです。 便宜上、当ブログでもそのように呼ばせていただこうと思います。
僕らがGitの運用に求めること
たかがブランチ戦略、されどもブランチ戦略。 システム運用の安定化という観点でも、開発アジリティ向上という観点でも、ブランチ戦略を精錬させ、日々見直しをかけていくことは投資対効果の高いものだと個人的には思っています。
内容のご紹介に入る前に、僕らがGitを運用するにあたって、 考慮するべきものは一体どのようなものがあるのか、書き出してみました。
各環境の状態がどのコードベースで適用されているのか可視性が高い状態であること
運用ナレッジの習得量が少なくても運用ができること = シンプルであること
高速且つ信頼性の高いデリバリーが実現できること
前バージョンへの切り戻しが高速且つ容易であること
ブランチ構成
上記を踏まえ、ブランチの構成、運用サイクルを以下のようにしました。
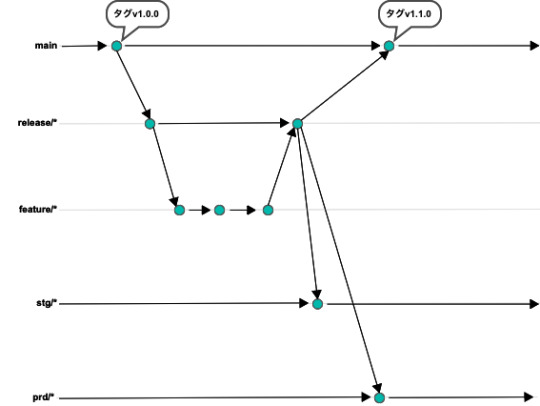
運用サイクル
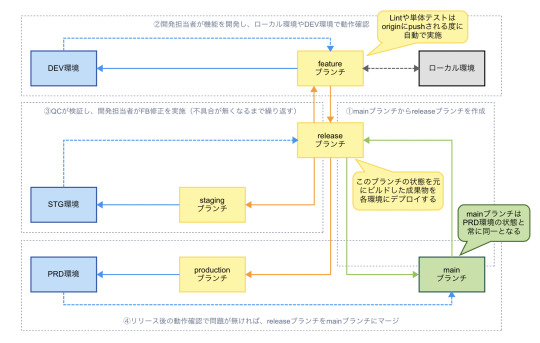
デリバリーの工夫点
shimoji-flowでは、デリバリーの速度と信頼性の向上を実現するために、 STG/PRD環境向けのデリバリーに関しては、ビルドとデプロイのトリガーを分離させています。
ビルドの責務はReleaseブランチのGitHashをイメージタグとして、コンテナレジストリへのプッシュまでを行うこととし、 Releaseブランチに機能群が出揃ったタイミングでビルドのワークフローを実行するようにしています。
また、同じビルドから作成されたコンテナイメージをSTG/PRD環境で参照するようにもしています。
このように一つのコードベースによる複数のビルド & デプロイが実行されることにより、
環境差異を最小限に抑えた検証が実現できる = 信頼性の向上
ビルドが事前に行われている = PRD環境へのデリバリーの高速化
が実現できていると感じます。
※ ご参考: The Teweleve-Factor App I. CodeBase https://12factor.net/codebase
まとめ
さて、ちゃんと冒頭に述べた要件が満たされているか振り返ってみましょう。
各環境の状態がどのコードベースで適用されているのか可視性が高い状態であること
->Releaseブランチによる各環境へのデプロイ後、環境名のブランチにマージすることにより、コードベースで適用状態がわかるようになりました。
運用ナレッジの習得量が少なくても運用ができること = シンプルであること
->開発の進行においては、Releaseブランチへのマージだけを考えれば良いという点でとてもシンプルかと思っています。ビルドやデプロイのワークフローも必ずReleaseブランチから実行されるという点も仕組み的にシンプルですよね。
高速且つ信頼性の高いデリバリーが実現できること
->上記に述べたデリバリーの仕組みにより実現できました。
前バージョンへの切り戻しが高速且つ容易であること
->各環境名のブランチにリリース後、マージする運用を取り入れているので、いざ切り戻しが必要になった場合、そのブランチのどのコミットまで戻せばいいのかという点に議論は収束されます。 環境名のブランチが存在するのでパッと見の可視性が高いのも個人的に○な点かなと思います。
さいごに
shimoji-flowいかがでしたでしょうか。
さすが2年間運用していて、たくさん改善もされているとのことだったので、完成度の高いものだと個人的には思いました。
良きものは世に出さねばと思って筆を取らせていただいた次第でしたが、みなさんにも、ブランチ戦略見直しのきっかけや、プラクティスの取り入れなどで活用いただいたら大変に嬉しく思います!!
0 notes