
Last Seen Blogs

ionlydidthistoscrollinpeace2022
Selkie222

tobinmcginnis2
The Life of Skipper 957


gamingwriter413
DJ Writer

ts0984458
Untitled
Text
¿Qué novedades presenta Octoparse 8.4.2?
Usuarios de Octoparse, ¿cómo va su viaje de raspado web con el software? En este mes, se lanzará la versión 8.4.2 del producto. ¿Quieren saber qué novedades presenta la próxima versión más reciente? ¡Sigue leyendo!
1. Integración de Zapier
En la versión 8.4.2, puedes exportar automáticamente tus datos en la nube con Zapier a Google Drive, Google Sheet y más software.

Encuentra más información aquí y pruébalo.
2. Raspar mientras se desplaza dentro de una sección determinada
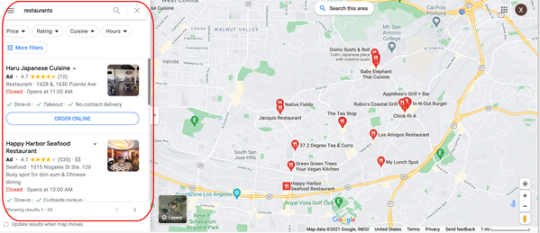
Tomamos Google Maps como ejemplo. Puedes ingresar a la página web y raspar los resultados de la búsqueda solo usando esta función en la versión 8.4.2. La función se puede implementar configurando el Xpath.
3. Personalizar el agente de usuario
Puedes cambiar la cadena del agente de usuario y el nombre del agente de usuario en los navegadores cuando utilices la versión 8.4.2 para extraer datos.
Para entender cómo funcionan los agentes de usuario, este artículo puede ser útil: Cómo cambiar los agentes de usuario en Chrome, Edge, Safari y Firefox
4. Realizar una copia de seguridad de los datos locales en la nube
Esta función solía estar disponible sólo para los usuarios empresariales. En la nueva versión 8.4.2, está abierta también a los usuarios con planes profesionales.
5. Formateo de la marca de tiempo
Esta función está diseñada principalmente para raspar plataformas de redes sociales. La conversión de la marca de tiempo de las publicaciones a la fecha está disponible en la versión 8.4.2.
6. Otras actualizaciones en las funciones existentes y la interfaz de usuario (UI)
Con las actualizaciones, la versión 8.4.2 será más estable y conveniente de usar en comparación con las versiones anteriores.
¡Qué más! El sistema de Octoparse 8.4.2 ahora está disponible en español, puedes cambiar el idioma según tu necesidad.
No dudes en contactarnos en [email protected] o enviar un ticket aquí si tienes alguna pregunta. El equipo de atención al cliente estará listo para ayudarte como siempre. ¡Te deseo un raspado aún más feliz!
#webscraping webscrapingtools webscrapingespañol datamining herramientas de web scraping#webscraping webscrapingtools webscrapingespañol datamining
0 notes
Text
Tripadvisor Scraper: los principales destinos abiertos a los ciudadanos bajo Covid
Las reglas de viaje están cambiando actualmente con la curva de casos de Covid. Con la variante Delta de la enfermedad, los casos están aumentando. Mientras estoy compilando este artículo, la UE está considerando volver a imponer restricciones de viaje a los visitantes estadounidenses.
De todos modos, he creado mi raspador de Tripadvisor con Octoparse y he analizado la información de los destinos que están abiertos a los ciudadanos estadounidenses. Prepárate siempre para un viaje refrescante.
Nota: si te diriges a estos países, es posible que desees comprobar si es necesaria la vacunación o la cuarentena.
Por cierto, el web scraping es definitivamente la mejor manera de ayudarnos a extraer los datos web y así poder examinarlos y sacar el máximo provecho de ellos. Mostraré cómo me ayuda a obtener los datos de viaje.
Web Scraping de Datos de Viajes
¿Tienes alguna idea sobre el big data en el turismo?
Los empresarios de la industria de viajes están rastreando todo tipo de datos, por ejemplo, datos comerciales de agentes de viajes y datos de comportamiento de los visitantes en todas las plataformas relacionadas con viajes. Es posible que conozcan sus hábitos de viaje mejor que tú. Toda la industria está aprovechando el big data para lanzar el producto adecuado y encontrar a las personas adecuadas para pagar por sus servicios.
El web scraping es la tecnología que lo hace posible.
Bueno, como viajero, quiero recopilar datos de viajes en la web para satisfacer mis necesidades: encontrar destinos entre los más atractivos y obtener las guías de Tripadvisor para mi referencia.
Que voy a hacer
En primer lugar, necesito una lista de países para investigar.
En segundo lugar, utilizaré una herramienta de raspado web, Octoparse, para crear un raspador de Tripadvisor y rastrear los datos de viajes de estos países.
¡Finalmente, voy a empacar mi equipaje y dirigirme al destino que más se ajuste a mis gustos de viaje!
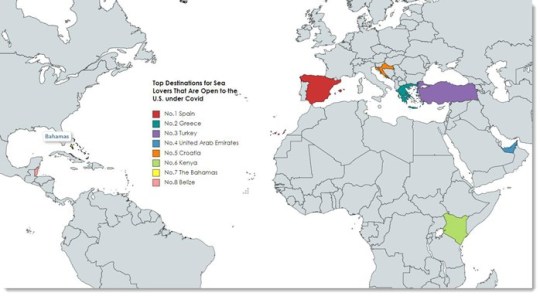
¿A Dónde Puede Ir un Estadounidense?
Entonces, ¿a dónde puede viajar un estadounidense ahora?
Este artículo de CNN enumeró los destinos que están abiertos a los EE. UU. (La lista podría actualizarse de vez en cuando).
Lo que quería hacer era extraer todos los nombres de países de esta página web en una hoja de cálculo para poder pegarlos en Octoparse y obtener datos más específicos de Tripadvisor.
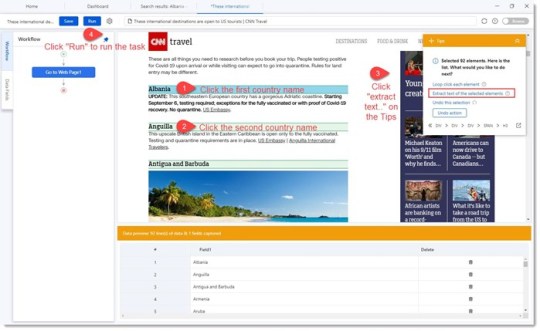
Octoparse: cómo obtener información de la lista en una página web en Excel
Octoparse puede obtener fácilmente información de la lista en una página web en Excel o CSV.
Esto es extremadamente útil cuando deseas obtener una lista de URL o una lista de datos, que deseas pegar y buscar en otra plataforma, o importar a un software de análisis de datos para tu análisis.
Ahora que tengo la lista de destinos de texto, voy a crear un raspador de TripAdvisor para obtener datos específicos sobre estos lugares.
Crear un Raspador de TripAdvisor
Los datos que voy a rastrear desde Tripadvisor:
Quiero comprobar la popularidad de los viajes en estos países. Consultaré con el número de reseñas sobre el país en Tripadvisor. (Mi hipótesis: más visitas, más reseñas).
Tengo mi tema de viaje. Soy un amante de la naturaleza interesado en eventos al aire libre y turismo en la naturaleza. Obtendré la información de la etiqueta de estos destinos para poder filtrar y ubicar el lugar perfecto donde pueda perseguir el viento, jugar en la playa o apreciar la grandeza de un pico.
Guardaré la URL de las guías de viaje en Tripadvisor para una mayor planificación de viajes. (¡Gracias contribuidores!)
Generar URL por Lotes con Nombres de Países
¿Dónde conseguir estos datos? Esta es una página de muestra: Tripadvisor Nepal.
Con la lista de nombres de países que he extraído en el paso anterior, puedo generar por lotes todas las páginas de países de Tripadvisor con Octoparse.
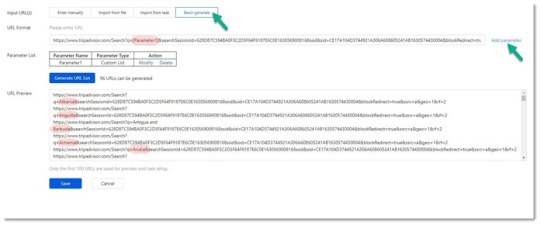
Ejemplos de páginas generadas:
Tripadvisor Ireland
Tripadvisor Israel
Tripadvisor Italy
Tripadvisor Kenya
Ahora que tengo una lista de páginas web de destino para extraer datos, voy a crear un raspador que comprenda qué datos estoy solicitando y los tomará por mí.
Crear un Raspador: Dime Lo Que Quieres
Construir un raspador es como compilar una carta para conversar con la computadora: dígale dónde y cómo obtener los datos que deseas. Solo que no hablas en lenguaje humano, sino en lenguajes de programación.
Y una herramienta de raspado web es como un traductor. Te permite compilar la carta utilizando lenguaje humano, gracias al flujo de trabajo comprensible y la interfaz de usuario intuitiva.
Si esto sigue siendo abstracto, no importa. Vamos a sumergirnos en algunas preguntas.
¿Qué puede hacer un raspador?
Visitar - abrir una página web.
Hacer clic - hacer clic en un enlace de la página web.
Extraer - rastrear datos como textos, URL, números, etc.
¿Qué datos necesito?
El nombre del país, el número de reseñas.
El enlace de la guía de viaje, el título de la guía y sus etiquetas.
¿Cómo actuará un raspador para obtener los datos que necesito?
Visitará la pagina web
Extraerá el nombre del país y el número de reseñas en la página
Buscará el enlace de la guía de viaje y hará clic en él
Extraerá la URL de la página, el título de la guía, las etiquetas de la guía
Regresará y visitará la siguiente página web
Repetirá los pasos anteriores (en Octoparse, esto se puede hacer con un bucle)
Bingo. Ese es el flujo de trabajo que construí aquí.
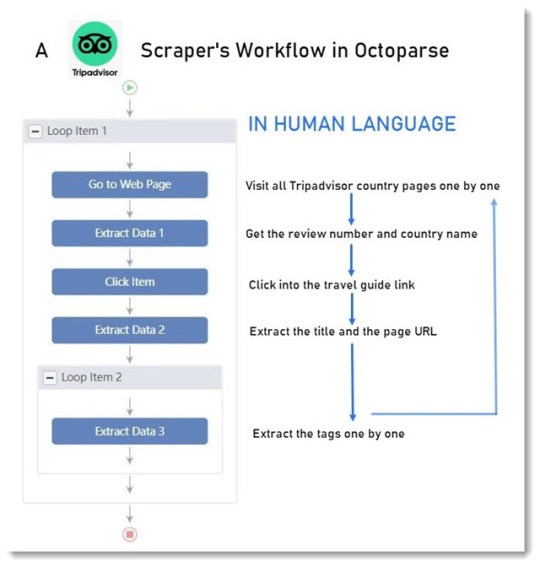
¿Cómo construir el flujo de trabajo?
Pan comido.
Ingresar las URL en la barra de búsqueda y comenzar una tarea de construcción. (Díle al raspador qué páginas web visitar)
Hacer clic en los datos que deseas en el navegador integrado. (Ayuda al raspador a localizar los datos)
Seleccionar las acciones que deseas que realice el raspador en el Panel de sugerencias. (Díle al raspador que visite, haga clic o extraiga datos)
¿Cómo se ven los datos?
Es una tabla larga ya que hay más de 100 líneas de datos en mi lista. La siguiente captura de pantalla ha hecho todo lo posible.
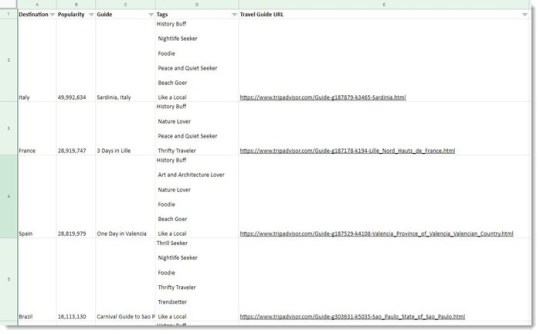
Lo sé, los datos sin procesar no son bonitos antes de cualquier visualización, pero son útiles. Con estos datos, encontré la mejor opción para un amante de la comida y la playa - ¡España!
Diviértete con Octoparse. Cualquier problema al usarlo, no dude en contactarnos en [email protected].
>> Empezar a raspar mis datos
>> Herramientas de visualización para mostrar (o mostrar) mis datos
0 notes
Text
9 herramientas de Web Scraping Gratuitas que No Te Puedes Perder en 2021
¿Cuánto sabes sobre web scraping? No te preocupe, este artículo te informará sobre los conceptos básicos del web scraping, cómo acceder a una herramienta de web scraping para obtener una herramienta que se adapte perfectamente a tus necesidades y por último, pero no por ello menos importante, te presentará una lista de herramientas de web scraping para tu referencia.
Web Scraping Y Como Se Usa
El web scraping es una forma de recopilar datos de páginas web con un bot de scraping, por lo que todo el proceso se realiza de forma automatizada. La técnica permite a las personas obtener datos web a gran escala rápidamente. Mientras tanto, instrumentos como Regex (Expresión Regular) permiten la limpieza de datos durante el proceso de raspado, lo que significa que las personas pueden obtener datos limpios bien estructurados en un solo lugar.
¿Cómo funciona el web scraping?
En primer lugar, un robot de raspado web simula el acto de navegación humana por el sitio web. Con la URL de destino ingresada, envía una solicitud al servidor y obtiene información en el archivo HTML.
A continuación, con el código fuente HTML a mano, el bot puede llegar al nodo donde se encuentran los datos de destino y analizar los datos como se ordena en el código de raspado.
Por último, (según cómo esté configurado el bot de raspado) el grupo de datos raspados se limpiará, se colocará en una estructura y estará listo para descargar o transferir a tu base de datos.
Cómo Elegir Una Herramienta De Web Scraping
Hay formas de acceder a los datos web. A pesar de que lo has reducido a una herramienta de raspado web, las herramientas que aparecieron en los resultados de búsqueda con todas las características confusas aún pueden hacer que una decisión sea difícil de alcanzar.
Hay algunas dimensiones que puedes tener en cuenta antes de elegir una herramienta de raspado web:
Dispositivo: si eres un usuario de Mac o Linux, debes asegurarte de que la herramienta sea compatible con tu sistema.
Servicio en la nube: el servicio en la nube es importante si deseas acceder a tus datos en todos los dispositivos en cualquier momento.
Integración: ¿cómo utilizarías los datos más adelante? Las opciones de integración permiten una mejor automatización de todo el proceso de manejo de datos.
Formación: si no sobresales en la programación, es mejor asegurarte de que haya guías y soporte para ayudarte a lo largo del viaje de recolección de datos.
Precio: sí, el costo de una herramienta siempre se debe tener en cuenta y varía mucho entre los diferentes proveedores.
Ahora es posible que desees saber qué herramientas de raspado web puedes elegir:
Tres Tipos De Herramientas De Raspado Web
Cliente Web Scraper
Complementos / Extensión de Web Scraping
Aplicación de raspado basada en web
Hay muchas herramientas gratuitas de raspado web. Sin embargo, no todo el software de web scraping es para no programadores. Las siguientes listas son las mejores herramientas de raspado web sin habilidades de codificación a un bajo costo. El software gratuito que se enumera a continuación es fácil de adquirir y satisfaría la mayoría de las necesidades de raspado con una cantidad razonable de requisitos de datos.
Software de Web Scraping de Cliente
1. Octoparse
Octoparse es una herramienta robusta de web scraping que también proporciona un servicio de web scraping para empresarios y empresas.
Dispositivo: como se puede instalar tanto en Windows como en Mac OS, los usuarios pueden extraer datos con dispositivos Apple.
Datos: extracción de datos web para redes sociales, comercio electrónico, marketing, listados de bienes raíces, etc.
Función:
- manejar sitios web estáticos y dinámicos con AJAX, JavaScript, cookies, etc.
- extraer datos de un sitio web complejo que requiere inicio de sesión y paginación.
- tratar la información que no se muestra en los sitios web analizando el código fuente.
Casos de uso: como resultado, puedes lograr un seguimiento automático de inventarios, monitoreo de precios y generación de leads al alcance de tu mano.
Octoparse ofrece diferentes opciones para usuarios con diferentes niveles de habilidades de codificación.
El Modo de Plantilla de Tareas Un usuario con habilidades básicas de datos scraping puede usar esta nueva característica que convirte páginas web en algunos datos estructurados al instante. El modo de plantilla de tareas solo toma alrededor de 6.5 segundos para desplegar los datos detrás de una página y te permite descargar los datos a Excel.
El modo avanzado tiene más flexibilidad comparando los otros dos modos. Esto permite a los usuarios configurar y editar el flujo de trabajo con más opciones. El modo avanzado se usa para scrape sitios web más complejos con una gran cantidad de datos.
La nueva función de detección automática te permite crear un rastreador con un solo clic. Si no estás satisfecho con los campos de datos generados automáticamente, siempre puedes personalizar la tarea de raspado para permitirte raspar los datos por ti.
Los servicios en la nube permiten una gran extracción de datos en un corto período de tiempo, ya que varios servidores en la nube se ejecutan simultáneamente para una tarea. Además de eso, el servicio en la nube te permitirá almacenar y recuperar los datos en cualquier momento.
2.
ParseHub
Parsehub es un raspador web que recopila datos de sitios web que utilizan tecnologías AJAX, JavaScript, cookies, etc. Parsehub aprovecha la tecnología de aprendizaje automático que puede leer, analizar y transformar documentos web en datos relevantes.
Dispositivo: la aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux, o puedes usar la extensión del navegador para lograr un raspado instantáneo.
Precio: no es completamente gratuito, pero aún puedes configurar hasta cinco tareas de raspado de forma gratuita. El plan de suscripción paga te permite configurar al menos 20 proyectos privados.
Tutorial: hay muchos tutoriales en Parsehub y puedes obtener más información en la página de inicio.
3.
Import.io
Import.io es un software de integración de datos web SaaS. Proporciona un entorno visual para que los usuarios finales diseñen y personalicen los flujos de trabajo para recopilar datos. Cubre todo el ciclo de vida de la extracción web, desde la extracción de datos hasta el análisis dentro de una plataforma. Y también puedes integrarte fácilmente en otros sistemas.
Función: raspado de datos a gran escala, captura de fotos y archivos PDF en un formato factible
Integración: integración con herramientas de análisis de datos
Precios: el precio del servicio solo se presenta mediante consulta caso por caso
Complementos / Extensión de Web Scraping1.
Data Scraper (Chrome)
Data Scraper puede extraer datos de tablas y datos de tipo de listado de una sola página web. Su plan gratuito debería satisfacer el scraping más simple con una pequeña cantidad de datos. El plan pagado tiene más funciones, como API y muchos servidores proxy IP anónimos. Puede recuperar un gran volumen de datos en tiempo real más rápido. Puede scrapear hasta 500 páginas por mes, si necesitas scrapear más páginas, necesitas actualizar a un plan pago.
2.
Web scraper
El raspador web tiene una extensión de Chrome y una extensión de nube.
Para la versión de extensión de Chrome, puedes crear un mapa del sitio (plan) sobre cómo se debe navegar por un sitio web y qué datos deben rasparse.
La extensión de la nube puede raspar un gran volumen de datos y ejecutar múltiples tareas de raspado al mismo tiempo. Puedes exportar los datos en CSV o almacenarlos en Couch DB.
3.
Scraper (Chrome)
El Scraper es otro raspador web de pantalla fácil de usar que puede extraer fácilmente datos de una tabla en línea y subir el resultado a Google Docs.
Simplemente selecciona un texto en una tabla o lista, haz clic con el botón derecho en el texto seleccionado y elige "Scrape similar" en el menú del navegador. Luego obtendrás los datos y extraerás otro contenido agregando nuevas columnas usando XPath o JQuery. Esta herramienta está destinada a usuarios de nivel intermedio a avanzado que saben cómo escribir XPath.
4.
Outwit hub(Firefox)
Outwit hub es una extensión de Firefox y se puede descargar fácilmente desde la tienda de complementos de Firefox. Una vez instalado y activado, puedes extraer el contenido de los sitios web al instante.
Función: tiene características sobresalientes de "Raspado rápido", que rápidamente extrae datos de una lista de URL que ingresas. La extracción de datos de sitios que usan Outwit Hub no requiere habilidades de programación.
Formación: El proceso de raspado es bastante fácil de aprender. Los usuarios pueden consultar sus guías para comenzar con el web scraping con la herramienta.
Outwit Hub also offers services of tailor-making scrapers.Outwit Hub también ofrece servicios de raspadores a medida.
Aplicación de raspado basada en web1.
Dexi.io (anteriormente conocido como raspado de nubes)
Dexi.io está destinado a usuarios avanzados que tienen habilidades de programación competentes. Tiene tres tipos de robots para que puedas crear una tarea de raspado - Extractor, Crawler, y Pipes. Proporciona varias herramientas que te permiten extraer los datos con mayor precisión. Con su característica moderna, podrás abordar los detalles en cualquier sitio web. Sin conocimientos de programación, es posible que debas tomarte un tiempo para acostumbrarte antes de crear un robot de raspado web. Consulta su página de inicio para obtener más información sobre la base de conocimientos.
El software gratuito proporciona servidores proxy web anónimos para raspar la web. Los datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de ser archivados, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios de pago para satisfacer tus necesidades de obtención de datos en tiempo real.
2.
Webhose.io
Webhose.io te permite obtener datos en tiempo real de raspar fuentes en línea de todo el mundo en varios formatos limpios. Incluso puedes recopilar información en sitios web que no aparecen en los motores de búsqueda. Este raspador web te permite raspar datos en muchos idiomas diferentes utilizando múltiples filtros y exportar datos raspados en formatos XML, JSON y RSS.
El software gratuito ofrece un plan de suscripción gratuito para que puedas realizar 1000 solicitudes HTTP por mes y planes de suscripción pagados para realizar más solicitudes HTTP por mes para satisfacer tus necesidades de raspado web.
0 notes
Text
¿Para qué se usa el screen scraping y cómo construir uno?
Screen Scraping
Por lo general, se refiere a analizar el HTML en el contenido web generado con programas diseñados para extraer patrones específicos de contenido.
El raspado de pantalla es el método de recopilar datos de visualización de pantalla de una aplicación y traducirlos para que otra aplicación pueda mostrarlos. Normalmente, esto se hace para capturar datos de una aplicación heredada con el fin de mostrarlos utilizando una interfaz de usuario más moderna.
A veces se confunde con el raspado de contenido, que es el uso de medios manuales o automáticos para extraer contenido de un sitio web sin la aprobación del propietario del sitio web. Muy a menudo, el raspado de pantalla se refiere a un cliente web que analiza las páginas HTML del sitio web de destino para extraer datos formateados.
Screen Scrapers
Un raspador de pantalla es un programa de computadora que utiliza una técnica de raspado de pantalla para traducir entre programas de aplicación heredados (escritos para comunicarse con dispositivos de entrada / salida e interfaces de usuario ahora generalmente obsoletos) y nuevas interfaces de usuario para que la lógica y los datos asociados con los programas heredados puede seguir utilizándose.

En los primeros días de las PC, los raspadores de pantalla emulaban un terminal (por ejemplo, IBM 3270) y pretendían ser un usuario para extraer y actualizar información de forma interactiva en el mainframe. En tiempos más recientes, el concepto se aplica a cualquier aplicación que proporcione una interfaz a través de páginas web.
¿Para qué se usa Screen Scrapers?
Los raspadores de pantalla se han aplicado en una amplia cantidad de campos para una variedad de casos de uso. Algunos usos potenciales incluyen:
aplicaciones bancarias y transacciones financieras
guardar datos significativos para su uso posterior
para realizar acciones que un usuario haría en un sitio web
para traducir datos de una aplicación heredada a una aplicación moderna
para agregadores de datos, como sitios web de comparación de precios
para rastrear perfiles de usuario para ver actividades en línea; y
para obtener datos
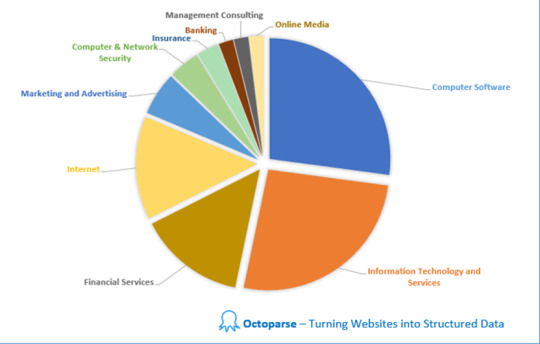
Top 10 industrias que utilizan screen scraping
Uno de los casos de uso más importantes ha sido el de la banca. Es posible que los prestamistas deseen utilizar el raspado de pantalla para recopilar los datos financieros de un cliente. Las aplicaciones basadas en finanzas pueden usar el rastreo de pantalla para acceder a múltiples cuentas de un usuario, agregando toda la información en un solo lugar. Sin embargo, los usuarios deberían confiar explícitamente en la aplicación, ya que confían en esa organización con sus cuentas, datos de clientes y contraseñas. El raspado de pantalla también se puede utilizar para aplicaciones de proveedores de hipotecas.
Es posible que una organización también desee utilizar el raspado de pantalla para traducir entre programas de aplicaciones heredados y nuevas interfaces de usuario (UI) para que la lógica y los datos asociados con los programas heredados puedan seguir utilizándose. Esta opción rara vez se usa y solo se ve como una opción cuando otros métodos no son prácticos.
Raspado de datos sin codificación

Si deseas probar la extracción, Octoparse te permite trabajar con datos dinámicos no estructurados con solo hacer clic en puntos de datos individuales y generará automáticamente un código eficiente para extraer datos. No se requiere codificación en este proceso. Además, te permite exportar datos a formatos de tu elección como Excel, JSON, CSV, TXT, HTML, incluso directamente a tu base de datos a través de API.
0 notes
Text
Un Marco Para Informes de Análisis de Datos
Cuando se resume un proyecto, es inevitable formar un informe de análisis de datos relativamente completo.
El informe también requiere múltiples situaciones. De acuerdo con la aplicación, se puede dividir en muchos tipos: algunos necesitan informar al correo electrónico, otros necesitan dar una explicación al equipo del proyecto y otros deben mostrarse e informarse directamente. Según el tipo de proyecto, también se puede dividir en varios tipos: evaluación del efecto del lanzamiento de un nuevo proyecto, resultados de la prueba AB, resumen de datos diarios, análisis de datos de actividad, etc.
Ya sea el texto o la diapositiva, las ideas centrales del informe de análisis de datos son todas iguales.
Tabla de Contenido
1. Debes tener una "historia"
2. Un marco para los informes de análisis de datos
3. Conclusión

1. Debes tener una "historia"
Mi propia idea es que los gerentes de producto deben aprender más conocimientos en campos relacionados, como aprender algunas especificaciones básicas de diseño, principios de interacción, conocimiento de marketing, conocimiento de psicología, conocimiento de algoritmos, etc. Además de una ayuda obvia para el trabajo, también puede ayudarlo a expandir su pensamiento. De hecho, para hacer un buen informe, debe aprender de agencias consultoras o instituciones de inversión.
El núcleo de un informe no contiene mucho contenido para que la audiencia o los lectores dediquen tiempo a comprenderlo, el núcleo es contar una historia simple. Antes de que las instituciones de consultoría e inversión hagan plan de negocios, se tomarán un tiempo para aclarar el storyline. De hecho, todo tipo de informes deberían ser así, primero aclara la historia que quieres contar.
2. Un marco para los informes de análisis de datos
Aquí hay un marco de informe que personalmente me gusta, que puede necesitar ser ajustado para diferentes escenarios de informes (como eliminar algunos pasos o agregar algunos detalles):
Antecedentes del proyecto: describir brevemente los antecedentes relevantes del proyecto, por qué se realiza y cuál es su propósito.
Avance del proyecto: resumir el avance general del proyecto y la situación actual.
Explicación del término: ¿Cuál es la definición de indicadores clave y por qué?
Método de adquisición de datos: cómo muestrear y cómo adquirir ¿Cuáles son los problemas?
Descripción general de los datos: tendencias de indicadores importantes, cambios y explicación de la causa del importante punto de inflexión.
División de datos: dividir diferentes dimensiones según la necesidad para complementar los detalles.
Resumen: resumir las principales conclusiones del análisis de datos anterior como una descripción general.
Mejora de seguimiento: analizar los problemas existentes y dar soluciones para mejorar y prevenir.
Agradecimiento & Adjunto: datos detallados.
Antecedentes del proyecto & Avance del proyecto
Antecedentes del proyecto, es necesario describir brevemente los antecedentes relevantes del proyecto, por qué se realiza y cuál es el propósito. Avance del proyecto,hay que resumir el avance general del proyecto y la situación actual. De hecho, no hay mucho que decir sobre estos dos puntos. Si el objetivo es un miembro del proyecto, puedes escribirlo de forma más sencilla. Si el objetivo es alguien que no comprende el proyecto, debes escribir más, pero aún así intentar uses las palabras más simples para explicar a los demás.
Explicación del término & Método de adquisición de datos
Explicación del término:¿Cuál es la definición de indicadores clave y por qué? Muchas personas pasan por alto este punto. De verdad, muchos malentendidos de los datos se deben a la falta de una definición unificada de los indicadores. Por ejemplo, la tasa de clics puede ser el número de clics / el número de vistas, o el número de clics de personas / el número de visitas de personas. El número de personas se puede deduplicar según las visitas o se pueden deduplicar según el día. Si no hay una explicación clara, diferentes personas entienden de manera diferente y la legibilidad de todos los datos se reducirá en gran medida.
Método de adquisición de datos:cómo muestrear y cómo adquirir ¿Cuáles son los problemas? Los datos originales a menudo tienen algunas deficiencias. Los datos deben limpiarse para eliminar el ruido y también se requieren algunas suposiciones para completar los datos. El método de limpieza y finalización de datos debe ser explicado y reconocido por el objeto de informe, de modo que la otra parte tenga una estimación del nivel de confianza.
Descripción general de los datos & División de datos
La descripción general de los datos debe tener tendencias de indicadores importantes, cambios y explicación de la causa del importante punto de inflexión.
La división de datos debe dividir diferentes dimensiones según la necesidad para complementar los detalles.
Este es básicamente el método de análisis de datos mencionado anteriormente. Si necesitas que la otra parte conozca la comparación o la tendencia, uses el gráfico, si necesitas que la otra parte conozca los datos específicos, uses la tabla. La tabla debe identificar claramente los números que deben enfatizarse. Los puntos a tener en cuenta son: los indicadores básicos deben ser pocos pero críticos, y los indicadores divididos deben ser significativos y detallados. Al mismo tiempo, si se trata de una diapositiva, basta con explicar una conclusión o explicar claramente una tendencia en cada página. La conclusión clave debe expresarse claramente en una oración.
Resumen & Mejora de seguimiento
Resumen,debes resumir las principales conclusiones del análisis de datos anterior como una descripción general.
Mejora de seguimiento,necesitas realizar una explicación direccional para iteraciones posteriores y medidas de mejora en base a las conclusiones y problemas del análisis de datos. Esta parte suele ser el propósito fundamental del análisis.
Agradecimiento & Adjunto
Los agradecimientos son el agradecimiento al equipo del proyecto y a los departamentos de asistencia relacionados, para el equipo del proyecto y los departamentos de asistencia relevantes, también esperan que su trabajo o cooperación activa pueda ver resultados de datos efectivos. En la cooperación posterior, será más armonioso.
El archivo adjunto es un suplemento de elección y no es necesario reflejarlo en el informe de datos, pero sigue siendo información valiosa. Para la diapositiva, esta parte también se puede colocar después del agradecimiento. Si tu colega tiene alguna pregunta, puede pasar a la última explicación en cualquier momento.
3. Conclusión
Un producto, si no puedes medirlo, no puedes entenderlo y, naturalmente, no puedes mejorarlo. Se trata de datos.El significado del informe de datos es similar: una vez finalizado el proyecto, se requiere un informe completo, por lo que es de gran importancia tanto para el informe como para el equipo.
0 notes
Text
4 Formas de Extraer Datos del Sitio Web a Excel
Probablemente sepas cómo usar funciones básicas en Excel. Es fácil hacer cosas como ordenar, aplicar filtros, hacer gráficos y delinear datos con Excel. Incluso puedes realizar análisis de datos avanzados utilizando modelos de pivote y regresión. Se convierte en un trabajo fácil cuando los datos en vivo se convierten en un formato estructurado.
El problema es, ¿Cómo podemos extraer datos y ponerlos en Excel? Esto puede ser tedioso si lo haces manualmente escribiendo, buscando, copiando y pegando repetidamente. En cambio, puedes lograr la extracciñon automática de datos de la web para sobresalir.
En este artículo, te presentaré varias formas de ahorrar tiempo y energía, scrapear datos web en Excel.
Descargo de responsabilidad: Hay muchas otras formas de scrapear datos desde una web utilizando lenguajes de programación como PHP, Python, Perl, Ruby, etc. Aquí solo hablamos sobre cómo obtener datos de una web en Excel para no codificadores.
Tabla de contenidos
Obtener datos web utilizando Excel Web Queries
Obtener datos de la web usando Excel VBA
Utilizar herramientas de web scraping automatizadas
Subcontratar tu proyecto de web scraping
Obtener datos web utilizando Excel Web Queries
Excepto para transformar manualmente los datos de una página web copiando y pegando, Excel Web Queries se utiliza para recuperar rápidamente datos de páginas web estándar en hojas de cálculo de Excel. Puede detectar automáticamente tablas incrustadas en el HTML de la página web. Excel Web queries también se pueden usar en situaciones en las que es difícil crear o mantener una conexión estándar ODBC (Open Database Connectivity). Puede scrapear directamente una tabla desde cualquier sitio web utilizando Excel Web Queries.
El proceso se reduce a varios pasos simples (consulta este artículo):
1. Ir a Datos> Obtener datos externos> Dar la web
2. Aparecerá una ventana del navegador llamada "New Web Query"
3. Escribir la dirección web en la barra de direcciones.
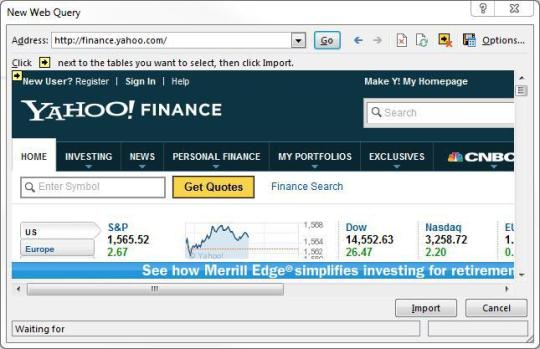
4. Se cargará y mostrará iconos amarillos contra datos/tablas en la página.
5. Seleccionar uno apropiado
6. Presionar el botón Importar.
Ahora has scrapeado los datos de la web en una hoja de cálculo de Excel, perfecta permutación en filas y columnas como desees.

Obtener datos de la web usando Excel VBA
La mayoría de nosotros usaría fórmulas en Excel (p. Ej. = Avg (...), = sum (...), = if (...), etc.) mucho, pero menos familiarizado con el lenguaje incorporado: Visual BasicVisual Basic for Application a.k.a VBA. Se conoce comúnmente como "Macros" y dichos archivos de Excel se guardan como a **.xlsm.
Antes de usarlo,
Primero debes habilitar la pestaña la pestaña Desarrollador en la barra (hacer clic con el botón derecho en Archivo -> Personalizar barra -> verificar la pestaña Desarrollador),
Luego configura tu diseño. En esta interfaz de desarrollador, puedes escribir código VBA adjunto a varios eventos. Haz clic AQUÍ (https://msdn.microsoft.com/en-us/library/office/ee814737(v=office.14).aspx) para comenzar a utilizar VBA en Excel 2010.

Usar Excel VBA va a ser un poco técnico, esto no es muy amigable para quienes no son programadores entre nosotros. VBA funciona ejecutando macros, procedimientos paso a paso escritos en Excel Visual Basic. Para scrapear datos de sitios web a Excel usando VBA, necesitamos construir u obtener un script VBA para enviar alguna solicitud a las páginas web y obtener datos devueltos de estas páginas web. Es común usar VBA con XMLHTTP y expresiones regulares para analizar las páginas web. Para Windows, puedes usar VBA con WinHTTP o InternetExplorer para scrapear datos de sitios web a Excel.
Con un poco de paciencia y práctica, te convendría aprender algo de código Excel VBA y algo de conocimiento HTML para que tu Web scraping en Excel sea mucho más fácil y eficiente para automatizar el trabajo repetitivo. Hay una gran cantidad de material y foros para que aprendas a escribir código VBA.
Utilizar herramientas de web scraping automatizadas
Para alguien que está buscando una herramienta rápida para scrapear datos de las páginas a Excel y no quiere configurar el código VBA tú mismo, te recomiendo encarecidamente herramientas de web scraping automatizadas como Octoparse para scrapear datos para tu hoja de cálculo de Excel directamente o mediante API.
No hay necesidad de aprender a programar. Puedes elegir uno de esos programas gratuitos de web scraping de la lista y comenzar a extraer datos de sitios web de inmediato y exportarlos a Excel. Las diferentes herramientas de web scraping tienen sus ventajas y desventajas, y puedes elegir la perfecta para tus necesidades.
Echa un vistazo a esta publicación y prueba estas TOP 30 herramientas gratuitas de web scraping.
Subcontratar tu proyecto de web scraping
Si el tiempo es tu activo más valioso y deseas enfocarte en tus negocios principales, la mejor opción sería subcontratar un trabajo tan complicado de scrapear de contenido web a un equipo competente de scrapear de contenido web que tenga experiencia y conocimientos.
Es difícil scapear datos de sitios web debido al hecho de que la presencia de bots anti-scrape restringirá la práctica del web scraping. Un equipo competente de web scraping te ayudaría a obtener datos de los sitios web de manera adecuada y a entregarte datos estructurados en una hoja de Excel o en cualquier formato que necesites.
Octoparse proporciona todo lo que necesitas para la extracción automática de datos. Puedes scrapear los datos web rápidamente sin codificar y convierte las páginas web en datos estructurados con clics, o simplemente relájate y déjanos el trabajo a nosotros, ofrecemos servico de datos que nuestro equipo de datos se reunirá contigo para analizar el rastreo web y los requisitos de procesamiento de datos.
0 notes
Text
Las 9 mejores herramientas de visualización de datos para no desarrolladores
Estamos inundados de datos y nos resulta difícil presentar el significado detrás de ellos. Aquí es donde entran en escena las herramientas de visualización de datos. Por lo tanto, te proporciono 9 herramientas útiles de visualización de datos para que comprendas tus datos. ¡Espero que este artículo te ayude bien!
Tabla de Contenidos
Datawrapper
Tableau
Chart.js
Raw
Infogram
Timeline JS
Plotly
DataHero
Visualize Free
Datawrapper
Datawrapper es una herramienta de visualización de datos en línea para crear gráficos interactivos. Una vez que cargues los datos del archivo CSV o los pegues directamente en el campo, Datawrapper generará una barra, línea o cualquier otra visualización relacionada. Muchos reporteros y organizaciones de noticias usan Datawrapper para integrar gráficos en vivo en sus artículos. Es muy fácil de usar y produce gráficos efectivos.
Pros
Diseñado específicamente para la visualización de datos en salas de redacción
El plan gratuito es una buena opción para sitios más pequeños
La herramienta incluye un comprobador de daltonismo incorporado
Contras
Fuentes de datos limitadas
Los planes pagados son caros
Tableau
Tableau Public es quizás la herramienta de visualización más popular que admite una amplia variedad de cuadros, gráficos, mapas y otros gráficos. Es una herramienta completamente gratuita y los gráficos que crea con ella se pueden incrustar fácilmente en cualquier página web. Tienen una bonita galería que muestra visualizaciones creadas a través de Tableau.
Aunque ofrece cuadros y gráficos que son mucho mejores que otras herramientas similares, no me "encanta" usar su versión gratuita debido al gran pie de página con el que viene. Si no te disgusta tanto como a mí, definitivamente deberías intentarlo. O si puedes pagarlo, puedes optar por una versión paga.
Pros
Cientos de opciones de importación de datos
Capacidad de mapeo
Versión pública gratuita disponible
Muchos videos tutoriales para guiarlo a través de cómo usar Tableau
Contras
Las versiones que no son gratuitas son caras ($ 70 / mes / usuario para el software Tableau Creator)
La versión pública no te permite mantener privados los análisis de datos
Chart.js
Chart.js se adapta perfectamente a proyectos más pequeños. Aunque cuenta con solo seis tipos de gráficos, la biblioteca de código abierto Chart.js es la herramienta de visualización de datos perfecta para pasatiempos y pequeños proyectos. Utilizando elementos de lienzo HTML 5 para representar gráficos, Chart.js crea diseños planos y receptivos y se está convirtiendo rápidamente en una de las bibliotecas de gráficos de código abierto más populares.
Pros
Gratis y de código abierto
Salida receptiva y compatible con varios navegadores
Contras
Tipos de gráficos muy limitados en comparación con otras herramientas
Soporte limitado fuera de la documentación oficial
RAWGraphs
Raw se define a sí mismo como "el link perdido entre las hojas de cálculo y los gráficos vectoriales". Está construido sobre D3.js y está extremadamente bien diseñado. Tiene una interfaz tan intuitiva que sentirá que la has usado antes. Es de código abierto y no requiere ningún registro.
Tiene una biblioteca de 21 tipos de gráficos para elegir y todo el procesamiento se realiza en el navegador. Entonces tus datos están seguros. RAW es altamente personalizable y extensible, e incluso puede aceptar nuevos diseños personalizados.
Pros
Gratis ycódigo abierto
Intuitivo y eficiente
Tiene documento de ayuda
Contras
No tiene muchas opciones ajustables
Infogram
Infogram te permite crear gráficos e infografías en línea. Tiene una versión gratuita restringida y dos opciones de pago que incluyen funciones como más de 200 mapas, uso compartido privado y biblioteca de iconos, etc.
Viene con una interfaz fácil de usar y sus gráficos básicos están bien diseñados. Una característica que no me gustó es el enorme logotipo que aparece cuando intentas insertar gráficos interactivos en tu página web (en la versión gratuita). Será mejor si pueden hacerlo como el pequeño texto que usa Datawrapper.
Pros
Precios escalonados, incluido un plan gratuito con funciones básicas
Incluye más de 35 tipos de gráficos y más de 550 tipos de mapas
Editor de arrastrar y soltar
API para importar fuentes de datos adicionales
Contras
Significativamente menos fuentes de datos integradas que otras aplicaciones
Timeline JS
Como sugiere el nombre, Timeline JS te ayuda a crear hermosas líneas de tiempo sin escribir ningún código. Es una herramienta gratuita de código abierto que utilizan algunos de los sitios web más populares como Time y Radiolab.
Es un proceso de cuatro pasos muy fácil de seguir para crear su línea de tiempo que se explica aquí. ¿Mejor parte? Puede extraer medios de una variedad de fuentes y tiene soporte integrado para Twitter, Flickr, Google Maps, YouTube, Vimeo, Vine, Dailymotion, Wikipedia, SoundCloud y otros sitios similares.
Pros
Hacer una historia ilustrativa con TimelineJS no es complejo y, a veces, podría darte un buen resultado
Contras
No es flexible y no da mucho espacio para ser creativo
También, es difícil adaptarlo bien a su sitio web
Plotly
Plotly es una herramienta de análisis y gráficos de datos basada en la web. Admite una buena colección de tipos de gráficos con funciones integradas para compartir en redes sociales. Los cuadros y tipos de gráficos disponibles tienen un aspecto profesional. Crear un gráfico es solo una cuestión de cargar su información y personalizar el diseño, los ejes, las notas y la leyenda. Si estás buscando comenzar, puedes encontrar algo de inspiración aquí.
Pros
Figuras creadas hermosas, interactivas y exportables con solo unas pocas líneas de código
Mucho más interactivo y visualmente flexible que Matplotlib o Seaborn
Contras
Configuración inicial confusa para usar Plotly sin una cuenta en línea
Mucho código para escribir
DataHero
DataHero te permite reunir datos de servicios en la nube y crear gráficos y paneles. No se requieren habilidades técnicas, por lo que esta es una gran herramienta para que la use todo tu equipo.
Pros
Capacidad de conectarse a otras plataformas y tener esos datos actualizados diariamente
Interfaz de usuario sencilla, muchas opciones e integraciones con otras aplicaciones
Funcionalidad de exportación y rapidez
Contras
La tarea de mostrar datos duros de una manera elegante y sencilla no es fácil de entender para todos
Necesitan mejores consejos sobre cómo generar tablas por encima del promedio
Visualize Free
Visualize Free es una herramienta alojada que te permite utilizar conjuntos de datos disponibles públicamente, o cargar los tuyos propios, y crear visualizaciones interactivas para ilustrar los datos. Las visualizaciones van mucho más allá de los gráficos simples, y el servicio es completamente gratuito y, si bien el trabajo de desarrollo requiere Flash, la salida se puede realizar a través de HTML5.
Pros
Los conjuntos de datos pueden ser archivos de Excel (XLS o XLSX) o texto (CSV o TEXT)
Crear cuadros de mando exploratorios y analíticos
Descubrir tendencias y asociaciones significativas
Contras
No debe utilizarse con fines comerciales
Sin modelos de datos ni mashups de datos
Estas son las 9 mejores herramientas de visualización de datos para no desarrolladores que recomendé.
Al final, quiero agregar que use estas herramientas en cooperación con Octoparse, una herramienta dedicada de raspado web que te ayudará a comprender los datos de manera más rápida, fácil y clara.
0 notes
Text
Web Scraping | Utilizar el servidor proxy para Web Scraping
Tabla de Contenidos
¿Por Qué Utilizar El Servidor Proxy Para El Web Scraping?
La Fiabilidad Del Proxy
Web Scraping En La Nube
Web Scrapers Populares Para Evitar El Bloqueo De IP
Octoparse
Import.io
Webhose.io
Screen Scraper
¿Por Qué Utilizar El Servidor Proxy Para El Web Scraping?
Web Scraper o spider se vuelve cada vez más popular en la ciencia de datos. Esta técnica automática puede ayudarnos a recuperar una gran cantidad de datos personalizados de la Web o de la base de datos. Sin embargo, el problema principal es que el sitio web puede rastrear fácilmente la solicitud de demasiadas páginas en un período de tiempo demasiado corto mediante una única dirección IP, por lo que el sitio web de destino puede bloquearlo. Para limitar las posibilidades de ser bloqueado, debemos intentar evitar raspar un sitio web con una única dirección IP. Y normalmente, utilizamos servidores proxy que incluyen direcciones IP de proxy discretas siempre que las solicitudes se enrutan a través del servidor de rastreo.
La Fiabilidad Del Proxy
Preocupados por el servidor proxy, la fiabilidad del proxy siempre debe ser lo primero en nuestra mente. En realidad, hay alrededor de 1000 lugares para comprar proxies y algunos proxies poco confiables irían demasiado rápido, lo que podría causar que se bloqueen. También hay otros enfoques que pueden estar más relacionados con la subcontratación de la rotación de IP (piensa en el proxy como un servicio), pero estos servicios generalmente tienen un costo más alto. Dado que existe un costo de comprar el proxy y el costo de volver a implementar el proxy cada vez que compra uno nuevo. Con mucha frecuencia, la confiabilidad tiene un costo y, a menudo, encontrará que "gratis" será muy poco confiable, "barato" será algo poco confiable y "más costoso" generalmente tendrá un costo adicional. Por lo tanto, recientemente se ha propuesto el concepto de extracción de datos basada en la nube.
Web Scraping En La Nube
Web Scraping basado en la nube es un verdadero servicio basado en la nube, puede ejecutarse desde cualquier sistema operativo y cualquier navegador. No tenemos que alojar nada nosotros mismos y todo se hace en la nube. Además, todas las visitas a la página del sitio web, la formación de datos y la transformación se pueden manejar en el servidor de otra persona. Los requisitos de proxy web pueden ser gestionados por nosotros mismos.
En el lado de la nube, estas máquinas son independientes, se puede acceder a ellas y ejecutarlas sin necesidad de instalarlas desde cualquier PC con acceso a Internet en todo el mundo. Este servicio administrará nuestros datos con un increíble hardware de back-end, más específicamente, podemos utilizar su función de proxy anónimo que podría rotar toneladas de direcciones IP para evitar ser bloqueadas por el sitio web de destino.
Web Scrapers Populares Para Evitar El Bloqueo De IP
En realidad, podemos adoptar un enfoque más conciso y eficiente mediante el uso de cierta herramienta Data Scraper con servicios basados en la nube, como Octoparse, Import.io. Estas herramientas pueden programar y ejecutar tu tarea en cualquier momento en el lado de la nube con toneladas de PC ejecutándose en el Mismo tiempo. Además, estas herramientas de raspador también pueden proporcionarnos una forma rápida de configurar manualmente estos servidores proxy según lo necesites. Aquí hay un tutorial que presenta cómo configurar proxies en Octoparse.
Algunas herramientas de raspador populares en el mercado incluyen Octoparse, Import.io, Webhose.io, Screen Scraper.
1.Octoparse
Octoparse es una herramienta de rastreo de datos poderosa y gratuita que puede rastrear casi todos los sitios web. Su extracción de datos basada en la nube puede proporcionar servidores proxy de dirección IP rotativos ricos para web scraping, lo que ha limitado las posibilidades de ser bloqueado y ahorrado mucho tiempo para la configuración manual. Han proporcionado instrucciones precisas y pautas claras para seguir los pasos de raspado. Básicamente, para esta herramienta, no es necesario tener habilidades de codificación. De todos modos, si deseas profundizar y fortalecer tu rastreo y raspado, ha ofrecido una API pública si lo necesitas. Además, su soporte de respaldo es eficiente y está disponible.
2.Import.io
Import.io también es un raspador de datos de escritorio fácil de usar. Tiene una interfaz de usuario sucinta y eficaz y una navegación sencilla. Para esta herramienta, también requiere menos habilidades de codificación. Import.io también posee muchas características poderosas, como el servicio basado en la nube que puede ayudarnos a cuidar mejor de nuestra tarea programada y mejorar nuestra capacidad de minería para su dirección IP rotativa. Sin embargo, Improt.io tiene dificultades para navegar a través de combinaciones de javascript / POST.
3.Webhose.io
Webhose.io es una herramienta de rastreo de datos basada en navegador que utiliza varias técnicas de rastreo de datos para rastrear cantidades de datos de múltiples canales. Si bien puede que no se comporte tan bien como las herramientas introducidas anteriormente sobre su servicio en la nube, lo que significa que el proceso de raspado relacionado con la rotación de IP o la configuración del proxy puede ser algo complejo. Han proporcionado un plan de servicio gratuito y de pago según lo necesites.
4.Screen Scraper
Screen Scraper es bastante ordenado y puede lidiar con ciertas tareas difíciles, incluida la localización precisa, la navegación y la extracción de datos, sin embargo, requiere que tengas habilidades básicas de programación / tokenización si deseas que funcione al máximo. Implica que debes configurar los ajustes y establecer los parámetros manualmente la mayor parte del tiempo, las ventajas de que puede personalizar tu proceso de minería distintivo, mientras que las desventajas son que requiere un poco de tiempo y es complejo. Además, es un poco caro.
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Text
Las 20 Mejores Herramientas de Web Scraping para 2021
Herramienta Web Scraping (también conocido como extracción de datos de la web, web crawling) se ha aplicado ampliamente en muchos campos hoy en día. Antes de que una herramienta de scraping llegue al público, es la palabra mágica para personas normales sin habilidades de programación. Su alto umbral sigue bloqueando a las personas fuera de Big Data. Una herramienta de web scraping es la tecnología de captura automatizada y cierra la brecha entre Big Data y cada persona.
Enumeré 20 MEJORES web scrapers incluyen sus caracterísiticas y público objetivo para que tomes como referencia. ¡Bienvenido a aprovecharlo al máximo!
Tabla de Contenidos
¿Cuáles son los beneficios de usar técnicas de web scraping?
20 MEJORES web scrapers
Octoparse
Cyotek WebCopy
HTTrack
Getleft
Scraper
OutWit Hub
ParseHub
Visual Scraper
Scrapinghub
Dexi.io
Webhose.io
Import. io
80legs
Spinn3r
Content Grabber
Helium Scraper
UiPath
Scrape.it
WebHarvy
ProWebScraper
Conclusión
¿Cuáles son los beneficios de usar técnicas de web scraping?
Liberar tus manos de hacer trabajos repetitivos de copiar y pegar.
Colocar los datos extraídos en un formato bien estructurado que incluye, entre otros, Excel, HTML y CSV.
Ahorrarte tiempo y dinero al obtener un analista de datos profesional.
Es la cura para comercializador, vendedores, periodistas, YouTubers, investigadores y muchos otros que carecen de habilidades técnicas.
1. Octoparse
Octoparse es un web scraper para extraer casi todo tipo de datos que necesitas en los sitios web. Puedes usar Octoparse para extraer datos de la web con sus amplias funcionalidades y capacidades. Tiene dos tipos de modo de operación: Modo Plantilla de tarea y Modo Avanzado, para que los que no son programadores puedan aprender rápidamente. La interfaz fácil de apuntar y hacer clic puede guiarte a través de todo el proceso de extracción. Como resultado, puedes extraer fácilmente el contenido del sitio web y guardarlo en formatos estructurados como EXCEL, TXT, HTML o sus bases de datos en un corto período de tiempo.
Además, proporciona una Programada Cloud Extracción que tle permite extraer datos dinámicos en tiempo real y mantener un registro de seguimiento de las actualizaciones del sitio web.
También puedes extraer la web complejos con estructuras difíciles mediante el uso de su configuración incorporada de Regex y XPath para localizar elementos con precisión. Ya no tienes que preocuparte por el bloqueo de IP. Octoparse ofrece Servidores Proxy IP que automatizarán las IP y se irán sin ser detectados por sitios web agresivos.
Octoparse debería poder satisfacer las necesidades de rastreo de los usuarios, tanto básicas como avanzadas, sin ninguna habilidad de codificación.
2. Cyotek WebCopy
WebCopy es un web crawler gratuito que te permite copiar sitios parciales o completos localmente web en tu disco duro para referencia sin conexión.
Puedes cambiar su configuración para decirle al bot cómo deseas capturar. Además de eso, también puedes configurar alias de dominio, cadenas de agente de usuario, documentos predeterminados y más.
Sin embargo, WebCopy no incluye un DOM virtual ni ninguna forma de análisis de JavaScript. Si un sitio web hace un uso intensivo de JavaScript para operar, es más probable que WebCopy no pueda hacer una copia verdadera. Es probable que no maneje correctamente los diseños dinámicos del sitio web debido al uso intensivo de JavaScript
3. HTTrack
Como programa gratuito de rastreo de sitios web, HTTrack proporciona funciones muy adecuadas para descargar un sitio web completo a su PC. Tiene versiones disponibles para Windows, Linux, Sun Solaris y otros sistemas Unix, que cubren a la mayoría de los usuarios. Es interesante que HTTrack pueda reflejar un sitio, o más de un sitio juntos (con enlaces compartidos). Puedes decidir la cantidad de conexiones que se abrirán simultáneamente mientras descarga las páginas web en "establecer opciones". Puedes obtener las fotos, los archivos, el código HTML de su sitio web duplicado y reanudar las descargas interrumpidas.
Además, el soporte de proxy está disponible dentro de HTTrack para maximizar la velocidad.
HTTrack funciona como un programa de línea de comandos, o para uso privado (captura) o profesional (espejo web en línea). Dicho esto, HTTrack debería ser preferido por personas con habilidades avanzadas de programación.
4. Getleft
Getleft es un web spider gratuito y fácil de usar. Te permite descargar un sitio web completo o cualquier página web individual. Después de iniciar Getleft, puedes ingresar una URL y elegir los archivos que deseas descargar antes de que comience. Mientras avanza, cambia todos los enlaces para la navegación local. Además, ofrece soporte multilingüe. ¡Ahora Getleft admite 14 idiomas! Sin embargo, solo proporciona compatibilidad limitada con Ftp, descargará los archivos pero no de forma recursiva.
En general, Getleft debería poder satisfacer las necesidades básicas de scraping de los usuarios sin requerir habilidades más sofisticadas.
5. Scraper
Scraper es una extensión de Chrome con funciones de extracción de datos limitadas, pero es útil para realizar investigaciones en línea. También permite exportar los datos a las hojas de cálculo de Google. Puedes copiar fácilmente los datos al portapapeles o almacenarlos en las hojas de cálculo con OAuth. Scraper puede generar XPaths automáticamente para definir URL para scraping.
No ofrece servicios de scraping todo incluido, pero puede satisfacer las necesidades de extracción de datos de la mayoría de las personas.
6. OutWit Hub
OutWit Hub es un complemento de Firefox con docenas de funciones de extracción de datos para simplificar sus búsquedas en la web. Esta herramienta de web scraping puede navegar por las páginas y almacenar la información extraída en un formato adecuado.
OutWit Hub ofrece una interfaz única para extraer pequeñas o grandes cantidades de datos por necesidad. OutWit Hub te permite eliminar cualquier página web del navegador. Incluso puedes crear agentes automáticos para extraer datos.
Es una de las herramientas de web scraping más simples, de uso gratuito y te ofrece la comodidad de extraer datos web sin escribir código.
7. ParseHub
Parsehub es un excelente web scraper que admite la recopilación de datos de la web que utilizan tecnología AJAX, JavaScript, cookies, etc. Sutecnología de aprendizaje automático puede leer, analizar y luego transformar documentos web en datos relevantes.
La aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux. Incluso puedes usar la aplicación web que está incorporado en el navegador.
Como programa gratuito, no puedes configurar más de cinco proyectos públicos en Parsehub. Los planes de suscripción pagados te permiten crear al menos 20 proyectos privados para scrape sitios web.
ParseHub está dirigido a prácticamente cualquier persona que desee jugar con los datos. Puede ser cualquier persona, desde analistas y científicos de datos hasta periodistas.
8. Visual Scraper
Visual Scraper es otro gran web scraper gratuito y sin codificación con una interfaz simple de apuntar y hacer clic. Puedes obtener datos en tiempo real de varias páginas web y exportar los datos extraídos como archivos CSV, XML, JSON o SQL. Además de SaaS, VisualScraper ofrece un servicio de web scraping como servicios de entrega de datos y creación de servicios de extracción de software.
Visual Scraper permite a los usuarios programar un proyecto para que se ejecute a una hora específica o repetir la secuencia cada minuto, día, semana, mes o año. Los usuarios pueden usarlo para extraer noticias, foros con frecuencia.
9. Scrapinghub
Scrapinghub es una Herramienta de Extracción de Datos basada Cloud que ayuda a miles de desarrolladores a obtener datos valiosos. Su herramienta de scraping visual de código abierto permite a los usuarios raspar sitios web sin ningún conocimiento de programación.
Scrapinghub utiliza Crawlera, un rotador de proxy inteligente que admite eludir las contramedidas de robots para rastrear fácilmente sitios enormes o protegidos por robot. Permite a los usuarios rastrear desde múltiples direcciones IP y ubicaciones sin la molestia de la administración de proxy a través de una simple API HTTP.
Scrapinghub convierte toda la página web en contenido organizado. Su equipo de expertos está disponible para obtener ayuda en caso de que su generador de rastreo no pueda cumplir con sus requisitos
10. Dexi.io
Como web scraping basado en navegador, Dexi.io te permite scrapear datos basados en su navegador desde cualquier sitio web y proporcionar tres tipos de robots para que puedas crear una tarea de scraping: extractor, rastreador y tuberías.
El software gratuito proporciona servidores proxy web anónimos para tu web scraping y tus datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de que se archiven los datos, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios pagos para satisfacer tus necesidades de obtener datos en tiempo real.
11. Webhose.io
Webhose.io permite a los usuarios obtener recursos en línea en un formato ordenado de todo el mundo y obtener datos en tiempo real de ellos. Este web crawler te permite rastrear datos y extraer palabras clave en muchos idiomas diferentes utilizando múltiples filtros que cubren una amplia gama de fuentes
Y puedes guardar los datos raspados en formatos XML, JSON y RSS. Y los usuarios pueden acceder a los datos del historial desde su Archivo. Además, webhose.io admite como máximo 80 idiomas con sus resultados de crawling de datos. Y los usuarios pueden indexar y buscar fácilmente los datos estructurados rastreados por Webhose.io.
En general, Webhose.io podría satisfacer los requisitos elementales de web scraping de los usuarios.
12. Import. io
Los usuarios pueden formar sus propios conjuntos de datos simplemente importando los datos de una página web en particular y exportando los datos a CSV.
Puede scrapear fácilmente miles de páginas web en minutos sin escribir una sola línea de código y crear más de 1000 API en función de sus requisitos. Las API públicas han proporcionado capacidades potentes y flexibles, controla mediante programación Import.io para acceder automáticamente a los datos, Import.io ha facilitado el rastreo integrando datos web en su propia aplicación o sitio web con solo unos pocos clics.
Para satisfacer mejor los requisitos de rastreo de los usuarios, también ofrece una aplicación gratuita para Windows, Mac OS X y Linux para construir extractores y rastreadores de datos, descargar datos y sincronizarlos con la cuenta en línea. Además, los usuarios pueden programar tareas de rastreo semanalmente, diariamente o por hora.
13. 80legs
80legs es una poderosa herramienta de web crawling que se puede configurar según los requisitos personalizados. Admite la obtención de grandes cantidades de datos junto con la opción de descargar los datos extraídos al instante. 80legs proporciona un rastreo web de alto rendimiento que funciona rápidamente y obtiene los datos requeridos en solo segundos.
80legs es utilizado por una amplia variedad de empresas. Cualquier empresa que necesite datos extraídos de la web puede usar 80legs para sus necesidades.
14. Spinn3r
Spinn3r te permite obtener datos completos de blogs, noticias y sitios de redes sociales y RSS y ATOM. Spinn3r se distribuye con un firehouse API que gestiona el 95% del trabajo de indexación. Ofrece protección avanzada contra spam, que elimina spam y los usos inapropiados del lenguaje, mejorando así la seguridad de los datos.
Spinn3r indexa contenido similar a Google y guarda los datos extraídos en archivos JSON. El web scraper escanea constantemente la web y encuentra actualizaciones de múltiples fuentes para obtener publicaciones en tiempo real. Su consola de administración te permite controlar los scraping y la búsqueda de texto completo permite realizar consultas complejas sobre datos sin procesar.
15. Content Grabber
Content Grabber es un software de web crawler dirigido a empresas. Te permite crear agentes de rastreo web independientes. Puedes extraer contenido de casi cualquier sitio web y guardarlo como datos estructurados en el formato que elijes, incluidos los informes de Excel, XML, CSV y la mayoría de las bases de datos.
Es más adecuado para personas con habilidades avanzadas de programación, ya que proporciona muchas potentes de edición de guiones y depuración de interfaz para aquellos que lo necesitan. Los usuarios pueden usar C # o VB.NET para depurar o escribir scripts para controlar la programación del proceso de scraping. Por ejemplo, Content Grabber puede integrarse con Visual Studio 2013 para la edición de secuencias de comandos, la depuración y la prueba de unidad más potentes para un rastreador personalizado avanzado y discreto basado en las necesidades particulares de los usuarios.
16. Helium Scraper
Helium Scraper es un software visual de datos web scraping que funciona bastante bien cuando la asociación entre elementos es pequeña. No es codificación, no es configuración. Y los usuarios pueden obtener acceso a plantillas en línea basadas en diversas necesidades de web scraping.
Básicamente, podría satisfacer las necesidades de web scraping de los usuarios dentro de un nivel elemental.
17. UiPath
UiPath es un software robótico de automatización de procesos para capturar automáticamente una web. Puede capturar automáticamente datos web y de escritorio de la mayoría de las aplicaciones de terceros. Si lo ejecutas en Windows, puedes instalar el software de automatización de proceso. Uipath puede extraer tablas y datos basados en patrones en múltiples páginas web.
Uipath proporciona herramientas incorporados para un mayor web scraping. Este método es muy efectivo cuando se trata de interfaces de usuario complejas. Screen Scraping Tool puede manejar elementos de texto individuales, grupos de texto y bloques de texto, como la extracción de datos en formato de tabla.
Además, no se necesita programación para crear agentes web inteligentes, pero el .NET hacker dentro de ti tendrá un control completo sobre los datos.
18. Scrape.it
Scrape.it es un software node.js de web scraping. Es una herramienta de extracción de datos web basada en la nube. Está diseñado para aquellos con habilidades avanzadas de programación, ya que ofrece paquetes públicos y privados para descubrir, reutilizar, actualizar y compartir código con millones de desarrolladores en todo el mundo. Su potente integración te ayudará a crear un rastreador personalizado según tus necesidades.
19. WebHarvy
WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. WebHarvy puede scrapear automáticamente Texto, Imágenes, URL y Correos Electrónicos de sitios web, y guardar el contenido raspado en varios formatos. También proporciona un programador incorporado y soporte proxy que permite el rastreo anónimo y evita que el software de web crawler sea bloqueado por servidores web, tiene la opción de acceder a sitios web objetivo a través de servidores proxy o VPN.
Los usuarios pueden guardar los datos extraídos de las páginas web en una variedad de formatos. La versión actual de WebHarvy Web Scraper te permite exportar los datos raspados como un archivo XML, CSV, JSON o TSV. Los usuarios también pueden exportar los datos raspados a una base de datos SQL.
20. ProWebScraper
ProWebScraper es un web scraper automatizado diseñado para la extracción de contenido web a escala empresarial que necesita una solución a escala empresarial. Los usuarios comerciales pueden crear fácilmente agentes de extracción en tan solo unos minutos, sin ninguna programación. La API REST de Prowebscraper puede extraer datos de páginas web para ofrecer respuestas instantáneas en segundos.
Los usuarios pueden crear fácilmente agentes de extracción simplemente apuntando y haciendo clic.
Conclusión
Este artículo primero dio una idea sobre Web Scraping en general. Luego enumeró 20 de las mejores herramientas de raspado web del mercado, considerando una serie de factores. La principal conclusión de este artículo, por lo tanto, es que al final, un usuario debe elegir las herramientas de raspado web que se adapten a sus necesidades.
Deseo que este artículo te ayude a tomar una decisión informada con respecto a la mejor herramienta de raspado web para tu negocio o trabajo.
0 notes
Text
Uso de expresiones regulares para coincidir con HTML
"Vas a saber lo poderosa que es la expresión regular una vez que la uses". - Un desarrollador suspira de corazón.

Fuente
¿Qué es una expresión regular (RegEx)?
“Una expresión regular (a veces llamada expresión racional) es una secuencia de caracteres que definen un patrón de búsqueda, principalmente para su uso en la coincidencia de patrones con cadenas, o coincidencia de cadenas, es decir, operaciones similares a" buscar y reemplazar ".
El concepto surgió en la década de 1950, cuando el matemático estadounidense Stephen Kleene formalizó la descripción de un lenguaje regular y se volvió de uso común con la utilidad de procesamiento de texto de Unix ed (un editor de línea para el sistema operativo Unix), un editor y grep. (una utilidad de línea de comandos para buscar conjuntos de datos de texto sin formato para líneas que coincidan con una expresión regular), un filtro (un programa de computadora o subrutina para procesar una secuencia, produciendo otra secuencia) ". Este es un extracto de Wikipedia que se utiliza para definir la expresión regular.
Sintaxis de expresiones regulares
Las expresiones regulares se pueden concatenar para formar nuevas expresiones regulares; si A y B son expresiones regulares, AB también es una expresión regular. En general, si una cadena p coincide con A y otra cadena q coincide con B, la cadena pq coincidirá con AB. Esto es válido a menos que A o B contengan operaciones de baja precedencia; condiciones de contorno entre A y B; o tener referencias de grupo numeradas. Por lo tanto, las expresiones complejas se pueden construir fácilmente a partir de expresiones primitivas más simples como las que se describen aquí.
Las expresiones regulares pueden contener tanto caracteres especiales como ordinarios. La mayoría de los caracteres ordinarios, como 'A', 'a' o '0', son las expresiones regulares más simples; simplemente se emparejan a sí mismos. Puedes concatenar caracteres ordinarios, por lo que último coincide con la cadena 'último'. (En el resto de esta sección, escribiremos RE en este estilo especial, generalmente sin comillas, y las cadenas deben coincidir 'entre comillas simples').
¿Qué puedes hacer con RegEx?
Las expresiones regulares se pueden utilizar para hacer coincidir etiquetas HTML y extraer los datos en documentos HTML.
A continuación, se muestran algunos casos de uso de RegEx:
Uso de RegEx para extraer correos electrónicos
Uso de RegEx para extraer números de teléfono
RegEx para reformatear los datos extraídos
HTML se compone virtualmente de cadenas, y lo que hace que la expresión regular sea tan poderosa es que una expresión regular puede coincidir con diferentes cadenas.
Es cierto que una expresión regular no es la primera opción para analizar HTML correctamente, porque existen algunos errores comunes, como etiquetas de cierre faltantes, algunas etiquetas no coincidentes, etc. al analizar HTML con expresión regular. Además, es más probable que los programadores usen otros analizadores HTML perfectamente buenos como PHPQuery, BeautifulSoup, html5lib-Python, etc. Pero si deseas hacer coincidir rápidamente etiquetas HTML y sabes un poco sobre la sintaxis de expresiones regulares, es fácil de aprender pero difícil para dominar, puedes utilizar esta herramienta increíblemente conveniente para identificar patrones en documentos HTML.
Se recomienda encarecidamente a todo programador o alguien que desee extraer datos web que aprenda expresiones regulares porque esta herramienta mejora la eficiencia y la productividad de tu trabajo.
Veamos algunos ejemplos:
Expresiones regulares para coincidir con las etiquetas HTML:
<(.*)>.*?|<(.*) />
<(\S*?)[^>]*>.*?</\1>|<.*?/>
Expresión regular para coincidir con todas las etiquetas TD:
<td\s*.*>\s*.*<\/td>
Expresión regular para coincidir con <img src = "test.gif" />:
<[a-zA-Z]+(\s+[a-zA-Z]+\s*=\s*("([^"]*)"|'([^']*)'))*\s*/>
Podemos hacer coincidir una variedad de etiquetas HTML mediante el uso de una expresión regular y, por lo tanto, extraer datos fácilmente en documentos HTML.

(Descargar Octoparse - Abrir el software - Hacer clic en el icono de la caja de herramientas en la esquina inferior izquierda)
Herramienta RegEx gratuita - Octoparse
Octoparse, una herramienta de recopilación de datos web visual, proporciona una herramienta para generar expresiones regulares. Puede generar fácilmente algunas expresiones regulares simples para satisfacer tus diferentes necesidades de extraer contenido en documentos HTML. Además, Octoaprse es totalmente compatible con la verificación de expresiones regulares personalizadas.
0 notes
Text
Cumplimiento de RGPD en web scraping
El web scraping es una forma de extraer datos de la web mediante herramientas y tecnologías de automatización. Anteriormente, las empresas eran muy informales con la recopilación de datos web. Pero con el inicio de las regulaciones RGPD (o GDPR), la debida diligencia con respecto a la extracción de datos es imprescindible.
Recientemente, Polonia impuso una multa de 220.000 euros a una organización que recopiló datos de alrededor de 7 millones de personas, pero no les informó (informar a las personas es una regla según el artículo 14 del RGPD). Además, hace unos meses, la DPA francesa emitió una guía relacionada con el web scraping comercial. Entonces, pensamos en explicar qué significa GDPR y por qué es importante para la comunidad de scraping. Lee este artículo para saber todo lo que necesitas para cumplir con el RGPD mientras raspando la web.
Tabla de contenidos
¿Cuándo entra en juego el RGPD?
¿Qué califica como información de identificación personal (PII)?
¿Estás raspando la información personal de los ciudadanos de la UE?
¿Tienes una base legal para raspar datos personales?
¿Qué puedes hacer para cumplir con el RGPD?
Conclusión
¿Cuándo entra en juego el RGPD?
Primero, echamos un vistazo a lo que se puede extraer de la web y, luego, analizamos qué tipo de datos se incluyen en el RGPD y cuáles no.
Puedes raspar:
Anuncios inmobiliarios para realizar marketing personalizado,
índices accionarios, portales de noticias para la inteligencia de mercado,
Publicaciones de trabajo para impulsar tus servicios de RR.HH,
Sitios de redes sociales para analizar los sentimientos de los clientes,
Directorios online para prospección,
Datos públicos de sitios web gubernamentales para obtener perspectivas,
Datos de productos de sitios de comercio electrónico para seguimiento de la competencia e inteligencia de precios,
Blogs, videos y todo eso.
Por supuesto, los casos de uso de la extracción de datos no se limitan a estos, sino que a un nivel amplio, esto te da una idea sobre los diferentes tipos de datos que puedes extraer. Ahora, RGPD, que significa Reglamento General de Protección de Datos (UE) 2016/679, es una ley en la Unión Europea (UE) sobre protección de datos y privacidad de todas las personas dentro de la UE y el EEE. GDPR tiene dos propósitos:
Pone a las personas en control de cómo se utilizan sus datos
Simplifica el entorno regulatorio para las empresas que operan en la región de la UE
La pregunta es, ¿en qué terreno se cruzan el raspado de datos y el RGPD? ¿Cuándo deberías preocuparte por el RGPD? Una respuesta corta sería, cada vez que se extraigas la información personal de un individuo / ciudadano que resida en la UE.
Para saber si necesitas cumplir con GDPR o no, y para asegurarte de que tu proyecto de raspado cumpla con GDPR, encuentra las respuestas a las siguientes preguntas:
¿Qué califica como información de identificación personal (PII)?
¿Estás raspando la información personal de los ciudadanos de la UE?
¿Tienes una base legal para raspar datos personales?
¿Qué puedes hacer para cumplir con el RGPD?

¿Qué califica como información de identificación personal (PII)?
Cualquier dato que pueda ayudar a alguien a rastrear o identificar a una persona calificaría como PII. Algunos ejemplos pueden ser:
Nombre
Email
Números de Contacto
Direccion postal
Detalles de la tarjeta de crédito
Detalles del banco
Dirección IP
DOB
Imagen / video / audio de la persona
Informes médicos
Detalles de empleo, etc.,
¿Estás raspando la información personal de los ciudadanos de la UE?
El RGPD se ocupa estrictamente de la información de identificación personal de las personas dentro de la Unión Europea y el Espacio Económico Europeo (EEE). Entonces, la siguiente pregunta que surge es ¿estás raspando datos de ciudadanos europeos? Si la respuesta es un "No", entonces estás a salvo. Por lo tanto, digamos que si estás extrayendo datos que conciernen a India, EE. UU. O Australia, no debes preocuparte por el RGPD. En su lugar, debes buscar leyes de protección de datos dentro de su jurisdicción respectiva. La jurisdicción de RGPD se limita al EEE. Si tus proyectos de raspado necesitan que raspes la PII de los ciudadanos de la UE, debes tener una base legal para hacerlo.
¿Tienes una base legal para raspar datos personales?
Las bases legales se establecen en el artículo 6 del RGPD, y existen seis bases legales para el procesamiento de datos extraídos:
1. Consentimiento
Esta puede ser tu base legal cuando las personas, de las que estás extrayendo datos, te han dado su consentimiento para extraer sus datos para fines específicos.
2. Contrato
El contrato con las personas interesadas puede tener una base legal bajo RGPD si el contrato necesariamente requiere que tú proceses los datos.
3. Obligación Legal
El tercer tipo de base legal podría ser si el procesamiento de datos es necesario para que tú cumpla con una obligación legal.
4. Intereses Vitales
Puedes argumentar que Intereses Vitales es la base legal para tu proyecto de raspado si está destinado a salvar la vida de alguien.
5. Tareas Públicas
Cuando el tratamiento de los datos se realice por interés público o para el desempeño de tus funciones como funcionario, se contará como base jurídica.
6. Interés Legítimo
Si el procesamiento de datos es necesario para el interés legítimo del controlador de datos, también puedes contarlo como una base del procesamiento legal de datos bajo RGPD. Pero esta no será la base legal si anula los derechos o intereses fundamentales de una persona cuyos datos se recopilan y procesan.
En resumen, consentimiento y contrato son más o menos lo mismo. Si las personas te han dado su consentimiento, está bien procesar sus datos. ¿Cuándo será aplicable? Tomamos un ejemplo. Supongamos que existe un sitio web de venta minorista de moda que recopila reseñas de productos de los compradores, así como la PII del comprador, y la pone a disposición del público en las reseñas. La PII podría ser la edad, el nombre y la ubicación. Los datos generales serían el texto de revisión y el tiempo. Ahora, si necesitas raspar solo el texto de revisión para la investigación para impulsar el desarrollo de tu nuevo producto, entonces no debes preocuparte por RGPD. Pero si también estás raspando el nombre, la edad, la ubicación y otros detalles, entonces estás ingresando a la zona de PII y debes cumplir con RGPD para abordar el cumplimiento legal.
Los intereses vitales, las tareas públicas y las obligaciones legales rara vez formarían tus bases legales, ya que son conceptos claros y no hay mucho espacio para argumentos teóricos. Pero el interés legítimo podría ser tu base legal sólida si estás haciendo raspado web. Pero para la mayoría de las empresas, afirmar que esto también es un desafío.
El caso de HiQ vs Linkedin también es una lectura interesante.
¿Qué puedes hacer para cumplir con el RGPD?
Aquí hay una lista de verificación para que te asegures de que tu proyecto de procesamiento de datos y raspado cumpla con el RGPD:
Mantener alejado de la interpretación incorrecta de los artículos en el reglamento RGPD
Un mito es que cualquier información de identificación personal disponible públicamente se puede raspar y utilizar para marketing o para algún otro propósito. Este no es el caso. El consentimiento o los intereses legítimos solo podrían ser la base legal para procesar datos de PII incluso si están disponibles públicamente. Por lo tanto, no puedes lanzar campañas de marketing en las ID de correo electrónico obtenidas de las secciones de comentarios de las redes sociales si pertenecen a ciudadanos / sitios web de la UE.
Obtener el Consentimiento
Esto es obvio. Si no tienes un interés legítimo sólido en obtener PII, obtener el consentimiento es la única salida.
Informar a las personas sobre la recopilación de datos
El artículo 14 del RGPD obliga a informar a todas las personas cuyos datos no se hayan recopilado directamente de ellos.
Garantizar la conservación de los DSAR
Los residentes de la UE tienen derecho a solicitar una copia de los datos que poseen, retirar el consentimiento para extraer / conservar sus datos o incluso solicitar la eliminación de sus datos. Debes asegurarte de que tu proyecto cumpla con los Derechos de acceso del sujeto de datos (DSAR).
Informar violación de datos
El artículo 33 del RGPD requiere que informes a la autoridad supervisora en caso de violación de datos en un plazo de 3 días, a menos que sea poco probable que la violación de datos personales sea una amenaza para los derechos fundamentales de una persona.
Evaluación de impacto de protección de datos (DPIA)
En caso de que no puedas cumplir con el artículo 14 de GDPR que requiere informar a las personas sobre tu recopilación de datos, debes obtener DPIA.
Asegúrate de que tus proxies de IP residenciales también cumplan con el RGPD
Las empresas o los raspadores de datos a menudo utilizan proxies IP residenciales para rastrear la web a gran escala o para superar las técnicas anti-raspado implementadas por los sitios web.
Audita tus proyectos de raspado nuevos y antiguos de forma iterativa
Tiene sentido auditar todos tus proyectos de raspado existentes, nuevos y antiguos para verificar si cumplen con el RGPD o no y, en consecuencia, intervenir cuando sea necesario.
Conclusión:
El raspado de datos ha cambiado la forma en que operan las empresas. Algunas nuevas verticales comerciales, como la agregación de noticias, se han derivado del web scraping. Aún en su infancia, pero RGPD ha cambiado radicalmente la forma en que las empresas raspan la web. Es una de las leyes de protección de datos más completas e impactantes hasta la fecha. Si tsu proyecto de raspado necesita que raspes PII, para evitar multas considerables, es mejor asegurarte de que cumples con RGPD.
Algunos recursos de raspado para ti:
Utilizar el web scraping para obtener información sobre precios
Raspando en la Nube
Raspar las Bolsas de Trabajo
Descargamos de responsabilidad: este artículo no es un consejo legal para cumplir con el RGPD. Es solo para fines informativos. Descubre más sobre RGPD en su sitio web.
0 notes
Text
¿Cómo pueden los dropshippers aprender del negocio D2C?
Con el aumento del número de compradores en línea, los clientes se adaptan gradualmente al modelo de comercio electrónico y se vuelven más exigentes. El cambio en el comportamiento de compra ciertamente crea más oportunidades pero desafíos para los transportistas directos. Para la mayoría de los propietarios de negocios de envío directo, ahora la pregunta es, ¿cómo subir de nivel tu negocio para destacarse de la competencia y obtener continuamente más clientes?
Probablemente olfatees la nueva tendencia: D2C (Direct-to-customers). Aunque el término ha estado flotando durante un par de años, pocas personas prestaron atención hasta que ocurrió la pandemia de COVID-19. Con la creciente demanda de comercio electrónico que elimina la barrera entre los vendedores y los consumidores, ahora D2C es el nuevo negro.

Ciertamente, hay algunas cosas que podemos tomar prestadas del modelo de negocio D2C y usarlo en el negocio de dropship.
“Según el análisis de eMarketer en febrero de 2021, las ventas de comercio electrónico de D2C en los EE. UU. Han crecido un 45,5% en 2020, generando alrededor de $ 111,54 mil millones y representando el 14% de las ventas totales de comercio electrónico minorista. Se espera que D2C mantenga un crecimiento relativamente constante cada año hasta 2023, momento en el que las ventas de comercio electrónico de D2C podrían haber alcanzado los $ 174,98 mil millones ".
Tabla de contenidos
¿Qué es D2C y qué lo hace tan popular?
La diferencia entre D2C y dropshipping
Estrategia 1 de Drop-ship: comenzar con los proveedores adecuados
Estrategia 2 de Drop-ship: muestra tu marca con un escaparate en línea
Estrategia 3 de Drop-ship: subir de nivel los servicios
¿Qué es D2C y qué lo hace tan popular?
Bajo un modelo D2C o Direct-to-Customer, los propietarios de marcas pueden vender productos directamente a sus clientes en los sitios web oficiales de sus marcas, en lugar de depender de tiendas físicas, mercados de comercio electrónico o cualquier otra plataforma de intermediarios.
Esto ha trascendido el modelo de negocio tradicional B2C de muchas formas. Los propietarios de negocios que apliquen una estrategia D2C obtendrán más control sobre sus marcas sin que un minorista se interponga en el medio. Como resultado, pueden construir relaciones más estrechas con los clientes finales y ser más interactivos con la demanda del mercado.
¿En qué se diferencia D2C de Dropshipping?
No mezcla estos dos conceptos. Los dropshippers manejan los pedidos de los clientes directamente y luego envían los productos utilizando un proveedor externo. Como ya has notado, el costo del almacenamiento físico constituye el margen de oportunidad. Los dropshippers no tienen ninguna inversión inicial para mantener el inventario, PERO no es sostenible a largo plazo. Considerando que, D2C no suena como un enfoque esbelto, ya que no solo debes pagar por el almacenamiento, sino también por todo lo relacionado con la operación. Sin embargo, los partidarios del modelo D2C saben que aquellos que se acercan a los clientes pueden mantenerse firmes hasta el final de la competencia.
Si deseas construir un negocio de Dropshipping sostenible como el modelo D2C, no es difícil darte cuenta de que solo necesitas algunas cosas para salir adelante: proveedores confiables, conocer a tus clientes y una solución de cumplimiento de pedidos nivelada. Así es como se ve una estrategia de envío directo en un nivel alto:
Comenzando con los proveedores adecuados:
Un proveedor confiable que vende productos que se ajustan al nicho de marketing podría ganarte más probabilidades en el juego. Cuando pensamos en proveedores, pensamos en Aliexpress u otras empresas locales que pueden ofrecer productos de calidad a un costo menor.
Con tantas ideas de productos para mirar y tanta información disponible en línea, buscar una buena opción puede ser más desafiante a través de la investigación de mercados. Así es como el web scraping viene a tu rescate.
El wep scraping es la mejor práctica para recuperar datos web dispersos en un formato utilizable. Puede recoger información de productos de múltiples fuentes en un formato organizado y estructurado. Eventualmente, los datos se pueden sincronizar con tu tienda en línea a través de una integración de API, que conecta tus tiendas y proveedores en línea sin problemas. Puede proporcionarte información básica del producto que incluye: precios, nombre del producto, SKU, inventario y URL de imágenes.
A continuación, recopila datos para comprender verdaderamente a tus clientes.
Cada acción del cliente ofrece información valiosa sobre el comportamiento del cliente. Para determinar cómo reaccionan los clientes ante tus productos o tus competidores, puedes monitorear los productos en todos los mercados. Esto te brinda más información sobre tu posición en el mercado. Herramientas como Octoparse pueden recopilar información como reseñas, revisores, calificaciones, niveles de existencias, etc.
Muestra tu marca con un escaparate en línea:
En lugar de depender de un mercado como Amazon, que tiene un millón de variedades de productos que compiten entre sí en cada línea de productos, tener una tienda en línea independiente te permite mostrar tus productos únicos. La mejor parte es que tienes control total sobre el tráfico y los clientes finales con los que puedes entablar relaciones y compartir una experiencia de marca personalizada.
El gigante de las maquinillas de afeitar Harry's optó por la estrategia de marketing exacta que lo ayudó a ganar más de $ 1 millón en ventas en el primer mes y rápidamente subió a $ 100 millones en 2 años. Andy Katz-Mayfield, cofundador de Harry's, se dio cuenta del hecho de que lo que los consumidores necesitan son productos simples pero efectivos que se sientan bien de usar. Este es un gran avance para iniciar su propio negocio de maquinillas de afeitar, que ofrece un modelo de venta simple: una gran maquinilla de afeitar entregada directamente a tu puerta.
¿Encuentra la diferencia? Harry's intenta ofrecer un viaje de compra simplificado pero personalizado, además de una historia de marca genuina que resuene entre los clientes. Esto hace que los clientes se sientan más conectados con la marca y alivia fácilmente sus preocupaciones sobre un nuevo negocio.
Por último, subir de nivel los servicios de cumplimiento de pedidos y, por lo tanto, la experiencia del cliente.
Como dropshipper, probablemente te acostumbres a que los proveedores se ocupen de todo el proceso de cumplimiento del pedido y no le presten mucha atención. Pero si este trabajo de "última milla" se vuelve problemático, todo tu esfuerzo anterior para mejorar la experiencia del cliente se arruinará. Estado de pedido transparente, productos de calidad según lo prometido en los listados, paquetes con visibilidad de marca constante, servicio postventa receptivo ... Hay muchos aspectos que debes considerar para mejorar las soluciones de cumplimiento de pedidos.
En lugar de dedicar tiempo a pensar en hacer mandados, un proveedor confiable de soluciones de envío directo como BuckyDrop puede ser muy útil. Proporcionan servicios que incluyen cumplimiento de pedidos, abastecimiento de productos, gestión de suministros, servicio postventa y marca de la tienda. BuckyDrop es el único socio privado, agente, experto e inversor que necesitarás para ganar dropshipping. Tienen una solución de dropshipping integral de clase mundial que está abierta a cualquier emprendedor de dropshipping que aspire a construir una marca y tener éxito.
Es muy probable que crees la próxima marca en auge con la solución adecuada que te respalde. ¡Estamos aquí para ayudar!
0 notes
Text
¿Cómo resolver captcha mientras se raspa la web?
Los CAPTCHA son una de las técnicas anti-scraping más populares implementadas por los propietarios de sitios web. reCaptcha v3 es una solución de integración CAPTCHA de Google para detectar tráfico de bots en sitios web. NuCaptcha, hCaptcha son algunas otras soluciones CAPTCHA avanzadas. Pero los CAPTCHA son bastante irritantes, no solo para los usuarios sino también para los web scrapers. Resolver CAPTCHA es uno de los principales desafíos que enfrentan los web scrapers. Lee esta información para encontrar diferentes formas de resolver CAPTCHA mientras extraes el contenido de tu sitio web objetivo. Así es como está estructurado el artículo:
Tabla de contenidos:
¿Qué es un CAPTCHA? ¿Y qué es un reCaptcha?
Tipos populares de CAPTCHA
¿Cómo resolver / omitir reCAPTCHA mientras se raspa?
Resolución de captcha basada en humanos
Resolución de CAPTCHA mediante OCR (reconocimiento óptico de caracteres)
Auto-resolutivo
¿Omitir reCaptcha en Octoparse?
Tips para evitar que los CAPTCHA interrumpan tu experiencia de raspado
Conclusión
¿Qué es un CAPTCHA? ¿Y qué es un reCaptcha?
La Prueba de Turing pública y automática para diferenciar a las computadoras y los humanos (CAPTCHA) es una prueba basada en audio, visual o textual generada por algoritmos automatizados. Resolver CAPTCHA requiere tres habilidades en las que los humanos son mucho mejores que las computadoras:
Reconocimiento invariante (identificación de diferentes formas, imágenes del mismo alfabeto, objeto),
Segmentación (identificación de alfabetos superpuestos)
Análisis del contexto (comprensión integral de la imagen, el texto o el audio)
reCaptcha es la solución generadora de CAPTCHA más popular. Es de Google y se puede integrar fácilmente en un sitio web.
¿Cuáles son algunos tipos populares de CAPTCHA?
1. Captcha Normal
Este es el CAPTCHA más utilizado en el que una imagen distorsionada contiene texto pero es legible por humanos. Para resolver CAPTCHA normal, debes ingresar el texto distorsionado en el cuadro de texto.

2. Captcha de Texto
TextCaptcha no es tan popular, pero es ideal para usuarios con discapacidad visual. Esto no está basado en imágenes, es puramente texto. Un ejemplo de CURL de TextCaptcha:
TextCaptcha:
$ curl http://api.textcaptcha.com/[email protected]
{ "q":"If tomorrow is Saturday, what day is today?"
"a":["f6f7fec07f372b7bd5eb196bbca0f3f4",
"dfc47c8ef18b4689b982979d05cf4cc6"] }
CAPTCHA: Si mañana es sábado, ¿qué día es hoy?
SOLUCIÓN: viernes.
3. Key Captcha
KeyCaptcha es otro servicio de integración CAPTCHA en el que se supone que debes resolver un acertijo

4. Click Captcha
Los CAPTCHA de imagen que se incluyen en los rompecabezas basados en clasificación son los Click CAPTCHAs. reCaptcha, ASIRRA, Snapchat’s Ghost Captcha son ejemplos populares de Click CAPTCHAs basados en clasificación.

5. Rotate Captcha
Estos son rompecabezas CAPTCHA basados en la orientación de la imagen. En Rotate CAPTCHA, debes hacer clic una o varias veces para rotar una imagen de modo que cumpla con los términos de verificación. La condición de verificación más popular es colocar un objeto en la “posición correcta”. FunCaptcha es uno de los proveedores de integración "Rotate CAPTCHA", pero parece que no funciona. RVerify.js es una biblioteca de JavaScript de código abierto para verificar la orientación de la imagen.
6. GeeTest CAPTCHA
Los LosGeeTest CAPTCHAs son interesantes, aquí tienes que mover una pieza del rompecabezas, a menudo arrastrando un control deslizante, o tienes que seleccionar ciertas imágenes en un orden particular.
7. hCaptcha
hCaptcha es muy similar a reCaptcha. La única diferencia es que cuando usamos hCaptcha, varias empresas pueden aprovechar el beneficio del etiquetado de datos que los USUARIOS hacen en los sitios web cuando hacen clic en cualquier sitio web. El uso de reCaptcha solo Google se beneficia del etiquetado de datos de colaboración colectiva.
8. Capy puzzle
Similar a keyCaptcha, Capy Puzzle es un servicio CAPTCHA basado en rompecabezas. CAPY.ME CAPY.ME es un servicio para integrar rompecabezas de Capy en sitios web.

Lee más sobre los tipos de CAPTCHA.
¿Cómo resolver / omitir reCAPTCHA mientras se raspa?
Ya sea que estés raspando usando una herramienta avanzada de raspado de pantalla sin código de "hacer clic y raspar", o tu raspador escrito en Python, Java o Javascript, es posible resolver y omitir todo tipo de CAPTCHA. Aunque ningún servicio / solución garantiza una tasa de resolución de CAPTCHA del 100%, podemos obtener una eficiencia de hasta el 90% utilizando herramientas populares como DeathByCaptcha y 2captcha, etc.,
Hay dos enfoques populares para resolver CAPTCHAs
Resolución de captcha basada en humanos
Los CAPTCHAs están hechos para ser resueltos por humanos. Hay empresas que emplean a miles de humanos para resolver estos CAPTCHA en tiempo real, a un precio muy económico. La eficiencia es bastante alta, pero la latencia de tiempo es un problema con este enfoque.
Entonces, ¿cómo deberías usar un servicio de resolución de CAPTCHA mientras se raspa?
Hay varios proveedores de servicios de resolución de captcha en el mercado, algunos de los cuales son notables:
DeathByCaptcha
AZCaptcha
ImageTyperZ
EndCaptcha
BypassCaptcha
CaptchaTronix
AntiCaptcha
2Captcha
CaptchaSniper
Todos estos proveedores de servicios tendrían un enfoque similar:
Registrarse en su sitio web, obtener un token y las credenciales publicadas pagando el monto, o tal vez de forma gratuita si hay una versión de prueba disponible.
Implementar su API / complemento usando un lenguaje de tu elección, es decir, Python, PHP, Java, JS, etc.
Envíar tus CAPTCHAs a sus API
Recibir los CAPTCHAs resueltos en la respuesta de la API
Resolución de CAPTCHAs mediante OCRs (reconocimiento óptico de caracteres)
Este es un enfoque programático para resolver CAPTCHAs. OCR significa reconocimiento óptico de caracteres o lector óptico de caracteres. OCR es un enfoque electrónico o mecánico para convertir texto mecanografiado, escrito a mano o impreso en texto codificado por máquina. Puedes alimentar un documento escaneado, una imagen o una escena (ejemplo: Billboards) a los OCRs. Existen herramientas de código abierto como TESSERACT, GOCR, OCRAD, etc., para que puedas comenzar, por lo que no es necesario que comiences desde cero. Los OCRs tienen la capacidad de resolver con éxito diferentes tipos de CAPTCHA basados en imágenes.
Auto-resolutivo
If you’re scraping a single site that only verifies real users using reCAPTCHAs once in a while, you may want to bypass reCaptcha on your own manually. In such cases, you can configure your scraping workflow to
Si estás raspando un solo sitio que solo verifica a los usuarios reales que usan reCAPTCHAs de vez en cuando, es posible que desees omitir reCaptcha por tu cuenta manualmente. En tales casos, puedes configurar tu flujo de trabajo de raspado para
pausar el raspado durante un tiempo específico, permanecer 7-8 segundos
esperar a que un elemento de la página sea visible
esperar tu entrada hasta que comience a raspar de nuevo
Para detectar un reCaptcha, es importante comprender su implementación.
¿Cómo se integra reCaptcha en los sitios web?
La integración de reCaptcha implica los siguientes pasos:
1. Cargar de la API de JavaScript
<script src="https://www.google.com/recaptcha/api.js?render=reCAPTCHA_site_key">
</script>
2. Llamar a una función para manejar la devolución de llamada y vincularla a un botón o una acción.
<button class="g-recaptcha"
data-sitekey="reCAPTCHA_site_key"
data-callback='onSubmit'
data-action='submit'>Submit
</button>
Function:
<script>
function onSubmit(token) {
document.getElementById("demo-form").submit();
}
</script>
Ahora, si deseas detectar captcha, usa XPaths y detecta un reCaptcha buscando un elemento con texto de clase que contenga reCaptcha
Xpath: //*[contains(“@class”,”recaptcha”)]
Si un elemento está presente, significa que hay un Captcha en la página que debe resolverse. Puedes pausar tu raspador, resolver el captcha y reanudar el raspado nuevamente una vez resuelto.
Ahora veremos cómo resolver un reCaptcha en Octoparse.
¿Omitir reCaptcha en Octoparse?
¿Qué es Octoparse?
Como mencionamos anteriormente, puedes raspar la web usando las soluciones sin código Click & Scrape. Octoparse es una solución de raspado web sin código líder en la industria disponible en el mercado. Es gratis descargar y raspar la web. Para un scraping escalable a gran velocidad, también ofrece planes muy asequible. Si eres nuevo en Octoparse, puedes encontrar excelentes recursos aquí. Si estás familiarizado con Octoparse, así es como puedes resolver CAPTCHA en Octoparse:

1. Raspado de máquina local:
Mientras usas Octoparse para raspar la web en tu máquina local, se recomienda usar las funciones "esperar antes de la ejecución" o "esperar hasta que aparezca un elemento específico" proporcionadas en las opciones avanzadas de personalización del flujo de trabajo de raspado de Octoparse.
2. Raspado de nubes
Para proyectos grandes, el equipo de Octoparse ofrece el servicio de personalización de plantillas de JavaScript para solucionar el problema de CAPTCHA / reCAPTCHA
Tips para evitar que los CAPTCHA interrumpan tu experiencia de raspado
1. Utilizar proxies de IP rotativos, rotar los agentes de usuario y borrar sus cookies. Octoparse te proporciona opciones para configurarlos. Normalmente, el sitio web activa un servicio de detección anti-raspado integrado cuando la misma IP comienza a llegar a los servidores de forma agresiva. Si usas miles de proxies y los rotas, puedes escapar enfrentando CAPTCHAs
2. Obedecer el archivo Robots.txt. Este archivo contiene las reglas sobre las preferencias del sitio web. Por ejemplo, las reglas establecen si el sitio web te permite eliminarlo o no. Si es así, qué URL no quieres que raspe, etcétera.
3. Usar navegadores sin cabeza si estás escribiendo tu raspador web, herramientas como Octoparse se encargan automáticamente de esto, ya que son navegadores inteligentes.
4. Intentar usar encabezados y referencias en tus solicitudes al servidor si no estás usando un navegador a gran escala.
5. Para raspar los inicios de sesión detrás de los datos, guarda las cookies. Así es como se hace en Octoparse..
6. Tener cuidado con las trampas de honeypot invisibles en los sitios web. Estos son los elementos o enlaces que no son visibles, por lo que si has escrito un rastreador que raspa estos enlaces, el sitio web llega a saber que es un bot, ya que los humanos no pueden hacer clic en ese enlace con un navegador normal como Chrome o Firefox.
7. Mantener retrasos aleatorios entre solicitudes consecutivas. Especialmente, cuando visitas el sitio web con las mismas direcciones IP repetidamente.
8. Utilizar los servicios de resolución de CAPTCHA.
Conclusión
Explorar la web para extraer datos es muy importante para que las empresas obtengan conocimientos y tomen decisiones comerciales críticas basadas en datos. Los datos web también son importantes para entrenar algoritmos de aprendizaje automático. En este artículo, descubrimos diferentes tipos de CAPTCHA, diferentes enfoques para resolver reCaptcha, prevenir CAPTCHA y también hablamos sobre cómo resolver CAPTCHA en Octoparse. Para recordarte nuevamente, para proyectos grandes proporcionamos personalización de plantillas de Javascript para integrar los mejores servicios de resolución de CAPTCHA en Octoparse. Pónete en contacto con nuestro equipo para cualquier requisito de raspado. ¡Feliz raspado sin CAPTCHA!
0 notes
Text
Una forma fácil y gratuita para mejorar tu ranking de Google
SEO (optimización de motor de búsqueda) es el proceso de afectar la visibilidad (el posicionamiento) de un sitio web o una página web en Internet, dentro de los resultados orgánicos en los motores de búsqueda como, por ejemplo, Google. Con ese fin, los buscadores recogen el listado de páginas que hay en la web y lo ordenan en función de su algoritmo.De hecho, esta es la forma gratuita de mejorar tu ranking de Google y atraer más tráfico.

Tabla de contenidos
Mejora de SEO & ranking de Google
Investigación de palabras clave
Investigación de Backlinks
Mejora de SEO & ranking de Google
Un estudio de Infront Webworks mostró que la primera página de Google recibe el 95% del tráfico web web, y las páginas siguientes reciben un 5% o menos del tráfico total. Entonces, para la mayoría de las personas, especialmente para aquellos que desean comenzar su negocio con fondos limitados, el SEO (optimización de motores de búsqueda) es una buena manera de mejorar el ranking de Google para mostrar sus sitios web y atraer a más personas a los sitios web a un costo relativamente bajo.
Sin embargo, el SEO es una gran cosa con muchos factores que afectarían el ranking de Google, como:
Factores en la página: palabra clave en la etiqueta del título, palabra clave en la etiqueta H1, descripción, longitud del contenido, etc.
Factores del sitio: mapa del sitio, confianza del dominio, ubicación del servidor, etc.
Factores fuera de la página: el número de dominios de enlace, la autoridad de dominio de la página de enlace, la autoridad del dominio de enlace, etc.
Factores de dominio: duración del registro del dominio, historial del dominio, etc.
(Nota: Para obtener más detalles, puedes consultar Los 30 Factores De Ranking De Google Más Importantes Que Un Principiante Debe Saber)
La mayoría de estos factores se pueden investigar con herramientas de raspado web de forma gratuita (consulta Los 30 Mejores Software Gratuitos de Web Scraping en 2021 para obtener más información). Y con suficiente información, podrías desarrollar una mejor estrategia para mejorar tu ranking de Google.
So in this post I would only focus on the keyword and backlinks research to show you how to identify projected traffic and ultimately how to determine value of that ranking in a free and easy way if you don’t have any ideas.
Entonces, en este post solo me centraría en la investigación de palabras clave y backlinks para mostrarte cómo identificar el tráfico proyectado y, en última instancia, cómo determinar el valor de ese ranking de una manera fácil y gratuita si no tienes ninguna idea.
Investigación de palabras clave
Apuesto a que dirías: "Ah, es fácil. Ya sabes, hay muchas herramientas de búsqueda de palabras clave, como Keyword Planner, Buzzsumo, por ejemplo. Todos ellos podrían ayudarme a encontrar las palabras clave más valiosas para orientarme con SEO ".
Sí, está correcto. Pero, ¿cómo podrías juzgar el valor de las palabras clave? ¿Cómo sabes que recibes el tipo de visitantes adecuado?
La respuesta es investigar la demanda de palabras clave de tu mercado, predecir cambios en la demanda y producir contenido que los buscadores web estén buscando activamente. Las herramientas mencionadas anteriormente solo nos mostrarían las palabras clave que los visitantes suelen escribir en los motores de búsqueda. Sin embargo, no pueden mostrarnos directamente lo valioso que es recibir tráfico de esas búsquedas. Para comprender el valor de una palabra clave, debemos comprender nuestros propios sitios web, formular algunas hipótesis, probar y repetir—la fórmula clásica de marketing web. Aquí te mostraría cómo funciona.
Por ejemplo, suponga que has elegido algunas palabras clave específicas y has producido algunos contenidos antes, ahora necesitas medir los efectos. Es decir, cuando los buscadores utilizan estas palabras clave relevantes al realizar búsquedas en Google, encontrarán tu sitio web y accederán a él. Es por eso que primero necesitas conocer tu ranking. Tomaré Octoparse por ejemplo, para ilustrar eso.
¿Cómo puedo saber el ranking del dominio Octoparse cuando busco las dos palabras clave relevantes "herramienta gratuita de raspado web" y "servicio gratuito de raspado web"? ¿Y cómo podría conocer el rango de otra información detallada antes de Octoparse para poder conocer mejor el valor de las palabras clave buscadas?
La respuesta es la herramienta de raspado web. Con la herramienta de raspado web Octoparse, puedes raspar fácilmente la información que deseas buscando las palabras clave (consulta ¿Cómo capturar los términos de búsqueda ingresados y el resultado? Para obtener más detalles).
A continuación se muestra el resultado que obtuve con Servicio de Nube de Octoparse.

Exporto los datos extraídos a Excel y analizo los datos. Lamentablemente, no encontré el dominio de Octoparse en Excel, aunque encuentro que la mayoría de los visitantes llegan a mi sitio web al buscar estas dos palabras clave a través de la información de análisis de Google Search Console. Ese es el problema con el que se encontraría la mayoría de la gente, pero a menudo lo ignoraban sin darse cuenta. Por lo tanto, es necesario verificar tu ranking con frecuencia y ajustar las estrategias en consecuencia si deseas mejorar tu ranking de Google.
Por ejemplo, para mí, necesito verificar el dominio de estos sitios web y tratar de averiguar si tu Page Rank es más alto que el mío. En caso afirmativo, ¿podrían mis contenidos ser de mayor calidad? Si no es así, ¿qué otros factores podrían optimizarse para mejorar el ranking?
Este es un ejemplo simple que muestra que el uso de la herramienta de raspado web para SEO podría brindarte información valiosa sobre lo difícil que sería clasificar para la palabra clave dada, y también la competencia.
Investigación de Backlinks
Imagínate a Google como el centro de votación de Internet, contando los votos de todos los enlaces que encuentra en la web. A diferencia de tu democracia típica, donde una persona tiene un voto, Google da más peso a los votos de sitios web relevantes y autorizados. Por lo tanto, el factor más importante para determinar el ranking de Google tiende a basarse en esos pequeños enlaces azules que se ven en casi todos los sitios web.
Entonces, ¿cómo podrías conseguir estos enlaces azules? La forma más común es buscar vínculos de retroceso de la competencia a través de herramientas de SEO como Open Site Explorer. Vea los vínculos de retroceso de Octoparse que encuentro en Open Site Explorer a continuación.

Pero el problema es cómo puedo obtener esta información sin actualizar mi cuenta a una premium. ¡La respuesta es usar una herramienta de raspado web gratuita! Simplemente hacer un rastreador simple, toda la información que se muestra en línea se puede extraer sin ningún costo. Entonces tendrías la idea de acercarte a las fuentes adecuadas y ofrecer valor a cambio de un vínculo sólido.
Hay muchas formas de mejorar el ranking de sitios web. Y en mi experiencia personal, el uso de herramientas de raspado web es una de las formas más avanzadas de hacerlo con poco costo. ¡Sólo hay que probar!
0 notes
Photo

Las 30 Mejores Herramientas de Visualización de Datos en 2021
¿Cuál es la mejor herramienta de visualización de datos? Aquí hay una lista de las 30 mejores herramientas de visualización de datos en 2021, incluidos sus pros, contras y ejemplos. Luego puedes decidir cuál se adaptaría a tus necesidades.
Las dividimos en dos categorías: herramientas que no requieren programación y solo para desarrolladores. En cada categoría, las herramientas se clasifican en subgrupos según la especialización. Algunas como Tableau tienen una amplia gama de gráficos y tablas; Algunas herramientas como Infogram son bien conocidas para hacer infografías; Algunas herramientas comienzan a ganar popularidad debido a gráficos interactivos como Gephi.
0 notes
Text
¿Qué es el Big Data en el turismo?
De acuerdo con Viajes National Geographic, dentro de los 25 desinos más populares del mundo según los viajeros en 2019, los de países hispanohablantes ocupan 4 posiciones. La industria del turismo estaba superando a la economía global hasta 2019, y luego cayó en picada en 2020. Sí, ya sabes la razón. Pero la buena noticia es que los viajes y el turismo están recuperando terreno. Y la industria del turismo está aprovechando la tecnología para acelerar las cosas. Una tecnología tan impactante y transformadora para el sector de viajes y turismo es Big Data. Esta información pretende ser tu guía sobre "Big Data en el turismo". Después de leer esta información, vas a conocer:

Tabla de contenido
Parte 1 ¿Qué es el big data en el turismo?
Parte 2 ¿Cómo se puede aprovechar / extraer big data usando web scraping?
Parte 3 Casos de uso empresarial de big data en el turismo
Parte 4 Desafíos de Big Data en viajes & turismo
Conclusión
¿Qué es el big data en el turismo?
¿Qué es Big Data? Big data es un enfoque para extraer, procesar y visualizar sistemáticamente grandes conjuntos de datos. ¿Qué significa eso? Suponga que tienes datos personales, es decir, nombre, edad, sexo, país, etcétera, de 1000 clientes que visitaron Francia en 2020. ¿Se trata de big data? Realmente no. Pero si tienes datos sobre un millón de personas que llegaron a diferentes rincones del mundo, el hotel en el que se hospedaron, la comida que pidieron, los lugares que visitaron, los eventos que tuvieron lugar en diferentes geografías, los diferentes recursos en línea / fuera de línea que utilizaron, etc., entonces, idealmente, debería considerarse Big Data. En términos sencillos,
El big data suele tener un tamaño superior a varios terabytes (TB) y petabytes (PB) de datos..
Es alto en volumen, variedad y velocidad.
Para extraer, analizar y visualizar big data, los métodos tradicionales son ineficientes.
Entonces, usas
Técnicas modernas de extracción de datos como web scraping para extraer datos de la web.
Herramientas sofisticadas como Hadoop, KNIME, NodeXL, QlikView, FusionCharts, Watson analytics etc para realizar análisis de big data y visualizar las tendencias y patrones.
¿Qué tipo de big data se puede capturar en la industria del turismo?
Información de destino- Lugares para Visitar, Reglas & Regulaciones, etc.,
Datos de Hoteles & Restaurantes - Rating & Reseñas de Clientes, Precios, Detalles del Servicio, etc.
Datos de Transporte - Billetes de Avión, Mapas de Ruta, Datos de Tráfico
Datos de Eventos - Deportes, Festivales, Cumbres, etc.
Datos de Esquemas Gubernamentales
Datos Turísticos - Entrada & Salida de Turistas, Lugar de Origen, Edad, Idiomas Hablados, etc.
Datos Sociales - Publicaciones de los viajeros en las RRSS con geoetiquetas, Etiquetas de marca, Hashtags relacionados con viajes, etc.
Noticias de viajes & Hostelería
Datos Diversos: Búsqueda en la web, Visitas al sitio web, Aplicaciones solicitadas de pasaporte & Visa, Educación internacional y Empleo, etc.
¿Cómo extraer big data de viajes & turismo?
Para extraer big data de viajes & turismo, puedes preferir:
1. Web-scraping
El web scraping de turismo es un enfoque para extraer datos de manera programática de sitios web enfocados en viajes & turismo. Puedes utilizar herramientas de raspado web o escribir tus scripts para extraer datos de estos sitios web. Por ejemplo, supongamos que necesitas datos de hoteles & restaurantes, es decir, precios, reseñas, servicios prestados, ubicación, etc., de "Booking.com". Puedes extraer fácilmente cientos y miles de datos de hoteles & restaurantes de Booking.com en unos pocos minutos.
Utiliza herramientas de raspado web si lo necesitas
Para extraer rápidamente big data de turismo
Una solución asequible, escalable, robusta y segura
2. Recursos internos & externos
También puedes obtener los datos dentro de la empresa. Buscar datos valiosos en tu software de gestión de reservas, servicios & libros de cuentas, etc.
También podrías solicitar a las juntas de turismo y a los proveedores de datos de terceros que te proporcionen los datos. Pero la veracidad de los datos es mucho mayor si extraes mediante web scraping.
¿Cuáles son los casos de uso de Big Data en la industria turística?
La clave para revivir el turismo & otros sectores emparentados es aprovechar el poder de la cultura y la creatividad, optimizar las operaciones de viajes, personalizar las ofertas, brindar experiencias perfectas, y desbloquear nuevos canales de crecimiento. Big data puede ser de ayuda aquí:
1. Investigación de Mercado Turístico
En la última década, la penetración de los dispositivos móviles ha catalizado positivamente la cantidad de datos producidos por diferentes fuentes. En el sector del turismo, los datos se dividen en tres categorías:
Datos generados por el usuario: datos textuales en línea como blogs, publicaciones en RRSS, comentarios, reseñas, geo-etiquetado comida, restaurante, datos de imágenes de destino.
Datos del dispositivo: cámaras CCTV en lugares turísticos, hoteles, restaurantes, datos de GPS móviles & vehículos, datos de itinerancia móvil, datos de Bluetooth, datos meteorológicos, etc .;
Datos de transacciones: datos de motores de búsqueda, datos de visitas a páginas web, datos de reservas online, etc.
Todos estos datos pueden ser un buen alimento para que los investigadores lleven a cabo investigaciones relacionadas con el turismo. ¿Qué tipo de investigación? Se pueden analizar las tendencias turísticas, los hábitos y comportamientos turísticos, el impacto de ciertos esquemas / campañas en la afluencia de turistas, etc.
2. Asignación racional de recursos de tráfico
La identificación y predicción del estado del flujo de tráfico en tiempo real podría ser la respuesta para aliviar la congestión del tráfico en los puntos de atracción turística y en las rutas turísticas:
Correlación Temporal: Los detectores de flujo de tráfico fijos y móviles pueden ayudar a recopilar y analizar datos de tráfico.
Correlación Espacial: El flujo de tráfico en uno o más cruces impacta el flujo en los cruces vecinos.
Correlación Histórica: Los datos de tráfico en torno al flujo, la velocidad y la ocupación tienen características similares basadas en el tiempo en determinados días de la semana o fines de semana.
Los modelos de agrupación de tráfico, los modelos de fusión de datos, los modelos correlacionales y los modelos de optimización son los enfoques analíticos más comunes para explotar de manera eficiente el big data relacionado con el tráfico y manejar el tráfico de manera inteligente.
3. Gestión operativa de atractivos turísticos mediante el análisis de comportamientos turísticos
El análisis del comportamiento de los turistas podría ser útil para diferentes partes interesadas.
Estacionalidad de la demanda en viajes, turismo y hostelería para operaciones flexibles. El big data puede ser crucial para gestionar de forma rentable los aspectos operativos de las atracciones turísticas.
Además de las agencias de gestión de operaciones de destino, puede ser útil para cadenas minoristas, cadenas de hoteles y restaurantes, etcétera.
Los turistas tienen un alto potencial de gasto. Cuando los turistas visitan tu localidad, a menudo van de compras, exploran restaurantes y participan en festivales o eventos locales. El análisis de datos en torno a todos estos puntos ayuda a los ejecutivos en la toma de decisiones estratégicas.
Por ejemplo, basándose en las tendencias históricas y actuales, los actores del turismo pueden pronosticar la afluencia de turistas en una atracción turística en particular. En consecuencia, pueden hacer arreglos para el viaje, el alojamiento, la comida y otros recursos.
4. Estimación de la demanda de viajes
Las demandas de viajes tienen sus raíces en el concepto económico de "demanda". La demanda turística generalmente significa llegadas y gasto de turistas. Puedes recopilar y analizar datos de llegada de turistas o datos de gasto en función de tu objetivo, ya sea maximizar las pisadas de turistas o maximizar el gasto. Por ejemplo, los planificadores de paquetes turísticos pueden personalizar sus planes para adaptarse a los bolsillos de los turistas de un país de origen en particular. Digamos que si el gasto promedio de los turistas del país XYZ es mayor, entonces tal vez las juntas nacionales de turismo puedan planificar promover agresivamente el turismo en los EE. UU. E incluso planificar con los proveedores de servicios y los planificadores de paquetes turísticos para reducir los precios. Esto puede catalizar positivamente la afluencia de turistas.
5. Gestión de ingresos
Los hoteles y restaurantes pueden tener información sobre tasas de ocupación, reservas actuales, precios, etcétera, y combinarla con datos externos como condiciones climáticas, vacaciones escolares, eventos locales, información de vuelos, etcétera para pronosticar eficazmente las demandas y elaborar estrategias para maximizar los ingresos. Por ejemplo, subir sensiblemente los precios.
6. Gestión de marca, seguimiento de la competencia & experiencia del cliente
El 91% de los clientes jóvenes confía en las reseñas en línea. Hoy en día, las RRSS son tan poderosas que un tweet negativo de un influencer puede reducir drásticamente los ingresos de una empresa. Es importante monitorear la imagen de tu marca manteniendo un toque en las RRSS, blogs y plataformas de reseñas en línea. En una nota positiva, también puedeS monitorear lo que a los clientes les gusta de tu servicio y resaltarlo en tus campañas de marketing, mejorarlo aún más, etcétera. No solo pueded analizar los sentimientos de los clientes sobre tu marca, sino también
Monitorea a tus competidores
Analiza las estrategias de precios de los competidores y pon el precio que deseas a tus servicios inteligentemente.
7. Marketing personalizado
La diversidad, el ocio, los viajes de negocios, las reuniones con familiares, etcétera, son los principales factores que influyen en las personas para viajar. Si conoces la intención detrás de los viajes, puedes personalizar tus estrategias de marketing para obtener más ventas. Cuantos más datos calificados tengas, mejor podrás ejecutar un marketing personalizado dirigido.
8. Bots de viaje inteligentes
El uso de big data para PNL es un caso de uso independiente de la industria. El big data textual de las RRSS se pueden utilizar bien para alimentar algoritmos de aprendizaje automático. Dado que estas publicaciones en las RRSS relacionadas con el turismo son en su mayoría de turistas, es fácil desarrollar bots inteligentes orientados al cliente para abordar sus preguntas en un idioma que los turistas entiendan.
Desafíos de Big Data en la industria del turismo
Ciberseguridad & Privacidad de datos:
Las herramientas de web scraping han facilitado muchísimo la extracción de macrodatos turísticos de la web. Pero el big data también tiene sus desafíos. Con una mayor dependencia de los macrodatos turísticos, los riesgos de violaciones de datos son igualmente altos. Con cada violación, la confianza y las marcas se ponen en riesgo. La gobernanza y la ética de los datos es otra gran preocupación relacionada con el big data turístico.
Analizar datos no estructurados
Aunque es fácil raspar y recopilar datos utilizando herramientas de raspado web, la web está llena de datos erróneos y no estructurados que son difíciles de analizar. La eficiencia de los algoritmos ML sigue siendo un desafío.
Conclusión
La OMT ha pronosticado 1.800 millones de llegadas de turistas internacionales para 2030. Aprovechar con éxito el big data y otras tecnologías de transformación digital será clave para desbloquear y aprovechar nuevos canales de crecimiento en la industria del turismo. En esta información, te brindamos una perspectiva en profundidad de "Big Data en el turismo", cómo extraer datos de viajes y turismo, casos de uso de big data en el turismo, desafíos, etcétera. Con los avances tecnológicos, estamos viendo un flujo sin precedentes en el comportamiento de los clientes, las operaciones comerciales y la forma en que las personas viven y se comunican. Un tweet puede afectar a las empresas de formas impredecibles. Es importante tomar decisiones comerciales calculadas, validadas y basadas en pruebas.
0 notes