
ramsey-elbasheer
Machine Learning RSS
Ramsey Elbasheer
5147 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

pesosaludableucc2-blog
Peso Saludable 2

jejes-world
Join my little world

shittily-reviews-books
ShittyBooks

the-colossal
I Am Confusion

hockey-prose
I’ll Text You, Okay?
Text
Tips and Tricks in Machine Learning with Python to Avoid Data Leakage
https://cdn-images-1.medium.com/max/2600/0*XG1eZQ6WVIyzs-I-
Original Source Here
Tips and Tricks in Machine Learning with Python to Avoid Data Leakage
Writing a machine learning algorithm more efficiently
Photo by AbsolutVision on Unsplash
This article will become the very interesting one, we will talk about the tips and tricks used in machine learning to avoid data leakage. Many beginners learn machine learning algorithms just by splitting the data and feed the training data to the classifier. Oh! wait for a second, it looks way more simple for beginners but it’s way deeper to clear more things before we do modeling.
In machine learning, Data Leakage is shared information or data in the training process that relates with target feature i.e. highly correlated independent features to target feature cause the leakage.
It causes less accuracy on real-world data. To improve the leakage problem in machine learning there are some tips as shown below:
Never do data preprocessing before the train-test split of data.
Never use fit_transform to test set.
We should use transform on both train and test sets. The fit_transform for a train set and transform for the test set.
We should use pipeline from sklearn, it is well used in parameter tuning and cross-validation.
Example with python
After the train-test split, we should use standard scaling.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=random_state)
Now its time to use standard scaling
scaler = StandardScaler()
X_train_transformed = scaler.fit_transform(X_train)
model = LinearRegression().fit(X_train_transformed, y_train)
mean_squared_error(y_test, model.predict(X_test))
In the above example we noticed that the test data is not transformed so, it may affect the accuracy.
X_test_transformed = scaler.transform(X_test)
mean_squared_error(y_test, model.predict(X_test_transformed))
It is same with categorical data with train and test set after splitting.
one_hot_en = OneHotEncoder(handle_unknown='ignore', sparse=False)
one_hot_cols_train = pd.DataFrame(one_hot_en.fit_transform(X_train[cat_cols]))
one_hot_cols_test = pd.DataFrame(one_hot_en.transform(X_test[cat_cols]))
# One-hot encoding removed index; put it back
one_hot_cols_train.index = X_train.index
one_hot_cols_test.index = X_test.index
Using the pipeline method in machine learning to get a less chance of skipping some steps in transformation.
from sklearn.pipeline import make_pipeline
model = make_pipeline(StandardScaler(), LinearRegression())----------------------------------------------------------------
model.fit(X_train, y_train)
#output:
Pipeline(steps=[('standardscaler', StandardScaler()),
('linearregression', LinearRegression())])----------------------------------------------------------------
mean_squared_error(y_test, model.predict(X_test))
More Tips
When we save our model we use pickle but when the object is a very large numpy array then use the joblib method in some cases.
When we work on categorical data we should use MAE score in different cases to check which case score is less for the more efficient algorithm.
Heat maps also show the highly correlated features that can use leakage problems.
Tips in Support Vector Machine
To avoid the copy of the large Numpy dense input data then it is suggested to use SGDClassifier.
It is good practice to increase the size of the kernel cache size.
It is advisable to set the regularization parameter.
The invariant nature of SVM suggests scaling the data before modeling.
To make the training time short, we should use the shrinking parameter.
Tips in K-nearest neighbor
Select a good search technique.
Choose the distance metrics for a better and fast search.
Tips in K-means
Data points should be based on similarities.
Choose the proper k value with the elbow method.
I hope you like the article. Reach me on my LinkedIn and twitter.
Recommended Articles
NLP — Zero to Hero with Python
2. Python Data Structures Data-types and Objects
3. Data Preprocessing Concepts with Python
4. Principal Component Analysis in Dimensionality Reduction with Python
5. Fully Explained K-means Clustering with Python
6. Fully Explained Linear Regression with Python
7. Fully Explained Logistic Regression with Python
8. Basics of Time Series with Python
9. Data Wrangling With Python — Part 1
10. Confusion Matrix in Machine Learning
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Debate over accuracy of AI transcription services rages on
https://venturebeat.com/wp-content/uploads/2020/07/Working-from-home.GettyImages-1219924018-e1615216740861.jpg?zoom=3&resize=578%2C291&strip=all
Original Source Here
Join Transform 2021 for the most important themes in enterprise AI & Data. Learn more.
Transcription service companies continue to make claims about their AI, but in the absence of any formal set of benchmarks for natural language processing (NLP), most of those claims lack the context required to make a precise apples-to-apples comparison.
Dialpad, for example, recently announced that its Voice Intelligence AI technology has surpassed rivals in terms of both keyword and general accuracy. Along with Google, IBM, Microsoft, Cisco, Chorus.ai, Otter.ai, Avaya, Zoom, and Amazon Web Services (AWS), Dialpad provides end users with automated speech recognition (ASR) and NLP capabilities that can be applied to voice calls and videoconferencing sessions in real time.
An analysis of general word and keyword accuracy Dialpad published claims it achieves a word accuracy rating of 82.3% and a keyword accuracy rating of 92.5%. That’s compared to 79.8% for word accuracy and 90.9% for the Google Enhanced service. However, neither service is being evaluated using the same words and keywords running at the same time and spoken precisely in the same way. Dialpad created a collection of test sets that contain audio and the accompanying transcript, which is considered the “ground truth” of what was said in the audio. The company sent the audio to each service evaluated and received a transcript back, which it then compared to the ground truth. Dialpad then calculated the number of errors to determine an accuracy percentage.
In spite of these efforts, it can still be challenging to draw a definitive conclusion concerning how accurate one ASR is over another for specific use cases. There has been work to establish a set of benchmarks like the General Language Understanding Evaluation (GLUE) effort that seeks to evaluate ASRs based on accuracy within the context of a sentence. There are also initiatives such as Fisher and Switchboard to create standard datasets that academics have made to evaluate ASR systems. Thus far, however, no benchmark consensus has emerged. Even if such a consensus is reached, the jargon that is employed across industries tends to vary. AI transcription services that would be applied in, for example, the health care sector will need to be trained to understand specific nomenclature.
Less clear is to what degree such claims are likely to have a meaningful impact on any decision to standardize transcription services. It’s still early as far as transcription services are concerned, so most end user expectations are not all that high, said Zeus Kerravala, founder and principal analyst for ZK Research. “At this stage, a lot of end users expect there to be errors,” Kerravala said.
Dialpad contends that it will gradually become more apparent that embedding ASR capabilities within a communications platform will prove superior to approaches that rely on application programming interfaces (APIs) to access a speech-to-text service from a cloud service provider. The company acquired TalkIQ in 2018, an approach that has enabled the company to embed these capabilities as a set of microservices that run natively on its core communications platforms, Dialpad CEO Craig Walker said.
After continuously updating its platform over the last several years, the company has now analyzed more than 1 billion minutes of voice calls, Walker said. Each of those calls has enabled the Voice AI technology created by TalkIQ to both transcribe conversations more accurately and surface sentiment analytics in real time. The Dialpad contact center platform, for example, can recognize when sentiment turns negative during a call and alert a manager. “It becomes part of the workflow,” Walker said.
Organizations can also create their own custom dictionary of terms that the Voice Intelligence AI platform will learn to address use cases that might be unique to an industry or lexicon only employed in a specific region, Walker said.
It’s not clear to what degree organizations are evaluating accuracy as a criterion for selecting one conversational AI platform versus another. Avaya and other rivals are employing a mix of AI engines developed internally with services their platforms call externally via an API. However, Walker said it will continue to become apparent that conversational AI engines that run natively within a platform are not only more efficient but also less costly to implement because the amount of systems integration effort required is sharply reduced. There is no need to first set up and then maintain APIs to call an external cloud service, Walker said.
Regardless of the platform employed, the level of data mining applied to voice calls in real time is about to substantially increase. Previously, data mining could only be applied after a call was recorded and transcribed into text. A sentiment analytics report would then be generated long after the initial call or video conference ended.
The fact that voice calls are now being analyzed in real time is likely to have a profound impact on how individuals interact with one another. In many cases, one of the reasons individuals still prefer to make voice calls instead of sending an email is that they don’t necessarily want the substance of those communications to be recorded.
Regardless of the intent, however, the days when voice calls were exempt from the level of analytics already being applied to other communications mediums are clearly coming to an end.
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact.
Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
up-to-date information on the subjects of interest to you
our newsletters
gated thought-leader content and discounted access to our prized events, such as Transform
networking features, and more
Become a member
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Deep Learning — The Subfield of Machine Learning.

Original Source Here
Deep Learning — The Subfield of Machine Learning.
Deep learning is an artificial intelligence (AI) function that imitates the workings of the human brain in processing data and creating patterns for use in decision making. Deep learning is a subset of machine learning in artificial intelligence that has networks capable of learning unsupervised from data that is unstructured or unlabeled. Also known as deep neural learning or deep neural network.
How Deep Learning Works
Deep learning has evolved hand-in-hand with the digital era, which has brought about an explosion of data in all forms and from every region of the world. This data, known simply as big data, is drawn from sources like social media, internet search engines, e-commerce platforms, and online cinemas, among others. This enormous amount of data is readily accessible and can be shared through fintech applications like cloud computing.
Important: Deep learning unravels huge amounts of unstructured data that would normally take humans decades to understand and process.
Deep Learning vs. Machine Learning
One of the most common AI techniques used for processing big data is machine learning, a self-adaptive algorithm that gets increasingly better analysis and patterns with experience or with newly added data.
Deep learning, a subset of machine learning, utilizes a hierarchical level of artificial neural networks to carry out the process of machine learning. The artificial neural networks are built like the human brain, with neuron nodes connected together like a web. While traditional programs build analysis with data in a linear way, the hierarchical function of deep learning systems enables machines to process data with a nonlinear approach.
A Deep Learning Example
Using the fraud detection system mentioned above with machine learning, one can create a deep learning example. If the machine learning system created a model with parameters built around the number of dollars a user sends or receives, the deep-learning method can start building on the results offered by machine learning.
Each layer of its neural network builds on its previous layer with added data like a retailer, sender, user, social media event, credit score, IP address, and a host of other features that may take years to connect together if processed by a human being. Deep learning algorithms are trained to not just create patterns from all transactions, but also know when a pattern is signalling the need for a fraudulent investigation. The final layer relays a signal to an analyst who may freeze the user’s account until all pending investigations are finalized.
Key Take-Aways
1] Deep learning is an AI function that mimics the workings of the human brain in processing data for use in detecting objects, recognizing speech, translating languages, and making decisions.
2] Deep learning AI is able to learn without human supervision, drawing from data that is both unstructured and unlabeled.
3] Deep learning, a form of machine learning, can be used to help detect fraud or money laundering, among other functions.
“AI winters were not due to imagination traps, but due to lack of imaginations. Imaginations bring order out of chaos. Deep learning with deep imagination is the road map to AI springs and AI autumns.”
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
15 Habits I Stole from Highly Effective Data Scientists

Original Source Here
1. Stay up to date with technology.
How many current data science technologies arose only in the last ten or so years? Pretty much most of them.
By entering into the realm of data science with the motivation that you’re going to take a good crack at it, you’ve relegated yourself to a lifetime of constant learning. Don’t worry, it’s not as bleak as it sounds.
However, what should be kept in the back of your mind at all times is that to remain relevant in the workforce, you need to stay up to date with technology. So, if you’ve been doing data analysis with MATLAB your whole career, try learning to code in Python. If you’ve been creating your visualizations with Matplotlib, try using Plotly for something fresh.
How to implement this habit: Take an hour every week (or as much time as you can spare), and experiment with new technologies. Figure out which technologies are relevant by reading blog posts, and pick a couple you would like to add to your stack. Then, create some personal projects to learn how to use the new technologies to the best of their abilities.
2. Maintain proper documentation.
I always seem to be blessed with getting to read and deal with code that has terrible documentation and no supporting comments to help me understand what the heck is going on.
Part of me used to chalk it up to the whistful meanderings of programmers, until one day, I realized that it’s just the sign of a bad programmer.
All good programmers I’ve dealt with are those who provide clear, concise documentation to support their work and litter their programs with helpful comments to describe what certain lines of code are doing. This is especially pertinent for data scientists who are using complex algorithms and machine learning models to solve problems.
How to implement this habit: Take some time to either read good code documentation or articles on how to write good code documentation. To practice, write documentation for old personal projects, or take some time to revamp the documentation of your current projects. Since a good portion of the data science world runs on Python, check out this really well-written article on how to document Python code:
3. Be involved in data science communities.
The stereotype that developers are pasty-skinned social outcasts who lock themselves into solitude to write code destined for world domination is an outdated generalization that doesn’t reflect the modern complexities of the tech industry as a whole.
“Nobody is an island.” — the favorite quote of many data scientists
The intricacies of data science have made it such that a large support network of professionals both within and outside the data science community is necessary to solve the variety of problems that made data scientists necessary.
However, the importance of community doesn’t just stop at the professional level. With the data science field expanding, it’s necessary to help pave the way for future analysts and engineers so they too can make an impact and further support other data scientists.
With the “sexiness” of the data science field diminishing, the only way to make necessary changes will be to start a community-wide movement that inspires the industry to change for the better.
How to implement this habit: Become a mentor, write informative blog posts, join data science forums and help answer questions, start a Youtube channel to share your experiences, enter Kaggle competitions and hackathons, or create courses to help future data scientists learn the skills they need to break into the industry.
4. Regularly refactor your code.
Refactoring is the process of cleaning up your code without changing its original function. While refactoring is a process born from necessity in software development situations, refactoring can be a useful habit for data scientists.
My mantra when refactoring is “less is more”.
I find that when I initially write code to solve data science problems, I usually throw good coding practices out of the door in favor of writing code that works when I need it to. In other words, a lot of spaghetti code happens. Then, after I get my solution to work, I’ll go back and clean up my code.
How to implement this habit: Take a look at old code and ask if the same code could be written more efficiently. If so, take some time to educate yourself on best coding practices and look for ways where you can shorten, optimize, and clarify your code. Check out this great article that outlines best practices for code refactoring:
5. Optimize your workspace, tools, and workflow.
There are so many productivity-enhancing extensions for IDEs out there that, surprisingly, some people haven’t chosen to optimize their workflows yet.
This habit is so unique to everyone that it really comes to down determining which tools, workspaces, and workflows make you the most effective and efficient data scientist you could be.
How to implement this habit: Once a year (or more often if that works better for you), take stock of your overall effectiveness and efficiency, and determine where you could improve. Perhaps this means working on your machine learning algorithms first thing in the morning, or sitting on an exercise ball instead of a chair, or adding a new extension to your IDE that will lint your code for you. Experiment with different workspaces, tools, and workflows until you enter your optimal form.
6. Focus on understanding business problems.
From what I’ve seen, data science is 75% understanding business problems and 25% writing models to figure out how to solve them.
Coding, algorithms, and mathematics are the easy part. Understanding how to implement them so they can solve a specific business problem, not so much. By taking more time to understand the business problem and the objectives you’re trying to solve, the rest of the process will be much smoother.
To understand the problems facing the industry you’re working in, you need to do a little investigation to gather some context with which to support your knowledge of the problems you’re trying to solve. For instance, you need to understand what makes the customers of a particular business tick, or the specific goals an engineering firm is trying to reach.
How to implement this habit: Take some time to research the specific company you’re working for and the industry that they’re in. Write a cheat sheet that you can refer to, containing the major goals of the company, and the issues it may face within its specific industry. Don’t forget to include algorithms that you may want to use to solve business problems or ideas for machine learning models that could be useful in the future. Add to this cheat sheet whenever you discover something useful and soon you’ll have a treasure trove of industry-related tidbits.
7. Adopt a minimalist style.
No, not in life. In your code and your workflow.
It’s often argued that the best data scientists use the least amount of code, the least amount of data, and the simplest algorithms to get the job done.
Though by minimalist I don’t immediately want you to assume scarcity. Often when someone discusses the importance of minimalism in code that leads people to try to develop outrageous solutions that use only a few lines of code. Stop that. Yes, it’s impressive, but is that really the best use of your time?
Instead, once you get comfortable with data science concepts, begin to look for ways that you can optimize your code to make it simple, clean, and short. Use simple algorithms to get the job done, and don’t forget to write re-usable functions to remove redundancies.
How to implement this habit: As you progress as a data scientist, begin to push yourself to write more efficient solutions, write less code, and use simpler algorithms and models to get the job done. Learn how to shorten your code without reducing its effectiveness, and leave plenty of comments to explain how contracted versions of code works.
8. Use functions to eliminate complexity and redundancy.
I’ll be the first to admit that I severely neglect functions when I’m writing data analysis code for the first time. Spaghetti code fills my IDE as I struggle to reason my way through different analyses. If you looked at my code you would probably deem it too far gone and volunteer to take it out behind the barn to put it out of its misery.
Once I’ve managed to cobble together a half-decent result, I’ll then go back to try to fix the equivalent of a bad accident. By packaging my code into functions, I quickly remove unnecessary complexities and redundancies. If that’s the only thing I do to my code, then I will already have simplified it to a point that I can revisit the solution and understand how I got to that point.
How to implement this habit: Don’t forget the importance of functions when writing code. It’s often said that the best developers are lazy developers because they figure out how to create solutions that don’t require much work. After you’ve written a solution, go back and bundle redundant or complex code into functions to help organize and simplify your code.
9. Apply test-driven development methods.
Test-driven development (TDD) is a software development principle that focuses on writing code with incremental improvements that are constantly tested. TDD runs on a “Red, Green, Refactor” system that encourages developers to build a test suite, write implementation code, and then optimize the codebase.
TDD can be implemented successfully by data scientists to produce analytics pipelines, develop a proof of concept, work with data subsets, and ensure that functioning code isn’t broken during the development process.
How to implement this habit: Study up on test-driven development, and determine whether or not this technique can add something to your workflow. TDD isn’t the perfect answer for every problem, but it can be useful if implemented thoughtfully. Check out this article that gives a great description of TDD and offers an example of how to implement it into data science projects:
10. Make small, frequent commits.
Ever make a pull request and have your computer blow up with error messages and issues coming out of the wazoo? I have. It sucks.
During those moments when you feel like introducing whoever made such a large commit to your fist, take a breath, and remember that this person obviously didn’t take the time to implement good habits growing up.
What’s the golden rule of team-based software development? Make small, frequent commits.
How to implement this habit: Get into the practice of frequently committing your code changes and just as regularly making pull requests to get the latest code. Every change you or another person makes could break the whole project, so it’s important to make small changes that are easy to revert and likely only affect one part or layer of the project.
11. Make self-development a priority.
Depending on who you ask, the industry either has too many data scientists or too few.
Regardless of whether the industry is becoming saturated or arid, you will be competing with tons of highly qualified, and often over-qualified, candidates for a single job. This means that in the lead-up to applying for jobs, you need to have already developed the habit of self-improvement. Today, everyone is obsessed with upskilling, and for good reason. This trend should be no exception to data scientists.
How to implement this habit: Make a skill inventory and see how you stack up to the requirements employers include in job postings. Are you a Pythonista who can efficiently use relevant libraries such as Keras, NumPy, Pandas, PyTorch, TensorFlow, Matplotlib, Seaborn, and Plotly? Can you write a memo detailing your latest findings and how they can improve the efficiency of your company by 25%? Are you comfortable with working as part of a team to complete a project? Identify any shortcomings and find some good online courses or resources to bolster your skills.
12. Begin a project with the end in mind.
In 7 Habits of Highly Effective People, Stephen Covey discusses the principle of “beginning with the end in mind”.
To effectively relate this to data science projects, you need to ask yourself in the planning phase of a project what the desired outcome of the project is. This will help shape the path of the project and will give you a roadmap of outcomes that need to be met to reach the final goal. Not only that but determining the outcome of the project will give you an idea of the feasibility and sustainability of the project as a whole.
How to implement this habit: Begin each project with a planning session that lays out exactly what you hope to achieve at the end of the development period. Determine which problem you will be attempting to solve, or which piece of evidence you are trying to gather. Then, you can begin to answer feasibility and sustainability questions that will shape the milestones and outcomes of your project. From there, you can start writing code and machine learning models with a clear plan in place to guide you to the end of your project.
13. Understand so that you can be understood.
After attempting unsuccessfully to prepare a freshman lecture on why spin-V2 particles obey Fermi-Dirac statistics, Richard Feynman famously said “I couldn’t reduce it to the freshman level. That means we really don’t understand it.” Known as “The Great Explainer”, Feynman left a legacy that data scientists can only hope to emulate.
Data science, the art of using data to tell a compelling story, is only successful if the storyteller understands the story they are trying to tell. In other words, it’s your task to understand so that you can be understood. Developing this habit early on of understanding what you’re trying to accomplish, such that you can share it with someone else to a fair level of comprehension, will make you the most effective data scientist in the room.
How to implement this habit: Use The Feynman Technique to develop a deep level of understanding of the concepts you’re trying to discover and the problems you’re trying to solve. This method aligns itself well with the data science process of analyzing data and then explaining the results to generally non-data science stakeholders. In short, you refine your explanation of the topic to such a point that you can explain it in simple, non-jargon terms that can be understood by anyone.
14. Read research papers.
In a field dominated by Masters and Ph.D. holders, research papers are often used to share industry news and insight.
Research papers are useful ways to see how others are solving problems, widen our perspectives, and keep up to date with the latest trends.
How to implement this habit: Pick one or two research papers to read every week that are relevant to your current work or to technologies that you’re interested in pursuing or studying. Try to set aside time for this literature review every week to make this a priority. Become familiar with the Three-Pass Approach to reading research papers, which helps you gather pertinent information quickly. To really solidify your understanding of the papers, try to implement something that you learned from your reading into a personal project, or share what you learned with work colleagues.
15. Be open to change.
The world of data science is changing rapidly, from the technologies used to the goals being attained. Don’t be that data scientist who is stuck in their ways, unwilling to change.
Not only does being open to change force you to continue improving as a professional, but it also keeps you relevant in a quickly changing industry that will spit you out the moment you fall behind.
How to implement this habit: Whenever a new technology or practice makes the news, take a test-drive and see what that new technology or practice brings to the table. Even if you just read the documentation, you can keep yourself up-to-date on the changing trends of the industry. Furthermore, you can bring a perspective on the technology to your company and help them navigate technological changes and advances. Being that person in the office with your ear to the ground can help you stay ahead of the curve, and can also help you guide your team and company to better, more efficient solutions.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
MultiLabel Classification of sexual harassment personal stories. #MeToo

Original Source Here
5.Selection of right performance metric : 📏
F1-Score = 2 * (precision * recall) / (precision + recall)
In case of multilabel classification we have two types in calculating F1-Scores-
Macro Averaged F1-Score : In this case we simply calculate F1-Scores of each class individually and take the mean of F1_score to get overall F1-Score.We have 3 classes in our case so, we calculate precision and recall on individual classes and take mean of them to calculate Macro F1-score
Macro-Precision=(Precision 1+Precision 2+Precision 3)/3
Macro-Recall=(Recall 1+Recall 2+Recall 3)/3
Macro-F1= 2 * (Macro-Precision* Macro-Recall) / (Macro-Precision+ Macro- Recall)
Micro Averaged F1-Score : In this case we calculate the precision and recall on entire classes by summing up all the TP’s and Type Errors instead of doing them on individual class. Then we calculate the F1-Score as Harmonic mean of precision and recall.
Micro-Precision=(TP 1+TP 2 + TP 3)/(TP 1+FP 1+TP 2+FP 2 +TP 3+FP 3)
Micro-Recall= (TP 1+TP 2 + TP 3)/(TP 1+FN 1+TP 2+FN 2 + TP 3+FN 3)
Micro-F1=2 *(Micro-Precision* Micro-Recall)/(Micro-Precision+Micro- Recall)
Hamming loss : It is the fraction of labels that are classified incorrectly.
Ex: if 2 labels were classified incorrectly out of 3. Hamming loss = 2/3
Exact math ratio : It indicates the percentage of samples that have all their labels classified correctly. It only cares about correct classification and ignores partially correct classifications.
Here, classification of each description class is very important so we will use macro F1-Score as our performance metric. Because macro F1-score treats all the classes with equal importance’s whereas Micro F1-score only concentrates on all the classes combinedly.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Announcing the Second Wave of ODSC East 2021 Speakers

Original Source Here
Announcing the Second Wave of ODSC East 2021 Speakers
ODSC East 2021 is a little more than a month away, and we know that the most exciting part of the event is learning from a diverse cohort of speakers, researchers, founders, and practitioners from under the AI and data science umbrella. This year, we’re expanding our reach into new focus areas as well, aiming to showcase the diverse potential of AI across industries. To help you get excited about the event ahead, here are a few recently added ODSC East 2021 speakers that we’re excited to learn from this March 30th to April 1st.
A New Measurements-Based Approach to Machine Learning: Dr. Gerald Friedland | CTO & Co-Founder / Adjunct Professor, Electrical Engineering and Computer Sciences | Brainome / University of California, Berkeley
In this talk, Gerald will discuss an entirely new and different approach to supervised machine learning — one that is rooted in measurements. We will explain how this new approach (which is actually as old as science itself) can be used to solve difficult machine learning problems, many of which have previously been out of reach.
An Automatic Finite-Sample Robustness Metric: Can Dropping a Little Data Change Conclusions?: Tamara Broderick, PhD | Associate Professor | MIT
This session proposes a method to assess the sensitivity of data analyses to the removal of a small fraction of the data set. Our metric, which we call the Approximate Maximum Influence Perturbation, approximately computes the fraction of observations with the greatest influence on a given result when dropped.
Data Mastering at Scale: Mike Stonebraker, PhD | A.M. Turing Award Laureate, Professor, Co-Founder | MIT CSAIL, Tamr
As enterprise data grows exponentially, decades of technologies have failed to address the challenge of large data volume and variety and unintended data silos. In this talk, Michael Stonebraker dives into why the data accessibility gap exists and the leading methods to solve this data problem.
The Clinician’s AI Partner: Augmenting Clinician Capabilities Across the Spectrum of Healthcare: Serena Yeung, PhD | Assistant Professor of Biomedical Data Science | Stanford University
In this talk, Serena will discuss the potential of AI to function as a partner to clinicians, and augment their capabilities across the spectrum of healthcare delivery. With an emphasis on AI capabilities for visual reasoning, she will present examples and ongoing work towards building clinician and AI partnerships in settings ranging from hospital treatment to remote care and beyond.
https://odsc.com/boston/
XAI — Explanation in AI: From Machine Learning to Knowledge Representation & Reasoning and Beyond: Freddy Lecue, PhD | Chief AI Scientist, Research Associate | Thales, Inria
The term XAI refers to a set of tools for explaining AI systems of any kind, beyond Machine Learning. Even though these tools aim at addressing explanations in the broader sense, they are not designed for all users, tasks, contexts and applications. This presentation will describe progress to date on XAI by reviewing its approaches, motivation, best practices, industrial applications, and limitations.
An Overview of Methods to Handle Missing Values: Julie Josse, PhD | Advanced Researcher | Inria
In this tutorial, we will review the main approaches and implementation (in R and python) to tackle the issue of missing data. We will start by the inferential framework, where the aim is to estimate at best the parameters and their variance in the presence of missing data.
Art of BERT: Unlock the Full Potential of BERT for Domain-Specific Tasks(TensorFlow): Thushan Ganegedara | Senior Data Scientist, AI&ML Instructor | QBE Insurance, DataCamp
In this workshop, you will go beyond just using BERT and explore techniques to suit it for the domain-specific task at hand. By the end of this workshop, you will understand the types of data used by the model(s), how to combine BERT with downstream models, and advanced techniques to get even more impressive results.
A/B Testing for Data Science Using Python: Mary C Boardman, PhD | Senior Data Scientist, Instructor | TI Health, University of South Florida
In this workshop, you will have familiarity with the types of questions A/B testing can answer, how to design your own experiment, and what to watch out for on a conceptual level. You will also learn how to randomize control and test groups in Python before you conduct the experiment and analyze/test the results after the experiment ends.
Register now for ODSC East 2021
These are only a few of the many ODSC East 2021 speakers who will present their expertise this March. There’s still time to register now for 30% off before ticket prices go up — don’t miss your chance to improve your data science game!
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
4 Ways to Improve Class Imbalance for Image Data

Original Source Here
Adjustment #3: Resampling specific classes
A traditional way to combat large class imbalances in machine learning is to adjust class representation in the training set.
Oversampling infrequent classes is augmenting entries from the minority classes to match the quantity of the majority classes. This may be performed several ways, such as by generating synthetic data or by essentially copying entries from the minority class (e.g. via sklearn’s `resample` or TensorFlow’s tf.data sampler or PyTorch’s WeightedRandomSampler). The downside is that it can result in overfitting of the oversampled classes.
Undersampling frequent classes is removing entries from the majority classes so they match the quantity within the minority classes. The downside is that, by removing data points, you may remove valuable information or lead to poor generalization for real-world data. Or the imbalance may be so bad that the result of undersampling would be too small of a dataset.
Oversampling vs. Undersampling (image by author)
Note: both of these changes should occur after splitting data into train and validation sets to ensure that no data in the validation set is included in the training set.
For this example dataset, we implemented undersampling by selectively including tiles in the final training dataset. Labels contained in each image tile were counted and stored in a dataframe. We then created a sorting procedure to either include or discard each tile. All images containing at least one instance of a minority label (anything besides “Building” and “Small Cars”) were included in the training dataset. Then, to round out the dataset, we also included 10% of the tiles containing only the most frequent classes. No tiles with zero labels were included.
Change in object count by class. (image by author)
Bonus: tile curation also makes training more efficient.
Besides increasing average precision for minority classes, we’ve also decreased training time (by decreasing the dataset size) while only removing mostly redundant information.
Another boon to curating which tiles are included in training is that you can weed tiles that contain zero bounding boxes. With aerial photography, the original full-scale image can sometimes contain only 5–10 annotations, which leads to a significant number of “empty” tiles. A model trained on too many empty tiles may learn to predict no bounding boxes as the optimal solution.
Across use cases and types of content, many large scale images contain dead space that can be removed before training. For example, look how many tiles of a digitized pathology slide are 100% white:
Example digital pathology slide from PAIGE.ai.
So, when you have large raw images guaranteed to include white space, it’s often better to start thinking of the tiled dataset as the new training data. You can start exploring and cleaning it out with more granular control.
→ Worth it? Yes.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
5 Feature Selection Method from Scikit-Learn you should know
https://cdn-images-1.medium.com/max/2600/0*Biay7he5U46nqMLl
Original Source Here
3. Recursive Feature Elimination (RFE)
Recursive Feature Elimination or RFE is a Feature Selection method utilizing a machine learning model to selecting the features by eliminating the least important feature after recursively training.
According to Scikit-Learn, RFE is a method to select features by recursively considering smaller and smaller sets of features. First, the estimator is trained on the initial set of features, and the importance of each feature is obtained either through a coef_attribute or through a feature_importances_attribute. Then, the least important features are pruned from the current set of features. That procedure is recursively repeated on the pruned set until the desired number of features to select is eventually reached.
tl;dr RFE selects top k features based on the machine learning model that has coef_attribute or feature_importances_attribute from their model (Almost any model). RFE would eliminate the least important features then retrain the model until it only selects the K-features you want.
This method only works if the model has coef_ or features_importances_ attribute, if there are models out there having these attributes, you could apply RFE on Scikit-Learn.
Let’s use a dataset example. In this sample, I want to use the titanic dataset for the classification problem, where I want to predict who would survive.
#Load the dataset and only selecting the numerical features for example purposes
titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
X = titanic.drop('survived', axis = 1)
y = titanic['survived']
I want to see which features are the best to help me predict who would survive the titanic incident using RFE. Let’s use the LogisticRegression model to obtain the best features.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression# #Selecting the Best important features according to Logistic Regressionrfe_selector = RFE(estimator=LogisticRegression(),n_features_to_select = 2, step = 1)
rfe_selector.fit(X, y)
X.columns[rfe_selector.get_support()]
Image created by Author
By default, the number of features selected for RFE is the median of the total features, and the step (the number of features eliminated each iteration) is one. You could change it based on your knowledge or the metrics you used.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
The AI Monthly Top 3 — February 2021

Original Source Here
References
[1] Odei Garcia-Garin et al., Automatic detection and quantification of floating marine macro-litter in aerial images: Introducing a novel deep learning approach connected to a web application in R, Environmental Pollution, https://doi.org/10.1016/j.envpol.2021.116490.
[2] Rematas, K., Martin-Brualla, R., and Ferrari, V., “ShaRF: Shape-conditioned Radiance Fields from a Single View”, (2021), https://arxiv.org/abs/2102.08860
[3] Drew A. Hudson and C. Lawrence Zitnick, Generative Adversarial Transformers, (2021)
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Simulating the Hippocampus: How DeepMind Builds Neural Networks that can Replay Past Experiences
Original Source Here
Simulating the Hippocampus: How DeepMind Builds Neural Networks that can Replay Past Experiences
DeepMind researchers created a model to be able to replay past experiences in a way that simulate human imagination.
Source: https://www.nature.com/articles/nature14236
I recently started an AI-focused educational newsletter, that already has over 70,000 subscribers. TheSequence is a no-BS (meaning no hype, no news etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
The ability to use knowledge abstracted from previous experiences is one of the magical qualities of human learning. Our dreams are often influenced by past experiences and anybody that has suffered a traumatic experience in the past can tell you how constantly see flashes of it in new situations. The human brain is able to make rich inferences in the absence of data by generalizing past experiences. This replay of experiences is has puzzled neuroscientists for decades as its an essential component of our learning processes. In artificial intelligence(AI), the idea of neural networks that can spontaneously replay learned experiences seems like a fantasy. Recently, a team of AI researchers from DeepMind published a fascinating paper describing a method focused on doing precisely that.
In neuroscience, the ability of the brain to draw inferences from past experiences is called replay. Although many of the mechanisms behind experience replay are still unknown, neuroscience research have made a lot of progress explaining the cognitive phenomenon. Understanding the neuroscience roots of experience replay is essential in order to recreate its mechanics in AI agents.
The Neuroscience Theory of Replay
The origins of neural replay can be attributed to the work of researchers such as Nobel Prize in Medicine winner John O’Keefe. Dr. O’Keefe focus a lot of his work on explaining the role of the hippocampus in the creation of experiences. The hippocampus is a curved formation in the brain that is part of the limbic system and is typically associated with the formation of new memories and emotions. Because the brain is lateralized and symmetrical, you actually have two hippocampus. They are located just above each ear and about an inch-and-a-half inside your head.
Leading neuroscientific theories suggests that different areas of the hippocampus are related to different types of memories. For example, the rear part of the hippocampus is involved in the processing of spatial memories. Using a software architecture analogy, the hippocampus acts as a cache system for memories; taking in information, registering it, and temporarily storing it before shipping it off to be filed and stored in long-term memory.
Going back to Dr. O’Keefe’s work, one of his key contributions to neurociense research was the discovery of place cell, which are hippocampal cells that fire based on a specific environmental conditions such as a given place. One of Dr. O’Keefe’s experiments have, rats ran the length of a single corridor or circular track, so researchers could easily determine which neuron coded for each position within the corridor.
Source: https://www.nature.com/articles/nature14236
Following that experiment, the scientists recorded from the same neurons while the rats rested. During rest, the cells sometimes spontaneously fired in rapid sequences demarking the same path the animal ran earlier, but at a greatly accelerated speed. They called these sequences experience replay.
Source: https://www.nature.com/articles/nature14236
Despite we know that experience replay is a key part of the learning process, its mechanics are particularly difficult to recreated in AI systems. This is partly because experience replay depends on other cognitive mechanisms such as concept abstractions that are just started to make inroads in the world of AI. However, the team of DeepMind thinks that we have enough to get started.
Replay in AI
From the different fields of AI, reinforcement learning seems particularly well suited for the incorporation of experience replay mechanisms. A reinforcement learning agent, builds knowledge by constantly interacting with an environment which allows it to record and replay past experiences in a more efficient way than traditional supervised models. Some of the early works in trying to recreate experience replay in reinforcement learning agents dates back to a seminal 1992 paper that was influential in the creation of DeepMind’s DQN networks that mastered Atari games in 2015.
From an architecture standpoint, adding replay experiences to a reinforcement learning network seems relatively simple. Most solutions in the space relied on an additional replay buffer that records the experiences learned by the agent and plays them back at specific times. Some architectures choose to replay the experiences randomly while others use a specific preferred order that will optimize the learning experiences of the agent.
Source: https://www.nature.com/articles/nature14236
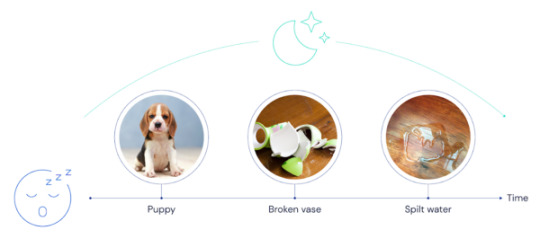
The way in which experiences are replayed in a reinforcement learning model play a key role in the learning experience of an AI agent. At the moment, two of the most actively experimented modes are known as the movie and imagination replays. To explain both modes let’s use an analogy from the DeepMind paper:
Suppose you come home and, to your surprise and dismay, discover water pooling on your beautiful wooden floors. Stepping into the dining room, you find a broken vase. Then you hear a whimper, and you glance out the patio door to see your dog looking very guilty.
A reinforcement learning agent based on the previous architecture will record the following sequence in the replay buffer.
Source: https://www.nature.com/articles/nature14236
The movie replay experience will replay the stored memories in the exact order in which they happened in the past. In this case, the replay buffer will replay the sequence e: “water, vase, dog” in that exact order. Architecturally, our model will use an offline learner agent to replay those experiences.
Source: https://www.nature.com/articles/nature14236
In the imagination strategy, replay doesn’t literally rehearse events in the order they were experienced. Instead, it infers or imagines the real relationships between events, and synthesizes sequences that make sense given an understanding of how the world works. The imagination theory skips the exact order of events and instead, infers the most correct association between experiences. In terms of the architecture of the agent, the replay sequence will depends on the current learned model.
Source: https://www.nature.com/articles/nature14236
Conceptually, neuroscience research suggests that that movie replay would be useful to strengthen the connections between neurons that represent different events or locations in the order they were experienced. However, the imagination replay might be foundational to the creation of new sequences. The DeepMind team pushed on this imagination replay theory and that the reinforcement learning agent was able to make generate remarkable new sequences based on previous experiences.
Source: https://www.nature.com/articles/nature14236
The current implementations of experience replay mostly follow the movie strategy based on its simplicity but researchers are starting to make inroads in models that resemble the imagination strategy. Certainly, the incorporation of experience replay modules can be a great catalyzer to the learning experiences of reinforcement learning agents. Even more fascinating is the fact that by observing how AI agents replay experiences we can develop new insights about our own human cognition.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
7 Useful Tricks for Python Regex You Should Know

Original Source Here
7 Useful Tricks for Python Regex to Learn
Write powerful and readable regex with them
Regular Expression (aka Regex) is one of the most important and common in any programming languages. Of course, this also applies to Python. Python has some quite unique regex usage patterns compared to other programming languages.
In this article, I’ve organised 7 useful tips regarding the regex in Python for you. They are either little tricks that can improve your productivity, solve some complex problems or improve your code readability. Hope they’ll be helpful!
1. Always use “r-string”
Photo by PublicDomainPictures on Pixabay
A lot of learners know that we should use “r-string” when we define a regex pattern. However, I found that many people don’t know the reason. Some learners think of the “r-string” as “regex string”, which is totally wrong. It should be “raw string” instead.
Just like other programming languages, Python has the “escape” mechanism in the strings. For example, when we want to have a string with quotes, they have to be escaped to let the compiler knows that the string should not finish, the quotes are just part of the string.
s = 'I\'m Chris'
Of course, not only the quotes can be escaped, there are a lot of other scenarios that we have to use backward slashes. For example, the \n in the following string will be interpreted as “new-line”.
print('a\nb')
If we mean to have the \n as part of the string, in other words, it should not be a new-line, we can use the “r-string” to tell Python do not interpret it.
print(r'a\nb')
When we write a regex pattern, sometimes we have to use slashes or other special characters. Therefore, to avoid that Python interpreter would interpret the string in the wrong way. It is always recommended to use “r-string” when defining a regex pattern.
Suppose we are searching for a pattern that several letters repeated after a few whitespaces, we can write the regex as follows.
re.search(r'(\w+)\s+\1', 'abc abc')
However, if we don’t use “r-string” here, the “group” indicator \1 won’t be recognised.
2. Use re.IGNORECASE Flag When Necessary
Photo by Kadres on Pixabay
The “flags” is kind of unique in Python Regex which not all the other programming languages would have. That is, create regex patterns that are case-insensitive.
Suppose we want to match a series of letters regardless of upper cases or lower cases. Of course, we can write it as follows.
re.search(r'[a-zA-Z]+', 'AbCdEfG')
This is definitely the standard way, and if we don’t add A-Z, it won’t match the whole string as expected.
However, Python provides such a way that we can focus more on the pattern itself and don’t need to worry about the cases of the letters. That is to use the re.IGNORECASE. You can even make it very short as re.I which does the same thing.
re.search(r'[a-z]+', 'AbCdEfG', re.IGNORECASE)
re.search(r'[a-z]+', 'AbCdEfG', re.I)
3. Use re.VERBOSE Flag to Improve the Readability
Photo by StockSnap on Pixabay
One of the major drawbacks of the regex is that it has poor readability. Usually, this is the comprising that we have to face. However, do you know that Python has a better way to improve the readability of a regex pattern string? That is to use the re.VERBOSE flag.
We can re-write the regex pattern in section 1. Originally, the pattern string has to be r'(\w+)\s+\1'. Well, this is not too bad, but suppose if we have a much more complex pattern, probably only the author can understand it. This is a very common issue with regex. However, with the verbose flag, we can write it this way.
re.search(r'''
(\w+) # Group 1: Match one or more letters, numbers or underscore
\s+ # Match one or more whitespaces
\1 # Match the Group 1 whatever it is
''', 'abc abc', re.VERBOSE)
It is exactly equivalent to the r'(\w+)\s+\1'. Please be noticed that the flag re.VERBOSE is a must-have thing if we want to write it in this way. Otherwise, the regex won’t work, of course.
Again, the flag has a short version — re.X.
4. Customise Substitution Behaviour of re.sub()
Photo by yongxinz on Pixabay
re.sub() is one of the most commonly used functions in Python regex. It tries to find a pattern (pattern)in a string (string) and replace it with the provided replacement string (repl).
re.sub() is one of the most commonly used functions in Python regex. It
re.sub(pattern, repl, string, count=0, flags=0)
For example, the following code will hide any mobile numbers in a string.
re.sub(r'\d', '*', 'User\'s mobile number is 1234567890')
Most developers will know the function up to here. However, fewer will know that we can actually use a function for the repl parameter.
For example, we still want to hide the user’s phone number, but we want to reveal the last 3 digits to make sure that the user has a clue what’s that number. We can define the following function first.
def hide_reserve_3(s):
return '*' * (len(s[0])-3) + s[0][-3:]
In this function, it takes a Python regex matched object (s) as the only argument. If there are multiple matches, the object s will contain multiple strings, so we need to loop it. But let’s be simple in the example just for demonstration purposes. s[0] would be the first phone number that has been matched.
Then, what we returned is the asterisks repeated several times. That is, if the length of the string is 10, then 10–3 = 7 asterisks will be returned. Then, the tailing 3 digits will be kept as-is, so it will be revealed.
Of course, a lambda function will also work. If the customised function is not too complex, using a lambda function is also fine.
re.sub(r'\d+', lambda s: '*' * (len(s[0])-3) + s[0][-3:], 'User\'s mobile number is 1234567890')
5. Use re.compile() to Enable Reusability
Photo by Shirley810 on Pixabay
Sometimes we may want to use a pattern multiple times. Most likely an r-string variable that can be reused is enough. However, if we want to use the pattern for different purposes, as well as want to improve the readability, using re.compile() might be a better choice.
pattern = re.compile('abc')
After defined the patter with re.compile(), we can use it as many time as needed.
6. Use Regex to Generate a Dictionary
Photo by PDPics on Pixabay
Sometimes we want to use regex to extract information from the strings that follow the same pattern. Then, put them into a dictionary is a pretty good idea. For example, the string "My name is Christopher Tao and I like Python." contains a person’s first name, last name and what language is preferred. If we have a lot of such string and want to extract information into a dictionary, we can actually do that without any overhead. The Python regex can achieve it out-of-the-box.
re.match(
r"My name is (?P<first_name>\w+) (?P<last_name>\w+) and I like (?P<preference>\w+).",
"My name is Christopher Tao and I like Python."
).groupdict()
In the regex pattern, we can define the “key” of the matched string, and then they will be automatically mapped into a dictionary.
We have to follow the pattern (?P<Y>...) where Y is the key name, ... is the defined regex pattern.
7. Use Regex Groups to Catch Repeat Patterns
Photo by StockSnap on Pixabay
We all know that regex can catch patterns. However, sometimes we want to catch the patterns in a more “advanced” way. For example, we don’t know what exactly the string will be matched by a pattern, but we want to catch the whole thing if it repeated multiple times.
In fact, the example we’ve used in section 1 and 3 exactly achieved this. Let me just provide another example. That is, we want to find out if there is a letter that has repeated in a string. If so, what it is?
pair = re.compile(r'''
.* # Match any number of any charaters
(.) # Match 1 character, whatever it is (except new-line), this will be the "group 1"
.* # Match any number of any charaters
\1 # Match the group 1
''', re.VERBOSE)pair.match('abcdefgc').groups()[0]
We need to first define the pattern. In here, I used the re.VERBOSE flag so it will be more readable and understandable. In the pattern, we use parentheses to define a “group”, then use this “group” \1 later to catch the “repeated” string.
Finally, we use the compiled regex pattern and try to match the string. Then, get the first element of the matched groups. It will be the first letter that has been found repeated in the string.
Summary
Photo by liming0759 on Pixabay
In this article, I have organised 7 litter tips that I think would be useful for some learners, as well as to supplement your knowledge if you never use the regex in such ways.
Let’s together write Python Regex with better readability with more convenience. Life is short, use Python!
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Delivery startup Refraction AI raises $4.2M to expand service areas
https://venturebeat.com/wp-content/uploads/2020/06/20200424_120944-scaled-e1593206157534.jpg?w=1200&strip=all
Original Source Here
Join Transform 2021 for the most important themes in enterprise AI & Data. Learn more.
Refraction AI, a company developing semi-autonomous delivery robots, today announced that it raised $4.2 million in seed funding led by Pillar VC. Refraction says that the proceeds will be used for customer acquisition, geographic expansion, and product development well into the next year.
The worsening COVID-19 health crisis in much of the U.S. seems likely to hasten the adoption of self-guided robots and drones for goods transportation. They require disinfection, which companies like Kiwibot, Starship Technologies, and Postmates are conducting manually with sanitation teams. But in some cases, delivery rovers like Refraction’s could minimize the risk of spreading disease. Recent market reports from Allied Market Research and Infiniti estimate that annual growth in the last-mile delivery sector over the next 10 years will exceed 14%, with the autonomous delivery segment projected to grow at over 24%, from $11.9 billion in 2021 to more than $84 billion globally by 2031.
Launched in July 2019, Refraction was cofounded by Matt Johnson-Roberson and Ram Vasudevan, both professors at the University of Michigan. Working alongside several retail partners, people within a few-mile radius can have orders delivered by Refraction’s REV-1 robot. After customers order through a dedicated website, Refraction’s employees load the vehicles at the store, and recipients receive text message updates, along with a code to open the robot’s storage compartment when it arrives.
REV-1, which is approximately the size of an electric bicycle and is legally categorized as an ebike, weighs approximately 100 pounds and stands roughly 4 feet tall, including its three wheels. It travels an average 10 to 15 miles per hour with a very short stopping distance, and the compartment holds about six bags of groceries.

REV-1’s perception system comprises 12 cameras, in addition to redundant radar and ultrasound sensors — a package the company claims costs a fraction of the lidar sensors used in rival rovers. The robot can navigate in inclement weather, including rain and snow, and it doesn’t depend on high-definition maps for navigation.
Prior to a partnership with Ann Arbor, Michigan-based Produce Station, REV-1 had been delivering exclusively from Ann Arbor restaurants, including Miss Kim and Tio’s Mexican Cafe, during lunchtime as part of a three-month pilot. The company charges the restaurant a flat $7.50, and Refraction’s over 500 customers pay a portion of that fee if the business chooses. (Tips go directly to Refraction’s partners.)
As of May 2020, Refraction had eight robots running in Ann Arbor, and it expects to have over 20 within the next few weeks. The latest investment brings its total raised to date to over $10 million.
“Last-mile delivery is the quintessential example of a sector that is ripe for innovation, owing to a powerful confluence of advancing technology, demographics, social values and consumer models. Conventional approaches have left businesses and consumers with few choices in this new environment as they struggle to keep pace with surging demand — burdened by the costs, regulatory, and logistical challenges of a legacy infrastructure,” Refraction CEO Luke Schneider, who took the helm in fall 2020, said in a press release. “Our platform uses technology that exists today in an innovative way, to get people the things they need, when they need them, where they live. And we’re doing so in a way that reduces business’ costs, makes roads less congested, and eliminates carbon emissions.”
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact.
Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
up-to-date information on the subjects of interest to you
our newsletters
gated thought-leader content and discounted access to our prized events, such as Transform
networking features, and more
Become a member
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
A quick Introduction to Responsible AI or rAI

Original Source Here
Source: Background vector created by starline — www.freepik.com
A quick Introduction to Responsible AI or rAI
An invitation to start thinking about the relevance of developing a responsible AI for business
More and more, Artificial intelligence (AI) supports profound decisions in our lives, our society, and our business.
The difference between AI and other decision technologies is that it ‘learns.’
And as AI becomes even more embedded in our lives, it will continue to become more autonomous, even acting without human supervision.
The implementation of AI requires careful management to avoid unintentional but significant damage to the reputation of the brand and employees, individuals, and society in general.
In this context, responsible AI or rAI ensures that these decisions are taken safely and reliably and proven and explained fashion.
Responsible AI is an essential standard that organizations must achieve because, almost universally, AI models can have a tremendous impact on someone’s quality of life.
The artificial intelligence model’s performance should not be the primary focus of academic data science research; these models must be explainable first, predictive second, and built within a Responsible AI standard. Otherwise, models can quickly become very complicated and cannot be explained.
The standard of rAI development is designed to enable organizations to understand and enforce four established management principles: accountability, justice, transparency, and, finally, responsibility.
Exploring the critical aspects of a Responsible AI
An excellent point to start is putting the question on whether organizations can figure out how to incorporate their cultural and societal values while outmaneuvering the competition, with businesses being pushed to move quickly-and even faster than they should-that pace comes at a cost?
When a company makes a mistake, the machines are held to account. Some areas of artificial intelligence will always be more relevant to our society than others.
Also, companies need to demonstrate how AI came to a specific decision, especially when it comes to highly regulated sectors, such as financial services and insurance. They need to be proactive in certifying their algorithms, clearly communicate their (learning) bias policies, and provide a clear explanation of why decisions were made, especially when there is a problem.
The advice here is simple: always consider using transparent and explainable algorithms for regulated / high-risk use cases, such as credit approvals, to make it easier for frontline employees to understand and explain customers’ decisions.
Why is it necessary to have a responsible AI in place?
Responsible AI is a critical standard that organizations must meet because, almost universally, AI models can have a tremendous impact on someone’s quality of life.
The artificial intelligence model’s performance should not be the primary focus of academic data science research; these models must be explainable first, predictive second, and built into the Responsible AI standard.
Otherwise, the models can quickly become very complicated and can not be explained.
To succeed in a highly automated but ever more conscious world, companies need to understand the challenges and potential risks posed by AI and ensure that its use in their organizations is ethical, meets regulatory requirements, and is supported by sound governance.
From the governance’s perspective, ethical AI means keeping the model in check and identifying its hidden biases.
A rigorous development process, coupled with latent resources’ visibility, helps ensure that analytical models work ethically. Latent characteristics must be continuously monitored for trends in changing environments.
It is a euphemism for “build right the first time.” operating environment models must be designed from the outset. The best method to build efficient models is to go the route described above. This dramatically reduces the error risk in the model, thus reducing expected business value while simultaneously impacting customers during analysis.
A framework for responsible development.
Several important AI companies like Microsoft, IBM, and many consultancy companies like Gartner, McKinsey, and others are working on define and implement frameworks that support the implementation of rAI.
One interesting approach, in my opinion, is defined by PwC in their “Practical Guide to Responsible Artificial Intelligence” report, that consists of a set of AI Responsibility tools designed to help companies focus on the five critical dimensions that need to be addressed in responsible AI projects, developments, and deployments.
They include governance, ethics, regulation; interpretation and explanation; robustness and security; impartiality, and justice.
The framework provides a sound and personalized methodology for technical decision-making and identifying, contextualizing, and mitigating ethical risks.
The toolkit supports AI assessment and development across the organization, enabling companies to develop high-quality, transparent, ethical, explainable, and trust-inspiring applications.
Challenges in the responsible AI roadmap
The most significant barrier to achieving the Responsible AI standard across all organizations is that most boards and CEOs do not have an adequate understanding of the analysis and its impact on business, including the damage that AI may cause.
And, as the use of AI is increasing in all sectors, government regulation is highly likely, if not inevitable. Rather than seeing regulation as punitive or inhibiting innovation, boards of directors, executives, and data scientists must accept Responsible AI as a beneficial and essential requirement.
Conclusion
There has also been a flood of news about racism, sexism, and infringements of privacy related to artificial intelligence. As a result, leaders are understandably concerned to ensure that the introduction of AI systems in their businesses does not have negative implications.
The best option, almost certainly, is not to stop using AI altogether-the value at stake can be too great, and getting to the AI early may have advantages.
What organizations should do is to ensure the responsible construction and implementation of AI, taking care to confirm that the implementation results are the same, that new levels of customization do not result in discrimination, that the acquisition and use of data does not compromise consumer privacy and that their organizations find a balance between the performance of the AI system and
Justice, openness, sympathy, and robustness must be the four key pillars of responsible AI policy for all businesses.
While organizations cannot slow down, there is a need to unite around a set of fundamental principles of respect for the customer and a sustainable (and probably profitable) vision for long-term success.
This is going to help to build a more fair AI environment for the world.
Where to learn more about Responsible AI on Medium
References
Responsible Ai — FICO. https://www.fico.com/blogs/what-responsible-ai
A practical guide to Responsible Artificial Intelligence (AI) — https://www.pwc.com/gx/en/issues/data-and-analytics/artificial-intelligence/what-is-responsible-ai/responsible-ai-practical-guide.pdf
The Importance Of Responsible AI In Our Fast-paced World …. https://tbtech.co/the-importance-of-responsible-ai-in-our-fast-paced-world/
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Google employee group urges Congress to strengthen whistleblower protections for AI researchers
https://venturebeat.com/wp-content/uploads/2019/10/google-ai-logo.jpg?fit=578%2C289&strip=all
Original Source Here
Join Transform 2021 for the most important themes in enterprise AI & Data. Learn more.
Google’s decision to fire its AI ethics leaders is a matter of “urgent public concern” that merits strengthening laws to protect AI researchers and tech workers who want to act as whistleblowers. That’s according to a letter published by Google employees today in support of the Ethical AI team at Google and former co-leads Margaret Mitchell and Timnit Gebru, who Google fired two weeks ago and in December 2020, respectively.
Firing Gebru, one of the best known Black female AI researchers in the world and one of few Black women at Google, drew public opposition from thousands of Google employees. It also led critics to claim the incident may have shattered Google’s Black talent pipeline and signaled the collapse of AI ethics research in corporate environments.
“We must stand up together now, or the precedent we set for the field — for the integrity of our own research and for our ability to check the power of big tech — bodes a grim future for us all,” reads the letter published by the group Google Walkout for Change. “Researchers and other tech workers need protections which allow them to call out harmful technology when they see it, and whistleblower protection can be a powerful tool for guarding against the worst abuses of the private entities which create these technologies.”
Google Walkout for Change was created by Google employees organizing to force change at Google. According to organizers, the 2018 global walkout involved 20,000 Googlers in 50 cities around the world.
The letter also urges academic conferences to refuse to review papers subjected to editing by corporate lawyers and to begin declining sponsorship from businesses that retaliate against ethics researchers. “Too many institutions of higher learning are inextricably tied to Google funding (along with other Big Tech companies), with many faculty having joint appointments with Google,” the letter reads.
The letter addressed to state and national lawmakers cites a VentureBeat article published two weeks after Google fired Gebru about potential policy outcomes that could include changes to whistleblower protection laws and unionization. That analysis — which drew on conversations with ethics, legal, and policy experts — cites UC Berkeley Center for Law and Technology co-director Sonia Katyal, who analyzed whistleblower protection laws in 2019 in the context of AI. In an interview with VentureBeat late last year, Katyal called them “totally insufficient.”
“What we should be concerned about is a world where all of the most talented researchers like [Gebru] get hired at these places and then effectively muzzled from speaking. And when that happens, whistleblower protections become essential,” Katyal told VentureBeat.
VentureBeat spoke with two sources familiar with Google AI ethics and policy matters who said they want to see stronger whistleblower protection for AI researchers. One person familiar with the matter said that at Google and other tech companies, people sometimes know something is broken but won’t fix it because they either don’t want to or don’t know how to.
“They’re stuck in this weird place between making money and making the world more equitable, and sometimes that inherent tension is very difficult to resolve,” that person, who spoke on condition of anonymity, told VentureBeat. “But I believe that they should resolve it because if you want to be a company that touches billions of people, then you should be responsible and held accountable for how you touch those billions of people.”
After Gebru was fired, that source described a sense among people from underrepresented groups at Google that if they push the envelope too far now they might be perceived as hostile and people will start filing complaints to push them out. They say this creates a feeling of “genuine unsafety” in the workplace and a “deep sense of fear.”
In addition to support for strengthening whistleblower laws, the person VentureBeat spoke with said for technology with the power to shape human lives, we need people throughout the design process with the power to overturn potentially harmful decisions and make sure models learn from mistakes.
“Without that, we run the risk of … allowing algorithms that we don’t understand to literally shape our ability to be human, and that inherently isn’t fair,” she said.
The letter also criticizes Google leadership for “harassing and intimidating” not only Gebru and Mitchell, but other Ethical AI team members as well. Ethical AI team members were reportedly told to remove their names from a paper under review at the time Gebru was fired. The final copy of that paper, titled “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” was published this week at AI ethics conference Fairness, Accountability, and Transparency (FAccT) and lists no authors from Google. But a copy of the paper VentureBeat obtained lists Mitchell as a coauthor of the paper, as well as three other members of the Ethical AI team, each with an extensive background in examining bias in language models or human speech. Google AI chief Jeff Dean questioned the veracity of the research represented in that paper in an email to Google Research. Last week, FAccT organizers told VentureBeat the organization has suspended sponsorship from Google.
The letter published today calls for action by academics and policymakers and follows changes to company diversity policy and reorganization of 10 teams within Google Research. These include Ethical AI, now under Google VP Marian Croak, who will report directly to AI chief Jeff Dean. As part of the change, Google will double staff devoted to employee retention and enact policy to engage HR specialists when certain employee exits are deemed sensitive. While Google CEO Sundar Pichai mentioned better de-escalation strategies as part of the solution in a companywide memo, in an interview with VentureBeat, Gebru called his memo “dehumanizing” and an attempt to characterize her as an angry Black woman.
A Google spokesperson told VentureBeat in an email following the reorganization last month that diversity policy changes were undertaken based on the needs of the organization, not in response to any particular team at Google Research.
In the past year or so, Google’s Ethical AI team has explored a range of topics, including the need for a culture change in machine learning and an internal algorithm auditing framework, algorithmic fairness issues specific to India, the application of critical race theory and sociology, and the perils of scale.
The past weeks and months have seen a rash of reporting about the poor experiences of Black people and women at Google, as well as reporting that raises concerns about corporate influence over AI ethics research. Reuters reported in December 2020 that AI researchers at Google were told to strike a positive tone when referring to “sensitive” topics. Last week, Reuters reported that Google will reform its approach to research review and additional instances of interference in AI research, including another paper about large language models. According to an email obtained by Reuters, a coauthor of that paper referred to edits made by Google’s legal department as “deeply insidious.”
In recent days, the Washington Post has detailed how Google treats candidates from historically Black colleges and universities in a separate and unequal fashion, and NBC News reported that Google employees who experienced racism or sexism were told by HR to “assume good intent” and encouraged to take mental health leave instead of addressing the underlying issues.
Instances of gender discrimination and toxic work environments for women and people of color have been reported at other major tech companies, including Amazon, Dropbox, Facebook, Microsoft, and Pinterest. Last month, VentureBeat reported that dozens of current and former Dropbox employees, particularly women of color, reported witnessing or experiencing gender discrimination. Former Pinterest employee Ifeoma Ozoma, who previously spoke with VentureBeat about whistleblower protections, helped draft legislation the Silenced No More Act in California last month. If passed, that law will allow employees to report discrimination even if they signed a non-disclosure agreement.
The letter published today is the latest in a range of correspondence sent to Google company leadership since Gebru was fired in December 2020. Thousands of Google employees signed a Google Walkout letter protesting the way Gebru was treated and “unprecedented research censorship.” That letter also called for a public inquiry into Gebru’s termination for the sake of Google users and employees. Members of Congress with records of proposing regulation like the Algorithmic Accountability Act, including Rep. Yvette Clark (D-NY) and Senator Cory Booker (D-NJ), also sent Google CEO Sundar Pichai an email questioning the way Gebru was fired, research integrity, and the steps the company takes to mitigate bias in large language models.
About a week after Gebru was fired, members of the Ethical AI team sent a letter to company leadership. According to a copy obtained by VentureBeat, Ethical AI team members demanded Gebru be reinstated, that Samy Bengio remain the direct report manager for the Ethical AI team, and states that reorganization is sometimes undertaken for “shunting workers who’ve engaged in advocacy and organizing into new roles and managerial relationships.” The letter described Gebru’s termination as having a demoralizing effect on the Ethical AI team and outlined a number of steps needed to re-establish trust. That letter also cosigns letters of support for Gebru from Google’s Black Researchers group and the DEI Working Group. A Google spokesperson told VentureBeat an investigation was carried out by outside counsel but declined to share details. That letter also demands Google maintain and strengthen its Ethical AI team, guarantee the integrity of independent research, and clarify its sensitive review process by the end of Q1 2021. And it calls for a public statement that guarantees research integrity at Google, including in areas tied to the company’s business interests, such as large language models or datasets like JFT-300, a dataset with over a billion labeled images.
In all, a Google spokesperson said Croak will oversee the work of about 100 AI researchers going forward. A source familiar with the matter told VentureBeat that a reorganization that brings Google’s numerous AI fairness efforts under a single leader makes sense and had been discussed before Gebru was fired. The question, they said, is whether Google will fund fairness testing and analysis.
“Knowing what these communities need consistently becomes hard when these populations aren’t necessarily going to make the company a bunch of money,” a person familiar with the matter told VentureBeat. “So yeah, you can put us all under the same team, but where’s the money at? Are you going to give a bunch of [head count] and jobs so that people can actually go do this work inside of products? Because these teams are already overtaxed — like these teams are really, really small in comparison to the products.”
Before Gebru and Mitchell, Google walkout organizers Meredith Whittaker and Claire Stapleton made claims of retaliation before leaving the company, as did employees who attempted to unionize, many of whom identify as queer. Shortly before Gebru was fired, the National Labor Review Board filed a complaint against Google that accuses the company of retaliating against and illegally spying on employees.
The AI Index, an annual accounting of performance advances and AI’s impact on startups, business, and government policy was released last week and found that the United States differs from other countries in its quantity of industry-backed research. The index report also called for more fairness benchmarks, found that Congress is talking about AI more than ever, and cites research finding only 3% of AI Ph.D. graduates in the U.S. are Black and 18% are women. The report concludes that AI ethics incidents — including Google firing Gebru — were among the most popular AI news stories of 2020.
VentureBeat requested an interview with Google VP Marian Croak, but a Google spokesperson declined.
In a related matter, VentureBeat analysis about the “fight for the soul of machine learning” was cited in a paper published this week at FAccT about power, exclusion, and AI ethics education.
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact.
Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
up-to-date information on the subjects of interest to you
our newsletters
gated thought-leader content and discounted access to our prized events, such as Transform
networking features, and more
Become a member
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Digital Artist: Creative Adversarial Networks(CAN)

Original Source Here
Digital Artist: Creative Adversarial Networks(CAN)
An interesting approach to make AI better at the art of “faking”!
Artificial Intelligence has surely stormed mankind in past years, the machines are extremely good at imitating what we tell them to do. But AI and creativity are counterparts, creativity is the abstract concept that is still missing from the core AI field.
For the past few years, researchers have been trying to decode the machine’s ability to mimic human-level intelligence to generate creative products such as jokes, poetry, problems, paintings, music, etc. The integral aim is to show that AI algorithms are in-fact intelligent enough to produce art without involving human artists but taking into account the human creative products in the learning process.
Several interesting algorithms like GANs(Generative Adversarial Networks) have been introduced to explore the creative space. GANs took the AI field by storm last year by generating human-like fake faces. It implements implicit techniques, that is, it learns with no data being passed to the network.
GANs constitute two networks i.e. Discriminator and Generator. The goal of the generator is to generate “fake” images and the discriminator tries to bust “fake” images developed by the Generator with the help of provided training data. The generator generates random images and asks for the feedback of the discriminator i.e. whether the discriminator finds it real or fake. At composure, the discriminator won’t be able to differentiate between randomly generated images and actual images in the training, and the goal of the generator is accomplished. Both Generator and Discriminator are independent of each other yet the iterative process helps both Discriminator and Generator to constantly learn from each other’s shortcomings to generate even better images.
GAN Workflow, Designed by Author
Let us infer that we are training our GAN on images of the painting. The motive of the generator is to generate images from training distribution so the discriminator can label them as “real”. Ultimately, the generator will start simulating existing art and the discriminator will be fooled right away, the model is generating the new images but the images are far from being called novel or creative. Thus, it can be concluded that GANs ability to generate creative ideas in their original design is limited.
The secret ingredient to developing an algorithm that can think creatively is to link their creative process to human art development throughout time. In simple words, we are trying to mimic exactly how humans develop art. Humans, throughout their lives, are exposed to the various art form and that’s where they get an impression for their new art, that’s the exact workflow we want our model to follow.
Experience and Create.
Principle of “Least Efforts”
CANs are derived from GANs and are based on Martindale’s principle, where he argued that the arts are made attractive by increasing their arousing potential that pushes it against its habituation. In simpler words, the art is perceived by viewers when they are presented with something exclusive yet associated with the historical pieces. But, the level of arousal must be controlled and not grow exponentially to gain a negative reaction.
The goal of the model is to satisfy “arousing potential” which refers to the levels of excitement in human beings. The level of arousal is least when a person is slept or relaxed and is highest when a person faces fury/danger/violence. Thus, too little arousing potential can be boring, and too much of it can activate the hostile situations. The situation can be best explained by the Wundt curve.
Wundt Curve, Source
Besides, if an artist keeps on producing a similar sort of work then it automatically decreases the arousing potential and leads to the viewer’s distaste. This can be concluded that habituation builds a constant pressure to generate a higher level of arousing potential.
The model tries to boost the arousing potential by increasing the “stylistic ambiguity” and still avoiding moving too far away from what we accept as art. The architecture of CANs is inherited from GANs with a slightly averted workflow. The discriminator is provided with a large set of art that have been experienced over mankind with their associated style labels as Renaissance, Baroque, Impressionism, Expressionism, etc. The generator is provided with no training example similar to GANs but is designed to accept two signals from the discriminator.
The first signal depicts whether the discriminator classifies the generated image as “art or not art”. In the traditional GANs, this signal will make the generator change the weights and try again to fool the discriminator by making it believe that the art is coming from the same custom distribution. But in CANs, the discriminator is trained over a large dataset of art, it can accurately distinguish the generated image as “art or not art” and will only ask the generator to converge into images that are already been accept as “art”.
The second signal tells the level of accuracy of the discriminator to classify generated art into already defined classes. If the generator, can generate a piece of art that can be regarded as “art” and can also be easily distinguished by the discriminator into an already defined class then it has successfully fooled the discriminator by generating some art that can be included in so-called humans accepted art. The generator tries to fool the discriminator by making it think of the generate piece as an “art” and also confuses it about the styles of work that has been generated.
CAN Workflow as described in official paper.
The two signals work opposite to each other, the first one pushes the generator to generate art that can be accepted as an “art” and if it succeeds it allows the discriminator to classify the images easily. However, the second signal will substantially penalize the generator for doing so, as the motive was to generate style-ambiguous art i.e. something that can’t be easily classified by discriminator but can still be regarded as “art”. Both signals work independently yet plays an essential role in perfecting each other just like in GAN.
Art-work generated by CANs, Source
Quantitative Validation
In the above table, the human viewers tried to rate four sets of artwork. The DCGAN is a standard GAN that mimics the established artwork closely but lacks creativity. The Abstract Expresionist dataset is a collection of art that was created between 1945 and 2007, whereas Art Basel 2016 constitutes images displayed in Art Basel 2016, a leading-edge art show.
Unsurprisingly, the images generated from CANs rank highest in arousal potential techniques i.e. Novelty, Surprising, Ambiguity, and Complexity. Also, they fooled the human viewers better into making them believe that the art was generated by humans.
References:
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
Keepsake — A Version Control For Machine Learning

Original Source Here
In this blog post, we’ll discuss about 🔥 Keepsake 🔥. Keepsake is a version control tool for machine learning experiments. I, myself as a machine learning engineer feel bewildered whenever I need to deploy a ML model in production. I have lot of questions before deploying like how to track the each model and its parameters, how to move back if some thing is screwed so many big and small questions.
Now, I think, I found a one good answer for all the problem. Keepsake.
From Keepsake Official Documents
Everyone uses version control for their software and it’s much less common in Machine Learning. This causes all sorts of problems: people are manually keeping track of things in spreadsheets, model weights are scattered on S3, and nothing is reproducible. It’s hard enough getting your own model from a month ago running, let alone somebody else’s.
So why isn’t everyone using Git? Git doesn’t work well with machine learning. It can’t handle large files, it can’t handle key/value metadata like metrics, and it can’t record information automatically from inside a training script. There are some solutions for these things, but they feel like band-aids.
In this post, I will walk you through how to use keepsake in your ML training and track there result in both local and cloud.
Installing Keepsake
pip install -U keepsake
How to use keepsake
Do everything you do normally while building a model. But just add two lines and one small yaml file.
Initialize an Experiment using keepsake
experiment = keepsake.init(
path=".",
# highlight-start
params={"learning_rate": learning_rate, "num_epochs": num_epochs},)
Creating Checkpoint for the Experiment
experiment.checkpoint(
path="model.pth",
step=epoch,
metrics={"loss": loss.item(), "accuracy": acc},
primary_metric=("loss", "minimize"),)
First line, we initialize keepsake.init(), which creates an experiment, each experiment is the one run of our training script. It stores hyperparameter and makes the copy of our training code and stores it into the path mentioned in the init().
Second line is experiment.checkpoint(), It creates an checkpoint for the experiment we are running. It tracks and saves all metrics we want to the path as mentioned in checkpoint function.
Complete script on Keepsake
Each experiment contains multiple checkpoints. You typically save your model periodically during training, because the best result isn’t necessarily the most recent one. A checkpoint is created just after you save your model, so Keepsake can keep track of versions of your saved model.
Storing Experiments
To store the experiments, we need to tell keepsake where to dump for experiment.
For Local : With below, we will create a hidden folder with name .keepsake and store the experiments, checkpoints and related metadata inside it. Store the below line in a .yaml in the same path as your training script.
repository: "file://.keepsake"
For Cloud : With below, we will pass all the experiments, checkpoints and related metadata inside a s3 bucket in your AWS setup. Here, keepsake-trial is the bucket name.
repository: "s3://keepsake-trial"
Running and Checkpoint Experiment
Executing main.py
Running Experiment
Creating checkpoints after each epoch and storing it in the s3 bucket.
Creating Checkpoint
Setting Up AWS For Keepsake
I am expecting people to know how to create a AWS account. Its as simple as creating Facebook account.
Use the Free tier provided by AWS.
Create bucket in S3, keep the required options default if you don’t know what to give while creating S3 bucket.
Go to your profile name on the top right corner and go to My Security Credentials for access key and secret key, store it in some text file if required.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes
Text
The Most Basic ‘String’ (Vibration) (Fluctuation) (Wave)
https://cdn-images-1.medium.com/max/2600/0*3zI1FxwSsiW4KMYc
Original Source Here
The Most Basic ‘String’ (Vibration) (Fluctuation) (Wave)
If zero, then one. (Meaning, if one, then, zero).
Photo by Juan Sisinni on Unsplash
In mathematics, in ‘string’ theory, we have an open and a closed ‘string.’
Open and Closed
Which is an ‘other’ way of saying we have a ‘zero’ and a ‘one.’
Zero and One
So, an intelligent observer should ask, where does the ‘zero’ and ‘one’ come from?
If zero, then one, means, if one, then zero. Which defines the most basic ‘string.’ (Neither zero nor one; both zero and one; zero and-or one; zero is one.)
This is proven, easily, by the abstraction: if circumference then diameter (meaning if diameter then circumference). This gives us the basis for ‘conditionality,’ and ‘similarity,’ explaining how ancient people were able to ‘build the pyramids.’
If zero, then one (if one, then zero).
That is, it’s basic math, which leads to basic physics, that the most basic string, is a self-referential recursion (quantum entanglement) called (the conservation of) a(n) (uber-basic) circle.
Conservation of the CIrcle
Explaining fluctuations, vibrations, and waves. Sometimes thought of as ‘quantum foam.’
Fluctuation. Vibration. Wave
Meaning, the circular relationship between circumference and diameter, produces the linear relationship between diameter and circumference. Explaining both repetition (reproduction) and sequence (reproduction). Basic ‘movement.’ Motion, in general. The (circular) relationship between general and specific.
Where zero is half-the-time one. Meaning zero is all-the-time one. Because it is impossible to have a half without a whole. A zero without a one.
Conservation of the Circle explains the circular relationship between ‘beginning’ and ‘end.’ Open and closed. Zero and one. Meaning, technically, no such thing as ‘quantum foam.’
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
Repost Source Here
0 notes