
Last Seen Blogs

gunshots-and-subway-trains
Soldier of Function

choochooitsmal
Your girl next door with the perfect legs


ikechan
ともっぴのブログ

ruden404
Welcome to my world :D
Text
How NLP can increase Financial Data Efficiency

The finance sector is driven to make a significant investment in natural language processing (NLP) in order to boost financial performance by the quickening pace of digitization. NLP has become an essential and strategic instrument for financial research as a result of the massive growth in textual data that has recently become widely accessible. Research reports, financial statistics, corporate filings, and other pertinent data gleaned from print media and other sources are all subject to the extensive time and resource analysis by analysts. NLP can analyze this data, providing chances to find special and valuable insights.
NLP & AI for Finance
The automation now includes a new level of support for workers provided by AI. If AI has access to all the required data, it can deliver in-depth data analysis to help finance teams with difficult decisions. In some situations, it might even be able to recommend the best course of action for the financial staff to adopt and carry out.
NLP is a branch of AI that uses machine learning techniques to enable computer systems to read and comprehend human language. The most common projects to improve human-machine interactions that use NLP are a chatbot for customer support or a virtual assistant.
Finance is increasingly being driven by data. The majority of the crucial information can be found in written form in documents, texts, websites, forums, and other places. Finance professionals spend a lot of time reading analyst reports, financial print media, and other sources of information. By using methods like NLP and ML to create the financial infrastructure, data-driven informed decisions might be made in real time.
NLP in finance – Use cases and applications
Loan risk assessments, auditing and accounting, sentiment analysis, and portfolio selection are all examples of finance applications for NLP. Here are some examples of how NLP is changing the financial services industry:
Chatbots
Chatbots are artificially intelligent software applications that mimic human speech when interacting with users. Chatbots can respond to single words or carry out complete conversations, depending on their level of intelligence, making it difficult to tell them apart from actual humans. Chatbots can comprehend the nuances of the English language, determine the true meaning of a text, and learn from interactions with people thanks to natural language processing and machine learning. They consequently improve with time. The approach employed by chatbots is two-step. They begin by analyzing the query that has been posed and gathering any data from the user that may be necessary to provide a response. They then give a truthful response to the query.
Risk assessments
Based on an evaluation of the credit risk, banks can determine the possibility of loan repayment. The ability to pay is typically determined by looking at past spending patterns and loan payment history information. However, this information is frequently missing, especially among the poor. Around half of the world’s population does not use financial services because of poverty, according to estimates. NLP is able to assist with this issue. Credit risk is determined using a range of data points via NLP algorithms. NLP, for instance, can be used to evaluate a person’s mindset and attitude when it comes to financing a business. In a similar vein, it might draw attention to information that doesn’t make sense and send it along for more research. Throughout the loan process, NLP can be used to account for subtle factors like the emotions of the lender and borrower.
Stock behavior predictions
Forecasting time series for financial analysis is a difficult procedure due to the fluctuating and irregular data, as well as the long-term and seasonal variations, which can produce major flaws in the study. However, when it comes to using financial time series, deep learning and NLP perform noticeably better than older methods. These two technologies provide a lot of information-handling capacity when utilized together.
Accounting and auditing
Businesses now recognize how crucial NLP is to gain a significant advantage in the audit process after dealing with countless everyday transactions and invoice-like papers for decades. NLP can help financial professionals focus on, identify, and visualize anomalies in commonplace transactions. When the right technology is applied, identifying anomalies in the transactions and their causes requires less time and effort. NLP can help with the detection of significant potential threats and likely fraud, including money laundering. This helps to increase the amount of value-creating activities and spread them out across the firm.
Text Analytics
Text analytics is a technique for obtaining valuable, qualitative structured data from unstructured text, and its importance in the financial industry has grown. Sentiment analysis is one of the most often used text analytics objectives. It is a technique for reading a text’s context to draw out the underlying meaning and significant financial entities.
Using the NLP engine for text analysis, you may combine the unstructured data sources that investors regularly utilize into a single, better format that is designed expressly for financial applicability. This intelligent format may give relevant data analytics, increasing the effectiveness and efficiency of data-driven decision-making by enabling intelligible structured data and effective data visualization.
Financial Document Analyzer
Users may connect their document finance solution to existing workflows using AI technology without altering the present processes. Thanks to NLP, financial professionals may now automatically read and comprehend a large number of financial papers. Businesses can train NLP models using the documentation resources they already have.
The databases of financial organizations include a vast amount of documents. In order to obtain relevant investing data, the NLP-powered search engine compiles the elements, conceptions, and ideas presented in these publications. In response to employee search requests from financial organizations, the system then displays a summary of the most important facts on the search engine interface.
Key Benefits of Utilizing NLP in Finance
Consider the following benefits of utilizing NLP to the fullest, especially in the finance sector:
Efficiency
It can transform large amounts of unstructured data into meaningful insights in real-time.
Consistency
Compared to a group of human analysts, who may each interpret the text in somewhat different ways, a single NLP model may produce results far more reliably.
Accuracy
Human analysts might overlook or misread content in voluminous unstructured documents. It gets eliminated to a greater extent in the case of NLP-backed systems.
Scaling
NLP technology enables text analysis across a range of documents, internal procedures, emails, social media data, and more. Massive amounts of data can be processed in seconds or minutes, as opposed to days for manual analysis.
Process Automation
You can automate the entire process of scanning and obtaining useful insights from the financial data you are analyzing thanks to NLP.
Final Thoughts
The finance industry can benefit from a variety of AI varieties, including chatbots that act as financial advisors and intelligent automation. It’s crucial to have a cautious and reasoned approach to AI given the variety of choices and solutions available for AI support in finance.
We have all heard talk about the potential uses of artificial intelligence in the financial sector. It’s time to apply AI to improve both the financial lives of customers and the working lives of employees. TagX has an expert labeling team who can analyze, transcribe, and label cumbersome financial documents and transactions.
0 notes
Text
MLOps and ML Data pipeline: Key Takeaways

If you have ever worked with a Machine Learning (ML) model in a production environment, you might have heard of MLOps. The term explains the concept of optimizing the ML lifecycle by bridging the gap between design, model development, and operation processes.
As more teams attempt to create AI solutions for actual use cases, MLOps is now more than just a theoretical idea; it is a hotly debated area of machine learning that is becoming increasingly important. If done correctly, it speeds up the development and deployment of ML solutions for teams all over the world.
MLOps is frequently referred to as DevOps for Machine Learning while reading about the word. Because of this, going back to its roots and drawing comparisons between it and DevOps is the best way to comprehend the MLOps concept.
MLOps vs DevOps
DevOps is an iterative approach to shipping software applications into production. MLOps borrows the same principles to take machine learning models to production. Either Devops or MLOps, the eventual objective is higher quality and control of software applications/ML models.
What is MLOps?
Machine Learning Operations is referred to as MLOps. Therefore, the function of MLOps is to act as a communication link between the operations team overseeing the project and the data scientists who deal with machine learning data.
For the development and improvement of machine learning and AI solutions, MLOps is a helpful methodology. By utilizing continuous integration and deployment (CI/CD) procedures with appropriate monitoring, validation, and governance of ML models, data scientists and machine learning engineers can work together and accelerate the speed of model creation and production by using an MLOps approach.
The key MLOps principles are:
Versioning – keeping track of the versions of data, ML model, code around it, etc.;
Testing – testing and validating an ML model to check whether it is working in the development environment;
Automation – trying to automate as many ML lifecycle processes as possible;
Reproducibility – we want to get identical results given the same input;
Deployment – deploying the model into production;
Monitoring – checking the model’s performance on real-world data.
What are the benefits of MLOps?
The primary benefits of MLOps are efficiency, scalability, and risk reduction.
Efficiency: MLOps allows data teams to achieve faster model development, deliver higher quality ML models, and faster deployment and production.
Scalability: Thousands of models may be supervised, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment thanks to MLOps’ extensive scalability and management capabilities. MLOps, in particular, makes ML pipelines reproducible, enables closer coordination between data teams, lessens friction between DevOps and IT, and speeds up release velocity.
Risk reduction: Machine learning models often need regulatory scrutiny and drift-check, and MLOps enables greater transparency and faster response to such requests and ensures greater compliance with an organization’s or industry’s policies.
Data pipeline for ML operations
One significant difference between DevOps and MLOps is that ML services require data–and lots of it. In order to be suitable for ML model training, most data has to be cleaned, verified, and tagged. Much of this can be done in a stepwise fashion, as a data pipeline, where unclean data enters the pipeline, and then the training, validating, and testing data exits the pipeline.
The data pipeline of a project involves several key steps:
Data collection:
Whether you source your data in-house, open-source, or from a third-party data provider, it’s important to set up a process where you can continuously collect data, as needed. You’ll not only need a lot of data at the start of the ML development lifecycle but also for retraining purposes at the end. Having a consistent, reliable source for new data is paramount to success.
Data cleansing:
This involves removing any unwanted or irrelevant data or cleaning up messy data. In some cases, it may be as simple as converting data into the format you need, such as a CSV file. Some steps of this may be automatable.
Data annotation:
Labeling your data is one of the most time-consuming, difficult, but crucial, phases of the ML lifecycle. Companies that try to take this step internally frequently struggle with resources and take too long. Other approaches give a wider range of annotators the chance to participate, such as hiring freelancers or crowdsourcing. Many businesses decide to collaborate with external data providers, who can give access to vast annotator communities, platforms, and tools for any annotating need. Depending on your use case and your need for quality, some steps in the annotation process may potentially be automated.
After the data has been cleaned, validated, and tagged, you can begin training the ML model to categorize, predict, or infer whatever it is that you want the model to do. Training, validation, and hold-out testing datasets are created out of the tagged data. The model architecture and hyperparameters are optimized many times using the training and validation data. Once that is finished, you test the algorithm on the hold-out test data one last time to check if it performs enough on the fresh data you need to release.
Setting up a continuous data pipeline is an important step in MLOps implementation. It’s helpful to think of it as a loop, because you’ll often realize you need additional data later in the build process, and you don’t want to have to start from scratch to find it and prepare it.
Conclusion
MLOps help ensure that deployed models are well maintained, performing as expected, and not having any adverse effects on the business. This role is crucial in protecting the business from risks due to models that drift over time, or that are deployed but unmaintained or unmonitored.
TagX is involved in delivering Data for each step of ML operations. At TagX, we provide high-quality annotated training data to power the world’s most innovative machine learning and business solutions. We can help your organization with data collection, Data cleaning, data annotation, and synthetic data to train your Machine learning models.
0 notes
Text
Implementation of Artificial Intelligence in Gaming

What is AI in Gaming?
AI in gaming is the use of artificial intelligence to create game characters and environments that are capable of responding to a player’s actions in a realistic and dynamic way. AI can be used to create believable characters that can interact with the player, create dynamic levels, and generate new gaming experiences. AI can even be used to create challenging opponents that require the player to think strategically.
AI Development in Gaming
AI development in gaming refers to the use of artificial intelligence (AI) to create non-player characters (NPCs) that can interact with players in a game environment. AI development is used in modern video games to create immersive and realistic gaming experiences. AI development has been used to create NPCs that can respond to players in various ways, such as offering advice and guidance. AI can also be used to create NPCs that can challenge players and offer a more realistic gaming experience. Additionally, AI development is used to create more complex and lifelike game environments, such as virtual worlds and cities. AI can also be used to create more intelligent game enemies that can react to players’ actions and strategies. AI development is also being used to create autonomous game characters that can act on their own or interact with players.
Features in AI Gaming include:
1. Dynamic Environments:
AI games can have dynamic environments that change in real-time. This allows for greater complexity and unpredictability compared to games that have a fixed environment.
2. AI Opponents:
AI opponents can be programmed to use a range of strategies to challenge the player and make the game more interesting.
3. Adaptive Learning:
AI games can learn from their mistakes and adjust their strategies over time to become more challenging.
4. Procedural Generation:
AI games can generate levels and opponents in real-time, making the game more unpredictable and providing an ever-changing challenge.
5. Natural Language Processing:
AI games can use natural language processing to interpret player commands and understand the player’s intent.
6. Real-Time Decision Making:
AI games can make decisions in real-time, allowing the game to be more responsive to the player’s actions.
7. Realistic Physics and Animation:
AI games can use realistic physics and animation to create a believable game world.
8. Audio Recognition:
AI games can use audio recognition to interpret player commands and understand the player’s intent.
How is AI used in Video Games?
Ai is used in video games to bring realism and challenge to the gaming experience. This can include non-player characters (NPCs) that react to the player’s actions, enemy units that use strategic decision-making, environment-specific behaviors, and more. AI can also be used to create and manage dynamic in-game events and levels, as well as to generate opponents that can adapt to the player’s skill level.
Application of AI in Games:
1. Autonomous Opponents:
Autonomous opponents are computer-controlled characters in a video game. AI can be used to create autonomous opponents that can adapt to the player’s behavior and provide a challenging gaming experience.
2. Pathfinding:
Pathfinding is a cornerstone of game AI and is used to help the characters and enemies move around the game environment correctly. AI techniques such as A* search and Dijkstra’s algorithm are used to calculate the best possible routes for characters to take.
3. Natural Language Processing:
Natural language processing (NLP) is a form of artificial intelligence that allows machines to understand and interpret human language. AI can be used to create virtual characters in games that are capable of understanding and responding to the player’s input in natural language.
4. Decision-Making and Planning:
AI can be used to create characters that can make decisions and plan actions based on the current game state. AI techniques such as Monte Carlo Tree Search and Reinforcement Learning are used to help characters make decisions in the most optimal way.
5. Procedural Content Generation:
Procedural content generation is a form of AI that can be used to generate content in games such as levels, items
Advantages of AI in Gaming:
1. Improved User Experiences:
Artificial Intelligence technology can be used to enhance the user experience in gaming by providing players with more engaging and immersive gameplay. AI can be used to generate more interesting scenarios, create more challenging puzzles, and provide better feedback to the player.
2. Increased Realism:
AI can be used to create more realistic environments, characters, and stories. This can lead to a more believable and engaging gaming experience.
3. Improved Performance:
AI can be used to optimize the performance of a game. AI can be used to analyze the user’s gaming experience and provide feedback on how to improve performance.
4. Greater Variety:
AI can be used to generate more diverse and interesting content. This can create more dynamic and exciting gaming experiences.
5. Improved Accessibility:
AI can be used to create more accessible gaming experiences. AI can be used to create more intuitive and user-friendly interfaces, making gaming more accessible to a wider range of players.
Top 5 AI Innovations in the Gaming Industry:
1. Autonomous AI Agents:
Autonomous AI agents are programmed to act independently in a virtual environment. These agents are able to interact with a game’s environment and other characters, as well as make decisions about when and how to act.
2. Natural Language Processing:
Natural language processing (NLP) is the ability of AI to understand and interpret human language. This technology is used in many video games to help players communicate with each other and the game itself.
3. Adaptive Difficulty:
Adaptive difficulty is a feature that allows the game to adjust its difficulty level based on the player’s performance. This helps keep the game interesting, as the challenge can be adjusted to match each player’s skill level.
4. Automated Level Design:
Automated level design is a technology that uses AI to create levels for video games. This allows developers to quickly and easily generate a variety of levels for their games.
5. AI-Driven NPCs:
Non-player characters (NPCs) are characters in a game that are controlled by the AI. This technology allows NPCs to act realistically and react to the player’s actions.
Conclusion:
AI in gaming has come a long way since its early days, and it will continue to evolve in the future. AI has changed the way games are designed, developed, and played, and has opened up new possibilities for gamers. It can help create immersive experiences, create smarter opponents, and create more realistic and varied gaming experiences. It will continue to be used to explore new ways of playing games, providing gamers with ever more exciting and engaging gaming experiences.
AI is being used in various aspects of gaming, from game design and development to helping players with strategy and tactics.AI can help game developers create games with more complex environments and have more intelligent opponents. It can also help players find better strategies and tactics to win games. AI can also be used to create games with more sophisticated storylines and narrative arcs. In the future, AI can be used to create virtual worlds with more diverse and complex populations, allowing for more immersive and dynamic gaming experiences.
0 notes
Text
Intelligent Document Processing Workflow and Use cases

Artificial Intelligence has stepped up to the front line of real-world problem solving and business transformation with Intelligent Document Processing (IDP) becoming a vital component in the global effort to drive intelligent automation into corporations worldwide.
IDP solutions read the unstructured, raw data in complicated documents using a variety of AI-related technologies, including RPA bots, optical character recognition, natural language processing, computer vision, and machine learning. IDP then gathers the crucial data and transforms it into formats that are structured, pertinent, and usable for crucial processes including government, banking, insurance, orders, invoicing, and loan processing forms. IDP gathers the required data and forwards it to the appropriate department or place further along the line to finish the process.
Organizations can digitize and automate unstructured data coming from diverse documentation sources thanks to intelligent document processing (IDP). These consist of scanned copies of documents, PDFs, word-processing documents, online forms, and more. IDP mimics human abilities in document identification, contextualization, and processing by utilizing workflow automation, natural language processing, and machine learning technologies.
What exactly is Intelligent Document Processing?
A relatively new category of automation called “intelligent document processing” uses artificial intelligence services, machine learning, and natural language processing to help businesses handle their papers more effectively. Because it can read and comprehend the context of the information it extracts from documents, it marks a radical leap from earlier legacy automation systems and enables businesses to automate even more of the document processing lifecycle.
Data extraction from complicated, unstructured documents is automated by IDP, which powers both back office and front office business operations. Business systems can use data retrieved by IDP to fuel automation and other efficiencies, including the automated classification of documents. Enterprises must manually classify and extract data from these papers in the absence of IDP. They have a quick, affordable, and scalable option with IDP.
How does intelligent document processing work?
There are several steps a document goes through when processed with IDP software. Typically, these are:
Data collection
Intelligent document processing starts with ingesting data from various sources, both digital and paper-based. For taking in digitized data, most IDP solutions feature built-in integrations or allow developing custom interfaces to enterprise software. When it comes to collecting paper-based or handwritten documents, companies either relies on its internal data or outsource the collection requirement to third party vendor like TagX who can handle the whole collection process for a specific IDP usecase.
Pre-processing
Intelligent document processing (IDP) can only produce trustworthy results if the data it uses is well-structured, accurate, and clean. Because of this, intelligent document recognition software cleans and prepares the data it receives before actually extracting it. For that, a variety of techniques are employed, ranging from deskewing and noise reduction to cropping and binarization, and beyond. During this step, IDP aims to integrate, validate, fix/impute errors, split images, organise, and improve photos.
Classification & Extraction
Enterprise documentation typically has multiple pages and includes a variety of data. Additionally, the success of additional analysis depends on whether the various data types present in a document are processed according to the correct workflow. During the data extraction stage, knowledge from the documents is extracted. Machine learning models extract specific data from the pre-processed and categorised material, such as dates, names, or numbers. Large volumes of subject-matter data are used to train the machine learning models that run IDP software. Each document’s pertinent entities are retrieved and tagged for IDP model training.
Validation and Analytics
The retrieved data is available to ML models at the post-processing phase. To guarantee the accuracy of the processing results, the extracted data is subjected to a number of automated or manual validation tests. The collected data is now put together into a finished output file, which is commonly in JSON or XML format. A business procedure or a data repository receives the file. IDP can anticipate the optimum course of action. IDP can also turn data into insights, automation, recommendations, and forecasts by utilising its AI capabilities.
Top Use Cases of Intelligent Document Processing
Invoice Processing
With remote work, processing bills has never been simpler for the account payable and human resources staff. Invoice collection, routing, and posting via email and paper processes results in high costs, poor visibility, and compliance and fraud risks. Also, the HR and account payable staff shares the lion’s part of their day on manual repetitive chores like data input and chasing information that leads to delay and inaccurate payment. However, intelligent document processing makes sure that all information is gathered is in an organised fashion, and data extraction in workflow only concentrates on pertinent data. Intelligent document processing assists the account payable team in automating error reconciliation, data inputs, and the decision-making process from receipt to payment. IDP ensures organizations can limit errors and reduce manual intervention.
Claims Processing
Insurance companies frequently suffer with data processing because of unstructured data and varying formats, including PDF, email, scanned, and physical documents. These companies mainly rely on a paper-based system. Additionally, manual intervention causes convoluted workflows, sluggish processing, high expenses, increased mistake, and fraud. Both insurers and clients must wait a long time during this entire manual process. However, intelligent document processing is a cutting-edge method that enables insurers to swiftly examine the large amount of structured and unstructured data and spot fraudulent activity. Insurance companies can quickly identify, validate, and integrate the data automatically and offer quicker claims settlement by utilising AI technologies like OCR and NLP.
Fraud Detection
Document fraud instances are increasing as a result of the processing of a lot of data. Additionally, the manual inspection of fraudulent documents and invoices is a time-consuming traditional procedure. Any fraudulent financial activity involving paper records may result in diminished client confidence and higher operating expenses. Therefore, implementing automated workflows for transaction validation and verification is essential to preventing fraudulent transactions. Furthermore, intelligent document processing has the ability to automatically identify and annotate questionable transactions for the fraud team. Furthermore, IDP frees the operational team from manual labour while reducing fraud losses.
Logistics
Every step of the logistics process, including shipping, transportation, warehousing, and doorstep consumer delivery, involves thousands of hands exchanging data. For manual processing by outside parties, this information must be authenticated, verified, cross-checked, and sometimes even re-entered. Companies utilize IDP to send invoices, labels, and agreements to vendors, contractors, and transportation teams at the supply chain level. IDP enables to read unstructured data from many sources, which eliminates the need for manual processing and saves countless hours of work. It also helps to handle the issue of document variability. IDP keeps up with enterprises as they grow and scale to handle larger client user bases due to intelligent automation of various document processing workflow components.
Medical records
It is crucial to keep patient records in the healthcare sector. In a particular situation, quick and easy access to information may be essential; as a result, it is crucial to digitize all patient-related data. IDP can now be used to effectively manage a patient’s whole medical history and file. Many hospitals continue to save patient information in manual files and disorganised paper formats that are prone to being lost. So it becomes a challenge for a doctor to sort through all the papers in the files to find what they’re looking for when they need to access a specific file. All medical records and diagnostic data may be kept in one location using an IDP, and only pertinent data can be accessed when needed.
The technologies behind intelligent document processing
When it comes to processing documents in a new, smart way, it all heavily relies on three cornerstones: Artificial intelligence, optical character recognition, and robotic process automation. Let’s get into a bit more detail on each technology.
Optical Character Recognition
OCR is a narrowly focused technology that can recognize handwritten, typed, or printed text within scanned images and convert it into a machine-readable format. As a standalone solution, OCR simply “sees” what’s there on a document and pulls out the textual part of the image, but it doesn’t understand the meanings or context. That’s why the “brain” is needed. Thus OCR is trained using AI and deep learning algorithms to increase its accuracy.
Artificial intelligence
Artificial intelligence deals with designing, training, and deploying models that mimic human intelligence. AI/ML is used to train the system to identify, classify, and extract relevant information using tags, which can be linked to a position or visual elements or a key phrase. AI is a field of knowledge that focuses on creating algorithms and training models on data so that they can process new data inputs and make decisions by themselves. So, the models learn to “understand” imaging information and delve into the meaning of textual data the way humans do.IDP heavily relies on such ML-driven technologies as
Computer Vision (CV)
CV utilizes deep neural networks for image recognition. It identifies patterns in visual data say, document scans, and classifies them accordingly. Computer vision uses AI to enable automatic extraction, analysis, and understanding of useful information from digital images. Only a few solutions leverage computer vision technology to recognize images/pictures within documents.
Natural Language Processing (NLP)
NLP finds language elements such as separate sentences, words, symbols, etc., in documents, interprets them, and performs a linguistic-based document summary. With the help of NLP, IDP solutions can analyze the running text in documents, understand the context, consolidate the extracted data, and map the extracted fields to a defined taxonomy. It can help in recognizing the sentiments from the text (e.g., from emails and other unstructured data) and in classifying documents into different categories. It also assists in creating summaries of large documents or data from charts using NLG by capturing key data points.
Robotic Process Automation
RPA is designed to perform repetitive business tasks through the use of software bots. The technology has proved to be effective in working with data presented in a structured format. RPA software can be configured to capture information from certain sources, process and manipulate data, and communicate with other systems. Most importantly, since RPA bots are usually rule-based, if there are any changes in the structure of the input, they won’t be able to perform a task.RPA bots can extend the intelligent process automation pipeline, executing such tasks as processing transactions, manipulating the extracted data, triggering responses, or communicating with other enterprises IT systems.
Conclusion
It is needless to say; the number of such documents will keep on piling up and making it impossible for many organizations to manage effectively. Organizations should be able to make use of this data for the benefit of businesses, but when it becomes so voluminous in physical documents gleaning insights from it will become even more tedious. With the use of Intelligent Document Processing, the time-consuming, monotonous, and tedious process is made simpler without any risks of manual errors. This way, data becomes more powerful even in varying formats and also helps organizations to ensure enhanced productivity and operational efficiency.
The implementation of IDP is not as easy. The big challenge is a lack of training data. For an artificial intelligence model to operate effectively, it must be trained on large amounts of data. If you don’t have enough of it, you could still tap into document processing automation by relying on third-party vendors like Tagx who can help you with the collection, classification, Tagging, and data extraction. The more processes you automate, the more powerful AI will become, enabling it to find ways to automate even more.
0 notes
Text
How Training Data is prepared for Computer Vision

As humans, we generally spend our lives observing our surroundings using optic nerves, retinas, and the visual cortex. We gain context to differentiate between objects, gauge their distance from us and other objects, calculate their movement speed, and spot mistakes. Similarly, computer vision enables AI-powered machines to train themselves to carry out these very processes. These machines use a combination of cameras, algorithms, and data to do so. Today, computer vision is one of the hottest subfields of artificial intelligence and machine learning, given its wide variety of applications and tremendous potential. Its goal is to replicate the powerful capacities of human vision.
Computer vision needs a large database to be truly effective. This is because these solutions analyze information repeatedly until they gain every possible insight required for their assigned task. For instance, a computer trained to recognize healthy crops would need to ‘see’ thousands of visual reference inputs of crops, farmland, animals, and other related objects. Only then would it effectively recognize different types of healthy crops, differentiate them from unhealthy crops, gauge farmland quality, detect pests and other animals among the crops, and so on.
How Does Computer Vision Work?
Computer Vision primarily relies on pattern recognition techniques to self-train and understand visual data. The wide availability of data and the willingness of companies to share them has made it possible for deep learning experts to use this data to make the process more accurate and fast.
Generally, computer vision works in three basic steps:
1: Acquiring the image Images, even large sets, can be acquired in real-time through video, photos, or 3D technology for analysis.
2: Processing and annotating the image The models are trained by first being fed thousands of labeled or pre-identified images. The collected data is cleaned according to the use case and the labeling is performed.
3: Understanding the image The final step is the interpretative step, where an object is identified or classified.
What is training data?
Training data is a set of samples such as videos and images with assigned labels or tags. It is used to train a computer vision algorithm or model to perform the desired function or make correct predictions. Training data goes by several other names, including learning set, training set, or training data set. It is used to train the machine learning model to get desired output. The model also scrutinizes the dataset repetitively to understand its traits and fine-tune itself for optimal performance.
In the same way, human beings learn better from examples; computers also need them to begin noticing patterns and relationships in the data. But unlike human beings, computers require plenty of examples as they don’t think as humans do. In fact, they don’t see objects or people in the images. They need plenty of work and huge datasets for training a model to recognize different sentiments from videos. Thus a huge amount of data needs to be collected for training
Types of training data
Images, videos, and sensor data are commonly used to train machine learning models for computer vision. The types of training data used include:
2D images and videos: These datasets can be sourced from scanners, cameras, or other imaging technologies.
3D images and videos: They’re also sourced from scanners, cameras, or other imaging technologies.
Sensor data: It’s captured using remote technology such as satellites.
Training Data Preparation
If you plan to use a deep learning model for classification or object detection, you will likely need to collect data to train your model. Many deep learning models are available pre-trained to detect or classify a multitude of common daily objects such as cars, people, bicycles, etc. If your scenario focuses on one of these common objects, then you may be able to simply download and deploy a pre-trained model for your scenario. Otherwise, you will need to collect and label data to train your model.
Data Collection
Data collection is the process of gathering relevant data and arranging it to create data sets for machine learning. The type of data (video sequences, frames, photos, patterns, etc.) depends on the problem that the AI model aims to solve. In computer vision, robotics, and video analytics, AI models are trained on image datasets with the goal of making predictions related to image classification, object detection, image segmentation, and more. Therefore, the image or video data sets should contain meaningful information that can be used to train the model for recognizing various patterns and making recommendations based on the same.
The characteristic situations need to be captured to provide the ground truth for the ML model to learn from. For example, in industrial automation, image data needs to collected that contains specific part defects. Therefore a camera needs to gather footage from assembly lines to provide video or photo images that can be used to create a dataset.
The data collection process is crucial for developing an efficient ML model. The quality and quantity of your dataset directly affect the AI model’s decision-making process. And these two factors determine the robustness, accuracy, and performance of the AI algorithms. As a result, collecting and structuring data is often more time-consuming than training the model on the data.
Data annotation
The data collection is followed by Data annotation, the process of manually providing information about the ground truth within the data. In simple words, image annotation is the process of visually indicating the location and type of objects that the AI model should learn to detect. For example, to train a deep learning model for detecting cats, image annotation would require humans to draw boxes around all the cats present in every image or video frame. In this case, the bounding boxes would be linked to the label named “cat.” The trained model will be able to detect the presence of cats in new images.
Once you have a good set of images collected you will need to label the images. Several tools exist to facilitate the labeling process. These include open-source tools such as labelImg and commercial tools such as Azure Machine Learning, which support image classification and object detection labeling. For large labeling projects, it is recommended to select a labeling tool that supports workflow management and quality reviews. These features are essential to ensure quality and efficiency in the labeling process. Labeling is a very tedious job. So companies prefer to outsource this to third-party labeling vendors like Tagx who take care of this whole labeling process.
What are the labels?
Labels are what the human-in-the-loop uses to identify and call out features that are present in the data. It’s critical to choose informative, discriminating, and independent features to label if you want to develop high-performing algorithms in pattern recognition, classification, and regression. Accurately labeled data can provide ground truth for testing and iterating your models.
Label Types of Computer Vision Data Annotation
Currently, most computer vision applications use a form of supervised machine learning, which means we need to label datasets to train the applications.
Choosing the correct label type for an application depends on what the computer vision model needs to learn. Below are four common types of computer vision models and annotations.
2D Bounding Boxes
Bounding boxes are one of the most commonly relied-on techniques for computer vision image annotation. It’s simple all the annotator has to do is draw a box around the target object. For a self-driving car, target objects would include pedestrians, road signs, and other vehicles on the road. Data scientists choose bounding boxes when the shape of target objects is less of an issue. One popular use case is recognizing groceries in an automated checkout process.
3D Bounding Boxes
Not all bounding boxes are 2D. Their 3D cousins are called cuboids. Cuboids create object representations with depth, allowing computer vision algorithms to perceive volume and orientation. For annotators, drawing cuboids means placing and connecting anchor points. Depth perception is critical for locomotive robots. Understanding where to place items on shelves involves an understanding of more than just height and width.
Landmark Annotation
Landmark annotation is also called dot/point annotation. Both names fit the process: placing dots or landmarks across an image, and plotting key characteristics such as facial features and expressions. Larger dots are sometimes used to indicate more important areas.
Skeletal or pose-point landmark annotations reveal body position and alignment. These are commonly used in sports analytics. For example, skeletal annotations can show where a basketball player’s fingers, wrist, and elbow are in relation to each other during a slam dunk.
Polygons
Polygon segmentation introduces a higher level of precision for image annotations. Annotators mark the edges of objects by placing dots and drawing lines. Hugging the outline of an object cuts out the noise that other image annotation techniques would include. Shearing away unnecessary pixels becomes critical when it comes to irregularly shaped objects, such as bodies of water or areas of land captured by autonomous satellites or drones.
Final thoughts
Training data is the lifeblood of your computer vision algorithm or model. Without relevant, labeled data, everything is rendered useless. The quality of the training data is also an important factor that you should consider when training your model. The work of the training data is not just to train the algorithms to perform predictive functions as accurately as possible. It is also used to retrain or update your model, even after deployment. This is because real-world situations change often. So your original training dataset needs to be continually updated.
If you need any help, contact us to speak with an expert at TagX. From Data Collection, and data curation to quality data labeling, we have helped many clients to build and deploy AI solutions in their businesses.
0 notes
Text
How Data Annotation is used for Speech Recognition
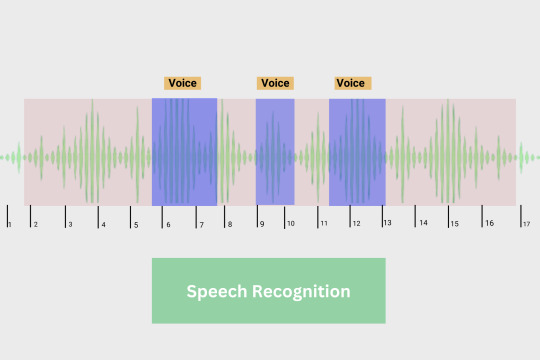
Speech recognition refers to a computer interpreting the words spoken by a person and converting them to a format that is understandable by a machine. Depending on the end goal, it is then converted to text or voice, or another required format. For instance, Apple’s Siri and Google’s Alexa use AI-powered speech recognition to provide voice or text support whereas voice-to-text applications like Google Dictate transcribe your dictated words to text.
Speech recognition AI applications have seen significant growth in numbers in recent times as businesses are increasingly adopting digital assistants and automated support to streamline their services. Voice assistants, smart home devices, search engines, etc are a few examples where speech recognition has seen prominence.
Data is required to train a speech recognition model because it allows the model to learn the relationship between the audio recordings and the transcriptions of the spoken words. By training on a large dataset of audio recordings and corresponding transcriptions, the model can learn to recognize patterns in the audio that correspond to different words and phonemes (speech sounds).
For example, if the model is trained on a large dataset of audio recordings of people speaking English, it will learn to recognize common patterns in the audio that corresponds to English words and phonemes. These patterns might include the frequency spectrum of different phonemes, the duration of different vowel and consonant sounds, and the context in which different words are used. By learning these patterns, the model can then take as input a new audio recording and use what it has learned to transcribe the spoken words in the audio. Without a large and diverse dataset of audio recordings and transcriptions, the model would not have enough data to learn these patterns and would not be able to perform speech recognition accuracy.
What is speech recognition data?
Speech recognition data refers to audio recordings of human speech used to train a voice recognition system. This audio data is typically paired with a text transcription of the speech, and language service providers are well-positioned to help.
The audio and transcription are fed to a machine-learning algorithm as training data. That way, the system learns how to identify the acoustics of certain speech sounds and the meaning behind the words.
There are many readily available sources of speech data, including public speech corpora or pre-packaged datasets, but in most cases, you will need to work with a data services provider to collect your own speech data through the remote collection or in-person collection. You can customize your speech dataset by variables like language, speaker demographics, audio requirements, or collection size.
The data collected need to be annotated for further training of the speech recognition model.
What is Speech or Audio Annotation?
For any system to understand human speech or voice, it requires the use of artificial intelligence (AI) or machine learning. Machine learning models that are developed to react to human speech or voice commands need to be trained to recognize specific speech patterns. The large volume of audio or speech data required to train such systems needs to go through an annotation or labeling process first, rather than being ingested in a raw audio file.
Effectively, audio or speech annotation is the technique that enables machines to understand spoken words, human emotions, sentiments, and intentions. Just like other types of annotations for image and video, audio annotation requires manual human effort where data labeling experts can tag or label specific parts of audio or speech clips being used for machine learning. One common misconception is that audio annotations are simply audio transcriptions, which are the result of converting spoken words into written words. Audio annotation goes beyond audio transcription, adding labeling to each relevant element of the audio clips being transcribed.
Speech annotation is the process of adding metadata to spoken language data. This metadata can include a transcription of the spoken words, as well as information about the speaker’s gender, age, accent, and other characteristics. Speech annotation is often used to create training data for natural language processing and speech recognition systems.
There are several different types of speech or audio annotation, including:
Transcription:
The process of transcribing spoken words into written text.
Part-of-speech tagging:
The process of identifying and labeling the parts of speech in a sentence, such as nouns, verbs, and adjectives.
Named entity recognition:
The process of identifying and labeling proper nouns and other named entities in a sentence, such as people, organizations, and locations.
Dialog act annotation:
The process of labeling the types of actions that are being performed in a conversation, such as asking a question or making a request.
Speaker identification:
The process of identifying and labeling the speaker in an audio recording.
Speech emotion recognition:
The process of identifying and labeling emotions that are expressed through speech, such as happiness, sadness, or anger.
Acoustic event detection:
The process of identifying and labeling specific sounds or events in an audio recording, such as the sound of a car horn or the sound of a person speaking.
These are just a few examples of the types of speech or audio annotation that can be performed. The specific types of annotation that are used will depend on the needs and goals of the natural language processing or speech recognition system being developed. Speech annotation can be a time-consuming and labor-intensive process, but it is an important step in the development of many natural language processing and speech recognition systems.
How to Annotate Speech Data
To perform audio annotation, organizations can use software currently available in the market. Free and open-source annotation tools exist that can be customized for your business needs. Alternatively, you can opt for paid annotation tools that have a range of features to support different types of annotation. Such paid annotation tools are generally supported by a team of professionals, who can configure the tool for your purpose. Another option would be to develop your own customized annotation tool within your organization. However, this can be slow and expensive and requires you to have an in-house team of annotation experts.
Companies that do not want to spend their resources on in-house annotation, can opt to outsource their work to an external service provider specializing in the annotation. Outsourcing may be the best choice for your organization, because service providers:
have a team of available data experts who are skilled in the time-intensive tasks of data cleaning and preparation that are required prior to data annotation
can often start immediately executing the type of labeling that your business needs
deliver high-quality data for your machine learning models and requirements
accelerate the scaling (and ROI) of your resource-intensive annotation initiatives
Use Cases of Speech Recognition
Speech recognition is a technology that allows computers to understand and interpret human speech. It has a wide range of applications, including:
Voice assistants:
Speech recognition is used in voice assistants, such as Apple’s Siri and Amazon’s Alexa, to allow users to interact with their devices using voice commands.
Dictation software:
Speech recognition can be used to transcribe spoken words into written text, making it easier for people to create documents and emails.
Customer service:
Speech recognition is used in customer service centers to allow customers to interact with automated systems using voice commands.
Education:
Speech recognition can be used to provide feedback to students on their pronunciation and speaking skills.
Healthcare:
Speech recognition is used in healthcare settings to transcribe doctors’ notes and to allow patients to interact with their electronic health records using voice commands.
Transportation:
Speech recognition is used in self-driving cars to allow passengers to give voice commands to the vehicle.
Home automation:
Speech recognition is used in smart home systems to allow users to control their appliances and devices using voice commands.
These are just a few examples of the many applications of speech recognition technology. It has the potential to revolutionize how we interact with computers and other devices, making it easier and more convenient for people to communicate with them.
Conclusion
With natural language processing (NLP) becoming more mainstream across business enterprises, the need for high-quality audio annotation services is being realized by organizations looking to build efficient machine-learning data models. Rather than developing in-house expertise, companies are finding that they are better served by outsourcing their annotation work to qualified third-party experts. TagX has extensive experience providing a variety of data annotation, cleansing, and enrichment services to its global clients. Want to know how data labeling could benefit your business? Please contact us anytime.
0 notes
Text
AI and Data Annotation for Manufacturing and Industrial Automation

Industrial automation refers to the use of technology to control and optimize industrial processes, such as manufacturing, transportation, and logistics. This can involve the use of automation equipment, such as robots and conveyor belts, as well as computer systems and software to monitor and control the operation of these machines. The goal of industrial automation is to increase the efficiency, accuracy, and speed of industrial processes while reducing the need for manual labor and minimizing the risk of errors or accidents.
Every manufacturer aims to find fresh ways to save and make money, reduce risks, and improve overall production efficiency. This is crucial for their survival and to ensure a thriving, sustainable future. The key lies in AI-based and ML-powered innovations. AI tools can process and interpret vast volumes of data from the production floor to spot patterns, analyze and predict consumer behavior, detect anomalies in production processes in real time, and more. These tools help manufacturers gain end-to-end visibility of all manufacturing operations in facilities across all geographies. Thanks to machine learning algorithms, AI-powered systems can also learn, adapt, and improve continuously.
Why use AI for the Manufacturing industry
There are several reasons why AI (artificial intelligence) can be helpful in industrial automation:
Improved accuracy:
AI algorithms can analyze large amounts of data and make decisions based on that analysis with a high degree of accuracy. This can help to improve the precision and reliability of industrial processes.
Enhanced efficiency:
AI-powered systems can work continuously without needing breaks, which can help to increase the overall efficiency of industrial operations.
Reduced costs:
By automating tasks that would otherwise need to be performed manually, AI can help to reduce labor costs and increase profitability.
Improved safety:
AI can be used to monitor industrial processes and alert operators to potential hazards or problems, which can help to improve safety in the workplace.
Increased speed:
AI-powered systems can often process and analyze data much faster than humans, which can help to speed up industrial processes
Use cases of Manufacturing AI
There are many potential use cases for AI in manufacturing and industry, including:
Quality control:
AI can be used to inspect products and identify defects or errors, improving the overall quality of the finished product.
Supply chain optimization:
AI can be used to optimize the flow of materials and components through the supply chain, reducing waste and increasing efficiency.
Predictive maintenance:
AI can be used to predict when equipment is likely to fail, allowing maintenance to be scheduled before problems occur.
Process optimization:
AI can be used to optimize manufacturing processes, such as by identifying bottlenecks, improving efficiency, and reducing waste.
Personalized product customization:
AI can be used to customize products to individual customer specifications, increasing the value of the finished product.
Energy management:
AI can be used to optimize the use of energy in industrial processes, reducing costs and improving sustainability.
Data Annotation to implement Manufacturing AI
Data annotation plays a key role in many applications of AI in manufacturing. In order for AI algorithms to be able to accurately analyze and make decisions based on data, the data must be properly labeled and organized. This is where data annotation comes in. By categorizing and labeling data, it becomes easier for AI algorithms to understand and make sense of the data, improving their accuracy and effectiveness.
Data annotation is an essential part of many AI applications in manufacturing, as it allows AI algorithms to effectively analyze and make decisions based on data, leading to improved efficiency, accuracy, and effectiveness.
Quality control:
Data annotation can be used to label images of products according to their defects or errors. This allows an AI algorithm to learn what constitutes a defect, and to identify defects in new images with a high degree of accuracy.
Supply chain optimization:
Data annotation can be used to label data points according to their position in the supply chain and their characteristics, such as their location, type, and quantity. This allows an AI algorithm to learn the patterns that are associated with efficient supply chain management, and to suggest ways to optimize the flow of materials and components.
Predictive maintenance:
Data annotation can be used to label data points according to the type of equipment, the maintenance history of the equipment, and other relevant factors. This allows an AI algorithm to learn the patterns that are associated with equipment failures, and to predict when maintenance will be needed in the future.
Process optimization:
Data annotation can be used to label data points according to the characteristics of the manufacturing process, such as the type of equipment being used, the materials being processed, and the output of the process. This allows an AI algorithm to learn the patterns that are associated with efficient manufacturing, and to suggest ways to optimize the process.
Personalized product customization:
Data annotation can be used to label data according to the specific characteristics and preferences of individual customers. This allows an AI algorithm to learn the patterns that are associated with customer preferences, and to suggest ways to customize products to meet the specific needs of individual customers.
Energy management:
Data annotation can be used to label data points according to the energy usage of different equipment and processes, as well as the factors that influence energy consumption. This allows an AI algorithm to learn the patterns that are associated with efficient energy management, and to suggest ways to optimize energy usage in industrial processes.
Final thoughts
AI will impact manufacturing in ways we have not yet anticipated. As the need for automation in factories continues to grow, factories will increasingly turn to AI-powered machines to improve the efficiency of day-to-day processes. This opens the door to introducing even smarter applications into today’s factories, from smart anomaly detection systems to autonomous robots and beyond. In conclusion, AI and data annotation are increasingly being used in the manufacturing industry to improve efficiency, reduce costs, improve quality, and increase the value of products. As AI and data annotation technologies continue to advance, it is likely that we will see even greater adoption of these technologies in the manufacturing industry in the coming years.
0 notes
Text
How Data Annotation is used for AI-based Recruitment

The ability of AI to assess huge data and swiftly estimate available possibilities makes process automation possible. AI technologies are increasingly being employed in marketing and development in addition to IT. It’s not surprising that some businesses have begun to adopt (or are learning to use) AI solutions in hiring, seeking to automate the hiring process and find novel ways to hire people. You’ll definitely kick yourself for not learning about and utilizing AI as one of the most crucial recruitment technology solutions.
Artificial intelligence has the potential to revolutionize the recruitment process by automating many of the time-consuming tasks associated with recruiting, such as resume screening, scheduling interviews, and sending follow-up emails. This can save recruiters a significant amount of time and allow them to focus on more high-level tasks, such as building relationships with candidates and assessing their fit for the company.
AI-powered recruitment tools use natural language processing (NLP) and machine learning (ML) to better match candidates with job openings. This can be done by analyzing resumes and job descriptions to identify the skills and qualifications that are most important for the position and then matching those with the skills and qualifications of the candidates. AI also facilitates more efficient scheduling, by taking into account the availabilities of the candidates and interviewers and suggesting the best times for an interview.
Applications of Recruitment AI
There are several use cases of AI in the recruitment process, including:
Resume screening: Resume screening is the first step in the recruitment and staffing process. It involves the identification of relevant resumes or CVs for a certain job role based on their qualifications and experience. AI can be used to scan resumes and identify the most qualified candidates based on certain criteria, such as specific skills or qualifications. This can save recruiters a significant amount of time that would otherwise be spent manually reviewing resumes.
Interview scheduling: AI can be used to schedule interviews by taking into account the availability of both the candidates and the interviewers, and suggesting the best times for the interviews.
Pre-interview screening: AI can be used to conduct pre-interview screening by conducting initial screening calls or virtual interviews to shortlist suitable candidates before passing it to the human interviewer.AI can be used to check the references of potential candidates by conducting automated reference checks over the phone or email.
Chatbots for recruitment: AI-powered chatbots can be used to answer candidates’ queries, schedule an interview and help them navigate the hiring process, which can improve the candidate’s experience. The use of bots to conduct interviews is beneficial to recruiters, as they guarantee consistency in the interview process since the same interview experience is meant to provide equal experiences to all candidates.
Interview evaluation: AI-powered video interview evaluation tools can analyze a candidate’s facial expressions, tone of voice, and other nonverbal cues during a video interview to help recruiters evaluate their soft skills and potential cultural fit within the organization. NLP-based reading tools can be used to analyze the speech patterns and written responses of candidates during the interview process. In addition, NLP algorithms can conduct an in-depth sentiment analysis of a candidate’s speech and expressions.
Job & Candidate matching: AI can be used to match candidates with job openings by analyzing resumes, job descriptions, and other data to identify the most qualified candidates for the position. This facet of AI in recruiting focuses on a customized candidate experience. It means the machine understands what jobs and type of content the potential candidates are interested in, monitors their behavior, then automatically sends them content and messages based on their interests.
Predictive hiring: AI can be used to predict which candidates are most likely to be successful in a given role by analyzing data on past hires, such as performance reviews and tenure data.
These are some of the most common ways AI is currently being used in the recruitment process, but as the technology continues to evolve, there will likely be new use cases for AI in the future.
Data Annotation for Recruitment AI
Data annotation is an important step in the process of training AI systems, and it plays a critical role in several cases of AI-based recruitment processes. Here are a few examples of how data annotation is used in AI-based recruitment:
Resume screening: For the implementation of the resume screening model to identify the most qualified candidates based on certain criteria, such as specific skills or qualifications, it is necessary to annotate a large dataset of resumes with relevant information, such as the candidate’s name, education, and work experience. Large volumes of resumes with diverse roles and skills are annotated to specify how much work experience the candidate has for a particular field, what skills, certifications, and education the candidate is qualified and much more.
Job matching: To train an AI system to match candidates with job openings, it is required to annotate large volumes of job descriptions with relevant information, such as the roles and responsibilities of a particular job and the requirements of the job opening.
Interview evaluation: For interview evaluation, different NLP models are trained like sentiment analysis and speech pattern evaluation. To analyze a candidate’s facial expressions, tone of voice, and other nonverbal cues during a video interview, it is necessary to annotate a large dataset of video interviews with labels that indicate the candidate’s level of engagement, energy, and enthusiasm.
Predictive hiring: Based on the job requirement details, the AI model can predict the most relevant candidates from a large pool of resumes. For training of such a model to predict which candidates are most likely to be successful in a given role, it is necessary to first annotate a large dataset of past hires with labels that indicate the candidate’s performance and tenure.
Chatbot Training: A chatbot can mimic a human’s conversational abilities in the sense that it’s programmed to understand written and spoken language and respond correctly. The dataset of questions and answers needs to be annotated appropriately in order to train the AI chatbot to comprehend the candidate’s inquiries and respond appropriately.
The process of data annotation is time-consuming but it is essential to ensure that the AI system is able to learn from the data and make accurate predictions or classifications. It’s also worth mentioning that as a part of data annotation quality assurance is also very crucial, as the model is only as good as the data it’s been trained on. Thus, quality annotation and quality assurance checks on the data are very important to ensure the model’s performance.
Advantages of Recruitment AI
There are several advantages to using AI in the recruitment process, including:
Efficiency: AI can automate many of the time-consuming tasks associated with recruiting, such as resume screening and scheduling interviews. This can save recruiters a significant amount of time, allowing them to focus on more high-level tasks, such as building relationships with candidates and assessing their fit for the company.
Objectivity: AI can help to reduce bias in the recruitment process by removing subjective elements such as personal prejudices. The algorithms are not influenced by personal biases, this can make the selection process more objective and fair, which can lead to better candidate selection.
Increased speed: AI can process resumes and conduct initial screening and job matching much faster than a human can. This can speed up the recruitment process and reduce the time it takes to fill a job opening.
Improved candidate matching: AI can use natural language processing and machine learning to better match candidates with job openings by analyzing resumes and job descriptions to identify the skills and qualifications that are most important for the position.
Increased scalability: AI can handle a high volume of resumes and job openings, which can be challenging for human recruiters. This can allow the companies to expand and increase their recruitment efforts.
Better candidate experience: AI-powered chatbots can be used to answer candidates’ queries, schedule an interview, and help them navigate the hiring process, which can improve the candidate’s experience and helps the company with candidate retention.
However, it’s important to note that AI is not a replacement for human recruiters, instead, it should be viewed as a tool to assist them. It is necessary to keep in mind that AI, despite its advantages, is not able to fully understand the nuances of a job or company culture and that the human touch is still necessary for the recruitment process.
Conclusion
Artificial intelligence in recruitment will grow because it is prominently beneficial for the company, recruiters, and candidates. With the right tools, software and programs, you can develop an automated process that improves the quality of your candidates and their experience. High-quality data annotation is required to train AI systems to effectively automate tasks such as resume screening, job matching, and predictive hiring.
TagX a data annotation company plays a vital role in helping organizations to implement AI-powered recruitment automation by providing them with high-quality annotated data that they can use to train their AI systems. With TagX, organizations can leverage the benefits of AI while still maintaining a high level of human oversight and judgment, leading to an overall more efficient, effective, and objective recruitment process.
0 notes
Text
The Ultimate Guide to Data Ops for AI

Data is the fuel that powers AI and ML models. Without enough high-quality, relevant data, it is impossible to train and develop accurate and effective models.
DataOps (Data Operations) in Artificial Intelligence (AI) is a set of practices and processes that aim to optimize the management and flow of data throughout the entire AI development lifecycle. The goal of DataOps is to improve the speed, quality, and reliability of data in AI systems. It is an extension of the DevOps (Development Operations) methodology, which is focused on improving the speed and reliability of software development.
What is DataOps?
DataOps (Data Operations) is an automated and process-oriented data management practice. It tracks the lifecycle of data end-to-end, providing business users with predictable data flows. DataOps accelerate the data analytics cycle by automating data management tasks.
Let's take the example of a self-driving car. To develop a self-driving car, an AI model needs to be trained on a large amount of data that includes various scenarios, such as different weather conditions, traffic patterns, and road layouts. This data is used to teach the model how to navigate the roads, make decisions, and respond to different situations. Without enough data, the model would not have been exposed to enough diverse scenarios and would not be able to perform well in real-world situations. DataOps needs high-performance and scalable data lakes, which can handle mixed workloads, and different data types audio, video, text, and data from sensors and that have the performance capabilities needed to keep the compute layer fully utilized.
What is the data lifecycle?
Data Generation: There are various ways in which data can be generated within a business, be it through customer interactions, internal operations, or external sources. Data generation can occur through three main methods:
Data Entry: The manual input of new information into a system, often through the use of forms or other input interfaces.
Data Capture: The process of collecting information from various sources, such as documents, and converting it into a digital format that can be understood by computers.
Data Acquisition: The process of obtaining data from external sources, such as through partnerships or external data providers like Tagx.
Data Processing: Once data is collected, it must be cleaned, prepared, and transformed into a more usable format. This process is crucial to ensure the data's accuracy, completeness, and consistency.
Data Storage: After data is processed, it must be protected and stored for future use. This includes ensuring data security and compliance with regulations.
Data Management: The ongoing process of organizing, storing, and maintaining data, from the moment it is generated until it is no longer needed. This includes data governance, data quality assurance, and data archiving. Effective data management is crucial to ensure the data's accessibility, integrity, and security.
Advantages of Data Ops
DataOps enables organizations to effectively manage and optimize their data throughout the entire AI development lifecycle. This includes:
Identifying and Collecting Data from All Sources: DataOps is widely used to identify and collect data from a wide range of sources, including internal data, external data, and public data sets. This is helpful for organizations to have access to the data they need to train and test their AI models.
Automatically Integrating New Data: DataOps enables organizations to automatically integrate new data into their data pipelines. This ensures that data is consistently updated and that the latest information is always available to users.
Centralizing Data and Eliminating Data Silos: Companies focus on Dataops to centralize their data and eliminate data silos. This improves data accessibility and helps to ensure that data is used consistently across the organization.
Automating Changes to the Data Pipeline: DataOps implementation helps to automate changes to their data pipeline. This increases the speed and efficiency of data management and helps to ensure that data is used consistently across the organization.
By implementing DataOps, organizations can improve the speed, quality, and reliability of their data and AI models, and reduce the time and cost of developing and deploying AI systems. Additionally, by having proper data management and governance in place, the AI models developed can be explainable and trustworthy, which can be beneficial for regulatory and ethical considerations.
TagX Data as a Service
Data as a service (DaaS) refers to the provision of data by a company to other companies. TagX provides DaaS to AI companies by collecting, preparing, and annotating data that can be used to train and test AI models.
Here's a more detailed explanation of how TagX provides DaaS to AI companies:
Data Collection: TagX collects a wide range of data from various sources such as public data sets, proprietary data, and third-party providers. This data includes image, video, text, and audio data that can be used to train AI models for various use cases.
Data Preparation: Once the data is collected, TagX prepares the data for use in AI models by cleaning, normalizing, and formatting the data. This ensures that the data is in a format that can be easily used by AI models.
Data Annotation: TagX uses a team of annotators to label and tag the data, identifying specific attributes and features that will be used by the AI models. This includes image annotation, video annotation, text annotation, and audio annotation. This step is crucial for the training of AI models, as the models learn from the labeled data.
Data Governance: TagX ensures that the data is properly managed and governed, including data privacy and security. We follow data governance best practices and regulations to ensure that the data provided is trustworthy and compliant with regulations.
Data Monitoring: TagX continuously monitors the data and updates it as needed to ensure that it is relevant and up-to-date. This helps to ensure that the AI models trained using our data are accurate and reliable.
By providing data as a service, TagX makes it easy for AI companies to access high-quality, relevant data that can be used to train and test AI models. This helps AI companies to improve the speed, quality, and reliability of their models, and reduce the time and cost of developing AI systems. Additionally, by providing data that is properly annotated and managed, the AI models developed can be explainable and trustworthy, which can be beneficial for regulatory and ethical considerations.
Conclusion
Gaining the agility to boost the speed of data processing and increasing the quality of data to derive actionable insights is the focus of many businesses. This focus creates a need for an agile data management approach such as DataOps.
In addition to applying DataOps technologies, processes and people also need to be considered for better data operations. For example, it is important to set up new data governance practices that are compatible with DataOps. The human factor is also crucial. TagX can assist if you need help developing DataOps for your business and deciding which technologies to use
0 notes
Text
Data Annotation: How it Can Boost Your AI Models?

As artificial intelligence (AI) continues to revolutionize various industries, data annotation has become an essential part of the process. Essentially, data annotation involves labeling data to make it usable for machine learning algorithms. By providing the right annotations, you can train your AI models to recognize patterns, classify data, and make accurate predictions. In this context, data annotation is more than just a technical process. It's a way to enhance the quality and reliability of your AI models, while also ensuring that they're optimized for specific use cases.
For More Information Visit - https://www.tagxdata.com/data-annotation-how-it-can-boost-your-ai-models
0 notes
Text
Data Annotation Outsourcing: How to choose a reliable vendor

Artificial Intelligence (AI) has rapidly grown and transformed the way businesses operate and interact with their customers. The success of an AI model is heavily dependent on the quality of the data it is trained on. This is why AI companies require data annotation services to provide the best possible outcome.
Data annotation refers to the process of labeling and categorizing data to make it more structured and usable for training AI models. It involves adding relevant information to the data, such as classifying images, transcribing audio recordings, and identifying the objects in an image. This process helps improve the accuracy and reliability of AI algorithms and ensures that the models are making predictions based on relevant and meaningful data.
In-house data annotation can be a time-consuming and resource-intensive task, especially for small and medium-sized companies that have limited budgets and manpower. This is why outsourcing data annotation services is an attractive option for AI companies. It not only reduces the workload on the in-house team but also ensures that the data is annotated efficiently and accurately by experienced professionals.
Need to outsource Data Annotation
There are several reasons why a company might choose to outsource their data annotation services instead of handling it in-house. Firstly, collecting and annotating large amounts of data can be a time-consuming and complex task. By outsourcing this work, companies can free up their in-house teams to focus on what they do best, such as developing the AI algorithms or building their business.
Another advantage of outsourcing data annotation is access to a larger pool of annotators. Data annotation companies often have a network of people trained in data annotation, allowing them to complete projects quickly and efficiently. This can be particularly beneficial for companies working on large-scale projects that would be challenging to complete in-house.
Additionally, outsourcing data annotation services can provide cost savings as it eliminates the need to invest in training and hiring in-house annotators. It also provides access to the latest annotation tools and technologies, helping companies to improve the quality and efficiency of their data annotation.
Primary factors for Data Annotation Vendor Selection
Gathering labeled datasets is a crucial step in building a machine-learning algorithm, but it can also be a time-consuming and complex task. Conducting data annotation in-house can take valuable resources away from your team's core focus - creating a strong AI. To overcome this challenge, many organizations are turning to outsource data annotation services to boost productivity, speed up development time, and stay ahead of the competition.
With the growing number of AI training data service providers, choosing the best one for your needs can be a daunting task. It is important to take a systematic approach when evaluating different data annotation companies to ensure that you make the right decision. Here are some ke y considerations that can help you choose the best vendor for your needs:
When choosing a data annotation vendor, there are several key factors to consider to ensure a successful collaboration:
Quality of Work: The vendor should be able to provide high-quality annotated data that meets your standards and requirements. You should also consider their track record and reviews from other clients to see if they deliver consistent and accurate results.
Speed of Delivery: The vendor should be able to deliver the annotated data in a timely manner, with fast turnaround times and the ability to scale up or down as needed.
Flexibility: The vendor should be able to work with different data types and annotate them in different formats, and be able to handle large volumes of data efficiently.
Cost: The vendor should be transparent about their pricing and provide a cost-effective solution. You should compare the vendor's pricing with other companies to ensure you're getting a good value.
Data Privacy and Security: The vendor should have robust security measures in place to protect your data and keep it confidential. You should also consider their data privacy policies and the measures they take to comply with relevant regulations.
Customer Support: The vendor should have a responsive and knowledgeable customer support team to answer your questions and address any concerns you may have.
Technology and Tools: The vendor should have a state-of-the-art infrastructure and use the latest tools and technologies for data annotation, including machine learning and natural language processing.
Considering these factors will help you choose a data annotation vendor that can deliver high-quality results, while also providing value for money and ensuring data security and privacy.
Steps to choose reliable Data Annotation Vendor
Building an Artificial Intelligence (AI) model or algorithm is a complex and time-consuming task, but the process is not complete without accurate and high-quality training data. A significant amount of time and effort goes into annotating data, which involves labeling and categorizing data for the AI system to learn from. This process is crucial for AI algorithms to work effectively and make accurate predictions.
While some companies try to handle data annotation in-house, it can be a time-consuming and distracting task that takes away from the focus on developing a strong AI. Outsourcing data annotation services is a proven way to boost productivity and reduce development time.
However, with the growing number of AI training data service providers, choosing the right data annotation vendor can be overwhelming. To help you make the right choice, here are the key steps to consider when selecting a data annotation vendor for your AI application:
Determine your data annotation needs
Before choosing a data annotation vendor, it's essential to understand your data annotation needs. This includes the type of data you need annotated, the volume of data, and the type of annotation you require.
Look for a vendor with experience in your industry
It is important to choose a vendor that has experience in your specific industry as they will be better equipped to understand the nuances of your data and provide relevant annotations.
Consider the quality of annotations
The quality of annotations is crucial for the success of your AI model. Make sure the vendor provides quality control measures to ensure accurate and consistent annotations.
Check for privacy and security
AI applications often involve sensitive data, and it is crucial to ensure the vendor has robust security and privacy measures in place to protect your data.
Consider the cost
Data annotation services can be costly, so it's essential to compare the prices of different vendors and ensure that you get the best value for your money.
Look for scalable solutions
As your AI application grows, your data annotation needs may increase. Choose a vendor that provides scalable solutions to meet the growing demands of your business.
Make decision based on your needs
Data annotation services are an essential component of AI development. Whether you are a startup or a large company, outsourcing data annotation can help you achieve faster results, reduce costs, and increase the accuracy of your AI models.
Why not include TagX in your list of potential data labelling vendors? In a variety of industries, including logistics, geospatial, automotive, and e-commerce, we have a wealth of expertise labelling data. To learn more about our expertise and past projects, get in touch with our experts. Trust us to help you boost productivity, reduce development time and stay ahead of the competition.
0 notes
Text
How Data Annotation drives precise AI Video Analytics

In the era of data-driven insights and intelligent automation, video analytics has emerged as a transformative technology, revolutionizing the way we extract valuable information from video data. At the heart of this innovation lies the power of artificial intelligence (AI) and its ability to analyze and interpret video content with remarkable accuracy and speed. Welcome to our blog, where we delve into the different applications of AI-powered video analytics and the use of data annotation to train these applications.
What is AI-powered video analytics?
AI-powered video analytics refers to using artificial intelligence (AI) techniques and algorithms to analyze video content and extract valuable insights and information from it. It involves the application of computer vision, machine learning, and deep learning algorithms to analyze video data in real time or post-processing.
With Video analytics, computers can understand and interpret the content of videos, enabling a wide range of applications such as surveillance, security, object detection and tracking, facial recognition, crowd monitoring, anomaly detection, and more. The AI algorithms can automatically detect and classify objects, recognize faces and actions, track movements, identify patterns, and generate actionable insights from video data.
By leveraging AI technologies, video analytics systems can process vast amounts of video data efficiently and accurately, enabling faster and more reliable analysis compared to manual human efforts. It allows organizations to extract valuable information from video footage, improve situational awareness, enhance security measures, optimize operations, and make data-driven decisions based on the insights obtained from the analyzed videos.
AI-powered video analytics has numerous applications across various industries, including public safety, retail, transportation, smart cities, healthcare, and entertainment. It offers advanced capabilities for video understanding, enabling organizations to unlock the full potential of their video data and leverage it for improved efficiency, safety, and decision-making.
Applications of AI-Powered Video Analytics:
From enhancing public safety and security through advanced surveillance systems to improving customer experience and optimizing operations in retail environments, organizations are leveraging this technology to gain invaluable insights from their video data. Let's explore some of the key applications of AI video analytics:
Intrusion Detection: AI-powered video analytics can automatically detect and alert security personnel in real time when unauthorized individuals or objects enter restricted areas. Combining object detection and tracking algorithms, it enhances security and reduces response time to potential threats.
Public Place Security: Video analytics can enhance security in public places such as airports, train stations, and stadiums by automatically detecting suspicious behavior, abandoned objects, or unauthorized access. This technology enables proactive measures to ensure public safety and prevent potential incidents.
Investigation and Forensics: AI video analytics assists law enforcement agencies and investigators in analyzing surveillance footage to identify suspects, track their movements, and reconstruct events. It accelerates investigations by automating the process of extracting relevant information from video data.
Crowding and Density Monitoring: Video analytics can analyze video feeds to determine crowd size, density, and movement patterns in public areas or events. This information helps authorities optimize crowd management, ensure safety, and prevent overcrowding.
Traffic Monitoring and Management: AI-powered video analytics can analyze traffic flow, detect congestion, and monitor incidents in real time. By providing accurate data on traffic patterns and identifying bottlenecks, it enables efficient traffic management and optimization of transportation systems.
Object Recognition and Tracking: Video analytics algorithms can detect and track specific objects of interest, such as vehicles, people, or animals. This capability is valuable in applications like inventory tracking, wildlife monitoring, or tracking assets in logistics and supply chain management.
Behavioral Analysis: AI video analytics can analyze human behavior in video footage, identifying abnormal or suspicious activities. This capability is crucial for ensuring safety in high-security environments, detecting potential threats, and preventing criminal activities.
Retail Analytics: Video analytics can analyze customer behavior and engagement in retail environments. It can track footfall, identify customer demographics, measure customer engagement with displays, and optimize store layouts to enhance the shopping experience and drive business insights.
Data Annotation for AI video analytics
Data collection and annotation are vital components in the development of AI video analytics. The process begins with collecting diverse and representative video data from various sources, including surveillance cameras, drones, or other recording devices. This data is then carefully curated and preprocessed to ensure its quality and relevance. The collected video data undergoes annotation, where human annotators or AI algorithms label and annotate specific objects, events, or attributes within the video frames. This annotation process can include tasks such as object detection, tracking, classification, segmentation, and activity recognition.
Data annotation plays a crucial role in training models for AI-powered video analytics. Here's why data annotation is important in this context:
Training Data Preparation: To build an effective AI model for video analytics, a large and diverse dataset is required. Data annotation involves the process of labeling or annotating the video data with relevant information, such as object bounding boxes, action recognition, or event labels. This annotated data serves as the foundation for training the AI model.
Accuracy and Precision: Data annotation ensures that the labeled information is accurate and precise, providing ground truth annotations for the AI model. This accuracy is essential for the model to learn and make accurate predictions on unseen video data. Proper annotation reduces the chances of misinterpretation and helps in generating reliable insights from the video analytics system.
Object Detection and Tracking: Video analytics often involves tasks like object detection and tracking, where the AI model needs to identify and track specific objects or individuals in the video footage. Data annotation helps in creating labeled datasets that contain annotated bounding boxes around the objects of interest. This annotated data enables the model to learn and recognize different objects accurately.
Action Recognition: In video analytics, understanding and recognizing human actions or events is vital. Data annotation allows for labeling specific actions or events occurring in the video, providing the necessary information for the AI model to learn the patterns and characteristics of various actions. This enables the model to recognize and classify actions in real time.
Performance Evaluation: Data annotation also plays a significant role in evaluating the performance of AI models for video analytics. Annotated datasets serve as ground truth data to measure the accuracy and performance of the model against specific metrics. The annotations act as a benchmark for evaluating the model's ability to detect, track, classify, or analyze video content.
By providing accurate and well-annotated training data, data annotation enables the AI model to learn and generalize from the labeled examples. This process enhances the model's ability to detect objects, recognize actions, and extract meaningful insights from video data. Quality data annotation ensures the reliability and effectiveness of AI-powered video analytics systems, making them capable of delivering valuable insights and actionable information for various applications such as surveillance, security, crowd monitoring, and more.
Conclusion
As AI continues to push the boundaries of what is possible, AI-powered video analytics emerges as a game-changer in harnessing the wealth of information hidden within video data. From improving safety and security to enabling data-driven decision-making, the applications of this technology are vast and transformative.
TagX specializes in providing precise data annotation services for AI video analytics. We have the expertise to accurately label video data, enabling AI models to detect objects, track movements, recognize actions, and analyze events. Our team ensures that every frame is annotated with meticulous attention to detail, ensuring high-quality training data for AI video analytics applications. Together, let's unlock the power of AI and transform the way we analyze and leverage video data for a smarter and more secure future.
0 notes
Text
Synthetic Data: Description, Benefits and Implementation

The quality and volume of data are critical to the success of AI algorithms. Real-world data collection is expensive and time-consuming. Furthermore, due to privacy regulations, real-world data cannot be used for research or training in most situations, such as healthcare and the financial sector. Another disadvantage is the data’s lack of availability and sensitivity. To power deep learning and artificial intelligence algorithms, we need massive data sets.
Synthetic data, a new area of artificial intelligence, relieves you of the burdens of manual data acquisition, annotation, and cleaning. Synthetic data generation solves the problem of acquiring data that would otherwise be impossible to obtain. Synthetic data generation will produce the same results as real-world data in a fraction of the time and with no loss of privacy.
Visual simulations and recreations of real-world environments are the focus of synthetic data generation. It is photorealistic, scalable, and powerful data that was created for training using cutting-edge computer graphics and data generation algorithms. It is highly variable, unbiased, and annotated with absolute accuracy and ground truth, removing the bottlenecks associated with manual data collection and annotation.
Why is synthetic data required?
Businesses can benefit from synthetic data for three reasons: privacy concerns, faster product testing turnaround, and training machine learning algorithms.
Most data privacy laws limit how businesses handle sensitive data. Any leakage or sharing of personally identifiable customer information can result in costly lawsuits that harm the brand’s reputation. As a result, one of the primary reasons why companies invest in synthetic data and synthetic data generation techniques is to reduce privacy concerns.
Any previous data remains unavailable for completely new products. Furthermore, human-annotated data is an expensive and time-consuming process. This can be avoided if businesses invest in synthetic data, which can be generated quickly and used to develop reliable machine learning models.
What is the creation of synthetic data?
Synthetic data generation is the process of creating new data as a replacement for real-world data, either manually using tools like Excel or automatically using computer simulations or algorithms. If the real data is unavailable, the fake data can be generated from an existing data set or created entirely from scratch. The newly generated data is nearly identical to the original data.
Synthetic data can be generated in any size, at any time, and in any location. Despite being artificial, synthetic data mathematically or statistically reflects real-world data. It is similar to real data, which is collected from actual objects, events, or people in order to train an AI model.
Real data vs. synthetic data
Real data is measured or collected in the real world. Such information is generated every time a person uses a smartphone, laptop, or computer, wears a smartwatch, accesses a website, or conducts an online transaction. Furthermore, surveys can be used to generate real data (online and offline).
In digital contexts, synthetic data is produced. With the exception of the portion that was not derived from any real-world occurrences, synthetic data is created in a way that successfully mimics the actual data in terms of fundamental qualities. The idea of using synthetic data as a substitute for actual data is very promising because it may be used to provide the training data that machine learning models require. But it’s not certain that artificial intelligence can solve every issue that arises in the real world. The substantial benefits that synthetic data has to provide are unaffected by this.
Where can you use synthetic data?
Synthetic data has a wide range of applications. When it comes to machine learning, adequate, high-quality data is still required. Access to real data may be restricted due to privacy concerns at times, while there may not be enough data to train the machine learning model satisfactorily at others. Synthetic data is sometimes generated to supplement existing data and aid in the improvement of the machine learning model.
Many sectors can benefit greatly from synthetic data:
1. Banking and financial services
2. Healthcare and pharmaceuticals
3. Internet advertising and digital marketing
4. Intelligence and security firms
5. Robotics
6. Automotive and manufacturing
Benefits of synthetic data
Synthetic data promises to provide the following benefits:
Customizable:
To meet the specific needs of a business, synthetic data can be created.
Cost-effective:
In comparison to genuine data, synthetic data is a more affordable solution. Imagine a producer of automobiles that needs access to crash data for vehicle simulations. In this situation, acquiring real data will cost more than producing fake data.
Quicker to produce:
It is possible to produce and assemble a dataset considerably more quickly with the right software and hardware because synthetic data is not gathered from actual events. This translates to the ability to quickly make a large amount of fabricated data available.
Maintains data privacy:
The ideal synthetic data does not contain any information that may be used to identify the genuine data; it simply closely mimics the real data. This characteristic makes the synthetic data anonymous and suitable for dissemination. Pharmaceutical and healthcare businesses may benefit from this.
Some real-world applications of synthetic data
Here are some real-world examples where synthetic data is being actively used.
Healthcare:
In situations where actual data is lacking, healthcare institutions are modeling and developing a variety of tests using synthetic data. Artificial intelligence (AI) models are being trained in the area of medical imaging while always maintaining patient privacy. In order to forecast and predict disease patterns, they are also using synthetic data.
Agriculture:
In computer vision applications that help with crop production forecasting, crop disease diagnosis, seed/fruit/flower recognition, plant growth models, and more, synthetic data is useful.
Banking and Finance:
As data scientists create and develop more successful fraud detection algorithms employing synthetic data, banks and financial institutions will be better able to detect and prevent online fraud.
Ecommerce:
Through advanced machine learning models trained on synthetic data, businesses gain the benefits of efficient warehousing and inventory management, as well as an improved customer online purchase experiences.
Manufacturing:
Companies are benefiting from synthetic data for predictive maintenance and quality control.
Disaster prediction and risk management:
Government agencies are using synthetic data to predict natural disasters in order to prevent disasters and lower risks.
Automotive & Robotics:
Synthetic data is used by businesses to simulate and train self-driving cars, autonomous vehicles, drones, and robots.
Synthetic Data Generation by TagX
TagX focuses on accelerating the AI development process by generating data synthetically to fulfill every data requirement uniquely. TagX has the ability to provide synthetically generated data that are pixel-perfect, automatically annotated or labeled, and ready to be used as ground truth as well as train data for instant segmentation.
Final Thoughts
In some cases, synthetic data may be used to address a company’s or organization’s lack of relevant data or data scarcity. We also investigated the methods for creating artificial data and the potential users. Along with a few examples from actual fields where synthetic data is used, we discussed some of the challenges associated with working with it.
When making business decisions, the use of actual data is always preferable. When such true raw data is unavailable for analysis, realistic data is the next best option. However, it should be noted that in order to generate synthetic data, data scientists with a solid understanding of data modeling are required. A thorough understanding of the actual data and its surroundings is also required. This is necessary to ensure that, if available, the generated data is as accurate as possible.
0 notes
Text
Synthetic Document Generation for NLP and Document AI

NLP (natural language processing) and document AI are technologies that are quickly developing and have a wide range of prospective applications. In recent years, the usage of NLP and document AI has significantly increased across a variety of industries, including marketing, healthcare, and finance. These solutions are being used to streamline manual procedures, accelerate data processing, and glean insightful information from massive amounts of unstructured data. NLP and document AI are anticipated to continue developing and revolutionizing numerous industries in the years to come with the introduction of sophisticated machine learning algorithms and data annotation techniques.
For different NLP and AI applications, large amounts of document data are necessary since they aid in the training of machine learning algorithms to comprehend the context, language, and relationships within the data. The algorithms are able to comprehend the subtleties and complexity of human language better the more data that is accessible, the more diverse the input. In turn, this aids the algorithms in producing predictions and classifications that are more precise. A more stable training environment is also provided by larger datasets, lowering the possibility of overfitting and enhancing the generalizability of the model. The likelihood that the model will perform well on unobserved data increases with the size of the dataset.
Data for Document AI
Document AI, or Document Artificial Intelligence, is an emerging field of artificial intelligence (AI) that focuses on the processing of unstructured data in documents, such as text, images, and tables. Document AI is used to automatically extract information, classify documents, and make predictions or recommendations based on the content of the documents.
It takes a lot of data to train a Document AI system. This information can originate from a variety of places, including internal document repositories, external data suppliers, and web repositories. To allow the Document AI system to learn from the data, it must be tagged or annotated. To offer information on the content of the documents, such as the document type, topic, author, date, or language, data annotation entails adding tags or metadata to the documents. The Document AI system can grow more precise as more data becomes accessible.
Training data for Document AI can come in various forms, including scanned documents, PDF files, images, and even audio or video files. The data can be preprocessed to remove noise or enhance the quality of the text or images. Natural Language Processing (NLP) techniques can also be applied to the text to extract entities, sentiments, or relationships. Overall, a large and diverse dataset of documents is crucial for building effective Document AI systems that can accurately process and analyze large volumes of unstructured data.
Application of Document AI
There are several applications of document AI, some of them are:
Document scanning and digitization: AI-powered document scanning tools make it possible to turn paper documents into digital files that can be accessed, searched for, and used.
Document classification and categorization: Depending on the content, format, and structure of the document, AI algorithms can be trained to categorize and classify various types of documents.
Content extraction and summarization: With AI, significant information may be culled from massive amounts of documents and condensed into key insights and summaries.
Document translation: AI-powered document translation tools can translate text from one language to another automatically, facilitating global communication for enterprises.
Analysis and management of contracts: With AI algorithms, contracts may be automatically reviewed to find important terms, risks, and duties.
Invoice processing and accounts payable automation: AI algorithms can be trained to process invoices automatically and make payments, reducing manual errors and increasing operational efficiency.
Customer service chatbots: AI-powered chatbots can help automate customer support interactions, respond to frequent customer questions, and point customers in the appropriate direction.
These are some of the different applications of document AI. The potential of this technology is vast, and the applications continue to expand as the technology evolves.
Document Data Collection
There are various ways to collect documents for AI applications, including the following:
Web scraping: Automatically extracting information from websites or other online sources.
Public data repositories: Utilizing publicly available datasets from organizations such as government agencies, universities, and non-profit organizations.
Internal data sources: Utilizing internal data sources within an organization, such as databases, CRM systems, and document management systems.
Crowdsourcing: Engaging a large group of people to annotate or label data through online platforms.
Purchasing datasets: Buying datasets from third-party providers who specialize in data collection and management.
However, real-world data is often limited and may not fully represent the diversity of documents and their variations. Synthetic data generation provides a solution to this problem by allowing the creation of large amounts of high-quality data that can be used to train and improve document AI models.
By generating synthetic data, companies can create training sets that represent a wide range of document types, formats, and styles, which can lead to more robust and accurate document AI models. Synthetic data can also help address issues of data bias, by ensuring that the training data is representative of the entire document population. Additionally, synthetic data generation can be more cost-effective and efficient than manual data collection, allowing companies to create large volumes of data quickly and at a lower cost.
Synthetic Document Generation
Synthetic data is generated for AI to address the challenges faced with real-world data such as privacy concerns, data scarcity, data imbalance, and the cost and time required for data collection and labeling. Synthetic data can be generated in large volumes and can be easily customized to meet the specific needs of a particular AI application. This allows AI developers to train models with a large and diverse dataset, without the constraints posed by real-world data, leading to better performance and accuracy. Furthermore, synthetic data can be used to simulate various scenarios and conditions, helping to make AI models more robust and versatile.
The primary reason for generating synthetic documents for AI is to increase the size of the training dataset, allowing AI algorithms to learn and make more accurate predictions. In addition, synthetic documents can also help in situations where it is difficult or expensive to obtain real-world data, such as in certain legal or privacy-sensitive applications.
To provide synthetic document generation for AI applications, the following steps can be taken:
Collect a sample of real-world data to serve as the base for synthetic data generation.
Choose a suitable method for generating synthetic data, such as data augmentation, generative models, or data sampling.
Use the chosen method to generate synthetic data that is representative of the real-world data.
Validate the quality of the synthetic data to ensure it is representative and relevant to the intended use case.
Integrate the synthetic data into the AI training process to improve the performance of the AI algorithms.
Synthetic Documents by TagX
TagX specializes in generating synthetic documents of various types, such as bank statements, payslips, resumes, and more, to provide high-quality training data for various AI models. Our synthetic document generation process is based on real-world data and uses advanced techniques to ensure the data is realistic and diverse. With this, we can provide AI models with the large volumes of data they need to train and improve their accuracy, ensuring the best possible results for our clients. Whether you're developing an AI system for financial services, HR, or any other industry, we can help you obtain the data you need to achieve your goals.
Synthetic documents are preferred over real-world documents as they do not contain any personal or sensitive information, making them ideal for AI training. They can be generated in large quantities, providing enough training data to help AI models learn and improve. Moreover, synthetic data is easier to manipulate, label, and annotate, making it a convenient solution for data annotation.
TagX can generate a wide variety of synthetic documents for different AI applications, including finance, insurance, chatbots, recruitment, and other intelligent document processing solutions. The synthetic documents can include, but are not limited to:
Payslips
We generate synthetic payslips in all languages to provide training data for AI models in finance, insurance, and other relevant applications. Our payslips mimic the structure, format, and language used in real-world payslips and are customizable according to the client's requirements.
Invoices
Our team can generate invoices in all languages to provide training data for various AI models in finance and other applications. The invoices we generate mimic the structure, format, and language used in real-world invoices and are customizable according to the client's needs.
Bank statements
Our team is proficient in generating synthetic bank statements in various languages and formats. These bank statements can be used to provide training data for different AI models in finance, insurance, and other relevant applications. Our bank statements mimic the structure, format, and language used in real-world bank statements and can be customized according to the client's requirements.
Resumes
We generate synthetic resumes in various languages and formats to provide training data for AI models in recruitment, HR, and other relevant applications. Our resumes mimic the structure, format, and language used in real-world resumes and are customizable according to the client's needs.
Utility bills
Our team is experienced in generating synthetic utility bills in various languages and formats. These utility bills can be used to provide training data for different AI models in finance, insurance, and other relevant applications. Our utility bills mimic the structure, format, and language used in real-world utility bills and can be customized according to the client's requirements.
Purchase orders
Our team can generate synthetic purchase orders in various languages and formats to provide training data for AI models in finance and other relevant applications. Our purchase orders mimic the structure, format, and language used in real-world purchase orders and are customizable according to the client's needs.
Passport and other personal documents
We generate synthetic passports and other personal documents in various languages and formats to provide training data for AI models in finance, insurance, and other relevant applications. Our passport and personal documents mimic the structure, format, and language used in real-world passports and personal documents and can be customized according to the client's requirements.
TagX Vision
TagX focuses on providing documents that are relevant to finance, insurance, chatbot, recruitment, and other intelligent document processing solutions. Our team of experts uses advanced algorithms to generate synthetic payslips, invoices in multiple languages, bank statements, resumes, utility bills, purchase orders, passports, and other personal documents. All of these documents are designed to look and feel like real-world examples, with accurate formatting, text, and images. Our goal is to ensure that the AI models trained with our synthetic data have the ability to process and understand a wide range of documents, so they can make accurate predictions and decisions.
We understand the importance of data privacy and security and ensure that all generated documents are de-identified and comply with the necessary regulations. Our goal is to provide our clients with a solution that is not only high-quality but also trustworthy and secure. Contact us to learn more about how our synthetic document generation services can help you achieve your AI goals.
0 notes
Text
A Comprehensive Overview of Object Detection Datasets in Computer Vision

Object detection datasets in computer vision refer to collections of labeled images or videos that are specifically curated and annotated for the task of object detection. These datasets are used to train and evaluate object detection models, which are algorithms designed to identify and locate objects of interest within an image or video.
Object detection datasets typically include images or video frames along with annotations that specify the presence and location of objects within the data. The annotations commonly include bounding boxes that outline the objects in the images or videos. Some datasets may also provide additional information such as object categories, segmentation masks, or keypoints. These datasets are crucial for training and evaluating object detection models, as they provide the necessary ground truth labels that enable the models to learn to detect objects accurately. The availability of diverse and well-annotated datasets is essential for advancing the state-of-the-art in object detection research and developing practical applications in various domains, such as autonomous driving, surveillance, robotics, and more.
Importance of Object Detection Datasets:
Object detection datasets are crucial for training and evaluating object detection algorithms. They provide labeled images or videos with annotations indicating the presence, location, and class of objects. These datasets serve as the foundation for algorithm development, enabling machines to learn the visual characteristics of objects and make accurate predictions in real-world scenarios.
Characteristics of Object Detection Datasets:
Object detection datasets exhibit several important characteristics:
1. Object Categories: Datasets cover a wide range of object categories, including everyday objects, animals, vehicles, humans, and specific industry-specific objects.
2. Annotation Format: Datasets use various annotation formats, such as bounding boxes, segmentation masks, keypoints, or attributes, to precisely delineate the objects of interest.
3. Scale and Diversity: Datasets vary in terms of the number of images, object instances per image, and environmental conditions. Some datasets focus on specific scales or domains, while others offer diversity in terms of object appearances, backgrounds, and imaging conditions.
Popular Object Detection Datasets:
Several popular object detection datasets have significantly influenced the development of computer vision algorithms. Here are a few noteworthy examples:
1. ImageNet: ImageNet is a large-scale dataset with millions of labeled images spanning thousands of object categories. While primarily known for its role in image classification, ImageNet also provides bounding box annotations, making it valuable for object detection research.
2. COCO (Common Objects in Context): COCO dataset is widely used for object detection tasks. It contains a large collection of images with annotations for multiple object categories, including people, animals, vehicles, and everyday objects. COCO has become a benchmark for evaluating object detection algorithms.
3. Pascal VOC (Visual Object Classes): The Pascal VOC dataset is another widely used benchmark dataset for object detection. It provides images with bounding box annotations for objects in various categories, such as animals, vehicles, and household items.
4. KITTI: The KITTI dataset focuses on object detection and other computer vision tasks related to autonomous driving. It offers a collection of images and videos captured from sensors mounted on a moving vehicle, along with annotations for objects like cars, pedestrians, and cyclists.
Specialized Object Detection Datasets:
Apart from general-purpose datasets, there are specialized object detection datasets tailored for specific domains and applications. These datasets focus on unique challenges and requirements of those industries. For example:
1. AgriVision: AgriVision is an object detection dataset for agricultural applications. It includes images of various crops, farm equipment, and objects commonly found in agricultural settings.
2. Cityscapes: Cityscapes dataset focuses on object detection and semantic segmentation in urban environments. It provides high-resolution images of street scenes with detailed annotations for objects like cars, pedestrians, and buildings.
3. LISA Traffic Sign Dataset: LISA dataset focuses on traffic sign detection and recognition. It contains images of various traffic signs captured in different environments and provides annotations for different traffic sign classes.
Impact and Future Directions:
Object detection datasets have played a pivotal role in advancing computer vision algorithms and technologies. They have facilitated the development of state-of-the-art models, benchmarking standards, and new research directions. By providing standardized evaluation metrics and challenges, datasets have fostered healthy competition and accelerated progress in the field.
As computer vision continues to evolve, future object detection datasets are expected to address new challenges, including fine-grained object detection, 3D object detection, and multi-modal object detection, among others. These datasets will enable researchers to tackle more complex real-world scenarios and push the boundaries of object detection algorithms.
Applications of Object Detection Datasets in Computer Vision:
Object detection is a fundamental task in computer vision that involves identifying and localizing objects within an image or video. It plays a crucial role in numerous real-world applications, enabling machines to perceive and understand their surroundings. To develop accurate and robust object detection algorithms, researchers and practitioners heavily rely on annotated datasets. These datasets provide the necessary training and evaluation resources to advance computer vision technologies. In this blog, we will explore the real-world applications of object detection datasets and their impact on various industries.
1. Autonomous Driving:
One of the most prominent applications of object detection datasets is in autonomous driving. Datasets like KITTI and BDD100K contain vast amounts of annotated images and videos captured from sensors in autonomous vehicles. These datasets enable the development of object detection algorithms to identify and track objects such as pedestrians, vehicles, traffic signs, and traffic lights, crucial for safe and reliable autonomous driving systems.
2. Surveillance and Security:
Object detection datasets have revolutionized surveillance and security systems. With datasets like the COCO dataset, researchers and developers can train models to detect and track objects in real-time video feeds. These applications help identify suspicious activities, monitor public spaces, and enhance security in various environments, including airports, shopping centers, and city streets.
3. Industrial Automation:
Object detection plays a vital role in industrial automation, enabling machines to detect and handle objects in manufacturing processes. Datasets tailored for industrial automation, such as the AgriVision dataset for agriculture or datasets focused on specific object types, help train models to identify defects, sort objects, and automate quality control tasks, improving efficiency and accuracy in manufacturing operations.
4. Retail and E-commerce:
In the retail and e-commerce industry, object detection datasets find applications in inventory management, product recognition, and augmented reality experiences. With datasets like Open Images or custom datasets created for specific product categories, retailers can develop systems that accurately identify products, track inventory, and enhance the shopping experience through virtual try-on or object recognition-based recommendations.
5. Robotics and Object Manipulation:
In robotics, object detection datasets are invaluable for enabling robots to perceive and interact with their environment. Datasets like YCB-Video provide annotated images and 3D object models, allowing robots to detect, localize, and manipulate objects with precision. This has applications in areas such as warehouse automation, assistive robotics, and household tasks.
6. Agriculture and Farming:
Object detection datasets play a crucial role in agriculture and farming applications. By utilizing datasets like PlantVillage or AgriVision, farmers and researchers can develop algorithms to detect diseases in crops, identify pests, and monitor plant health. These applications enable early intervention, precise pesticide usage, and improved crop management practices, leading to increased yields and reduced losses.
7. Traffic Management and Transportation:
Object detection datasets contribute to traffic management and transportation systems. With datasets like Cityscapes or LISA Traffic Sign Dataset, traffic authorities can develop algorithms to detect and classify vehicles, pedestrians, traffic signs, and signals. This information aids in traffic flow optimization, congestion management, and improving overall road safety.
8. Construction and Infrastructure:
In the construction industry, object detection datasets play a role in safety and efficiency. By utilizing datasets like Open Images or custom datasets, construction companies can develop algorithms to detect and track construction equipment, monitor worker safety, and optimize construction site operations, leading to improved productivity and enhanced safety measures.
9. Waste Management and Recycling:
Object detection datasets find applications in waste management and recycling processes. With datasets like TrashNet or custom datasets, algorithms can be developed to detect and classify different types of waste materials, aiding in automated sorting systems, optimizing recycling processes, and reducing environmental impact.
10. Sports Analytics:
Object detection datasets have applications in sports analytics. By utilizing datasets with annotated sports videos, algorithms can be developed to detect and track players, identify events, and extract valuable insights for coaches, broadcasters, and sports analysts, enhancing performance analysis and fan engagement.
Final Thoughts:
As a leading provider of object detection solutions, TagX is dedicated to revolutionizing the way businesses and researchers work with object detection datasets in computer vision. By leveraging TagX's advanced services, users can unlock new possibilities and maximize the potential of their computer vision projects.
TagX offers a comprehensive suite of services to streamline the entire lifecycle of object detection datasets. From dataset collection and annotation to model training and evaluation, TagX's provide a seamless and efficient workflow.
TagX is a trusted partner that empowers businesses and researchers by providing a comprehensive object detection services, expert guidance, and advanced technology. With TagX by their side, users can overcome challenges, maximize efficiency, and achieve breakthroughs in their computer vision endeavors.
0 notes
Text
Data preparation for AI-fueled Geospatial Analysis

Its been ages since businesses, governments, researchers, and journalists are using satellite data that helps understand the physical world and take action. As the geospatial industry evolves, so are the ways in which geospatial professionals use data to solve problems. Satellite imagery contains information that is useful for data-related projects. That’s why we’re seeing the rise of AI and ML in this industry.
Geospatial intelligence provides geographical information and distribution of elements in a geographic space and is now an essential tool for everything, from national security to land use and planning to agriculture and a host of commercial and government functions.
AI and Computer Vision for Geospatial Analysis
Artificial intelligence (AI) is revolutionizing the field of geospatial analysis by providing advanced tools and techniques to process and analyze vast amounts of geospatial data. Geospatial data includes information about the Earth's surface, such as satellite imagery, aerial photographs, and geographic information systems (GIS) data.AI algorithms and computer vision techniques are used to extract meaningful insights from geospatial data. These technologies enable automated data processing, pattern recognition, and scalable analysis, significantly improving the efficiency and accuracy of geospatial analysis tasks.
One of the key advantages of using AI in geospatial analysis is the ability to process large volumes of data quickly. Traditional manual methods of analyzing geospatial data can be time-consuming and labor-intensive. AI-powered algorithms can analyze massive datasets in a fraction of the time, enabling faster decision-making and response.AI also enhances the accuracy of geospatial analysis by reducing human error and subjectivity. Computer vision algorithms can detect and classify objects in satellite imagery, such as buildings, roads, and vegetation, with high precision. This helps in various applications like urban planning, disaster response, and environmental monitoring. Below are a few applications of Geospatial AI which cater to many industries and use cases:
Object detection
One of the primary applications of AI and Computer Vision in geospatial and satellite imagery is object detection and recognition. Through deep learning algorithms, AI models can accurately identify and classify objects such as buildings, roads, vegetation, and water bodies in satellite images. This capability is crucial for urban planning, environmental monitoring, disaster response, and infrastructure development.
Classification
Another significant use case is land cover classification, which involves categorizing different land types based on satellite imagery. AI algorithms can analyze multispectral and hyperspectral data to identify land cover classes like forests, agricultural fields, urban areas, and water bodies. This information is vital for land management, ecological studies, and monitoring of changes in land use over time.
Anomaly detection
AI and Computer Vision also play a crucial role in change detection and anomaly detection in geospatial imagery. By comparing satellite images taken at different times, AI models can identify changes in the landscape, such as deforestation, urban expansion, or natural disasters. This helps in monitoring environmental changes, detecting illegal activities, and supporting disaster management efforts.
Furthermore, AI-powered image segmentation techniques enable the extraction of detailed information from geospatial imagery. For instance, semantic segmentation can accurately delineate different land cover classes within an image, while instance segmentation can identify and track individual objects or features of interest. These capabilities find applications in precision agriculture, infrastructure monitoring, and resource management.
Map better with Data preparation for Geospatial AI
Accurate training data is essential for geospatial AI applications to provide precise and reliable results to users. Geospatial AI involves analyzing and interpreting data related to geographic locations, such as maps, satellite imagery, and spatial databases. Training data acts as the foundation for training machine learning algorithms and models in geospatial AI systems. Here are the typical steps involved in data preparation for geospatial AI:
Data Collection
Data collection involves gathering relevant geospatial data from various sources. This can include satellite imagery, aerial photography, GIS databases, GPS data, sensor data, and user-generated content. The data collection process should align with the specific requirements of the geospatial AI application. For example, if the application involves mapping and navigation, data collection may focus on obtaining accurate and up-to-date map data, including road networks, points of interest, and traffic information. If the application is related to land use analysis, data collection may involve acquiring satellite imagery with land cover information. The goal is to collect a diverse and representative dataset that encompasses the geographical area of interest.
Data Curation
Data curation involves the process of cleaning, organizing, and preparing the collected geospatial data for training AI models. This step is crucial for ensuring the accuracy, consistency, and quality of the data. Data cleaning entails removing duplicate records, addressing missing or erroneous values, and handling outliers or noise present in the dataset. It may also involve standardizing the data formats, ensuring consistent coordinate systems, and resolving any inconsistencies or conflicts within the data. Additionally, data curation may involve preprocessing steps like rescaling or normalizing numerical attributes to facilitate effective model training. The goal of data curation is to create a refined and reliable dataset that is ready for subsequent analysis and model training.
Data Annotation
Data annotation is the process of labeling or tagging specific features or regions of interest within the geospatial data. It involves assigning semantic or spatial labels to the data to provide the necessary ground truth for training supervised AI models. In geospatial AI, annotation can encompass various tasks such as object detection, segmentation, classification, or tracking. For example, in satellite imagery, data annotation may involve marking buildings, roads, vegetation, or water bodies. In aerial imagery, it could involve labeling objects like vehicles, pedestrians, or buildings. The annotation process can be performed manually by human annotators with domain expertise or using automated tools in some cases. Data preparation services encompass various annotation techniques tailored to geospatial applications.

Point Annotation: Point annotation involves marking specific points or coordinates within geospatial data. It is commonly used for tasks that require pinpointing precise locations or points of interest. For example, annotating specific addresses, landmarks, or geographic coordinates enables accurate geocoding, location-based searches, or geofencing.

Image Classification: Image classification in geospatial AI enables tasks such as environmental monitoring, land use planning, infrastructure assessment, or change detection. It provides valuable insights and information by automatically categorizing and analyzing large volumes of geospatial data. Data annotation experts classify objects in images based on custom taxonomies, such as land, road, vehicles, residential properties, and more.

Conclusion
Data preparation plays a pivotal role in the success of geospatial AI applications, enabling accurate and reliable results in various geographic contexts. Geospatial AI relies on diverse and precise data, collected from various sources, to train models effectively. By emphasizing TagX's expertise in each step of the data preparation cycle, we demonstrate our ability to deliver high-quality geospatial AI solutions. Our proficiency in data collection, curation, and annotation ensures that the training data we provide is accurate, reliable, and tailored to meet the unique requirements of our clients. With our comprehensive data preparation process, we empower users to leverage geospatial AI effectively and achieve their goals with super-sharp results.
0 notes
Text
Text Analytics: Unlocking the power of Business Data

Due to the development in the use of unstructured text data, both the volume and diversity of data used have significantly increased. For making sense of such huge amounts of acquired data, businesses are now turning to technologies like text analytics and Natural Language Processing (NLP).
The economic value hidden in these massive data sets can be found by using text analytics and natural language processing (NLP). Making natural language understandable to machines is the focus of NLP, whereas the term “text analytics” refers to the process of gleaning information from text sources.
What is text analysis in machine learning?
The technique of extracting important insights from texts is called text analysis.
ML can process a variety of textual data, including emails, texts, and postings on social media. This data is preprocessed and analyzed using specialized tools.
Textual analysis using machine learning is quicker and more effective than manually analyzing texts. It enables labor expenses to be decreased and text processing to be accelerated without sacrificing quality.
The process of gathering written information and turning it into data points that can be tracked and measured is known as text analytics. To find patterns and trends in the text, it is necessary to be able to extract quantitative data from unprocessed qualitative data. AI allows this to be done automatically and at a much larger scale, as opposed to having humans sift through a similar amount of data.
Process of text analysis
Assemble the data- Choose the data you’ll research and how you’ll gather it. Your model will be trained and tested using these samples. The two main categories of information sources are. When you visit websites like forums or newspapers, you are gathering outside information. Every person and business every day produces internal data, including emails, reports, chats, and more. For text mining, both internal and external resources might be beneficial.
Preparation of data- Unstructured data requires preprocessing or preparation. If not, the application won’t comprehend it. There are various methods for preparing data and preprocessing.
Apply a machine learning algorithm for text analysis- You can write your algorithm from scratch or use a library. Pay attention to NLTK, TextBlob, and Stanford’s CoreNLP if you are looking for something easily accessible for your study and research.
How to Analyze Text Data
Depending on the outcomes you want, text analysis can spread its AI wings across a variety of texts. It is applicable to:
Whole documents: gathers data from an entire text or paragraph, such as the general tone of a customer review.
Single sentences: gathers data from single sentences, such as more in-depth sentiments of each sentence in a customer review.
Sub-sentences: a sub-expression within a sentence can provide information, such as the underlying sentiments of each opinion unit in a customer review.
You can begin analyzing your data once you’ve decided how to segment it.
These are the techniques used for ML text analysis:
Data extraction
Data extraction concerns only the actual information available within the text. With the help of text analysis, it is possible to extract keywords, prices, features, and other important information. A marketer can conduct competitor analysis and find out all about their prices and special offers in just a few clicks. Techniques that help to identify keywords and measure their frequency are useful to summarize the contents of texts, find an answer to a question, index data, and generate word clouds.
Named Entity Recognition
NER is a text analytics technique used for identifying named entities like people, places, organizations, and events in unstructured text. It can be useful in machine translation so that the program wouldn’t translate last names or brand names. Moreover, entity recognition is indispensable for market analysis and competitor analysis in business.
Sentiment analysis
Sentiment analysis, or opinion mining, identifies and studies emotions in the text.
The emotions of the author are important for understanding texts. SA allows to classify opinion polarity about a new product or assess a brand’s reputation. It can also be applied to reviews, surveys, and social media posts. The pro of SA is that it can effectively analyze even sarcastic comments.
Part-of-speech tagging
Also referred to as “PoS” assigns a grammatical category to the identified tokens. The AI bot goes through the text and assigns each word to a part of speech (noun, verb, adjective, etc.). The next step is to break each sentence into chunks, based on where each PoS is. These are usually categorized as noun phrases, verb phrases, and prepositional phrases.
Topic analysis
Topic modeling classifies texts by subject and can make humans’ lives easier in many domains. Finding books in a library, goods in the store and customer support tickets in the CRM would be impossible without it. Text classifiers can be tailored to your needs. By identifying keywords, an AI bot scans a piece of text and assigns it to a certain topic based on what it pulls as the text’s central theme.
Language Identification
Language identification or language detection is one of the most basic text analysis functions. These capabilities are a must for businesses with a global audience, which in the age of online, is the majority of companies. Many text analytics programs are able to instantly identify the language of a review, social post, etc., and categorize it as such.
Benefits of Text Analytics
There is a range of ways that text analytics can help businesses, organizations, and event social movements:
1. Assist companies in recognizing customer trends, product performance, and service excellence. As a result, decisions are made quickly, business intelligence is improved, productivity is raised, and costs are reduced.
2. Aids scholars in quickly explore a large amount of existing literature and obtain the information that is pertinent to their inquiry. This promotes quicker scientific advancements.
3. Helps governments and political bodies make decisions by assisting in the knowledge of societal trends and opinions.
4. Search engines and information retrieval systems can perform better with the aid of text analytics tools, leading to quicker user experiences.
5. Refine user content recommendation systems by categorizing similar content.
Conclusion
Unstructured data can be processed using text analytics techniques, and the results can then be fed into systems for data visualization. Charts, graphs, tables, infographics, and dashboards can all be used to display the results. Businesses may immediately identify trends in the data and make decisions thanks to this visual data.
Robotics, marketing, and sales are just a few of the businesses that use ML text analysis technologies. To train the machine on how to interact with such data and make insightful conclusions from it, special models are used. Overall, it can be a useful strategy for coming up with ideas for your company or product.
0 notes