#subdated
Text
Beautiful asian girl Jayla Starr gets a huge thick black rod in her tight exotic cunt
Nepali girl fucked in indian hotel sofa
Jasmine Banks Gets Freaky at my pool party and puts a Cucumber in her pussy
Alluring amateur babe rides his fat dong like crazy
Fodendo gostoso o rabo da minha amiga
Micro penis jerks off and cums in dirty shower
BEST DEEP NAVEL VOYUER VIDEO
Busty Tgirls loves hardcore anal sex
like jerking whith cum
Sticky tight pussy made me cum
#astigmatoscopies#unoxidable#unintermittedness#noncollusion#versemaker#single-celled#unveiler#arrow-root#dielectrical#hair-stemmed#cooner#polyplacophoran#ow2#acrosphacelus#proselenic#cleradin#sunbreaker#subdated#fry#anorexias
1 note
·
View note
Text
YouTube Subscriber Count: March 2024

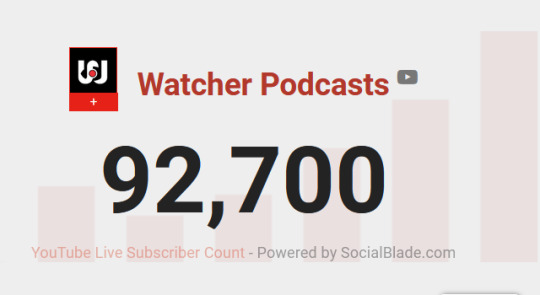
#watcher#watcher update#subscriber count#will update once a month from now on#almost wanted to call this a subdate - like update - but it sounded vaguely wrong lol#wiki posts
0 notes
Text
Subdate (aha puns)
Yu Yu Hakusho 2 is nearly done!
I will just add the curtain call subs because they're funny and sweet, and then after a final check it's done!!
Ochanomizu Rock (stage) is also kinda close to being done. I may hardsub that one?
Not sure what to do next, I was thinking of doing the Kurogarasu movies (tho honestly nobody would care if I did those), so suggestions are welcome ( I own a lot of dvds for Mankai Stage, Toumyu, and most plays Sakiyama Tsubasa is in + a bunch of things Sasamori Hiroki and Okamiya Kurumu are in..., for anything else I'd need the video.)
3 notes
·
View notes
Text
Course: Data Analysis Tools | Assignment Week 2
The following scripts is an extension of the script of Week 1 Assignment. It investigates into 4 different income groups of gapminder dataset (<15k, <30k, <45k, <60k income) whether the average life expectancy is larger or smaller than 78 years.
The results show that only income group 1 has a statistically robust deviation from the other groups based on the Chi Squared Test.
Console Output (Chi Squared related, for rest see previous Tumblr entry):
INCGROUPS15K 15k 30k 45k 60k
LIFEEXPGROUPS70Y
(45, 78] 136 2 0 0
(78, 90] 8 16 9 1
INCGROUPS15K 15k 30k 45k 60k
LIFEEXPGROUPS70Y
(45, 78] 0.944444 0.111111 0.000000 0.000000
(78, 90] 0.055556 0.888889 1.000000 1.000000
chi-square value, p value, expected counts
(113.1514634839443, 2.30160388506565e-24, 3, array([[115.53488372, 14.44186047, 7.22093023, 0.80232558],
[ 28.46511628, 3.55813953, 1.77906977, 0.19767442]]))
Adjusted p value (Bonferroni Adjustment: 4 groups --> 6 pairwise comparisons
0.008333333333333333
COMP1v2 15k 30k
LIFEEXPGROUPS70Y
(45, 78] 136 2
(78, 90] 8 16
COMP1v2 15k 30k
LIFEEXPGROUPS70Y
(45, 78] 0.944444 0.111111
(78, 90] 0.055556 0.888889
chi-square value, p value, expected counts
(81.5640285326087, 1.696744687700559e-19, 1, array([[122.66666667, 15.33333333],
[ 21.33333333, 2.66666667]]))
COMP1v3 15k 45k
LIFEEXPGROUPS70Y
(45, 78] 136 0
(78, 90] 8 9
COMP1v3 15k 45k
LIFEEXPGROUPS70Y
(45, 78] 0.944444 0.000000
(78, 90] 0.055556 1.000000
chi-square value, p value, expected counts
(67.236328125, 2.4083516525272384e-16, 1, array([[128., 8.],
[ 16., 1.]]))
COMP1v4 15k 60k
LIFEEXPGROUPS70Y
(45, 78] 136 0
(78, 90] 8 1
COMP1v4 15k 60k
LIFEEXPGROUPS70Y
(45, 78] 0.944444 0.000000
(78, 90] 0.055556 1.000000
chi-square value, p value, expected counts
(3.317199130809731, 0.0685585370880382, 1, array([[1.35062069e+02, 9.37931034e-01],
[8.93793103e+00, 6.20689655e-02]]))
COMP2v3 30k 45k
LIFEEXPGROUPS70Y
(45, 78] 2 0
(78, 90] 16 9
COMP2v3 30k 45k
LIFEEXPGROUPS70Y
(45, 78] 0.111111 0.000000
(78, 90] 0.888889 1.000000
chi-square value, p value, expected counts
(0.0675, 0.7950121719642381, 1, array([[ 1.33333333, 0.66666667],
[16.66666667, 8.33333333]]))
COMP2v4 30k 60k
LIFEEXPGROUPS70Y
(45, 78] 2 0
(78, 90] 16 1
COMP2v4 30k 60k
LIFEEXPGROUPS70Y
(45, 78] 0.111111 0.000000
(78, 90] 0.888889 1.000000
chi-square value, p value, expected counts
(0.0, 1.0, 1, array([[ 1.89473684, 0.10526316],
[16.10526316, 0.89473684]]))
COMP3v4 45k 60k
LIFEEXPGROUPS70Y
(78, 90] 9 1
COMP3v4 45k 60k
LIFEEXPGROUPS70Y
(78, 90] 1.000000 1.000000
chi-square value, p value, expected counts
(0.0, 1.0, 0, array([[9., 1.]]))
Code:
Import Libraries
import pandas
import numpy
import seaborn
import matplotlib.pyplot as plt
smf provides ANOVA F-test
import statsmodels.formula.api as smf
multi includes the package to do Post Hoc multi comparison test
import statsmodels.stats.multicomp as multi
scipy includes the Chi Squared Test of Independence
import scipy.stats
bug fix for display formats to avoid run time errors
pandas.set_option('display.float_format', lambda x:'%f'%x)
Set Pandas to show all colums and rows in Dataframes
pandas.set_option('display.max_columns', None)
pandas.set_option('display.max_rows', None)
Import gapminder.csv
data = pandas.read_csv('gapminder.csv', low_memory=False)
Replace all empty entries with 0
data = data.replace(r'^\s*$', numpy.NaN, regex=True)
Extract relevant variables from original dataset and save it in subdata set
print('List of extracted variables in subset')
subdata = data[['incomeperperson', 'lifeexpectancy', 'suicideper100th']]
Safe backup file of reduced dataset
subdata2 = subdata.copy()
Convert all entries to numeric format
subdata2['incomeperperson'] = pandas.to_numeric(subdata2['incomeperperson'])
subdata2['lifeexpectancy'] = pandas.to_numeric(subdata2['lifeexpectancy'])
subdata2['suicideper100th'] = pandas.to_numeric(subdata2['suicideper100th'])
All rows containing value 0 / previously had no entry are deleted from the subdata set
subdata2 = subdata2.dropna()
print(subdata2)
Describe statistical distribution of variable values
print('Statistics on "Income per Person"')
desc_income = subdata2['incomeperperson'].describe()
print(desc_income)
print('Statistics on "Life Expectancy"')
desc_lifeexp = subdata2['lifeexpectancy'].describe()
print(desc_lifeexp)
print('Statistics on "Suicide Rate per 100th"')
desc_suicide = subdata2['suicideper100th'].describe()
print(desc_suicide)
Identify min & max values within each column
print('Minimum & Maximum Income')
min_income = min(subdata2['incomeperperson'])
print(min_income)
max_income = max(subdata2['incomeperperson'])
print(max_income)
print('')
print('Minimum & Maximum Life Expectancy')
min_lifeexp = min(subdata2['lifeexpectancy'])
print(min_lifeexp)
max_lifeexp = max(subdata2['lifeexpectancy'])
print(max_lifeexp)
print('')
print('Minimum & Maximum Suicide Rate')
min_srate = min(subdata2['suicideper100th'])
print(min_srate)
max_srate = max(subdata2['suicideper100th'])
print(max_srate)
print('')
Split up income into percentiles
subdata2['INCGROUPS15K']=pandas.qcut(subdata2.incomeperperson, 5, labels=["1=0%tile","2=15%tile","3=50%tile","4=75%tile","5=100%tile"])
inc_dist_percent = subdata2['INCGROUPS15K'].value_counts(sort=False, normalize=True, dropna=True)
subdata2['INCGROUPS15K'] = subdata2['INCGROUPS15K'].astype('category')
print(inc_dist_percent)
print(subdata2)
subdata2['INCGROUPS15K'] = pandas.cut(subdata2.incomeperperson, [0, 15000, 30000, 45000, 60000])
subdata2['INCGROUPS15K'] = subdata2['INCGROUPS15K'].astype('category')
subdata2['INCGROUPS15K'] = subdata2['INCGROUPS15K'].cat.rename_categories(["15k", "30k", "45k", "60k"])
inc_dist_dollar = subdata2['INCGROUPS15K'].value_counts(sort=False, normalize=True, dropna=True)
subdata2['INCGROUPS15K'] = subdata2['INCGROUPS15K'].astype('category')
print(inc_dist_dollar)
subdata2['LIFEEXPGROUPS70Y'] = pandas.cut(subdata2.lifeexpectancy, [45, 78, 90])
lifeexp_dist = subdata2['LIFEEXPGROUPS70Y'].value_counts(sort=False, normalize=True, dropna=True)
subdata2['LIFEEXPGROUPS70Y'] = subdata2['LIFEEXPGROUPS70Y'].astype('category')
print(lifeexp_dist)
The following cross table compares income and life expectancy of different groups
print('First, simplified comparison of income and life expectancy')
comparison = pandas.crosstab(subdata2['INCGROUPS15K'], subdata2['LIFEEXPGROUPS70Y'])
print(comparison)
Univeriate plots
seaborn.countplot(x='INCGROUPS15K', data=subdata2)
plt.xlabel('Average Income of Income Group')
plt.title('Count distribution of Income per Person')
Biveriate plots
seaborn.catplot(x='INCGROUPS15K', y='lifeexpectancy', data=subdata2, kind="bar", ci=None)
plt.xlabel('Income Group')
plt.ylabel('Life Expectancy')
seaborn.catplot(x='INCGROUPS15K', y='suicideper100th', data=subdata2, kind="bar", ci=None)
plt.xlabel('Income Group')
plt.ylabel('Suicide Rate per 100 persons')
New script section for ANOVA F-Testing
subdata3 = subdata2.dropna()
print ('means for lifeexpectancy by income groups (15K steps)')
m1= subdata3.groupby('INCGROUPS15K').mean()
print (m1)
print ('standard deviations for lifeexpectancy by income groups (15K steps)')
sd1 = subdata3.groupby('INCGROUPS15K').std()
print (sd1)
using ols (ordinary least squares) function for calculating the F-statistic and associated p value / C indicates Categorical Value
model1 = smf.ols(formula='lifeexpectancy ~ C(INCGROUPS15K)', data=subdata2)
results1 = model1.fit()
print (results1.summary())
mc1 = multi.MultiComparison(subdata3['lifeexpectancy'], subdata3['INCGROUPS15K'])
res1 = mc1.tukeyhsd()
print(res1.summary())
New script section for Chi Squared Test of Independence
First part: Chi Squared test of independence of all sample groups (income groups up to 15k, 30k, 45k, 60k).
Life expectancy is split up into <70 and >70 years
subdata4 = subdata2.dropna()
contingency table of observed counts
ct1=pandas.crosstab(subdata4['LIFEEXPGROUPS70Y'], subdata4['INCGROUPS15K'])
print (ct1)
column percentages
colsum=ct1.sum(axis=0)
colpct=ct1/colsum
print(colpct)
chi-square
print ('chi-square value, p value, expected counts')
cs1= scipy.stats.chi2_contingency(ct1)
print (cs1)
Post Hoc Testing (pairwise)
subdata5 = subdata2.dropna()
recode1 = {'15k': '15k', '30k': '30k'}
subdata5['COMP1v2']= subdata5['INCGROUPS15K'].map(recode1)
Target p-value after Bonferroni Adjustment. Reminder how to adjust: p (Post Hoc Test) = p / number of sample groups that are checked
p = 0.05
p_bonferroni = p / 6
print('')
print('Adjusted p value (Bonferroni Adjustment: 4 groups --> 6 pairwise comparisons')
print(p_bonferroni)
contingency table of observed counts
print('')
ct2=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP1v2'])
print (ct2)
column percentages
colsum=ct2.sum(axis=0)
colpct=ct2/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs2= scipy.stats.chi2_contingency(ct2)
print (cs2)
Pairwise comparison #2
recode2 = {'15k': '15k', '45k': '45k'}
subdata5['COMP1v3']= subdata5['INCGROUPS15K'].map(recode2)
contingency table of observed counts
print('')
ct3=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP1v3'])
print (ct3)
column percentages
colsum=ct3.sum(axis=0)
colpct=ct3/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs3= scipy.stats.chi2_contingency(ct3)
print (cs3)
Pairwise comparison #3
recode3 = {'15k': '15k', '60k': '60k'}
subdata5['COMP1v4']= subdata5['INCGROUPS15K'].map(recode3)
contingency table of observed counts
print('')
ct4=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP1v4'])
print (ct4)
column percentages
colsum=ct4.sum(axis=0)
colpct=ct4/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs4= scipy.stats.chi2_contingency(ct4)
print (cs4)
Pairwise comparison #4
recode4 = {'30k': '30k', '45k': '45k'}
subdata5['COMP2v3']= subdata5['INCGROUPS15K'].map(recode4)
contingency table of observed counts
print('')
ct5=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP2v3'])
print (ct5)
column percentages
colsum=ct5.sum(axis=0)
colpct=ct5/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs5= scipy.stats.chi2_contingency(ct5)
print (cs5)
Pairwise comparison #5
recode5 = {'30k': '30k', '60k': '60k'}
subdata5['COMP2v4']= subdata5['INCGROUPS15K'].map(recode5)
contingency table of observed counts
print('')
ct6=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP2v4'])
print (ct6)
column percentages
colsum=ct6.sum(axis=0)
colpct=ct6/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs6= scipy.stats.chi2_contingency(ct6)
print (cs6)
Pairwise comparison #6
recode6 = {'45k': '45k', '60k': '60k'}
subdata5['COMP3v4']= subdata5['INCGROUPS15K'].map(recode6)
contingency table of observed counts
print('')
ct7=pandas.crosstab(subdata5['LIFEEXPGROUPS70Y'], subdata5['COMP3v4'])
print (ct7)
column percentages
colsum=ct7.sum(axis=0)
colpct=ct7/colsum
print('')
print(colpct)
print('')
print ('chi-square value, p value, expected counts')
cs7= scipy.stats.chi2_contingency(ct7)
print (cs7)
0 notes
Text
Compared with the original openGauss, Dolphin modifies the time/date function as follows:
The dayofmonth, dayofweek, dayofyear, hour, microsecond, minute, quarter, second, weekday, weekofyear, year, and current_date functions are added.
The curdate, current_time, curtime, current_timestamp, localtime, localtimestamp, now, and sysdate functions are added.
The makedate, maketime, period_add, period_diff, sec_to_time, and subdate functions are added.
The subtime, timediff, time, time_format, timestamp, and timestamppadd functions are added.
The to_days, to_seconds, unix_timestamp, utc_date, utc_time, and utc_timestamp functions are added.
The date_bool and time_bool functions are added.
The dayname, monthname, time_to_sec, month, day, date, week, yearweek functions are added and the last_day function is modified.
The datediff, from_days, convert_tz, date_add, date_sub, adddate, addtime functions are added and the timestampdiff function is modified.
The get_format, date_format, from_unixtime, str_to_date functions are added, and the extract function is modified.
0 notes
Text
Tableplus run stored function mysql

TABLEPLUS RUN STORED FUNCTION MYSQL MOD
Returns the maximum value in a set of values Returns the natural logarithm of a number to base 2 Returns the natural logarithm of a number to base 10 Returns the natural logarithm of a number, or the logarithm of a number to a Returns the natural logarithm of a number Returns the smallest value of the list of arguments Returns the greatest value of the list of arguments Returns the largest integer value that is = to a number Returns the average value of an expression Returns the arc tangent of one or two numbers Removes leading and trailing spaces from a string Returns a substring of a string before a specified number of Returns a string of the specified number of space characters Right-pads a string with another string, to a certain length Replaces all occurrences of a substring within a string, with a newĮxtracts a number of characters from a string (starting from right) Repeats a string as many times as specified Left-pads a string with another string, to a certain lengthĮxtracts a substring from a string (starting at any position) Returns the position of the first occurrence of a substring in a string Returns the length of a string (in bytes) Returns the position of the first occurrence of a string in another stringĮxtracts a number of characters from a string (starting from left) Inserts a string within a string at the specified position and for a certain Returns the position of a string within a list of stringsįormats a number to a format like "#,#,#.#", rounded to a Returns the index position of a value in a list of values Returns the length of a string (in characters)Īdds two or more expressions together with a separator Returns the ASCII value for the specific character This reference contains string, numeric, date, and some advanced functions MySQL Examples MySQL Examples MySQL Quiz MySQL Exercises
TABLEPLUS RUN STORED FUNCTION MYSQL MOD
String Functions ASCII CHAR_LENGTH CHARACTER_LENGTH CONCAT CONCAT_WS FIELD FIND_IN_SET FORMAT INSERT INSTR LCASE LEFT LENGTH LOCATE LOWER LPAD LTRIM MID POSITION REPEAT REPLACE REVERSE RIGHT RPAD RTRIM SPACE STRCMP SUBSTR SUBSTRING SUBSTRING_INDEX TRIM UCASE UPPER Numeric Functions ABS ACOS ASIN ATAN ATAN2 AVG CEIL CEILING COS COT COUNT DEGREES DIV EXP FLOOR GREATEST LEAST LN LOG LOG10 LOG2 MAX MIN MOD PI POW POWER RADIANS RAND ROUND SIGN SIN SQRT SUM TAN TRUNCATE Date Functions ADDDATE ADDTIME CURDATE CURRENT_DATE CURRENT_TIME CURRENT_TIMESTAMP CURTIME DATE DATEDIFF DATE_ADD DATE_FORMAT DATE_SUB DAY DAYNAME DAYOFMONTH DAYOFWEEK DAYOFYEAR EXTRACT FROM_DAYS HOUR LAST_DAY LOCALTIME LOCALTIMESTAMP MAKEDATE MAKETIME MICROSECOND MINUTE MONTH MONTHNAME NOW PERIOD_ADD PERIOD_DIFF QUARTER SECOND SEC_TO_TIME STR_TO_DATE SUBDATE SUBTIME SYSDATE TIME TIME_FORMAT TIME_TO_SEC TIMEDIFF TIMESTAMP TO_DAYS WEEK WEEKDAY WEEKOFYEAR YEAR YEARWEEK Advanced Functions BIN BINARY CASE CAST COALESCE CONNECTION_ID CONV CONVERT CURRENT_USER DATABASE IF IFNULL ISNULL LAST_INSERT_ID NULLIF SESSION_USER SYSTEM_USER USER VERSION
0 notes
Text
Google doc merge cell commande

#GOOGLE DOC MERGE CELL COMMANDE HOW TO#
#GOOGLE DOC MERGE CELL COMMANDE MOD#
#GOOGLE DOC MERGE CELL COMMANDE UPDATE#
For more info, see Data sources you can use for a mail merge.įor more info, see Mail merge: Edit recipients.įor more info on sorting and filtering, see Sort the data for a mail merge or Filter the data for a mail merge. Connect and edit the mailing listĬonnect to your data source. The Excel spreadsheet to be used in the mail merge is stored on your local machine.Ĭhanges or additions to your spreadsheet are completed before it's connected to your mail merge document in Word.įor more information, see Prepare your Excel data source for mail merge in Word. For example, to address readers by their first name in your document, you'll need separate columns for first and last names.Īll data to be merged is present in the first sheet of your spreadsheet.ĭata entries with percentages, currencies, and postal codes are correctly formatted in the spreadsheet so that Word can properly read their values. In case you need years as well, you'll have to create the formula in the neighboring column since JOIN works with one column at a time: JOIN (', ',FILTER (C:C,A:AE2)) So, this option equips Google Sheets with a few functions to combine multiple rows into one based on duplicates.
#GOOGLE DOC MERGE CELL COMMANDE HOW TO#
We hope this tutorial will help you learn how to merge cells in Google Docs. Select the cells you want to merge, go to Format on the toolbar on top, then press Table and Merge cells here. This lets you create a single 'master' document (the template) from which you can generate many similar documents, each customized with the data being merged.
#GOOGLE DOC MERGE CELL COMMANDE UPDATE#
A mail merge takes values from rows of a spreadsheet or other data source and inserts them into a template document. Data manipulation language (DML) statements in Google Standard SQL INSERT statement DELETE statement TRUNCATE TABLE statement UPDATE statement MERGE. Make sure:Ĭolumn names in your spreadsheet match the field names you want to insert in your mail merge. Method 2: And also, there is another way to merge cells in a table in Google Docs. Performing Mail Merge with the Google Docs API. the diffusion model checkpoint file to (and/or load from) your Google Drive. This SQL keywords reference contains the reserved words in SQL.Here are some tips to prepare your Excel spreadsheet for a mail merge. For issues, join the Disco Diffusion Discord or message us on twitter at. The app allows users to create and edit files online while collaborating with other users in real-time.
#GOOGLE DOC MERGE CELL COMMANDE MOD#
String Functions: ASCII CHAR_LENGTH CHARACTER_LENGTH CONCAT CONCAT_WS FIELD FIND_IN_SET FORMAT INSERT INSTR LCASE LEFT LENGTH LOCATE LOWER LPAD LTRIM MID POSITION REPEAT REPLACE REVERSE RIGHT RPAD RTRIM SPACE STRCMP SUBSTR SUBSTRING SUBSTRING_INDEX TRIM UCASE UPPER Numeric Functions: ABS ACOS ASIN ATAN ATAN2 AVG CEIL CEILING COS COT COUNT DEGREES DIV EXP FLOOR GREATEST LEAST LN LOG LOG10 LOG2 MAX MIN MOD PI POW POWER RADIANS RAND ROUND SIGN SIN SQRT SUM TAN TRUNCATE Date Functions: ADDDATE ADDTIME CURDATE CURRENT_DATE CURRENT_TIME CURRENT_TIMESTAMP CURTIME DATE DATEDIFF DATE_ADD DATE_FORMAT DATE_SUB DAY DAYNAME DAYOFMONTH DAYOFWEEK DAYOFYEAR EXTRACT FROM_DAYS HOUR LAST_DAY LOCALTIME LOCALTIMESTAMP MAKEDATE MAKETIME MICROSECOND MINUTE MONTH MONTHNAME NOW PERIOD_ADD PERIOD_DIFF QUARTER SECOND SEC_TO_TIME STR_TO_DATE SUBDATE SUBTIME SYSDATE TIME TIME_FORMAT TIME_TO_SEC TIMEDIFF TIMESTAMP TO_DAYS WEEK WEEKDAY WEEKOFYEAR YEAR YEARWEEK Advanced Functions: BIN BINARY CASE CAST COALESCE CONNECTION_ID CONV CONVERT CURRENT_USER DATABASE IF IFNULL ISNULL LAST_INSERT_ID NULLIF SESSION_USER SYSTEM_USER USER VERSION SQL Server Functions Google Sheets is a spreadsheet program included as part of the free, web-based Google Docs.
0 notes
Photo

Rolex Submariner on a French Ammo Military Strap #rolex #rolexsubmariner #rolexsub #rolexdaytona #rolexdatejust #submariner #rolex1601 #subdate #ammostraps #ammostrap #rolexexplorer #rolexwatches #rolexwatch #sandiego #dalucastraps #madeinusa #leatherstrap https://www.instagram.com/p/BpkmdRjnKZO/?utm_source=ig_tumblr_share&igshid=30p8bm31ufmd
#rolex#rolexsubmariner#rolexsub#rolexdaytona#rolexdatejust#submariner#rolex1601#subdate#ammostraps#ammostrap#rolexexplorer#rolexwatches#rolexwatch#sandiego#dalucastraps#madeinusa#leatherstrap
8 notes
·
View notes
Photo

Only 1 Guy Want To Have Date For Daily Work, He Sent me The #16610 for This Project 😬😬 3️⃣0️⃣0️⃣/1️⃣0️⃣0️⃣0️⃣ #rolexthailandproject #patina #vintagerolexmania #nofilter #mysecondproject #subdate #vintagewatch #project #submariner #16610 #reddepth #custommade #rolex #vintagerolex #womw #watches #wristshot #wristwatch #oyster #steel #siamnaliga #watchesoftheday #watchesofinstagram #vintagerolexforum #vintagerolexasylum #wruw (at Bangkok, Thailand)
#vintagerolexforum#reddepth#mysecondproject#vintagerolex#vintagerolexasylum#project#submariner#womw#wristwatch#watches#subdate#oyster#watchesoftheday#wruw#patina#siamnaliga#custommade#wristshot#rolex#vintagerolexmania#rolexthailandproject#vintagewatch#steel#16610#nofilter#watchesofinstagram
13 notes
·
View notes
Photo

@pdx_rolex showing us off "Mr. Popular" - the Black Rubber Everest Band on the Rolex Subc. Maybe the most perfect setup when it comes to Rolex/Everest combos. Great #wristi brother! Customize your Rolex at www.everestbands.com
5 notes
·
View notes
Note
Theory one of MOC.
This is going to sound so weird but hear me out y/n never escaped the military. They what she is so they can’t kill her, but they do subdate her to point she can’t move or talk eventually she falls into a coma which comes in the members. The members are actually her into different way, she falls in love with San because San understand her more than anyone and she never wakes up from her coma and when she dies she honestly believes her dream world is so real that her death as a siren makes her and that world real.
i can confirm this is one of the most interesting and unique theories i’ve ever gotten!!! and it would certainly be a huge twist 🧐 while we don’t know all the potential powers of sirens and what each individual one has, then there’s the breakdown of the different churches and all that jazz, who knows? could a siren have reality shifting powers? maybe, maybe not?
2 notes
·
View notes
Photo

Unworn 36mm Rolex Date Just in 18ct Rose Gold and Steel. Available in store now. ✉️[email protected] ☎️01625 403030 #rolex #subdate #rolexaholic #rolexwrist #cheshire #cwc #cheshirewatchcompany #wilmslow #datejust #datejust36 http://bit.ly/2L7AJov
0 notes
Text
Dying
Was supposed to study calculus, played hrizon zero dawn all day and watched wonder woman, super tired bc iit's supetlate here and i'm nor even bothering with the mistakes i make writng this bc inso fuckibg tirec i hav to study j rtegral calculus durhig my entire subdat fkr a test on mo day goodnight fuckas
1 note
·
View note
Text
MySQL ADDDATE () Function | Sintaks | Contohnya
MySQL ADDDATE () Function | Sintaks | Contohnya
In MySQL tutorial, we will discuss about mysql ADDDATE() function. We would love to share with you mysql ADDDATE() functions syntax & examples.
MySQL menyediakan berbagai fungsi tanggal dan waktu untuk bekerja dengan Tanggal. Dalam tutorial kami sebelumnya, kami memiliki daftar fungsi MySQL Date bersama yang tersedia untuk bekerja dengan Tanggal dan waktu.
Fungsi MySQL ADDDATE ()
Fungsi MySQL…
View On WordPress
#mysql add datetime#mysql adddate#mysql adddate example#mysql adddate function#mysql adddate interval#mysql adddate interval month#mysql adddate minutes#mysql adddate month#mysql adddate subdate#mysql adddate year
0 notes
Last Seen Blogs




