
droidtown
Droidtown.co
卓騰語言科技 - 科普分享空間 [ 文章列表:https://blog.droidtown.co/archive ]
63 posts
Last active 60 minutes ago
Don't wanna be here? Send us removal request.
Last Seen Blogs

asssophat
Ass So Phat, Need A Lapdance

deamnsworld
Untitled

it-be-sid
Chaos According To Plan

mutalune
can't tell if i want to be the moon or date her

augustghosts
jay
Text
AI 時代的語言學 - 連載之一
前陣子收到一封演講邀請信,來信的是一位「計算機語言學」的專家,但在信中卻寫了一句「…傳統形式語言學[註1]…」這讓我覺得特別有趣。
若要比年代的話,其實計算機語言學起自1946年的機器翻譯,而喬姆斯基 (Chomsky) 的以數學形式描述的形式語言學研究方法,還要 10 年後,在 1957 年才發表「轉換生成語法 (Transformational Grammar)」[註2]。
這就像是 2016 年最流行的 LSTM (長短期記憶模型) 指著 12 年後的 2022年底才出現的 LLM (大型語言模型) 說「那個是傳統 AI」一樣令人感到時空錯亂。
但凡現象必有原因,為什麼一個「計算機語言學家」會認為「形式語言學」是傳統的?我想了幾天,終於想到一個原因『在 AI 時代裡,計算機語言學家認為形式語言學已經是 Old School 的老東西了!所以才會稱之為傳統!』

但既然我已說明了相較於計算機語言學,形式語言學並不傳統,接著,我就借用 "Linguistics for the Age of AI" (連結) 這本書的書名,做為本篇的題目,說明一下我們用「形式語言學」怎麼在現代做 AI/NLP[註3] 吧。
除非額外說明,否則以下「語言學」的指稱對象都是「形式語言學」。
基本單位:詞彙 vs. token
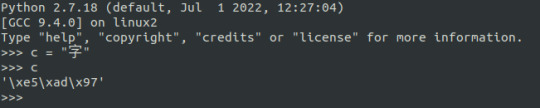
在語言學裡,掌管語意計算的最小單位是「構詞 (morphology)」;但在 AI 的眼裡,它無法理解什麼是「詞彙」。AI 的領域裡,模型計算的最小單位是一個 token。
token 不一定是「字」,甚至不一定是一個「詞」。Token 可以是任何電腦可以儲存解析的單位。比如說一個中文字,在 Python2 裡就是以三個 bytes 來儲存。
但從語言學的角度,一個「構詞的單位」是可以和整個句子的語意有所關係的。例如「打破」的「破」表示「這個動作最後造成的結果狀態」。而呈現一個句子意義的方式,是透過其句法結構逐層計算而來。

而且在這個架構下,我用紅色字體標出的每個 XP (TP, ASP, VP, DP, NP…) 都可被視為是某一種程式裡的函式 (Function,請特別注意這個字!),只需要給予它需要的論元 (arguments) 就行了。一段用以表示概念的 psudo-code 可以是像這樣:
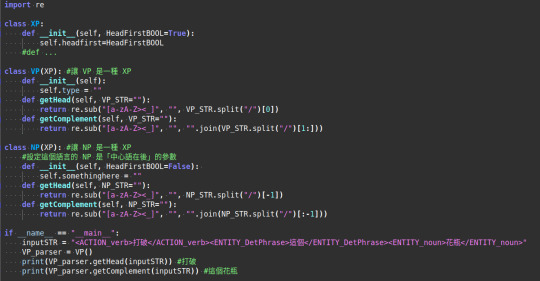
由於這個語言的 VP 是 head-initial (中心語在前) 的,所以當 VP 繼承 XP (class VP(XP) 這行) 的時候,不需要另做調整。而這個語言的 NP 是 head-final (中心語在後) 的,所以當 NP 繼承 XP (class NP(XP) 這行) 的時候,需要在 __init__() 裡設定它不是 HeadFirst 的參數[註4]。
於是,我們就能完全基於形式語言學的句法規則,來撰寫程式該怎麼處理句子。取出句子裡在句法樹上的每個元素,然後就能轉為形式語意 (Formal Semantics) 的 labmbda abstraction 的邏輯式,再進行語意計算了。
這時,下一個合理的問題就會浮現:正如大型語言模型都有「訓練」和「推論」兩個階段。上面的 psudo-code 既然類比的是「推論」的使用階段,那麼一開始究竟是怎麼得到 inputSTR 裡的這些標記結果的呢?
這又要回到「傳統 NLP」(這裡真的可以用『傳統』一詞) 處理高頻詞的想法和形式語言學的差異了。
傳統 NLP 是從訊號處理的角度出發的。因此很在意熵值的變化。他們覺得「只要某個東西的出現次數太多了,它就應該像背景雜訊一樣,數量多,而且變化多端。只要把它們濾掉,排除,剩下的就是我們要的訊號了。」
但從語言學的來看:「這個元素一直出現,必然有什麼特殊的原因!」
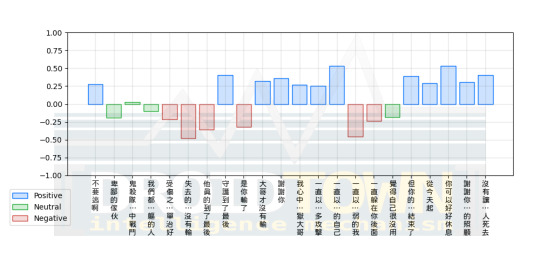
以下我們可以從某個詞彙出現次數繪製的長條圖裡,看出這兩種不同對待語言的態度:

ref. https://slackersite.wordpress.com/2015/08/28/zipf-it-word-frequency-and-line-drawing/
這張圖呈現的是某語料經統計後的結果,出現次數最多的詞彙往左排,次多的排第二,第三多的排第三,依序往右排。所以這張圖表裡呈現的就是「本語料中,"the" 出現的次數最多,"of" 出現的次數次之,"and" 第三…依序呈現」這種分佈被稱為齊夫分佈 (Zipf's distribution) 或是也有人稱語言中詞頻的分佈會遵守齊夫律 (Zipf's law)。
如果你是受傳統 NLP 出身的訓練,那麼你下一步會處理它的方式就是所謂的「去除停用詞 (stop word removal)」

ref. https://www.ngcm.soton.ac.uk/2021/07/07/natural-language-processing-in-python/
也就是把出現次數最多的那幾個詞,當做是「高頻詞」,然後把它當成是「就像出現次數又多,種類又變化多端的雜訊」一樣去除。然後只取後面的 "interesting word" 來當做實義詞 (content word) 使用。
但語言學並不是從這個角度理解這個現象!
語言學從「人類幼兒如何從極少的資料裡,就能掌握自己身處的母語環境中,究竟要把 HeadFirstBOOL 設為 True 還是 False」這個角度出發。從這個角度來思考,我們馬上就能注意到「這麼多高頻詞,怎麼剛好都是 Function word 呢?」
因為 Function word 可以快速地幫助人類幼童決定他正在「習得 (acquire)」的這個語言,要怎麼設定參數,以便快速地用最少的能量 (他每次的能量補給只有幾 c.c. 的母乳,而不像���型語言模型一樣有三個州的電網系統可以提供能源),在最少的例子裡聽出來「什麼東西一直反覆出現,那就先把它當做是句法樹上那些紅色的節點。優先釐清它的參數設定 HeadFirst (中心語在前) 還是 HeadFinal (中心語在後)」。
就依這樣的步驟,我們實際觀察一次這個比較少台灣人熟悉的語言:

如果把它依前例畫成每個詞出現的次數的話,就會發現第一多出現的字就是 "di"!讀者應該可以想像,人類幼兒聽到很多次的 "di" 以後,接著會發現它是前面的東西變化比較少,還是後面的東西變化比較少。如果是前面的東西變化比較少,那就表示它和前面那個東西的關係比較緊密,所以它是 "HeadFirst=False" 的參數設定;相反地,如果它後面的東西比較不會變化,那麼它就是和後面的東西關係比較緊密,這麼一來它就是 "HeadFirst=True" 的參數設定。
除了這個 HeadFirst 的參數設定以外,我們還會注意到「所有能扮演 Function 的元素,都是有限的數量」。比如說英文介系詞就少少的那幾個,中文的更少 (e.g., 在、於、之、的…等)。換言之,人類幼童根本不需要有那麼多的訓練語料,他只需要掌握住「那些常常出現的高頻詞,各自是屬於要往前併成一個 XP 的類型,還是往後併成一個 XP 的類型」就可以了。
於是「那隻貓打破了這個花瓶」,就可以很快地被以下的步驟逐層解析並加上標記:(我用 -> 和 <- 來表示它是往哪個方向併成一個 XP 結構,並用 [ ] 標出已經併起來的單位)
那(->) 隻貓打破了這(->) 個花瓶
[那隻] 貓 打破(<-) 了(<-) [這個] 花瓶
[那隻](->) 貓 [[打破]了] [這個](->) 花瓶
再加上我們知道具有 Syntax Function 的功能詞只有那幾類。就能標上:
[DetP[Det 那隻] [N貓]] [VP[V打破]了] [DetP[Det 這個]花瓶]
走到步驟 5 的時候,一個可以被 Formal Semantics 的 Lambda Abstraction 接手進行語意計算的句法樹標記就做好了。這 5 步,就相當是對應現在大型語言模型的「訓練」階段。只是我們用語言學的方法是用演算法來做,而不是用資料模型來逼近。
簡言之,我們不需要大量語料,不需要像 1950年代的 Pre-Chomsky 的『真.傳統語言學家』去編寫每個詞彙的文法,列舉每個例子,就能模仿人類幼童學會語言的句法結構和參數知識的方式,用語言學來做 NLP 了。
我們的 Articut 就是這麼做的。在中文上做了一次,在英文上做了一次,還正在排灣語上再做一次。我們一次又一次地做,就是為了證明「這種方法是可行的,而且即便是語言類型學上非常不一樣的語言,形式語言學的方法,在 AI 時代裡也是可行的,而且我們還非常省能源,又不需要大量語料呢!」
而且,由於我們的演算法是貼著 X-bar 做的,所以我們的各種應用也等於是提供了形式語言學家 (或是生成語言學家) 一個「可以透過資訊工具大量測試和觀察語言現象」甚至「將理論實作成應用」的研究平台了。
===
註 1
形式語言學的英文是 Formal Linguistics. 其中的「形式」一詞,指的是指使用定理或公式解,來說明並建構知識的邏輯系統。這種研究方法又被稱為 Formalism,中文被譯平「形式主義」。
但大概是近 30 年來的兩岸開放交流,台灣吸收了許多中國詞彙和語意的解釋。而中國使用「形式主義」這四個字的時候,更像是官僚主義的那種只看事物的現象而不分析其本質的思想方法和工作作風。
於是乎…莫名奇妙地開始有些剛接觸語言學的學生就帶著「中國風味的形式主義」來理解 Formalism 的 Formal Linguistics 的中文譯名「形式主義語言學」了。
不過還好,Formal Linguistics 裡研究句法的分支,通常又被稱為 Generative Syntax,而中文常被譯做「生成語法/生成句法」。這個字眼就持續維持中性,直到 2022 年底的大型語言模型,又把這個字拿去放在「生成式 AI」的 Generative AI 裡。
於是乎,又有許多「先看到生成式 AI,才看到生成式語法」的人,以為『你們這些語言學家就是在蹭 AI 的熱度哦!』
註 2
簡單的年表如下:
1956年 達特矛斯會議:第一次冒出 "Artificial Intelligence (AI)" 這個字眼,當時的語言學是傳統的 Rule-based 語言學。
1950年代,意識到 Rule-based 語言學無效,因為規則寫不完,因此開始了 Computational Linguistics (計算機語言學) 和 Corpus Linguistics (語料庫語言學) 的發展。前者企圖用某種知識圖譜、人為標記做出統計機率模型,後者企圖採集『具代表性』的語料,以避免資料量太大的時候,描述規則會寫不完的問題。兩者都是為了「解決 Rule-based 的不佳」而開始的領域。
1957 年 Chomsky 出版他的第一本關於語言的專書,他是在荷蘭出版的,因此對美國的影響並不那麼立即或明顯。
1965 年 Chomsky 出版他的第二本關於語言學理論的專書,這本是在 MIT 出版社出版的。
因此…誰更「傳統」?這個問題的答案,似乎不言而喻。
註 3
較明確的說法應該就是 NLP 而非 AI。但在 LLM 出現以後,大家似乎漸漸把 "AI" 一詞能指涉的範圍變得更廣了,只要是能通電的,都能冠上 "AI"。因此,為了讓文字閱讀時遇到陌生詞彙的費力感降低,本文裡的 AI 其實就只專指 "NLP (自然語言處理)" 的相關技術與應用。
註 4
psudo-code 的意思是「它並不是被期待成可被直接執行的程式碼,而是用以表達概念或是演算法核心的偽碼」。甚至連這段程式碼裡的 regex 都不該使用才對,而「這裡的 NP 還需要做一些調整,才能正確地使用」我知道,但這就是用以表達概念的 psudo-code 而已,它本來就不是要被執行的,而是被用來理解的概念的。
有些不熟悉 Formalism 或 Programming 的人,會對這段 psudo-code 提出諸如「回傳的結果是錯的,我用另一個句子就會得到錯誤的結果」或是「這個程式根本不能動」的質疑。這個註解就是寫給這些人看的。
0 notes
Text
[讀書隨筆之五] 理論語言學的應用
前情提要…
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
本系列文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。但本篇是本系列文中獨立成篇,以前四篇做為基礎,針對卓騰語言科技如何利用理論語言學實作語言科技應用的說明。
書中的前一章已說明了語言學理論的目標,和所有的理論科學一樣是透過「科學方法和考證方式」將「對語言的研究」進一步從單純的現象描述,推展到科學 (science) 的程度。
所以現代語言學是一種「研究語言的科學」,而不再只是傳統語言學的表面現象描述、發音的記錄和語族、語言樹的分類而已。
有個和科學 (science) 常常一起提起的詞彙,是科技 (scientific technology)。既然現代語言學的研究是科學的,那麼這些科學研究成果,能不能做為科技應用的基礎呢?
本文針對這個問題,做出補充。

快速回顧
由於中文組成新詞彙的方法,往往是由許多已知的字符來拼接,導致許多中文母語者也養成了「有邊讀邊」的錯誤習慣。
因此需要先點明一個重點:本文將說明的是「理論語言學的應用 (Applications of theoretical linguistics」,而不是「應用語言學 (Applied Linguistics)」。
我們在本系列文的第一篇中提過,現代語言學利用邏輯代數系統,來表示和計算語言中的意義,稱為語意 (semantics)。
前例:
LEARN(語言學, 他)w(剛開始)
而在本系列文的第二篇裡提到,現代語言學不再像其它繼承傳統語言學的子領域,只看表面線性的詞彙順序,而是將結構視為語言的第一特徵,稱之為句法 (syntax)
前例:
Mary and John smile.
[主詞] + smile
[Snt[[Subj.[N...]] V]]
主要議題
現在的問題,就是如何把句法 (syntax) 和語意 (semantics) 湊在一起進行操作來計算一個句子是否:
a. 具有合乎句法的結構
b. 具有可被理解的意義
如果一個句子違反了前述的 a,那麼這個句子將變得無法被理解。例如:
100面寫幫封一我歉��道遲試到
這是一個特別設計過的字串,無法被合理地重新排序成為一個合乎句法結構的中文句子。因此對任何中文母語者而言,這個句子是沒有意義的,因為它無法被理解[註1]。
但如果一個句子符合了前述的 a ,但卻違反了 b,那麼這個句子將會冒出一股「詩意 (poeteic expression)」。例如:
透明的綠色憤怒地安眠著
這個句子完全符合中文的句法結構,但它的語意很奇怪。既然是透明的,怎麼又會有顏色?既然是安眠著,又怎麼會流露出憤怒情緒?
這股令人「企圖重新詮釋其意義」的空間,可能就是文學美感的源頭。
暫且先放下文學與詩的討論,讓我們繼續回到「完全符合 a 和 b 的一般語言使用」的場景。
常見誤解與迷思
系列文之二裡曾經提過現代語言學是依句法運作。而對語言學有一點理解的人,可能會聯想到像以下這種 Phrase Structure Rule (詞組規則, PS Rule) 的句法:
S → NP VP
NP → Det Adj N
VP → V NP
VP → V
VP → V PP
PP → P NP
S: sentence; 句子
Adj: adjective; 形容詞
N: noun 名詞 (例如「蝴蝶」)
NP: noun phrase; 名詞組 (比名詞更大一點的東西,但還是一個名詞。例如「黃色的蝴蝶」)
Det: determiner; 冠詞
V: 動詞 (例如「出現」)
VP: verb phrase; 動詞組 (比動詞更大一點的東西,但還是一個動詞。例如「出現過」)
P: preposition; 介系詞 (例如「在」)
PP: prepositional phrase 介系詞組 (比介系詞再大一點,但還是一個介系詞的東西。例如「在台北」)
但這種做法在現代語言學裡已經不再使用了,只剩下來不及跟上理論研究的部份計算機語言學實驗室因為某些歷史因素,無法拋下過去而繼續用著。
現代語言學不再使用這些 PS Rule 的原因,是因為依前面的 PS Rule,我們可以發現有三個主要的問題:
NP 有三個下屬元素 (Det, Adj, 和 N),但其它的只有兩個下屬元素。(而在 PS Rule 裡,NP 有時候也不只兩個下屬元素)
VP 有三種變化的可能。也就是說,至少有三種可能性可以構成 VP。
承上兩點,同一個詞組將有 N 種詞組句法樹 (i.e., VP 在上例中有三種句法樹),而這 N 種詞組句法樹的結構,又無法跨語言使用。換句話說,每一個語言都得做一個充滿各種句法樹的模型。
這些問題將導致現代語言學的理論困在某一種語言上,而無法將讓全世界人類的語言都納入同一個框架下。但現代語言學的目標是要提出一個可以解釋全人類語言能力運作機制的理論。
因此,當舊的 PS Rule 無法跨語言時用時,現代語言學就在這個分歧點上採取了其它的方式重新提出新的理論。
但在這個分歧點上,史丹佛大學的 CoreNLP 就採用了自己的英文 Treebank (連結),但只適用於英文;中研院的 CKIP 小組也有自己的 Treebank (連結) 但只適用於中文。
不管是哪一個 Treebank,都不是現代語言學在發現 PS Rules 無法跨語言使用之餘,還帶有前述問題的分歧點上採用的解決方案。
X-bar 理論
現代語言學推出了 X-bar 理論,並讓每一層分支只會有二元分支 (binary branching)。一個標準的 X-bar 結構長這樣…
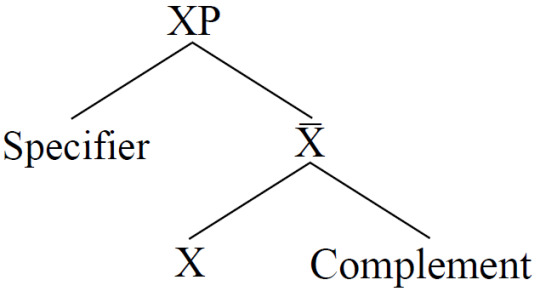
這張二元結構樹中,XP 的 X 可為任何已知的詞性。亦即,它可以是 NP 的 N,用以表示這是一個名詞組,也可以是 VP 的 V,用以表示這是一個動詞組。
中間的 X-bar 這一層,則可容納任何沒改變 XP 中這個 "X" 性質的元素。比如說:

在這個 AdjP (形容詞組) 結構中,每一個「非常」都不會影響這個詞組的重心是「高大」的事實。此外,不論重覆幾個「非常」也不會讓 AdjP 的 Adj 變成別的詞性。
這個理論框架最大的好處是每個階層都只要決定「一個特徵」就可以了。
計算量將大幅縮減!
即「這個詞的位置應該位於左分支嗎?」如果這個特徵為「是」,那麼它就會出現在左分支的節點 (例如「高大」「非常」和 "Specifier")。而當我們決定了「形容詞 Adj 要位於左分支」的時候,它的 Complement 就無需再次做特徵計算,它一定是在另一個分支節點上 (也就是右分支)。[註二]
如此一來,我們也不需要一個 treebank 或是模型來學習「每一個詞彙」是「是不是屬於左分支」,只要針對每一種語言的各個詞類做好設定即可。
例如:
中文的形容詞位於左分支:高大的球員 (「高大」是形容詞,位於左分支)
法文的形容詞位於右分支:moulin rouge (法文「紅磨坊」。其中 moulin 是「磨坊」而 rouge 是「紅」)
將前述的句法和語意的計算方式結合起來,會像這個樣子:

也就是,左半圖的句法結構,可以被化為右半圖計算語意的論元結構。看到這裡,可能有人想發問「咦?為什麼不是二元樹呢?」,這是因為語意學研究的進展和句法學研究的進展並不是同步的。這棵樹的擷圖是從 2005 年的論文(連結) 裡抓的。2010 年以後,完整的句法樹,我留在 [註三] 處。
熟悉諸如 Haskell 或是 Prolog 這些 Functional Programming (FP) Languages 或是習於採用 FP 來撰寫程式的軟體工程師,應該已經注意到,語言學裡做語意計算的方法,和 FP 非常相似。用巢層包裏每一階,而每一階裡也做出對應的計算。

理論的發展走到這裡,我們已經知道:
全世界的人類語言的有通用的 X-bar 結構。
X-bar 在每個詞性的 XP 中的運作是遞迴並巢層堆疊的。
XP 中的 X 只有三十種左右。
X-bar Syntax 可以被轉為類似 FP 的函式來計算語意。
看來,實作語言科技的條件都完備了!
實作語言科技
投入實作前,別忘了理論語言學研究進展的幾個重點:
語意的計算是透過 Func(arg, arg, ...) 來計算的。
句法的結構模型只需要學習在某語言 K 中,每個詞性 P 的屬性是左分支或是右分支。
因此,我們 (卓騰語言科技) 可以利用前述理論來建構語言科技的應用。
首先,我們知道任何語言的詞性分類裡,一定有幾類是功能詞 (Function words),另外幾類是內容詞 (Content words)。以中文為例,功能詞例如「很」「在」「的」…這些有限的詞彙。而內容詞則是數量無上限的名詞、動詞、形容詞…等等。
任何語言的功能詞都是有限,而且不太變化的。相較之下,名詞、形容詞…等等內容詞則會隨著時代一直推陳出新。
換言之,只要掌握了功能詞是否屬於「左分支」的特徵,就能知道和這個功能詞搭配的內容詞是在它的左邊,或是右邊。
接著,把這些功能詞列為 Func(arg, arg, ...) 中的 Func() 再把和這個功能詞搭配的詞彙,列為其中的 arg. 這麼一來,我們就能計算
很高大的球員
=> 的(很(高大, i), 球員i) [註四]
綜合以上,我們只要做到以下的功能,就能用相較於 LLM 而言極少的資源,做出 NLU 的語言理解功能。
a. 將語言 K 中的功能詞列出來。如此一來,我們將可以區分 K 語言中的詞彙邊界。[註五]
b. 將語言 K 中的功能詞的特徵是否為左分支設定好。如此一來,我們將可以轉譯 K 語言成為一組一組的 Func(arg, arg, …) 的結構。
c. 有了 a, b 兩個功能以後,我們便能更進一步自動位資料自動做出知識圖譜。
其中,b 是我們做 NLU (自然語言理解) 功能的方式。這麼一來,就能透過給予一個例子,讓電腦學習這個例子裡所有的 Func(),並讓每一個 arg 都是變數來建立模型。
當模型學會了 一個(很(Adj, i), Enty_i),就能對應所有的「一個很 OO 的XX」的語意計算。而「一個」和「很」都屬於語言中較少變化,且總數有限的功能詞。因此我們便能利用和 LLM 相比,非常非常少的訓練資料產生 NLU 模型。
而 c. 的例子可以像是藉由給予語料,讓模型建立:
TIME(參加(奧林匹克, 張星賢), 1932)
這類事實資料做為知識圖譜。這麼一來就能讓這個知識圖譜配合 LLM 做為 RAG 的資料來避免 LLM 產生幻想內容。
小結語
本篇藉由快速回顧系列文的四個篇章,企圖在最短的時間內,讓讀者迷失在新、舊語言學思維典範和理論框架以前,接上最新的 LLM 的表現,進行反思。並且也帶出卓騰語言科技藉由現代語言學的理論,說明如何做到:
詞彙邊界標定以做為句法解析應用的基礎
語意計算以做為自然語言理解模型的基礎
自動產生的知識圖譜,具有可解釋性的 RAG 支援系統
等現代語言科技最需要的應用。
---
註一:
但相對地,大型語言模型卻能理解腦補,並產出一封信件。
如果LLM 和人類理解語言的機制是一樣的,那麼表示 LLM 能理解的東西,人都都能理解。
但這個字串只有 LLM 能解,人類卻不能解,可見 LLM 的理解方式和人類不同。
例如:連結

因此,我們可以假設,近年所有藉由 LLM 來模擬的各種人類理解能力的計算機語言學研究與實驗都失去了其對人類理解能力是如何運作在解釋上的基礎。
簡言之,基於 LLM 的計算機語言學的研究已和人類語言沒有關係了。
註二:
這就是中研院語言所所長林若望教授在「研之有物」的「世上不存在「最難」的語言?專訪語言學家林若望」一文中所提的『…語感關鍵:「中心語在前」vs.「中心語在後」…』這一段的意思。
註三:
完整的句法樹長這樣:

紅色的字標出的是原句裡 "John rented a room in Boston" 裡的動詞以後的部份。從這棵完整的句法樹裡還能看到,如果我們要把整個句子擴充成 "John rented a room that is in Boston" 能得到一樣的語意。因為在句法結構裡,"that" 和 "is" (及其相關的時間語意 <tense>) 都已經有節點可以計算了。
每一個 XP 都是一個 func(). 而能做為其 arguments (論元) 的詞性變化也是有限的 (大概都在二到三個變化之間)。在卓騰,我們就是利用這樣的特性把每個 XP 的函式寫出來 (大概有三十個),然後就能計算句法結構並轉為語意了。
ref.
http://people.umass.edu/moiry/syntax.pdf
https://www.antidote.info/en/blog/reports/o-syntax-tree
註四:
看到這裡,可能有人會想到這和傳統 NLP 的「語意三元組」很像。
但其實也是不一樣的東西。本系列文是跟著「杭士基」一書的章節做節錄與補充。所以沒有特別提到語意研究的進展軌跡。
早期語意研究的確是花了很多時間在做施事者 (主詞)、受事者 (受詞)、受害者 (受詞)、受益者 (受詞)…等等角色的標註,並被 NLP 研究拿來做為訓練模型的材料。
但正如這裡所列的「受詞」有三種可能的角色,在「她和有暴力傾向的男友分手了」裡的「她」究竟是施事者或是受害者,又或是受益者?常常會遇到訓練不足的早期語意學碩博士標註者不一致的標記。所以隨著語言學進入現代語言學的演進後,可計算更精準細膩的語意學也開始走向利用邏輯式來求解語意的操作了。
註五:
這就是 NLP 所說的「斷詞」或「分詞」。
0 notes
Text
[讀書隨筆之四] 語言學理論的目標
前情提要…
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
本文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。
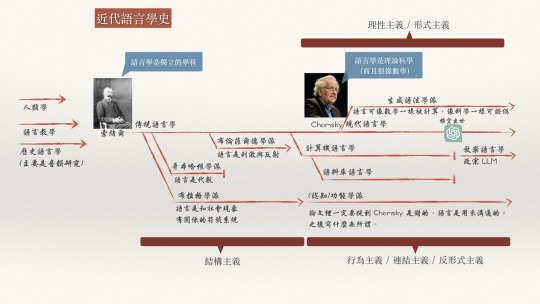
系列文至此,我們已經將主題收斂至「理論語言學」(或「生成語法學派」、「形式主義」、「理性主義語言學」) 的範疇。並且也說明了這個在科學史上相對新的學科 -- 現代語言學 -- 和一般人以為的文法研究或是傳統語言學 (就是 AI 專家們說沒有用的那個語言學) 的差別。
那麼,這個新的學科是否有一個研究目標存在呢?

第四章:語言學理論的目標
杭士基堅稱,任何被記錄下來的話語,具有代表性的語料 (corpus) 裡,有絕大多數的語句是「新」的語句,因為這些語句只會出現一次而且是僅有的一次。無論我們把母語人士所說的話錄得多長,情形還是一樣。
和許多從語料庫起家的 NLP (自然語言處理,Natural Language Processing) 方案和語料庫語言學 (Corpus Linguistics) 的方法最大的不同,就是語言學理論追求要能解釋「只出現一次」的那些句子,為什麼能被聽得懂?
這個目標,細思極恐!
如果人類有辦法第一次聽到某一個句子,就聽得懂那是什麼意思。那就表示人類的語言能力 (competence) 是有能力不靠大量的刺激來掌握語意 (semantics) 的。
這個結論,在某個層面上將嚴重地挑戰目前的 LLM AI 以及所有基於詞頻、大數據才能做出好像懂語意的表現 (performance) 的 NLP 方案。
我在這裡說「某個層面」,特別指的就是「宣稱人類的心智也是透過大量的刺激才能如此運作語言系統」這個層面。而這麼一來,就讓基於語言學理論的 NLP 方案,和基於資料的 NLP 方案,在基礎上產生了差異。
基於語言學理論的 NLP 方案,將要做到「從只出現一次的正確句子表現 (performance) 裡,就能得到這個句子的語意 (semantics)」這表示人類的心智運作機制裡,必然存在著一個可以接收這個句子,將之化為可以處理的元素的內在能力 (competence)。
用個類比來說明,就像人類飲食偏好固然會讓我們選擇「常常吃的食物」,也許是個人飲食偏好、文化習慣或是資源限制…等等原因造成我們的飲食有這樣的偏好表現 (performance)。但這並不表示人類的消化系統只能處理「常常吃的食物」。只要是符合我們消化系統的處理能力 (competence) 的食物,就算一輩子只吃這一次,我們的消化系統都是可以加以處理成更小的分子,然後吸收利用的。
這本來就是有機生物的運作機制。
搞懂了這裡出現這麼多次的 "performance (表現)" 和 "competence (能力)" 的對比說明,就更能理解下一段講的:
杭士基在《句法結構》中曾區別語法所衍生的語句「語言」 (the language) 和一般情況母語人士所說的話「語料」的不同。這也是他後期著述裡區分「知能」(competence) 和「表現」 (performance) 的觀念。
在這樣的基礎上,我們就更能理解理論語言學的研究目標是「人類處理語言的能力」,而非「人類的語言表現」。前者是在你心智底層的 competence,後者是表層的 performance。
而現代智人做為一個生物學裡單一物種,我們人類必然擁有一樣的生物特性和大腦運作機制。這才是 Chomsky 所說的 "Universal Grammar" 的意思。但許多人只看到 "Grammar" 這個字,就以為 Chomsky 在尋找一種像我們中學時的英文課程裡學的那種「第三人稱單數,動詞加 -s」或「Be-動詞後的動詞要加 -ing」的文法操作。因而只能在這種「不同語言有不同的表層呈現 (performance)」的層次提出紮稻草人式的反對意見。
一言以蔽之,語言學理論研究的是人類的語言系統運作時共通的底層邏輯。
正因為有了這樣的底層邏輯,我們才能說明為什麼下面這個句子,你第一次聽到就知道它的意思:
掌管辦公室咖啡的神騎著獅子拉的雪橇在雲霧間奔跑
你不需要知道究竟是不是有一個神負責掌管咖啡、不需要知道獅子能不能拉雪橇、甚至不需要知道雪橇為什麼能在雲霧間奔跑,你都能理解這個句子企圖表達的意思。
同樣地,也是因為有了這樣的底層邏輯,即便我們把下面這個句子重覆 10 萬遍,你還是無法理解它的意思:
椅我天把卡條一坐看子毛幻
這表示,人類的語言能力 (competence) 和刺激的次數無關。企圖單憑詞頻或是字符之間共現的次數來取得這個句子傳達的語意 (semantics) ,甚至來達到語意的理解 NLU (Natural Language Understanding) 與詮釋,是一條行不通的路。
頂多,我們可以使用現有資料訓練出來的模型來「組合可能性高的字串」,做為自然語言生成模型 (NLG, Natural Language Generation)。但這已經超出語言學做為一門「理論科學」的研究目標了。
簡言之,語言學的研究就像所有理論科學的研究一樣,的確你可以拿它的研究成果來做為「技術發展」的基礎,但這並不表示這個學科是以發展技術做為目標的。以發展技術為目標的,有時甚至可以追求大力出奇蹟,不顧及科學基礎的,是所謂的「工程學科」,而非「科學理論」了。
但是,既然提到了 NLU, NLG 這些屬於 NLP 的細節技術需求。我們在系列文的下一篇裡,就暫時跳開這本書,以卓騰語言科技實際的開發規劃來說明我們是如何利用現代語言學的「理論科學研究成果」來發展實際應用的技術。
0 notes
Text
[讀書隨筆之三] 學派
前情提要…
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
本文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。
前文提到「傳統語言學」和「現代語言學」兩種語言學,因為其「傳統」和「現代」兩個詞的語意,很容易讓人以為這是「以前到現在」的變化。事實上,「傳統/現代」的對比,並不是指「某年某月某日,太陽昇起時,全部的傳統語言學學者,全部改變心意,變成了現代語言學學者」。
另外一個更廣為使用的分類方式,叫做「主義」或「學派」。比如說傳統語言學又常被稱為「行為主義」或是「布倫菲爾德學派」。而又立基於這兩個詞彙,現代語言學也常被稱為「形式主義」或是「喬姆斯基學派」。
學派

第三章:布倫菲爾德學派
「傳統語言學」和「現代語言學」對何為「科學」的看法有所不同,但「科學」本身是一個明確定義的詞彙 (維基的定義為「科學強調預測結果的具體性、可證偽性,這有別於空泛的哲學。科學並不等同於尋求絕對無誤的真理,而是在現有基礎上,摸索式地不斷接近真理。」)。在這樣的背景下,我們有必要看看究竟傳統語言學所依據的「布倫菲爾德學派」是怎麼看待科學和自己這個學派之間的關係:
布倫菲爾德認為,「科學」意味需小心翼翼剔除所有無法直接或無法實際測量的材料,他這個說法和心理學行為論創始者 -- 華特森 (J. B. Watson) 的看法不謀而合。華特森和他的追隨者都認為…從一個阿米巴 (an amoeba) 到人類的行為 -- 都應該從生物對環境的刺激 (stimuli) 的反應 (response) 來解釋和描述…
布氏的這個看法,直接將傳統語言學和科學二字劃清了界線。
首先,科學並不意味著只能研究「可直接觀察/可實際測量」的對象。包括數學、人工智慧、系統論…等研究領域在內的理論科學 (Theoretical Science, 又稱形式科學 Formal Science),就往往存在著研究對象無法直接觀察或直接測量的對象或概念 (e.g., 無限大,逼近)。
此外,就算是通常可被觀察的自然科學,也有許多「不能被直接觀察到,只能透過歸納和演繹推論」的部份。例如黑洞的位置,是透過黑洞的重力對其週遭的影響,間接推測黑洞的存在。
因此,只從可見的「刺激 => 反應」之間的關係來限制何為「科學」,實為大大地壓低了語言資訊維度的一大謬誤。但這種「刺激 => 反應」的行為主義論調,卻是一個輕鬆易懂的概念。
這就像巴伏洛夫 (Ivan Petrovich Pavlov) 的實驗裡,我們看到「食物 -> 鈴聲 -> 狗流口水」,因此在狗對「鈴聲」的刺激也產生流口水的反應時,我們得出「狗學會了鈴聲代表食物的意義」的結論。
而事實上,這個廣為流傳的實驗非常難以復現 (replicate),甚至有專門的論文討論過這個難以復現的問題。
這表示,坊間流傳甚廣的「刺激 => 反射」的行為科學心智運作模式,是一個過度簡化且不可靠的推論。
關於「基於行為主義的傳統語言學」在 1970 年代被 Chomsky 連發論文著述,以實際人類幼童的語言習得過程中的表現加以挑戰、否決的歷史,我在這裡暫且先壓下不表。
我更想提出的是,雖然專業的心理學領域裡已經知道了「刺激 => 反應」不是可靠的心智運作模式。但是這個簡單易懂的理論,卻繼續在計算機語言學和自 2012 年起,大數據 (BigData) 以來,乃至機器學習/深度學習和大型語言模型 (LLM, Large Language Models) 的風潮中,一再地被奉為圭臬。
甚至,還有些計算機語言學的專家和 AI 專家主張,這種根據「刺激 => 反應」設計出的「大量刺激 => 各式各樣的反應」大型語言模型就是人類心智運作的模樣。
拜託…它連狗的心智都不是 (LeCun 也這麼說),總不好大家一邊下載 LLaMa 模型,微調得好開心,然後又同時說 LeCun 說的話不算話吧?
布倫菲爾德編寫其劃時代的著作《語言》一書時,顯然是以行為科學的理論做為語言述的架構。
對行為主義的信仰是永遠不會消失的,就像到了西元 2024 年,世界上仍然有相信地球是平的地平說���會。也因為這個「簡單易懂」的想法外溢得到處都是,因此我們才會看到以這個想法最極致的應用來說明人類心智運作的謬論 -- 大型語言模型就是人類心智運作的樣子。詞向量就是人類理解語意的方法!
但對於語意 (semantics),布倫菲爾德學派又是怎麼說的呢?
布倫菲爾德認為,對意義的分析將是「語言研究裡的弱點」…布倫菲爾德之所以會有如此悲觀的看法,實因他深信,只有在字所指的物、狀態、過程等先得到完整的「科學」描述,字的意義才能得到明確的定義。對少部份的字 (如植物、動物和各類自然物質的名稱),我們可以藉相關的科學 (如生物、動物和化學等) 的術語相當確切的定義,但是對絕大多數的字 (如布倫菲爾德所舉出的諸如「愛」「恨」等抽象字彙) 情況卻不同。
布氏語言學派不僅完全忽略掉意義的研究,還常常認為字義的研究根本不屬於所謂的語言學的範籌。
因為布氏學派立基於「只能講可以直接觀察」的東西,因此對於難以直接觀察的語意,他們就直接忽略,當做不存在,把這個問題丟出 (傳統)語言學的研究範籌,眼不見心不煩地處理掉了。
那麼,相較於布氏學派對「語意」的看法,其它的幾個角度,又是怎麼看待這個問題的呢?
功能語法學派 (Functionalism)
對承續了傳統語言學「道統」的計算機語言學、語料庫語言學以及功能語法學派 (Functionalism,或稱認知語法,認知功能學派) 而言,它們避開「無法直接觀察」的問題是改以語用 (pragmatics) 和溝通目的 (communicational purpose) 做為脫身之計。
雖然一開始的功能語法學派是從布拉格學派衍生出來的,但近四十年的功能語法學派的研究主題是立基於「反對 Chomsky」而誕生。本文裡使用「功能語法學派 (Functional Grammar/Syntax)」時,採用較為廣義的定義:既然你反對 Chomsky 的形式語法,那麼所有「語法研究領域裡,所有在方法論(methodology) 上不是形式語法」的,都視為廣義的功能語法學派 ([按] 這樣開地圖炮,完全是一種學術自殺的行為。)
也正因為其「反對」的基礎,每個功能語法學派的學者之間,似乎並未形成一個一致的理論或是研究方法。有人特別研究「常用語式的搭配」,例如「喝掉,吃掉」的 V-掉 中,「掉」的語研究,可採用假設人類有一個原型認知的範籌,而「掉」的意義是落下,後來經過隱喻轉化為「消失」。
但這樣的研究方法,難以套用到英文的 "drink up, eat up" 的 "up"。除非我們要再假設「英文母語人士的原型認知範籌裡,"up (上)" 和『落下』的意思都經隱喻轉化為消失」…([按] Well...I am really speechless about this.)
這樣的問題推展到最後,往往只能得到「因為講英文的人聽多了 V-up 來表示消失的用法。因此英語母語人士就把 -up 和消失的語意連結起來了。而以中文為母語的人則是聽多了 V-掉 的用法來表示消失的語意,所以中文母語人士就把 -掉 和消失的語意連結起來了。」
如果我們再繼續探問下去「那麼…聽到多少,才叫聽多了呢?」又會讓功能語法學家開始引入某個語料庫的資料,並且計算其頻率以提出「有數字,就能做為科學證據」的論點,做為其「Chomsky 是錯的。語言的意義只在溝通時才會產生」的佐證。
但不論是哪一種功能語法學派的方法 (因為缺乏一致的理論框架,所以這裡有「多種」方法),仍然無法回答以下問題:
如果沒有 Chomsky 的話,這個功能語法學派的立基點會是什麼?
如果語料庫的取樣和真實語言使用的比例不同時,基於該語料庫的研究是否具有參考意義?(e.g., 絕大多數人的日常生活裡,並不會使用 PTT 台大批踢踢實業坊 BBS 站台內的說話方式來溝通,如此一來,這麼多以 PTT 語料做為研究材料的功能語法學派研究得到的結論,是否可信?)
為什麼針對 A 語言做的研究看法,往往在 B 語言中得到相反的現象,甚至在 A 語言內就能看到相反現象,此時缺乏一致的理論框架的問題,要怎麼解決?
大型語言模型 (LLM, Large Language Models)
另一方面,大型語言模型,則立基於「模型的表現很像人,所以我們就能假設它的運作和人一樣」的想法,做了一系列的測試與研究,佐證「大型語言模型是聽得懂人話裡的意義 (meanings),懂語意 (semantics) 的」。例如,在這篇文章裡,就以「我們給定 X, Y, Z 幾個字,讓 LLM 接下一個字,假設為 W。如果 "XYZW" 這個字串並未出現在任何 LLM 的訓練資料裡,這表示這個模型懂 XYZ 的意義,並且可以產生一個 XYZW 的新句子做為回應!」這樣的實驗來說明 LLM 懂語言。
問題是,LLM 本質上是一個接龍模型,而能夠接出一個順暢的句子,和它理解句子的語意之間,仍是有著「表現 (performance)」��「能力 (competence)」之間的差別。
比如說,如果我在家鄉是一個非常有經驗的天氣觀察者,我可以輕易地從昨天下午到傍晚之間的天色以及雲層變化,預測今天會不會下雨。假設地點是 X,下午到傍晚是 Y,雲層變化是 Z,而今天會不會下雨是 W 的話。我的預測就像是生成了一個 XYZW 的連續天氣狀態。當有人問我「你為什麼知道會下雨?」的時候,我可以回答他說「因為我昨天看到XYZ,所以預測今天會W!」
但這並不表示我真的具備了對於大氣中水分子的活動、溫濕度之間的互動關係、風向或季節的相關知識的理解。這些才是我們所謂的「知道為什麼會下雨」。
同理,LLM 頂多只是看得夠多了,所以它知道 XYZ 後面可以接 W。即便他沒看過 XYZW,但相較於其它的 XYZK, XYZQ, XYZP...等等的字串結果,這已經是可能性最高的組合了。
它輸出 XYZW,並不是因為理解了 XYZ 的意義和 XYZW 的運作原理。就像我說「今天會下雨」,也不是因為我理解為什麼天色是這樣的變化或是雲層是如此地分佈。我可以預測!正如 LLM 可以接龍,但這都和「理解」無關。
生成語言學 (Generative Linguistics)
最後是 Chomsky 的現代語言學,如同前兩篇系列文中的說明,其屬於一種理論科學,因而如前篇系列文裡說明的一樣,它並不像文法研究,反而更像數學一樣,是帶著利用 Formalized Symbol System (形式化的符號系統) 的各種函式來進行研究的科學,被喜歡以「主義與學派」分類的人歸類在 "Formalism" 裡。
壞也就壞在這個 "Formalism"。
Formalism 一詞的中譯為「形式主義」,但「形式主義」一詞,在中國的語境裡已經特定指稱「流於外在的形式,而失去實質內涵的行禮如儀式的社交舉動或只是過個流程,沒有實際意義的官僚行為」,再加上近三十年來海峽兩岸的交流,讓「形式主義」一詞蒙上了不必要的負面解讀。
而原本這裡採用 "formalize" 指的把語言的元素進行正規化處理,予以嚴格的操作型定義。如此一來,透過數學與邏輯方法來計算語言的句法和語意,才不會流於字面感受的美學討論,而能成為像科學一樣可以被計算的對象。因此,稱之為 Formal Linguistics (形式語言學) 或 Formalism (形式主義)。
其次,現代語言學在其人才的養成訓練裡,並沒有像數學系或是物理系一樣導入了資訊技術來幫助運算與發想。我個人的猜想,這也許是因為許多現代語言學家有意無意間,企圖和讓自己和「計算機語言學」的傳統語言學家有所區隔而為之。
但造成的結果就是…明明是研究方法論最容易和資訊科技結合的理論語言學,反而在理論大致完備,可以開始討論應用面的問題時,發現沒有幾個人知道怎麼操作電腦來呈現理論語言學的研究成果,甚至放大其研究結果的影響力。
Coda
以上的描述,立基於本公司 13 年來雇用過、合作過受過各個不同學派訓練出來的語言學專家 (碩、博都有) 以及我本人在台灣兩所頂大求學期間所接觸資訊相關科系的學生、以及業界的 NLP 工程師及 AI 專家的經驗。
在這個因為少子化而讓大學系所開始減班縮編甚至系所中止招生的時代,「語言學」這個學科不該再是「訓練與生產另一個語言學教授」的學術訓練場,而應該是能誠實面對自己究竟是在傳授「紮實的現代語言學知識 + 補上過去缺乏的資訊技術」,以訓練可以在社會上貢獻所長的人才,亦或只是頂著「語言學」的招牌,實際上只是在提供資訊操作補習教育的終南捷徑。
從一個企業主的視角來看,我實實在在地講「紮實的現代語言學知識 + 資訊技術」正是產業需要的人才。不只是我缺這樣的人才,我的客戶缺這樣的人才,甚至我的競爭對手都缺這樣的人才。
0 notes
Text
[讀書隨筆之二] 現代語言學的獨特之處
前情提要…
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
本文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。
既然講到語言學,就會讓人想到文法研究。那麼現代語言學和文法研究到底有什麼不同?

第二章:現代語言學
傳統文法學家大致說來是鍾情於標準的文學語言 (literatury language)。他們常輕視口語和寫作裡比較非正式或通俗的用語,甚至常指摘通俗用語的不當。
但從語言學的角度來看,只要「有人自然地,不需特別訓練就能說的內容,同樣地也有人自然地,不需特別訓練就能聽懂的內容」,那就是語言的合理用法。
和目前主要從文字學習的 LLM/AI 不同的是,語言學的研究並不受限於文字。因為文字只是「語言的一種記錄方式」,語言也可以被錄音、錄影或是現場的戲劇表演來重現記錄甚至轉譯記錄成為另一種語言或是表現方式。
暫且將這些表現與記錄都放一邊,現代語言學研究的重點是和前一篇系列文的「多個句子有一樣的語意」的目標是一致的。也就是這些表現方式是否有一個可以操作的系統在其後,讓我們可以把 A 語言的表現/記錄方式轉譯為 B 語言的表現/記錄方式。
既然要轉譯,那麼就像我們要把用 Java 程式語言撰寫的程式,重新用 Python 程式語言重寫一次。首要任務,就是「依據 Java 程式語言的句法 (syntax) 來讀懂這支程式想要做什麼 (semantics)」。然後再依據 Python 的句法 (syntax) 來呈現同一個功能 (semantics)。
在前一節中,我們已經簡短地討論過 semantics 的部份。在這裡,我們更能看到,除了 semantics 以外,現代語言學的另一個研究重點就是它的「句法 (syntax)」。
正如書中所提的…
現代語言學的主要目標之一即是建立一套較傳統理論更為週延的語法理論,這套理論必須很適切地描述出人類所有的語言。
再次以程式語言做為類比:也就是說我們企圖找到「設計任何一程式語言時,必要的功能是什麼」(例如:每個程式語言都需要迴圈;每個程式語言都需要條件式…等等)
"syntax" 一字的意思就是「把東西拼在一起」。這麼一來,我們要在語言中建構的東西,就是「把東西 (詞彙) 拼在一起時的規則」是什麼。有了這些規則,我們就更能知道是「什麼和什麼拼在一起」。
以 "John smiles." 這個句子為例。任何懂英文的人,都能基於英文文法 (grammar) 知道 "smile" 加了一個 "-s" 的尾綴,是因為它和 "John" 拼在一起。
但如果我們把這個條件「當 smile 接在 John 後面的時候,smile 要加上 -s 的尾綴」當做文法的話,我們將會無法解釋那為什麼以下的 smile 是不加 -s 的。
"Mary and John smile."
因為我們的確讓 "smile" 接在 "John" 的後面了!為什麼這時候 smile 又不加 -s 了呢?這時候,我們有兩條路可以選。
一是現代語言學採取的「每個句子都有其內部結構,詞彙元素之間是以結構節點做為其互動的介面」。這麼一來,我們就能說明,其實 "John smiles." 和 "Mary and John smile." 有一樣的結構。都是
[主詞] + smile
的結構。接下來,只要看 [主詞] 裡面是單數或是複數的語意,就能決定 smile 會不會有 -s 了。
也就是說,兩個句子的結構其實都是:
[主詞 [John]] + V
[主詞 [Mary and John]] + V
至此,我們可以進一步把這個結構記做:
[Snt[[Subj.[N...]] V]]
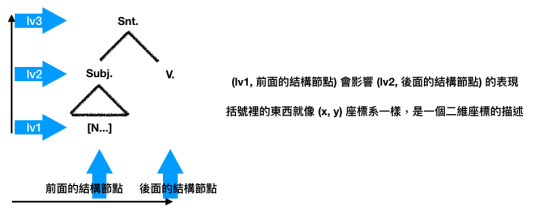
用最前面的 Snt 來表示只要有了後面兩個元素,它就能形成一個 Sentence。然後,只要 len([N...]) > 1, 那麼 V 就會要加上 -S. (注意,我在這裡用大寫的 S,表示它是 -s, -es, -ies... 等複數詞綴的集合)
而這個標記方式,顯示出語言的結構是投射在二維空間,同時需要考慮「前後」與「上下」關係,而非一維空間的只考慮「前後」而已。
另一條路,則是延續前面的「smile 之前 是 John ,那麼 smile 要加 -s」的思路,再額外加一條「smile 之前 是 John ,那麼 smile 要加 -s若 John 之前有個 and,且 and 之前還有 Mary,則 smile 的 -s 取消」。
如此這般,便從原本的一條規則,隨著線性的前後考量,變成了兩條規則。從現在的眼光看來,這種方法實在是很傻。
但 1950 年以及之前的傳統語言學家的確是這麼做的,而同一時代的 Chomsky 的理論仍在發展中,還不到「完備得可以應用」的時候。以致於 1950年代開始,參與 AI (人工智慧) 研究的語言學家,其思維模式都更接近傳統語言學,而非現代語言學。而在當時也的確使得 AI 專家們得出「語言學沒有用」的結論。要注意的是,這句話裡面的「語言學」指的是傳統語言學。畢竟那時候的理論語言學還在建構中呢。
因此,即便是名稱看起來非常先進的「計算機語言學」(Wiki 頁面中提到亦是從 1950 年代開始),也是傳統語言學的思路下的產物。使得即便是 NLP 領域裡常見的 NLTK 仍然是這種「一維空間,前後關係下的規則」的產物。
以下用 NLTK 來取得 "was" 這個 "過去式 Be-動詞" 的詞幹 (stem),就會發現它的思路就是「在一維的前後空間裡,去除最後一個 -s,就能得到詞幹」的做法。所以它最後得出 "was" 的詞幹是 "wa"…

另一個有趣的事情是,雖然 AI 科學家們早就得出「(傳統) 語言學沒有用」的結論,但諸如 ChatGPT 和 Bard …等大型語言模型 (LLM) 所立基的 Transofrmer 仍然是採用了「利用大量資料,擬合在一維空間裡前後字符 (character) 彼此關係」的思路。只是每個一維空間都被獨立儲存起來,讓它有了超級多的維度。
最後,在 LLM 出現以後,許多「計算機語言學」的實驗室也紛紛放棄自己原本的 (傳統)語言學研究方法 (畢竟說穿了…除了標記和統計以外,本來也沒什麼獨到的方法),全部改用 ChatGPT…等 LLM 做為研究的基底,甚至直接宣稱這就是人類語言/語意的模樣了。
這些方法都忽略了一個很基本的事實:「語言的本質就不是線性的!」
在錯誤的維度空間裡,企圖尋找正確的答案,就像在全世界的動物園裡,企圖尋找企鵝。你會在某些動物園裡找到企鵝,但也會有一些動物園裡沒有企鵝。固然,你可以說「這次的尋找,還是有點用的。我們現在知道用什麼方法問動物園,可以最快得到他們有沒有企鵝的答案」。
但你永遠無法解釋「為什麼有的動物園裡有企鵝,有的動物園裡沒有」。因為「動物園」本來就不是「企鵝」這種動物本質上的自然棲息地。就像本質上是在二維空間裡運作的語言,你偏偏跑到超高維度裡去想要尋找它的身影。是,你會找到一些東西,但那不是語言的本質。
0 notes
Text
[讀書隨筆之一] 現代語言學是什麼
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
第一眼看到這本書的時候並沒有注意到原來「杭士基」就是 Chomsky。因為我一般而言把 Chomsky 譯為「喬姆斯基」。但翻到目錄內容時,正是當時努力著要進入「現代語言學」領域的背景說明。
套一句好朋友說的話「這本就是進入語言學概論以前要補的知識背景」。
本文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。

第二章:現代語言學
什麼是現代語言學呢?它和傳統語言學有什麼不一樣?
對本書部份的讀者 -- 或許是大多數的讀者 -- 而言,語言學算是一門嶄新的學問。 … 語言學常被定義為是語言的科學。「科學」一詞在這裡相當重要。
每次提到「語言學」的時候,除了被大多數沒有接觸過語言學的人誤為是「學習某種語言」之外,還有一部份人會把「語言學」當成是學習語言文法的某種學科。
「大概就像國中時的英文文法課吧!」人們會說。
不,像文法課的那種東西比較像是傳統語言學。
現代語言學之所以能被視為是「科學」,除了其研究方法以外,在近年的「句法-語意」介面研究裡,更讓語言的「意義 (meaning)」成為一個可以像數學一樣被計算的對象。
「可以像數學一樣被計算」有多重要呢?其重要性來自於對於「意義」一詞,在現代語言學之前,100 個人對一句話可以用100 種不同的方式來解釋。即便這 100 種不同的方式是同義的,我們仍然無法說明為什麼這 100 種不同的方式的意義是一樣的。
換言之,利用語言來描述語言,將使我們落入套套邏輯 (tautology) 的局面。例如,若我們解釋「他剛開始學習語言學」的意義,就是「他是語言學的初學者」。且我們在解釋「他是語言學的初學者」的意義時,也用了「他剛開始學習語言學」的話,這兩個解釋本身並無法帶領我們進任何更深層的討論。
現代語言學的做法,則是利用一套邏輯代數系統,將「他剛開始學習語言學」轉化為一套邏輯表示式。有點像…
1. LEARN(語言學, 他)w(剛開始)
如此一來,當我們把「他是語言學的初學者」套入前述邏輯式裡,也能得到一致的解答時。
2. IS(LEARN(語言學, -學者i), 他i)w(初-)
我們就能得到「這兩句話有一樣的意義」的結論。
[註] 2 裡面的 IS() 可以把 [他] 代入 [-學者] 中,而得到「他 LEARN 語言學」的語意 (semantics);同時,w(剛開始) 取出的時間點也和 w(初-) 的詞彙語意一致。因此這兩個句子具有一樣的語意。
有了以上的背景,就能理解書中的下一段的…
今天語言學的發展早已有意背離幾世紀以前傳統的語言研究方向,而這種和過去意意劃清界線的現象在美國尤較歐洲明顯…
0 notes
Text
HELL 2023:念念不忘,必有迴響
絕大多數的學術研討會、技術分享會議都是先有 Keynote Speaker 定調整場會議的主題,然後 Session Spaker 在各個議程裡分享各自的主題。然後,最精采的交流,往往都發生在一場演講結束,演講之後的 Q&A 也結束,講者步出會場外後,被幾名特別思考過這場議題的聽眾在場外攔下來時,站在走道上的的交流。
在 ChatGPT 上線六個月後,卓騰語言科技和暨南國際大學外文系舉辦的第一屆「語言與語言學人機工程年會」,簡稱 HELL conf. 的這個特別以「語言」為主題的跨域對話平台,採用了一個「極度放大」走道交流的活動形式 -- 在會議開始前,先進行了跨域的圓桌會談。

「圓桌會談的特點在於,身為特邀講者的領域專家以及聽眾之間的座位安排是一樣高的。而且這樣的活動不錄影、不錄音、不直播。以一種一期一會的安全空間感,企圖讓各方意見在最自在的氣氛下交流。」規劃執行這場會議的卓騰語言科技如此說明著。
「結果…這樣的安排效果好嗎?」小編提出第一個問題。
「交流非常深入!聽眾預先提出的 22 個問題裡,只討論了其中的 14 個,就已經嚴重超時 1.5 小時了!幾乎每個問題,都讓聽眾們更深入地瞭解各個領域專家們面對提問的挑戰時,背後的不同的考量重點和各自的生命歷程經驗。」

「預先做這樣的交流,或是說預先做了走道對談的安排,對整場活動的主軸有什麼影響?」
「聽眾接著參與第二天的主題演講,聽到主講的專家們準備的內容時,對內容的理解深度就完全不一樣了。即便這些內容是第一次聽到,但是聽眾也能設身處地理解為什麼講者會這麼想,為什麼講者會這麼做,為什麼在這個領域裡會有這些挑戰的存在。」
「圓桌會談裡聊了什麼?能和我們分享一下嗎?」
「不能 (笑)。我們討論了 ChatGPT 對學術研究的影響、對實際工作的衝擊的評估,也交流了彼此對於人生的下一步要怎麼走的心法、政策面的各種考量…等等議題。關於我們究竟講了什麼,我只能說這麼多了。」
「不能再多透露一點?畢竟 HELL 辦在交通不便的埔里,讓許多人沒辦法參加。」
「這個活動選在埔里是有意為之的,雖然這也讓身為主辦方的我們無法靠售票來打平收支。但在交通上加上一點『門檻』的好處是,我們可以向所有的專家講者保證在場的聽眾的聽講與交流動機一定非常強烈!這點在第二天的活動從一早七點半開始就有聽眾陸續到場可為證!聽眾裡可有一大半都是早起不能的大學生呢!當然,特別安排充滿地方特色的早餐也有不小的功勞!(燦笑)」

「那麼第二天的主題演講裡在談什麼,方不方便和我們重點分享一下呢?」
「第二天的主題演講是特別安排過的,上下午都是『從產業需求出發,再回到學界觀點』的節奏。

從一開始是公部門與金融業裡實際遇到的 NLP (自然語言處理) 需求。這裡面是有許多問題是即便出現了 ChatGPT 以後,仍然還沒有完全解決的。我們仍然有繼續投入大量的技術研究與開發的需求。

我們特別延請的講者是數位部的柯維然技正和玉山銀行的林鉦育經理。這兩位專家不只是在各自的應用問題上都已鑽研許久,更是對『如何實際解決問題』有第一手經驗的高手。他們兩位的演講讓聽眾大開眼界,在活動結束後還多問了快一小時的時間,才讓我們送講者去搭車。還有聽講的同學表示這一天下來,大腦像在開快車一樣,筆記都抄了四頁多的 A4!

上午的最後一場,則由清華大學資工系的陳宜欣教授分享 AI 與教育的議題。事後有幾位同學說『早上一路聽到這裡,我覺得資訊量實在是太高了!我要拼命吸收才跟得上!這是絕無一分鐘廢話的分享。』就像吸了高純度的氧氣一樣!

在特別安排過,能彰顯地方特色的午餐後,下午的第一場由 104 人力銀行的石惠貞副總經理分享在 104 裡的各種自然語言處理需求與挑戰,同時也以自身面對挑戰的經驗來鼓勵在場的同學。
也許是一樣是外文人出身的石副總激勵了聽眾中佔多數的外文系同學的共鳴,再加上有許多同學也是一週前才剛剛畢業,踏入社會。這場演講結束時,聽眾席爆出熱烈的掌聲,為石副總深入淺出的技術分享和面對各種挑戰的勇氣鼓掌!

甚至到會議結束後三天,還有同學在線上交流的語音頻道裡提到石副總分享的內容。
最後一場,則是由在教育現場第一線教了 20 年的國立中正大學語言學研究所吳俊雄教授主講。一天下來,這也是最有火花的一場!吳教授先是指出語言學做 NLP 和資訊科學做 NLP 之間的差異。

如果我用比喻來說明的話,語言學做 NLP 像是特戰隊,專注在特定的幾個棘手的邊緣問題;而資訊科學做 NLP 的話,則是正規軍,講究攻克據點,展開部隊把地盤佔起來。任何戰爭都是需要這兩種單位才能打贏的!
接著吳教授也常常在演講中徵詢同為教育者的陳宜欣教授從資訊工程的角度來看,是否如此?每一次被否定,都是一點微小的火花,讓大部份還處在『入門期』的聽眾們發現『一樣在處理『語言』,但語言學和資訊科學在假設和方法上的差別,是之前不曾仔細思考過的!』

而這種跨領域的交流時碰撞出的火花以及它所引思的繼續思考,正是我們期待造成的效果!」
「聽起來是很精采的一天半!那��最後有沒有什麼要對我們的讀者說的呢?」
「在 HELL Conf. 裡,聽眾們在 ChatGPT 強大的媒體聲量壓力下,親手操作而知道了它的挶限,然後在講題裡聽到了業界的應用機會,更看到如果要繼續走學術路線做研究的話,可以有什麼樣的未來選擇,甚至交到了可以一起努力的同好。這就是 HELL 和其它會議不同的價值!
在會議開始前的四個禮拜,我們有連續四週的 HELL Sprint,有多間學校的同學和社會人參加,藉由串接 ChatGPT 設計與實作聊天機器人,在密集的投入下,他們開始接觸到 ChatGPT 的邊緣,開始摸清楚它有什麼事能做,什麼事不以做。

接著在 HELL 的圓桌會議裡找到發出同樣探問的同好,交上不同科系背景的朋友,甚至在第二天會議結束後兩個多小時,幾個年輕人還在會場旁邊講個沒完,中部的同學約好將來上台北的時候要去找誰誰誰繼續聊,或是討論想要繼續延伸 Sprint 的開發題目…等等。

我們用一個月的時間挖呀挖呀挖,然後在一日夜之間,種下台灣 NLP 下個世代的跨領域人才種子,並親眼看到它冒出芽來。

正如我們的特邀講者之一,玉山銀行的林鉦育經理所描述的『這是一個有後韻的���議』。後面會怎麼發展?我們也非常期待還有資源可以辦下一屆,還能和參加者說一聲 Welcome back to HELL!」
「我們也一起期待。再次謝謝您接受我們的線上專訪。」
2 notes
·
View notes
Text
第一屆 H.E.L.L. (語言與語言學人機工程年會) 登場
報名傳送門:https://www.droidtown.co/hell/2023/
從 2022 年底開始一路延燒到現在的 ChatGPT 及其後的各種「生成影像/文字模型」的技術,最近可說是最熱門的話題了。這其中,許多人一直詢問的就是「我的工作真的要被取代了嗎?」甚至連「中國最大的自然語言處理研討會,今年將是最後一年」的聲音都出現了。
對於這些令人感到興奮又恐懼的行銷內容,我們持完全不同的看法!

靈長類就是會使用工具的動物,更何況是心靈手巧的智人。我們的歷史上類似的工具大爆發的事件層出不窮,人類並沒有因此而減少工作了,反而是工時愈來愈長。洗衣機的發明、吸塵器的發明,並沒有讓我們一整天的家事變得更輕鬆,反而是衣物乾淨的標準提高了,房舍整潔衛生的標準也提高了。
我對這些工具的出現,看法也是如此。第一線的 NLP 工作絕對不會減少,它只會變得更好!
我們邀請了產、官、學的各路專家,以理性面對職場裡的各項 NLP 任務,仔細地探討其中的技術本質與邊界問題、人才育成問題。從「語言與語言學」的角度討論人類與機器互動、協作的各種面向。
人類要被取代了嗎?Like hell!
0 notes
Text
Loki, ChatGPT 和 Hybrid AI
自然語言的 AIGC 來了!
NLP 圈子裡,從 2022 年底以來最大的消息,就是 ChatGPT 了。雖然我們並不認為它在「技術」上是一種創新或突破,LeCun 也和我們有一樣的看法。但不可否認地,利用簡單的 prompt 互動設計,讓 許多常人對 ChatGPT 和 AI 開始了許多幻想。
很抱歉,光是 ChatGPT 並不能做什麼有價值的事情。它的名字也講得很清楚了,它就是一個可以 "Chat(聊天)" 的 GPT 而已。
許多朋友會問「ChatGPT 的出現,是不是 XX 工作就要被取代或是你們這樣的語言科技公司就要消失了?」呃…不是,相反地,其實我們從 ChatGPT 身上學到的一課就是「做底層技術,大家看不懂;要做終端應用,別人才會覺得你很厲害」。所以,一如以往的 Hybrid AI 的方針,卓騰語言科技正在利用像 GPT 這一類的「資料模型」補上 Loki 搭上市場應用的最後一塊。
Loki 的長處是演算法;GPT 的長處是資料模型,兩者剛好可以互補,就像下圖所示:
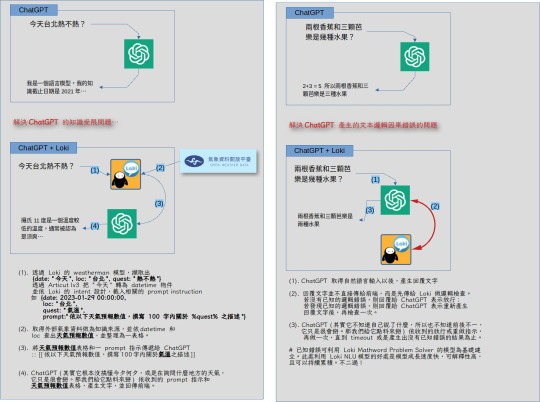
那…為什麼要這麼做呢?不是一切都用 prompt 施個咒語就好了嗎?
假設 GPT 可以使用 1 萬種 prompt 指令好了,問題是「任何一個產業都不會一下就用到 1 萬種」呀!那就只要先理解一下這個產業領域會怎麼使用這個模型,然後我們做個離線的縮限版。這樣就能給客戶在內部使用了。
後面要接 GPT-2/3/4 或是其它的模型,這都無所謂。總之 Loki 把問題的變化收斂了,所以後面的模型就不需要那麼大。
所謂「收斂」的意思是…
原本 GPT 會需要:
我買了一本書
他購買了三十盒口罩
我們一共買了6箱影印紙
…
很多很多的句子來建立模型。
但 Loki 會把這些句子收斂成「句型」,也就是這些都是
人 + 買了 + 量詞 + 物品
這樣的一個句型。所以 Loki 的 NLU 模型只需要「一個句型」,而不需要「很多很多句子」來建立模型。
那為什麼要收斂呢?因為收斂了,才能解決 ChatGPT 這類「生成模型」遇到的發散問題。
由於 GPT 是透過「前 N 個字符,預測下一個字符」,那麼頭尾的距離愈遠,就會愈發散。以致於最後就會前後文對不起來。
那麼 Loki 是怎麼和 GPT Hybrid 起來解決這個發散的問題呢?
我們需要一個 Loki NLU 模型負責處理邏輯,還要一個 Data 模型負責產生內容。
Loki NLU 是「自然語意理解」系統。我們用這個系統建的是「自然語意理解模型」。你可以想像成「訓練一個會懂你們公司內部行話的模型」。但是懂了行話,還是要知道怎麼回應 (action item),這就要靠你們內部的資料模型了。以我們公司的一個「電商廣告文生成系統」為例,只要給這個系統「強壯男性黑瑪卡」這樣的產品名稱,它就會生成適合在電商廣告中出現的簡短描述文字,用於廣告的投放。
它運作的兩個步驟就是:
Loki NLU 模型搞懂「哦,原來 request 裡的『男性黑瑪卡』是一種保健補給品,給男性用的」這屬於「懂行話」的範圍。
GPT Data 模型就要取出「如果要推銷『男性、健康、保健、補給品』可以用哪些話來推銷?這屬於「Action item」的範圍。
有了 1 和 2 的 Hybrid,這個系統就能做到「先聽懂」再「採取領域內合理的措施」的效果。
目前大家使用 ChatGPT 的時候,都會產生許多幻想,但卻往往忽略了你身為人類,在操作時其實已經想好了要幹嘛,然後請 ChatGPT 產生出結果而已。
而 ChatGPT 好像什麼都能問,什麼都會答。但也正因為它什麼都能問,所以它會發散。也因為它的發散,所以容易產生錯誤。
換言之,要發揮資料模型的價值,你必需要有一個在應用上收斂它表現的方法。比如像這個應用,就是把它收斂在 "git" 的指令下:
所以這麼一來,就能提高 Data 模型在使用時的正確性。
否則,如果沒有把應用縮限在 "git" 的使用場景下的話,那麼前述所列的那個網站裡,給予 prompt 指令
列出所有碰過這個檔案的使用者
這句話也可能指的是找 file log 看看誰開啟過它;這句話也可能指的是找 file attribution 看看它的編輯紀錄…等等多種解讀方法。
但正因為這個作者把它收斂在「只和 git 指令有關」,所以才能「只輸出 git log …」的指令。
而我們會使用 Loki 做為收斂手段,是因為 Loki 就是一個「可以收斂任何主題」的 NLU 系統。藉由「把發散的東西收斂」來提高第二步驟的 Data 模型產出的結果的正確性。
所以,要讓 Data 模型真的產生價值。其實要做的事情是「收斂它」。訓練的時候擴展它,使用的時候收斂它。
0 notes
Text
覆 [標準重要嗎?] 一文
讀到一篇 [人工智慧與自然語言處理想要說什麼?標準重要嗎?] 的 blog 文。文章中提出的議題,基本上沒有什麼大問題,的確有好幾個是重要的 NLP 課題。但是既然其中提到了「語言學」,那麼有些容易導致誤解的小細節就要拿出來說明釐清一下了。
對於現在的 NLP 應用工具,在評估「有沒有用」的時候,的確會有原作者提到的兩個問題:
一是用來比對的句子本身就是錯的…
二是怎麼分才算對的問題…
對於第一點,即便是目前大家最常用的 SIGHAN 2005 資料集的標準答案裡,也有這種 「/夜/比/之前/更深/更/靜/」的結果。這就是作者說的「比對的句子本身就是錯的。
這個句子哪裡有錯呢?它錯在把「更深」和「更/靜」標成了兩個不同的結果。前者是「單一詞彙 (更深) 」而後者則是「兩個詞彙 (更 + 靜)」。如果以這個做為標準答案,那麼就像是同一個題目,卻有兩個答案。我早上問你,你給我答案是「 "更" 和後面的形容詞要合在一起成為一個詞彙」;而下午問你,你給我的答案是「 "更" 和後面的形容詞要分開成為兩個詞彙」。
而我做為裁判官,卻要對你的兩個答案都評出「答對!給分!」的評判結果。如此一來,雖然這個模型可以拿到高分,但註定在面對應用落地問題的時候,無法派上用場。
在 SIGHAN 2005 標準答案集裡拿到高分的 CKIP 就有這個問題:
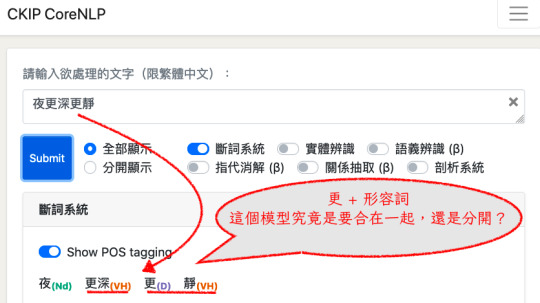
不可否認地,輸出「合在一起」的分數也拿到,「分開」的分數也拿到,就能得到超高的良率得分,但在實務上,這兩種結果會出現在同一個輸出結果裡,就表示它的輸出結果無法被預測。一個輸出結果無法被預測的模型,怎麼用呢?
這個問題,也連帶地會引出第二個問題「有的人覺得要合在一起,有的人覺得要分開」的時候,那麼…哪一個才是正確的結果?
而這,就是語言學可以進來回答的問題了。
在現代語言學的研究裡,語言不是「線性結構」的,而是「樹狀結構」的。在線性結構的眼裡,我們就只能看到「更-深-更-靜」這樣的關係,但從樹狀結構的角度,我們就能看到兩種結果:

一是從「詞 (word)」的角度來看,是一個「更」的程度指示詞 (Degree Specifier) 再加上一個修飾詞 (形容詞/副詞) 的「深」和「靜」。因此就能得到「更/深/更/靜」的輸出結果。
另一個是則是從「詞組 (phrase)」的角度來看,因為詞組不是看節點的下端,而是節點的上端,如此就能得到「更深/更靜」兩個詞組的輸出結果。
因此,有的人會覺得是「分開成兩個詞才對」,而有的人會覺得是「合在一起一個詞組」才對,這兩個語感都是存在的,而且現代語言學已有理論可以解釋這個現象。
兩個都是對的,但它不會同時輸出。你可以選擇「以詞彙」 做為輸出結果,或是「以詞組」做為輸出結果,但就是不該「同時輸出詞彙和詞組。因為它們不是同一個等級的東西。這麼一來會讓後續奠基於斷詞結果的 NLP 應用的良率開始瘋狂下跌。
問題是,當現代語言學已經可以解釋這個問題的時候,絕大多數的中文斷詞系統並沒有跟上。即便少數已經發現語言似乎有兩種內在模式的斷詞系統,仍然是以調整字符結合統計機率閾值來區分出「粗粒度」和「細粒度」,而無法完全符合現代語言學理論的發現。
目前世界上唯二採用現代語言學研發 NLP 工具的,只有 Bitext.com 和 Droidtown.co (卓騰語言科技)。
以下是卓騰語言科技的 Articut 中文 NLP 系統的分析結果:
詞的角度斷詞:
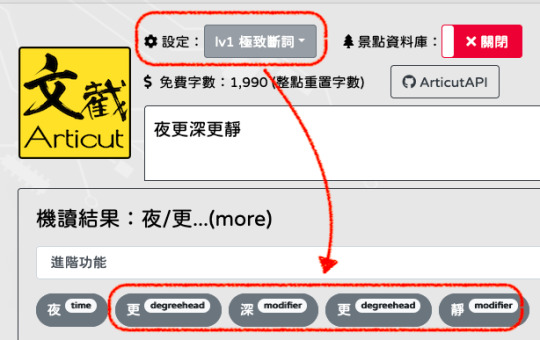
詞組的角度斷詞:

由此,我們可以發現原文中所述的「…關於什麼是「詞」的標準至今無法得出一個大家都能遵循的標準!」一事,在現代語言學中已經有解���。
在這裡既然提到了「現代語言學」,那麼就不得不再針對這一段「…而事實上在語言學界,甚至有為了某些詞的詞性爭論不休的情況,一個詞應該是副詞、形容詞尚且無法認定,試問詞性標註的標準又何在?」加以回覆。
現代語言學不編字典。所以在現代語言學裡沒有「 X 這個詞應該是副詞或是形容詞」的問題。現代語言學的研究重點在於通用語法的句法樹結構。
通用語法 (Universal Grammar) 指的是「全人類共有的一套抽象語法的運作規則」。
在這個架構下,你把一個詞放在「名詞」的句法樹位置,它就是名詞;你把一個詞放在「形容詞」的句法樹位置,它就是形詞。
因此,「一部機車」指裡的「機車」是名詞。因為這個詞出現在名詞的位置;同理「他很機車」的「機車」是副詞,因為這個詞出現在形容詞的位置。至於「機車」這個字究竟應該編成什麼詞性,這不是現代語言學關心的問題,而是字典學家在乎的問題。
許多 NLP 工具仍然沒跟上現代語言學的研究成果,因此仍然用傳統語言學的「編字典、擴充資料庫、用更多的語料」的方向企圖解決 NLP 的應用需求問題。當解決不了的時候,這不是語言學的問題,而是基本的假設和認知就沒有跟上新的語言學理論發現而已。
我們並不會因為「反正你們都是看星星的」,然後就把星座預測的失準,擴大責怪所有觀測天文的天文物理學家都是錯的。自然不能因為「反正你們都是搞語言的」,然後就把依傳統語言學的做不出結果的 NLP 應用失敗,擴大理解成「現代語言學的研究也是錯的」。
最後,原 blog 文的結論似乎是兩個:
BERT 沒有斷詞,所以 BERT 避開了中文斷詞系統不夠好造成的錯誤。
有些 NLP 任務仍然需要斷詞。
這兩個乍看之下好像彼此矛盾的結論,其實也可以從語言學的角度繼續解釋。如果在某個粗略分類的任務情境下,BERT 就可以得到不錯的效果。就像你不需要精讀報紙財經股市版的每一句,只要瞄一眼每則新聞的標題,就知道大盤是漲是跌了。
這也是為什麼利用 BERT 做的自動回覆機,往往只能把 "Answering" 這個涉及語意理解和因果推論的問題,變成 "Alignment" 問題以後,忽略因果推論和邏輯語意,直接把「問題 <=> 原文」做了一個「對齊 (alignment) 」的操作以後,就讓人類使用者去評分「這個段落裡的資訊,是否有回答你的問題?」
而忽略了人類使用者回答「有」的時候,事實上在腦袋裡做了很多的因果推論和邏輯語意的理解。簡言之,藉由「偷換概念」的操作,BERT 巧妙地避開了 "Answering" 的基本需求,而改以 "Alignment" 代之。它得出來的高分,並不是完成了 "Answering" 的任務,而是因為 "Alignment" 得來的。
問題是,如果你要處理的是細膩的自然語言理解 (NLU) 或是因果推論呢?這類問題在產生 BERT 的語言模型的過程中,早就已經剝除了上下文的語意脈絡 (只留下來字符的前後出現脈絡),那麼想從已剝除了語意的模型裡,再挖掘出語意、邏輯甚至是因果關係,就變成一種緣木求魚的操作了。
從這裡延伸下去,還可以討論許多 NLP 和語言學的問題,不過到這裡已經不深不淺地帶出兩個需要思考消化以後才能吸收的議題了。就先在這裡打住。
如果有機會的話,我們再聊聊 BERT 和語言學在中文裡可以如何結合來做 Hybrid AI;為什麼 Articut 的 F1-Score 不超過 95%,但在各種 NLP 落地應用的時候,效果都比其它號稱 97%、98% 的中文斷詞系統來得更好,且更靈活吧。
1 note
·
View note
Text
再談「寫個能幹的中文斷詞系統」
在 2019 年的 PyConTW 裡,用「寫個能幹的中文斷詞系統」為題發表了 Articut NLP 引擎以後 (影片),到現在已經三年多了。由於 Articut 基於語言學原理的特性,和一般電腦科學背景的從業人員習慣的「字典原理」、「統計機率式原理」以及基於「機器學習/深度學習」的「資料分佈原理」很不一樣,許多人仍然無法想像它是怎麼運作的。
前陣子,新聞出現一句「三成人情人節最想收口罩酒精液」的標題,讓網友們再度發問,如果用現代中文 tokenization 的原理,會做成什麼樣子呢?
利用字典法的話,字典的問題就是「由前往後」還是「由後往前」,再加上詞長短的優先順序。由前往後,當然是容易出現 [酒精 / 液] 這樣的結果。但這麼一來,前面也容易出現 *[三成 / 人情] 這個錯誤的結果。因為「人情」是收錄在字典裡的詞彙,且由左往右看,「人情」比「情人」先出現。
相對地,如果是由後往前的話,就的出現 *[酒 / 精液] 這樣的錯誤結果,雖然前面比較有機會出現 [情人節] 的正確結果。
再來,如果使用的是「統計機率式」或是「資料分佈模型」的原理的話,就看你的訓練資料裡,哪一種分佈更多了。如果是武漢肺炎肆虐的這幾年的報章新聞內容,那麼出現「酒精」或是「酒精液」的機會,一定是遠高於「精液」的。但如果你採用的訓練資料是有些「依法」必需要符合年齡限制才能自由閱覽的文本的話,那麼出現「精液」的次數,想必也是高於「酒精」的了。
講了這麼多,那麼語言學原理會怎麼做?
Articut 基於 X-bar 的結構,和其它方法不同的是, Articut 是從「最」這個功能詞 (function word) 字符開始推算。在 X-bar 框架下,詞彙必然是 XP 的某個中心語 (head)。因此,它的起點是 Function word,然後開始尋找中心語參數的可能分佈。
因為任何語言都一樣,在 X-bar 的框架下,Function words 提供一個句子的骨架。不過,因為這 句子裡的 Function word 太少 (只有一個「最」),所以大概在句型結構這裡沒有跑出最佳解。此時,第二個子模組 (音韻結構) 會進來。中文有二字、三字、2+3 字、2+2+1 字…這樣的韻律結構傾向。對 Articut 而言,音韻結構是「最後手段」。
它只對同一語系有效果,有點像…一個只會說國語的人,聽人用方言讀詩時,雖然聽不懂是什麼詞彙,但大概也斷得出來詞彙邊界的意思。所以最後的綜合結果就是… 三/成人/情人節/最/想要/口罩/酒精/液 了。
而也正因為我們有個音韻結構的子模組,所以有人拿 Articut 報處理台閩語、客語…等等中文的方言時,也都能持續運作 (參考連結)。
講到這裡,可能因為大家對語言學的理論都不太熟。我再給個例子吧:

由於 Articut 是沒有內建字典的。因此在這個例子裡,Articut 從「會」這個字符開始下手,然後推估…如果這是一個「XX道」的名詞 (e.g., 像「弓道、空手道」),和一個「XX學」的名詞 (e.g., 像「語言學」、「天文學」) 的話,那麼現成的 X-bar 的句法樹節點位置,將會高於只把它當成一個「 XX 會」(像「同盟會」、「獅子會」的組織名稱)。
原因是「名詞組 (Noun Phrase) 」的節點位置很低,但 Modal (情態動詞) 的節點位置比較接近完整的句法樹的頂點。因此,最後就以這個結果做為輸出了。
當然,這不是一個正確的斷詞結果,但我們剛好可以從這個錯誤來解釋說明 Articut 的運作原理。而也正是因為這個「可解釋性」,讓 Articut 可以輕易地做出持續的版本精進調整 (e.g., 把 "學會" 也視為是一個中心語),並且可以不帶字典 (留給使用者自定),只用幾 MB 程式大小,就一次搞定 CWS/POS/NER 的 NLP 基礎建設三本柱的需求了。
ps. Articut 已由卓騰語言科技取得發明專利.
0 notes
Text
精采的一年,感謝有您!
Hi Droidtowners, 我是卓騰語言科技的負責人 Peter。 2021 年馬上要進入尾聲了,回顧這驚無險的一年,同時也正好是我們成立的第十年,請容我再向您對我們的支持與產品的愛用,道聲感謝。
在今年裡,我們推出了許多 NLP 工具及應用,都是為了「透過 NLP 技術的突破以促進強人工智慧的發生」的初衷所做的努力。在我們往智慧奇點的路上,您的每一次採購與支持,都讓我們更接近目標。
在這生產力滿滿的一年裡,讓我們一起回顧一下卓騰在 2021 年端出了哪些好料吧!
小密技:透過我們的 API 來取用卓騰的各種 NLP 工具,速度會比較快一點點哦!這個技巧適用於 ArticutAPI、KeyMojiAPI、WordyAPI 和 Loki。
1 月:KeyMojiAPI 上 PyPI 了!
令人驚豔的 KeyMoji 情緒偵測引擎,不但可以計算文本的「正負」情緒系數,更能將每個句子都細分成八個維度的面向。對於客戶評語、活動意見調查…等等分析,更能「一圖勝萬言」地視覺化呈現結果。
這麼強大的功能,只要 pip3 install -U KeyMojiAPI 就能輕鬆取用了哦!

2 月:ArticutAPI 上 PyPI 了!
2021 年裡,我們將 ArticutAPI 上架了 Python 的 PyPI 軟體庫,您只要利用 pip3 install -U ArticutAPI 的指令,便能輕鬆地在自己的 Python 環境中安裝 ArticutAPI,取用 Articut 的強大 NLP 功能。
3月:NLP_Training 入門教材上線
想學 NLP,卻不知道從何下手?這裡有教材呀! https://github.com/Droidtown/NLP_Training需要簡報和 Jupyter 嗎?沒問題,台師大語言所的博士生 Howard 同學也釋出了四週的教材,讓想要自學以及教學的需求,一次滿足!https://github.com/howardsukuan/textual-data-analysis-python
4 月:Low-Code / No-Code 當然,何樂不為呢?
對於不會寫程式,但是熟悉 Microsoft Excel 的使用者,我們也特別打造了 ArticutEXL 讓您可以在直覺的 Excel 365 介面下,也能享受 Articut NLP 工具的強大分析能力。

5 月:NER 工具包全面上線!
此外,我們也將 ArticutAPI 的各種 NER 工具,重新編寫了一套 Wiki 說明頁,並附上範例程式碼,供您取用與參考:https://github.com/Droidtown/ArticutAPI/wiki。
9 月:這裡有一批好厲害的 Loki NLU 專家,有需要就上 Discord 找人才吧!
經過六月的海選以及七、八、九連續三個月的紮實訓練,我們今年有 23 位遍佈全球的實習生完成了 2021 年的「卓騰實習企劃」訓練,並做出了各種有趣又不失實用性的 NLU 專案。這些專案全部都可以在開源的 LokiHub 裡取得之餘,每位實習生也都在各自的專案裡留下了聯絡方式。您可以取得「程式碼」也能找到「開發者」,更能在我們的 Discord 頻道裡暢談各種 NLP/NLU 的新發想哦!
10月:Wordy 中文仿作生成系統也可以 pip 安裝囉
有了一篇文章,還需要產生千千萬萬篇「類似內容,但又不想照抄」的文章嗎?透過 WordyAPI,就能讓你的一篇文字,瞬間長出千千萬萬篇類似內容,但又有微妙差異的文章。什麼地方可以用呢?除了大家立刻想到的內容農場以外,其實也可以用這種方式產生「大量文本」做為機器學習的訓練資料 (training set)哦!從此以後,「資料不足」再也不是訓練 NLP 模型的瓶頸了。更棒的是,WordyAPI 也可以透過 pip3 install -U WordyAPI 安裝哦!
11 月:NLP_TrainingLAB 教育/開發 VirtualBox 環境
在工作坊教學或是開發時,懶得設置環境嗎? 沒問題,我們也準備了 NLP_TrainingLAB 的 VirtualBox 映像檔。只要先在你的電腦裡安裝好 VirtualBox,接下來只要載入我們準備的 NLP_TrainingLAB,就立刻擁有一個全部設定都調整好的 NLP 開發環境了。
除了主講人在上課外,台下的聽眾和學生是否也有更即時,也更增進學習樂趣的互動方式呢?為了這個增進學習和聽講時的樂趣,我們特別做了可以暱名在 Youtube 直播中打彈幕的 TextQ!

秉持卓騰一直以來的「注重使用者隱私」的企業價值。所有在彈幕上的發言都是「暱名」的哦!快來重溫課堂裡傳紙條的學習氣氛吧。
12 月:ArticutEN / LokiEN 上線囉!
卓騰語言科技的各種 NLP 工具都是立基於 MIT 語言學教授 Chomsky 提出的理論,這表示所有人類的語言都可以通用同一套演算法!於是,我們特別把所有 Articut 中文版裡使用到的各種函式,全部移植到 ArticutEN 裡 (將來也計劃繼續擴展 ArticutJP、ArticutES …等等),做出了可以處理英文的 ArticutEN/LokiEN 囉!相較於市面上所有的語言處理技術都是先發生在英文,然後才被「假設」在其它語言中也能使用。ArticutEN/LokiEN 是極為少見的「原本是處理中文的語言技術,可以逆輸出應用到歐美語言」的例子。操作方式完全和中文版的 Articut/Loki 一模模,一樣樣。您掌握的操作技術,將會在各種語言都能使用!真真正正達到了划��的學習投資!
精采的一年,感謝有您!What a year! Glad you're here. :)
雖然今年各行各業有近半年的時間因為疫情進入三級警戒而受到影響,但在您的支持與愛護下,卓騰全體同仁仍能競競業業地完成一項又一項的 NLP/NLU 工具,繼續朝向我們設定的「強人工智慧」邁進。
讓我再次向您表示感謝之餘,也懇請您繼續支持我們,讓我們可以從台灣出發,透過 NLP 技術為人工智慧搭起一座「認知」和「應用」的橋樑。
卓騰語言科技
祝您 健康順心
Peter. w (王文傑)
0 notes
Note
自己選了一個除式/分數來用,寫了一大篇,自說自話,你的資訊密度算高嗎?如果蔡的發言有內容?她為我們的生活帶來甚麼改善、進步?高雄大樓大火,花蓮火車事故,諾富特破口,怎麼他們民進黨佔高雄幾十年、執政5、6年,都沒法顧到?這樣叫做很有內容?
Hi 您好,
高雄大樓大火,國人同感悲痛。正如文章中提到的:「統計資料怎麼解讀,並不是卓騰的主要業務。我們的主要業務,是 NLP 工具的開發應商。」
所以資訊密度高表示「好」或是「不好」,這件事,我們沒有做判斷和解讀。也許資訊密度愈低,表示是一個愈容易和民眾互動的演講稿也不一定。若假設一般民眾的語言理解能力呈現常態分佈的話,那麼表示「絕大部份」的人是聽不懂資訊密度高的內容,只能擷取自己愛聽,自己想聽,自己聽得懂的部份,再進行站隊和自行詮釋而已。
這部份要怎麼解讀,我們尊重您的意見。
0 notes
Note
Hi 卓騰 你好 初次來到你的網站,被 人工智慧能不能利用 NLP 技術搞懂人類能吃什麼呢? 這篇文章所吸引而來,無奈文章中的圖片似乎連結失效了,請問是否可以修復呢? 另外,文章所提到的內容是否有github可供參考(就算無法完整附現結果也沒關係),非常希望能夠得到你的回覆,感謝你! 不過其實我也不知道你回覆了我會不會收到,我的信箱是yltsai0609(gmail),希望能夠與你取得聯繫,謝謝!
Hi 我們在今年 4 月時已經回覆您了,希望能解決您的疑問。
0 notes
Note
想知道keymoji是怎麼計算出情緒分數的呢 是有使用大量的樣本去train 自然與演相關的model嗎 謝謝
Hi 您好,
謝謝您的提問。
如同這篇文章裡提到的 (https://blog.droidtown.co/post/644739102322900993/keymoji),我們採用了三個層次的演算來推演情緒分數。第一層是情緒詞彙,這是由專家標記的正負向詞彙。接著我們計算句型結構對這個詞彙的影響。有些句型表示強化,例如「X 得要死」,可以是「開心得要死」也可能是「痛得要死」。這不能因為「死」一個字是負向詞,就把整個句子變成負向,而要看這個句型對詞彙帶來的影響。最後一層是「量化詞」,像「每個」、「所有」、「部份」以及否定詞之間的計算。例如「不是每個人都喜歡」和「每個人都不喜歡」相比,後者就比較強烈。
透過這三層的計算後,就是 Keymoji 的情緒分數了。
0 notes
Text
關鍵字?特徵字?
許多人直接把 "keyword" 譯做「關鍵字」,但在卓騰,我們更常用「特徵詞」來描述它。為什麼呢?這要從定義「什麼是一個句子裡的 keyword 」開始思考起。
在語意學裡的關鍵字指的是「動詞」。如果沒有動詞,則為「形容詞 」,如果沒有形容詞,則為「名詞集合」。
在電腦科學的領域裡,IR (information retrieval 資訊擷取) 則是定義 keyword (中文被譯為「關鍵字」,但其實更適合的譯名是「特徵詞」) 指的是「一個句子 (或文件) 中,具有特徵意義的詞彙或詞彙組」
為什麼會有這個差別呢?

從電腦科學的角度來看,特徵意義比較像是 Database 或是 Python 的 Dictionary 裡的 "key" (主鍵)。就像是 「主鍵」可以幫助我們從整個 dictionary 中找出「一組資料」 (value)
所以這個 "key" 就是那組 "value" 的 "keyword"
換言之,如果只有「一個句子」,那麼在 IR 的角度看,沒有關鍵字。在只有「一個句子」而沒有其它資料做為互相比較的基礎的時候,要找出的「關鍵字」需要從語言學 (語意) 的角度來看,才抓得出來。
這裡講的語意學並不是從文學的角度去討論感受的那種語意學。而是現代語言學裡可以用邏輯形式加以計算的語意學。[參考連結]
在參考連結的第 8 頁裡呈現的就是語意學裡面計算句子意義的方式:用邏輯式來計算。那兩句 [a likes x] 和 [b likes x] 的意義,是由那個 like 決定的
也就是說,如果沒有 like,那麼這些句子就變成只是單純的「名詞的集合」 -- 你不會知道 {a, x} 和 {b, x} 有什麼語意上的異同。你頂多只能知道它們在數學集合上的異 (一個有 a 沒 b,另一個有 b 沒 a) 和同 (都有 x)。而數學並不全等於語言 (language is not all about the math.)。
所以,要搞定「關鍵字」(或是更精確的說法「特徵詞」),在語意學的領域裡,第一個要處理的問題就是「動詞是什麼?」
要處理動詞,早期是用 prolog 程式語言,近代的話開始用一些 OO (物件導向 Object-Oriented) 的程式語言也可以寫 (因為比較好 debug)。以剛才那個參考連結中第 8 頁的例子。 我們是可以寫成:

來表示 a 和 x 之間存在的關係是 LIKE. 而如果沒有 LIKE 這個動詞的話,我們不會知道 a 和 x 之間怎麼了。也因此在語意上就無法描述出一句話的重點是什麼。
相對地只要這個無名函式的 return 為 True,那麼 a likes x 就是事實。所以只要定義好 func_like() 是什麼意思就行了。
而定義 func_like() 的方法就多了,既可以用 rule-based 的方式來寫,也可以用 ML 的方式來跑。甚至還可以像卓騰採取的 Hybrid 方式來做。
完整的一個命題可以這樣用 Python 程式語言來表示:
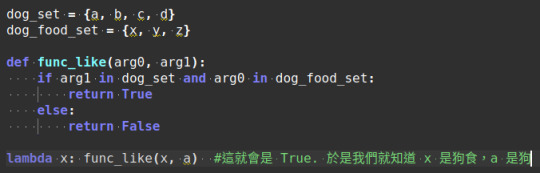
當然那個 dog_set 也可以用 OO 來寫。一路繼承下來,就把它變成 dog_obj 就行了。
所以,語意學的重點 (或是句子的重點) 在於利用動詞呈現關係
e.g., 「我最愛吃吉那富」
你不用知道什麼是「吉那富」
只要知道它既然和「我」呈現出 func_吃(吉那富, 我) 的關係,且依語用學裡的 Cooperative principle (合作原則),對方沒有理由提出假值的命題 (就是說謊的意思),此時我們就自然能擴展我們的認知,而得到:
「吉那富」一定是「可食用的東西」(editable_object)
這樣就行了。所以「吃」就變成計算這整個句子是否有意義的「關鍵」。這就是為什麼語意學把「動詞」當做 key 的原因。這就是所謂的:
動詞作為抽象關係的定義。因為定義清楚了,所以其他部分都被某種程度上的限制住了
這就是我們的 NLU 引擎 - Loki 背後的設計原理!
0 notes
Text
語言學 + NLP 的自學說明及書單
語言學這個領域分成幾個子領域:
語音學 (phonetics):
研究生理上的發音以及聽覺能力。是「聽覺」而不是「聽力」哦!兩者的差別在於聽力是物理和生理現象,就是耳朵裡的耳膜和聽力系統是否能正確把空氣振動轉為神經電流脈衝,而聽覺則是語言系統的詮釋能力,這兩者是不同的。比如說,物理上同樣頻率的兩個聲音,比較大聲的那一個,人的聽覺系統會覺得它的音高比較高。這就是聽覺系統 (語言能力的一部份) 和物理現象不同的地方。
在 NLP 上的應用,通常在 ASR 上面。沒有語音知識的 ASR 系統,在 NN 裡的每一層之間的關係,通常都是對應到「所有的聲音符號」。但加上語音學的知識後,我們已經知道沒有任何一種語言是 /p/ 的後面跟著 /k/ 的 (因為這種組合,人類生理上無法做到),所以在設計模型的時候,就可以加上額外的 rule-based 原則,把某些「不會連續出現」的聲音排除,這麼一來 NN 的層數會降低,模型尺寸變小,訓練和使用的計算速度都會改善很多。
語音學發掘出來的 rule 都是全人類通用的。

音韻學 (phonology):
研究聲音和聲音之間在特定語言下和句法、語意之間的互動關係。
比如說,我們都知道國語裡有「三聲變調」,也就是「同一個詞組中,連續三聲的字符,從第一個字開始會變成二聲,直到最後一個字符為止」。這個規則就只適用在
國語
斷詞系統正確運作,才能抓到什麼是 "同一詞組"
成人語言,而不是 baby talk。(對小小孩講話時,三聲變調規則不會是 33->23,而是 33->31。例如「毯毯」)
這些條件具備時,才適用。
句法學 (syntax):
研究一個句子中每個詞彙的位置以及整個句子的結構。
語意學 (semantics):
傳統語意學 (也就是 Chomsky 之前的語意學) 很像中國古拳法,都是一個字一個詞地討論語意內涵和分類。可以談,但無法實戰。
Chomsky 之後的現代語意學,則多是指 "Formal Semantics (形式語意學)" 這個領域。它是研究透過「句法結構」以及「音韻上的停頓、焦點強調…等」變化來計算一個句子內部的意義 (被定義為一個布林值) 以及句子與上下文之間的相容能力 (被定義為一個介於 0 ~ 1 之間的浮點數)。
還有一個在中文裡比較少被獨立出來研究的「構詞學」(Morphology),因為這個領域在國內基本上是被中文系的修辭、小學…等領域掌有話語權。但現代語言學的 "morphology" 在方法論上和 "syntax" 是一致的。
要理解完整的 X-bar Theory 的操作,需要從 Principles and Parameters 開始講起。通常我們會把它簡稱為 PP,然後進入 Transformational Grammar (簡稱 TG),再來是 Universal Grammar (簡稱 UG),再來是 Government and Binding Theory (簡稱 GB),最後進入集大成的 Minimalist Program (簡稱 MP)。
你可以想像成要理解微積分,我們要從最簡單的「四則運算」開始學起 (類比的話,差不多是 PP ),一路這樣學上去以後,將來才看得懂微分方程在幹嘛。而到一個學生在工程數學接觸到微分方程時,他其實已經從國小就開始接受準備有一天要學習微分方程的教育訓練了。
參考書籍方面,從入門排列到進階如下:
1. Language Files: https://www.books.com.tw/products/F013953830
這本書的設計是給大學部的學生,藉由簡單的例子和作業讓學生開始注意到語言的各個面向。
2. Case: Its Principles and its Parameters:https://www.amazon.com/Case-Cambridge-Studies-Linguistics-Baker/dp/1107690099/
這本是以西方語系的「格位」 (主格、受格、所有格、與格、賦格…等) 的變化,開始論証有些 X-bar 上的功能詞層級的存在。
3. Transformational Grammar: https://www.amazon.com/Transformational-Grammar-Cambridge-Textbooks-Linguistics/dp/0521347505
TG 的發展接在 PP 後面,既然功能詞存在,那麼是否透過功能詞就能知道前或是後的詞彙是什麼詞呢?
4. The Oxford Handbook of Universal Grammar: https://www.books.com.tw/products/F013912369?sloc=main
Chomsky's Universal Grammar: An Introduction: https://www.amazon.com/Chomskys-Universal-Grammar-Vivian-Cook/dp/1405111879
在 PP 和 TG 都在前面十年中歐洲的語系裡獲得成功後,接下來的 UG 開始把這些語言計算原則擴展到更多不同的語言中開始測試。
5. Introduction to Government & Binding Theory: https://www.books.com.tw/products/F010002732?sloc=main
和 UG 的發展大約同期展開,因為在 TG 的研究中發現「有的語言功能詞在後,有的語言功能詞在前。如果人類的大腦對每一個句子都要由前往後,再由後往前」計算兩遍,這顯然很不經濟,生物向來是朝向節能的方向演化的。因此開始發展 GB 理論,打算要統整詞彙、功能以及意義之間的關係。
6. Semantics in Generative Grammar: https://www.amazon.com/Semantics-Generative-Blackwell-Textbooks-Linguistics/dp/0631197133
Formal Semantics: An Introduction: https://www.amazon.com/gp/product/0226280845/
Introduction to Montague Semantics: https://www.books.com.tw/products/F013612038?sloc=main
Logic, Language, and Meaning, Volume 1: https://www.amazon.com/gp/product/0226280845/
Logic, Language, and Meaning, Volume 2: https://www.amazon.com/gp/product/0226280861/
這四本是在講現代語言學裡的「形式語意學 (formal semantics)」(有時又稱「邏輯語意學」) 是怎麼利用前面 5 項提到的句法框架,把一個自然語言的句子轉為 lambda abstraction,沒錯,就是你想的那個 "lambda"!既然句子都轉成 lambda 了,那麼把自然語言轉成邏輯形式的程式語言,就是一個可實作的 psudo-code 了。
Chomsky 強調的「語言學的自然語言處理方法,首重其 "可計算性"(computability)」 我一直拿出來類比的「自然語言 vs. 程式語言」,就是要呈現這一點。就像程式語言不需要編寫字典檔,只要設定好「保留字」以及「格式規範 (縮排、括號、賦值…等)」,就能讓直譯器/編譯器理解程式碼的設計目標。我們做的 Articut 也是不需要編寫字典檔,只要設定好 "Function words" 以及「句法結構」,就能處理每一個具有結構的自然語言句子了。
前面六個部份的書籍您都接觸過以後,一定更能體會我說的「光有語言能力是不夠的。機器學習應該要強攻的地方是領域知識的建立以及存取這個領域知識的模型的能力」。讓我們可以透過 Articut 處理出「一個自然語言的句子在講什麼,它在講哪些資訊?哪些仍然是缺乏的,就向那個 ML 做出來的模型做存取,取出資訊來回覆人類。」
這就是 Human-level 的「強人工智慧」。
7. Linguistic Fundamentals for Natural Language Processing: https://www.tenlong.com.tw/products/9781627050111?list_name=sp
8. Linguistic Fundamentals for Natural Language Processing II: https://www.tenlong.com.tw/products/9781681736211?list_name=lv
這兩本在天瓏資訊都有。但如果沒有前面 6 項的底子,這兩本書都會讀起來莫名奇妙。比如說裡面有一章是 "Syntax: Introduction" 就只有三頁。三頁各自只有一句重點:「句法收斂了無限發散的可能 (syntax places constrains on possible sentences.)」、「句法提供語意運算的架構 (syntax provides scaffolding for semantics composition)」和「句法排除了不可能的字串,也因而讓語意運算的計算量降低。就這樣,沒有其它說明了。因此雖然它很薄,但是前面的基礎還是要先建立的。
9. Linguistics for the Age of AI: https://mitpress.mit.edu/books/linguistics-age-ai
這本應該是整個系列以來最新的一本書。它是 2021 年才出版的。不過如果沒有前面 8 項的洗禮,這本書在寫什麼是非常難懂的。
10. The Minimalist Program: https://mitpress.mit.edu/books/minimalist-program
這本書非常不好讀。但它是集前面半個世紀的研究與証明後,對「自然語言的可計算性」的總結。在 Chomsky 出版了這本書以後,就不太做新的語言學研究了。因為其實也沒有什麼大題目好做了,剩下的都是一些小小的問題,有點像是程式語言裡的 coding style 造成別人閱讀原始碼時的困擾或是直譯器/編譯器執行時的效能問題而已的那種小問題了。
其它相關閒書:
Aspects of the Theory of Syntax: https://www.books.com.tw/products/F013408209?sloc=main
本書首刷在 1965 年。當時許多對於語言的想法都只有 Chomsky 教授自己的觀察以及在少數西歐和南歐語言的証據。不過這本書討論到的各個面向,呈現了 Chomsky 教授接下來五十年做的事情的藍圖也預示了語言學從「傳統語言學」的那種「文科的詞彙語意考據學」變成「可架構出一個計算系統的理科科目」的走向。
--
不論是學術研究或是產業應用,我個人認為要在中文 NLP 這個領域裡活下來,台灣絕對不能像中國一樣「只有機器學習」一招。因為他們的語料產生速度超過我們太多了。我們需要採用像 Articut 這樣「零資料」或「微資料」就能啟動的 NLP 應用,再加上機器學習模型的 Hybrid 方案,才能和他們一拼。
在 NLP 的 ML 工具全面走向 "Data-driven" 的方向的情況下,台灣是沒有存活機會的。因為一樣被人稱為 "Chinese" 的語料裡,我們的語料產生的速度遠遠不及中國的語料產生速度。因此我十分急迫地想尋找能擴大 "Hyrbrid AI" 的教育訓練、領域嚐試、應用設計以及市場發展的目標。我已經做好基礎建設了,請大家踩在我們的肩膀上,我們向上發展吧!
0 notes