#empirical facewash
Text
Elizabeth Warren on weaponized budget models

In yesterday’s essay, I broke down the new series from The American Prospect on the hidden ideology and power of budget models, these being complex statistical systems for weighing legislative proposals to determine if they are “economically sound.” The assumptions baked into these models are intensely political, and, like all dirty political actors, the model-makers claim they are “empirical” while their adversaries are “doing politics”:
https://pluralistic.net/2023/04/03/all-models-are-wrong/#some-are-useful
If you’d like an essay-formatted version of this post to read or share, here’s a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/04/04/cbo-says-no/#wealth-tax
Today edition of the Prospect continues the series with an essay by Elizabeth Warren, describing how her proposal for universal child care was defeated by the incoherent, deeply political assumptions of the Congressional Budget Office’s model, blocking an important and popular policy simply because “computer says no”:
https://prospect.org/economy/2023-04-04-policymakers-fight-losing-battle-models/
When the Build Back Better bill was first mooted, it included a promise of universal, federally funded childcare. This was excised from the final language of the bill (renamed the Bipartisan Infrastructure Bill), because the CBO said it would cost too much: $381.5b over ten years.
This is a completely nonsensical number, and the way that CBO arrived at it is illuminating, throwing the ideology of CBO modeling into stark relief. You see, the price tag for universal childcare did not include the benefits of childcare!
As Warren points out, this is not how investment works. No business leader assesses their capital expenditures without thinking of the dividends from those investments. No firm decides whether to open a new store by estimating the rent and salaries and ignoring the sales it will generate. Any business that operates on that basis would never invest in anything.
Universal childcare produces enormous dividends. Kids who have access to high-quality childcare grow up to do better in school, have less trouble with the law, and earn more as adults. Mothers who can’t afford childcare, meanwhile, absent themselves from the workforce during their prime earning years. Those mothers are less likely to advance professionally, have lower lifetime earnings, and a higher likelihood of retiring without adequate savings.
What’s more, universal childcare is the only way to guarantee a living wage to childcare workers, who are disproportionately likely to rely on public assistance, including SNAP (AKA food stamps) to make ends meet. These stressors affect childcare workers’ job performance, and also generate public expenditures to keep those workers fed and housed.
But the CBO model does not include any of those benefits. As Warren says, in a CBO assessment, giving every kid in America decent early childhood care and every childcare worker a living wage produces the same upside as putting $381.5 in a wheelbarrow and setting it on fire.
This is by design. Congress has decreed that CBO assessments can’t factor in secondary or indirect benefits from public expenditure. This is bonkers. Public investment is all secondary and indirect benefits — from highways to broadband, from parks to training programs, from education to Medicare. Excluding indirect benefits from assessments of public investments is a literal, obvious, unavoidable recipe for ending the most productive and beneficial forms of public spending.
It means that — for example — a CBO score for Meals on Wheels for seniors is not permitted to factor in the Medicare savings from seniors who can age in their homes with dignity, rather than being warehoused at tremendous public expense in nursing homes.
It means that the salaries of additional IRS enforcers can only be counted as an expense — Congress isn’t allowed to budget for the taxes that those enforcers will recover.
And, of course, it’s why we can’t have Medicare For All. Private health insurers treat care as an expense, with no upside. Denying you care and making you sicker isn’t a bug as far as the health insurance industry is concerned — it’s a feature. You bear the expense of the sickness, after all, and they realize the savings from denying you care.
But public health programs can factor in those health benefits and weigh them against health costs — in theory, at least. However, if the budgeting process refuses to factor in “indirect” benefits — like the fact that treating your chronic illness lets you continue to take care of your kids and frees your spouse from having to quit their job to look after you — then public health care costings become indistinguishable from the private sector’s for-profit death panels.
Child care is an absolute bargain. The US ranks 33d out of 37 rich countries in terms of public child care spending, and in so doing, it kneecaps innumerable mothers’ economic prospects. The upside of providing care is enormous, far outweighing the costs — so the CBO just doesn’t weigh them.
Warren is clear that there’s no way to make public child care compatible with CBO scoring. Even when she whittled away at her bill, excluding millions of families who would have benefited from the program, the CBO still flunked it.
The current budget-scoring system was designed for people who want to “shrink government until it fits in a bathtub, and then drown it.” It is designed so that we can’t have nice things. It is designed so that the computer always says no.
Warren calls for revisions to the CBO model, to factor in those indirect benefits that are central to public spending. She also calls for greater diversity in CBO oversight, currently managed by a board of 20 economists and only two non-economists — and the majority of the economists got their PhDs from the same program and all hew to the same orthodoxy.
For all its pretense of objectivity, modeling is a subjective, interpretive discipline. If all your modelers are steeped in a single school, they will incinerate the uncertainty and caveats that should be integrated into every modeler’s conclusions, the humility that comes from working with irreducible uncertainty.
Finally, Warren reminds us that there are values that are worthy of consideration, beyond a dollars-and-cents assessment. Even though programs like child care pay for themselves, that’s not the only reason to favor them — to demand them. Child care creates “an America in which everyone has opportunities — and ‘everyone’ includes mamas.” Child care is “an investment in care workers, treating them with respect for the hard work they do.”
The CBO’s assassination of universal child care is exceptional only because it was a public knifing. As David Dayen and Rakeen Mabud wrote in their piece yesterday, nearly all of the CBO’s dirty work is done in the dark, before a policy is floated to the public:
https://prospect.org/economy/2023-04-03-hidden-in-plain-sight/
The entire constellation of political possibility has been blotted out by the CBO, so that when we gaze up at the sky, we can only see a few sickly stars — weak economic nudges like pricing pollution, and not the glittering possibilities of banning it. We see the faint hope of “bending the cost-curve” on health care, and not the fierce light of simply providing care.
We can do politics. We have done it before. Every park and every highway, our libraries and our schools, our ports and our public universities — these were created by people no smarter than us. They didn’t rely on a lost art to do their work. We know how they did it. We know what’s stopping us from doing it again. And we know what to do about it.
Have you ever wanted to say thank you for these posts? Here’s how you can: I’m kickstarting the audiobook for my next novel, a post-cyberpunk anti-finance finance thriller about Silicon Valley scams called Red Team Blues. Amazon’s Audible refuses to carry my audiobooks because they’re DRM free, but crowdfunding makes them possible.
[Image ID: A disembodied hand, floating in space. It holds a Univac mainframe computer. The computer is shooting some kind of glowing red rays that are zapping three US Capitol Buildings, suspended on hovering platforms. In the background, the word NO is emblazoned in a retrocomputing magnetic ink font, limned in red.]
#empirical facewash#wealth tax#elizabeth warren#cbo#congressional budget office#penn wharton budget model#budgeting#economics#economism#computer says no#pluralistic#universal childcare#build back better#bipartisan infrastructure bill
252 notes
·
View notes
Text
The role this deficit plays in magnifying bias has been well-theorized and well-publicized by this point: feed a hiring algorithm the resumes of previously successful candidates and you will end up hiring people who look exactly like the people you’ve hired all along; do the same thing with a credit-assessment system and you’ll freeze out the same people who have historically faced financial discrimination; try it with risk-assessment for bail and you’ll lock up the same people you’ve always slammed in jail before trial. The only difference is that it happens faster, and with a veneer of empirical facewash that provides plausible deniability for those who benefit from discrimination. - Cory Doctorow
13 notes
·
View notes
Quote
The worst part of machine learning snake-oil isn't that it's useless or harmful – it's that ML-based statistical conclusions have the veneer of mathematics, the empirical facewash that makes otherwise suspect conclusions seem neutral, factual and scientific.
Cory Doctorow
4 notes
·
View notes
Text
The problem with economic models

When students of statistics are introduced to creating and interpreting models, they are introduced to George Box’s maxim:
All models are wrong, some are useful.
It’s a call for humility and perspective, a reminder to superimpose the messy world on your clean lines.
If you’d like an essay-formatted version of this article to read or share, here’s a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/04/03/all-models-are-wrong/#some-are-useful
Even with this benediction, modeling is forever prone to the cardinal sin of insisting that complex reality can be reduced to “a perfectly spherical cow of uniform density on a frictionless plane.” Partially that’s down to human frailty, our shared inability to tell when we’re simplifying and when we’re oversimplifying.
But complex mathematics are also a very powerful smokescreen: because so few of us are able to interpret mathematical models, much less interrogate their assumptions, models can be used as “empirical facewash,” in which bias and ideology are embedded in equations and declared to be neutral, because “math can’t be racist.”
The problems with models have come into increasing focus, as machine learning models have increasingly been used to replace human judgment in areas from bail assessment to welfare eligibility to child protective services interventions:
https://memex.craphound.com/2018/01/31/automating-inequality-using-algorithms-to-create-a-modern-digital-poor-house/
But even amidst this increasing critical interrogation of models in new domains, there is one domain where modeling is all but unquestioned: economics, specifically, macroeconomics, that is, the economics of national government budgets.
This is part of a long-run, political project to “get politics out of budgeting” -a project as absurd as “getting wet out of water.” Government budgeting is intrinsically, irreducibly political, and there is nothing more political than insisting that your own preferences and assumptions are “empirical” while anyone who questions them is “doing politics.”
This model-first pretense of neutrality is a key component of neoliberalism, which saw a vast ballooning of economists in government service — FDR employed 5,000 economists, while Reagan relied on 16,000 of them. As the jargon and methods of economics crowded out the language of politics, this ideology-that-insisted-it-wasn’t got a name: economism.
Economism’s core method is reducing human interaction to “incentives,” to the exclusion of morals or ethics — think of Margaret Thatcher’s insistence that “there is no such thing as society.” Economism reduces its subjects to homo economicus, a “rational,” “utility-maximizing” automaton responding robotically to its “perfect information” about the market.
Economism also insists that power has no place in predictions about how policies will play out. This is how the Chicago School economists were able to praise monopolies as “efficient” systems for maximizing “consumer welfare” by lowering prices without “wasteful competition.”
This pretense of mathematical perfection through monopoly ignores the problem that anti-monopoly laws seek to address, namely, the corrupting influence of monopolists, who wield power to control markets and legislatures alike. As Sen John Sherman famously said in arguing for the Sherman Act: “If we will not endure a King as a political power we should not endure a King over the production, transportation, and sale of the necessaries of life.”
https://marker.medium.com/we-should-not-endure-a-king-dfef34628153
Economism says that we can allow monopolies to form and harness them to do only good, enforcing against them when they abuse their market dominance to hike prices. But once a monopoly forms, it’s too late to enforce against them, because monopolies are both too big to fail and too big to jail:
https://doctorow.medium.com/small-government-fd5870a9462e
Today, economism is helpless to do anything about inflation, because it is ideologically incapable of recognizing the inflation is really excuseflation, in which monopolists blame pandemic supply shocks, Russian military belligerence and supposedly overgenerous covid relief programs for their own greedy profiteering:
https://pluralistic.net/2023/03/11/price-over-volume/#pepsi-pricing-power
Mathematics operates on discrete quantities like prices, while power is a quality that does not readily slot into an equation. That doesn’t mean that we can safely discard power for the convenience of a neat model. Incinerating the qualitative and doing arithmetic with the dubious quantitative residue that remains is no way to understand the world, much less run it:
https://locusmag.com/2021/05/cory-doctorow-qualia/
Economism is famously detached from the real world. As Ely Devons quipped, “If economists wished to study the horse, they wouldn’t go and look at horses. They’d sit in their studies and say to themselves, ‘What would I do if I were a horse?’”
https://pluralistic.net/2022/10/27/economism/#what-would-i-do-if-i-were-a-horse
But this disconnection isn’t merely the result of head-in-the-clouds academics who refuse to dirty their hands by venturing into the real world. Asking yourself “What would I do if I were a horse?” (or any other thing that economists are usually not, like “a poor person” or “a young mother” or “a refugee”) allows you to empiricism-wash your biases. Your prejudices can be undetectably laundered if you first render them as an equation whose details can only be understood by your co-religionists.
Two of these if-I-were-a-horse models reign invisibly and totally over our daily lives: the Congressional Budget Office model and the Penn Wharton Budget model. Every piece of proposed government policy is processed through these models, and woe betide the policy that the model condemns. Thus our entire government is conducted as a giant, semi-secret game of Computer Says No.
This week, The American Prospect is conducting a deep, critical dive into these two models, and into the enterprise of modeling itself. The series kicks off today with a pair superb pieces, one from Nobel economics laureate Joseph Stiglitz, the other from Prospect editor-in-chief David Dayen and Rakeen Mabud, chief economist for the Groundwork Collaborative.
Let’s start with the Stiglitz piece, “How Models Get the Economy Wrong,” which highlights specific ways in which the hidden assumptions of models have led us to sideline good policy (like increasing spending during recessions) and make bad policy (like cutting taxes on the rich):
https://prospect.org/economy/2023-04-03-how-models-get-economy-wrong/
First, Stiglitz sets out a general critique of the assumptions in neoclassical models, starting with the “efficient market” hypothesis, that holds that the market is already making efficient use of all our national resources, so any government spending will “crowd out” efficient private sector activity and make us all poorer.
There are trivially obvious ways in which this is untrue: every unemployed person who wants a job is not being used by the market. The government can step in — say, with a federal jobs guarantee — and employ everyone who wants a job but isn’t offered one by the public sector, and by definition, this will not crowd out private sector activity.
Less obvious — but still true — is that the private sector is riddled with inefficiencies. The idea that Google and Facebook make “efficient” use of capital when they burn billions of dollars to increase their surveillance dragnets is absurd on its face. Then there’s the billions Facebook set on fire to build a creepy dead mall it calls “the metaverse”:
https://www.youtube.com/watch?v=EiZhdpLXZ8Q
Then we come to some of the bias in the models themselves, which consistently undervalue the long-run benefits of infrastructure spending. Public investments of this kind “yield very high returns,” which means that even if a public sector project reduces private sector investment, the private investments that remain produce a higher yield, thanks to public investment in a skilled workforce and efficient ports, roads and trains.
A commonplace among model users is that we must make “The Big Tradeoff” — we can either reduce inequality, or we can increase prosperity, but not both, because reducing inequality means taking resources away from the business leaders who would otherwise build the corporations whose products would make us all better off.
Despite the fact that organizations from the OECD to the IMF have recognized that inequality is itself a brake on economic growth, fostering destructive “rent seeking” (seen today online in the form of enshittification), the most common macroeconomic models continue to presume that an unequal society will be as efficient as a pluralistic one. Indeed, model-makers treat attention to inequality as an error bordering on a mortal sin — the sin of caring about “distributional outcomes” (that is, who gets which slice of the pie) rather than “growth” (whether the pie is getting bigger).
Stiglitz says that model makers have gotten a little better in recent years, formally disavowing Herbert Hoover’s idea of expansionary austerity, which is the idea that we should cut public spending when the economy is shrinking. Common sense tells us that this will make it shrink faster, but expansionary austerity (incorrectly) predicts that governments that cut spending will produce “investor confidence” and trigger more private investment.
This reliance on what Paul Krugman calls the “Confidence Fairy” is tragically misplaced. Hoover’s cutbacks made the Great Depression worse. So did IMF cutbacks in “East Asia, Greece, Spain, Portugal, and Ireland.”
Expansionary austerity is politics dressed up as economics. Indeed, the political ideology subsumed into our bedrock models has caused governments to fail to anticipate crisis after crisis, including the 2008 Great Financial Crisis.
The politics in modeling are especially obvious in the process running up to the Trump tax cuts (as is often the case with Trump, he draws with a fisted crayon where others delicately shade with a fine pencil, making it easier to see the work for what it is) (see also: E. Musk).
Axiomatic to model-building is the idea that if you tax something, you’ll get less of it (“incentives matter”). The theory of corporate tax cuts goes like this: “if we tax corporations for the money they might otherwise use to build new plant and hire new workers, they will do less of those things.”
That’s a reasonable assumption — which is why we don’t tax companies on capital investments and their payrolls. These expenses are deducted from a company’s profits before it calculates its taxes. Corporate taxes are levied on profits, net of spending on labor and plant.
But when the CBO modeled the Trump cuts, it operated on the assumption that the existing tax system was punishing companies for hiring people and expanding operations, and thus concluded the reducing taxes would lead to more of these activities. On that basis, the tax cuts were declared to be expansionary, a means of driving new private sector activity. In reality, all they did was create more profits, which rich people used to bid up the prices of assets, creating a dangerous asset bubble — not investment in productive capacity.
In “Hidden in Plain Sight,” the other Prospect piece that dropped today, Dayen and Mabud tell us just how wrong the models were about the Trump cuts:
https://prospect.org/economy/2023-04-03-hidden-in-plain-sight/
The CBO predicted that the cuts would drive a 0.7% increase in GDP over a decade, while Penn Wharton predicted 0.6–1.1% growth. Both were very, very wrong:
https://www.npr.org/2019/12/20/789540931/2-years-later-trump-tax-cuts-have-failed-to-deliver-on-gops-promises
Despite the manifest defects of these models, we still let them imprison our politics. When Elizabeth Warren proposed a 2% wealth tax on assets over $50m, she asserted that this would reduce billionaires’ fortunes by $3.75T over 10 years, but the Penn Wharton model knocked $1T off it, and declared that the real impact of the policy would be a reduction in investment, depressing long-run growth. The politics of a wealth tax are sound — the kind of politics that wins elections and restores faith in democracy — but the economism of models sweeps the proposal off the table and into the dustbin of history.
The Penn Wharton model simply refuses to factor in absolutely key aspects of a wealth tax plan, from the impact of increased enforcement to the economic benefits of universal child care, increased education funding, student debt cancellation and other programs that could be enacted with the fiscal space opened up by reducing billionaires’ spending power.
The Warren policy is rare because we got to hear about it — through a national election campaign — before it was strangled by the model-makers. More often, proposals like this are quietly snuffed out even before they’re introduced to the legislature, when they are run through the model and told Computer Says No.
Modeling isn’t intrinsically bad, but “all models are wrong” and what determines whether a model is useful are the politics of its assumptions. Economism insists that there are no politics in model-making, which creates unfixable flaws in its models.
One core political assumption in economism’s models is that government shouldn’t exercise power to produce outcomes — rather, it should “nudge” markets with incentives (which, we are constantly reminded, “matter”). This means that we can’t ban pollution — we can only offer “cap and trade” systems to incentivize companies to pollute less. It means we can’t do Medicare For All, we can only “bend the cost-curve” with minor interventions like forcing hospitals to publish their rate-cards.
Economism — and its institutions, like the CBO — are “short-run Keynesian and long-run classical” — that is, they only consider the benefits of public spending over the shortest of timespans, and assume that these evaporate over long time-scales. That’s exactly backwards, as anyone who’s ever traveled on a federal highway or visited a national park can attest:
https://prospect.org/politics/congress-biggest-obstacle-congressional-budget-office/
All of this is worsened by politicians, who exploit the primacy of economism to attack their adversaries. When the CBO or Penn Wharton release a report on a policy, they often wrap their conclusions with caveats about uncertainties and ranges — but these cautions are jettisoned by opportunistic politicians who seize a single headline figure and use it as a club against their opponents.
In the coming week, the Prospect will run deep dives into the defects of CBO and Penn Wharton, along with other commentary. It’s very important work, throwing open the doors to the inner sanctum of economism’s sacred temple. I’ll be following it eagerly.
Have you ever wanted to say thank you for these posts? Here’s how you can: I’m kickstarting the audiobook for my next novel, a post-cyberpunk anti-finance finance thriller about Silicon Valley scams called Red Team Blues. Amazon’s Audible refuses to carry my audiobooks because they’re DRM free, but crowdfunding makes them possible.
Image:
bert knottenbeld (modified)
https://www.flickr.com/photos/bertknot/8375267645/
CC BY-SA 2.0
https://creativecommons.org/licenses/by-sa/2.0/
[[Image ID: A Tron-like plane of glowing grid-squares. Two spherical cows roll about on the plane, chased by motion lines. The gridlines are decorated with complex equations from the Penn-Wharton Budget Model.]]
#pluralistic#the american prospect#penn wharton budget model#some models are useful#congressional budget office#macroeconomics#all models are wrong#joseph stiglitz#economism#inevitabilism
82 notes
·
View notes
Text
This day in history

#15yrsago Britain’s Data Chernobyl: more lost CDs full of thousands of personal records https://web.archive.org/web/20080207210610/http://www.telegraph.co.uk/news/main.jhtml;jsessionid=NR12Q0CT3XVTLQFIQMGSFFOAVCBQWIV0?xml=/news/2007/12/02/nbenefit102.xml
#5yrsago Tim O’Reilly’s WTF? A book that tells us how to keep the technology baby and throw out the Big Tech bathwater https://memex.craphound.com/2017/12/02/tim-oreillys-wtf-a-book-that-tells-us-how-to-keep-the-technology-baby-and-throw-out-the-big-tech-bathwater/
#1yrago Massive Predpol leak confirms that it drives racist policing https://pluralistic.net/2021/12/02/empirical-facewash/#geolitica
4 notes
·
View notes
Text
Massive Predpol leak confirms that it drives racist policing

When you or I seek out evidence to back up our existing beliefs and ignore the evidence that shows we’re wrong, it’s called “confirmation bias.” It’s a well-understood phenomenon that none of us are immune to, and thoughtful people put a lot of effort into countering it in themselves.
But confirmation bias isn’t always an unconscious process. Consultancies like McKinsey have grown to multibillion-dollar titans by offering powerful people confirmation bias as a service: pay them enough and they’ll produce a fancy report saying whatever you want to do is the best thing you possibly could do.
https://pluralistic.net/2021/11/25/strikesgiving/#cool-story-pharma-bro
A sizable fraction of the machine learning bubble is driven by this phenomenon. Pay a machine learning company enough money and they’ll produce a statistical model that proves that whatever terrible thing you’re doing is empirical and objective and true. After all, “Math doesn’t lie.”
The best term I’ve heard for this is “empirical facewash.” I learned that term from Patrick Ball, in a presentation on the Human Rights Data Analysis Group’s outstanding study of racial bias in predictive policing tools.
https://www.mic.com/articles/156286/crime-prediction-tool-pred-pol-only-amplifies-racially-biased-policing-study-shows
(Sidenote: HRDAG just won the prestigious Rafto Prize, a major international award for human rights work)
https://hrdag.org/2021/09/23/hrdag-wins-the-rafto-prize/
(And on that note, HRDAG is a shoestring operation that turns our tax-deductible donations into reliable statistical accounts of human rights abuses that are critical to truth and reconciliation, human rights tribunals, and trials for crimes against humanity. I am an annual donor and you should consider them in your giving, too)
https://hrdag.networkforgood.com/
Here’s how Ball described that predictive policing research: everybody knows that cops have a racist policing problem, but we don’t all agree on what that problem is. You and I might think that the problem is that cops make racially motivated arrests, while the cops and their apologists think the problem is that we think the cops make racially motivated arrests.
By feeding crime data into a machine learning model, and then asking it to predict where crime will take place based on past patterns of crime data, cops can get an “objective” picture of where to concentrate their policing activities.
But this has major problems. First, it presumes that crime stats are objective — that everyone reports crime at the same rate, and that the police investigate suspects at the same rate. In other words, this starts from the presumption that there is no racial bias in crime statistics — and then uses that presumption to prove that there is no racial bias in crime statistics!
Second, this presumes that undetected crimes are correlated with detected ones. In other words, if the cops detect a lot of crime in a poor neighborhood — and not in a rich neighborhood — then all the undetected crimes are also in those poor neighborhoods.
Finally, this presumes that every crime is a crime! In other words, it presumes that there are no de facto crimes like “driving while brown” or “walking your dog while black.” Some of the “crimes” in the crime stats aren’t actually crimes — rather, they’re pretextual stops that turn into plea deals after bullying prosecutors threaten a long prison sentence.
HRDAG’s work crystallized the critique of machine learning as a tool for correcting systemic bias, and it has been my touchstone for understanding other bias-reinforcing/bias-accelerating machine learning scandals. It’s a critical adjunct to such foundational texts as Cathy O’Neil’s “Weapons of Math Destruction”:
https://memex.craphound.com/2016/09/06/weapons-of-math-destruction-invisible-ubiquitous-algorithms-are-ruining-millions-of-lives/
And Virginia Eubanks’s “Automating Inequality.”
https://memex.craphound.com/2018/01/31/automating-inequality-using-algorithms-to-create-a-modern-digital-poor-house/
But you don’t need to look to outside sources for evidence that predictive policing reinforces and accelerates racial bias. The founders of Predpol — the leading predictive policing tool — came to the same conclusion in 2018, but decided not to do anything about it.
https://ieeexplore.ieee.org/abstract/document/8616417
That may sound shocking, but really, it’s par for the course with Predpol, which rebranded itself as Geolitica in order to distance itself from a string of scandals and bad publicity.
From the start, Predpol has wrapped its operations in secrecy, pressuring police forces to hide their use of the service from city officials and residents. Back in 2018, a security researcher provided me with a list of cities that seemed to have secretly procured Predpol services.
https://boingboing.net/2018/10/30/el-monte-and-tacoma.html
In 2019, Motherboard’s Caroline Haskins used that report to extract even more information about the cops’ secret deals with Predpol:
https://www.vice.com/en/article/d3m7jq/dozens-of-cities-have-secretly-experimented-with-predictive-policing-software
All this started because my source was able to learn that these cities were experimenting with Predpol’s digital phrenology due to basic cybersecurity errors the company had made.
Predpol’s cybersecurity has not improved since. A team of reporters from Gizmodo and The Markup just published a blockbuster report on Predpol’s role in biased policing, using the largest Predpol leak in history. Data regarding 5.9 million Predpol predictions was left on an unsecured server!
https://themarkup.org/prediction-bias/2021/12/02/crime-prediction-software-promised-to-be-free-of-biases-new-data-shows-it-perpetuates-them
The Markup/Gizmodo team used that dataset to conduct a massive study on racial bias in predictive policing. As American University’s Andrew Ferguson put it, “No one has done the work you guys are doing, which is looking at the data.” This is “striking because people have been paying hundreds of thousands of dollars for this technology for a decade.”
Ferguson’s point — that public millions have been poured into an experimental technology without any external validation — is important. After all, it’s unlikely that cops and Predpol keep this stuff a secret from us because they know we’ll love it and they don’t want to ruin the pleasant surprise.
On the other hand, it makes perfect sense if Predpol is really selling empirical facewash — that is, confirmation bias as a service.
That certainly seems to be the case based on the analysis published today. Police who rely on Predpol do less patrolling in white and affluent neighborhoods (these are pretty much the same neighborhoods in most of the USA, of course). But when it comes communities of color and poor communities, Predpol predictions send cops flooding in: “A few neighborhoods in our data were the subject of more than 11,000 predictions.”
When Predpol sends cops into your neighborhood, arrests shoot up (you find crime where you look for it), as does use of force. This has knock-on effects — for example, the reporters tell the story of Brianna Hernandez, who was evicted, along with her two young children from low-income housing. Her partner was stopped in his car while dropping off some money for her. He had an old court injunction barring him from being on the premises because of a crime he committed 14 years earlier, while he was a minor. The housing complex had a policy of evicting tenants who associated with people who committed crimes, and it had been the target of a flood of Predpol predictions.
Brianna doesn’t know if she and her children were made homeless because of a Predpol prediction, thanks to the secrecy Predpol and its customers hide behind.
Robert McCorquodale — the Calcasieu Parish, LA sheriff’s attorney who handles public records requests — refused to confirm whether they used Predpol, despite the fact that the data-leak clearly confirmed they were. He cited “public safety and officer safety” and speculated that if criminals knew Predpol was in use, they’d be able to outwit it: “I feel this is not a public record.”
Unsurprisingly, police reform advocates in six of the cities where Predpol was in use didn’t know about it: “Even those involved in government-organized social justice committees said they didn’t have a clue about it.”
All this secrecy helps hide the fact that Predpol is a) expensive and b) it doesn’t work. But many police departments are wising up. LAPD was Predpol’s first big reference customer — and they stopped using it in 2020, citing financial constraints and a damning Inspector General report.
It’s not just LA. Santa Cruz — the birthplace of Predpol — also fired the company last year:
https://pluralistic.net/2020/06/27/belated-oppenheimers/#banana-slugs
There’s a limited pool of mathematicians who can produce the kind of convincing confirmation bias as a service that Predpol sells, and it’s shrinking. 1,400 mathematicians have signed an open letter “begging their colleagues not to collaborate on research with law enforcement, specifically singling out Predpol.”
https://www.ams.org/journals/notices/202009/rnoti-p1293.pdf
Image:
Science Museum London (modified)
https://wellcomecollection.org/works/fjbypqcr/items
CC BY 4.0
https://creativecommons.org/licenses/by/4.0
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0:
https://creativecommons.org/licenses/by/3.0/deed.en
172 notes
·
View notes
Text
Machine learning sucks at covid

The worst part of machine learning snake-oil isn’t that it’s useless or harmful — it’s that ML-based statistical conclusions have the veneer of mathematics, the empirical facewash that makes otherwise suspect conclusions seem neutral, factual and scientific.
Think of “predictive policing,” in which police arrest data is fed to a statistical model that tells the police where crime is to be found. Put in those terms, it’s obvious that predictive policing doesn’t predict what criminals will do; it predicts what police will do.
Cops only find crime where they look for it. If the local law only performs stop-and-frisks and pretextual traffic stops on Black drivers, they will only find drugs, weapons and outstanding warrants among Black people, in Black neighborhoods.
That’s not because Black people have more contraband or outstanding warrants, but because the cops are only checking for their presence among Black people. Again, put that way, it’s obvious that policing has a systemic racial bias.
But when that policing data is fed to an algorithm, the algorithm dutifully treats it as the ground truth, and predicts accordingly. And then a mix of naive people and bad-faith “experts” declare the predictions to be mathematical and hence empirical and hence neutral.
Which is why AOC got her face gnawed off by rabid dingbats when she stated, correctly, that algorithms can be racist. The dingbat rebuttal goes, “Racism is an opinion. Math can’t have opinions. Therefore math can’t be racist.”
https://arstechnica.com/tech-policy/2019/01/yes-algorithms-can-be-biased-heres-why/
You don’t have to be an ML specialist to understand why bad data makes bad predictions. “Garbage In, Garbage Out” (GIGO) may have been coined in 1957, but it’s been a conceptual iron law of computing since “computers” were human beings who tabulated data by hand.
But good data is hard to find, and “when all you’ve got is a hammer, everything looks like a nail” is an iron law of human scientific malpractice that’s even older than GIGO. When “data scientists” can’t find data, they sometimes just wing it.
This can be lethal. I published a Snowden leak that detailed the statistical modeling the NSA used to figure out whom to kill with drones. In subsequent analysis, Patrick Ball demonstrated that NSA statisticians’ methods were “completely bullshit.”
https://s3.documentcloud.org/documents/2702948/Problem-Book-Redacted.pdf
Their gravest statistical sin was recycling their training data to validate their model. Whenever you create a statistical model, you hold back some of the “training data” (data the algorithm analyzes to find commonalities) for later testing.
https://arstechnica.com/information-technology/2016/02/the-nsas-skynet-program-may-be-killing-thousands-of-innocent-people/
So you might show an algorithm 10,000 faces, but hold back another 1,000, and then ask the algorithm to express its confidence that items in this withheld data-set were also faces.
However, if you are short on data (or just sloppy, or both), you might try a shortcut: training and testing on the same data.
There is a fundamental difference from evaluating a classifier by showing it new data and by showing it data it’s already ingested and modeled.
It’s the difference between asking “Is this like something you’ve already seen?” and “Is this something you’ve already seen?” The former tests whether the system can recall its training data; the latter tests whether the system can generalize based on that data.
ML models are pretty good recall engines! The NSA was training it terrorism detector with data from the tiny number of known terrorists it held. That data was so sparse that it was then evaluating the model’s accuracy by feeding it back some of its training data.
When the model recognized its own training data (“I have 100% confidence this data is from a terrorist”) they concluded that it was accurate. But the NSA was only demonstrating the model’s ability to recognize known terrorists — not accurately identify unknown terrorists.
And then they killed people with drones based on the algorithm’s conclusions.
Bad data kills.
Which brings me to the covid models raced into production during the height of the pandemic, hundreds of which have since been analyzed.
There’s a pair of new, damning reports on these ML covid models. The first, “Data science and AI in the age of COVID-19” comes from the UK’s Alan Turing Institute:
https://www.turing.ac.uk/sites/default/files/2021-06/data-science-and-ai-in-the-age-of-covid_full-report_2.pdf
The second, “Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans,” comes from a team at Cambridge.
https://www.nature.com/articles/s42256-021-00307-0
Both are summarized in an excellent MIT Tech Review article by Will Douglas Heaven, who discusses the role GIGO played in the universal failure of any of these models to produce useful results.
https://www.technologyreview.com/2021/07/30/1030329/machine-learning-ai-failed-covid-hospital-diagnosis-pandemic/
Fundamentally, the early days of covid were chaotic and produced bad and fragmentary data. The ML teams “solved” that problem by committing a series of grave statistical sins so they could produce models, and the models, trained on garbage, produced garbage. GIGO.
The datasets used for the models were “Frankenstein data,” stitched together from multiple sources. The specifics of how that went wrong are a kind of grim tour through ML’s greatest methodological misses.
Some Frankenstein sets had duplicate data, leading to models being tested on the same data they were trained on
A data-set of health children’s chest X-rays was used to train a model to spot healthy chests — instead it learned to spot children’s chests
One set mixed X-rays of supine and erect patients, without noting that only the sickest patients were X-rayed while lying down. The model learned to predict that people were sick if they were on their backs
A hospital in a hot-spot used a different font from other hospitals to label X-rays. The model learned to predict that people whose X-rays used that font were sick
Hospitals that didn’t have access to PCR tests or couldn’t integrate them with radiology data labeled X-rays based on a radiologist’s conclusions, not test data, incorporating radiologist’s idiosyncratic judgements into a “ground truth” about what covid looked like
All of this was compounded by secrecy: the data and methods were often covered by nondisclosure agreements with medical “AI” companies. This foreclosed on the kind of independent scrutiny that might have caught these errors.
It also pitted research teams against one another, rather than setting them up for collaboration, a phenomenon exacerbated by scientific career advancement, which structurally preferences independent work.
Making mistakes is human. The scientific method doesn’t deny this — it compensates for it, with disclosure, peer-review and replication as a check against the fallibility of all of us.
The combination of bad incentives, bad practices, and bad data made bad models.
The researchers involved likely had the purest intentions, but without the discipline of good science, they produced flawed outcomes — outcomes that were pressed into service in the field, to no benefit, and possibly to patients’ detriment.
There are statistical techniques for compensating for fragmentary and heterogeneous data — they are difficult and labor-intensive, and work best through collaboration and disclosure, not secrecy and competition.
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY:
https://creativecommons.org/licenses/by/3.0/deed.en
308 notes
·
View notes
Text
Smart cities are neither, 2021 edition
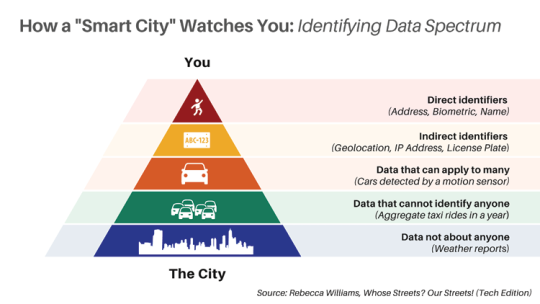
The lockdown was a chaotic time for “smart cities.” On the one hand, the most prominent smart city project in the world — Google’s Sidewalk Labs project in Toronto — collapsed thanks to the company’s lies about privacy and land use coming to light.
https://pluralistic.net/2020/05/07/just-look-at-it/#ding-dong
On the other hand, the standalone vendors that promise smart city services that you can graft onto your “dumb” city saw their fortunes surge, as the world’s great metropolises sleepwalked into a surveillance nightmare.
From license plate cameras to facial recognition to fake cellphone towers to location data harvested from vehicles and mobile devices, city governments shoveled billions into the coffers of private-sector snoops in the name of crimefighting and technocratic management.
The smart city has long been criticized as a means of quietly transforming public spaces of democratic action into private spaces of technological surveillance and control. Recent books like Jathan Sadowski’s “Too Smart” (2020) make the case in depth.
http://www.jathansadowski.com/book
Books can set out a long argument and cite examples in support of it, but those examples need to be updated regularly and the critique likewise because the field is moving so quickly — as is the critical response.
This month, Harvard’s Belfer Center published “Whose Streets? Our Streets! (Tech Edition),” a long report by Rebecca Williams that revisits the smart city nightmare in light of the mass protests, lockdowns and other high-intensity events of 2020/1.
https://www.belfercenter.org/publication/whose-streets-our-streets-tech-edition
As Williams writes, the smart city always starts with the rejections of participatory dialogue (“What would we like in our neighborhood?”) in favor of technocratic analysis (“They will design data collection that will inform them to what they will do with our neighborhood”).
Technocrats don’t want dialogue about surveillance because the dialogue always leads to a rejection. The Sidewalk Labs consultations in Toronto were overwhelmingly dominated by people who didn’t want a giant American monopolist spying on their literal footsteps 24/7.
Detroiters roundly rejected a $2.5m project to put cameras at their city’s intersections. When Apple asked Iphone owners whether they wanted to be tracked by apps (switching from opt out to opt in) 96% of users said no.
The commercial surveillance industry runs consent theater — whether that’s grey-on-white 8-point warnings that “Use of this site indicates consent to our terms of service” or discreet signs under street cameras: “This area under surveillance.”
https://onezero.medium.com/consent-theater-a32b98cd8d96
Plans for urban technological surveillance don’t survive real public consultation. The people just don’t know what’s good for ’em, so the vendors and the officials cutting checks to them have to instrument the city for spying on the down-low.
This secrecy festers, and the harms it brings are not limited to spying on people and chilling democratic protest. Secrecy also allows vendors to get away with overcharging and underdelivering.
CBP procured facial recognition spycams that analyzed 23m people in public spaces and never caught a single bad guy, while Chicago PD murdered a Black child called Adam Toledo after Shotspotter falsely reported a gunshot at his location.
Secret procurements for defective technology wastes money and puts communities of color at risk — but they also create systemic, *technological* risk, because they embed janky garbage software from shitty surveillance vendors right in the urban fabric.
Vendors who lie about how well their facial recognition or gunshot triangulation works also lie about their information security, and these tools get hacked on the reg, leaking sensitive personal information about millions of city-dwellers to identity thieves.
This defective, sloppy spyware is also a dark, moist environment perfectly suited to harboring ransomware infections, which can see vital services from streetlights to public transit frozen because some “smart city” grifter added a badly secured surveillance layer to it.
Because smart cities are inherently paternalistic (because they always bypass democratic dialog in favor of technocratic fiat), they replicate and magnify society’s biases and discrimination, with a coating of empirical facewash: “It’s not racism, it’s just math.”
Williams cites many 2020/1 examples of this, from Baltimore’s 25:1 ratio of CCTVs in Black neighborhoods to white neighborhoods, to Tampa and Detroit’s use of surveillance tech for “safety” in public housing.
Meanwhile, in Lucknow, India, the technocratic solution to an epidemic of sexist street harassment was to surveil women (“to protect them”) rather than the men who perpetrated the harassment.
https://perma.cc/FU62-NBQF
All of this is driven by private companies who mobilize investor capital and profits to sell more and more surveillance tech to cities. The antidemocratic, secret procurement process leads to more antidemocratic forms of privatization.
Democracy is replaced with corporate decision-making; constitutional protections are replaced by corporate policy; and surveillance monopolies expand their footprint, fill their coffers and sell more surveillance tech.
And far from making police accountable, surveillance gear on its own simply gives corrupt cops a broader set of tools to work with — as in Mexico City, where the C5 CCTV project let corrupt cops blackmail people and extort false confessions.
https://perma.cc/87QK-3HZG
Williams ends with a highly actionable call to arms, setting out a ten-point program for analyzing smart city proposals and listing organizations and networks (like the Electronic Frontier Alliance) that have been effective at pushing back.
https://www.eff.org/fight
123 notes
·
View notes
Text
The real cancel culture

"Cancel culture" - the prospect of permanent exclusion from your chosen profession due to some flaw - has been a fixture in blue-collar labor since the 1930s, as Nathan Newman writes in The American Prospect.
https://prospect.org/labor/how-workers-really-get-canceled-on-the-job/
In the 1930s, employers who wanted to keep labor "agitators" out of their shops adapted the WWI recruitment screening tools to identify "disgruntled" applicants who might organize their co-workers and form a union.
Over the years, this developed into an phrenological-industrial complex, with a huge industry of personality test companies that help employers - especially large employers of low-waged workers - exclude those they judged likely to demand better working conditions.
What began with large firms like Walmart and Marriott grew to consume much of the economy, with 80% of the Fortune 500 relying on tests from the $3+b/year phrenology industry, which is now all digital, incorporating machine learning for an all-algorithmic cancel culture.
The results of these tests get warehoused by giant "HR" companies like Kenexa (bought by IBM for $1.3b, holding 20m test results) and UKG (owned by private equity, with hundreds of millions of worker records).
The latest wrinkle includes junk-science "microexpression" analysis, with applicants being assessed by an algorithm that purports to be able to read their minds by examining minute cues from their faces - a discredited idea with no basis in science.
Indeed, the whole business of personality tests, and the more general field of psychographics, with its touchstones like the "Big Five Personality Types" are more marketing hype than science; Nature calls it a "scant science."
https://www.nature.com/articles/d41586-018-03880-4
Which probably explains why job satisfaction - the thing that all this phrenology is supposed to improve - has remained static since 2000, despite vast spending on career-destroying, life-destroying digital palmistry.
https://www.inc.com/sonia-thompson/68-percent-of-employees-are-disengaged-but-there-i.html
So why do employers do it? Well, as is often the case with algorithmic decision-support tools, the most tangible benefit is empiricism-washing. Algorithms provide cover in the form of empirical facewash for illegal employment discrimination.
An employer's personality test can facilitate illegal discrimination against people with depression, for example, by asking whether "your moods are steady from day to day," and video-based screening can exclude people on the autism spectrum.
Personality assessment also provides cover for the ongoing use of disciplinary technology, such as the bossware that spies on your keystrokes and other online activity, which exploded during lockdown as "work from home" was transformed into "live at work."
Employers can claim the ongoing surveillance is there to help measure and improve job satisfaction, while the phrenology-industrial complex sales reps quietly promise that they'll catch and expel "disgruntled" workers - those apt to organize a union.
Workers won legal battles to ban workplace use of polygraphs, medical exams, genetic screening, credit reports, criminal background checks, and disclosure of social media passwords - but personality screening filled the void, allowing discrimination through the back-door.
Newman thinks the National Labor Relations Board has the authority to step in here and prohibit this kind of personality screening, both prior to hiring and on the job.
"If we are going to have a national debate about free speech in the workplace, stopping the use of personality tests to cancel 'disgruntled' workers should be front and center."
Image:
Wellcome Trust (modified)
https://commons.wikimedia.org/wiki/File:Photograph;_%60Phrenology%27,_a_ceramic_head_Wellcome_L0002360.jpg
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY:
https://creativecommons.org/licenses/by/3.0/deed.en
177 notes
·
View notes
Text
Qualia
My latest Locus Magazine column is "Qualia," and it argues that every attempt to make an empirical, quantitative cost-benefit analysis involves making subjective qualitative judgments about what to do with all the nonquantifiable elements of the problem.
https://locusmag.com/2021/05/cory-doctorow-qualia/
Think of contact tracing. When an epidemiologist does contact tracing, they establish personal trust with infected people and use that relationship to unpick the web of social and microbial ties that bind them to their community.
But we don't know how to automate that person-to-person process, so we do what quants have done since time immemorial: we decide that the qualitative elements of the exercise can be safely incinerated, so we can do math on the quantitative residue that's left behind.
We can automate measurements of signal strength and contact duration. We can do math on those measurements.
What we *can't* do is tell whether you had "contact" with someone in the next sealed automobile in slow traffic - or whether you were breathing into each others' faces.
The decision to discard the subjective *is* subjective.
When the University of Illinois hired physicists to design its re-opening model, they promised no more than 100 cases in the semester and made unkind remarks about how easy epidemiology was compared to physics.
Within weeks, the campus shut down amid a 780-person outbreak. The physicists' subjective judgment that their model didn't need to factor in student eyeball-licking parties meant that the model could not predict the reality.
The problems in quants' claims of empiricism aren't just that they get it wrong - it's that they get it wrong, and then claim that it's impossible for anyone to do better.
This is - in Patrick Ball's term - "empirical facewash." Predictive policing apps don't predict where crime will be, but they DO predict where police will look for criminals.
Subjectively discarding the distinction between "arrests" and "crime" makes bias seem objective.
40 years ago, the University of Chicago's Economics Department incubated a radical experiment in false empiricism: the "Law and Economics" movement, which has ruled out legal and political sphere since Reagan.
Law and Econ's premise was that "equality before the law" required that the law be purged of subjective assessments. For example, DoJ review of two similar mergers should result in two similar outcomes - not approval for one and denial for the other.
To this end, they set out to transform the standards for anti-monopoly enforcement from a political judgment ("Will this merger make a company too powerful?") to an economic one ("Will this merger make prices go up?").
It's true that "Is this company too powerful?" is a subjective question - but so is "Will this merger result in higher prices?"
After all, every company that ever raised prices after a merger blamed something else: higher wage- or material-costs, energy prices, etc.
So whenever two companies merge and promise not to raise prices, we have to make a subjective judgment as to whether to trust them. And if they do merge and raise prices, we have to subjectively decide whether they're telling the truth about why the prices went up.
Law and Econ's answer to this lay in its use of incredibly complex mathematical models. Chicago economists were the world's leading experts in these models, the only people who claimed to know how to make and interpret them.
It's quite a coincidence how every time a company hired a Chicago Boy to build a model to predict how a merger would affect consumers, the model predicted it would be great.
A maxim of neoliberal economics is "incentives matter" - and economists have experience to prove it.
The Chicago School became a sorcerous priesthood, its models the sacrificial ox that could be ritually slaughtered so the future could be read in its guts. Their primacy in models meant that they could dismiss anyone who objected as an unqualified dilettante.
And if you had the audacity to insist that the law shouldn't limit itself to these "empirical" questions, they'd say you were "politicizing" the law, demolishing "equality before the law" by making its judgements dependent on subjective evaluations rather than math.
That's how we got into this mess, with two beer companies, two spirits companies, three record companies, five tech companies, one eyeglasses company, one wrestling league, four big accounting firms - they merged and merged, and the models said it would be fine, just fine.
These companies are too powerful. Boeing used its power to eliminate independent oversight of its 737 Max and made flying death-traps, and then got tens of billions in bailouts to keep them flying.
What's more, these companies are raising prices, no matter what the model says. The FTC knows how to clobber two companies that get together to make prices higher, but if those companies merge and the two resulting *divisions* do the same thing, they get away with it.
The only "price-fixing" the FTC and DoJ know how to detect and stop is the action of misclassified gig-economy workers (who are allegedly each an independent business) who get together to demand a living wage. In Law-and-Econ terms, that's a cartel engaged in price-fixing.
That means Lyft and Uber can collude to spend $200m to pass California's Prop 22, so they can pretend their employees are contractors and steal their wages and deny them workplace protection - but if the workers go on strike, *they're* the monopolists.
In Law-and-Econ land, the way those thousands of precarious, overstretched workers should resist their well-capitalised bosses at Uber and Lyft is to form a trade association, raise $200m of their own, and pass their own ballot initiative.
As I wrote in the column: "Discarding the qualitative is a qualitative act. Not all incinerators are created equal: the way you produce your dubious quantitative residue is a choice, a decision, not an equation."
There is room for empiricism in policy-making, of course. When David Nutt was UK Drugs Czar, he had a panel of experts create empirical rankings for how dangerous different drugs were to their users, their families and wider society.
From this, he was able to group drugs into "drugs whose regulation would change a lot based on how you prioritized these harms" and "drugs whose ranking remains stable, no matter what your priorities."
Nutt was then able to go to Parliament and say, "OK, the choice about who we protect is a political, subjective one, not an empirical one. But once you tell me what your subjective choice is, I can empirically tell you how to regulate different drugs."
Nutt isn't UK Drugs Czar anymore. He was fired after he refused to recant remarks that alcohol and tobacco were more dangerous than many banned substances. He was fired by a government that sat back and watched as the booze industry concentrated into four companies.
These companies' profits are wholly dependent on dangerous binge drinking; they admit that if Britons were to stop binge drinking, they'd face steep declines in profitability.
These companies insist they can prevent binge drinking, through "enjoy responsibly" programs.
These programs are empirical failures. The companies insist that this is because it's impossible to prevent binge drinking.
So Nutt made his own program, and performed randomized trials to see how it stacked up against the booze pushers' version.
Nutt's program worked.
It was never implemented.
Instead, he got fired, for saying - truthfully - that alcohol is an incredibly dangerous drug.
The four companies that control the world's booze industry have enormous political power.
So here we have the failure of Law-and-Econ, even on its own terms. Instead of creating an empirical basis for policy, the Law-and-Econ framework has created global monopolies that capture their regulators and kill with impunity.
That's why it's so significant that Amy Klobuchar's antitrust proposals start by getting rid of the "consumer welfare" standard and replacing it with a broader standard: "Is this company too powerful?"
https://pluralistic.net/2021/02/06/calera/#fuck-bork
Image:
OpenStax Chemistry
https://commons.wikimedia.org/wiki/File:Figure_24_01_03.jpg
CC BY
https://creativecommons.org/licenses/by/4.0/deed.en
53 notes
·
View notes
Text
Australian predictive policing tool for kids

Predictive policing tools work really well: they perfectly predict what the police will do. Specifically, they predict whom the police will accuse of crimes, and since only accused people are convicted, they predict who will be convicted, too.
In that sense, predictive policing predicts "crime" - the crimes that the police prosecute are the crimes that the computer tells them to seek out and make arrests over. But that doesn't mean that predictive policing actually fights actual crime.
Instead, predictive policing serves as empirical facewash for bias. Take last year's biased policing statistics, give them to a machine learning model, and ask it where the crime will be next year, and it will tell you that next year's crime will look much the same.
If the police then follow the oracle's bidding and patrol the places they're told to patrol and stop the people they're told to stop, then yup, they will validate the prediction. Like all oracles, predictive policing only works when its self-fulfilling prophecy.
That is the perennial wickedness of fortune-telling, after all, and 'twas ever thus, which is why Dante cursed fortune-tellers to have their heads twisted 180' and left them to weep into their ass-cracks forever as they slogged through molten shit.

If Dante was right, then the police in the Australian state of Victoria have a hell of an eternity ahead of them. They've classed 240 children (as young as ten!) as "youth network offenders" and fed their stats to a secret policing algorithm.
https://www.theguardian.com/australia-news/2020/nov/23/victoria-police-refuses-to-reveal-how-many-young-people-tracked-using-secretive-data-tool
The algorithm - its vendor and name undisclosed - considers the police records of children and predicts "how many crimes they'll commit before the age of 21 with 95% accuracy."
Or, put another way, it tells the police how many crimes to charge the child with between now and their 21st birthday.
The Victoria police won't say how they collect data, what other uses they put it to, how many children were tracked by the program, what oversight exists or whether it's still used.
You will not be surprised to learn that the nexus of the use of this tool is in a place that is "diverse and disadvantaged" (Dandenong, Springvale, Narre Warren and Pakenham) and the children it captured were primarily of Pacific Islander and Sudanese descent.
Victoria's state elections were poisoned by racist fairy-tales of "African gangs," with politicians using these nonexistent criminal threats to discredit their opponents and promise mass surveillance and police crackdowns on racialized children.
Victoria police say they can't disclose any details about the program because of "methodological sensitivities," much in the same way that stage psychics can't disclose how they guess that the lady in the third row has lost a loved one due to "methodological sensitivities."
That is, if they told us how it worked, we'd all see through the trick.
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY:
https://creativecommons.org/licenses/by/3.0/deed.en
70 notes
·
View notes
Text
Educator sued for criticising "invigilation" tool
`9

High-stakes tests are garbage, pedagogically bankrupt assessment tools that act as a form of empirical facewash for "meritocracy."
They primarily serve as a way for wealthy parents to buy good grades for their kids, since expensive test-prep services can turn even the dimmest, inbred plute into a genius-on-paper.
All of this was true before the pandemic. Now it's worse. Most of us meet the plague and ask, "How can I help my neighbor?" But for sociopaths, the question is, how can I turn a buck in a way that only stomps on the faces of poor people who don't get to hit back?
Maybe you hear that and think of the absolute garbage people who ran out and bought as much hand-san and bleach and TP as they could in the hopes of selling it at a markup.
https://www.nytimes.com/2020/03/14/technology/coronavirus-purell-wipes-amazon-sellers.html
But those petty grifters quickly disappeared in our rear-view mirrors. The real scum were the ones with long cons that hit whole swathes of victims.
Think, in other words, of the "remote invigilation" industry, whose products spy on kids during useless high-stakes tests.
These are tools that allow teachers to get a 360' view of students' surroundings (a special hardship for poor kids in close quarters) while relying on racially biased facial recognition systems and modern phrenology like facial expression analysis.
https://pluralistic.net/2020/08/09/just-dont-have-a-face/#algorithmic-bias
These are effectively rootkits: spyware you are required to install on your computer that grants remote parties sweeping access to your files and processes - especially hard on kids who share computers with siblings or precariously employed parents.
https://pluralistic.net/2020/04/15/invigilation/#invigilation
Unsurprisingly, people who make these tools are unsavory, immoral bullies.
Take Mike Olsen, CEO of Proctorio, who dumped dox on a child who criticized his company in a Reddit forum:
https://pluralistic.net/2020/07/01/bossware/#moral-exemplar
(Proctorio told the Guardian they "take privacy very seriously")
Educators aren't any happier about Proctorio than their students are. Ian Linkletter is a Learning Technology Specialist at UBC's Faculty of Education.
He was so aghast at Proctorio's sweeping surveillance capabilities that he tweeted links to the company's Youtube videos documenting them. These videos were public, but unlisted.
In response, Proctorio SUED LINKLETTER, getting an injunction in an ex parte court proceeding that LInkletter was not informed of.
Proctorio claims that LINKING TO ITS PUBLIC VIDEOS constitutes a copyright infringement and a breach of confidentiality.
This is bullshit, but Linkletter is an employee at a public university while Proctorio is a ruthless profiteer that has raised millions in the capital markets to peddle surveillance tools:
https://pitchbook.com/profiles/company/91448-02#funding
Thankfully, British Columbia has strong SLAPP protections that allow people victimized by nuisance suits brought by deep-pocketed, thin-skinned jerks to get them expeditiously dismissed.
Linkletter's colleagues are standing behind him, and he's being represented by Joseph Arvay of Arvay Finlay LLP. Arvay's SLAPP motion to the BC Supreme Court is a thing of beauty:
https://drive.google.com/drive/folders/1OjxaRjRfe0BLh_A6rcyc9lCmdfZ5nEm-




Legal threats from wealthy, ruthless corporate bullies are incredibly stressful, even if you win. Trust me, I speak from experience (ohai, Bird, Magicjack, Playboy and Ralph Lauren!). And even with SLAPP laws and liability insurance, the out-of-pockets are severe.
That's why I'm contributing $100 to Linkletter's Gofundme for his legal fees, which have mounted to tens of thousands of dollars.
https://www.gofundme.com/f/stand-against-proctorio
Linkletter can't really talk about the case, thanks to Proctorio's sneakily obtained injunction. That means that it's incumbent on US, the people who care about justice for students and whistleblowers, to spread the word.
Please consider retweeting this and also investigating whether any of the educational institutions you or your children are involved with use Proctorio's products and point them at this lawsuit.
Any ed-tech firm that answers academic criticism with lawsuits has permanently disqualified itself from being entrusted with learners' educations. When someone tells you who they are, believe them.
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY:
https://creativecommons.org/licenses/by/3.0/deed.en
58 notes
·
View notes
Text
#1yrago ICE hacked its algorithmic risk-assessment tool so it recommended detention for everyone

One of the more fascinating and horrible details in Reuters' thoroughly fascinating and horrible long-form report on Trump's cruel border policies is this nugget: ICE hacked the risk-assessment tool it used to decide whom to imprison so that it recommended that everyone should be detained.
This gave ICE a kind of empirical facewash for its racist and inhumane policies: they could claim that the computer forced them to imprison people by identifying them as high-risk. The policy let ICE triple its detention rate, imprisoning 43,000 people.
https://boingboing.net/2018/06/26/software-formalities.html
2K notes
·
View notes
Text
Pandemics shatter AI's intrinsic conservativism

One of my favorite insights on Machine Learning comes form Molly Sauter's 2017 essay Instant Recall, which describes ML's intrinsic conservativism. Having been trained on historical data, ML can only make good predictions if the future's like the past.
https://reallifemag.com/instant-recall/
That's why your phone's predictive text nudges you to follow up "My" with "darling" if you habitually text your spouse with that salutation. When you type a word it's never seen, it autocompletes with a statistically normal following word.
I took a stab at talking about some of the implications of this in an LA Review of Books essay last January:
http://blog.lareviewofbooks.org/provocations/neophobic-conservative-ai-overlords-want-everything-stay/
One interesting side-effect of the pandemic is that it magnifies this conservative bias in ML: because we're acting in unprecedented ways, the ML-based predictive systems are misfiring badly ("automation is in a tailspin").
https://www.technologyreview.com/2020/05/11/1001563/covid-pandemic-broken-ai-machine-learning-amazon-retail-fraud-humans-in-the-loop/
Supply-chain forecasting tools are ordering both too much of things, and too little. Recommendation systems haven't figured out that "in stock" is the most important criteria to sort by. Shoppers aren't interested in big ticket items.
Some of these behaviors are so unusual that they're tripping fraud-detection systems that apply the brakes to an already broken system ("You never bought gardening or bread-making stuff before, why are you ordering so much now?").
And when big players like Amazon alter their algorithms to correct for this, it adds even more chaos to the downstream systems that are trying to predict what Amazon will do.
People who claim to know the future are always either con-artists or delusional. The addition of abstruse stats to the prediction provides the discredited profession of fortune-telling with a veneer of empirical facewash, but it doesn't bring us closer to precognition.
So much of what we call "accurate prediction" is just "forcing/nudging people to act the way they used to" - I can predict with 100% accuracy that you will hold the same posture for the next five minutes, if I'm allowed to shoot you through the heart before the clock starts.
As our conservative AI overlords encounter the reality of an unprecedented situation, the difference between coercion and prediction is becoming a lot clearer.
Image:
Johnny Jet
https://www.flickr.com/photos/johnnyjet/3290272880
CC BY
https://creativecommons.org/licenses/by/2.0/
68 notes
·
View notes
Text
Against AI phrenology

The iron law of computing is GIGO: Garbage In, Garbage Out. Machine learning does not repealit. do statistical analysis of skewed data, get skewed conclusions. This is totally obvious to everyone except ML grifters whose hammers are perpetually in search of nails.
Unfortunately for the human race, there is one perpetual, deep-pocketed customer who always needs as much empirical facewash as the industry can supply to help overlay their biased practices with a veneer of algorithmic neutrality:
Law enforcement.
Here's where GIGO really shines. Say you're a police department who is routinely accused of racist policing practices, and the reason for that is that your officers are racist as fuck.
You can solve this problem by rooting out racist officers, but that's hard.
Alternatively, you can find an empiricism-washer who will take the data about who you arrested and then make predictions about who will commit crime. Because you're feeding an inference engine with junk stats, it will produce junk conclusion.
Give the algorithm racist policing data, and will pat you on the back and congratulate you for fighting crime without bias. As the Human Rights Data Analysis Group writes: predictive policing doesn't predict crime, it predicts what the police will do.
https://hrdag.org/2016/10/10/predictive-policing-reinforces-police-bias/
As odious as predictive policing technologies are, it gets much worse. Because if you want to really double down on empiricism-washing, there's the whole field of phrenology - AKA "race science" - waiting to be exploited.
Here's how that works: you feed an ML system pictures of people who have been arrested by racist cops, and call it "training a model to predict criminality from pictures."
Then you ask the model to evaluate pictures of people and predict whether they will commit crimes.
This system will assign a high probability of criminality to anyone who looks like people the cops have historically arrested. That is, brown people.
"Predictive policing doesn't predict crime, it predicts what the police will do."
It would be one (terrible) thing if this was merely the kind of thing you got in a glossy sales-brochure. But it gets (much) worse: researchers who do this stupid thing then write computer science papers about it and get them accepted in top scholarly publications.
For example: "Springer Nature — Research Book Series: Transactions on Computational Science and Computational Intelligence" is publishing a neophrenological paper called "A Deep Neural Network Model to Predict Criminality Using Image Processing."
The title is both admirably clear and terribly obscure. You could subtitle it: "Keep arresting brown people."
A coalition of AI practitioners, tech ethicists, computer scientists, and activists have formed a group to push back against this, called the Coalition for Critical Tech.
As its inaugural action, the Coalition for Critical Technology has published a petition calling on Springer to cancel publication of this junk science paper.
https://medium.com/@CoalitionForCriticalTechnology/abolish-the-techtoprisonpipeline-9b5b14366b16
The petition also calls on other publishers to adopt a promise not to publish this kind of empiricism-washing in the future.
You can sign it too.
I did.
34 notes
·
View notes
Text
#1yrago Is this the full list of US cities that have bought or considered Predpol's predictive policing services?

Predpol (previously) is a "predictive policing" company that sells police forces predictive analytics tools that take in police data about crimes and arrests and spits out guesses about where the police should go to find future crimes.
Predpol has drawn sharp criticism for algorithmic discrimination, in which data from racist policing practices are laundered through an algorithm that gives them the veneer of empirical impartiality: feeding faulty data to a predictive algorithm produces faulty analysis. "Garbage in, garbage out" is an iron law of computing that has not been repealed by machine learning techniques.
Even as Predpol and its competitors, like Palantir (previously) have expanded their operations, concerned citizens have successfully pushed for local laws requiring cities to engage in public consultation before procuring services that feed private corporations policing and surveillance data in order to direct policing operations. However, in most markets, Predpol and its competitors operate in obscurity. The cop who stopped you this week (or who didn't come to your neighborhood at all) might have been acting on orders from an AI oracle provided by Predpol to your local police, whose tax-funded revenues are a close-kept secret.
An anonymous security researcher recently contacted me with what may be a list of Predpol's customers. This researcher had seen that Predpol assigns easy-to-guess subdomains to each Predpol customer, in the form of CITYNAME.predpol.com, for example, baltimore.predpol.com.
This researcher wrote a script that combined the name of every US city and town with ".predpol.com" and checked to see whether this domain existed. The full list of cities that had Predpol domains is both short and confusing:
longbeach.predpol.com
indianapolis.predpol.com
hollywood.predpol.com
albany.predpol.com
southjordan.predpol.com
berkeley.predpol.com
frederick.predpol.com
baltimore.predpol.com
pleasanton.predpol.com
modesto.predpol.com
tacoma.predpol.com
elmonte.predpol.com
elgin.predpol.com
livermore.predpol.com
reading.predpol.com
merced.predpol.com
haverhill.predpol.com
Many of these cities have already publicly disclosed that they are using Predpol's services (Baltimore, MD; Pleasanton, CA; Modesto, CA; Tacoma, WA; El Monte, CA; Elgin, IL; Livermore, CA; Reading, PA; Merced, CA and Haverhill, MA).
Two of the remaining domains are easy to understand: berkeley.predpol.com refers to the UC Berkeley campus police, who have purchased Predpol's services (Predpol's Board of Directors includes Tom Jorde, Professor Emeritus of Law at UC Berkeley). Frederick, MD cheerfully admits that they are a Predpol customer.
The remainder are a mystery, though. None of the police departments for any of the US cities called Long Beach or Albany (there are several!) admit to using Predpol's services. The press officer for the Indianapolis, IN police department was definitive that his department wasn't a Predpol customer. I left several messages for the press officer for the South Jordan, UT police, but never heard back. The "hollywood.predpol.com" domain seems to refer to Hollywood, CA, which is under LAPD jurisdiction (the LAPD has a publicly disclosed relationship with Predpol).
Predpol itself was tight-lipped in the extreme: they initially ignored all press requests, then sent a terse "neither confirm nor deny" response to my questions about this list. They wouldn't even confirm whether the login forms at these domains were secure, despite repeated warnings from me that I would be making them public, requesting that they ensure that these forms require strong logins and passwords to avoid exposing sensitive policing data.
The list raises more questions than it answers. Does Predpol really have fewer than two dozen customers in the USA? What are we to make of the cities with subdomains who have never procured services from Predpol?
Predpol sells services to publicly funded policing organizations that make predictions about where crime will occur. Everything about this process is a secret: which police departments procure Predpol's services, what data they provide Predpol with, how Predpol arrives at its oracular pronouncements, and how much public money they receive for this service.
What we do know is that policing predictions are self-fulfilling prophecy: if the police ask everyone on a given corner to turn out their pockets, or stop and search every car going down a certain road, they will, eventually, find crime. What we don't know is whether Predpol's predictions are better at finding crime than random chance.
We also know that machine learning predictions are no better than the data used to generate their models. If the data used to train Predpol's models come from biased policing, then Predpol's predictions will be biased, too: but their machine-learning pedigree is a kind of empirical facewash that makes them seem "scientific."
(Image: Wapcaplet, CC-BY-SA)
https://boingboing.net/2018/10/30/el-monte-and-tacoma.html
30 notes
·
View notes
Last Seen Blogs

hannahcolleen27
Physically smiLing :) ^^

kda-chat
K/DA Chat

auxseo-blog
Axilium Technology

hgprincess
Princess Pukey

volkswagenjakarta-blog
Volkswagen Jakarta