#ladataweb
Text
[PowerBi] Catálgo de diseños para reportes
Hace tiempo he escrito un artículo para tener presente que la UI puede manipularse y mejorarse por herramientas terceras. Ciertamente, no es algo para tomar a la ligera, lleva su tiempo aporta un enorme valor para el usuario final.
En este artículo reflejé una, de muchas formas, que podemos usar para construir fondos para nuestros informes de PowerBi. Usando PowerPoint, podemos delimitar colores, sombras, espacios, alineamientos, etc. Las prestaciones de manipulación de formas y colores es mayor que lo que PowerBi nos represente. Sin duda, podemos hacer mucho en el canva de PowerBi, pero... ¿a que precio.? Tal vez generar un buen fondo nos tome el agregado de 15 formas. No es lo mismo que el fondo sea una imagen a que PowerBi renderice 15 elementos antes de siquiera pensar en sus números.
Como regalo para este mes de mi cumpleaños, quise entregar una nueva sección de LaDataWeb inspirada en Temas, Plantillas, Themes, Templates o como quieran llamarle.
Me alegra mucho presentarles este nuevo espacio "Temas". En él encontraran un pequeño catálogo de ejemplos UIUX para tableros que nos ayudaría a inspirar nuevas ideas.

Así mismo incorporé la posibilidad de descargarlo en máximo detalle, puesto que el .zip incluye:
Archivo.pbix
Imagen vácio de fondo
Imagen de Dashboard ejemplo de como desarrollar encima del fondo
Tema.json
Con esto serán capaces de llevar más comodamente los tableros que quieran hacer igual o guiarse a partir de uno de los ejemplos.
Hay también un enlace a GitHub en caso que quieran aportar algunos ustedes como contribuyentes de este catálogo.
Link al sitio: https://www.ladataweb.com.ar/templates.html
¡Espero que lo disfruten y traiga nuevas ideas para sus proyectos!
#storytelling#dataviz#datavisual#uxui#powerbi#power bi#ladataweb#power bi cordoba#power bi jujuy#power bi argentina
1 note
·
View note
Text
[Fabric] Dataflows Gen2 destino "archivos" - Opción 1
La mayoría de las empresas que utilizan la nube para construir una arquitectura de datos, se están inclinando por una estructura lakehouse del estilo "medallón" (bronze, silver, gold). Fabric acompaña esta premisa permitiendo estructurar archivos en su Lakehouse.
Sin embargo, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Para comprender mejor a que me refiero con "Tablas (Spark Catalog) y Archivos" de un Lakehouse y porque si hablamos de una arquitectura medallón estaríamos necesitando utilizar "Archivos". Les recomiendo leer este post anterior: [Fabric] ¿Por donde comienzo? OneLake intro
Fabric contiene un servicio llamado Data Factory que nos permite mover datos por el entorno. Este servicio tiene dos items o contenidos que fortalecen la solución. Por un lado Pipelines y por otro Dataflow Gen2. Veamos un poco una comparación teórica para conocerlos mejor.
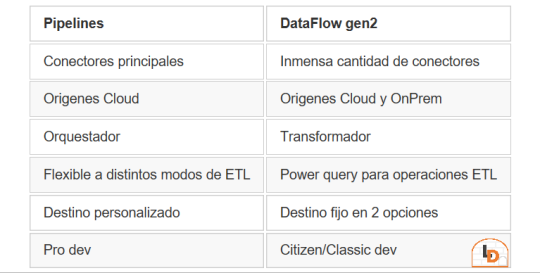
NOTA: al momento de conectarnos a origenes on premise, leer las siguientes consideraciones: https://learn.microsoft.com/es-es/fabric/data-factory/gateway-considerations-output-destinations
Esta tabla nos ayudará a identificar mejor cuando operar con uno u otro. Normalmente, recomendaria que si van a usar una arquitectura de medallón, no duden en intentarlo con Pipelines dado que nos permite delimitar el destino y las transformaciones de los datos con mayor libertad. Sin embargo, Pipelines tiene limitada cantidad de conectores y aún no puede conectarse onpremise. Esto nos lleva a elegir Dataflow Gen2 que dificilmente exista un origen al que no pueda conectarse. Pero nos obliga a delimitar destino entre "Tablas" del Lakehouse (hive metastore o spark catalog) o directo al Warehouse.
He en este intermedio de herramientas el gris del conflicto. Si queremos construir una arquitectura medallón limpia y conectarnos a fuentes onpremise o que no existen en Pipelines, no es posible por defecto sino que es necesario pensar un approach.
NOTA: digo "limpia" porque no considero prudente que un lakehouse productivo tenga que mover datos crudos de nuestro Spark Catalog a Bronze para que vaya a Silver y vuelva limpio al Spark Catalog otra vez.
¿Cómo podemos conseguir esto?
La respuesta es bastante simple. Vamos a guiarnos del funcionamiento que Dataflow Gen2 tiene en su background y nos fortaleceremos con los shortcuts. Si leemos con detenimiento que hacen los Dataflows Gen2 por detrás en este artículo, podremos apreciar un almacenamiento intermedio de pre viaje a su destino. Esa es la premisa que nos ayudaría a delimitar un buen orden para nuestro proceso.
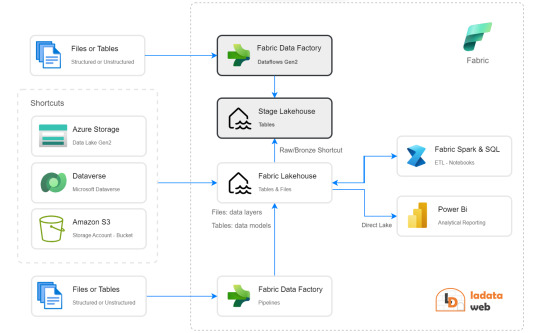
Creando un Lakehouse Stage (no es el que crea Fabric de caja negra por detrás sino uno creado por nosotros) que almacene los datos crudos provenientes del origen al destino de Tables. Nuestro Lakehouse definitivo o productivo haría un shortcut desde la capa Bronze a este apartado intermedio para crear este puntero a los datos crudos. De esta manera podemos trabajar sobre nuestro Lakehouse con un proceso limpio. Los notebooks conectados a trabajar en bronze para llevar a silver lo harían sin problema. Para cuando lleguemos a "Tables" (spark catalog o hive metastore), donde normalmente dejaríamos un modelo dimensional, tendríamos las tablas pertinentes a un modelo analítico bien estructurado.
Algunos ejemplos de orígenes de datos para los cuales esta arquitectura nos servirían son: Oracle, Teradata, SAP, orígenes onpremise, etc.
Espero que esto los ayude a delimitar el proceso de manera más limpia. Por lo menos hasta que Pipelines pueda controlarlo como lo hace Azure Data Factory hoy.
¿Otra forma?
Seguramente hay más, quien sabe, tal vez podamos mostrar un segundo approach más complejo de implementar, pero más caja negra para los usuarios en un próximo post.
#power bi#powerbi#ladataweb#fabric#microsoft fabric#fabric tips#fabric tutorial#fabric training#dataflow gen2#fabric data factory#data factory#data engineering
0 notes
Text
Seteo PowerBi Rest API por primera vez
En múltiples oportunidades me encuentro con problemas que se solucionarían sencillamente con la Power Bi Rest API. Siempre la suelo recomendar pero cada vez me encuentro más con usuarios que quedan un poco asustados de la interacción con la API.
Éste artículo nos va a acompañar a setear las configuraciones necesarias para poder autenticar y comenzar a utilizar la Power Bi Rest API con Python usando SimplePBI pero recordando que el seteo es independiente del lenguaje de programación. Cualquier lenguaje podría usarse una vez listas las credenciales.
¿Qué es una API?
Como quien repasa, las API son mecanismos que permiten a dos componentes de software comunicarse entre sí mediante un conjunto de definiciones y protocolo. Dicho de otro modo, queremos escribir un código que se comunique con Power Bi Service. La API es el puente que nos permite establecer esta comunicación. Ahora bien, el punte esta vigilado por protocolos de seguridad. Por esta razón, necesitamos una credencial de acceso para que nuestra vía de comunicación pueda funcionar.
Toda API tiene una documentación sobre los requests y categorias para utilizarla. A continuación el enlace de la Power Bi Rest API Doc con sus categorías según permisos:
https://learn.microsoft.com/en-us/rest/api/power-bi/
Service Principal vs Usuario profesional
Las credenciales pueden ser de dos tipos. Por un lado, puede estar bajo el nombre de una Cuenta Profesional de Microsoft. Un modo que permite delimtiar el usuario específico que accedió pero con la desventaja que queda atado al usuario y si el usuario deja la institución, otra persona no puede usar su credencial a menos que sea modificada. Por otro lado, puede estar bajo el acceso de una gran Clave/Key que de acceso. Esta credencial permite a cualquier usuario que la porte pueda usar la vía de comunicación. Suele ser la opción más elegida para establecer desarrollos puesto que son independientes de una persona (Service Principal).
IMPORTANTE: Tengamos presente que si queremos usar Service Principal, los permisos en Power Bi Service quedan atados a la aplicación. Esto significa que cuando quiera "Ver mis Áreas de Trabajo", solo veremos las áreas que tengan a la Aplicación registrada como miembro.
Registrar una App en Azure
Las aplicaciones de Azure son las credenciales que nos permiten cruzar determinados puentes o mejor dicho comunicarnos con distintos servicios dentro de la nube Microsoft. Para registrar una nueva App vamos a ingresar al Portal de Azure (https://www.portal.azure.com)
Dentro del servicio Entra ID (antes llamado Active Directory) podemos encontrar un menú de Aplicaciones Registradas donde podremos poner "Nuevo Registro"

El proceso para usar la API es muy simple, solo escribiendo el nombre bastará. Si bien, hay más opciones de configuración, no serán necesarias para hacer consultas con la Power Bi Rest API
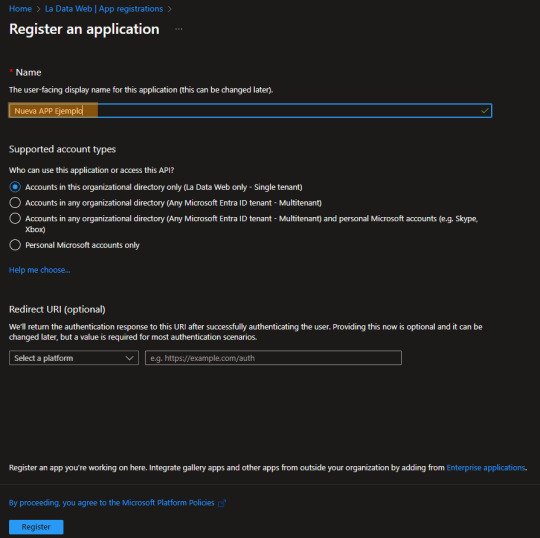
Ya creada, veamos algunos valores importantes para usarlar:

TenantID o ID de Organización: Primero e indispensable puesto que sería única por institución. Esto significa que cualquier puente de comunicación a cualquier servicio necesita especificar el mismo ID.
App o Client ID: este es el identificatorio de la credencial. También pensado o usado como Usuario de una aplicación.
Paso siguiente podemos configurar un poco más de detalle. Ya tendríamos la credencial para atravesar el puente, ahora tenemos que delimitar a que tenemos acceso de dicho lado del puente. Con esto me refiero a ¿Puedo ver los datasets?, ¿Puedo configuar un refresh?, ¿Puedo ver mis areas de trabajo?, etc.
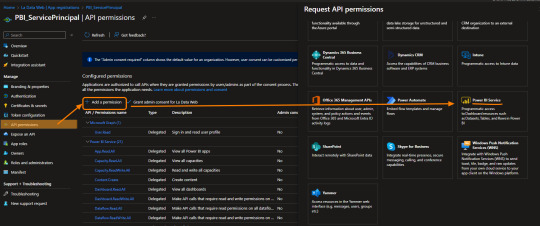
Vamos a nutrirnos de los permisos delegados que nos permiten elegir lo que queremos ver.
NOTA: Los permisos de aplicación son los que permiten embeber Power Bi

En este ejemplo le damos permiso a leer y escribir sobre Paneles/Dashboards. Esto significa que podríamos comunicarnos con toda la sección de Paneles de la API que esta en su documentación.
Creada y con permisos, la credencial pertenece a un Usuario Owner para utilizarla. Si quisieramos cambiar esto y usarla con Clave (Service Principal) solo bastaría generarla.

Tengamos presente que las claves tienen fecha de expiración por seguridad y que solo nos muestra su valor una vez para ser copiadas. Cuando salgamos del sitio no podremos volver a ver jamás la clave. La nomenclatura con la que nos podemos referir a la clave es "Secreto".
A partir de ese momento nuestra clave puede funcionar como contraseña de nuestros accesos y tendremos todo listo para que nuestro código hable con el de Power Bi Service.
Autenticación con Python y SimplePBI
Para autenticar contra la Power Bi Rest API necesitamos la dirección de logueo y algunos varios argumentos que pongan a prueba la validez de la credencial que enviamos. Si todo esta correcto obtendremos un Bearer Token de la respuesta que será como un pulcera VIP de pase libre a algunos requests. SimplePBI, la librería de Python para usar la Power Bi Rest API, nos ayudará que ese proceso sea muy sencillo.
from simplepbi import token
obj_tok = token.Token(tenant_id, app_client_id, username=None, password=None, app_secret_key, use_service_principal=True)
Dependiendo si seteamos en False o True el último argumento, autenticaríamos con Service Principal o una Cuenta Profesional de Microsoft. El ejemplo está seteado con Service Principal. Simplemente importando el objeto Token y enviando los parámetros que explicamos antes como Tenant, App Id y Secret nos bastaría para comunicarnos.
Para conocer como continuar interactuando con cada una de las categorías que vimos en la documentación de la API puede leer más sobre la librería SimplePBI en su documentación pública https://github.com/ladataweb/SimplePBI/tree/main/
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#ladataweb#Power bi service#power bi rest api#simplepbi#python power bi rest api#power bi python
0 notes
Text
[Fabric] ¿Cómo funciona Dataflow gen2? ¿Qué es staging?
Fabric ya es una materia frecuente en la comunidad de datos y cada vez se analiza en mayor profundidad. En esta oportunidad iremos al servicio de Data Factory que cuenta con dos tipos de procesos de movimientos de datos. Pipelines, que vimos un ejemplo de la simpleza de su asistente para copiar datos y por otro lado, dataflows gen2.
Tal vez el nombre resuene porque fue usada en varias oportunidades dentro de diferentes servicios. No nos confundamos con los que existían en Azure Data Factory, éstos son creados con la experiencia de Power Query Online. En este artículo nos vamos a enfocar en Dataflow gen2. Vamos a conocerlos y en particular describir sobre su característica de "Staging" que podría ser la más influeyente y distinta a los conceptos que manejaban en la primera generación.
Indiscutiblemente, la experiencia de power query online, permite a diversos tipos de profesionales realizar una ingesta de datos con complejas transformaciones. Tanto usuarios expertos (que usan mucho código) como convencionales (que prefieren más clicks que código) puede aprovechar la buena experiencia de usuario de la herramienta para desarrollar joins, agregaciones, limpieza y transformaciones de datos, etc.
Dataflows gen2 es la evolución de los Power Bi Dataflows con mejores capacidades de computo y preparado con capacidades de movimientos de datos a diversos destinos de Fabric y Azure. Aquí la primera gran diferencia, establecer un destino para el job de power query online. Podemos apreciar la nueva sección en la siguiente imagen:
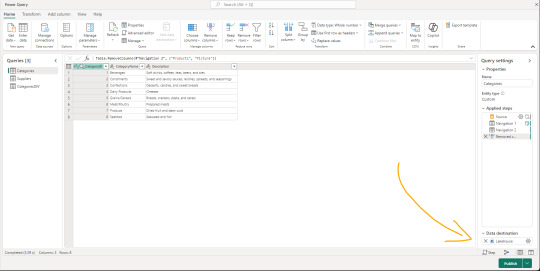
Los proyectos de movimientos de datos suelen tener algunos desafíos que hacen variar el modo en que construimos. Algunos escenarios buscan transformar datos para ingestarlos en un limpio almacenamiento, mientras que otros prefieren pasar por estapas o stages que tengan distintas granularidad o limpieza de datos. Otro gran desafío es la orquestación. Garantizar que la ingesta y transforaciones puedan calendarizarse apropiadamente.
Como todo proyecto de datos es distinto, depende de cada uno cual sería la forma apropiada de mover datos. Si bien datalfows gen2 puede realizarlo, no significa que siempre sea la mejor opción. Por ejemplo, los escenarios de big data cuando grandes volumenes deben ser ingestados con complejos patrones para tomar la información de diversos origenes de datos, tal vez sea mejor dejar ese lugar a Pipelines de Data Factory. Dataflows gen2 también puede usarse para transformaciones dentro de Fabric. Esto significa que podemos tener de origen de un dataflow gen2 a nuestros archivos de Lakehouse crudos y limpiarlos para llevarlos a un warehouse.
Una de las fortaleza más grande de dataflows gen2, pasa por la cantidad de conectores que power query tiene desarrollado. Indudablemente, una de las herramientas con mayor integración del mercado.
¿Cómo funcionan?
Para inciar, llamaremos al proceso que interpreta Power Query y ejecuta su lenguaje como "Mashup engine". Los dataflow gen2 nos permiten obtener datos de muchos origenes diversos y a cada uno de ellos delimitar un destino. Ese destino puede ser reemplazando/pisando la tabla de arribo o puede ser haciendo append de lo que lea.
En medio de este proceso, existe la posibilidad de poner un almacenamiento intermedio que llamaremos Staging. El staging llega a nosotros para fortalecer a power query para algunas operaciones que eran muy complejas de resolver de un solo tirón dentro del Mashup Engine como por ejemplo "merges".
La nueva característica Staging viene activada por defecto y podemos elegir si usarla o no, con un simple click derecho "Enagle Staging". Cuando no esté activada el título de la tabla estará en cursiva.
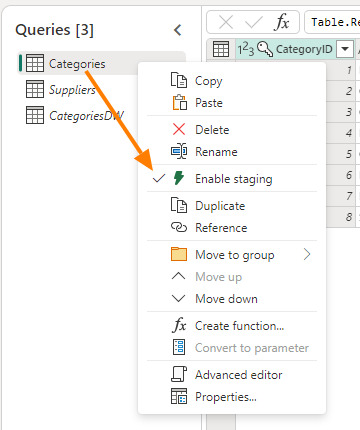
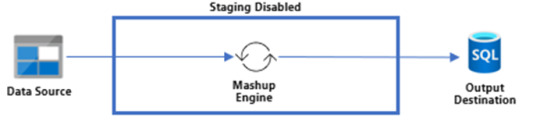
Activar esa opción hará que los pasos ejecutados por el Mashup Engine se depositen primero en un Lakehouse Staging oculto para nosotros. Si tenemos configurado el destino, el paso siguiente sería llevarlo a destino. Según activemos la característica, nuestro dato podría viajar de dos formas:
Sin Staging
Con Staging
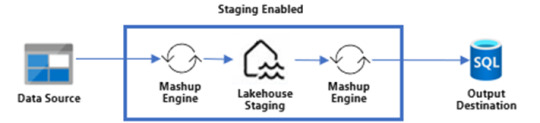
Puede que estén pensando ¿Por qué guardaríamos dos veces nuestra data? Cierto es que puede sonar redundante, pero en realidad es muy provechoso si lo utilizamos a nuestro favor. Como dije antes, hacer merge es algo que Power Query tenía muy dificil de lograr en una sola ejecución del Mashup Engine contra el origen. Ahora bien, ¿que tal si obtenemos datos de dos tablas, prendemos su staging pero no activamos su destino?. Eso dejaría nuestra dos tablas en staging oculto sin destino. Esto nos da pie para crear una tercer consulta en la interfaz de Power Query que haga el Merge de ambas tablas con destino. De este modo, realizaríamos un segundo Mashup Engine que esta vez tiene como origen Tablas de un Lakehouse oculto a nuestro destino. Ejecutar el merge contra el lakehouse oculto será más performante que contra el origen que no siempre dispone de las mejores capacidades de joins. Algo asi:
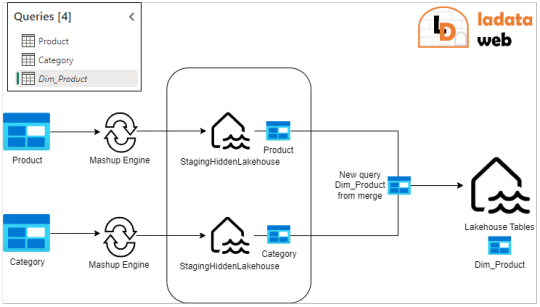
Fíjense como Product y Category tienen staging prendido. La nueva query que hace un merge de Table.Combine esta cursiva, lo que significa que no tiene Staging. Ésta última es la única con un destino configurado.
Algunas pautas para no hacer staging son:
Si tu fuente de datos no contiene grandes volúmenes de datos
Si no estás uniendo datos de diferentes fuentes de datos (joins/merges)
Si no estás realizando transformaciones intensivas en computo/memoria como unir o agregar grandes volúmenes de datos
Destino
La nueva característica de destino tiene cuatro asociados pero seguramente la usaríamos para hacer ingesta de Fabric Warehouse o Fabric Lakehouse. Cuando hablamos de warehouse su funcionamiento es tal y como se lo imaginen. Sin embargo, para lakehouse hay que prestar atención a un detalle. Cuando nuestro destino es el Lakehouse de Fabric, nuestra tablas será almacenadas en formato delta parquet sobre la carpeta "Tables". Hoy no podemos configurar que el destino sea "Files". Si no estan seguros de lo que hablo, pueden repasarlo en este post anterior sobre OneLake.
Esto ha sido todo nuestro artículo para introducirlos a la nueva generación de Dataflows en Fabric Data Factory. Espero les sea útil y los ayude a mover datos.
#power bi#powerbi#fabric#fabric data factory#fabric dataflows#fabric dataflows gen2#dataflows gen2#fabric argentina#fabric cordoba#fabric jujuy#fabric tutorial#fabric tips#fabric training#ladataweb
0 notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
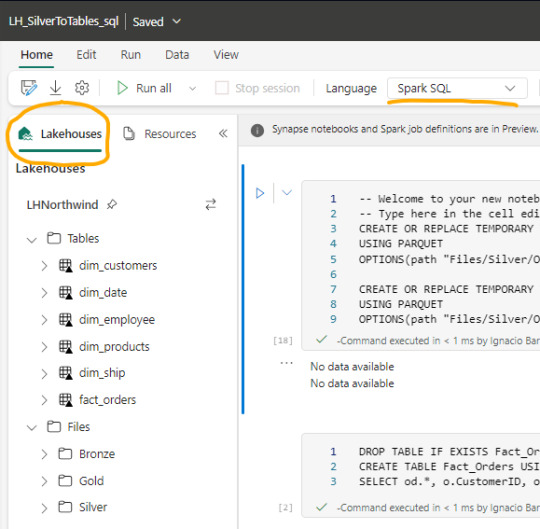
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp
USING PARQUET
OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders
USING PARQUET
OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
Consultas y transformaciones
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
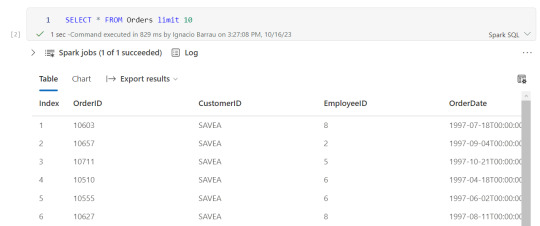
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS
SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
Resultado
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes
Text
Data Wrangler el método de transformación python similar a PowerBi Query Editor
Hace tiempo que existe una extensión para limpieza de datos en el mercado que no para de llamar la atención. Normalmente me encontré con dos tipos de perfiles que limpian datos, los que aman código (usan python o R) y los que usan herramientas de Bi (power bi, tableau, etc). Creo que esta extensión busca integrar lo mejor de ambos mundos. Utilizar el poder de python con la comodidad visual de las herramientas tradicionales.
Este artículo nos cuenta sobre Data Wrangler. La extensión que permite hacer transformaciones de datos de un archivo de python o jupyter con clicks como si fuera una herramienta de BI.
Para comenzar, veamos la definición de Data Wrangler.
"Es una herramienta de limpieza de datos centrada en código integrada a visual studio code. Apunta a incrementar la productividad de expertos en datos haciendo limpieza al proveer una interfaz que automatiza funciones core de la librería Pandas y muestra útiles insights de las columnas."
Also así traducido es la definición que le dan los creadores. Si bien, al momento de crear este post solo acepta Pandas, ya anunciaron que tienen foco en que también pueda usarse con PySpark Frames.
Para encontrar la herramienta basta con buscarla por VS Code o podes conocer más del proyecto Open Source en su repositorio github. En el mismo encontrarán también opciones de descarga.
Una vez instalado, abrirlo es tan simple como realizar un "head" para un Pandas DataFrame:
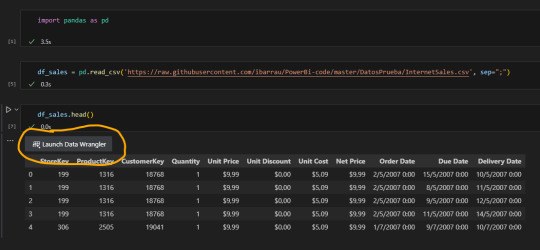
Nos sugiere un botón para iniciar la extensión.
La interfaz nos muestra rapidamente información útil. La veamos por partes:
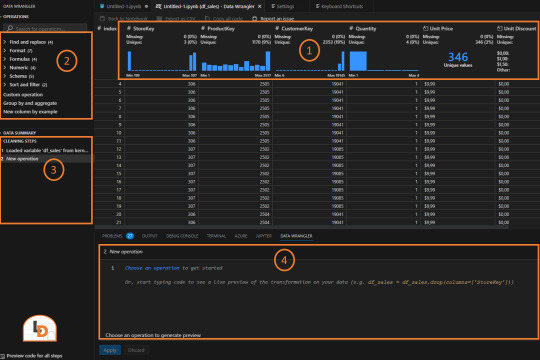
Columnas con distribución y estadísticas que nos permiten entenderlas más rapidamente.
Acciones de transformaciones disponibles para ejecutar separadas por categorías
Lista de pasos de transformaciones ejecutados para repasar la historia
Código generado. Esta sección es ideal para aprender más sobre el lenguaje puesto que nos mostrará como es la ejecución de una acción y también nos permitirá modificarla a gusto.
A mano izquierda vemos las transformaciones que podemos elegir seleccionando una columna previamente. Por ejemplo, cambiemos el formato de nuestra columna Order Date. Seleccionamos en las opciones de formato "DateTime formatting example" para mostrarle tal como queremos que sea el formato. Eso nos genera una nueva columna que definiendo el ejemplo se completará y creará luego de darle Apply:
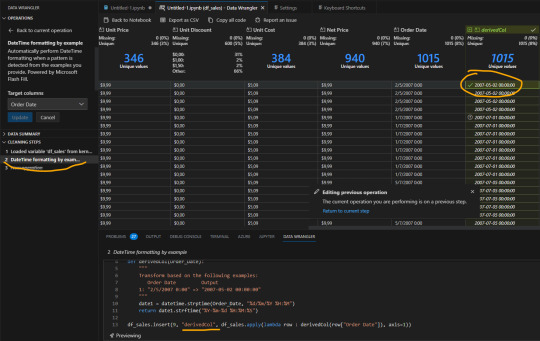
Si nos ubicamos en el paso anterior podremos ver el código ejecutado como así también modificarlo. Si quisieramos cambiar el nombre de la nueva columna derivedCol por "Fecha de Orden", bastaría con ir al código subrayado donde vemos el nombre y cambiarlo.
NOTA: solo podemos cambiar el código del paso anterior. Los pasos más viejos quedan en preview para evitar sobrecargar la memoria.
Hay operaciones tradicionales de texto como split que simplemente con el delimitador nos ajustaría las columnas
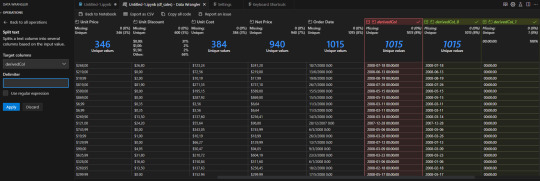
En caso que conozcamos más sobre el lenguaje también tenemos un espacio para escribir una fórmula de python para una columna nueva o actual. Por ejemplo una operación matemática sencilla:
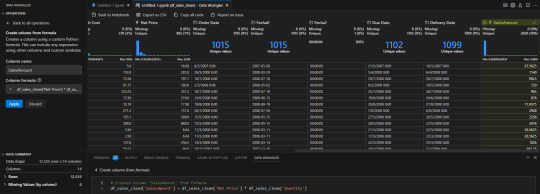
Algunos otros ejemplos que estuve probando son reemplazar cadenas de texto, eliminar columnas, agregar columnas por ejemplo y cambiar tipo.
Si en algún momento queremos regresar, tenemos un botón "Back to Notebook" que nos permitiría reordenar código y/o ajustar de manera manual a todo lo que se generó.
Consideremos que si volvemos al notebook, no podremos volver al wrangler tal cual estaba con sus pasos para ver y editar, sino que tendríamos que generar un "head()" nuevo del dataframe del paso de limpieza más reciente para volver a iniciarlo y ejecutar pasos faltantes.
Integración con Fabric
Además del uso local antes mencionado, la herramienta fue integrada con los lanzamientos de Microsoft Build 2023. Notebooks de Fabric no solo pueden ser abiertos en visual studio code para utilizarlo desde allí, sino que tienen una pestaña data que detecta pandas frames para abrir Data Wrangler.

Así abriremos algo muy similar a lo que vimos en visual studio code
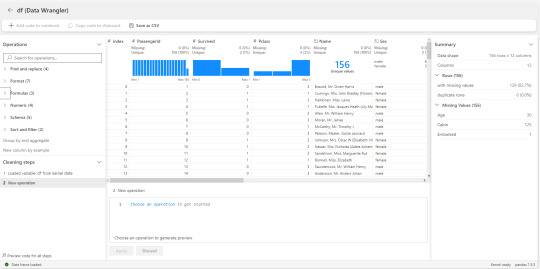
Si bien se ve idéntica pero en versión clara, tiene algunas diferencias. La integración con Fabric no cuenta con todas las opciones locales como por ejemplo "Create column from formula". No tenemos la opción de escribir el código de una columna. El resto es bastante similar a lo que antes mencionamos.
Conclusión
Esta es una excelente herramienta que puede fortalecer nuestros inicios con Python para mejorar la experiencia de usuario y aprender sobre el código viendo lo que genera finalmente luego de aplicar las operaciones.
Si la comparamos con un editor de consultas de Power Bi se siente algo tosca. De todas formas tiene mucho potencial y oportunidad de crecimiento para ir mejorando.
Una excelente alternativa para quienes no terminan de amigarse con Python y necesitan ejecutar algunas transformaciones entre capas de Lake o ingesta de datos.
#data wrangler#python data wrangler#python#fabric#powerbi#power bi#power bi service#fabric notebooks#python notebooks#ladataweb#fabric argentina#fabric jujuy#fabric cordoba#synapse
0 notes
Text
[Fabric] Data Factory - copy data más simple
Recuerdo iniciar data factory cuando todavía ni interfaz gráfica tenía. Cierto es que poco a poco fue ganando experiencia de usuario para convertirse en una herramienta super cómoda para orquestar y mover datos.
Recientemente, tuve que usarla pero dentro del dominio de Fabric y quedé sorprendido como en pocos pasos/clicks podía mover datos de un origen a un Lakehouse con un solo pipeline y parámetros delimitados. Esté pequeño artículo te muestra lo simple que es
Viniendo de una época donde antes de si quiera pensar en lo que iba a mover, dentro de pipelines tanto de data factory como synapse, tenía que agregar orígenes, linked services, etc... sentí al nuevo wizard de data factory en Fabric muy veloz.
Si hay algo en lo que solía darle la derecha a Dataflows de Power Bi, era la simpleza con la que usaba un conector para llegar a los datos. Ahora los Pipelines de data factory se ponen al corriendo con el "asistente".
Creemos un Pipeline para verlo mejor. Cambiamos el servicio a Data Factory y elegimos Pipeline.

Luego buscamos la actividad estrella "Copy Data" y vemos el segundo tem del menú:
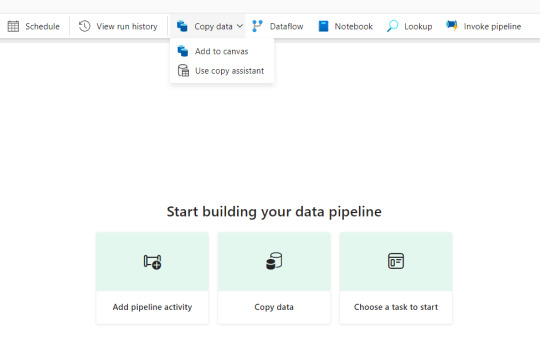
De manera muy familiar una pantalla con muchos orígenes de datos se abre y podemos ver pronto la cantidad de conectores que tenemos.

Eligiendo la opción deseada y con un par de siguientes, veamos un ejemplo conectado a una base de datos SQL Server (completar campos instancia y base de datos). A la izquierda vemos que con tan solo 5 pasos, tendríamos todo creado. Pronto encontramos las tablas involucradas y podemos elegir más de una.
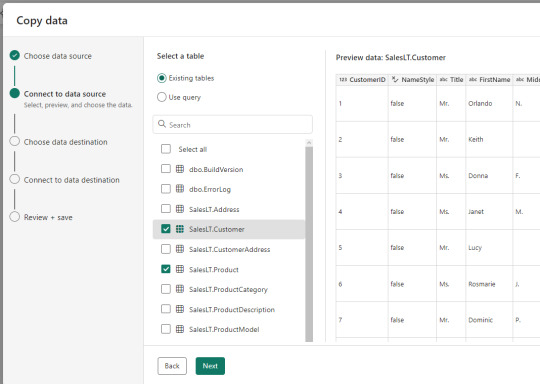
Con un par de clicks tendremos completado un muy sencillo movimiento de datos parametrizado de un origen. Si mal no recuerdo, he pasado bastante tiempo buscando realizar un lookup, agregar un for each, introducir el copy data, configurar todo, etc.
Antes de concluir tenemos la posibilidad de delimitar el destino, que en nuestro caso sería lakehouse, y formato de archivos/tablas.
Por ejemplo, vamos a dejar las tablas en capa Bronze de nuestro lake y formato "parquet".

Nuestro resultado de pipeline crea automáticamente un for each para realizar un copy data por cada tabla especificada en los parámetros. Algo así:
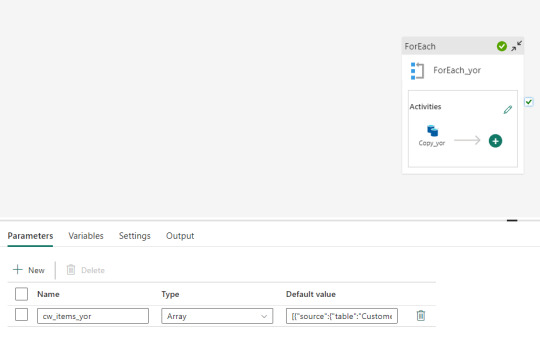
Al ejecutarlo podremos apreciar lo creado en nuestro LakeHouse
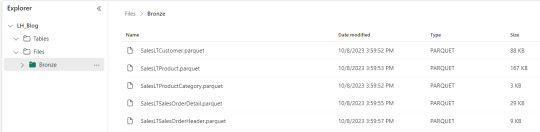
Asi de simple es mover datos con Data Factory de Fabric. Cabe aclarar que aqui solo movemos raw data para dejarla en nuestro lake y luego procesarlo. Si quisieramos aplicar una acción más compleja podemos llamar notebooks, dataflows, otro pipeline, etc.
Espero que les sirva para conocer más de Fabric y ver la evolución del producto para que haya cada vez menos trabajas sino simples clicks.
#fabric#data fabric#fabric onelake#fabric tips#fabric tutorial#fabric training#fabric argentina#fabric jujuy#fabric cordoba#ladataweb#fabric ladataweb#power bi service#data factory#fabric data factory#fabric pipelines
1 note
·
View note
Text
Origen web para evitar gateway PowerBi y Azure Functions
Existen diversos escenarios donde PowerBi nos va a exigir un gateway para actualizar nuestra información. A veces es muy necesario y tiene sentido, pero otras veces no y resulta hasta molesto.
Puede que haya muchos escenarios más que los que voy a mencionar pero normalmente al escrapear un sitio web (funcion Web.Pages de power query) se exige un gateway. Tal vez tenes alguna operación tan compleja que se te ocurre usar Python para resolverla porque esta dentro de Power Bi, pero con eso también te exige Gateway.
Este artículo mostrará como podemos usar Azure Functions para realizar una operación simple con Python para luego leerlo desde PowerBi como un simple Get Request de API.
Primero que nada un poco de teoría. Existen escenarios web los cuales requeiren de Gateway para su tratamiento. Aun si estamos en power query online (dataflows) necesitaremos uno. Hay tres funciones cláscias que son de inter��s y funcionan distinto. WebContent, WebPages y WebContentBrowser. Si quieren conocer la diferencia y entender cual pide gateway y cual no, pueden leer la siguiente doc: https://learn.microsoft.com/en-us/power-query/connectors/web/web-troubleshoot
Me gustaría comenzar aclarando que no voy a hacer una introducción a Azure Functions. No voy a explicar que es, cómo funciona y cómo setear el entorno. Para eso ya hay excelentes videos en internet o podemos leer más en la siguiente doc de microsoft:
https://learn.microsoft.com/es-es/azure/azure-functions/create-first-function-vs-code-python?pivots=python-mode-configuration
Para este post necesitamos conocimientos previos en Python básico y Visual Studio Code. Asumiendo que ya tenemos el entorno seteado con las extensiones de Visual Studio code, vamos a comenzar con un ejemplo sencillo conectando a una API. Ya logueados en el apartado de Azure y con visibilidad a nuestra suscripción, vamos a crear una Function App. Podemos pensarlo como el servidor de procesamiento de muchas Azure Functions. En ese espacio podemos tener muchas functions, pensemos a cada una como un request.
Al momento de crearla tenemos 4 pasos
Ese nombre será participe de la URL de la API que estamos generando.
Ahora podremos crear la función. Se almacenará en la carpeta que tengamos apuntando el Visual Studio Code. Clickeamos el rayito para crear una función dentro de la Function App

La aplicación creada se verá así:
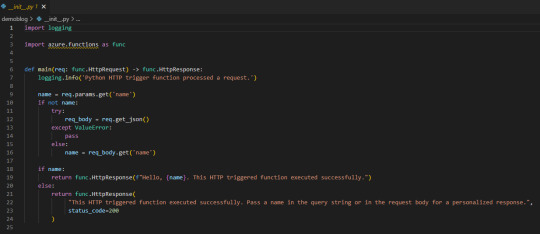
Lo que necesitamos saber es que tenemos una función main donde se ejecutará el código principal. Luego depende si llamamos a la función con get o post si podemos capturar items de parametros de url o body. Eso nos ayudaría a incrementar la seguridad puesto que sin los parametros correctos o autenticación no podríamos obtener la respuesta. A modo de ejemplo vamos a hacer una simple lógica para que la url retorne el resultado cada vez que sea llamada sin necesidad de nada más puesto que considero que no es sensible la data del nombre de los workspaces en mi tenant de demo.
Veamos que simple es escribir código dentro de main devolviendo un dict o json en el return bajo el status_code deseado. Podemos aprovecharnos de los mensajes para ser claros en fallas para recibirlas en Power Bi.

Usando SimplePBI para obtener grupos, pueden ver que simplemente generamos token, creamos objeto de grupo (workspaces) y llamamos a los workspaces que nuestro Service Principal puede ver.
Luego agregue al return una aclaración adicional para cuando lo que queremos devolver no es un “texto” literal sino un dict o json que es el “mimetype”.
NOTA: Si no sabes que es SimplePBI podes pasar por aqui.
IMPORTANTE: aclaro que tenemos un secret expuesto en este código, lo mejor para una azure function así sería usar un Azure KeyVault a nuestras contraseñas y secretos para que no queden expuestos.
Si vamos a usar una librería importada tendremos que buscar el archivo requirements.txt en el panel de recursos y agregarla. Yo lo hice para SimplePBI.
Si necesitamos utilizar pandas para tomar datos de un origen estructurado, podemos utilizar “ DataFrame.to_dict(orient="records") ” en el json.dumps del return para convertir nuestro frame al formato de mimetype json.
Get data
Mucho sobre python y funciones, vamos a PowerBi Desktop a conectarnos. Usaremos el conector web para traer la información con credenciales anónimas.
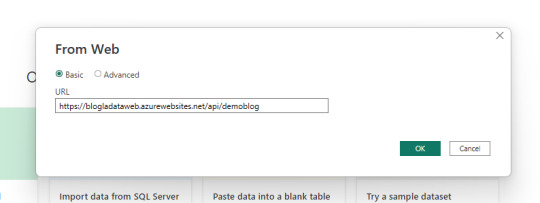
Dependiendo como orientamos nuestro json devuelto en la API que nos generamos en Azure Functions vamos a tener que efectuar transformaciones en power query. En este caso la devuelta por SimplePBI es muy uniforme y el motor practicamente lo resuelve solo.
Veamos como queda:
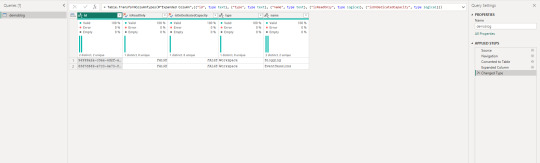
Ahora tenemos nuestra data cargada en Power Bi usando python sin necesidad de un gateway personal. Ya podemos publicar nuestro informe al servicio de power bi y configurar las credenciales como anónimas.
ACLARACIÓN: las Azure Functions tiene un límte de uso (timeout) en 5 minutos. Nuestra ejecución no puede durar más de eso o fallaría y nuestro propósito quedaría perdido.
Conclusión
Esta metodología puede ayudarnos a dar más velocidad a pequeños desarrollos, scrappings u origenes cloud complicados que PowerBi no tenga connector sin driver (ejemplo: oracle o mysql). Con una Azure Function construir rápido y fácilmente una API que responda. Para aumentar la seguridad es necesario utilizar Azure KeyVaults en nuestro código y en caso de necesitar disponibilizar data más sensible, lo mejor sería pedir un parámetro o body con alguna clase de key (que puede ser inventada por nosotros) para que no todo quede sobre una URL pública. Espero que este ejemplo les despierte nuevas ideas.
#powerbi#power bi#power bi desktop#power bi python#python power bi#azure functions#Azure functions python#power bi tips#power bi argentina#power bi jujuy#power bi cordoba#power bi tutorial#power bi training#azure functions power bi#ladataweb
0 notes
Text
Nueva Suscripción a LaDataWeb
Muchos sitios y blogs contienen una gran opción para estar al día con lo que sucede en su red. La nuestra se lo debía a la comunidad y hoy se cumple esa feature.
Nos emociona mucho contarles que en el lanzamiento de mejoras estéticas de sitio web hemos incluido una nueva opción, una para "Suscribirse" a LaDataWeb.
Lee más para conocer como hacerlo y que incluye.
Suscripción
Nuestra suscripción no es un login sino más bien un newsletter mensual. Una oportunidad para estar al día con los lanzamientos de la comunidad de LaDataWeb y, tal vez en un futuro, la comunidad en español.
¿Como suscribirse?
Si estas navegando nuestro Blog, entonces podes encontrar botones más pequeños con flecha o abajo con el texto

El nuevo sitio cuenta con un gran botón arriba a la derecha que te pedirá un correo. Tan simple como eso.

Una vez que nos suscribamos recibiremos un correo de bienvenida para corroborar que todo salió correctamente.
¿Qué encontrare en el newsletter mensual?
Nuestro correo se encargará de transmitir las siguientes novedades:
Últimos dos artículos del blog
Un artículo antiguo random
Release notes de la última actualización de SimplePBI
Descripción del último Storytelling de nuestro sitio
Esperamos que encuentre el correo sencillo y fácil de leer. Si bien el texto general de las secciones y saludos están en ingles, recuerden que nuestro contenido siempre es en español ;)
#ladataweb#storytelling#power bi storytelling#simplepbi#power bi rest api python#power bi rest api#power bi español#power bi argentina#power bi cordoba#power bi jujuy
0 notes
Text
[Fabric] Integración de datos al OneLake
Ya viste todos los videos con lo que Fabric puede hacer y queres comenzar por algo. Ya leiste nuestro post sobre Onelake y como funciona. Lo siguiente es la ingesta de datos.
En este artículos vamos a ver muchas formas y opciones que pueden ser usadas para añadir datos a onelake. No vamos a ver la profundidad de como usar cada método, sino una introducción a ellos que nos permita elegir. Para que cada quien haga una instrospección de la forma deseada.
Si aún tenes dudas sobre como funciona el Onelake o que es todo eso que apareció cuando intentaste crear uno, pasa por este post para informarte.
Ingesta de datos
Agregar datos al Onelake no es una tarea difícil pero si analítica puesto que no se debe tomar a la ligera por la gran cantidad de formas disponibles. Algunas serán a puro click click click, otras con más o menos flexibilidad en transformaciones de datos, otras con muchos conectores o tal vez con versatilidad de destino. Cada forma tiene su ventaja y posibilidad, incluso puede que haya varias con la que ya tengan familiaridad.
Antes de iniciar los métodos repasemos que para usar nuestro Onelake primero hay que crear una Lakehouse dentro de un Workspace. Ese Lakehouse (almacenado en onelake) tiene dos carpetas fundamentales, Files y Tables. En Files encontrabamos el tradicional filesystem donde podemos construir una estructura de carpetas y archivos de datos organizados por medallones. En Tables esta nuestro spark catalog, el metastore que puede ser leído por endpoint.

Nuestra ingesta de datos tendrá como destino una de estos dos espacios. Files o Tables.
Métodos
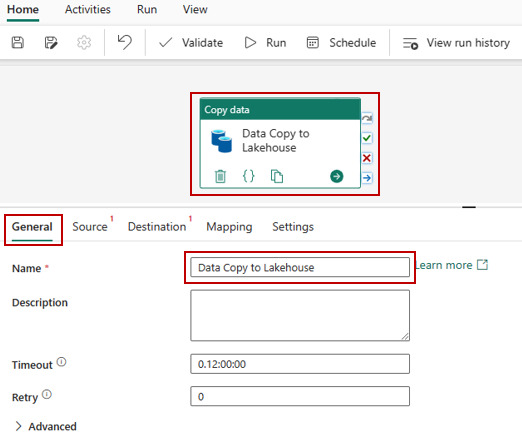
Data Factory Pipelines (dentro de Fabric o Azure): la herramienta clásica de Azure podría ser usada como siempre lo fue para este escenario. Sin embargo, hay que admitir que usarla dentro de Fabric tiene sus ventajas. El servicio tiene para crear "Pipelines". Como ventaja no sería necesario hacer configurationes como linked services, con delimitar la forma de conexión al origen y seleccionar destino bastaría. Por defecto sugiere como destino a Lakehouse y Warehouse dentro de Fabric. Podemos comodamente usar su actividad estrella "Copy Data". Al momento de determinar el destino podremos tambien elegir si serán archivos en Files y de que extensión (csv, parquet, etc). Así mismo si determinamos almacenarlo en Tables, automáticamente guardará una delta table.
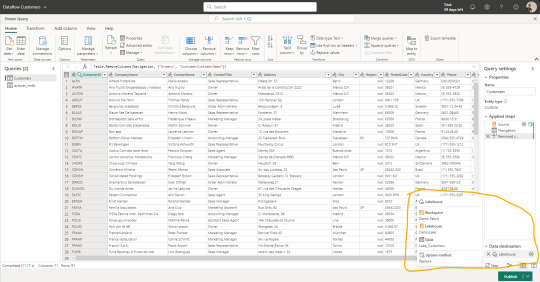
Data Factory Dataflows Gen2: una nueva incorporación al servicio de Data Factory dentro de Fabric son los Dataflows de Power Query online. A diferencia de su primera versión esta nueva generación tiene fuertes prestaciones de staging para mejor procesamiento, transformación y merge de datos junto a la determinación del destino. Así mismo, la selección del destino nos permite determinar si lo que vamos a ingestar debería reemplazar la tabla destino existente o hacer un append que agregue filas debajo. Como ventaja esta forma tiene la mayor cantidad de conectores de origen y capacidades de transformación de datos. Su gran desventaja por el momento es que solo puede ingestar dentro de "Tables" de Lakehouse bajo formato delta table. Mientras este preview también crea unos elementos de staging en el workspace que no deberíamos tocar. En un futuro serán caja negra y no los veremos.
Notebooks: el hecho de tener un path a nuestro onelake, path al filesystem con permisos de escritura, hace que nuestro almacenamiento pueda ser accedido por código. El caso más frecuente para trabajarlo sería con databricks que, indudablemente, se convirtió en la capa de procesamiento más popular de todas. Hay artículos oficiales de la integración. En caso de querer usar los notebooks de fabric también son muy buenos y cómodos. Éstos tienen ventajas como clickear en files o tablas que nos genere código de lectura automáticamente. También tiene integrada la herramienta Data Wrangler de transformación de datos. Además cuenta con una muy interesante integración con Visual Studio code que pienso podría integrarse a GitHub copilot.
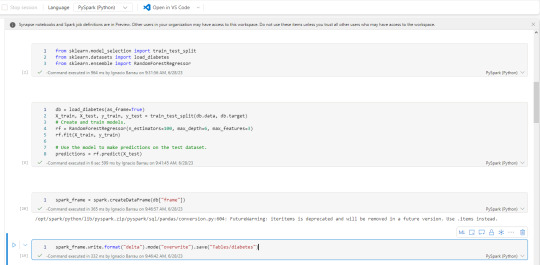
Shortcuts (accesos directos): esta nueva opción permite a los usuarios hacer referencia a datos sin copiarlos. Genera un puntero a archivos de datos de otro lakehouse del onelake, ADLS Gen2 o AWS S3 para tenerlo disponible como lectura en nuestro Lakehouse. Nos ayuda a reducir los data silos evitando replicación de datos, sino punteros de lectura para generar nuevas tablas transformadas o simplemente lectura para construcción de un modelo o lo que fuere. Basta con clickear en donde lo queremos (tables o files) y agregarlo.
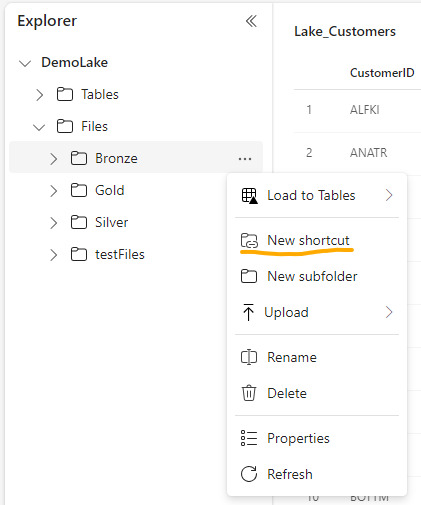
Upload manual: con la vista en el explorador de archivos (Files) como si fuera un Azure Storage explorer. Tenemos la clásica posibilidad de simplemente agregar archivos locales manualmente. Esta posibilidad solo estaría disponible para el apartado de Files.
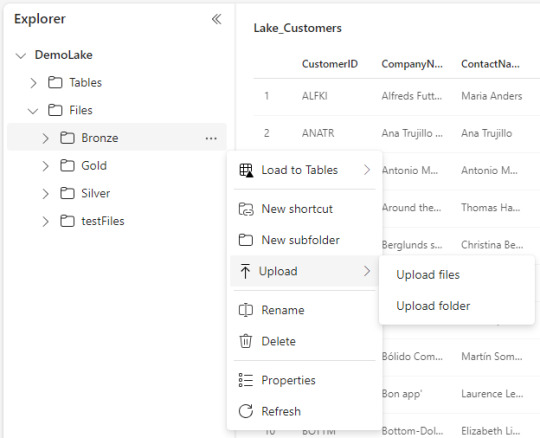
Explorador de archivos Onelake (file explorer): una de las opciones más atractivas en mi opinión es este cliente para windows. Es incontable la cantidad de soluciones de datos que conllevan ingresos manuales de hojas de cálculo de distintas marcas en distintas nubes. Todas son complicadas de obtener y depositar en lake. Esta opción solucionaría ese problema y daría una velocidad impensada. El cliente de windows nos permite sincronizar un workspace/lakehouse que hayan compartido con nosotros como si fuera un Onedrive o Sharepoint. Nunca hubo una ingesta más simple para usuarios de negocio como ésta que a su vez nos permita ya tener disponible y cómodamente habilitado el RAW del archivo para trabajarlo en Fabric. Usuarios de negocio o ajenos a la tecnología podrían trabajar con su excel cómodos locales y los expertos en data tenerlo a mano. Link al cliente.
Conclusión
Como pudieron apreciar tenemos muchas formas de dar inicio a la carga del onelake. Seguramente van a aparecer más formas de cargarlo. Hoy yo elegí destacar éstas que son las que vinieron sugeridas e integradas a la solución de Fabic porque también serán las formas que tendrán integrados Copilot cuando llegue el momento. Seguramente los pipelines y notebooks de Fabric serán sumamente poderosos el día que integren copilot para repensar si estamos haciendo esas operaciones en otra parte. Espero que les haya servido y pronto comiencen a probar esta tecnología.
#fabric#fabric tutorial#fabric tips#fabric training#data fabric#data engineer#data engineering#microsoft fabric#fabric argentina#fabric jujuy#fabric cordoba#ladataweb#power query#power query online#powerbi#power bi#power bi dataflows#data factory#data factory data flows#power bi service
0 notes
Text
[Fabric] ¿Por donde comienzo? OneLake intro
Microsoft viene causando gran revuelo desde sus lanzamientos en el evento MSBuild 2023. Las demos, videos, artículos y pruebas de concepto estan volando para conocer más y más en profundidad la plataforma.
Cada contenido que vamos encontrando nos cuenta sobre algun servicio o alguna feature, pero muchos me preguntaron "¿Por donde empiezo?" hay tantos nombres de servicios y tecnologías grandiosas que aturden un poco.
En este artículo vamos a introducirnos en el primer concepto para poder iniciar el camino para comprender a Fabric. Nos vamos a introducir en OneLake.
Si aún no conoces nada de Fabric te invito a pasar por mi post introductorio así te empapas un poco antes de comenzar.
Introducción
Para introducirnos en este nuevo mundo me gustaría comenzar aclarando que es necesaria una capacidad dedicada para usar Fabric. Hoy esto no es un problema para pruebas puesto que Microsoft liberó Fabric Trials que podemos activar en la configuración de inquilinos (tenant settings) de nuestro portal de administración.
Fabric se organiza separando contenido que podemos crear según servicios nombrados como focos de disciplinas o herramientas como PowerBi, Data Factory, Data Science, Data Engineering, etc. Estos son formas de organizar el contenido para visualizar lo que nos pertine en la diaria. Sin embargo, al final del día el proyecto que trabajamos esta en un workspace que tiene contenidos varios como: informes, conjuntos de datos, lakehouse, sql endpoints, notebooks, pipelines, etc.
Para poder comenzar a trabajar necesitaremos entender LakeHouse y OneLake.
Podemos pensar en OneLake como un storage único por organización. Esta única fuente de datos puede tener proyectos organizados por Workspaces. Los proyectos permiten crear sub lagos del único llamado LakeHouse. El contenido LakeHouse no es más que una porción de gran OneLake. Los LakeHouses combinan las funcionalidades analíticas basadas en SQL de un almacenamiento de datos relacional y la flexibilidad y escalabilidad de un Data Lake. La herramienta permite almacenar todos los formatos de archivos de datos conocidos y provee herramientas analíticas para leerlos. Veamos una imagen como referencia estructural:
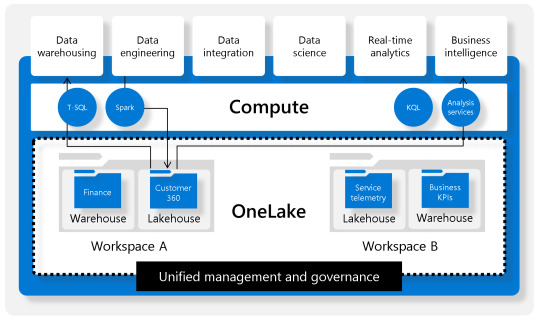
Beneficios
Usan motores Spark y SQL para procesar datos a gran escala y admitir el aprendizaje automático o el análisis de modelado predictivo.
Los datos se organizan en schema-on-read format, lo que significa que se define el esquema según sea necesario en lugar de tener un esquema predefinido.
Admiten transacciones ACID (Atomicidad, Coherencia, Aislamiento, Durabilidad) a través de tablas con formato de Delta Lake para conseguir coherencia e integridad en los datos.
Crear un LakeHouse
Lo primero a utilizar para aprovechar Fabric es su OneLake. Sus ventajas y capacidades será aprovechadas si alojamos datos en LakeHouses. Al crear el componente nos encontramos con que tres componentes fueron creados en lugar de uno:
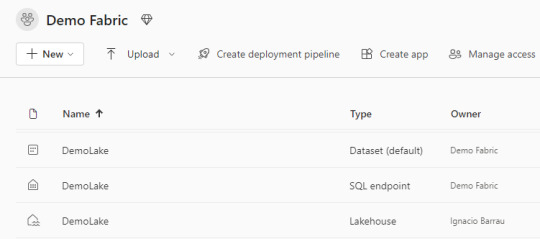
Lakehouse contiene los metadatos y la porción el almacenamiento storage del OneLake. Ahi encontraremos un esquema de archivos carpetas y datos de tabla para pre visualizar.
Dataset (default) es un modelo de datos que crea automáticamente y apunta a todas las tablas del LakeHouse. Se pueden crear informes de PowerBi a partir de este conjunto. La conexión establecida es DirectLake. Click aqui para conocer más de direct lake.
SQL Endpoint como su nombre lo indica es un punto para conectarnos con SQL. Podemos entrar por plataforma web o copiar sus datos para conectarnos con una herramienta externa. Corre Transact-SQL y las consultas a ejecutar son únicamente de lectura.
Lakehouse
Dentro de este contenido creado, vamos a visualizar dos separaciones principales.
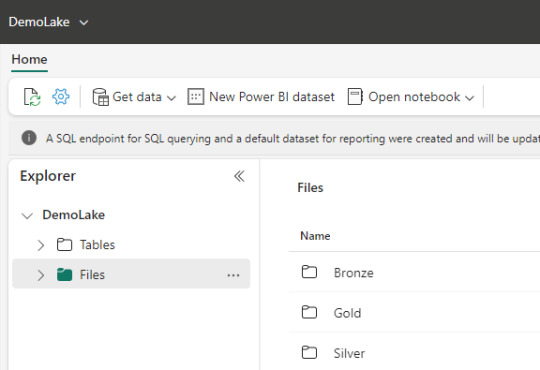
Archivos: esta carpeta es lo más parecido a un Data Lake tradicional. Podemos crear subcarpetas y almacenar cualquier tipo de archivos. Podemos pensarlo como un filesystem para organizar todo tipo de archivos que querramos analizar. Aquellos archivos que sean de formato datos como parquet o csv, podrán ser visualizados con un simple click para ver una vista previa del contenido. Como muestra la imagen, aquí mismo podemos trabajar una arquitectura tradicional de medallón (Bronze, Silver, Gold). Aquí podemos validar que existe un único lakehouse analizando las propiedades de un archivo, si las abrimos nos encontraremos con un ABFS path como en otra tecnología Data Lake.
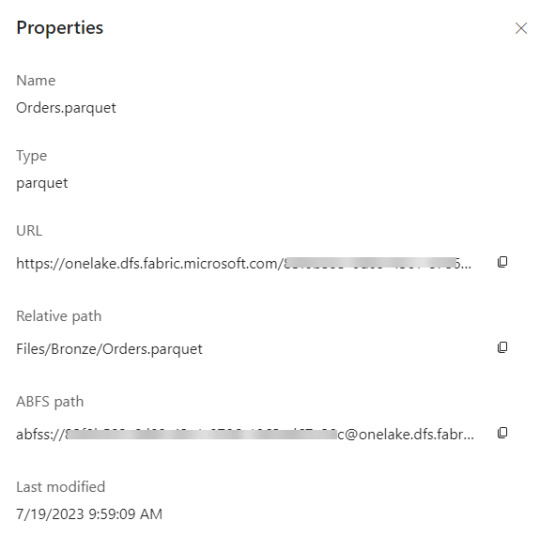
Tablas: este espacio vendría a representar un Spark Catalog, es decir un metastore de objetos de data relacionales como son las tablas o vistas de un motor de base de datos. Esta basado en formato de tablas DeltaLake que es open source. Delta nos permite definir un schema de tablas en nuestro lakehouse que podrá ser consultado con SQL. Aquí no hay subcarpetas. Aqui solo hay un Meta store tipo base de datos. De momento, es uno solo por LakeHouse.
Ahora que conocemos más sobre OneLake podemos iniciar nuestra expedición por Fabric. El siguiente paso sería la ingesta de datos. Podes continuar leyendo por varios lugares o esperar nuestro próximo post sobre eso :)
#onelake#fabric#microsoft fabric#fabric onelake#fabric tutorial#fabric training#fabric tips#azure data platform#ladataweb#powerbi#power bi#fabric argentina#fabric jujuy#fabric cordoba#power bi service
0 notes
Text
[PowerBi] Integración con AzureDevOps Git Repos
El lanzamiento de Power Bi Developer Mode durante el evento Microsoft Build está causando gran revuelo no solo por su posibilidad resguardar un proyecto de PowerBi sino también porque por primera vez tendríamos la posibilidad de que dos o más usuarios trabajen en un mismo proyecto. Esto no es trabajo concurrente instantáneo como Word Online sino más bien cada quien modificando los mismos archivos de un repositorio y logrando integrarlos al final del día.
La deuda de versionado y trabajo en equipo finalmente estaría cumplida. Según uno de los personajes más importantes del equipo, Rui Romano, aún hay mucho por hacer. Veamos que nos depara esta característica por el momento.
Vamos a iniciar asumiendo que el lector tiene un conocimiento básico de repositorios. Entienden que en un repositorio se almacenan versiones de archivos. Se pueden crear ramas/branches por persona que permita modificar archivos y luego se puedan integrar/merge para dejar una versión completa y definitiva.
Todo esto es posible gracias a la nueva característica de Power Bi Desktop que nos permite guardar como proyecto. Esto dividirá nuestro pbix en dos carpetas y un archivo:
Carpeta de <nombre del archivo>.Dataset: Una colección de archivos y carpetas que representan un conjunto de datos de Power BI. Contiene algunos de los archivos más importantes en los que es probable que trabajes, como model.bim.
Carpeta de <nombre del archivo>.Report: Una colección de archivos y carpetas que representan un informe de Power BI. El archivo más importante es "report.json", aunque durante la vista previa no se admiten modificaciones externas en este archivo.
Archivo <nombre del archivo>.pbip: El archivo PBIP contiene un enlace a una carpeta de informe. Al abrir un archivo PBIP, se abre el informe en Power Bi Desktop y el modelo correspondiente.
Entorno
Lo primero es configurar y determinar nuestro entorno para poder vincular las herramientas. Necesitamos una cuenta en Azure DevOps y un workspace con capacidad en Power Bi Service. Para que la integración sea permitida necesitamos asegurarnos que nuestra capacidad y la de la Organización de Azure DevOps estén en la misma región.
La región de una organización de Azure DevOps puede ser elegida al crearla, al igual que podemos elegir la región de una capacidad cuando creamos una premium, embedded o fabric.
En caso de utilizar capacidad PowerBi Premium Per User o Fabric Trial, no podríamos elegir la región. Sin embargo, podríamos revisar la región de nuestro PowerBi para elegir la misma en Azure DevOps
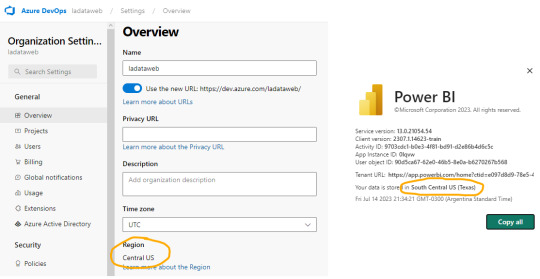
En ese caso creamos la organización de DevOps igual que nuestro PowerBi porque haremos el ejemplo con un workspace PPU.
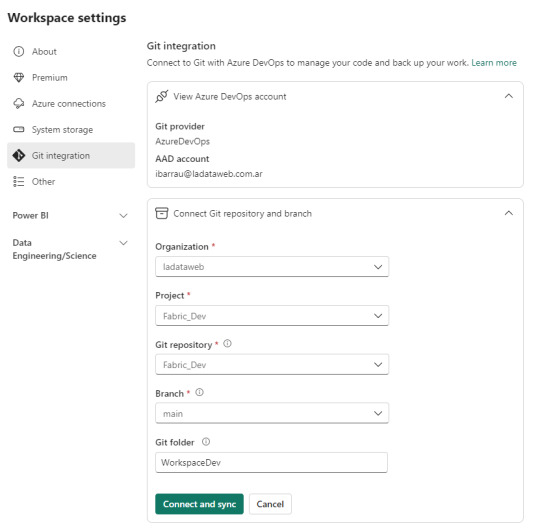
Seteo
Dentro de Power Bi Service y el Área de trabajo con capacidad que queremos versionar iremos a la configuración. Con la misma cuenta de ambos entornos completaremos los valores de organización, proyecto, repositorio, rama y carpeta (opcional).
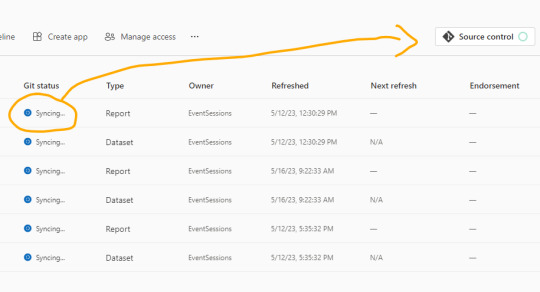
Como nuestro repositorio esta vacío, lo primero que sucederá cuando conectemos será una sincronización de todos los items del área de trabajo en el repositorio. Ahora bien, si teníamos reportes en el repositorio y en el area, tendremos un paso más para coordinar la operación deseada si pisar o integrar.
Una vez que todo tenga tilde verde y esté sincronizado, podremos ver como queda el repositorio.
En caso que ya tuvieramos informes cuando inicio el proceso, se crearán carpetas pero no el archivo .pbip que nos permitiría abrirlo con Power Bi Desktop.
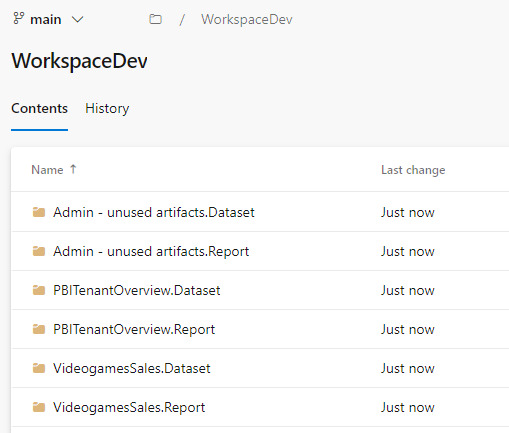
Si crearamos el informe con Power Bi Desktop y eligieramos “Guardar como proyecto” si se crearía. Entonces podríamos hacer un commit al repositorio y automáticamente se publicaría en nuestra área de trabajo.
El archivo pbip es un archivo de texto. Podemos abrirlo con un bloc de notas para conocer como se constituye para generarlo en caso que necesitemos abrir con Desktop uno de los informes que sincronizamos antes. Ejemplo del archivo:
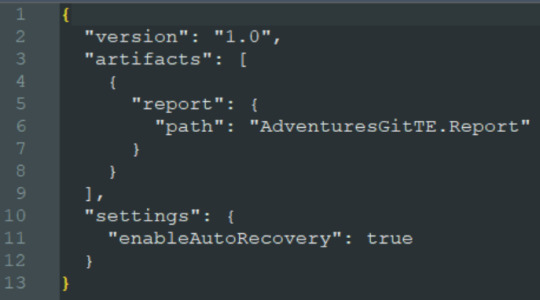
Al tener sincronizado el repositorio con el workspace podemos usar un entorno local. Si está en el repositorio en la rama principal, entonces estará publicado en el área de trabajo. Veamos como sería el proceso.

Esta sincronización también nos favorece en el proceso de Integración y Deploy continuo puesto que varios desarrolladores podrían tener una rama modificada y al integrarlo con la principal delimitada en el área de trabajo tendríamos automáticamente todo deployado.
Si algo no se encuentra en su última versión o hacemos modificaciones en línea, podemos acceder al menú de source control que nos ayudaría a mantener ordenadas las versiones.
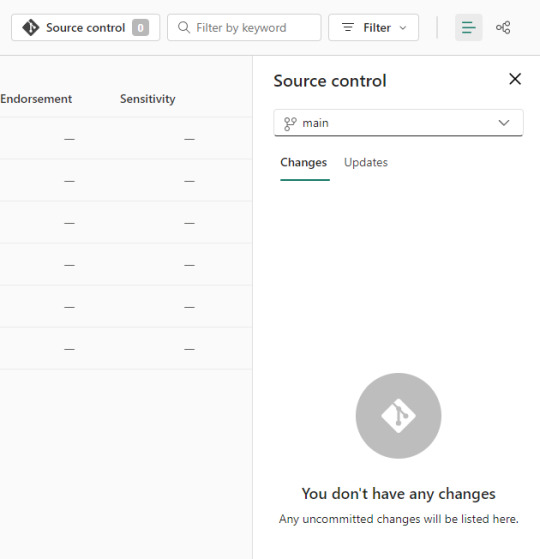
Alternativa Pro
Con las nuevas actualizaciones de Fabric en agosto 2023, podremos por primera vez, trabajar en equipo en PowerBi sin licencia por capacidad o premium. Guardar como proyecto es una característica de PowerBi Desktop. Por lo tanto, podemos usarla contra un repositorio Git en cualquier tecnología. Al termino del desarrollo, una persona encargada debería abrir el PBIP y publicarlo al área pertinente. Ahora podemos publicar desde Desktop los informes guardados como proyectos. Esto nos permite que los casos de puras licencias pro puedan aprovechar las características de histórico y control de versiones. Quedará pendiente la automatización para deploy e integración que aún no podría resolverse solo con PRO.
Conclusión
Esta nueva característica nos trae una práctica indispensable para el desarrollo. Algo que era necesario hace tiempo. Sería muy prudente usarlo aún en proyectos que no modifiquen un informe al mismo tiempo puesto que ganamos una gran capacidad en lo que refiere a control de versiones.
Si no tenemos capacidad dedicada, deberíamos trabajar como vimos en post anteriores sobre metodología de integración continua de repositorio https://blog.ladataweb.com.ar/post/717491367944781824/simplepbicd-auto-deploy-informes-de-powerbi
Esperemos que pronto tengamos una opción para importar por API estos proyectos al PowerBi Service para poder idear nuestros propios procesos sin usar las integraciones por defecto sino una personalizada a nuestro gusto.
#powerbi#power bi#power bi desktop#power bi git#azure devops#azure repos#power bi tutorial#power bi tips#power bi training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb#power bi developer mode
0 notes
Text
[DAX] Descripciones en medidas con Azure Open AI
Hace un tiempo lanzamos un post sobre documentar descripciones de medidas automaticamente usando la external tool Tabular Editor y la API de ChatGPT. Lo cierto es que la API ahora tiene un límite trial de tres meses o una cantidad determinada de requests.
Al momento de decidir si pagar o no, yo consideraría que el servicio que presta Open AI dentro de Azure tiene una diferencia interesante. Microsoft garantiza que tus datos son tus datos. Qué lo que uses con la AI será solo para vos. Para mi eso es suficiente para elegir pagar ChatGPT por Open AI o por Azure.
Este artículo nos mostrará como hacer lo que ya vimos antes pero deployando un ChatGPT 3.5 y cambiando el script de C# para utilizar ese servicio en Azure.
Para poder realizar esta práctica necesitamos contar con un recurso de Azure Open AI. Este recurso se encuentra limitado al público y solo podremos acceder llenando una encuesta. Fijense al momento de crear el recurso debajo de donde seleccionaríamos el precio.

La respuesta de Microsoft para permitirnos usar el recurso puede demorar unos días. Una vez liberado nos permitirá usar un Tier S0. Este recurso es un espacio que nos permite explorar, desarrollar, deployar modelos. En nuestro caso queremos deployar uno ya existente. Al crear el recurso veremos lo siguiente y antes de ingresar a Deploy, copiaremos valores de interes.
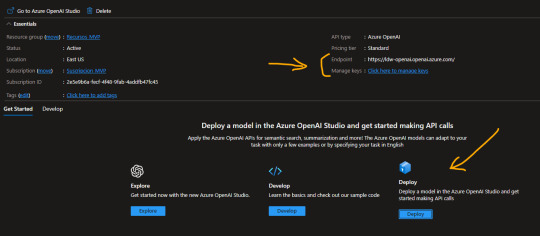
Para nuestro script vamos a necesitar el “Endpoint” y una de las “Keys” generadas. Luego podemos dar click en “Deploy”.
Al abrir Azure AI Studio vamos a “Deployments” para generar uno nuevo y seguimos esta configuración:
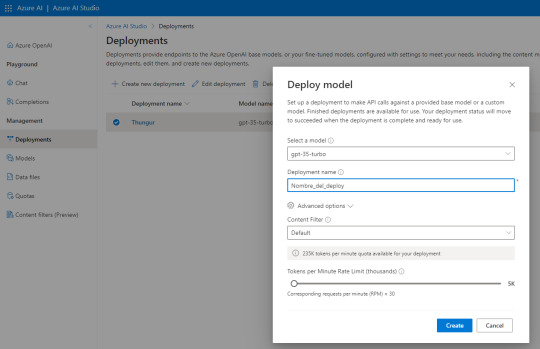
El nombre del deploy es importante puesto que será parte de la URL que usamos como request. Seleccionen esa versión de modelo que se usa para Chat especificamente de manera que repliquemos el comportamiento deseado de ChatGPT.
Atención a las opciones avanzadas puesto que nos permiten definir la cuota de tokens por minuto y el rate limiting de requests por minuto. Para mantenerlo similar a la API gratuita de Open AI lo puse en 30. Son 10 más que la anterior.
NOTA: ¿Por qué lo hice? si ya intentaron usar la API Trial de GPT verán que les permite ver sus gastos y consumos. Creo que manteniendo ese rate limiting tuve un costo bastante razonable que me ayudó a que no se extienda demasiado puesto que no solo lo uso para descripciones DAX. Uds pueden cambiar el valor
Con esto sería suficiente para tener nuestro propio deploy del modelo. Si quieren probarlo pueden ir a “Chat” y escribirle. Nos permite ver requests, json y modificarle parámetros:

Con esto ya creado y lo valores antes copiados podemos proceder a lo que ya conocemos. Abrimos PowerBi Desktop del modelo a documentar. Luego abrimos Tabular Editor y usaremos el siguiente Script para agregar descripciones a todas las medidas que no tengan descripción previa. Tiene un pausador al llegar a 30 porque es el rate limiting que yo definí en mi modelo. Eso pueden cambiarlo
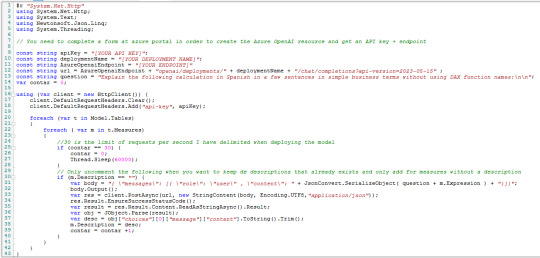
Las primeras variables son los valores que copiamos y el nombre del deployment. Completando esos tres el resto debería funcionar. El script lo pueden copiar de mi Github.
Con esto obtendrán las descripciones de las medidas automaticamente en sus modelos utilizando el servicio de Azure Open AI, espero que les sirva.
#powerbi#power bi#power bi desktop#azure openai service#azure ai#power bi argentina#power bi jujuy#power bi cordoba#power bi tips#power bi training#power bi tutorial#ladataweb#fabric
0 notes
Text
[PowerQuery] Transformar columnas con condición personalizada
No hay nada más molesto para hacer informes o análisis que datos sumamente sucios. Con esto me refiero a malos ingresos de datos, normalmente proveniente de encuestas u hojas de cálculo.
Power Query es una buena herramienta de ETL pero es importante usarla bien para no reventar de pasos insostenibles en nuestro script. Para eso ya escribimos un post que nos ayude a reducir pasos. Lo que veremos en este artículo esta enfocado en simular lo que podemos hacer dentro de “Agregar Columna Personalizada” pero transformando la columna que necestamos limpiar sin crear otra columna con el código personalizado deseado.
En el proceso iremos agregando codiciones varias para ver el poder que tenemos.
Antes de iniciar me gustaría aclarar que este artículo mostrará técnicas avanzadas de power query para usarse como ETL en respuesta a procesamiento de datos. Eso no quita que haya mejores prácticas. Nada superará a hacer el procesamiento en un único origen de verdad como warehouse o lakehouse que sería la mejor de las prácticas.
¿Cuántes veces tuvieron que crear una columna personalizada en power query porque no existía un modo en la interfaz para reemplazar valores con un sencillo if?
Me quedó media larga la pregunta pero ciertamente ocurre que a veces necesitamos limpiar un conjunto de datos con una columna numérica mal escriba y caemos en hacer muchisimas operaciones de “Reemplazar Valores”. Lo cierto es que reemplazar valores solo cambia una cadena de texto por otra. Eso esta bien para cosas pequeñas como errores de tipeo tradicionales. Sin embargo, con una condición más complicado, digamos, si queremos que salga un determinado texto tras encontrar una determinada cadena sin reemplazarla, entonces se complicaría. Ejemplo, cada vez que encontremos el texto “hombr” debería salír “Varón”. Si aparece homb, hombre, hombrrrre, hombre pues, hombrecito, hombreton o algo similar, lo reconocería como hombre y le pondríamos “Varón”.
Vamos a ver tres ejemplos de reemplazo y limpiezas.
Supongamos que enviamos una encuesta de sueldos a un grupo de personas que trabajan remoto. Tenemos una tabla con salarios y una descripción que no todos llenan sobre el pago en dólares.
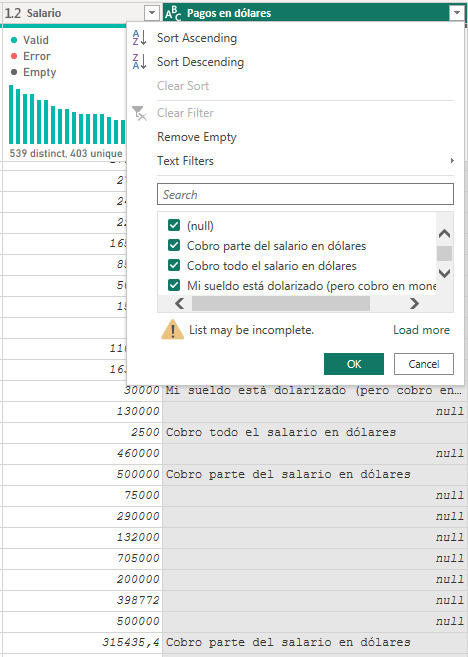
Lo primero que podríamos pensar es agregar otra columna más limpia, pero podríamos limpiar esta. ¿Qué tal si reemplazamos “USD” cuando encuentra la palabra “dólares” y “ARS” cuando no lo hace?
Veamos el proceso. Cuando queremos reemplazar bajo condición en una columna necesitamos usar la función ReplaceValues de tabla. Veamos la teoría:
Table.ReplaceValue(table as table, oldValue as any, newValue as any, replacer as function, columnsToSearch as list) as table
Esta función nos deja reemplazar una cadena oldValue (en este caso el mismo valor de la columna porque queremos reemplazar cada aparición sin importar su valor) con un newValue (resultado de una condición que armemos) en una clásica condición de reemplazo Replacer y la columna columnsToSearch en la cual buscará el oldValue para cambiar por el newValue. Basados en la tabla anterior nos quedaría algo así:
= Table.ReplaceValue(
#"Paso Anterior",
each [#"Pagos en dólares"] ,
each if Text.Contains([#"Pagos en dólares"], "dólares")
then "ARS"
else "USD",
Replacer.ReplaceValue,{"Pagos en dólares"}
)
De este modo en cada aparición del valor propio de la columna hace un reemplazo de lo que tenga por la condición elegida. Dejandonos con un pobre pero inicial resultado:
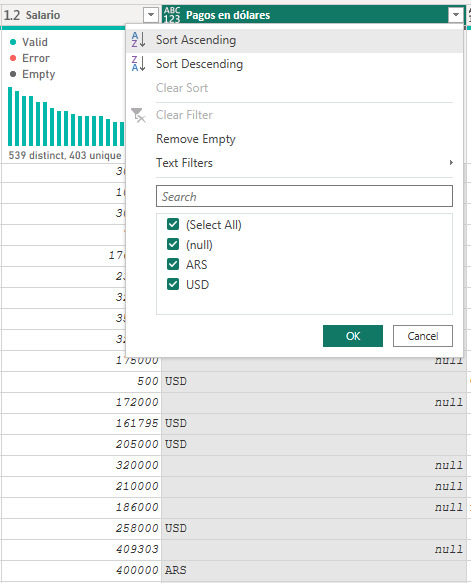
La lógica se cumplió y aprendimos a hacer un reemplazo en la columna. Sin embargo, la limpieza fue medio pobre y no hemos contemplado los escenarios correctamente. Recordemos que tenemos muchos null y también hay casos que tienen “Parte del salario en dolares”, lo cual no quedaría contemplado con ARS y USD.
Para mejorar nuestro limpieza sobre la columna vamos a realizar una condición entre las dos columnas. Por vivir en este páis tengo claro que no existe un Salario menos a 15000 ARS en la industria remota de tiempo completo (FullTime) y sería también dificil que una persona tenga un salario de 15000 USD mensuales.. Entonces voy a usar ese conocimiento para limpiar con una condición numérica la primera elección y luego preguntar por la palabra “parte” cuando recibie en ambas monedas el salario.
Veamos el caso
= Table.ReplaceValue(
#"Renamed Columns",
each [#"Pagos en dólares"],
each if [Salario]< 15000
then "USD"
else if Text.Contains([#"Pagos en dólares"], "parte") and [#"Pagos en dólares"] <> null
then "Híbrido"
else "ARS",
Replacer.ReplaceValue,
{"Pagos en dólares"}
)
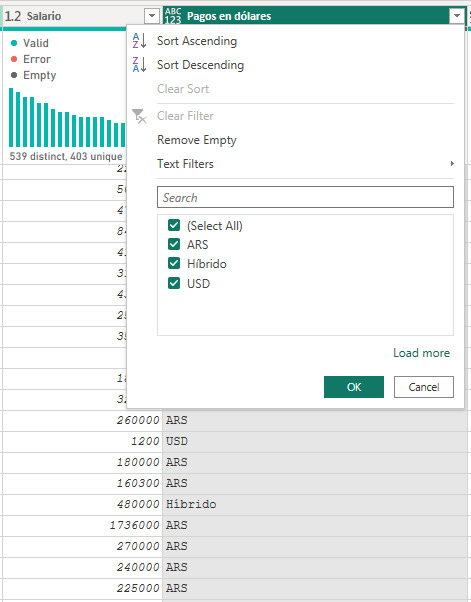
Hacemos la primera condición coladores si el número es menor a 15000 entonces USD. Para la segunda condición en el if vamos a ir por "parte” y sumamos que no sea nulo porque sino Text.Contains ignora preguntar a los nulos y esas filas quedarían nulas aunque existiera el else.
De este modo el reemplazo quedaría más completo dejando nuestra columna con todas las opciones posibles:
Condición IN SQL en Power Query
Los casos anteriores suelen ser un clásico, pero que ocurre cuando tenemos algo más complejo. Cuando necesitamos una serie de reemplazos masivos del estilo “IN” de SQL. Por ejemplo, veamos la siguiente imagen y digamos que necesitamos reemplazar todos las apariciones de cadenas de texto que conlleven a Hombre, Varón, Macho y Masculino. Algo tipo hombr, var, mach, masc. Si encontramos algo con eso, entonces reemplacemos por “Varón”.
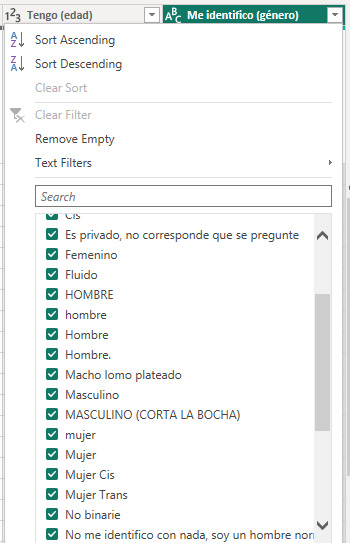
La condición semejante a IN en SQL se construye con List.Contains. Veamos la teoría:
List.Contains(list as list, value as any, optional equationCriteria as any) as logical
La función necesita una lista de valores bajo los cuales comparar y el valor a recibir. Dicho de otro modo si algun string de la lista coincide con value entonces true.
Para poder realizar esta compleja tarea necesitamos dos operaciones. Por un lado construir la lista de valores a reemplazar en cada valor de nuestra columna puesto que los comparadores masivos hacen comparación de valores exactos. Dicho de otro modo el reemplazo ejecutado se vería tipo:
List.Contains({”hombre”, “Hombre”, “Hombre.”, “Macho lomo plateado”, “Masculino”, “[entre otros....]”} , [#”Me identifico (Género)”])
Necesitamos construir esa lista de manera tal que por cada coincidencia podamos reemplazarlo por “Varón”.
En nuestro editor de consulta vamos a crear una variable. Una variable no es más que un paso más que no está relacionado con el “Paso anterior” y vive en nuestro script para usarlo. La generación de la lista sería filtrar la tabla por valores únicos cuando el texto contenga lo deseado y convertirlo a lista. Veamos:
Lista_de_varones = Table.ToList(
Table.SelectRows(
Table.Distinct(#"Paso Origen"[[#"Me identifico (género)"]]),
each (Text.Contains(Text.Lower([#"Me identifico (género)"]), "hombr")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "var")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "mach")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "masc")
) and (not Text.Contains(Text.Lower([#"Me identifico (género)"]), "trans")
)
)
)
Fijense que si bien hace referencia a un paso anterior, no lo vamos a usar en el siguiente. A la tabla de una única columna género distintiva le filtramos las filas cuando contenga lo antes acordado “hombr”, “var”, “mach”, “masc” y le agregue que no contenga “trans” puesto que sería otro género. Así obtenemos una lista con todos los resultados para nuestro IN de SQL. Son más de 50 resultados, pero solo mostraré algunos porque esto se descontroló

Con esa variable en lista que llamaremos al paso reemplazador que veníamos construyendo para aplicarlo sobre nuestra columna:
= Table.ReplaceValue(
#"Paso Origen",
each [#"Me identifico (género)"],
each if List.Contains( Lista_de_varones, [#"Me identifico (género)"] )
then "Varón"
else [#"Me identifico (género)"],
Replacer.ReplaceText,
{"Me identifico (género)"}
)
Fijense como se acortó la lista. Pasamos de casi 150 valores distintos de género a tener casi 80.
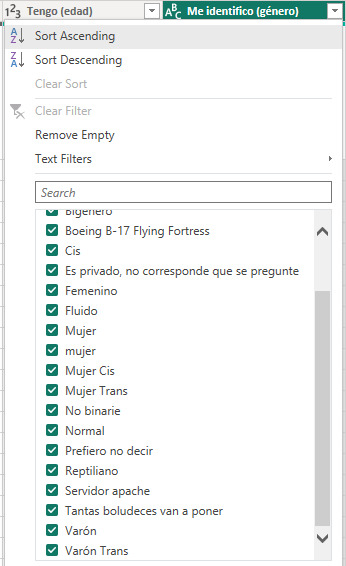
De este modo podríamos repetirlo con apariciones para Mujer, No Binario, Mujer Trans, Varón Trans y dejar al resto en Otro.
Antes de concluir me gustaría hacer incapie en que este es un proceso muy pesado. Recorrer el conjunto para obtener la lista que luego usamos de reemplazo puede tardar mucho si la lista demora en generarse. El reemplazo es rápido pero la lista no. Por ello recomiendo fuertemente hardcodear la lista si el origen de datos es una encuesta cerrada como este caso. Hacemos la ejecución para conocer los valores y ya conociendolos los registramos en otro origen:

Pueden copiar a notepadd++ y generar un macro que ponga comiilas y comas en menos de un minuto.
Ahora si llegamos al final del post y hemos aprendido a reemplazar valores de una columna según condiciones personalizadas en cualquier otra columna de la misma fila inclusive con múltiples reemplazos de porciones de cadenas de texto. Ojalá les sirva para limpiar esos datos sucios que nos llegan.
#power bi#powerbi#power bi tips#power bi tutorial#power bi training#power query#powerquery#power query tips#power query tutorial#power query training#ladataweb#power bi cordoba#power bi jujuy#power bi argentina
0 notes
Text
[Azure] Pause Resume Fabric, Embedded o AAS con SimplePBI
Hace un poco más de un mes que Fabric llegó y no para de causar revuelo. La posibilidad de una capacidad con todas las características de Premium y más pero al estilo pay as you go como lo es Power Bi Embedded me parece excelente.
En este artículo voy a hablar de la última actualización de la librería de Python SimplePBI que permite Pausar y/o Resumir los recursos de Bi. Si usan Analysis services, PowerBi Embedded o Fabric y les gustaría ahorrar cuando las herramientas no se usan, entonces este código nos ayudará a ejecutar la acción. Luego podemos ver como agregarlo a un schedule en Azure para que se automático.
Pre-Requisitos
Lo primero que necesitas son dos prerequisitos.
1- La versión 0.1.4 de SimplePBI o superior. En esa versión incorporaron la clase azpause que nos ayudará. Para actualizarla pueden usar pip:
pip install simplepbi --upgrade
2- Una App Registrada en Azure con secreto creado para usar como Service Principal. Copiaremos el Tenant Id, Client o App Id y Secret generado.
Ejecución
Para iniciar vamos a ir a nuestro recurso de Azure (Fabric, PBI Embedded o AAS) y daremos permiso en el control de accesos (IAM) al Service Principal (App Registrada) como “Contributor”. Este permiso le dará posibilidad de ejecutar acciones como prendido y apagado. A partir de ese momento seremos libres de ejecutar el sencillo código.
from simplepbi import azpause
# Initialize the object authenticating Azure
azure = azpause.Azpause(TENANT_ID, client_id, client_secret)
# Run method of the object for pause or resume
azure.resume_resource(subscriptionId, resourceGroupName, resourceType, resourceName) azure.pause_resource(subscriptionId, resourceGroupName, resourceType, resourceName)
Así de simple con tres líneas. Importar librería, autenticar creando objeto y llamar el método del objeto especificando valores que podemos copiar del “Overview” del recurso:
suscriptionId: el id de la suscripción, no del tenant.
resourceGroupName: nombre del grupo de recursos donde creamos el recurso
resourceType: tipo de recurso, recibe uno de tres valores posibles “FABRIC”, “PBI” o “AAS”
resourceName: nombre del servidor AAS o la capacidad Fabric/Embedded
Enlace al repo con su doc: https://github.com/ladataweb/SimplePBI/blob/main/AzPauseResume.md
Automatizarlo en Azure
Uno de los mejores usos de esa acción es programar la ejecución de dichas líneas conociendo las brechas de tiempo en que no se usan. Para ello podemos hacerlo de manera local con Windows Schedule o en Azure para no depender de una VM. Dentro de Azure hay diversos servicios, podríamos usar por ejemplo Azure Functions. En mi caso voy a mostrar el ejemplo con una cuenta de Automation creando un Runbook.
En el portal de Azure crearemos una cuenta de automatización o en ingles Automation Account. El código que usaremos estará en Python 3.8. Una vez creada la cuenta busquemos la opción Python Packages donde agregaremos la librería:
Para agregar la librería primero descargaremos el archivo Wheel de SimplePBI. Pueden encontrarlo en: https://pypi.org/project/SimplePBI/#files
Con el archivo descargado basta con seleccionar “Add a Python Package” con signo +. Tras añadir el archivo “whl” debería reconocer el nombre y ustedes seleccionen 3.8 en la versión de python
Todo esto es para poder importar simplepbi en el código de nuestro runbook. Luego de cargar la librería, que puede tardar varios minutos, crearemos un runbook en el menú de la izquierda dentro de la cuenta de automatización
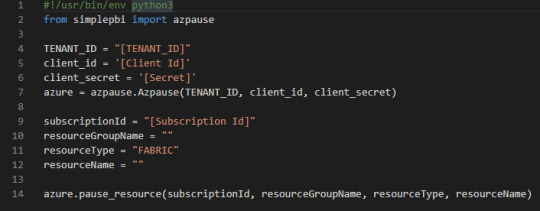
El ejemplo lo haremos con el Pausado. El código sería igual para el Resumir el servicio solo que cambiaría el último método. Creado nos guiará a una interfaz para comenzar a escribir nuestro código Python. Esto sería bastante sencillo. Algo así:
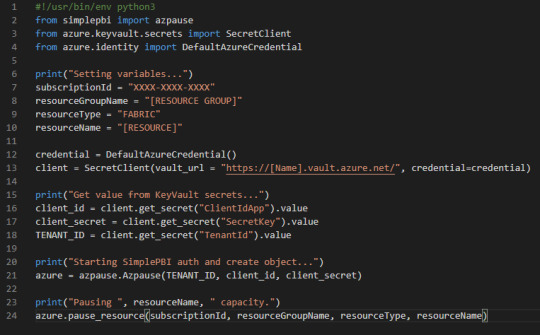
Sin embargo, recordemos que exponer claves en código es una falta de seguridad grave. Entonces lo mejor sería crear un Azure KeyVault para guardar nuestros secretos o IDs y que no queden expuestos. Para ello basta con crear el recurso KeyVault, añadir su cuenta como Key Vault Administrator y crear el secreto. Si quieren conocer más sobre esto pueden buscar ejemplos o seguir el training: https://learn.microsoft.com/en-us/training/modules/configure-and-manage-azure-key-vault/
Si usan KeyVaults se vería así:
Guardar y publicar. Luego podemos darle play para ver que todo funcione correctamente.
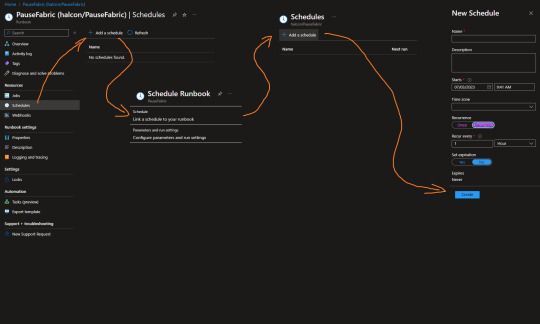
Lo último que haremos será calendarizar la corrida del script. Si ya conocemos el uso del recurso sabremos sus tiempos y horarios. Puede ser que se apague de noche o los fines de semana. Para ello, vamos al runbook y nos fijamos en el menú “Schedule” y seguimos las indicaciones de la imagen:
De ese modo podemos configurar corridas recurrentes del código para asegurarnos que todo esté en orden.
Así es como terminamos de construir nuestra Pausa de Fabric, PowerBi Embedded o Azure Analysis Services usan SimplePBI. Seguramente haría falta que repitan el proceso para “Resumir” el recurso de manera que prenda cuando necesiten usarlo.
#azure#azure automation#python#power bi python#microsoft fabric#power bi embedded#azure analysis services#azure tips#azure training#azure tutorial#ladataweb#simplepbi
0 notes
Text
youtube
Luego del gran evento de Power Bi en español de inicio de año, me alegra compartirles la sesión que expuse durante el evento "Intro Scripting C# en Power Bi con Tabular Editor".
En la misma vamos a conocer como hacer scripts desde 0 sin conocimientos previos en C# o Tabular Editor, contra un modelo de Power Bi Desktop.
#power bi#power bi argentina#powerbi#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#Tabular Editor#power bi external tools#Youtube
0 notes
Last Seen Blogs


sparkle-candy-star-prinzessin
i swear i'm not completely inactive on here

kaism1th
Ninja Never Quit

oyajidayon
題名未設定
