#U CAN GO TO WIKIPEDIAS SOURCES AND GET IT FROM ACTUAL PLACES THEY GOT IT FROM
Text
Those motherfucking cunts *takes a drag and starts crying again*
#cherry says#IM SURE WHEN I TELL THE TEACHER HES NOT GONNA BE NICE EITHER AND NOT GIVE ME EXTRA CREDIT NO NOTHING#and ill just raise it with the exam grade#FUCK I GOT PUT IN THE TANKER BC OF THESE HOS WHO DID NOT LISTEN!!! I SAID REWRITE UR INTRO ITS CONFUSING#DONT LINK ANY VIDEO LEAVE THE REST#SO WE CAN SLOWLY FRAME THE THESIS UP AND SUMMARIZE THE RISE OF MUSICAL ON FILM#WHICH HE POINTED OUT IN THE RUBRIC SO SAURRRRRRRRRR#AND THIS FUCKER AND HIS EXTRA SLIDE HIS EXTRA SLIDE DID IT WHY DID U PUT THAT SLIDE THIS IS NOT ABOUT A#MARILYN MONROE MUSICAL THATS NOT GOOD WHY DID U PUT SO MUCH WRITING ON IT I SAID LEAVE IT ALONNNNEEEEE#AND WHY DID U NOT ONLY NOT PUT MLA CITATION BITCH GOOGLE THAT BUT U PUT WIKIPEDDIIIAAAAAAAAA#U CAN GO TO WIKIPEDIAS SOURCES AND GET IT FROM ACTUAL PLACES THEY GOT IT FROM#U STUPID FUCKING CUNNNTTTTTTTTTT#AT LEAST HE DID SAY HE LIKED MY CARMEN JONES BIT BUT THE REST DID NOT LOOK WELL DIRECTING TO IT#FUUUUUUUUUCCCCCCKKK EACH OF YOU
4 notes
·
View notes
Text
1047
What’s the most historic thing that has happened in your lifetime?
I can think of a few things. There’s 9/11 though I was barely conscious then, Osama Bin Laden’s death, the 2004 Indian Ocean tsunami, 2011 Japan earthquake, and the H1N1 and Covid pandemics. In my country, there were typhoons Ondoy and Yolanda, the Manila hostage crisis, and the Hello Garci election corruption scandal. Out of these, though, I’d say the heaviest ones to bear have been 9/11 and Covid.
What happens in your country regularly that people in most countries would find strange or bizarre?
We use a spoon and fork to eat and only really fancy shmancy restaurants give you a knife and a fork. Many eat with their hands as well, though this is way more common in provinces.
Everyone is late to everything and punctuality isn’t a thing, which is a big culture pet peeve of mine and I still like arriving early/on time anywhere.
This applies to Asia in general lmao, but shoes typically aren’t allowed or at least frowned upon if they go beyond the main entrance of houses.
We start Christmas as early as September, and we end it by the last week of January
When families get together, aunts/uncles will usually greet their nieces/nephews by asking if they already have a boy/girlfriend and/or telling them that they got fat. Horror relatives will greet you with both.
People generally like to keep to themselves, so striking a friendly conversation with strangers even if you have the pure, genuine intention to be simply friendly will just lead them to think you’re being a creep lol
What has been blown way out of proportion?
The effects of video games and the question of it increasing violence among kids. Sure there’ve been gruesome accounts and no one’s invalidating those, but the overwhelmingly vast amount of people who play video games end up okay. I had so many killing binges on GTA but to this day I can’t even look at a real gun without shuddering, lol.
When was a time you acted nonchalant but were going crazy inside?
This is me every morning at work. 9 AM-11 AM is always the busiest period and it’s a lot of shit happening at the same time and a lot of morning deadlines to meet, but unlike college I can’t exactly call for a timeout whenever I want and have panic attacks anymore.
What’s about to get much better?
I hope my fucking life is next in line. I’m tired of being tired of being tired.
What are some clever examples of misdirection you’ve seen?
Probably all the times WWE would mislead viewers on a rumored return or debut of a big name by saying they’re in another city, implying that there’s no way they’d be appearing on a WWE show. This happened with Ronda Rousey and it was so fucking exciting when she finally showed up, haha.
What’s your funniest story involving a car?
I don’t know, really...I don’t try to be funny when I’m on the wheel lol. Probably the time I let Angela use my car on campus, and when she needed to make a u-turn she ended up doing an awkward 90º turn and had an SUV nearly crash towards us. She had only driven a handful of times at that point so she was a little clumsy, but neither of us had any idea she’d fuck up a simple u-turn as badly as she ended up doing lmao.
What would be the click-bait titles of some popular movies?
I can think of more clickbait posters than titles, but I can’t seem to remember what those films are called right now.
If you built a themed hotel, what would the theme be and what would the rooms look like?
Themed hotels generally make me cringe. The most theme-y place we ever stayed at was the lodge in Sagada and it was really just more homey than anything. I’m not into themes when it comes to hotels as I find it a little cheap lol and I’ve always preferred a straightforward experience in the places I stay at for vacations.
What scientific discovery would change the course of humanity overnight if it was discovered?
A way to live forever. < This is a good one. Also, maybe a huge asteroid or meteor bound to hit the planet that will make widespread extinction a certainty? I can’t even begin to imagine the panic that will rise from something like that.
Do you think that humans will ever be able to live together in harmony?
I doubt it. It sounds difficult especially when you realize we’re 7 billion in total.
What would your perfect bar look like?
As long as there aren’t any annoying younger college kids, who are almost always the loudest crowd and not in a good way, I’m okay with any kind of bar.
What’s the scariest non-horror movie?
Some shots in 2001: A Space Odyssey are freaky as fuck. There were several scenes that included sudden HAL shots, and I did not enjoy those. How the fuck Kubrick managed to make a computer scary is beyond me. I’ve also always skipped the vortex scene with the creepy face shots after seeing it once.
What’s the most amazing true story you’ve heard?
This is a really vague question... a few months ago I watched this video diary of parents who had a child born at like 25 weeks. Just way too early, basically. And they recorded the kid’s weekly progress, how she kept fighting, and her journey of being transported from one machine to another while she still needed them. It was beautiful to see her get bigger and plumper with each week that passed and it was just such a feel-good story to watch. I was so relieved when they showed footage of her as a normal, healthy toddler by the end of the clip.
What’s the grossest food that you just can’t get enough of?
I know balut is pretty unpopular in the Western part of the world, but I’ll gladly eat a dozen of them in one sitting. In general Asian street food is usually considered gross - pig intestines, chicken intestines, chicken feet, pig ears, etc., but all are normal in the culture I was raised in.
What brand are you most loyal to?
It’s annoying and I can’t help it, but Apple.
What’s the most awkward thing that happens to you on a regular basis?
I try not to make it regular, but sometimes a mistake on my end will slip through in an email I’m sending and I have to send another email correcting myself and apologizing for the oversight. One of my least favorite parts about work.
If you had to disappear and start a whole new life, what would you want your new life to look like?
I’m not wishing for much. I just wish it was easier to remove any trace of me on social media sites and have it be as if I never existed because I think that would make it easier for me to move on from...well, you know what. I still have trouble verbalizing it and I don’t feel like mentioning it tonight.
But idk, I like staying connected to my family and friends, so idk if I can ever achieve that. And that said, I think I’m bound to always keep seeing her around.
What movie or book do you know the most quotes from?
I memorize a pathetic amount of dialogue from Love Actually, Twilight, Titanic, and The Proposal.
What was one of the most interesting concerts you’ve been to?
I guess Coldplay? They gave assigned lightsticks for each section and the crowd looked amazing when the production crew activated the lights for certain songs. I still have some of the clips because I posted them on Snapchat, so I’m really glad I did that; otherwise I would’ve lost the videos forever.
Where are you not welcome anymore?
I’ve felt pretty unwelcome around her. How she could do a 180 and just not be interested in having anything to do with me is really soul-crushing.
What do you think could be done to improve the media?
Fact fucking check, please. Also keeping sources balanced, avoiding clickbait headlines, being more objective than neutral, and don’t fucking sensationalize. How timely that this landed on a journalism graduate, hahaha.
What’s the most recent show you’ve binge watched?
Start Up but I haven’t continued in the last two weeks :/ I think it’s because I know I’m nearing the finale and I subconsciously just don’t want to run out of Start Up episodes to watch lol but yeah, I still have four episodes left and I have no clue when I’ll watch it again.
What’s a common experience for many people that you’ve never experienced?
Being close with their mom and considering them as their rock.
What are some misconceptions about your hobby?
I don’t know enough about embroidery to know misconceptions about it.
What did you Google last?
2001: A Space Odyssey because I needed to be sure of the scenes I planned on citing in the question above that made me mention the movie.
What’s the dumbest thing someone has argued with you about?
Not being able to find a restaurant to eat at. The backstory is a little complicated but it’s the same fight that led my younger brother to slap me across the face, and what subsequently led me to stop speaking to him.
If money and practicality weren’t a problem, what would be the most interesting way to get around town?
Probably a tank.
What’s the longest rabbit hole you’ve been down?
It’s always the ones on Wikipedia lol. I find weird and interesting articles on there all the time; there’s always something new to read.
What odd smell do you really enjoy?
The rain, though sometimes it can be too overpowering when the humidity has been high. I like it for the most part, though.
What fashion trend makes you cringe or laugh every time you see it?
Streetwear is so fucking dull to me. I never saw the appeal.
What’s your best story of you or someone else trying to be sneaky and failing miserably?
Hahahaha this happened just a few weeks ago actually. My parents and I were headed out to have some ramen, and I opened the car door to hop onto the backseat. They didn’t prepare beforehand and they left the Christmas gift I asked for - a corkboard - in the backseat, so I was able to see the whole thing, unwrapped and with price tag and all. Their mortified faces knowing that their secret’s been blown were hilarious. They had no choice but to just give it up, and the corkboard has been on my wall since.
If you had a HUD that showed three stats about any person you looked at, what three stats would you want it to show?
I guess the stability of our relationship, their general mood for the day, and erm how badly they need a hug because I’m always willing to give some.
What’s the best way you or someone you know has gotten out of a ticket / trouble with the law?
My mom fake-cries her way out and it’s always been hilarious to see a grown ass woman do it and pull it off every time.
Tear gas makes people cry and laughing gas makes people giggle, what other kinds of gases do you wish existed?
I don’t really want to manipulate people’s action in this way, so pass.
4 notes
·
View notes
Note
Do you have advice for reading yeoldie handwriting, because honestly that's one of the hardest things when I'm doing research.
It really varies based on what time period you’re dealing with, but a few general tips for people off the top of my head…
1. This first one may seem insultingly obvious, but…
If you don’t already know it - LEARN CURSIVE.
I completely understand why they don’t teach it anymore, but if you are planning to work with historical documents in any capacity it is NOT an optional skill.
It also helps to find a period penmanship chart specific to the era you’re working with and learn how all the individual letters were written then - a lot of times they’ve changed.
Some letters, that you wouldn’t necessarily think of as being similar, looked a lot alike at certain points in history. Capital W’s, H’s and N’s are pretty darn indistinguishable in a lot of mid-19th century documents. Same with capital S’s and L’s.
2. Practicing writing in whatever style writing you are trying to read is also incredibly helpful.
Try writing with a fountain pen or a quill to see how it changes how you write.
I mentioned before in a post that I never got the point of the “long s” before I tried writing with a quill and discovered what a pain writing two s’s in a row was.
Sometimes if you can’t figure out a word, copying it out yourself will make something click.
Practicing like this will also really help you understand why you see a lot of the common writing quirks/errors I’m going to mention in my next tip.
3. It may seem obvious, but keep always keep in mind that people are people and they make mistakes. They skip words, make spelling errors, get their/there/they’re or to/too mixed up, squish letters/words together, forget to dot their i’s and cross their t’s, etc.
The most common handwriting quirks/errors that seem to throw people off are…
-‘i’ dots not being above the ‘i’ (or not being there at all)/‘t’ crosses not actually crossing the ‘t’, being forgotten, or just crossing the entire word with no regard for where the ‘t’ actually is
for example…
vacation…
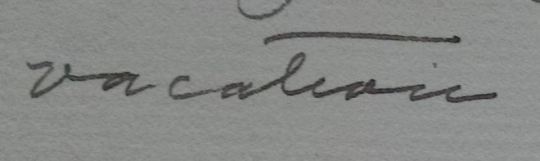
father…
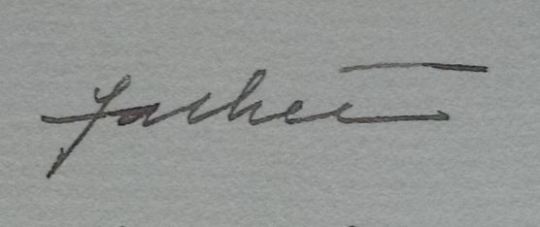
that (in which Rachel manages to cross the H and miss the two T’s entirely)…
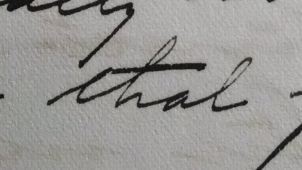
-Numerous what I call “bumpy letters” (notably: m, n, r, u, w) in a row.
I must stop now…
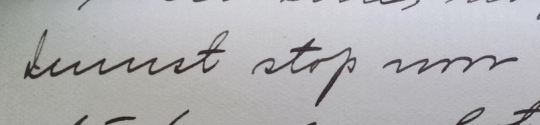
Sometimes counting the bumps works (3 for m, 2 for n/u, etc) but, because people are people, there aren’t always as many as there should be.
(side note: combining “I” with the following word, like it is above, it is something you see a lot around turn of the century.)
3. CONTEXT. Context is your best friend in reading any handwriting.
For example this word on it’s own may stump you…
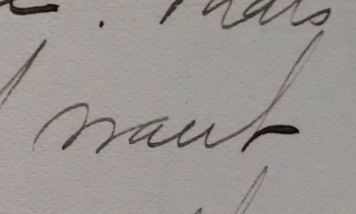
but in context it because pretty clear, even without the t’s crossed…
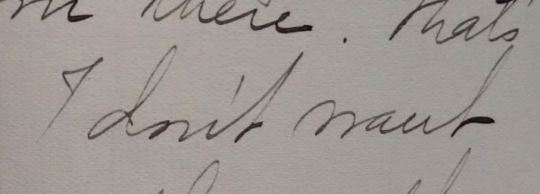
If you’re stumped by a word don’t just stop. Read to the end of the sentence or the paragraph. Lots of times the context will clear it up right away.
4. My best tip for if you get stuck with a word is to go through the document and compare the letters in the problem word to other letters in the document you can read or figure out by context. People tend to be pretty consistent in the way they form letters.
For example: Rachel’s “e”’s threw me off for the longest time until I took specific note of how she wrote them…
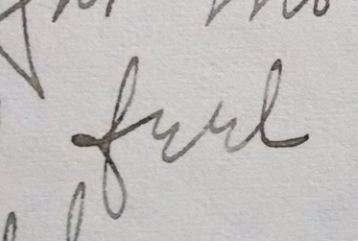
Honestly for a few cases of really horrible handwriting I’ve worked with I’ve actually gone through and made myself self a photoshop chart with samples of how the writer writes each letter so I could compare as I went without going back through the document.
5. For names you can’t make out - googling or checking other sources to compare is always helpful.
Just today Jennie was talking about a French violinist she saw whose name I couldn’t figure out at all besides the “M” at the beginning. So I went to Wikipedia and found a list of French classical violinists, went through all the names starting with “M” and figured it out pretty easily from there.
If you’re working with a lot of material written by the same person; keeping a list of all the family/friends/associates/places that they’ve mentioned is incredibly helpful for figuring out problem names later on.
6. If you’re stuck on something and it’s not of absolutely vital importance to you understanding the document - just skip it and move on. It’s not worth obsessing over one word.
I just searched my huge Rachel & Co. master document and found 686 results for “[?]” and 203 for “[illegible]”. I’m sure I’ll figure a lot of those out when I eventually go back and proofread, but transcriptions in the National Archives still contain a whole lot of words even the experts can’t figure out.
Also, lots of times if you’re getting frustrated - walking away, reading something else, and coming back later can work wonders.
7. But honestly, like acquiring any skill, the best thing is just lots and lots of practice.
I’ve had quite a few instances with frustrating handwriting where it’s almost like staring at a Magic Eye picture. You’re struggling along and suddenly something in your brain just clicks and you’re left wondering how you couldn’t see that before.
The more you read the easier it gets. Promise.
645 notes
·
View notes
Note
Thank you so much for your work on the sun-moon signs!! Well I followed you after reading some of your bangtan astrology posts cos they sounded really interesting and stayed cos you're so nice and you keep providing so much insight into kpop idols and astrology in general! I'd just like to ask one more thing if you're not too busy - what are your views on venus in taurus conjunct algol?
Hey there!! 💕💕💕 I’m so sorry I’m so late to replying to you skdjnfksjn I saw this and I wanted to talk about the fixed stars ajsbjsbaahhh but I finally got time (and energy) to reply now!! 💕💕 Thank u so much for sending this in ;; and liking the stuff aaahsjb it really means a lot to me so thank u so much! 💕💕
[Venus conjunct Algol]
Technically, I’m not an expert on this so I’ll try to help out the best that I can ;; 💕
From my understanding, Algol is a fixed star and it’s at 26′01 Taurus (since we’re counting precessions through the years) — so hopefully if your Taurus Venus is around 2′ of that 26′ –it would be conjuncted
Also take note where Capulus is, since it’s the hand that beheaded Medusa– it should be around 24′12 right now, but see if it’s aspected anything (below 1′ if possible) too 💕
Capus Algor as a binary star actually does a lil eclipse over other stars in it’s close range, making it look like the blinking snakies eyes 💕
What people said about it representing Medusa’s head is because… well, it’s placed there. Which coincides with it being in the Perseus constellation (who actually beheaded Medusa) and it’s also a part of the Behenian Fixed Stars (more known for having power/magical properties or ‘roots’ of certain planetary placements, witchy pals this is ur jam)
I think with Algor, and with fixed stars in general— while most of the interpretations are fatalistic, learning about the myths and it’s connections to other things are also important too (for research)💕
So with Algor, Jupiter + Saturn (discipline and then indulgence) also has a theme going on. While most of the stuff is fatalistic (with the beheading and stuff, and whilst in the older days we might see it as something that’s literal. Nowadays it’s more to do with well… losing your head/inhibition over things) – it’s good to keep in mind that it’s mostly to do with the extremities of Taurus (and the darker side of well, Venus or Aphrodite)
Where it falls on the chart, what house it’s in. Can possibly show us where we tend to show some of our more unpleasant Taurusean traits as well. This is putting it mildly, since I’m a PG blog. But over-indulgence in something can lead to obsession. Possessiveness over something can lead to detriments. While it might sound obvious, think of Algor as having more of a fatalistic affect. As in, it doesn’t just affect us but other people can see and often think of us that way as well.
Often time, it’s too late to realize how drastic/real the consequences of Algor is until it’s dolled out to us. In this case, we might be hoping for people to be more forgiving, or more tolerant of us but it turns out they aren’t. Leaving us stranded, hurt, or y know. Worse. But it’s not always bad or as dramatic akjsnd sometimes it’s minor issues, but it’s good to look out for re-occuring patterns like this in order to deal and handle it.
Algor conjunct Venus might also show us areas in which we exhibit our worse self (sorry that was ;; um) The areas in which we aren’t look kindly upon/for and often discriminated against. It’s an area in which we might want to look forward to understanding our differences, on the rare occasion that it’s not….us, but rather how we’re perceived (Medusa being violated by Poseidon and punished by Pallas Athena) there’s an element of duality to them— where beauty is there within Medusa (she IS beautiful) but within that is ugliness/fear/danger as well (lashing out, retribution, retaliation).
It’s not all bad… it’s just a warning. As fixed signs tends to do (some) are fatalistic while others are more y know, blessful. With Algor it jus is?? Like the message it might show, is that alcohol/delusions (Neptune - Poseidon) might often make this placement reactivate. Look into where Neptune is placed as well, and what you might need to guard against as well.
Algor doesn’t have to be all bad however, Medusa is also someone who suffers from pain. She wants to heal, soothing the pain and suffering even though currently (while she was living as Medusa transformed/mutated) she may have let the affect of the consequences get to the best of her.
Think of healing from the pain, but also to not be brash or deluded (false sense of bravado) in what you’re doing. It can make someone extremely confident of who they are/their integrity, but at the same time jus keep in mind the tales of Medusa and how this might work against your favour as well.
Having Algor aspected to your personal placement doesn’t always mean you’re undesirable, unworthy or that you’re evil or something. Whilst it can be brutal to have the darker side of Venus giving you no favors, it does however exemplify the idea of having both beauty and unconventionality (or like, madness) being praised but also hated, being loved but also misunderstood. Where it falls— whether it’s within a partner, an indulgence in the past, an indulgence with work. Matters a lot. Because this can direct and shift the ‘deformation’ that Algor brings, in making us use the darker side of Venus there as well (laziness, indulgence, hellanistic tendencies with things we do want, control and freedom, wanting and desiring something)
Being careful and taking care at using your voice, or your influence (especially on the public/those around you) with a little more restriction and healing than most might help. Ahhh I dont really know what to say with fixed stars ;; Since in essence, it’s the ‘root’ of the problem and the point of power (well atleast with this one being in the Behenian list) If you know more about this than I do, please feel free to drop by and tell me what you think!! Even if you don’t, let me know what you think if you have time/energy is appreciated as well!! 💕 💕 💕 Thanks for sending in the asks aaah 💕💕
Since I didn’t know much, here are the sources I used💕:
AstrologyKing: Fixed Stars | Algor | Wikipedia Behenian Fixed Stars |
Darkstarastrology - Algor
Llewellyn Journal - Fixed Stars
Reddit/r/ - Venus conjunc. Algor
15 notes
·
View notes
Text
Something awesome project: Getting familiar with linux commands
The first task of my project was to get familiar with the linux commands. Instead doing a bunch of reading, I thought I could learn more by actually running the commands by myself, so I planned to achieve this goal by going through bandit overthewire. Actually, it did took longer to complete the game than I have expected. I started earlier than I panned so that I have more time to work on the next tasks. However, that didn’t happened. So I couldn’t get to the final rounds, but I might come back when I complete the other tasks. But this task was really interesting because it not only went through the basic linux commands, but also touches several kinds of encryption and concepts of SSH, SSL. It definitely made me more comfortable with the commands.
(EDIT:: after I’ve completed jazz’s exercise, I completed some more levels on bandit!)
These are the list of commands that I learned throughout this week. Also includes that was challenging or interesting to me.
find:
-size x will find a file with particular byte x.
-group x will find files which belongs to group x.
-user x will find files which belongs to the user x.
cat:
- basically reads file
- | grep is used to search for text
- to find a unique line: cat data.txt | sort | uniq -u (should be in this order)
base64 -d data.txt: base64 encoded data
Rot13 encryption is a simple letter substitution cipher that replaces a letter with the 13th letter after it.

(from Wikipedia)
xxd: hex dump
zcat: decompress and concatenate files to standard output
tar: (is a type of file) create, extract, or list files from a tar file
bzip2: compress file
Level 12:
Level Goal
The password for the next level is stored in the file data.txt, which is a hexdump of a file that has been repeatedly compressed. For this level it may be useful to create a directory under /tmp in which you can work using mkdir. For example: mkdir /tmp/myname123. Then copy the datafile using cp, and rename it using mv (read the manpages!)
Commands you may need to solve this level
grep, sort, uniq, strings, base64, tr, tar, gzip, bzip2, xxd, mkdir, cp, mv, file
For this level, I created a directory under /tmp. Because data.txt is a hexadump which is repeatedly compressed, we have to decompress the file and check until we get the correct format.
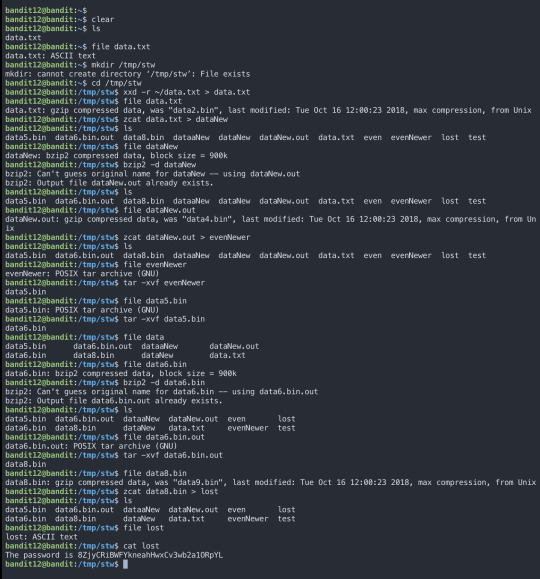
Level 13:
Level Goal
The password for the next level is stored in /etc/bandit_pass/bandit14 and can only be read by user bandit14. For this level, you don’t get the next password, but you get a private SSH key that can be used to log into the next level. Note: localhost is a hostname that refers to the machine you are working on
Commands you may need to solve this level
ssh, telnet, nc, openssl, s_client, nmap

As we can see from the above screenshot, we are now moved to bandit14.
Level14:
Level Goal
The password for the next level can be retrieved by submitting the password of the current level to port 30000 on localhost.
Commands you may need to solve this level
ssh, telnet, nc, openssl, s_client, nmap
For this level, I used telnet to connect to localhlost.
Telnet: telnet is a protocal used on the internet or local area network to provide bidirectional interactive text-oriented communication facility using a virtual terminal connection. (source: Wikipedia)
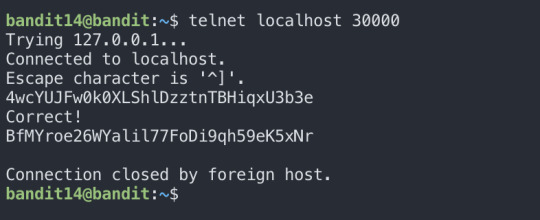
Level15:
Level Goal
The password for the next level can be retrieved by submitting the password of the current level to port 30001 on localhost using SSL encryption.
Helpful note: Getting “HEARTBEATING” and “Read R BLOCK”? Use -ign_eof and read the “CONNECTED COMMANDS” section in the manpage. Next to ‘R’ and ‘Q’, the ‘B’ command also works in this version of that command…
Commands you may need to solve this level
ssh, telnet, nc, openssl, s_client, nmap
I think level 15 was a bit tricky for me. The task required to submit the password of the current level to port 30001 on localhost using SSL encryption. Thus, I had to use SSL commands.
nmap / netcat : basic port scans
setuid(set user id) / setgid(set group id) : access rights flags that allow users to run executable and to change behaviour in directories
whoami = print the user name associated with the current effective user id
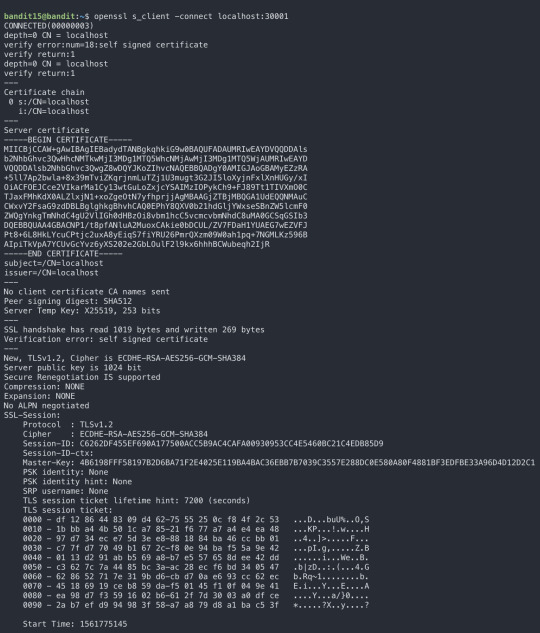
Level 16:
Level Goal
The credentials for the next level can be retrieved by submitting the password of the current level to a port on localhost in the range 31000 to 32000. First find out which of these ports have a server listening on them. Then find out which of those speak SSL and which don’t. There is only 1 server that will give the next credentials, the others will simply send back to you whatever you send to it.
Commands you may need to solve this level
ssh, telnet, nc, openssl, s_client, nmap
For level 16, we had to submit the password of the current level to a port on localhost in the range 31000 to 32000 to get the next level’s password. To accomplish this task, we had to find which of these ports have a server listening on them. Then find out which of those speak SSL and which don’t. There will be only 1 server that will give the next password.
We can run scans to find the listening server.
(netcat: also does basic port scans. Useful because many systems have that by default and we may have situations where we can’t use nmap.)

There were 2 opened, so I checked each of them. Then I found 31790 is the actual working port.
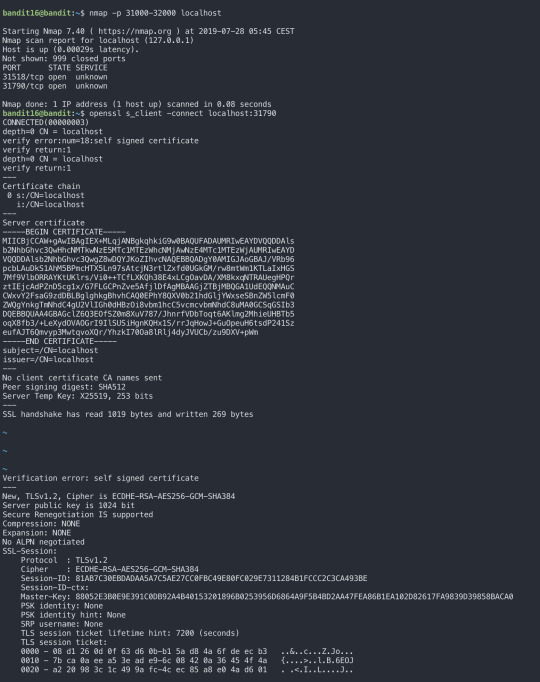
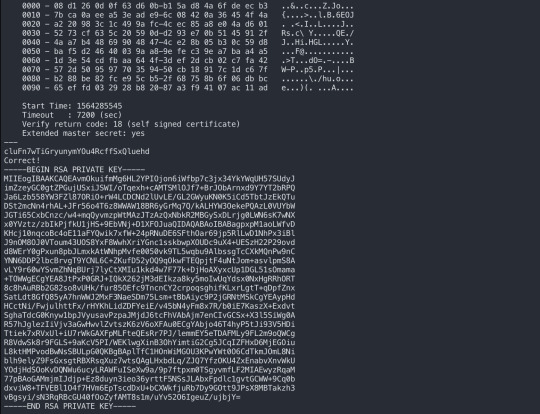
Now, we got an RSA private key to the next level. So we now have to save the key to a file and use it to ssh to the next level.
Level 17:
Level Goal
There are 2 files in the homedirectory: passwords.old and passwords.new. The password for the next level is in passwords.new and is the only line that has been changed between passwords.old and passwords.new
NOTE: if you have solved this level and see ‘Byebye!’ when trying to log into bandit18, this is related to the next level, bandit19
when we ls, we can see passwords.old. and passwords.new. The password for the lext level is in passwords.
we can simply use diff to find which line is different between two files. The password is: kfBf3eYk5BPBRzwjqutbbfE887SVc5Yd
Level18:
Level Goal
The password for the next level is stored in a file readme in the homedirectory. Unfortunately, someone has modified .bashrc to log you out when you log in with SSH.
Commands you may need to solve this level
ssh, ls, cat
The password for this level is stored in readme which is located in the home directory. However, .bashrc has been modified so that it logs me out when I log in with SSH. So when we try to connect to bandit18, it prints out an error message. So I tried cat when I’m ssh-ing.

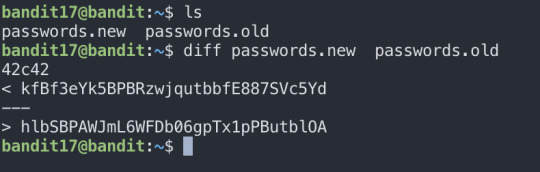
Level19:
Level Goal
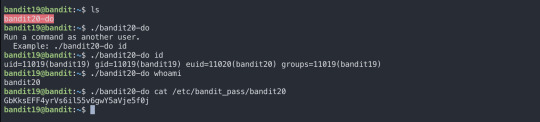
To gain access to the next level, you should use the setuid binary in the homedirectory. Execute it without arguments to find out how to use it. The password for this level can be found in the usual place (/etc/bandit_pass), after you have used the setuid binary.
Level20:
Level Goal
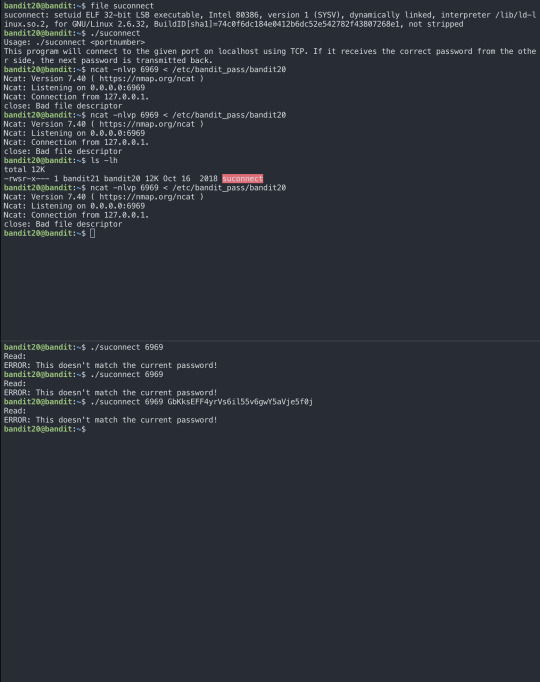
There is a setuid binary in the homedirectory that does the following: it makes a connection to localhost on the port you specify as a commandline argument. It then reads a line of text from the connection and compares it to the password in the previous level (bandit20). If the password is correct, it will transmit the password for the next level (bandit21).
NOTE: Try connecting to your own network daemon to see if it works as you think
Commands you may need to solve this level
ssh, nc, cat, bash, screen, tmux, Unix ‘job control’ (bg, fg, jobs, &, CTRL-Z, …)
Level 21:
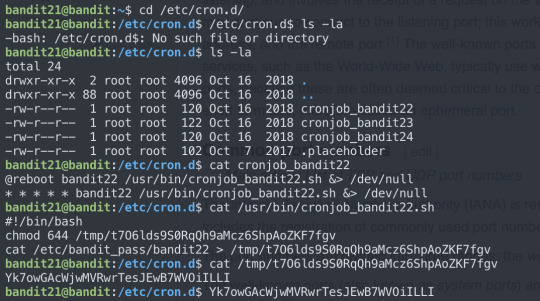
Level Goal
A program is running automatically at regular intervals from cron, the time-based job scheduler. Look in /etc/cron.d/ for the configuration and see what command is being executed.
Commands you may need to solve this level
cron, crontab, crontab(5) (use “man 5 crontab” to access this)
level 21 was quite interesing. The level required cron job, which is a time-based job scheduler. It is suitable for scheduling repetitive tasks.
Level24:
Level Goal
A daemon is listening on port 30002 and will give you the password for bandit25 if given the password for bandit24 and a secret numeric 4-digit pincode. There is no way to retrieve the pincode except by going through all of the 10000 combinations, called brute-forcing.
for level 24, we had to brute force to get the code, so i created a script. Until now, I never had experience of write a script by myself(always used given files), so I think it was a good practice for me.

0 notes
Text
Letter to an interested student.
I had the good luck to chat with a high-school student who was interested in doing the most good she could do with hacker skills. So I wrote the letter I wish someone had written me when I was an excitable, larval pre-engineer. Here it is, slightly abridged.
Hi! You said you were interested in learning IT skills and using them for the greater good. I've got some links for learning to code, and opportunities for how to use those skills. There's a lot to read in here--I hope you find it useful!
First, on learning to code. You mentioned having a Linux environment set up, which means that you have a Python runtime readily available. Excellent! There are a lot of resources available, a lot of languages to choose from. I recommend Python--it's easy to learn, it doesn't have a lot of sharp edges, and it's powerful enough to use professionally (my current projects at work are in Python). And in any case, mathematically at least, all programming languages are equally powerful; they just make some things easier or more difficult.
I learned a lot of Python by doing Project Euler; be warned that the problems do get very challenging, but I had fun with them. (I'd suggest attempting them in order.) I've heard good things about Zed Shaw's Learn Python the Hard Way, as well, though I haven't used that method to teach myself anything. It can be very, very useful to have a mentor or community to work with; I suggest finding a teacher who's happy to help you with your code, or at the very least sign up for stackoverflow, a developer community and a very good place to ask questions. (See also /r/learnprogramming's FAQ.) The really important thing here is that you have something you want to do with the skills you want to learn. (As it is written, "The first virtue is curiosity. A burning itch to know is higher than a solemn vow to pursue truth.") Looking at my miscellaneous-projects directory on my laptop, the last thing I wrote was a Python script to download airport diagrams from the FAA's website (via some awful screenscraping logic), convert them from PDFs to SVGs, and upload them to Wikimedia Commons. It was something I was doing by hand, and then I automated it. I've also used R (don't use R if you can help it; it's weird and clunky) to make choropleth maps for internet arguments, and more Python to shuffle data to make Wikipedia graphs. It's useful to think of programming as powered armor for your brain.
You asked about ethical hacking. Given that the best minds of my generation are optimizing ad clicks for revenue, this is a really virtuous thing to want to do! So here's what I know about using IT skills for social good.
I mentioned the disastrous initial launch of healthcare.gov; TIME had a narrative of what happened there; see also Mikey Dickerson (former SRE manager at Google)'s speech to SXSW about recruiting for the United States Digital Service. The main public-service organizations in the federal government are 18F (a sort of contracting organization in San Francisco) and the United States Digital Service, which works on larger projects and tries to set up standards. The work may sound unexciting, but it's extraordinarily vital--veterans getting their disability, immigrants not getting stuck in limbo, or a child welfare system that works. It's easy to imagine that providing services starts and ends with passing laws, but if our programs don't actually function, people don't get the benefits or services we fought to allocate to them. (See also this TED talk.)
The idea is that most IT professionals spend a couple of years in public service at one of these organizations before going into the industry proper. (I'm not sure what the future of 18F/USDS is under the current administration, but this sort of thing is less about what policy is and more about basic competence in executing it.)
For a broader look, you may appreciate Bret Victor's "What Can a Technologist Do About Climate Change?", or consider Vi Hart and Nicky Case's "Parable of the Polygons", a cute web-based 'explorable' which lets you play with Thomas Schelling's model of housing segregation (i.e., you don't need actively bitter racism in order to get pretty severe segregation, which is surprising).
For an idea of what's at stake with certain safety-critical systems, read about the Therac-25 disaster and the Toyota unintended-acceleration bug. (We're more diligent about testing the software we use to put funny captions on cat pictures than they were with the software that controls how fast the car goes.) Or consider the unintended consequences of small, ubiquitous devices.
And for an example of what 'white hat' hacking looks like, consider Google's Project Zero, which is a group of security researchers finding and reporting vulnerabilities in widely-used third-party software. Some of their greatest hits include "Cloudbleed" (an error in a proxying service leading to private data being randomly dumped into web pages en masse), "Rowhammer" (edit memory you shouldn't be able to control by exploiting physical properties of RAM chips), and amazing bug reports for products like TrendMicro Antivirus.
To get into that sort of thing, security researchers read reports like those linked above, do exercises like "capture the flag" (trying to break into a test system), and generally cultivate a lateral mode of thinking--similar to what stage magicians do, in a way. (Social engineering is related to, and can multiply the power of, traditional hacking; Kevin Mitnick's "The Art of Deception" is a good read. He gave a public talk a few years ago; I think that includes his story of how he stole proprietary source code from Motorola with nothing but an FTP drop, a call to directory assistance and unbelievable chutzpah.)
The rest of this is more abstract, hacker-culture advice; it's less technical, but it's the sort of thing I read a lot of on my way here.
For more about ethical hacking, I'd be remiss if I didn't mention Aaron Swartz; he was instrumental in establishing Creative Commons licensing, the RSS protocol, the Markdown text-formatting language, Reddit and much else. As part of his activism, he mass-harvested academic journal articles from JSTOR using a guest account at MIT. The feds arrested him and threatened him with thirty-five years in prison, and he took his own life before going to trial. It's one of the saddest stories of the internet age, I think, and it struck me particularly because it seemed like the kind of thing I'd have done, if I'd been smarter, more civic-minded, and more generally virtuous. There's a documentary, The Internet's Own Boy, about him.
Mark Pilgrim is a web-standards guy who previously blogged a great deal, but disappeared from public (internet) life around 2011. He wrote about the freedom to tinker, early internet history, long-term preservation (see also), and old-school copy protection, among other things.
I'll leave you with two more items. First, a very short talk, "wat", by Gary Bernhardt, on wacky edge cases in programming language. And second, a book recommendation. If you haven't read it before, Gödel, Escher, Bach is a wonderfully fun and challenging read; it took me most of my senior year of high school to get through it, but I'd never quite read anything like it. It's not directly about programming, but it's a marvelous example of the hacker mindset. MIT OpenCourseWare has a supplemental summer course (The author's style isn't for everyone; if you do like it, his follow-up Le Ton beau de Marot (about language and translation) is also very, very good.)
I hope you enjoy; please feel free to send this around to your classmates--let me know if you have any more specific questions, or any feedback. Thanks!
4 notes
·
View notes
Note
Re: The Wendigo argument, there's this instability trait which is prevalent on the internet these days. There are a lot of very unstable young men and women who try to give themselves meaning and worth by deeming themselves "gatekeepers" of either political correctness or cultural appropriation. Down to a man the ones I've seen in CS and in other communities are typically insecure to the point of near-mania and with any number of mental issues. Gatorbite and VCR are like poster boys. 1 of 2
- The best way to deal with this sort of nonsense isn’t to argue with them which is ultimately narcissistic supply and a means for them to try and show how morally “superior” they are to their victim, it’s simply best to flat out block them if needed or ignore them. Might seem harsh but I have personal issue with the way they use issues of gender and culture to bully every community they touch and to intimidate younger people with threats of dubbing them “bad people” or public defamation. 2 of 2
(1)Citing “Windigo Psychosis: the anatomy of an emic-etic confusion” an academic journal by a group of anthropologists: “When the windigo phenomenon is considered from the point of view of group sociodynamics rather than from that of individual psychodynamics, the crucial question is not what causes a person to become a cannibalistic maniac, but under what circumstances a Northern Algonkian is likely to be accused of having become a cannibalistic maniac(2)and thus run the risk of being executed as such. It is argued that those so executed were victims of triage homicide or witch hunts, events common in societies under stress.” Hell just that alone should be enough. Algonkians and other natives were straight up murdered over a mythological creature that was used against them. No one besides Algonkians are in any placeto make a CS/adopt design based on something with such a dark historical context.(3)Looking beyond Wikipedia could have easily told you this. Also, no anon, you fucking idiot, the wendigo was a thing before the term “wendigo psychosis” even existed as a culture-bound syndrome. AND IF YOU PUT TWO AND TWO TOGETHER… usually “culture-bound” syndromes are inherently racist and untrue.
Didn’t vcr-wolfe get called out for something too tho like if you’re gonna be the 1# sjw for everything wouldn’t it be ironic to get a call out for a shitty thing you’ve done
OH MY GOD. that post is LITERALLY a whole fucking year ago. once again vendetta anons pull shit from their ass. that character isnt even a freaking adopt, and vcr doesnt even have a species and has hardly sold maybe 3 adopts in the last 6 months? maybe if yall weren’t reaching so far into the past for some petty bs we could stay on topic for once lmao
Wait is there any proof of them being white?? I’ve I beleive I saw vcr wolfe say they’re native or smth before. But the thunderbird thing is so stupid lmao in the Wild West tm a lot of towns only had like white people because natives were driven out. I mean depending on the characters setting. Plus there’s majority of white people. Thunderbirds aren’t like a wendigo, you can say it’s name and talk about it and it wouldn’t attack just you so I don’t see a problem lmao
I think the issue here is you’re going to have people from a culture saying something is offensive, but someone else from the same culture saying that it’s not offensive and they’re glad you’re taking interest in their culture in the first place. See: Every East Asian mythology based CS out there, basically. Literally there is no right or wrong across the board, nobody “wins”, and that’s just how life is. Grey morality exists, just let people make content they enjoy ffs.
I think the issue here is you’re going to have people from a culture saying something is offensive, but someone else from the same culture saying that it’s not offensive and they’re glad you’re taking interest in their culture in the first place. See: Every East Asian mythology based CS out there, basically. Literally there is no right or wrong across the board, nobody “wins”, and that’s just how life is. Grey morality exists, just let people make content they enjoy ffs.
People act like VCR-WOLFE’s word is law or something. I can see being passionate about causes and all but they take the cake for extremism. People should be allowed to make a character any race to fit their preferences or just their likes, of course within being respectful. I think VCR gets some kind of high and mighty buzz by going after people, especially us evil whites.
multiple poc: hey this is offensive. yall: uhm idk that sounds fake :/. one poc: yeah it’s fake. yall, digging your claws in: YOU SEE? WE WERE RIGHT ALL ALONG! THIS ONE POC HAS VALIDATED OUR RACISM FOREVER! *pterodactyl screech*
Is vcr wolfe a serious account or is it just some random asshole that enjoys stirring up people by being the dictionary image for the social justice warrior stereotype that literally everyone hates. I have seen them be a little weiner before (cue them accusing me of misgendering them), I would take nothing they say seriously because honestly they are a joke.
Why does this Wendigo shit still come up? This is the same as the sombrero Mario crap that blew up on twitter. Quit speaking for other cultures that you don’t belong to. Native American people have expressed both support and distain for the issue. A wendigo is a monster, why is making a monster be a monster suddenly such a taboo? You can white knight the subject to death, you aren’t in the wrong but you’re certainly not in the right either. If you don’t support it then don’t.
context: the wendigo was used as a slur and label for natives/Algonquins who were mentally ill (aka called them canibals; hence “wendigo psychosis”) and was used to justify their genocide so making an adopt out of such a theme isn’t taken lightly as this has a historic context you can’t erase (source: I live in the algonquin northeast) (½)mythical creatures such as vampires and werewolves come from a ton of different cultures and generally they’ve been reinterpreted so often that it doesn’t retain its origin context. here’s another point- the Algonquin people still exist. despite the mythical creature being used against them they are more than in the right to use it how they see fit. it’s sorta like how the lgbt community took back the word “queer” while a straight person should definitely not call a gay person “a queer” (2/2)
Btw the wendigo isn’t a legend ! It’s a tale told up north and is taken very seriously. The reason people don’t want you to use it is because saying the name is suppose to make you a victim ( aa I forgot I’m sorry ) BUT I still beleive if you do your research u should be okay like just don’t make it a xD murderer monster cannibal
The thing with a wendigo character is not everyone is going to see/research the full story of them, because they’ve been big in media for awhile now. Until Dawn, Supernatural, even My Little Pony. And tbh, it’s something that while drifting away from the original intent, does bring traditional stories to the homes of others, who otherwise would never know the term, or know of the monsters. Mass media is keeping our culture alive, even as we kill it ourselves by not letting others near it.
this just in: vcr-wolfe solely dictates what can and cannot be used from cultures in character designs
VCR is mixed actually lol
VCR-wolfe is actually half mexican. So maybe don’t be fucking racist?
Can we stop the “ insulting = I’m right” thing it’s so stupid. If someone’s discussing something or DOESNT KNOW you don’t have to insult them. You look like a jerk js ( this is towards the anon in the wendigo post about wendigo-psychosis). The person was just basically saying ‘fun fact’ no need to call them a fucking idiot jeez
Mixed with what? I’ve seen this argument on another drama site. If they are mixed, they are white enough to pass as entirely white. Even then your word isn’t some divine rule on what is right & wrong. VCR constantly leans on the “I’m mentally ill” schtick, maybe they should focus on themselves for a bit & quit badgering people that want to enjoy another culture. Geez would bringing back segregation make you fuckers happy, let start DNA testing before you can draw or create a non white character.
The anon about wendigo pychosis got their panties in a twist lmao. If we can’t use anything with “” dark historical context" or “ only ____ are allowed to use this” then we all might as well sick to our own religions and make nothing but what we’re born into/practice. So if you’re native and you make a nun rabbit prepare for a ass chewing ! :( keep whining about everything you just sound like a broken record lmao you “” fucking idiot “”
Wait so if vcr-Wolfe isn’t native what say do they got in it then??? If they’re Mexican/white ??? Why don’t they step down and let real native/mixed natives speak for themselves and not have someone gatekeeping their beliefs Jesus lord I LOVE when none natives try to speak for my culture
Multi poc people: this is bad y'all: SEE ITS EVIL Multi poc: its alright do your research tho Y'all: WTF THATS BAD WHAT ABOUT OUR TOKEN FRRIENDS SAYING ITS OKAY AAAA Get your head out your ass dude there’s two sides to the shit just because people back your opinion doesn’t mean you can use your poc friends as a way to wave it around. You’re being just as bad to diss other peoples opinions FROM THE SAME GROUP lmao
i’m ndn, and personally my opinion on the entire thing is, don’t make wendigo characters for profit in general, especially if you’re not ndn. i don’t even like seeing my brothers, sisters, and two-spirited brethren do it. it’s one thing to make one for personal use, and as long as you’re not making them uwu edgy wendigo doggo that eats people uwu then.. honestly? who cares. but stop making wendigos when you know nothing about the culture, or that many tribes have different lore on it.
also the entire thing of wendigo psychosis being a thing: false. that was a term made up waaaaay after the fact. the thing is, there are multiple tribes that believe in wendigo, many have different names for it, and there’s even variations born differently like wechuge. but the fact of the matter is that most people don’t even read in or pay attention beyond the edgy cannibal shit to know that a wendigo is pretty much a skeleton made out of ice in most tribal cultures LMAO not a fucking dog
the entire purpose of people saying ‘hey if you don’t understand it, don’t make it’ is so that you don’t make a mockery of our legends, lore, culture, and history. not so you can’t have fun. it’s like me making a black character and making them stereotypical and completely shitting on it, and then doubling back with the ‘oh i made a black character so i understand black struggles’ shit like. it’s not cute when you do it to any race or culture so stop.
Why is it a crime to make Wendigo characters but when some family lines (before me, I don’t care) wouldn’t approve of the use of nordic mythos no one bats an eye at adopts that play off them, or for that matter, movies and shows that paint them in completely inaccurate ways. You can’t close the mythos of one culture & make it untouchable while saying some are fine to take from, that isn’t how it works.
VCR is mixed Mexican Navajo and saying a mixed person is basically white is just fucking ugly and racist as shit, holy shit
Nordic myth is white myth and white people are not in any danger of having their culture stamped out and then reinterpreted by their oppressors while they are punished for trying to access it, unlike, you know, Native American myth. Reverse racism isn’t real
‘nordic myth is white myth and–’ it’s still someone’s religion, so yeah actually it still stands, either all religions are sacred inherently and are off limits or none are and you can’t bitch and whine and moan and throw a social justice tantrum into that being untrue, people making shitty wendigo ocs isn’t stamping anyone’s religion out any more than marvel making a shitty version of loki is, they’re equally stupid but harmless
Except there is a huge fucking difference between open and closed religions? Nordic pagan worship is an open religion. Native folk religions are closed religions. Christianity is an open religion. The Amish are, by and large, a closed sect. Sincerely, an nordic heathen who knows full well what people can take from my belief system
“Werehyenas can’t be made into species and characters because they appropriate African culture uwu~” The hyena and werehyena have a very similar negative connotation in African folklore by you don’t see them getting so butt hurt over them being used. I get so sick and tired of people saying you can’t base a CS or Character off of a fictional monster. I guess I should toss out my Church Grim OC because that’s an insult to English and Scandinavian Folklore as it guards a place considered sacred
literally no one is saying dont ever do it theyre saying be respectful, follow the originating culture’s traditions, and dont slap a native myth on a white character because its disrespectful to the culture you supposedly like so much youre pulling from them. entitled much?
"my friend finds this thing offensive! your friend doesn't find this offensive? stop tokenising your friends, also YOUR friends are WRONG!" so native voices only count when they agree with you? maybe accept that an individual can't speak for an entire group, and that people from within the same culture can have very different ideas about what cultural appropriation even is.
Everyone yelling about wendigos when they're ignoring the fact Sincommonstitches literally made a design based off the imperial rising sun (you know- rape of Nanking?? Children and women slaughtered?) and day of the dead (mexican holiday already shit on for $$$) guardians, sold them for profit, and then bitched in a journal when they got called out how they shouldn't have to deal with this and they need their fiance to handle their pr now lmfao
Keeping all this in one post, anything new sent in will be added to this post. While it is on topic, it is far from species related.
2 notes
·
View notes
Note
o(〃^▽^〃)o i'm greedy so here we go: 2, 5, 10, 11 (i know for some people it needs to be completely quiet but for me i need music), 12, 17, 20, 21, aaaaaaand 49 (。’▽’。)♡
2. things that motivate you. a lot of my motivation actually comes with sharing my fics and ideas with people. sure the Validation™ is a part of it, but also just talking about the idea and getting excited about it enough with a friend to actually write it.... That’s usually what gets a fic going for me lmao.
5. since how long do you write? The very first thing I remember writing is this shitty Inuyasha fanfic back in probably like… 2007? First Naruto fanfic I put online was made in either 07 or 08 lmao. It was terrible. Awful. The thing I wrote in 2010 for Naruto got like super popular, but was still bad. Idk which of those to mark as when I first started writing, though. Each one is just… A different start, sorta.
10. how do you do your researches? Google and Wikipedia are my friends. If I don’t know something I’ll just ask google, and 99% of the time I go to a wikia of some sort.
11. do you listen to music when writing? Sometimes. I used to all the time but I’ve started not doing it and found I can focus a lot better lmao.
12. favorite place to write. My desk. Just alone at my desk is best place.
17. favorite AU to write. I love writing college AUs, but one of these days I’m gonna get a fantasy AU out there, just u wait
20. favorite character to write. It’s a tie between Oikawa and Iwaizumi, honestly. Oikawa’s fun because he’s… very Extra with how he acts. And I adore writing Iwaizumi especially for fluff. Writing him in any romantic sense is a trip because he feels so tsundere but also soft af.
21. least favorite character to write. I don’t have any one character in mind, tbh. I mostly just don’t like writing about characters I also don’t read about. An example would be Tsukishima, I guess. I loved him in season 3 and he’s growing on me, but I don’t really care for him outside of canon? Idk it’s hard to articulate lol
49. writing advice. I’m gonna preface by saying I am no means an expert in writing, but these are some things I’ve learned over the years.First off, if you’re writing and a scene just isn’t cooperating, either skip it for now and come back later, or just push through it. You can always come back and edit it later.Secondly, reread your old stuff. I know it can be cringey and terrible and make you wish you didn’t have eyes, but it’s good. Realize what it is you don’t like about what you’re reading, and learn from it, basically.Third, if you’re having a writing block, step away from it. Don’t force anything if nothing is coming lol. Whether it’s a day or even a week, take a break, but always come back to it.Fourth, thesaurus.com (or any thesaurus source) is your friend. Use it well.Fifth, do not be afraid of “said”. Don’t make your character “chuckle” or “muse” or whatever else if all they’re doing is simply talking. Of course, don’t use “said” every single time there’s dialogue, but it’s okay if it’s used more than the other words. It is what the character is doing, after all.also omg also thank you for even considering asking me for advice??? oh my god
2 notes
·
View notes
Text
Unintuitive equivalency involving multiple dual operators
Obligatory apologies if this subject is too "homework-y" for the mainline math sub.
I tend to get exceedingly long-winded when I type out reddit posts so I will do my best to keep this short. Skip to the quoted material if you don't eff with mostly-unnecessary context.
I am an ex math major who had my higher-education cut short for medical reasons. I have always been fond of recreational maths. Dual numbers in particular have always tickled my brain in a particular way. This question specifically I have been coming back to for over a year with little-to-no forward progress. I have done my best to read the appropriate reference material, but (as most technical writing online) it is rather dense. Here's hoping the answer to this leans-trivial or at least can be condensed to a handful of wikipedia articles rather than the 30 I've been going back to.
I am less familiar with all of this now than I once was; its been a while I've been back to this. Sorry. Hopefully I haven't retreaded some of my previous mistakes.
Also I've never used latex and cannot find a reliable plugin/script for firefox and thus have no way of knowing if this will display properly. At the very least it is formatted poorly. Sorry. I will be including a link to an image of the rendered text in case I wiff the formatting and/or for mobile users
I also realize I include a significant amount of math that's likely unnecessary. I get I could've condensed this to like three lines; most papers I read on grassman numbers didn't bother to touch this algebraic stuff. Or if they did they wrote it in lanquage i couldn't understand. It is included here to give context to my thought process.
[; \varepsiloni * \varepsilon_j = -\varepsilon_j * \varepsilon_i :, \ Let: \varepsilon_i = \varepsilon_j:; \varepsilon_i * \varepsilon_i = 0 = -\varepsilon_i * \varepsilon_i \ \dot{.\hspace{.095in}.}\hspace{.5in} \varepsilon_i2 = 0\ \forall\ \varepsilon \ \dot{.\hspace{.095in}.}\hspace{.5in} \varepsilon : \textrm{are } \emph{nilpotent} \ \ (\varepsilon_i + \varepsilon_j)2 = \varepsilon_i2 + \varepsilon_i \varepsilon_j + \varepsilon_j \varepsilon_i + \varepsilon_j2 = 0 + \varepsilon_i \varepsilon_j - \varepsilon_i \varepsilon_j + 0 = 0 \ (\sum{k=0}{n} \varepsilon{i_k})2 = \sum{k=0}{n} \varepsilon{i_k}2 + \sum{k=0}{n}(\varepsilon{i_k}\sum{j=k+1}{n}\varepsilon_{i_j}) - \sum{k=0}{n}(\varepsilon{ik}\sum{j=k+1}{n}\varepsilon_{i_j}) = 0 \ \dot{.\hspace{.095in}.}\hspace{.5in} \textrm{sums of } \varepsilon: \textrm{are } \emph{nilpotent} \ \ ex = 1 + x + \frac{x2}{2!} + ... + \frac{xn}{n!} + ... = \sum{i=0}{n} \frac{xn}{n!} \ e\varepsilon = 1 + \varepsilon :, : (\textrm{for } \emph{all} \textrm{ nilpotents of degree 2}) \ e{\varepsilon_i+\varepsilon_j} = 1 + \varepsilon_i + \varepsilon_j : (\textrm{as } \varepsilon_i + \varepsilon_j \textrm{ is nilpotent}) \ \dot{.\hspace{.095in}.}\hspace{.5in} e{\sum{k=0}{n} \varepsilon{i_k}} = 1 + \sum{k=0}{n} \varepsilon{i_k} \ \ \prod{k=0}{n}(1 + \varepsilon{i_k}) \ = 1 + \varepsilon{i0} + \varepsilon{i1} + ... + \varepsilon{in} \ + \varepsilon{i0}\varepsilon{i1} + \varepsilon{i0} \varepsilon{i2} + ... + \varepsilon{i0} \varepsilon{in} \ + \varepsilon{i1}\varepsilon{i2} + \varepsilon{i1}\varepsilon{i3} + ... + \varepsilon{i1}\varepsilon{in} \ + ... \ + \varepsilon{i{n-1}}\varepsilon{in} \ + \varepsilon{i0}(\varepsilon{i1}\varepsilon{i2} + \varepsilon{i1}\varepsilon{i3} + ... + \varepsilon{i1}\varepsilon{in}) \ + \varepsilon{i1}(\varepsilon{i2}\varepsilon{i3} + \varepsilon{i2}\varepsilon{i4} + ... + \varepsilon{i1}\varepsilon{in} + ... + \varepsilon{i{n-1}}\varepsilon{in}) \ + ... \ + \varepsilon{i{n-2}}\varepsilon{i{n-1}}\varepsilon{i{n}} \ + ... \ + \varepsilon{i{0}}\varepsilon{i{1}}...:\varepsilon{i{n-1}}\varepsilon{i{n}} \ \ =\prod{k=0}{n}e{\varepsilon_{i_k}} \ \ = e{\sum{k=0}{n}\varepsilon{i_k}} \ \ = 1 + \sum{k=0}{n}\varepsilon{ik} = 1 + \varepsilon{i0}+\varepsilon{i1}+ ... + \varepsilon{i{n-1}} + \varepsilon{i_n} ;]
SUMMARY AND WHY IT MATTERS:
These epsilon operators are defined to anti-commute with one another. As a result each operator is nilpotent (epsilon2 = 0)
Sums and products of these operators are also nilpotent. ( i think? maybe this is as simple as me messing up the non-commutative multiplication.)
enilpotent = 1 + nilpotent
Every combination of n coefficient-less operators can be generated with the provided product formula
the product can be rewritten as the product of exponential functions which can be condensed into a single exponential function
this exponential can be rewritten as a simple sum of single operators
My problem is that this sum is included in the original product (which it is ostensibly equal to), but the product goes on to include more items. A few questions arise:
Where did I mess up this math?
when using one of these numbers is it simply identical to leave out the remainder of the original product? I can see intuitively why this may be the case but do not know how to "prove" or otherwise explore this exhaustively.
If there is nothing wrong this result, does it continue to hold with an infinite amount of operators? (i am interested in exploring the properties of these for myself)
Can a similar result be found when considering the "full" sum where each variable has unique coefficients? (i am interested in exploring the properties of these variations myself; this is what got me looking into this in the first place)
if not, do there exist coefficients where the equality still holds true?
why are these "supernumbers" always formatted even differently than this? example (it is particularly strange to me that, in the case of the infinite, I am hardpressed to find an example that does not include the converging factorials) *in Dewitt's paper on the subject (afaik the premier source on the topic) why does he say "the soul need not be nilpotant"? is this related? incomplete google archive. (Found directly under 1.1.4)
I would appreciate any insight on this topic. I find it hard to maintain my interest in mathematics for very long when I inevitably run into large roadblocks like these. I am not opposed to doing the research; the roadblock for me is knowing what exactly to research. I endeavor to get to a point where I can stay out of the hospital for long enough to continue taking classes; i can practically feel my synapses rerouting around the rudimentary base I had built up five years ago.
Please do not feel the need to speculate on my knowledge-base or use that to temper your response. I have more than enough time to actually look into this--the right way. I finished a significant amount of my undergraduate mathematics in high school and have a handful of semesters under my belt filling out that base. I suspect I am a course or two away from this being a "well duh"-type problem.
EDIT: sorry in advance if i do not reply to your comments. I promise they are no less appreciated. I cannot use my hands for long periods of time and I am afraid i may have already overdid it with all this. My access to people who are generous to notate for me is limited and i am working on a more permanent accessibility solution
submitted by /u/SigmaGod
[link] [comments]
from math https://ift.tt/3ab6zs2
from Blogger https://ift.tt/3cjgCwT
0 notes
Text
My Data Is NOT Your Data
Research the GDPR online privacy regulations that went into effect last Friday. Link to an official government communication from the EU or another governmental body about these new technological restrictions. Then, find an example of art or advertising in the the city you’re in (not online) that deals with similar issues of privacy or surveillance.

If you click “Keep reading” below, you are acknowledging that I am not keeping any of your data to sell it. Frankly, I don’t really care. I already know that you like Stranger Things. Tumblr on the other hand, probably does. I don’t know, I’m not Tumblr. Anyways, let’s get to the post! Auf Geht’s!
This past Friday, The European Union passed a bill called the GPDR (General Data Protection Regulation). In general, this bill prohibits companies and websites to collect personal information on you without your knowing and selling that information. Your data is YOUR data. You own it, at least, that’s what the EU thinks (@ America, where u at?.) In the past, all that was needed was “consent” in the form of checking a little box and not reading the Terms and Agreements. This is an astounding step in the fight for internet privacy. Now, companies that operate in the EU cannot sell your information gathered (i.e. social media interests, Buzzfeed quizzes, etc.). In addition, if you are in the EU, you can access ALL of the data that social media companies have one you (Thanks Dr. Scott!). We had a really good discussion in class today about the whole debate and how this affects Europe. I won’t go too much into detail, because it’s all over the interenet right now.... except for, who could’ve guessed it, the good ole U.S. of A.! I have yet to see ANYTHING from any news source in America about this. That may be, because of the GDPR, we’ll just say for now, that America doesn’t care. There are more stories that are more important in the U.S. than some silly little European bill. Yay capitalism! Thanks Trump! (Don’t quote me on that. I cringed so much when typing it.)
Anyways, If you want to see the GDPR bill/law/thing in its entirety, look here!
or here if you hate embedded links: https://gdpr-info.eu/

I was walking around Berlin earlier today, specifically near the Oberbaumbrücke, and I came across a small little sticker ad. All that was on it was “FIGHT FOR YOUR DIGITAL RIGHTS” and a website thats right here: https://netzpolitik.org/
Looking more into this website, I found that this is an actual news website dedicated to fighting for internet rights and digital freedoms. It’s name is called Netzpolitik.org, or more simply, Netzpolitik. Of course, the whole site is in German, and I am not reallt in the mood to translate, so here is their wikipedia page:
https://de.wikipedia.org/wiki/Netzpolitik.org#Ermittlungen_wegen_Verdachts_des_Landesverrats (Pro-tip: Translate it in English if you have Chrome bc there is no English page.)
This is SO COOL! I’m not sure if they were for or against the GDPR bill, but they do seem to be very vehement in their beliefs. They were actually investigated bu the German government for TREASON. Yep. That happened. I do believe that they were all too happy when the law was passed. I’ll confirm this it in a few years when I’m actually fluent in German.
All in all, this little sticker is an eye-opener to the theoretical public sphere of internet and digital rights. This obviously is corrupted, since I see A LOT of bias and feelings involved, but hey, it’s a cool conversation starter in the U.S. when it comes to your rights on the internet.
Here are some other cool street art that I found, that have to do with privacy, surveillance, and the internet in general. Some are from the internet, others are some that i have found walking around this past month.

This is more relating to America, but I feel it’s still relevant. Was the Patriot Act a mistake? More at a 11. Back to you John.
THIS is what i was originally looking for, since it’s a quick train and bus ride from our hotel. If you look now (like I did) you’ll see that its ALL GONE. It’s painted over black. There’s also construction, which is probably why it’s not there, but this got me LIVID when I found out it’s not there... NOT OKAY :’(

If you imagine the rocks are iPads, Macs, social media, or any other computer technology, I feel like this would be a great way to represent today’s global culture when it comes to electronics and social media. Plus that curry and chilly place looks really good, but I don’t know if my “bowls” can handle it.

I think we all need to be on Do Not Disturb mode when it comes to the internet most times. Especially when the FBI agent assigned to me wants to talk to me through my computer.
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from Blogger http://ift.tt/2mZ44C0
via IFTTT
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://moz.com/blog/an-investigation-into-googles-maccabees-update
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://ift.tt/2mXRXp5
via IFTTT
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
An Investigation Into Google’s Maccabees Update
Posted by Dom-Woodman
December brought us the latest piece of algorithm update fun. Google rolled out an update which was quickly named the Maccabees update and the articles began rolling in (SEJ , SER).
The webmaster complaints began to come in thick and fast, and I began my normal plan of action: to sit back, relax, and laugh at all the people who have built bad links, spun out low-quality content, or picked a business model that Google has a grudge against (hello, affiliates).
Then I checked one of my sites and saw I’d been hit by it.
Hmm.
Time to check the obvious
I didn’t have access to a lot of sites that were hit by the Maccabees update, but I do have access to a relatively large number of sites, allowing me to try to identify some patterns and work out what was going on. Full disclaimer: This is a relatively large investigation of a single site; it might not generalize out to your own site.
My first point of call was to verify that there weren’t any really obvious issues, the kind which Google hasn’t looked kindly on in the past. This isn’t any sort of official list; it's more of an internal set of things that I go and check when things go wrong, and badly.
Dodgy links & thin content
I know the site well, so I could rule out dodgy links and serious thin content problems pretty quickly.
(For those of you who'd like some pointers on the kinds of things to check for, follow this link down to the appendix! There'll be one for each section.)
Index bloat
Index bloat is where a website has managed to accidentally get a large number of non-valuable pages into Google. It can be sign of crawling issues, cannabalization issues, or thin content problems.
Did I call the thin content problem too soon? I did actually have some pretty severe index bloat. The site which had been hit worst by this had the following indexed URLs graph:
However, I’d actually seen that step function-esque index bloat on a couple other client sites, who hadn’t been hit by this update.
In both cases, we’d spent a reasonable amount of time trying to work out why this had happened and where it was happening, but after a lot of log file analysis and Google site: searches, nothing insightful came out of it.
The best guess we ended up with was that Google had changed how they measured indexed URLs. Perhaps it now includes URLs with a non-200 status until they stop checking them? Perhaps it now includes images and other static files, and wasn’t counting them previously?
I haven’t seen any evidence that it’s related to m. URLs or actual index bloat — I'm interested to hear people’s experiences, but in this case I chalked it up as not relevant.
Appendix help link
Poor user experience/slow site
Nope, not the case either. Could it be faster or more user-friendly? Absolutely. Most sites can, but I’d still rate the site as good.
Appendix help link
Overbearing ads or monetization?
Nope, no ads at all.
Appendix help link
The immediate sanity checklist turned up nothing useful, so where to turn next for clues?
Internet theories
Time to plow through various theories on the Internet:
The Maccabees update is mobile-first related
Nope, nothing here; it’s a mobile-friendly responsive site. (Both of these first points are summarized here.)
E-commerce/affiliate related
I’ve seen this one batted around as well, but neither applied in this case, as the site was neither.
Sites targeting keyword permutations
I saw this one from Barry Schwartz; this is the one which comes closest to applying. The site didn’t have a vast number of combination landing pages (for example, one for every single combination of dress size and color), but it does have a lot of user-generated content.
Nothing conclusive here either; time to look at some more data.
Working through Search Console data
We’ve been storing all our search console data in Google’s cloud-based data analytics tool BigQuery for some time, which gives me the luxury of immediately being able to pull out a table and see all the keywords which have dropped.
There were a couple keyword permutations/themes which were particularly badly hit, and I started digging into them. One of the joys of having all the data in a table is that you can do things like plot the rank of each page that ranks for a single keyword over time.
And this finally got me something useful.
The yellow line is the page I want to rank and the page which I’ve seen the best user results from (i.e. lower bounce rates, more pages per session, etc.):
Another example: again, the yellow line represents the page that should be ranking correctly.
In all the cases I found, my primary landing page — which had previously ranked consistently — was now being cannabalized by articles I’d written on the same topic or by user-generated content.
Are you sure it’s a Google update?
You can never be 100% sure, but I haven’t made any changes to this area for several months, so I wouldn’t expect it to be due to recent changes, or delayed changes coming through. The site had recently migrated to HTTPS, but saw no traffic fluctuations around that time.
Currently, I don’t have anything else to attribute this to but the update.
How am I trying to fix this?
The ideal fix would be the one that gets me all my traffic back. But that’s a little more subjective than “I want the correct page to rank for the correct keyword,” so instead that’s what I’m aiming for here.
And of course the crucial word in all this is “trying”; I’ve only started making these changes recently, and the jury is still out on if any of it will work.
No-indexing the user generated content
This one seems like a bit of no-brainer. They bring an incredibly small percentage of traffic anyway, which then performs worse than if users land on a proper landing page.
I liked having them indexed because they would occasionally start ranking for some keyword ideas I’d never have tried by myself, which I could then migrate to the landing pages. But this was a relatively low occurrence and on-balance perhaps not worth doing any more, if I’m going to suffer cannabalization on my main pages.
Making better use of the Schema.org "About" property
I’ve been waiting a while for a compelling place to give this idea a shot.
Broadly, you can sum it up as using the About property pointing back to multiple authoritative sources (like Wikidata, Wikipedia, Dbpedia, etc.) in order to help Google better understand your content.
For example, you might add the following JSON to an article an about Donald Trump’s inauguration.
[ { "@type": "Person", "name": "President-elect Donald Trump", "sameAs": [ "https://en.wikipedia.org/wiki\Donald_Trump", "http://dbpedia.org/page/Donald_Trump", "https://www.wikidata.org/wiki/Q22686" ] }, { "@type": "Thing", "name": "US", "sameAs": [ "https://en.wikipedia.org/wiki/United_States", "http://dbpedia.org/page/United_States", "https://www.wikidata.org/wiki/Q30" ] }, { "@type": "Thing", "name": "Inauguration Day", "sameAs": [ "https://en.wikipedia.org/wiki/United_States_presidential_inauguration", "http://dbpedia.org/page/United_States_presidential_inauguration", "https://www.wikidata.org/wiki/Q263233" ] } ]
The articles I’ve been having rank are often specific sub-articles about the larger topic, perhaps explicitly explaining them, which might help Google find better places to use them.
You should absolutely go and read this article/presentation by Jarno Van Driel, which is where I took this idea from.
Combining informational and transactional intents
Not quite sure how I feel about this one. I’ve seen a lot of it, usually where there exist two terms, one more transactional and one more informational. A site will put a large guide on the transactional page (often a category page) and then attempt to grab both at once.
This is where the lines started to blur. I had previously been on the side of having two pages, one to target the transactional and another to target the informational.
Currently beginning to consider whether or not this is the correct way to do it. I’ll probably try this again in a couple places and see how it plays out.
Final thoughts
I only got any insight into this problem because of storing Search Console data. I would absolutely recommend storing your Search Console data, so you can do this kind of investigation in the future. Currently I’d recommend paginating the API to get this data; it’s not perfect, but avoids many other difficulties. You can find a script to do that here (a fork of the previous Search Console script I’ve talked about) which I then use to dump into BigQuery. You should also check out Paul Shapiro and JR Oakes, who have both provided solutions that go a step further and also do the database saving.
My best guess at the moment for the Maccabees update is there has been some sort of weighting change which now values relevancy more highly and tests more pages which are possibly topically relevant. These new tested pages were notably less strong and seemed to perform as you would expect (less well), which seems to have led to my traffic drop.
Of course, this analysis is currently based off of a single site, so that conclusion might only apply to my site or not at all if there are multiple effects happening and I’m only seeing one of them.
Has anyone seen anything similar or done any deep diving into where this has happened on their site?
Appendix
Spotting thin content & dodgy links
For those of you who are looking at new sites, there are some quick ways to dig into this.
For dodgy links:
Take a look at something like Searchmetrics/SEMRush and see if they’ve had any previous penguin drops.
Take a look into tools Majestic and Ahrefs. You can often get this free, Majestic will give you all the links for your domain for example if you verify.
For spotting thin content:
Run a crawl
Take a look at anything with a short word count; let’s arbitrarily say less than 400 words.
Look for heavy repetition in titles or meta descriptions.
Use the tree view (that you can find on Screaming Frog, for example) and drill down into where it has found everything. This will quickly let you see if there are pages where you don’t expect there to be any.
See if the number of URLs found is notably different to the indexed URL report.
Soon you will be able to take a look at Google’s new index coverage report. (AJ Kohn has a nice writeup here).
Browse around with an SEO chrome plugin that will show indexation. (SEO Meta in 1 Click is helpful, I wrote Traffic Light SEO for this, doesn’t really matter what you use though.)
Index bloat
The only real place to spot index bloat is the indexed URLs report in Search Console. Debugging it however is hard, I would recommend a combination of log files, “site:” searches in Google, and sitemaps when attempting to diagnose this.
If you can get them, the log files will usually be the most insightful.
Poor user experience/slow site
This is a hard one to judge. Virtually every site has things you can class as a poor user experience.
If you don’t have access to any user research on the brand, I will go off my gut combined with a quick scan to compare to some competitors. I’m not looking for a perfect experience or anywhere close, I just want to not hate trying to use the website on the main templates which are exposed to search.
For speed, I tend to use WebPageTest as a super general rule of thumb. If the site loads below 3 seconds, I’m not worried; 3–6 I’m a little bit more nervous; anything over that, I’d take as being pretty bad.
I realize that’s not the most specific section and a lot of these checks do come from experience above everything else.
Overbearing ads or monetization?
Speaking of poor user experience, the most obvious one is to switch off whatever ad-block you’re running (or if it’s built into your browser, to switch to one without that feature) and try to use the site without it. For many sites, it will be clear cut. When it’s not, I’ll go off and seek other specific examples.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Last Seen Blogs

negroalooscuro-blog
A Lo Oscuro TV
The Spanish Podcast

i-act-like-im-5
The Confessions of a 21 Year Old

sleepymccoy
you are an absolute champion. call me sleepy

littlelottinka
lottinka

astermedipharm
Untitled