#Audio Annotation for NLP
Link
#nlp#Audio Annotation for NLP#Speech Annotation for NLP#healthcare nlp datasets#nlp sentiment analysis#nlp service#nlp datasets#text dataset for nlp
1 note
·
View note
Text
Unlocking the Potential of Speech Recognition Dataset: A Key to Advancing AI Speech Technology
In the realm of artificial intelligence (AI), speech recognition has emerged as a transformative technology, enabling machines to understand and interpret human speech with remarkable accuracy. At the heart of this technological revolution lies the availability and quality of speech recognition datasets, which serve as the building blocks for training robust and efficient speech recognition models.
A speech recognition dataset is a curated collection of audio recordings paired with their corresponding transcriptions or labels. These datasets are essential for training machine learning models to recognize and comprehend spoken language across various accents, dialects, and environmental conditions. The quality and diversity of these datasets directly impact the performance and generalization capabilities of speech recognition systems.
The importance of high-quality speech recognition datasets cannot be overstated. They facilitate the development of more accurate and robust speech recognition models by providing ample training data for machine learning algorithms. Moreover, they enable researchers and developers to address challenges such as speaker variability, background noise, and linguistic nuances, thus enhancing the overall performance of speech recognition systems.
One of the key challenges in building speech recognition datasets is the acquisition of diverse and representative audio data. This often involves recording a large number of speakers from different demographic backgrounds, geographic regions, and language proficiency levels. Additionally, the audio recordings must capture a wide range of speaking styles, contexts, and environmental conditions to ensure the robustness and versatility of the dataset.
Another crucial aspect of speech recognition datasets is the accuracy and consistency of the transcriptions or labels. Manual transcription of audio data is a labor-intensive process that requires linguistic expertise and meticulous attention to detail. To ensure the reliability of the dataset, transcriptions must be verified and validated by multiple annotators to minimize errors and inconsistencies.
The availability of open-source speech recognition datasets has played a significant role in advancing research and innovation in the field of AI speech technology. Projects such as the LibriSpeech dataset, CommonVoice dataset, and Google's Speech Commands dataset have provided researchers and developers with access to large-scale, annotated audio datasets, fostering collaboration and accelerating progress in speech recognition research.
Furthermore, initiatives aimed at crowdsourcing speech data, such as Mozilla's Common Voice project, have democratized the process of dataset creation by enabling volunteers from around the world to contribute their voice recordings. This approach not only helps to diversify the dataset but also empowers individuals to participate in the development of AI technologies that directly impact their lives.
In conclusion, speech recognition datasets are indispensable assets in the development of AI speech technology. By providing access to high-quality, diverse, and representative audio data, these datasets enable researchers and developers to train more accurate and robust speech recognition models. As AI continues to reshape the way we interact with technology, the role of speech recognition datasets will remain paramount in driving innovation and progress in this dynamic field.
0 notes
Text
The Invisible Heroes of AI: Understanding the Significance of Data Annotation

The Foundation of Machine Learning:
At the heart of machine learning (ML) and AI lies the fundamental concept of learning from data. Whether it's recognizing objects in images, understanding speech, or making predictions, AI algorithms require vast amounts of labelled data to generalise patterns and make accurate decisions. This is where data annotation becomes indispensable. By annotating data, human annotators assign labels, tags, or attributes to each data point, providing the necessary context for machines to learn and make sense of the information.
Methodologies of Data Annotation:
Data annotation encompasses various methodologies tailored to different types of data and AI tasks:
Image Annotation: In computer vision tasks, such as object detection and image segmentation, annotators outline objects, draw bounding boxes, or create pixel-level masks to highlight relevant features within images.
Text Annotation: Natural language processing (NLP) tasks rely on text annotation, where annotators label entities, sentiment, or parts of speech to train models for tasks like named entity recognition, sentiment analysis, and machine translation Medical datasets
Audio Annotation: For speech recognition and audio processing, annotators transcribe spoken words, label audio segments, or identify key sounds within recordings.
Video Annotation: Video annotation involves annotating objects or actions within video frames, enabling AI systems to understand temporal relationships and dynamic scenes.
The Human Element:
Despite advances in automation, data annotation remains a predominantly human-driven task. Annotators bring contextual understanding, domain expertise, and nuanced judgement that automated systems often lack. Their ability to interpret ambiguous data, adapt to diverse contexts, and refine annotations based on feedback is invaluable in ensuring the accuracy and relevance of labelled datasets.
Challenges in Data Annotation:
While data annotation is crucial, it's not without its challenges:
Scalability: As AI applications demand increasingly large and diverse datasets, scaling data annotation processes while maintaining quality and consistency becomes a significant challenge.
Subjectivity: Annotation tasks can be subjective, leading to inconsistencies among annotators. Establishing clear guidelines, providing adequate training, and implementing quality control measures are essential to mitigate this issue.
Cost and Time: Data annotation can be resource-intensive in terms of both time and cost, especially for specialised domains requiring domain expertise or intricate labelling.
Data Bias: Annotator biases can inadvertently introduce biases into labelled datasets, leading to skewed model outputs and ethical concerns. Addressing bias requires careful consideration of dataset composition, diversity, and fairness.
The Impact on AI Advancements:
Despite these challenges, data annotation remains a cornerstone of AI advancements. High-quality annotated datasets serve as the fuel that powers AI innovation, enabling the development of robust models with real-world applicability. From autonomous vehicles to personalised healthcare, the quality and diversity of annotated data directly influence the performance and reliability of AI systems, shaping their ability to address complex challenges and deliver meaningful solutions.
Conclusion:
In the ever-evolving landscape of AI, data annotation stands as a silent yet pivotal force driving progress and innovation. Behind every AI breakthrough lies a meticulously annotated dataset, crafted by human annotators who play a critical role in shaping the future of AI. As we continue to push the boundaries of what AI can achieve, let us not forget to acknowledge the unsung heroes – the data annotators – whose dedication and expertise fuel the journey towards AI excellence.
How GTS.AI Can Help You?
At Globose Technology Solutions Pvt Ltd (GTS), data collection is not service; It is our passion and commitment to fueling the progress of AI and ML technologies.GTS.AI can leverage natural language processing capabilities to understand and interpret human language. This can be valuable in tasks such as text analysis, sentiment analysis, and language translation.GTS.AI can be adapted to meet specific business needs. Whether it's creating a unique user interface, developing a specialised chatbot, or addressing industry-specific challenges, customization options are diverse.
0 notes
Text
Synthetic Document Generation for NLP and Document AI

NLP (natural language processing) and document AI are technologies that are quickly developing and have a wide range of prospective applications. In recent years, the usage of NLP and document AI has significantly increased across a variety of industries, including marketing, healthcare, and finance. These solutions are being used to streamline manual procedures, accelerate data processing, and glean insightful information from massive amounts of unstructured data. NLP and document AI are anticipated to continue developing and revolutionizing numerous industries in the years to come with the introduction of sophisticated machine learning algorithms and data annotation techniques.
For different NLP and AI applications, large amounts of document data are necessary since they aid in the training of machine learning algorithms to comprehend the context, language, and relationships within the data. The algorithms are able to comprehend the subtleties and complexity of human language better the more data that is accessible, the more diverse the input. In turn, this aids the algorithms in producing predictions and classifications that are more precise. A more stable training environment is also provided by larger datasets, lowering the possibility of overfitting and enhancing the generalizability of the model. The likelihood that the model will perform well on unobserved data increases with the size of the dataset.
Data for Document AI
Document AI, or Document Artificial Intelligence, is an emerging field of artificial intelligence (AI) that focuses on the processing of unstructured data in documents, such as text, images, and tables. Document AI is used to automatically extract information, classify documents, and make predictions or recommendations based on the content of the documents.
It takes a lot of data to train a Document AI system. This information can originate from a variety of places, including internal document repositories, external data suppliers, and web repositories. To allow the Document AI system to learn from the data, it must be tagged or annotated. To offer information on the content of the documents, such as the document type, topic, author, date, or language, data annotation entails adding tags or metadata to the documents. The Document AI system can grow more precise as more data becomes accessible.
Training data for Document AI can come in various forms, including scanned documents, PDF files, images, and even audio or video files. The data can be preprocessed to remove noise or enhance the quality of the text or images. Natural Language Processing (NLP) techniques can also be applied to the text to extract entities, sentiments, or relationships. Overall, a large and diverse dataset of documents is crucial for building effective Document AI systems that can accurately process and analyze large volumes of unstructured data.
Application of Document AI
There are several applications of document AI, some of them are:
Document scanning and digitization: AI-powered document scanning tools make it possible to turn paper documents into digital files that can be accessed, searched for, and used.
Document classification and categorization: Depending on the content, format, and structure of the document, AI algorithms can be trained to categorize and classify various types of documents.
Content extraction and summarization: With AI, significant information may be culled from massive amounts of documents and condensed into key insights and summaries.
Document translation: AI-powered document translation tools can translate text from one language to another automatically, facilitating global communication for enterprises.
Analysis and management of contracts: With AI algorithms, contracts may be automatically reviewed to find important terms, risks, and duties.
Invoice processing and accounts payable automation: AI algorithms can be trained to process invoices automatically and make payments, reducing manual errors and increasing operational efficiency.
Customer service chatbots: AI-powered chatbots can help automate customer support interactions, respond to frequent customer questions, and point customers in the appropriate direction.
These are some of the different applications of document AI. The potential of this technology is vast, and the applications continue to expand as the technology evolves.
Document Data Collection
There are various ways to collect documents for AI applications, including the following:
Web scraping: Automatically extracting information from websites or other online sources.
Public data repositories: Utilizing publicly available datasets from organizations such as government agencies, universities, and non-profit organizations.
Internal data sources: Utilizing internal data sources within an organization, such as databases, CRM systems, and document management systems.
Crowdsourcing: Engaging a large group of people to annotate or label data through online platforms.
Purchasing datasets: Buying datasets from third-party providers who specialize in data collection and management.
However, real-world data is often limited and may not fully represent the diversity of documents and their variations. Synthetic data generation provides a solution to this problem by allowing the creation of large amounts of high-quality data that can be used to train and improve document AI models.
By generating synthetic data, companies can create training sets that represent a wide range of document types, formats, and styles, which can lead to more robust and accurate document AI models. Synthetic data can also help address issues of data bias, by ensuring that the training data is representative of the entire document population. Additionally, synthetic data generation can be more cost-effective and efficient than manual data collection, allowing companies to create large volumes of data quickly and at a lower cost.
Synthetic Document Generation
Synthetic data is generated for AI to address the challenges faced with real-world data such as privacy concerns, data scarcity, data imbalance, and the cost and time required for data collection and labeling. Synthetic data can be generated in large volumes and can be easily customized to meet the specific needs of a particular AI application. This allows AI developers to train models with a large and diverse dataset, without the constraints posed by real-world data, leading to better performance and accuracy. Furthermore, synthetic data can be used to simulate various scenarios and conditions, helping to make AI models more robust and versatile.
The primary reason for generating synthetic documents for AI is to increase the size of the training dataset, allowing AI algorithms to learn and make more accurate predictions. In addition, synthetic documents can also help in situations where it is difficult or expensive to obtain real-world data, such as in certain legal or privacy-sensitive applications.
To provide synthetic document generation for AI applications, the following steps can be taken:
Collect a sample of real-world data to serve as the base for synthetic data generation.
Choose a suitable method for generating synthetic data, such as data augmentation, generative models, or data sampling.
Use the chosen method to generate synthetic data that is representative of the real-world data.
Validate the quality of the synthetic data to ensure it is representative and relevant to the intended use case.
Integrate the synthetic data into the AI training process to improve the performance of the AI algorithms.
Synthetic Documents by TagX
TagX specializes in generating synthetic documents of various types, such as bank statements, payslips, resumes, and more, to provide high-quality training data for various AI models. Our synthetic document generation process is based on real-world data and uses advanced techniques to ensure the data is realistic and diverse. With this, we can provide AI models with the large volumes of data they need to train and improve their accuracy, ensuring the best possible results for our clients. Whether you're developing an AI system for financial services, HR, or any other industry, we can help you obtain the data you need to achieve your goals.
Synthetic documents are preferred over real-world documents as they do not contain any personal or sensitive information, making them ideal for AI training. They can be generated in large quantities, providing enough training data to help AI models learn and improve. Moreover, synthetic data is easier to manipulate, label, and annotate, making it a convenient solution for data annotation.
TagX can generate a wide variety of synthetic documents for different AI applications, including finance, insurance, chatbots, recruitment, and other intelligent document processing solutions. The synthetic documents can include, but are not limited to:
Payslips
We generate synthetic payslips in all languages to provide training data for AI models in finance, insurance, and other relevant applications. Our payslips mimic the structure, format, and language used in real-world payslips and are customizable according to the client's requirements.
Invoices
Our team can generate invoices in all languages to provide training data for various AI models in finance and other applications. The invoices we generate mimic the structure, format, and language used in real-world invoices and are customizable according to the client's needs.
Bank statements
Our team is proficient in generating synthetic bank statements in various languages and formats. These bank statements can be used to provide training data for different AI models in finance, insurance, and other relevant applications. Our bank statements mimic the structure, format, and language used in real-world bank statements and can be customized according to the client's requirements.
Resumes
We generate synthetic resumes in various languages and formats to provide training data for AI models in recruitment, HR, and other relevant applications. Our resumes mimic the structure, format, and language used in real-world resumes and are customizable according to the client's needs.
Utility bills
Our team is experienced in generating synthetic utility bills in various languages and formats. These utility bills can be used to provide training data for different AI models in finance, insurance, and other relevant applications. Our utility bills mimic the structure, format, and language used in real-world utility bills and can be customized according to the client's requirements.
Purchase orders
Our team can generate synthetic purchase orders in various languages and formats to provide training data for AI models in finance and other relevant applications. Our purchase orders mimic the structure, format, and language used in real-world purchase orders and are customizable according to the client's needs.
Passport and other personal documents
We generate synthetic passports and other personal documents in various languages and formats to provide training data for AI models in finance, insurance, and other relevant applications. Our passport and personal documents mimic the structure, format, and language used in real-world passports and personal documents and can be customized according to the client's requirements.
TagX Vision
TagX focuses on providing documents that are relevant to finance, insurance, chatbot, recruitment, and other intelligent document processing solutions. Our team of experts uses advanced algorithms to generate synthetic payslips, invoices in multiple languages, bank statements, resumes, utility bills, purchase orders, passports, and other personal documents. All of these documents are designed to look and feel like real-world examples, with accurate formatting, text, and images. Our goal is to ensure that the AI models trained with our synthetic data have the ability to process and understand a wide range of documents, so they can make accurate predictions and decisions.
We understand the importance of data privacy and security and ensure that all generated documents are de-identified and comply with the necessary regulations. Our goal is to provide our clients with a solution that is not only high-quality but also trustworthy and secure. Contact us to learn more about how our synthetic document generation services can help you achieve your AI goals.
0 notes
Text
Unlocking Precision: The Role of Annotation for Machine Learning in AI Development
In the ever-evolving landscape of artificial intelligence (AI), the accuracy and reliability of machine learning models hinge on the quality of the data they are trained on. One pivotal aspect that ensures the efficacy of these models is the meticulous process of data annotation in AI. Annotation serves as the foundation upon which machine learning algorithms learn and make predictions, making it a crucial step in the development of intelligent systems.
At its core, annotation for machine learning involves labeling or tagging data to provide meaningful context to algorithms. This can include identifying objects in images, transcribing audio, or even highlighting specific features in text. The goal is to create a labeled dataset that allows machine learning models to understand patterns and correlations, ultimately enabling them to make accurate predictions when faced with new, unseen data.
The significance of data annotation in AI becomes particularly evident in computer vision applications. Image recognition, object detection, and facial recognition systems heavily rely on annotated datasets to learn and generalize from examples. For instance, annotating images to specify the location and category of objects within the image enables the algorithm to recognize and differentiate similar objects in real-world scenarios.
Text annotation is another critical aspect of annotation for machine learning. Natural Language Processing (NLP) models, which power language-related AI applications, require labeled datasets for tasks like sentiment analysis, named entity recognition, and text summarization. Annotated text data provides the necessary context for these models to understand and interpret language nuances.
The process of data annotation in AI is not only about labeling data but also about maintaining consistency and accuracy. Annotated datasets need to be meticulously curated to avoid biases and errors that could impact the performance of machine learning models. Quality control measures, continuous feedback loops, and human-in-the-loop annotation approaches are employed to ensure the precision of annotated datasets.
The demand for accurate and diverse annotated datasets has given rise to specialized annotation services and tools. These services employ skilled annotators who understand the nuances of specific domains, ensuring that the annotations are not only accurate but also contextually relevant. Tools with features like bounding box annotation, polygon annotation, and semantic segmentation aid in the efficient labeling of complex datasets.
In conclusion, annotation for machine learning is a cornerstone of AI development, shaping the capabilities of machine learning models and their real-world applications. As the AI industry continues to advance, the quality of annotated datasets will play a pivotal role in pushing the boundaries of what intelligent systems can achieve. The meticulous process of data annotation in AI is not just about labeling; it is about empowering machines to comprehend, learn, and make informed decisions in a rapidly evolving digital landscape.
0 notes
Text
Decoding the Power of Speech: A Deep Dive into Speech Data Annotation

Introduction
In the realm of artificial intelligence (AI) and machine learning (ML), the importance of high-quality labeled data cannot be overstated. Speech data, in particular, plays a pivotal role in advancing various applications such as speech recognition, natural language processing, and virtual assistants. The process of enriching raw audio with annotations, known as speech data annotation, is a critical step in training robust and accurate models. In this in-depth blog, we'll delve into the intricacies of speech data annotation, exploring its significance, methods, challenges, and emerging trends.
The Significance of Speech Data Annotation
1. Training Ground for Speech Recognition: Speech data annotation serves as the foundation for training speech recognition models. Accurate annotations help algorithms understand and transcribe spoken language effectively.
2. Natural Language Processing (NLP) Advancements: Annotated speech data contributes to the development of sophisticated NLP models, enabling machines to comprehend and respond to human language nuances.
3. Virtual Assistants and Voice-Activated Systems: Applications like virtual assistants heavily rely on annotated speech data to provide seamless interactions, and understanding user commands and queries accurately.
Methods of Speech Data Annotation
1. Phonetic Annotation: Phonetic annotation involves marking the phonemes or smallest units of sound in a given language. This method is fundamental for training speech recognition systems.
2. Transcription: Transcription involves converting spoken words into written text. Transcribed data is commonly used for training models in natural language understanding and processing.
3. Emotion and Sentiment Annotation: Beyond words, annotating speech for emotions and sentiments is crucial for applications like sentiment analysis and emotionally aware virtual assistants.
4. Speaker Diarization: Speaker diarization involves labeling different speakers in an audio recording. This is essential for applications where distinguishing between multiple speakers is crucial, such as meeting transcription.
Challenges in Speech Data Annotation
1. Accurate Annotation: Ensuring accuracy in annotations is a major challenge. Human annotators must be well-trained and consistent to avoid introducing errors into the dataset.
2. Diverse Accents and Dialects: Speech data can vary significantly in terms of accents and dialects. Annotating diverse linguistic nuances poses challenges in creating a comprehensive and representative dataset.
3. Subjectivity in Emotion Annotation: Emotion annotation is subjective and can vary between annotators. Developing standardized guidelines and training annotators for emotional context becomes imperative.
Emerging Trends in Speech Data Annotation
1. Transfer Learning for Speech Annotation: Transfer learning techniques are increasingly being applied to speech data annotation, leveraging pre-trained models to improve efficiency and reduce the need for extensive labeled data.
2. Multimodal Annotation: Integrating speech data annotation with other modalities such as video and text is becoming more common, allowing for a richer understanding of context and meaning.
3. Crowdsourcing and Collaborative Annotation Platforms: Crowdsourcing platforms and collaborative annotation tools are gaining popularity, enabling the collective efforts of annotators worldwide to annotate large datasets efficiently.
Wrapping it up!
In conclusion, speech data annotation is a cornerstone in the development of advanced AI and ML models, particularly in the domain of speech recognition and natural language understanding. The ongoing challenges in accuracy, diversity, and subjectivity necessitate continuous research and innovation in annotation methodologies. As technology evolves, so too will the methods and tools used in speech data annotation, paving the way for more accurate, efficient, and context-aware AI applications.
At ProtoTech Solutions, we offer cutting-edge Data Annotation Services, leveraging expertise to annotate diverse datasets for AI/ML training. Their precise annotations enhance model accuracy, enabling businesses to unlock the full potential of machine-learning applications. Trust ProtoTech for meticulous data labeling and accelerated AI innovation.
#speech data annotation#Speech data#artificial intelligence (AI)#machine learning (ML)#speech#Data Annotation Services#labeling services for ml#ai/ml annotation#annotation solution for ml#data annotation machine learning services#data annotation services for ml#data annotation and labeling services#data annotation services for machine learning#ai data labeling solution provider#ai annotation and data labelling services#data labelling#ai data labeling#ai data annotation
0 notes
Text
Elevate, Annotate, Accelerate: Powering AI with Premium Data Annotation Service
In today's digital era, Artificial Intelligence (AI) stands at the forefront of technological evolution, promising innovations and solutions that seemed fantastical just a few decades ago. Yet, the magic of AI isn't just in complex algorithms or computing power—it's in the data. And not just any data, but meticulously annotated data. This article explores how premium data annotation services elevate, annotate, and accelerate AI development, driving it from theoretical potential to tangible innovations.
1.Elevate: The Rise of Quality Over Quantity
While the digital universe is flooded with zettabytes of data, not all of it is fit for AI consumption. This is where data annotation services come into play.
Raw to Refined: Premium annotation services transform raw, unstructured data into organized, labeled, and refined datasets.
Specialization: Different AI applications, be it autonomous vehicles, medical imaging, or voice assistants, require uniquely tailored data. Annotation services specialize in creating datasets that match specific AI domains.
Quality Control: With rigorous quality checks, these services ensure that data not only is abundant but is of the highest caliber.
Annotate: Crafting AI's Dictionary
Annotated data is to AI what a dictionary is to a learner. It provides context, meaning, and clarity.
Image and Video Annotation: For computer vision models, services might involve bounding boxes, semantic segmentation, or keypoint annotations to identify and categorize objects.
Text Annotation: NLP models benefit from services like entity recognition, sentiment analysis, and text categorization, guiding them in understanding and generating human language.
Audio Annotation: For voice-activated AI, distinguishing between sounds, recognizing speech patterns, and understanding context is facilitated through detailed audio annotations.
Accelerate: Speeding Up AI Deployment
With the heavy lifting of data annotation handled by experts, AI developers can focus on what they do best—designing, training, and deploying models.
Reduced Time-to-Market: Ready-to-use high-quality datasets significantly shorten the AI development lifecycle.
Optimized Performance: AI models trained on premium annotated data are more accurate, reliable, and efficient.
Iterative Refinement: With feedback loops and continuous data enrichment, annotation services ensure that AI models evolve, learn, and improve over time.
Choosing Premium Over Basic
In the world of data annotation, not all services are made equal. Premium services offer:
Scalability: Ability to handle vast datasets without compromising on quality.
Security: Ensuring data privacy and adhering to global data protection regulations.
Customization: Tailoring annotation processes to match specific project requirements.
Expertise: Leveraging a combination of human expertise and automated tools for impeccable annotations.
Conclusion
As AI continues its transformative journey across industries, the importance of foundational data cannot be overlooked. Premium data annotation services play a pivotal role, elevating the quality of AI input, annotating it with precision, and accelerating the journey from AI concept to concrete solution. In this AI-driven future, these services aren't just facilitators; they're game-changers.
0 notes
Text
How is Data Annotation shaping the World of Deep Learning Algorithms?
The size of the global market for data annotation tools was estimated at USD 805.6 million in 2022, and it is expected to increase at a CAGR of 26.5% from 2023 to 2030. The growing use of image data annotation tools in the automotive, retail, and healthcare industries is a major driver of the expansion. Data Labeling or adding attribute tags to data, users can enhance the value of the information.

The Emergence of Data Annotation The industrial expansion of data annotation tools is being driven by a rising trend of using AI technology for document classification and categorization. Data annotation technologies are gaining ground as practical options for document labeling due to the increasing amounts of textual data and the significance of effectively classifying documents. The increased usage of data annotation tools for the creation of text-to-speech and NLP technologies is also changing the market.
The demand for automated data annotation tools is being driven by the growing significance of automated data labeling tools in handling massive volumes of unlabeled, raw data that are too complex and time-consuming to be annotated manually. Fully automated data labeling helps businesses speed up the development of their AI-based initiatives by reliably and quickly converting datasets into high-quality input training data.
Automated data labeling solutions can address these problems by precisely annotating data without issues of frustration or errors, in contrast to the time-consuming and more error-prone manual data labeling procedure.
Labeling Data is the basis of Data Annotation When annotating data, two things are required:
Data
A standardized naming system
The labeling conventions are likely to get increasingly complex as labeling programs develop.
Additionally, you might find that the naming convention was insufficient to produce the predictions or ML model you had in mind after training a model on the data. Applying labels to your data using various techniques and tools is the main aspect of data annotation tools. While some solutions offer a broad selection of tools to support a variety of use cases, others are specifically optimized to focus on particular sorts of labeling.
To help you identify and organize your data, almost all include some kind of data or document classification. You may choose to focus on specialists or use a more general platform depending on your current and projected future needs. Several forms of annotation capabilities provide data annotation tools for creating or managing guidelines, such as label maps, classes, attributes, and specific annotation types.
Types of Data Annotations
Image: Bounding boxes, polygons, polylines, classification, 2-D and 3-D points, or segmentation (semantic or instance), tracking, transcription, interpolation, or transcription are all examples of an image or video processing techniques.
Text: Coreference resolution, dependency resolution, sentiment analysis, net entity relationships (NER), parts of speech (POS), transcription, and sentiment analysis.
Audio: Time labeling, tagging, audio-to-text, and audio labeling
The automation, or auto-labeling, of many data annotation systems, is a new feature. Many solutions that use AI will help your human labelers annotate your data more accurately(e.g., automatically convert a four-point bounding box to a polygon) or even annotate your data without human intervention. To increase the accuracy of auto-labeling, some tools can also learn from the activities done by your human annotators.
Are you too looking for advanced Data Annotation & Data Labelling Services?
Contact us and we will provide you with the best solution to upgrade your operations efficiently.
0 notes
Text
Speech datasets for machine learning.

Introduction:
Speech datasets for machine learning are collections of audio recordings and their corresponding transcriptions or annotations. These datasets are used to train and evaluate speech recognition and synthesis models, which are key components of natural language processing (NLP) systems. Speech datasets typically contain recordings of human speech, along with information about the language, dialect, and gender of the speakers. The recordings may be segmented into smaller units, such as words or phonemes, and annotated with their corresponding transcriptions or labels. In addition, some speech datasets may include metadata such as background noise, speaker characteristics, and speech emotions. There are many publicly available speech datasets for machine learning, such as the Common Voice dataset from Mozilla, the Libri Speech dataset, and the Vox Celeb dataset. These datasets vary in size and complexity, ranging from thousands to millions of audio samples, and from simple transcriptions to detailed annotations of various linguistic features. Speech datasets are essential for developing accurate and robust speech recognition and synthesis models. By using these datasets to train machine learning models, researchers can improve the accuracy and performance of NLP systems, making it possible to build more sophisticated and effective applications for speech-based interactions.
What is the best dataset for speech recognition?
There are several datasets that are commonly used for training and testing speech recognition systems. The best dataset for speech recognition depends on the specific task and application for which the system is being developed.
Here are a few popular speech recognition datasets:
Common Voice:
Common Voice is an open-source dataset created by Mozilla that contains recordings of people reading aloud various texts. It includes over 9,000 hours of speech datasets in multiple languages.
LibriSpeech:
LibriSpeech is a dataset created by Vassil Panayotov and his team at Carnegie Mellon University. It contains over 1,000 hours of speech data from audiobooks, and it is available for non-commercial use.
VoxCeleb:
VoxCeleb is a dataset of speech recordings from celebrities that contains over 200,000 utterances from over 1,000 celebrities. It is often used for speaker recognition tasks.
TIMIT:
TIMIT is a widely used dataset that contains speech recordings of phonetically-balanced sentences spoken by 630 speakers from eight different dialects of American English. It is often used for speech recognition and speech-to-text tasks.
WSJ:
The Wall Street Journal (WSJ) dataset is a corpus of speech recordings from the Wall Street Journal that is widely used for speech recognition research. These datasets are just a few examples, and there are many other speech recognition datasets available, each with their own strengths and weaknesses. It's important to choose a dataset that is appropriate for the specific task and application being developed.
How do I find good datasets for machine learning?
Finding good datasets for machine learning can be a challenging task, but there are several resources available to help you.
Kaggle:
Kaggle is a popular platform for data science competitions and hosts a large number of datasets. You can browse through the datasets and find one that suits your needs.
UCI Machine Learning Repository:
The UCI Machine Learning Repository is a collection of datasets that are commonly used in the machine learning community. The repository contains datasets for classification, regression, and clustering problems.
Google Dataset Search:
Google Dataset Search is a search engine for datasets that allows you to search for datasets across a wide range of domains.
Data.gov:
Data.gov is a repository of government datasets that cover a wide range of topics, including health, energy, and climate.
OpenML:
OpenML is an open-source platform for machine learning that hosts a large number of datasets and allows you to contribute your own datasets.
GitHub:
GitHub is a code hosting platform that also hosts a large number of datasets. You can search for datasets on GitHub and also contribute your own datasets.
When selecting a dataset, make sure that it is relevant to your problem and that it has enough data to train your model. Also, ensure that the dataset is of good quality and has been properly labeled and cleaned. Speech datasets are essential for developing and training machine learning models that can accurately recognize and understand human speech. Speech recognition technology has come a long way over the years, thanks to advancements in deep learning algorithms, natural language processing, and the availability of large-scale speech datasets. In this blog post, we'll explore the importance of speech datasets, their characteristics, and some of the popular speech datasets used in machine learning.
Importance of Speech Datasets.
Speech datasets are vital for training and testing speech recognition systems. These datasets contain speech samples recorded in various contexts and environments, which help the machine learning models to learn and recognize speech patterns. Without these datasets, speech recognition systems would struggle to identify different accents, dialects, and variations in pronunciation, making it difficult to understand human speech accurately. Speech datasets are also crucial for improving the accuracy of speech recognition models. By using these datasets, developers can train machine learning models with vast amounts of data, allowing them to recognize and understand speech more accurately. This helps in improving the overall user experience of speech recognition systems, making them more reliable and efficient.
Characteristics of Speech Datasets
Speech datasets have several characteristics that make them unique from other types of datasets. Some of the essential characteristics of speech datasets are:
Variability:
Speech datasets contain speech samples recorded in different contexts, environments, and languages. This variability is essential for training models that can recognize and understand speech accurately, regardless of the environment or context in which it was recorded.
Size:
Speech datasets are typically much larger than other datasets due to the vast amount of audio data they contain. Large datasets are crucial for training deep learning models that require massive amounts of data to achieve high accuracy.
Annotation:
Speech datasets are often annotated with additional information, such as transcription, speaker information, and audio quality. This information is essential for training and testing speech recognition models and evaluating their performance.
How GTS can help you?
Global Technology Solutions is a AI based Data Collection and Data Annotation Company understands the need of having high-quality, precise datasets to train, test, and validate your models. As a result, we deliver 100% accurate and quality tested datasets. image annotation, Speech datasets, Text datasets, ADAS annotation and Video datasets are among the datasets we offer. We offer services in over 200 languages.
0 notes
Text
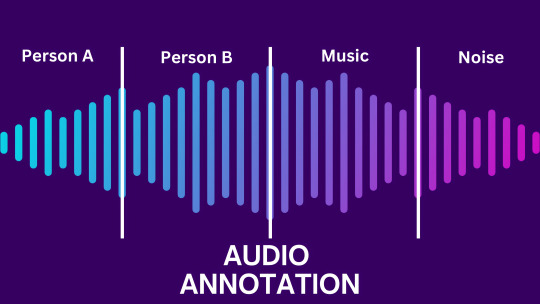
The complete guide to Audio Annotation | Acgence
Audio Annotation are valuable tools for building natural language processing (NLP) models with multiple benefits. Chatbots and virtual assistant devices use it to recognize sounds so they can comprehend them through machine learning. In this process, components of audio from humans, animals, the environment, instruments, etc. are classified and made understandable by machines, including human conversations and animal roars. For the best AI Data Collection and Data Transcription, top tech giants like Google, TCS, and Accenture use AI training services.
For More Info :- https://bit.ly/3lF3ADN
Contact No. :- +91-9958189900
AI data sets
AI Data Annotation
AI Catalogs
AI Data Enhancement
AI Data Generation
AI Data sourcing
#audio annotation#acgence#ai data annotation#ai data collection#AI Data sourcing#AI Catalogs#AI data sets
0 notes
Text
Understanding Zero-Shot Learning And It’s Potential Impact On AI Technology
Zero-shot learning (ZSL) is an emerging subfield of artificial intelligence (AI) and machine learning (ML) that enables machines to recognize objects, concepts, or events that they have never seen before. It is a form of transfer learning that allows a machine learning model to generalize across domains, tasks, and contexts.

At the heart of zero-shot learning is the ability to understand the relationships between different concepts, and to reason about them based on their semantic properties. Rather than simply learning to associate specific inputs with specific outputs, zero-shot learning algorithms learn to map inputs to a space of attributes or features that capture the underlying semantics of the data.
This allows the model to recognize new classes or concepts based on their similarity to previously learned attributes.
Some Common Examples Of Zero-Shot Learning Include:
Recognizing a new species of bird based on its physical characteristics, even if the model has never seen that specific bird before.
Identifying the sentiment of a text in a language that the model has not been trained on.
Classifying images based on their content, even if the model has never seen those specific images before.
One of the key benefits of zero-shot learning is that it can greatly reduce the amount of labeled data required to train a machine-learning model. Rather than relying on large, annotated datasets to teach the model how to recognize specific objects or concepts, zero-shot learning allows the model to learn from a smaller set of labeled data and then generalize to new contexts and domains.
To achieve this, zero-shot learning models often rely on a variety of techniques such as semantic embeddings, knowledge graphs, and transfer learning. Semantic embeddings are representations of data in a high-dimensional space that capture the underlying semantics of the data.
Knowledge graphs are structured representations of concepts and their relationships that can be used to reason about new concepts. Transfer learning is the process of using pre-trained models to extract features from new data.
Data tagging is an essential component of zero-shot learning, as it allows the model to understand the relationships between different concepts and to reason about them based on their semantic properties.
There Are Many Different Types Of Data Tagging, Including:
1. Entity Tagging: Identifying specific entities within the text, such as people, places, or organizations.
2. Sentiment Tagging: Identifying the sentiment of a text, such as positive, negative, or neutral.
3. Topic Tagging: Identifying the topic or subject of a text, such as sports, politics, or entertainment.
4. Image Tagging: Identifying objects, people, or events within an image.
5. Audio Tagging: Identifying sounds or speech within an audio clip.
There Are Many Different Tools And Platforms That Can Be Used For Data Tagging, Including:
1. Amazon Mechanical Turk: A crowdsourcing platform that allows users to create and manage tasks, including data tagging tasks.
2. Google Cloud AutoML: A suite of machine learning tools that includes a data labeling service for image, text, and video data.
3. Hugging Face Datasets: A collection of pre-built datasets for natural language processing (NLP) tasks, including entity recognition and sentiment analysis.
4. Labelbox: A data labeling platform that allows users to create and manage labeling tasks for images, videos, and text data.
5. Tagtog: A collaborative data annotation tool that supports multiple types of data, including text, image, and audio data.
In conclusion, zero-shot learning is a powerful technique that allows machines to recognize objects, concepts, or events that they have never seen before. To achieve this, zero-shot learning models rely on techniques such as semantic embeddings, knowledge graphs, and transfer learning, and data tagging is an essential component of this process.
There are many different types of data tagging and many different tools and platforms available to support this process, making it easier than ever to develop powerful zero-shot learning. Any errors in the data can impact the performance of AI models, thus EnFuse Solutions offer custom AI training datasets in over 300 languages for different machine learning models.
#TaggingServices#TaggingSolutions#TagManagementSolutions#TagManagementCompany#DataAnnotationServices#MachineLearningSolutions#MachineLearningServicesInIndia#AIMLServices#AIMLSolutions#EnFuseSolutions#EnFuseSolutionsIndia
1 note
·
View note
Text
Using Microsoft Syntex to turn SharePoint into an intelligent KMS
SharePoint is the preferred platform for many organizations – especially those that run their enterprise operations on Office 365 – to store, manage, share and track business documents through a centralized location. While SharePoint is certainly a powerful document management system (DMS), its document library capabilities are quite limited. For example, it doesn’t possess any built-in high-powered search functionality – which means finding documents can sometimes be a frustrating experience for users who do not know exactly where to look, especially in large enterprises with a massive library of active business documents.
In addition, SharePoint does not provide advanced annotation capabilities or intelligent routing and profiling functions to end-users, who are often forced to resort to inefficient manual processes in order to complete complex tasks. The good news is that these shortcomings can be overcome with the help of Syntex, Microsoft’s new AI-driven knowledge management solution designed specifically for SharePoint.
How does SharePoint work?
SharePoint is a cloud-based collaborative platform that allows users to share, manage and access data across multiple platforms. It’s ideal for companies looking to streamline their document management processes while reducing costs associated with managing large amounts of data across multiple platforms. The software allows organizations to create websites where employees can store documents and share them with others in the organization. SharePoint also includes features such as wikis and blogs that allow teams to collaboratively work together on projects and keep everyone informed about new developments.
One of the main limitations of SharePoint is its limited ability to handle unstructured data. SharePoint can manage structured data, such as documents, spreadsheets, and lists effectively and that’s one of its highly useful benefits for most organizations. However, unstructured data, such as emails, social media posts, and customer feedback, are becoming increasingly important for organizations to manage, something which SharePoint cannot do on its own.
Another limitation of SharePoint is its lack of built-in AI/ML capabilities. While SharePoint can be integrated with other AI and ML tools, it does not offer these capabilities outside of the box.
Additionally, SharePoint’s search functionality is limited and not as accurate as other search engines like Google, Bing, etc.
Furthermore, SharePoint’s scalability is also a limitation. As the number of users and the amount of data increases, SharePoint can become slow and difficult to manage.
An introduction to Microsoft Syntex
Microsoft Syntex is an intelligent platform for organizing a wide range of content that businesses use in different contexts. It allows organizations to extract insights and meaning from unstructured data, such as text, audio, and video using AI, ML, and natural language processing (NLP).
One of the key capabilities of Microsoft Syntex is its ability to understand and extract information from unstructured data. It uses NLP techniques such as sentiment analysis, entity recognition, and topic modeling to automatically extract relevant information from text-based data.
Another key capability of Microsoft Syntex is its ability to automatically classify and categorize data. It uses ML algorithms to identify patterns and relationships in data, which can be used to sort and filter data, or to train models for predictive analytics.
Microsoft Syntex supports any Knowledge Management System (KMS) built on SharePoint by integrating with the platform. Through such an integration, it can automatically extract and organize information from SharePoint sites and documents, thus simplifying the process of searching for and accessing the relevant documents and information.
Additionally, Microsoft Syntex can be integrated with other Microsoft products such as Azure Cognitive Search, Power Automate and Dynamics 365 which allows organizations to extract insights from multiple sources of data, including social media, customer feedback, and more.
Overall, Microsoft Syntex is a powerful platform that can help organizations extract insights and meaning from unstructured data, automate data classification and organization, and integrate with other Microsoft products to gain insights from multiple sources of data.
Key features and benefits of Microsoft Syntex
Microsoft Syntex has several key features and benefits that make it a powerful tool for extracting insights and meaning from unstructured data. Some of the main features and benefits include:
Natural Language Processing (NLP) capabilities: Microsoft Syntex uses NLP techniques such as sentiment analysis, entity recognition, and topic modeling to automatically extract relevant information from text-based data. This way, users can simplify large volumes of unstructured data into easily consumable and comprehensible insights that aid decision-making.
Machine Learning (ML) capabilities: Microsoft Syntex uses ML algorithms to identify patterns and relationships in data, which can be used to sort and filter data, or to train models for predictive analytics. This allows organizations to automatically classify and categorize data, making it easier to find and access the information they need.
Integration with other Microsoft products: Microsoft Syntex can be integrated with other Microsoft products such as Azure Cognitive Search, Power Automate, and Dynamics 365, which allows organizations to extract insights from multiple sources of data, including social media, customer feedback, and more.
Knowledge Management System (KMS): Microsoft Syntex can be integrated with SharePoint to automatically extract and organize information from SharePoint documents and lists, making it easier for users to find and access the information they need.
Scalable, customizable, and secure: Microsoft Syntex is built on Azure, which allows organizations to scale up or down as needed, and to customize the platform to meet their specific needs. Being on the cloud, the platform can be accessed and configured by anyone authorized to use it from anywhere and at any time. Being built on Azure, the platform is protected by Microsoft’s world-class security and compliance standards.
Use cases and examples of how Microsoft Syntex can be applied
Microsoft Syntex can be used in a variety of industries and scenarios to extract insights and meaning from unstructured data. Some examples of use cases for Microsoft Syntex include:
Customer service: An organization could use Microsoft Syntex to automatically classify and categorize customer feedback, such as email and social media posts. This would allow the organization to quickly and easily identify common issues and concerns, and to respond to customers more efficiently.
Healthcare: A hospital could use Microsoft Syntex to extract information from patient medical records and to classify the data based on symptoms, diagnoses, and treatment plans. This would allow doctors and nurses to quickly and easily find the information they need to make informed decisions.
Retail: A retail company could use Microsoft Syntex to extract sentiment and emotion from customer feedback and reviews, which can then be used to improve their products and services.
Finance: A bank or financial services firm could use Microsoft Syntex to extract insights from financial reports, news articles, and other unstructured data. The platform could be used to identify trends and patterns, which can then be used to predict future market movements and make more informed investment decisions.
HR: A company could use Microsoft Syntex to extract insights from resumes, cover letters and other unstructured data to identify patterns and trends, which can then be used to improve their recruitment process.
These are just a few examples, but Microsoft Syntex can be applied to a wide variety of industries and scenarios to extract insights and meaning from unstructured data, making it easier for organizations to make informed decisions.
Integrating Microsoft Syntex with SharePoint
The integration of Microsoft Syntex and SharePoint allows organizations to build a unified knowledge management system (KMS) with multi-level search capabilities. The Syntex platform can be used to build multiple SharePoint sites dedicated to different categories of business data with each site having its own categorization and search configurations. Once the user has logged into their SharePoint site, they would be able to see all of their data stored within Syntex. If they wanted to view or make changes to any records, they could do so via this interface by clicking on any of the fields available within each record.
Microsoft Syntex can be configured to index SharePoint content, allowing users to perform complex searches across not only the documents stored in SharePoint but also those stored in other file repositories like Exchange Server mailboxes and SQL databases.
The integration between Microsoft Syntex and SharePoint is especially beneficial because it allows administrators to assign different permissions. It allows you to take advantage of the advanced search capabilities provided by Microsoft Syntex, while also providing seamless integration with SharePoint’s document management features. This can help make your organization more efficient and productive by allowing employees to easily find the content they need without having to leave SharePoint.
The ability to annotate documents, along with the built-in search functionality and business intelligence tools, makes Syntex a powerful tool for improving productivity and streamlining processes. The solution can help you manage your SharePoint data more efficiently, allowing you to make better decisions about what content is important and how best to use it.
Tips and best practices for maximizing the potential of the integration
Start small: Begin by integrating Microsoft Syntex with a small subset of your SharePoint data, and gradually expand as needed.
Keep data organized: Make sure that your SharePoint data is well-organized, with consistent naming conventions and clear categories. This will make it easier for Microsoft Syntex to extract and classify the data.
Train the model regularly: Regularly retrain the model on new data to improve its accuracy and relevance.
Monitor the results: Monitor the results of the integration to identify any issues and optimize configurations to see the results you want.
Use additional Microsoft products: Integrate Microsoft Syntex with other Microsoft products such as Azure Cognitive Search, Power Automate, and Dynamics 365 to extract insights from multiple sources of data.
By following these tips and best practices, organizations can maximize the potential of the integration and extract valuable insights from their SharePoint data.
Conclusion
Syntex is a powerful tool that can transform your SharePoint into an intelligent KMS. The solution comes with built-in search functionality and annotation capabilities, allowing users to find documents quickly and easily without having to resort to manual processes like emailing files around the office.
The solution also allows users to view and edit any documents stored within SharePoint, which can be useful if you need to make changes on the fly. Syntex is integrated with Microsoft Office 365, making it easy for users to access their data from anywhere at any time.
0 notes
Text
The Essential Guide to Speech Data Collection for Machine Learning Models
Introduction:
Speech data collection is a critical step in training robust and accurate machine learning models for speech recognition, synthesis, and understanding. High-quality speech datasets are essential for developing models that can accurately transcribe spoken language, respond to voice commands, and even simulate human-like conversational interactions. In this article, we'll explore the importance of speech data collection, best practices for gathering speech data, and challenges in the field.
Importance of Speech Data Collection:
Speech data collection is the foundation of building effective speech recognition and synthesis models. The quality and diversity of the data directly impact the performance and generalisation capabilities of these models. Collecting a diverse range of voices, accents, and languages helps ensure that the models are inclusive and can accurately understand and respond to a wide variety of speakers.
Best Practices for Speech Data Collection:
Define the Scope: Clearly define the goals and requirements of the speech data collection project. Determine the languages, accents, and dialects you want to include, as well as the types of speech (e.g., casual conversation, dictation, etc.) and the recording conditions (e.g., noisy environments, different devices).
Data Collection Methods: There are several methods for collecting speech data, including crowdsourcing platforms, in-house recordings, and partnerships with organisations or communities. Each method has its advantages and challenges, so choose the one that best suits your project's needs.
Data Annotation: Annotate the collected speech data with relevant metadata, such as speaker demographics, recording conditions, and transcription or translation of the speech. This metadata is crucial for training and evaluating machine learning models.
Quality Control: Implement quality control measures to ensure the collected data is accurate and reliable. This may include manual review of recordings, automated checks for audio quality, and consistency checks for annotations.
Challenges in Speech Data Collection:
Privacy and Ethics: Collecting speech data raises privacy and ethical concerns, especially when dealing with sensitive or personal information. It's essential to obtain consent from speakers and anonymize data to protect privacy.
Data Imbalance: Ensuring a balanced dataset with sufficient representation of different voices, accents, and languages can be challenging. Imbalanced datasets can lead to biassed models that perform poorly on underrepresented groups.
Data Diversity: Collecting diverse speech data is crucial for building inclusive models. However, obtaining data from diverse populations, especially in terms of language, accent, and culture, can be challenging.
Conclusion:
Speech data collection is a critical step in developing effective machine learning models for speech recognition and synthesis. By following best practices and addressing challenges in data collection, researchers and developers can build more accurate and inclusive models that can better understand and interact with speakers from diverse backgrounds.

0 notes
Text
Principal Difficulties For Audio Annotation And Audio Transcription

You wish to supply large amounts of raw data to Artificial Intelligence (AI) robots to ensure that they can carry out tasks like humans do. The issue is that these machines will only operate in accordance with the parameters you specified in the AI Training Datasets. Annotating data is the most important method of bridging the gap between data examples and machine learning/AI.
Data annotation involves adding labels, categories as well as other aspects of context to a data set in order computers can understand and use the data.
The application of annotation of data in applications along with some current and anticipated benefits of the technique are described in more depth below. The power of machine learning initiatives in general is the data. Your conclusions is more precise the more data you can gather. Raw data on its own, while may be sufficient, is not sufficient. To enable machines to be able to precisely detect objects in an image, comprehend spoken languages, as well as complete many other things it is necessary to annotate the data.
Audio data is increasingly common in public networks, and especially on platforms that are based on the Internet. Therefore, it is vital to organize and analyze the data that is audio so that we can have continuous accessibility to the data. The non-stationary nature of audio signals and their irregularities makes segmenting and separating them extremely challenging tasks. The difficulties in separating and deciding on the best audio features makes automated annotation and music classification difficult.
What are the main issues in data annotation?
Costing annotation data can be done either manually or automatically or both. Manually annotation takes a lot of time, and it is essential to keep the integrity of the data
Accuracy of annotations Poor data quality could be the result of human errors and directly affects the accuracy of AI/ML models to predict the future. A Gartner study revealed that bad data quality can cost businesses 15percent of revenues.
In the next section, we will go into greater detail on the way data annotation can be used in different applications and some of the present and future benefits of this method.
Data is the primary resource of machine learning projects generally. If you have more data the better your final choice will become more reliable. Raw data on its own is not enough. It is necessary to annotate the data to enable the machine learning system to detect objects within an image, understand spoken languages, and perform many other things.
Sentiment annotation: In this method an annotation by a human gathers the text used to train AI while the text is highlighted with phrases and words' arbitrary and emotional meanings. Sentiment annotation can help AI understand the significance in the texts.
Audio Annotation
An audio annotation may be achieved in five ways:
Audio Transcription For creating NLP models it is crucial to accurately translate spoken words into texts. The recording of speech and the conversion into text, identifying words and sounds according to how they are spoken is essential for this method. Proper punctuation is also essential to this technique.
Audio ClassificationMachines are able to distinguish the sounds and voices using this method. It is crucial to utilize this method of labeling audio in the development of virtual assistants since it lets an AI model to identify the person speaking.
natural Language UtteranceHuman speech is recorded using natural language in order to distinguish dialects, semantics and intonations. Therefore, it is crucial to train chatbots and virtual assistants with natural spoken language.
Speech Labeling An annotator for data labeled sound recordings using keyword phrases after an extraction of the needed sounds. Chatbots that use this method are able to be able to handle repetitive tasks.
Music ClassificationData annotations can be made using audio annotations to label the genres or instruments. Music classification is essential to keep the music libraries in order and for refining user suggestions.
An audio annotation relies heavily on audio data that is high-quality. With a platform-independent annotation method and a workforce in-house, Anolytics can satisfy your requirements for audio data. We can assist you with getting the audio training data you require for your specific needs.
Image Analysis
Image annotation's primary purpose is to provide information on images as well as descriptors, keywords, and other information with respect to different elements of images. With annotation of images screen readers, screen readers are able to look at images and aids websites like stock image aggregators find and share the right images to answer user questions.
Contextual annotations have been added to more detailed photos of people's bodies as they age, which is improving AI capabilities. These are images used to practice for autonomous vehicles as well as the medical equipment for diagnosis.
Text classification
According to the subject matter the text categorization assigns categories to specific words within the document or paragraph. Users can discover the information they require on the site.
Audio annotations
A lot of smartphones as well as Internet of Things (IoT) devices rely on the use of voice recognition as well as other audio comprehension functions. However, they are unable to discover the meanings of sounds following frequent annotation of audio. By using speech or other sound effects as their beginning point, audio annotators label and classify Audio Datasets recordings by factors such as intonation dialect, pronunciation, in addition to the volume. Home assistants and other devices depend on audio annotation to aid in audio and speech recognition.
YouTube comments
Video annotation blends several audio annotation and images to assist AI (AI) in assessing the significance of the audio and visual elements of the video clip. Video annotation is becoming increasingly crucial as technology like autonomous vehicles and even home appliances are able to recognize the importance of video annotation.
Benefits
data that has annotations. Since it acts as a facilitator instead of a final product of developing solid AI the benefits could be related to increasing the effectiveness and reliability in AI. AI engine. It is a main benefit and its primary goal. The advantages it offers are intrinsically with those of AI.
0 notes
Text
How Text Annotation Is Enabling Businesses Take Advantage Of Ai

We humans can process 800 words per minute, and it takes us on average 0.6 seconds to name what we see. Forming ideas and inferences based on what someone is saying to us comes easy. As businesses seek greater precision and contextual understanding from their AI and machine learning products, they require them to emulate these simple semantic features of the human brain. But with much of the available data existing in unstructured formats, training AI tools with contextual information is hard. That’s where data annotation services come into the picture.
Research shows that the data annotation tools market size exceeded USD 1 billion in 2021 and is anticipated to grow at a CAGR of over 30% between 2022 and 2028. Images, video, audio, and text – of these formats text is the most popular in terms of application, yet relatively complex to comprehend. Let’s take an example – “They were rocking!” While as humans we would interpret this statement as applause, encouragement, or awe, the typical machine or Natural Language Processing (NLP) model is more likely to perceive the word ‘rocking’ literally, missing its true intent. Here’s where text annotation proves a critical enabler, one on which numerous NLP technologies like chatbots, automatic voice recognition, and sentiment analysis algorithms are founded.
What is text annotation?
Text annotation is nothing but labeling a text document or different elements of its content into a pre-defined classification. Written language can convey a lot of underlying information to a reader, including emotions, sentiments, examples, and opinions. To help machines recognize its true context we need humans to annotate the text that conveys exactly this information.
How does it work?
A human annotator is given a group of text, along with specific labels and guidelines set by the project owner or client. Their task is to map each text with the right labels. Once a sizable number of textual datasets are annotated in this manner they are entered into machine learning algorithms to help the model learn the semantics behind when and why each text was assigned a specific label. When done right, accurate training data helps develop a robust text annotation model enabling AI products to perform better and with little human intervention.
Why do we need it?
Businesses can use text annotation data in a variety of ways, such as:
Improving the accuracy of responses by digital assistants and chatbots
Improving the relevance of search results
Understanding the sentiment behind product reviews and other user-generated content, such as reviews
Extracting details from documents and forms while maintaining their confidentiality
Facilitating accurate translation of text from one language to another
Types of text annotation and their applications 1. Text classification
In this type, the entire body or line of text is annotated with a single label. Variants within text classification include:
Product categorization: To help improve the accuracy and relevance of search results that show up on, for instance, e-commerce sites, this type of annotation proves crucial. Annotators are generally given product titles and descriptions that need to be categorized by choosing from a set list of departments provided by the e-commerce firm. Below is an example.
Source: Schema.org
Document classification: In this case, the annotator segregates the documents based on a topic or subject. This is generally useful for sectors like education, finance, law, and healthcare that have large online repositories and knowledge platforms requiring a recall of text-based content.
Insurance contracts, bills and receipts, medical reports, and prescriptions are some common use cases of document classification.
Source: ResearchGate
2. Entity annotation
This type of annotation is used in developing robust training datasets for chatbots and other NLP-based platforms. Variants within this type of annotation include:
Named entity recognition (NER): Annotators of NER are required to label text into relevant entities, such as names, places, brand or organization names, and other similar identifiers. For example, Netscribes helped a leading digital commerce platform improve the efficiency of their AI-powered chatbot by accurately tagging entities in their customer query data. This enabled faster responses, increased conversions, and greater customer satisfaction.
Part-of-speech (POS) tagging: In this type, annotators are essentially expected to tag the parts of speech in grammar like nouns, verbs, adjectives, pronouns, adverbs, prepositions, conjunctions, etc. This helps digital assistants understand the different types of sentence framing possibilities within a language.
Source: Baeldung
3. Intent annotation
Understanding the underlying intent in human speech is something that machines must be able to identify to be truly useful. For chatbots, if the customer’s intent is not understood correctly, the customer could leave frustrated, or for a business aiming to automate its customer support, it may mean more person-hours invested. That’s why it’s critical for annotators within this type to understand the intent behind a customer’s input, whether in a search bar or chatbot. Here’s an example of the types of classification under intent annotation for a restaurant’s chatbot.
Source: Cloud Academy
4. Sentiment annotation
For any business having a pulse of what customers are saying about its brand, product, or service on online forums is critical. This requires access to the right sentiment data. In sentiment annotation, human annotators are employed to evaluate texts across online websites and social media to tag keywords as positive, neutral, or negative.
Source: AWS
Customer-centric companies often partner with Netscribes to understand not just the broad sentiment from their reviews but a more granular one as depicted above. This helps create strong training data equipped for advanced levels of sentiment analysis. From accurately gauging customer signals to driving personalized responses sentiment annotation finds its use across AI-powered survey tools, digital assistants, and more.
5. Linguistic annotation
This type of annotation is based on phonetics. Here, annotators are tasked with evaluating nuances like natural pauses, stress, intonations, and more, within text and audio datasets to ensure accurate tagging. This approach is of specific importance for training machine translation models, and virtual and voice assistants to name a few.
All in all, to empower AI products to work with precision businesses need accurate and high-quality training data rendered quickly, efficiently, and at scale. It is no wonder savvy brands collaborate with data and text annotation providers like Netscribes to give their customers the best experience while driving higher ROI.
Netscribes provides custom AI solutions with the combined power of humans and technology to help organizations fast-track innovation, accelerate time to market, and increase ROI on their AI investments.
0 notes
Text
Is NLP possible in the absence of text annotation services?

Is it possible to create Natural Language Processing systems that do not rely on text annotation and text data collection services? Can machines learn the intricacies of human language on their own and perform their tasks efficiently? To answer these problems, one must first comprehend text annotation and NLP, as well as their relationship.
What exactly is text annotation?
Text Annotation is the process of identifying and extracting insights from text or audio recordings. It is the process of finding and categorizing meaningful words in a text. It aids in the addition of critical information to raw data and makes it understandable for machines to carry out tasks.
Text Annotation Service Types
Annotation of Entities
The technique of recognizing, extracting, and annotating entities inside text is known as entity annotation. It entails locating and tagging a specific section of the text that contains proper names or functional parts of speech like nouns, verbs, adverbs, and adjectives.
Annotation of Relationships
This type of text annotation entails identifying and capturing the relationship between two elements. Entity linking can be accomplished in two ways: linking two entities inside a text and linking the entities to knowledge databases that are relevant to them.
Classification of Documents
Document classification, also known as text classification, entails labelling a complete document or a line of text. Text annotators examine the content and detect the intent, subject, and sentiment within it, then assign it to a specified category.
Annotation of Sentiment
It entails identifying the emotion concealed within a text or email. Sentiment annotated data assists robots in understanding the sentiment behind the text as well as casual forms of communication such as wit, sarcasm, and so on.

Annotation Linguistic
Linguistic annotation is primarily used to provide labelled image data collection for the development of Natural Language Processing (NLP) models such as chatbots, interpreters, and virtual assistants. It entails annotating language data in audio recordings and text, which primarily consists of phonetic, grammatical, and semantic aspects.
NLP
NLP is an Artificial Intelligence subfield that enables machines to interpret human language. It facilitates human-computer interaction by deriving meaning from human discourse.

Among the most common instances of NLP are:
Siri, Alexa, Cortana, and OK Google are examples of intelligent assistants that identify patterns in speech.
Gmail's email classification divides inbox emails into three categories: primary, social, and promotional.
Autocomplete and autocorrect features that finish a word or propose a related one and rearrange words to give meaning to the entire message, respectively.
Language translators capable of translating from one language to another Search engines such as Google display appropriate results based on user intent
NLP Text Annotation Services
Human language is complex and dynamic, conveying a great deal of information. It assists us in understanding and forecasting human behavior. Computers cannot detect information travelling via natural languages because the computers must grasp the words as well as the concepts that are linked to providing the intended information. Because natural languages are not native to machines, they must be trained using intermediate data structures (labelled data) that assist them in understanding what people desire from texts. Text labelling services transform unstructured input into structured data, which is subsequently used to train NLP algorithms to extract meaning from phrases and collect usable data. As a result, high-quality annotated data is a critical component of the NLP ecosystem. It may be impossible to create an effective NLP system without text annotation services.
Regarding GTS
Global Technology Solutions specializes in providing scalable AI training dataset and labelling services to assist you in building accurate and precise machine learning models. Our data is used in a variety of areas, including healthcare, banking, and technology.
0 notes
Last Seen Blogs

z4ckk
Zack

sapphicphilhellene
Violets for Mytiléne

decifrandos-world
Sem título

plugincaro
PlugInCaroo

flimsy-flower
Flimsy Flower