
Last Seen Blogs

theanoninyourinbox
Just That Anon In Your Inbox

kaidanalenkosprmanager
Through shoals of dust, I will return to where I began.

akechifan1
foxswedding

beanstalk-nicholas
I Post Art Here Sometimes

erickeagl753-blog
No-Hassle Methods For Arbitrator - Insights
Text
Behold! Big Data at Fast Speed!
Oak0.2 Release: Significant Improvements to Throughput, Memory Utilization, and User Interface
By Anastasia Braginsky, Sr. Research Scientist, Verizon Media Israel

Creating an open source software is an ongoing and exciting process. Recently, Oak open-source library delivered a new release: Oak0.2, which summarizes a year of collaboration. Oak0.2 makes significant improvements in throughput, memory utilization, and user interface.
OakMap is a highly scalable Key-Value Map that keeps all keys and values off-heap. The Oak project is designed for Big Data real-time analytics. Moving data off-heap, enables working with huge memory sizes (above 100GB) while JVM is struggling to manage such heap sizes. OakMap implements the industry-standard Java8 ConcurrentNavigableMap API and more. It provides strong (atomic) semantics for read, write, and read-modify-write, as well as (non-atomic) range query (scan) operations, both forward and backward. OakMap is optimized for big keys and values, in particular, for incremental maintenance of objects (update in-place). It is faster and scales better with additional CPU cores than the popular Java’s ConcurrentNavigableMap implementation ConcurrentSkipListMap.
Oak data is written to the off-heap buffers, thus needs to be serialized (converting an object in memory into a stream of bytes). For retrieval, data might be deserialized (object created from the stream of bytes). In addition, to save the cycles spent on deserialization, we allow reading/updating the data directly via OakBuffers. Oak provides this functionality under the ZeroCopy API.
If you aren’t already familiar with Oak, this is an excellent starting point to use it! Check it out and let us know if you have any questions.
Oak keeps getting better: Introducing Oak0.2
We have made a ton of great improvements to Oak0.2, adding a new stream scanning for improved performance, releasing a ground-up rewrite of our Zero Copy API’s buffers to increase safety and performance, and decreasing the on-heap memory requirement to be less than 3% of the raw data! As an exciting bonus, this release also includes a new version of our off-heap memory management, eliminating memory fragmentation.
Below we dive deeper into sub-projects being part of the release.
Stream Data Faster
When scanned data is held by any on-heap data structures, each next-step is very easy: get to the next object and return it. To retrieve the data held off-heap, even when using Zero-Copy API, it is required to create a new OakBuffer object to be returned upon each next step. Scanning Big Data that way will create millions of ephemeral objects, possibly unnecessarily, since the application only accesses this object in a short and scoped time in the execution.
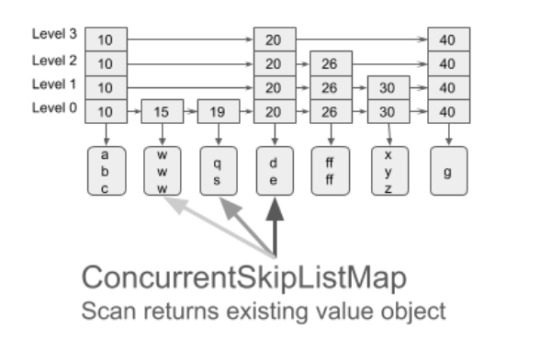
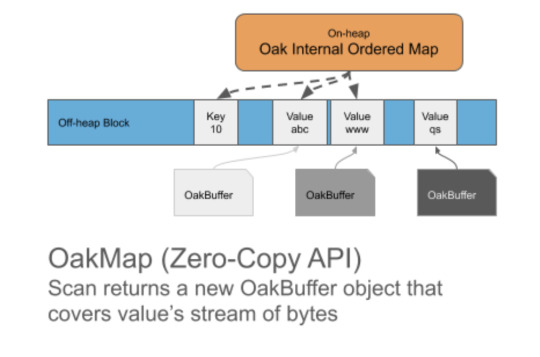
To avoid this issue, the user can use our new Stream Scan API, where the same OakBuffer object is reused to be redirected to different keys or values. This way only one element can be observed at a time. Stream view of the data is frequently used for flushing in-memory data to disk, copying, analytics search, etc.
Oak’s Stream Scan API outperforms CSLM by nearly 4x for the ascending case. For the descending case, Oak outperforms CSLM by more than 8x even with less optimized non-stream API. With the Stream API, Oak’s throughput doubles. More details about the performance evaluation can be found here.


Safety or Performance? Both!
OakBuffers are core ZeroCopy API primitives. Previously, alongside with OakBuffers, OakMap exposed the underlying ByteBuffers directly to the user, for the performance. This could cause some data safety issues such as an erroneous reading of the wrong data, unintentional corrupting of the data, etc. We couldn’t choose between safety and performance, so strived to have both!
With Oak0.2, ByteBuffer is never exposed to the user. Users can choose to work either with OakBuffer which is safe or with OakUnsafeDirectBuffer which gives you faster access, but use it carefully. With OakUnsafeDirectBuffer, it is the user's responsibility to synchronize and not to access deleted data, if the user is aware of those issues, OakUnsafeDirectBuffer is safe as well.
Our safe OakBuffer works with the same, great and known, OakMap performance, which wasn’t easy to achieve. However, if the user is interested in even superior speed of operations, any OakBuffer can be cast to OakUnsafeDirectBuffer.
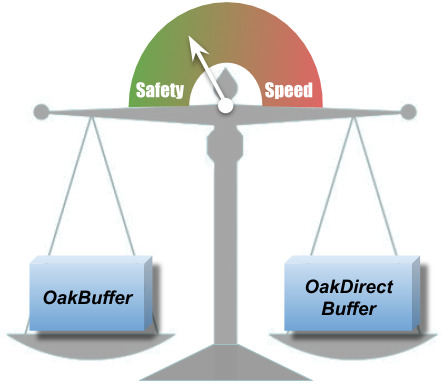
Less (metadata) is more (data)
In the initial version of OakMap we had an object named handler that was a gateway to access any value. Handler was used for synchronization and memory management. Handler took about 256 bytes per each value and imposed dereferencing on each value access.
Handler is now replaced with an 8-bytes header located in the off-heap, next to the value. No dereferencing is needed. All information needed for synchronization and memory manager is kept there. In addition, to keep metadata even smaller, we eliminated the majority of the ephemeral object allocations that were used for internal calculations.
This means less memory is used for metadata and what was saved goes directly to keep more user data in the same memory budget. More than that, JVM GC has much less reasons to steal memory and CPU cycles, even when working with hundreds of GBs.
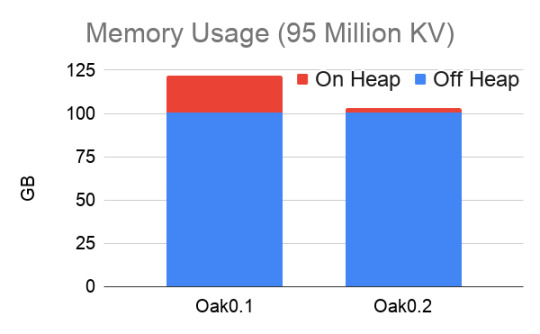
Fully Reusable Memory for Values
As explained above, 8-byte off-heap headers were introduced ahead of each value. The headers are used for memory reclamation and synchronization, and to hold lock data. As thread may hold the lock after a value is deleted, the header's memory couldn’t be reused. Initially the header's memory was abandoned, causing a memory leak.
The space allocated for value is exactly the value size, plus header size. Leaving the header not reclaimed, creates a memory “hole” where a new value of the same size can not fit in. As the values are usually of the same size, this was causing fragmentation. More memory was consumed leaving unused spaces behind.
We added a possibility to reuse the deleted headers for new values, by introducing a sophisticated memory management and locking mechanism. Therefore the new values can use the place of the old deleted value. With Oak0.2, the scenario of 50% puts and 50% deletes is running with a stable amount of memory and performs twice better than CSLM.
We look forward to growing the Oak community! We invite you to explore the project, use OakMap in your applications, raise issues, suggest improvements, and contribute code. If you have any questions, please feel free to send us a note. It would be great to hear from you!
Acknowledgements:
Liran Funaro, Eshcar Hilel, Eran Meir, Yoav Zuriel, Edward Bortnikov, Yonatan Gottesman
#open source#big data#performance#concurrency#multi-threading#scalability#java off-heap#key-value store#memory utilization
6 notes
·
View notes
Text
Apache Storm 2.2.0 Improvements - NUMA Support, Auto Refreshing SSL Certificates for All Daemons, V2 Tick Backwards Compatibility, Scheduler Improvements, & OutputCollector Thread Safety
Kishor Patil, PMC Chair Apache Storm & Sr. Principal Software Systems Engineer, Verizon Media
Last year, we shared with you many of the Apache Storm 2.0 improvements contributed by Verizon Media. At Yahoo/Verizon Media, we’ve been committing to Storm for many years. Today, we’re excited to explore a few of the new features, improvements, and bug fixes we’ve contributed to Storm 2.2.0.
NUMA Support
The server hardware is getting beefier and requires worker JVMs to be NUMA (Non-uniform memory access) aware. Without constraining JVMs to NUMA zones, we noticed dramatic degradation in the JVM performance; specifically for Storm where most of the JVM objects are short-lived and continuous GC cycles perform complete heap scan. This feature enables maximizing hardware utilization and consistent performance on asymmetric clusters. For more information please refer to [STORM-3259].
Auto Refreshing SSL Certificates for All Daemons
At Verizon Media, as part of maintaining thousands of Storm nodes, refreshing SSL/TLS certificates without any downtime is a priority. So we implemented auto refreshing SSL certificates for all daemons without outages. This becomes a very useful feature for operation teams to monitor and update certificates as part of hassle free continuous monitoring and maintenance. Included in the security related critical bug fixes the Verizon Media team noticed and fixed are:
Kerberos connectivity from worker to Nimbus/Supervisor for RPC heartbeats [STORM-3579]
Worker token refresh causing authentication failure [STORM-3578]
Use UserGroupInformation to login to HDFS only once per process [STORM-3494]
AutoTGT shouldn't invoke TGT renewal thread [STORM-3606]
V2 Tick Backwards Compatibility
This allows for deprecated metrics at worker level to utilize messaging and capture V1 metrics. This is a stop-gap giving topology developers sufficient time to switch from V1 metrics to V2 metrics API. The Verizon Media Storm team also provided shortening metrics names to allow for metrics names that conform to more aggregation strategies by dimension [STORM-3627]. We’ve also started removing deprecated metrics API usage within storm-core and storm-client modules and adding new metrics at nimbus/supervisor daemon level to monitor activity.
Scheduler Improvements
ConstraintSolverStrategy allows for max co-location count at the Component Level. This allows for better spread - [STORM-3585]. Both ResourceAwareScheduler and ConstraintSolverStrategy are refactored for faster performance. Now a large topology of 2500 component topology requesting complex constraints or resources can be scheduled in less than 30 seconds. This improvement helps lower downtime during topology relaunch - [STORM-3600]. Also, the blacklisting feature to detect supervisor daemon unavailability by nimbus is useful for failure detection in this release [STORM-3596].
OutputCollector Thread Safety
For messaging infrastructure, data corruption can happen when components are multi-threaded because of non thread-safe serializers. The patch [STORM-3620] allows for Bolt implementations that use OutputCollector in other threads than executor to emit tuples. The limitation is batch size 1. This important implementation change allows for avoiding data corruption without any performance overhead.
Noteworthy Bug Fixes
For LoadAwareShuffle Grouping, we were seeing a worker overloaded and tuples timing out with load aware shuffle enabled. The patch checks for low watermark limits before switching from Host local to Worker local - [STORM-3602].
For Storm UI, the topology visualization related bugs are fixed so topology DAG can be viewed more easily.
The bug fix to allow the administrator access to topology logs from UI and logviewer.
storm cli bug fixes to accurately process command line options.
What’s Next
In the next release, Verizon Media plans to contribute container support with Docker and RunC container managers. This should be a major boost with three important benefits - customization of system level dependencies for each topology with container images, better isolation of resources from other processes running on the bare metal, and allowing each topology to choose their worker OS and java version across the cluster.
Contributors
Aaron Gresch, Ethan Li, Govind Menon, Bipin Prasad, Rui Li
6 notes
·
View notes
Text
Announcing RDFP for Zeek - Enabling Client Telemetry to the Remote Desktop Protocol
Jeff Atkinson, Principal Security Engineer, Verizon Media
We are pleased to announce RDFP for Zeek. This project is based off of 0x4D31’s work, the FATT Remote Desktop Client fingerprinting. This technique analyzes client payloads during the RDP negotiation to build a profile of client software. RDFP extends RDP protocol parsing and provides security analysts a method of profiling software used on the network. BlueKeep identified some gaps in visibility spurring us to contribute to Zeek’s RDP protocol analyzer to extract additional details. Please share your questions and suggestions by filing an issue on Github.
Technical Details
RDFP extracts the following key elements and then generates an MD5 hash.
Client Core Data
Client Cluster Data
Client Security Data
Client Network Data
Here is how the RDFP hash is created:
md5(verMajor;verMinor;clusterFlags;encryptionMethods;extEncMethods;channelDef)
Client Core Data
The first data block handled is Client Core Data. The client major and minor versions are extracted. Other information can be found in this datagram but is more specific to the client configuration and not specific to the client software.
Client Cluster Data
The Client Cluster Data datagram contains the Cluster Flags. These are added in the order they are seen and will provide information about session redirection and other items - ex: if a smart card was used.
Client Security Data
The Client Security Data datagram provides the encryptionMethods and extEncryptionMethods. The encryptionMethods details the key that is used and message authentication code. The extEncryptionMethods is a specific flag designated for French locale.
Client Network Data
The Client Network Data datagram contains the Channel Definition Structure, (Channel_Def). Channel_Def provides configuration information about how the virtual channel with the server should be set up. This datagram provides details on compression, MCS priority, and channel persistence across transactions.
Here is the example rdfp.log generated by the rdfp.zeek script. The log provides all of the details along with the client rdfp_hash.
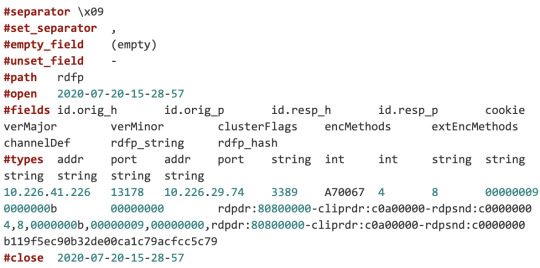
This technique works well, but notice that RDP clients can require TLS encryption. Reference the JA3 fingerprinting technique for TLS traffic analysis. Please refer to Adel’s blog post for additional details and examples about ways to leverage the RDP fingerprinting on the network.
Conclusion
Zeek RDFP extends network visibility into client software configurations. Analysts apply logic and detection techniques to these extended fields. Analysts and Engineers can also apply anomaly detection and additional algorithms to profile and alert suspicious network patterns.
Please share your questions and suggestions by filing an issue on Github.
Additional Reading
John B. Althouse, Jeff Atkinson and Josh Atkins, “JA3 — a method for profiling SSL/TLS clients”
Ben Reardon and Adel Karimi, “HASSH — a profiling method for SSH clients and servers”
Microsoft Corporation, “[MS-RDPBCGR]: Remote Desktop Protocol: Basic Connectivity and Graphics Remoting”
Adel Karimi, “Fingerprint All the Things!”
Matt Bromiley and Aaron Soto, “What Happens Before Hello?”
John Althouse, “TLS Fingerprinting with JA3 and JA3S”
Zeek Package Contest 3rd Place Winner
Acknowledgments
Special thanks to Adel, #JA3, #HASSH, and W for reminding me there’s always more on the wire.
1 note
·
View note
Text
Vespa Product Updates, June 2020: Support for Approximate Nearest Neighbor Vector Search, Streaming Search Speedup, Rank Features, & GKE Sample Application
Kristian Aune, Tech Product Manager, Verizon Media
In the previous update, we mentioned Improved Slow Node Tolerance, Multi-Threaded Rank Profile Compilation, Reduced Peak Memory at Startup, Feed Performance Improvements, and Increased Tensor Performance. This month, we’re excited to share the following updates:
Support for Approximate Nearest Neighbor Vector Search
Vespa now supports approximate nearest neighbor search which can be combined with filters and text search. By using a native implementation of the HNSW algorithm, Vespa provides state of the art performance on vector search: Typical single digit millisecond response time, searching hundreds of millions of documents per node, but also uniquely allows vector query operators to be combined efficiently with filters and text search - which is usually a requirement for real-world applications such as text search and recommendation. Vectors can be updated in real-time with a sustained write rate of a few thousand vectors per node per second. Read more in the documentation on nearest neighbor search.
Streaming Search Speedup
Streaming Search is a feature unique to Vespa. It is optimized for use cases like personal search and e-mail search - but is also useful in high-write applications querying a fraction of the total data set. With #13508, read throughput from storage increased up to 5x due to better parallelism.
Rank Features
The (Native)fieldMatch rank features are optimized to use less CPU query time, improving query latency for Text Matching and Ranking.
The new globalSequence rank feature is an inexpensive global ordering of documents in a system with stable system state. For a system where node indexes change, this is inaccurate. See globalSequence documentation for alternatives.
GKE Sample Application
Thank you to Thomas Griseau for contributing a new sample application for Vespa on GKE, which is a great way to start using Vespa on Kubernetes.
...
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweet or email) about any of these new features or future improvements you’d like to request.
0 notes
Text
Announcing Spicy Noise - Identify and Monitor WireGuard at Wire Speed
Jeff Atkinson, Principal Security Engineer, Verizon Media
Today we are excited to announce the release of Spicy Noise. This open source project was developed to address the need to identify and monitor WireGuard traffic at line speed with Zeek. The Spicy framework was chosen to build the protocol parser needed for this project. Please share your questions and suggestions by filing an issue on Github.
WireGuard was implemented on the Noise Protocol Framework to provide simple, fast, and secure cryptographic communication. Its popularity started within the Linux community due to its ability to run on Raspberry Pi and high end servers. The protocol has now been adopted and is being used cross platform. To explain how Spicy Noise works, let’s look at how Zeek and Spicy help monitor traffic.
Zeek is a network monitoring project that is robust and highly scalable. It supports multiple protocol analyzers on a standard install and provides invaluable telemetry for threat hunting and investigations. Zeek has been deployed on 100 gigabit networks.
Spicy is a framework provided by the Zeek community to build new protocol analyzers. It is replacing Binpac as a much simpler method to build protocol parsers. The framework has built-in integration with Zeek to enable analysis at line speed.
How it works
Zeek’s Architecture begins by reading packets from the network. The packets are then routed to “Event Engines” which parse the packets and forward events containing details of the packet. These events are presented to the “Policy Script Interpreter” where the details from the event can be acted upon by Zeek scripts. There are many scripts which ship with Zeek to generate logs and raise notifications. Many of these logs and notifications are forwarded to the SIEM of a SOC for analysis.
To build the capability to parse WireGuard traffic a new “Event Engine” has been created. This is done with Spicy by defining how a packet is parsed and how events are created. Packet parsing is defined in a .spicy file. Events are defined in a .evt file which will forward the details extracted by the .spicy parser for the “Policy Script Interpreter”. A dynamic protocol detection signature has to be defined so Zeek knows how to route packets to the new Event Engine. Refer to the diagram below to understand the role of the .spicy and .evt files of the new WireGuard parser or “Event Engine”.

Technical Implementation
The first step to building a new “Event Engine” is to define how the packet is to be parsed. Referring to the WireGuard protocol specification, there are four main UDP datagram structures. The four datagram structures defined are the Handshake Initiation, Handshake Response, Cookie Reply, and Transport Data. The diagram below depicts how the client and server communicate.

We will focus on the first, Handshake Response, but the same method is used to apply to the other three packet structures. The following diagram from the WireGuard whitepaper illustrates the structure of the Handshake Initiation packet.

The sections of the packet are defined with their respective sizes. These details are used in the .spicy file to define how Spicy will handle the packet. Note that the first field is the packet type and a value of 1 defines it as a Handshake Initiation structured packet. Below is a code snippet of wg-1.spicy from the repository. A type is created to define the fields and their size or delimiters.

Spicy uses wg-1.spicy as the first part of the “Event Engine” to parse packets. The next part needed is to define events in the .evt file. An event is created for each packet type to pass values from the “Event Engine” to the “Policy Script Interpreter”.

The .evt file also includes an “Analyzer Setup” which defines the Analyzer_Name, Transport_Portocol and additional details if needed.

The Analyzer_Name is used by dynamic protocol detection (DPD). Zeek reads packets and compares them against DPD signatures to identify which Analyzer or “Event Engine” to use. The Wireguard DPD signature looks for the first byte of a UDP datagram to be 1 followed by the reserved zeros as defined in the protocol specification. Below is the DPD signature created for matching on the WireGuard Handshake_Initiation packet which is the first in the session.

Now as Spicy or Zeek parse packets, anytime a packet is parsed by the Handshake_Initiation type it will generate an event. The event will include connection details stored in the $conn variable which is passed from the stream processor portion of the “Event Engine.” The additional fields are extracted from the packet as defined in the corresponding .spicy file type. These events are received by the “Policy Script Interpreter” and can be acted upon to create logs or raise notifications. Zeek scripts define which events to receive and what action is to be taken. The example below shows how the WireGuard::Initiation event can be used to set the service field in Zeek’s conn.log.

The conn.log file will now have events with a service of WireGuard.

Conclusion
Wireguard provides an encrypted tunnel which can be used to circumvent security controls. Zeek and Spicy provide a solution to enhance network telemetry allowing better understanding of the traffic. Standard network analysis can be applied with an understanding that WireGuard is in use and encrypting the traffic.
1 note
·
View note
Text
Bindable: Open Source Themeable Design System Built in Aurelia JS for Faster and Easier Web Development
Joe Ipson, Software Dev Engineer, Verizon Media
Luke Larsen, Sr Software Dev Engineer, Verizon Media

As part of the Media Platform Video Team we build and maintain a set of web applications that allow customers to manage their video content. We needed a way to be consistent with how we build these applications. Creating consistent layouts and interfaces can be a challenge. There are many areas that can cause bloat or duplication of code. Some examples of this are, coding multiple ways to build the same layout in the app, slight variations of the same red color scattered all over, multiple functions being used to capitalize data returned from the database. To avoid cases like this we built Bindable. Bindable is an open source design system that makes it possible to achieve consistency in colors, fonts, spacing, sizing, user actions, user permissions, and content conversion. We’ve found it helps us be consistent in how we build layouts, components, and share code across applications. By making Bindable open source we hope it will do the same for others.
Theming
One problem with using a design system or library is that you are often forced to use the visual style that comes with it. With Bindable you can customize how it looks to fit your visual style. This is accomplished through CSS custom properties. You can create your own custom theme by setting these variables and you will end up with your own visual style.
Modular Scale
Harmony in an application can be achieved by setting all the sizing and spacing to a value on a scale. Bindable has a modular scale built in. You can set the scale to whatever you wish and it will adjust. This means your application will have visual harmony. When you need, you can break out of the modular scale for custom sizing and spacing.

Aurelia
Aurelia is a simple, powerful, and unobtrusive javascript framework. Using Aurelia allows us to take advantage of its high performance and extensibility when creating components. Many parts of Bindable have added features thanks to Aurelia.
Tokens
Tokens are small building blocks that all other parts of Bindable use. They are CSS custom properties and set things like colors, fonts, and transitions.
Layouts
The issue of creating the same layout using multiple methods is solved by Layouts in Bindable. Some of the Layouts in Bindable make it easy to set a grid, sidebar, or cluster of items in a row. Layouts also handle all the spacing between components. This keeps all your spacing orderly and consistent.

Components
Sharing these components was one of the principal reasons the library exists. There are over 40 components available, and they are highly customizable depending on your needs.

Access Modifiers
Bindable allows developers to easily change the state of a component on a variety of conditions. Components can be hidden or disabled if a user lacks permission for a particular section of a page. Or maybe you just need to add a loading indicator to a button. These attributes make it easy to do either (or both!).
Value Converters
We’ve included a set of value converters that will take care of some of the most basic conversions for you. Things like sanitizing HTML, converting CSV data into an array, escaping a regex string, and even more simple things like capitalizing a string or formatting an ISO Date string.
Use, Contribute, & Reach Out
Explore the Bindable website for helpful details about getting started and to see detailed info about a given component. We are excited to share Bindable with the open source community. We look forward to seeing what others build with Bindable, especially Aurelia developers. We welcome pull requests and feedback! Watch the project on GitHub for updates. Thanks!
Acknowledgements
Cam Debuck, Ajit Gauli, Harley Jessop, Richard Austin, Brandon Drake, Dustin Davis
0 notes
Text
Change Announcement - JSON Web Key (JWK) for Public Elliptic-curve (EC) Key
Ashish Maheshwari, Software Engineer, Verizon Media
In this post, we will outline a change in the way we expose the JSON Web Key (JWK) for our public Elliptic-curve (EC) key at this endpoint: https://api.login.yahoo.com/openid/v1/certs, as well as, immediate steps users should take. Impacted users are any clients who parse our JWK to extract the EC public key to perform actions such as verify a signed token.
The X and Y coordinates of our EC public key were padded with a sign bit which caused it to overflow from 32 to 33 bytes. While most of the commonly used libraries to parse a JWK to public key can handle the extra length, others might expect a length strictly equal to 32 bytes. This change can be a breaking change for those.
Here are the steps affected users should take:
Any code/flow which needs to extract our EC public key from the JWK needs to be tested for this change. Below is our pre and post change production JWK for EC public key. Please verify that your code can successfully parse the new JWK. Notice the change in base64url value of the Y coordinate in the new JWK.
We are planning to make this change live on July 20th, 2020. If you have any questions/comments, please tweet @YDN or email us.
Current production EC JWK:
{“keys”:[{“kty”:“EC”,“alg”:“ES256”,“use”:“sig”,“crv”:“P-256”,“kid”:“3466d51f7dd0c780565688c183921816c45889ad”,“x”:“cWZxqH95zGdr8P4XvPd_jgoP5XROlipzYxfC_vWC61I”,“y”:“AK8V_Tgg_ayGoXiseiwLOClkekc9fi49aYUQpnY1Ay_y”}]}
EC JWK after change is live:
{“keys”:[{“kty”:“EC”,“alg”:“ES256",“use”:“sig”,“crv”:“P-256",“kid”:“3466d51f7dd0c780565688c183921816c45889ad”,“x”:“cWZxqH95zGdr8P4XvPd_jgoP5XROlipzYxfC_vWC61I”,“y”:“rxX9OCD9rIaheKx6LAs4KWR6Rz1-Lj1phRCmdjUDL_I”}]}
2 notes
·
View notes
Text
Introducing vSSH - Go Library to Execute Commands Over SSH at Scale
Mehrdad Arshad Rad, Sr. Principal Software Engineer, Verizon Media
vSSH is a high performance Go library designed to execute shell commands remotely on tens of thousands of network devices or servers over SSH protocol. The vSSH high-level API provides additional functionality for developing network or server automation. It supports persistent SSH connection to execute shell commands with a warm connection and returns data back quickly.
If you manage multiple Linux machines or devices you know how difficult it is to run commands on multiple machines every day, and appreciate the significant value of automation. There are other open source SSH libraries available in a variety of languages but vSSH has great features like persistent SSH connection, the ability to limit sessions, to limit the amount of data transferred, and it handles many SSH connections concurrently while using resources efficiently. Go developers can quickly create the network device, server automation, or tools, by using this library and focusing on the business logic instead of handling SSH connections.

vSSH can run on your application asynchronous and then you can call the APIs/methods through your application (safe concurrency). To start, load your clients information and add them to vSSH using a simple method. You can add labels and other optional attributes to each client. By calling the run method, vSSH sends the given command to all available clients or based on your query, it runs the command on the specific clients and the results of the command can be received in streaming (real-time) or the final result.
One of the main features of vSSH is a persistent connection to all devices and the ability to manage them. It can connect to all the configured devices/servers, all the time. The connections are simple authenticated connections without session at the first stage. When vSSH needs to run a command, it tries to create a session and it closes the session when it’s completed. If you don’t need the persistence feature then you can disable it, which results in the connection closing at the end. The main advantage of persistence is that it works as a warm connection and once the run command is requested, it just needs to create a session. The main use case is when you need to run commands on the clients continuously or the response time is important. In both cases, vSSH multiplexes sessions at one connection.
vSSH provides a DSL query feature based on the provided labels that you can use to select / filter clients. It supports operators like == != or you can also create your own logic. I wrote this feature with the Go abstract syntax tree (AST). This feature is very useful as you can add many clients to the library at the same time and run different commands based on the labels.
Here are three features that you can use to control the load on the client and force to terminate the running command:
By limiting the returned data which comes from stdout or stderr in bytes
Terminate the command by defined timeout
Limit the concurrent sessions on the client
Use & Contribute
To learn more about vSSH, explore github.com/yahoo/vssh and try the vSSH examples at https://pkg.go.dev/github.com/yahoo/vssh.
0 notes
Text
Data Disposal - Open Source Java-based Big Data Retention Tool
By Sam Groth, Senior Software Engineer, Verizon Media
Do you have data in Apache Hadoop using Apache HDFS that is made available with Apache Hive? Do you spend too much time manually cleaning old data or maintaining multiple scripts? In this post, we will share why we created and open sourced the Data Disposal tool, as well as, how you can use it.
Data retention is the process of keeping useful data and deleting data that may no longer be proper to store. Why delete data? It could be too old, consume too much space, or be subject to legal retention requirements to purge data within a certain time period of acquisition.
Retention tools generally handle deleting data entities (such as files, partitions, etc.) based on: duration, granularity, or date format.
Duration: The length of time before the current date. For example, 1 week, 1 month, etc.
Granularity: The frequency that the entity is generated. Some entities like a dataset may generate new content every hour and store this in a directory partitioned by date.
Date Format: Data is generally partitioned by a date so the format of the date needs to be used in order to find all relevant entities.
Introducing Data Disposal
We found many of the existing tools we looked at lacked critical features we needed, such as configurable date format for parsing from the directory path or partition of the data and extensible code base for meeting the current, as well as, future requirements. Each tool was also built for retention with a specific system like Apache Hive or Apache HDFS instead of providing a generic tool. This inspired us to create Data Disposal.
The Data Disposal tool currently supports the two main use cases discussed below but the interface is extensible to any other data stores in your use case.
File retention on the Apache HDFS.
Partition retention on Apache Hive tables.
Disposal Process

The basic process for disposal is 3 steps:
Read the provided yaml config files.
Run Apache Hive Disposal for all Hive config entries.
Run Apache HDFS Disposal for all HDFS config entries.
The order of the disposals is significant in that if Apache HDFS disposal ran first, it would be possible for queries to Apache Hive to have missing data partitions.
Key Features
The interface and functionality is coded in Java using Apache HDFS Java API and Apache Hive HCatClient API.
Yaml config provides a clean interface to create and maintain your retention process.
Flexible date formatting using Java's SimpleDateFormat when the date is stored in an Apache HDFS file path or in an Apache Hive partition key.
Flexible granularity using Java's ChronoUnit.
Ability to schedule with your preferred scheduler.
The current use cases all use Screwdriver, which is an open source build platform designed for continuous delivery, but using other schedulers like cron, Apache Oozie, Apache Airflow, or a different scheduler would be fine.
Future Enhancements
We look forward to making the following enhancements:
Retention for other data stores based on your requirements.
Support for file retention when configuring Apache Hive retention on external tables.
Any other requirements you may have.
Contributions are welcome! The Data team located in Champaign, Illinois, is always excited to accept external contributions. Please file an issue to discuss your requirements.
2 notes
·
View notes
Text
Vespa Product Updates, May 2020: Improved Slow Node Tolerance, Multi-Threaded Rank Profile Compilation, Reduced Peak Memory at Startup, Feed Performance Improvements, & Increased Tensor Performance
Kristian Aune, Tech Product Manager, Verizon Media
In the April updates, we mentioned Improved Performance for Large Fan-out Applications, Improved Node Auto-fail Handling, CloudWatch Metric Import and CentOS 7 Dev Environment. This month, we’re excited to share the following updates:
Improved Slow Node Tolerance
To improve query scaling, applications can group content nodes to balance static and dynamic query cost. The largest Vespa applications use a few hundred nodes. This is a great feature to optimize cost vs performance in high-query applications. Since Vespa-7.225.71, the adaptive dispatch policy is made default. This balances load to the node groups based on latency rather than just round robin - a slower node will get less load and overall latency is lower.
Multi-Threaded Rank Profile Compilation
Queries are using a rank profile to score documents. Rank profiles can be huge, like machine learned models. The models are compiled and validated when deployed to Vespa. Since Vespa-7.225.71, the compilation is multi-threaded, cutting compile time to 10% for large models. This makes content node startup quicker, which is important for rolling upgrades.
Reduced Peak Memory at Startup
Attributes is a unique Vespa feature used for high feed performance for low-latency applications. It enables writing directly to memory for immediate serving. At restart, these structures are reloaded. Since Vespa-7.225.71, the largest attribute is loaded first, to minimize temporary memory usage. As memory is sized for peak usage, this cuts content node size requirements for applications with large variations in attribute size. Applications should keep memory at less than 80% of AWS EC2 instance size.
Feed Performance Improvements
At times, batches of documents are deleted. This subsequently triggers compaction. Since Vespa-7.227.2, compaction is blocked at high removal rates, reducing overall load. Compaction resumes once the remove rate is low again.
Increased Tensor Performance
Tensor is a field type used in advanced ranking expressions, with heavy CPU usage. Simple tensor joins are now optimized and more optimizations will follow in June.
...
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweet or email) about any of these new features or future improvements you’d like to request.
0 notes
Text
Vespa Product Updates, April 2020: Improved Performance for Large Fan-out Applications, Improved Node Auto-fail Handling, CloudWatch Metric Import, & CentOS 7 Dev Environment
Kristian Aune, Tech Product Manager, Verizon Media
In the previous update, we mentioned Ranking with LightGBM Models, Matrix Multiplication Performance, Benchmarking Guide, Query Builder and Hadoop Integration. This month, we’re excited to share the following updates:
Improved Performance for Large Fan-out Applications
Vespa container nodes execute queries by fanning out to a set of content nodes evaluating parts of the data in parallel. When fan-out or partial results from each node is large, this can cause bandwidth to run out. Vespa now provides an optimization which lets you control the tradeoff between the size of the partial results vs. the probability of getting a 100% global result. As this works out, tolerating a small probability of less than 100% correctness gives a large reduction in network usage. Read more.
Improved Node Auto-fail Handling
Whenever content nodes fail, data is auto-migrated to other nodes. This consumes resources on both sender and receiver nodes, competing with resources used for processing client operations. Starting with Vespa-7.197, we have improved operation and thread scheduling, which reduces the impact on client document API operation latencies when a node is under heavy migration load.
CloudWatch Metric Import
Vespa metrics can now be pushed or pulled into AWS CloudWatch. Read more in monitoring.
CentOS 7 Dev Environment
A development environment for Vespa on CentOS 7 is now available. This ensures that the turnaround time between code changes and running unit tests and system tests is short, and makes it easier to contribute to Vespa.
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweet or email) about any of these new features or future improvements you’d like to request.
0 notes
Text
Yahoo Knowledge Graph Announces COVID-19 Dataset, API, and Dashboard with Source Attribution
Amit Nagpal, Sr. Director, Software Development Engineering, Verizon Media
Among many interesting teams at Verizon Media is the Yahoo Knowledge (YK) team. We build the Yahoo Knowledge Graph; one of the few web scale knowledge graphs in the world. Our graph contains billions of facts and entities that enrich user experiences and power AI across Verizon Media properties. At the onset of the COVID-19 pandemic we felt the need and responsibility to put our web scale extraction technologies to work, to see how we can help. We have started to extract COVID-19 statistics from hundreds of sources around the globe into what we call the YK-COVID-19 dataset. The YK-COVID-19 dataset provides data and knowledge that help inform our readers on Yahoo News, Yahoo Finance, Yahoo Weather, and Yahoo Search. We created this dataset by carefully combining and normalizing raw data provided entirely by government and public health authorities. We provide website level provenance for every single statistic in our dataset, so our community has the confidence it needs to use it scientifically and report with transparency. After weeks of hard work, we are ready to make this data public in an easily consumable format at the YK-COVID-19-Data GitHub repo.
A dataset alone does not always tell the full story. We reached out to teams across Verizon Media to get their help in building a set of tools that can help us, and you, build dashboards and analyze the data. Engineers from the Verizon Media Data team in Champaign, Illinois volunteered to build an API and dashboard. The API was constructed using a previously published Verizon Media open source platform called Elide. The dashboard was constructed using Ember.js, Leaflet and the Denali design system. We still needed a map tile server and were able to use the Verizon Location Technology team’s map tile service powered by HERE. We leveraged Screwdriver.cd, our open source CI/CD platform to build our code assets, and our open source Athenz.io platform to secure our applications running in our Kubernetes environment. We did this using our open source K8s-athenz-identity control plane project. You can see the result of this incredible team effort today at https://yahoo.github.io/covid-19-dashboard.
Build With Us
You can build applications that take advantage of the YK-COVID-19 dataset and API yourself. The YK-COVID-19 dataset is made available under a Creative Commons CC-BY-NC 4.0 license. Anyone seeking to use the YK-COVID-19 dataset for other purposes is encouraged to submit a request.
Feature Roadmap
Updated multiple times a day, the YK-COVID-19 dataset provides reports of country, state, and county-level data based on the availability of data from our many sources. We plan to offer more coverage, granularity, and metadata in the coming weeks.
Why a Knowledge Graph?
A knowledge graph is information about real world entities, such as people, places, organizations, and events, along with their relations, organized as a graph. We at Yahoo Knowledge have the capability to crawl, extract, combine, and organize information from thousands of sources. We create refined information used by our brands and our readers on Yahoo Finance, Yahoo News, Yahoo Search and others sites too.
We built our web scale knowledge graph by extracting information from web pages around the globe. We apply information retrieval techniques, natural language processing, and computer vision to extract facts from a variety of formats such as html, tables, pdf, images and videos. These facts are then reconciled and integrated into our core knowledge graph that gets richer every day. We applied some of these techniques and processes relevant in the COVID-19 context to help gather information from hundreds of public and government authoritative websites. We then blend and normalize this information into a single combined COVID-19 specific dataset with some human oversight for stability and accuracy. In the process, we preserve provenance information, so our users know where each statistic comes from and have the confidence to use it for scientific and reporting purposes with attribution. We then pull basic metadata such as latitude, longitude, and population for each location from our core knowledge graph. We also include a Wikipedia id for each location, so it is easy for our community to attach additional metadata, as needed, from public knowledge bases such as Wikimedia or Wikipedia.
We’re in this together. So we are publishing our data along with a set of tools that we’re contributing to the open source community. We offer these tools, data, and an invitation to work together on getting past the raw numbers.
Yahoo, Verizon Media, and Verizon Location Technology are all part of the family at Verizon.
24 notes
·
View notes
Text
Dash Open 21: Athenz - Open Source Platform for X.509 Certificate-based Service AuthN & AuthZ
By Ashley Wolf, Open Source Program Manager, Verizon Media
In this episode, Gil Yehuda (Sr. Director, Open Source) interviews Mujib Wahab (Sr. Director, Software Dev Engineering) and Henry Avetisyan (Distinguished Software Dev Engineer). Mujib and Henry discuss why Verizon Media open sourced Athenz, a platform for X.509 Certificate-based Service Authentication and Authorization. They also share how others can use and contribute to Athenz.
Audio and transcript available here.
You can listen to this episode of Dash Open on iTunes, SoundCloud, and Spotify.
1 note
·
View note
Text
Dash Open 20: The Benefits of Presenting at Meetups
By Rosalie Bartlett, Open Source Community, Verizon Media
In this episode, Ashley Wolf, Open Source Program Manager, interviews Eran Shapira, Software Development Engineering Manager, Verizon Media. Based in Tel Aviv, Israel, Eran manages the video activation team. Eran shares about his team’s focus, which technology he’s most excited about right now, the value of presenting at meetups, and his advice for being a great team member.
Audio and transcript available here.
You can listen to this episode of Dash Open on iTunes, SoundCloud, and Spotify.
P.S. Learn more about job opportunities (backend engineer, product manager, research scientist, and many others!) at our Tel Aviv and Haifa offices here.
0 notes
Text
Search COVID-19 Open Research Dataset (CORD-19) using Vespa - Open Source Big Data Serving Engine
Kristian Aune, Tech Product Manager, Verizon Media
After being made aware of the COVID-19 Open Research Dataset Challenge (CORD-19), where AI experts have been asked to create text and data mining tools that can help the medical community, the Vespa team wanted to contribute.
Given our experience with big data at Yahoo (now Verizon Media) and creating Vespa (open source big data serving engine), we thought the best way to help was to index the dataset, which includes over 44,000 scholarly articles, and to make it available for searching via Vespa Cloud.
Now live at https://cord19.vespa.ai, you can get started with a few of the sample queries or for more advanced queries, visit CORD-19 API Query. Feel free to tweet us @vespaengine or submit an issue, if you have any questions or suggestions.
Please expect daily updates to the documentation and query features. Contributions are appreciated - please refer to our contributing guide and submit PRs. You can also download the application, index the data set, and improve the service. More info here on how to run Vespa.ai on your own computer.
2 notes
·
View notes
Text
Dash Open 19: KDD - Understanding Consumer Journey using Attention-based Recurrent Neural Networks
By Ashley Wolf, Open Source Program Manager, Verizon Media
In this episode, Rosalie Bartlett, Sr. Open Source Community Manager, interviews Shaunak Mishra, Sr. Research Scientist, Verizon Media. Shaunak discusses two papers he presented at Knowledge Discovery and Data Mining (KDD) - “Understanding Consumer Journey using Attention-based Recurrent Neural Networks” and “Learning from Multi-User Activity Trails for B2B Ad Targeting”.
Audio and transcript available here.
You can listen to this episode of Dash Open on iTunes, SoundCloud, and Spotify.
0 notes
Text
Introducing Accessible Audio Charts - An Open Source Initiative for Android Apps
Sukriti Chadha, Senior Product Manager, Verizon Media
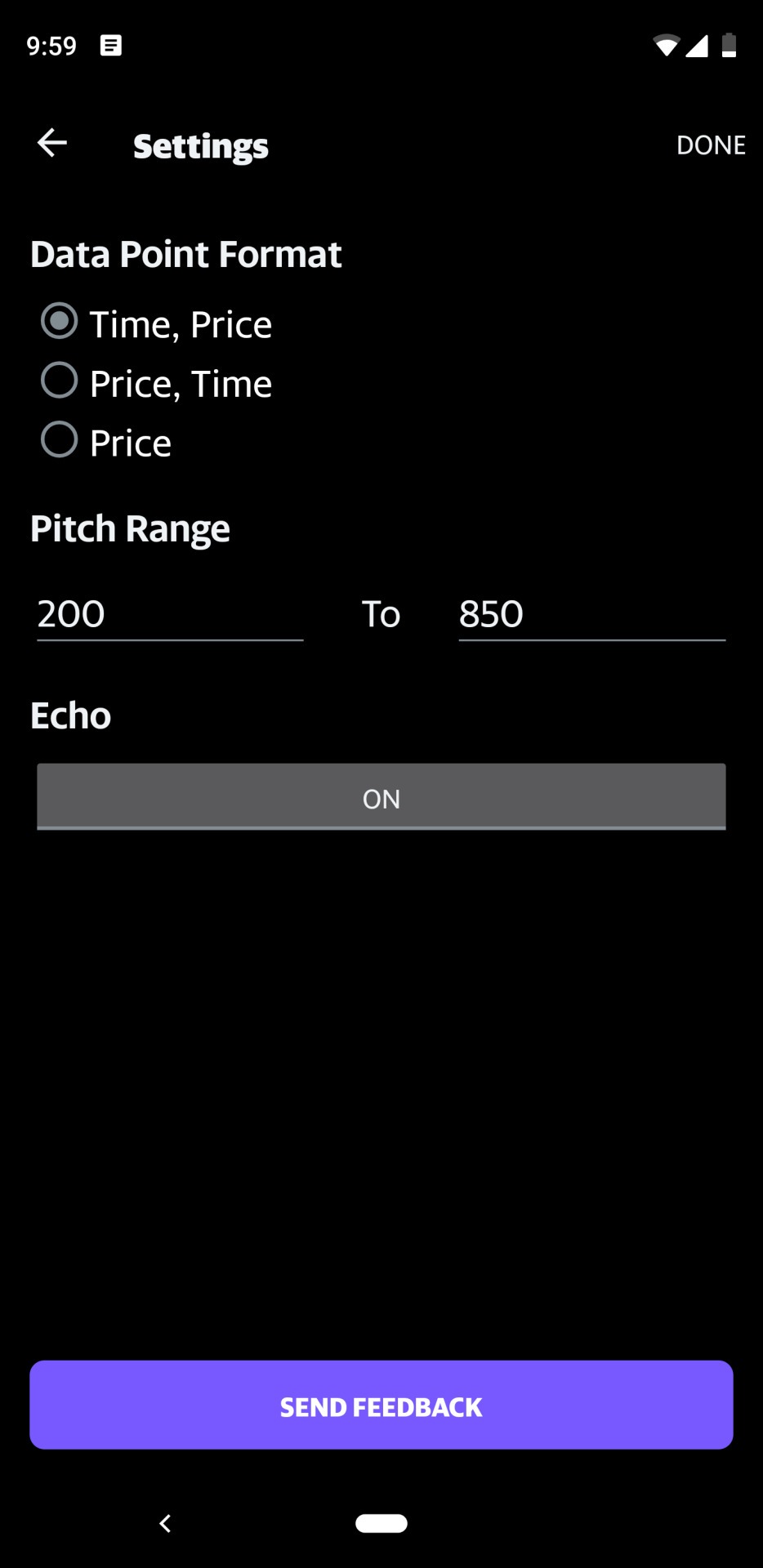
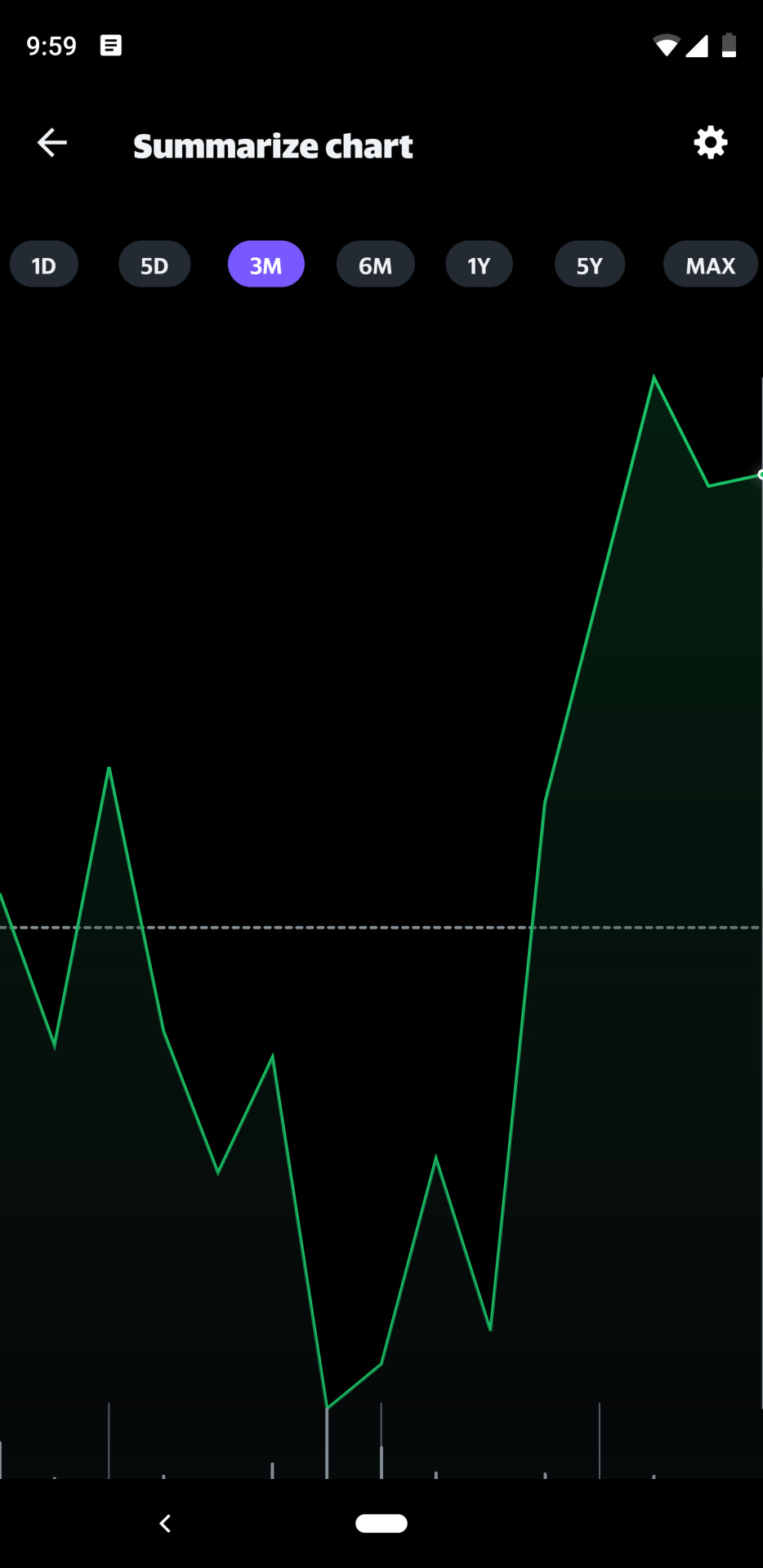
Finance charts quickly render hundreds of data points making it seamless to analyze a stock’s performance. Charts are great for people who can see well. Those who are visually impaired often use screen readers. For them, the readers announce the data points in a table format. Beyond a few data points, it becomes difficult for users to create a mental image of the chart’s trend. The audio charts project started with the goal of making Yahoo Finance charts accessible to users with visual impairment. With audio charts, data points are converted to tones with haptic feedback and are easily available through mobile devices where users can switch between tones and spoken feedback.
The idea for the accessible charts solution was first discussed during a conversation between Sukriti Chadha, from the Yahoo Finance team, and Jean-Baptiste Queru, a mobile architect. After building an initial prototype, they worked with Mike Shebanek, Darren Burton and Gary Moulton from the Accessibility team to run user studies and make improvements based on feedback. The most important lesson learned through research and development was that users want a nuanced, customizable solution that works for them in their unique context, for the given product.
Accessible charts were launched on the production versions of the Yahoo Finance Android and iOS apps in 2019 and have since seen positive reception from screen reader users. The open source effort was led by Yatin Kaushal and Joao Birk on engineering, Kisiah Timmons on the Verizon Media accessibility team, and Sukriti Chadha on product.
We would love for other mobile app developers to have this solution, adapt to their users' needs and build products that go from accessible to truly usable. We also envision applications of this approach in voice interfaces and contextual vision limitation scenarios. Open sourcing this version of the solution marks an important first step in this initiative.
To integrate the SDK, simply clone or fork the repository. The UI components and audio conversion modules can be used separately and modified for individual use cases. Please refer to detailed instructions on integration in the README. This library is the Android version of the solution, which can be replicated on iOS with similar logic. While this implementation is intended to serve as reference for other apps, we will review requests and comments on the repository.
We are so excited to make this available to the larger developer community and can't wait to see how other applications take the idea forward! Please reach out to [email protected] for questions and requests.
youtube


3 notes
·
View notes