
the-linguist-ll
The_Linguist_LL
Linguistics, languages (Nivaclé in particular) and.... actually that's about it.
15 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

redhead7799
Satisfy me..

goodpvppy
good puppy

eatmezayn
zayn be my queen

analbumayear
An Album a Day:

mackieblr
Mackie's Simblr
Text

Updated phylogenies, reformatted the tree, changed some names, and added speaker counts.
Speaker counts from Cataloguing the World's Endangered Languages by Lyle Campbell & Anna Belew et al (2020)
Also yeah this is technically my third post about a single tree(s) lol
Name changes:
Enlhet -> Enlhet Norte (To disambiguate)
Enxet -> Enxet Sur (To disambiguate)
Chamacoco -> Ishír (Internally preferred name)
Phylogenetic changes:
Reformatted the Guaicuruan family to be in line with a phylogeny composite between that offered by Glottolog, and one offered in Hierarchical Alignment and Comparative Linguistics in the Guaykuruan Languages: An Exhaustive Alignment Approach by Jens E. L. Van Gysel (2019)
Worth noting that some sources distinguish seperate Chorote & Wichí language subdivisions. I may add those.
1 note
·
View note
Text
Hello Grambank! A new typological database of 2,467 language varieties
Grambank has been many years in the making, and is now publically available!
The team coded 195 features for 2,467 language varieties, and made this data publically available as part of the Cross-Linguistic Linked Data-project (CLLD). They plan to continue to release new versions with new languages and features in the future.
Below are maps for two features I’ve selected that show very different distribution across the world’s languages. The first map codes for whether there are prepositions (in yellow), and we can see really clear clustering of them in Europe, South East Asia and Africa. Languages without prepositions might have postpostions or use some other strategy. The second map shows languages with an existential verb (e.g. there *is* an existential verb, in yellow), we see a different distribution.
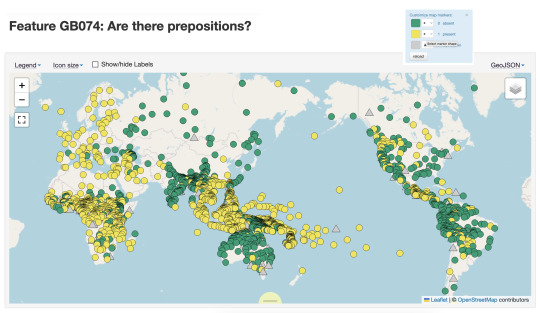
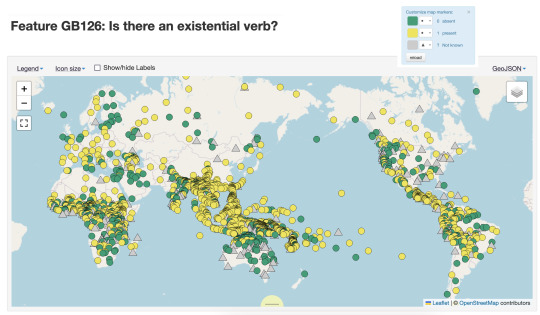
What makes Grambank particularly interesting as a user is that there is extensive public documentation of processes and terminology on a companion GitHub site. They also have been very systematic selecting values and coding for them for all the sources that they have. This is a different approach to that taken for the World Atlas of Linguistic Structures (WALS), which has been the go-to resource for the last two decades. In WALS a single author would collate information on a sample of languages for a feature they were interested in, while in Grambank a single coder would add information on all 195 features for a single grammar they were entering data for.
I’m very happy that Lamjung Yolmo is included in the set of languages in Grambank, with coding values taken from my 2016 grammar of the language. Thanks to the transparent approach to coding in this project, you can not only see the values that the coding team assigned, but the pages of the reference work that the information was sourced from.
431 notes
·
View notes
Text
Just noticed the Mocoví-Abipón group is missing the descending line, so now you have to as well

I made this tree of my favorite language families, Matacoan, Mascoian, and Guaicuruan.
6 notes
·
View notes
Text
How is there not an equivalent to CSs Hello World Collection for syntax frameworks in linguistics? That's literally all I have to say on the topic, there needs to be one.
12 notes
·
View notes
Text
A textbook called Grammatical Theory by Stefan Müller just came out, and man, he's dropping some truth bombs!

Furthermore, the claim that first language acquisition is effortless and rapid when compared to second language acquisition is a myth as has been shown by estimations by Klein (1986: 9): if we assume that children hear linguistic utterances for five hours a day (as a conservative estimate), then in the first five years of their lives, they have 9100 hours of linguistic training. But at the age of five, they have still not acquired all complex constructions. In comparison, second-language learners, assuming the necessary motivation, can learn the grammar of a language rather well in a six-week crash course with twelve hours a day (500 hours in total).
And then...

In Chapter 13, it was shown that all the evidence that has previously been brought forward in favor of innate linguistic knowledge is in fact controversial. In some cases, the facts are irrelevant to the discussion and in other cases, they could be explained in other ways. Sometimes, the chains of argumentation are not logically sound or the premises are not supported. In other cases, the argumentation is circular. As a result, the question of whether is innate linguistic knowledge remains unanswered. All theories that presuppose the existence of this kind of knowledge are making very strong assumptions.
In short: Human linguistic abilities aren't magic, and children aren't elves.
In meme form:

4K notes
·
View notes
Text
Role and Reference Grammar (RRG) resources:
Cambridge has a book introduction on pre-order about RRG. Coming online June 2023, and in print sometime after that this year. I don't know what the price plan is or anything, maybe the online version will be free like some of their other books, or maybe not.
Why I like RRG (Well one small brief reason, saving some for a post): RRG, unlike other frameworks of syntax (cough, most generative frameworks) was designed with the understanding that languages vary a lot, and it was built from *many* diverse languages rather than just English. I seriously do not understand how to this day there are linguists who do not see the problem with thinking English represents the structure of every language on Earth.
3 notes
·
View notes
Text
I made this tree of my favorite language families, Matacoan, Mascoian, and Guaicuruan.
#nivaclé#pilagá#enlhet#matacoan#mascoian#guaicuruan#linguistics#lingblr#langblr#historical linguistics
6 notes
·
View notes
Text
Using this to segue to how fucked Ethnologue is. Shouldn't cost $100s to $1,000s for an independent researcher (or native speaker of a threatened language) to access vital cultural information that Ethnologue didn't even create in the first place (and that's the basic plan). They give you credits for access if you submit data, but the credits are so small that even if you gave them a library of information on an underdocumented language, you still wouldn't have access. How was that allowed to happen, the data they host should be 100% free to everyone, especially native speakers and researchers. Support alternatives like ELARArchive or Glottolog.
I could also segue into how much academia sucks and screws everyone over, or how universities take intellectual claim over research on endangered languages, but I'll save it for a full post.
Now that we don't have zlibrary here are some websites you SHOULDN'T use in ANY circumstances. They let you download books for FREE so you should steer clear of them unless they are legal like some of these:
Archive.org: works like a library but online, gives you access to a book for up to 2 weeks with possibility to extend. It's legal!!
Zlibrary.to: apparently a backup domain for zlibrary or something but completely separated from the normal one bc it's the only one i've found that works. Seems to have less books than the original or they are harder to find, but a big database nonetheless
Libgen: not a very nice interface but it has a lot of books too, zlibrary got many of their books from here
Project gutenberg: over 60 000 free ebooks but mostly books with expired copyright. Seems pretty legal
Oceanofpdf: pretty nice interface but idk the amount of books in there. They believe that knowledge and information should be free and accessible
Pdf drive: over 80 000 000 ebooks in pdf format. Messy interface with overlapping buttons and other things but looks like it could be used to get books easily
Z-epub: has a lot of books but only free domain. This means it's a legal website so it would be good to use
You definitely SHOULD NOT use the sites that aren't mentioned as legal above, I'm just telling you so that you know which ones to avoid!! More sites to avoid in the reblogs
6K notes
·
View notes
Text
Quickly falling out of love with generative syntax. It's built on a lot of ideas that I don't believe in (UG for one), and is becoming increasingly hard to justify without those ideas.
Arc Pair Grammar & Nanosyntax will remain of interest to me, but programs like Role & Reference grammar are likely to become my syntactic home.
Happy to discuss more, whether it's my reasoning for my own switch, or your defense of either functionalist or generative approaches. (Or another altogether, I really just want to hear why people subscribe to the syntactic frameworks they do.)
Last note: I am not anti-generative. The Linguistic Wars took enough of a toll on linguistic theory that is still felt today, what at the end of the day simply amounts to differing frameworks are not something that need to be necessarily pitted against eachother.
5 notes
·
View notes
Text
YES
In addition, they should be written in such a way that the researcher's thoughts at every step of the idea formulation process are obvious to the reader, so they can be a learning tool for research and academic writing.
Would be particularly useful in linguistics where many linguists already have the attitude that "I don't particularly care if my name is on it, the data needs to be out there".
Sometimes I wonder how many unpublished scraps of unfinished reference grammars are out there for undocumented / underdocumented languages, where even those scraps would significantly increase how much is known of the language.
Would be nice if the papers also included a section for getting started for other researchers wanting to continue, complete with contact information.

3K notes
·
View notes
Text
Japanese is not alone, it has a family. For some reason the Ryukyuan languages are classified as being dialects of Japenese within Japan, despite the fact that they're not even mutually intelligible with eachother let alone a totally different branch of the family, and the fact that they clearly diverged at least as long ago as the Romance language family did from eachother.
Compare Okinawan
う名前や何やいびーが?
(u naamee ta nuu yaibiiga?)
with Japanese
お名前はなんですか?
(o-namae wa nan desu ka)
Meaning "What is your name"

6 notes
·
View notes
Text
The fact that I found this after I gave up on Google and just said "fuck it" and decided to see what the Tumblr search bar could do for me.
linguistics is one of those things where i know enough to have hard-to-google questions but not enough to work out the answers on my own
19 notes
·
View notes
Text
Any interest in a Discord server for discussing linguistics papers? (Both regularly assigned papers for everyone to discuss, and papers you want to discuss). Basically a reading discussion group but for linguistics papers.
4 notes
·
View notes
Text
What I'm excited about: Just started learning Arc Pair Grammar
What I'm dreading: Just started learning Arc Pair Grammar
Been looking to start for a while, and my resources arrived yesterday. I'll make posts about why I'm interested in it as a framework compared to other syntax theories and frameworks soon. Obviously since I just started formally learning it yesterday I won't have all the answers, just what I know already about its strengths and ideas.
The book is Arc Pair Grammar by Johnson and Postal, most copies seem to be up there in price, but I got a good deal on it, if I see a similar good price go up again I'll let y'all know.

2 notes
·
View notes
Text
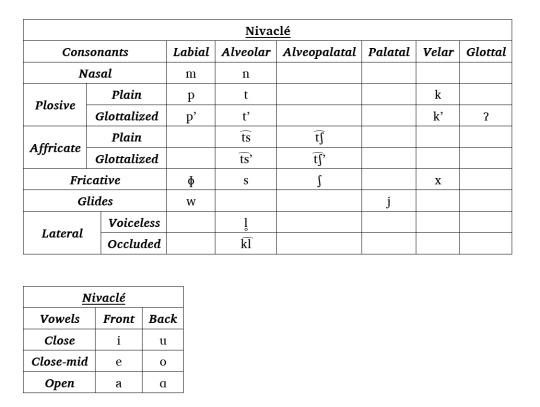
Phonology of Nivaclé real quick
2 notes
·
View notes