#counted how many canon* prefixes/suffixes there are for this
Text
Everybody wake up new generator just dropped
https://perchance.org/clovers-clan-gen
Warrior cat clan generator!!! Yippee!!! This generator features:
Over 300 prefixes for your cats and clan
Over 100 suffixes for your cats
1-30 warriors for your clan, not counting the leader, deputy, medic, and any apprentices
Your leader’s and all your apprentices’ warrior names
A 50/50 for every cat to have an apprentice
Coat and eye colors, patterns, and scar counts (between 0 and 15) for every cat, including apprentices
A biome your clan’s territory is in
Details (names, colors/patterns/scar counts, biome) bolded for convenience
Update 20/1/2023: bolded the number of warriors in your clan, added up to 5 queens with 0-7 kits each, added up to 10 elders
#counted how many canon* prefixes/suffixes there are for this#theres a lot. also that * um i altered a few prefixes (bubbling -> bubble#etc) and took out star- and ex-kittypet prefixes like bella- and riley-#also added bat- because batear is canon to me#364 prefixes and 116 suffixes#well 119 technically cause the gen doesnt inclue -star -paw or -kit cause. warrior named havenkit would be weird#actually 120 because i forgot i also took out -spirit for my generators#haven did stay btw! havenpelt just kinda spawned so i figured leave it in for fun#i might consider tossing in some kittypet names at some point but idk. id want to make them separate from clan prefixes to give them#different odds but i had to type out every single cat individually it would be so much work.....#also i want to go back and bold the warrior counts but. again thats tracking down and bolding 30 numbers in one long massive single line of#text. cause you cant make it multiple lines on perchance#edit i did that lmao#zoracontent#clovers generators#<- that tag never pops up in the used tags so i always think its wrong lmao#warrior cats#warrior cats generator#warriors#warriors generator#wc#wc generator#warrior cats clan#warriors clan#wc clan#wc oc clan#warriors oc clan#warrior cats oc clan#<- not trying to be obnoxious just trying to get this to the people who would use it#clan generator
65 notes
·
View notes
Text
I’m curious so please tell me. Reblog in the tags (or in a straight-up reblog, do what you want) with answers to the following:
Starclan or StarClan?
Fireheart or FireHeart?
Are female cats called mollies or she-cats?
Is your preferred naming style traditional (as in prefix refers to appearance and is restricted to locale and suffix refers to the individual’s traits)? Lyrical (anything goes)? Canon only (only uses prefixes and suffixes canon has used)? Some hybrid of them? Something else entirely?
Name one thing you consider not canon. Explaining why is optional. It can be a book, an event, whatever.
Do you have any fanclans? Gush about them if you’d like.
If you’ve answered yes to the above, how many tortie/calico toms are in them? I’m not judging; I’ve got a tortie tom in my own fanclans.
How many canon characters do you interpret as LGBT+? No need to go over who exactly, just “this is the amount of characters” is all I want to know, but if you want to go over who you think is LGBT+, go right on ahead.
Is age a deterrent for choosing a cat as leader? Example, Squirrelflight, Crowfeather, and Reedwhisker are nearly old enough for the elders’ den.
How pleased are you with revelation of the Imposter’s identity? As in, are you pleased with who it is? If not, who would you have preferred instead?
Would you consider the Warriors books good in terms of overall quality?
What’s one warrior name you really love? What warrior name do you really hate?
Do you find clan expletives/insults charming, weird, fitting, or something else I can’t think of? Words like foxdung, mousebrain, etc.
Do you have a government-assigned warrior name? What is it? Did you “cheat” to get it or did you roll with the first thing you got?
Do you actually still read the books or do you just get the synopses from second-hand sources like the wiki or a friend?
When you make Warriors OCs, are you okay with using a name that belongs to a canon cat? Is importance a factor? (Such as you'll use Appledawn, but not Jayfeather)
How much does realism matter to you? Do your battlecat OCs follow realistic cat behaviors with a slightly more intelligent mind, or are they human minds in fuzzy coats? Are your designs realistic, stylized realistic, semi-realistic, semi-fanciful, or entirely fanciful (note that if a fanclan setting’s gimmick is “warriors, but they’re also monsters!” this doesn’t really count)? Do they age realistically? Are real-life genetic quirks treated with the same weight as they are in real life (tortoiseshell toms, vitilago, blue-eyed white cats, albinism, etc)? Are disabilities (either born with or gained) realistically handled with your cats?
I am so curious for the outcome of this thing.
Also this should be a no-brainer, but I feel I need to say this outright. DON’T MOCK OTHER PEOPLE FOR THEIR PREFERENCES OR SAY THEY’RE LESS VALID BECAUSE OF ONE REASON OR ANOTHER. This is so I can gather data, not for people laugh at others for not having the right opinion.
#lynx asks a bigass question#warrior cats ask thing#ill add my own two cents later#but not right now
166 notes
·
View notes
Text
Text Preprocessing for NLP and Machine Learning Tasks

As soon as you start working on a data science task you realize the dependence of your results on the data quality. The initial step — data preparation — of any data science project sets the basis for effective performance of any sophisticated algorithm.
In textual data science tasks, this means that any raw text needs to be carefully preprocessed before the algorithm can digest it. In the most general terms, we take some predetermined body of text and perform upon it some basic analysis and transformations, in order to be left with artefacts which will be much more useful for a more meaningful analytic task afterward.
The preprocessing usually consists of several steps that depend on a given task and the text, but can be roughly categorized into segmentation, cleaning, normalization, annotation and analysis.
Segmentation, lexical analysis, or tokenization, is the process that splits longer strings of text into smaller pieces, or tokens. Chunks of text can be tokenized into sentences, sentences can be tokenized into words, etc.
Cleaning consists of getting rid of the less useful parts of text through stop-word removal, dealing with capitalization and characters and other details.
Normalization consists of the translation (mapping) of terms in the scheme or linguistic reductions through stemming, lemmatization and other forms of standardization.
Annotation consists of the application of a scheme to texts. Annotations may include labeling, adding markups, or part-of-speech tagging.
Analysis means statistically probing, manipulating and generalizing from the dataset for feature analysis and trying to extract relationships between words.
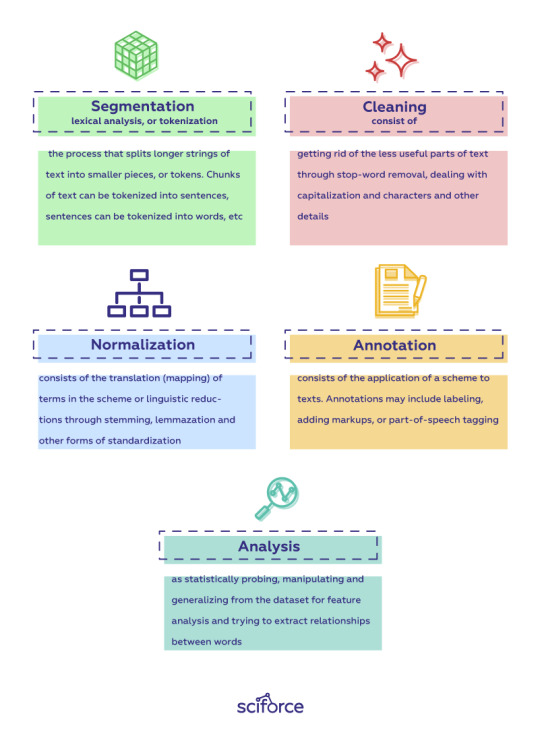
Segmentation
Sometimes segmentation is used to refer to the breakdown of a text into pieces larger than words, such as paragraphs and sentences, while tokenization is reserved for the breakdown process which results exclusively in words.
This may sound like a straightforward process, but in reality it is anything but. Do you need a sentence or a phrase? And what is a phrase then? How are sentences identified within larger bodies of text? The school grammar suggests that sentences have “sentence-ending punctuation”. But for machines the point is the same be it at the end of an abbreviation or of a sentence.
“Shall we call Mr. Brown?” can easily fall into two sentences if abbreviations are not taken care of.
And then there are words: for different tasks the apostrophe in he’s will make it a single word or two words. Then there are competing strategies such as keeping the punctuation with one part of the word, or discarding it altogether.
Beware that each language has its own tricky moments (good luck with finding words in Japanese!), so in a task that involves several languages you’ll need to find a way to work on all of them.
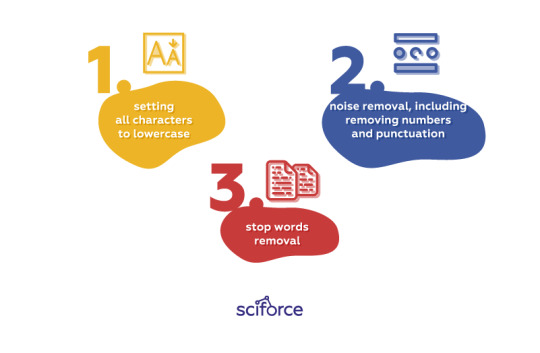
Cleaning
The process of cleaning helps put all text on equal footing, involving relatively simple ideas of substitution or removal:
setting all characters to lowercase
noise removal, including removing numbers and punctuation (it is a part of tokenization, but still worth keeping in mind at this stage)
stop words removal (language-specific)
Lowercasing
Text often has a variety of capitalization reflecting the beginning of sentences or proper nouns emphasis. The common approach is to reduce everything to lower case for simplicity. Lowercasing is applicable to most text mining and NLP tasks and significantly helps with consistency of the output. However, it is important to remember that some words, like “US” and “us”, can change meanings when reduced to the lower case.
Noise Removal
Noise removal refers to removing characters digits and pieces of text that can interfere with the text analysis. There are various ways to remove noise, including punctuation removal, special character removal, numbers removal, html formatting removal, domain specific keyword removal, source code removal, and more. Noise removal is highly domain dependent. For example, in tweets, noise could be all special characters except hashtags as they signify concepts that can characterize a tweet. We should also remember that strategies may vary depending on the specific task: for example, numbers can be either removed or converted to textual representations.
Stop-word removal
Stop words are a set of commonly used words in a language like “a”, “the”, “is”, “are” and etc in English. These words do not carry important meaning and are removed from texts in many data science tasks. The intuition behind this approach is that, by removing low information words from text, we can focus on the important words instead. Besides, it reduces the number of features in consideration which helps keep your models better sized. Stop word removal is commonly applied in search systems, text classification applications, topic modeling, topic extraction and others. Stop word lists can come from pre-established sets or you can create a custom one for your domain.
Normalization
Normalization puts all words on equal footing, and allows processing to proceed uniformly. It is closely related to cleaning, but brings the process a step forward putting all words on equal footing by stemming and lemmatizing them.
Stemming
Stemming is the process of eliminating affixes (suffixes, prefixes, infixes, circumfixes) from a word in order to obtain a word stem. The results can be used to identify relationships and commonalities across large datasets. There are several stemming models, including Porter and Snowball. The danger here lies in the possibility of overstemming where words like “universe” and “university” are reduced to the same root of “univers”.
Lemmatization
Lemmatization is related to stemming, but it is able to capture canonical forms based on a word’s lemma. By determining the part of speech and utilizing special tools, like WordNet’s lexical database of English, lemmatization can get better results:
The stemmed form of leafs is: leaf
The stemmed form of leaves is: leav
The lemmatized form of leafs is: leaf
The lemmatized form of leaves is: leaf
Stemming may be more useful in queries for databases whereas lemmazation may work much better when trying to determine text sentiment.

Annotation
Text annotation is a sophisticated and task-specific process of providing text with relevant markups. The most common and general practice is to add part-of-speech (POS) tags to the words.
Part-of-speech tagging
Understanding parts of speech can make a difference in determining the meaning of a sentence as it provides more granular information about the words. For example, in a document classification problem, the appearance of the word book as a noun could result in a different classification than book as a verb. Part-of-speech tagging tries to assign a part of speech (such as nouns, verbs, adjectives, and others) to each word of a given text based on its definition and the context. It often requires looking at the proceeding and following words and combined with either a rule-based or stochastic method.
Analysis
Finally, before actual model training, we can explore our data for extracting features that might be used in model building.
Count
This is perhaps one of the more basic tools for feature engineering. Adding such statistical information as word count, sentence count, punctuation counts and industry-specific word counts can greatly help in prediction or classification.
Chunking (shallow parsing)
Chunking is a process that identifies constituent parts of sentences, such as nouns, verbs, adjectives, etc. and links them to higher order units that have discrete grammatical meanings, for example, noun groups or phrases, verb groups, etc..
Collocation extraction
Collocations are more or less stable word combinations, such as “break the rules,” “free time,” “draw a conclusion,” “keep in mind,” “get ready,” and so on. As they usually convey a specific established meaning it is worthwhile to extract them before the analysis.
Word Embedding/Text Vectors
Word embedding is the modern way of representing words as vectors to redefine the high dimensional word features into low dimensional feature vectors. In other words, it represents words at an X and Y vector coordinate where related words, based on a corpus of relationships, are placed closer together.
Preparing a text for analysis is a complicated art which requires choosing optimal tools depending on the text properties and the task. There are multiple pre-built libraries and services for the most popular languages used in data science that help automate text pre-processing, however, certain steps will still require manually mapping terms, rules and words.
3 notes
·
View notes
Text
May Writing Challenge: May 5th
Prompts are from @deity-prompts 's May Writing Challenge, original post linked here
~
I got a little carried away with worldbuilding in this prompt, so... enjoy some nice sci-fi linguistics from someone who doesn't know how linguistics works. Sera and Ammie are learning more about the future that Sera found herself in. No spoilers, is canonical!
Content Warnings: Swear words, sexual content mention (for academic purposes only I promise) Neither of these are tagged.
May 5th: Swearing in a foreign language
~
When understanding the Curralian approach to language, we must first see how much effort they went through to write effective jokes within their own language. Known in English as a ‘play-on-words,’ their basis for communicating relies on one’s understanding of each word and any other possible meanings. On top of this, their swear words also double as a ‘play-on-words,’ which is a subject that has fascinated many ever since an effective basis for translation was discovered.
Let’s see an example. The Cullastrin statement would be “Toolga forrha fiershjka” *(Romanization has been done for ease of reading. For an in-depth look at their writing system, please see my other work, Sub-Linguistics: Writing a language made for underwater living). A word-for-word translation of this statement would exclude the true meanings behind each word, and would simply be “It is a nice day in which to meet you.” And while an entire book could detail the relationship between each Cullastrin word* (and there is one available, please see my other work, Play on Play on Words: A Cullastrin Deep-dive) what’s important to know is that the closest equivalent phrase in English would be “It’s grape to meet you!”
Moving onto swear words, the Cullastrin swear word equivalent of ‘fuck’ would be “kadalk,” which is it’s own play on words, as the prefix ‘kad’ can be used to mean ‘sexual activities,’* (Please see my other work, Linguistics is Sexy: How Procreation Affects Language for more on this topic) as well as ‘swimming,’ while the suffix ‘alk’ can be used to mean ‘within,’ as well as ‘beneath water.’ Therefore, the word has a meaning of ‘committing sexual acts while swimming underwater.’ An equivalent English joke that plays into this is “This coffee is awful, it’s like having sex in a canoe. It’s fucking close to water.”
Sera stopped reading, groaned, and set her forehead on the table for just a moment. “Oh my god.”
“Right?” Ammie smiled. “This author writes about the craziest things. It feels less like studying and more like you’re listening to this guy rant about languages in the funniest way possible.”
“I hate puns, so much. But, I mean, the way this guy writes is so engaging. Is it alright if I keep this book?” she asked.
“Absolutely, you can keep any of the books in the library. All of this guy’s books are in that same place I got that one, if you want to see those. I honestly think that the sexy linguistics book is the best one out of his entire bibliography.”
Sera flipped to the front of the book, where the author’s information and list of works were listed in order. “Holy shit, this guy has…” she counted under her breath. “Twenty-five books, and those are just the ones published before this one.” Her eyes strayed to the author’s picture, which was of a Terra-Astrian with lime green skin and bright yellow hair stood, posing with a thumbs-up, above the name of ‘Edward “The Language Guy” Staffen.’ “Does this guy only write and nothing else?”
“Apparently so. He lives on Earth if you ever want to meet him.”
“Oh god, he’d love to study the way I talk, since I talk like I’m from old Earth. Which I am.”
“Right, you know all about those old languages, don’t you. I mean, you knew of Chinese before it was localized, and French, and… I don’t really know a lot of old Earth languages.” She tapped her fingers on the table.
“I know rudimentary Spanish. And also a surprising amount of Latin, since a lot of law stuff is written in old Latin for some reason.”
“Having met him, I think he’d probably kill to get an interview with you. I’ll leave that up to you if you ever want to be asked a trillion questions.”
“I’m good.” Sera chuckled. “Okay. I should probably be going back to actually studying. Not that I care about the history of the…” she sighed, “the hyperlink drive.”
“And I’ll be here if you have any questions,” she replied, the smile staying on her face. “Or if you want another break, I can probably find another book that doesn’t sound like pure torture to read.”
“How about this one,” Sera said, pointing towards one of the books that Staffen had written. “Can’t Tell the Difference Between Blue and Green? This Language Can’t Either: An in-depth look at the so-called ‘colorblind language’ known as Terrastran, which is strange because English, Localized Chinese, and Astran all have words for colors, and why this happened. That’s the whole title?”
“Oh, that one is so cool. We literally have no idea why Terrastran doesn’t have words for colors.”
Sera sighed. “This whole world is so different. I mean, good different, of course. It’s just crazy to think about all the things that have happened in the last two-hundred and fifty years.”
Ammie nodded. “I can’t imagine how overwhelming it would be, considering this world is all I’ve experienced. But, if you need any support, I’m right here.”
“Thanks, Ammie. I might need it.”
#cactus writes#mtbow#creative writing#writeblr#writer#writing#i feel like i took this in a different direction than I first thought of doing when i started writing#and i had so much fun writing this in-world textbook excerpt too
0 notes
Photo

This is treeclans meficine cat. Her prefix is bone, but i cant figure out if her prefix should be storm or scar. Can you please help me?
Hi there! This was a difficult one to answer.
This blog mainly focuses on realism and the making and use of traditional naming systems. With this in mind, I recommend that, if you aren’t going to use any of this, search for a blog that better suits your settings and worldbuilding since my opinion and thoughts on this character won’t be too useful for you, I think. I would love recommending you a lyrical and fantasy worldbuilding blog but I don’t know of any since it really isn’t my thing. If anyone knows of a good blog that could help, please feel free to add in opinions and thoughts!
Let’s start from the beginning, this cat is hairless, the photo looks like it may be a sphinx. You see, a cat’s fur absorbs the body oils that the cat segregates. A hairless cat can’t absorb these body oils and needs to be groomed daily for its health to be on check; with grooming I don’t mean that the cat needs to clean itself daily, I mean that it needs humans to properly care for them, bathe them and, in some cases, use special products on them. Most newborn kittens face many problems when they are born as they are extremely susceptible to respiratory infections caused by their lack of fur. The amount of time these cats stay out in the sun must be measured, skin cancer is something you should worry about. Normal cats have their fur as protection, sphinxes on the other hand don’t. With this in mind, these cats just wouldn’t survive outside of a house for too long.
Genetically talking, for a cat to be born hairless you need both its parents to carry this gene and, in a clan, that lives outdoors, where a sphinx cat is not likely to survive its first weeks even less survive to reproduce, that seems… unlikable. Of course two cats may have… different purebred kittypet parents but, counting their low survival rate outdoors and two different mollies reproducing with a hairless kittypet (most likely purebred whose owner is not likely to let outside just like that since they are just that sensitive and expensive) the odds are completely against it. Summary, hairless cats would die within weeks in a clan setting.
Now, I know that your clans have fantasy cats. I think I remember Treeclan having a prehensile tail? But, the way you talked about them, it seemed just that. A cat with a prehensile tail. If you want them to remain cats, I recommend taking this into consideration.
As for the prefix, I don’t recommend using dead things as a prefix. Blood-, Bone-, Death-´, Poison-,… are not names you will see in a traditional naming (unless you think about Dead-, a name change prefix used when a cat gets badly hurt in battle and that can be used in combination with –tail, -eye and –foot). Ask yourself, what made this cat’s mother think ‘Bone is the perfect name for this kit’? Why would her mother name her after something dead? It seems cruel and something clan life wouldn’t accept as all cats should be respected and given the same opportunities and treatment from their very birth. Pale-, Patch-, Pink-, Gray-, etc seem more likely to be chosen by a loving queen and a normal clan society to accept and choose. Maybe the cat decided to change their name as they grow older and got Nofur or Missingfur as their name. Thinking about clan culture and how a clan would react to kit abuse is important when naming them. Summary, Bone- seems kind of cruel to use.
And finally, the suffix. First of all, I must say that to choose a suffix for a cat you should take into consideration their personality and skills; I know anything of this cat so I can’t really help you with the choosing. Secondly, what does –scar mean in this context? In most traditional naming systems, you would use Scarred- as a prefix and a boy part as the suffix and it would make a great name change name. but in this content? I can read Bonescar as a cat that has a scar on their bones. This scar is not visible therefor I would recommend using Broken (foot, tail, jaw), twisted (jaw, foot, tail), etc. As for –storm, in traditional naming this prefix would be given to a cat with an unpredictable and dynamic nature tough the use of it can change from one clan setting to another.
I know that your clan settings are incredibly different from the rest and I insist, don’t reduce yourself to warrior cats. Your story is unique and completely different from the canon, split from it, Call it your own!
I really can’t help you here since the help I offer in this blog is ‘realist’ and this is too fantastic and lyrical for me to know what to say. If anyone knows of any good advice for this person, please do contribute!
#warriors#warrior cats#worldbuilding help#ask#i really dont like lyrical naming#or too fantastic settings#so I really am at a loss at how to help you#i am sorry#submission
2 notes
·
View notes
Last Seen Blogs

haeundaeroomsalon
부산해운대룸싸롱고구려010.8680.3882

papaneko
Untitled

fancyfrey
doot doot doot

evascarlettwang
Eva Scarlett Wang

tiannacrosscd
Tianna's Dreams