
assertlabs
ASSERT Lab
ASSERT - Advanced System and Software Engineering Research Technologies Lab
115 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

georgeanzaldo-blog
How I got over.

soulxsymphonist
"..Predictable"

fbadsaccounts6216
Untitled

cozzzynook
cozy

suykotzuly
Suyko
Text
Dissertação de Mestrado Nº 1.727
Pós-Graduação em Ciência da Computação – UFPE
Defesa de Dissertação de Mestrado Nº 1.727
Aluno: Wilson Alves da Silva
Orientador: Prof. Vinicius Cardoso Garcia
Título: Uma Arquitetura para Orquestração da Distribuição de Água no Semiárido Brasileiro Baseada em Internet das Coisas e Computação em Nuvem
Data: 29/08/2017
Hora/Local: 10h – Centro de Informática – Sala E423
Banca Examinadora:
Prof. Kiev Santos da Gama (UFPE / Centro de Informática)
Prof. Nelio Alessandro Azevedo Cacho (UFRN / DIMAp)
Prof. Vinicius Cardoso Garcia(UFPE / Centro de Informática)
RESUMO:
Na região Semiárida brasileira o regime de chuvas é caracterizado por períodos longos de estiagem com secas prolongadas, fazendo com que no ano de 2016 fossem gastos mais de um bilhão de Reais em programas de distribuição de água à população carente dessa região, dos quais cerca de 14% desse recurso foi gasto em fiscalização. A forma de fiscalização atual não contempla nenhuma maneira de mensurar a quantidade ou a qualidade da água recebida e várias notícias de fraudes publicadas pela mídia em geral indicam que essa fiscalização é um processo caro e propício a erro. O problema então é como melhorar o monitoramento e fiscalização na distribuição de água, ampliando a transparência e a eficiência de programas federais de distribuição deste recurso. Sistemas de Internet das Coisas (IoT) são capazes de transmitir informações sobre volume e qualidade da água, estas informações podem ser usadas de forma integrada com os sistemas de tomada de decisão para fins de gestão. No entanto, as limitações dos dispositivos IoT requerem uma Tecnologia como Computação em Nuvem para complementar suas aplicações, dado que a Computação em Nuvem possui capacidades praticamente ilimitadas em termos de armazenamento e processamento. Motivado pela importância do programa de distribuição de água para o Semiárido brasileiro e pela necessidade de definição de um framework para permitir a integração de soluções parciais para fiscalização destes tipos de programas, este trabalho apresenta uma arquitetura baseada em IoT e Computação em Nuvem que disponibiliza serviços para orquestrar a distribuição de água no Semiárido brasileiro. Para atingir os objetivos deste trabalho foi realizado um mapeamento das principais tecnologias empregadas em Sistemas de Gerenciamento de Recursos Hídricos que utilizam IoT e foi realizada uma análise do emprego da Tecnologia da Informação como instrumento de apoio à fiscalização do programa de distribuição de água. Apoiado nestes conhecimentos foi especificada, projetada e implementada uma arquitetura de referência. Por fim, a partir de uma avaliação pôde-se mensurar o quão a Arquitetura Proposta está apta para ser implantada em um contexto real.
Palavras-chave: Internet das Coisas, Computação em Nuvem, Engenharia de Software Baseada em Evidência, Segurança, Arquitetura de Software, Distribuição de Água, Seca.
0 notes
Text
SMARTCLUSTER: A METAMODEL INDICATORS FOR SMART AND HUMAN CITIES
Pós-Graduação em Ciência da Computação – UFPE
Defesa de Tese de Doutorado Nº 352
Aluno: Ricardo Alexandre Afonso
Orientador: Prof. Vinicius Cardoso Garcia
Título: SMARTCLUSTER: A METAMODEL INDICATORS FOR SMART AND HUMAN CITIES
Data: 13/03/2017
Hora/Local: 9h – Centro de Informática – Sala A14
Banca Examinadora:
Prof. Carlos Andre Guimarães Ferraz(UFPE / CIn - Centro de Informática)
Prof. Kiev Santos da Gama(UFPE / CIn - Centro de Informática)
Prof. Julieta Maria de Vasconcelos Leite(UFPE / Arquitetura e Urbanismo)
Prof. Alexandre Álvaro(UFSCAR / DC)
Prof. Jones Oliveira de Albuquerque(UFRPE / DEINFO)
Abstract:
Currently, there are several works on smart cities and the advances offered to the routine of its inhabitants and optimization of resources, however, there is still no consensus on the definition of the term "Smart Cities", nor their domains and indicators. The lack of a clear and widely usable definition, as well as the delimitation of domains and indicators makes it impossible to compare or measure cities in this context. This work presents a proposal for a metamodel called SmartCluster, which was developed to allow uniformity in intelligent city models so that they can be used in any context and can be expanded at any time. The use of this metamodel will allow indicators drawn from public databases to serve to assist municipal managers in measuring, comparing and managing resources of smart cities.
Keywords: Smart Cities, e-Government, Metamodel, Ontology
Resumo:
Atualmente, existem vários trabalhos sobre cidades inteligentes e os avanços oferecidos à rotina de seus habitantes e otimização de recursos, no entanto, ainda não há consenso sobre a definição do termo "Cidades Inteligentes", nem seus domínios e indicadores. A falta de uma definição clara e amplamente utilizável, bem como a delimitação de domínios e indicadores torna impossível comparar ou medir as cidades neste contexto. Este trabalho apresenta uma proposta para um metamodelo chamado SmartCluster, que foi desenvolvido para permitir a uniformidade em modelos de cidades inteligentes para que eles possam ser usados em qualquer contexto e podem ser expandidos a qualquer momento. A utilização deste metamodelo permitirá que indicadores elaborados a partir de bases de dados públicas sirvam para auxiliar os gestores municipais na medição, comparação e gestão de recursos das cidades inteligentes.
Palavras-chave: Cidades Inteligentes, Governo Eletrônico, Metamodelo, Ontologia
0 notes
Text
Buscando a proposição de uma forma de configuração e comercialização de computação em nuvem com alto nível de abstração com base no mapeamento sistemático da literatura sobre serviço medido
Pós-Graduação em Ciência da Computação CIn / UFPE
Defesa de Dissertação de Mestrado Profissional Nº 225
Nome do Aluno: Fernando Estrela Vaz
Nome do Orientador: Vinícius Cardoso Garcia
Título da Dissertação: Buscando a proposição de uma forma de configuração e comercialização de computação em nuvem com alto nível de abstração com base no mapeamento sistemático da literatura sobre serviço medido.
Data: 10/03/2017
Hora: 09h
Local: Sala A-14
Membros da Banca:
1º Examinador: Kelvin Lopes Dias (UFPE)
2º Examinador: Júlio César Damasceno (UFRPE)
3º Examinador: Vinicius Cardoso Garcia (UFPE)
Resumo:
A computação em nuvem é um dos temas da tecnologia da informação mais discutidos atualmente. Pesquisas relacionadas à segurança e elasticidade têm contribuído substancialmente na evolução do modelo. Nesse estudo, é realizado um mapeamento sistemático da literatura em busca de experimentos que explicitem as linhas de pesquisas que estão sendo trabalhadas atualmente sobre outra característica básica do modelo de computação em nuvem, trata-se do serviço medido. A pesquisa apontou que o serviço medido ainda é um campo pouco explorado cientificamente mesmo já possuindo um modelo de configuração e comercialização consolidado no mercado atual. A configuração e comercialização do modelo de computação em nuvem por meio de instâncias proporciona aos usuários do serviço uma experiência próxima à aquisição de uma máquina física com a possibilidade de escolha de máquinas virtuais (VMs) pré-configuradas e customizadas mas apesar de existirem estudos e experimentos que buscam evoluir esse modelo de comercialização e configuração não foi encontrado nenhum estudo que busque comprovar o poder de processamento real do conjunto provido pela instância de máquina virtual, frente às garantias de SLA atuais, que buscam comprovar apenas as grandezas unitárias de cada item que compõem a VM como processador, memória ram, discos de armazenamento e largura de banda, e, também, não foi encontrado nenhum experimento que buscasse calcular de forma precisa a demanda computacional de cada projeto de migração para o modelo de computação em nuvem com o objetivo de oportunizar o cálculo do investimento financeiro necessário com um projeto de migração e ou adoção ao modelo de computação em nuvem. Frente a esse cenário esse estudo encaminha a construção de um modelo de processamento por porta que busca abstrair ao máximo o conceito de instância de máquina virtual, extraindo desse conceito apenas o coeficiente de processamento dos itens que compõem o conjunto da VM os comercializando por meio de uma porta com largura de processamento possível de ser facilmente gerida, medida e regulamentada via SLA. O modelo proposto confronta algumas características do modelo de instâncias e projeta ganhos ao modelo de computação em nuvem com a sua adoção tomando como base outros modelos de prestação de serviço de alto nível de abstração e configuração aos usuários finais.
Palavras-Chave: Computação em Nuvem, Serviço Medido, PaaS, IaaS, Modelo de Configuração, Modelo de Comercialização, Instâncias, Porta de Processamento
0 notes
Text
ASSERT @ SBTI'2016
Prezad*s,
É com prazer que informamos que os artigos “Uma biblioteca Multi-Tenant para o framework Django”, de autoria de José de Arimatea Rocha Neto, Vanilson Burégio e Vinicius Cardoso Garcia e "Estudo de mapeamento sistemático sobre as tendências e desafios do cloud gaming" de autoria de Chrystian José Soares da Silva, Leandro Marques do Nascimento e Vinicius Cardoso Garcia foram aceitos para apresentação no V Simpósio Brasileiro de Tecnologia da Informação (SBTI'2016) que vai ser realizado entre os dias 05 a 07 de Outubro em João Pessoa-PB.
O resumo do primeiro artigo seguinte descreve o trabalho:
Nos últimos anos o modelo de entrega de software como serviço, ou Software as a Service (SaaS), surgiu trazendo software mais flexíveis e reutilizáveis. Este modelo provê suporte a diversos usuários sobre uma mesma infraestrutura configurável, oferecendo funcionalidades sob demanda. Multi-Tenancy, ou Multi-Inquilino, é uma abordagem organizacional do modelo SaaS. Características de uma arquitetura Multi-Tenant são: compartilhamento de recursos de hardware, alto grau de configurabilidade e bancos de dados compartilhados. Alguns benefícios da utilização desta arquitetura são: melhor utilização dos recursos de hardware, maior manutenibilidade e redução nos custos globais do sistema. Tomando como base as características desta arquitetura, esta pesquisa propõe facilitar o desenvolvimento de aplicações Web Multi-Tenant através de uma biblioteca open source para o framework Django. Assim, os desenvolvedores podem focar seus esforços na regra de negócio e não com a arquitetura, já implementada pela biblioteca.
O resumo do segundo artigo seguinte descreve o trabalho:
A fim de apresentar um panorama sobre as dificuldades e os possíveis caminhos em direção ao aumento da adoção do Cloud Gaming, este trabalho analisou, através de um mapeamento sistemático, as tendências e desafios na utilização da computação em nuvem para jogos digitais. Após a definição do protocolo do mapeamento, diversos critérios de seleção e exclusão foram aplicados aos estudos encontrados. Em seguida, uma análise foi realizada e teve seus dados apresentados e interpretados através de gráficos, tabelas, além de descrição textual. Foram identificados como problemas e desafios a limitação de banda e compressão dos vídeos, alocação de recursos de rede para servidores com máquinas virtuais, entre outros. Como possíveis tendências do serviço, os estudos evidenciaram o foco no streaming baseado em gráficos, ao invés do streaming baseado em vídeo e virtualização de GPU.
0 notes
Text
ASSERT @ SBBD'2016
Prezad*s,
É com prazer que informamos que o artigo “A centralized platform for access of heterogeneous data on human genome repositories for supporting clinical decisions”, de autoria de Andrêza Leite de Alencar, Vanilson Burégio, Marcel Caraciolo, Jamisson Freitas e Vinicius Cardoso Garcia foi aceito para apresentação no Database Systems Industry Day Workshop (DSIDW'2016) do Simpósio Brasileiro de Banco de Dados (SBBD'2016) que vai ser realizado entre os dias 04 a 07 de Outubro em Salvador.
O resumo seguinte descreve o trabalho:
The Data integration is a key challenge in clinical genetics area where analysts need to handle multiple heterogeneous data sources on biological and clinical domains. The research reported in this paper aims to provide unified access to these diverse data sources to support various clinical decisions. In this context, this article describes the work in progress for the construction and implementation of a platform that allows integration and unified access to sources of heterogeneous data. We detail the architecture defined for the platform and an online usage scenario for processing and annotation of clinical variants, which uses the main public data repositories genome as OMIM, Clinvar, Lovd, ExAC6500, and others. Thus, this platform helps in decision making of analysts and geneticists to release results of genetic tests.
1 note
·
View note
Text
ASSERT @ CBIS'2016
[post atualizado novamente em 16/08/2016]
[post atualizado em 12/08/2016]
Prezad*s,
É com prazer que informamos que os artigos "Cidades Inteligentes: IDH como Indicador de Serviços" e "DendroIDH: Agrupando Cidades por Semelhança de Indicadores", ambos de autoria de Ricardo Afonso, Raquel Cabral, Alexandre Alvaro e Vinicius Cardoso Garcia e o artigo "A centralized platform on human genome for supporting clinical decisions" de autoria de Andrêza Leite de Alencar, Vanilson Burégio, Marcel Caraciolo, Jamisson Freitas e Vinicius Cardoso Garcia foram aceitos para apresentação no XV Congresso Brasileiro de Informática em Saúde (CBIS'2016) que vai ser realizado entre os dias 27 a 30 de Novembro em Goiânia.
O resumo do primeiro artigo detalha o trabalho da seguinte forma:
Objetivo: as cidades inteligentes estão surgindo mediante a necessidade de otimização de recursos e ampliação do bem-estar dos seus habitantes. Atualmente não existem dados claros sobre como comparar cidades inteligentes com base em indicadores que utilizem dados públicos, principalmente na área de Saúde. Método: este trabalho propõe a utilização de indicadores de IDH para comparar estatisticamente e agrupar cidades com semelhança de indicadores, e assim, oferecer aos seus gestores, a possibilidade de adotar estratégias de gestão baseadas em visualização de dados dispostos em dendrogramas. Resultado: foram realizados cálculos com a utilização de uma ferramenta estatística em bases de dados públicas para obter dendrogramas de dados. Conclusão: o agrupamento de cidades por semelhança de indicadores se mostrou promissor para comparar e medir cidades com semelhantes características.
Já em relação ao segundo e terceiro, vale destacar que a apresentação dos mesmos no evento permitirá que eles sejam publicados no (JHI) Journal of Health Informatics. O Journal of Health Informatics (J. Health Inform.) é uma publicação oficial da Sociedade Brasileira de Informática em Saúde. É um periódico de revisão pareada, de acesso livre e aberto o qual é publicado trimestralmente.
O J. Health Inform. oferece um meio internacional de disseminação de resultados originais de pesquisa e revisões interpretativas concernentes ao campo da Informática em Saúde.
O resumo do segundo artigo detalha o trabalho da seguinte forma:
Objetivo: A área de saúde pública no Brasil é detentora de grandes bases de dados sobre atendimento à população, e ainda assim, estes dados muitas vezes não são explorados suficientemente para identificar possibilidades de melhoria nos atendimentos. Método: este trabalho propõe a utilização dessas bases de dados combinadas com a utilização de técnicas estatísticas para visualizar dados que identifiquem a qualidade de vida das cidades.Resultado: foram analisados os dados de todas as cidades dos nove estados nordestinos e comparados os gráficos de agrupamento. Conclusão: a utilização de grandes repositórios de dados combinados com ferramentas estatísticas permitiram obter diversas visualizações de dados sob a perspectiva de agrupamento de cidades.
Finalmente, o resumo do terceiro artigo detalha o trabalho da seguinte forma:
The Data integration is a key challenge in clinical genetics area where analysts need to handle multiple heterogeneous data sources on biological and clinical domains. The research reported in this paper aims to provide unified access to these diverse data sources to support various clinical decisions. In this context, this article describes the work in progress for the construction and implementation of a platform that allows integration and unified access to sources of heterogeneous data. We detail the architecture defined for the platform and an online usage scenario for processing and annotation of clinical variants, which uses the main public data repositories genome as OMIM, Clinvar, Lovd, ExAC6500, and others. Thus, this platform helps in decision making of analysts and geneticists to release results of genetic tests.
0 notes
Text
ASSERT @SBSI 2016
É com prazer que informamos que o artigo “Modelos de Negócios Inovadores na Era da Computação em Nuvem”, de autoria de Ricardo Batista Rodrigues, Carlo Marcelo R. da Silva, Vinicius C. Garcia e Silvio R. L. Meira foi aceito para apresentação como minicurso e para publicação como capítulo de livro XII Simpósio Brasileiro de Sistemas de Informação (SBSI’2016).
O resumo do artigo diz que:
Modelos de negócios passam uma imagem inicial de algo complexo e trabalhoso, visto por muitos como desnecessário. Os modelos de negócios se tornaram uma ferramenta fundamental para empreendedores. Com a evolução tecnológica, surgiram diversos negócios baseado na Internet, parte desses negócios estão ou são baseados em nuvem. Este minicurso apresenta uma série de conceitos, tais como: Computação em Nuvem, Lean Startup, Modelo de Negócio Canvas e uma série de estratégias que podem ajudar o empreendedor a criar um Produto Mínimo Viável (MVP) de seu negócio, de modo a maximizar as chances de sucesso em um novo negócio.
1 note
·
View note
Text
ASSERT @ NOMS 2016
É com prazer que informamos que os artigos "A Meta-Analysis for Security Threats over the Web Ecosystem“ e “Towards a Taxonomy for Security Threats on the Web Ecosystem” ambos de autoria de Carlo Marcelo Revoredo da Silva, Jose Lutiano Costa da Silva, Ricardo Batista Rodrigues, Daniel Couto Gatti, Pericles Cunha Barbosa de Miranda, Kellyton dos Santos Brito, Leandro Marques do Nascimento, Rodrigo Elia Assad, Ruy José Guerra Barreto de Queiroz e Vinicius Cardoso Garcia foram aceitos para apresentação no IEEE/IFIP Network Operations and Management Symposium (NOMS 2016), que vai ser realizado entre os dias 25 a 29 de Abril de 2016 na cidade de Istambul.
O abstract dos artigos são os seguintes:
A Meta-Analysis for Security Threats over the Web Ecosystem: This article presents an analysis on the attacks related to the sensitive data breach in the Web ecosystem. The study is based on an Meta-Analysis which identified the significance of 21 years of relevant contributions to the subject. Considering the results we elaborate two contributions: (i) we group attacks according to their behavior and (ii) we reveal the most serious emerging attacks. Additionally, we present our critical sense in relation to an overall perspective on the results.
Towards a Taxonomy for Security Threats on the Web Ecosystem: The aim of this paper is to present a taxonomy for security threats on the Web ecosystem. We proposes a classification model based on 21 vectors divided into 8 distinct security threats, making use of levels of abstraction and criteria for discrimination which consider propagation and similarity in vulnerabilities. We also propose to estimate the risk factor and impacts on assets, considering data breaches, human aspects and service reliability. In addition, we validate the taxonomic model proposed through the catalogues of attacks facing the public. Thus, it was possible to observe its applicability for most of the attacks which appear before the public.
Maiores informações sobre o primeiro trabalho podem ser encontradas no post Uma Meta-Análise sobre Ameaças à Segurança no Ecossistema Web.
0 notes
Text
Uma Meta-Análise sobre Ameaças à Segurança no Ecossistema Web
Não há dúvidas que nos dias atuais a Web se consagra como um dos mecanismos computacionais mais preciosos para a humanidade. Seus usuários, através de um computador pessoal, smartphone ou smart tv, que uma vez munido de um navegador Web, é capaz de consumir serviços como e-mail, e-commerce, redes sociais e transações online, seja para fins de lazer ou negócios, beneficiando pessoas ou organizações, caracterizando assim o ecossistema Web.
Um ecossistema por definição padrão é tido como um conjunto que designa a observação do comportamento e interação entre diferentes indivíduos em um mesmo ambiente. A interação entre o conjunto de usuários, navegadores Web, redes sociais, dispositivos, aplicações e demais serviços na Web é o que definimos como o ecossistema Web, conforme a Figura 1.
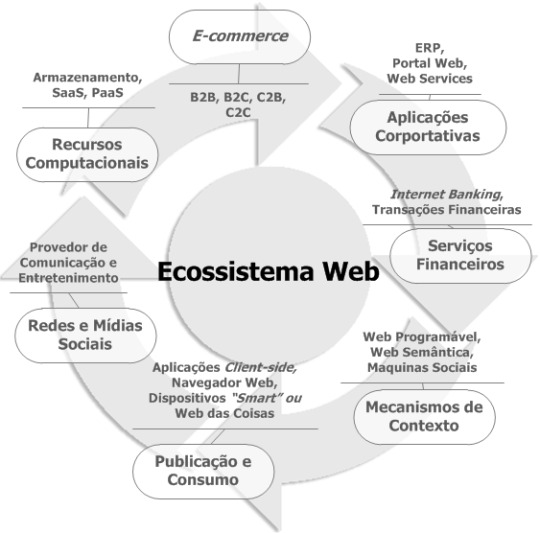
Contudo, apesar dos benefícios, podemos afirmar que esse ecossistema é um ambiente hostil diante aos casos cada vez mais frequentes de ataques que resultam na violação dos dados sensíveis de seus usuários ou serviços [1]. Nos repositórios acadêmicos, há exatamente 21 anos, desde o início de 1994 até final de 2014, nosso estudo identificou artigos que abordam sobre essa problemática. O que podemos perceber é a notória necessidade de catalogar esses incidentes no intuito de inventariar os comportamentos relacionados, facilitando na identificação e prevenção de vulnerabilidades decorrentes. Um bom exemplo são organizações como MITRE e OWASP que mantêm periodicamente catálogos destas ameaças, auxiliando a manutenção e desenvolvimento de aplicações projetadas para o ecossistema Web [2] [3].
Diante disso, a problemática abordada por este estudo pretende considerar violação de dados sensíveis oriundas de aplicações ou serviços Web, bem como mecanismos como o navegador Web, além de aspectos relacionados ao comportamento humano nesse ecossistema, a exemplo da engenharia social. Segundo [4], um dado sensível é um ativo do usuário, pois é uma informação que tem valor agregado para o mesmo. Além disso, o acesso e armazenamento desse dado devem ser restritos ao seu proprietário. Uma vez que o dado sensível seja visualizado, modificado ou indisponível, sem a devida autorização do seu proprietário, é reproduzida uma violação.
Este estudo tem como objetivo identificar os ataques mais emergentes na literatura que estão relacionados à violação de dados sensíveis no ecossistema Web. A meta-análise está estruturada da seguinte forma: (i) Descrevemos a contextualização da problemática, onde apresentamos conceitos, atores, riscos e impactos sobre os dados sensíveis. (ii) Desenvolvemos uma metodologia baseada em três etapas que propõe uma análise dos principais ataques no contexto do ecossistema Web. Essa análise visa responder alguns questionamos acerca da problemática do estudo, tendo como base para as respostas as publicações da literatura. (iii) Identificamos estudos correlatos na literatura e descrevemos nossos pontos chaves que diferem dos demais. E por fim, (IV) descrevemos nossas conclusões e trabalhos futuros a serem explorados durante a evolução deste estudo.
[1]. Secunia, 2014. “Secunia Vulnerability Review” Disponível em: http://goo.gl/6nqBAQ
[2]. MITRE, 2014. “Common Weakness Enumeration” Disponível em: http://cwe.mitre.org/
[3]. OWASP, 2013. “Top Ten 2013”. Disponível em: https://goo.gl/qRgSkl
[4]. Allen, 2001. “The CERT guide to system and network security practices Series in software engineering” Addison-Wesley.
0 notes
Text
Introdução ao desenvolvimento de Máquinas Sociais hiper-escaláveis
A evolução atual da máquina de turing e sua complexidade são incentivadas por desafios que confrontam os ambientes computacionais. Dentre os inúmeros fatores, temos mudança de requisitos dos usuários (pessoas que usavam PCs preferem a mobilidade de smartphones), as leis de Moore [1] e Amdahl [2] que desafiam o desenvolvimento de algorítmos, a falta de viabilidade financeira, falta de maturidade de modelos e processos, ou o crescimento instantâneo e exponencial de serviços (spikes).
Big Players como Google, Netflix, Amazon.com ou Twitter têm se encontrado em um mundo único de inovações devido a singularidade de seus cenários alavancados por um dos maiores desafios da computação: o crescimento.
Seja devido ao sucesso de um serviço homogêneo disponibilizado através de plataformas como Twitter e Netflix, a expansão global de lojas virtuais como a Amazon.com ou o crescimento rápido de empresas de apostas como a Paddy Power com turnover de 6 Billhões de euros por volta de 2015, a resposta para o fator crescimento o é desenvolver sistemas distribuídos escaláveis [3].
Escalabilidade é a capacidade que um sistema tem de adicionar mais recursos a fim de atender a necessidade de uma carga de trabalho maior [4]. Além disso, é preciso que tais sistemas apresentem respostas adequadas à solicitações on-demand. Portanto, que também sejam elásticos. Nossa pesquisa visa diretamente lidar com sistemas distribuídos que adotam alta escalabilidade e elasticidade como propriedades fundamentais em sua composição.
Inicialmente, entendemos que para construir tais sistemas é necessária a definição de um elemento básico de software que possa ser adicionado ou removido do ambiente a fim de possibilitar alta escalabilidade e eslasticidade ao sistema. Para representar tal elemento utilizamos o conceito de máquinas sociais devido a seu foco no inter-relacionamento entre os elementos que compõem uma arquitetura [5].
Também, entendemos que o elemento básico dessa arquitetura (a máquina social) deve ser delimitado pelo dominio real do problema. Exemplificando, teríamos uma máquina social A responsável pelo departamento de CDs e outra máquinas social B responsável pelo departamento de livros. Partindo da premissa que ha apenas essas 2 instâncias heterogêneas ativas no ambiente, caso a quantidade de trabalho aumentasse além da capacidade da máquinas social A (CDs), bastaria inserir uma nova instância no sistema [7].
Acerca de sistemas distribuídos monolíticos já existentes, estamos trabalhando no desenvolvimento de uma melhor estratégia para o desmembramento dos "domínios reais" existentes e transformando-os em máquinas sociais. Atualmente estamos usando uma solução opensource a fim de validar o conceito através de um problema real.
Até o momento esse estudo visa contribuir com o desenvolvimento de novas tecnologias e simplificar o desenvolvimento de aplicações distribuídas escaláveis através da definição de conceitos, estratégias, e uma arquitetura hiper-escalável.
[1] Green, C.; The end of Moore's Law? Why the theory that computer processors will double in power every two years may be becoming obsolete. http://www.independent.co.uk/life-style/gadgets-and-tech/news/the-end-of-moores-law-why-the-theory-that-computer-processors-will-double-in-power-every-two-years-10394659.html
[2] Herlihy, Maurice and Shavit, Nir; The art of multiprocessor programming. Elsiever 2008
[3] Vogels, Werner. A Conversation with Werner Vogels. ACM QEUE 2006.
[4] Lins, Helaine S. Análise da Completude dos Relatos de Experimentos em Elasticidade na Computação em Nuvem: Um Mapeamento Sistemático. Dissertação de mestrado, UFPE 2015.
[5] Buregio, V. The Emerging Web of Social Machines. http://vanilson.com/2013/03/10/142/.
[6] Wikipedia. Monolithic system. https://en.wikipedia.org/wiki/Monolithic_system
[7] ABBOTT, ML; FISHER, M.T. THE ART OF SCALABILITY: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise
0 notes
Text
Algoritmos de detecção de resistência a drogas do HIV e porque devemos otimiza-los
A manipulação de dados biomoleculares pode apresentar características tratadas em computação como problemas de Big Data. Estes, são comumente armazenados em grandes bases de dados estruturadas ou não, apresentam certo grau de complexidade e as técnicas tradicionais de gerenciamento e processamento desses dados podem não ser muito úteis. Sobretudo para os casos em que existem inconsistências e a possibilidade de combinações imprevisíveis.
Segundo Prajapati (2013), a caracterização enquanto Big Data vem dos requisitos de volume, velocidade e variedade. Essas características são encontradas na interpretação de resistência a drogas do Vírus da Imunodeficiência Humana (HIV).
Existem diversos algoritmos que se propõem a fazer essa interpretação de resistência a drogas para o HIV. O HIValg, mantido pela Universidade de Stanford, permite que sequencias de código genético viral sejam avaliadas quanto a resistência a drogas pelos algoritmos HIVdb (da própria Standford), Rega e ANRS. Essa análise é feita a partir da manipulação de uma sequência de 9181 caracteres que é cortada e comparada com milhares de sequências de mesmo tamanho presentes nas bases de dados desses algoritmos.
Partimos da premissa de que a performance desses algoritmos é satisfatória para a análise de apenas uma sequência genética por vez. No entanto, o mesmo não acontece de forma escalável para a análise de várias sequências ao mesmo tempo devido à natureza de alto consumo de recursos computacionais da realização de operações com grandes cadeias de caracteres e dado o contínuo aumento dessas bases de dados com de códigos genéticos do HIV.
O objetivo de nossa pesquisa é otimizar o tempo e o consumo de recursos computacionais do algoritmo de interpretação de resistência a drogas Rega, utilizando técnicas de manipulação e gerenciamento de Big Data. Considerando como recursos computacionais a o consumo de tempo de processamento e memória RAM, observando para que não haja prejuízo da corretude das análises.
Os benefício dessa otimização é uma provável redução de tempo e custo para a realização de pesquisas científicas sobre a resistência a drogas do HIV. Essa resistência tem aumentado o número de mortes por AIDS em 14% para pacientes em tratamento. O índice de resistência às drogas utilizadas como terapia inicial tem sido de 9% na Polônia (Parczewski, 2014), 11.7% na França (Frange, 2015), de até 64% na Libéria (Loubet, 2015) e de 35% do Brasil (De Souza, 2015).
Um provável caminho para se chegar a esta otimização é a utilização de tecnologias como o Apache Hadoop, que é um framework para pesquisa e processamento de Big Data em clusters de servidores. A segunda versão deste framework deixa o gerenciamento de recursos e o apontamento de responsabilidades para ferramentas como YARN e Mesos. Outra ferramenta útil a este contexto é o Spark, que provê um engine de execução para o processamento de grandes quantidades de dados manipulados em memória de forma paralela utilizando diversas linguagens de programação.
Referências
De Souza Cavalcanti, J., Ferreira, J. L. D. P., Guimaraes, P. M. D. S., Vidal, J. E., & Brigido, L. F. D. M. (2015). High frequency of dolutegravir resistance in patients failing a raltegravir-containing salvage regimen. Journal of Antimicrobial Chemotherapy, 70(3), 926–929. http://doi.org/10.1093/jac/dku439
Frange, P., 1, 2, * L. A., 3, Descamps, D., 4, 5, … Wirden, M. (2015). HIV-1 subtype B-infected MSM may have driven the spread of transmitted resistant strains in France in 2007– 12: impact on susceptibility to first-line strategies ´, (February), 2084–2089. http://doi.org/10.1093/jac/dkv049
Loubet, P., Charpentier, C., Visseaux, B., Borbor, a., Nuta, C., Adu, E., … Descamps, D. (2015). Prevalence of HIV-1 drug resistance among patients failing first-line ART in Monrovia, Liberia: a cross-sectional study. Journal of Antimicrobial Chemotherapy, (February), 1881–1884. http://doi.org/10.1093/jac/dkv030
Parczewski, M., Leszczyszyn-Pynka, M., Witak-J dra, M., Maciejewska, K., Rymer, W., Szymczak, a., … Urba ska, a. (2014). Transmitted HIV drug resistance in antiretroviral-treatment-naive patients from Poland differs by transmission category and subtype. Journal of Antimicrobial Chemotherapy, 70(1), 233–242. http://doi.org/10.1093/jac/dku372
Prajapati, V. (2013). Big data analytics with R and Hadoop. Packt Publishing Ltd.
0 notes
Text
Uma Metodologia de Recomendação Híbrida Para Sistemas de Armazenamento em Nuvem
Um estudo realizado pela KPMG International apontou que cerca de 50% das empresas participantes optam por armazenar dados em nuvem. Com essa crescente utilização de armazenamento em nuvem, são formados grandes volumes de dados. Essa propagação do uso de sistemas de armazenamento em nuvem teve como resultado a migração de grandes volumes de dados para esses sistemas.
A escassez de informação disponível deu lugar a uma imensa massa de dados ao alcance de todos. Entretanto, esta inversão também acabou gerando um problema: como encontrar dados relevantes em meios a uma grande massa de dados? A filtragem de conteúdo relevante em meio a essa imensidão de dados é complexa, demanda tempo e recursos computacionais. Outro ponto a ser considerado neste cenário é como proporcionar aos usuários a melhor utilização dos recursos em nuvem, na enfadonha tarefa de filtrar conteúdo relevante em meio a grandes massas de dados. Um forma de amenizar esses problemas pode ser o uso de técnicas de recomendação. Para isto, é necessário informações sobre o indivíduo alvo da recomendação ou sobre o ambiente que influenciará na geração da recomendação. A partir destas informações, um sistema de recomendação poderá recomendar arquivos que apresentem maior semelhança com as preferências do usuário alvo [2].
Nesse contexto, este trabalho tem como proposta de pesquisa propor uma metodologia de recomendação de arquivos para sistemas de armazenamento em nuvem, utilizando as técnicas de recomendação mais utilizadas e características de ambientes de armazenamento em nuvem. O objetivo deste modelo é recomendar aos usuários arquivos que sejam similares a suas preferências e em paralelo proporcionar uma melhor utilização dos recursos do ambiente em nuvem.
Como resultado, no desenvolver deste trabalho serão propostos dois modelos de recomendação e uma metodologia híbrida (conjunto de boas praticas para recomendação de arquivos em sistemas de armazenamento em nuvem). Serão utilizadas as técnicas de recomendação por filtragem colaborativa e recomendação baseada em conteúdo. Essas técnicas serão associadas as características que representem ambientes de armazenamento em nuvem.
[1] G. Jung, T. Mukherjee, S. Kunde, H. Kim, N. Sharma, and F. Goetz. Cloudadvisor: A recommendation-as-a-service platform for cloud configuration and pricing. In Services (SERVICES), 203 IEEE Ninth World Congress on, pages 456–463, 2013.
#ufpe #cin #phd
0 notes
Link
Reproduzo aqui o post que o prof. Fernando Castor fez sobre o seminário apresentado pelo prof. Alexandre Motta acerca sobre seus trabalhos com Métodos Formais.
Estes seminários fazem parte de uma iniciativa do Laboratório de Engenharia de Software do CIn-UFPE.
0 notes
Text
Gerenciamento de dados heterogêneos: quando e como começar
Nas últimas décadas, o aumento do poder computacional produziu um fluxo impressionante de dados que provocou uma mudança de paradigma no processamento de dados em grande escala. Assim, tivemos uma explosão no volume, velocidade e na variedade de tipos e fontes de dados, a qual podemos nos referir como Big Data. Contudo, o acesso a estes diversos tipos e fontes de dados tornou se complexo. Heterogeneidade, escala, pontualidade, complexidade, privacidade e valor são os desafios do Big Data.
Heterogeneidade de dados é um desafio importante em qualquer contexto onde um software lida diretamente com os dados. Nos dias atuais, a necessidade de homogeneização está conduzindo várias técnicas e práticas da indústria, conhecidas com várias expressões similares tais como federação de dados e integração de dados empresariais, que pode ser classificada em dois tipos de abordagens gerais para o problema: gerenciamento de dados mestres (master data management); e transformação de dados.
A maior expectativa de sistemas complexos é uma integração transparente, onde os dados possam ser acessados, recuperadas e tratados com técnicas, ferramentas e algoritmos uniformes. Dessa maneira, integração pode ser vista como o oposto da heterogeneidade. Mas passar de dados altamente heterogêneos para dados integrados é o tema principal da integração de dados, disciplina essa que estabelece, em termos formais, todos os processos e as etapas técnicas e algorítmicas necessárias para transformar dados.
A heterogeneidade é um problema duplo. Ele tem uma conotação técnica e uma teórica. Os dados podem ser distribuídos em fontes de dados diferentes, memorizados em vários formatos e tipos de codificação, e serem consultados através de interfaces de programação incompatíveis. A partir de um ponto de vista técnico, todos estes tipos de problemas podem ser resolvidos com a criação de arquiteturas de adaptação adequadas, envolvendo a presença de um certo número de conectores de homogeneização. Por outro lado, o problema principal com a heterogeneidade é que os dados podem ser intrinsecamente diferentes porque diferentes modelos de dados (coleções de entidades estruturais) são adotados para os organizar. Uma instância de um banco de dados relacional é intrinsicamente diferente de um arquivo XML ou da coleção de objetos em um repositório NoSQL.
As divergências não são somente técnicas mas também representacionais. Assim, para gerenciar com um grande volume de dados heterogêneos, é necessário lidar com técnicas de integração de dados sob várias perspectivas pois ela envolve soluções tanto para muitas questões técnicas, tais como a combinação de protocolos, gerenciamento de fluxo de dados (stream), escolha de interfaces técnicas (drivers) quanto para a adequação conceitual e formal dos modelos de dados envolvidos.
Do ponto de vista teórico, uma opção é utilizar o gerenciamento de modelos (Model Management) como framework para formalizar problemas de tradução. Um esquema, instância de um determinado modelo será traduzido para outra instância do esquema de um modelo de destino. De acordo com Bernstein [1], model management é um framework teórico que define uma álgebra sobre modelos de dados. Neste contexto, este trabalho identificou a necessidade de uma solução independente de modelo para tradução de esquemas e dados e para problemas de model management e propõe uma plataforma baseada em uma abordagem orientada a metadados que pretende ser mais abrangente do que master data management ou integração de dados empresariais.
[1] P. A. Bernstein. Applying model management to classical meta dataproblems. In CIDR Conference, pages 209–220, 2003.
0 notes
Text
Assert @SBSeg 2015 – Trilha Principal
Com prazer informamos que o artigo “Uma Avaliação da Proteção de Dados Sensíveis através do Navegador Web” de autoria de Carlo Marcelo Revoredo da Silva, José Lutiano Costa da Silva, Daniel Couto Gatti, Ricardo Batista Rodrigues, Kellyton dos Santos Brito, Leandro Marques do Nascimento, Ruy José Guerra Barretto de Queiroz, Rodrigo Elia Assad e Vinicius Cardoso Garcia foi aceito para apresentação como artigo completo na trilha principal do XV Simpósio Brasileiro em Segurança da Informação e de Sistemas Computacionais.
Segue um resumo do artigo:
Navegadores Web são ferramentas de extrema importância no que diz respeito ao consumo de dados na internet, pois possibilitam a interação e consumo de informações providas por diversos serviços disponíveis na Web. Em contrapartida, é nítida a dificuldade destas ferramentas em evitar que seus usuários sejam vítimas de vulnerabilidades, sejam localizadas em seus próprios mecanismos internos, oriundas de aplicações Web disponíveis ou resultadas pela ingenuidade do próprio usuário. Tais vulnerabilidades quando exploradas resultam em violações aos dados trafegados, produzindo consequências devastadoras, e muitas vezes irreversíveis aos negócios. Através deste artigo, apresentamos um estudo que evidencia a carência de soluções eficazes em analisar e minimizar tal problemática nestes cenários. Nosso estudo tem como objetivo duas contribuições: (i) o desenvolvimento de um ambiente controlado, que se define como uma aplicação Web que simula vulnerabilidades reais suscetíveis a 13 ataques distintos, considerados mais explorados da atualidade. (ii) E uma avaliação da eficácia de 25 ferramentas que visam proteger os usuários de navegadores web contra estes ataques.
0 notes
Text
Uma máquina para publicação dos dados governamentais
A primeira legislação sobre transparência e liberdade da informação data do século 18, sendo a Suécia o pioneiro ao criar esta legislação em 1776. Dois séculos depois, nos anos após a segunda guerra mundial, os Estados Unidos começaram a discutir o "direito de saber" (the right to know) e aprovaram sua legislação em 1966, sendo seguido por inúmeros países. Assim, no final do século 20 as leis de acesso a informação já eram populares na maioria dos países democráticos.
Com o surgimento da Web 2.0 e das novas tecnologias de publicação e consumo de dados esse movimento resurgiu como Governo Aberto, levando a iniciativas de Dados Abertos Governamentais (OGD - do inglês Open Government Data), iniciando a "segunda onda" de transparência. Porém, apesar de muitos governos ao redor do mundo lançarem portais de OGD, os mesmos tem sido muito criticados principalmente por falharem em cumprir os requisitos básicos de OGD, além de alguns críticos considerarem que "...muitos governos focam no desenvolvimento de um portal nacional de dados abertos governamentais como se isso fosse mais prioritário do que desenvolver a infraestrutura técnica para abertura dos dados para uso por terceiros...".
Nesse contexto, em sua tese de doutorado Kellyton Brito considera que os governos deveriam basear a publicação dos seus dados a partir de um modelo mais abstrato, como um modelo de máquinas computacionais. O que leva a uma questão principal: existe um modelo computacional abstrato e genérico capaz de descrever os dados governamentais e possível de ser implementado como um sistema de informação na forma de um portal de dados abertos governamental?
Com o objetivo de responder a esta questão, Kellyton definiu a MAGDA - MAchine for Government Data (Máquina para Dados Governamentais), um modelo abstrato e genérico de máquina computacional que satisfaz os requisitos do domínio de OGD, e usou esse modelo para projetar, desenvolver e disponibilizar portais de dados abertos, usando dados reais publicados pelos governos, como os dados dos parlamentares federais e de todas as 270 mil escolas do Brasil.
Posteriormente, de forma a validar a utilidade da proposta, foram desenvolvidos aplicativos utilizando os dados desse portais. Estes aplicativos, além de demonstrarem a viabilidade e benefícios da proposta, receberam diversos prêmios de órgãos oficiais, como a Câmara dos Deputados e o Ministério das Comunicações. Além disso, também demonstraram ser de grande utilidade pública. Como exemplo, em uma pesquisa realizada durante o período das Eleições 2014, 58% dos respondentes que visitaram um desses aplicativos, o Meu Congresso Nacional (www.meucongressonacional.com) afirmaram que sua visita ao mesmo teve muita ou extrema influência na sua decisão de voto.
0 notes
Text
Rastreabilidade de Artefatos Heterogêneos de Software – Um Mapeamento Sistemático
O aluno Charles Everton Oliveira Gomes entrou no mestrado em 2013 e vem estudando a rastreabilidade de artefatos heretogêneos de software, em programas de desenvolvimento.
A rastreabilidade tem sido reconhecida como uma tarefa importante no desenvolvimento de sistemas de software. As relações de rastreabilidade podem reduzir custos, o tempo de desenvolvimento e melhorar a qualidade do produto. Diferentes tipos de artefato podem ser rastreados, em níveis variáveis de granularidade e em quantidade. Complexidades são introduzidas pelo fato de que as ligações de rastreio devem ser criadas e mantidas através de artefatos heterogêneos que podem residir em uma variedade de ferramentas de terceiros. Com isso, estabelecer a infraestrutura tecnológica, promover o planejamento estratégico e o desenvolvimento de novas técnicas de ligação e visualização dos vínculos de rastreabilidade para apoiar a integração de dados através de uma ampla variedade de ferramentas e formatos de dados são alguns dos desafios atuais da área.
Estes desafios continuam a ser um pesadelo devido à falta de ferramentas adaptáveis de domínio específico e soluções que apoiam a manutenção de vínculos de rastreabilidade de forma automática durante o ciclo de vida dos processos da engenharia de software. Muitos pesquisadores tem se dedicado a este tema e publicado os seus estudos ao longo dos anos. Portanto, este estudo tem como objetivo investigar o estado atual das pesquisas sobre rastreabilidade de software em artefatos heterogêneos, fornecendo como resultado uma compreensão sobre a abordagem utilizada, as relações estabelecidas, o contexto de uso, as tecnologias, ferramentas e indicadores de desempenho obtidos.
A quantidade de estudos primários envolvidos até o momento foi de 603 no total. Onde foi realizada pesquisa manual limitado às publicações de uma dos mais importantes eventos da área TEFSE (Traceability in Emerging Forms of Software Engineering), e pesquisa automática utilizando o motor de busca do Scopus. Este número foi reduzido na primeira sessão de triagem, que consistiu em avaliar o título, resumo e palavras-chave, deixando apenas 140 estudos primários potencialmente relevantes. Depois da segunda fase, que consistiu na leitura e análise de todo o estudo, foi definido o conjunto final de documentos. O conjunto final resumiu em 7 estudos primários. Pode-se perceber que a maioria dos estudos trata apenas da criação dos links de rastreabilidade, onde em sua totalidade utiliza uma abordagem semiautomática, onde envolve ações manuais para o estabelecimento e recuperação das ligações. Os artefatos mais frequentemente relacionados envolvem as áreas de requisitos e design de software.
No total, 7 temas diferentes foram exploradas pela estudos primários. Os tópicos foram identificados com base na descrição dada pelos autores dos estudos primários. Em geral, os autores não são muito claros ao descrever o contexto, a impressão obtida é que o fato da rastreabilidade ser empregada em diversos cenários dificulta a limitação ou especificação do contexto específico da aplicação. Dentre os desafios relatados estão à integração do processo de gestão e manutenção dos links de rastreabilidade ao processo de desenvolvimento de software, a granularidade do links em relação aos artefatos, a escalabilidade, a redução de esforços humanos e aumento da precisão e recall dos vestígios.
0 notes