
Last Seen Blogs

pvrpl3witch
@aga.thia_

ech03s
echoes,

honeyflies05
honey

lostinthevale
Official tumblr for "Lost in the Vale"

odwolania566
wzory inne 9639
Text
Refinery29 x #BUILTBYGIRLS
#BUILTBYGIRLS is an organization that aims to get more young women interested and involved in tech-focused industries. This year, Refinery29 signed on as a #BBG advisor partner in which a dozen members of our P&E team are mentoring teenage #BBG members in 1-1 sessions, introducing them to various career opportunities in tech.

In addition to the mentor program, yesterday we hosted 50 #BUILTBYGIRLS members for a “Tech of Lifestyle” hashtag event at our office.

The event kicked off with a panel discussion with 3 members of our engineering team (Cara Warner, Nicole Pikulin, and Stasha Rosen) followed by a challenge activity in which our guests were asked to brainstorm technology-led solutions for how Refinery29 could provide personalized experiences for our users.



Not surprisingly, our guests came up with some truly brilliant ideas like content recommendations based on cookie data, social media likes, R29 editors you “follow”, the ability to customize the categories in the site nav, and even content suggestions based on the time of day (eg: R29 makeup tutorials in the morning, recipes in the evening).

Makin it rain with brilliant ideas at our Tech of Lifestyle Media event at @refinery29 🙌 #BUILTBYGIRLS @BUILTBYGIRLS

@refinery29 always inspired while working here but today more than ever #builtbygirls @builtbygirls reaching out to young women who are interested in tech @_princesstigerlilly

surrounded by #bossbetch(es) #builtbygirls #refinery29 @nichole.ricketts
Thanks to everyone who came out!
6 notes
·
View notes
Photo

Check us out! Refinery29 is featured on the Apple site, promoting the new iPad.
Want to learn more about our responsive “channel pages” design? Catch up on an older blog post here.
0 notes
Text
SEO A/B Testing With S.E.O.L. (soul)
[Editor’s Note: This post was originally published on Medium here.]


A/B testing is a standard procedure for using data to inform decision-making in the tech world. Modifications introduced to a product can be compared to either another variation or some baseline, allowing us to understand exactly just how much this modification increases the value of the product or introduces risk. When we see significant positive results, we roll out the change with confidence.
This approach is pretty simple with conversion-based A/B testing: you compare the number of conversions occurring on two variations of a page. Conversions could be any measurable behavior — checkouts, link clicks, impressions on some asset, or reaching a specified destination. The math for this also works out pretty simply: a rate or mean calculation and a p-value calculation on that value.
But the methodology for A/B testing conversion rates doesn’t translate to an SEO context!
First, SEO-based modifications don’t usually affect user behavior; they affect how search bots rank the page. Second, it doesn’t make sense to create 2 different versions of the same page because search rankings are negatively impacted by duplicates. Third, you can’t directly compare test and control groups in an SEO context, because SEO behavior is different for every single page. Lastly, there isn’t a clear conversion metric. With SEO-based testing, in the absence of knowledge of the inner workings of Google’s ranking algorithm, we want to see if our changes affect the volume of traffic we receive from search services like Google. Thus in order to understand how SEO based changes affect traffic, we need to compare the performance after the change to the performance we’d expect. To do so we created SEOL (pronounced soul), the Search Engine Optimization Legitimator.
SEOL Oracle — Prediction vs. Reality
The way SEOL works, is by first fitting a forecasting model to historical data for a group of pages in question. Once the model is fit, the performance of the group of pages is forecasted for the dates from the starting of the intervention (launch date), till the end of the test. Finally, when we have our forecast and we have the data about how it actually performed, we perform tests to measure whether deviations from our expectation (forecast) are statistically significant. If we see significant results in the test group, either positive or negative, and we don’t see the same fluctuations in the control group, we can confidently say that our changes have made an effect. If both groups are affected in the same direction, even if the deviation is significant, we can conclude that the deviation was something systemic, and was not caused by the update in question.
This is typically a 3 part process: group selection, performance forecasting, significance testing. I’d like to explain each one of these steps in more detail.
Group Selection
Before we can perform this analysis we must first select stories to be in the test and control groups. We want to select groups that are the most statistically similar — you can think of this as selecting groups with the highest pearson correlation coefficient. In addition to being correlated, you’d also want them to be in the most similar scale possible, so this you can consider as the minimum Euclidean distance between the two time series (using time step as a dimension). In simpler language, select groups that look/perform the same, as much as possible. We must also be wary of selecting groups that have a similar number of stories in them, each of which perform proportionately similar as well. If the test group has 10 stories, and 5 of them contribute 80% of the performance (ideally each story contributes an equal amount), then there should also be 10 item in the control group, 5 of which contribute 80% of the performance. In addition, avoiding seasonally driven stories is also important. These could perform as outliers, throwing off the results of the test. The purpose of this is to select groups you can be confident will perform similarly, and won’t have any unexpected perturbations to group performance.
SEO Performance Forecasting
The task of forecasting a group of pages performance breaks down into two parts:
Separating the performance data we already have into its behavioral cadence and metric trends
Modeling/forecasting in each component, and recombining them
Let’s start with discussing the decomposition of the performance data.
Below is an illustration of the signal decomposition results. We decompose the signal so that we can model the underlying shape that characterizes the general behavior in the data. This is called making the data stationary (you can learn more about that here). There are various approaches to this, but we stationarized the data by taking a rolling mean of the data, in which any given point represents average of some previous time periods (e.g., a week), and then subtracting that moving average from the vanilla signal. Thus, perturbations due to the ebb and flow of story popularity are cancelled out, leaving behind the natural cadence of weekday/weekend behavior. The moving average is also plotted, on the right, because this is the trend component. The trend represents the popularity of the group’s stories over time.

Now that we’ve decomposed our signal, we have to forecast performance from the intervention date until the end of the dates in the data set. This is done using regression methods. We used Polynomial Regression to model the stationary signal, and linear regression to model the trend.
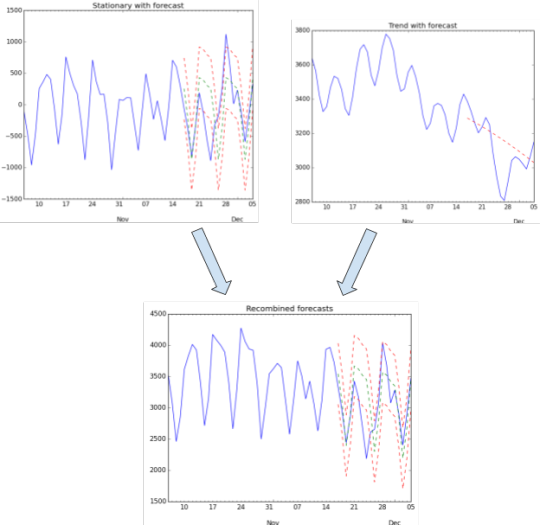
Now that we’ve made forecasts on our decomposed items, we simply sum them to recover our original data. Now that we have our performance data and forecasts, we can perform our statistical tests. Note that we also model what our predictions look like plus and minus 1 standard deviation. This helps us get a sense of the kinds of variations in the reality that should fall into an acceptable range.
Forecast vs. Reality Statistical Significance Testing

Now that we have our data representing the reality of how the pages performed, and our forecast for what we expected in that same time frame, we can perform statistical significance tests to see if our expectation meets the reality or not. For this task we use 2-sided paired t-tests. The paired is designed for before/after testing. Here we use the forecast as our ‘before’ data, and the reality as our ‘after’ data. Here’s a bit more detail:
“Examples for the use are scores of the same set of student in different exams, or repeated sampling from the same units. The test measures whether the average score differs significantly across samples (e.g. exams). If we observe a large p-value, for example greater than 0.05 or 0.1 then we cannot reject the null hypothesis of identical average scores. If the p-value is smaller than the threshold, e.g. 1%, 5% or 10%, then we reject the null hypothesis of equal averages.”
[Quote found here. I’m using this exact software to perform the test]
In addition we also test to see if the reality equals forecast plus/minus 1 standard deviation, and plus/minus ½ standard deviation to get more precision on how the performance actually turned out. So when we perform our paired t-test, for example comparing reality & expectation + 1 standard deviation, we receive a p-value. If the p-value is below 0.05 then we reject the hypothesis that they are equal, otherwise we accept. If the test group has a significant result that the control group does not also have, then we can conclude that there was indeed a real change in the test group.
Post Analysis notes
After the duration of the test period, one may want to inspect how the stories in each group actually performed. If a story had an outlier performance, perhaps due to unforeseeable circumstances, then you may want to remove it from the analysis. For example, David Bowie content got a boost in the time surrounding his death. There’s no way for us to have predicted that, and hence it would alter how our groups perform against the expectation. If this is the case, find the story or stories needing removal, and run the test again. In addition, in the case of online publication, like our business, we found that it makes more sense to analyze only pages (stories) that were published before the test period. Older stories tend to have a trend they follow, making modeling more straight forward and effective. Lastly, try not to perform these types of tests during periods with seasonal effects. For example Christmas and New Years results in dips to our traffic, as I’d expect for most websites, and this causes added difficulty to the modeling process.
Results Overview
We’ve recently completed a big project as a department. Our goal was to move our slideshow template to a new technology stack. This stack included a front and back end, making our pages faster, and adding in some new capabilities, but didn’t change anything else. Meaning we didn’t introduce any changes with the intention of affecting SEO. But before we planned a full release, we wanted to conduct a test on a small set of stories to see if our new template introduced any risk to our product.
So we chose test and control groups that included about 8000 stories, each of which have little impact on our bottom line (making them somewhat safe to test with), let them run for a couple weeks, and conducted our SEOL analysis. You can see those results below.
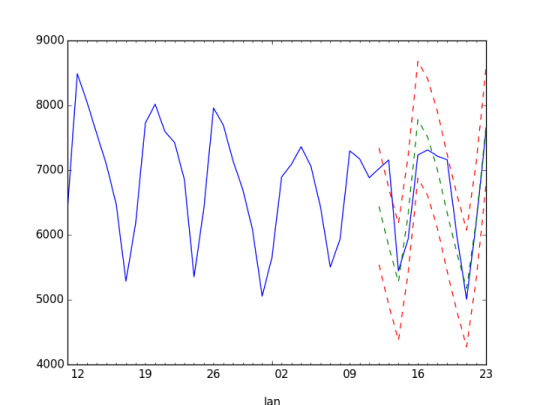
Test Group
Actual performance with expectation and +/- 1 standard deviation

standard deviation = 882.672983891
performance = expected + std: pval = 1.05651517695e-05
performance = expected + std/2: pval = 9.58082513196e-09
performance = expected: pval = 0.310003313956
performance = expected — std/2: pval = 3.78494096065e-10
performance = expected — std: pval = 0.000193616202526
Control Group
Actual performance with expectation and +/- 1 standard deviation
performance = expected + std: pval = 0.000571541676843
performance = expected + std/2: pval = 1.28055991188e-09
performance = expected: pval = 0.303194513375
performance = expected — std/2: pval = 7.21701889467e-11
performance = expected — std: pval = 2.45454965489e-05
Interpretation
Both the test and control groups showed that we must accept the hypothesis that performance is at expectation. This means that the new template appeared to perform on par with the old template at garnering organic traffic. This was good news for us, implying that our work didn’t have negative affects on crucial search traffic. This was our goal!
Conclusion
In order to test SEO-related changes we need to evaluate how they perform versus some expectation. Because SEO relates to the behavior of people and products outside of our ecosystem, we can make guesses on how they will perform, and then test against that, but directly comparing them is not a valid test method. This gives us the capability to test any SEO based changes with great detail, and a reliable way to ensure we’re not launching products that hurt us.
So to anyone needing a better way to understand how SEO based changes affect your products, try using an approach like SEOL.
-- Aaron Bernkopf, Data Scientist @ Refinery29
0 notes
Text
Ghosts Are Real
Ghost Inspector Automated Website Testing - Save Time, Money, and quite possibly Souls.
[Editor’s Note: This post was originally published on Medium here.]
I test software for a living but for all intents and purposes, I’m a ghost. If I do my job well, you won’t ever know what I did. If I do it perfectly, you won’t know that I ever even existed.
My name is Cedric, and I am a Quality Assurance Engineer.
Refinery29 is a team of 450 people and growing. I am one of 4 QA Engineers who supports a team of 50 onsite and remote Software Engineers.
The heart of our business is the ability of our writers, editors, contributors, video producers and support staff to publish content 24/7 using a content management system that we developed and refer to internally as “DASH”. We publish somewhere between 700 & 800 new stories per week so if this online printing press of ours were to crash, R29 production would come to a complete standstill.
DASH was built over 5 years ago. Over time, new code was added to old code, then newer code added to that, over, and over, and over again. The Old DASH story editor wasn’t bad but it certainly wasn’t optimal for a company that’s more than doubled its size in the past two years alone.
Roughly 5 months ago, a team of 10 developers, 1 UX Designer, and 1 Product Manager embarked on the monumental task of completely redoing the DASH Story Editor from the ground up. They had to do it using our existing live content and databases, they had to implement this along side a new powerful asset management system and it all had to be done without any interruption to everyday editorial productions.

The new DASH story editor and asset management toolset included dozens of brand new editing features like large batch asset management with duplicate image rejection, batch asset metadata duplications, hi-res auto-image sizing for multiple devices, inline image asset placements, third-party video service integrations, and support for conflict-free multi-user story-editing, to name a few. These updates would touch every aspect of our site. The risks were tremendous. I was the QA Engineer assigned to the project.
Not only were we able to get this done, we got it done without a single fire drill level issue presenting itself. Not one writer delayed, nor a single editor blocked.
I make my living trashing the work of people a lot smarter than me. I don’t mean like the vitriol a hack book critic might spew at a gifted author, no, what I do is much much worse. I take the meticulously labored over babies from the very proud hands of anxious developer parents. I hold these babes up to the sunlight and then I promptly begin to tell them the cruel, dark, ugly truth of everything that is wrong with them. How colicky their code is, how gassy, burpy, and poopy their feature appears to be. I detail with subdued glee the sleepless nights they are likely to encounter because their code never stops crying and a new operating system has just been released that absolutely hates crying. Hates it.
Now I know, even for a metaphorical “software-baby”, this is harsh treatment. Try to understand that sometimes, every now and again, one of these “babies” is actually a terrorist pretending. As cute as they may first appear, they are completely strapped with sticks of bad intention. If I let this little guy through my QA check point well, DASH is to crashes, dust to dust. (You read that right.)
I question the intent of every “loving” code update, modification, and feature that approaches me. No exceptions.
Then, after the feature has passed user acceptance testing (UAT), I still have to ensure that it won’t break any of our existing DASH features or websites through regression and integration testing. This means that for every update, every new feature, every pull request created for the new DASH story editor, I had to go into the old one and make sure the new modifications hadn’t broken any of the existing features our editorial staff depended on.
To do this meant I had to manually conduct hundreds of very repetitive test steps like creating “new” fully formed stories where I inserted valid data in all the required data fields, upload multiple images, videos, and third-party embedded assets. I would have to tag, label and credit uploaded photographs, assign content categories, keywords, regional details, duplicate the finished story to different countries, then I’d have to edit an existing story, insert all those same data and asset types, before finally ensuring that all of those updates could be saved, validated and published to a live website.
Those tests were run for every branch that contained even a minor code update before it was ever allowed to be merged into our production environment. All of those tests were completed by a single entity no one using the story editor even knew existed. An apparition.
A complete — fucking — ghost!
Four months ago, we discovered a new automation tool. A tool so bold and accommodating that when I first used it, I cried. Ok, I may be stretching a bit to make my point but dammit, this tool is just that good.
It’s called “Ghost Inspector”.
Ghost Inspector offers a Chrome Extension that allows you to record and translate every interaction you take on a web page into sequential test steps that you can save and run anytime you wish from your Ghost Inspector Dashboard.
This tool effectively allows you to screen capture your web page interactions and then… well that’s it. Every mouse-click, link selection, button tap, image upload, data field entry or form submission gets converted in real-time to test steps ordered in the sequence of the action taken. You can then save, edit or update your test steps at any point.
Any test you create can also be combined with other tests you’ve created within a test “suite”. (Picture a folder full of tests.) Now you can run OR schedule your test suite or individual tests against any remote developer instance or environment you designate.
All the tests within a suite run concurrent by default which really speeds up your testing cycles. I’ve written dozens of tests and packaged them within well-labeled suites so that ANYBODY can run them. This means any developer, project manager or intern can run a full site wide regression test suite against any remote environment they specify.
So, I’ve described having to manually conduct hundreds of very repetitive test steps before any code update is merged into production. All of those steps are now automated.
Ghost Inspector!
When a Ghost Inspector test run has completed, a test status alert is sent to my email along with a link to the test results. These results not only show me the test outcomes but if they fail, they show me at which step. On top of this, there’s a Youtube video of the test interactions performed, embedded within each test. I know, right?
youtube
Every completed test within a suite has a video recording that you can visually inspect step-by-step up until the point of success or failure. This feature left me speechless because it empowers even non-technical people with critical information they need to communicate about “what’s broken”.
youtube
Additionally, Ghost Inspector offers a host of build deployment integration options. We hooked up our tests to both Slack and Github, so in addition to receiving email alerts I also get “Slack” notifications when tests complete and whenever a pull request branch of code is tagged as “ready-for-testing” our Github integration automatically triggers a suite of Ghost lite-regression tests to run against it. Upon test completion, the test result URL, test status details and the target instance its run against are injected into that pull request as a comment where the developer can immediately review it.

This means every new feature goes through a suite of regression tests before I ever get started.
So, where do I go from here? Well, these tests aren’t going to write and maintain themselves. There’s a lot of evaluation and study required for me to fully begin to understand all of the implications it presents and I already accept that there is simply no substitute for good human judgement or intuition. It is also quite impractical to attempt to automate tests that consider any visual modifications, nor can I expect to fairly evaluate a features “form or usability ” by employing a scheduled pre-written anything.
There also are some features that I’d like to see added to Ghost Inspector like “batch suite” editing where changes can be applied to all the tests in a suite at once. I’d also like to see a more complex hierarchical suite/test capability like perhaps nested tests. For example you can create test-step-modules like for a “login function” in one suite and then import that test-module directly into other suites but a nested-test-module structure that can live within a suite might be more intuitive and a bit easier to manage.
In our planning meetings, I will have to pass new features through an “automate or manual test” decision grid to evaluate when automation makes sense and when it doesn’t. It will also be a challenge to formulate a strident set of best practices for how to organize our suites, structure our tests, and how best to implement them.
There remains an entire engineering team I’ve yet to introduce Ghost to - let alone document for training purposes and all of this continues in the background while I’m still learning about its full potential.
All that said, Ghost Inspector has already proven to be an invaluable QA tool. Thousands of tests are run each month, hundreds of manual testing hours are saved each month and I swear to you, hand to god, my soul is no longer trapped between worlds. I now exist as a fully formed physical being. A Quality Assurance Engineer in the flesh.
-- Cedric Gore, QA Engineer
Special thanks to:
Justin Klemm of Ghost Inspector: Justin offers amazing support and is an all around good Earth human.
Matt Anderson VP of Engineering at Audeo: for his assistance with Slack, Jenkins and Github integrations. He’s a generous engineer with a heart of gold.
Greg Shakar Engineering Team Lead, Product and Engineering Refinery29: When I need to do anything “tricked-out” on a test, he’s my goto code guru. He’s also a professor at night because, a Superhero’s gonna do what they do, baby!
Brittnee Cann Team Lead, QA Manager, Product and Engineering. My manager Brittnee stumbled upon Ghost Inspector whilst searching for the Ark of the Covenant. She picked it up, dusted it off, and was nearly blinded by its glow. Not sure if staring into it would turn her to stone, she made the hasty executive decision to quickly hand it to me for an assessment the results of which by now, you’ve certainly read.
#engineering#testing#QA Engineers#qa testing#automated testing#github#devops#QA#insideR29#how we work#software development#refinery29#ghost inspector
0 notes
Text
What We’re Reading: Rework & The Five Dysfunctions of a Team
I’m always on the lookout for advice from people who’ve observed or built successful organizations. In that spirit, I decided to crack open a couple of leadership-oriented books over the holidays: Rework (2010), by Jason Fried and David Heinemeier Hansson of the software company 37signals, and The Five Dysfunctions of a Team (2002), written by business consultant Patrick Lencioni. I found each illuminating in its own way, in spite of a few hitches that come with the territory of books of their genre.

About Rework & The Five Dysfunctions of a Team:
The Five Dysfunctions of a Team defines a set of common points of failure that its author asserts are endemic to companies big and small, and prescribes a framework that purports to solve them. Lencioni accomplishes this with a narrative device he calls a “leadership fable”— he tells the short story of a CEO named Kathryn Petersen, who’s hired by a fictional company exhibiting all five of the titular dysfunctions. Petersen assumes the role of an omniscient surrogate for Lencioni’s model, over the course of the book’s plot, we see her thrust into a top leadership role at the company, where she observes that the team indeed suffers from all of the five issues and slowly convinces each of them that these flaws are institutional in nature and that they all have workable remedies. Lencioni injects a bit of drama by creating decently fleshed out characters who resemble typical personalities on an executive team and bestowing them full narrative arcs. There’s the self-centered, sarcastic lead technical architect, the irritable product marketing head who’s the most resistant to the program’s “mumbo jumbo,” and a few others who might remind readers of their own co-workers. Some make it through Kathryn’s program, while others don’t.
Rework’s authors draw liberally from their own experience running and growing their company. The book contains bite-sized portions of real world advice on running an effective small business... in fact, many of the chapters in the book were adapted from posts on 37signals’ blog, and can still be found online for free. These chapters cover everything about how to run a lean and successful organization— topics include personal productivity, hiring, and company culture. Rework presents the entrepreneur (or “starter,” as the authors propose as an alternative term) with a specific set of concrete approaches, with the implication that she can try them out piecemeal if desired. In one chapter, Hansson and Fried suggest discouraging employees from working long hours, on the grounds that it negatively impacts team morale and that you wouldn’t be doing good work anyway. Another recommendation is to follow a very specific set of rules for meetings so that they don’t waste people’s time. Most of this advice is bound by the basic principle of cutting back on the perfunctory and doing more with less (“finding judo solutions”) yet each area of guidance is individually actionable.

What I Learned:
In reading and reflecting on both books, what made the deepest impression on me was when I’d find overlapping advice, even if it would be presented from different perspectives.
Decision Making— Of the prescriptions in both books, there are a number of little things in common that draw from classical business knowledge. For example, both Rework and The Five Dysfunctions make it a point to remind the reader that making some decision is often better than making no decision, even if that decision is made with imperfect knowledge.
Honesty— The values of openness and honesty are two big takeaways from both books as well. In Rework, honesty is presented as a precondition of gaining credibility when conducting day-to-day operations. For example, you’ll have a much easier time handling P.R. emergencies if you try to be forthcoming with what happened. In The Five Dysfunctions, being vulnerable and open with people on your team is demonstrated to be a hard requirement of engaging in productive conflict, something Lencioni flags as an activity that’s absolutely essential to a good team.
Trust— Similarly, trust is a value that the three authors return to repeatedly. Trust is invoked as an essential catalyst of a productive working environment in Rework — people just work better when they’re given privacy and autonomy, Fried and Hansson assert. And in Lencioni’s model, trust between members of your team is what enables the radical vulnerability cited above.
That Rework and The Five Dysfunctions often come to similar conclusions from divergent premises is not to say that their advice is all-encompassing, or even fully convincing. One of Rework’s selling points is that all of its pointers reflect the process and culture that 37signals has put into place. However, without having the first-hand experiences of the authors, my curiosity as to why particular processes worked well for them was often left unfulfilled, and the lack of case studies in the text contributed to this.
Lencioni doesn’t make any claims about his prior experience in the book. Even then, The Five Dysfunctions manages to come off as a bit more sagely than Rework— the corporate melodrama was surprisingly realistic, leaving me with the impression that the author had been around his fair share of dysfunction and convincing me to pay attention to his advice. (But that advice also suffers a bit from a lack of scenarios drawn from the real world... a familiar narrative is still only a narrative.)

When it comes down to it, industries, companies, and teams vary so widely that no one person’s advice will ever fully diagnose any one organization’s problems to a tee. So while neither Rework nor The Five Dysfunctions is likely to be a team leader's panacea, I don’t think a “business book” can ever be. All the same, both these books have great advice within them, and especially given the short lengths and brisk writing styles of both, I’d definitely recommend giving them a read.
-- Carlo Francisco, Senior Software Engineer
#books#engineering#software engineering#software development#the five dysfunctions of a team: a leadership fable lencioni#rework#insider29#refinery29
0 notes
Text
Refinery29 Channel Pages: A Better Way to Aggregate Content
Editor’s Note: This article was originally published on Medium here: http://r29.co/2h5OmkG

As we transition Refinery29 towards a new site architecture, we seized a design opportunity to improve the workflow for our developers and editors – ultimately making the discovery of our content better for our users. This was the process behind designing our new Channel Pages.
Refinery29 is all about finding that new style you never thought you could pull off, learning that secret little beauty hack to get you out of a tricky situation, or stumbling upon that tiny piece of creative inspiration that motivated you to take on that weekend project you’ve been putting off. Our content is meant to be carefully curated, surprising, fresh, and yet easily discoverable. Being able to deliver that content to our users efficiently will always be one of our top priorities.
The relationship between our content creators and our platform is much like that of a fashion designer and the runway they send their clothes down. While there is no one perfect runway design for every single style, the ultimate goal is to provide a sustainable method to showcase each piece in its own light.
That’s how we try to approach designing the main vehicle for our content. From custom illustrations, powerful essays, original photography, to scripted video, our job is to develop a flexible — yet consistent — platform for all of our content to be discovered and seen.
When it comes to the design of our site, we want a content aggregation system that’s inclusive to the breadth of our content and empowering for our editors to shine a light on our most engaging stories.
The Focus on Channels
Refinery29 content is divided categorically into what we call Channels. We refer to a Channel as a place that lists any collection of published content around a common topic. A Channel could potentially be as niche as Korean Beauty to as big as the entirety of our content represented by our Homepage. Aside from our Homepage, some of our biggest channels are Fashion, Beauty, and Video.
While it’s important for us to establish patterns for how our users browse our content regardless of Channel, we also recognize the desire for different types of content to be displayed in different ways. For example, video content lends itself to a different visual format than written articles.
In the past, we only had a single template for top-level Channels represented in our main navigation. They contained a fixed design with a fixed number of stories, all manually populated by an editor. All other Channels had a list style card design that was automatically populated by a query in reverse chronology.

Furthermore for our top two Channels of Fashion and Beauty, we designed completely custom templates that each took 2+ months of dedicated engineering time to develop, test, and launch.
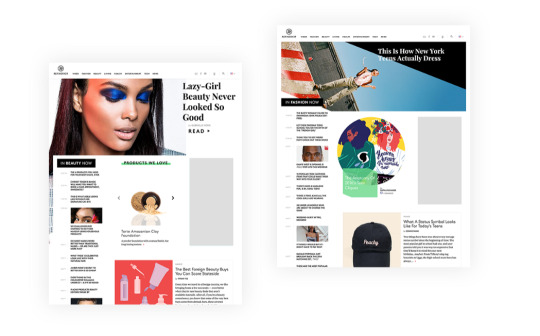
While these were premium ways to represent the Channels we stand strongly behind, they did not help us in the way of establishing a familiar reading pattern for our users. Not to mention each of these one-off undertakings took significant time from our developers to produce, making it unsustainable to scale.
A Predictable System
We wanted to design a predictable system with elements of variability. The overall goal being to streamline our site such that Channels can be auto-generated, yet easily customizable by an editor at any time, while also allowing us to maintain control over User Interface patterns we want to carefully set, test, and upgrade.
We used a wireframe card-based foundation — in your typical Lego-building workshop — to determine how we wanted our system to be constructed.

We looked at the specific use cases of our Homepage and Fashion channels, as well as low-touch, auto-generated Channels (created from our tagging functionality). We envisioned how these pages would potentially be built and rendered on various devices.
Building In Rows
From these workshopping sessions, we ultimately made the conscious decision to base our design system on a scaffolding of rows. What is a row exactly? For us, a row is just a pre-designed horizontal slice of the page.

We would then offer our editors a variety of row types to choose from in order to build and customize their Channels. Being able to isolate our design into a limited pool of reusable row types is advantageous for us in maintaining and scaling our design patterns across site. It also gives us the ability to make our designs responsive in a predictable and bite-sized manner.
Instead of focusing on design compositions of individual pages as a whole, we decided to focus on designing individual blocks and the relationships between those blocks, which offers us the potential for an infinite amount of possibilities.

We decided to begin with three basic row types to start, with the intention of expanding our offering down the road to give our designs room to evolve.
Four Story Hero
Our Four Story Hero is based on our highly effective classic hero style. We touched up the UI to aesthetically fit into a more logical system.

Three Standard Single Cards
Our Three Standard Single Cards row type is our base-level row type meant to display stories in a more dense manner, while still offering adequate space to showcase art and content.

One Standard Full Card
Our One Standard Full Card row type is meant to give the page some breathing room, and also showcase bigger content pieces that we would like users to recognize.

A Quick Test
At this point we wanted to quickly test and see if our users would negatively react to a new card-based reading pattern before going any further in building out our system.

Using our proposed row types and initial card designs, we made a purely UI-only update to our Homepage and ran an A/B test to compare performance.
Here were a few metrics we wanted to keep our eyes on:
Bounce Rate & Exit Rate — Will our new UI pattern turn people away?
Scroll Depth — Our taller cards and bigger imagery will require more scrolling from our users. Will they put up with it?
Clicks — Are we helping our users find content that interests them?
We wanted to make sure that we were going down the right path before we made a big investment in restructuring our entire front-end. The results were overwhelmingly positive.
Some key findings:
The new UI reduced exit rate for returning users by 17%, it reduced exit rate for new users by 9%
28% increase in users scrolling to the bottom of the page.
Based on our findings we rolled out the visual update of our Homepage to 100% of our users.
Moving Onto Modules
In our system we established that row types would be used to build Modules. Modules allow our editors to curate custom clusters of content around specific sub-topics within their Channels.
In our custom CMS, we proposed a way for editors to have the ability to easily create Modules for Channel pages and modify the layout of those Modules using a build tool.
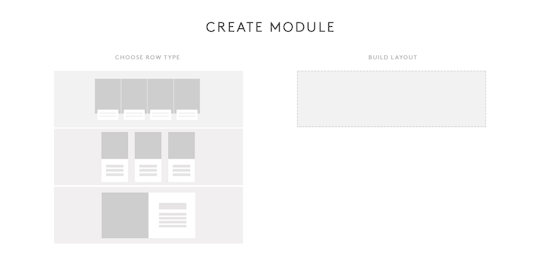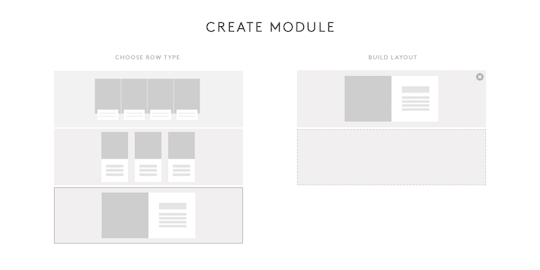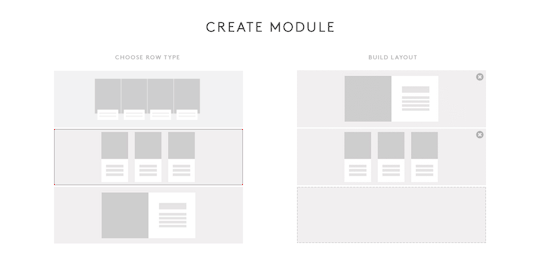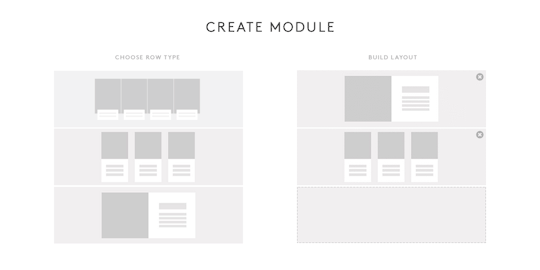
[Note: Above is not an actual representation of the final build tool.]
Each Module that’s created can be given a custom name to describe the content cluster. This name will be displayed automatically at the top of the Module in a default header style.

Modules can be created, deleted, and modified on the fly through our CMS. This gives our editors the ultimate flexibility in presenting their content without requiring the assistance of a single developer or designer.
Curation & Automation: The Balance of Power
It’s been shown that one of the most recognizable qualities of Refinery29 is our voice. This is largely due in part to our highly-curated content with a strong point-of-view.
Because our ability to curate is so important, much of the way we do things is very hands-on. This usually ends up being at odds with our desires to scale processes with technology.
In the past, we constantly created custom curated pages that quickly became stale if neglected. In rebuilding our system, we wanted smartly integrate the ability to curate alongside automatic population when it came to powering our Modules. We wanted to ensure that our editors could quickly promote stories and topics exactly where they saw fit, while making sure that content also stays fresh throughout time.
When an editor saves a layout for a Module using available row types, it is automatically numbered to show how stories will logically flow through the design.

An editor must then choose a query (or tag) as a baseline to power the Module. The Module will now populate with a reverse chronological feed of stories tagged with the named query.
In our CMS we show the editor a list preview of stories that will occupy each numbered slot at the current time. The editor then has an option to search through our full database of stories and override any numbered slot in the Module. Manually inserting a story into a position will just shift over the stories already populated via query.
Offering this level of flexibility makes the process of creating new Channels effortless, curate-able, infinitely customizable, and easily manageable.

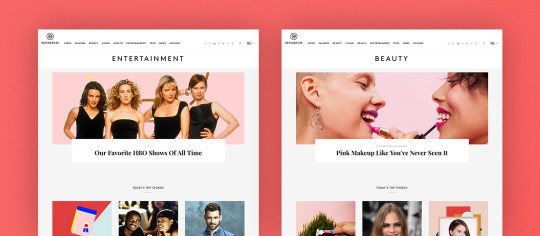
[Example of a completed module — just in time for the holidays.]
Scaling For The Future
Now that the base of our system is in place, we can now focus our efforts on scale. This includes designing more row types, analyzing performance of existing row types, and seeing where incremental improvements can be made.
Soon after the initial launch of our new Channel pages, we released a new row type to be offered as an alternative to our Four Story Hero.

Adding diversity to our row types creates an additional dimension of individuality for our Channel pages. Although we can add an endless variety row types to our available pool, we are still exercising discipline in deciding what justifies additional styles of row types.
We don’t want to add a plethora of styles for row types merely for aesthetic variety. It could easily detract from our visual consistency and dilute the visual hierarchy we’ve established. When implementing a new row type, it’s based purely on if it adds value to the content browsing experience.
The Test Of Time
Over time, we will be looking deeper into how our users enjoy discovering our content, and constantly figuring out how to optimize the experience. Having our Channel pages designed with this new structure will allow us to be more nimble when it comes to testing and observing the performance of our designs. Our plan is to continually try and test a variety of row types, as well as module compositions to find the best browsing habits.
Now that we have a solid foundation in place we can move a lot more quickly and effectively to implement design changes at scale.
We’re excited to see how our Channel pages can evolve moving forward.
* THE TEAM *
Special thanks to everyone who had a hand throughout the entire project:
Product & Design — Emily Hengemihle, Nicole Pikulin, Aziz Hasan, Frank Conway
Engineering, Development & Testing — Daniel Habib, Ryan Catlin, Chris Sloop, Carlo Francisco, Patty Delgado, Jake McGraw, Jen Calloway, Josip Herceg, Melissa Bulzomi, Cara Warner, Ming Hou, Graham Daniels, Jing Flint, Rachel Shatkin, Jennifer Refat, Claudia Sosa.
-- James Cabrera, Interface Designer
0 notes
Text
*NEW* Comments & The Benefits of Working With a Feature Flag
Earlier this year, with the news that Disqus would soon begin incorporating ads into their commenting modules we made a decision to switch to a new comment provider. After much research our product team found Spot.IM and, excited by the features and support they could offer us, it was decided that they would be *it*. But unlike just adding a new site feature, having to maintain commenting abilities while switching from one third party vendor to another would come with its own complexities. One way we minimized these and made it easier for our partners at Spot.IM to work with us was through the use of a feature flag.

Truth be told, our team loves feature flags and we use them whenever possible. Feature flag development that allows us to push code changes to production is great for us because...
Our team deploys code on a CI schedule (any time, all the time) so releasing to production fast and often is needed to ensure that our code changes don’t become quickly outdated.
We can do additional testing in production with 100% confidence. Of course we do testing in pre-production environments before release too but staging stacks are not quite a 1:1 predictor of how something will behave in production. Reason being, it’s hard to mimic things like traffic and CDN rules.
Feature flags give us a lot of control so we can do scaled roll outs or a/b testing if desired. (Note: We didn’t do this for new comments but we will be for a project coming soon.)
It makes launching something very easy… in most cases we just remove the flag and DONE!
Be sure to check out the new commenting tools on Refinery29. In addition to the way we’ve customized our icons and anonymous user names, Spot.IM has more features that we’ll be looking to add in the future like on-site notifications and a “news feed” service that shows users all of the conversation happening on Refinery29.
-- Brittnee Cann, QA Team Lead
0 notes
Text
Refinery29 x General Assembly: Mentorship in Tech Panel
On Wednesday 10/26 @ 6:30pm some of our engineering managers will be speaking at General Assembly about mentorship in tech. The event is FREE, all you have to do is RSVP so come meet up with us IRL!
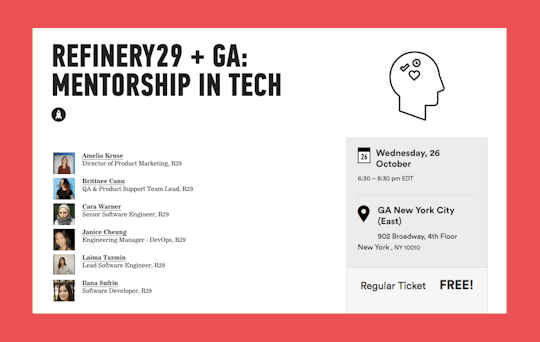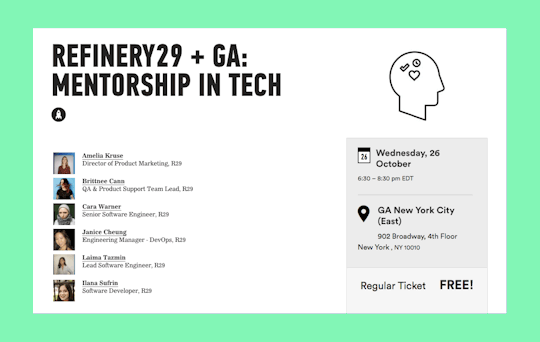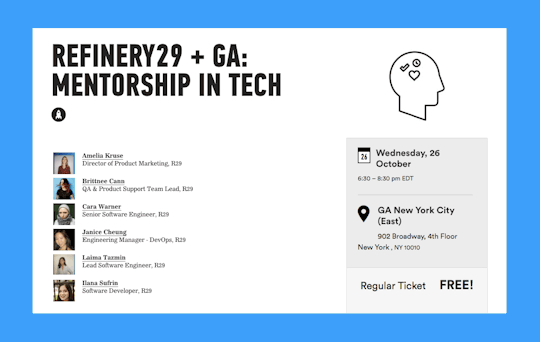
About This Event
For today’s tech managers, fostering and developing junior talent extends far beyond making the hire. Join General Assembly and the team at global media brand Refinery29 for a panel event focused on the critical role mentorship plays in empowering tomorrow’s tech leaders.
Connect with your fellow managers and hear leaders from R29’s product and engineering teams discuss:
What it takes to effectively recruit and hire junior tech talent.
How they onboard, mentor, and develop their talent.
How their responsibilities as tech managers have evolved.
The role of mentorship in their field.
RSVP HER: http://ga.co/2dRWdov
0 notes
Text
Improving Our Affiliate Marketing Strategy
This past summer Refinery29′s Product & Engineering team hosted three talented interns, who worked on different projects pertaining to (1) email acquisition improvements, (2) enhancements to our digital asset management system in our CMS, and (3) our affiliate marketing strategy through shopping products. Below, Maggie Love, who worked on affiliate marketing, recaps her project.

As a member of Refinery29 Engineering’s shopping team, I spent the summer working on ways to improve how shoppable products are featured on the site. To do this, we wanted to first find out more about our most popular products. We then wanted to give writers and editors better tools to use when integrating those products into their content.
What’s Working?
The way our affiliate marketing model works, when a reader clicks an external product link from an R29 story and makes a purchase, Refinery29 gets a small commission for being the referring site. The API we use to track users’ clicks and purchases provides us with information about the number of orders, order value, and our commission rate. Given this data, we wanted to give our team a quick, regular snapshot of the best performing products according to these metrics. We did this using a Python script that this data out every Friday in an email, which we call the “Top Products Digest”.

ABOVE: An example products digest email.
The data we needed was available to us through reports in Domo, an application we use to create datasets from various sources. We formatted this data into email-friendly tables and used the Postmark API to send the email to an internal listserv. We also programmed the script to timestamp the titles of the datasets we downloaded from Domo as they were named, then upload them to an Amazon Simple Storage Service bucket for future reference. The program is hosted on Linode, and the script is run through a weekly cron job, with daily and ninety-day options as well.
From the data collected and sent in these emails, so far we’ve seen an interesting mix of highest performing products on the site--some are tied to time-sensitive sales, some are products readers are less likely to see on other sites, and some are evergreen. Given the variation we’ve seen, at this point we’re still exploring possibilities for how we might best use this information.
Integrated Products vs. Text Links
There are currently two ways Refinery29 features products in a story. The first--and ideal--way consists of a featured product module embedded in the page, with brand, retailer, and price information. The second is a plain-text description of a product accompanied by a hyperlink to the retailer’s site.
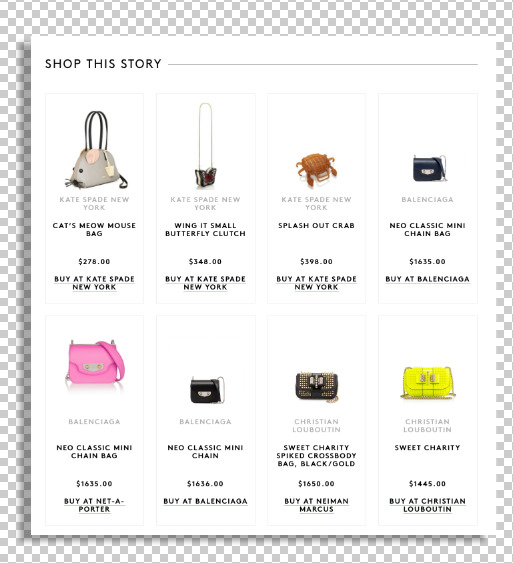
ABOVE: An example of integrated product modules on www.refinery29.com/baby-bags.

ABOVE: An example of a plain-text product description with a link out to retailer’s site on http://www.refinery29.com/everlane-leggings-stretch-skinny-pant-review.
In both cases, the reader sees the same information about a product, but with the embedded products module, readers are given an at-a-glance view of all items in the story without having to click slides or scroll through a story, the way they would have to with the link-only implementation. As you would imagine, the product module encourages more engagement from our readers. Additionally, embedded products are stored in a Refinery29 products database (which we can use for many things), while products featured as static images alongside text links are not.
It’s clear that the integrated product modules are the preferred way to go but the catch is that to create them, it’s a non-trivial amount of addition work for our editorial team. Especially when weighed against the effort it takes to create a hyperlink (a.k.a almost none) it’s clear why they don’t always have the time to create the product integrations. The challenge in front of us was to find new ways to show product recommendations to our readers without significantly impacting our editor team’s workflow.
Backfilling the Database & Moving Forward
For our first task we set out to backfill our product database with all of the shoppable products on the site that were only added as text links (and were therefore not in our database). After building a proof-of-concept “product scraper” using Python, Beautiful Soup, urllib2, and Flask, which accepted a retailer and product page URL and returned product information as JSON, we realized the maintenance this would require and ultimately reached out to Semantics3 for help. With the information gathering portion of the project basically figured out, the next step was exploring our two options for adding products.
We wrote a program that scrapes recently published stories for links to products and sends that data to Semantics3, which then returns information about each individual product. With this information, the program creates products in our Refinery29 database, then makes associations between these products and the articles in which they were referenced. So, when you return to a story that previously only had a hyperlink to a product, an embedded product now appears… no editorial team effort required.
With this part done, our goal now is to create a better product creation workflow for our editors, one that will pre-populate our CMS product form with the data we get from Semantics3. With this, our editorial staff will be able to generate integrated products modules in articles much faster and at the time of publication, rather than post-publication, like we do with the backfill process.

ABOVE: A view of the shopping product form in our CMS, the tools editors use to create and associate shopping products to their stories.
At the time my summer internship ended, we were just beginning discussions with our CMS engineers and UX team members to brainstorm how we could best do this. Having since been hired to work with Refinery29 full-time (woohoo!) I am continuing to help build out the new product form, which we plan to roll out to select editors for beta testing. Stay tuned!
-- Maggie Love, Software Engineer
#refinery29#insider29#engineering#affiliate marketing#e-commerce#shopping#software engineering#software development
0 notes
Text
R29 Profile: Patty Delgado

What’s your name and where are you from?
Patty Delgado, Texas born and raised
What is your job title at Refinery29 and what do you do?
I’ve worn many hats at R29, but now I’m focused on being a tech lead and senior software engineer. I’m also the resident Mac And Cheese cook-off champion.
How did you get into engineering?
I’ve always been obsessed with the internet and computers, since we first got a family Mac wayyy back in the day. I built websites for myself and my friends, basically blogs or message board sites on various topics, just for fun. I never really considered it a career path. Instead I focused on my love of writing and researching society, which led to my BA in Journalism and MA in Sociology. While still in school, I began to feel my job prospects in long-form journalism were slim (I also had sizeable student loan debt coming at me--thanks NYU!). Through some clever hustling and string pulling, I got my first official web job for work study on campus. I also picked up a lot of freelance work managing and building websites. I really fell in love with the job, since it had always been something that was a hobby for me, and my boss Tim Libert mentored me on what I needed to learn to get a job out of college. He was really great, and since then I’ve always made it a point to reach out to people as mentors in my career.
What’s a recent project that you’re proud of?
Refinery29 is currently rewriting our core web platform to be a responsive, React & Redux isomorphic website! We just launched this new app to about 75% of our pages, and are full steam ahead at converting the rest. It’s such a pleasure to work with the team that is building this app, and on a technology stack as progressive and forward-looking as this. Seeing our render times drop 30% and shaving literal seconds off the page speed is so, so beautiful.
If you weren’t an engineer, what would you want to be doing?
Traveling the world and writing essays and fiction pieces about the things I experience. Which is sort of what I do now except I’m writing code :)
What’s your favorite thing about working at R29?
The people. I’ve made so many for-life friends working here; it’s great to be able to work with so many inspiring people.
If you had a sandwich named after you, what would be on it?
Mortadella, ricotta cheese, castelvetrano olives, arugula, sliced tomato, and Croatian olive oil on whole wheat bread. These are basically all of my favorite sandwich things, with a shout out to the amazing olive oil from Croatia.
-- Patty Delgado, Senior Software Engineer
0 notes
Text
R29 AltMoji for iOS & Android
Last week we launched out first emoji keyboard, Altmoji, because it’s 2016 and everyone who is anyone is doing that these days, right? (JK... kind of.) Our keyboard is filled with diverse, beautiful designs illustrated by the R29 creative team which means some of these graphics will look familiar as you’ve likely seen them across our site, Instagram and Snapchat accounts.
Download the app to upgrade your texting game and remember that these also work on Facebook messenger, WhatsApp, etc.
R29 AltMoji for iOS | R29 AltMoji for Android

0 notes
Text
R29 Engineering Intern: Sehr Ahmed
This summer Refinery29′s Product & Engineering team hosted three talented interns, who worked on different projects pertaining to (1) email acquisition improvements, (2) enhancements to our digital asset management system in our CMS, and (3) our affiliate marketing strategy through shopping products. Below, Sehr Ahmed, who worked on email acquisition, recaps her project.

During my summer as an engineering intern at Refinery29, I worked with the Growth Team on a project aimed at optimizing the email funnel. The “Email Funnel” is the conversion funnel for subscribers to our email lists. Our goal was to optimize this funnel as much as possible, by increasing the amount of users joining every month (acquisition), and decreasing the rate at which they unsubscribe (retention).
After cataloging R29’s own acquisition modules and doing some competitive analysis, we brainstormed acquisition and retention ideas to stop any leaks in the funnels.

We began by launching a mobile acquisition banner triggered by scroll depth that appears on the US, UK, and German mobile feed. After our initial launch of the banner, we made some styling tweaks and began using cookies to limit the frequency of banner appearances. Our first set or analytics indicated a greater acquisition rate for the banner than some of our other mobile acquisition modules.

After launching the mobile banner, we wanted to create a similar module for desktop. Like the mobile banner, the desktop popup is also triggered by scroll depth, appearing on scrollable articles on the US site. This module would allow users to sign up directly, without redirecting them to a separate sign up page.

As these tests are relatively new we’ll need more time to determine whether or not these acquisition modules are successful. With enough data we can then decide to either launch full implementations of these modules or test out other options. In the meantime, we hope to continue trying different email optimization tests to eliminate any gaps in our funnel and increase the overall user engagement for the Refinery29 newsletters.
-- Sehr Ahmed, Refinery29 Engineering Intern: summer 2016
0 notes
Text
Girls Who Code @ Refinery29
Getting young women interested in STEM careers is something near and dear to the hearts of our team members-- both the men and women here at Refinery29. We pride ourselves on the 50/50 gender split of our Product & Engineering team because we know that the really best ideas come from diverse teams. So when Girls Who Code approached us about doing another event with their campers, of course we were in.

Last week we hosted close to 40 young Girls Who Code students, ages 16-17, split them into 4 teams and paired them off with female mentors from all areas of our staff including Product Managers, Engineers, UX Designers, Product Marketers and QA Testers. The groups were given a specific Refinery29 product and asked to brainstorm ways to improve it. After their brainstorming, they presented to a panel of R29 judges including our Chief Revenue Officer Melissa Goidel and co-founder and Executive Creative Director Piera Gelardi.
Despite only having just started their 8-week camp session, we were blown away by how strong the girls’ ideas were in terms of their approach to thinking of improvements that would work toward a product’s benchmarking goals (eg: user retention, acquisition, etc.), their careful thinking through technical feasibility, and their confident storytelling to the judges when it came time to present their ideas. Major shout outs to everyone who participated!
For more about Girls Who Code and to join their mission go to: www.girlswhocode.com
1 note
·
View note
Text
R29 Profile: Claudia Sosa

What’s your name and where are you from?
My name is Claudia. I was born in New York and raised in New Jersey.
What is your job title at Refinery29 and what do you do?
I'm a Quality Assurance engineer here at R29. Anytime our team deploys a new feature or a bug fix to production, QA is the last step in the process before it goes live. My job is to ensure each product meets the highest quality standards to ensure the best possible experience for all R29 readers. I help support several platforms including our desktop site, mobile feed, a proprietary content-management system, an iOS app, etc. I work closely with developers and product management throughout the lifetime of every project.
How did you get into engineering?
I have family in tech and they helped me learn more of the many opportunities available to me. I liked what I was exposed to and enrolled myself into a computer science program. I developed somewhat of an understanding on the areas in tech I could possibly work in at that time. I interviewed for a position right after college, then started my first real job in tech. That's when I was introduced to what happens behinds the scenes and I was truly fascinated.
What’s a recent project that you’re proud of?
We launched a responsive homepage last month that sits on a spanking new backend architecture. We came across a few challenges but at the end we launched a great product that we learned a lot from. Even though this launch was only the beginning of what remains to be transitioned over to the new architecture, it's rewarding to see the positive impact we are starting to see already.
If you weren’t an engineer, what would you want to be doing?
I would love to hand select pieces from local emerging talented designers to sell in this imaginary clothing store of mine. It would be the go to place of a woman that exudes confidence, that's not afraid of taking risks and loves wearing colors. I would also tie in a unique virtual experience to anyone visiting the store. I'd enjoy doing anything art related, really... I'd also love to dedicate time to learn another language, perhaps Portuguese.
What’s your favorite thing about working at R29?
I really enjoy being a part of a team of so many creative people. I admire the fact that each person brings a unique aspect to the company. It's great to be surrounded by individuals that are always up to learning something new and are willing to challenge one another.
When you go to the bodega to get milk, what are your other impulse buys while there?
I'm a big fan of sour and watermelon flavored candy. Watermelon slice pops. watermelon sour patches, and watermelon blow pops. When I'm not in the mood for sugar, I usually gravitate towards anything spicy- hot flamin' cheetos or hot cheese popcorn.
-- Claudia Sosa, QA Engineer
0 notes
Text
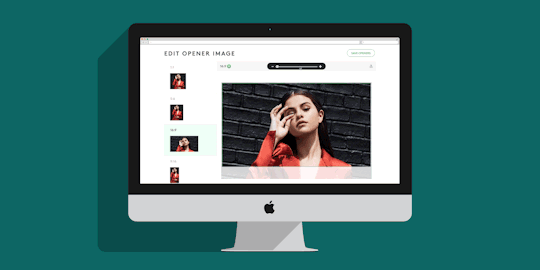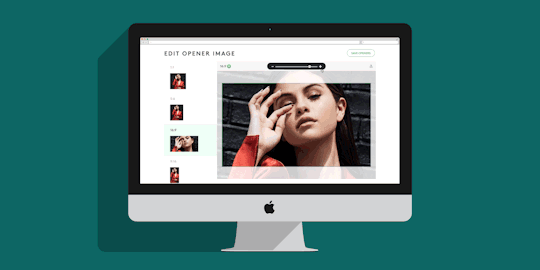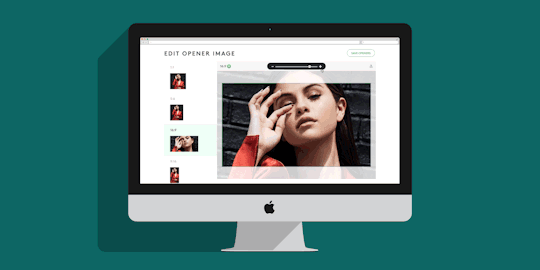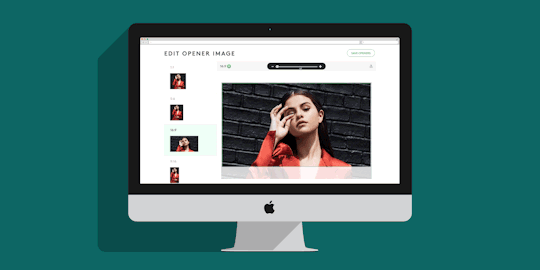
Refinery29’s New Crop Tool: One Image To Rule Them All
Editor’s Note: This article was originally published on Medium here: http://bit.ly/28Xy3lL
At Refinery29, we’ve been overhauling our Content Management System, Dash. This complete redesign is taking place while we are in the midst of relaunching our site as a completely responsive site. To support our beautiful new responsive site, we needed to change the way our editors and designers are creating and cropping images for all of their stories. We are under a constant barrage of new screen resolutions that require support and users consuming more content across a number of retina devices leaves us searching for an easier way to support large images sizes and create a wide range of images for devices without increasing the amount of time it takes to create and publish a story.
The entire redesign of our CMS is a 6-month-long mega project (more on that soon!). We know that we can’t redesign and reengineer the entire product in one shot, so we chose to break it up into manageable chunks. We explored the features we could advance without disrupting the entire product, which we also know has a huge payoff to the user. We want to give them a taste of what’s to come.

We started by creating a cropping tool where all of the art we use in opener images, or promotional spots for stories on Refinery29.com could be edited. When an editor requests a photo or illustration to accompany the story they are writing, our creative department gets to work. They create the artwork, and have to crop that image 9 times for all of the different placements it may appear on our site and on platforms like Facebook’s Instant Articles, Apple News or other social channels.
We did the math, and it’s as time consuming as it sounds! Designers spent an overall total of 8 hours per day cropping images for roughly the 80 stories we publish per day. With the new cropping tool, it now takes only a total of 1 hour, or 40 seconds per story.
The time saved is enough to fly to Paris from New York, visit the Eiffel Tower and eat a croissant (or five).

Having multiple images in a variety of sizes allows us to create new ways to display our content across the site and other platforms with confidence, and without having to worry about someone’s head getting chopped off. The tool allows the user to upload a single image, and then crop and reposition that image so that it looks good in each of the different image ratios we support. If the image they chose doesn’t look good in a particular crop, the user can override that single crop size with a new one, or replace them all.
After releasing the tool to a small group of beta testers, we trained the creative department on how to use it and released it out to them. The response was overwhelmingly positive. Our desire to roll it out to all of our editors across the globe in NY, LA, the UK and Germany was stymied by the fact that a little bit of on-boarding is necessary, so training in-person and all at once was a difficult option.
We produced a training video to live alongside the tool as a guide for our editors to essentially train themselves. Creating a tool that was so easy to use, coupled with great training was something that we had not done in the past. It was a pleasant surprise to roll out the product, sit back, and watch the excitement roll in (…while eating more croissants, of course).
Croissants for all of the people that worked on this, but extra gluten-filled praise to the lead Software Engineer for the tool, Laima Tazmin and our Product Manager, Sara Okin. Without their efforts, this tool would not have been possible!
-- Nicole Pikulin, Senior UX Designer
#ux#ux design#medium#refinery29#insider29#how we work#nicole pikulin#responsive design#design#cms#cms development
1 note
·
View note
Text
Refinery29 ‘This AM’ Now On Amazon Echo

This week, our This AM app is officially available on Amazon Echo. That means anyone with an Echo can just ask Amazon's concierge, Alexa, for Refinery29's top eight stories each day. You'll get everything from impactful news to inspiring tidbits and major pop-culture moments — in less than two minutes.
To listen: Go to Settings inside your Alexa app. Choose “Flash Briefing” and select Refinery29. Then ask your Echo, “Alexa, what’s the news?” Just like that, Alexa will share our single-sentence roundups that leave you informed and ready for the day.
Wake up, tune in, and instantly feel a little smarter.
0 notes
Text
Experimenting With Recommended Content
Earlier in the year we decided to make the change to alleviate a timing challenge with the launch of some new technology on our homepage. This challenge opened up an opportunity to also institute some design consistency across the site with our new, what we call, “card types” for displaying content.
The existing logic for recommend content was set up so that we showed users’ our top 3 stories from the homepage across all the articles on the site. We believed that a curated selection of our best content would perform well-- meaning users would click through and continue reading. And while that logic was okay, we knew we recognized that it could be improved. First by adding more articles here, increased the number of recommended stories from 3 to 14.

Then we looked at the logic of the recommendation engine and decided to change it to show stories from the same category (or subcategory) as the article that the user had come to our site to consume. For example, if a user comes to our site for this story “22 Healthy Snacks That Are (Almost) Too Good To Be True”, which is of the ‘Food & Drinks’ category, we would recommend 14 other stories tagged for ‘Food & Drinks’.

This change resulted in a decreased in our bounce rate by nearly 40%. And at the same time, we’ve seen a 300% increase in clicks on the recommended content. So not only are fewer people leaving the page but more people are clicking to read another piece of content too.
This change that has proven to be highly successful only took one developer about a week and half to complete. It has been a tremendous change for us but true to our teams’ iterative nature, we will continue experimenting with our recommendation engine as well as where and how much recommended content we display to users.
-- Sara Livengood, Senior Product Manager
Have feedback for us about related content or other features on our site? Email [email protected] to reach out!
0 notes