#Data Engineer
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier.
3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards.
4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning.
6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it.
7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query.
8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable.
9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science.
10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
2 notes
·
View notes
Text
#Databricks Certified Data Engineer#Lagozon Technologies#Databricks Data Engineer#Data Engineer#data engineering
0 notes
Text
#UNICEF UK#Job Vacancy#Data Engineer#London#Permanent#Part home/Part office#£52#000 per annum#Enterprise Data Platform#Data Ingestion Pipelines#Data Models#UUK Data Strategy#Information Team#Data Solutions#Data Integrations#Complex Data Migrations#Code Development#Datawarehouse Environment#Snowflake#Apply Online#Closing Date: 7 March 2024#First Round Interview: 5 April 2024#Second Round Interview: 6 June 2024#Excellent Pay#Benefits#Flexible Working#Annual Leave#Pension#Discounts#Wellbeing Tools
0 notes
Text
Best Machine Learning Courses in Bangalore
Explore the top Machine Learning courses in Bangalore offering expert-led sessions and hands-on learning in Python. Gain proficiency in supervised and unsupervised learning, statistics, and data analysis. Start your journey to becoming a Machine Learning expert today
Visit us: https://www.limatsoftsolutions.co.in/Course/Machine-Learning
Read More:
Location: Electronics City Phase 1, Opp, Bengaluru, Karnataka 560100
#Python Programming#Data Analysis#Data Visualization#Statistical Foundations#Data Engineer#AI Engineer#Python Developer#Internship Grade projects and certification.
1 note
·
View note
Text
Understanding Artificial Intelligence (AI):The Driving Force Shaping the Future .:.
Artificial intelligence (AI) is revolutionizing our world, silently powering the technologies that shape our daily lives. You may have heard the term before, but what exactly is AI, and how does it work? In this article, we’ll explore AI, algorithms, and data in simple terms, and uncover how this technology has the potential to transform our society for the better.
At its core, AI refers to…
View On WordPress
#21st Century#AI#analytics#Artificial Intelligence#CHATGPT#Critical Thinking#data engineer#Google Bard#Learning#Personal Development#Understanding
1 note
·
View note
Text
Data Analysts and Data Engineers are critical roles for organizations seeking to harness the power of information in the data-driven era.
1 note
·
View note
Text
#data science training in Chandigarh#Data science course in Chandigarh#data analysis course in chandigarh#the best institute for data analysis in Chandigarh#python for data analysis#data engineer#data warehouse
0 notes
Text
0 notes
Video
Advance Oracle Sql Class--3 // @Software_Knowledge //#sql #oracle #mysql... https://youtu.be/wvEe7IZtkpo ,https://youtu.be/5FSk-F0t70U,#sql
0 notes
Text
Career Paths in DATA SCIENCE
Data science is a fascinating field that combines mathematics, computer science, and domain expertise to extract valuable insights from data. It's a rapidly growing field with a wide range of career opportunities. In this blog, we'll explore the career path of data science in simple terms, from entry-level roles to advanced positions.

1. Data Analyst
Role: Data analysts are the entry point for many in the field of data science. They focus on collecting, cleaning, and organizing data to help organizations make informed decisions.
Skills: Excel, SQL, data visualization, basic statistics.
Typical tasks include creating reports, generating charts and graphs, and identifying trends in data.
Why it's Great: You get to work with data and start building a strong foundation in data manipulation and analysis.
2. Data Scientist
Role: Data scientists dig deeper into data, using advanced statistical and machine learning techniques to solve complex problems.
Skills: programming (Python/R), machine learning, data cleaning, statistical modeling.
Typical tasks include building predictive models, A/B testing, and finding patterns in data.
Why it's Great: You get to apply cutting-edge techniques to solve real-world problems and impact business decisions.
3. Machine Learning Engineer
Role: Machine learning engineers focus on designing, implementing, and deploying machine learning models at scale.
Skills: advanced programming (Python, Java, etc.), deep learning, model deployment.
Typical tasks include developing recommendation systems, natural language processing applications, and model deployment pipelines.
Why it's Great: You work on the engineering side of data science, making models operational for production use.
4. Data Engineer
Role: Data engineers build and maintain the infrastructure that allows organizations to collect, store, and access data efficiently.
Skills: big data technologies (Hadoop, Spark), database management, and ETL (Extract, Transform, Load) processes.
Typical tasks include designing data pipelines, optimizing databases, and ensuring data quality.
Why it's Great: You lay the foundation for data-driven decision-making by ensuring data is accessible and reliable.
5. Data Science Manager/Director
Role: Managers and directors oversee data science teams, set goals, and ensure projects align with business objectives.
Skills: leadership, project management, and strategic thinking.
Typical tasks include setting team goals, resource allocation, and communicating with stakeholders.
Why it's Great: You have a significant impact on an organization's data strategy and help drive business success.
6. Chief Data Officer (CDO)
Role: The CDO is a top-level executive responsible for an organization's data strategy, governance, and data-driven initiatives.
Skills: leadership, strategic planning, and business acumen.
Typical tasks include defining data strategies, ensuring data compliance, and aligning data efforts with business goals.
Why it's Great: You shape the entire data ecosystem of an organization and drive innovation.
7. Data Science Researcher
Role: Researchers work in academia or industry, pushing the boundaries of data science through advanced research.
Skills: strong academic background, deep expertise in a specific data science area.
Typical tasks include conducting experiments, publishing research papers, and staying up-to-date with the latest advancements.
Why it's Great: You contribute to the cutting edge of data science knowledge and innovation.
The career path of data science offers a wide range of opportunities, from entry-level data analysis to high-level executive positions. It's a dynamic field that continues to evolve, making it an exciting and rewarding choice for those who are passionate about working with data to solve real-world problems. Remember, the key to success in this field is continuous learning and staying updated with the latest trends and technologies. So, whether you're just starting or are already on your data science journey, there's always room to grow and excel in this exciting field.

If you want to gain knowledge in data science, then you should contact ACTE Technologies. They offer certifications and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested.
If you like this answer, give it an upvote and comment with your thoughts. Thanks for reading.
1 note
·
View note
Text
Why You Need to Enroll in a Data Engineering Course

Data science teams consist of individuals specializing in data analysis, data science, and data engineering. The role of data engineers within these teams is to establish connections between various components of the data ecosystem within a company or institution. By doing so, data engineers assume a pivotal position in the implementation of data strategy, sparing others from this responsibility. They are the initial line of defense in managing the influx of both structured and unstructured data into a company’s systems, serving as the bedrock of any data strategy.
In essence, data engineers play a crucial role in amplifying the outcomes of a data strategy, acting as the pillars upon which data analysts and data scientists rely. So, why should you enroll in a data engineering course? And how will it help your career? Let’s take a look at the top reasons.
1. Job Security and Stability
In an era where data is considered one of the most valuable assets for businesses, data engineers enjoy excellent job security and stability. Organizations heavily rely on their data infrastructure, and the expertise of data engineers is indispensable in maintaining the smooth functioning of these systems. Data engineering roles are less susceptible to outsourcing since they involve hands-on work with sensitive data and complex systems that are difficult to manage remotely. As long as data remains crucial to businesses, data engineers will continue to be in demand, ensuring a stable and secure career path.
2. High Salary Packages
The increasing demand for data engineers has naturally led to attractive salary packages. Data engineers are among the highest-paid tech professionals because their work is so specialized. Companies are willing to offer competitive compensation to attract and retain top talent. In the United States, the average pay for a data engineer stands at approximately $109,000, while in India, it ranges from 8 to 9 lakhs per annum. Moreover, as you gain experience and expertise in the field, your earning potential will continue to grow.
3. Rewarding Challenges
Data engineering is a highly challenging yet rewarding profession. You’ll face tough challenges like data integration, data quality, scalability, and system reliability. Designing efficient data pipelines and optimizing data processing workflows can be intellectually stimulating and gratifying. As you overcome these challenges and witness your solutions in action, you will experience a sense of accomplishment that comes from playing a critical role in transforming raw data into actionable insights that drive business success.
4. Contributing to Cutting-Edge Technologies
Data engineering is at the forefront of technological advancements. As a data engineer, you will actively engage in creating and implementing innovative solutions to tackle big data challenges. This may include working with distributed systems, real-time data processing frameworks, and cloud-based infrastructure. By contributing to cutting-edge technologies, you become a key player in shaping the future of data management and analytics. The rapid evolution of data engineering technologies ensures that the field remains dynamic and exciting, providing continuous opportunities for learning and growth.
5. Positive Job Outlook
The demand for data engineers has consistently been high and is projected to continue growing. Companies of all sizes recognize the importance of data-driven decision-making and actively seek skilled data engineers to build and maintain their data infrastructure. The scarcity of qualified data engineers means that job opportunities are abundant, and you’ll have the flexibility to choose from a diverse range of industries and domains. Whether you’re interested in finance, healthcare, e-commerce, or any other sector, there will be a demand for your skills.
6. The Foundation of Data Science
Data engineering forms the backbone of data science. Without robust data pipelines and reliable storage systems, data scientists would be unable to extract valuable insights from raw data. As a data engineer, you get to collaborate with data scientists, analysts, and other stakeholders to design and implement data solutions that fuel an organization’s decision-making process. Your contributions will directly impact how organizations make strategic decisions, improve customer experiences, optimize operations, and gain a competitive edge in the market.
Why choose Datavalley’s Data Engineering Course?
Datavalley provides a Data Engineering course specifically designed for individuals at the beginner level. Our course offers a perfectly structured learning path that encompasses comprehensive facets of data engineering. Irrespective of one’s technical background or the transition from a different professional domain, our course is for all levels.
Here are some reasons to consider our course:
Comprehensive Curriculum: Our course teaches you all the essential topics and tools for data engineering. The topics include, big data foundations, Python, data processing, AWS, Snowflake advanced data engineering, data lakes, and DevOps.
Hands-on Experience: We believe in experiential learning. You will work on hands-on exercises and projects to apply your knowledge.
Project-Ready, Not Just Job-Ready: Upon completion of our program, you will be prepared to start working immediately and carry out projects with confidence.
Flexibility: Self-paced learning is suitable for both full-time students and working professionals because it allows learners to learn at their own speed and convenience.
Cutting-Edge Curriculum: Our curriculum is regularly updated to reflect the latest trends and technologies in data engineering.
Career Support: We offer career guidance and support, including job placement assistance, to help you launch your data engineering career.
On-call Project Assistance After Landing Your Dream Job: Our experts are available to assist you with your projects for up to 3 months. This will help you succeed in your new role and confidently tackle any challenges that come your way.
Networking Opportunities: Joining our course opens doors to a network of fellow learners, professionals, and employers.
Course format:
Subject: Data Engineering
Classes: 200 hours of live classes
Lectures: 199 lectures
Projects: Collaborative projects and mini projects for each module
Level: All levels
Scholarship: Up to 70% scholarship on all our courses
Interactive activities: labs, quizzes, scenario walk-throughs
Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Big Data Engineer Masters Program visit Datavalley’s official website.
Conclusion
In conclusion, becoming a data engineer offers a promising and fulfilling career path for several compelling reasons. The demand for data engineers continues to soar as companies recognize the value of data-driven decision-making. This high demand translates into excellent job opportunities and competitive salaries. To start this exciting journey in data engineering, consider enrolling in a Big Data Engineer Masters Program at Datavalley. It will equip you with the skills and knowledge needed to thrive in the world of data and technology, opening up limitless possibilities for your career.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#data analytics course#data science course#power bi#business intelligence#data engineering course#data engineering training#data engineer#online data engineering course#data engineering roles
1 note
·
View note
Text
[Fabric] Integración de datos al OneLake
Ya viste todos los videos con lo que Fabric puede hacer y queres comenzar por algo. Ya leiste nuestro post sobre Onelake y como funciona. Lo siguiente es la ingesta de datos.
En este artículos vamos a ver muchas formas y opciones que pueden ser usadas para añadir datos a onelake. No vamos a ver la profundidad de como usar cada método, sino una introducción a ellos que nos permita elegir. Para que cada quien haga una instrospección de la forma deseada.
Si aún tenes dudas sobre como funciona el Onelake o que es todo eso que apareció cuando intentaste crear uno, pasa por este post para informarte.
Ingesta de datos
Agregar datos al Onelake no es una tarea difícil pero si analítica puesto que no se debe tomar a la ligera por la gran cantidad de formas disponibles. Algunas serán a puro click click click, otras con más o menos flexibilidad en transformaciones de datos, otras con muchos conectores o tal vez con versatilidad de destino. Cada forma tiene su ventaja y posibilidad, incluso puede que haya varias con la que ya tengan familiaridad.
Antes de iniciar los métodos repasemos que para usar nuestro Onelake primero hay que crear una Lakehouse dentro de un Workspace. Ese Lakehouse (almacenado en onelake) tiene dos carpetas fundamentales, Files y Tables. En Files encontrabamos el tradicional filesystem donde podemos construir una estructura de carpetas y archivos de datos organizados por medallones. En Tables esta nuestro spark catalog, el metastore que puede ser leído por endpoint.

Nuestra ingesta de datos tendrá como destino una de estos dos espacios. Files o Tables.
Métodos
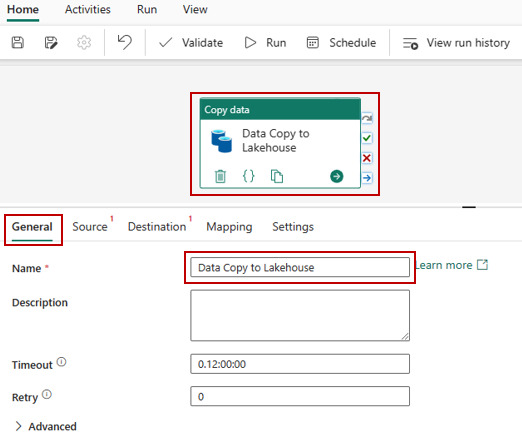
Data Factory Pipelines (dentro de Fabric o Azure): la herramienta clásica de Azure podría ser usada como siempre lo fue para este escenario. Sin embargo, hay que admitir que usarla dentro de Fabric tiene sus ventajas. El servicio tiene para crear "Pipelines". Como ventaja no sería necesario hacer configurationes como linked services, con delimitar la forma de conexión al origen y seleccionar destino bastaría. Por defecto sugiere como destino a Lakehouse y Warehouse dentro de Fabric. Podemos comodamente usar su actividad estrella "Copy Data". Al momento de determinar el destino podremos tambien elegir si serán archivos en Files y de que extensión (csv, parquet, etc). Así mismo si determinamos almacenarlo en Tables, automáticamente guardará una delta table.
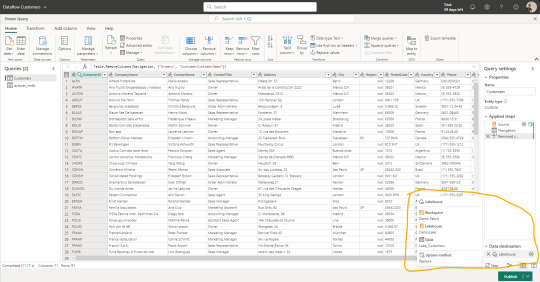
Data Factory Dataflows Gen2: una nueva incorporación al servicio de Data Factory dentro de Fabric son los Dataflows de Power Query online. A diferencia de su primera versión esta nueva generación tiene fuertes prestaciones de staging para mejor procesamiento, transformación y merge de datos junto a la determinación del destino. Así mismo, la selección del destino nos permite determinar si lo que vamos a ingestar debería reemplazar la tabla destino existente o hacer un append que agregue filas debajo. Como ventaja esta forma tiene la mayor cantidad de conectores de origen y capacidades de transformación de datos. Su gran desventaja por el momento es que solo puede ingestar dentro de "Tables" de Lakehouse bajo formato delta table. Mientras este preview también crea unos elementos de staging en el workspace que no deberíamos tocar. En un futuro serán caja negra y no los veremos.
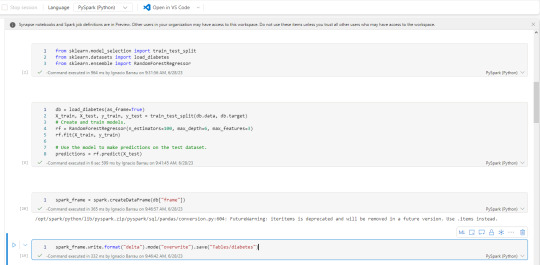
Notebooks: el hecho de tener un path a nuestro onelake, path al filesystem con permisos de escritura, hace que nuestro almacenamiento pueda ser accedido por código. El caso más frecuente para trabajarlo sería con databricks que, indudablemente, se convirtió en la capa de procesamiento más popular de todas. Hay artículos oficiales de la integración. En caso de querer usar los notebooks de fabric también son muy buenos y cómodos. Éstos tienen ventajas como clickear en files o tablas que nos genere código de lectura automáticamente. También tiene integrada la herramienta Data Wrangler de transformación de datos. Además cuenta con una muy interesante integración con Visual Studio code que pienso podría integrarse a GitHub copilot.
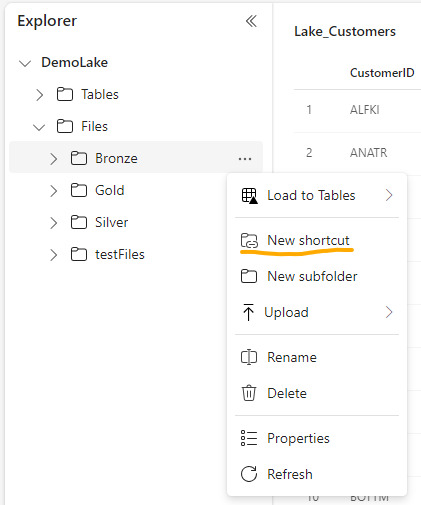
Shortcuts (accesos directos): esta nueva opción permite a los usuarios hacer referencia a datos sin copiarlos. Genera un puntero a archivos de datos de otro lakehouse del onelake, ADLS Gen2 o AWS S3 para tenerlo disponible como lectura en nuestro Lakehouse. Nos ayuda a reducir los data silos evitando replicación de datos, sino punteros de lectura para generar nuevas tablas transformadas o simplemente lectura para construcción de un modelo o lo que fuere. Basta con clickear en donde lo queremos (tables o files) y agregarlo.
Upload manual: con la vista en el explorador de archivos (Files) como si fuera un Azure Storage explorer. Tenemos la clásica posibilidad de simplemente agregar archivos locales manualmente. Esta posibilidad solo estaría disponible para el apartado de Files.
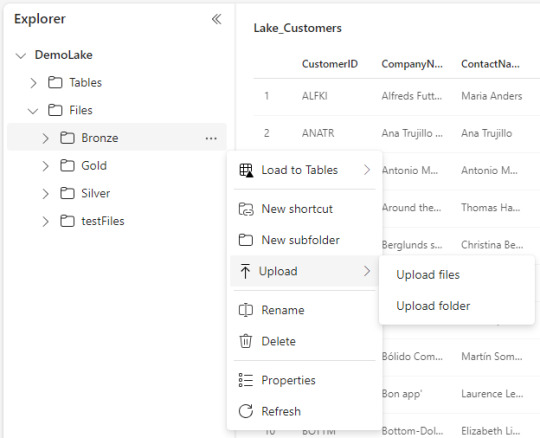
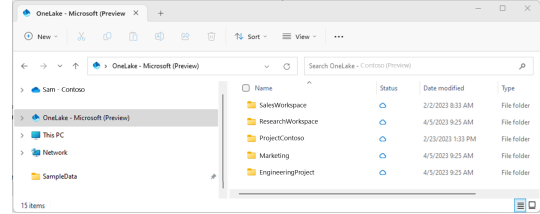
Explorador de archivos Onelake (file explorer): una de las opciones más atractivas en mi opinión es este cliente para windows. Es incontable la cantidad de soluciones de datos que conllevan ingresos manuales de hojas de cálculo de distintas marcas en distintas nubes. Todas son complicadas de obtener y depositar en lake. Esta opción solucionaría ese problema y daría una velocidad impensada. El cliente de windows nos permite sincronizar un workspace/lakehouse que hayan compartido con nosotros como si fuera un Onedrive o Sharepoint. Nunca hubo una ingesta más simple para usuarios de negocio como ésta que a su vez nos permita ya tener disponible y cómodamente habilitado el RAW del archivo para trabajarlo en Fabric. Usuarios de negocio o ajenos a la tecnología podrían trabajar con su excel cómodos locales y los expertos en data tenerlo a mano. Link al cliente.
Conclusión
Como pudieron apreciar tenemos muchas formas de dar inicio a la carga del onelake. Seguramente van a aparecer más formas de cargarlo. Hoy yo elegí destacar éstas que son las que vinieron sugeridas e integradas a la solución de Fabic porque también serán las formas que tendrán integrados Copilot cuando llegue el momento. Seguramente los pipelines y notebooks de Fabric serán sumamente poderosos el día que integren copilot para repensar si estamos haciendo esas operaciones en otra parte. Espero que les haya servido y pronto comiencen a probar esta tecnología.
#fabric#fabric tutorial#fabric tips#fabric training#data fabric#data engineer#data engineering#microsoft fabric#fabric argentina#fabric jujuy#fabric cordoba#ladataweb#power query#power query online#powerbi#power bi#power bi dataflows#data factory#data factory data flows#power bi service
0 notes
Text
Who is Data Engineer and what they do? : 10 key points
In today’s data-driven world, the demand for professionals who can organize, process, and manage vast amounts of information has grown exponentially. Enter the unsung heroes of the tech world – Data Engineers. These skilled individuals are instrumental in designing and constructing the data pipelines that form the backbone of data-driven decision-making processes. In this article, we’ll explore…

View On WordPress
#Big Data#Blogging#Career#cloud computing#Data Analyst#Data Architecture#Data Engineer#Data Engineering#Data Governance#Data Integration#data modeling#Data Science#data security#Database Management#ETL#Technology#WordPress
0 notes
Text
Bachelor of Science in Information Systems and Cybersecurity - Northwood University
Northwood’s Bachelor of Science in Information Systems and Cybersecurity is designed to equip students about techniques to protect against cybersecurity threats, as well as the ethical and legal issues involved in securing sensitive information.
https://northwest.education/northwood-bachelor-of-science-in-information-systems-and-cybersecurity/
#BS-computer-science#Northwood-bs-computer-science#STEM-certified-program#Java#MySQL#C++#Python#Networking#Agile development#data engineer#cloud engineer#software developer#software architect#web developer
0 notes
Text
Reddit • YouTube
#data#top post#statistics#web browsers#chrome#google chrome#educational#Firefox#opera#mozilla#mozilla firefox#internet explorer#internet#statistical data#video#Netscape#data is beautiful#I still use Firefox and probably will forever unless it closes down#switch from your default browser to Firefox and use DuckDuckGo’s search engine#this goes for mobile users too.
104K notes
·
View notes
Last Seen Blogs

nisargphotography-blog
Nisarg Photography

negikogok
NeG

randoms-little-posts
! Randoms Idea Cave !

10speedcognition
10 SPEED COGNITION

mrkomplikado-blog
THE ESCAPIST