#data engineering training
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering
Classes: 200 hours of live classes
Lectures: 199 lectures
Projects: Collaborative projects and mini projects for each module
Level: All levels
Scholarship: Up to 70% scholarship on this course
Interactive activities: labs, quizzes, scenario walk-throughs
Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps
Classes: 180+ hours of live classes
Lectures: 300 lectures
Projects: Collaborative projects and mini projects for each module
Level: All levels
Scholarship: Up to 67% scholarship on this course
Interactive activities: labs, quizzes, scenario walk-throughs
Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
Projects and Challenges in a Data Engineering Bootcamp

Participants in a data engineering bootcamp can expect to work on real-world projects involving data pipelines, ETL processes, data warehousing, and big data technologies. Challenges may include designing and implementing scalable data architectures, optimizing workflows, and integrating various data sources. Additionally, participants may tackle issues related to data quality, data governance, and using cloud-based data engineering tools to solve practical data-related problems.
For more information visit: https://www.webagesolutions.com/courses/data-engineer-training
#Data Engineering Bootcamp#Data Engineering#Data Engineering course#Data Engineering training#Data Engineering certification
0 notes
Text
Embarking on the Cloud Journey: Introduction to Data Engineering

Overview of the Cloud Journey:
The decision to move to the cloud is driven by the need for agility, scalability, and cost-effectiveness. This journey involves transitioning from traditional infrastructure to cloud-based solutions.
Significance of Data Engineering in the Cloud:Data engineering is a pivotal aspect of the cloud journey, playing a crucial role in organizing, processing, and making sense of vast amounts of data. It enables organizations to derive actionable insights and drive informed decision-making.
Foundations of Data Engineering:Data Ingestion: Capturing data from various sources, including databases, applications, and external feeds.Data Transformation: Shaping raw data into a structured format suitable for analysis and storage. Data Storage: Choosing appropriate cloud storage solutions based on the nature of data, such as object storage, databases, or data lakes.Data Processing: Employing cloud-based tools for scalable and efficient data processing, such as serverless computing or distributed processing frameworks.
Cloud Platforms for Data Engineering:Explore the offerings of major cloud providers like AWS, Azure, and Google Cloud. These platforms provide managed services for databases, data warehouses, and big data processing, reducing the operational burden on organizations.
Key Considerations in Data Engineering:Security and Compliance: Implementing robust security measures and ensuring compliance with industry regulations to safeguard sensitive data.Scalability and Cost Optimization: Leveraging the scalability of cloud resources while optimizing costs by selecting the right service tiers and monitoring resource usage.Data Governance: Establishing policies and procedures to manage data throughout its lifecycle, ensuring quality, consistency, and adherence to standards.
Integration with Data Science and Analytics:Data engineering lays the groundwork for effective data science and analytics initiatives, providing a well-organized and accessible data infrastructure for analytics, reporting, and machine learning.
Real-world Applications and Best Practices:Explore practical examples of successful data engineering implementations in the cloud. Highlight best practices for designing scalable architectures, managing data pipelines, and ensuring data reliability.
#software course#software development classes#software development courses#courses software engineering#course on software engineering#artificial intelligence#software training institute#program developer course#best software courses#software engineer classes#data engineering courses#data engineer certification#data engineer classes#data engineering training#cloud data engineering#learn data engineering#best data engineer certification#data engineering with cloud computing#CloudEcosystems#DataManagement#TechInnovation#BigData#CloudTechnology#DataSecurity#MachineLearning#DigitalTransformation#CloudComputing
0 notes
Text
You know, in some ways, I actually do think that the so-called "AI" algorithms are a great example of commodity fetishism. The way people speak about AI suggests that it has a genuine mind of its own and moves independent from humans which couldn't be further from the truth. All the folks expressing concern over AI "stealing" jobs and "replacing" humans to our ultimate detriment seem to think that this is a process driven by the algorithms themselves, and that human beings are powerless to stop it. But that isn't the case. Humans have developed these algorithms, humans decide how to use them, and humans ultimately decide whether these algorithms leave us without a means to sustain ourselves. To be very clear, it is human beings and their human labor that is creating and maintaining these algorithms. It is human employers who will decide whether to fore people and replace them with data aggregating algorithms. Human beings will also be the ones to decide how we respond to that. Whether we will allow people to be replaced by algorithms without adequate compensation to allow them to maintain a livelihood will be up to us.
"AI" programs and our reactions to them are not driven by the programs themselves. These are computing programs that people have designed to be used on computer systems that people have built. We could collectively "pull the plug" tomorrow and the programs couldn't say boo about it because they do not have sentience or agency. Idk, it's just wild to me to see tech industry folks talking about these computer programs like they're living, independent beings. Like, I knew these guys were all massive idiots, but I at least thought they understood that computer programs weren't actually alive. Like, what are we doing here.
#woolly rambles#i will continue to put “ai” in quotations until someone proves to me that an algorithm has actual measureable intelligence#until then chatgpt and its ilk are data aggregating programs and yes i will die on this hill#flashback to my childhood where i watched irobot and my computer engineer dad spent hours going on about how that literally couldnt happen#ive been on this train for a while babes toot toot all aboard
9 notes
·
View notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Note
please delete your philosophy gpt-3 post. it's most likely stolen writing.
philosophy?? idk which one you're referring to sorry. also no . if it's the poetry one, see in tags. actually see in tags anyway. actually pls look at my posts on AI too . sorry if it's badly worded i'm very tired :')
#GPT3 is a large language model (LLM) and so is trained on massive amounts of data#so what it produces is always going to be stolen in some way bc...it cant be trained on nothing#it is trained on peoples writing. just like you are trained on peoples writing.#what most ppl are worried about w GPT3 is openAI using common crawl which is a web crawler/open database with a ridiculous amt of data#in it. all these sources will obviously include some published books in which case...the writing isnt stolen. its a book out in the open#meant to be read. it will also include Stolen Writing as in fanfics or private writing etc that someone might not want shared in this way#HOWEVER . please remember GPT3 was trained on around 45TB of data. may not seem like much but its ONLY TEXT DATA. thats billions and#billions of words. im not sure what you mean by stolen writing (the model has to be trained on...something) but any general prompt you give#it will pretty much be a synthesis of billions and billions and billions of words. it wont be derived specifically from one stolen#text unless that's what you ask for. THAT BEING SAID. prompt engineering is a thing. you can feed the model#specific texts and writings and make sure you ask it to use that. which is what i did. i know where the writing is from.#in the one post i made abt gpt3 (this was when it was still in beta and not publicly accessible) the writing is a synthesis of my writing#richard siken's poetry#and 2 of alan turing's papers#im not sure what you mean by stolen writing and web crawling def needs to have more limitations . i have already made several posts about#this . but i promise you no harm was done by me using GPT3 to generate a poem#lol i think this was badly worded i might clarify later but i promise u there are bigger issues w AI and the world than me#feeding my own work and a few poems to a specifically prompt-engineered AI#asks#anon
11 notes
·
View notes
Text

https://www.instagram.com/mictcral/
#computer courses#it training#software engineering#webdevelopment#data science course#machine learning#fiberoptics#artificial intelligence#internet of things#graphic design courses online#python course#fullstacktraining#python django#reactjs web development#nodejs#angularjs
2 notes
·
View notes
Text
tech workers need to unionize
#im ok and im not thinking about the soul crushing fact#that the us military and dod are so deeply intertwined with the past and present of computing technologies#modern internet? darpa. military project#spacex? military project#all social media companies? have already sold your data to law enforcement#ai predictive policing palantir amazon microsoft ICE etc etc etc#these arent just superficial ties they r the foundation of the industry#(just as imperialism is a foundation of the country)#and these connections arent going to break except under immense pressure#from outside AND inside the workplace#OH YEAH AND NOT EVEN VIDEO GAMES ARE INNOCENT#UR FAVORITE MAJOR 3D ENGINE HAS MILITARY CONTRACTS FOR DEVELOPING TRAINING SIMULATIONX#truly therr r just#tooooooooo many goddamn examples
2 notes
·
View notes
Text
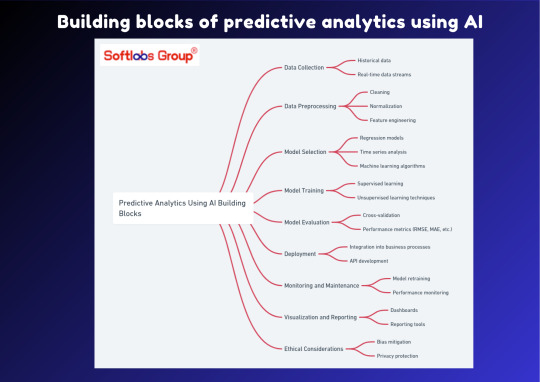
Explore the building blocks of predictive analytics using AI with our informative guide. This simplified overview breaks down the essential components that enable accurate forecasting and decision-making, empowering businesses to anticipate trends and make informed decisions. Perfect for those interested in leveraging AI for predictive insights. Stay informed with Softlabs Group for more insightful content on cutting-edge advancements in AI.
0 notes
Text
50 Big Data Concepts Every Data Engineer Should Know

Big data is the primary force behind data-driven decision-making. It enables organizations to acquire insights and make informed decisions by utilizing vast amounts of data. Data engineers play a vital role in managing and processing big data, ensuring its accessibility, reliability, and readiness for analysis. To succeed in this field, data engineers must have a deep understanding of various big data concepts and technologies.
This article will introduce you to 50 big data concepts that every data engineer should know. These concepts encompass a broad spectrum of subjects, such as data processing, data storage, data modeling, data warehousing, and data visualization.
1. Big Data
Big data refers to datasets that are so large and complex that traditional data processing tools and methods are inadequate to handle them effectively.
2. Volume, Velocity, Variety
These are the three V’s of big data. Volume refers to the sheer size of data, velocity is the speed at which data is generated and processed, and variety encompasses the different types and formats of data.
3. Structured Data
Data that is organized into a specific format, such as rows and columns, making it easy to query and analyze. Examples include relational databases.
4. Unstructured Data
Data that lacks a predefined structure, such as text, images, and videos. Processing unstructured data is a common challenge in big data engineering.
5. Semi-Structured Data
Data that has a partial structure, often in the form of tags or labels. JSON and XML files are examples of semi-structured data.
6. Data Ingestion
The process of collecting and importing data into a data storage system or database. It’s the first step in big data processing.
7. ETL (Extract, Transform, Load)
ETL is a data integration process that involves extracting data from various sources, transforming it to fit a common schema, and loading it into a target database or data warehouse.
8. Data Lake
A centralized repository that can store vast amounts of raw and unstructured data, allowing for flexible data processing and analysis.
9. Data Warehouse
A structured storage system designed for querying and reporting. It’s used to store and manage structured data for analysis.
10. Hadoop
An open-source framework for distributed storage and processing of big data. Hadoop includes the Hadoop Distributed File System (HDFS) and MapReduce for data processing.
11. MapReduce
A programming model and processing technique used in Hadoop for parallel computation of large datasets.
12. Apache Spark
An open-source, cluster-computing framework that provides in-memory data processing capabilities, making it faster than MapReduce.
13. NoSQL Databases
Non-relational databases designed for handling unstructured and semi-structured data. Types include document, key-value, column-family, and graph databases.
14. SQL-on-Hadoop
Technologies like Hive and Impala that enable querying and analyzing data stored in Hadoop using SQL-like syntax.
15. Data Partitioning
Dividing data into smaller, manageable subsets based on specific criteria, such as date or location. It improves query performance.
16. Data Sharding
Distributing data across multiple databases or servers to improve data retrieval and processing speed.
17. Data Replication
Creating redundant copies of data for fault tolerance and high availability. It helps prevent data loss in case of hardware failures.
18. Distributed Computing
Computing tasks that are split across multiple nodes or machines in a cluster to process data in parallel.
19. Data Serialization
Converting data structures or objects into a format suitable for storage or transmission, such as JSON or Avro.
20. Data Compression
Reducing the size of data to save storage space and improve data transfer speeds. Compression algorithms like GZIP and Snappy are commonly used.
21. Batch Processing
Processing data in predefined batches or chunks. It’s suitable for tasks that don’t require real-time processing.
22. Real-time Processing
Processing data as it’s generated, allowing for immediate insights and actions. Technologies like Apache Kafka and Apache Flink support real-time processing.
23. Machine Learning
Using algorithms and statistical models to enable systems to learn from data and make predictions or decisions without explicit programming.
24. Data Pipeline
A series of processes and tools used to move data from source to destination, often involving data extraction, transformation, and loading (ETL).
25. Data Quality
Ensuring data accuracy, consistency, and reliability. Data quality issues can lead to incorrect insights and decisions.
26. Data Governance
The framework of policies, processes, and controls that define how data is managed and used within an organization.
27. Data Privacy
Protecting sensitive information and ensuring that data is handled in compliance with privacy regulations like GDPR and HIPAA.
28. Data Security
Safeguarding data from unauthorized access, breaches, and cyber threats through encryption, access controls, and monitoring.
29. Data Lineage
A record of the data’s origins, transformations, and movement throughout its lifecycle. It helps trace data back to its source.
30. Data Catalog
A centralized repository that provides metadata and descriptions of available datasets, making data discovery easier.
31. Data Masking
The process of replacing sensitive information with fictional or scrambled data to protect privacy while preserving data format.
32. Data Cleansing
Identifying and correcting errors or inconsistencies in data to improve data quality.
33. Data Archiving
Moving data to secondary storage or long-term storage to free up space in primary storage and reduce costs.
34. Data Lakehouse
An architectural approach that combines the benefits of data lakes and data warehouses, allowing for both storage and structured querying of data.
35. Data Warehouse as a Service (DWaaS)
A cloud-based service that provides on-demand data warehousing capabilities, reducing the need for on-premises infrastructure.
36. Data Mesh
An approach to data architecture that decentralizes data ownership and management, enabling better scalability and data access.
37. Data Governance Frameworks
Defined methodologies and best practices for implementing data governance, such as DAMA DMBOK and DCAM.
38. Data Stewardship
Assigning data stewards responsible for data quality, security, and compliance within an organization.
39. Data Engineering Tools
Software and platforms used for data engineering tasks, including Apache NiFi, Talend, Apache Beam, and Apache Airflow.
40. Data Modeling
Creating a logical representation of data structures and relationships within a database or data warehouse.
41. ETL vs. ELT
ETL (Extract, Transform, Load) involves extracting data, transforming it, and then loading it into a target system. ELT (Extract, Load, Transform) loads data into a target system before performing transformations.
42. Data Virtualization
Providing a unified view of data from multiple sources without physically moving or duplicating the data.
43. Data Integration
Combining data from various sources into a single, unified view, often involving data consolidation and transformation.
44. Streaming Data
Data that is continuously generated and processed in real-time, such as sensor data and social media feeds.
45. Data Warehouse Optimization
Improving the performance and efficiency of data warehouses through techniques like indexing, partitioning, and materialized views.
46. Data Governance Tools
Software solutions designed to facilitate data governance activities, including data cataloging, data lineage, and data quality tools.
47. Data Lake Governance
Applying data governance principles to data lakes to ensure data quality, security, and compliance.
48. Data Curation
The process of organizing, annotating, and managing data to make it more accessible and valuable to users.
49. Data Ethics
Addressing ethical considerations related to data, such as bias, fairness, and responsible data use.
50. Data Engineering Certifications
Professional certifications, such as the Google Cloud Professional Data Engineer or Microsoft Certified: Azure Data Engineer, that validate expertise in data engineering.
Elevate Your Data Engineering Skills
Data engineering is a dynamic field that demands proficiency in a wide range of concepts and technologies. To excel in managing and processing big data, data engineers must continually update their knowledge and skills.
If you’re looking to enhance your data engineering skills or start a career in this field, consider enrolling in Datavalley’s Big Data Engineer Masters Program. This comprehensive program provides you with the knowledge, hands-on experience, and guidance needed to excel in data engineering. With expert instructors, real-world projects, and a supportive learning community, Datavalley’s course is the ideal platform to advance your career in data engineering.
Don’t miss the opportunity to upgrade your data engineering skills and become proficient in the essential big data concepts. Join Datavalley’s Data Engineering Course today and take the first step toward becoming a data engineering expert. Your journey in the world of data engineering begins here.
#datavalley#data engineering#dataexperts#data analytics#data science course#data analytics course#data science#business intelligence#dataexcellence#power bi#data engineering roles#online data engineering course#data engineering training#data#data visualization
1 note
·
View note
Text
How Data Engineering Training Course Providers are Using AI
As the demand for data engineering expertise continues to surge, training course providers are increasingly integrating Artificial Intelligence (AI) to enhance the learning experience and equip professionals with advanced skills.
This article will explore how data engineering training course providers leverage AI to deliver comprehensive and innovative learning experiences.
AI-Powered Learning Platforms
Data engineering training course providers are harnessing AI to create dynamic and personalized learning platforms, revolutionizing how professionals acquire data engineering skills.
Personalized Learning Paths: AI algorithms analyze individual learning patterns and preferences, tailoring course content and pace to meet the unique needs of each learner.
Adaptive Assessments: AI-powered assessments dynamically adjust based on the learner's performance, providing targeted feedback and identifying areas for improvement.
Intelligent Recommendations: AI algorithms recommend supplementary learning materials, projects, or exercises based on the learner's progress and interests, fostering a holistic learning experience.
Enhanced Curriculum Design
AI is influencing the design and delivery of data engineering training courses, enriching the curriculum and ensuring its alignment with industry trends and emerging technologies.
AI-Driven Course Content: Course providers leverage AI to curate and update course content, ensuring it reflects the latest advancements in data engineering and aligns with industry best practices.
Real-Time Industry Insights: AI tools analyze industry trends and job market demands, enabling course providers to integrate relevant and future-focused topics into their curriculum.
Project Guidance: AI-powered project guidance systems offer real-time feedback and suggestions to learners, enhancing their practical application of data engineering concepts.
Intelligent Mentorship and Support
AI is being employed to augment mentorship and support services, providing learners with intelligent and responsive assistance throughout their learning journey.
AI-Powered Chatbots: Course providers integrate AI chatbots to offer instant support, answer learner queries, provide resources, and offer technical assistance.
Smart Feedback Systems: AI tools analyze learner submissions and interactions, offering targeted feedback and guidance to enhance comprehension and skill development.
Predictive Interventions: AI algorithms identify potential learning obstacles and provide proactive interventions to support learners in overcoming challenges.
Adaptive Learning Technologies
Data engineering training course providers are embracing AI-powered adaptive learning technologies to cater to diverse learning styles and optimize learning outcomes.
Personalized Learning Modules: AI systems customize learning modules based on individual learning styles, ensuring an adaptive and engaging learning experience.
Cognitive Skills Development: AI-powered platforms focus on developing cognitive skills such as problem-solving, critical thinking, and data interpretation through interactive exercises and scenarios.
Performance Analytics: AI analytics provide comprehensive insights into learner performance, enabling course providers to tailor interventions and support mechanisms.
AI-Enabled Certification Pathways
AI technologies are reshaping the certification pathways offered by data engineering training course providers, ensuring relevance, rigor, and industry recognition.
AI-Driven Assessment: Certification assessments are enhanced through AI technologies that offer advanced proctoring, plagiarism detection, and robust evaluation mechanisms.
Competency-Based Badging: AI-powered badging systems recognize and credential learners based on demonstrated competencies and skill mastery, offering a nuanced representation of expertise.
Real-Time Credentialing: AI streamlines and accelerates the credentialing process, providing instant certification outcomes and feedback to learners.
Conclusion
Data engineering training course providers are leveraging AI to revolutionize the learning experience, empowering professionals with advanced skills and expertise in data engineering.
By integrating AI technologies into their learning platforms, curriculum design, mentorship, and certification pathways, providers like Web Age Solutions ensure that learners receive a comprehensive, adaptive, and industry-relevant education in data engineering.
For more details, visit: https://www.webagesolutions.com/courses/data-engineer-training
1 note
·
View note
Text
Why Data Engineering with Cloud? Unlocking the Potential

In the fast-paced world of technology, data engineering has become a cornerstone for businesses aiming to thrive on data-driven insights. With the advent of cloud computing, the landscape of data engineering has undergone a revolutionary transformation, unlocking unprecedented potential and opportunities.
Introduction
In the digital era, where data is often considered the new currency, the role of data engineering cannot be overstated. Data engineering involves the collection, processing, and transformation of raw data into meaningful information, forming the backbone of decision-making processes for organizations.
Understanding Data Engineering
Data engineering encompasses a broad range of activities, from data collection and storage to processing and analysis. Traditionally, this field faced challenges such as scalability, resource constraints, and time-consuming processes. However, with the rise of cloud technology, a new era has dawned for data engineers.
Rise of Cloud Technology in Data Engineering
Cloud computing has emerged as a game-changer in the realm of data engineering. The ability to store and process vast amounts of data in the cloud offers unparalleled advantages. Major cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) have become the go-to choices for organizations seeking to optimize their data engineering workflows.
Benefits of Data Engineering with Cloud
Scalability and Flexibility
One of the primary advantages of leveraging the cloud for data engineering is scalability. Cloud platforms allow organizations to scale their resources up or down based on demand, ensuring optimal performance without unnecessary costs.
Cost-Effectiveness
Cloud-based data engineering eliminates the need for significant upfront investments in infrastructure. With a pay-as-you-go model, organizations can optimize costs by only paying for the resources they use.
Improved Data Security
Cloud providers implement robust security measures, often surpassing what individual organizations can achieve on their own. This ensures the confidentiality and integrity of data, addressing concerns that have hindered the widespread adoption of cloud solutions.
Real-Time Processing Capabilities
Cloud-based data engineering enables real-time processing, a crucial feature in today's fast-paced business environment. Organizations can extract valuable insights from data as it is generated, allowing for more informed and timely decision-making.
Challenges and Solutions
Despite the numerous advantages, challenges such as data privacy concerns, integrity issues, and potential latency must be addressed when implementing cloud-based data engineering solutions.
Addressing Data Privacy Concerns
Organizations must prioritize data privacy and compliance with regulations. Implementing encryption, access controls, and regular audits can help mitigate privacy concerns.
Ensuring Data Integrity and Reliability
Cloud platforms offer robust tools for ensuring data integrity, including backup and recovery solutions. Implementing best practices in data engineering, such as version control and validation processes, is essential.
Overcoming Potential Latency Issues
While cloud-based solutions offer high-speed processing, latency can still be a concern. Optimizing data pipelines, utilizing edge computing, and strategic resource allocation can help minimize latency issues.
Best Practices for Data Engineering in the Cloud
Utilizing Serverless Architecture
Serverless architecture, offered by many cloud providers, allows organizations to focus on writing code without managing the underlying infrastructure. This promotes agility and efficiency in data engineering processes.
Implementing Efficient Data Pipelines
Designing and implementing streamlined data pipelines is crucial for optimal performance. Cloud-based solutions provide tools for orchestrating complex workflows, ensuring data flows seamlessly from source to destination.
Optimizing Data Storage and Retrieval
Cloud platforms offer various storage options. Choosing the right storage solution based on data access patterns, retrieval speed requirements, and cost considerations is essential for effective data engineering.
#software course#software development classes#software development courses#program developer course#courses software engineering#artificial intelligence#software training institute#course on software engineering#best software courses#software engineer classes#data engineering courses#data engineer certification#data engineer classes#data engineering training#cloud data engineering#learn data engineering#best data engineer certification#data engineering with cloud computing#Cloud based data engineering#DataManagement#TechInnovation#BigData#CloudTechnology#DataSecurity#MachineLearning#DigitalTransformation#CloudComputing
0 notes
Text
Unveiling the Power Why Data Engineering and Analytics Training
In today's data-driven world, the ability to harness the power of data through effective data engineering and analytics is paramount for organizations looking to gain competitive advantages, drive innovation, and make informed decisions. At The DataTech Labs, we understand the importance of data engineering and analytics training in unlocking the full potential of data-driven insights. In this blog post, we'll delve into why data engineering and analytics training matters and explore the transformative impact it can have on organizations.

0 notes
Text
Data Engineering | Molinatech

Molinatech is at the forefront of data engineering solutions, providing cutting-edge services tailored to meet the evolving needs of businesses in the digital age. Data engineering is a crucial component of modern technology infrastructure, focusing on developing and managing data pipelines, data warehouses, and analytics systems. Businesses may use Molinatech data engineering skills to maximize operational efficiency, spur new growth prospects, and make well-informed decisions using data. Our team of talented data engineers specializes in creating solid and scalable data architectures that guarantee your data infrastructure's dependability, security, and efficiency. Whether you're working with batch processing, real-time streaming, or unstructured Data Engineering, Molinatek has the skills and expertise to meet all your data engineering requirements. We use cutting-edge technologies like Apache Spark, Hadoop, Kafka, and others to create unique solutions for your needs. Molinatek ensures that all of its data engineering services are Google-friendly since it recognizes how important it is to optimize information for internet visibility. We improve the discoverability of our services by adding pertinent keywords and metadata, which makes it simpler for companies looking for data engineering solutions to locate us in search engine results. Join Molinatek to receive all-inclusive data engineering services that enable your company to utilize your data to its maximum extent. We can assist you in thriving in the data-driven world, whether your goal is to optimize your current systems or create a data infrastructure from the ground up. To learn more about our data engineering services and how we can help you achieve your business goals, contact us right now.
0 notes
Text

Arduino Data Types
Arduino is an open-source hardware and software platform that enables the design and creation of electronic devices. The platform includes microcontroller kits and single-board interfaces that can be used to build electronic projects.
There are several Arduino data types that can be used in Arduino programming, including:
void
int
Char
Float
Double
Unsigned int
short
long
Unsigned long
byte
word
#besttraininginstitute#onlinetraining#traininginstitute#online#education#training#tutorial#coding#programming#oops#arduino#applications#datatypes#data#types#software#code#trending#technology#tech#engineering#development#softwaredevelopment
1 note
·
View note
Text
Cybersecurity Report: Protecting DHS Employees from Scams Targeting Personal Devices
🔒 DHS Cybersecurity Alert! 🔒 Scammers targeting personal devices threaten national security. Our new report reveals these risks & offers robust solutions - MFA, security software, cybersecurity training & more. Safeguard yourself & critical operations!
Introduction
The digital age has ushered in an era of unprecedented connectivity and technological advancements, but it has also given rise to a new breed of threats that transcend traditional boundaries. Cybercriminals are constantly evolving their tactics, exploiting vulnerabilities in both organizational systems and personal devices to gain unauthorized access, steal sensitive data, and…

View On WordPress
#access controls#antivirus#awareness campaigns#best practices#collaboration#cyber resilience#cybersecurity#cybersecurity training#data backup#data protection#DHS#firewall#government#impersonation#incident response#insider threats#malware#multi-factor authentication#national security#password management#personal device security#phishing#physical security#public outreach#risk assessment#scams#social engineering#software updates#threat intelligence#VPN
0 notes
Last Seen Blogs

kitty-angell
kitty_angel

2resell
2Resell

pjsandapony
PJs and a Pony

netadror
NETA DROR | Photographer

levo-art
The Trash Compactor