#collection classification and presentation of statistical data
Text
The Data Scientist's Toolkit: Essential Tools and Techniques for Analysis and Exploration

In the ever-evolving landscape of data science, professionals wield a diverse array of tools and techniques to uncover insights, extract value, and drive decision-making. From data collection and cleaning to modeling and visualization, the data scientist's toolkit is vast and dynamic, constantly adapting to new challenges and opportunities. In this blog post, we'll delve into some of the essential tools and techniques that every data scientist should master for effective analysis and exploration, making it essential for anyone pursuing a data science course to understand these foundational elements.
1. Data Collection and Cleaning:
Before diving into analysis, data scientists often spend a significant amount of time collecting and cleaning data to ensure its quality and reliability. Tools like Python's pandas library and R's dplyr package provide powerful capabilities for data manipulation, transformation, and cleansing. Additionally, tools like Apache Spark and Apache Flink enable processing of large-scale datasets in distributed environments.
2. Exploratory Data Analysis (EDA):
Exploratory Data Analysis (EDA) is a crucial phase in any data science project, allowing practitioners to understand the underlying patterns, relationships, and trends within the data. Techniques such as summary statistics, data visualization, and correlation analysis help uncover insights and inform subsequent modeling decisions. Popular visualization libraries like Matplotlib, Seaborn, and ggplot2 enable the creation of insightful plots and charts to explore data visually.
3. Machine Learning Modeling:
Machine learning lies at the heart of many data science applications, enabling predictive modeling, classification, clustering, and more. Data scientists leverage a variety of algorithms and techniques, including linear regression, decision trees, support vector machines, and deep learning. Frameworks like scikit-learn, TensorFlow, and PyTorch provide comprehensive toolsets for building, training, and evaluating machine learning models.
4. Model Evaluation and Validation:
Once models are trained, it's essential to evaluate their performance and validate their effectiveness before deployment. Techniques such as cross-validation, confusion matrices, and ROC curves help assess model accuracy, precision, recall, and other performance metrics. Tools like scikit-learn and TensorFlow provide built-in functions for model evaluation and validation, streamlining the process for data scientists.
5. Data Visualization and Interpretation:
Effective communication of insights is critical in data science, and data visualization plays a key role in conveying complex findings in a clear and intuitive manner. Data scientists leverage a variety of visualization techniques, including histograms, scatter plots, heatmaps, and interactive dashboards, to communicate insights to stakeholders. Tools like Tableau, Power BI, and Plotly enable the creation of dynamic and interactive visualizations for exploring and presenting data.
6. Model Deployment and Monitoring:
The final step in the data science lifecycle is deploying models into production environments and monitoring their performance over time, a crucial aspect that aspiring data scientists often encounter in their journey, especially those involved in a Campus Ambassador program. Tools like Flask, Django, and FastAPI facilitate the deployment of machine learning models as web services, while monitoring tools like Prometheus and Grafana enable real-time tracking of model performance and behavior, offering valuable insights and ensuring the success of projects undertaken by participants in the program.In conclusion, the field of data science is vast and multifaceted, encompassing a wide range of tools and techniques for analysis and exploration. By mastering the essential tools outlined in this post and staying abreast of emerging technologies and best practices, data scientists can unlock the full potential of data to drive innovation, inform decision-making, and create value in today's data-driven world.
#best data science course#full stack data science course#data science course#data analytics course online
0 notes
Text
What Data Science Is
In the sphere of technology, data science has become a game-changer, transforming how businesses get insights and make choices. Fundamentally, data science is a multidisciplinary synthesis of many methods, models, and procedures with the goal of revealing patterns, trends, and insights from enormous volumes of data. It includes many different approaches, such as data mining, statistical analysis, machine learning, and visualization techniques. Let's examine more closely what data science means and how important it is in many fields.
Overview of Data Science
In a nutshell, data science is the art of concluding
information of significance from data. To support well-informed decision-making, it entails the gathering, handling, analyzing, and interpreting of both structured and unstructured data. Data scientists now play a crucial role in today's data-driven environment, as organizations are constantly dealing with large volumes of data. Data scientists may uncover the potential hidden in data to obtain important insights that spur business growth and innovation by utilizing sophisticated analytics tools and procedures.
Go deep into Data Science
Important Ideas in Data Science Preprocessing and Data Collection
Data must be gathered and ready for analysis before any analysis can begin. To guarantee the data's accuracy, consistency, and completeness, cleaning and preparation are necessary. To efficiently preprocess the data, data scientists use a variety of methods including feature engineering, data wrangling, and outlier detection.
Analysing and Interpreting Data
Following preprocessing, the data is subjected to statistical techniques and machine learning algorithms to identify patterns, trends, and linkages. To glean useful insights from data, data analysis techniques include exploratory data analysis (EDA), hypothesis testing, and model construction. Understanding the implications of the findings and formulating well-informed judgements based on them requires a thorough interpretation of the results.
Predictive modelling and machine learning
A kind of artificial intelligence known as machine learning allows computers to learn from data without explicit programming. Regression, classification, clustering, and deep learning are just a few of the machine learning techniques that data scientists use to create predictive models that can anticipate future events or categorise data.
Information Visualisation
The graphical depiction of data for ease of comprehension and interpretation is known as data visualisation. It entails making dashboards, graphs, and charts to effectively convey findings to stakeholders. When it comes to telling stories and presenting complicated information in an aesthetically pleasing and comprehensible way, data visualisation is essential.
Data Science Applications
Data science is being applied in a wide range of fields and industries, transforming the way companies function and make strategic choices. Among the most important uses of data science are:
Analytics for Business
Organisations may better understand their consumers, market trends, and operational efficiencies with the help of data science. Businesses may enhance customer satisfaction, boost revenue growth, and optimise their plans by analysing market dynamics and client behaviour.
Medical Care
Data science is utilised in healthcare for patient monitoring, personalised treatment, medication discovery, and illness diagnostics. Healthcare providers can lower costs, improve patient outcomes, and provide higher-quality care by analysing genomic data, electronic health records (EHRs), and medical imaging.
Money
Data science is used in the finance sector for consumer segmentation, algorithmic trading, risk management, and fraud detection. Financial institutions can reduce risks, find profitable opportunities, and make data-driven decisions by evaluating financial data and market trends.
Marketing Data science makes personalised marketing campaigns, customer segmentation, and sentiment analysis possible, thereby revolutionising the marketing industry. Marketers may target the right audience with the right message at the right time by analysing customer demographics and online behaviour, which will increase conversion rates and return on investment.
Social Networks
With its ability to analyse user activity, sentiment analysis, and content recommendation, data science is essential to social media platforms. Social media firms may improve user experience, increase user engagement, and optimise content distribution by utilising user-generated data.
Data Science Requires Specific Skills
Developing a broad skill set that includes technical, analytical, and domain-specific knowledge is necessary to become a competent data scientist. Among the fundamental abilities needed for data science are:
Languages for Programming
Data processing, analysis, and model construction require fluency in programming languages like Python, R, and SQL.
Analytical Statistics
For the purposes of regression analysis, experimental design, and hypothesis testing, a strong grasp of statistical concepts and procedures is essential.
Automated Learning Systems
To develop predictive models, one must be familiar with a variety of machine learning methods and techniques, including neural networks, decision trees, and linear regression.
Tools for Data Visualisation
To create visualisations that effectively communicate insights to stakeholders, one must be proficient in data visualisation tools like Tableau, matplotlib, and ggplot2.
Data Science Challenges
Although data science has many advantages, there are a few issues that data scientists need to deal with:
Quantity and Quality of Data
To get trustworthy and accurate insights, it is essential to ensure both the quantity and quality of data. Missing data, outliers, and data biases are common problems faced by data scientists that might compromise the accuracy of their findings.
Privacy Issues
As data collecting and analytics have grown in popularity, privacy issues have grown to be quite important. Ensuring compliance with legislation like GDPR and HIPAA and navigating ethical considerations are crucial tasks for data scientists in safeguarding individuals' privacy rights.
Model Interpretability
It might be difficult to interpret intricate machine learning models and communicate their predictions to stakeholders. To improve the interpretability of their models, data scientists need to use strategies like feature importance analysis and model explainability.
Staying Up to Date with Developments
The area of data science is developing quickly as new methods, software, and instruments are created regularly. To stay competitive in the field, data scientists need to keep up with the latest developments and constantly improve their skills.
Prospects for Data Science in the Future
In the near future, several new developments are expected to influence data science, including:
Integration of Artificial Intelligence
More complex and advanced analyses will be possible with the integration of artificial intelligence (AI) technologies like computer vision and natural language processing (NLP) into data science workflows.
Cutting-Edge Computing
Real-time analytics and decision-making will be made possible by edge computing, which processes data closer to its source rather than in a centralized data center. This technology will proliferate.
Automated Machine Learning
By automating the model-building process, automated machine learning (AutoML) platforms will democratize data science by making it simple for non-experts to create and implement predictive models.
Moral Aspects to Take into Account
It will be crucial to address ethical issues including prejudice, justice, and openness as data science becomes more widely used. In their work, data scientists should uphold responsible AI methods and give priority to ethical values.
Feligrat's course offers comprehensive data science training for all experience levels, ensuring job stability and real-world project experience, paving the way for financial success.
0 notes
Text
Data Science Life Cycle: Detailed Explanation
Data Science Lifecycle revolves around the use of machine learning and different analytical strategies to produce insights and predictions from information in order to acquire a commercial enterprise objective. The complete method includes a number of steps like data cleaning, preparation, modelling, model evaluation, etc. It is a lengthy procedure and may additionally take quite a few months to complete. So, it is very essential to have a generic structure to observe for each and every hassle at hand. The globally mentioned structure in fixing any analytical problem is referred to as a Cross Industry Standard Process for Data Mining or CRISP-DM framework.

Data science is an interdisciplinary field that uses scientific methods, algorithms, processes, and systems to extract insights and knowledge from structured and unstructured data. It incorporates various techniques from statistics, mathematics, computer science, and domain expertise to analyze and interpret complex data sets. Data science involves collecting, cleaning, and preprocessing data, exploring and visualizing it Data science is an interdisciplinary field that uses scientific methods, algorithms, processes, and systems to extract insights and knowledge from structured and unstructured data. It incorporates various techniques from statistics, mathematics, computer science, and domain expertise to analyze and interpret complex data sets. Data science involves collecting, cleaning, and preprocessing data, exploring and visualizing it to uncover patterns and trends, and ultimately making predictions or decisions based on the findings.
Key components of data science include:
Data Collection: Gathering data from various sources such as databases, APIs, sensors, social media, etc.
Data Cleaning and Preprocessing: Removing noise, handling missing values, standardizing formats, and preparing the data for analysis.
Exploratory Data Analysis (EDA): Analyzing and visualizing data to understand its structure, identify patterns, correlations, and outliers.
Statistical Analysis: Applying statistical methods to derive insights and validate hypotheses from the data.
Machine Learning: Building models that can learn from data to make predictions or decisions without being explicitly programmed. This includes techniques like classification, regression, clustering, and anomaly detection.
Data Visualization: Presenting data visually through charts, graphs, and interactive dashboards to communicate insights effectively.
Data Interpretation and Communication: Extracting actionable insights from the analysis and communicating findings to stakeholders in a clear and understandable manner.
Data science has applications in various fields such as finance, healthcare, marketing, cybersecurity, and more. It plays a crucial role in helping organizations make data-driven decisions, optimize processes, and gain a competitive edge in today's data-driven world.
1 note
·
View note
Text

Citizen astronomers and AI discover 30,000 ring galaxies
Building on the synergy between citizen astronomer classifications and AI, astronomers have discovered approximately 400,000 spiral galaxies and 30,000 ring galaxies in data from the Subaru Telescope. This is the first example of research building on the classification data from the citizen science project "GALAXY CRUISE."
Galaxies display a wide variety of morphologies that reflect their histories. Data sets from powerful cutting-edge facilities like the Subaru Telescope contain so many galaxies that astronomers cannot classify them all by hand. In the GALAXY CRUISE citizen science project, professional astronomers asked more than 10,000 citizen astronomer volunteers to do the classifications. But even divided among thousands of volunteers, classification still takes time.
AI can conduct classifications quickly, but first it needs to be trained on a catalog of classification examples prepared by humans.
For this new study, a team led by Rhythm Shimakawa, associate professor at Waseda University, trained an AI on a set of 20,000 galaxies classified by humans as part of GALAXY CRUISE. The team then turned the AI loose on all 700,000 galaxies in the Subaru Telescope data set.
The AI classified 400,000 of them as spiral galaxies and 30,000 as ring galaxies. Even though ring galaxies account for less than 5% of all galaxies, this research yielded a sample large enough for meaningful statistical analysis.
Statistical analysis showed that on average, ring galaxies show intermediate characteristics between spiral and elliptical galaxies. This is consistent with the latest supercomputer simulations. The article, "GALAXY CRUISE: Spiral and ring classifications for bright galaxies at z = 0.01–0.3" was presented in Publications of the Astronomical Society of Japan on January 29, 2024.
Shimakawa comments about the role of GALAXY CRUISE in his research and future prospects, "Although AI classification takes less than one hour even for 700,000 galaxies, this work cannot be done without the data collected by GALAXY CRUISE over the past two years. We would like to thank all the citizen astronomers who participate in the project. I hope to see more collaborative outcomes in the future."
IMAGE....From top to bottom, randomly selected cutout images of spiral galaxies for model training (first row), those detected from the trained model (second–sixth rows), ring galaxies for the model training (seventh row), and those detected from the trained model (eighth–twelfth rows), respectively. Credit: Publications of the Astronomical Society of Japan (2024). DOI: 10.1093/pasj/psae002
youtube
1 note
·
View note
Text
Top 10 Uses of R Programming Language in 2024
R has become one of the popular programming languages for data analysis and statistical computing. With its vast collection of packages and active user community, R offers endless possibilities for data scientists, statisticians, and analysts. As we move into 2024, here are 10 of the top uses of R programming:

1. Data Visualization
With libraries like ggplot2, R makes it easy to create custom, publication-quality graphics to visualize data. Complex visualizations like interactive charts, maps, and network diagrams can be made with just a few lines of code.
2. Statistical Modeling
R has a wide range of statistical and machine learning packages like stats, caret, and more. These make it possible to build and evaluate predictive models for classification, regression, clustering, time series analysis, etc. Models can be compared to select the best performers.
3. Data Wrangling
The dplyr and tidyr packages in R provide a grammar of data manipulation, making it easy to slice, dice, reshape, join, and transform data sets before analysis. This helps automate the data-cleaning process.
4. Reporting
R Markdown integrates prose, code, and visualizations into a single document. Reports and presentations with embedded statistical analysis can be dynamically generated from R scripts. The knit package enables code chunking to keep code separate from outputs.
5. Web Scraping
Packages like Rvest and RSelenium enable scraping data from HTML web pages and dynamic websites. This data can then be processed using R's other analytics capabilities.
6. Bioinformatics
Bioconductor provides over 1,600 packages for analyzing genetic data, DNA sequences, gene expression data, and more. R is heavily used in genomics research.
7. Finance
R packages like quantmod, TTR, and PerformanceAnalytics provide capabilities for analyzing financial data, estimating risk, simulating portfolios, and calculating returns. R is popular in fintech and quantitative finance.
8. Machine Learning
Packages like caret, mlbench, Keras, and H2O provide R users with tools like regression, naïve Bayes classification, random forests, gradient boosting machines, neural networks, and more.
9. Big Data Analytics
Packages like ff, big memory, and SparkR allow the handling and analysis of large datasets that are larger than a computer's RAM. This enables scalable data analysis with R.
10. Mapping & Spatial Analysis
Many R packages like ggmap, geospatial, leaflet, and sf support working with geospatial data. This makes R useful for creating maps, spatial data visualizations, and location analytics.
Conclusion
R has evolved into a powerful, versatile tool for data analysis and statistical computing. In 2024, R will continue to be valued for its extensibility via user-contributed packages, interactivity for iterative analysis, and visualization capabilities. Key strengths like effective data wrangling, modeling, reporting, and machine learning will ensure R remains popular across domains, including academia, finance, technology, genomics, and more.
While other languages like Python, Julia, and MATLAB will also have niche uses, R's focused support for statistical analysis gives it an edge for data science applications. The low-cost and open-source nature of R is attractive to both students and companies. With new packages expanding R's capabilities all the time, it is certain that R will be a highly utilized programming language in 2024 and remain a staple of data scientists' toolkits for years to come.
0 notes
Text
Getting Started with Big Data Analytics: Essential Concepts Explained
In today's data-driven world, organizations are constantly inundated with vast amounts of data. This influx of data presents both challenges and opportunities. Big data analytics has emerged as a powerful tool for extracting valuable insights from large datasets, driving informed decision-making, and gaining a competitive edge in various industries. In this blog post, we'll explore the essential concepts of big data analytics, covering everything from its definition to its practical applications.

Understanding Big Data Analytics
Big data analytics refers to the process of examining large and varied datasets to uncover hidden patterns, correlations, and other insights. It involves using advanced analytics techniques and technologies to process, analyze, and interpret massive volumes of data that traditional data processing methods cannot handle effectively.
Key Components of Big Data Analytics
Data Collection
The first step in big data analytics is collecting data from diverse sources such as social media, sensors, devices, and transactional systems. This data can be structured, semi-structured, or unstructured, posing unique challenges for analysis.

Data Storage
Once collected, the data needs to be stored scalable and efficiently. Traditional relational databases may not be suitable for handling the volume, velocity, and variety of big data. Instead, organizations often turn to distributed storage systems like Hadoop Distributed File System (HDFS) or cloud-based storage solutions.
Data Processing
Big data analytics involves processing large datasets to extract meaningful insights. This typically requires parallel processing frameworks like Apache Hadoop or Apache Spark, which distribute the computational workload across clusters of computers.
Data Analysis
After processing, the data is analyzed using various statistical and machine learning algorithms to identify trends, patterns, and correlations. Regression analysis, clustering, classification, and natural language processing are commonly employed in big data analytics.
Data Visualization
Once insights are derived, it's essential to communicate them effectively. Data visualization tools like Tableau, Power BI, or Matplotlib allow analysts to create visual representations of data trends, making complex information more accessible and understandable.

Decision Making
Ultimately, the goal of big data analytics is to inform decision-making and drive action. By leveraging insights gleaned from data analysis, organizations can optimize processes, improve customer experiences, launch targeted marketing campaigns, mitigate risks, and identify new business opportunities.
Practical Applications of Big Data Analytics
Big data analytics finds applications across various industries and domains, revolutionizing how businesses operate and innovate. Some notable examples include:
Healthcare
Big data analytics enables healthcare providers to analyze patient records, medical images, and genomic data to improve diagnoses, personalize treatments, and enhance patient outcomes. Predictive analytics can also help identify individuals at risk of developing certain diseases, enabling proactive interventions.
Retail
Retailers leverage big data analytics to analyze customer purchase histories, browsing behaviors, and social media interactions to personalize marketing efforts, optimize pricing strategies, and forecast demand. Recommendation engines use collaborative filtering algorithms to suggest relevant products to customers, driving sales and customer satisfaction.
Finance
In the finance industry, big data analytics is used for fraud detection, risk management, algorithmic trading, and customer segmentation. By analyzing transactional data in real time, financial institutions can detect suspicious activities and prevent fraudulent transactions before they occur.
Manufacturing
Manufacturers harness big data analytics to optimize production processes, minimize downtime, and improve product quality. IoT sensors embedded in machinery collect real-time data on performance and maintenance needs, enabling predictive maintenance strategies that reduce costs and maximize uptime.
Marketing
In marketing, big data analytics empowers organizations to segment audiences, personalize content, and measure campaign effectiveness with precision. Social media listening tools analyze conversations and sentiment around brands, products, and competitors, providing valuable insights for targeted marketing campaigns.
Transportation and Logistics
In transportation and logistics, big data analytics is used to optimize route planning, fleet management, and supply chain operations. By analyzing traffic patterns, weather forecasts, and historical data, companies can minimize delivery times, reduce fuel consumption, and enhance overall efficiency.
Conclusion
As the volume and variety of data continue to grow exponentially, the importance of big data analytics will only increase. By understanding the key concepts and practical applications of big data analytics, organizations can harness the power of data to drive innovation, enhance decision-making, and achieve business success.
Ready to dive deeper into the world of Big Data Analytics? Enroll in BIA's Big Data Analytics Course in Hyderabad today and take the first step towards mastering the skills needed to thrive in this dynamic field. With expert-led instruction and hands-on experience, you'll be equipped to tackle real-world data challenges and drive innovation in your organization.
0 notes
Text
What are the job opportunities available in data science?

Pursuing a Master of Science in Data Science in today's fast-paced digital era is definitely a great career choice. Data science is not just a popular field, but the discipline itself has become an indispensable part of almost every industry. It is one of the most rewarding professional path in today's competitive job market. Hunting for jobs in today's cut-throat competition is a hassle. Candidates must have distinctive qualities and backgrounds to find the right role. An MS in Data Science is one of the most dough-after degrees that employers are seeking for. The additional perk of a master of science in data science is that the knowledge and skills attained during the course may be relevant across industries.
Let us identify the various career opportunities that are available for a professional with a degree of Master of Science in Data Science in this blog. It's ideal that prospective candidates have comprehensive knowledge of what skills and roles do a certain position entail. We will explore the top jobs after an MS in Data Science that candidates can get started with.
Job Opportunities after MS in Data Science
Data Scientist: A Data Scientist is also rightly known as the jack of all trades. They have in-depth insights and knowledge about the best solutions for a certain project, while detecting larger patterns and trends in the data. They are often tasked with the role of researching and creating new approaches and algorithms. A data scientist handles all the aspects of a project, starting from knowing the critical elements of the business, to data collection and analysis and presenting the result in a proper and effective data visualization. In most of the bigger organizations, data scientists also play the role of a team lead, given their specialized skill in guiding a project from start to the end.
Data Analyst: As a Data Analyst, you will be responsible majorly for the visualizing tasks. You will visualize, transform and manipulate data, as well as tracking analytics and A/B testing analysis. Data Analysts take care of data preparation for business communications. They prepare reports to show the trends and give insights they generated from their analysis.
Data Engineers: They design, build, and maintain data pipelines. They are responsible for testing the business' ecosystem and prepare them for running algorithm by Data Scientists. Their job also includes working on batch processing of collected data and matching the format to the stored data.
Data Architect: The roles and duties of data architects are common with that of Data engineers. Their tasks involve ensuring the data is well-formatted and are made accessible for data scientists and analysts, and altogether enhance the performance of the data pipelines. They also design and develop new database systems that match the need of the specific business model.
Machine Learning Scientist: Machine Learning Scientist performs the task of researching new approaches and strategies of data manipulation to design new algorithms. They are the core member of the Research and Development (R&D) section of any organization. Their work also involves publication of Research papers. Not only that, but they are typically found active in academics rather than in the practical Industry. Furthermore, they are also known as Research Scientists or Research Engineers.
Machine Learning Engineer: This is among the top in demand positions today. Machine Learning Engineers are required to have strong programming and statistic skills, be familiar with various machine learning algorithms including clustering, categorization and classification, stay abreast with latest research advances. They must have a strong foundation in the fundamental knowledge of software engineering. ML Engineers' primary role is to design and build machine learning systems. They are required to run tests while simultaneously monitoring the performance and functionality of different systems.
Business Intelligence Developer: Also known as BI developers, they are responsible for planning and sketching strategies that equip businesses with the information needed for making quick and efficient decisions. BI Developers must be thus conversant with BI tools or developing custom ones that provide business insights and in-depth analytics. Their jobs are significantly business-oriented, hence they should also have knowledge of the basics of business strategy and the intricacies of the company's business model.
Database Administrator: A database administrator's job is to monitor the database, ensuring its proper functioning and keeping track of the data flow while creating backups and recoveries. They also supervise the security of the database by granting access permission to different employees based on their roles and requirements level.
Technology Specialized Roles: There are several other roles in Technology domain that MS in Data Science graduates can land. They can go on to take up data science specialized roles across industries.
0 notes
Text
Understanding the Role of a Data Analyst: Unravelling the Insights
In today's data-driven world, organisations across industries rely heavily on data to make informed decisions. One crucial player in this process is the data analyst. A data analyst plays a pivotal role in transforming raw data into actionable insights, helping businesses gain a competitive edge. This article delves into the intricacies of the job role, responsibilities, and skills required for a successful career as a data analyst.
Definition of a Data Analyst
At its core, a data analyst is a professional who interprets, processes, and analyses data to help businesses make informed decisions. They work with large sets of data to identify trends, patterns, and correlations that can guide strategic planning and decision-making.
Data Collection and Cleaning
One of the primary responsibilities of a data analyst is to collect and clean data. This involves gathering information from various sources, such as databases, spreadsheets, and external datasets. Cleaning the data is crucial to ensure accuracy and reliability, as analysts need to deal with inconsistencies, missing values, and outliers that may impact the analysis.
Data Exploration and Descriptive Statistics
Once the data is collected and cleaned, data analysts engage in exploratory data analysis. This phase involves using statistical methods and visualization tools to understand the structure and characteristics of the data. Descriptive statistics, charts, and graphs help in summarizing and presenting key insights, providing a foundation for further analysis.
Data Analysis and Modeling
Data analysts employ various statistical and machine learning techniques to analyze the data and build models. Regression analysis, clustering, and classification are some common approaches used to extract meaningful patterns and relationships from the data. These models contribute to predictive analytics, enabling organizations to forecast trends and make data-driven predictions.
Interpretation of Results
Interpreting analysis results is a critical aspect of a data analyst's role. Analysts need to translate complex findings into understandable insights for non-technical stakeholders. Effective communication is key, as analysts must convey the implications of their findings to guide strategic decision-making at different levels within the organization.
Reporting and Visualization
To communicate their insights effectively, data analysts create reports and visualizations. Dashboards, charts, and graphs are powerful tools that allow stakeholders to grasp complex information quickly. Visualization not only enhances communication but also aids in identifying trends and outliers that might be less apparent in raw data.
Continuous Monitoring and Optimization
Data analysis is an iterative process. Analysts need to continuously monitor the performance of models, assess the relevance of variables, and optimize their methods to adapt to evolving business needs. This ongoing cycle ensures that organizations can respond proactively to changes in the market or operational landscape.
Collaboration with Cross-Functional Teams
Data analysts often work collaboratively with teams from various departments. They collaborate with business analysts, data scientists, and decision-makers to align data-driven insights with organizational objectives. This collaborative approach fosters a holistic understanding of business challenges and opportunities.
Technical Skills Required
A successful data analyst possesses a blend of technical skills. Proficiency in programming languages like Python or R is essential for data manipulation and analysis. Knowledge of databases and query languages, such as SQL, is crucial for extracting and managing data. Additionally, familiarity with data visualization tools like Tableau or Power BI enhances the ability to convey insights effectively.
Educational Background and Professional Development
While a degree in a relevant field such as statistics, mathematics, or computer science is beneficial, data analysts can come from diverse educational backgrounds. Continuous learning and staying updated with the latest tools and techniques are essential for success in this dynamic field. Professional development through certifications and online courses can further enhance a data analyst's skills and marketability.
Conclusion
In conclusion, the job role of a data analyst is multifaceted, involving data collection, cleaning, analysis, interpretation, and collaboration with various stakeholders. As businesses increasingly rely on data for decision-making, the demand for skilled data analysts continues to grow. Those considering a career in data analysis should focus on developing a strong foundation in both technical and communication skills to thrive in this evolving and impactful profession.
0 notes
Text
The Power of Python in Data Science: Unleashing Insights and Opportunities
Introduction
In the realm of data science, Python has emerged as a powerhouse programming language, playing a pivotal role in unlocking insights, making data-driven decisions, and addressing complex business challenges. With its simplicity, versatility, and extensive libraries, Python is the go-to choice for data scientists worldwide. In this article, we'll explore how Python is used in data science and the role of specialized training, such as a Data Science with Python course, in harnessing its potential.
1. Data Collection and Extraction
Python's libraries and frameworks, such as Requests and BeautifulSoup, facilitate web scraping and data extraction. Data scientists can effortlessly collect data from websites, APIs, and databases, making it a crucial tool for acquiring diverse datasets.
Tip: Enrolling in a Data Science with Python course can provide hands-on experience in web scraping and data collection techniques.
2. Data Cleaning and Preprocessing
Data is rarely pristine, often requiring extensive cleaning and preprocessing. Python, with libraries like Pandas and NumPy, allows data scientists to efficiently handle missing values, outliers, and data transformation tasks.
Tip: Specialized courses cover data cleaning best practices and advanced techniques, enhancing your skills in data preprocessing.
3. Data Visualization
Python's Matplotlib, Seaborn, and Plotly libraries empower data scientists to create insightful visualizations that convey complex patterns and trends. Visualizations aid in data exploration, presentation, and storytelling.
Tip: A Data Science with Python course typically includes modules on data visualization, providing you with the skills to create compelling charts and graphs.
4. Machine Learning and Predictive Modeling
Python is synonymous with machine learning. Libraries like Scikit-Learn, TensorFlow, and Keras enable data scientists to build and deploy machine learning models for classification, regression, clustering, and more.
Tip: Specialized courses offer in-depth coverage of machine learning algorithms, model evaluation, and deployment strategies using Python.
5. Statistical Analysis
Python offers a wide range of statistical libraries, including SciPy and Statsmodels, that facilitate hypothesis testing, regression analysis, and advanced statistical techniques.
Tip: A Data Science with Python course typically includes modules on statistical analysis, providing you with a strong foundation in statistical methods.
6. Big Data and Distributed Computing
Python seamlessly integrates with big data frameworks like Apache Spark and Hadoop through libraries like PySpark. This enables data scientists to work with large-scale datasets and distributed computing.
Tip: Advanced courses in Data Science with Python cover big data processing and distributed computing concepts.
7. Deployment and Automation
Python's simplicity extends to deploying machine learning models and automating workflows. Frameworks like Flask and Django are commonly used for building web applications, while tools like Airflow automate data pipelines.
Tip: Specialized courses delve into deployment strategies and automation techniques using Python.
8. Natural Language Processing (NLP)
Python's NLTK and spaCy libraries make it a powerful choice for NLP tasks, including sentiment analysis, text classification, and language generation.
Tip: Courses often include modules on NLP, allowing you to explore text data and language processing techniques.
Conclusion
Python's prominence in data science is undeniable, offering a comprehensive ecosystem of tools and libraries that streamline every aspect of the data analysis pipeline. However, to become a proficient data scientist using Python, it's essential to invest in specialized training, such as a Data Science with Python course.
These courses provide hands-on experience, in-depth knowledge, and practical skills in using Python for data science. Whether you're a beginner looking to enter the field or an experienced data scientist seeking to expand your skillset, a Data Science with Python course can empower you to leverage Python's full potential, opening up a world of opportunities in the dynamic field of data science.
0 notes
Text
Data Science: Overview, History and FAQs
What Is Data Science?
Data Science is an interdisciplinary field that encompasses techniques, processes, algorithms, and systems used to extract meaningful information, insights, and knowledge from large and complex datasets. It combines elements from various disciplines including statistics, computer science, mathematics, and domain-specific expertise.
Data scientists work with vast and diverse sets of data, employing a range of methods such as data cleaning, transformation, statistical analysis, machine learning, and data visualization to uncover patterns, trends, and valuable insights. These insights can be used to inform decision-making, solve complex problems, and drive innovation in various industries and domains.
In essence, data science is about leveraging data to gain a deeper understanding of phenomena, make predictions, and enable data-driven strategies and actions. It plays a crucial role in fields like business intelligence, healthcare, finance, marketing, and many others where making sense of large volumes of data is essential for success and progress.
Understanding Data Science
Understanding Data Science involves grasping the fundamental concepts, methods, and applications of this interdisciplinary field. Here's a breakdown to help you comprehend it better:
Foundation in Data Handling:
Data Collection: Gathering relevant information from various sources, which can be structured (like databases) or unstructured (like text or images).
Data Cleaning and Preprocessing: Ensuring data quality by removing errors, duplicates, or irrelevant information.
Statistical Analysis:
Descriptive Statistics: Summarizing and describing the main features of a dataset (mean, median, variance, etc.).
Inferential Statistics: Making predictions or inferences about a population based on a sample.
Programming and Tools:
Languages: Proficiency in programming languages like Python, R, and SQL, which are widely used in data science.
Tools: Familiarity with libraries and frameworks such as Pandas, NumPy, and Scikit-learn for data manipulation, analysis, and machine learning.
Machine Learning:
Supervised Learning: Training models on labeled data to make predictions or classifications.
Unsupervised Learning: Identifying patterns and relationships in unlabeled data.
Deep Learning: Using neural networks for complex tasks like image recognition or natural language processing.
Data Visualization:
Creating Graphs and Charts: Representing data visually to aid in understanding and communication.
Interpreting Visualizations: Extracting insights from visual representations of data.
Domain Knowledge:
Understanding the specific industry or field in which data science is being applied. For example, healthcare, finance, e-commerce, etc.
Problem-Solving Skills:
Formulating Questions: Defining clear and relevant research questions or problem statements.
Developing Strategies: Deciding which techniques and approaches are appropriate for a given problem.
Ethical Considerations:
Privacy: Ensuring the protection and ethical use of sensitive or personal data.
Bias and Fairness: Addressing and mitigating potential biases in algorithms and data.
Communication and Presentation:
Explaining Results: Effectively conveying findings to non-technical stakeholders.
Visual Storytelling: Presenting insights in a clear and compelling manner.
Continuous Learning and Adaptation:
Keeping up with the latest trends, tools, and techniques in the rapidly evolving field of data science.
Understanding Data Science involves the ability to leverage data to extract valuable insights, make informed decisions, and drive positive outcomes. It's a dynamic field that continues to evolve with advancements in technology and an increasing volume of available data.
The Purpose of Data Science
The purpose of Data Science is to extract meaningful insights and knowledge from large and complex datasets to drive informed decision-making, solve complex problems, and create value across various industries and domains. Here are some key purposes and objectives of Data Science:
Informed Decision-Making:
Data Science helps organizations and individuals make decisions based on evidence and facts rather than intuition or assumptions.
Predictive Analytics:
By analyzing historical data, Data Science enables the prediction of future trends and events, aiding in proactive planning and strategy.
Optimizing Processes:
Data-driven insights can lead to process optimization, resource allocation, and efficiency improvements, resulting in cost savings and enhanced productivity.
Personalization and Recommendations:
Data Science powers recommendation engines, allowing businesses to offer tailored products, services, or content to individual users.
Risk Management:
In finance, healthcare, and other sectors, Data Science is used to assess and mitigate risks associated with various activities or decisions.
Customer Insights:
Understanding customer behavior, preferences, and sentiment helps businesses tailor their products, services, and marketing strategies.
Product Development and Innovation:
Data-driven insights can inform the development of new products or features, ensuring they meet the needs and preferences of the target audience.
Healthcare and Life Sciences:
Data Science plays a crucial role in medical research, drug discovery, disease diagnosis, and personalized treatment plans.
Fraud Detection and Security:
Data Science is used to identify anomalies or suspicious activities, helping prevent fraud and enhance security measures.
Environmental Sustainability:
Data Science can analyze environmental data to develop strategies for conservation, pollution control, and sustainable resource management.
Social Impact and Public Policy:
Governments use Data Science to inform policy decisions, allocate resources effectively, and address social issues.
Scientific Research:
Data Science is applied in various scientific disciplines to analyze experimental data, model phenomena, and draw conclusions.
Marketing and Customer Acquisition:
Data-driven marketing strategies help businesses target the right audience, optimize campaigns, and measure their impact.
Supply Chain Optimization:
Data Science helps streamline supply chain operations by optimizing inventory levels, demand forecasting, and logistics.
Education and E-Learning:
Data-driven education platforms can personalize learning experiences, track student progress, and improve instructional content.
In summary, Data Science serves as a powerful tool to transform raw data into valuable insights, enabling organizations and individuals to make informed decisions, innovate, and drive positive outcomes across a wide range of fields and industries.
A Brief History of Data Science
The history of Data Science is marked by significant milestones in statistics, computing, and the emergence of big data. Here's a brief overview:
Early Developments (1700s-1800s):
The foundations of statistics were laid by pioneers like Francis Galton, Karl Pearson, and Ronald A. Fisher. They introduced concepts like correlation, regression, and the normal distribution.
Computational Era (1950s-1980s):
With the advent of computers, data processing became more efficient. The field of statistics merged with computer science, giving rise to computational statistics.
Database Management Systems (DBMS) (1960s-1970s):
The development of DBMS like IBM's IMS and CODASYL's database model facilitated efficient data storage and retrieval.
The Rise of Data Warehousing (1980s):
Data warehousing emerged as a solution for storing and managing large volumes of data for analytical purposes. Ralph Kimball and Bill Inmon were pioneers in this area.
Data Mining (1990s):
Data mining techniques were developed to uncover patterns and relationships in large datasets. This laid the groundwork for predictive analytics.
Internet and the Digital Revolution (1990s-2000s):
The proliferation of the internet and digital technologies led to an explosion of data. Websites, social media, and e-commerce platforms generated vast amounts of information.
Emergence of Big Data (2000s):
The term "big data" gained prominence as datasets grew too large to be handled by traditional database management systems. Technologies like Hadoop and MapReduce were developed to process and analyze massive amounts of data.
Machine Learning and AI (2010s):
Advances in machine learning algorithms, along with the availability of massive datasets, propelled Data Science into the mainstream. Techniques like deep learning and neural networks gained prominence.
Data Science in Industry (2010s-Present):
Data Science became an integral part of various industries, including finance, healthcare, marketing, and technology. Companies started investing heavily in data-driven decision-making.
Ethical Considerations (2010s-Present):
As data collection and analysis became more prevalent, ethical considerations around privacy, bias, and transparency gained significant attention.
Interdisciplinary Nature (Present):
Data Science has evolved into an interdisciplinary field, integrating statistics, computer science, mathematics, domain expertise, and ethics to extract meaningful insights from data.
Continual Evolution (Present):
Data Science continues to evolve with advancements in technology, the development of new algorithms, and the increasing availability of data from various sources.
Today, Data Science plays a critical role in shaping various aspects of our lives, from business operations to healthcare and beyond. It continues to be a dynamic field at the forefront of innovation and discovery.
How Data Science Is Applied
Data Science is applied across various industries and domains to extract valuable insights and drive informed decision-making. Here are some examples of how Data Science is commonly applied:
Business and Finance:
Customer Segmentation: Analyzing customer data to group them based on behavior, demographics, or preferences for targeted marketing strategies.
Risk Assessment: Using predictive models to assess financial risks for loans, investments, or insurance.
Fraud Detection: Identifying suspicious activities or transactions to prevent financial fraud.
Healthcare and Life Sciences:
Clinical Trials and Drug Discovery: Analyzing clinical data to identify effective treatments and optimize drug development processes.
Disease Diagnosis and Prediction: Using machine learning models to assist in diagnosing diseases or predicting patient outcomes.
Healthcare Resource Allocation: Optimizing the allocation of resources like hospital beds, staff, and medical supplies.
E-commerce and Retail:
Recommendation Systems: Suggesting products or content to users based on their browsing and purchasing history.
Demand Forecasting: Predicting future demand for products to optimize inventory levels and supply chain management.
Price Optimization: Analyzing market trends and customer behavior to set optimal pricing strategies.
Marketing and Advertising:
Campaign Optimization: Evaluating the performance of marketing campaigns and adjusting strategies for better results.
Customer Churn Prediction: Identifying customers who are likely to stop using a product or service, allowing for targeted retention efforts.
Sentiment Analysis: Analyzing social media and customer feedback to understand public opinion about a brand or product.
Manufacturing and Operations:
Quality Control: Using data analysis to monitor and maintain product quality on the production line.
Predictive Maintenance: Anticipating when machinery or equipment is likely to fail in order to schedule maintenance and prevent costly downtime.
Energy and Environmental Sustainability:
Energy Consumption Optimization: Analyzing data to identify opportunities for reducing energy consumption and costs.
Environmental Monitoring: Using data to track and address environmental issues such as pollution levels or resource depletion.
Telecommunications and Networking:
Network Performance Optimization: Analyzing network data to identify and resolve performance bottlenecks or issues.
Customer Behavior Analysis: Understanding how users interact with telecom services to improve offerings and customer experience.
Education and E-Learning:
Personalized Learning: Using data to customize educational content and experiences for individual students.
Student Performance Prediction: Predicting student outcomes and identifying early intervention opportunities.
Government and Public Policy:
Crime Analysis and Public Safety: Analyzing crime data to allocate resources and develop crime prevention strategies.
Healthcare Policy Planning: Using data to inform healthcare policies, resource allocation, and emergency response planning.
These examples demonstrate the versatility and impact of Data Science across a wide range of industries and applications. By leveraging data effectively, organizations can gain valuable insights that lead to improved operations, better services, and a competitive edge in the market.
Fast Fact
Fast Fact:
The term "Data Science" was coined by statistician William S. Cleveland in 2001, in an article published in the International Statistical Review. Since then, the field has grown exponentially and become a cornerstone of modern technology and business.
Data Scientists
Data Scientists are professionals who possess a blend of skills in programming, statistics, domain expertise, and a deep understanding of data. They are instrumental in extracting meaningful insights and knowledge from large and complex datasets. Here are some key aspects of data scientists:
Skills and Expertise:
Programming: Proficient in languages like Python, R, SQL, and others for data manipulation and analysis.
Statistics and Mathematics: Strong foundation in statistical analysis, probability, and mathematical modeling.
Machine Learning: Familiarity with various machine learning algorithms and techniques for predictive modeling.
Data Visualization: Ability to create visual representations of data to aid in interpretation and communication.
Domain Knowledge: Understanding of the specific industry or field in which they work, enabling them to ask relevant questions and extract meaningful insights.
Responsibilities:
Data Cleaning and Preprocessing: Ensuring data quality by removing errors, duplicates, or irrelevant information.
Exploratory Data Analysis (EDA): Understanding the structure and characteristics of the dataset through visualizations and summary statistics.
Model Development: Building and training machine learning models to make predictions or classifications.
Model Evaluation: Assessing the performance of models and fine-tuning them for better results.
Interpreting Results: Extracting meaningful insights from model outputs and data analyses.
Problem Solving:
Formulating clear and relevant research questions or problem statements.
Developing strategies and approaches to address specific data-related challenges.
Ethical Considerations:
Ensuring privacy and ethical use of sensitive or personal data.
Addressing and mitigating potential biases in algorithms and data.
Communication Skills:
Effectively conveying findings to non-technical stakeholders.
Presenting insights in a clear and compelling manner.
Adaptability and Continuous Learning:
Staying updated with the latest trends, tools, and techniques in the field, given its dynamic nature.
Team Collaboration:
Working closely with other stakeholders such as domain experts, engineers, and business analysts to achieve common objectives.
Industry Applications:
Data scientists can be found in a wide range of industries including finance, healthcare, e-commerce, marketing, and more. They play a crucial role in transforming raw data into actionable insights.
Impact and Value:
Their work leads to informed decision-making, improved processes, innovative product development, and ultimately, added value to businesses and organizations.
Data scientists are instrumental in harnessing the power of data to solve complex problems, drive innovation, and ultimately contribute to the success of businesses and industries across the globe.
Data Science Today
As of my last knowledge update in September 2021, Data Science continues to be a rapidly evolving and influential field. Here are some trends and developments in Data Science as of that time:
Advanced Machine Learning Techniques:
Deep Learning and Neural Networks: These advanced techniques are being applied to solve complex problems in areas like computer vision, natural language processing, and more.
Exponential Growth in Data Volumes:
The amount of data being generated continues to grow at an unprecedented rate, driving the need for more sophisticated tools and techniques for processing and analysis.
Explainable AI and Model Transparency:
There is an increasing emphasis on making machine learning models interpretable and explainable, especially in critical applications like healthcare and finance.
AI Ethics and Responsible AI:
Addressing issues of bias, fairness, privacy, and accountability in AI and Data Science applications has become a prominent concern.
AI in Edge Computing:
Implementing AI models directly on devices (edge computing) rather than relying solely on cloud-based solutions for faster processing and real-time decision-making.
Natural Language Processing (NLP) Advancements:
NLP models have become more sophisticated, enabling tasks like sentiment analysis, chatbots, and language translation to be more accurate and natural.
AI in Healthcare:
Data Science is playing a crucial role in medical imaging analysis, drug discovery, personalized medicine, and health record analysis.
Data Science for Climate and Sustainability:
Data-driven approaches are being used to address environmental challenges, including climate modeling, resource conservation, and sustainable energy solutions.
Data Science in Cybersecurity:
Advanced analytics and machine learning are being applied to detect and respond to cybersecurity threats in real-time.
Data Governance and Compliance:
There is an increased focus on establishing robust data governance frameworks to ensure data integrity, privacy, and compliance with regulations like GDPR.
AI-driven Personalization:
Companies are increasingly using AI to provide highly personalized experiences for customers, from product recommendations to tailored marketing.
Data Science for Social Good:
Organizations and governments are using Data Science to address societal challenges, such as poverty, education, and healthcare access.
Please note that these trends were based on information available up until September 2021. The field of Data Science is dynamic and continually evolving, so there may have been further advancements or shifts in trends beyond that date.
Don't All Sciences Use Data?
Yes, all sciences, to some extent, use data as a foundational element in their research and decision-making processes. However, the extent and nature of data usage can vary significantly across different scientific disciplines. Here's a brief overview:
Physical Sciences (Physics, Chemistry, Astronomy, Geology):
These disciplines heavily rely on empirical data obtained through experiments, observations, and measurements. Data is used to formulate and validate hypotheses, model physical phenomena, and make predictions.
Biological Sciences (Biology, Genetics, Ecology):
Data is central to understanding biological systems. This includes genetic sequences, ecological surveys, clinical trial results, and various forms of biological measurements.
Social Sciences (Psychology, Sociology, Economics):
Social sciences gather and analyze data to understand human behavior, societal trends, economic patterns, and more. This often involves surveys, experiments, and statistical analysis.
Computer and Information Sciences:
Data is not only used but is also a fundamental focus of study in computer science. This includes algorithms for data processing, storage, retrieval, and analysis.
Environmental Sciences:
Environmental scientists collect data on factors like climate, pollution levels, biodiversity, and land use to understand environmental processes and make informed decisions about conservation and policy.
Medical and Health Sciences:
Data is crucial for medical diagnoses, treatment evaluations, drug development, and epidemiological studies. Electronic health records and clinical trial data are examples of essential data sources.
Political Sciences:
Data in political science is used for studying voting patterns, public opinion, policy analysis, and political behavior. Surveys, voting records, and demographic data are common sources.
Mathematics and Statistics:
While mathematics provides the theoretical framework for understanding and manipulating data, statistics is the science of collecting, analyzing, interpreting, and presenting data.
Agricultural Sciences:
Agricultural scientists use data for crop yield predictions, soil analysis, livestock management, and other aspects of sustainable agriculture.
Materials Sciences:
Data is used to characterize the properties and behaviors of materials, aiding in the development of new materials for various applications.
In summary, while all sciences use data, the types of data, methods of collection, and the specific focus on data analysis can vary widely depending on the field. Data Science as a specific discipline is characterized by its emphasis on advanced techniques for handling, analyzing, and extracting insights from large and complex datasets, making it a crucial tool in many scientific endeavors.
What Is Data Science Useful for?
Data Science is useful for a wide range of applications across various industries and domains. Here are some of the key areas where Data Science plays a crucial role:
Predictive Analytics: Data Science enables organizations to make predictions about future trends, behaviors, and events based on historical data. This is invaluable for planning and decision-making.
Recommendation Systems: Data-driven recommendation engines are used in e-commerce, streaming services, and content platforms to suggest products, movies, music, and more to users based on their preferences and behavior.
Customer Segmentation and Personalization: Data Science helps businesses understand their customer base and tailor products, services, and marketing strategies to specific segments for improved customer satisfaction and retention.
Healthcare and Life Sciences: Data Science is applied in areas such as medical imaging analysis, drug discovery, personalized medicine, disease diagnosis, and health outcomes prediction.
Financial Services: In finance, Data Science is used for risk assessment, fraud detection, portfolio optimization, credit scoring, and algorithmic trading.
Marketing and Advertising: Data-driven marketing strategies involve analyzing customer behavior, demographics, and preferences to optimize advertising campaigns, target specific audiences, and measure campaign performance.
Supply Chain Optimization: Data Science helps optimize inventory levels, demand forecasting, and logistics, leading to more efficient and cost-effective supply chain operations.
Energy and Sustainability: Data Science is applied to optimize energy consumption, monitor environmental impact, and develop sustainable solutions for resource management.
Social Media and Content Platforms: Data Science is used to analyze user engagement, sentiment analysis, content recommendations, and ad targeting.
Education and E-Learning: Personalized learning experiences, student performance prediction, and curriculum optimization are areas where Data Science is applied in education.
Manufacturing and Operations: Data Science aids in quality control, predictive maintenance, process optimization, and production planning.
Cybersecurity: Data Science techniques are employed to detect and respond to security threats, identify patterns of malicious behavior, and protect against cyberattacks.
Environmental Sciences: Data Science helps in analyzing climate data, tracking environmental changes, and developing strategies for conservation and sustainability.
Government and Public Policy: Data Science is used in areas such as crime analysis, urban planning, healthcare policy, and resource allocation.
Transportation and Logistics: Data Science is applied to optimize routes, manage fleets, and improve transportation efficiency.
Telecommunications: Data Science helps in network optimization, customer behavior analysis, and improving service quality.
Agriculture: Data Science assists in precision agriculture, crop yield prediction, and livestock management for sustainable and efficient farming practices.
Entertainment and Gaming: Data Science is used for content recommendation, user behavior analysis, and game performance optimization.
These are just a few examples, and the applications of Data Science continue to grow as technology advances and the availability of data increases. It is a versatile and powerful tool that has a profound impact on numerous industries and sectors, ultimately driving innovation, efficiency, and informed decision-making.
What Are Some Downsides of Data Science?
While Data Science has immense potential and benefits, it's important to be aware of its potential downsides and challenges. Here are some of the key considerations:
Privacy Concerns:
Collecting and analyzing large amounts of data raises significant privacy issues. Ensuring that sensitive information is handled securely and in compliance with privacy regulations is crucial.
Bias and Fairness:
Data used for modeling can contain biases, which may lead to biased predictions or decisions. It's important to actively work towards identifying and mitigating these biases.
Data Quality and Accuracy:
Inaccurate or incomplete data can lead to incorrect conclusions or predictions. Data cleaning and validation are critical steps in the Data Science process.
Interpretability of Models:
Some advanced machine learning models, like deep learning neural networks, can be complex and difficult to interpret. This can make it challenging to understand why a model makes a particular prediction.
Overfitting and Generalization:
Overfitting occurs when a model performs very well on the training data but poorly on new, unseen data. Striking the right balance between model complexity and generalization is a challenge.
Resource Intensiveness:
Some advanced models, particularly in deep learning, can be computationally expensive to train and deploy. This may require significant computing resources.
Ethical Considerations:
Ethical dilemmas can arise in areas like surveillance, facial recognition, and decision-making algorithms. Decisions about how to use data and deploy models should be made with ethical considerations in mind.
Data Security Risks:
Handling large datasets can pose security risks. Protecting data from breaches and ensuring compliance with data protection regulations is essential.
Lack of Domain Expertise:
Effective Data Science often requires a deep understanding of the specific domain in which it is being applied. Without this knowledge, it can be challenging to ask the right questions and interpret results correctly.
Data Accessibility and Bias:
Some populations or groups may be underrepresented in the data, leading to biased models that do not accurately represent all segments of the population.
Regulatory Compliance:
Data Science initiatives need to comply with various legal and regulatory frameworks, such as GDPR in Europe. Navigating these requirements can be complex.
Continuous Learning and Adaptation:
The field of Data Science is rapidly evolving. Staying up-to-date with the latest techniques and technologies requires ongoing learning and professional development.
Overemphasis on Data:
In some cases, an over-reliance on data and analytics can lead to neglect of other important factors, such as intuition, creativity, and qualitative insights.
It's important for Data Scientists and organizations to be aware of these potential downsides and to take proactive steps to address them. This may include investing in robust data governance practices, incorporating ethical considerations into modeling, and continuously monitoring and improving models and processes.
Read more: https://computertricks.net/data-science-overview-history-and-faqs/
0 notes
Text
Gain knowledge about Machine Learning for Digital Healthcare Innovation at the 14IHNPUCG from our experts.

How does machine learning work?
A subfield of artificial intelligence (AI) and computer science called machine learning focuses on using data and algorithms to simulate how humans learn, gradually increasing the accuracy of the system.
IBM has a long history with artificial intelligence. With his research on the game of checkers, one of its own, Arthur Samuel, is credited with coining the term "machine learning" (link outside of ibm.com). In 1962, Robert Nealey, a self-described checkers master, competed against an IBM 7094 computer, but he was defeated. This achievement seems insignificant in light of what is now possible, but it is regarded as a significant turning point for artificial intelligence.
Machine learning-based products like Netflix's recommendation engine and self-driving cars have been made possible in recent years because to technical advancements in storage and processing capability.
A casual format for presenting research findings or showcasing cutting-edge techniques is the poster session. The CME/CPD accredited 14th International Healthcare, Hospital Management, Nursing and Patient Safety Conference offers you the chance to present your original ideas in a less formal setting than a paper presentation. Submit your paper, and join us in Holiday Inn Dubai, UAE & Virtual from July 25–27, 2024. Submit here: https://nursing-healthcare.universeconferences.com/submit-abstract/
The rapidly expanding discipline of data science includes machine learning as a key element. Algorithms are trained using statistical techniques to produce classifications or predictions and to find important insights in data mining projects. The decisions made as a result of these insights influence key growth indicators in applications and enterprises, ideally. Data scientists will be more in demand as big data continues to develop and flourish. They will be expected to assist in determining the most pertinent business questions and the information needed to address them. The majority of the time, machine learning algorithms are developed utilising accelerated solution development frameworks like TensorFlow and PyTorch.
Increase in ML in medical settings
As technology advances, machine learning offers an exciting potential in the field of healthcare to enhance the precision of diagnoses, personalise care, and discover fresh approaches to problems that have persisted for decades. A tangible influence on the health of your community can result from using machine learning to programme computers to make connections and predictions and to unearth crucial insights from vast volumes of data that healthcare providers might otherwise overlook.
Machine learning seeks to enhance patient outcomes and generate previously unobtainable medical insights. Through predictive algorithms, it offers a means of validating the judgement and judgements of physicians. Consider a scenario where a patient is given a specific drug by a doctor. Then, using data from a patient who received the same treatment and benefited from it, machine learning can verify this treatment plan.
Internet of Medical Things and machine learning in healthcare
A constantly changing patient data set is essential when using machine learning in the healthcare industry. These data can be used to identify trends that help medical practitioners identify new diseases, assess risks, and forecast treatment outcomes. Due to the sheer number of patients and the variety of medical technology available for data collection, having medical equipment sync to a central "network" is an efficient approach to gather enormous amounts of data.
The network of medical apps and equipment that may connect with one another through online networks is known as the Internet of Medical Things (IoMT). Nowadays, a lot of medical gadgets come with Wi-Fi, enabling them to interface with other machines through cloud platforms or other devices connected to the same network. This makes it possible to track information from wearable devices, track medical histories, and monitor patients remotely, among other things. The IoMT is expected to grow rapidly as more wearable medical devices with internet connectivity hit the market.
Now is your chance to claim your Best Poster Award/Best Speaker Award certificates for the CME/CPD credited 14th International Healthcare, Hospital Management, Nursing and Patient Safety Conference, which will take place in Holiday Inn Dubai, UAE, on July 25–27, 2024. Attend the seminar right away to receive these certifications for the lowest price.
Register, grab your slot & certificates here: https://nursing-healthcare.universeconferences.com/registration/
How is machine learning applied in the medical field?
Numerous healthcare use cases involve the use of machine learning, and much of this technology's potential stems from its capacity to manage complicated data.
HEALTHCARE MACHINE LEARNING
disease prediction and treatment
medical imaging and diagnostic services
finding and creating new medications
Putting medical records in order
As data sets in the healthcare sector grow in size, they are frequently organised as unstructured data in electronic health records (EHRs). Machine learning organises this data into more organised groupings using natural language processing so that healthcare practitioners can swiftly draw conclusions from them.
For pharmaceutical businesses, machine learning and AI have also had an impact on medication research and development. Drugmakers are hoping that machine learning (ML) will be able to forecast how patients will react to different medications and pinpoint which individuals have the best probability of benefiting from the drug. The technology has already supported central nervous system clinical trials.
Additionally, machine learning advancements in healthcare have benefited telemedicine, as some machine learning firms are researching how to organise and deliver patient information to doctors during telemedicine sessions as well as capture information during virtual visits to streamline workflows.
On behalf of the Utilitarian Conferences Gathering, we are delighted to extend our warmest invitation to you to attend the upcoming Nursing Conference: 14th International Healthcare, Hospital Management, Nursing, and Patient Safety Conference. This prestigious event will be held from July 25-27, 2024 at Dubai, UAE. The theme of the conference is “displaying the most recent research results and innovations that underpin evidence-based nursing practise. Innovations in Nursing Research and Evidence-Based Practice.”
As a leading figure in the nursing profession, your presence and expertise would be invaluable to our conference. The event aims to foster collaboration, knowledge sharing, and professional growth among nurses and healthcare practitioners from all corners of the industry.
Connect with us:
WhatsApp: https://wa.me/442033222718
Email: [email protected]
Visit: : https://nursing-healthcare.universeconferences.com/
Call for Papers: https://nursing-healthcare.universeconferences.com/submit-abstract/
Register here: https://nursing-healthcare.universeconferences.com/registration/
Nursing conferences 2023 | Nursing conferences in Dubai | Dubai Nursing Conference | Healthcare Conference in UAE | UCE Nursing Conference | Emirates Nursing Conference | Nursing Event | Nursing Symposium | Healthcare Conferences 2023 | Patient Safety Conferences in Dubai | Nursing Conferences | Nursing Meetings | Registered Nursing Congress | Healthcare Workshop | Patient Safety Symposiums | Patient Education Seminars | Healthcare Research | Healthcare Exhibitions | Healthcare Exhibitions | Registered Nurse Meetings | Registered Nurse Congress | Registered Nurse Workshop | Registered Nurse Symposiums | Registered Nurse Seminars | Registered Nurse Expo | Registered Nurse Exhibitions
0 notes
Text
Vital Signs Monitoring Devices Market 2023-2030
According to Fortune Business Insights the Research Analyst have added a new research study on Title "Vital Signs Monitoring Devices Market", Global Outlook and Forecast 2023-2030 with detailed information & Key Players. The Study provides in-depth comprehensive analysis includes Market definitions, classifications, manufacturing processes, cost structures, development policies and plans. The facts and data are well presented in the Vital Signs Monitoring Devices Market report using diagrams, graphs, pie charts, and other pictorial representations with respect to its current trends, dynamics, and business scope & key statistics.
List of Key Companies Operating in Vital Signs Monitoring Devices Market:
Koninklijke Philips N.V.
Medtronic
Nihon Kohden Corporation
GE Healthcare
Masimo
Omron Healthcare
Contec Medical Systems Co. Ltd
A&D Company Ltd.
Nonin Medical Inc.
SunTech Medical, Inc.
Other Players
Segmentation Analysis:
The report gives an extensive analysis of various segments of the market by studying the product range, applications, major regions, and leading companies in the industry. Additionally, the Vital Signs Monitoring Devices Market report also dedicates an individual section to give a detailed analysis of the manufacturing process, which includes information collected through both primary and secondary sources of data collection. The primary source of data collection contains interviews of industry experts who offer accurate insights into the future market scenario.
Competitive landscape:
The report sheds light on critical information relating to the company profiles, product portfolio, growth prospects, cost assessment, total sales, revenue generated, market shares held by key regions, established companies, and emerging players. The study includes a SWOT analysis of key market players in the Vital Signs Monitoring Devices Market to assess their Strengths, Weaknesses, Opportunities, Threats, and examines the company’s internal & external environments and the elements present that could affect the growth of the industry.
About Us:
Fortune Business Insights™ offers expert corporate analysis and accurate data, helping organizations of all sizes make timely decisions. Our reports contain a unique mix of tangible insights and qualitative analysis to help companies achieve sustainable growth. Our team of experienced analysts and consultants use industry-leading research tools and techniques to compile comprehensive market studies, interspersed with relevant data.
Contact Us:
Fortune Business Insights™ Pvt. Ltd.
Icon Tower, 9th Floor
Baner - Mahalunge Road,
Pune-411045, Maharashtra, India.
Phone: US:+1 424 253 0390,
UK: +44 2071 939123,
APAC: +91 744 740 1245
Email: [email protected]
0 notes
Text
Know Everything About Predictive Analytics
Predictive analytics is the process of using data, statistical algorithms, and machine learning techniques to analyze historical data and make predictions about future events or outcomes. It involves extracting meaningful patterns and relationships from past data to forecast what might happen in the future.
What is Predictive Analytics
Predictive analytics is a field of data analysis that involves using historical data and statistical algorithms to make predictions about future events or outcomes. It’s a form of advanced analytics that goes beyond describing what happened in the past or analyzing the present but instead focuses on forecasting what might happen in the future.
The main goal of predictive analytics is to identify patterns, trends, and relationships in historical data and use this information to make informed predictions about potential future scenarios. By leveraging these insights, businesses, and organizations can make better decisions, anticipate risks, optimize processes, and gain a competitive advantage.
The process of predictive analytics involves several steps, including data collection, data preprocessing, data exploration, model selection, model training, model evaluation, model deployment, and ongoing monitoring and maintenance.
Predictive analytics is widely used in various industries and applications. For example, it can be applied to predict customer churn in businesses, forecast sales and demand for products, detect fraudulent activities in financial transactions, optimize supply chain operations, predict equipment failures in maintenance processes, and even forecast disease outbreaks in healthcare.
Predictive Analytics Techniques
Predictive analytics employs a variety of techniques and methods to make accurate predictions based on historical data. Here are some commonly used techniques in predictive analytics:
Regression Analysis: Regression models are used to establish relationships between dependent and independent variables. It helps in predicting a continuous numeric value, such as predicting sales or estimating a person’s age based on various factors.
Classification: Classification techniques are used to predict categorical outcomes, such as whether a customer will buy a product (yes/no) or whether an email is spam or not. Common classification algorithms include Decision Trees, Random Forests, Support Vector Machines (SVM), and Logistic Regression.
Time Series Analysis: Time series models are used when dealing with sequential data points that are collected over time. They are useful for predicting future values based on past observations and trends. Time series forecasting is widely used in finance, economics, and various other fields.
Machine Learning Algorithms: Various machine learning algorithms, such as k-Nearest Neighbors (k-NN), Naive Bayes, and Neural Networks, can be used for predictive analytics tasks depending on the problem at hand and the nature of the data.
Clustering Analysis: Clustering techniques are used to group similar data points together. While clustering itself is not a prediction task, it can help identify patterns within the data that may aid in making predictions or segmenting customers based on behavior.
Text Mining and Natural Language Processing (NLP): These techniques are used to analyze and extract insights from unstructured text data. Sentiment analysis, for instance, can predict the sentiment of customer reviews or social media comments.
Ensemble Methods: Ensemble techniques combine the predictions of multiple models to improve accuracy and reduce overfitting. Bagging (e.g., Random Forest) and boosting (e.g., Gradient Boosting Machines) are popular ensemble methods.
Anomaly Detection: Anomaly detection techniques are used to identify unusual patterns or outliers in data, which can be useful for predicting rare events or detecting anomalies in real time.
Collaborative Filtering: This technique is widely used in recommendation systems. It predicts a user’s preference for a product or service based on the preferences of similar users.
Survival Analysis: Survival analysis is used to predict the time to an event’s occurrence, such as predicting customer churn or the lifespan of a product.
The choice of predictive analytics technique depends on the specific problem, the type of data available, and the desired outcome. Often, a combination of different techniques and data preprocessing steps is necessary to create an accurate predictive model.
How to Implement Predictive Analytics in Your Business
Implementing predictive analytics in your business involves several key steps to ensure its successful integration and utilization. Here’s a general guide to help you get started:
Define Your Objectives: Clearly outline the business objectives you want to achieve with predictive analytics. Identify the specific problems you want to solve or the opportunities you want to explore. Having well-defined goals will help you focus your efforts and resources effectively.
Collect and Prepare Data: Gather relevant data from various sources within your organization. This data could include historical records, customer information, sales data, website activity, and any other data that is pertinent to your objectives. Clean and preprocess the data to ensure its accuracy and consistency.
Select the Right Tools and Techniques: Choose the appropriate predictive analytics tools and techniques that align with your objectives and data. Consider the nature of your data (numeric, categorical, sequential), the type of predictions you want to make (regression, classification, time series forecasting), and the available resources (software, hardware, expertise).
Build Predictive Models: Train and build predictive models using the preprocessed data and selected techniques. This step involves splitting your data into training and testing sets to assess the model’s performance. Experiment with various algorithms to find the best fit for your data.
Validate and Evaluate Models: Validate the models using testing data to ensure they perform well and generalize to unseen data. Evaluate the models using appropriate metrics such as accuracy, precision, recall, or mean squared error, depending on the nature of your predictive task.
Implement Models in Your Business Processes: Once you have validated and selected the best-performing models, integrate them into your business processes. This could involve deploying the models into existing software systems, creating APIs for real-time predictions, or building dashboards for decision-makers.
Train Your Team: Provide training to your team members who will be working with predictive analytics. Ensure they understand the models, their implications, and how to interpret the results. This will help your team effectively use predictive analytics insights to make data-driven decisions.
Monitor and Update: Continuously monitor the performance of your predictive models and update them as needed. As new data becomes available, retrain the models to keep them accurate and up-to-date.
Start Small and Scale: Consider starting with smaller pilot projects to test the feasibility and effectiveness of predictive analytics in your business. Once you gain confidence and see positive results, you can gradually scale up and apply predictive analytics to more areas of your business.
Stay Compliant with Data Regulations: Ensure that you comply with data privacy and security regulations when implementing predictive analytics. Protect sensitive data and obtain necessary permissions from customers or stakeholders, as required.
Remember that implementing predictive analytics is an iterative process. It’s essential to continuously learn from your results, refine your models, and adapt to changing business needs. With time and effort, predictive analytics can become a valuable asset in making informed decisions and gaining a competitive advantage in your industry.
#predictive analytics services#predictive analytics consulting#predictive analytics solutions#predictive analytics consulting services
0 notes
Text
Data Annotation for Fine-tuning Large Language Models(LLMs)

The beginning of ChatGPT and AI-generated text, about which everyone is now raving, occurred at the end of 2022. We always find new ways to push the limits of what we once thought was feasible as technology develops. One example of how we are using technology to make increasingly intelligent and sophisticated software is large language models. One of the most significant and often used tools in natural language processing nowadays is large language models (LLMs). LLMs allow machines to comprehend and produce text in a manner that is comparable to how people communicate. They are being used in a wide range of consumer and business applications, including chatbots, sentiment analysis, content development, and language translation.
What is a large language model (LLM)?
In simple terms, a language model is a system that understands and predicts human language. A large language model is an advanced artificial intelligence system that processes, understands, and generates human-like text based on massive amounts of data. These models are typically built using deep learning techniques, such as neural networks, and are trained on extensive datasets that include text from a broad range, such as books and websites, for natural language processing.
One of the critical aspects of a large language model is its ability to understand the context and generate coherent, relevant responses based on the input provided. The size of the model, in terms of the number of parameters and layers, allows it to capture intricate relationships and patterns within the text.
While analyzing large amounts of text data in order to fulfill this goal, language models acquire knowledge about the vocabulary, grammar, and semantic properties of a language. They capture the statistical patterns and dependencies present in a language. It makes AI-powered machines understand the user’s needs and personalize results according to those needs. Here’s how the large language model works:
LLMs need massive datasets to train AI models. These datasets are collected from different sources like blogs, research papers, and social media.
The collected data is cleaned and converted into computer language, making it easier for LLMs to train machines.
Training machines involves exposing them to the input data and fine-tuning its parameters using different deep-learning techniques.
LLMs sometimes use neural networks to train machines. A neural network comprises connected nodes that allow the model to understand complex relationships between words and the context of the text.
Need of Fine Tuning LLMs

Fine-tuning a large language model involves adjusting and adapting a pre-trained model to perform specific tasks or cater to a particular domain more effectively. The process usually entails training the model further on a targeted dataset that is relevant to the desired task or subject matter. The original large language model is pre-trained on vast amounts of diverse text data, which helps it to learn general language understanding, grammar, and context. Fine-tuning leverages this general knowledge and refines the model to achieve better performance and understanding in a specific domain.
Fine-tuning a large language model (LLM) is a meticulous process that goes beyond simple parameter adjustments. It involves careful planning, a clear understanding of the task at hand, and an informed approach to model training. Let's delve into the process step by step:
Identify the Task and Gather the Relevant Dataset -The first step is to identify the specific task or application for which you want to fine-tune the LLM. This could be sentiment analysis, named entity recognition, or text classification, among others. Once the task is defined, gather a relevant dataset that aligns with the task's objectives and covers a wide range of examples.
Preprocess and Annotate the Dataset -Before fine-tuning the LLM, preprocess the dataset by cleaning and formatting the text. This step may involve removing irrelevant information, standardizing the data, and handling any missing values. Additionally, annotate the dataset by labeling the text with the appropriate annotations for the task, such as sentiment labels or entity tags.
Initialize the LLM -Next, initialize the pre-trained LLM with the base model and its weights. This pre-trained model has been trained on vast amounts of general language data and has learned rich linguistic patterns and representations. Initializing the LLM ensures that the model has a strong foundation for further fine-tuning.
Fine-Tune the LLM -Fine-tuning involves training the LLM on the annotated dataset specific to the task. During this step, the LLM's parameters are updated through iterations of forward and backward propagation, optimizing the model to better understand and generate predictions for the specific task. The fine-tuning process involves carefully balancing the learning rate, batch size, and other hyperparameters to achieve optimal performance.
Evaluate and Iterate -After fine-tuning, it's crucial to evaluate the performance of the model using validation or test datasets. Measure key metrics such as accuracy, precision, recall, or F1 score to assess how well the model performs on the task. If necessary, iterate the process by refining the dataset, adjusting hyperparameters, or fine-tuning for additional epochs to improve the model's performance.
Data Annotation for Fine-tuning LLMs
The wonders that GPT and other large language models have come to reality due to a massive amount of labor done for annotation. To understand how large language models work, it's helpful to first look at how they are trained. Training a large language model involves feeding it large amounts of data, such as books, articles, or web pages so that it can learn the patterns and connections between words. The more data it is trained on, the better it will be at generating new content.
Data annotation is critical to tailoring large-language models for specific applications. For example, you can fine-tune the GPT model with in-depth knowledge of your business or industry. This way, you can create a ChatGPT-like chatbot to engage your customers with updated product knowledge. Data annotation plays a critical role in addressing the limitations of large language models (LLMs) and fine-tuning them for specific applications. Here's why data annotation is essential:
Specialized Tasks: LLMs by themselves cannot perform specialized or business-specific tasks. Data annotation allows the customization of LLMs to understand and generate accurate predictions in domains or industries with specific requirements. By annotating data relevant to the target application, LLMs can be trained to provide specialized responses or perform specific tasks effectively.
Bias Mitigation: LLMs are susceptible to biases present in the data they are trained on, which can impact the accuracy and fairness of their responses. Through data annotation, biases can be identified and mitigated. Annotators can carefully curate the training data, ensuring a balanced representation and minimizing biases that may lead to unfair predictions or discriminatory behavior.
Quality Control: Data annotation enables quality control by ensuring that LLMs generate appropriate and accurate responses. By carefully reviewing and annotating the data, annotators can identify and rectify any inappropriate or misleading information. This helps improve the reliability and trustworthiness of the LLMs in practical applications.
Compliance and Regulation: Data annotation allows for the inclusion of compliance measures and regulations specific to an industry or domain. By annotating data with legal, ethical, or regulatory considerations, LLMs can be trained to provide responses that adhere to industry standards and guidelines, ensuring compliance and avoiding potential legal or reputational risks.
Final thoughts
The process of fine-tuning large language models (LLMs) has proven to be essential for achieving optimal performance in specific applications. The ability to adapt pre-trained LLMs to perform specialized tasks with high accuracy has unlocked new possibilities in natural language processing. As we continue to explore the potential of fine-tuning LLMs, it is clear that this technique has the power to revolutionize the way we interact with language in various domains.
If you are seeking to fine-tune an LLM for your specific application, TagX is here to help. We have the expertise and resources to provide relevant datasets tailored to your task, enabling you to optimize the performance of your models. Contact us today to explore how our data solutions can assist you in achieving remarkable results in natural language processing and take your applications to new heights.
0 notes
Text
IBM Data Science Professional Certificate - SkillUp Online
Are you ready to embark on a journey into the world of data science? SkillUp Online is thrilled to offer the IBM Data Science Course , a comprehensive program designed to equip you with the knowledge and skills needed to excel in the field of data science. Developed in collaboration with IBM, this certificate program combines theoretical foundations with practical applications, providing you with a holistic learning experience.
1. Introduction to Data Science
In this introductory module, you'll gain a solid understanding of the fundamental concepts and principles of data science. You'll explore the role of data scientists and the significance of data-driven decision-making in various industries. Through engaging lectures and real-world examples, you'll discover the potential of data science and its impact on businesses and society.
2. Data Analysis and Visualization
Data analysis is a crucial aspect of data science. In this module, you'll learn how to clean, transform, and analyze data using popular tools and techniques. You'll also explore data visualization methods to effectively communicate insights and findings. By the end of this module, you'll be proficient in extracting valuable information from datasets and presenting it in a visually appealing manner.
3. Machine Learning with Python
Machine learning is at the heart of data science. In this module, you'll delve into the world of machine learning algorithms and their applications. Using the Python programming language, you'll learn how to implement various machine learning models, including classification, regression, clustering, and recommendation systems. You'll also gain hands-on experience in evaluating and optimizing the performance of these models.
4. Data Science Tools and Libraries
To be an effective data scientist, you need to be familiar with the tools and libraries that streamline the data science workflow. In this module, you'll explore popular data science tools such as Jupyter Notebooks, Pandas, NumPy, and scikit-learn. You'll learn how to leverage these tools to manipulate data, perform statistical analysis, and build machine learning models efficiently.
5. Data Science Methodology
A structured approach is crucial for successful data science projects. In this module, you'll be introduced to the data science methodology, which includes a step-by-step framework for solving problems using data science techniques. You'll learn how to frame business problems as data science questions, collect and analyze data, and develop models that address the problem at hand. You'll also gain insights into the ethical considerations surrounding data science.
6. Applied Data Science Capstone Project
In this final module, you'll apply all the knowledge and skills gained throughout the program to a real-world data science project. Working on a comprehensive capstone project, you'll tackle a complex problem, gather and analyze relevant data, and develop a data-driven solution. This project will showcase your proficiency in data science and serve as a valuable addition to your portfolio.
Conclusion
The IBM Data Science Professional Certificate offered by SkillUp Online is your gateway to a rewarding career in data science. By completing this certificate program, you'll acquire the essential skills and knowledge required to excel in the field. Whether you're a beginner or have some experience in data science, this program will equip you with the necessary tools to tackle complex problems, extract meaningful insights from data, and make informed decisions.
Source:- https://skillup.online/datascience-ibm-professional-certificate/
0 notes
Text
Data Science Certificates that is Low Cost
Before we look at the Certifications, we look at What is Data Science, Data Mining, Data Analysis.
What is Data Science and Data Mining?
What is CRISP DM? For Data Mining process, we usually use CRISP DM data mining process:

Based on: https://www.datascience-pm.com/crisp-dm-2/
Data Mining process steps includes Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment.
- Business Understanding step - we need to understand the business and establish the question we need to answer for the data mining
- Data Understanding step - we need to understand the data. We can use statistics such as descriptive, regression analysis to understand the data.
- Data Preparation step - it is the cleaning of the data and we can remove duplicates here.
- Modeling step - we create clustering models, prediction models, classification models.
- Evaluation step - we evaluate which models is more accurate and select.
- Deployment steps - we can create data products.
For Data Science, at the Deployment steps, we create data products for businesses. We can create softwares that predicts something. In the table, the goal is to build data products for a business.
For Data Mining, at the Deployment steps, we create reports or PowerPoints slides on our results. In the table, the goal is to extracting important information.
Read More on CRISP DM: http://edatascience.great-site.net/2023/03/08/what-is-crisp-dm/
Data Analysis Process
What is Data Analysis Process? The following is the summary of Data Analysis process:
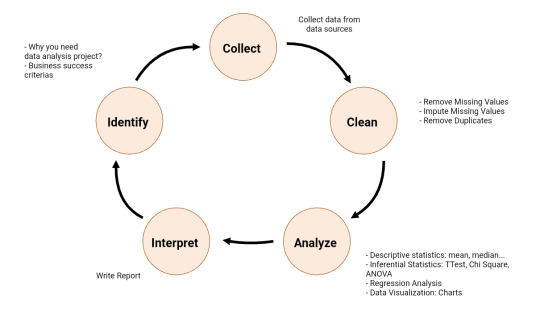
Identify - You need to identify why you need data analysis in the first place?
Collect - As the name suggest, this is the step you collect data.
Analyse - To analyze data, you can use descriptive statistics (mean, median, …), inferential statistics, data visualizations (charts) to analyze the data.
Interpret - It is time to interpret your results. Write report.
Read more: http://edatascience.great-site.net/2023/03/09/what-is-data-analysis-process/
Coursera and IBM Professional Certificate in Data Science (Python, SQL)
The author also have this certificate. This programme has 9 courses that will provide you with job ready skills, including open source tools, Python, SQL, data visualization, data analysis, statistic, predictive modeling, and machine learning. You will learn data science through hands-on practice. Upon completion of these courses, you will have built a portfolio to provide you with confidence to go into data science. In addition to earning a professional certificate, you will receive a digital badge from IBM. The courses are ACE® recommended, you can earn 12 college credits and the credits can transfer to your University, which is up to your University to approve.
https://www.coursera.org/professional-certificates/ibm-data-science
Coursera and IBM Professional Certificate Data Analysis
This professional certificate does not require prior programming skills, and is suitable for learners without degrees. Upon successful completion of this program, you will be able to analyze real world datasets, create interactive dashboards, present reports. It will give you the confidence and the portfolio to start a career as junior data analyst. This program is ACE® recommended - you can earn 12 college credits and the credits can transfer to your University, which is up to your University to approve.
Many university does not teach Microsoft Excel for Data Science, hence, this programme is good if you want to know more about Excel.
https://www.coursera.org/professional-certificates/ibm-data-analyst
Coursera and Google Professional Certificate in Data Analytics (Spreadsheets, SQL, Tableau, R)
Data Analysis has Identify, Collect, Clean, Analyze, Intepret. This programme has eight courses - Foundations: Data, Data Everywhere course, Ask Question to make Data Decision course (Identify), Prepare Data for Exploration course (Collect, Clean), Process Data from Dirty to Clean course (Clean), Analyze Data to Answer Question (Analyze), Share Data Through the Art of Visualization (Analyze), Data Analysis with R Programming, Google Data Analytics Capstone. You will learn from Google Employees and you can complete the certificate in less than 6 months. The certificate will prepare you for jobs that includes junior data analyst, data adminsitrator and more. Upon completion of the certificate, you can directly apply for jobs with Google, and over 150 US employers.
According to Google, 75% of Google Career Certificate Graduates in the United States report an improvement in their career trajectory (e.g. new job or career, promotion or raise) within 6 months of certificate completion²
https://www.coursera.org/professional-certificates/google-data-analytics
EdX and Harvard University Professional Certificate in Data Science (R Programming)
When we say case studies, we are studying MBA degree. Read more:
https://www.onlinemanipal.com/blogs/mba-case-studies This programme uses case study. In each course, Harvard University use motivating case studies, ask specific questions, and learn by answering these through data analysis. Case Studies include Trends in World Health and Economics, US Crime Rates, The Financial Crisis of 2007 to 2008, Election Forecasting.
The HarvardX Data Science program prepares you with necessary knowledge and skills to tackle real world challenges. The program consists of probability, inference, regression, machine learning, and R programming. Data wrangling with dplyr, data visualization with ggplot2, version control with GitHub, reproducible document preparation with RStudio.
Read More on dplyr, ggplot2: http://edatascience.great-site.net/2023/03/12/what-are-they-dplyr-ggplot2-caret-rmarkdown-r-libraries/
https://www.edx.org/professional-certificate/harvardx-data-science
EdX and Harvard University Professional Certificate in Learn Python for Data Science (Python)
This professional Certificate has three courses – CS50’s Introduction to Programming with Python course, Fat Chance: Probability form the Ground Up course, Introduction to Data Science with Python course. This profession Certificate focuses on hands-on learning, and each course will build upon each other, preparing you to solve complex challenges using data analysis. No Prior programming experience is required. Taught by experts in the field, you will learn the foundations of Python and statistics before moving to more advanced Python for machine learning and AI. You will use libraries such as Pandas, numPy, matplotlib, and SKLearn.
Read more on Pandas, matplotlib, sklearn: http://edatascience.great-site.net/2023/03/12/92/
https://www.edx.org/professional-certificate/harvardx-learning-python-for-data-science
EdX and Rochester Institute of Technology Professional Certificate in Data Analysis for Decision Making (Excel, Tableau)
This programme has three courses - Data Literacy Foundations course, Data Processing and Analysis with Excel course, and Data Representation and Visualization in Tableau course. Data Literacy Foundations course teaches about leader in data driven decision making. Data Processing and Analysis with Data course teaches Microsoft Excel to organize and clean data so that it can be analyzed. Data Representation and Visualization in Tableau course teaches Tableau to explore data and discovers insights.
Many university does not teach Microsoft Excel for Data Science, hence, this programme is good if you want to know more about Excel and Tableau.
https://www.edx.org/professional-certificate/ritx-data-analysis-for-decision-making
SVBook Certified Data Miner using Python
SVBook Certified Data Miner using Python are given to people who have completed the following courses:
- Create Your Calculator: Learn Python Programming Basics Fast (Python Basics)
- Applied Statistics using Python with Data Processing (Data Understanding and Data Preparation)
- Advanced Data Visualizations using Python with Data Processing (Data Understanding and Data Preparation)
- Machine Learning with Python (Modeling and Evaluation)
and passed a 50 questions. The four courses are created to help learner understand about Python programming basics, then applied statistics (descriptive, inferential, regression analysis) and data visualizations (bar chart, pie chart, boxplot, scatterplot matrix, advanced visualizations with seaborn, and Plotly interactive charts ) with data processing basics to understand more about the the data understanding and data preparation stage of IBM CRISP DM model. Learner will then learn about machine learning and confusion matrix, which is the modeling and evaluation stages of the IBM CRISP DM model. Learner will be able
http://emhacademy.great-site.net/?i=1
SVBook Certified Data Miner using R
SVBook Certified Data Miner using R are given to people who have completed the following courses:
- Create Your Calculator: Learn R Programming Basics Fast (R Basics)
- Applied Statistics using R with Data Processing (Data Understanding and Data Preparation)
- Advanced Data Visualizations using R with Data Processing (Data Understanding and Data Preparation)
- Machine Learning with R (Modeling and Evaluation)
and passed a 50 questions Exam. The four courses are created to help learner understand about R programming basics, then applied statistics (descriptive, inferential, regression analysis) and data visualizations (bar chart, pie chart, boxplot, scatterplot matrix, advanced visualizations with ggplot2) with data processing basics to understand more about the the data understanding and data preparation stage of IBM CRISP DM model. Learner will then learn about machine learning and confusion matrix, which is the modeling and evaluation stages of the IBM CRISP DM model. Learner will be able to do data mining project after learning the courses.
http://emhacademy.great-site.net/?i=1
If you want to learn more about data science, you can go to http://svbook.great-site.net/?i=1
SVBook Pte. Ltd. assists people to know What is Data Science, Text Analysis, Text Mining, Text Analytics, AI and Machine Learning, process of data, Data Mining to Insights Process using CRISP DM. Data Mining Process Steps includes Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment.
DSTK.Tech (https://dstk2.sourceforge.io/) creates tools and technologies for Data Science, develops open source tools for data science.
EMHAcademy (http://emhacademy.great-site.net/) offers courses to help people become Certified Data Scientist.
Thanks for readings.
Kind Regards,
Eric Goh
Buy me a cup of coffee:https://www.buymeacoffee.com/gohminghui
Read the full article
0 notes




