#spark-sql
Text
WEEK 2: SparkML
1) Select the best definition of a machine learning system.
-> A machine learning system applies a specific machine learning algorithm to train data models. After training the model, the system infers or “predicts” results on previously unseen data.
2) Which of the following options are true about Spark ML inbuilt utilities?
-> Spark ML inbuilt utilities includes a linear algebra package.
->…
View On WordPress
0 notes
Text
[Python] PySpark to M, SQL or Pandas
Hace tiempo escribí un artículo sobre como escribir en pandas algunos códigos de referencia de SQL o M (power query). Si bien en su momento fue de gran utilidad, lo cierto es que hoy existe otro lenguaje que representa un fuerte pie en el análisis de datos.
Spark se convirtió en el jugar principal para lectura de datos en Lakes. Aunque sea cierto que existe SparkSQL, no quise dejar de traer estas analogías de código entre PySpark, M, SQL y Pandas para quienes estén familiarizados con un lenguaje, puedan ver como realizar una acción con el otro.
Lo primero es ponernos de acuerdo en la lectura del post.
Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #“Paso anterior” hablamos de una tabla.
En Python, asumiremos a "df" como un pandas dataframe (pandas.DataFrame) ya cargado y a "spark_frame" a un frame de pyspark cargado (spark.read)
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, PySpark, Pandas, Power Query.
En SQL:
SELECT TOP 5 * FROM table
En PySpark
spark_frame.limit(5)
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
spark_frame.count()
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
spark_frame.select("column1", "column2")
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]]
O podría ser:
Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
spark_frame.filter("column1 = 2")
# OR
spark_frame.filter(spark_frame['column1'] == 2)
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
spark_frame.filter((spark_frame['column1'] > 1) & (spark_frame['column2'] < 25))
O con operadores OR y NOT
spark_frame.filter((spark_frame['column1'] > 1) | ~(spark_frame['column2'] < 25))
df.loc[(df['column1'] > 1) & (df['column2'] < 25)]
O con operadores OR y NOT
df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 )
O con operadores OR y NOT
Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
from pyspark.sql.functions import col
spark_frame.filter(
(col('column1').between(1, 5)) &
(col('column2').isin(20, 30, 40, 50)) &
(col('column3').like('%arcelona%'))
)
# O
spark_frame.where(
(col('column1').between(1, 5)) &
(col('column2').isin(20, 30, 40, 50)) &
(col('column3').contains('arcelona'))
)
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Sería correcto cambiar el alias de columnas de mismo nombre así:
spark_frame1.join(spark_frame2, spark_frame1["column_id"] == spark_frame2["column_id"], "left").select(spark_frame1["column1"].alias("column1_df1"), spark_frame2["column1"].alias("column1_df2"))
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left')
df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas
df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]]
#"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter)
#"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
from pyspark.sql.functions import count
spark_frame.groupBy("column1").agg(count("*").alias("count"))
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
from pyspark.sql.functions import sum as spark_sum
spark_frame.groupBy("store").agg(spark_sum("sales").alias("total_sales")).filter("total_sales > 1000")
df_grouped = df.groupby('store')['sales'].sum()
df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}})
#"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
spark_frame.orderBy("column1", ascending=False)
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
spark_frame1.union(spark_frame2)
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2)
pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre PySpark, Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL. Puede que su resultado no sea idéntico pero si similar para el caso a resolver.
Analizar el contenido de una tabla
spark_frame.summary()
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
spark_frame.groupBy("column1").count().show()
df.value_counts("columna1")
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
spark_frame = spark.createDataFrame([(1, "Boris Yeltsin"), (2, "Mikhail Gorbachev")], inferSchema=True)
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
spark_frame.drop("column1")
df.drop(columns=['column1'])
df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
spark_frame.withColumn("column1", col("column1") + 1)
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con PySpark, SQL, Pandas y Power Query para que conociendo uno sepamos usar el otro.
#spark#pyspark#python#pandas#sql#power query#powerquery#notebooks#ladataweb#data engineering#data wrangling#data cleansing
0 notes
Text
Data Analysis Online: Crafting a Learning Path for Success

In today's data-driven world, mastering data analysis is essential for professionals across various industries. As the demand for data analysis skills continues to grow, individuals are turning to online learning platforms to acquire the knowledge and expertise needed to succeed in this field. Crafting a structured learning path is key to achieving success in data analysis online. Let's explore how to design a learning path tailored to mastering data analysis and advancing your career aspirations.
1. Assess Your Current Skill Level:
Before diving into data analysis online, it's essential to assess your current skill level and identify areas for improvement. Evaluate your proficiency in essential tools and concepts such as Python programming, SQL querying, and basic statistical analysis. Understanding your strengths and weaknesses will help you tailor your learning path to address specific skill gaps and build a solid foundation for success.
2. Identify Learning Objectives:
Define clear learning objectives to guide your data analysis journey. Whether you're aiming to become proficient in Python programming for data analysis, master SQL for database querying, or explore advanced topics like machine learning and big data analytics, setting specific goals will help you stay focused and motivated throughout your learning experience.
3. Choose High-Quality Courses:
Selecting the right courses is crucial for mastering data analysis online. Look for reputable online platforms that offer a wide range of courses covering various aspects of data analysis, including Python programming, SQL querying, and specialized topics like Apache Spark for big data analytics. Consider factors such as course content, instructor expertise, hands-on learning opportunities, and student reviews when choosing the best data analysis courses online.
4. Build a Solid Foundation:
Begin your learning journey by focusing on building a solid foundation in essential data analysis skills. Start with introductory courses that cover fundamental concepts and techniques, such as Python programming basics, SQL querying fundamentals, and data manipulation and visualization. These foundational skills will serve as the building blocks for more advanced topics and specialized areas of data analysis.
5. Dive Deeper into Specialized Topics:
Once you've established a strong foundation, explore specialized topics and advanced techniques to expand your data analysis skill set. Delve into courses that cover advanced Python programming for data analysis, advanced SQL querying and database management, and specialized tools and libraries for tasks like data visualization, machine learning, and big data processing with Apache Spark. By exploring specialized topics, you can deepen your expertise and unlock new opportunities in data analysis.
6. Practice, Practice, Practice:
Practice is essential for mastering data analysis skills. Apply what you've learned in your courses to real-world projects, datasets, and problem-solving scenarios. Engage in hands-on exercises, projects, and challenges to reinforce your learning, develop practical skills, and build a portfolio of work that showcases your expertise in data analysis.
In conclusion, crafting a learning path for success in data analysis online requires careful planning, dedication, and a commitment to continuous learning. By assessing your current skill level, setting clear learning objectives, choosing high-quality courses, building a solid foundation, exploring specialized topics, practicing regularly, and staying updated with industry trends, you can embark on a rewarding journey to master data analysis and achieve your career goals.
#apache spark course#data analysis#data analysis skill#python course#best python course#data analysis course#data analysis course online#master data analysis#python course online#sql course#sql course online#best sql course#data analysis online#python course training#sql course training#apache spark course online#best apache spark course#scholarnest#scholarnest technologies
1 note
·
View note
Link
0 notes
Video
youtube
5:Spark- Community and Ecosystem #spark #python #programming #datascienc...
0 notes
Text
What is a Data Pipeline?
What is Data Pipeline?
#sql #database #language #query #schema #ddl #dml#analytics #engineering #distributedcomputing #dataengineering #science #news #technology #data #trends #tech #hadoop #spark #hdfs #bigdata
A data pipeline is a process that extracts data from various sources, transforms it into a suitable format, and is loaded to a data warehouse or other data storage layer. Data pipelines are an integral part of Data engineering that produces data suitable for data owners or downstream users to analyze and produce and business-ready datasets to consume. It enables organizations to collect, store,…
View On WordPress
0 notes
Text
Greetings from Ashra Technologies
we are hiring.....
#ashra#ashratechnologies#ashrajobs#jobsearch#jobs#hiring#recruiting#recruitingpost#Flex#dataengineer#gcp#spark#python#java#datalake#aws#cloudplatform#sql#azure#chennai#pune#apply#applynow#linkedin
0 notes
Text
Unlocking the Full Power of Apache Spark 3.4 for Databricks Runtime!
You've dabbled in the magic of Apache Spark 3.4 with my previous blog "Exploring Apache Spark 3.4 Features for Databricks Runtime", where we journeyed through 8 game-changing features
You’ve dabbled in the magic of Apache Spark 3.4 with my previous blog “Exploring Apache Spark 3.4 Features for Databricks Runtime“, where we journeyed through 8 game-changing features—from the revolutionary Spark Connect to the nifty tricks of constructing parameterized SQL queries. But guess what? We’ve only scratched the surface!
In this sequel, we’re diving deeper into the treasure trove of…

View On WordPress
#Apache Spark#Azure Databricks#Azure Databricks Cluster#Data Frame#Databricks#databricks apache spark#Databricks SQL#Memory Profiler#NumPy#performance#Pivot#pyspark#PySpark UDFs#SQL#SQL queries#SQL SELECT#SQL Server
0 notes
Text
Hiring BIGDATA ENGINEER Role for Plano TX (Onsite/Hybrid)
Hiring BIGDATA ENGINEER Role for Plano TX (Onsite/Hybrid)
Greetings From Cloudious!
Job title: BIGDATA ENGINEER
Location: Plano TX (Onsite/Hybrid)
Duration: 6+ Months
Start Date: ASAP
8+ Years of Exp Needed
Must Have: Enterprise level implementation and hands on experience in – Spark (PySpark preferred, Dataframe, Filters, UDF, Partition), SQL, Python
Required Skills: ANSI SQL, Python, Apache Hadoop, PySpark.
Detailed JD:
Experience in Agile Methodology…

View On WordPress
0 notes
Photo

😂😂 funny one 😺. For data science related content. Do check ✅ out my bio. And subscribe the channel ❤️. Follow me for more updates 🙂. #pyspark #pysparktutorial #pysparktraining #pysparktutorialforbeginners #spark #pysparkrdd #whatispyspark #pysparkdataframetutorial #datascience #datascienceforbeginners #datasciencecourse #datasciencetutorial #whatisdatascience #datasciencejobs #learndatascience #sql #tsql #sqli #mysql #mssql #t-sql #mysql #nosql #whysql #sqlite (at Bangalore, India) https://www.instagram.com/p/Cj9iNDxvRw3/?igshid=NGJjMDIxMWI=
#pyspark#pysparktutorial#pysparktraining#pysparktutorialforbeginners#spark#pysparkrdd#whatispyspark#pysparkdataframetutorial#datascience#datascienceforbeginners#datasciencecourse#datasciencetutorial#whatisdatascience#datasciencejobs#learndatascience#sql#tsql#sqli#mysql#mssql#t#nosql#whysql#sqlite
0 notes
Text
WEEK 1: Spark for Data Engineering
1) Select the option where all four statements about streaming data characteristics are correct.
-> Data is generated continuously; often originates from more than one source; is unavailable as a complete data set; requires incremental processing.
2) Select the data sink option that is not fault-tolerant and that is recommended for debugging only.
-> Console and Memory
3) Select the answer…
View On WordPress
0 notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
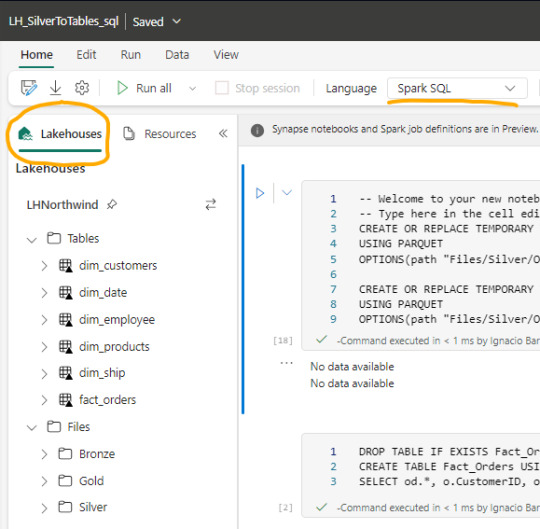
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp
USING PARQUET
OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders
USING PARQUET
OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
Consultas y transformaciones
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
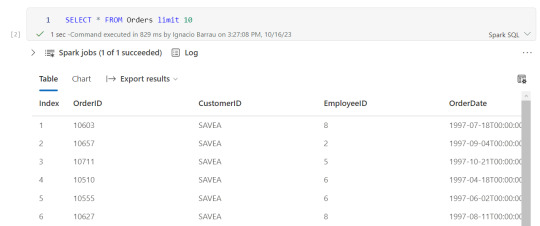
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS
SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
Resultado
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
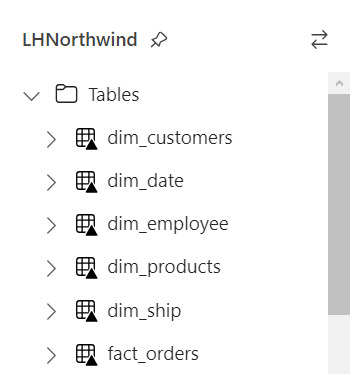
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes
Text
SQL Course Training: Advancing Your Database Skills

In the realm of data analysis and management, SQL (Structured Query Language) stands as a foundational skill indispensable for professionals seeking to navigate and manipulate databases effectively. As the demand for data-driven insights continues to soar, honing your SQL proficiency through targeted training can significantly enhance your capabilities in data analysis and open doors to diverse career opportunities. Let's explore the significance of SQL course training and how it can advance your database skills.
Understanding the Importance of SQL in Data Analysis:
SQL serves as the universal language for communicating with relational databases, enabling users to retrieve, manipulate, and manage data efficiently. Whether you're a data analyst, data scientist, or database administrator, mastering SQL empowers you to extract valuable insights, perform complex queries, and optimize database performance. With its widespread adoption across industries, SQL proficiency has become a prerequisite for roles involving data analysis and database management.
Key Components of SQL Course Training:
SQL course training encompasses a range of topics tailored to equip learners with comprehensive database management skills. From basic SQL syntax to advanced query optimization techniques, these courses cover essential concepts and best practices for leveraging SQL effectively. Key components of SQL course training include:
- SQL Fundamentals: Understanding basic SQL commands, data types, and database objects.
- Querying Databases: Crafting SELECT statements to retrieve data from tables and apply filtering, sorting, and aggregation.
- Data Manipulation: Performing INSERT, UPDATE, DELETE operations to modify data within tables.
- Database Design: Understanding principles of database normalization, table relationships, and entity-relationship modeling.
- Advanced SQL Topics: Exploring advanced SQL features such as joins, subqueries, stored procedures, and triggers.
- Optimization and Performance Tuning: Techniques for optimizing SQL queries, indexing strategies, and enhancing database performance.
Choosing the Best SQL Course:
When selecting a SQL course online, it's essential to consider factors such as:
- Curriculum: Ensure the course covers a comprehensive range of SQL topics, from fundamentals to advanced concepts.
- Hands-On Practice: Look for courses that offer hands-on exercises and projects to reinforce learning and practical application.
- Instructor Expertise: Choose courses led by experienced SQL professionals with a track record of delivering high-quality instruction.
- Student Reviews: Assess feedback from past learners to gauge the course's effectiveness and relevance to your learning goals.
- Certification: Some SQL courses offer certification upon completion, which can validate your skills and enhance your credentials in the job market.
Integrating SQL with Data Analysis:
SQL proficiency synergizes seamlessly with data analysis tasks, enabling analysts to extract, transform, and analyze data stored in relational databases. Whether you're performing ad-hoc analysis, generating reports, or building data pipelines, SQL serves as a powerful tool for accessing and manipulating data effectively. By mastering SQL alongside data analysis skills and tools such as Python and Apache Spark, you can enhance your capabilities as a data professional and tackle complex analytical challenges with confidence.
Conclusion:
Investing in SQL course training is a strategic step towards mastering database management skills and advancing your career in data analysis. Whether you're a novice seeking to build a solid foundation in SQL or an experienced professional aiming to sharpen your expertise, there are ample opportunities to enhance your database skills through online SQL courses. By selecting the best SQL course that aligns with your learning objectives and investing time and effort into mastering SQL concepts, you can unlock new possibilities in data analysis and become a proficient database practitioner poised for success in today's data-driven world.
#apache spark course#data analysis#data analysis skill#python course#best python course#data analysis course#data analysis course online#master data analysis#python course online#sql course#sql course online#best sql course#data analysis online#python course training#sql course training#apache spark course online#best apache spark course#learn python#learn apache spark#learn data analysis#learn sql
1 note
·
View note
Link
0 notes
Text
Data Science
📌Data scientists use a variety of tools and technologies to help them collect, process, analyze, and visualize data. Here are some of the most common tools that data scientists use:
👩🏻💻Programming languages: Data scientists typically use programming languages such as Python, R, and SQL for data analysis and machine learning.
📊Data visualization tools: Tools such as Tableau, Power BI, and matplotlib allow data scientists to create visualizations that help them better understand and communicate their findings.
🛢Big data technologies: Data scientists often work with large datasets, so they use technologies like Hadoop, Spark, and Apache Cassandra to manage and process big data.
🧮Machine learning frameworks: Machine learning frameworks like TensorFlow, PyTorch, and scikit-learn provide data scientists with tools to build and train machine learning models.
☁️Cloud platforms: Cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure provide data scientists with access to powerful computing resources and tools for data processing and analysis.
📌Data management tools: Tools like Apache Kafka and Apache NiFi allow data scientists to manage data pipelines and automate data ingestion and processing.
🧹Data cleaning tools: Data scientists use tools like OpenRefine and Trifacta to clean and preprocess data before analysis.
☎️Collaboration tools: Data scientists often work in teams, so they use tools like GitHub and Jupyter Notebook to collaborate and share code and analysis.
For more follow @woman.engineer
#google#programmers#coding#coding is fun#python#programminglanguage#programming#woman engineer#zeynep küçük#yazılım#coder#tech
24 notes
·
View notes
Text
The Modern Data Stack: Empowering Data-Driven Organizations
What is modern data stack and how it helps organization to be data driven?
#data #modern #technology #python #spark #sql #aws #google #tableau #ai #azure #netflix #facebook #shopify #linkedin
In today’s world, technology has incorporated a web connecting everything, from people and organizations, leading to an increase in data on a daily basis. In this data-driven world, organizations are constantly looking for ways to harness the power of data to gain insights, make educated decisions, and gain a competitive edge. The traditional approach to data management and analytics is no longer…
View On WordPress
0 notes
Last Seen Blogs

regalthecat
Actually Black Canary

myimaginarywonderland
mywonderland

a-rose-by-any-other-gender
Just a Trans Umbreon ^^

guiajato-line
Uma ampla variedade de produtos de diversas lojas.

jesshooligan
HOOLIGAN FOR LIFE