#google algorithm
Text
Google Ads to Promote Business
Google Ads is an online advertising platform developed by Google, where advertisers can bid on specific keywords or phrases to display their ads to a targeted audience.
Why use Google Ads?
Google Ads is the most popular online advertising platform, with over 3.5 billion searches per day. It offers advanced targeting options, real-time reporting, and a variety of ad formats to suit your business needs.
Benefits of using Google Ads:
Using Google Ads (formerly known as Google AdWords) offers several benefits for businesses looking to promote their products or services online. Here are some of the key advantages:
Targeted Advertising: Google Ads provides powerful targeting options that allow advertisers to reach specific audiences based on keywords, location, language, device type, demographics, and even user behavior. This level of precision enables businesses to tailor their ads to the right people at the right time, increasing the likelihood of attracting potential customers who are genuinely interested in their offerings. Targeted advertising helps improve conversion rates and reduces wasted ad spend on irrelevant audiences.
Measurable Results: One of the most significant advantages of Google Ads is the ability to track and measure the performance of your ads in real-time. Advertisers can access a wealth of data, including clicks, impressions, click-through rates (CTRs), conversions, and more. By analyzing these metrics, businesses can gain valuable insights into the effectiveness of their campaigns. This data-driven approach allows for continuous optimization, enabling advertisers to make data-backed decisions and improve the overall ROI of their advertising efforts.
Cost-effective Marketing: Google Ads operates on a pay-per-click (PPC) or pay-per-impression (CPM) model, which means advertisers only pay when someone clicks on their ad or when their ad is shown a certain number of times (in the case of CPM). This pay-as-you-go approach makes Google Ads a cost-effective marketing option, as advertisers have control over their budget and can set daily or monthly spending caps. Additionally, the targeting options help avoid spending on irrelevant audiences, making each ad dollar more efficient.
Increased Brand Awareness: Google is one of the most widely used search engines, with billions of searches conducted daily. By running ads on Google, businesses can expose their brand to a massive audience and increase brand visibility. Even if users don’t click on the ads immediately, they are still exposed to the brand name and message, which can lead to increased brand recall and consideration when the users are ready to make a purchase. Remarketing features also allow businesses to reconnect with users who have previously interacted with their website or app, reinforcing brand awareness and encouraging return visits.
Overall, Google Ads provides a versatile and results-driven advertising platform that empowers businesses of all sizes to reach their target audience effectively, track campaign performance accurately, manage ad spend efficiently, and enhance their brand’s presence in the digital landscape. When used strategically, Google Ads can be a powerful tool for driving traffic, generating leads, and boosting sales.
Types of Google Ads:
Google Ads offers various types of ad formats to advertisers, allowing them to target different audiences and achieve specific marketing goals. Here are the main types of Google Ads:
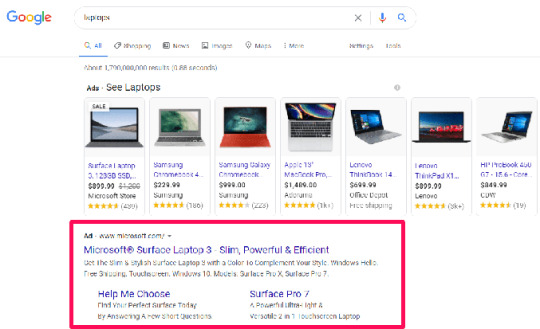
Search Ads: Search ads appear at the top or bottom of the Google search results page when users enter relevant keywords or phrases. These ads are text-based and typically consist of a headline, description lines, and a display URL. Advertisers bid on keywords, and when a user’s search query matches those keywords, their ad may appear. Search ads are great for reaching users actively looking for products or services, making them highly effective for generating leads and conversions.
For example, below are the search campaign ads for the keyword “laptops”. They appear on the search result page with the black “Ad” symbol next to the URL.
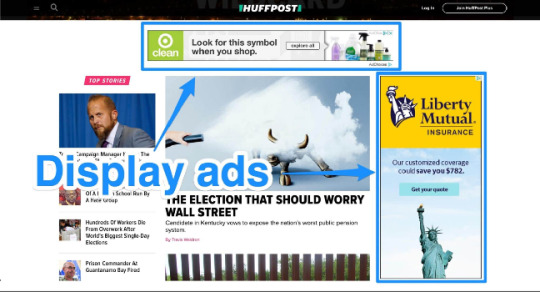
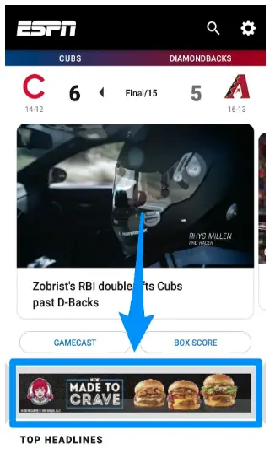
2. Display Ads: Display ads are visual advertisements that appear on websites within the Google Display Network (GDN). The GDN includes millions of websites and reaches a vast audience across various interests and demographics. Display ads can be in the form of banners, images, interactive ads, or even video. They are ideal for building brand awareness, reaching a broad audience, and showcasing products or services to potential customers.
The Display Network leverages Google’s vast website partners to showcase your ad on different websites all over the Internet. These ads appear on third-party websites like so:
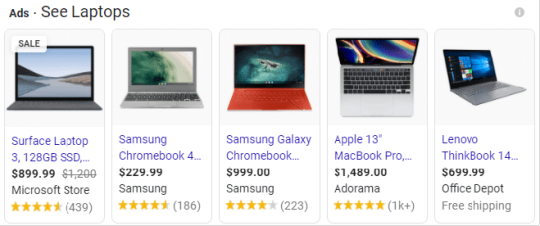
3. Shopping Ads: Shopping ads (formerly known as Product Listing Ads or PLAs) are product-centric advertisements that appear on Google search results and Google Shopping. These ads display product images, prices, and other essential details directly in the search results. Shopping ads are particularly beneficial for e-commerce businesses as they allow users to see product information before clicking on the ad, leading to more qualified leads and higher conversion rates.
A shopping campaign allows you to promote your products in a much more visual way. These ads can appear as images on the search results page:
4. Video Ads: Video ads are advertisements that appear on YouTube and other Google partner sites. These ads can be in various formats, such as skippable in-stream ads, non-skippable in-stream ads, video discovery ads, and bumper ads.
Video ads are an effective way to engage users visually and deliver impactful brand messages. They are suitable for storytelling, product demonstrations, and increasing brand visibility through video content.
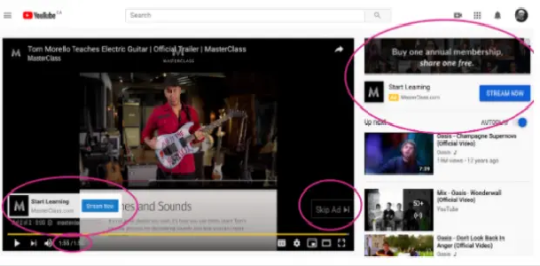
5. App Ads: App ads, also known as Universal App Campaigns (UAC), are designed to promote mobile apps across Google’s ecosystem, including Google Search, Google Play Store, YouTube, and the Display Network.
Advertisers can specify their app’s destination and ad text, and Google’s algorithm optimizes the campaign to reach users who are most likely to install the app. App ads are excellent for driving app downloads and increasing the user base for mobile applications.
Each type of Google ad has its unique advantages, and advertisers can choose the most appropriate ad formats based on their marketing objectives and target audience. The combination of different ad types allows businesses to create comprehensive and effective advertising strategies across various platforms and reach potential customers at different stages of the customer journey.
Conclusion:
In conclusion, Google Ads is a powerful tool that can help businesses of all sizes reach their target audience and achieve their marketing goals.
By utilizing its targeting capabilities, cost-effective pricing model, and detailed analytics, businesses can create effective campaigns and see measurable results.
Check out - The Ultimate Guide to Google Ads to get deep understanding of the topic.
Hope you enjoyed reading. 😄
Thanks!
About Me:
Hi! I’m Amisha Jaiswal. I’m a creative and passionate Digital Marketer. I strive to bring innovative ideas to life while making a meaningful impact.
Let’s connect — www.linkedin.com/in/amisha-jaiswal
#marketing#marketing trends#marketing digital#marketing strategy#marketing online#digital marketing#google ads#google adwords#google advertising#business#google algorithm#digital marketing tips#digital marketing trends
7 notes
·
View notes
Text
Week 3 Post
Big data and algorithms are powerful tools used by large companies. They have the power to filter, track, identify patterns and predict future behavior of consumers. This can help companies directly market and tailor their products to their customers. This can be a good thing, or a bad thing depending on how you look at it. They know the best ways to make you buy things. Meaning they are essentially controlling you without you even knowing it.
This can be damaging to consumers. There are many risks involved including fraud, Identity theft, explicit content, causing children low self esteem. I think on a personal level its on parents to filter their children's use. On a professional level I think having a company wide system that filters searches, apps, and screen time. And on a societal level its on each and every person to filter themselves and what they post. Knowing that your data is being collected and monitored should make one think twice about each and everything they post.
7 notes
·
View notes
Text
The Ultimate Guide to Dominating Google Rankings
Understanding Google’s Algorithm
To effectively outrank competing websites, it is crucial to comprehend the fundamental principles that govern Google’s algorithm. While the algorithm consists of numerous complex factors, we will focus on key elements that can significantly impact your rankings.
1. Keyword Research and Optimization
Keywords form the bedrock of SEO, allowing search engines to understand the relevance of your content. Extensive keyword research is essential to identify the most valuable and competitive terms in your niche. By strategically incorporating these keywords into your content, headings, meta tags, and URLs, you can enhance your website’s visibility and improve its chances of outranking other articles.
2. High-Quality and Engaging Content
Content is king, and producing exceptional, informative, and engaging content is paramount to achieving higher rankings. Aim to create long-form articles that provide in-depth insights and address the needs of your target audience. Read more.
10 notes
·
View notes
Text
September 2023 Helpful Content Update
youtube
#seo services#google algorithm#google updates#content creator#content creation#content marketing#content seller#premium content#Youtube
2 notes
·
View notes
Text
#seo#search engine optimization#on page seo#seo marketing#seo optimization#content marketing#google algorithm#search eninge#develop#google seo#seo services#search engine marketing#seo expert
4 notes
·
View notes

Text

Search engine algorithms are constantly evolving to provide better search results. #SEO helps you stay ahead by adapting to these updates. By regularly monitoring algorithm changes and adjusting your strategy accordingly, you can maintain your rankings and ensure your website remains visible to your target audience.
Boost your Website.
2 notes
·
View notes
Text
Enfermo de mí mismo
La identidad algorítmica es un medio de control y consuelo.
Según la historia común sobre nuestra caída en la posmodernidad, ser uno mismo se ha convertido en un trabajo duro. Antes, la gente nacía en situaciones relativamente estables en las que la identidad se prescribía en función del lugar de nacimiento y de quién era. Había pocas opciones en cuanto al tipo de vida que uno llevaría, y poca movilidad social o geográfica. Las categorías sociales -clase, género, etnia, religión- que determinaban las posibilidades de la propia vida eran esencialmente fijas, al igual que la forma en que se definían esas categorías. Pero la industrialización y la llegada de los medios de comunicación de masas desbarataron esas categorías con el paso del tiempo y convirtieron las normas sociales en algo más fluido y maleable. La identidad dejó de ser asignada y se convirtió en un proyecto que los individuos debían realizar. Se convirtió en una oportunidad y una responsabilidad, una carga. Ahora se puede dejar de ser alguien.

Algunos sociólogos y psicólogos etiquetan esta condición como "inseguridad ontológica". En The Divided Self (El yo dividido), R.D. Laing lo define como cuando uno carece de "la experiencia de su propia continuidad temporal" y no tiene "un sentido primordial de consistencia o cohesión personal". Sin este sentido estable del yo, sostiene Laing, toda interacción amenaza con abrumar al individuo con el temor de perderse en el otro o de ser borrado por su indiferencia. "Puede sentirse más insustancial que sustancial, e incapaz de asumir que la materia de la que está hecho es genuina, buena, valiosa", escribe Laing sobre los ontológicamente inseguros. "Y puede sentir su yo como parcialmente forzado desde su cuerpo".
Un sentido estable del yo a través del tiempo hace que la vida tenga sentido; nos permite experimentar y transmitir un sentido de "autenticidad". Pero este yo estable y auténtico tiende a representarse como el medio para su propio fin: El yo se consigue siendo uno mismo y encontrándose a sí mismo. Esta tautología nos aboca al fracaso y al interminable trabajo de intentar expresarnos y realizarnos. El sociólogo Alain Ehrenberg (en un pasaje que cita Byung-Chul Han en The Burnout Society) relaciona esta carga con el auge de la depresión como enfermedad mental: "La depresión comenzó su ascenso cuando el modelo disciplinario de los comportamientos, las reglas de autoridad y la observancia de los tabúes que daban a las clases sociales, así como a ambos sexos, un destino específico, rompieron con las normas que nos invitaban a emprender la iniciativa personal ordenándonos ser nosotros mismos... El individuo deprimido es incapaz de estar a la altura; está cansado de tener que llegar a ser él mismo".
Puede que no sean sólo las personas deprimidas las que estén cansadas de tener que llegar a ser ellas mismas. En unas condiciones económicas en las que la maximización de nuestro "capital humano" es primordial, nos vemos sometidos a una presión incesante para sacar el máximo partido de nosotros mismos y de nuestras conexiones sociales y exponerlo todo para mantener nuestra viabilidad social. Somos perpetuamente "incapaces de estar a la altura": debemos, como cualquier otra empresa capitalista, demostrar la capacidad de mantener el crecimiento o quedarnos obsoletos. La exigencia neoliberal de que convirtamos nuestras vidas en capital y lo hagamos crecer se apodera sistemáticamente del ideal de la autoexpresión y lo despoja de su dignidad y encanto.
Pero no ser nadie no es todavía una gran alternativa.
Este es el contexto en el que los medios sociales han prosperado: Resuelven el problema del yo bajo el neoliberalismo, ampliando una plataforma para el desarrollo del capital humano al tiempo que ofrecen una base aparentemente estable para la "seguridad ontológica". Podría parecer que los medios de comunicación social, al hacer que la interacción social sea asíncrona, al trasladar una parte de ella en línea a un espacio "virtual" indefinido y al someterla toda a un seguimiento, una medición y una evaluación constantes, no serían una receta para producir una sensación de continuidad personal. La forma en que nuestra autoexpresión se clasifica en "me gusta" y "compartidos" en las redes sociales parece subordinar la identidad a la competencia por la atención cuantificada, dividiendo a los compañeros en ganadores y perdedores. Y la creación de la identidad en forma de archivo de datos parecería moldear no un yo fundamentado sino un doble siempre incompleto e inadecuado: un "yo parcialmente forzado desde el cuerpo". Uno siempre corre el peligro de enfrentarse a su incoherencia, a la evidencia de un yo pasado que ahora se rechaza o a una versión mal interpretada y mal procesada del propio archivo que se distribuye como el verdadero yo.
Si Laing tiene razón sobre la inseguridad ontológica, las redes sociales parecen estar diseñadas para generarla: Imponen sistemáticamente una sensación de insustancialidad a los usuarios, convirtiendo la identidad en incoherencia al asimilar y exigir constantemente más datos sobre nosotros, haciendo de nuestro yo un vacío que nunca se llena, por mucho que se vierta. Nuestra identidad es recalibrada y recalculada constantemente, y podemos intentar siempre "corregirla" con más fotos, más actualizaciones, más posts, más datos.
Pero esta misma desestabilización abre la posibilidad de que se produzcan reaseguros compensatorios: los placeres en serie de comprobar los "me gusta" y otras formas de micro reconocimiento que cobran sentido de repente por la aguda inseguridad. Incluso cuando las redes sociales desestabilizan la experiencia vivida de la continuidad de nuestro yo, abordan la disolución de la identidad con un sistema dinámico de captura de la misma. Registran todo lo que hacemos en línea e insisten en su importancia, registrándolo en bases de datos relacionales en las que se analizará su contribución esencial a nuestra personalidad general y, en última instancia, se expresará en algún contenido específico más adelante.
Proporcionan un punto focal, un perfil de identificación único en torno al cual se puede organizar toda la recopilación de datos y la puntuación de la reputación que permanece con nosotros a través de todos nuestros cambios ostensibles. Si todas las normas sociales que rodean a un individuo cambian, el perfil de las redes sociales no lo hace.
El perfil sustituye a los antiguos estabilizadores de la identidad (familia, geografía, religión, etc.) y se convierte en la robusta pizarra en blanco en la que se pueden inscribir diversos papeles mientras permanecemos abiertos a la saturación de tantas influencias diferentes como sea posible. Puede sostener nuestras vidas mientras estamos ocupados reinventándonos constantemente para los mercados laborales. Los medios de comunicación social exacerban la inseguridad ontológica a la vez que se hacen pasar por su cura.
Las burbujas algorítmicas que los medios sociales construyen a nuestro alrededor son parte fundamental del consuelo que proporcionan las plataformas. Su presencia constante y fiable nos permite consumir una sensación de seguridad ontológica que las plataformas están erosionando.

La burbuja de filtros no es un desafortunado accidente, como sugirió Mark Zuckerberg en su manifiesto de la "comunidad global", sino una fuente esencial del atractivo de las redes sociales, el aspecto que les permite contrarrestar el vértigo posmodernista. Si todos los contenidos de Facebook se adaptan a la construcción de la empresa sobre quiénes somos, consumirlos es como consumir una versión coherente de nosotros mismos.
También refuerza la idea de que el mejor lugar para vislumbrar nuestra identidad social estable es Facebook. El compromiso con las redes sociales indica entonces nuestra aceptación de esta figura algorítmica del yo, una identidad en la que entramos cuando accedemos a las plataformas y que se siente como si siempre hubiera estado dentro de nosotros de alguna manera.
Entonces, ¿cómo sabe un sistema algorítmico quién eres? ¿Y qué hace que este conocimiento sea lo suficientemente eficaz como para mantener los niveles de participación en las redes sociales? ¿Por qué nos reconocemos a nosotros mismos en las muchas formas oscuras e indirectas en que nos saluda una plataforma de medios sociales, aunque este reconocimiento no sea consciente, aunque sólo se produzca a nivel de no aburrirse? ¿Por qué la clasificación algorítmica de contenidos funciona en todas las plataformas en las que se prueba, a menudo en contra de las protestas de los usuarios, que inevitablemente llegan a tolerarla o amarla?
El libro We Are Data, del profesor de estudios digitales John Cheney-Lippold, publicado hace varios meses, explora la identidad algorítmica, pero no en términos de la seguridad subjetiva o el placer que puede proporcionar. Le preocupa más el control que imponen los sistemas algorítmicos a través de la forma en que los agregadores de datos estructuran diversas categorías sociales. Describe el modo en que las empresas de redes sociales, los vendedores y las instituciones estatales utilizan nuestros rastros de datos para calcular las probabilidades de nuestra edad, raza, género, clase, nacionalidad, etc., y cómo esas probabilidades se utilizan para remodelar nuestras realidades individualizadas.
A medida que los teléfonos, las plataformas de redes sociales, los rastreadores de actividad física, el software de reconocimiento facial y otras formas de vigilancia capturan más información sobre nosotros, los algoritmos nos asignan marcadores de identidad y nos colocan en categorías basadas en correlaciones con patrones extraídos de conjuntos de datos masivos, independientemente de que éstos se correspondan con la idea que tenemos de nosotros mismos. Nos convertimos, hasta cierto punto, en lo que hacen otras personas, ya que sus datos contribuyen a la interpretación de los nuestros. El sistema inferirá nuestra identidad, de acuerdo con las categorías que defina o invente, y las utilizará para dar forma a nuestros entornos y guiar aún más nuestro comportamiento, afinar la forma en que hemos sido clasificados y hacer que los datos sobre nosotros sean más densos, más profundos. A medida que estos sistemas positivistas saturan la existencia social, anulan la idea de que hay algo sobre la identidad que no puede ser capturado como datos.
Dado que lo que los sistemas algorítmicos calculan como raza, género, edad o afiliación política es una selección de marcadores de datos que puede no tener ninguna relación con los indicadores sociales utilizados para determinar esas categorías -puede incluso ignorar cómo se autoidentifican los individuos-, Cheney-Lippold los diferencia: raza frente a "raza" estimada algorítmicamente, género frente a "género", etc. Estos pares son analíticamente distintos, pero se alimentan mutuamente a través de la forma en que las categorías probabilísticas se despliegan para anticipar lo que la gente hará o querrá ver, dando forma a cómo se les trata y qué oportunidades se les ofrecen. Puedes encontrarte en una lista de vigilancia de terroristas o en cuarentena por una gripe que no tienes, simplemente por las asociaciones de datos. No importa si la "raza" coincide con la raza, o si la "edad" se aproxima con exactitud a la edad: esto suele ser irrelevante para el diseño de estos sistemas. Por lo general, tratan de maximizar la participación de los usuarios o de captar las tendencias de grandes poblaciones, más que de simular a un usuario concreto.

Pero mientras tenemos alguna idea (aunque poco control) de lo que conforman estas categorías en la vida social fuera de Internet, no sabemos cómo los algoritmos determinan las probabilidades sobre nuestra identidad dentro de ella: se basan en estereotipos estadísticos más que sociales, como señala Cheney-Lippold. Para un sistema algorítmico, es posible que tengas un 45% de probabilidades de ser mujer y un 45% de probabilidades de ser hombre al mismo tiempo. Cada categoría social puede subdividirse infinitamente en la práctica, y cada combinación de probabilidades constituye un pseudo género propio. "Como el género de Google es de Google, no mío, no puedo ofrecer una crítica de ese género, ni puedo practicar lo que podríamos llamar una política de género de primer orden que cuestione lo que significa el género de Google, cómo distribuye los recursos y cómo llega a definir nuestras identidades algorítmicas", escribe Cheney-Lippold.
También podríamos preguntarnos en qué momento el "género" de Google deja de ser tratado como género y se convierte en otra cosa dentro de sus sistemas, dado que para el sistema, la etiqueta de "género" para ese particular es totalmente arbitraria. Las máquinas no dan el paso adicional que dan los humanos de naturalizar las categorías y hacerlas absolutas. Las categorías algorítmicas pueden comprender cualquier número de categorías sociales discretas y, en la forma en que se despliegan, se alejan por completo de la forma en que se utilizan socialmente o interpersonalmente.
Esto haría pensar que los sistemas rechazan las definiciones esencialistas de las categorías de identidad, permitiendo identidades fluidas producidas de forma contingente, situación a situación. Pero la fluidez dentro de las categorías es menos importante que el hecho de que los sistemas pueden estar entrenados para asociar ciertos datos con categorías específicas y socialmente cargadas, reforzando su significado percibido para la participación social. Se pide al sistema que calcule la probabilidad de tu raza porque, en parte, está diseñado para reproducir el significado de esa distinción. Por tanto, aunque un día te considere de una raza determinada y al siguiente de otra diferente, o vuelva a calcular tu probabilidad de ser blanco con cada nueva página web que visites, sigue contribuyendo a reproducir las condiciones en las que ser blanco tiene un valor determinado, tiene ciertas ramificaciones, crea ciertas posibilidades.
El sistema algorítmico amplía el significado de esas categorías más allá de contextos contingentes específicos a la clase de situaciones que pueden darse en cualquier momento y en cualquier lugar en línea, incluso sin presencia humana: la discriminación se produce siempre que se consulta la base de datos, con sistemas que generan lo que Cheney-Lippold llama "identidades justo a tiempo... hechas, ad hoc". Proyectan interpretaciones jerárquicas de las categorías en escenarios en los que a los agentes humanos ni siquiera se les ocurriría discriminar.
No hay nada que impida, por ejemplo, que los minoristas en línea ejerzan una discriminación de precios basada en quién sabe qué base. Uno puede imaginarse a los bancos o a los agentes inmobiliarios operando en líneas similares, donde los propios representantes no pueden explicar por qué
ciertos candidatos han sido rechazados. (Frank Pasquale detalla este tipo de "puntuación de caja negra" en The Black Box Society).
Las probabilidades calculadas algorítmicamente también pueden convertirse en instrumentos para engatusar un comportamiento más normativo de los individuos para los que las categorías sociales recibidas son importantes, anclando su sentido personal de identidad. Los algoritmos pueden utilizarse para establecer lo que, por ejemplo, se supone que es el comportamiento masculino o el comportamiento saludable y animar indirectamente a los sujetos interesados en cumplir esas expectativas a reorientar su comportamiento en consecuencia, incluso cuando esos objetivos en sí mismos siguen siendo dinámicos. A medida que se persiguen los objetivos -con nuevos datos que se introducen para tratar de ajustar el perfil- este mismo comportamiento alimenta y refuerza la forma en que el sistema ha empezado a definir la categoría. El algoritmo hace surgir el comportamiento que simplemente debía identificar, convirtiéndose en "un motor, no una cámara", según la frase del sociólogo Donald Mackenzie. Esto es ideal para las empresas y organismos que administran los modelos, ya que hace que los sistemas de datos sean más eficaces, aunque menos "precisos". Pueden crear el tipo de temas que buscan.

Los sistemas de identidad basados en datos perpetúan el significado social de las categorías al tiempo que eliminan la negociación de lo que significa cualquier categoría de la esfera social e interpersonal, colocándolas en su lugar en sistemas opacos y privados. Los usuarios que intentan cumplir las normas de estas categorías no tienen más remedio que proporcionar más datos para intentar cumplir los objetivos móviles. Y, como sostiene Cheney-Lippold, "no hay fidelidad a las nociones de nuestra historia individual y nuestra autoevaluación" en la forma en que los algoritmos de caja negra nos clasifican. La forma en que nos clasifican se mantiene clasificada, y cambia dependiendo del contexto y de lo que se le pida al sistema algorítmico. Lo que somos depende de lo que se haga con nosotros.
Al igual que no sabemos cómo estos sistemas calculan nuestra identidad y la clasifican para diversos fines, a menudo tampoco sabemos por qué. Esto significa que pueden utilizarse a nuestras espaldas para marcarnos como personas de interés para la policía y los agentes fronterizos, o para señalarnos como un riesgo para el seguro o para otras formas categóricas de discriminación sin que ningún agente humano tenga conocimiento directo. Pueden hacer que ciertas concatenaciones de datos sean normales y otras sean desviadas y socialmente descalificadoras. Estos prejuicios aprendidos por las máquinas pueden no tener siquiera nombres humanos, lo que hace más difícil que las personas se unan y luchen contra ellos. Las etiquetas no pueden reclamarse como principios de solidaridad.
Inconformes con cualquier categoría social preexistente, estas identidades sumergidas e invisibles en teoría pueden ser empujadas al mundo social y hacerlas reflexivas allí. En otras palabras, los sistemas pueden inventar razas y perpetuar la lógica del racismo: que es "racional" buscar patrones de datos sobre las poblaciones y hacerlos manifiestos y socialmente salientes, definitivos para los así identificados. A nivel individual, la discriminación a medida por algoritmo puede hacer imposible saber cuándo y por qué se está excluyendo o señalando a alguien. "Quién somos y qué significa quiénes somos en Internet nos viene dado", afirma Cheney-Lippold. "Nos vemos obligados a existir en un 'territorio del yo' a la vez extraño y desconocido, una base de integridad subjetiva que es estructuralmente desigual".
De manera más mundana, el análisis algorítmico puede simplemente buscar formas de aprovechar la información sobre los usuarios en su contra, haciendo que la identidad no sea tan fluida como más precaria. La recopilación de datos se utiliza para crear marcadores de identidad sobre nosotros que no vemos ni controlamos, a los que no podemos evaluar ni acceder ni modificar directamente. Las empresas saben más de nosotros como consumidores que nosotros mismos, en la medida en que limitamos nuestra identidad al comportamiento de consumo. Pero no necesariamente nos controlan ocultando cómo nos categorizan; pueden beneficiarse revelando cómo nos ven, pintando una versión aspiracional de nosotros mismos que mantiene el compromiso con los sistemas que nos perfilan. Si los sistemas algorítmicos funcionasen principalmente "obligándonos a existir" en escenarios que no nos aportarán ningún beneficio tangible, pronto encontraríamos formas de eludirlos.
Desde el principio, no nos autoinventamos.
Nacemos en un contexto social que constituye el marco y las limitaciones de nuestro autoconocimiento. Conocernos a nosotros mismos significa comprender este contexto inmutable que no hemos elegido. Los sistemas algorítmicos modelan ese contexto, concretando las formas en que la identidad sustituye a los cuerpos individuales y emerge entre personas y grupos, dentro de las instituciones y las posibilidades tecnológicas.

#technology#giovannachadid#writers on tumblr#cosmotechnics#philosophy#hack the planet#bogotá#malwaremedusa#technique#tech news#technician#technical#algoritmo#fuck the algorithm#google algorithm#algorithmic stablecoin#artificial intelligence#artificial brain#the dark artifices#followme
11 notes
·
View notes
Link
6 notes
·
View notes
Text
Am All Of Them🧘🏻 - Ec4you Digital Marketing
#digital marketing#social media influencers#google adwords#seo expert#google algorithm#web design#webdevelopment#websitedevelopment#web developers#websitedesign#graphic design#seo services#seo#search engine optimization#search engine marketing#smm services#branding#business#marketing
1 note
·
View note
Text
Google Algorithm Update History from 2023 to 2024
Stay up-to-date with the latest Google algorithm updates from 2023 to 2024. Learn how these changes may impact your website's search rankings and how to adapt your SEO strategy accordingly.
0 notes
Text
Google Says Indexing & Algorithm Updates Are Independent
Google: Indexing & Algorithm Updates Are Independent
Google once again said that its indexing systems are completely independent of its ranking updates, like the core update. Gary Illyes from Google said indexing, canonicalization, and those types of “systems are independent” of core updates.
Truth is, this is not news, Google has said this numerous times. In 2016, Gary Ilyes said crawl rate…

View On WordPress
0 notes
Text
#AI trends#Competitive Strategies#competitor research#Content creation#content update#digital marketing#Engaging Content#Expired Domain Abuse#Google Algorithm#Google Core Update#Google News Ranking#Google Search Results#google spam policies#google updates#Long-form Content#Manipulative Behaviors#March 2024 Core Update#organic traffic#Originality#Scaled Content Abuse#Search Engine Optimization#SEO Impact#Site Reputation Abuse#Spam Policies#User Engagement.#Website Quality
0 notes
Text
Your Ultimate Guide to Enhance Google Rankings with White Hat Monthly SEO
In today's online world, getting noticed on Google is key for any business. That's where Search Engine Optimization (SEO) comes in. But not all SEO is created equal. White hat monthly SEO is the way to go. It's all about using ethical strategies to improve your website's visibility.
What is White Hat SEO?
White hat SEO means playing by the rules. Instead of trying to trick search engines, you focus on giving users what they're looking for. That means creating great content, doing keyword research, and following Google's guidelines.
Why Monthly SEO Matters
SEO isn't a one-time thing. It's an ongoing process. Monthly SEO means keeping an eye on your site's performance and making adjustments as needed. This helps you stay ahead of the competition and keep your rankings high.
Key Components of White Hat Monthly SEO Keyword Research: Find out what your audience is searching for and use those keywords in your content.
Content Optimization: Create top-notch content that's easy to read and full of relevant keywords.
On-Page SEO: Make sure your website's pages are properly optimized with titles, descriptions, and headings.
Technical SEO: Keep your site running smoothly by fixing any technical issues that might hold you back.
Link Building: Earn quality back-links from other reputable websites to Enhance your site's authority.
Monitoring and Analysis: Keep track of how your site is performing and make changes as needed to improve your rankings.
In Conclusion:
Mastering white hat monthly SEO is essential for success online. By using ethical strategies and staying on top of your site's performance, you can climb the Google rankings and attract more visitors to your site. Remember, SEO is an ongoing process, so keep learning and adapting to stay ahead of the game.
For more detailed insights on each component of White Hat SEO, you can visit this link (https://www.fiverr.com/sudhanshunft/do-white-hat-seo-to-rank-website-and-keywords) for additional resources.
#google ranking#keywords research#SEO strategy#on page SEO#off page SEO#SEO#white hat SEO#monthly SEO service#content optimization#google algorithm
0 notes

Last Seen Blogs

shadowpocket69
art-doodles-sketches

ek-vitki-pixels
The Traveler

pearlsintodiamonds
pearls

acshivamhrx9797
Untitled

itokirimaru
itokiri