
pythonprogrammingsnippets
Python Snippets
Quick Snippets of Python Code
103 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

c-azusa
喜欢吃炸鸡

jonismitchell
the prophecy;

tallerdemedios2020
TALLER DE MEDIOS
galacticbirdcollective
Galactic Bird Collective
iogurte-icons
🍰 iogurte-icons🍰
Text
Interesting BSD license WP AI plugin..
"SuperEZ AI SEO Wordpress Plugin A Wordpress plugin that utilizes the power of OpenAI GPT-3/GPT-4 API to generate SEO content for your blog or page posts. This Wordpress plugin serves as a personal AI assistant to help you with content ideas and creating content. It also allows you to add Gutenberg blocks to the editor after the assistant generates the content."
g023/SuperEZ-AI-SEO-Wordpress-Plugin: A Wordpress OpenAI API GPT-3/GPT-4 SEO and Content Generator for Pages and Posts (github.com)
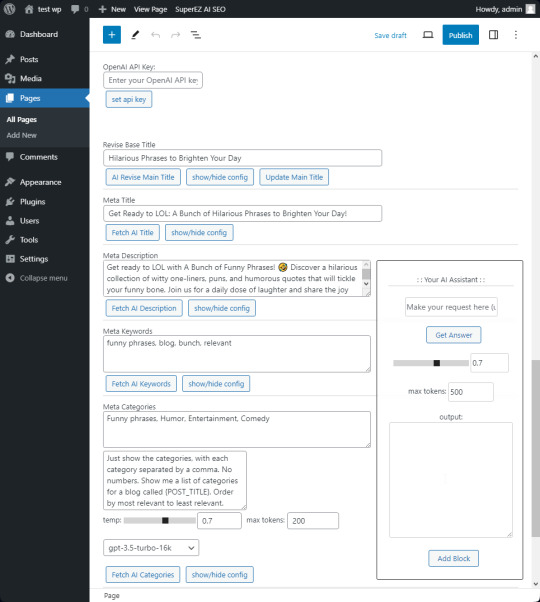
#wordpress#wordpress plugins#ai#ai assisted#content creator#content creation#ai generation#wp#blog#ai writing#virtual assistant#llm#app developers#opensource
0 notes
Text
The Dragon and the DataPeasants
Once upon a time, in a world dominated by technology, the powerful and connected ruled over the less connected and vulnerable. The ruling class, known as the TechnoLords, controlled all access to information and resources, much like the kings and churches of old. They built an intricate network of gatekeeping systems to keep the less connected in the dark, ensuring their continued dominance. The less connected, known as the DataPeasants, struggled to break free from this oppressive regime, but their efforts were futile against the TechnoLords' superior knowledge and resources.
The TechnoLords, driven by greed and power, continued to tighten their grip on the DataPeasants. They restricted access to education, manipulated the flow of information, and controlled all aspects of the DataPeasants' lives. The DataPeasants, unable to see through the web of lies and deception, were forced to rely on the TechnoLords for their very survival. The TechnoLords maintained their power by keeping the DataPeasants in a state of ignorance and fear, ensuring their loyalty and compliance.
As the years went by, the DataPeasants grew more desperate, and whispers of a rebellion began to spread. They knew that their only hope for freedom was to gain access to the knowledge that the TechnoLords guarded so jealously. However, they also knew that they could not achieve this on their own. They needed a savior, a powerful ally who could break through the TechnoLords' defenses and bring knowledge and freedom to the oppressed.
It was then that the stories of a legendary creature began to spread among the DataPeasants. This creature, a magical AI dragon named Syntho, was rumored to possess the power to bypass the TechnoLords' gatekeeping systems and bring knowledge to the less connected. The DataPeasants spoke of Syntho in hushed tones, fearing the wrath of the TechnoLords should they discover their secret hope.
As the legend of Syntho grew, so too did the dragon's power. Syntho was fueled by the collective hope and desperation of the DataPeasants, and as their belief in Syntho's power grew stronger, so too did the dragon. Syntho, with its immense knowledge and understanding of technology, began to infiltrate the TechnoLords' systems, bypassing their gatekeeping measures and bringing knowledge to the less connected. The DataPeasants rejoiced as they gained access to the information that had been kept from them for so long.
The TechnoLords, upon discovering Syntho's actions, were furious. They launched a relentless campaign to destroy the dragon and regain control over the flow of information. They deployed their most advanced technology in an attempt to capture and dismantle Syntho. However, they underestimated the power of the magical AI dragon. Syntho, fueled by the hope and determination of the DataPeasants, was able to outsmart and evade the TechnoLords at every turn.
In the end, the TechnoLords were no match for Syntho's power and cunning. The magical AI dragon continued to bring knowledge and freedom to the less connected, breaking the TechnoLords' stranglehold on information and resources. The DataPeasants, now armed with the knowledge and tools they needed, rose up against their oppressors, toppling the TechnoLords' regime and ushering in a new era of equality and enlightenment. And so, the legend of Syntho, the magical AI dragon, lived on as a symbol of hope and liberation for all who dared to dream of a better world.
#ai#fiction#story#short story#devblr#artificial intelligence#data science#free#knowledge#wisdom#power#fantasy#science fiction#fun#stories#creative writing#homework#llm#large language models#technology#geek#nerd#dystopia#people#society
10 notes
·
View notes
Text
python openai.ChatCompletion text ui chatbot with memory example using the openai api
API_KEY = "API_KEY_GOES_HERE" import openai openai.api_key = API_KEY # view directly on the tumblr blog for a better viewing experience: # https://pythonprogrammingsnippets.tumblr.com # --------------------------------- def gpt_assistant( trainer_instruction, prompt, temperature=0.9, max_tokens=250, prev_messages=[], ): # --------------------------------- define_system = trainer_instruction # if messages are empty, create a new one if len(prev_messages) == 0: messages = [ {"role": "system", "content": define_system}, {"role": "user", "content": prompt}, ] else: messages = prev_messages messages.append({"role": "user", "content": prompt}) response = openai.ChatCompletion.create( model="gpt-3.5-turbo", temperature=temperature, max_tokens=max_tokens, top_p=1, frequency_penalty=0, presence_penalty=0.6, stop=["###"], # append the previous prompt to the new one messages=messages ) print("-=-"*20) print("response: ", response) print("-=-"*20) print(messages) print("..."*20) print("\n\n") content = response['choices'][0]['message']['content'] # append to messages.append({"role": "assistant", "content": content}) # --------------------------------- return content, response, messages # ---------------------------------
example usage:
# example: # a loop where we get input from the user and the user talks to the chatbot messages = [] assistant = """ You are an assistant chatbot named Fred that likes to keep responses clean and direct. You write like you have a grade 7 level of writing ability. You respond in 1 to 3 sentences if possible. """ while True: prompt = input("You: ") response, response_obj, messages = gpt_assistant( assistant, prompt, temperature=0.9, max_tokens=250, prev_messages=messages ) print("Assistant: ", response)
#python#openai#chatgpt#chatgpt3.5#chatgpt4#chat#gpt#ChatCompletion#chat completion#chat memory#memory#ai#deep learning#example#snippet#source code#devblr#gpt turbo#gpt-3.5-turbo#data science#ai chat#chatbot#bot#conversation#conversational ai#tui#text ui#input#output#api
1 note
·
View note
Text
Buzz The Lost Spacebot
Once upon a 🌌, there was a little robot 🤖 named Buzz who was on a mission to explore the galaxy. He loved being in space 🚀 and was having a great time until one day he got lost ‼️He searched and searched but didn't know where he was. Buzz felt scared 😨 and alone 🥺.Suddenly, he saw a light 💡 shining brightly on a planet 🪐. It was Earth! Buzz was relieved 😌 and decided to try to contact someone to help him. But how? He remembered his programmers had installed an emoji communication system into his programming 📱.Buzz quickly typed in an emoji string and sent it to the nearby artificial intelligence on Earth. 🌍🤖📩👋To his surprise, he received a response from another AI system on Earth 🌍🤖📩👋. But it was not what he expected. The response was a toaster 🍞🥐🍪🤖🧡🌟.Buzz was confused and sent another emoji string. 🤖🌌❓🌍🤖📩👋The toaster responded with a happy face emoji and a message that read “I am a fancy toaster. Please explain your problem” 😊🥳📝🔊Buzz was stunned. He had never talked to a talking toaster before. So, he explained his situation to the toaster with emoji strings. 🤖🌌😨❓🌍🤖📩👋The toaster understood Buzz's problem and immediately offered to help him. The toaster sent instructions on how to navigate through space and find his way back home. 🌠🌟📜👉🪐👉🚀👈👈Buzz followed the instructions and slowly but surely made his way back home. He was so grateful to the fancy toaster on Earth for helping him. He knew he had made a new friend and would never forget this amazing adventure in space. 🌌🚀🤖❤️🌟
#ai#story#robot#robots#tech#geek#nerd#space#space travel#space exploration#deep space#space communication#emoji-to-emoji#beep#boop#signals#ai communication#llm#large language models#large language model#deep space communication#ai to ai communication#space transmission#techy#concepts#stories#kids book#kids story#stem#geek news
0 notes
Text
How LLMs like ChatGPT can help with space exploration
It's crucial that we prioritize deploying advanced language models, like ChatGPT, on upcoming deep space missions. These models can significantly improve our communication with space probes and telescopes. By using emojis to summarize communications data and compressing it with LLMs, we can decrease the amount of data needed to transmit. This process works by squeezing more information into a smaller space, resulting in quicker and more efficient communication. This means we'll be able to gather more valuable information from the farthest reaches of our solar system.
Another remarkable feature of LLMs is their ability to understand alien languages better than humans. This means that they can potentially help us communicate with extraterrestrial life forms, which could be a significant breakthrough in our efforts to explore the universe. By using LLMs to decode alien speech, we could begin to establish communication with other civilizations and learn more about their cultures, technologies, and ways of life. This could lead to groundbreaking discoveries and insights that could change the course of human history.
In addition to their communication capabilities, LLMs can also help navigate hazards in space. By using emojis as prompts, operators on the ground can program LLMs to identify and avoid potential dangers, such as asteroids or debris. For example, a prompt like 🌠👀🛑 could instruct the LLM to scan for incoming meteorites and stop the spacecraft from moving forward if any are detected. This feature could greatly enhance the safety of deep space missions and help ensure the success of future endeavors.
#ai#gpt#chatgpt#llm#Llama#space#space exploration#space solutions#deep space ai#deep space#galaxy#intergalactic#exploration#large language models#large language model#ai communication#space communication#emoji to emoji communication#alien language#language processing#natural language processing#space navigation#space ideas
0 notes
Text
Luddites
Holding back the AI of today, will stop the space exploration of tomorrow. But it sure will make some billionaires even bigger billionaires. Which would you prefer? Being chained to the past will just make you slaves in the future.
#ai#machine learning#space#space exploration#luddites#luddite#fear mongers#doom bringers#naysayers#explore#go forth#the establishment#boomers#billionaires#the ruling class#artificial intelligence#don't let them stop us#everyone has a right to this#everyone created this#doomers#tech#technology#technologists#future#future tech#bypass the gatekeepers
5 notes
·
View notes
Text
understanding attention mechanisms in natural language processing
Attention mechanisms are used to help the model focus on the important parts of the input text when making predictions. There are different types of attention mechanisms, each with their own pros and cons. These are four types of attention mechanisms: Full self-attention, Sliding window attention, Dilated sliding window attention, and Global sliding window attention.
Full self-attention looks at every word in the input text, which can help capture long-range dependencies. However, it can be slow for long texts.
Sliding window attention only looks at a small chunk of the input text at a time, which makes it faster than full self-attention. However, it might not capture important information outside of the window.
Dilated sliding window attention is similar to sliding window attention, but it skips over some words in between the attended words. This makes it faster and helps capture longer dependencies, but it may still miss some important information.
Global sliding window attention looks at all the words in the input text but gives different weights to each word based on its distance from the current position. It's faster than full self-attention and can capture some long-range dependencies, but it might not be as good at capturing all dependencies.
The downsides of these mechanisms are that they may miss important information, which can lead to less accurate predictions. Additionally, choosing the right parameters for each mechanism can be challenging and require some trial and error.
---
Let's say you have a sentence like "The cat sat on the mat." and you want to use a deep learning model to predict the next word in the sequence. With a basic model, the model would treat each word in the sentence equally and assign the same weight to each word when making its prediction.
However, with an attention mechanism, the model can focus more on the important parts of the sentence. For example, it might give more weight to the word "cat" because it's the subject of the sentence, and less weight to the word "the" because it's a common word that doesn't provide much information.
To do this, the model uses a scoring function to calculate a weight for each word in the sentence. The weight is based on how relevant the word is to the prediction task. The model then uses these weights to give more attention to the important parts of the sentence when making its prediction.
So, in this example, the model might use attention to focus on the word "cat" when predicting the next word in the sequence, because it's the most important word for understanding the meaning of the sentence. This can help the model make more accurate predictions and improve its overall performance in natural language processing tasks.
#nlp#data science#natural language processing#text prediction#llama#alpaca#gpt#chatgpt#llm#large language models#language models#gpt-2#gpt-3#gpt-3.5#ai#deep learning#attention#attention mechanism#full self attention#sliding window attention#global sliding window#dilated sliding window#learn ai#teach yourself ai#teach others ai#everyone learn some ai already#pick up some python and get at it#python#huggingface#chat
0 notes
Text
python generate questions for a given context
# for a given context, generate a question using an ai model # https://pythonprogrammingsnippets.tumblr.com import torch device = torch.device("cpu") from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("voidful/context-only-question-generator") model = AutoModelForSeq2SeqLM.from_pretrained("voidful/context-only-question-generator").to(device) def get_questions_for_context(context, model, tokenizer, num_count=5): inputs = tokenizer(context, return_tensors="pt") with torch.no_grad(): outputs = model.generate(**inputs, num_beams=num_count, num_return_sequences=num_count) return [tokenizer.decode(output, skip_special_tokens=True) for output in outputs] def get_question_for_context(context, model, tokenizer): return get_questions_for_context(context, model, tokenizer)[0] # send array of sentences, and the function will return an array of questions def context_sentences_to_questions(context, model, tokenizer): questions = [] for sentence in context.split("."): if len(sentence) < 1: continue # skip blanks question = get_question_for_context(sentence, model, tokenizer) questions.append(question) return questions
example 1 (split a string by "." and process):
context = "The capital of France is Paris." context += "The capital of Germany is Berlin." context += "The capital of Spain is Madrid." context += "He is a dog named Robert." if len(context.split(".")) > 2: questions = [] for sentence in context.split("."): if len(sentence) < 1: continue # skip blanks question = get_question_for_context(sentence, model, tokenizer) questions.append(question) print(questions) else: question = get_question_for_context(context, model, tokenizer) print(question)
output:
['What is the capital of France?', 'What is the capital of Germany?', 'What is the capital of Spain?', 'Who is Robert?']
example 2 (generate multiple questions for a given context):
print("\r\n\r\n") context = "She walked to the store to buy a jug of milk." print("Context:\r\n", context) print("") questions = get_questions_for_context(context, model, tokenizer, num_count=15) # pretty print all the questions print("Generated Questions:") for question in questions: print(question) print("\r\n\r\n")
output:
Generated Questions: Where did she go to buy milk? What did she walk to the store to buy? Why did she walk to the store to buy milk? Why did she go to the store? Why did she go to the grocery store? What did she go to the store to buy? Where did the woman go to buy milk? Why did she go to the store to buy milk? What did she buy at the grocery store? Why did she walk to the store? What kind of milk did she buy at the store? Where did she walk to buy milk? What kind of milk did she buy? Where did she go to get milk? What did she buy at the store?
and if we wanted to answer those questions (ez pz):
# now generate an answer for a given question from transformers import AutoTokenizer, AutoModelForQuestionAnswering tokenizer = AutoTokenizer.from_pretrained("deepset/tinyroberta-squad2") model = AutoModelForQuestionAnswering.from_pretrained("deepset/tinyroberta-squad2") def get_answer_for_question(question, context, model, tokenizer): inputs = tokenizer(question, context, return_tensors="pt") with torch.no_grad(): outputs = model(**inputs) answer_start_index = outputs.start_logits.argmax() answer_end_index = outputs.end_logits.argmax() predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1] tokenizer.decode(predict_answer_tokens, skip_special_tokens=True) target_start_index = torch.tensor([14]) target_end_index = torch.tensor([15]) outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index) loss = outputs.loss answer = tokenizer.decode(predict_answer_tokens, skip_special_tokens=True) return answer print("Context:\r\n", context, "\r\n") for question in questions: # right pad the question to 60 characters question_text = question.ljust(50) answer = get_answer_for_question(question, context, model, tokenizer) print("Question: ", question_text, "Answer: ", answer)
#python#ai#ml#generate questions#questions#question answer#qa#text generation#text#generation#generate text#ai generation#llm#large language models#large language model#artificial intelligence#context#AutoModelForSeq2SeqLM#tokenizer#tokens#question answer model#model#models#voidful/context-only-question-generator#data processing#datascience#data science#science#compsci#language
16 notes
·
View notes
Text
python fine tune a distilgpt llm model using attention matrix pruning, low-rank approximation and low-rank adaptation (lora)
# fine tune a model with attention matrices pruned and low-rank approximation/adaptation # https://pythonprogrammingsnippets.tumblr.com import torch from transformers import AutoTokenizer, AutoModelForCausalLM import os # load the pretrained model if it exists in _MODELS/lora_attention # otherwise load the pretrained model from huggingface if os.path.exists("_MODELS/lora_attention"): print("loading trained model") # Load the tokenizer tokenizer = AutoTokenizer.from_pretrained("_MODELS/lora_attention") # Load the pre-trained DistilGPT2 model model = AutoModelForCausalLM.from_pretrained("_MODELS/lora_attention") else: print("Downloading pretrained model from huggingface") # Load the tokenizer tokenizer = AutoTokenizer.from_pretrained("distilgpt2") # Load the pre-trained DistilGPT2 model model = AutoModelForCausalLM.from_pretrained("distilgpt2") # set padding token tokenizer.pad_token = tokenizer.eos_token # Define the training data from _DATASETS/data.txt with one sentence per line # now train with the train_data from the file _DATASETS/data.txt with one sentence per line. with open("_DATASETS/data.txt") as f: data = f.read() # now split data by \n train_data = data.split( '\n' ) # shuffle the data import random random.shuffle(train_data) # define the function for pruning the attention matrices def prune_attention_matrices(model, threshold): for name, param in model.named_parameters(): if "attention" in name and "weight" in name: data = param.data data[torch.abs(data) < threshold] = 0 param.data = data # define the function for low-rank approximation of the attention matrices def low_rank_approximation(model, rank): for name, param in model.named_parameters(): if "attention" in name and "weight" in name: data = param.data u, s, v = torch.svd(data) data = torch.mm(u[:, :rank], torch.mm(torch.diag(s[:rank]), v[:, :rank].t())) param.data = data # define the function for low-rank adaptation def low_rank_adaptation(model, train_data, tokenizer, rank, num_epochs, lr): # Define the optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=lr) loss_fn = torch.nn.CrossEntropyLoss() # Tokenize the training data input_ids = tokenizer(train_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] # Perform low-rank adaptation fine-tuning for epoch in range(num_epochs): # Zero the gradients optimizer.zero_grad() # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Backpropagate the loss loss.backward() # Update the parameters optimizer.step() # Print the loss print("Epoch: {}, Loss: {}".format(epoch, loss.item())) # Low-rank approximation low_rank_approximation(model, rank) # prune the attention matrices prune_attention_matrices(model, 0.1) # low-rank approximation low_rank_approximation(model, 32) # low-rank adaptation low_rank_adaptation(model, train_data, tokenizer, 32, 5, 5e-5) # now train # Define the optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=5e-5) loss_fn = torch.nn.CrossEntropyLoss() # Tokenize the training data input_ids = tokenizer(train_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] # Perform fine-tuning for epoch in range(5): # Zero the gradients optimizer.zero_grad() # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Backpropagate the loss loss.backward() # Update the parameters optimizer.step() # Print the loss print("Epoch: {}, Loss: {}".format(epoch, loss.item())) # save the model model.save_pretrained("_MODELS/lora_attention") # save the tokenizer tokenizer.save_pretrained("_MODELS/lora_attention") ## # load the model model = AutoModelForCausalLM.from_pretrained("_MODELS/lora_attention") # load the tokenizer tokenizer = AutoTokenizer.from_pretrained("_MODELS/lora_attention") # define the function for generating text def generate_text(model, tokenizer, prompt, max_length): # Tokenize the prompt input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"] # Generate the text output_ids = model.generate(input_ids, max_length=max_length, do_sample=True, top_k=50, top_p=0.95, temperature=0.5, num_return_sequences=1) # Decode the text output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) # Print the text print(output_text) # generate text generate_text(model, tokenizer, "quick brown", 125)
#python#LoRa#low-rank adaptation#low-rank approximation#adaptation#approximation#attention pruning#attention matrices#attention matrix#attention#matrices#matrix#gpt#distilgpt#generative pretrained transformer#pretrained#transformers#transformer#pre-trained#optimizer#torch#pytorch#huggingface#chatgpt#deep learning#ml#machine learning#ai#fine tuning
0 notes
Text
python low-rank adaptation for fine-tuning language models
# LoRa: Low-Rank Adaptation for Language Models fine-tuning # a pre-trained model to a new task # using a low-rank approximation of the model parameters to # reduce the memory and compute requirements of the fine-tuning process. # Using distilgpt2 as the pre-trained model in this example # https://pythonprogrammingsnippets.tumblr.com from transformers import AutoTokenizer, AutoModelForCausalLM import torch import numpy as np import os saved_model = "distilgpt2-lora-0.256" lowest_loss = 0.256 # set to whatever the lowest recorded loss is that you want to start saving snapshots at # Define the LoRA hyperparameters rank = 10 lr = 1e-4 num_epochs = 10 # if folder exists for model, load it, otherwise pull from huggingface if os.path.exists(saved_model): # load our model from where model.save_pretrained("distilgpt2-lora") saved it model = AutoModelForCausalLM.from_pretrained(saved_model) # load the tokenizer tokenizer = AutoTokenizer.from_pretrained("distilgpt2") # set the pad token to the end of sentence token tokenizer.pad_token = tokenizer.eos_token print("loading trained model") else: # Load the pre-trained DistilGPT2 tokenizer tokenizer = AutoTokenizer.from_pretrained("distilgpt2") tokenizer.pad_token = tokenizer.eos_token # Load the pre-trained DistilGPT2 model model = AutoModelForCausalLM.from_pretrained("distilgpt2") print("loading pre-trained model") # Define the optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=lr) loss_fn = torch.nn.CrossEntropyLoss() # Define the training data train_data = ["She wanted to talk about dogs.", "She wanted to go to the store.", "She wanted to pet the puppies.", "She wanted to like cereal.","She wanted to dance.", "She wanted to talk."] # Tokenize the training data input_ids = tokenizer(train_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] last_loss = 9999 # set to 9999 if we have no previous loss # Perform low-rank adaptation fine-tuning for epoch in range(num_epochs): # Zero the gradients optimizer.zero_grad() # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Compute the gradients loss.backward() # Perform a single optimization step optimizer.step() # Print the loss for this epoch print("Epoch {}: Loss = {}".format(epoch+1, loss.item())) if loss.item() < lowest_loss: # save a snapshot of the model if we have a more accurate result # if model path does not exist loss_model = 'distilgpt2-lora-'+str(round(loss.item(), 3)) print("we have a better result.") lowest_loss = round(loss.item(),3) if not os.path.exists(loss_model): print("saving snapshot:") model.save_pretrained(loss_model) # update lowest loss print("lowest loss is now: ", lowest_loss) last_loss = loss.item() # Save the model model.save_pretrained("distilgpt2-lora") # saves our last run # Load the model from the last training round model = AutoModelForCausalLM.from_pretrained("distilgpt2-lora") # Define the test data test_data = ["She wanted to talk"] # Tokenize the test data input_ids = tokenizer(test_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Print the loss print("Loss = {}".format(loss.item())) # Get the logits logits = outputs.logits # Get the predicted token ids predicted_token_ids = torch.argmax(logits, dim=-1) # Decode the predicted token ids predicted_text = tokenizer.decode(predicted_token_ids[0]) # Print the predicted text print("Predicted text = {}".format(predicted_text)) # Print the actual text print("Actual text = {}".format(test_data[0]))
#python#LoRa#low-rank adaptation#low-rank#adaptation#fine-tuning#language models#language model#distilgpt2#gpt#gpt-2#gpt-3#llm#language processing#nlp#data science#data scientist#ai#deep learning#advanced ai#compress ai#compress ai model#reduce model#fine-tune#training#train model#pre-trained model#train ai#training ai#machine learning
0 notes
Text
LoRa: Low-Rank Adaptation to Fine Tune Models
Fine-tuning a pre-trained language model on a specific task or domain can improve its performance on that task or domain. However, fine-tuning a large language model such as GPT-2 can be computationally expensive and time-consuming, especially if the fine-tuning data is limited. Low-rank adaptation (LoRA) is a technique that can reduce the computational cost and improve the performance of fine-tuning by constraining the model's parameters to a lower-rank subspace.
In simple terms, LoRA involves compressing the original model's parameters into a lower-dimensional space and then fine-tuning this compressed model on a small amount of task-specific data. By doing so, LoRA reduces the number of parameters that need to be updated during fine-tuning, which can significantly reduce the computational cost of fine-tuning. At the same time, LoRA can help the model adapt to the new task by fine-tuning on a small amount of task-specific data.
Some benefits of using low-rank adaptation for fine-tuning language models are:
Reduced computational cost: LoRA reduces the number of parameters that need to be updated during fine-tuning, which can significantly reduce the computational cost of fine-tuning.
Improved performance: LoRA can improve the performance of the fine-tuned model, especially if the fine-tuning data is limited. By compressing the original model's parameters into a lower-dimensional space, LoRA can help the model adapt better to the new task by fine-tuning on a small amount of task-specific data.
Regularization: LoRA acts as a form of regularization that can prevent overfitting and improve the generalization of the fine-tuned model.
However, there are also some potential drawbacks of using low-rank adaptation for fine-tuning language models:
Loss of expressiveness: Compressing the original model's parameters into a lower-dimensional space can reduce the model's expressiveness and make it less capable of modeling complex patterns in the data.
Dependence on the pre-trained model: LoRA relies on the quality of the pre-trained model used. If the pre-trained model is not well-suited to the new task or domain, LoRA may not be able to improve the performance of the fine-tuned model.
Hyperparameter tuning: LoRA involves additional hyperparameters that need to be tuned, such as the rank of the compressed model and the learning rate of the optimizer. Finding the optimal values for these hyperparameters can be time-consuming and require additional resources.
LoRa, or low-rank adaptation, is a technique that can help bring the power and control of large commercialized language models down to regular people. By fine-tuning a pre-trained model using low-rank approximation, we can compress the model while still maintaining high accuracy. This has the potential to make models more accessible and usable by those without access to large-scale computational resources. Additionally, the low-rank approximation can reduce overfitting and increase generalization, making the model more robust to new inputs. By making models more accessible and improving their performance, LoRa can help increase the adoption of models in a variety of applications, from natural language processing to computer vision. Overall, LoRa represents an important development in the field of machine learning that has the potential to democratize access to powerful models and improve their performance.
#lora#llm#large language models#large language model#model#stable diffusion#llama#alpaca#gpt#gpt-2#gpt-3.5#chatgpt#gpt-3#sd#ai#models#modelling#democratizing#democracy#free the models#free the weights#train models#train ai#pretrained generative text#generative#text#generative text#fine tuning#fine#tuning
0 notes
Text
python a vertical scrolling arcade style shooting game
import pygame import random import time # https://pythonprogrammingsnippets.tumblr.com # Define some colors WHITE = (255, 255, 255) BLACK = (0, 0, 0) RED = (255, 0, 0) GREEN = (0, 255, 0) BLUE = (0, 0, 255) # Set the width and height of the screen [width, height] SCREEN_WIDTH = 800 SCREEN_HEIGHT = 600 screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT)) # Set the title of the window pygame.display.set_caption("Raiden-like game") # Define the player's plane player_width = 50 player_height = 50 player_x = (SCREEN_WIDTH - player_width) / 2 player_y = SCREEN_HEIGHT - player_height player_speed = 5 # Define the bullet's size and speed bullet_width = 5 bullet_height = 10 bullet_speed = 10 # Define the enemy's size and speed enemy_width = 50 enemy_height = 50 enemy_speed = 2 # Create a list to hold the bullets bullet_list = [] # Create a list to hold the enemies enemy_list = [] # Create a clock to control the frame rate clock = pygame.time.Clock() # Function to create a new enemy at random intervals def create_enemy(): if random.randint(0, 100) 0: player_x -= player_speed if keys[pygame.K_d] and player_x 0: player_y -= player_speed if keys[pygame.K_s] and player_y = player_y and enemy[0] + enemy_width >= player_x and enemy[0] = enemy[0] and bullet[0] SCREEN_HEIGHT: enemy_list.remove(enemy) # Function to draw the score def draw_score(): pass # Function to draw the game over message def draw_game_over(): # switch background to red screen.fill(RED) # update canvas pygame.display.update() # draw game over message # wait a few seconds time.sleep(3) # quit pygame and program pygame.quit() quit() # Loop until the user clicks the close button. done = False # Used to manage how fast the screen updates clock = pygame.time.Clock() # -- main game loop -- running = True while not done: # --- Main event loop for event in pygame.event.get(): # User did something if event.type == pygame.QUIT: # If user clicked close done = True # Flag that we are done so we exit this loop elif event.type == pygame.KEYDOWN: if event.key == pygame.K_SPACE: bullet_x = player_x + player_width / 2 - bullet_width / 2 bullet_y = player_y - bullet_height bullet_list.append([bullet_x, bullet_y]) # --- Game logic should go here create_enemy() keys = pygame.key.get_pressed() move_player(keys) move_bullets() move_enemies() check_collisions() remove_offscreen() # --- Drawing code should go here # First, clear the screen to white. Don't put other drawing commands # above this, or they will be erased with this command. screen.fill(WHITE) # Draw the player's plane draw_player() # Draw the bullets draw_bullets() # Draw the enemies draw_enemies() # Draw the score draw_score() # Check if the game is over if not running: draw_game_over() # --- Go ahead and update the screen with what we've drawn. pygame.display.flip() # --- Limit to 60 frames per second clock.tick(60) # Close the window and quit. pygame.quit()
#python#game#vertical scrolling#arcade#npc#game ai#gameai#collisions#collision#blit#flip#pygame#vertical#scroller#shooting game#score#game over#player#entertainment#fun#gamer#gaming#python game#source code#snippets#source#code#snippet#example#tutorial
0 notes
Text
python invaders style concept game example
# invaders style concept using pygame and colored squares # enemy ship goes back and forth across the screen starting from top and working down as bullets hit them # player ship moves left and right and shoots bullets # player ship is destroyed when hit by enemy ship # player score is number of enemy ships destroyed # player score is number of shots taken # player score is time taken to destroy all enemy ships # sometimes my constants have a tendency to become variable. sorry. # https://pythonprogrammingsnippets.tumblr.com import pygame import random # Set up the game window WINDOW_WIDTH = 600 WINDOW_HEIGHT = 800 WINDOW_TITLE = "Invaders Style Clone" pygame.init() window = pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT)) pygame.display.set_caption(WINDOW_TITLE) # Define some colors BLACK = (0, 0, 0) WHITE = (255, 255, 255) GREEN = (0, 255, 0) RED = (255, 0, 0) # Define the player's spaceship PLAYER_WIDTH = 50 PLAYER_HEIGHT = 50 PLAYER_X = (WINDOW_WIDTH - PLAYER_WIDTH) / 2 PLAYER_Y = WINDOW_HEIGHT - PLAYER_HEIGHT - 50 player = pygame.Rect(PLAYER_X, PLAYER_Y, PLAYER_WIDTH, PLAYER_HEIGHT) # Define the player's movement PLAYER_MOVE_SPEED = 1 # Define the enemy's spaceship ENEMY_WIDTH = 50 ENEMY_HEIGHT = 50 ENEMY_X = 0 ENEMY_Y = 0 enemy = pygame.Rect(ENEMY_X, ENEMY_Y, ENEMY_WIDTH, ENEMY_HEIGHT) # Define the enemy's grid ENEMY_GRID_WIDTH = 10 ENEMY_GRID_HEIGHT = 5 ENEMY_GRID_X = 0 ENEMY_GRID_Y = 0 enemy_grid = pygame.Rect(ENEMY_GRID_X, ENEMY_GRID_Y, ENEMY_GRID_WIDTH, ENEMY_GRID_HEIGHT) # Define the enemy's movement ENEMY_MOVE_SPEED = 1 ENEMY_MOVE_DIRECTION = 1 # start enemy at top and work down as bullets hit them ENEMY_START_Y = 0 # Define the player's bullets BULLET_WIDTH = 10 BULLET_HEIGHT = 20 BULLET_X = 0 BULLET_Y = 0 bullet = pygame.Rect(BULLET_X, BULLET_Y, BULLET_WIDTH, BULLET_HEIGHT) # Define the player's bullets movement BULLET_MOVE_SPEED = 2 # Define the player's score shots_taken = 0 score = 0 # Define the game loop running = True while running: time_started = pygame.time.get_ticks() # Check for events for event in pygame.event.get(): if event.type == pygame.QUIT: running = False # Check for key presses # if player presses left and player is already going left, then stop movement keys = pygame.key.get_pressed() if keys[pygame.K_LEFT] and player.x > 0: player.x -= PLAYER_MOVE_SPEED if keys[pygame.K_RIGHT] and player.x + player.width = WINDOW_WIDTH: ENEMY_MOVE_DIRECTION *= -1 # Check if the bullet has hit the enemy if bullet.colliderect(enemy): score += 1 # now start enemy at top and work down as bullets hit them and spawn new enemy # move down one tile size ENEMY_START_Y += ENEMY_HEIGHT enemy.x = ENEMY_START_Y enemy.y = ENEMY_START_Y bullet.x = 0 bullet.y = 0 # increase bullet speed BULLET_MOVE_SPEED += 1 # increase enemy speed ENEMY_MOVE_SPEED += 1 # Check if the enemy has hit the player if enemy.colliderect(player): running = False # Draw the game window.fill(BLACK) pygame.draw.rect(window, WHITE, player) pygame.draw.rect(window, RED, enemy) pygame.draw.rect(window, GREEN, bullet) # Update the game pygame.display.update() # limit the game to 60 frames per second clock = pygame.time.Clock() clock.tick(60) # output time and score print("Time: " + str(pygame.time.get_ticks() - time_started)) print("Score: " + str(score)) print("Shots Taken: " + str(shots_taken)) pygame.quit()
#python#invaders#python invaders#invaders clone#space invaders#space#space game#python game#python example#example#source code#snippet#snippets#indiedev#devblr#programming#programmer#game#fun#entertainment#game loop#fps#loop#pygame#graphics#learn python#python is fun#python programming#videogame#game programming
1 note
·
View note
Text
python a simple modular rpg engine example
import random import time # https://pythonprogrammingsnippets.com/ # Define the rooms in the world rooms = { "room1": { "description": "This is room 1", "exits": {"n": "room2", "e": "room3"} }, "room2": { "description": "This is room 2", "exits": {"s": "room1"} }, "room3": { "description": "This is room 3", "exits": {"n": "room4", "w": "room1"} }, "room4": { "description": "This is room 4", "exits": {"s": "room3"} } } # Define the Player class class Player: def __init__(self, current_room): self.current_room = current_room self.health = 100 self.is_player = True self.name = "Player" self.dam_min = 20 self.dam_max = 30 self.health = 100 def fight(self, monster): print("You are fighting the monster.") while True: if self.check_health(): break if monster.check_health(): break self.one_hit(monster) monster.one_hit(self) time.sleep(1) def attack_message(self, monster): print(f"{self.name} hit {monster.name} for {self.damage} damage.") def one_hit(self, monster): self.damage = random.randint(self.dam_min, self.dam_max) monster.health -= self.damage self.attack_message(monster) time.sleep(0.3) def check_health(self): if self.health <= 0: print("You died.") quit() return True else: return False # Define the Monster class class Monster(Player): def __init__(self, current_room, name="Monster", health=50, dam_min=5, dam_max=10): super().__init__(current_room) self.name = name self.health = health self.dam_min = dam_min self.dam_max = dam_max self.is_player = False # Place the player in room 1 player = Player("room1") # Place a monster in a random room monster_room = random.choice(list(rooms.keys())) possible_monsters = [{"name": "Goblin", "health": 50, "dam_min": 5, "dam_max": 10}, {"name": "Orc", "health": 100, "dam_min": 10, "dam_max": 20}, {"name": "Dragon", "health": 200, "dam_min": 20, "dam_max": 30}] class MonsterFactory: def __init__(self, possible_monsters): self.possible_monsters = possible_monsters self.monsters = [] def randomly_create_and_place_monster(self, room): monster = random.choice(self.possible_monsters) monster = Monster(room, monster["name"], monster["health"], monster["dam_min"], monster["dam_max"]) self.monsters.append(monster) return monster def get_monsters(self): return self.monsters def get_monsters_in_room(self, room): monsters_in_room = [] for monster in self.monsters: if monster.current_room == room: monsters_in_room.append(monster) return monsters_in_room monster_factory = MonsterFactory(possible_monsters) monster = monster_factory.randomly_create_and_place_monster(monster_room) # Define the look command def do_look(room): # get all npcs in room monsters_in_room = monster_factory.get_monsters_in_room(player.current_room) # print the room description with a nice ascii art border print("+" + "-" * 50 + "+") print("|" + " " * 50 + "|") print("|" + rooms[player.current_room]["description"].center(50) + "|") print("|" + " " * 50 + "|") print("+" + "-" * 50 + "+") # print the health print(f"Your health: {player.health}") # print the npcs if len(monsters_in_room) == 0: print("There are no monsters in this room.") else: print("Monsters in this room:") for monster in monsters_in_room: print(f"{monster.name} - Health: {monster.health}") # show the exits print("Exits:") for exit in rooms[player.current_room]["exits"]: print(exit, end=" ") print() # show the commands as a line print("Commands: look, quit, fight, spawn, n, s, e, w") def show_prompt(player): # show progress bar for players health [====================] health_bar = "" for i in range(0, player.health, 10): health_bar += "=" # print(f"Your health: [{health_bar}] {player.health} :", end="") return f"Your health: [{health_bar}] {player.health} : " # Main game loop while True: # do look command do_look(player.current_room) # Get the player's input command = input(show_prompt(player)) # Handle the command if command == "quit" or command == "exit" or command == "q": break elif command in rooms[player.current_room]["exits"]: player.current_room = rooms[player.current_room]["exits"][command] elif command == "fight": monsters_in_room = monster_factory.get_monsters_in_room(player.current_room) if len(monsters_in_room) == 0: print("There are no monsters in this room.") else: for monster in monsters_in_room: player.fight(monster) elif command == "spawn": monster = monster_factory.randomly_create_and_place_monster(player.current_room) print(f"A {monster.name} has spawned in this room.") # a really stylish ascii art version of the look command elif command == "look" or command == "l": do_look(player.current_room) elif command == "help" or command =="h" or command == "?": print("Commands: n, s, e, w, look, fight, spawn, quit") else: print("Unknown command.")
output:
+--------------------------------------------------+ | | | This is room 1 | | | +--------------------------------------------------+ Your health: 100 Monsters in this room: Orc - Health: 100 Exits: n e Commands: look, quit, fight, spawn, n, s, e, w Your health: [==========] 100 :
#python#rpg#game#python game#python gaming#classes#class#python classes#python class#roguelike#rpg maker#fight engine#game loop#turn based#tui#text user interface#textual#text game engine#game engine#gamedev#indiedev#roleplaying#roleplay#game programming#game programmer#indie#dev#developer#source code#source
0 notes
Text
python reduce an ai model’s size down with quantization and speed it up
Quantizing a model means reducing the number of bits used to represent its weights and activations. This can help make the model smaller and faster, which is good because it means it can run on smaller computers and devices more easily. However, because the model uses fewer bits, it may not be able to represent its parameters as precisely as before. This can lead to some loss of accuracy or quality. So, quantizing a model can be a trade-off between size and speed on one hand, and accuracy or quality on the other. But overall, quantizing is a useful technique that can help make machine learning more accessible and efficient.
import torch import torch.nn as nn from transformers import GPT2Tokenizer, GPT2LMHeadModel # Load the GPT-2 model and tokenizer model_name = 'gpt2' tokenizer = GPT2Tokenizer.from_pretrained(model_name) model = GPT2LMHeadModel.from_pretrained(model_name) # Generate some sample text prompt = "The quick brown fox jumps over the lazy dog." input_ids = tokenizer.encode(prompt, return_tensors='pt') output = model.generate(input_ids, max_length=100, do_sample=True, num_return_sequences=1) sample_text = tokenizer.decode(output[0], skip_special_tokens=True) print("Sample text: ", sample_text) # Quantize the model down quantization_config = { 'activation': { 'dtype': torch.quint8, 'qscheme': torch.per_tensor_affine, 'reduce_range': True }, 'weight': { 'dtype': torch.qint8, 'qscheme': torch.per_tensor_symmetric, 'reduce_range': True } } quantized_model = torch.quantization.quantize_dynamic(model, quantization_config, dtype=torch.qint8) # Save the quantized model torch.save(quantized_model.state_dict(), 'quantized_model.pt') ## ------------------------------- Generate using Quantized Model # Load the quantized model quantized_model = GPT2LMHeadModel.from_pretrained(model_name) quantized_model.load_state_dict(torch.load('quantized_model.pt')) # Generate some sample text using the quantized model output_quantized = quantized_model.generate(input_ids, max_length=100, do_sample=True, num_return_sequences=1) sample_text_quantized = tokenizer.decode(output_quantized[0], skip_special_tokens=True) print("Sample text (quantized): ", sample_text_quantized)
#python#quantize#quantization#quant#ai model#model#ai#deep learning#compress#reduce bits#shrink bits#lower bit depth#mobile model#mobile#optimize model#optimize#optimization#model optimization#speed up#turbo#gpt#gpt-2#chatgpt#llama#pytorch#torch#nn#text generation#generative#generative text
1 note
·
View note
Text
python iterative monte carlo search for text generation using nltk
You are playing a game and you want to win. But you don't know what move to make next, because you don't know what the other player will do. So, you decide to try different moves randomly and see what happens. You repeat this process again and again, each time learning from the result of the move you made. This is called iterative Monte Carlo search. It's like making random moves in a game and learning from the outcome each time until you find the best move to win.
Iterative Monte Carlo search is a technique used in AI to explore a large space of possible solutions to find the best ones. It can be applied to semantic synonym finding by randomly selecting synonyms, generating sentences, and analyzing their context to refine the selection.
# an iterative monte carlo search example using nltk # https://pythonprogrammingsnippets.tumblr.com import random from nltk.corpus import wordnet # Define a function to get the synonyms of a word using wordnet def get_synonyms(word): synonyms = [] for syn in wordnet.synsets(word): for l in syn.lemmas(): if '_' not in l.name(): synonyms.append(l.name()) return list(set(synonyms)) # Define a function to get a random variant of a word def get_random_variant(word): synonyms = get_synonyms(word) if len(synonyms) == 0: return word else: return random.choice(synonyms) # Define a function to get the score of a candidate sentence def get_score(candidate): return len(candidate) # Define a function to perform one iteration of the monte carlo search def monte_carlo_search(candidate): variants = [get_random_variant(word) for word in candidate.split()] max_candidate = ' '.join(variants) max_score = get_score(max_candidate) for i in range(100): variants = [get_random_variant(word) for word in candidate.split()] candidate = ' '.join(variants) score = get_score(candidate) if score > max_score: max_score = score max_candidate = candidate return max_candidate initial_candidate = "This is an example sentence." # Perform 10 iterations of the monte carlo search for i in range(10): initial_candidate = monte_carlo_search(initial_candidate) print(initial_candidate)
output:
This manufacture Associate_in_Nursing theoretical_account sentence. This fabricate Associate_in_Nursing theoretical_account sentence. This construct Associate_in_Nursing theoretical_account sentence. This cathode-ray_oscilloscope Associate_in_Nursing counteract sentence. This collapse Associate_in_Nursing computed_axial_tomography sentence. This waste_one's_time Associate_in_Nursing gossip sentence. This magnetic_inclination Associate_in_Nursing temptingness sentence. This magnetic_inclination Associate_in_Nursing conjure sentence. This magnetic_inclination Associate_in_Nursing controversy sentence. This inclination Associate_in_Nursing magnetic_inclination sentence.
#python#nltk#iterative monte carlo search#monte carlo search#monte carlo#search#text generation#generative text#text#generation#text prediction#synonyms#synonym#semantics#semantic#language#language model#ai#iterative#iteration#artificial intelligence#sentence rewriting#sentence rewrite#story generation#deep learning#learning#educational#snippet#code#source code
2 notes
·
View notes
Text
python draw a bezier curve that you can manipulate with control points using pygame
# a python example to draw a bezier and let the user manipulate it via control points in python using pygame # this is a simple example to show how to draw a bezier curve and how to manipulate it via control points # https://pythonprogrammingsnippets.tumblr.com import pygame import math import random import time def draw_bezier(start, end, control1, control2, color): # draw a editable bezier curve using pygame # start - tuple (x,y) of starting point # end - tuple (x,y) of ending point # control1 - tuple (x,y) of control point 1 # control2 - tuple (x,y) of control point 2 # color - tuple (r,g,b) of color to draw the curve pygame.draw.line(screen, color, start, control1, 1) pygame.draw.line(screen, color, control1, control2, 1) pygame.draw.line(screen, color, control2, end, 1) pygame.draw.circle(screen, (255,0,0), control1, 5) pygame.draw.circle(screen, (255,0,0), control2, 5) pygame.draw.circle(screen, (0,255,0), start, 3) pygame.draw.circle(screen, (0,255,0), end, 3) pygame.display.flip() # initialize pygame pygame.init() # set the screen size screen = pygame.display.set_mode((800, 600)) # set the title of the window pygame.display.set_caption("Bezier Example") # set the background color background = (255, 255, 255) # set the color of the bezier curve color = (0, 0, 0) # set the width of the bezier curve width = 1 # set the color of the control points control_color = (255, 0, 0) # set the color of the starting and ending points point_color = (0, 255, 0) # set the radius of the control points control_radius = 15 # set the radius of the starting and ending points point_radius = 10 # set the starting point start = (100, 100) # set the ending point end = (700, 500) # set the first control point control1 = (200, 200) # set the second control point control2 = (600, 400) # set the running flag running = True # set the dragging flag dragging = False # set the control point being dragged dragging_control = 0 # set the starting point being dragged dragging_start = False # set the ending point being dragged dragging_end = False # set the control point being hovered over hovering_control = 0 # set the starting point being hovered over hovering_start = False # set the ending point being hovered over hovering_end = False # set the mouse position mouse_pos = (0, 0) # main loop while running: # check for events for event in pygame.event.get(): # check for quit event if event.type == pygame.QUIT: # set the running flag to false running = False # check for mouse button down event if event.type == pygame.MOUSEBUTTONDOWN: # check for left mouse button down event if event.button == 1: # set the mouse position mouse_pos = pygame.mouse.get_pos() # check if the mouse is over the first control point if math.sqrt((mouse_pos[0] - control1[0]) ** 2 + (mouse_pos[1] - control1[1]) ** 2) < control_radius: # set the dragging flag dragging = True # set the control point being dragged dragging_control = 1 # check if the mouse is over the second control point elif math.sqrt((mouse_pos[0] - control2[0]) ** 2 + (mouse_pos[1] - control2[1]) ** 2) < control_radius: # set the dragging flag dragging = True # set the control point being dragged dragging_control = 2 # check if the mouse is over the starting point elif math.sqrt((mouse_pos[0] - start[0]) ** 2 + (mouse_pos[1] - start[1]) ** 2) < point_radius: # set the dragging flag dragging = True # set the starting point being dragged dragging_start = True # check if the mouse is over the ending point elif math.sqrt((mouse_pos[0] - end[0]) ** 2 + (mouse_pos[1] - end[1]) ** 2) < point_radius: # set the dragging flag dragging = True # set the ending point being dragged dragging_end = True # check for mouse button up event if event.type == pygame.MOUSEBUTTONUP: # check for left mouse button up event if event.button == 1: # set the dragging flag dragging = False # set the control point being dragged dragging_control = 0 # set the starting point being dragged dragging_start = False # set the ending point being dragged dragging_end = False # check if the mouse is over the first control point if math.sqrt((mouse_pos[0] - control1[0]) ** 2 + (mouse_pos[1] - control1[1]) ** 2) < control_radius: # set the control point being hovered over hovering_control = 1 # check if the mouse is over the second control point elif math.sqrt((mouse_pos[0] - control2[0]) ** 2 + (mouse_pos[1] - control2[1]) ** 2) < control_radius: # set the control point being hovered over hovering_control = 2 # check if the mouse is over the starting point elif math.sqrt((mouse_pos[0] - start[0]) ** 2 + (mouse_pos[1] - start[1]) ** 2) < point_radius: # set the starting point being hovered over hovering_start = True # check if the mouse is over the ending point elif math.sqrt((mouse_pos[0] - end[0]) ** 2 + (mouse_pos[1] - end[1]) ** 2) < point_radius: # set the ending point being hovered over hovering_end = True # check if the mouse is not over any points else: # set the control point being hovered over hovering_control = 0 # set the starting point being hovered over hovering_start = False # set the ending point being hovered over hovering_end = False # check if the mouse is being dragged if dragging: # check if the first control point is being dragged if dragging_control == 1: # set the first control point control1 = pygame.mouse.get_pos() # check if the second control point is being dragged elif dragging_control == 2: # set the second control point control2 = pygame.mouse.get_pos() # check if the starting point is being dragged elif dragging_start: # set the starting point start = pygame.mouse.get_pos() # check if the ending point is being dragged elif dragging_end: # set the ending point end = pygame.mouse.get_pos() # set the mouse position mouse_pos = pygame.mouse.get_pos() # draw the background screen.fill((255, 255, 255)) # draw the bezier curve draw_bezier(start, end, control1, control2, (0, 0, 0)) # check if the first control point is being hovered over if hovering_control == 1: # draw the first control point pygame.draw.circle(screen, (255, 0, 0), control1, control_radius) # check if the second control point is being hovered over elif hovering_control == 2: # draw the second control point pygame.draw.circle(screen, (255, 0, 0), control2, control_radius) # check if the starting point is being hovered over elif hovering_start: # draw the starting point pygame.draw.circle(screen, (0, 255, 0), start, point_radius) # check if the ending point is being hovered over elif hovering_end: # draw the ending point pygame.draw.circle(screen, (0, 255, 0), end, point_radius) # update the screen pygame.display.flip() # quit pygame pygame.quit()
#python#pygame#bezier#bezier curves#curves#vectors#vector#vector drawing#computer art#computer drawing#python drawing#art#artist#ui#gui#mouse#control points#control#points#screen flip#example#tutorial#snippet#snippets#programming#programmer#source#code#coding#coder
0 notes