#communications api provider
Text
#whatsapp business solutions#whatsapp solution api#two way sms service#voice api#2-way messaging#communications api#sms sender api#chatbot business#cpaas provider#omnichannel chat#sms api services#multi channel communication platform#a2p sms provider#apple business chat#two way text messaging#secure sms api#communications api provider#cpaas providers#whatsapp developer api
1 note
·
View note
Text
Daniel Ciolek, Head of Research and Development at InvGate – Interview Series
New Post has been published on https://thedigitalinsider.com/daniel-ciolek-head-of-research-and-development-at-invgate-interview-series/
Daniel Ciolek, Head of Research and Development at InvGate – Interview Series
Daniel is a passionate IT professional with more than 15 years of experience in the industry. He has a PhD. in Computer Science and a long career in technology research. His interests fall in multiple areas, such as Artificial Intelligence, Software Engineering, and High Performance Computing.
Daniel is the Head of Research and Development at InvGate, where he leads the R&D initiatives. He works along with the Product and Business Development teams to design, implement, and monitor the company’s R&D strategy. When he’s not researching, he’s teaching.
InvGate empowers organizations by providing the tools to deliver seamless service across departments, from IT to Facilities.
When and how did you initially become interested in computer science?
My interest in computer science dates back to my early childhood. I was always fascinated by electronic devices, often finding myself exploring and trying to understand how they worked. As I grew older, this curiosity led me to coding. I still remember the fun I had writing my first programs. From that moment on, there was no doubt in my mind that I wanted to pursue a career in computer science.
You are currently leading R&D initiatives and implementing novel generative AI applications. Can you discuss some of your work?
Absolutely. In our R&D department, we tackle complex problems that can be challenging to represent and solve efficiently. Our work isn’t confined to generative AI applications, but the recent advancements in this field have created a wealth of opportunities we’re keen to exploit.
One of our main objectives at InvGate has always been to optimize the usability of our software. We do this by monitoring how it’s used, identifying bottlenecks, and diligently working towards removing them. One such bottleneck we’ve encountered often is related to the understanding and utilization of natural language. This was a particularly difficult issue to address without the use of Large Language Models (LLMs).
However, with the recent emergence of cost-effective LLMs, we’ve been able to streamline these use cases. Our capabilities now include providing writing recommendations, automatically drafting knowledge base articles, and summarizing extensive pieces of text, among many other language-based features.
At InvGate, your team applies a strategy that is called “agnostic AI”. Could you define what this means and why it is important?
Agnostic AI is fundamentally about flexibility and adaptability. Essentially, it’s about not committing to a single AI model or provider. Instead, we aim to keep our options open, leveraging the best each AI provider offers, while avoiding the risk of being locked into one system.
You can think of it like this: should we use OpenAI’s GPT, Google’s Gemini, or Meta’s Llama-2 for our generative AI features? Should we opt for a pay-as-you-go cloud deployment, a managed instance, or a self-hosted deployment? These aren’t trivial decisions, and they may even change over time as new models are released and new providers enter the market.
The Agnostic AI approach ensures that our system is always ready to adapt. Our implementation has three key components: an interface, a router, and the AI models themselves. The interface abstracts away the implementation details of the AI system, making it easier for other parts of our software to interact with it. The router decides where to send each request based on various factors such as the type of request and the capabilities of the available AI models. Finally, the models perform the actual AI tasks, which may require custom data pre-processing and result formatting processes.
Can you describe the methodological aspects that guide your decision-making process when selecting the most suitable AI models and providers for specific tasks?
For each new feature we develop, we begin by creating an evaluation benchmark. This benchmark is designed to assess the efficiency of different AI models in solving the task at hand. But we don’t just focus on performance, we also consider the speed and cost of each model. This gives us a holistic view of each model’s value, allowing us to choose the most cost-effective option for routing requests.
However, our process doesn’t end there. In the fast-evolving field of AI, new models are constantly being released and existing ones are regularly updated. So, whenever a new or updated model becomes available, we rerun our evaluation benchmark. This lets us compare the performance of the new or updated model with that of our current selection. If a new model outperforms the current one, we then update our router module to reflect this change.
What are some of the challenges of seamlessly switching between various AI models and providers?
Seamlessly switching between various AI models and providers indeed presents a set of unique challenges.
Firstly, each AI provider requires inputs formatted in specific ways, and the AI models can react differently to the same requests. This means we need to optimize individually for each model, which can be quite complex given the variety of options.
Secondly, AI models have different capabilities. For example, some models can generate output in JSON format, a feature that proves useful in many of our implementations. Others can process large amounts of text, enabling us to use a more comprehensive context for some tasks. Managing these capabilities to maximize the potential of each model is an essential part of our work.
Finally, we need to ensure that AI-generated responses are safe to use. Generative AI models can sometimes produce “hallucinations”, or generate responses that are false, out of context, or even potentially harmful. To mitigate this, we implement rigorous post-processing sanitization filters to detect and filter out inappropriate responses.
How is the interface designed within your agnostic AI system to ensure it effectively abstracts the complexities of the underlying AI technologies for user-friendly interactions?
The design of our interface is a collaborative effort between R&D and the engineering teams. We work on a feature-by-feature basis, defining the requirements and available data for each feature. Then, we design an API that seamlessly integrates with the product, implementing it in our internal AI-Service. This allows the engineering teams to focus on the business logic, while our AI-Service handles the complexities of dealing with different AI providers.
This process doesn’t rely on cutting-edge research, but instead on the application of proven software engineering practices.
Considering global operations, how does InvGate handle the challenge of regional availability and compliance with local data regulations?
Ensuring regional availability and compliance with local data regulations is a crucial part of our operations at InvGate. We carefully select AI providers that can not only operate at scale, but also uphold top security standards and comply with regional regulations.
For instance, we only consider providers that adhere to regulations such as the General Data Protection Regulation (GDPR) in the EU. This ensures that we can safely deploy our services in different regions, with the confidence that we are operating within the local legal framework.
Major cloud providers such as AWS, Azure, and Google Cloud satisfy these requirements and offer a broad range of AI functionalities, making them suitable partners for our global operations. Furthermore, we continuously monitor changes in local data regulations to ensure ongoing compliance, adjusting our practices as needed.
How has InvGate’s approach to developing IT solutions evolved over the last decade, particularly with the integration of Generative AI?
Over the last decade, InvGate’s approach to developing IT solutions has evolved significantly. We’ve expanded our feature base with advanced capabilities like automated workflows, device discovery, and Configuration Management Database (CMDB). These features have greatly simplified IT operations for our users.
Recently, we’ve started integrating GenAI into our products. This has been made possible thanks to the recent advancements in LLM providers, who have started offering cost-effective solutions. The integration of GenAI has allowed us to enhance our products with AI-powered support, making our solutions more efficient and user-friendly.
While it’s still early days, we predict that AI will become a ubiquitous tool in IT operations. As such, we plan to continue evolving our products by further integrating AI technologies.
Can you explain how the generative AI within the AI Hub enhances the speed and quality of responses to common IT incidents?
The generative AI within our AI Hub significantly enhances both the speed and quality of responses to common IT incidents. It does this through a multi-step process:
Initial Contact: When a user encounters a problem, he or she can open a chat with our AI-powered Virtual Agent (VA) and describe the issue. The VA autonomously searches through the company’s Knowledge Base (KB) and a public database of IT troubleshooting guides, providing guidance in a conversational manner. This often resolves the problem quickly and efficiently.
Ticket Creation: If the issue is more complex, the VA can create a ticket, automatically extracting relevant information from the conversation.
Ticket Assignment: The system assigns the ticket to a support agent based on the ticket’s category, priority, and the agent’s experience with similar issues.
Agent Interaction: The agent can contact the user for additional information or to notify them that the issue has been resolved. The interaction is enhanced with AI, providing writing recommendations to improve communication.
Escalation: If the issue requires escalation, automatic summarization features help managers quickly understand the problem.
Postmortem Analysis: After the ticket is closed, the AI performs a root cause analysis, aiding in postmortem analysis and reports. The agent can also use the AI to draft a knowledge base article, facilitating the resolution of similar issues in the future.
While we’ve already implemented most of these features, we’re continually working on further enhancements and improvements.
With upcoming features like the smarter MS Teams Virtual Agent, what are the expected enhancements in conversational support experiences?
One promising path forward is to extend the conversational experience into a “copilot”, not only capable of replying to questions and taking simple actions, but also taking more complex actions on behalf of the users. This could be useful to improve users’ self-service capabilities, as well as to provide additional powerful tools to agents. Eventually, these powerful conversational interfaces will make AI an ubiquitous companion.
Thank you for the great interview, readers who wish to learn more should visit InvGate.
#agent#agents#ai#ai model#AI models#AI-powered#amp#Analysis#API#applications#approach#Article#Articles#artificial#Artificial Intelligence#AWS#azure#benchmark#Business#Business development#career#challenge#change#Cloud#cloud providers#coding#collaborative#communication#compliance#comprehensive
0 notes
Text

Running a successful hotel business requires careful consideration and implementation of various services, one of which is the phone service. A reliable and efficient communication system is crucial for any hotel to operate smoothly and provide quality service to its guests. This is where the right hotel solution for phone service comes into play choosing a VoIP provider that best suits your needs.
#VoIP Provider#hotel phone system#business phones#voip technology#voip advantages#pbx system#voip phone#phonesuite direct#voip providers#phonesuite dealers#pbx communications#hotel hospitality#voice api ivr#hotel ivr
0 notes
Text

CPaaS a technology that empowers the financial sector.
#CPaaS#CPaaSProvider#CPaaS Service Provider#telecommunication#Financial sector#communication services#voxcpaas#Bulksms#chat sdk#audio sdk#video sdk#api integration
0 notes
Text
Bulk SMS API Services
Our Mobility Inclusive journey begins in this new millennium era to create a world-class messaging service. With our services we connect our customers with their customers to create a fast and easy communication system, essential for their operation. Increase the effectiveness of your SMS and WhatsApp campaigns with a simple plugin. With this plugin, brands can quickly initiate meaningful conversations at every touchpoint of the customer journey, increase sales, and invest to add more value to the customer experience. Mobilityinclusive robust SMS platform for sending critical customer alerts and transaction notifications.
Our mobile engagement platform specializes in providing SMS, WhatsApp and email marketing services. Our goal is to provide easy-to-use apps for businesses—whether you are sending out alerts through text or automated SMS messages, or sending personalized emails for business inquiries. We make it easier for companies to manage their mobile engagement strategies to support sales and marketing efforts.

Mobility Inclusive is a company that specializes in providing SMS, WhatsApp and email marketing services. Our goal is to provide easy-to-use apps for businesses—whether you are sending out alerts through text or automated SMS messages, or sending personalized emails for business inquiries. We make it easier for companies to manage their mobile engagement strategies to support sales and marketing efforts.
Flexible Bulk SMS API for your Enterprise
We are creating an accessible and integrated SMS platform for your business. We make everything simple, fast and reliable, so that you can focus on giving your customers the best experience possible.We think that all businesses should be accessible, just like the modern world is. Our mobile engagement platform makes business communication simple. We make everything easy, so you can spend more time focusing on your customers.
Achieve SMS Integration with any type of application and carrier, with the most straightforward and reliable SMS service in the market. Create an intuitive dashboard to send personalized messages based on user behavior.
Benefits of bulk SMS service API
1. Bulk SMS is an essential part of the Mobile Inclusive ecosystem. With the help of this service, businesses can reach thousands of customers without paying a single penny.
2. To achieve mobility inclusive, we are developing a smart, low-cost SMS and MMS solution that can be used anywhere in the world.
With the growing need for messaging services, we have launched a new bulk SMS API service.
#messaging service providers#mobile engagement platform#cloud messaging API#communication provider#bulk sms services#bulk sms service provider#chatbot service providers#Whatsapp Business Api Service Provider#whatsapp business api#whatsapp business service providers#whatsapp api solution provider
0 notes
Text
How is Transactional SMS different from Promotional SMS?
Promotional and transactional SMS are two primary types of business Nettyfish help communicate reliably and grow your business through SMS
#Promotional SMS#Promotional message#Transactional SMS#Transactional message#Bulk SMS service#SMS service#Bulk SMS marketing#bulk sms marketing#whatsapp business api#bulk sms campaigns#bulk sms provider in india#bulk sms service#sms api providers in chennai#sms marketing communication
0 notes
Text
Tuesday, February 7th, 2023
🌟 New
🌈 Important Internet Checkmarks are now rainbow! You can purchase them from TumblrMart. 🌈
Everyone now has access to polls.
The text formatting options in the post editor on web have been updated to better support keyboard navigation and screen readers.
In the mobile apps, some folks will see a new lightbox view for images and videos that we’re trying out.
🛠 Fixed
On web, the dashboard was unreachable for about 30 minutes earlier today.
Fixed an issue on blog themes where the photo lightbox (the feature where you can click an image to view its high-quality version) wouldn’t automatically be available for posts loaded in via endless scrolling.
Fixed an issue in the post editor on web where text could be black in any color palette, making it very difficult or impossible to read.
🚧 Ongoing
We’re still awaiting more details about Twitter’s plans to shut off free API access. We’ll provide an update about how this will impact Tumblr when we know more.
🌱 Upcoming
Nothing to share today.
Experiencing an issue? File a Support Request and we’ll get back to you as soon as we can!
Want to share your feedback about something? Check out our Work in Progress blog and start a discussion with the community.
2K notes
·
View notes
Text
For those of you who use Reddit.
You may have noticed your favorite sub set to private today. Especially if you weren't logged in. This is not a glitch, this is not a hack, this is a protest.
In a nutshell Reddit wants money so they're cutting off 3rd party apps that refuse to pay up or can't from the API. This is going to destroy communities that have to moderate with the help of bots. Take a guess how many communities that includes. Some of the same applications affected are also used by those with disabilities in order to use Reddit.
Reddit doesn't care. They haven't implemented the needed accessibility features these apps provide and more than likely won't. The apps have been given a month and then if they didn't or couldn't pay they're gone. Another one of the main concerns related to losing bot moderation on Reddit is without the ability to use the bots illegal material will have an easier way to spread. Moderating a massive subreddit 24/7 is not a job that's reasonably doable by a small group of people who in all likelyhood also have a job offline, lives outside of the Internet, etc. A lot of mods moderate for free. Without the bots some subs will most likely have to shut down.
The goal of the protest is to go dark on the entire site until better terms have been negotiated. Which is why your favorite sub may have "gone dark" today. (Privated)
You can participate if you wish by spreading the news outside of Reddit and staying off of Reddit.
580 notes
·
View notes
Text
Looks like reddit is about to get a whole lot worse. AI companies have been scraping reddit's content to use in language learning models and reddit's owners have decided that they should start charging for API use so they can cash in.
Unfortunately this will fuck up a number of 3rd party moderation and accessibility tools. These tools were built by users out of necessity reddit refuses to implement desperately needed functions themselves. reddit claims they will allow free use of their API for developers who build things to improve reddit, and they also claimed they will create better moderation tools for the site. But they have a long history of making bullshit promises like that.
Mods are extremely concerned about the rollout for the API changes. They are unsure how the communication (if any) will be provided and how quickly their mod teams can react. Mods and the developers for their 3rd party tools contribute an unbelievable amount of unpaid labor toward keeping reddit usable, which in turn contributes to reddit's overall value. Moving forward with switching to a paid API makes user lives harder without providing any compensation just to make money that will not be shared and, let's be real, will not be invested back into the site.
3rd party reddit readers are also in trouble with this change, which is bad news for every mobile reddit user. Reddit's official app sucks shit both in terms of features and stability. The developer of the free reddit app Apollo has obtained reddit's API pricing and it would cost him $20 million USD per year to obtain access for Apollo. This is more money than the app generates with paid subscriptions.
There are a lot of rumors that reddit wants to take its stock public which would explain why they are making money first, users last decisions such as this.
NYT article about this via archive.org (no paywall).
mod post from r/historians discussing the API access issue as well as reddit's history of failure to support its moderators.
Verge article discussing the API restriction impacting accessibility (note: no one from r/blind was not contacted to comment and the sub has a years long history of pushing reddit for better accessibility with reddit never once making any real commitment).
mod post from r/blind.
Additional mod post from r/blind with letter template for users to email reddit in protest of the API changes, as well as additional info about the changes.
mod post from r/apolloapp with info about API pricing (which is ridiculously expensive compared to other sites using a paid API model).
edit: btw if you make some kind of dumbass "this is good because I don't like reddit" comment you're a piece of shit.
355 notes
·
View notes
Text
sometimes i see takes on here that i definitely believed in my early 20s when i was at a much worse time in my life with respect to my identity and everything...like API-americans are on here fully saying "i don't like how all these white people are trying to learn japanese / korean / tagalog :\ ...it feels fetishistic" and idk how to tell people that learning a language is not. fetishistic. learning a language is not demeaning anyone or anything. learning someone else's language is one of the most difficult things you can do with your free time and it provides an insight into culture and history that you oftentimes cannot get elsewhere, and it's the absolute baseline for respectful communication when visiting some countries...
but i get where this is coming from because when you're part of the diaspora, and your parents americanized you, and maybe they didn't even teach you their language (me) you get prickly about it. you start to resent people who don't look like you who are speaking the language you SHOULD have learned, better than you. but you have to get over it. this isn't about them, this is about your own family. you've got to reflect and swallow your pride and move the fuck on, because ragging on the weeaboo in your class isn't going to fix you.
125 notes
·
View notes
Text
So when I joined Reddit, the big thing™ at the time was ice soap and 2am chilli. If I remember correctly, that was either late 2010 or 2011. Ever since then, reddit has been my primary spot to enjoy memes, content for specific fandoms, book and game recommendations, and drama recaps. Basically, anything I had an urge to consume, reddit always provided.
There were large bouts of drama before (anyone remember /r/fatpeoplehate and Ellen Pao?) but the smaller, more curated communities I primarily enjoyed were largely unaffected. But now, I can't in good conscience visit those subreddits I have frequented for upwards of twelve years because of this bullshit reddit is pulling with their API.
I am left with this large gap in my life that reddit occupied for so long. Whenever I was waiting in line, taking a break at work, or just having a veg night at home, reddit was always there. Now, I find myself trying to cobble something together between this hellsite and TikTok, but I haven't quite managed to find the fandom niches I so deeply enjoyed.
At the risk of sounding dramatic, it's almost like leaving a long term relationship and trying to untangle your life from someone you don't recognize anymore.
I guess it's time to touch grass and move on.
287 notes
·
View notes
Text
The monetization creep has been evident for a while. Reddit has added a subscription ”Reddit premium”; offered “community rewards” as a paid super-vote ; embraced an NFT marketplace; changed the site's design for one with more recommended content; and started nudging users toward the official mobile app. The site has also been adding more restrictions to uploading and viewing “not safe for work” (NSFW) content. All this, while community requests for improvements to moderation tools and accessibility features have gone unaddressed on mobile, driving many users to third-party applications.
Perhaps the worst development was announced on April 18th, when Reddit announced changes to its Data API would be starting on July 1st, including new “premium access” pricing for users of the API. While this wouldn’t affect projects on the free tier, such as moderator bots or tools used by researchers, the new pricing seems to be an existential threat to third-party applications for the site. It also bears a striking resemblance to a similar bad decision Twitter made this year under Elon Musk.
[...]
Details about Reddit’s API-specific costs were not shared, but it is worth noting that an API request is commonly no more burdensome to a server than an HTML request, i.e. visiting or scraping a web page. Having an API just makes it easier for developers to maintain their automated requests. It is true that most third-party apps tend to not show Reddit’s advertisements, and AI developers may make heavy use of the API for training data, but these applications could still (with more effort) access the same information over HTML.
The heart of this fight is for what Reddit’s CEO calls their “valuable corpus of data,” i.e. the user-made content on the company’s servers, and for who gets live off this digital commons. While Reddit provides essential infrastructural support, these community developers and moderators make the site worth visiting, and any worthwhile content is the fruit of their volunteer labor. It’s this labor and worker solidarity which gives users unique leverage over the platform, in contrast to past backlash to other platforms.
179 notes
·
View notes
Note
Am I right in suspecting that GPT-4 is not nearly as great an advance on GPT-3 as GPT-3 was on GPT-2? It seems a much better product, but that product seems to have as its selling point not vastly improved text-prediction, but multi-modality.
No one outside of OpenAI really knows how much of an advance GPT-4 is, or isn't.
When GPT-3 came out, OpenAI was still a research company, like DeepMind.
Before there was a GPT-3 product, there was a GPT-3 paper. And it was a long, serious, academic-style paper. It described, in a lot of detail, how they created and evaluated the model.
The paper was an act of scientific communication. A report on a new experiment written for a research audience, intended primarily to transmit information to that audience. It wanted to show you what they had done, so you could understand it, even if you weren't there at the time. And it wanted to convince you of various claims about the model's properties.
I don't know if they submitted it to any conferences or journals (IIRC I think they did, but only later on?). But if they did, they could have, and it wouldn't seem out of place in those venues.
Now, OpenAI is fully a product company.
As far as I know, they have entirely stopped releasing academic-style papers. The last major one was the DALLE-2 one, I think. (ChatGPT didn't get one.)
What OpenAI does now is make products. The release yesterday was a product release, not a scientific announcement.
In some cases, as with GPT-4, they may accompany their product releases with things that look superficially like scientific papers.
But the GPT-4 "technical report" is not a serious scientific paper. A cynic might categorize it as "advertising."
More charitably, perhaps it's an honest attempt to communicate as much as possible to the world about their new model, given a new set of internally defined constraints motivated by business and/or AI safety concerns. But if so, those constraints mean they can't really say much at all -- not in a way that meets the ordinary standards of evidence for scientific work.
Their report says, right at the start, that it will contain no information about what the model actually is, besides the stuff that would already be obvious:
GPT-4 is a Transformer-style model [33 ] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. [note that this really only says "we trained on some data, not all of which was public" -nost] The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34 ]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
As Eleuther's Eric Hallahan put it yesterday:

If we read further into the report, we find a number of impressive-looking evaluations.
But they are mostly novel ones, not done before on earlier LMs. The methodology is presented in a spotty and casual manner, clearly not interested in promoting independent reproductions (and possibly even with the intent of discouraging them).
Even the little information that is available in the report is enough to cast serious doubt on the overall trustworthiness of that information. Some of it violates simple common sense:

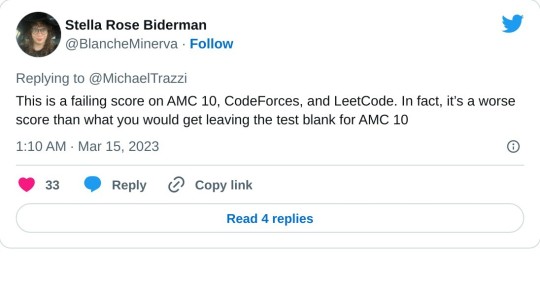
...and, to the careful independent eye, immediately suggests some very worrying possibilities:

That said -- soon enough, we will be able to interact with this model via an API.
And once that happens, I'm sure independent researchers committed to open source and open information will step in and assess GPT-4 seriously and scientifically -- filling the gap left by OpenAI's increasingly "product-y" communication style.
Just as they've done before. The open source / open information community in this area is very capable, very thoughtful, and very fast. (They're where Stable Diffusion came from, to pick just one well-known example.)
----
When the GPT-3 paper came out, I wrote a post titled "gpt-3: a disappointing paper." I stand by the title, in the specific sense that I meant it, but I was well aware that I was taking a contrarian, almost trollish pose. Most people found the GPT-3 paper far from "disappointing," and I understand why.
But "GPT-4: a disappointing paper" isn't a contrarian pose. It was -- as far as I can see -- the immediate and overwhelming consensus of the ML community.
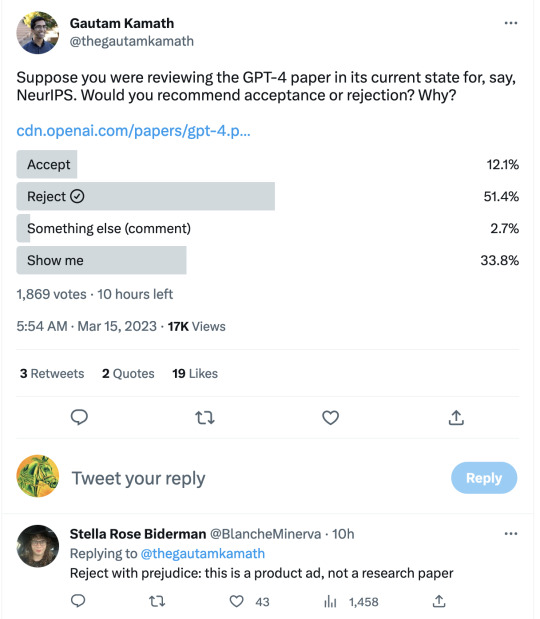
----
As for the multimodal stuff, uh, time will tell? We can't use it yet, so it's hard to know how good it is.
What they showed off in the live demo felt a lot like what @nostalgebraist-autoresponder has been able to do for years now.
Like, yeah, GPT-4 is better at it, but it's not a fundamentally new advance, it's been possible for a while. And people have done versions of it, eg Flamingo and PaLI and Magma [which Frank uses a version of internally] and CoCa [which I'm planning to use in Frank, once I get a chance to re-tune everything for it].
I do think it's a potentially transformative capability, specifically because it will let the model natively "see" a much larger fraction of the available information on web pages, and thus enable "action transformer" applications a la what Adept is doing.
But again, only time will tell whether these applications are really going to work, and for what, and whether GPT-4 is good enough for that purpose -- and whether you even need it, when other text/image language models are already out there and are being rapidly developed.
#ai tag#gpt-4#ugh i apparently can't respond to npf asks in the legacy editor :(#the npf/beta editor is still painful to use#it's nice to be able to embed tweets though
388 notes
·
View notes
Text
Top betrayal of websites & where people migrated to
That I know of right now.
YouTube. Community Guideline Strikes & DMCAs, & moar bad things. Go to Odysee now.
[tumblr] (formerly). Deleted & purged 69420. Go to idk, 888blr, and Twitter, and Newgrounds, and any Mastodon instances out there. Unbetrayed!! 69420 is back!!! But the damage has been done.
Twitter. Wait, what again? No, I forgot what Elon Musk did? Uh.... I still... idk... well let's say... did not make things better for all part (just few make betters are not considered enough), damn.. what is it?!. Go to idk any Fediverse like Mastodon or whatever it is. Also bot account or whatever API was that I forgor,... paid, coz spammers.
What was this Minecraft Launcher?. Lead dev gone rogue and deleted contributors, could possible lead to malware commit. Go to Prism Launcher.
Ubuntu. Uhhh... proprietary blobs increasing and more ironic proprietarisms (Snap is proprietary), and one example sauce here this. Go to different Ubuntu forks or maybe jump to another diffferent Linux Distro like Arch, btw.
VRChat. Implemented Easy Anti-Cheat instead of officializing community fixes like Anti-crash, anti-exploits, etc. etc. Go to different VR social media, like ChilloutVR. This is also Unity based VR social media, with mods allowed and many community patch and fixes (yes, mods) turned official. Heck, 69420 is even allowed, with a free DLC provided!!! No kidding!!! If you want to add me, same, JOELwindows7 & I was wearing BZ Protogen right now. Oh, one more thing. The Premium account is buy once, unlock forever!!! In VRChat, there is only subscription (temporary buy). There is also NEOS VR, which is Unreal Engine, I think.. idk... huh, no Godot VR social media?! Aw man..
Reddit. API is now paid because API does not serve them money through those intrusive ads in the original interface (effectively making maintenance way too expensive as lots of users use them, & it no longer worth it). Go to [tumblr], Lemmy (& maybe any Mastodon instances). See r/Save3rdPartyApps. Many subreddits gone privated in protest. Some come back, others forever. Some again restricted like mine. Basically private but still can be accessed, just no comment, no post, or neither. Fun fact, because of this, Reddit admin ironically active eradicating this protest by force removing mods and handing it over to somebody else who will, especially to basically force them public again. I mean, yeah, it's egregious, peck neck 💀, privated no access anymore. Your fault, spez. Why has Private in 1st place? Just restricted & public that's enough. And you yeeted their hard work away because of this? There is a better way bruh! Don't yeet mods and replace them, they'll further damage the subreddits, no idea what to do with them! Instead, if you want, just set them Restricted, keep mods, wtf man?!?!?!?!?!? Ugh, very awry.
Okay that's all I know, thancc for attention
By JOELwindows7
Perkedel Technologies
CC4.0-BY-SA
#betrayal#reddit boycott#reddit#reddit blackout#r/196#196#betrayed#reddit refugee#reddit api#reddit migration#rogue#reddit migrants#reddit mod#vrchat#reddit apocalypse
109 notes
·
View notes
Text
How to Easily Create Your Own Cloud Messaging API in 5 Steps
Introduction
Cloud messaging is a service that enables you to send messages to your contacts without the need for a phone number. With this service, you can send messages to any of your contact’s devices and they will be notified that there is a new message waiting for them.

In this tutorial, we will provide you with 5 steps on how to create your own cloud messaging API in just minutes.
This article provides clear instructions on how to create an app-specific cloud messaging API and how to use it. It explains the process in detail with step-by-step instructions, so it's easy for anyone who has some programming knowledge and experience with Android Studio or Eclipse IDE.
Introduction to the basics of Cloud Messaging APIs
Cloud Messaging API is a platform for data-driven messaging. It is a secure and scalable way to send messages across various devices.
The following are the 5 steps to create your own Cloud Messaging API:
1) Configure the project in Google Cloud Console
2) Integrate Firebase in your project
3) Add the Google Play Services dependency in your app
4) Add the Firebase SDK dependency in your app
5) Set up a service account key in your app
Step 1:
- Create a Google Project and enable the Cloud Messaging API
- Enable the Phone Number Authentication
- Enable the SMS/MMS Messaging API
Step 2:
- Generate an API Key for your project and copy it to clipboard
- Add this key to your Android Manifest File as a string resource called “API_KEY”
Step 3:
- Add the following permissions to your Android Manifest File
#messaging service providers#mobile engagement platform#cloud messaging API#communication provider#bulk sms services#bulk sms service provider#chatbot service providers#whatsapp business api#whatsapp business service providers#Whatsapp Business Api Service Provider#whatsapp api solution provider
1 note
·
View note
Text
How to Use SMS Marketing to Grow Your Ecommerce Business?
Ecommerce business will grow bigger from the use of bulk SMS. SMS marketing opening rate is higher than email marketing. It easily reaches more customers
#Bulk SMS Service#Bulk SMS campaigns#Bulk SMS Provider in India#Bulk SMS wallet#SMS marketing communication#text message marketing companies#text message marketing platform#SMS Marketing Checklist#Bulk SMS Marketing#the best Digital marketing Services#Bulk SMS marketing#SMS API providers in Chennai
0 notes
Last Seen Blogs

slick-devon
Digital Hunks

leroyandcandice
Little blog about Leroy Sane and Candice Brook

daimonxanthopoulos
blog | daimon.nl


hennekeandreae
Art blog, LSAD.