#Apache spark
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text


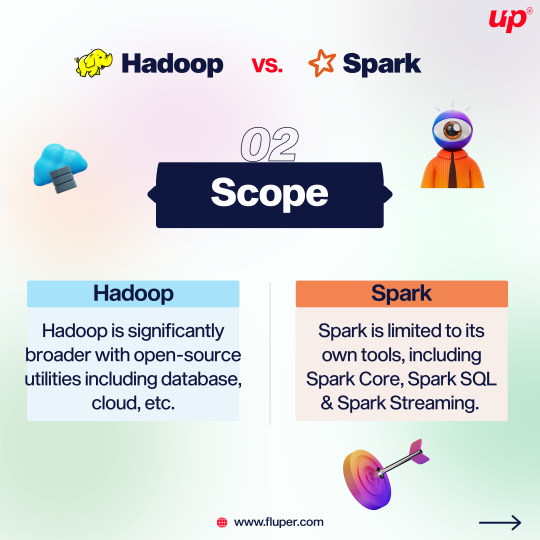




Apache Spark and Apache Hadoop are both popular, open-source data science tools offered by the Apache Software Foundation.
.
.
.
.
Join the development and support of the community with Fluper, and continue to grow in popularity and features.
2 notes
·
View notes
Text
instagram
#hadoop#alarm#Apache spark#coding#code#machinelearning#programming#datascience#python#programmer#artificialintelligence#deeplearning#ai#Instagram
6 notes
·
View notes
Text

In this blog post, we’ll discuss how hotel marketers can take advantage of Apache Spark and the cloud for big data processing to gain a better understanding of their customers, make decisions faster and improve efficiency within their business operations. Read More...
#Apache Spark#Cloud Computing#hotel VoIP#phonesuite dealers#VoIP Advantages#VoIP#VoIP hotel system#Cloud Hosted PBX#Phones#Business Phones#hospitality communication#PBX Communications#VoIP Technology
3 notes
·
View notes
Text
FRAMEWORKS Y DEEP LEARNING
Un artículo que habla sobre las frameworks y deep learning, originado de mi investigación por la red para redes neurales artificiales
INTRODUCCIÓN
Deep Learning es una rama de la inteligencia artificial que se basa en la utilización de redes neuronales profundas para el análisis de datos. Estas redes están compuestas por varias capas de nodos o neuronas, las cuales se encargan de procesar y analizar los datos de entrada. Una de las principales ventajas de las redes neuronales profundas es su capacidad para aprender y mejorar…

View On WordPress
#Apache Spark#Deep Learning#Flutter#Frameworks#Iónico#Keras#Laravel#Pytorch#Tecnología#Tensorflow#Xamarín
3 notes
·
View notes
Text
Apache Spark won the 2022 SIGMOD System Award
The 2022 ACM SIGMOD Systems Award goes to “Apache Spark”, an innovative, widely-used, open-source, unified data processing system encompassing relational, streaming, and machine-learning workloads.
Source: https://sigmod.org/2022-sigmod-awards/
5 notes
·
View notes
Text
Inside DBRX: Databricks Unleashes Powerful Open Source LLM
New Post has been published on https://thedigitalinsider.com/inside-dbrx-databricks-unleashes-powerful-open-source-llm/
Inside DBRX: Databricks Unleashes Powerful Open Source LLM
In the rapidly advancing field of large language models (LLMs), a new powerful model has emerged – DBRX, an open source model created by Databricks. This LLM is making waves with its state-of-the-art performance across a wide range of benchmarks, even rivaling the capabilities of industry giants like OpenAI’s GPT-4.
DBRX represents a significant milestone in the democratization of artificial intelligence, providing researchers, developers, and enterprises with open access to a top-tier language model. But what exactly is DBRX, and what makes it so special? In this technical deep dive, we’ll explore the innovative architecture, training process, and key capabilities that have propelled DBRX to the forefront of the open LLM landscape.
The Birth of DBRX The creation of DBRX was driven by Databricks’ mission to make data intelligence accessible to all enterprises. As a leader in data analytics platforms, Databricks recognized the immense potential of LLMs and set out to develop a model that could match or even surpass the performance of proprietary offerings.
After months of intensive research, development, and a multi-million dollar investment, the Databricks team achieved a breakthrough with DBRX. The model’s impressive performance on a wide range of benchmarks, including language understanding, programming, and mathematics, firmly established it as a new state-of-the-art in open LLMs.
Innovative Architecture
The Power of Mixture-of-Experts At the core of DBRX’s exceptional performance lies its innovative mixture-of-experts (MoE) architecture. This cutting-edge design represents a departure from traditional dense models, adopting a sparse approach that enhances both pretraining efficiency and inference speed.
In the MoE framework, only a select group of components, called “experts,” are activated for each input. This specialization allows the model to tackle a broader array of tasks with greater adeptness, while also optimizing computational resources.
DBRX takes this concept even further with its fine-grained MoE architecture. Unlike some other MoE models that use a smaller number of larger experts, DBRX employs 16 experts, with four experts active for any given input. This design provides a staggering 65 times more possible expert combinations, directly contributing to DBRX’s superior performance.
DBRX differentiates itself with several innovative features:
Rotary Position Encodings (RoPE): Enhances understanding of token positions, crucial for generating contextually accurate text.
Gated Linear Units (GLU): Introduces a gating mechanism that enhances the model’s ability to learn complex patterns more efficiently.
Grouped Query Attention (GQA): Improves the model’s efficiency by optimizing the attention mechanism.
Advanced Tokenization: Utilizes GPT-4’s tokenizer to process inputs more effectively.
The MoE architecture is particularly well-suited for large-scale language models, as it allows for more efficient scaling and better utilization of computational resources. By distributing the learning process across multiple specialized subnetworks, DBRX can effectively allocate data and computational power for each task, ensuring both high-quality output and optimal efficiency.
Extensive Training Data and Efficient Optimization While DBRX’s architecture is undoubtedly impressive, its true power lies in the meticulous training process and the vast amount of data it was exposed to. DBRX was pretrained on an astounding 12 trillion tokens of text and code data, carefully curated to ensure high quality and diversity.
The training data was processed using Databricks’ suite of tools, including Apache Spark for data processing, Unity Catalog for data management and governance, and MLflow for experiment tracking. This comprehensive toolset allowed the Databricks team to effectively manage, explore, and refine the massive dataset, laying the foundation for DBRX’s exceptional performance.
To further enhance the model’s capabilities, Databricks employed a dynamic pretraining curriculum, innovatively varying the data mix during training. This strategy allowed each token to be effectively processed using the active 36 billion parameters, resulting in a more well-rounded and adaptable model.
Moreover, DBRX’s training process was optimized for efficiency, leveraging Databricks’ suite of proprietary tools and libraries, including Composer, LLM Foundry, MegaBlocks, and Streaming. By employing techniques like curriculum learning and optimized optimization strategies, the team achieved nearly a four-fold improvement in compute efficiency compared to their previous models.
Training and Architecture
DBRX was trained using a next-token prediction model on a colossal dataset of 12 trillion tokens, emphasizing both text and code. This training set is believed to be significantly more effective than those used in prior models, ensuring a rich understanding and response capability across varied prompts.
DBRX’s architecture is not only a testament to Databricks’ technical prowess but also highlights its application across multiple sectors. From enhancing chatbot interactions to powering complex data analysis tasks, DBRX can be integrated into diverse fields requiring nuanced language understanding.
Remarkably, DBRX Instruct even rivals some of the most advanced closed models on the market. According to Databricks’ measurements, it surpasses GPT-3.5 and is competitive with Gemini 1.0 Pro and Mistral Medium across various benchmarks, including general knowledge, commonsense reasoning, programming, and mathematical reasoning.
For instance, on the MMLU benchmark, which measures language understanding, DBRX Instruct achieved a score of 73.7%, outperforming GPT-3.5’s reported score of 70.0%. On the HellaSwag commonsense reasoning benchmark, DBRX Instruct scored an impressive 89.0%, surpassing GPT-3.5’s 85.5%.
DBRX Instruct truly shines, achieving a remarkable 70.1% accuracy on the HumanEval benchmark, outperforming not only GPT-3.5 (48.1%) but also the specialized CodeLLaMA-70B Instruct model (67.8%).
These exceptional results highlight DBRX’s versatility and its ability to excel across a diverse range of tasks, from natural language understanding to complex programming and mathematical problem-solving.
Efficient Inference and Scalability One of the key advantages of DBRX’s MoE architecture is its efficiency during inference. Thanks to the sparse activation of parameters, DBRX can achieve inference throughput that is up to two to three times faster than dense models with the same total parameter count.
Compared to LLaMA2-70B, a popular open source LLM, DBRX not only demonstrates higher quality but also boasts nearly double the inference speed, despite having about half as many active parameters. This efficiency makes DBRX an attractive choice for deployment in a wide range of applications, from content creation to data analysis and beyond.
Moreover, Databricks has developed a robust training stack that allows enterprises to train their own DBRX-class models from scratch or continue training on top of the provided checkpoints. This capability empowers businesses to leverage the full potential of DBRX and tailor it to their specific needs, further democratizing access to cutting-edge LLM technology.
Databricks’ development of the DBRX model marks a significant advancement in the field of machine learning, particularly through its utilization of innovative tools from the open-source community. This development journey is significantly influenced by two pivotal technologies: the MegaBlocks library and PyTorch’s Fully Sharded Data Parallel (FSDP) system.
MegaBlocks: Enhancing MoE Efficiency
The MegaBlocks library addresses the challenges associated with the dynamic routing in Mixture-of-Experts (MoEs) layers, a common hurdle in scaling neural networks. Traditional frameworks often impose limitations that either reduce model efficiency or compromise on model quality. MegaBlocks, however, redefines MoE computation through block-sparse operations that adeptly manage the intrinsic dynamism within MoEs, thus avoiding these compromises.
This approach not only preserves token integrity but also aligns well with modern GPU capabilities, facilitating up to 40% faster training times compared to traditional methods. Such efficiency is crucial for the training of models like DBRX, which rely heavily on advanced MoE architectures to manage their extensive parameter sets efficiently.
PyTorch FSDP: Scaling Large Models
PyTorch’s Fully Sharded Data Parallel (FSDP) presents a robust solution for training exceptionally large models by optimizing parameter sharding and distribution across multiple computing devices. Co-designed with key PyTorch components, FSDP integrates seamlessly, offering an intuitive user experience akin to local training setups but on a much larger scale.
FSDP’s design cleverly addresses several critical issues:
User Experience: It simplifies the user interface, despite the complex backend processes, making it more accessible for broader usage.
Hardware Heterogeneity: It adapts to varied hardware environments to optimize resource utilization efficiently.
Resource Utilization and Memory Planning: FSDP enhances the usage of computational resources while minimizing memory overheads, which is essential for training models that operate at the scale of DBRX.
FSDP not only supports larger models than previously possible under the Distributed Data Parallel framework but also maintains near-linear scalability in terms of throughput and efficiency. This capability has proven essential for Databricks’ DBRX, allowing it to scale across multiple GPUs while managing its vast number of parameters effectively.
Accessibility and Integrations
In line with its mission to promote open access to AI, Databricks has made DBRX available through multiple channels. The weights of both the base model (DBRX Base) and the finetuned model (DBRX Instruct) are hosted on the popular Hugging Face platform, allowing researchers and developers to easily download and work with the model.
Additionally, the DBRX model repository is available on GitHub, providing transparency and enabling further exploration and customization of the model’s code.
For Databricks customers, DBRX Base and DBRX Instruct are conveniently accessible via the Databricks Foundation Model APIs, enabling seamless integration into existing workflows and applications. This not only simplifies the deployment process but also ensures data governance and security for sensitive use cases.
Furthermore, DBRX has already been integrated into several third-party platforms and services, such as You.com and Perplexity Labs, expanding its reach and potential applications. These integrations demonstrate the growing interest in DBRX and its capabilities, as well as the increasing adoption of open LLMs across various industries and use cases.
Long-Context Capabilities and Retrieval Augmented Generation One of the standout features of DBRX is its ability to handle long-context inputs, with a maximum context length of 32,768 tokens. This capability allows the model to process and generate text based on extensive contextual information, making it well-suited for tasks such as document summarization, question answering, and information retrieval.
In benchmarks evaluating long-context performance, such as KV-Pairs and HotpotQAXL, DBRX Instruct outperformed GPT-3.5 Turbo across various sequence lengths and context positions.
DBRX outperforms established open source models on language understanding (MMLU), Programming (HumanEval), and Math (GSM8K).
Limitations and Future Work
While DBRX represents a significant achievement in the field of open LLMs, it is essential to acknowledge its limitations and areas for future improvement. Like any AI model, DBRX may produce inaccurate or biased responses, depending on the quality and diversity of its training data.
Additionally, while DBRX excels at general-purpose tasks, certain domain-specific applications may require further fine-tuning or specialized training to achieve optimal performance. For instance, in scenarios where accuracy and fidelity are of utmost importance, Databricks recommends using retrieval augmented generation (RAG) techniques to enhance the model’s output.
Furthermore, DBRX’s current training dataset primarily consists of English language content, potentially limiting its performance on non-English tasks. Future iterations of the model may involve expanding the training data to include a more diverse range of languages and cultural contexts.
Databricks is committed to continuously enhancing DBRX’s capabilities and addressing its limitations. Future work will focus on improving the model’s performance, scalability, and usability across various applications and use cases, as well as exploring techniques to mitigate potential biases and promote ethical AI use.
Additionally, the company plans to further refine the training process, leveraging advanced techniques such as federated learning and privacy-preserving methods to ensure data privacy and security.
The Road Ahead
DBRX represents a significant step forward in the democratization of AI development. It envisions a future where every enterprise has the ability to control its data and its destiny in the emerging world of generative AI.
By open-sourcing DBRX and providing access to the same tools and infrastructure used to build it, Databricks is empowering businesses and researchers to develop their own cutting-edge Databricks tailored to their specific needs.
Through the Databricks platform, customers can leverage the company’s suite of data processing tools, including Apache Spark, Unity Catalog, and MLflow, to curate and manage their training data. They can then utilize Databricks’ optimized training libraries, such as Composer, LLM Foundry, MegaBlocks, and Streaming, to train their own DBRX-class models efficiently and at scale.
This democratization of AI development has the potential to unlock a new wave of innovation, as enterprises gain the ability to harness the power of large language models for a wide range of applications, from content creation and data analysis to decision support and beyond.
Moreover, by fostering an open and collaborative ecosystem around DBRX, Databricks aims to accelerate the pace of research and development in the field of large language models. As more organizations and individuals contribute their expertise and insights, the collective knowledge and understanding of these powerful AI systems will continue to grow, paving the way for even more advanced and capable models in the future.
Conclusion
DBRX is a game-changer in the world of open source large language models. With its innovative mixture-of-experts architecture, extensive training data, and state-of-the-art performance, it has set a new benchmark for what is possible with open LLMs.
By democratizing access to cutting-edge AI technology, DBRX empowers researchers, developers, and enterprises to explore new frontiers in natural language processing, content creation, data analysis, and beyond. As Databricks continues to refine and enhance DBRX, the potential applications and impact of this powerful model are truly limitless.
#Accessibility#ai#ai model#AI systems#Analysis#Analytics#Apache#Apache Spark#APIs#applications#approach#architecture#Art#artificial#Artificial Intelligence#attention#attention mechanism#benchmark#benchmarks#billion#chatbot#code#collaborative#Collective#Community#comprehensive#computation#computing#content#content creation
0 notes
Text
Harness the Power of Big Data with Associative’s Apache Spark Solutions

In an increasingly data-driven world, the ability to extract meaningful insights from massive datasets is a key competitive advantage. Apache Spark, a lightning-fast unified analytics engine, has emerged as a leading solution for businesses looking to capitalize on their big data assets. Associative, a Pune-based Apache Spark development company, helps you unlock the hidden potential within your data.
What is Apache Spark?
Apache Spark is an open-source distributed processing framework designed to handle large-scale data analytics. Its key advantages include:
Speed: Spark’s in-memory processing and optimized execution engine allow it to outperform traditional data processing technologies significantly.
Versatility: Spark supports diverse workloads, including batch processing, streaming analytics, machine learning, and graph computations.
Scalability: Spark seamlessly scales from a single laptop to massive clusters, adapting effortlessly to growing data volumes.
Developer-Friendly: Spark offers APIs in Python, Java, Scala, and R, making it accessible to a wide range of developers.
Associative’s Apache Spark Expertise
Associative’s team of experienced Apache Spark developers delivers tailored solutions to address your unique big data challenges:
Custom Spark Applications: We design and implement bespoke Spark applications to meet your specific data processing and analytics requirements.
Data Pipelines and ETL: We build robust, scalable ETL (Extract, Transform, Load) pipelines powered by Spark to streamline your data workflows.
Real-Time Streaming Analytics: We leverage Spark’s capabilities to deliver actionable insights from live data streams, enabling timely decision-making.
Machine Learning at Scale: We train and deploy sophisticated machine learning models on large datasets using Spark’s MLlib library.
Performance Optimization: We fine-tune your Spark applications and clusters to maximize efficiency and minimize resource costs.
Why Choose Associative?
Focus on Business Impact: We work closely with you to understand your core business objectives and translate them into effective Spark solutions.
End-to-End Support: We guide you through the entire process, from architecture and deployment to ongoing maintenance and optimization.
Pune-Based Advantage: Benefit from convenient collaboration and real-time communication with our team located in your time zone.
Transform Your Business with Apache Spark
Associative has a proven track record of successful Apache Spark projects across industries. Let their expertise help you:
Uncover Hidden Insights: Delve into your data to discover trends, patterns, and correlations that inform strategic business decisions.
Enhance Customer Experience: Personalize product recommendations, detect anomalies, and optimize processes in real-time using Spark’s insights.
Drive Operational Efficiencies: Use Spark to streamline supply chains, predict equipment failures, and optimize resource allocation.
Get Started with Associative’s Apache Spark Solutions
Contact Associative today to explore how their Apache Spark development services can transform your business. Experience the power of data-driven insights.
0 notes
Text
my head hurts should i suffer and choose a nosql database to build my app or should i just "fuck it we ball" and go with postgresql
i mean i have a really structured data but also lots of rows in the tables (like, millions) and potentially a lot of people could use it at the same time and i plan on using spark to analyze stuff?? like will my app survive like that? i don't know shit
#apache spark#nosql#postgresql#of how the tables have turned i post about programming on tumblr#don't ask me why i am doing this if i don't know enough i just want to graduate#i don't even like databases anymore#chatgpt said it's okay to use postgreql and apache spark in this case so it's something#i had to beg it to give me an answer it kept saying “depends on your project blah blah blah”
1 note
·
View note
Text
Free Apache Spark and Scala Course offers a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation of real-life Spark projects to give you a headstart and enable you to bag top Big Data Spark jobs in the industry.
0 notes
Text
Unlocking the Full Power of Apache Spark 3.4 for Databricks Runtime!
You've dabbled in the magic of Apache Spark 3.4 with my previous blog "Exploring Apache Spark 3.4 Features for Databricks Runtime", where we journeyed through 8 game-changing features
You’ve dabbled in the magic of Apache Spark 3.4 with my previous blog “Exploring Apache Spark 3.4 Features for Databricks Runtime“, where we journeyed through 8 game-changing features—from the revolutionary Spark Connect to the nifty tricks of constructing parameterized SQL queries. But guess what? We’ve only scratched the surface!
In this sequel, we’re diving deeper into the treasure trove of…

View On WordPress
#Apache Spark#Azure Databricks#Azure Databricks Cluster#Data Frame#Databricks#databricks apache spark#Databricks SQL#Memory Profiler#NumPy#performance#Pivot#pyspark#PySpark UDFs#SQL#SQL queries#SQL SELECT#SQL Server
0 notes
Text
Unleashing the Potential of Apache Spark: A Complete Guide by Ksolves
Unlock the full potential of Apache Spark with our comprehensive guide. Ksolves provides in-depth insights into Spark's capabilities, optimizations, and practical use cases, empowering you to harness the true power of big data processing
0 notes
Text
What is Snowpark?

Snowpark is an open-source programming model and language. It aims to simplify the process of writing and executing data processing tasks on various data platforms. Snowpark provides a unified interface for developers to write code in their preferred languages, such as:
Java
Scala
Python.
This makes it seamlessly integrate with the underlying data processing frameworks.
In this microblog, we will explore Snowpark's key features and delve into its significant advantages.
Key Features of Snowpark
Here are the top 3 key features of Snowpark:
Polyglot Support: Snowpark supports multiple programming languages. Thus, allowing developers to code in their preferred language and leverage their existing skills.
Seamless Integration: Snowpark integrates with popular frameworks like Apache Spark. This provides a unified interface for developers to access the full capabilities of these frameworks in their chosen language.
Interactive Development: Snowpark offers a REPL (Read-Eval-Print Loop) environment for interactive code development. This enables faster iteration, prototyping, and debugging with instant feedback.
So, Snowpark allows developers to leverage their language skills and work more flexibly, unlike Spark or PySpark. Furthermore, discover the unique advantages of Snowpark and know about the difference it makes.
Advantages of Implementing Snowpark
Here are the advantages of Snowpark over other programming models:
Language Flexibility: Snowpark stands out by providing polyglot support. Thus, allowing developers to write code in their preferred programming language. In contrast, Spark and PySpark primarily focus on Scala and Python. Snowpark's language flexibility enables organizations to leverage their existing language skills and choose the most suitable language.
Ease of Integration: It seamlessly integrates with frameworks like Apache Spark. This integration enables developers to harness the power of Spark's distributed computing capabilities while leveraging Snowpark's language flexibility. In comparison, Spark and PySpark offer a narrower integration scope which limits the choice of languages.
Interactive Development Environment: Snowpark provides an interactive development environment. This environment allows developers to write, test, and refine code iteratively, offering instant feedback. In contrast, Spark and PySpark lack this built-in interactive environment, potentially slowing down the development process.
Expanded Use Cases: While Spark and PySpark primarily target data processing tasks, Snowpark offers broader applicability. It supports diverse use cases such as data transformations, analytics, and machine learning. This versatility allows organizations to leverage Snowpark across a wider range of data processing scenarios, enabling comprehensive solutions and flexibility.
Increased Developer Productivity: Snowpark's language flexibility and interactive environment boost developer productivity. Developers can work in their preferred programming language, receive real-time feedback, and streamline the development process. In contrast, Spark and PySpark's language constraints may hinder productivity due to the need to learn new languages or adapt to limited options.
Therefore, Snowpark revolutionizes big data processing by offering a versatile platform that supports multiple programming languages. By adopting Snowpark, developers can enhance their efficiency in executing data processing tasks.
This powerful tool has the potential to drive innovation. It can also streamline development efforts and open exciting new opportunities for businesses. Also, stay updated with Nitor Infotech’s latest tech blogs.
#snowpark#snowflake#blog#Bigdata#data processing services#Data transformation#Apache Spark#Open-source#nitorinfotech#big data analytics#automation#software services
0 notes
Video
youtube
Apache Spark in Machine Learning: Best Practices for Scalable Analytics
1 note
·
View note
Text
WEEK 2: SparkML
1) Select the best definition of a machine learning system.
-> A machine learning system applies a specific machine learning algorithm to train data models. After training the model, the system infers or “predicts” results on previously unseen data.
2) Which of the following options are true about Spark ML inbuilt utilities?
-> Spark ML inbuilt utilities includes a linear algebra package.
->…
View On WordPress
0 notes
Last Seen Blogs

lovehotelreservation
New Year, New Breed

karenfordonte
Caring For Donte

mdzs-fic
MDZS fic recs

word-wanderer
as_radiant_as_the_sun

alvaroboese69
fuck you