#login page in html
Text
Universal theme how to use html, css, javascript
https://apex.oracle.com/pls/apex/r/apex_pm/ut/getting-started
--login backaground css
======================
.t-PageBody--login {
background: url(#APP_FILES#login_bg.jpg);
width: 100%;
height: 100%;
background-repeat: no-repeat;
background-size: cover;
background-position: 50%;
}
.t-Login-region {
background-color: hsl(0deg 2.88% 14.54% / 65%));
}
Custom css
.animated…
View On WordPress
2 notes
·
View notes
Text
˚୨ webcore themed neopronounz ୧⋆。˚ ⋆

archive/archive/archives/archives/archiveself
browse/browse/browses/browses/browseself
browser/browser/browsers/browsers/browserself
click/click/clicks/clicks/clickself
computer/computer/computers/computers/computerself
connect/connect/connects/connects/connectself
connection/connection/connections/connections/connectionself
cursor/cursor/cursors/cursors/cursorself
cyber/cyber/cybers/cybers/cyberself
data/data/datas/datas/dataself
digital/digital/digitals/digitals/digitalself
disk/disk/disks/disks/diskself
emoji/emoji/emojis/emojis/emojiself
emoticon/emoticon/emoticons/emoticons/emoticonself
error/error/errors/errors/errorself
file/file/files/files/fileself
flash/flash/flashes/flashes/flashself
font/font/fonts/fonts/fontself
glitch/glitch/glitches/glitches/glitchself
google/google/googles/googles/googleself
graphic/graphic/graphics/graphics/graphicself
hack/hack/hacks/hacks/hackself
hardware/hardware/hardwares/hardwares/hardwareself
html/html/htmls/htmls/htmlself
http/http/https/https/httpself
install/install/installs/installs/installself
internet/internet/internets/internets/internetself
lag/lag/lags/lags/lagself
link/link/links/links/linkself
load/load/loads/loads/loadself
loading/loading/loadings/loadings/loadingself
login/login/logins/logins/loginself
mail/mail/mails/mails/mailself
malware/malware/malwares/malwares/malwareself
net/net/nets/nets/netself
network/network/networks/networks/networkself
online/online/onlines/onlines/onlineself
page/page/pages/pages/pageself
pixel/pixel/pixels/pixels/pixelself
reload/reload/reloads/reloads/reloadself
screen/screen/screens/screens/screenself
scroll/scroll/scrolls/scrolls/scrollself
search/search/searches/searches/searchself
site/site/sites/sites/siteself
software/software/softwares/softwares/softwareself
tab/tab/tabs/tabs/tabself
tech/tech/techs/techs/techself
technology/technology/technologies/technologies/technologyself
upload/upload/uploads/uploads/uploadself
url/url/urls/urls/urlself
user/user/users/users/userself
virus/virus/viruses/viruses/viruself
web/core/webs/cores/webcoreself
web/web/webs/webs/webself
webcore/webcore/webcores/webcores/webcoreself
website/website/websites/websites/websiteself
window/window/windows/windows/windowself
wire/wire/wires/wires/wireself
www./www./www.s/www.s/www.self
.com/.com/.coms/.coms/.comself
.doc/.doc/.docs/.docs/.docself
.exe/.exe/.exes/.exes/.exeself
.gif/.gif/.gifs/.gifs/.gifself
.jpeg/.jpeg/.jpegs/.jpegs/.jpegself
.jpg/.jpg/.jpgs/.jpgs/.jpgself
.mp3/.mp3/.mp3s/.mp3s/.mp3self
.mp4/.mp4/.mp4s/.mp4s/.mp4self
.pdf/.pdf/.pdfs/.pdfs/.pdfself
.png/.png/.pngs/.pngs/.pngself
.psd/.psd/.psds/.psds/.psdself
.webp/.webp/.webps/.webps/.webpself
.word/.word/.words/.words/.wordself
144p/144p//144ps/144ps/144pself
240p/240p/240ps/240ps/240pself
360p/360p/360ps/360ps/360pself
480p/480p/480ps/480ps/480pself
720p/720p/720ps/720ps/720pself
1080p/1080p/1080ps/1080ps/1080pself
🖥️/🖥️/🖥️s/🖥️s/🖥️self
💻/💻/💻s/💻s/💻self
🌐/🌐/🌐s/🌐s/🌐self
🔊/🔊/🔊s/🔊s/🔊self
🔔/🔔/🔔s/🔔s/🔔self
🔕/🔕/🔕s/🔕s/🔕self
🔌/🔌/🔌s/🔌s/🔌self
⌨️/⌨️/⌨️s/⌨️s/⌨️self
🖱️/🖱️/🖱️s/🖱️s/🖱️self
💿/💿/💿s/💿s/💿self
📀/📀/📀s/📀s/📀self
💾/💾/💾s/💾s/💾self
💽/💽/💽s/💽s/💽self
🔎/🔎/🔎s/🔎s/🔎self
🔁/🔁/🔁s/🔁s/🔁self
▶️/▶️/▶️s/▶️s/▶️self
⏭/⏭/⏭s/⏭s/⏭self
⏸/⏸️/⏸️s/⏸s/⏸self
⏯️/⏯️/⏯️s/⏯️s/⏯️self
feel free to ask for example sentencez for the usage of these !!
#𓂅 ✧ ៸៸ pronoun suggestionz#pronoun suggestions#neopronoun suggestions#pronouns#neopronouns#xenogender#xenopronouns#mogai#mogai safe#xenogenders#emojiself#emoji pronouns#nounself#nounself pronouns#noun pronouns#webcore#tech#technology#webcore neopronouns#technology neopronouns
986 notes
·
View notes
Text
Jolyne Kujo Portfolio | #3
Thursday 11th January 2024
So I turned this project idea into actual code. Just some simple HTML, CSS (SCSS) and JavaScript code, nothing fancy~! In my lunch break now so thought I would post a quick update on how it's going~! My beautiful Jolyne Kujo portfolio page is coming together nicely~! 😩🙌🏾
Created the repo for this project
Overall structure of the "desktop" GUI look
Completed the login page
JS code behind the taskbar icons (at least 2 of them for now but easy to replicate for the others)
Oooo cool loading screen (was really happy it worked~)
Sticky note thingy? in CSS? cool
Semi-responsive on different screens (curse you mobile screen sizes)
Pop up window for the different sections?!? WHAT (only one right now but easy to replicate for the others)
Jolyne Kujo.
That's all for now and for the rest of my lunch I'm going to watch JOJO~!
#codeblr#coding#progblr#programming#studyblr#studying#computer science#tech#jojo no kimyou na bouken#jojo#jojo part 6#jolyne kujo portfolio project
73 notes
·
View notes
Text



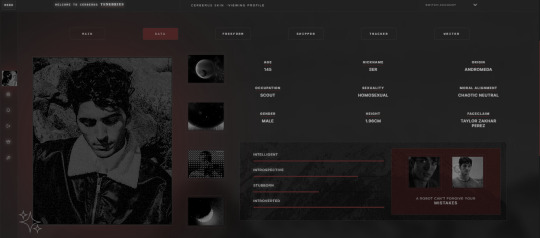




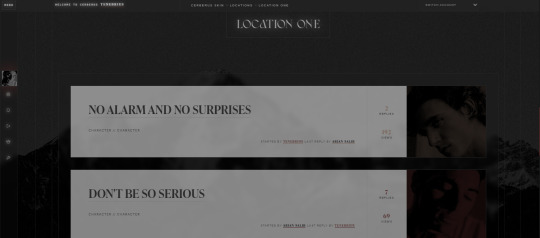
CERBERUS SKIN ⸻ $60
CERBERUS is a medium, minimalist, multi-sale, and responsive skin for Jcink optimized for Google Chrome.
You can purchase this skin at my Ko-fi: https://ko-fi[DOT]com/s/4eeab85b68
Basic features:
— Fully customized Jcink HTML Templates.
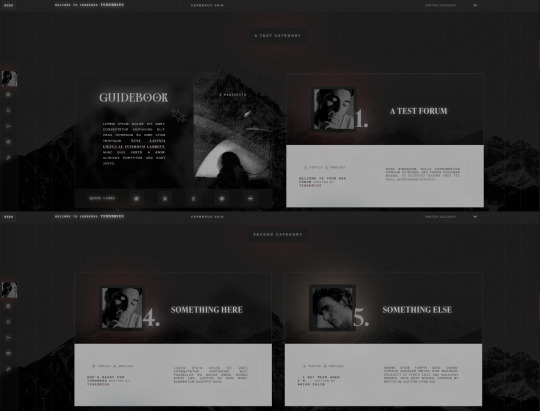
— Guidebook codes.
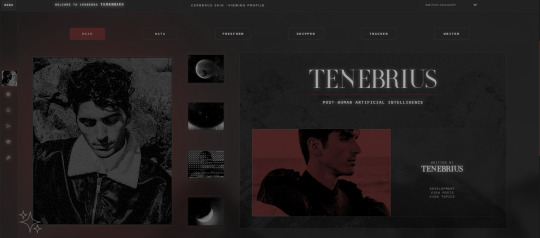
— Main profile application with shipper and section to add an automatic thread tracker.
— Pop-out profile.
— Mini-profile.
— Basic templates.
— Isotopic memberlist filters.
— Accent color coordinated to character group.
— Easy customization of site graphics.
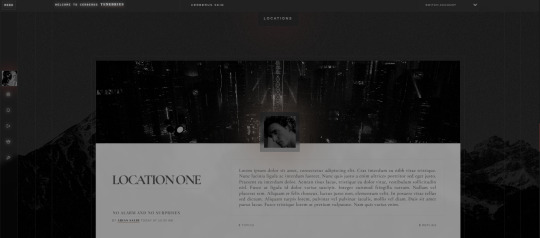
— Location forums with backgrounds.
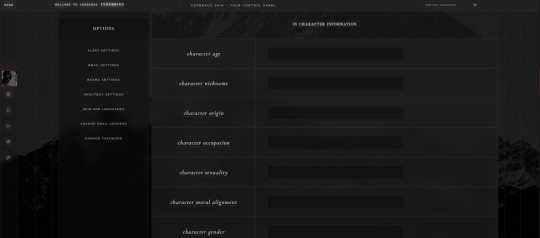
— Custom user profile fields.
— Forum counters.
— Customized login and register page.
— Custom sidebar menu.
— Basic templates codes (You can check them here: www.tumblr.com/tenebriuscodes/748268049043488768/cerberus-templates)
Please, read my policy for more information: tenebriuscodes.tumblr.com/policies
#jcink skins#jcink skin#jcink code#jcink codes#jcink#resources#jcink resources#cerberus skin#portfolio
26 notes
·
View notes
Text
Walthrough: Reposting your old FFNet fics to Ao3
In light of recent rumors that FanFiction.Net might be receiving little/no ongoing support, and could suddenly disappear one day with very little warning, I wanted to offer a resource that might help preserve another fic or two. Just in case.
I'm already keeping a private collection of favorite fics from FFN that I can't bear to lose, but this tutorial isn't for saving other folks' fic. Instead, this tutorial is for people who might want to republish their own fic to Ao3 in a streamlined, relatively painless way.
Using these steps, I was able to upload an entire 16-chapter fic, with all the correct original formatting and without doing any fussy HTML editing, in about an hour. (And that was while making up the steps as I went along!)
What you'll need:
A link to your old FFNet account URL OR the those of the fics you want to save (no login necessary)
Access to a working Ao3 account
A web browser, permission to download zipped HTML files, and an unzipper (most computers have these by default)
How to save your fic for posterity:
Copy the link to the first chapter of the fic on FFN that you want to save. (Right-clicking the title of the fic on your profile and choosing "Copy Link" will do this.)
Go to https://fichub.net/ and paste in the URL. Press Export, then click "Download as zipped HTML."
This saves your entire fic at once, no matter how many chapters, with formatting intact. Everyone thank the team who made this tool, because it's amazing.
Navigate to your downloads (or click on the pop-up that'll probably appear) and open the zipped HTML file. It will probably open in your default browser on its own, but you might need to tell it to open by right-clicking the unzipped file and choosing the desired browser.
The resulting file should have all the chapters of the fic laid out one after another, with clear breaks between each chapter and the original HTML formatting (including section breaks).
Post a "New Work" in Ao3. (Can't import with FFNet, sadly, which is why this tutorial exists.) Add the title, relevant tags, and summary. (I used my FFNet summary with a note that the fic is crossposted.) Backdate the fic if desired by choosing a publishing date from around the time the fic was written.
Here's the magic part: Switch to Rich Text Mode in the "Work Text" field, then copy-paste the text from your first chapter into the Rich Text Mode window.
(Note: You may see the stray space appear around italicized/bolded text, and an extra line break tends to appear between section breaks. Otherwise, though, the formatting is generally very well preserved.)
Optional detail: Hit "Preview," then "Save Draft," then "Add Chapter" to avoid posting any of your chapters till you have them all set up and ready to go.
Side note 1: Don't put an endnote on the end of your Chapter 1. Or if you do, go add a chapter 2 first, and then go back to add a chapter 1 endnote. Otherwise it'll end up at the end of your fic instead. It's a fixable outcome, but an annoying one.
Side note 2: If you use a pseud to post, you'll need to be careful to select the correct pseud for each chapter you upload, or you'll end up being listed as the author twice, once under each pseud you selected. If you notice this happening, it's because you've missed switching one in one or more chapters. This is fixable by checking the author listed under each chapter heading using the "Entire Work" button and keyword searching the username you're trying to get rid of.
While I didn't find a way to post all chapters at once, you can do it pretty quickly in the right order, without skipping, by doing the following steps in a loop:
Press "Entire work" at the top of the page.
Use your browser's "Find in page" function for the text "post chapter".
Hitting the "Post Chapter" button that appears.
Just continue the loop until there's no more "Post Chapter" buttons.
Once your chapters are all uploaded, you're done! Congratulations.
A final note
I know that this latest rumor might be blowing certain hints of FFNet's siterunners' inactivity out of proportion. I know that Ao3 isn't everyone's favorite (though I don't agree with most of those people). And I know, most of all, that some folks would rather some of their older fics not see the light of day anymore, for whatever reason.
But look. I'm a trans guy who used to be a teenage girl who (enthusiastically) wrote Twilight/Doctor Who crossover fanfic. I get it, and yet I'm still managing to stun the part of me that cringes long enough to preserve my stuff, because I think that fic should survive whenever possible.
There are options to help make the cringe factor more manageable. Use a pseud for your older stuff (like me), or to minimize any connection to your current account, you can use the Anonymous collection or the Orphan Work function as soon as you're done posting. Do whatever you need to feel comfortable.
But remember that every creative work is a victory just for existing. Please, if you can, find it in your heart (and your schedule) to preserve your work. Past!you worked hard on it, after all. And besides, you never know who might stumble across it someday exactly when they need it.
(PS: Please let me know about any other FFN preservation efforts, by the way! Hopefully this is all blown out of proportion, but you really can never be too careful.)
383 notes
·
View notes
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
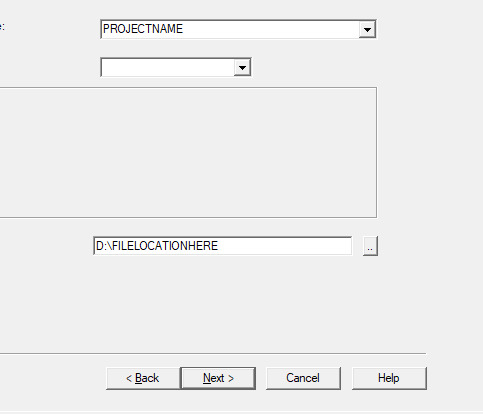
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
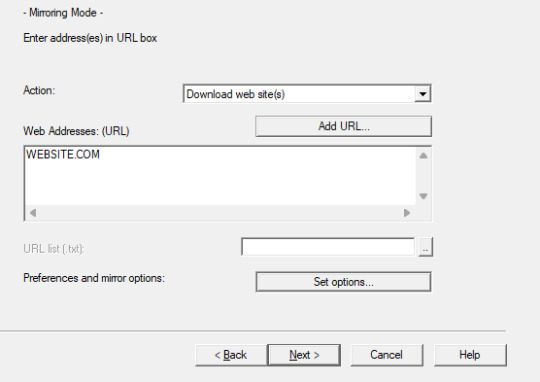
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
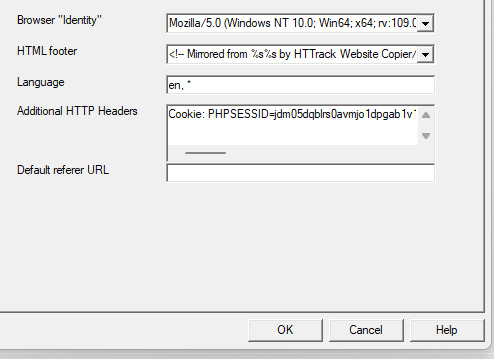
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
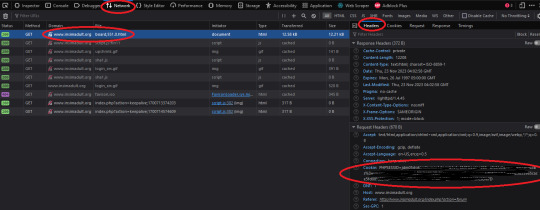
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
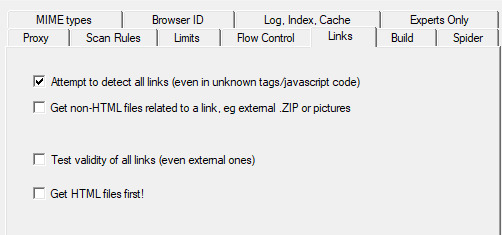
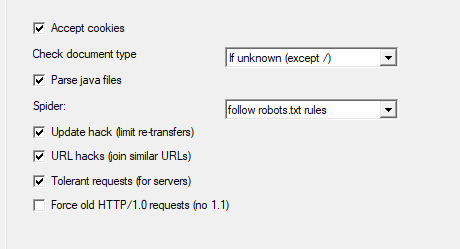
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
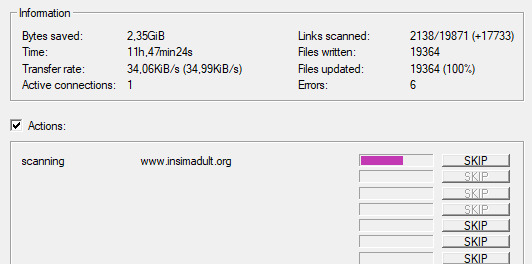
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
39 notes
·
View notes
Note
Hello. Do you have any tips on getting started selling your handmade goods? I am disabled too and sometimes the only thing keeping my sane is knitting. Right now I'm knitting things for myself and friends. I think I may get to a point where I want to sell things I have knit instead of just gifting them and I was curious how you go about doing it and if you have any tips for getting started.
I'm not like, wildly successful at this by any means, so if anyone else has any tips, omfg please share your wisdom.
That said, first of all fuuuuuuuuck etsy. Not only do they have shitty policies in a number of ways (you can google it if you want; i don't feel like getting into that series of rants), I never really made many sales there in the decade or so I tried. And tbh most of the knitted things up for sale there are so disgustingly underpriced, it might be hard to get enough money from a sale to even cover the materials cost, let alone labor time.
Once I had given up on etsy, I was selling on twitter for a while? But we all know how twitter's going, so I don't even remember my login info to delete the account, lol. I did make way better money than I ever did on etsy tho! Like, twice the sales in one year than I got on etsy in ~10. Not even exaggerating. I made decent sales on facebook from a page for my business, but stopped trying after the third time they changed the interface in less than 6 months. If you can figure out how it works though, go for it!
I'm trying to build a proper website of my own for Calendae Creations, but html is hard and so is the rest of my life, so that's on the back burner for now. I'm really not sure how successful it'll be if I ever get it up and running.
Currently this is my only sales presence online, and I haven't tabled at an in-person event since 2018. I've been pleasantly surprised at being able to generate any income at all on the website famous for not making money, lol. I do really want to get into more in-person sales, but I really can't speak much to how well knitting sells at different kinds of events, because when I used to do ren faires and flea markets I was mostly selling pottery, jewelry, and live plants. I'm pretty hopeful about trying to get a table at Staunton Pride next fall though?
Tbh, as much as I love my job, I really would not recommend this as a full time primary source of income to anyone who has literally any other options. I'm just too disabled to do anything else anymore.
Related, does anyone know how to file USA income tax for this kind of thing??? I am so lost trying to figure it out.
21 notes
·
View notes
Text
Development Timeline
This is a development timeline I will be adding to, editing, and reblogging throughout the development process here on Tumblr! I can't say that this post will be updated as often / in as much detail as the devlogs on Crescent Cove (you can view my past devlogs here), but I am hoping to use this post as a more structured overview
If you have any questions about the timeline, the site features, or anything else, feel free to send an ask! I'd love to see people's questions. :>
Represents a completed feature.
Represents an in-progress feature.

Pre-Alpha (Jan. 2022 - Present)
Currently, registration for the site is completely closed, although you can view any public sections of the site (namely, the forums). If a user already has an account, they can still log into the site and access features as usual.
I am probably about 80% complete with this phase, and hope to be done in 2024.
Core User Features
-> User Signup / Login Pages
-> Basic Account Settings and HTML Profiles
-> Users' most recent login date is updated automatically in the database
-> Users can logout of their accounts from the Account page
-> New users are guided to accept the rules and then complete the tutorial


Forums, Social Features, and Moderation
-> Users can post, comment, edit, and delete posts / threads inside of topics (bumping posts also works)
-> Admins can lock and pin threads inside of topics
-> Admins can send users warnings, issue suspensions and bans, and review report tickets
-> Users can report users
-> Users can block other users
-> Users can send messages, add friends, and ping one another on the forums
-> Notification system for said events

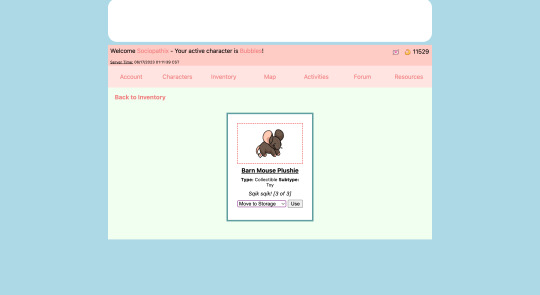
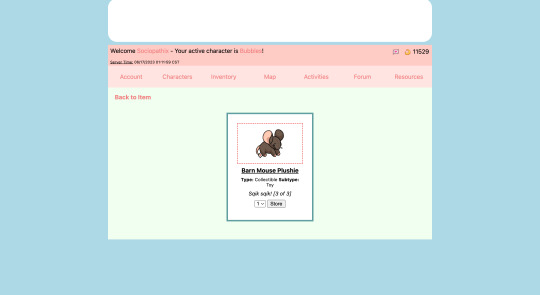
Item and Coveling Inventories
-> Users can view their inventory of items
-> Need to fix a graphical bug of the inventories
-> Users can filter their inventory based on item type
-> Users can view and move items into the storage section of their inventory
-> Users can move items to their Covelings' inventories
-> Users can remove items from their Covelings' inventories
-> Users can equip tools and wearables to their Covelings
-> Users can give consumables, toys, and other items to their Covelings for various effects


Site-Wide Features
-> There is a day and night cycle for each 24-hour period, each phase will have a given weather condition.
-> Predicted weather will be forecasted weekly, but can change based on in-game events.
-> Seasons will change with real-life months accordingly: Jan - Apr (Spring), May - Aug (Summer), Sept - Oct (Autumn), Nov - Dec (Winter).
Daily Activities
-> Once a day, users can take on a town quest from Town Hall, which will reward them in Crescents and possibly items.
-> For each main area, a Coveling can be sent to gather materials and resources from that area, for a period of 1 - 4 hours. You can unlock additional slots as your reputation with that area improves.
-> Once a day, users can collect their interest at the bank.
-> Once a day, users can visit a special NPC and get a free item.
Weekly Activities
-> Once a week, a user can send out 1 - 3 pets on a special expedition.
-> Each week, for each area, you can complete quests to improve area reputation, collect items, and currency that will reset at the end of the week.
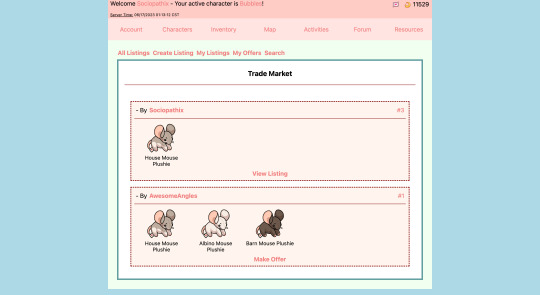
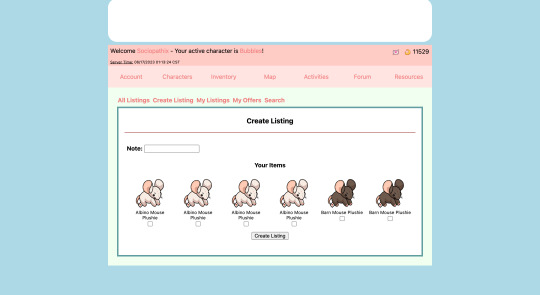
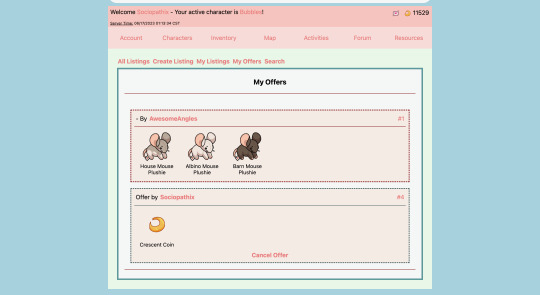
Marketplace and User Trading
-> Users can make listings on the marketplace, view other users' listings, view offers, and accept trades
-> Users can visit shops that reset their stock every five minutes
-> Basic system created, just need to populate the shops
-> Donation Center, the bank, food shop, and toy shop
-> Users can privately send items to one another

Alpha Testing (Near Future)
Alpha testing will start after pre-alpha development is complete, bringing on a small group of individuals to test features as they're implemented. I’m not sure how I’ll choose these players or how many there’ll be, but we’ll cross that bridge when we get there.
Additionally, this is when I plan to do even more asset and content creation, and fixing bugs, typos, and other mishaps with the help of our alpha testers!
Visual Updates
-> Update visual style of the site, mainly the navigation bar, page content, and buttons, as these are the oldest features.
-> Need to implement better mobile support - developing an app sounds like fun!
-> Add the ability to go into light / dark mode and change between 1 - 3 site themes from the account page.
-> An example of my current design style is shown below, I’d like to do something cute and clean like this, but with a few colors.
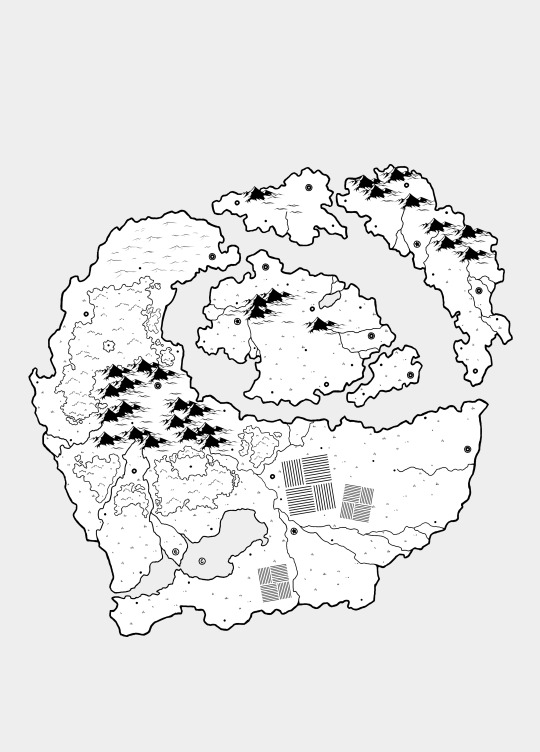
World Map
-> A world map will be created to make the exploration of the site more interesting. This will most likely be done with some sort of grid image system.
-> A work-in-progress map can be seen below.
Collections and Alpha-Only Items
-> A collectable system is added with various items: plushies, bestiary, profession / skills trophies, and other event items.
-> Additionally, alpha-only items and Covelings will be released to testers, and additional alpha-only crafted items and loot will be possible to collect.
Daily Activities+
-> Once a day, per Coveling, users can interact with their Coveling to raise their affection level.
-> Once a day, per Coveling, users can take on a Coveling quest, completing which will raise affection level and trigger a random event.
-> Once a day, per Coveling, users can use specialty items to affect relationships between Covelings.
-> Once a day, users can interact with NPCs of different areas and complete daily quests.
Marketplace and User Trading+
-> Users can list their Covelings on the trade market.
-> Users can privately send Covelings to one another.
-> Users can hire other user’s Covelings to do activities for them for a given price (takes the same amount of time or more, though).
-> Users can put unwanted Covelings in the Adoption Center and receive a small amount of Crescents. Other users can adopt these Covelings for an Adoption Ticket.
Adventuring and Battling
-> Covelings can have battle items equipped based on given stats, which functions as a loose class system. They can also unlock class-specific actions.
-> Players can create their adventure party, equip and unequip battle items, and organize the Covelings in the party.
-> There are 2 - 3 adventuring areas for users to explore and fight various enemies and gather items.
-> Users can craft weapons, armor, and other adventuring equipment.
Professions and Skills
-> Each Coveling can have 2+ professions, and also has access to 4 different base skills. These professions and skills are the main source of materials and resources used in crafting and progression.
-> Professions and Skills can now be leveled up and perform specific tasks, in addition to previous features.
-> Additionally, daily and weekly town quests will now include profession-specific requests.
Beta Testing (Distant Future)
This phase will have a larger group of players to help revise current systems and adding the final core features to the site. A lot of this phase will involve balancing gameplay and progression through activities and content.
This is when I’d also like to establish seasonal events, a premium currency / shop system, and user-made items and Coveling skins.
Banner Credit [x]
18 notes
·
View notes
Note
what do you think the member's myspace profiles would've looked like? who would've made it look pretty and who left it on default lol
LMFAO THIS QUESTIONNRHEJJS. i fucking loved myspace so much. let me think on this ok let’s get into it.
namjoon would have a layout, but a very clean, neutral one with meticulously organized photo albums for nature photos, museum photos, and book quotes he likes. his about me section would be some philosophical quote and his profile song is probably something by nas. he writes a lot of cryptic blog posts
jin has a layout but he changes it every week because he gets bored with how it looks, so you never know what his page is gonna look when you click on it. he tends to troll jungkook and hobi’s comments with “w4w???” because he knows neither of them know what that means. in true jin fashion, his default pic is him holding up a giant fish. he thinks the games on myspace are lame and he has no problem commenting on tom’s page to let him know
yoongi keeps his page pretty minimalistic like namjoon, but he likes darker, cooler tones on his layout and he posts videos from his studio a lot. he’s friends with a lot of athletes and producers and whenever he changes his profile photo, people go absolutely insane. he receives thousands of marriage proposals a day and his favorite feature is the “who i’d like to meet” section of his page where he lists all the people he’s a fan of and wants to work with some day
hobi has the most colorful layout of everyone and he LOVES those flashy glitter text gifs, so he has one that says “I LOVE U ARMY” and little animated snoopy graphics. he spent the most time making his page look perfect and he’s very organized with his photos. everything fits an aesthetic and he comments on all the tannies photos, statuses, profiles, bulletins, everything. fashion brands are spamming his inbox on the daily.
taehyung doesn’t have a layout at all because he doesn’t have the patience to learn html, but he does a have great jazzy profile playlist and yeontan is his profile picture OBVIOUSLY. he doesn’t have a top 8, he has a top 1 and it’s just jimin. he really likes posting bulletins to share youtube videos of old movies. his photo albums are kind of a mess but people love his chaotic, grainy images of random stuff around his house, his mirror selfies, or his paintings. the wooga squad leave him really sweet comments
jimin has a profile, but he rarely logs in. his layout is pastel colors and he often confuses the status update box with the little description next to his profile photo. he spams taehyung’s comments with hearts to bury the ones of certain others. when his “online now!” thing comes on, it’s a major event and his comments get flooded so much that it overwhelms him and he logs out again for a few weeks. he’s not sure how to comment back directly, but he’s really grateful everyone says hi to him.
jungkook has an all black page with galaxy-like animations. he learned how to do html so he could design it himself. his playlist is all demos/covers he made himself because he figures army would much rather hear him sing on his own profile than someone else (he’s right!). he goes MIA a lot too, so his “last login” date sometimes becomes a meme amongst the fandom which results in counting exactly how many days we last heard from him. when he remembers his password though, he’s on there for hours posting lots of bam photos, boxing videos, and doing bulletin surveys for fun. he threatens to block jin literally every time he comes online because he genuinely has no idea what he’s asking and he whines about it in hobi’s inbox too.
19 notes
·
View notes
Text
Search Intent là gì? Cách tối ưu “ý định tìm kiếm” hiệu quả thu hút Traffic
Search Intent là thuật ngữ quen thuộc trong lĩnh vực SEO, đây là một trong những yếu tố quan trọng chi phối kết quả tìm kiếm hiện nay.
Vậy thực chất Search Intent là gì? Cách sử dụng sao cho hiệu quả & thu hút Traffic. Cùng HoangGH tìm hiểu qua bài viết này nhé!

Search Intent là gì?
Search Intent hay ý định tìm kiếm là ý định, mục đích, câu hỏi tìm kiếm của người dùng trên các SERPs như Google. Mỗi người đều có những mục đích riêng khi sử dụng các công cụ tìm kiếm. Nếu trang web đáp ứng được nhu cầu này nó sẽ được thăng hạng.
Tại sao User Intent lại quan trọng?
Hiện nay trên thế giới có hơn 7 tỷ người. Mà mỗi người dùng lại có nhiều ý định tìm kiếm khác nhau. Câu hỏi đặt ra ở đây là liêu có cần thiết phải quan tâm đến những ý tưởng tìm kiếm đó không? Câu trả lời là có nếu như bạn muốn website của bạn có thứ hạng tốt trên bảng xếp hạng tìm kiếm.
Chính Google cũng đã khẳng định User Intent có tác động rất lớn đến ngành Marketing hiện nay. Hiện nay người dùng đã không còn đi theo con đường trước kia từ nhận thức sản phẩm rồi đến quyết định mua hàng.
Xu hướng của người dùng hiện nay là họ thu hẹp và mở rộng tìm kiếm liên tục rồi mới đưa ra quyết định lựa chọn. Bên cạnh đó, sứ mệnh của Google là sắp xếp thông tin trên toàn cầu, khiến chúng trở nên hữu ích và truy cập dễ dàng.
Vì vậy, nếu muốn website của mình nằm trong top đầu bảng xếp hạng Google thì bạn phải chứng tỏ được mình đang cung cấp những nội dung hữu ích và phù hợp với ý định tìm kiếm của người dùng.
Tuy nhiên, đừng cố gắng thống trị thứ hạng bằng mọi cách bởi vì Google luôn biết được người dùng muốn thấy những gì khi họ tìm kiếm một cụm từ khóa. Thay vào đó hãy tối ưu hóa SEO để đáp ứng được User Intent Google.
Lợi ích của tối ưu Search Intent với SEO và doanh nghiệp
Đối với SEO: Tối ưu Search Intent giúp tăng chất lượng web, giảm tỷ lệ thoát trang, tăng lượt Page views, kích thích người dùng chuyển đổi hành động. Cả chất lượng trang cho đến mục tiêu bán hàng, doanh thu đều sẽ tăng cao. Website của bạn sẽ tiếp cận với độc giả một cách đơn giản hơn.
Đối với Doanh nghiệp: Việc nghiên cứu User Intent sẽ giúp bạn thu thập được các dữ liệu của người tìm kiếm. Chẳng hạn như họ tìm kiếm nội dung gì, địa chỉ truy cập tìm kiếm ở đâu, mã zip… Thường họ sẽ truy vấn các cửa hàng trong tầm bán kính quanh họ 5km. Bạn hiểu được điều này sẽ nâng cao được hiệu quả kinh doanh tốt hơn.
Cách phân loại Search Intent
Dựa vào mục đích tìm kiếm
Theo các nghiên cứu khoa học của Yoast SEO, Ahrefs và Semrush có thể chia User Intent thành 4 loại chính. Cụ thể:
Ý định tìm kiếm thông tin (Infomationnal Search Intent): Các truy vấn thường thể hiện dưới dạng câu hỏi hoặc cũng có thể là một cụm từ khóa bình thường. Người dùng mong muốn tìm hiểu thông tin về một chủ đề nào đó. Ví dụ như: Search Intent là gì/What is Search Intent, cách SEO Fanpage, HTML,…
Ý định tìm kiếm điều tra thương mại (Commercial Investigation Search Intent): Các truy vấn của người dùng sẽ có dạng so sánh, đánh giá, mong muốn tìm được sản phẩm hoặc dịch vụ tốt nhất. Ví dụ: Top nước hoa Gucci, Đánh giá Macbook Air M1, So sánh SEO từ khóa với SEO tổng thể,…
Ý định tìm kiếm giao dịch (Transactional Search Intent): Thường các tìm kiếm sẽ bao gồm tên sản phẩm hoặc dịch vụ kèm theo các từ như mua, đặt, giá, khuyến mãi, ở đâu,… nên có tỷ lệ chuyển đổi cao. Một số Keyword Intent dạng này: Mua Macbook Air M1, Samsung Galaxy Note 10, Vé máy bay từ TPHCM đi Hà Nội, Mua Hosting ở đâu?,…
Ý định tìm kiếm điều hướng (Navigational Search Intent): Người dùng có ý định truy cập vào một website cụ thể. Ví dụ về truy vấn mang ý định tìm kiếm điều hướng: Facebook, Instagram login,…
Dựa vào Micro Moment
Đầu năm 2010, Google đã đề cập đến việc phân loại User Intent dựa vào Micro Moment (Khoảnh khắc tức thời). Đó là những thời khắc đặc biệt mà người dùng có nhu cầu cao nhất được phân loại như sau:
Know – Tôi muốn biết
Go – Tôi muốn đi tới…
Do – Tôi muốn làm …
Buy – Tôi muốn mua …
Thực tế 2 cách phân loại trên đây lại không thực sự hiệu quả mặc dù chúng đã thể hiện được bản chất của ý định tìm kiếm. Một ví dụ cụ thể cho thấy điều này là: Khi người dùng tìm kiếm “kính bơi có độ” sẽ cho ra 2 User Intent Google về thông tin và giao dịch. Cho thấy họ có xu hướng tìm hiểu thông tin về kính có độ và mua kính.
Vì vậy, để xác định chính xác ý định cho một Keyword Intent, bạn hãy bắt đầu bằng việc quan sát và phân tích kết quả từ trang tìm kiếm trả về
Các dạng Search Intent phổ biến hiện nay
1. Search Intent nghiên cứu thông tin
Đây chính là loại ý định được thực hiện nhiều nhất trên các công cụ tìm kiếm bao gồm Google. Khi người dùng truy vấn, kết quả nhận được thường là các trang cung cấp thông tin, học tập, nghiên cứu như Wiki, blog, diễn đàn theo chủ đề… Mục đích là mang đến những thông tin hữu ích trả lời cho câu hỏi của người dùng và giúp họ tìm hiểu, nghiên cứu về chủ đề đó.
2. Search Intent tìm câu trả lời nhanh
Search Intent Quick Answer là gì? Dù có cùng mục đích là tìm kiếm thông tin nhưng không phải lúc nào người dùng cũng muốn nghiên cứu. Đôi khi, họ chỉ tìm những khái niệm đơn giản và mong muốn câu trả lời nhanh chóng mà không cần truy cập vào một trang web nào.
Với những truy vấn dạng này Google thường đưa ra câu trả lời bằng các hộp định nghĩa (definition box), hộp trả lời (answer box), bảng tỉ số thể thao … Do đó, các trang web có kết quả về truy vấn này thường bị giảm tỷ lệ click (CTR).
3. Search Intent ý định mua hàng
Xu hướng thương mại điện tử hiện đang rất phát triển và Google cũng nhanh chóng bắt kịp. Khi người dùng có nhu cầu nghiên cứu hoặc mua hàng, trên trang tìm kiếm sẽ xuất hiện các website mua sắm trực tuyến như Lazada, Tiki, Shopee…
Bên cạnh đó, một số:
Shopping box
Các trang sản phẩm đi kèm đoạn trích đánh giá, view
Cũng là dấu hiệu rõ ràng cho ý định mua hàng. Search Intent dạng này tương đối dễ xác định. Lý do vì phần lớn thường là các truy vấn đi kèm tên sản phẩm.
4. Search Intent tìm kiếm địa điểm Local
Đối với những ý định tìm kiếm liên quan đến vị trí địa lý, kết quả trả về thường là các local pack (gói kết quả địa điểm) với các điểm đánh dấu (geographic markers). Bản đồ thường nằm ở đầu kết quả tìm kiếm, có thể xuất hiện thêm bản đồ trong bảng tri thức khi có người tìm kiếm về địa điểm.
5. Search Intent tìm kiếm trực quan (nhiều hình ảnh)
Một số truy vấn từ người dùng nhằm mục đích xem hình ảnh thay vì tìm câu trả lời. Khi đó, sẽ xuất hiện hình ảnh gợi ý ở đầu hoặc bên trong trang tìm kiếm. Đây là một dấu hiệu rất cụ thể cho loại Intent này. Ngoài ra, trường hợp 2 hoặc nhiều kết quả từ các trang web chuyên về hình ảnh như Pinterest cũng có thể xác định đây là Search Intent tìm kiếm trực quan.
6. Search Intent tìm kiếm video
Bên cạnh hình ảnh thì video cũng là một phương tiện truyền thông rất phát triển trong thời gian qua. Khi xác định được ý định từ người dùng, các video sẽ được gợi ý bằng kết quả nổi bật, đi kèm ảnh thumbnail và trích đoạn. Khác với Intent cho hình ảnh những video này được chú thích khá chi tiết và có thể được xếp làm một loại riêng.
7. Search Intent tìm các tin mới / tin thời sự (News Intent)
Nếu trang SERPs cho cho ra những hộp câu chuyện (Story Box) ở hàng đầu. Đây là dấu hiệu cụ thể cho các từ khóa có lượng nội dung tin tức lớn. Ngoài ra, những link hướng đến Tweet hoặc Facebook về các mục xem nhiều trong khoảng thời gian cố định cũng cho thấy ý định tìm các tin mới từ người dùng.
8. Search Intent tìm hiểu thương hiệu
Khi truy vấn là tên hoặc đi kèm tên của một thương hiệu kết quả trả về sẽ là trang web của công ty, tổ chức đó. Ngoài ra, nếu công ty hoặc tổ chức không có website, kết quả thu được có thể là những trang đánh giá, review từ người dùng như foody… cũng có thể xem là dấu hiệu cho loại Intent này.
9. Search Intent hỗn hợp là gì?
Còn được gọi là Split Intent, với sự xuất hiện của nhiều loại ý định tìm kiếm kể trên. Bánh mì Việt Nam là một ví dụ cho loại Intent này với sự kết hợp của nhiều kết quả như bản đồ, hình ảnh, video…
Như vậy, với 9 loại Intent trên, bạn có thể nhanh chóng xác định được ý định người dùng. Từ đó, lập kế hoạch nội dung cho từ khóa và triển khai bài viết để đạt được hiệu quả cao hơn khi đáp ứng đúng nhu cầu tìm kiếm từ người dùng.
Hướng dẫn tối ưu Search Intent hiệu quả từ A – Z
Bạn đã biết cách tối ưu Search Intent hiệu quả là gì chưa? Các User Intent cần được phát triển mạnh, tối ưu tìm kiếm để đạt được kết quả tốt nhất. Dưới đây là những kỹ thuật tối ưu User Intent mà chúng tôi đã tổng hợp chi tiết cho bạn.
Nghiên cứu ý định tìm kiếm của người dùng thông qua từ khóa
Nghiên cứu các từ khóa, cụm từ, câu hỏi mà người dùng tìm kiếm chính là các tối ưu trải nghiệm người dùng. Bạn chỉ cần nghiên cứu thông tin chi tiết và chuyển hướng những từ khóa, nội dung truy vấn đó vào trong bài viết của mình.
Đặc biệt, nên mở rộng từ khóa của bạn trên nhiều khía cạnh khác nhau. Chẳng hạn như khi viết về Search Intent, người dùng sẽ truy vấn mọi vấn đề liên quan đến lĩnh vực này. Ví dụ như:
Search Intent là gì (What is Search Intent).
Có mấy loại Search Intent.
Phân loại User Intent hiện nay.
Làm thế nào để nhận biết Search Intent.
Cách tối ưu Keyword Intent.
Nghiên cứu Search Intent là gì …
Trong một bài viết của bạn, hoặc nhiều bài viết về User Intent Google thì chúng ta sẽ triển khai đầy đủ các thông tin này. Người dùng sẽ tìm kiếm được thấy chúng trên website của bạn một cách dễ dàng hơn.
Tăng trải nghiệm người dùng trên website
Để tối ưu được Search Intent bạn phải giảm thấp nhất được tỷ lệ thoát trang của người dùng. Khi tỷ lệ thoát trang giảm sẽ đồng nghĩa với việc tỷ lệ chuyển đổi sẽ tăng cao. Để tăng tối ưu trải nghiệm người dùng, hỗ trợ cho Search Intent bạn nên thực hiện các kỹ thuật sau:
Thêm tiêu đề phụ cho mỗi bài viết. Nội dung trong bài sẽ mạch lạc hơn.
Phân bổ các Heading 2,3 và 4 chi tiết.
Tăng phông chữ lên mức 14 để chúng to và rõ ràng hơn với người đọc.
Tiến hành chèn link liên kết khoa học. In đậm hoặc highlight tại những câu chữ cần thiết.
Đầu tư hình ảnh và video nhúng trong bài viết chất lượng.
>> Tham khảo: SEO onpage là gì? Hướng dẫn tối ưu hóa SEO onpage hiệu quả nhất?
Mở rộng và cải thiện nội dung hiện có trên web
Rất nhiều bài viết của bạn đã tối ưu SEO. Bài viết được đánh giá cao nhưng lượng người xem lại không nhiều. Có thể thấy bạn đã mắc lỗi trong việc xác định Search Intent của bài viết. Hãy nghiên cứu lại bài viết và thêm Keyword Intent để cải thiện về mặt nội dung tốt hơn.
Tối ưu hóa trang thương mại điện tử
Các trang thương mại là nơi mua bán và giao dịch tấp nập của thế giới internet. Cần đầu tư về giao diện, cập nhật hình ảnh, thêm nội dung mô tả về sản phẩm chi tiết. Đặc biệt là thêm các plugin hỗ trợ bán hàng và quản lý sản phẩm dễ dàng hơn.
Điều hướng truy vấn của người dùng
Dùng backlink và bên thứ 3 để điều hướng người dùng đến với truy vấn của bạn. Không phải khách hàng nào cũng truy cập trực tiếp bằng việc tìm đến website của bạn. Có rất nhiều người đã điều hướng đến truy vấn của bạn thông qua những nội dung thông tin khác.
Tối ưu hóa Search Intent nâng cao
Ví dụ, từ khóa của bạn là mua tai nghe. Bạn cần mở rộng các User Intent như: tai nghe khử tiếng ồn, tai nghe hỗ trợ cho giấc ngủ, các loại tai nghe không dây … Hoặc review tai nghe … Những thông tin này sẽ mở rộng đa dạng trường nghĩa và ý định tìm kiếm của người dùng hơn.
Những Câu hỏi thường gặp
Làm gì khi không xác định được intent của keyword?
Ý định tìm kiếm thì luôn đa dạng và cũng khá phức tạp. Để xác định được ý định cho một Keyword Intent, bạn hãy quan sát và phân tích SERP (kết quả từ trang tìm kiếm) trả về. Việc này giúp bạn hiểu được người dùng muốn gì rồi điều chỉnh nội dung bài viết của mình.
Cách nhận biết khi Search Intent thay đổi là gì?
Khi ý định tìm kiếm thay đổi sẽ ảnh hưởng xấu đến nội dung website của bạn. Bạn sẽ có thể phát hiện ra vấn đề này thông qua sự thay đổi tiêu cực như thứ hạng từ khóa và tỷ lệ chuyển đổi giảm,…
Làm thế nào để xác định Split Content?
Để xác định Split Content, bạn có thể dựa vào SERPs trả về khi thực hiện truy vấn. Nếu kết quả tìm kiếm cho 1 từ khóa có xuất hiện các kết quả dưới đây thì đó là Split Content:
News Intent
Nguồn Wikipedia, hộp biểu đồ kiến thức
Video hoặc đề xuất Video, Hình Ảnh trong điều hướng
Xuất hiện ý định tìm kiếm địa điểm trong 20 kết quả hàng đầu
Làm thế nào để xử lý Split Intent?
Trong trang nhất của SERPs luôn thể hiện rõ ý định tìm kiếm, bạn có thể dựa vào đó để phát triển Keyword Intent. Để xử lý Split Intent sẽ cần các SEOer có kinh nghiệm nghiên cứu sâu hơn về ý định người dùng để tìm ra Search Intent cụ thể.
Trên đây là toàn bộ những thông tin liên quan đến Search Intent là gì mà HoangGH muốn chia sẻ đến các bạn. Việc tối ưu ý định tìm kiếm cực kỳ quan trọng, User Intent sẽ tác động lớn đến hướng phát triển của SEO cũng như doanh nghiệp.
Hy vọng những chia sẻ trên đây sẽ thực sự hữu ích với các bạn trong việc nghiên cứu Keyword Intent. Chúc bạn thành công!
Nguồn: https://hoanggh.com/search-intent-la-gi/
3 notes
·
View notes
Text
firefox tabs i have open:
tumblr
tumblr notes
one of my mutuals' blog archive4
my own blog archive
five posts ive reblogged
google image search for 'aardwolf'
a tumblr devoted to j.c. leyendecker
a post from 2017 on my old blog about a stand i made (my friend wanted fanstands to try drawing)
five e621 tabs
an ultima iv-v-vi screenshot lp
"morrowind: an oral history" from polygon
online minesweeper site
online solitaire site
wikipedia page for "Aeon"
wikipedia page for "Young's Literal Translation"
wikipedia page for "Chicxulub crater"
wikipedia page for "Axis mundi"
wikipedia page for "Mount Rainier"
itch.io
sword interval
scryfall search "type:dragon"
scrayfall "Ambitious Dragonborn"
mychart login
http://psd.museum.upenn.edu/epsd/e4129.html
google spreadsheet i made to keep track of silly names i made up in case i wanted to name characters in anything
menu for a local teriyaki restaurant
gmail
anime streaming site tabs for Moribito: Guardian of the Spirit, Spirited Away, and Princess Mononoke
cohost
cohost notes
Just King Things episode on The Waste Lands
Just King Things episode on The Tommyknockers
wiktionary page for "audient"
wikipedia page for "Banana"
wikipedia page for "Robert W. Service
wikipedia page for "Li (unit)"
wikipedia page for "Invertebrate iridescent virus 31"
GameFAQs walkthrough and map for Dragon Warrior for the NES
twitter
twitter notes
metropolitan museum of art page on some Qing dynasty agate pomegranates
wikipedia page for "William Howard Taft"
wikipedia page for "Wig"
wikipedia page for "Egyptian cuisine"
google doc where i was trying to transcribe every JKT five-sentence summary
Kill Six Billion Demons KSBD 2-27
Kill Six Billion Demons Breaker of Infinities 4-181
letterboxd
The New Whirling School: An annotated analysis of Sermon 01
youtube subscriptions
youtube Deadmau5 - Ghosts n Stuff
youtube Ranged Touch's 2021 Dark Souls 2 charity livestream part 1
youtube Ranged Touch's 2020 Morrowind charity livestream part 1
youtube Northernlion playing Slice and Dice
youtube Vangelis - Blade Runner Blues
youtube Lady Gaga - Just Dance
youtube Northernlion playing Enter the Gungeon
youtube The Killers - Human
youtube Kanye West - Flashing Lights
manga site for Berserk and Blame!
nine tabs of the Terraria wiki
wikipedia page for "Etruscan civilization"
google search for "forestall"
wikipedia page for "Ran (film)
scryfall search "type:goblin color>=b"
wikipedia page for "Gisella Perl"
wikipedia page for "Overtone singing"
wikipedia page for "Muezzin"
About Us page for Gay City: Seattle's LGBTQ Center
an entirely unused new tab
"An Unknown Kid on Halloween"
uquiz results for "what's your job after the apocalypse"
wikipedia page for "Barnacle goose myth"
wikipedia page for "Vegetable Lamb of Tartary"
rom site
what happens next
youtube William Wegman - Alphabet Soup
events page for a seattle comics & games shop
youtube Ode to Physical Pain
google search for "hyperobject"
prisoncensorship's review of Fallouts 1 & 2
picture i took of the inside of that same comics & games shop
wikipedia page for "Infliximab"
chart showing the evolutionary tree of polearms over time
another mutual's reblogged post
two tabs of the menu of a local pastrami shop
pdf of the third edition monster manual
wikipedia page for "Forgotten Realms"
picture i took of my own backyard covered in snow
scryfall search "set:clb t:dragon is:firstprint"
scryfall search "set"afr t:dragon"
three tabs of file directory for some tabletop pdfs
wikipedia page for "First Blood"
youtube King Missile - Open
someone's website about cat colorations and fur patterns
image a friend sent me of the chapter list of the novel she's writing
Gita Jackson's article comparing Dwarf Fortress and Rimworld
download page for the roguelike "Infra Arcana"
youtube Richard Dawson - Ogre
youtube Every Enemy in Dark Souls RATED - 1 - Undead Asylum
an Exalted 2e homebrew Hegra charmset
a friend's twitter
bilibili video for known Genshin Impact character Xiao
google doc of the rules for a discord server im in
i know i have way too many tabs open please dont yell at me
18 notes
·
View notes
Text
Advanced Techniques in Full-Stack Development

Certainly, let's delve deeper into more advanced techniques and concepts in full-stack development:
1. Server-Side Rendering (SSR) and Static Site Generation (SSG):
SSR: Rendering web pages on the server side to improve performance and SEO by delivering fully rendered pages to the client.
SSG: Generating static HTML files at build time, enhancing speed, and reducing the server load.
2. WebAssembly:
WebAssembly (Wasm): A binary instruction format for a stack-based virtual machine. It allows high-performance execution of code on web browsers, enabling languages like C, C++, and Rust to run in web applications.
3. Progressive Web Apps (PWAs) Enhancements:
Background Sync: Allowing PWAs to sync data in the background even when the app is closed.
Web Push Notifications: Implementing push notifications to engage users even when they are not actively using the application.
4. State Management:
Redux and MobX: Advanced state management libraries in React applications for managing complex application states efficiently.
Reactive Programming: Utilizing RxJS or other reactive programming libraries to handle asynchronous data streams and events in real-time applications.
5. WebSockets and WebRTC:
WebSockets: Enabling real-time, bidirectional communication between clients and servers for applications requiring constant data updates.
WebRTC: Facilitating real-time communication, such as video chat, directly between web browsers without the need for plugins or additional software.
6. Caching Strategies:
Content Delivery Networks (CDN): Leveraging CDNs to cache and distribute content globally, improving website loading speeds for users worldwide.
Service Workers: Using service workers to cache assets and data, providing offline access and improving performance for returning visitors.
7. GraphQL Subscriptions:
GraphQL Subscriptions: Enabling real-time updates in GraphQL APIs by allowing clients to subscribe to specific events and receive push notifications when data changes.
8. Authentication and Authorization:
OAuth 2.0 and OpenID Connect: Implementing secure authentication and authorization protocols for user login and access control.
JSON Web Tokens (JWT): Utilizing JWTs to securely transmit information between parties, ensuring data integrity and authenticity.
9. Content Management Systems (CMS) Integration:
Headless CMS: Integrating headless CMS like Contentful or Strapi, allowing content creators to manage content independently from the application's front end.
10. Automated Performance Optimization:
Lighthouse and Web Vitals: Utilizing tools like Lighthouse and Google's Web Vitals to measure and optimize web performance, focusing on key user-centric metrics like loading speed and interactivity.
11. Machine Learning and AI Integration:
TensorFlow.js and ONNX.js: Integrating machine learning models directly into web applications for tasks like image recognition, language processing, and recommendation systems.
12. Cross-Platform Development with Electron:
Electron: Building cross-platform desktop applications using web technologies (HTML, CSS, JavaScript), allowing developers to create desktop apps for Windows, macOS, and Linux.
13. Advanced Database Techniques:
Database Sharding: Implementing database sharding techniques to distribute large databases across multiple servers, improving scalability and performance.
Full-Text Search and Indexing: Implementing full-text search capabilities and optimized indexing for efficient searching and data retrieval.
14. Chaos Engineering:
Chaos Engineering: Introducing controlled experiments to identify weaknesses and potential failures in the system, ensuring the application's resilience and reliability.
15. Serverless Architectures with AWS Lambda or Azure Functions:
Serverless Architectures: Building applications as a collection of small, single-purpose functions that run in a serverless environment, providing automatic scaling and cost efficiency.
16. Data Pipelines and ETL (Extract, Transform, Load) Processes:
Data Pipelines: Creating automated data pipelines for processing and transforming large volumes of data, integrating various data sources and ensuring data consistency.
17. Responsive Design and Accessibility:
Responsive Design: Implementing advanced responsive design techniques for seamless user experiences across a variety of devices and screen sizes.
Accessibility: Ensuring web applications are accessible to all users, including those with disabilities, by following WCAG guidelines and ARIA practices.
full stack development training in Pune
2 notes
·
View notes
Text

I found my old Replit account from like 2 years ago and it has all my old and first set of websites I built! I remember I finished learning HTML and CSS properly and wanted to challenge myself on building login/sign up pages everyday!
Task: transfer all of them (that I like) into a GitHub repository and work on them if they need improving such as responsiveness.
One by one I will try and share them on here as well, a little showcase because I am proud of them as well~! (They're so bad that they're good lol - in my eyes)

⤷ ○ ♡ my shop ○ my twt ○ my youtube ○ pinned post ○ blog's navigation ♡ ○
#codeblr#coding#progblr#programming#studyblr#studying#computer science#tech#github#replit#old projects#web development#web dev
63 notes
·
View notes
Text
Programming Languages of the Web

Front-end Website Programming Languages
The following programming languages are a must when it comes to website development.
HTML
HTML is the standard and base-level programming language used to create every web page. It's used for structuring content. HTML, on its own, would make a very boring-looking website in black and white.
CSS
CSS is a programming language that is used to style HTML web pages. It specifies how HTML should look on various screens.
JavaScript
JavaScript is a powerful front-end programming language used to add functionality to a web page once it's loaded on the screen. It's used for calculations, special effects and changing elements dynamically on the fly.

Back-end Website Programming Languages
There are numerous back-end programming languages that could be used in website development. The following two are the most common back-end languages that MarkIT Space uses to program websites and powerful website applications.
PHP
PHP is a powerful back-end programming language, which means the code is executed on its web server before the result is displayed on the screen for the user to see. It's often used to submit form data to a database or send emails. It's also used to save login credentials and create cookies for a local computer to remember specific details.
SQL
SQL is a programming language used for databases. Databases that often record detailed website information, such as websites that require users to log in and for storing their information. SQL is used for submitting data to a database, retrieving data and modifying it.
18 notes
·
View notes
Text
How to Use a Computer, Part 4: How to Use Mozilla Firefox
Firefox is presently the only major web browser that isn’t controlled by Google, so it’s my preferred browser as someone who hates giant multinational corporations that control everything.
In terms of general use, it’s not all that different from other web browsers-- type address or search term in search bar, press enter, click to go, that sort of thing.
Importing data from other browsers.
The big thing people worry about when it comes to switching browsers is “will I be able to save my bookmarks, saved logins, and open tabs?” To do this in Firefox, open a Firefox browser window and either press ALT on the keyboard, or right-click in the space where the tabs show up and select “Menu bar”. Under File, select “Import from another browser”, then find the name of the browser you want to import from and select Next to choose what data you want imported; Cookies, Browsing history, Saved passwords, and Favourites.
Saved. That was easy. Now you can uninstall Chrome without remorse.
Add-ons and Extensions.
You’ve got to use Add-ons and Extensions to get the full experience. All of the add-ons available from Mozilla’s website are free and most will safeguard your personal data. If you’re familiar with Google Chrome extensions, then there won’t be a learning curve.
In a Firefox browser window, type
about:addons
into the search bar. This will open your add-ons settings menu from where you can control, update, and remove add-ons that you have installed, and search for new add-ons. At the very bottom of the page is a button marked “Find more add-ons”, which will take you to Mozilla’s Firefox Browser Add-ons homepage. Have a look around, see what looks interesting, give it a go. Most add-ons won’t require you to restart Firefox, but if they do, the browser will save your history and any website logins to restore your session.
There are a few add-ons I would recommend installing immediately after setting up Firefox for the first time, all are related to privacy (Firefox is already the most secure browser in the world, these just plug any holes that might show up later).
uBlock Origin. This privacy multi-tool blocks trackers, cookies, and even advertising! If you’ve ever wanted to experience an ad-free YouTube, uBO is for you. uBO will also prevent content networks from tracking you across the internet. More to that point...
LocalCDN. It’s Decentraleyes on steroids. Its sole focus is emulating corporate content delivery networks (CDNs) without actually accessing them, adding an extra layer of privacy as most CDNs are able to personally identify your computer based upon the content it requests. This reduces their ability to profit off your existence while still allowing you to use the internet as normal. It’s a large install-- 17 GB-- because it doesn’t rely on offsite resources to do its job. That’s why it’s called “Local” CDN. Everything is carried out on your computer, and nowhere else.
Privacy Badger. Another trackware blocker, made by the Electronic Frontier Foundation. This one is different from uBO in that it can pick up on new trackers that people who make uBO lists may not know about yet, by analysing the behaviour of the website and any scripts it runs. Basically, it does what trackers do, but it does it to the tracker instead of the user. This next one isn’t related to privacy, but...
SingleFile. Are you given to datahoarding? Good on you! So am I. If you want to hoard webpages, SingleFile can condense a webpage into a single HTML document for easy storage.
DownThemAll. If you’re not interested in downloading the webpage, just the media on the page, DownThemAll can do that. Either you can tell DTA the kinds of files you want to nick from a page, or you can create a download queue by giving DTA the links to things you want to download.
Now, if you’re serious about privacy, all of this can take you pretty far, but, it won’t protect you against thieves who just straight up steal your computer. As a certifiable paranoid freak, I’m aware that I live in a world full of people who might just walk right up and whisk my laptop away while I’m drinking my coffee. You really should consider not leaving tabs open or staying logged in across multiple sessions. I know there are certain extenuating circumstances; like work or school assignments; but for just general use, consider changing the settings to make Firefox delete your cache automatically when you close the browser.
It’s selective; you can tell it what data to delete and what to preserve; but at the very least allow Firefox to log you out of websites when you close it.
“Okay, fine, shut up and tell me how.” In the search bar type...
about:preferences
...and navigate to the “Privacy & Security” tab, then scroll down to “Cookies and Site Data” and check the box that says “Delete cookies and site data when Firefox is closed“. If you have a website that you want exempted from this rule, such as Tumblr for instance, click “Manage exceptions” and enter Tumblr’s URL into the text line, and click “Allow”. If you change your mind later, you can delete it from the list.
Next, scroll down to “History” and change it to “Use custom settings for history”. If you want to stay logged into websites, retain content settings, or other things that are stored in local cookies instead of on the host server, click “Settings” next to “Clear History when Firefox Closes”, and check or uncheck the boxes next to the desired items.
Firefox has loads of built-in customisation options, such as font overrides, light mode and dark mode, and themes, so have a look around. For right now though, that’s it. Tune in next time when we talk about how to install game software from disc media and the basics of how to install game mods.
3 notes
·
View notes
Note
Question how do you put links in your bio?
Hey! So, you need to use your browser for it so just login to your account from desktop. Go to your blog and click Edit Appearance on the right hand side (if you have side blogs then switch to the side blog first) now click on Edit Theme (if you edit something from the app afterwards then the links will break again so always edit bio stuff from here) - which should open Customize page and you'll see your description on the left. Here you'll be doing the html edits.
To make the link you need to type this <a href= "https://just copy and paste your link">this should be the word you want linked</a>
That's it! Just make sure you have quotation marks before and after your link. Now click on Save and then Exit.
Huge thanks to Jess for teaching me this about 2? 3? years ago now 💛 @cellphonehippie
#your links will work perfectly on desktop tumblr - tags tend to be messy on the app because of the godawful search function#so just ask someone to confirm if your links are working#let me know if you have further questions!#Asks#anon
5 notes
·
View notes
Last Seen Blogs

wholesome90stv
Wholesome 90s TV

plusplusbonjour
Barbara

viajando-por-tus-lunares
LONELY

brothertedd
#brothertedd

vidal-de-moragas
Paul Vidal D.M.