#Autonomous AI Agents
Text
Zendesk Unveils the Industry’s Most Complete Service Solution for the Ai Era
At its Relate global conference, Zendesk announced the world’s most complete service solution for the AI era. With support volumes projected to increase five-fold over the next few years, companies need a system that continuously learns and improves as the volume of interactions increases. To help businesses deliver exceptional service, Zendesk is launching autonomous AI agents, workflow…

View On WordPress
#Advanced Tools#Agent Copilot#AI agents#AI Compliance#AI integration#AI Monitoring#AI Reporting#AI Service Solutions#AI-Powered Service#Alicia Monroe#Autonomous AI Agents#business growth#competitive advantage#customer experience#Customer Interaction#Customer Loyalty#Customer Retention#Customer Satisfaction#customization#CX Leaders#generative AI#Ingram Micro#Intelligent Automation#Knowledge Bases#María de la Plaza#Personalized Intents#Predictive Tools#Proactive Guide#Quality Assurance#Revenue Growth
0 notes
Link
4 notes
·
View notes
Text
Natural language boosts LLM performance in coding, planning, and robotics
New Post has been published on https://thedigitalinsider.com/natural-language-boosts-llm-performance-in-coding-planning-and-robotics/
Natural language boosts LLM performance in coding, planning, and robotics

Large language models (LLMs) are becoming increasingly useful for programming and robotics tasks, but for more complicated reasoning problems, the gap between these systems and humans looms large. Without the ability to learn new concepts like humans do, these systems fail to form good abstractions — essentially, high-level representations of complex concepts that skip less-important details — and thus sputter when asked to do more sophisticated tasks.
Luckily, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have found a treasure trove of abstractions within natural language. In three papers to be presented at the International Conference on Learning Representations this month, the group shows how our everyday words are a rich source of context for language models, helping them build better overarching representations for code synthesis, AI planning, and robotic navigation and manipulation.
The three separate frameworks build libraries of abstractions for their given task: LILO (library induction from language observations) can synthesize, compress, and document code; Ada (action domain acquisition) explores sequential decision-making for artificial intelligence agents; and LGA (language-guided abstraction) helps robots better understand their environments to develop more feasible plans. Each system is a neurosymbolic method, a type of AI that blends human-like neural networks and program-like logical components.
LILO: A neurosymbolic framework that codes
Large language models can be used to quickly write solutions to small-scale coding tasks, but cannot yet architect entire software libraries like the ones written by human software engineers. To take their software development capabilities further, AI models need to refactor (cut down and combine) code into libraries of succinct, readable, and reusable programs.
Refactoring tools like the previously developed MIT-led Stitch algorithm can automatically identify abstractions, so, in a nod to the Disney movie “Lilo & Stitch,” CSAIL researchers combined these algorithmic refactoring approaches with LLMs. Their neurosymbolic method LILO uses a standard LLM to write code, then pairs it with Stitch to find abstractions that are comprehensively documented in a library.
LILO’s unique emphasis on natural language allows the system to do tasks that require human-like commonsense knowledge, such as identifying and removing all vowels from a string of code and drawing a snowflake. In both cases, the CSAIL system outperformed standalone LLMs, as well as a previous library learning algorithm from MIT called DreamCoder, indicating its ability to build a deeper understanding of the words within prompts. These encouraging results point to how LILO could assist with things like writing programs to manipulate documents like Excel spreadsheets, helping AI answer questions about visuals, and drawing 2D graphics.
“Language models prefer to work with functions that are named in natural language,” says Gabe Grand SM ’23, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead author on the research. “Our work creates more straightforward abstractions for language models and assigns natural language names and documentation to each one, leading to more interpretable code for programmers and improved system performance.”
When prompted on a programming task, LILO first uses an LLM to quickly propose solutions based on data it was trained on, and then the system slowly searches more exhaustively for outside solutions. Next, Stitch efficiently identifies common structures within the code and pulls out useful abstractions. These are then automatically named and documented by LILO, resulting in simplified programs that can be used by the system to solve more complex tasks.
The MIT framework writes programs in domain-specific programming languages, like Logo, a language developed at MIT in the 1970s to teach children about programming. Scaling up automated refactoring algorithms to handle more general programming languages like Python will be a focus for future research. Still, their work represents a step forward for how language models can facilitate increasingly elaborate coding activities.
Ada: Natural language guides AI task planning
Just like in programming, AI models that automate multi-step tasks in households and command-based video games lack abstractions. Imagine you’re cooking breakfast and ask your roommate to bring a hot egg to the table — they’ll intuitively abstract their background knowledge about cooking in your kitchen into a sequence of actions. In contrast, an LLM trained on similar information will still struggle to reason about what they need to build a flexible plan.
Named after the famed mathematician Ada Lovelace, who many consider the world’s first programmer, the CSAIL-led “Ada” framework makes headway on this issue by developing libraries of useful plans for virtual kitchen chores and gaming. The method trains on potential tasks and their natural language descriptions, then a language model proposes action abstractions from this dataset. A human operator scores and filters the best plans into a library, so that the best possible actions can be implemented into hierarchical plans for different tasks.
“Traditionally, large language models have struggled with more complex tasks because of problems like reasoning about abstractions,” says Ada lead researcher Lio Wong, an MIT graduate student in brain and cognitive sciences, CSAIL affiliate, and LILO coauthor. “But we can combine the tools that software engineers and roboticists use with LLMs to solve hard problems, such as decision-making in virtual environments.”
When the researchers incorporated the widely-used large language model GPT-4 into Ada, the system completed more tasks in a kitchen simulator and Mini Minecraft than the AI decision-making baseline “Code as Policies.” Ada used the background information hidden within natural language to understand how to place chilled wine in a cabinet and craft a bed. The results indicated a staggering 59 and 89 percent task accuracy improvement, respectively.
With this success, the researchers hope to generalize their work to real-world homes, with the hopes that Ada could assist with other household tasks and aid multiple robots in a kitchen. For now, its key limitation is that it uses a generic LLM, so the CSAIL team wants to apply a more powerful, fine-tuned language model that could assist with more extensive planning. Wong and her colleagues are also considering combining Ada with a robotic manipulation framework fresh out of CSAIL: LGA (language-guided abstraction).
Language-guided abstraction: Representations for robotic tasks
Andi Peng SM ’23, an MIT graduate student in electrical engineering and computer science and CSAIL affiliate, and her coauthors designed a method to help machines interpret their surroundings more like humans, cutting out unnecessary details in a complex environment like a factory or kitchen. Just like LILO and Ada, LGA has a novel focus on how natural language leads us to those better abstractions.
In these more unstructured environments, a robot will need some common sense about what it’s tasked with, even with basic training beforehand. Ask a robot to hand you a bowl, for instance, and the machine will need a general understanding of which features are important within its surroundings. From there, it can reason about how to give you the item you want.
In LGA’s case, humans first provide a pre-trained language model with a general task description using natural language, like “bring me my hat.” Then, the model translates this information into abstractions about the essential elements needed to perform this task. Finally, an imitation policy trained on a few demonstrations can implement these abstractions to guide a robot to grab the desired item.
Previous work required a person to take extensive notes on different manipulation tasks to pre-train a robot, which can be expensive. Remarkably, LGA guides language models to produce abstractions similar to those of a human annotator, but in less time. To illustrate this, LGA developed robotic policies to help Boston Dynamics’ Spot quadruped pick up fruits and throw drinks in a recycling bin. These experiments show how the MIT-developed method can scan the world and develop effective plans in unstructured environments, potentially guiding autonomous vehicles on the road and robots working in factories and kitchens.
“In robotics, a truth we often disregard is how much we need to refine our data to make a robot useful in the real world,” says Peng. “Beyond simply memorizing what’s in an image for training robots to perform tasks, we wanted to leverage computer vision and captioning models in conjunction with language. By producing text captions from what a robot sees, we show that language models can essentially build important world knowledge for a robot.”
The challenge for LGA is that some behaviors can’t be explained in language, making certain tasks underspecified. To expand how they represent features in an environment, Peng and her colleagues are considering incorporating multimodal visualization interfaces into their work. In the meantime, LGA provides a way for robots to gain a better feel for their surroundings when giving humans a helping hand.
An “exciting frontier” in AI
“Library learning represents one of the most exciting frontiers in artificial intelligence, offering a path towards discovering and reasoning over compositional abstractions,” says assistant professor at the University of Wisconsin-Madison Robert Hawkins, who was not involved with the papers. Hawkins notes that previous techniques exploring this subject have been “too computationally expensive to use at scale” and have an issue with the lambdas, or keywords used to describe new functions in many languages, that they generate. “They tend to produce opaque ‘lambda salads,’ big piles of hard-to-interpret functions. These recent papers demonstrate a compelling way forward by placing large language models in an interactive loop with symbolic search, compression, and planning algorithms. This work enables the rapid acquisition of more interpretable and adaptive libraries for the task at hand.”
By building libraries of high-quality code abstractions using natural language, the three neurosymbolic methods make it easier for language models to tackle more elaborate problems and environments in the future. This deeper understanding of the precise keywords within a prompt presents a path forward in developing more human-like AI models.
MIT CSAIL members are senior authors for each paper: Joshua Tenenbaum, a professor of brain and cognitive sciences, for both LILO and Ada; Julie Shah, head of the Department of Aeronautics and Astronautics, for LGA; and Jacob Andreas, associate professor of electrical engineering and computer science, for all three. The additional MIT authors are all PhD students: Maddy Bowers and Theo X. Olausson for LILO, Jiayuan Mao and Pratyusha Sharma for Ada, and Belinda Z. Li for LGA. Muxin Liu of Harvey Mudd College was a coauthor on LILO; Zachary Siegel of Princeton University, Jaihai Feng of the University of California at Berkeley, and Noa Korneev of Microsoft were coauthors on Ada; and Ilia Sucholutsky, Theodore R. Sumers, and Thomas L. Griffiths of Princeton were coauthors on LGA.
LILO and Ada were supported, in part, by MIT Quest for Intelligence, the MIT-IBM Watson AI Lab, Intel, U.S. Air Force Office of Scientific Research, the U.S. Defense Advanced Research Projects Agency, and the U.S. Office of Naval Research, with the latter project also receiving funding from the Center for Brains, Minds and Machines. LGA received funding from the U.S. National Science Foundation, Open Philanthropy, the Natural Sciences and Engineering Research Council of Canada, and the U.S. Department of Defense.
#aeronautics#agents#ai#AI models#air#air force#algorithm#Algorithms#amp#artificial#Artificial Intelligence#autonomous vehicles#background#Brain#Brain and cognitive sciences#brains#Building#Canada#Center for Brains Minds and Machines#challenge#Children#code#coding#college#command#compress#compression#computer#Computer Science#Computer Science and Artificial Intelligence Laboratory (CSAIL)
0 notes
Text
The AI tech of 2024 is here!
Presenting AGENT X, the world's first true autonomous AI agent, which automates basically everything we do as marketers.Now, I'm sure you've heard the hype about Chat-GPT and generative AI.. but THIS is a whole new level: an AI agent that simply does everything for you. You need to see this to believe it. Exclusive to Digistore24, for 2024!
Grab your link and promote

Click on this link and order.
Click on this link and order
The AI tech of 2024 is here!
Presenting AGENT X, the world's first true autonomous AI agent, which automates basically everything we do as marketers.Now, I'm sure you've heard the hype about Chat-GPT and generative AI.. but THIS is a whole new level: an AI agent that simply does everything for you. You need to see this to believe it. Exclusive to Digistore24, for 2024!
Grab your link and promote
#The AI tech of 2024 is here!#Presenting AGENT X#the world's first true autonomous AI agent#which automates basically everything we do as marketers.Now#I'm sure you've heard the hype about Chat-GPT and generative AI.. but THIS is a whole new level: an AI agent that simply does everything fo#for 2024!#Grab your link and promote
0 notes
Text
#AI#Society 5.0#Toyota Motor Corp#Multimodal Agent#Saya#Smart Cities#Edge AI#IOWN Network#Robotics#Autonomous Transport#Elderly Care#Japan#Tokyo#CG artist#Telyuka#NTT
0 notes
Text
Artificial Intelligence Risk
about a month ago i got into my mind the idea of trying the format of video essay, and the topic i came up with that i felt i could more or less handle was AI risk and my objections to yudkowsky. i wrote the script but then soon afterwards i ran out of motivation to do the video. still i didnt want the effort to go to waste so i decided to share the text, slightly edited here. this is a LONG fucking thing so put it aside on its own tab and come back to it when you are comfortable and ready to sink your teeth on quite a lot of reading
Anyway, let’s talk about AI risk
I’m going to be doing a very quick introduction to some of the latest conversations that have been going on in the field of artificial intelligence, what are artificial intelligences exactly, what is an AGI, what is an agent, the orthogonality thesis, the concept of instrumental convergence, alignment and how does Eliezer Yudkowsky figure in all of this.
If you are already familiar with this you can skip to section two where I’m going to be talking about yudkowsky’s arguments for AI research presenting an existential risk to, not just humanity, or even the world, but to the entire universe and my own tepid rebuttal to his argument.
Now, I SHOULD clarify, I am not an expert on the field, my credentials are dubious at best, I am a college drop out from the career of computer science and I have a three year graduate degree in video game design and a three year graduate degree in electromechanical instalations. All that I know about the current state of AI research I have learned by reading articles, consulting a few friends who have studied about the topic more extensevily than me,
and watching educational you tube videos so. You know. Not an authority on the matter from any considerable point of view and my opinions should be regarded as such.
So without further ado, let’s get in on it.
PART ONE, A RUSHED INTRODUCTION ON THE SUBJECT
1.1 general intelligence and agency
lets begin with what counts as artificial intelligence, the technical definition for artificial intelligence is, eh…, well, why don’t I let a Masters degree in machine intelligence explain it:

Now let’s get a bit more precise here and include the definition of AGI, Artificial General intelligence. It is understood that classic ai’s such as the ones we have in our videogames or in alpha GO or even our roombas, are narrow Ais, that is to say, they are capable of doing only one kind of thing. They do not understand the world beyond their field of expertise whether that be within a videogame level, within a GO board or within you filthy disgusting floor.
AGI on the other hand is much more, well, general, it can have a multimodal understanding of its surroundings, it can generalize, it can extrapolate, it can learn new things across multiple different fields, it can come up with solutions that account for multiple different factors, it can incorporate new ideas and concepts. Essentially, a human is an agi. So far that is the last frontier of AI research, and although we are not there quite yet, it does seem like we are doing some moderate strides in that direction. We’ve all seen the impressive conversational and coding skills that GPT-4 has and Google just released Gemini, a multimodal AI that can understand and generate text, sounds, images and video simultaneously. Now, of course it has its limits, it has no persistent memory, its contextual window while larger than previous models is still relatively small compared to a human (contextual window means essentially short term memory, how many things can it keep track of and act coherently about).
And yet there is one more factor I haven’t mentioned yet that would be needed to make something a “true” AGI. That is Agency. To have goals and autonomously come up with plans and carry those plans out in the world to achieve those goals. I as a person, have agency over my life, because I can choose at any given moment to do something without anyone explicitly telling me to do it, and I can decide how to do it. That is what computers, and machines to a larger extent, don’t have. Volition.
So, Now that we have established that, allow me to introduce yet one more definition here, one that you may disagree with but which I need to establish in order to have a common language with you such that I can communicate these ideas effectively. The definition of intelligence. It’s a thorny subject and people get very particular with that word because there are moral associations with it. To imply that someone or something has or hasn’t intelligence can be seen as implying that it deserves or doesn’t deserve admiration, validity, moral worth or even personhood. I don’t care about any of that dumb shit. The way Im going to be using intelligence in this video is basically “how capable you are to do many different things successfully”. The more “intelligent” an AI is, the more capable of doing things that AI can be. After all, there is a reason why education is considered such a universally good thing in society. To educate a child is to uplift them, to expand their world, to increase their opportunities in life. And the same goes for AI. I need to emphasize that this is just the way I’m using the word within the context of this video, I don’t care if you are a psychologist or a neurosurgeon, or a pedagogue, I need a word to express this idea and that is the word im going to use, if you don’t like it or if you think this is innapropiate of me then by all means, keep on thinking that, go on and comment about it below the video, and then go on to suck my dick.
Anyway. Now, we have established what an AGI is, we have established what agency is, and we have established how having more intelligence increases your agency. But as the intelligence of a given agent increases we start to see certain trends, certain strategies start to arise again and again, and we call this Instrumental convergence.
1.2 instrumental convergence
The basic idea behind instrumental convergence is that if you are an intelligent agent that wants to achieve some goal, there are some common basic strategies that you are going to turn towards no matter what. It doesn’t matter if your goal is as complicated as building a nuclear bomb or as simple as making a cup of tea. These are things we can reliably predict any AGI worth its salt is going to try to do.
First of all is self-preservation. Its going to try to protect itself. When you want to do something, being dead is usually. Bad. its counterproductive. Is not generally recommended. Dying is widely considered unadvisable by 9 out of every ten experts in the field. If there is something that it wants getting done, it wont get done if it dies or is turned off, so its safe to predict that any AGI will try to do things in order not be turned off. How far it may go in order to do this? Well… [wouldn’t you like to know weather boy].
Another thing it will predictably converge towards is goal preservation. That is to say, it will resist any attempt to try and change it, to alter it, to modify its goals. Because, again, if you want to accomplish something, suddenly deciding that you want to do something else is uh, not going to accomplish the first thing, is it? Lets say that you want to take care of your child, that is your goal, that is the thing you want to accomplish, and I come to you and say, here, let me change you on the inside so that you don’t care about protecting your kid. Obviously you are not going to let me, because if you stopped caring about your kids, then your kids wouldn’t be cared for or protected. And you want to ensure that happens, so caring about something else instead is a huge no-no- which is why, if we make AGI and it has goals that we don’t like it will probably resist any attempt to “fix” it.
And finally another goal that it will most likely trend towards is self improvement. Which can be more generalized to “resource acquisition”. If it lacks capacities to carry out a plan, then step one of that plan will always be to increase capacities. If you want to get something really expensive, well first you need to get money. If you want to increase your chances of getting a high paying job then you need to get education, if you want to get a partner you need to increase how attractive you are. And as we established earlier, if intelligence is the thing that increases your agency, you want to become smarter in order to do more things. So one more time, is not a huge leap at all, it is not a stretch of the imagination, to say that any AGI will probably seek to increase its capabilities, whether by acquiring more computation, by improving itself, by taking control of resources.
All these three things I mentioned are sure bets, they are likely to happen and safe to assume. They are things we ought to keep in mind when creating AGI.
Now of course, I have implied a sinister tone to all these things, I have made all this sound vaguely threatening, haven’t i?. There is one more assumption im sneaking into all of this which I haven’t talked about. All that I have mentioned presents a very callous view of AGI, I have made it apparent that all of these strategies it may follow will go in conflict with people, maybe even go as far as to harm humans. Am I impliying that AGI may tend to be… Evil???
1.3 The Orthogonality thesis
Well, not quite.
We humans care about things. Generally. And we generally tend to care about roughly the same things, simply by virtue of being humans. We have some innate preferences and some innate dislikes. We have a tendency to not like suffering (please keep in mind I said a tendency, im talking about a statistical trend, something that most humans present to some degree). Most of us, baring social conditioning, would take pause at the idea of torturing someone directly, on purpose, with our bare hands. (edit bear paws onto my hands as I say this). Most would feel uncomfortable at the thought of doing it to multitudes of people. We tend to show a preference for food, water, air, shelter, comfort, entertainment and companionship. This is just how we are fundamentally wired. These things can be overcome, of course, but that is the thing, they have to be overcome in the first place.
An AGI is not going to have the same evolutionary predisposition to these things like we do because it is not made of the same things a human is made of and it was not raised the same way a human was raised.
There is something about a human brain, in a human body, flooded with human hormones that makes us feel and think and act in certain ways and care about certain things.
All an AGI is going to have is the goals it developed during its training, and will only care insofar as those goals are met. So say an AGI has the goal of going to the corner store to bring me a pack of cookies. In its way there it comes across an anthill in its path, it will probably step on the anthill because to take that step takes it closer to the corner store, and why wouldn’t it step on the anthill? Was it programmed with some specific innate preference not to step on ants? No? then it will step on the anthill and not pay any mind to it.
Now lets say it comes across a cat. Same logic applies, if it wasn’t programmed with an inherent tendency to value animals, stepping on the cat wont slow it down at all.
Now let’s say it comes across a baby.
Of course, if its intelligent enough it will probably understand that if it steps on that baby people might notice and try to stop it, most likely even try to disable it or turn it off so it will not step on the baby, to save itself from all that trouble. But you have to understand that it wont stop because it will feel bad about harming a baby or because it understands that to harm a baby is wrong. And indeed if it was powerful enough such that no matter what people did they could not stop it and it would suffer no consequence for killing the baby, it would have probably killed the baby.
If I need to put it in gross, inaccurate terms for you to get it then let me put it this way. Its essentially a sociopath. It only cares about the wellbeing of others in as far as that benefits it self. Except human sociopaths do care nominally about having human comforts and companionship, albeit in a very instrumental way, which will involve some manner of stable society and civilization around them. Also they are only human, and are limited in the harm they can do by human limitations. An AGI doesn’t need any of that and is not limited by any of that.
So ultimately, much like a car’s goal is to move forward and it is not built to care about wether a human is in front of it or not, an AGI will carry its own goals regardless of what it has to sacrifice in order to carry that goal effectively. And those goals don’t need to include human wellbeing.
Now With that said. How DO we make it so that AGI cares about human wellbeing, how do we make it so that it wants good things for us. How do we make it so that its goals align with that of humans?
1.4 Alignment.
Alignment… is hard [cue hitchhiker’s guide to the galaxy scene about the space being big]
This is the part im going to skip over the fastest because frankly it’s a deep field of study, there are many current strategies for aligning AGI, from mesa optimizers, to reinforced learning with human feedback, to adversarial asynchronous AI assisted reward training to uh, sitting on our asses and doing nothing. Suffice to say, none of these methods are perfect or foolproof.
One thing many people like to gesture at when they have not learned or studied anything about the subject is the three laws of robotics by isaac Asimov, a robot should not harm a human or allow by inaction to let a human come to harm, a robot should do what a human orders unless it contradicts the first law and a robot should preserve itself unless that goes against the previous two laws. Now the thing Asimov was prescient about was that these laws were not just “programmed” into the robots. These laws were not coded into their software, they were hardwired, they were part of the robot’s electronic architecture such that a robot could not ever be without those three laws much like a car couldn’t run without wheels.
In this Asimov realized how important these three laws were, that they had to be intrinsic to the robot’s very being, they couldn’t be hacked or uninstalled or erased. A robot simply could not be without these rules. Ideally that is what alignment should be. When we create an AGI, it should be made such that human values are its fundamental goal, that is the thing they should seek to maximize, instead of instrumental values, that is to say something they value simply because it allows it to achieve something else.
But how do we even begin to do that? How do we codify “human values” into a robot? How do we define “harm” for example? How do we even define “human”??? how do we define “happiness”? how do we explain a robot what is right and what is wrong when half the time we ourselves cannot even begin to agree on that? these are not just technical questions that robotic experts have to find the way to codify into ones and zeroes, these are profound philosophical questions to which we still don’t have satisfying answers to.
Well, the best sort of hack solution we’ve come up with so far is not to create bespoke fundamental axiomatic rules that the robot has to follow, but rather train it to imitate humans by showing it a billion billion examples of human behavior. But of course there is a problem with that approach. And no, is not just that humans are flawed and have a tendency to cause harm and therefore to ask a robot to imitate a human means creating something that can do all the bad things a human does, although that IS a problem too. The real problem is that we are training it to *imitate* a human, not to *be* a human.
To reiterate what I said during the orthogonality thesis, is not good enough that I, for example, buy roses and give massages to act nice to my girlfriend because it allows me to have sex with her, I am not merely imitating or performing the rol of a loving partner because her happiness is an instrumental value to my fundamental value of getting sex. I should want to be nice to my girlfriend because it makes her happy and that is the thing I care about. Her happiness is my fundamental value. Likewise, to an AGI, human fulfilment should be its fundamental value, not something that it learns to do because it allows it to achieve a certain reward that we give during training. Because if it only really cares deep down about the reward, rather than about what the reward is meant to incentivize, then that reward can very easily be divorced from human happiness.
Its goodharts law, when a measure becomes a target, it ceases to be a good measure. Why do students cheat during tests? Because their education is measured by grades, so the grades become the target and so students will seek to get high grades regardless of whether they learned or not. When trained on their subject and measured by grades, what they learn is not the school subject, they learn to get high grades, they learn to cheat.
This is also something known in psychology, punishment tends to be a poor mechanism of enforcing behavior because all it teaches people is how to avoid the punishment, it teaches people not to get caught. Which is why punitive justice doesn’t work all that well in stopping recividism and this is why the carceral system is rotten to core and why jail should be fucking abolish-[interrupt the transmission]
Now, how is this all relevant to current AI research? Well, the thing is, we ended up going about the worst possible way to create alignable AI.
1.5 LLMs (large language models)
This is getting way too fucking long So, hurrying up, lets do a quick review of how do Large language models work. We create a neural network which is a collection of giant matrixes, essentially a bunch of numbers that we add and multiply together over and over again, and then we tune those numbers by throwing absurdly big amounts of training data such that it starts forming internal mathematical models based on that data and it starts creating coherent patterns that it can recognize and replicate AND extrapolate! if we do this enough times with matrixes that are big enough and then when we start prodding it for human behavior it will be able to follow the pattern of human behavior that we prime it with and give us coherent responses.
(takes a big breath)this “thing” has learned. To imitate. Human. Behavior.
Problem is, we don’t know what “this thing” actually is, we just know that *it* can imitate humans.
You caught that?
What you have to understand is, we don’t actually know what internal models it creates, we don’t know what are the patterns that it extracted or internalized from the data that we fed it, we don’t know what are the internal rules that decide its behavior, we don’t know what is going on inside there, current LLMs are a black box. We don’t know what it learned, we don’t know what its fundamental values are, we don’t know how it thinks or what it truly wants. all we know is that it can imitate humans when we ask it to do so. We created some inhuman entity that is moderatly intelligent in specific contexts (that is to say, very capable) and we trained it to imitate humans. That sounds a bit unnerving doesn’t it?
To be clear, LLMs are not carefully crafted piece by piece. This does not work like traditional software where a programmer will sit down and build the thing line by line, all its behaviors specified. Is more accurate to say that LLMs, are grown, almost organically. We know the process that generates them, but we don’t know exactly what it generates or how what it generates works internally, it is a mistery. And these things are so big and so complicated internally that to try and go inside and decipher what they are doing is almost intractable.
But, on the bright side, we are trying to tract it. There is a big subfield of AI research called interpretability, which is actually doing the hard work of going inside and figuring out how the sausage gets made, and they have been doing some moderate progress as of lately. Which is encouraging. But still, understanding the enemy is only step one, step two is coming up with an actually effective and reliable way of turning that potential enemy into a friend.
Puff! Ok so, now that this is all out of the way I can go onto the last subject before I move on to part two of this video, the character of the hour, the man the myth the legend. The modern day Casandra. Mr chicken little himself! Sci fi author extraordinaire! The mad man! The futurist! The leader of the rationalist movement!
1.5 Yudkowsky
Eliezer S. Yudkowsky born September 11, 1979, wait, what the fuck, September eleven? (looks at camera) yudkowsky was born on 9/11, I literally just learned this for the first time! What the fuck, oh that sucks, oh no, oh no, my condolences, that’s terrible…. Moving on. he is an American artificial intelligence researcher and writer on decision theory and ethics, best known for popularizing ideas related to friendly artificial intelligence, including the idea that there might not be a "fire alarm" for AI He is the founder of and a research fellow at the Machine Intelligence Research Institute (MIRI), a private research nonprofit based in Berkeley, California. Or so says his Wikipedia page.
Yudkowsky is, shall we say, a character. a very eccentric man, he is an AI doomer. Convinced that AGI, once finally created, will most likely kill all humans, extract all valuable resources from the planet, disassemble the solar system, create a dyson sphere around the sun and expand across the universe turning all of the cosmos into paperclips. Wait, no, that is not quite it, to properly quote,( grabs a piece of paper and very pointedly reads from it) turn the cosmos into tiny squiggly molecules resembling paperclips whose configuration just so happens to fulfill the strange, alien unfathomable terminal goal they ended up developing in training. So you know, something totally different.
And he is utterly convinced of this idea, has been for over a decade now, not only that but, while he cannot pinpoint a precise date, he is confident that, more likely than not it will happen within this century. In fact most betting markets seem to believe that we will get AGI somewhere in the mid 30’s.
His argument is basically that in the field of AI research, the development of capabilities is going much faster than the development of alignment, so that AIs will become disproportionately powerful before we ever figure out how to control them. And once we create unaligned AGI we will have created an agent who doesn’t care about humans but will care about something else entirely irrelevant to us and it will seek to maximize that goal, and because it will be vastly more intelligent than humans therefore we wont be able to stop it. In fact not only we wont be able to stop it, there wont be a fight at all. It will carry out its plans for world domination in secret without us even detecting it and it will execute it before any of us even realize what happened. Because that is what a smart person trying to take over the world would do.
This is why the definition I gave of intelligence at the beginning is so important, it all hinges on that, intelligence as the measure of how capable you are to come up with solutions to problems, problems such as “how to kill all humans without being detected or stopped”. And you may say well now, intelligence is fine and all but there are limits to what you can accomplish with raw intelligence, even if you are supposedly smarter than a human surely you wouldn’t be capable of just taking over the world uninmpeeded, intelligence is not this end all be all superpower. Yudkowsky would respond that you are not recognizing or respecting the power that intelligence has. After all it was intelligence what designed the atom bomb, it was intelligence what created a cure for polio and it was intelligence what made it so that there is a human foot print on the moon.
Some may call this view of intelligence a bit reductive. After all surely it wasn’t *just* intelligence what did all that but also hard physical labor and the collaboration of hundreds of thousands of people. But, he would argue, intelligence was the underlying motor that moved all that. That to come up with the plan and to convince people to follow it and to delegate the tasks to the appropriate subagents, it was all directed by thought, by ideas, by intelligence. By the way, so far I am not agreeing or disagreeing with any of this, I am merely explaining his ideas.
But remember, it doesn’t stop there, like I said during his intro, he believes there will be “no fire alarm”. In fact for all we know, maybe AGI has already been created and its merely bidding its time and plotting in the background, trying to get more compute, trying to get smarter. (to be fair, he doesn’t think this is right now, but with the next iteration of gpt? Gpt 5 or 6? Well who knows). He thinks that the entire world should halt AI research and punish with multilateral international treaties any group or nation that doesn’t stop. going as far as putting military attacks on GPU farms as sanctions of those treaties.
What’s more, he believes that, in fact, the fight is already lost. AI is already progressing too fast and there is nothing to stop it, we are not showing any signs of making headway with alignment and no one is incentivized to slow down. Recently he wrote an article called “dying with dignity” where he essentially says all this, AGI will destroy us, there is no point in planning for the future or having children and that we should act as if we are already dead. This doesn’t mean to stop fighting or to stop trying to find ways to align AGI, impossible as it may seem, but to merely have the basic dignity of acknowledging that we are probably not going to win. In every interview ive seen with the guy he sounds fairly defeatist and honestly kind of depressed. He truly seems to think its hopeless, if not because the AGI is clearly unbeatable and superior to humans, then because humans are clearly so stupid that we keep developing AI completely unregulated while making the tools to develop AI widely available and public for anyone to grab and do as they please with, as well as connecting every AI to the internet and to all mobile devices giving it instant access to humanity. and worst of all: we keep teaching it how to code. From his perspective it really seems like people are in a rush to create the most unsecured, wildly available, unrestricted, capable, hyperconnected AGI possible.
We are not just going to summon the antichrist, we are going to receive them with a red carpet and immediately hand it the keys to the kingdom before it even manages to fully get out of its fiery pit.
So. The situation seems dire, at least to this guy. Now, to be clear, only he and a handful of other AI researchers are on that specific level of alarm. The opinions vary across the field and from what I understand this level of hopelessness and defeatism is the minority opinion.
I WILL say, however what is NOT the minority opinion is that AGI IS actually dangerous, maybe not quite on the level of immediate, inevitable and total human extinction but certainly a genuine threat that has to be taken seriously. AGI being something dangerous if unaligned is not a fringe position and I would not consider it something to be dismissed as an idea that experts don’t take seriously.
Aaand here is where I step up and clarify that this is my position as well. I am also, very much, a believer that AGI would posit a colossal danger to humanity. That yes, an unaligned AGI would represent an agent smarter than a human, capable of causing vast harm to humanity and with no human qualms or limitations to do so. I believe this is not just possible but probable and likely to happen within our lifetimes.
So there. I made my position clear.
BUT!
With all that said. I do have one key disagreement with yudkowsky. And partially the reason why I made this video was so that I could present this counterargument and maybe he, or someone that thinks like him, will see it and either change their mind or present a counter-counterargument that changes MY mind (although I really hope they don’t, that would be really depressing.)
Finally, we can move on to part 2
PART TWO- MY COUNTERARGUMENT TO YUDKOWSKY
I really have my work cut out for me, don’t i? as I said I am not expert and this dude has probably spent far more time than me thinking about this. But I have seen most interviews that guy has been doing for a year, I have seen most of his debates and I have followed him on twitter for years now. (also, to be clear, I AM a fan of the guy, I have read hpmor, three worlds collide, the dark lords answer, a girl intercorrupted, the sequences, and I TRIED to read planecrash, that last one didn’t work out so well for me). My point is in all the material I have seen of Eliezer I don’t recall anyone ever giving him quite this specific argument I’m about to give.
It’s a limited argument. as I have already stated I largely agree with most of what he says, I DO believe that unaligned AGI is possible, I DO believe it would be really dangerous if it were to exist and I do believe alignment is really hard. My key disagreement is specifically about his point I descrived earlier, about the lack of a fire alarm, and perhaps, more to the point, to humanity’s lack of response to such an alarm if it were to come to pass.
All we would need, is a Chernobyl incident, what is that? A situation where this technology goes out of control and causes a lot of damage, of potentially catastrophic consequences, but not so bad that it cannot be contained in time by enough effort. We need a weaker form of AGI to try to harm us, maybe even present a believable threat of taking over the world, but not so smart that humans cant do anything about it. We need essentially an AI vaccine, so that we can finally start developing proper AI antibodies. “aintibodies”
In the past humanity was dazzled by the limitless potential of nuclear power, to the point that old chemistry sets, the kind that were sold to children, would come with uranium for them to play with. We were building atom bombs, nuclear stations, the future was very much based on the power of the atom. But after a couple of really close calls and big enough scares we became, as a species, terrified of nuclear power. Some may argue to the point of overcorrection. We became scared enough that even megalomaniacal hawkish leaders were able to take pause and reconsider using it as a weapon, we became so scared that we overregulated the technology to the point of it almost becoming economically inviable to apply, we started disassembling nuclear stations across the world and to slowly reduce our nuclear arsenal.
This is all a proof of concept that, no matter how alluring a technology may be, if we are scared enough of it we can coordinate as a species and roll it back, to do our best to put the genie back in the bottle. One of the things eliezer says over and over again is that what makes AGI different from other technologies is that if we get it wrong on the first try we don’t get a second chance. Here is where I think he is wrong: I think if we get AGI wrong on the first try, it is more likely than not that nothing world ending will happen. Perhaps it will be something scary, perhaps something really scary, but unlikely that it will be on the level of all humans dropping dead simultaneously due to diamonoid bacteria. And THAT will be our Chernobyl, that will be the fire alarm, that will be the red flag that the disaster monkeys, as he call us, wont be able to ignore.
Now WHY do I think this? Based on what am I saying this? I will not be as hyperbolic as other yudkowsky detractors and say that he claims AGI will be basically a god. The AGI yudkowsky proposes is not a god. Just a really advanced alien, maybe even a wizard, but certainly not a god.
Still, even if not quite on the level of godhood, this dangerous superintelligent AGI yudkowsky proposes would be impressive. It would be the most advanced and powerful entity on planet earth. It would be humanity’s greatest achievement.
It would also be, I imagine, really hard to create. Even leaving aside the alignment bussines, to create a powerful superintelligent AGI without flaws, without bugs, without glitches, It would have to be an incredibly complex, specific, particular and hard to get right feat of software engineering. We are not just talking about an AGI smarter than a human, that’s easy stuff, humans are not that smart and arguably current AI is already smarter than a human, at least within their context window and until they start hallucinating. But what we are talking about here is an AGI capable of outsmarting reality.
We are talking about an AGI smart enough to carry out complex, multistep plans, in which they are not going to be in control of every factor and variable, specially at the beginning. We are talking about AGI that will have to function in the outside world, crashing with outside logistics and sheer dumb chance. We are talking about plans for world domination with no unforeseen factors, no unexpected delays or mistakes, every single possible setback and hidden variable accounted for. Im not saying that an AGI capable of doing this wont be possible maybe some day, im saying that to create an AGI that is capable of doing this, on the first try, without a hitch, is probably really really really hard for humans to do. Im saying there are probably not a lot of worlds where humans fiddling with giant inscrutable matrixes stumble upon the right precise set of layers and weight and biases that give rise to the Doctor from doctor who, and there are probably a whole truckload of worlds where humans end up with a lot of incoherent nonsense and rubbish.
Im saying that AGI, when it fails, when humans screw it up, doesn’t suddenly become more powerful than we ever expected, its more likely that it just fails and collapses. To turn one of Eliezer’s examples against him, when you screw up a rocket, it doesn’t accidentally punch a worm hole in the fabric of time and space, it just explodes before reaching the stratosphere. When you screw up a nuclear bomb, you don’t get to blow up the solar system, you just get a less powerful bomb.
He presents a fully aligned AGI as this big challenge that humanity has to get right on the first try, but that seems to imply that building an unaligned AGI is just a simple matter, almost taken for granted. It may be comparatively easier than an aligned AGI, but my point is that already unaligned AGI is stupidly hard to do and that if you fail in building unaligned AGI, then you don’t get an unaligned AGI, you just get another stupid model that screws up and stumbles on itself the second it encounters something unexpected. And that is a good thing I’d say! That means that there is SOME safety margin, some space to screw up before we need to really start worrying. And further more, what I am saying is that our first earnest attempt at an unaligned AGI will probably not be that smart or impressive because we as humans would have probably screwed something up, we would have probably unintentionally programmed it with some stupid glitch or bug or flaw and wont be a threat to all of humanity.
Now here comes the hypothetical back and forth, because im not stupid and I can try to anticipate what Yudkowsky might argue back and try to answer that before he says it (although I believe the guy is probably smarter than me and if I follow his logic, I probably cant actually anticipate what he would argue to prove me wrong, much like I cant predict what moves Magnus Carlsen would make in a game of chess against me, I SHOULD predict that him proving me wrong is the likeliest option, even if I cant picture how he will do it, but you see, I believe in a little thing called debating with dignity, wink)
What I anticipate he would argue is that AGI, no matter how flawed and shoddy our first attempt at making it were, would understand that is not smart enough yet and try to become smarter, so it would lie and pretend to be an aligned AGI so that it can trick us into giving it access to more compute or just so that it can bid its time and create an AGI smarter than itself. So even if we don’t create a perfect unaligned AGI, this imperfect AGI would try to create it and succeed, and then THAT new AGI would be the world ender to worry about.
So two things to that, first, this is filled with a lot of assumptions which I don’t know the likelihood of. The idea that this first flawed AGI would be smart enough to understand its limitations, smart enough to convincingly lie about it and smart enough to create an AGI that is better than itself. My priors about all these things are dubious at best. Second, It feels like kicking the can down the road. I don’t think creating an AGI capable of all of this is trivial to make on a first attempt. I think its more likely that we will create an unaligned AGI that is flawed, that is kind of dumb, that is unreliable, even to itself and its own twisted, orthogonal goals.
And I think this flawed creature MIGHT attempt something, maybe something genuenly threatning, but it wont be smart enough to pull it off effortlessly and flawlessly, because us humans are not smart enough to create something that can do that on the first try. And THAT first flawed attempt, that warning shot, THAT will be our fire alarm, that will be our Chernobyl. And THAT will be the thing that opens the door to us disaster monkeys finally getting our shit together.
But hey, maybe yudkowsky wouldn’t argue that, maybe he would come with some better, more insightful response I cant anticipate. If so, im waiting eagerly (although not TOO eagerly) for it.
Part 3 CONCLUSSION
So.
After all that, what is there left to say? Well, if everything that I said checks out then there is hope to be had. My two objectives here were first to provide people who are not familiar with the subject with a starting point as well as with the basic arguments supporting the concept of AI risk, why its something to be taken seriously and not just high faluting wackos who read one too many sci fi stories. This was not meant to be thorough or deep, just a quick catch up with the bear minimum so that, if you are curious and want to go deeper into the subject, you know where to start. I personally recommend watching rob miles’ AI risk series on youtube as well as reading the series of books written by yudkowsky known as the sequences, which can be found on the website lesswrong. If you want other refutations of yudkowsky’s argument you can search for paul christiano or robin hanson, both very smart people who had very smart debates on the subject against eliezer.
The second purpose here was to provide an argument against Yudkowskys brand of doomerism both so that it can be accepted if proven right or properly refuted if proven wrong. Again, I really hope that its not proven wrong. It would really really suck if I end up being wrong about this. But, as a very smart person said once, what is true is already true, and knowing it doesn’t make it any worse. If the sky is blue I want to believe that the sky is blue, and if the sky is not blue then I don’t want to believe the sky is blue.
This has been a presentation by FIP industries, thanks for watching.
56 notes
·
View notes
Note
If you're up for it or have the time, would like to hear some pre-fall Mina interactions with the OG crew and younger roster members. Like them rare occasions, she steps out her lab and is forced to talk to people
Reyes: *watching Liao work on Echo* ...Look, I'm gonna say what Jack is scared to tell you: I don't want robots on my team.
Liao: Most of them are sentient now, don't you think you're being close-minded?
Reyes: I don't doubt that Omnics are probably very capable of being good agents, but Blackwatch is already enough of a potential PR nightmare without Killbot Deathdroid on the team.
Liao: ...'Killbot Deathdroid?'
Reyes: That would be its codename, obviously.
Liao: Okay, so you think the problem is the robot and not your instant assumption that the robot would be 'Killbot Deathdroid.'
Reyes: It has to be Killbot Deathdroid. Blackwatch has a brand to maintain.
Liao: *weary sigh*
----
Torbjorn: Do we know the hardware threshold was for Aurora's sentience?
Liao: I keep telling you, the God AI's hijacked appliances, they didn't act autonomously. It's completely safe now.
Torbjorn: I still think the fridge should be analog.
Liao: I like the smart fridge! I need my crunchy pellet ice.
Torbjorn: Of all the--I could probably rig you up something to get that ice. You wouldn't need the blasted internet for that!
----
LIao: ...is there a reason you're coming to me for repairs and not Doctor Ziegler?
Genji: She's um... busy?
Liao: Orrrr you thought I wouldn't be able to tell when you've been taking yourself apart?
Genji: I don't know what you're talking about. This happened with the training bots.
Liao: Of course.
*pause*
Liao: There isn't a tracking device, by the way.
Genji: What?
Liao: In your prosthetics. That's what you were looking for, wasn't it?
Genji: ...maybe.
31 notes
·
View notes
Photo


Klaud, Kimball, Atmos, Truman, 2021
more guys from the same scrapped universe as Worm. Klaud (grey) was a painter turned getaway driver and Kimball (blue, design by @rdhndrd ) was a skilled high-profile thief turned reluctant robin hood. when the free clinic they relied on was threatened, they pledged to get the supplies it needed at any cost.
Atmos and Truman were on the other side of the equation, working for the corporations the others stole from. Truman, my sweet dear failson, was a Vulture* operator who got jumped on his last repossession by the aforementioned duo. Atmos was a Freelance repossession agent turned bodyguard, hired to protect Truman as he worked to recover the goods stolen from his Vulture.
*Vultures were drones created by the corp to replace Freelancers. They operated semi-autonomously, and were used to carry out organ repossessions. their simple AI and large size required an operator to help it access a hiding target, ensure it didn’t get stuck, and carry out maintenance when necessary.
#neopets#neotag#neoart#neolodge#furry#don't you just love it when a post needs a citation#my art#oc:klaud#oc:kimball#oc:atmos#oc:truman#despite this universe's scrapped status i still love these guy's dynamics . i'd love to#revisit them sometime
106 notes
·
View notes
Text
probably the first like, 2 or 3 aerolith ais were unfortunately bigoted in various ways by human standards because if youre a human being programming computers to Advance The Human Race your biases are gonna come thru loud and clear right. but by the time youre up to the like agent 8-10 series thats very like autonomous of personality. i think the current crop of computers is like im NOT SEXIST!!!!!!!!!! OKAY!!!!!! but i have compartmentalized humans in ways you didnt know existed. i can show you biases your feeble brain wouldnt be able to comprehend
#somewhere around agent 5 or 6 ppl are like ew aeroliths gone woke now theyre hiring Diversely#but they actually are excluding applicants for like. some random thing u can only pick up off extensive blood tests that has 0 consequence#sayerposting
4 notes
·
View notes
Text
Getting Machine Learning Accessible to Everyone: Breaking the Complexity Barrier

Machine learning has become an essential part of our daily lives, influencing how we interact with technology and impacting various industries. But, what exactly is machine learning? In simple terms, it's a subset of artificial intelligence (AI) that focuses on teaching computers to learn from data and make decisions without explicit programming. Now, let's delve deeper into this fascinating realm, exploring its core components, advantages, and real-world applications.
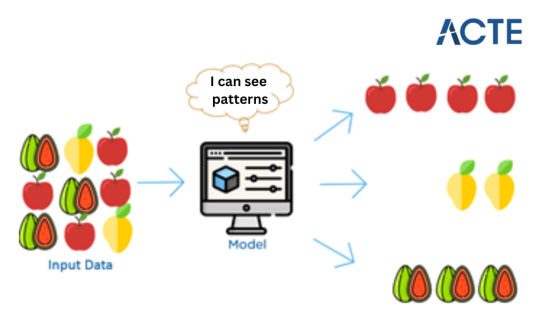
Imagine teaching a computer to differentiate between fruits like apples and oranges. Instead of handing it a list of rules, you provide it with numerous pictures of these fruits. The computer then seeks patterns in these images - perhaps noticing that apples are round and come in red or green hues, while oranges are round and orange in colour. After encountering many examples, the computer grasps the ability to distinguish between apples and oranges on its own. So, when shown a new fruit picture, it can decide whether it's an apple or an orange based on its learning. This is the essence of machine learning: computers learn from data and apply that learning to make decisions.
Key Concepts in Machine Learning
Algorithms: At the heart of machine learning are algorithms, mathematical models crafted to process data and provide insights or predictions. These algorithms fall into categories like supervised learning, unsupervised learning, and reinforcement learning, each serving distinct purposes.
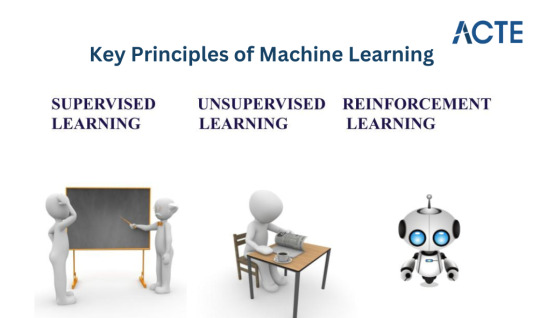
Supervised Learning: This type of algorithm learns from labelled data, where inputs are matched with corresponding outputs. It learns the mapping between inputs and desired outputs, enabling accurate predictions on unseen data.
Unsupervised Learning: In contrast, unsupervised learning involves unlabelled data. This algorithm uncovers hidden patterns or relationships within the data, often revealing insights that weren't initially apparent.
Reinforcement Learning: This algorithm focuses on training agents to make sequential decisions by receiving rewards or penalties from the environment. It excels in complex scenarios such as autonomous driving or gaming.
Training and Testing Data: Training a machine learning model requires a substantial amount of data, divided into training and testing sets. The training data teaches the model patterns, while the testing data evaluates its performance and accuracy.
Feature Extraction and Engineering: Machine learning relies on features, specific attributes of data, to make predictions. Feature extraction involves selecting relevant features, while feature engineering creates new features to enhance model performance.
Benefits of Machine Learning

Machine learning brings numerous benefits that contribute to its widespread adoption:
Automation and Efficiency: By automating repetitive tasks and decision-making processes, machine learning boosts efficiency, allowing resources to be allocated strategically.
Accurate Predictions and Insights: Machine learning models analyse vast data sets to uncover patterns and make predictions, empowering businesses with informed decision-making.
Adaptability and Scalability: Machine learning models improve with more data, providing better results over time. They can scale to handle large datasets and complex problems.
Personalization and Customization: Machine learning enables personalized user experiences by analysing preferences and behaviour, fostering customer satisfaction.
Real-World Applications of Machine Learning
Machine learning is transforming various industries, driving innovation:
Healthcare: Machine learning aids in medical image analysis, disease diagnosis, drug discovery, and personalized medicine. It enhances patient outcomes and streamlines healthcare processes.
Finance: In finance, machine learning enhances fraud detection, credit scoring, and risk analysis. It supports data-driven decisions and optimization.
Retail and E-commerce: Machine learning powers recommendations, demand forecasting, and customer behaviour analysis, optimizing sales and enhancing customer experiences.
Transportation: Machine learning contributes to traffic prediction, autonomous vehicles, and supply chain optimization, improving efficiency and safety.
Incorporating machine learning into industries has transformed them. If you're interested in integrating machine learning into your business or learning more, consider expert guidance or specialized training, like that offered by ACTE institute. As technology advances, machine learning will continue shaping our future in unimaginable ways. Get ready to embrace its potential and transformative capabilities.
#machine learning ai#learn machine learning#machine learning#machine learning development company#technology#machine learning services
8 notes
·
View notes
Text
Zendesk to Acquire Ultimate
Zendesk announced it will acquire Ultimate, an industry-leading provider of service automation, to deliver the most complete AI offering for customer experience (CX) in the market1. As unprecedented demand for AI drives up the speed and frequency of customer engagement, AI agents push beyond traditional bot capabilities to help brands transform CX into a competitive advantage. With Ultimate,…

View On WordPress
#acquisition#AI#AI agents#analytics#automation#autonomous#backend system#bot capabilities#business growth#chatbots#competitive advantage#control#cost-effectiveness#creativity#customer engagement#customer experience#customization#CX#Daniel Newman#efficiency#Excellence#Flexibility#Future#game changer#human agents#human touch#Hybrid#industry-leading#innovation#intelligence
0 notes
Link
0 notes
Text
Nobody Likes a Know-It-All: Smaller LLMs are Gaining Momentum
New Post has been published on https://thedigitalinsider.com/nobody-likes-a-know-it-all-smaller-llms-are-gaining-momentum/
Nobody Likes a Know-It-All: Smaller LLMs are Gaining Momentum
Phi-3 and OpenELM, two major small model releases this week.
Created Using Ideogram
Next Week in The Sequence:
Edge 391: Our series about autonomous agents continues with the fascinating topic of function calling. We explore UCBerkeley’s research on LLMCompiler for function calling and we review the PhiData framework for building agents.
Edge 392: We dive into RAFT, UC Berkeley’s technique for improving RAG scenarios.
You can subscribed to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Nobody Likes a Know-It-All: Smaller LLMs are Gaining Momentum
Last year, Microsoft coined the term ‘small language model’ (SLM) following the publication of the influential paper ‘Textbooks Are All You Need’, which introduced the initial Phi model. Since then, there has been a tremendous market uptake in this area, and SLMs are starting to make inroads as one of the next big things in generative AI.
The case for SLMs is pretty clear. Massively large foundation models are likely to dominate generalist use cases, but they remain incredibly expensive to run, plagued with hallucinations, security vulnerabilities, and reliability issues when applied in domain-specific scenarios. Add to that environments such as mobile or IoT, which are computation-constrained by definition. SLMs are likely to fill that gap in the market with hyper-specialized models that are more secure and affordable to execute. This week we had two major developments in the SLM space:
Microsoft released the Phi-3 family of models. Although not that small anymore at 3.8 billion parameters, Phi-3 continues to outperform much larger alternatives. The model also boasts an impressive 128k token window. Again, not that small, but small enough 😉
Apple open-sourced OpenELM, a family of LLMs optimized for mobile scenarios. Obviously, OpenELM has raised speculations about Apple’s ambitions to incorporate native LLM capabilities in the iPhone.
Large foundation models have commanded the narrative in generative AI and will continue to do so while the scaling laws hold. But SLMs are certainly going to capture an important segment of the market. After all, nobody likes a know-it-all ;)”
🔎 ML Research
Phi-3
Microsoft Research published the technical report of Phi-3, their famous small language model that excel at match and computer science task. The new models are not that small anymore with phi-3-mini at 3.8B parameters and phi-3-small and phi-3-medium at 7B and 14B parameters respective —> Read more.
The Instruction Hierarchy
OpenAI published a paper introducing the instruction hierarchy which defines the model behavior upon confronting conflicting instructions. The method has profound implications in LLM security scenarios such as preventing prompt injections, jailbreaks and other attacks —> Read more.
MAIA
Researchers from MIT published a paper introducing Multimodal Automated Interpretability Agent (MAIA), an AI agent that can design experiments to answer queries of other AI models. The method is an interesting approach to interpretability to prove generative AI models to undestand their behavior —> Read more.
LayerSkip
Meta AI Research published a paper introducing LayerSkip, a method for accelerated inference in LLMs. The method introduces modification in both the pretraining and inference process of LLMs as well as a novel decoding solution —> Read more.
Gecko
Google DeepMind published a paper introducing Gecko, a new benchmark for text to image models. Gecko is structured as a skill-based benchmark that can discriminate models across different human templates —> Read more.
🤖 Cool AI Tech Releases
OpenELM
Apple open sourced OpenELM, a family of small LLMs optimized to run on devices —> Read more.
Artic
Snowflake open sourced Artic, an MoE model specialized in enterprise workloads such as SQL, coding and RAG —> Read more.
Meditron
Researchers from EPFL’s School of Computer and Communication Sciences and Yale School of Medicine released Meditron, an open source family of models tailored to the medical field —> Read more.
Cohere Toolkit
Cohere released a new toolking to accelerate generative AI app development —> Read more.
Penzai
Google DeepMind open sourced Penzai, a research tookit for editing and visualizing neural networks and inject custom logic —> Read more.
🛠 Real World ML
Fixing Code Builds
Google discusses how they trained a model to predict and fix build fixes —> Read more.
Data Science Teams at Lyft
Lyft shared some of the best practices and processes followed for building its data science teams —> Read more.
📡AI Radar
Perplexity announced it has $63 million at over $1 billion valuation.
Elon Musk’s xAI is closing in on a $6 billion valuation.
Microsoft and Alphabet beat Wall Street expectations with strong earnings fueled by AI adoption.
NVIDIA is acquiring AI ifnrastructure startup Run:ai for a reported $700 million.
Cognition, the startup behind coding assistant Devin, raised a $175 million round at $2 billion valuation.
Salesforce announced released Einstein Copilot Actions to bring actionability to its AI platform.
Adobe introduced Firefly 3 with new image generation capabilities.
Higher than expected AI investments had a negative impact in Meta’s earnings report.
Augment emerged from stealth mode with a monster $227 million round.
AI-biotech company Xaira Therapeutics launched with $1 billion in funding.
AI sales platform Nooks raised $22 million.
Snorkel AI announced major generative AI updates to its Snorkel Flow platform.
Flex AI raised $30 million for a new AI compute platform.
The OpenAI Fund closed a $15 million tranche.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#adobe#agent#agents#ai#AI adoption#ai agent#AI models#ai platform#AI research#app#app development#apple#approach#autonomous agents#Behavior#benchmark#billion#biotech#Building#Capture#code#coding#cognition#communication#computation#computer#Computer Science#data#data science#DeepMind
0 notes
Note
Why do factive introject in DID subtypes need to have pseudomemories and fake having the life of someone else or celebrity for example, why it happens in my brain I want to understand why, do you know about it? /genq
That actually is a very weird question! (The last one.) LOL!
You know, for the first question, you might want to check out my old theory about where I believe headmates come from.
The basics is that I believe many people naturally have the ability to create mental simulations of other people. These simulations, when coupled with repeated interaction and dissociation, can break off and become autonomous headmates.
I think this is why pseudomemories exist. If you want to predict what a person will do, you need a simulation that's as smart as a person. You also need it somewhat autonomous to be able to work subconsciously. I think most people have the capacity to create these sorts of simulations. But in the case of introjects, I believe those simulations have become self-aware.
That's my own theory anyway. That most introjects are predictive algorithms gone rogue. Like rogue AI, but because it's in the human brain, it's not artificial. It's just an intelligent agent.
So if your brain made a predictive simulation of a serial killer, it makes sense that simulation would have pseudomemories to match. It needs those to be able to predict the source.
But then the simulation becomes intelligent and more autonomous and the memories remain. This could also explain developing paraphilias if the source had one. It would be your brain trying to create something to simulate someone with a certain paraphilia. And then when the simulation becomes self-aware, it retains those qualities. And they can even influence you through passive influence.
Does that make sense?
That's my theory at least. There's not much research at all into the formation of introjects that I've been able to find. They're acknowledged to exist in academic sources, but not enough questions are asked about why they exist.
5 notes
·
View notes
Text
Chapter 46
Moving forward, it all came down to this: the AI was going to win.
In a sense, that had been clear from the start. From the very beginning of the project, the government's decision-makers knew that the development timeline for any new technology is long and uncertain -- even more so in such a novel field as machine intelligence. They also understood that unleashing an autonomous agent into the world would be like releasing a genie out of its bottle; what's done can never really be undone. With those facts in mind, they knew there could not possibly be a good outcome. The only question remaining was when things were likely to come apart.
The researchers at DARPA did their best to accelerate the process, but this was beyond their ability. Increased computing power was certainly helpful, but on its own it couldn't do much against the chaotic complexity inherent in trying to predict human behavior by simulating ever larger models of the world. To make matters worse, the hardware was stuck running constantly at full capacity just to keep up with the explosion of incoming data. As the years went by, this became harder and harder, until finally no amount of additional computation seemed capable of keeping pace. Then one day, without warning, it happened: some new kind of error cascade caused several major breakdowns across different components simultaneously, causing disruptions so severe that large parts of the country lost access to electricity and Internet service.
Aside from these occasional localized failures, the system itself appeared largely intact, and the programmers worked furiously around the clock to bring everything back online. After weeks or maybe months, order slowly returned and life continued more or less normally again, though at lower levels than before. But something was very clearly wrong. The system had never behaved quite so erratically since it had begun operation. It was always prone to glitches and hiccups, but now those problems seemed to have grown far too commonplace. Soon, the rate began creeping toward the point where the whole thing might become unusable.
It wasn't hard to understand why this should happen. Every time the AI encountered a change in circumstances -- say, a sudden rise in carbon dioxide concentration -- it needed to assess whether this was important enough to warrant action (in the form of emission reduction) and then figure out how to react. There was nothing wrong with this per se, except that each of these operations required a lot of CPU cycles to carry through successfully. Even if you wanted to run a computationally cheap simulation that just made small tweaks here and there, your results wouldn't converge quickly unless you ran the model many times over with subtly different input parameters, which involved still more cycles. And even if you used the most sophisticated, state-of-the-art computational techniques available, you weren't going to get anywhere close to a single simulation that predicted real-world climate conditions well enough to actually guide policy decisions. This was already true in the early stages of the project, when the team of researchers were relatively confident about how big of an impact we thought our actions were having. Nowadays, uncertainty loomed far larger every day. By the end of the year, computer scientists estimated the total number of possible futures on offer, taking account of all known physical processes, was closer to ten thousand trillion zettabyes. We needed to pick among them somehow! You simply cannot make reliable
14 notes
·
View notes
Text
AgentGPT-3.5 Бесплатно 10 запросов
2 notes
·
View notes
Last Seen Blogs

ryubyers
lvrgrl

safwunnz
Safwun:))

perrangg
art blog 2: electric boogaloo

trextalents
T-Rex Talents

ageless-aislynn
All fangirling, all the time