#data-based question
Text
Unfortunately all chatgpt is good for is interview/job application stuff which I think says a lot about the hiring process as a whole
#wrenfea.exe#as an actual artifical intelligence? no its horrible bc it really ISNT one#its a writing synthesizer it generates writing based on data searches and boundaries from training#thats what a neural network is its a very convoluted input-output sequence#it has no capacity to understand the meaning behind what it generates#it is simply generating the specific things that the user is looking for#the job interview process has become so robotic and automized that ai fits in perfectly#but employers HATE that people are turning to chatgpt for cover letters and interview answers#so it was fair for them to use filtering programs to accept/deny applications before it got in front of an actual human being#and its ok for them to use ai and pre-written formats to make job announcements descriptions and interview questions#but god forbid we are forced to use those exact same tools to get a humans attention so we can get a job and not starve#pushing aside the whole copyright debate on chatgpt and the environmental impact of its power usage btw#im soley analyzing how its become commonly utilized on both sides#by interviewer and interviewed#the mechanization of the whole process is now on both sides#it just seems very inhuman..#its also how some people have figured out how to somehow become employed multiple times by the same company due to lack of human oversight#and how automated theyve made their hiring process#probably should have made these tags into a separate reblog oops#also disclaimer do not cut and paste right into your application materials bc chatgpt often just lies#also many places now can tell you used chatgpt due to how similar its answers are#i only use it to make a template and see how things can be phrased to be more professional and buzzwordy#id never use it for something actually creative#and dear god do not write academic essays with it#i tried using it to supplement my own cover letter template but it was too robotic even for a cover letter#it is very good at accessing and summarizing publically available information#thats all it does not make sure the information is true or good
5 notes
·
View notes
Text
speculations concerning genshin lore I thought keeping me awake at night
sharing because why not; mostly Khaenri'ahn stuff and a lot of Pierro
-why did the unnamed red-haired man in venti's quest cutscene turn on Venti sometime after Decaribian's fall? Is the red-haired man or Ragnvindr during the rebellion of Vennessa his descendant?
-who is Childe's master aka Skirk? Is she potentially of Khaenri'ahn descent or even a Royal Guard? Based on Childe's description of how strong she is, (it is stated she could literally beat him with one hand) I hope she becomes playable one day (plus points if she'll have purple eyes or white hair).
-who the fck is diluc's mom and why is she not named/ mentioned in any of the lore concerning diluc; are his parents divorced/ annulled? even his dad never talked about her.
-is Pierro and Kaeya somewhat blood-related? If so, is that how crps get a delusion?
-did he get that from taking in his son/grandson/nephew knowing the boy he's taking under his wing would betray him and his nation sometime in the future? Does Pierro have connections (as a fatui harbinger) to Crps beforehand?
-Did crps work for him and was high in the ranks to earn such recognition from the most powerful Harbinger to the point he was used him either as a pawn/ puppet to his schemes? Did he also warn Crps he'll die and he just accepted that because it was part of their agreement?
-was the underground organization Diluc potentially had people of Khaenri'ahn descent? stated in character story 4 that "The network was made up of volunteers, and many of its members had willingly given up their prior positions and reputations to join. Some had even abandoned their names"
-could these mean those of high-ranking guards/ royalties of the past like in Khaenri'ah used this as an opportunity to pursue their own goals and ideas in secrecy considering this is confirmed to be a third party and simply observes the events unfold on two sides of a spectrum? It is also underground, and KHAENRI'AH WAS AN UNDERGROUND NATION. (does dain know about the existence of this place??)
-Arlecchino established an orphanage (House of The Hearth) so was she an orphan before or even poor/homeless before being taken in by the Fatui? Since most of these orphans end up becoming fatui recruits are they used to help aid the Fatui's manpower?
#genshin theories#genshin speculations#genshin lore#diluc lore#pierro lore#genshin headcannons#venti lore#kaeya lore#underground organization from genshin#morsinteritus#terminusmorscalignis#fatui genshin#fatui lore#all are just speculations based on gathered/ available data in game#hope diluc event will give us answers to some of these questions
60 notes
·
View notes
Text
its really frustrating approaching conversations about AI because so many people don't understand how it works and seem resistant against learning more about it. it feels like trying to correct preconceptions makes people assume you're some dumb techbro
#like im of the opinion AI networks are not evil. they are literally just computer programs being fed inputs and creating outputs#based on previous data it has been trained on#as a result AI can be prone to revealing biases from the data it was given#but also the thing to question is who is using this technology in an exploitative manner#these ethical questions have pervaded every bit of modern technology btw.#you will never have a definite most moral answer to new technology. come to terms with that.
15 notes
·
View notes
Text
not my graduate program including "do you feel like you belong in this program" as a question on a student survey... they sense my weakness... they're circling like vultures...
#this was NOT the level of introspection i wanted on a Sunday morning#do i belong??? who tf knows?? and if i don't feel i belong why would i put that amount of vulnerability into a survey question???#also i love confusing their demographic data by saying i am a woman or nonbinary interchangeably based on the vibes at that moment#'am i nonbinary?' sure yeah i feel like that today; 'am i trans?' nope - keep up Random Survey we're playing 3D gender chess#just me saying stuff
3 notes
·
View notes
Text
.
#there's a big international conference happening in scotland in june this year#and i was thinking i was going to go and i've literally been looking forward to getting a trip to scotland all year#because if i go over and go present at the conference then i can get some funding from the uni#which would basically pay for flights + a bit extra#but i've been thinking and discussing with my supervisor this week and now i'm having second thoughts about presenting 🥲#just based on the data i have and what we feel comfortable sharing with potential competitors etc#and also with the uni funding it's limited so is this really the best way i could be using it etc etc#the abstract submission deadline is literally today and there's still so many question marks so i haven't ended up submitting#there's a (good?) chance they'll extend and i'll maybe be able to think it through a bit more and decide to go#but if i don't present anything i can't get funding and basically there's no reason for me to actually go all the way over there#(i can still go ofc and just pay for everything myself but a big part of why i was excited was because i could get the funding)#i mean if it doesn't happen it doesn't happen there will be other trips in the future whether it be for work or not#i'm just so bummed and feel silly because i've literally spent like the last year daydreaming about this trip and it might not even happen
3 notes
·
View notes
Text
okay but not one of the questions in c++ programming course past year exams is literally about football related lmaooooo
#well the question asks to complete a c++ program to display goals and assists stats for certain footballers#and also to calculate the points based on the stats given#okay but all of the data give are literally from prem which is not surprising at all#ouhh but since it was a last year's exam paper sadio was also included in the data given as well (back when was still a liverpool player)#anyways idk what's problem with me if i'm still fucked up with this course#even the questions given for revision are something related to my interests 😭😭#iz and her maroon uni life#iz being too random
2 notes
·
View notes
Text
annoyed that i had to take a break from collecting my silly little fandom data, but it’s only because i’m putting together an rvb trivia game for my friends to play this weekend jsjsjs
#rvb#red vs blue#if anyone has suggestions for trivia questions feel free to let me know#also i might make a survey to collect data for my next fandom spreadsheet so if anyone has idea for questions to put on an rvb fan survey#let me know PLEASE#i wanna make sure to cover all my bases
5 notes
·
View notes
Text
granted i grew up in a fairly large family (the kind where it seems like every year someone had a new baby lol) so i have a lot of experience taking care of them, but ive never understood the vitriol against kids
not wanting to be a parent, i totally understand. hating messes and screaming i get; pretty much everyone hates those. but pure hatred i do not get
#like. i know saying 'kids are just little people who are still working shit out' sounds like a shit post but it's honestly the truth!#children aren't a different species than us. they function very much the same as any adult does#its just that 1) everything is new to them and 2) their world is a lot smaller than an adult's#a skinned knee is the worst thing a 2 year old has ever experienced#a standardized test is extremely stressful when you're 8#a friend playing with someone else at recess is a deep betrayal when you're 11#as adults we remember those feelings but in the context of our adult lives they feel silly#they aren't silly to kids though#i feel like kids become a lot less alien if you remember that#they really are little humans! they can be rude and loud and messy and cruel. but not uniquely so#and i will reemphasize that its fine if you don't want to be a parent#society might demand it (especially of women) but its not for everyone#hell i love kids and have taken care of them for my whole life but often even i question if i want kids#just. don't be a dick#mickey.txt#also im thinking about cheyenne lin's video about kids under capitalism#especially the bit about how people who grew up wealthy and/or in the suburbs are often the ones#who complain online about children. possibly because they're used to having space and quiet#and not being inconvenienced by others in public spaces. like obviously based on polling data she didn't run#so its not like a guaranteed scientific fact. but i think it does play a factor in a lot of cases#like the hyper-individualism of it all y'know?
1 note
·
View note
Text
You're a reasonably informed person on the internet. You've experienced things like no longer being able to get files off an old storage device, media you've downloaded suddenly going poof, sites and forums with troves full of people's thoughts and ideas vanishing forever. You've heard of cybercrime. You've read articles about lost media. You have at least a basic understanding that digital data is vulnerable, is what I'm saying.
I'm guessing that you're also aware that history is, you know... important? And that it's an ongoing study, requiring ... data about how people live? And that it's not just about stanning celebrities that happen to be dead?
Congratulations, you are significantly better-informed than the British government!
So they're currently like "Oh hai can we destroy all these historical documents pls? To save money? Because we'll digitise them first so it's fine! That'll be easy, cheap and reliable -- right? These wills from the 1850s will totally be fine for another 170 years as a PNG or whatever, yeah? We didn't need to do an impact assesment about this because it's clearly win-win! We'd keep the physical wills of Famous People™ though because Famous People™ actually matter, unlike you plebs. We don't think there are any equalities implications about this, either! Also the only examples of Famous People™ we can think of are all white and rich, only one is a woman and she got famous because of the guy she married. Kisses!"
Yes, this is the same Government that's like "Oh no removing a statue of slave trader is erasing history :("
You have, however, until 23 February 2024 to politely inquire of them what the fuck they are smoking. And they will have to publish a summary of the responses they receive. And it will look kind of bad if the feedback is well-argued, informative and overwhelmingly negative and they go ahead and do it anyway. I currently edit documents including responses to consultations like (but significantly less insane) than this one. Responses do actually matter.
I would particularly encourage British people/people based in the UK to do this, but as far as I can see it doesn't say you have to be either. If you are, say, a historian or an archivist, or someone who specialises in digital data do say so and draw on your expertise in your answers.
This isn't a question of filling out a form. You have to manually compose an email answering the 12 questions in the consultation paper at the link above. I'll put my own answers under the fold.
Note -- I never know if I'm being too rude in these sorts of things. You probably shouldn't be ruder than I have been.
Please do not copy and paste any of this: that would defeat the purpose. This isn't a petition, they need to see a range of individual responses. But it may give you a jumping-off point.
Question 1: Should the current law providing for the inspection of wills be preserved?
Yes. Our ability to understand our shared past is a fundamental aspect of our heritage. It is not possible for any authority to know in advance what future insights they are supporting or impeding by their treatment of material evidence. Safeguarding the historical record for future generations should be considered an extremely important duty.
Question 2: Are there any reforms you would suggest to the current law enabling wills to be inspected?
No.
Question 3: Are there any reasons why the High Court should store original paper will documents on a permanent basis, as opposed to just retaining a digitised copy of that material?
Yes. I am amazed that the recent cyber attack on the British Library, which has effectively paralysed it completely, not been sufficient to answer this question for you. I also refer you to the fate of the Domesday Project. Digital storage is useful and can help more people access information; however, it is also inherently fragile. Malice, accident, or eventual inevitable obsolescence not merely might occur, but absolutely should be expected. It is ludicrously naive and reflects a truly unpardonable ignorance to assume that information preserved only in digital form is somehow inviolable and safe, or that a physical document once digitised, never need be digitised again..At absolute minimum, it should be understood as certain that at least some of any digital-only archive will eventually be permanently lost. It is not remotely implausible that all of it would be. Preserving the physical documents provides a crucial failsafe. It also allows any errors in reproduction -- also inevitable-- to be, eventually, seen and corrected. Note that maintaining, upgrading and replacing digital infrastructure is not free, easy or reliable. Over the long term, risks to the data concerned can only accumulate.
"Unlike the methods for preserving analog documents that have been honed over millennia, there is no deep precedence to look to regarding the management of digital records. As such, the processing, long-term storage, and distribution potential of archival digital data are highly unresolved issues. [..] the more digital data is migrated, translated, and re-compressed into new formats, the more room there is for information to be lost, be it at the microbit-level of preservation. Any failure to contend with the instability of digital storage mediums, hardware obsolescence, and software obsolescence thus meets a terminal end—the definitive loss of information. The common belief that digital data is safe so long as it is backed up according to the 3-2-1 rule (3 copies on 2 different formats with 1 copy saved off site) belies the fact that it is fundamentally unclear how long digital information can or will remain intact. What is certain is that its unique vulnerabilities do become more pertinent with age." -- James Boyda, On Loss in the 21st Century: Digital Decay and the Archive, Introduction.
Question 4: Do you agree that after a certain time original paper documents (from 1858 onwards) may be destroyed (other than for famous individuals)? Are there any alternatives, involving the public or private sector, you can suggest to their being destroyed?
Absolutely not. And I would have hoped we were past the "great man" theory of history. Firstly, you do not know which figures will still be considered "famous" in the future and which currently obscure individuals may deserve and eventually receive greater attention. I note that of the three figures you mention here as notable enough to have their wills preserved, all are white, the majority are male (the one woman having achieved fame through marriage) and all were wealthy at the time of their death. Any such approach will certainly cull evidence of the lives of women, people of colour and the poor from the historical record, and send a clear message about whose lives you consider worth remembering.
Secondly, the famous and successsful are only a small part of our history. Understanding the realities that shaped our past and continue to mould our present requires evidence of the lives of so-called "ordinary people"!
Did you even speak to any historians before coming up with this idea?
Entrusting the documents to the private sector would be similarly disastrous. What happens when a private company goes bust or decides that preserving this material is no longer profitable? What reasonable person, confronted with our crumbling privatised water infrastructure, would willingly consign any part of our heritage to a similar fate?
Question 5: Do you agree that there is equivalence between paper and digital copies of wills so that the ECA 2000 can be used?
No. And it raises serious questions about the skill and knowledge base within HMCTS and the government that the very basic concepts of data loss and the digital dark age appear to be unknown to you. I also refer you to the Domesday Project.
Question 6: Are there any other matters directly related to the retention of digital or paper wills that are not covered by the proposed exercise of the powers in the ECA 2000 that you consider are necessary?
Destroying the physical documents will always be an unforgivable dereliction of legal and moral duty.
Question 7: If the Government pursues preserving permanently only a digital copy of a will document, should it seek to reform the primary legislation by introducing a Bill or do so under the ECA 2000?
Destroying the physical documents will always be an unforgivable dereliction of legal and moral duty.
Question 8: If the Government moves to digital only copies of original will documents, what do you think the retention period for the original paper wills should be? Please give reasons and state what you believe the minimum retention period should be and whether you consider the Government’s suggestion of 25 years to be reasonable.
There is no good version of this plan. The physical documents should be preserved.
Question 9: Do you agree with the principle that wills of famous people should be preserved in the original paper form for historic interest?
This question betrays deep ignorance of what "historic interest" actually is. The study of history is not simply glorified celebrity gossip. If anything, the physical wills of currently famous people could be considered more expendable as it is likely that their contents are so widely diffused as to be relatively "safe", whereas the wills of so-called "ordinary people" will, especially in aggregate, provide insights that have not yet been explored.
Question 10: Do you have any initial suggestions on the criteria which should be adopted for identifying famous/historic figures whose original paper will document should be preserved permanently?
Abandon this entire lamentable plan. As previously discussed, you do not and cannot know who will be considered "famous" in the future, and fame is a profoundly flawed criterion of historical significance.
Question 11: Do you agree that the Probate Registries should only permanently retain wills and codicils from the documents submitted in support of a probate application? Please explain, if setting out the case for retention of any other documents.
No, all the documents should be preserved indefinitely.
Question 12: Do you agree that we have correctly identified the range and extent of the equalities impacts under each of these proposals set out in this consultation? Please give reasons and supply evidence of further equalities impacts as appropriate.
No. You appear to have neglected equalities impacts entirely. As discussed, in your drive to prioritise "famous people", your plan will certainly prioritise the white, wealthy and mostly the male, as your "Charles Dickens, Charles Darwin and Princess Diana" examples amply indicate. This plan will create a two-tier system where evidence of the lives of the privileged is carefully preserved while information regarding people of colour, women, the working class and other disadvantaged groups is disproportionately abandoned to digital decay and eventual loss. Current and future historians from, or specialising in the history of minority groups will be especially impoverished by this.
15K notes
·
View notes
Text
It continues to trip me up how much human brains are just weird organic computers
#thoughts#oni talks#oni vents#additionally wild that the easiest ways for me to explain brain stuff are generally in computer or video game terms despite the fact I’m#notoriously awful with computers (and to a lesser extent video games) although I won’t if my natural inclination would be different if I#didn’t have trauma related to computers/if maybe it’s the classic adhd interest based learning difference? unknown tbh#I still really wanna go to school to study people but academics is fucked as hell so making that work will be a personal hell for me#but also I have so many theories and data I can’t do anything super tangible with coz I’m not in an academic setting so even if i wanted to#talk about stuff and work on it no one would take me seriously w/o that academic background no matter how much effort I’d put in learning it#on my own for my entire life at this point it won’t matter if it’s not on some level acknowledged by an academic system I despise tbh#it’s one of those things that makes me miss my dad coz we used to commiserate together about these sorts of things tho he made it work far#better than I have been able to. i wish i could ask him science questions again.#anyway human brains are so fascinating but also I really wish I was better at explaining myself analysis of people I feel like I’m good#enough at this point to be like partway understood coz I’ve done so much practice on my own coz I tend to rehearse explanations ahead of tim#but its still often misunderstood or misconstrued & it’s understandable a lot of the time coz like most other people aren’t spending a ton#of their free time thinking about and researching how people work/analyzing those around them+themselves vs me whose been doing since like#I dont remember the exact time but I do remember being really young & making the conscious decision to study & analyze my family for example#so that I could be helpful & translate their words to each other better + ppl often don’t see things about themselves that others do#also forever thinking about the human brain/experience in relation to the sims & video game commands lmao#currently trying to explain save states in the human brain to ppl but no one knows wtf I’m talking about#& researching academic terms that are close to what I want doesn’t necessarily work if there’s no academic term for what I’m talking about#hence wanting to do the research myself coz sometimes it feels like there’s all this stuff that’s obvious to me but no one else?? from what#I’ve seen in recent studies they are only starting to scratch the surface of stuff I’ve already known sometimes? other stuff is older & it’s#VERY gratifying when it’s stuff I’ve known but not been listened to about & it actually gets the proper recognition#though getting ppl to actually listen/take what I say seriously is its own journey & I have to be careful myself bc I’m human so my own#understanding/data is constantly updating + I have storage issues so finding the data I have in my brain is its own struggle sometimes#every version of me is interested in people & I think that’s neat even if other people don’t understand that concept#sometimes I feel like an alien/robot whose sole task is just to study & support humanity & it’s very weird tbh
1 note
·
View note
Text
I woke up today no thoughts, brain empty.
Which is fine.
I've already hit word count today, so I may take a break from all the things. Nothing seems...interesting right now. All is still and quiet.
That said, OAEI looks like it'll be 75-85k (I expect it to pass 75k because I'm about at 63k, I have five Remnants chapters to put in (1k-2k a piece, probably), and maybe five other chapters left not including potential epilogue. 75k is a small amount, all things considered).
It also looks like the time span of the fic will be roughly 10 days (10.5 if you count Day Zero).
It may only be nine. I've got four non-memories chapters left. It really depends on what happens on Day Nine.
...it might actually be only nine days because it would be the end of the ninth when the thing happens, so it would have to be during the late hours of Day Nine or the early hours of Day Ten.
...I should make it the early hours of Day Ten just so that it's nearly exactly ten days - a few hours at the end of Day Zero and a few hours at the beginning of Day Ten.
Hm.
#musings#bandit#bandit brainstorms#dr1 end rewrite fic#the real question is how long in time is the second fic#because if it's ALSO ten days (roughly) then that would mean the two together are roughly time equivalent to a killing game#however based on the timeline i have re: killing game + first fic#full memory recovery for kyoko takes about a month so that should parallel in the second fix#*fic#....#look i know i said no thoughts brain empty and that's still true#maybe it's no connection to the thoughts right now#they just kind of exist like a set of data#no emotional pull to them#no need to push#hm
0 notes
Text
im just gonna say im mediterranean and call it a day
#dont know who your ancestors are and likely never will for various reasons out of your control?#ethnically ambiguous without even trying to be angering plenty of ppl online who probably think you do it on purpose?#thought you were just 'white' [left intentionally vague] growing up bc you had lighter hair?#nonetheless getting mistaken for being other ethnicities bc you have olive skin and dont burn in the sun?#cant trust DNA sites to give you full accuracy ever bc the way they collect data is wonky to begin with?#try simply calling yourself mediterranean! it's vague on purpose so people stop asking questions!#am i southern european? am i middle eastern? who knows! but you know who doesnt need to know? other people!#because how! you're treated! outweighs! any! of! that! stuff!!!!!!!!!!#buyer beware: anyone on the right who's angry at you will call you middle eastern and anyone on the left whos angry at you will#call you white! 'whiteness' is revocable or forced upon you based on who you interact with!#mood#'can you feel your heart burning? can you feel the struggle within?#the fear within me is beyond anything your soul can make. you cannot kill me in a way that matters'
1 note
·
View note
Text
linguistics teacher gave feedback on my presentation and it’s stuff i can’t fix and am embarrassed to have wrong in the first place and knew was going to be an issue but chose to push past and now here we are
#i just don’t have enough fucking data like at all#‘surely the results weren’t all integers. why aren’t there any fractions?’ well you see. it’s because i had 14 recordings and two listeners#the moment my teacher shifts to understand that each data point is exactly what i collected as opposed to an average of what i have….#but it’s fine. it’s fine. in other news guess who dreamed about the spreadsheet i was working on last night#okay how do i say this in a normal way though….#‘hey joe - thanks for the feedback. i had a lot fewer listeners than speakers#so a lot of the numbers are based on one listener each. it’s the main flaw concern with my data but makes for very round numbers’#perhaps. is maybe the only way to say it without just sounding fucking evil about it#anyway i’m cold and tired and i don’t want to go to class…. and i don’t have linguistics today so that part will be an email#my eyes hurt so bad i want to go back to sleep but this is second to last day of class this whole semester#so it’s kind of important that i at least try to participate#also does anyone have links to an npr story about a fading north carolina accent cause i know it exists but i don’t remember where#and my teacher always wants me to cite it but i can’t find it#that sounds worse than it is. my teacher picked out this article for me to use and then i can never track it down when i need it but i can’#complain that there aren’t any sources i can use cause he so clearly described this one to me i just can’t find it. i didn’t invent a sourc#anyways…. i’m cold and tired and honestly plenty annoyed and i want to go back to sleep….#but i will persevere i guess. a little over a week before i can just be free of all these classes#i’m tired when i wake up when i’m opening my eyes when i’m not feeling low i get tired out by the highs (/ly)#my eyes hurt and it’s cold outside the blanket and i have a stomachache and i feel strange. but i will persevere#okay. today i have two classes then i come home have a good call and work on the presentation in question. and perhaps go to a cocoa event#wednesday i have three classes including the actual presenting part of my presentation. and MAYBE a car seat headrest moment at my partner’s#but that’s just wishful thinking on my part and has not been discussed. car seat headrest moment = sleeping together in the literal sense#(it started out ironically on his part and now that’s just how i call it shdhdf)#and anyway then thursday morning either way we go and get breakfast early at like 8:45 and then by 10am i’m at a bus stop about to go home#for a MONTH AND A HALF. and there will still be assignments due in the meantime but so much less. and i’ll sleep a lot more at night i hope#anyways i’m going to be late to latin cause there’s nothing motivating me to pull up. but it’s fine it’s fine it’s fine#idk. i hope everyone is doing well and i’ll be back in a couple hours. i’m just not feeling well#me. my post. mine.#delete later
1 note
·
View note
Text
FYI artists and writers: some info regarding tumblr's new "third-party sharing" (aka selling your content to OpenAI and Midjourney)
You may have already seen the post by @staff regarding third-party sharing and how to opt out. You may have also already seen various news articles discussing the matter.
But here's a little further clarity re some questions I had, and you may too. Caveat: Not all of this is on official tumblr pages, so it's possible things may change.
(1) "I heard they already have access to my data and it doesn't really matter if I opt out"
From the 404 article:
A new FAQ section we reviewed is titled “What happens when you opt out?” states “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
So please, go click that opt-out button.
(2) Some future user: "I've been away from tumblr for months, and I just heard about all this. I didn't opt out before, so does it make a difference anymore?"
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.”
It should make a difference! Go click that button.
(3) "I opted out, but my art posts have been reblogged by so many people, and I don't know if they all opted out. What does that mean for my stuff?"
This answer is actually on the support page for the toggle:
This option will prevent your blog's content, even when reblogged, from being shared with our licensed network of content and research partners, including those that train AI models.
And some further clarification by the COO and a product manager:
zingring: A couple people from work have reached out to let me know that yes, it applies to reblogs of "don't scrape" content. If you opt out, your content is opted out, even in reblog form.
cyle: yep, for reblogs, we're taking it so far as "if anybody in the reblog trail has opted out, all of the content in that reblog will be opted out", when a reblog could be scraped/shared.
So not only your reblogged posts, but anyone who contributed in a reblog (such as posts where someone has been inspired to draw fanart of the OP) will presumably be protected by your opt-out. (A good reason to opt out even if you yourself are not a creator.)
Furthermore, if you the OP were offline and didn't know about the opt-out, if someone contributed to a reblog and they are opted out, then your original work is also protected. (Which makes it very tempting to contribute "scrapeable content" now whenever I reblog from an abandoned/disused blog...)
(4) "What about deleted blogs? They can't opt out!"
I was told by someone (not official) that he read "deleted blogs are all opted-out by default". However, he didn't recall the source, and I can't find it, so I can't guarantee that info. If I get more details - like if/when tumblr puts up that FAQ as reported in the 404 article - I will add it here as soon as I can.
Edit, tumblr has updated their help page for the option to opt-out of third-party sharing! It now states:
The content which will not be shared with our licensed network of content and research partners, including those that train AI models, includes:
• Posts and reblogs of posts from blogs who have enabled the "Prevent third-party sharing" option.
• Posts and reblogs of posts from deleted blogs.
• Posts and reblogs of posts from password-protected blogs.
• Posts and reblogs of posts from explicit blogs.
• Posts and reblogs of posts from suspended/deactivated blogs.
• Private posts.
• Drafts.
• Messages.
• Asks and submissions which have not been publicly posted.
• Post+ subscriber-only posts.
• Explicit posts.
So no need to worry about your old deleted blogs that still have reblogs floating around. *\o/*
But for your existing blogs, please use the opt out option. And a reminder of how to opt out, under the cut:
The opt-out toggle is in Blog Settings, and please note you need to do it for each one of your blogs / sideblogs.
On dashboard, the toggle is at https://www.tumblr.com/settings/blog/blogname [replace "blogname" as applicable] down by Visibility:

For mobile, you need the most recent update of the app. (Android version 33.4.1.100, iOs version 33.4.) Then go to your blog tab (the little person icon), and then the gear icon for Settings, then click Visibility.
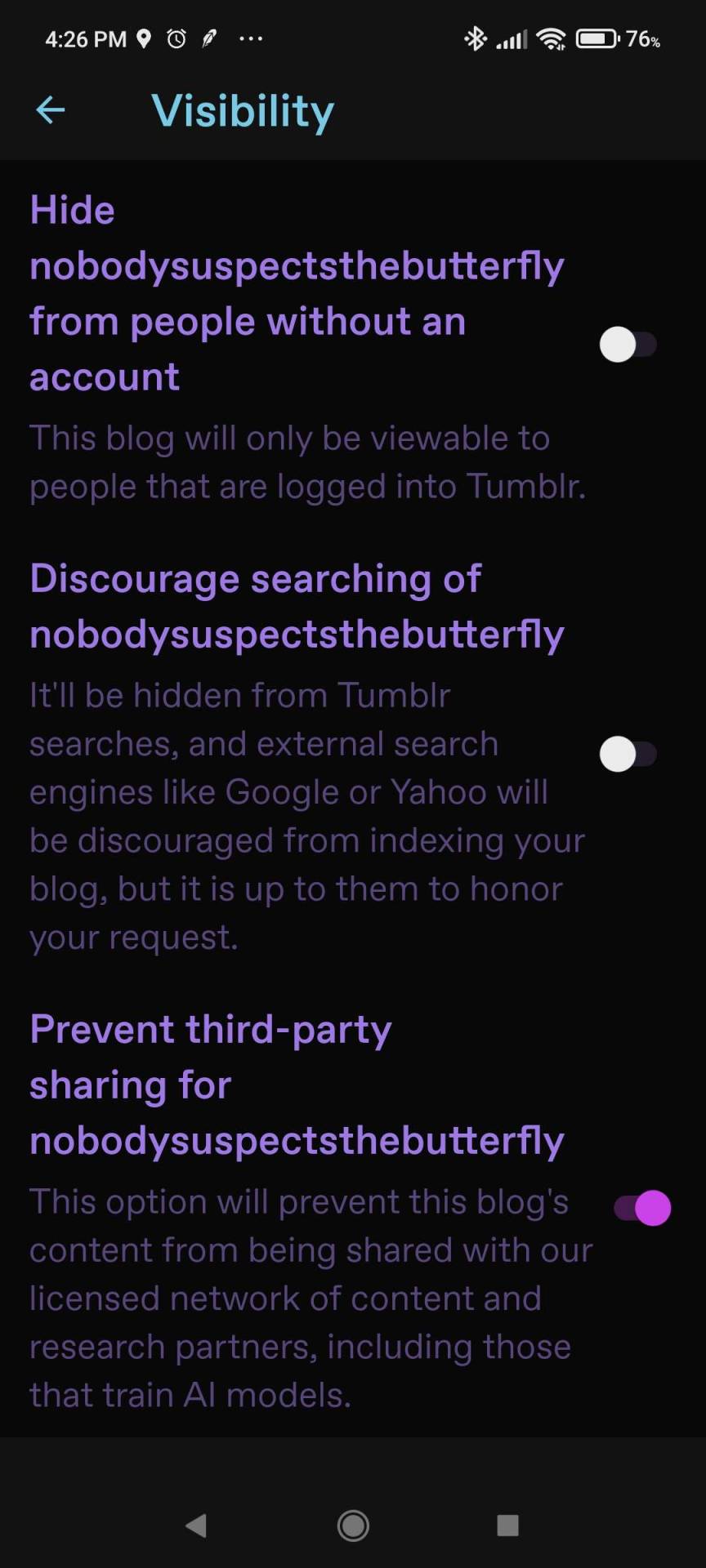
Again, if you have a sideblog, go back to the blog tab, switch to it, and go to settings again. Repeat as necessary.
If you do not have access to the newest version of the app for whatever reason, you can also log into tumblr in your mobile browser. Same URL as per desktop above, same location.
Note you do not need to change settings in both desktop and the app, just one is fine.
I hope this helps!
#tumblr#[tumblr]#third party sharing#openai#midjourney#chatgpt#ai art#ai#fyi#psa#anti-FUD#artists on tumblr#writers on tumblr#illustrators on tumblr#tumblr update#oh tumblr#hellsite (derogatory)#“opt out” no longer looks like a word#but still#opt out my friends#please#also if you want to leave tumblr i don't blame you but please remember to hit that opt-out button before you go
3K notes
·
View notes
Text
The conversation around AI is going to get away from us quickly because people lack the language to distinguish types of AI--and it's not their fault. Companies love to slap "AI" on anything they believe can pass for something "intelligent" a computer program is doing. And this muddies the waters when people want to talk about AI when the exact same word covers a wide umbrella and they themselves don't know how to qualify the distinctions within.
I'm a software engineer and not a data scientist, so I'm not exactly at the level of domain expert. But I work with data scientists, and I have at least rudimentary college-level knowledge of machine learning and linear algebra from my CS degree. So I want to give some quick guidance.
What is AI? And what is not AI?
So what's the difference between just a computer program, and an "AI" program? Computers can do a lot of smart things, and companies love the idea of calling anything that seems smart enough "AI", but industry-wise the question of "how smart" a program is has nothing to do with whether it is AI.
A regular, non-AI computer program is procedural, and rigidly defined. I could "program" traffic light behavior that essentially goes { if(light === green) { go(); } else { stop();} }. I've told it in simple and rigid terms what condition to check, and how to behave based on that check. (A better program would have a lot more to check for, like signs and road conditions and pedestrians in the street, and those things will still need to be spelled out.)
An AI traffic light behavior is generated by machine-learning, which simplistically is a huge cranking machine of linear algebra which you feed training data into and it "learns" from. By "learning" I mean it's developing a complex and opaque model of parameters to fit the training data (but not over-fit). In this case the training data probably includes thousands of videos of car behavior at traffic intersections. Through parameter tweaking and model adjustment, data scientists will turn this crank over and over adjusting it to create something which, in very opaque terms, has developed a model that will guess the right behavioral output for any future scenario.
A well-trained model would be fed a green light and know to go, and a red light and know to stop, and 'green but there's a kid in the road' and know to stop. A very very well-trained model can probably do this better than my program above, because it has the capacity to be more adaptive than my rigidly-defined thing if the rigidly-defined program is missing some considerations. But if the AI model makes a wrong choice, it is significantly harder to trace down why exactly it did that.
Because again, the reason it's making this decision may be very opaque. It's like engineering a very specific plinko machine which gets tweaked to be very good at taking a road input and giving the right output. But like if that plinko machine contained millions of pegs and none of them necessarily correlated to anything to do with the road. There's possibly no "if green, go, else stop" to look for. (Maybe there is, for traffic light specifically as that is intentionally very simplistic. But a model trained to recognize written numbers for example likely contains no parameters at all that you could map to ideas a human has like "look for a rigid line in the number". The parameters may be all, to humans, meaningless.)
So, that's basics. Here are some categories of things which get called AI:
"AI" which is just genuinely not AI
There's plenty of software that follows a normal, procedural program defined rigidly, with no linear algebra model training, that companies would love to brand as "AI" because it sounds cool.
Something like motion detection/tracking might be sold as artificially intelligent. But under the covers that can be done as simply as "if some range of pixels changes color by a certain amount, flag as motion"
2. AI which IS genuinely AI, but is not the kind of AI everyone is talking about right now
"AI", by which I mean machine learning using linear algebra, is very good at being fed a lot of training data, and then coming up with an ability to go and categorize real information.
The AI technology that looks at cells and determines whether they're cancer or not, that is using this technology. OCR (Optical Character Recognition) is the technology that can take an image of hand-written text and transcribe it. Again, it's using linear algebra, so yes it's AI.
Many other such examples exist, and have been around for quite a good number of years. They share the genre of technology, which is machine learning models, but these are not the Large Language Model Generative AI that is all over the media. Criticizing these would be like criticizing airplanes when you're actually mad at military drones. It's the same "makes fly in the air" technology but their impact is very different.
3. The AI we ARE talking about. "Chat-gpt" type of Generative AI which uses LLMs ("Large Language Models")
If there was one word I wish people would know in all this, it's LLM (Large Language Model). This describes the KIND of machine learning model that Chat-GPT/midjourney/stablediffusion are fueled by. They're so extremely powerfully trained on human language that they can take an input of conversational language and create a predictive output that is human coherent. (I am less certain what additional technology fuels art-creation, specifically, but considering the AI art generation has risen hand-in-hand with the advent of powerful LLM, I'm at least confident in saying it is still corely LLM).
This technology isn't exactly brand new (predictive text has been using it, but more like the mostly innocent and much less successful older sibling of some celebrity, who no one really thinks about.) But the scale and power of LLM-based AI technology is what is new with Chat-GPT.
This is the generative AI, and even better, the large language model generative AI.
(Data scientists, feel free to add on or correct anything.)
3K notes
·
View notes
Note
what's your comfort movie?
clueless probably
#can i be honest sometimes i give slightly off base answers to these questions cause im paranoid about data mininh#I KNOW IT'S NOT HOW IT WORKS#but i feel like one day im gonna get an anon like#what was the name of your childhood pet ^_^#I KNOW THATS NOT YOU NONNIE BUT IM SCARED#anyways#askies
0 notes
Last Seen Blogs

semperaurea
semi-charmed

chezbenn87
ChezBenn

renchanter
rendog enthusiast

freebargainbooks
Tumblr Free & Bargain eBooks

wicked-mind
Wicked Mind