#ai art copyright
Text
I was meeting a client at a famous museum’s lounge for lunch (fancy, I know) and had an hour to kill afterwards so I joined the first random docent tour I could find. The woman who took us around was a great-grandmother from the Bronx “back when that was nothing to brag about” and she was doing a talk on alternative mediums within art.
What I thought that meant: telling us about unique sculpture materials and paint mixtures.
What that actually meant: an 84yo woman gingerly holding a beautifully beaded and embroidered dress (apparently from Ukraine and at least 200 years old) and, with tears in her eyes, showing how each individual thread was spun by hand and weaved into place on a cottage floor loom, with bright blue silk embroidery thread and hand-blown beads intricately piercing the work of other labor for days upon days, as the labor of a dozen talented people came together to make something so beautiful for a village girl’s wedding day.
What it also meant: in 1948, a young girl lived in a cramped tenement-like third floor apartment in Manhattan, with a father who had just joined them after not having been allowed to escape through Poland with his pregnant wife nine years earlier. She sits in her father’s lap and watches with wide, quiet eyes as her mother’s deft hands fly across fabric with bright blue silk thread (echoing hands from over a century years earlier). Thread that her mother had salvaged from white embroidery scraps at the tailor’s shop where she worked and spent the last few days carefully dying in the kitchen sink and drying on the roof.
The dress is in the traditional Hungarian fashion and is folded across her mother’s lap: her mother doesn’t had a pattern, but she doesn’t need one to make her daughter’s dress for the fifth grade dance. The dress would end up differing significantly from the pure white, petticoated first communion dresses worn by her daughter’s majority-Catholic classmates, but the young girl would love it all the more for its uniqueness and bright blue thread.
And now, that same young girl (and maybe also the villager from 19th century Ukraine) stands in front of us, trying not to clutch the old fabric too hard as her voice shakes with the emotion of all the love and humanity that is poured into the labor of art. The village girl and the girl in the Bronx were very different people: different centuries, different religions, different ages, and different continents. But the love in the stitches and beads on their dresses was the same. And she tells us that when we look at the labor of art, we don’t just see the work to create that piece - we see the labor of our own creations and the creations of others for us, and the value in something so seemingly frivolous.
But, maybe more importantly, she says that we only admire this piece in a museum because it happened to survive the love of the wearer and those who owned it afterwards, but there have been quite literally billions of small, quiet works of art in billions of small, quiet homes all over the world, for millennia. That your grandmother’s quilt is used as a picnic blanket just as Van Gogh’s works hung in his poor friends’ hallways. That your father’s hand-painted model plane sets are displayed in your parents’ livingroom as Grecian vases are displayed in museums. That your older sister’s engineering drawings in a steady, fine-lined hand are akin to Da Vinci’s scribbles of flying machines.
I don’t think there’s any dramatic conclusions to be drawn from these thoughts - they’ve been echoed by thousands of other people across the centuries. However, if you ever feel bad for spending all of your time sewing, knitting, drawing, building lego sets, or whatever else - especially if you feel like you have to somehow monetize or show off your work online to justify your labor - please know that there’s an 84yo museum docent in the Bronx who would cry simply at the thought of you spending so much effort to quietly create something that’s beautiful to you.
#shut up e#long post#Saturday thoughts#this has been in my drafts for a week haha#also this is the heart of why AI art feels so wrong#forget the discussion of copyright and theft etc - even if models were only trained on public domain they would still feel very wrong#because they’re not art. art is the labor of creation#even commercial art and art commissioned by the popes and kings of history: there is humanity in the labor of it#unrelated: I did not know living in the Bronx was now something to brag about. How the fuck do y’all New Yorkers afford this city???
26K notes
·
View notes
Text
The US Copyright Office is opening a public comment period around AI
American friends! The US Copyright Office (which we know exerts huuuge influence in how these things are treated elsewhere) wants to hear opinions on copyright and AI.
"The US Copyright Office is opening a public comment period around AI and copyright issues beginning August 30th as the agency figures out how to approach the subject."
We can assume that the opposing side will definitely be using all of their lobbying power towards widespread AI use, so this is a very good chance to let them know your thoughts on AI and how art and creative content of all kinds should be protected.
25K notes
·
View notes
Text
Alright US mutuals, if you are interested in, morbidly fascinated by, or anxiously doomscrolling through AI news, including Stable Diffusion, Llama, ChatGPT or Dalle, you need to be aware of this.
The US Copyright Office has submitted a request for comment from the general public. Guidelines can be found on their site, but the gist of it is that they are taking citizen statements on what your views on AI are, and how the Copyright Office should address the admittedly thorny issues in rulings.
Be polite, be succinct, and be honest. They have a list of questions or suggestions, but in truth are looking to get as much data from the general public as possible. If you have links to papers or studies examining the economic impacts of AI, they want them. If you have anecdotal stories of losing commissions, they want them. If you have legal opinions, experience using these tools, or even a layman's perspective of how much human input is required for a piece of work to gain copyright, they want it.
The deadline is Oct 18th and can be submitted via the link in the article. While the regulatory apparatus of the US is largely under sway by corporate interests, this is still the actual, official time for you to directly tell the government what you think and what they should do. Comments can be submitted by individuals or on behalf of organizations. So if you are a small business, say a print shop, you can comment on behalf of the print shop as well.
20K notes
·
View notes
Text
AI Copyright: Protecting Creativity in the Digital World
1. Use All in One Marketing BlocksTo make your promotion more appealing, consider using All in One Marketing Blocks. It's a fantastic tool that helps you create eye-catching ads and content, making your promotion more effective and engaging.
Click HERE
Recommending All in One Marketing BlocksTo enhance your affiliate marketing efforts, All in One Marketing Blocks is an excellent tool. It allows you to create stunning visuals and graphics to showcase the benefits of AI copyright tools. Engaging visuals can capture your audience's attention and encourage them to explore further.
In Conclusion
copyright is like a guardian for creators, protecting their hard work and imagination. By explaining AI copyright simply, highlighting its features, sharing success stories, and using tools like All in One Marketing Blocks, you can effectively promote AI copyright services as an affiliate. Join the movement and help creators keep their work safe and secure in the digital world!
#ai copyright#ai copywriting#Ai copy right#ai art generator#ai art copyright#ai artwork copyright#artwork copyright#keywords research#banner design#Free too#l#Chatgpt copyright#Copyright ai#ai generated#copy right ai
0 notes
Photo
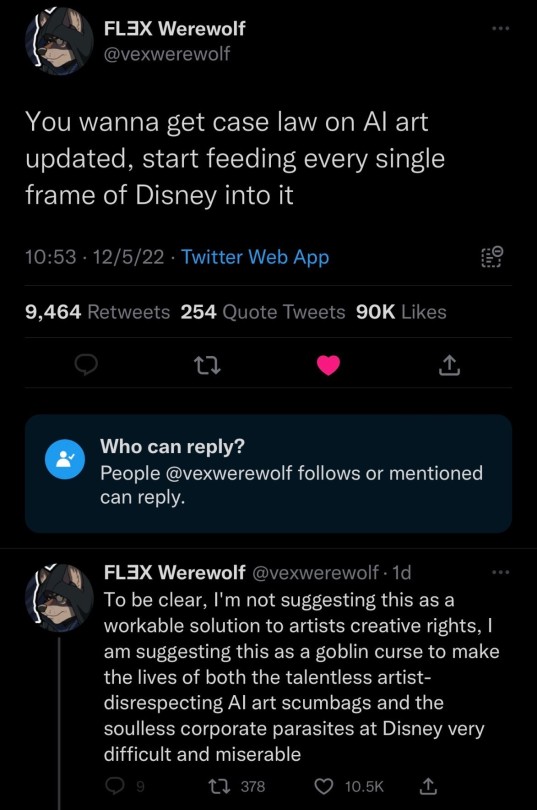
22K notes
·
View notes
Text
So the AI art industry might be done before it had a chance to get started.
In other news, PETA might have accidentally done something good, for once.
19K notes
·
View notes
Text
AI models can seemingly do it all: generate songs, photos, stories, and pictures of what your dog would look like as a medieval monarch.
But all of that data and imagery is pulled from real humans — writers, artists, illustrators, photographers, and more — who have had their work compressed and funneled into the training minds of AI without compensation.
Kelly McKernan is one of those artists. In 2023, they discovered that Midjourney, an AI image generation tool, had used their unique artistic style to create over twelve thousand images.
“It was starting to look pretty accurate, a little infringe-y,” they told The New Yorker last year. “I can see my hand in this stuff, see how my work was analyzed and mixed up with some others’ to produce these images.”
For years, leading AI companies like Midjourney and OpenAI, have enjoyed seemingly unfettered regulation, but a landmark court case could change that.
On May 9, a California federal judge allowed ten artists to move forward with their allegations against Stability AI, Runway, DeviantArt, and Midjourney. This includes proceeding with discovery, which means the AI companies will be asked to turn over internal documents for review and allow witness examination.
Lawyer-turned-content-creator Nate Hake took to X, formerly known as Twitter, to celebrate the milestone, saying that “discovery could help open the floodgates.”
“This is absolutely huge because so far the legal playbook by the GenAI companies has been to hide what their models were trained on,” Hake explained...
“I’m so grateful for these women and our lawyers,” McKernan posted on X, above a picture of them embracing Ortiz and Andersen. “We’re making history together as the largest copyright lawsuit in history moves forward.” ...
The case is one of many AI copyright theft cases brought forward in the last year, but no other case has gotten this far into litigation.
“I think having us artist plaintiffs visible in court was important,” McKernan wrote. “We’re the human creators fighting a Goliath of exploitative tech.”
“There are REAL people suffering the consequences of unethically built generative AI. We demand accountability, artist protections, and regulation.”
-via GoodGoodGood, May 10, 2024
#ai#anti ai#fuck ai art#ai art#big tech#tech news#lawsuit#united states#us politics#good news#hope#copyright#copyright law
2K notes
·
View notes
Text
People who try to make robots and AI look as humanoid as possible should BURN IN HELL. I want to see the mechanism...
646 notes
·
View notes
Text

Are we all just very tired yeah?
Follow for more art | Explore the Shop | Commission
279 notes
·
View notes
Text
AI “art” and uncanniness

TOMORROW (May 14), I'm on a livecast about AI AND ENSHITTIFICATION with TIM O'REILLY; on TOMORROW (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

When it comes to AI art (or "art"), it's hard to find a nuanced position that respects creative workers' labor rights, free expression, copyright law's vital exceptions and limitations, and aesthetics.
I am, on balance, opposed to AI art, but there are some important caveats to that position. For starters, I think it's unequivocally wrong – as a matter of law – to say that scraping works and training a model with them infringes copyright. This isn't a moral position (I'll get to that in a second), but rather a technical one.
Break down the steps of training a model and it quickly becomes apparent why it's technically wrong to call this a copyright infringement. First, the act of making transient copies of works – even billions of works – is unequivocally fair use. Unless you think search engines and the Internet Archive shouldn't exist, then you should support scraping at scale:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
And unless you think that Facebook should be allowed to use the law to block projects like Ad Observer, which gathers samples of paid political disinformation, then you should support scraping at scale, even when the site being scraped objects (at least sometimes):
https://pluralistic.net/2021/08/06/get-you-coming-and-going/#potemkin-research-program
After making transient copies of lots of works, the next step in AI training is to subject them to mathematical analysis. Again, this isn't a copyright violation.
Making quantitative observations about works is a longstanding, respected and important tool for criticism, analysis, archiving and new acts of creation. Measuring the steady contraction of the vocabulary in successive Agatha Christie novels turns out to offer a fascinating window into her dementia:
https://www.theguardian.com/books/2009/apr/03/agatha-christie-alzheimers-research
Programmatic analysis of scraped online speech is also critical to the burgeoning formal analyses of the language spoken by minorities, producing a vibrant account of the rigorous grammar of dialects that have long been dismissed as "slang":
https://www.researchgate.net/publication/373950278_Lexicogrammatical_Analysis_on_African-American_Vernacular_English_Spoken_by_African-Amecian_You-Tubers
Since 1988, UCL Survey of English Language has maintained its "International Corpus of English," and scholars have plumbed its depth to draw important conclusions about the wide variety of Englishes spoken around the world, especially in postcolonial English-speaking countries:
https://www.ucl.ac.uk/english-usage/projects/ice.htm
The final step in training a model is publishing the conclusions of the quantitative analysis of the temporarily copied documents as software code. Code itself is a form of expressive speech – and that expressivity is key to the fight for privacy, because the fact that code is speech limits how governments can censor software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech/
Are models infringing? Well, they certainly can be. In some cases, it's clear that models "memorized" some of the data in their training set, making the fair use, transient copy into an infringing, permanent one. That's generally considered to be the result of a programming error, and it could certainly be prevented (say, by comparing the model to the training data and removing any memorizations that appear).
Not every seeming act of memorization is a memorization, though. While specific models vary widely, the amount of data from each training item retained by the model is very small. For example, Midjourney retains about one byte of information from each image in its training data. If we're talking about a typical low-resolution web image of say, 300kb, that would be one three-hundred-thousandth (0.0000033%) of the original image.
Typically in copyright discussions, when one work contains 0.0000033% of another work, we don't even raise the question of fair use. Rather, we dismiss the use as de minimis (short for de minimis non curat lex or "The law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Busting someone who takes 0.0000033% of your work for copyright infringement is like swearing out a trespassing complaint against someone because the edge of their shoe touched one blade of grass on your lawn.
But some works or elements of work appear many times online. For example, the Getty Images watermark appears on millions of similar images of people standing on red carpets and runways, so a model that takes even in infinitesimal sample of each one of those works might still end up being able to produce a whole, recognizable Getty Images watermark.
The same is true for wire-service articles or other widely syndicated texts: there might be dozens or even hundreds of copies of these works in training data, resulting in the memorization of long passages from them.
This might be infringing (we're getting into some gnarly, unprecedented territory here), but again, even if it is, it wouldn't be a big hardship for model makers to post-process their models by comparing them to the training set, deleting any inadvertent memorizations. Even if the resulting model had zero memorizations, this would do nothing to alleviate the (legitimate) concerns of creative workers about the creation and use of these models.
So here's the first nuance in the AI art debate: as a technical matter, training a model isn't a copyright infringement. Creative workers who hope that they can use copyright law to prevent AI from changing the creative labor market are likely to be very disappointed in court:
https://www.hollywoodreporter.com/business/business-news/sarah-silverman-lawsuit-ai-meta-1235669403/
But copyright law isn't a fixed, eternal entity. We write new copyright laws all the time. If current copyright law doesn't prevent the creation of models, what about a future copyright law?
Well, sure, that's a possibility. The first thing to consider is the possible collateral damage of such a law. The legal space for scraping enables a wide range of scholarly, archival, organizational and critical purposes. We'd have to be very careful not to inadvertently ban, say, the scraping of a politician's campaign website, lest we enable liars to run for office and renege on their promises, while they insist that they never made those promises in the first place. We wouldn't want to abolish search engines, or stop creators from scraping their own work off sites that are going away or changing their terms of service.
Now, onto quantitative analysis: counting words and measuring pixels are not activities that you should need permission to perform, with or without a computer, even if the person whose words or pixels you're counting doesn't want you to. You should be able to look as hard as you want at the pixels in Kate Middleton's family photos, or track the rise and fall of the Oxford comma, and you shouldn't need anyone's permission to do so.
Finally, there's publishing the model. There are plenty of published mathematical analyses of large corpuses that are useful and unobjectionable. I love me a good Google n-gram:
https://books.google.com/ngrams/graph?content=fantods%2C+heebie-jeebies&year_start=1800&year_end=2019&corpus=en-2019&smoothing=3
And large language models fill all kinds of important niches, like the Human Rights Data Analysis Group's LLM-based work helping the Innocence Project New Orleans' extract data from wrongful conviction case files:
https://hrdag.org/tech-notes/large-language-models-IPNO.html
So that's nuance number two: if we decide to make a new copyright law, we'll need to be very sure that we don't accidentally crush these beneficial activities that don't undermine artistic labor markets.
This brings me to the most important point: passing a new copyright law that requires permission to train an AI won't help creative workers get paid or protect our jobs.
Getty Images pays photographers the least it can get away with. Publishers contracts have transformed by inches into miles-long, ghastly rights grabs that take everything from writers, but still shifts legal risks onto them:
https://pluralistic.net/2022/06/19/reasonable-agreement/
Publishers like the New York Times bitterly oppose their writers' unions:
https://actionnetwork.org/letters/new-york-times-stop-union-busting
These large corporations already control the copyrights to gigantic amounts of training data, and they have means, motive and opportunity to license these works for training a model in order to pay us less, and they are engaged in this activity right now:
https://www.nytimes.com/2023/12/22/technology/apple-ai-news-publishers.html
Big games studios are already acting as though there was a copyright in training data, and requiring their voice actors to begin every recording session with words to the effect of, "I hereby grant permission to train an AI with my voice" and if you don't like it, you can hit the bricks:
https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence
If you're a creative worker hoping to pay your bills, it doesn't matter whether your wages are eroded by a model produced without paying your employer for the right to do so, or whether your employer got to double dip by selling your work to an AI company to train a model, and then used that model to fire you or erode your wages:
https://pluralistic.net/2023/02/09/ai-monkeys-paw/#bullied-schoolkids
Individual creative workers rarely have any bargaining leverage over the corporations that license our copyrights. That's why copyright's 40-year expansion (in duration, scope, statutory damages) has resulted in larger, more profitable entertainment companies, and lower payments – in real terms and as a share of the income generated by their work – for creative workers.
As Rebecca Giblin and I write in our book Chokepoint Capitalism, giving creative workers more rights to bargain with against giant corporations that control access to our audiences is like giving your bullied schoolkid extra lunch money – it's just a roundabout way of transferring that money to the bullies:
https://pluralistic.net/2022/08/21/what-is-chokepoint-capitalism/
There's an historical precedent for this struggle – the fight over music sampling. 40 years ago, it wasn't clear whether sampling required a copyright license, and early hip-hop artists took samples without permission, the way a horn player might drop a couple bars of a well-known song into a solo.
Many artists were rightfully furious over this. The "heritage acts" (the music industry's euphemism for "Black people") who were most sampled had been given very bad deals and had seen very little of the fortunes generated by their creative labor. Many of them were desperately poor, despite having made millions for their labels. When other musicians started making money off that work, they got mad.
In the decades that followed, the system for sampling changed, partly through court cases and partly through the commercial terms set by the Big Three labels: Sony, Warner and Universal, who control 70% of all music recordings. Today, you generally can't sample without signing up to one of the Big Three (they are reluctant to deal with indies), and that means taking their standard deal, which is very bad, and also signs away your right to control your samples.
So a musician who wants to sample has to sign the bad terms offered by a Big Three label, and then hand $500 out of their advance to one of those Big Three labels for the sample license. That $500 typically doesn't go to another artist – it goes to the label, who share it around their executives and investors. This is a system that makes every artist poorer.
But it gets worse. Putting a price on samples changes the kind of music that can be economically viable. If you wanted to clear all the samples on an album like Public Enemy's "It Takes a Nation of Millions To Hold Us Back," or the Beastie Boys' "Paul's Boutique," you'd have to sell every CD for $150, just to break even:
https://memex.craphound.com/2011/07/08/creative-license-how-the-hell-did-sampling-get-so-screwed-up-and-what-the-hell-do-we-do-about-it/
Sampling licenses don't just make every artist financially worse off, they also prevent the creation of music of the sort that millions of people enjoy. But it gets even worse. Some older, sample-heavy music can't be cleared. Most of De La Soul's catalog wasn't available for 15 years, and even though some of their seminal music came back in March 2022, the band's frontman Trugoy the Dove didn't live to see it – he died in February 2022:
https://www.vulture.com/2023/02/de-la-soul-trugoy-the-dove-dead-at-54.html
This is the third nuance: even if we can craft a model-banning copyright system that doesn't catch a lot of dolphins in its tuna net, it could still make artists poorer off.
Back when sampling started, it wasn't clear whether it would ever be considered artistically important. Early sampling was crude and experimental. Musicians who trained for years to master an instrument were dismissive of the idea that clicking a mouse was "making music." Today, most of us don't question the idea that sampling can produce meaningful art – even musicians who believe in licensing samples.
Having lived through that era, I'm prepared to believe that maybe I'll look back on AI "art" and say, "damn, I can't believe I never thought that could be real art."
But I wouldn't give odds on it.
I don't like AI art. I find it anodyne, boring. As Henry Farrell writes, it's uncanny, and not in a good way:
https://www.programmablemutter.com/p/large-language-models-are-uncanny
Farrell likens the work produced by AIs to the movement of a Ouija board's planchette, something that "seems to have a life of its own, even though its motion is a collective side-effect of the motions of the people whose fingers lightly rest on top of it." This is "spooky-action-at-a-close-up," transforming "collective inputs … into apparently quite specific outputs that are not the intended creation of any conscious mind."
Look, art is irrational in the sense that it speaks to us at some non-rational, or sub-rational level. Caring about the tribulations of imaginary people or being fascinated by pictures of things that don't exist (or that aren't even recognizable) doesn't make any sense. There's a way in which all art is like an optical illusion for our cognition, an imaginary thing that captures us the way a real thing might.
But art is amazing. Making art and experiencing art makes us feel big, numinous, irreducible emotions. Making art keeps me sane. Experiencing art is a precondition for all the joy in my life. Having spent most of my life as a working artist, I've come to the conclusion that the reason for this is that art transmits an approximation of some big, numinous irreducible emotion from an artist's mind to our own. That's it: that's why art is amazing.
AI doesn't have a mind. It doesn't have an intention. The aesthetic choices made by AI aren't choices, they're averages. As Farrell writes, "LLM art sometimes seems to communicate a message, as art does, but it is unclear where that message comes from, or what it means. If it has any meaning at all, it is a meaning that does not stem from organizing intention" (emphasis mine).
Farrell cites Mark Fisher's The Weird and the Eerie, which defines "weird" in easy to understand terms ("that which does not belong") but really grapples with "eerie."
For Fisher, eeriness is "when there is something present where there should be nothing, or is there is nothing present when there should be something." AI art produces the seeming of intention without intending anything. It appears to be an agent, but it has no agency. It's eerie.
Fisher talks about capitalism as eerie. Capital is "conjured out of nothing" but "exerts more influence than any allegedly substantial entity." The "invisible hand" shapes our lives more than any person. The invisible hand is fucking eerie. Capitalism is a system in which insubstantial non-things – corporations – appear to act with intention, often at odds with the intentions of the human beings carrying out those actions.
So will AI art ever be art? I don't know. There's a long tradition of using random or irrational or impersonal inputs as the starting point for human acts of artistic creativity. Think of divination:
https://pluralistic.net/2022/07/31/divination/
Or Brian Eno's Oblique Strategies:
http://stoney.sb.org/eno/oblique.html
I love making my little collages for this blog, though I wouldn't call them important art. Nevertheless, piecing together bits of other peoples' work can make fantastic, important work of historical note:
https://www.johnheartfield.com/John-Heartfield-Exhibition/john-heartfield-art/famous-anti-fascist-art/heartfield-posters-aiz
Even though painstakingly cutting out tiny elements from others' images can be a meditative and educational experience, I don't think that using tiny scissors or the lasso tool is what defines the "art" in collage. If you can automate some of this process, it could still be art.
Here's what I do know. Creating an individual bargainable copyright over training will not improve the material conditions of artists' lives – all it will do is change the relative shares of the value we create, shifting some of that value from tech companies that hate us and want us to starve to entertainment companies that hate us and want us to starve.
As an artist, I'm foursquare against anything that stands in the way of making art. As an artistic worker, I'm entirely committed to things that help workers get a fair share of the money their work creates, feed their families and pay their rent.
I think today's AI art is bad, and I think tomorrow's AI art will probably be bad, but even if you disagree (with either proposition), I hope you'll agree that we should be focused on making sure art is legal to make and that artists get paid for it.
Just because copyright won't fix the creative labor market, it doesn't follow that nothing will. If we're worried about labor issues, we can look to labor law to improve our conditions. That's what the Hollywood writers did, in their groundbreaking 2023 strike:
https://pluralistic.net/2023/10/01/how-the-writers-guild-sunk-ais-ship/
Now, the writers had an advantage: they are able to engage in "sectoral bargaining," where a union bargains with all the major employers at once. That's illegal in nearly every other kind of labor market. But if we're willing to entertain the possibility of getting a new copyright law passed (that won't make artists better off), why not the possibility of passing a new labor law (that will)? Sure, our bosses won't lobby alongside of us for more labor protection, the way they would for more copyright (think for a moment about what that says about who benefits from copyright versus labor law expansion).
But all workers benefit from expanded labor protection. Rather than going to Congress alongside our bosses from the studios and labels and publishers to demand more copyright, we could go to Congress alongside every kind of worker, from fast-food cashiers to publishing assistants to truck drivers to demand the right to sectoral bargaining. That's a hell of a coalition.
And if we do want to tinker with copyright to change the way training works, let's look at collective licensing, which can't be bargained away, rather than individual rights that can be confiscated at the entrance to our publisher, label or studio's offices. These collective licenses have been a huge success in protecting creative workers:
https://pluralistic.net/2023/02/26/united-we-stand/
Then there's copyright's wildest wild card: The US Copyright Office has repeatedly stated that works made by AIs aren't eligible for copyright, which is the exclusive purview of works of human authorship. This has been affirmed by courts:
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
Neither AI companies nor entertainment companies will pay creative workers if they don't have to. But for any company contemplating selling an AI-generated work, the fact that it is born in the public domain presents a substantial hurdle, because anyone else is free to take that work and sell it or give it away.
Whether or not AI "art" will ever be good art isn't what our bosses are thinking about when they pay for AI licenses: rather, they are calculating that they have so much market power that they can sell whatever slop the AI makes, and pay less for the AI license than they would make for a human artist's work. As is the case in every industry, AI can't do an artist's job, but an AI salesman can convince an artist's boss to fire the creative worker and replace them with AI:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
They don't care if it's slop – they just care about their bottom line. A studio executive who cancels a widely anticipated film prior to its release to get a tax-credit isn't thinking about artistic integrity. They care about one thing: money. The fact that AI works can be freely copied, sold or given away may not mean much to a creative worker who actually makes their own art, but I assure you, it's the only thing that matters to our bosses.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/13/spooky-action-at-a-close-up/#invisible-hand
#pluralistic#ai art#eerie#ai#weird#henry farrell#copyright#copyfight#creative labor markets#what is art#ideomotor response#mark fisher#invisible hand#uncanniness#prompting
241 notes
·
View notes
Text

Hey, you know how I said there was nothing ethical about Adobe's approach to AI? Well whaddya know?
Adobe wants your team lead to contact their customer service to not have your private documents scraped!
This isn't the first of Adobe's always-online subscription-based products (which should not have been allowed in the first place) to have sneaky little scraping permissions auto-set to on and hidden away, but this is the first one (I'm aware of) where you have to contact customer service to turn it off for a whole team.
Now, I'm on record for saying I see scraping as fair use, and it is. But there's an aspect of that that is very essential to it being fair use: The material must be A) public facing and B) fixed published work.
All public facing published work is subject to transformative work and academic study, the use of mechanical apparatus to improve/accelerate that process does not change that principle. Its the difference between looking through someone's public instagram posts and reading through their drafts folder and DMs.
But that's not the kind of work that Adobe's interested in. See, they already have access to that work just like everyone else. But the in-progress work that Creative Cloud gives them access to, and the private work that's never published that's stored there isn't in LIAON. They want that advantage.
And that's valuable data. For an example: having a ton of snapshots of images in the process of being completed would be very handy for making an AI that takes incomplete work/sketches and 'finishes' it. That's on top of just being general dataset grist.
But that work is, definitionally, not published. There's no avenue to a fair use argument for scraping it, so they have to ask. And because they know it will be an unpopular ask, they make it a quiet op-out.
This was sinister enough when it was Photoshop, but PDF is mainly used for official documents and forms. That's tax documents, medical records, college applications, insurance documents, business records, legal documents. And because this is a server-side scrape, even if you opt-out, you have no guarantee that anyone you're sending those documents to has done so.
So, in case you weren't keeping score, corps like Adobe, Disney, Universal, Nintendo, etc all have the resources to make generative AI systems entirely with work they 'own' or can otherwise claim rights to, and no copyright argument can stop them because they own the copyrights.
They just don't want you to have access to it as a small creator to compete with them, and if they can expand copyright to cover styles and destroy fanworks they will. Here's a pic Adobe trying to do just that:

If you want to know more about fair use and why it applies in this circumstance, I recommend the Electronic Frontier Foundation over the Copyright Alliance.
177 notes
·
View notes
Text
just watched the hbomberguy video and omg
the parts where he says that business people don't know how to be creative so they just steal
like so true literally the source of so many of our problems in creative fields with AI and plagiarism and copyright is just business people who aren't creative stealing instead of practicing creativity
214 notes
·
View notes
Text
...There's this thing going around by the Concept Art Association trying to raise money to fund anti-AI-Art stuff, that big stupid "Protecting Artists From AI Technologies" Gofundme, and I feel the need to inform y'all that it's a scam, or at least suspicious as hell.
Like, the main person behind it, Karla Ortiz, is a major NFT person and the organization they're trying to get buddy-buddy with; the Copyright Alliance; is basically an astroturf organization funded by megacorps like Disney and Warner to push against orgs like the EFF who're doing good work to push back against said corps overreach.
It bears all the signs of an astroturfing attempt to cozy up with megacorps and expand copyright law to something akin to what the music industry has. Which, as anyone familiar with that industry will tell you, you do not want.
Regardless of your views on AI art, the expansion of copyright is a bad idea for all artists, especially anyone who does fanart, and we shouldn't let the people trying to use this wave of panic to smuggle in a draconian expansion of copyright law that will only be used to hurt independent artists and help megacorps.
Remember, no matter what anyone says, Disney is not your friend. If they get their way on expanding copyright law, they will stab you in the back and then discard you.
1K notes
·
View notes
Text
incredibly funny how a bunch of people interpreted “ao3 was almost certainly scraped as part of the gpt training dataset because it’s a big easily accessible body of english language text, so you can prompt gpt with surprisingly vague stuff and it will autocomplete with snarry underage or wangxian a/b/o” as “elon musk Personally is Currently scraping ao3 and training an ai to plagiarize fic, going to go lock ALL my works on ao3 IMMEDIATELY”
its. its already in the dataset. how do you think these things work. “locking my works to registered users only until after the scraping stops!” my dude the ao3 team just needs to like add a robots.txt and check the useragent and stuff to prevent this from happening in the future*, and theyre already on it, but not only is the existing body of work presumably In the Dataset, the model has ALREADY BEEN TRAINED. that omelet isnt going to get unscrambled
(*im assuming that everyone gathering datasets for large language models is being reasonably Polite about it bc these are both very simple to circumvent — if this assumption is false then ao3 might need to graduate to Offensive Measures but also we would definitely need to bully the culprits off of hacker news)
anyway im not taking any Stance one way or the other on the “ai art debate” (other than maybe “none of you know what the hell you’re talking about”) but we’re definitely going to see a whole new world of copyright claims against the big art models and ml researchers developing new tools for “removing” stuff from a trained model, and i for one think that it will be SO entertaining to watch
#i cant believe how many fucking. layers of stupid misinformation are in this rumor#ELON MUSK COFOUNDED OPENAI BUT HE LEFT THE BOARD IN 2018#the trashcan speaks#currently i think the main ‘anti plagiarism’ tool is blacklisting prompt keywords which is…………. just SO hacky#(wrt ai art. i think for gpt you would need to blacklist popular fandoms from the output at the very least)#(which they probably wont unless they get copyright claimed.)#(IMAGINE. hottest legal battle of 2025 is google vs. disney litigating whether ai generated fanfiction is fair use……….)
716 notes
·
View notes
Text


Stealing from ai is fun
Also helps me with anime practice
#stealing from ai#ai is not art#remember kids ai ocs can’t be copyrighted#nonbinary artist#digital art#digital artist#artists on tumblr#art#nonbinary#procreate#artblr#art tumblr#queue art#anime#anime art#redesign#ai redraw
70 notes
·
View notes
Text
The US Copyright Office is currently asking for input on generative AI systems ...
... to help assess whether legislative or regulatory steps in this area are warranted.
Here is what I wrote to them, and what I want as a creative professional:
AI systems undermine the value of human creative thinking and work, and harbor a danger for us creative people that should not be underestimated. There is a risk of a transfer of economic advantage to a few AI companies, to the detriment of hundreds of thousands of creatives. It is the creative people with their works who create the data and marketing basis for the AI companies, from which the AI systems feed.
AI systems cannot produce text, images or music without suitable training material, and the quality of that training material has a direct influence on the quality of the results. In order to supply the systems with the necessary data, the developers of those AI systems are currently using the works of creative people - without consent or even asking, and without remuneration. In addition, creative professionals are denied a financial participation in the exploitation of the AI results created on the basis of the material.
My demand as a creative professional is this: The works and achievements of creative professionals must also be protected in digital space. The technical possibility of being able to read works via text and data mining must not legitimize any unlicensed use!
The remuneration for the use of works is the economic basis on which creative people work. AI companies are clearly pursuing economic interests with their operation. The associated use of the work for commercial purposes must be properly licensed, and compensated appropriately.
We need transparent training data as an access requirement for AI providers! In order to obtain market approval, AI providers must be able to transparently present this permission from the authors. The burden of proof and documentation of the data used - in the sense of applicable copyright law - lies with the user and not with the author. AI systems may only be trained from comprehensible, copyright-compliant sources.
____________________________
You can send your own comment to the Copyright Office here: https://www.regulations.gov/document/COLC-2023-0006-0001
My position is based on the Illustratoren Organisation's (Germany) recently published stance on AI generators:
https://illustratoren-organisation.de/2023/04/04/ki-aber-fair-positionspapier-der-kreativwirtschaft-zum-einsatz-von-ki/
170 notes
·
View notes
Last Seen Blogs

hongxuanqi
Malaysia Culture Food in Johor Bahru

khalid-23
Untitled

houseblend1781
HouseBlendCafe

leadvalets
LeadValets

weissicles
bhu