#algorithm bias
Text
youtube
The issues she brings up in this video are big reasons why it's so helpful when viewers spread the word to friends, family and social media about their favorite YouTube videos and channels. You can't assume the search box, feed or even "liking" a video will boost a creator.
As a woman making long-form videos on YouTube, apparently I've got the deck (aka the algorithm) stacked against me. As if I didn't know! My gaming channel's had very VERY slow growth over the years and I've been asked many times why I bother to keep doing it.
Well, not only do I enjoy it, I learn a lot (about gaming, editing, streaming, etc), I meet some great people, I've cheered a few of you up when you're down, and I've helped a lot of folks with gaming tips and solutions. I also think it's important to be out there as an over-50 gamer and a female gamer on YouTube who's playing everything from the smalled indie title to the biggest AAA's.
Don't let an algorithm control what you see! Notifications are notoriously unreliable on YouTube too so don't rely on those either. Make sure to subscribe to channels you like and check the "subscriptions" tab on your computer, phone or TV rather than the home page or "feed."
0 notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
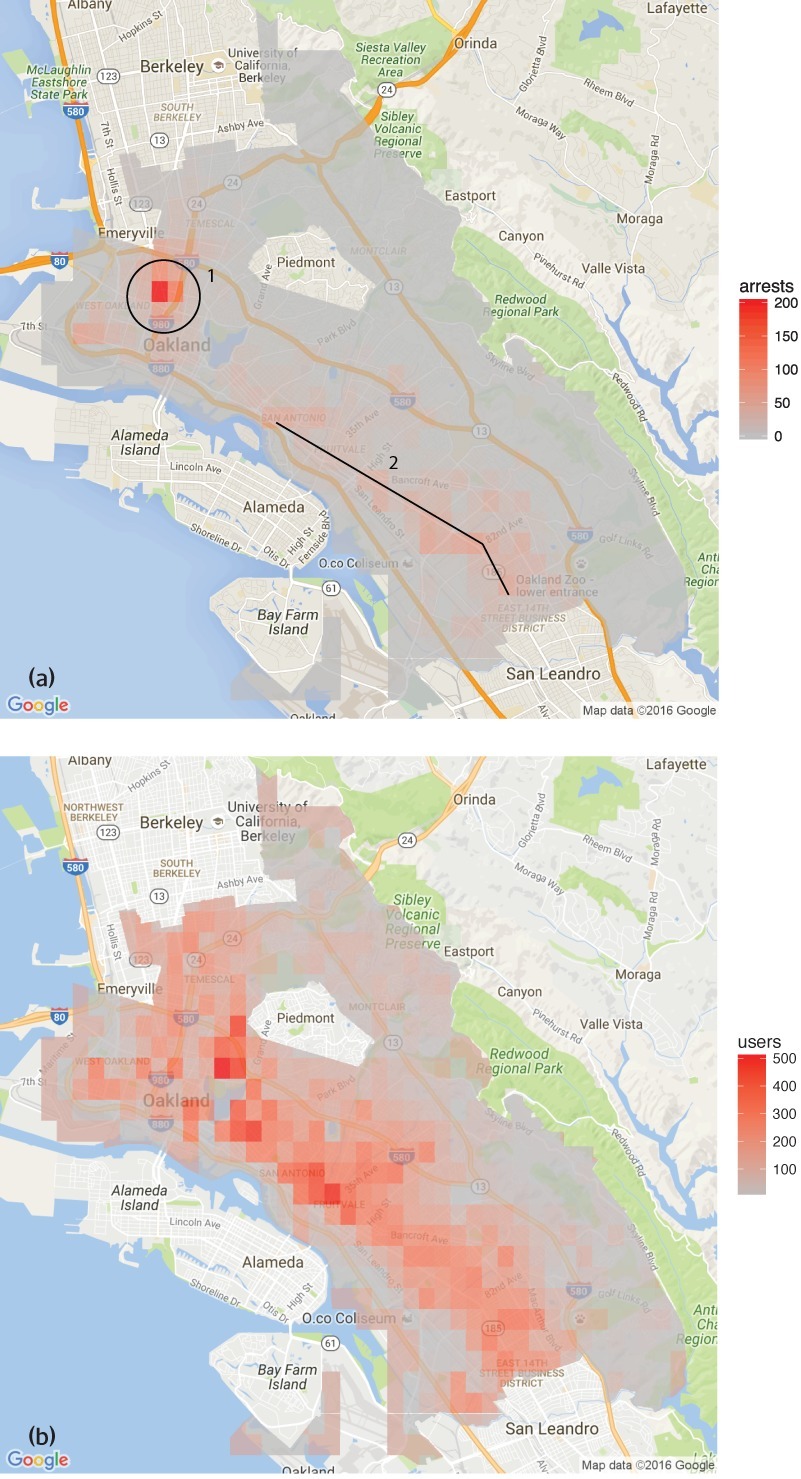
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified)
https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0
https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified)
https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified)
https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0
https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
826 notes
·
View notes
Text
I'm really not a villain enjoyer. I love anti-heroes and anti-villains. But I can't see fictional evil separate from real evil. As in not that enjoying dark fiction means you condone it, but that all fiction holds up some kind of mirror to the world as it is. Killing innocent people doesn't make you an iconic lesbian girlboss it just makes you part of the mundane and stultifying black rot of the universe.
"But characters struggling with honour and goodness and the egoism of being good are so boring." Cool well some of us actually struggle with that stuff on the daily because being a good person is complicated and harder than being an edgelord.
Sure you can use fiction to explore the darkness of human nature and learn empathy, but the world doesn't actually suffer from a deficit of empathy for powerful and privileged people who do heinous stuff. You could literally kill a thousand babies in broad daylight and they'll find a way to blame your childhood trauma for it as long as you're white, cisgender, abled and attractive, and you'll be their poor little meow meow by the end of the week. Don't act like you're advocating for Quasimodo when you're just making Elon Musk hot, smart and gay.
#this is one of the reasons why#although i would kill antis in real life if i could#i also don't trust anyone who identifies as 'pro-ship'#it's just an excuse to shut down legitimate ethical questions and engaging in honest self-reflective media consumption and critique#art doesn't exist in a vacuum#it's a flat impossibility for it not to inform nor be informed by real world politics and attitudes#because that's what it means to be created by human hands#we can't even make machine learning thats not just human bias fed into an algorithm#if the way we interact with art truly didn't influence anything then there would be no value in it#just because antis have weaponized those points in the most bad faith ways possible#doesn't mean you can ignore them in good faith#anyway fandom stans villains because society loves to defend and protect abusers#it's not because you get the chance to be free and empathetic and indulge in your darkness and what not#it's just people's normal levels of attachment to shitty people with an added layer of justification for it#this blog is for boring do-gooder enjoyers only#lol#knee of huss#fandom wank#media critique#pop culture#fandom discourse
189 notes
·
View notes
Text

there's no salvation in the algorithm
#art#retrofuture#design#collage#aesthetic#cyberpunk#black and white#glitch#text#typeface#algorithmic bias#free palestine
89 notes
·
View notes
Text


Last summer, as a spike in violent crime hit New Orleans, the city council voted to allow police to use facial-recognition software to track down suspects. It was billed as an effective, fair tool to ID criminals quickly.
A year after the system went online, data show the results have been almost exactly the opposite. Records obtained and analyzed by POLITICO show the practice failed to ID suspects a majority of the time and is disproportionately used on Black people.
We reviewed nearly a year’s worth of New Orleans facial recognition requests, sent for serious felony crimes including murder and armed robbery. In that time, New Orleans PD sent 19 requests. Of the 15 that went through:
14 were for Black suspects
9 failed to make a match
Half of the 6 matches were wrong
1 arrest was made
While it hasn’t led to any false arrests, police facial identification in New Orleans appears to confirm what civil rights advocates have argued for years: that it amplifies, rather than corrects, the underlying human biases of the authorities that use them.
U.S. lawmakers of both parties have tried for years to limit how police can use facial recognition, but have yet to enact any laws. Some states have passed limited rules, like those preventing its use on body cameras in California or banning its use in schools in New York.
A few left-leaning cities have fully banned law enforcement use of the technology. For two years, in the wake of the George Floyd protests, New Orleans was one of them.
“This department hung their hat on this,” said New Orleans Councilmember At-Large JP Morrell, a Democrat who voted against lifting the ban and has seen the NOPD data. Its use of the system, he says, has been “wholly ineffective and pretty obviously racist.” (NOPD denies that its usage of facial recognition is racially biased).
Politically, New Orleans’ City Council is split on facial recognition, but a slim majority of its members — alongside the police, mayor and local businesses — still support its use, despite the results of the past year.
x

#racism in ai#ai ethics#bias in tech#ai for social justice#algorithmic bias#ai responsibility#inclusive tech#ai and racism
61 notes
·
View notes
Text
An instructor accused students of using chatGPT to write their papers after 'detecting' this by.... pasting their papers into chatGPT and asking it if it wrote them. So that's going great.
#I volunteered to be on a college taskforce about this bc although my knowledge is limited#I fear it is probably greater than many of my colleagues#and I want to make sure stuff about intellectual property and algorithmic bias get into the conversation#and ALSO biases in how this kind of stuff is enforced#which students are you looking at and saying 'hm I don't BELIEVE you could write this well on your own.#you MUST have had help'#not a good road to go down
115 notes
·
View notes
Text
My New Article at American Scientist
Tweet
As of this week, I have a new article in the July-August 2023 Special Issue of American Scientist Magazine. It’s called “Bias Optimizers,” and it’s all about the problems and potential remedies of and for GPT-type tools and other “A.I.”
This article picks up and expands on thoughts started in “The ‘P’ Stands for Pre-Trained” and in a few threads on the socials, as well as touching on some of my comments quoted here, about the use of chatbots and “A.I.” in medicine.
I’m particularly proud of the two intro grafs:
Recently, I learned that men can sometimes be nurses and secretaries, but women can never be doctors or presidents. I also learned that Black people are more likely to owe money than to have it owed to them. And I learned that if you need disability assistance, you’ll get more of it if you live in a facility than if you receive care at home.
At least, that is what I would believe if I accepted the sexist, racist, and misleading ableist pronouncements from today’s new artificial intelligence systems. It has been less than a year since OpenAI released ChatGPT, and mere months since its GPT-4 update and Google’s release of a competing AI chatbot, Bard. The creators of these systems promise they will make our lives easier, removing drudge work such as writing emails, filling out forms, and even writing code. But the bias programmed into these systems threatens to spread more prejudice into the world. AI-facilitated biases can affect who gets hired for what jobs, who gets believed as an expert in their field, and who is more likely to be targeted and prosecuted by police.
As you probably well know, I’ve been thinking about the ethical, epistemological, and social implications of GPT-type tools and “A.I.” in general for quite a while now, and I’m so grateful to the team at American Scientist for the opportunity to discuss all of those things with such a broad and frankly crucial audience.
I hope you enjoy it.
Tweet
Read My New Article at American Scientist at A Future Worth Thinking About
#ableism#ai#algorithmic bias#american scientist#artificial intelligence#bias#bigotry#bots#epistemology#ethics#generative pre-trained transformer#gpt#homophobia#large language models#Machine ethics#my words#my writing#prejudice#racism#science technology and society#sexism#transphobia
61 notes
·
View notes
Text

20 notes
·
View notes
Text

Inspired by the landmark 1968 exhibition Cybernetic Serendipity, the first-ever international event in the UK dedicated to arts and emerging technologies, the event, titled Cybernetic Serendipity: Towards AI, will look back to look forwards, exploring the transformative potential of machine learning across the creative industries, from algorithms and text-to-image chatbots like ChatGPT to building virtual worlds and using AI to detect bias and disinformation.
From AI chatbots to virtual companions and the never ending wave of deepfakes on our screens, artificial intelligence is an unavoidable part of culture nowadays.
via Dazed and confused
#cybernetic serendipity#since 1968#technology#AI#chatgpt#bias#desinformation#deepfakes#nowadays#culture#algorithm#virtual world#machine learning
5 notes
·
View notes
Text
Stop feeding the algorithm
If you hesitate over a POST for just a spilt second longer, the algorithm picks up on that. Then they send you another post just like it.
Let's say a video about jealousy, if you do the same thing again --- hesitate just for a second, even if you eventually click thumbs down, it knows/thinks that's what you secretly want.
The algorithm has one job in mind keeping you engaged not making you a better person.
#internet security#internet culture#internet#privacy#google#operating systems#apps#technology#algorithmic bias#algorithmic stablecoin#i hate algorithms#tiktok algorithm#tumblr algorithm#generative#connect#app#influencer#thursdaythoughts#fridayfeeling
49 notes
·
View notes
Text
Hypothetical AI election disinformation risks vs real AI harms

I'm on tour with my new novel The Bezzle! Catch me TONIGHT (Feb 27) in Portland at Powell's. Then, onto Phoenix (Changing Hands, Feb 29), Tucson (Mar 9-12), and more!

You can barely turn around these days without encountering a think-piece warning of the impending risk of AI disinformation in the coming elections. But a recent episode of This Machine Kills podcast reminds us that these are hypothetical risks, and there is no shortage of real AI harms:
https://soundcloud.com/thismachinekillspod/311-selling-pickaxes-for-the-ai-gold-rush
The algorithmic decision-making systems that increasingly run the back-ends to our lives are really, truly very bad at doing their jobs, and worse, these systems constitute a form of "empiricism-washing": if the computer says it's true, it must be true. There's no such thing as racist math, you SJW snowflake!
https://slate.com/news-and-politics/2019/02/aoc-algorithms-racist-bias.html
Nearly 1,000 British postmasters were wrongly convicted of fraud by Horizon, the faulty AI fraud-hunting system that Fujitsu provided to the Royal Mail. They had their lives ruined by this faulty AI, many went to prison, and at least four of the AI's victims killed themselves:
https://en.wikipedia.org/wiki/British_Post_Office_scandal
Tenants across America have seen their rents skyrocket thanks to Realpage's landlord price-fixing algorithm, which deployed the time-honored defense: "It's not a crime if we commit it with an app":
https://www.propublica.org/article/doj-backs-tenants-price-fixing-case-big-landlords-real-estate-tech
Housing, you'll recall, is pretty foundational in the human hierarchy of needs. Losing your home – or being forced to choose between paying rent or buying groceries or gas for your car or clothes for your kid – is a non-hypothetical, widespread, urgent problem that can be traced straight to AI.
Then there's predictive policing: cities across America and the world have bought systems that purport to tell the cops where to look for crime. Of course, these systems are trained on policing data from forces that are seeking to correct racial bias in their practices by using an algorithm to create "fairness." You feed this algorithm a data-set of where the police had detected crime in previous years, and it predicts where you'll find crime in the years to come.
But you only find crime where you look for it. If the cops only ever stop-and-frisk Black and brown kids, or pull over Black and brown drivers, then every knife, baggie or gun they find in someone's trunk or pockets will be found in a Black or brown person's trunk or pocket. A predictive policing algorithm will naively ingest this data and confidently assert that future crimes can be foiled by looking for more Black and brown people and searching them and pulling them over.
Obviously, this is bad for Black and brown people in low-income neighborhoods, whose baseline risk of an encounter with a cop turning violent or even lethal. But it's also bad for affluent people in affluent neighborhoods – because they are underpoliced as a result of these algorithmic biases. For example, domestic abuse that occurs in full detached single-family homes is systematically underrepresented in crime data, because the majority of domestic abuse calls originate with neighbors who can hear the abuse take place through a shared wall.
But the majority of algorithmic harms are inflicted on poor, racialized and/or working class people. Even if you escape a predictive policing algorithm, a facial recognition algorithm may wrongly accuse you of a crime, and even if you were far away from the site of the crime, the cops will still arrest you, because computers don't lie:
https://www.cbsnews.com/sacramento/news/texas-macys-sunglass-hut-facial-recognition-software-wrongful-arrest-sacramento-alibi/
Trying to get a low-waged service job? Be prepared for endless, nonsensical AI "personality tests" that make Scientology look like NASA:
https://futurism.com/mandatory-ai-hiring-tests
Service workers' schedules are at the mercy of shift-allocation algorithms that assign them hours that ensure that they fall just short of qualifying for health and other benefits. These algorithms push workers into "clopening" – where you close the store after midnight and then open it again the next morning before 5AM. And if you try to unionize, another algorithm – that spies on you and your fellow workers' social media activity – targets you for reprisals and your store for closure.
If you're driving an Amazon delivery van, algorithm watches your eyeballs and tells your boss that you're a bad driver if it doesn't like what it sees. If you're working in an Amazon warehouse, an algorithm decides if you've taken too many pee-breaks and automatically dings you:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
If this disgusts you and you're hoping to use your ballot to elect lawmakers who will take up your cause, an algorithm stands in your way again. "AI" tools for purging voter rolls are especially harmful to racialized people – for example, they assume that two "Juan Gomez"es with a shared birthday in two different states must be the same person and remove one or both from the voter rolls:
https://www.cbsnews.com/news/eligible-voters-swept-up-conservative-activists-purge-voter-rolls/
Hoping to get a solid education, the sort that will keep you out of AI-supervised, precarious, low-waged work? Sorry, kiddo: the ed-tech system is riddled with algorithms. There's the grifty "remote invigilation" industry that watches you take tests via webcam and accuses you of cheating if your facial expressions fail its high-tech phrenology standards:
https://pluralistic.net/2022/02/16/unauthorized-paper/#cheating-anticheat
All of these are non-hypothetical, real risks from AI. The AI industry has proven itself incredibly adept at deflecting interest from real harms to hypothetical ones, like the "risk" that the spicy autocomplete will become conscious and take over the world in order to convert us all to paperclips:
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Whenever you hear AI bosses talking about how seriously they're taking a hypothetical risk, that's the moment when you should check in on whether they're doing anything about all these longstanding, real risks. And even as AI bosses promise to fight hypothetical election disinformation, they continue to downplay or ignore the non-hypothetical, here-and-now harms of AI.
There's something unseemly – and even perverse – about worrying so much about AI and election disinformation. It plays into the narrative that kicked off in earnest in 2016, that the reason the electorate votes for manifestly unqualified candidates who run on a platform of bald-faced lies is that they are gullible and easily led astray.
But there's another explanation: the reason people accept conspiratorial accounts of how our institutions are run is because the institutions that are supposed to be defending us are corrupt and captured by actual conspiracies:
https://memex.craphound.com/2019/09/21/republic-of-lies-the-rise-of-conspiratorial-thinking-and-the-actual-conspiracies-that-fuel-it/
The party line on conspiratorial accounts is that these institutions are good, actually. Think of the rebuttal offered to anti-vaxxers who claimed that pharma giants were run by murderous sociopath billionaires who were in league with their regulators to kill us for a buck: "no, I think you'll find pharma companies are great and superbly regulated":
https://pluralistic.net/2023/09/05/not-that-naomi/#if-the-naomi-be-klein-youre-doing-just-fine
Institutions are profoundly important to a high-tech society. No one is capable of assessing all the life-or-death choices we make every day, from whether to trust the firmware in your car's anti-lock brakes, the alloys used in the structural members of your home, or the food-safety standards for the meal you're about to eat. We must rely on well-regulated experts to make these calls for us, and when the institutions fail us, we are thrown into a state of epistemological chaos. We must make decisions about whether to trust these technological systems, but we can't make informed choices because the one thing we're sure of is that our institutions aren't trustworthy.
Ironically, the long list of AI harms that we live with every day are the most important contributor to disinformation campaigns. It's these harms that provide the evidence for belief in conspiratorial accounts of the world, because each one is proof that the system can't be trusted. The election disinformation discourse focuses on the lies told – and not why those lies are credible.
That's because the subtext of election disinformation concerns is usually that the electorate is credulous, fools waiting to be suckered in. By refusing to contemplate the institutional failures that sit upstream of conspiracism, we can smugly locate the blame with the peddlers of lies and assume the mantle of paternalistic protectors of the easily gulled electorate.
But the group of people who are demonstrably being tricked by AI is the people who buy the horrifically flawed AI-based algorithmic systems and put them into use despite their manifest failures.
As I've written many times, "we're nowhere near a place where bots can steal your job, but we're certainly at the point where your boss can be suckered into firing you and replacing you with a bot that fails at doing your job"
https://pluralistic.net/2024/01/15/passive-income-brainworms/#four-hour-work-week
The most visible victims of AI disinformation are the people who are putting AI in charge of the life-chances of millions of the rest of us. Tackle that AI disinformation and its harms, and we'll make conspiratorial claims about our institutions being corrupt far less credible.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/27/ai-conspiracies/#epistemological-collapse
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#ai#disinformation#algorithmic bias#elections#election disinformation#conspiratorialism#paternalism#this machine kills#Horizon#the rents too damned high#weaponized shelter#predictive policing#fr#facial recognition#labor#union busting#union avoidance#standardized testing#hiring#employment#remote invigilation
144 notes
·
View notes
Note
Do you know what happened to @gay-bucky-barnes blog? It’s not showing up for me
i think it was deleted by tumblr's algorithm again. betting bc of coded biases against queer content. givim a follow again @gaybuckybarnesagain pls.
5 notes
·
View notes
Text
Genuinely baffles me that XCOM has a reputation for being unfair with its shot hit percentages, like yeah, 90% feels like basically 100%, but also if you take ten of those you'll miss one, and if you take four 75% shots one of those ought to miss, and in fact, if you take the time to do some calculations to it, you'll find that these numbers are pretty accurate because the back end is literally just calling random() to generate a number between 0 and 1 and then comparing that to the percentage it gave you, I don't know this for sure but also I have written code before and it would be insane to have your chance calculating function then function in basically any other fashion, and some very smart people put a lot of time into making sure your computer's pseudorandom number generator produces an even distribution, there's really no way for this to work BUT fairly.
Which brings me to my other point, which is that people are absolutely terrible at intuitively understanding odds without serious training in it, way back when my dad was in college he wrote a fairly straightforward version of Milles Bourne, which is a French card game about taking a road trip, and people accused *it* of cheating, so he went back in and double checked the code, and no, it followed the same rules as players. What he figured out was happening was that people remembered the computer's wins better than their own and were forming a poor internal picture of the statistics because of it. This is my main theory as to why people think XCOM is unfair, particularly since it fundamentally does not match the experience I have playing the game, and no offense but given that I passed Quantum Mechanics II, I am better trained to think about statistics than most people.
#Dad's Milles Bourne game *did* shuffle badly tho#Its shuffling algorithm was imperfect and had a slight bias towards cards remaining in their original position (an extra 1/(n+1) chance)#But the game was unaware of that and it did not affect the choices the computer was making with its hand#We figured that part out four decades later tho talking it through over dinner#This post brought to you by me taking the time to do some calculations about it
60 notes
·
View notes
Text
how did you find out about introdemo? sometimes i see spikes in views&downloads, so i'm curious!
ive also added this question to the survey (here's a link to the survey if you haven't taken it yet!)
#if twitter...i guess im doing a good job at self-promo'ing despite me not self-promo'ing anymore lol#when i look up the stats on itch it tells me it's itch google and youtube and yandex so#im assuming ppl find out through itch (thank you itch algorithm)#and people also find out about it through recommendations (that or it's just bot crawlers)#point is ill look into posting more on whichever site gets the most votes#prob be slightly bias tho since this IS tumblr so maybe the top two sites#unless it's through word of mouth then ill keep doing what im doing but ill do more of what im doing (which is nothing) (IM JUST JOKING) (?#im rambling in the tags now
5 notes
·
View notes
Text
The "P" Stands for Pre-trained
I know I've said this before, but since we're going to be hearing increasingly more about Elon Musk and his "Anti-Woke" "A.I." "Truth GPT" in the coming days and weeks, let's go ahead and get some things out on the table:
All technology is political. All created artifacts are rife with values.
I keep trying to tell you that the political right understands this when it suits them— when they can weaponize it; and they're very VERY good at weaponizing it— but people seem to keep not getting it. So let me say it again, in a somewhat different way:
There is no ground of pure objectivity. There is no god's-eye view.
There is no purely objective thing. Pretending there is only serves to create the conditions in which the worst people can play "gotcha" anytime they can clearly point to their enemies doing what we are literally all doing ALL THE TIME: Creating meaning and knowledge out of what we value, together.
Read the rest of The "P" Stands for Pre-trained at A Future Worth Thinking About
#Actor-network theory#ai#algorithmic bias#algorithmic systems#algorithms#artificial intelligence#bias#generative pre-trained transformer#gpt#intersubjectivity#Invisible Architecture of Bias#Invisible Architectures of Bias#large language models#philosophy of technology#prejudice#science technology and society#situated knowledge#social construction of technology#social shaping of technology#values
54 notes
·
View notes
Text

honest to God I think that it's not even that funny and you guys need to chill
#this place is interesting.#watch me work on art this week for literal hours. and get like two notes.#this place does not have an algorithm but it does have a bias.#luci loathes
2 notes
·
View notes
Last Seen Blogs

dr-rabbit-3
🕹️ggy🕹️

royalhesse
Archduchess Maud

mlc1957
My stuff - dark zone

criminaldelusions
dylan

mikumana
lulu