#Diverse Art Form
Text
An Introduction to Digital Art: A Guide for Beginners
Digital art has become an increasingly popular form of expression in recent years, thanks to the advancements in technology and the widespread availability of digital tools. From photorealistic paintings to abstract designs, digital art offers endless possibilities for creativity. Whether you are a complete beginner or just looking to expand your artistic skills, this guide provides a…

View On WordPress
#Art Education#Artistic Development#Artistic Expression#Beginner Guide#Computer Graphics#Design#Digital Art#Digital Creation#Diverse Art Form#Illustration#Inspiration#Introduction#Learning Resources#Painting#technology#Tools
6 notes
·
View notes
Text
one thing i noticed (form personal experience and by observing other artists) is that the longer you draw and create, the more boring it gets to simply replicate references, especially when it comes to characers' fashion choices.
with bnha, i keep mine pretty simple and basic because teens ARE very trend-loyal, but mainly im just lazy lol, but when i AM motivated, i love to think about characters' personal style, what could influence them, but also more trivial things such as budget into account, which is why i love to draw Deku in basic tees or clothes provided by his school (while bakugo gets to wear ed hardy and shoto wears arcteryx). i also love to limit the items like its just more realistic to me when someone as ordinary as deku wears the same 5 crewnecks all the time
which brings me to my actual point, namely that the more frequently you draw, the more you learn to do research andto combine your findings into sth new rather than staying faithful to one reference, and i think that's what makes good art so good, being able to draw inspiratioin from all kinds of niches and creating something that feels very authentic and suspends the spectator's disbelief. sometimes i see art and i know exactly which fashion editorial or which kpop idol was referenced, and I'm not insinuating these are bad things i do that too (less frequently now but i sure did!), my point is it's kind of nice to see how ALL artist start out with rather derivative art but eventually move on to create more authentic art that is less about drawing beautiful and perfect people and more about trying to individualize them and that ALSO means giving them weird clothes, scars, asymmetric eyes, a receding hairline etc. like drawing the same beautiful character 200 times gets so boring and it's just more fun to try and make them a bit more human
#i do have a lot of fashion headcanons but i rarely actually draw like that im so lazy#and again im also still stikcing to references and sometimes pretty closely#but this is an observation that i like to think about#as i said i just love artists that draw from a big and diverse source of references and inspirations#and the same applies to other forms of art as well ofc#just because you enjoy one genre and want to write in that genre doesnt mean you should limit your knowledge and inspiration to that genre#its pretty detrimental like you have to read ALL kinds of things#otherwise it's hard NOT to create a derivative work#and you see that with a lot of mangas#like you can kinda tell which battle shonen mangkas are only into other battle shonen and which ones are well read overall#SORRY#or when people who only read fics write their first original story and its an apposition of tropes#my point is its important to dabble in all kinds of niches#dont aim for perfect skills in one niche i think its more fun and beneficial to give everything a try
141 notes
·
View notes
Text

Goddess(^∀^●)
#ever after high#c.a cupid#somewhat based on a couple physical descriptions of Aphrodite i read#basically just the “practically naked and covered in jewelry” parts because of course my gay magpie ass focused on only that#i have been thinking recently “what does cupid looks like at home?”#in canon she seems to stay in whatever form she had been wearing last#but like what does she wear? what does her family wear? how ancient greek is it? do they wear anything at all?#diversity win! the gods are all queer nudists. cupid brings blondie to meet her family and the girl legit dies from a heart attack#im getting off track.#anyway this also begs the question: does cupid have a true form? she normally just stays in her current one until she gets a new form#but whats the original form?#bro i literally just wanted to draw her hot but now im losing my mind#my art
42 notes
·
View notes
Text
not to be aggressively southern on main but ppl who think that singing with a twang and saying yeehaw to whatever beat they threw together automatically makes it a country song or even a country fusion………… this is simply not the case
#also making fun of country music is just not it man#like yes absolutely most mainstream stadium country artists are embarrassing bootlickers pandering to the least common denominator#but the genre as a whole has a very rich and diverse history and the way ppl throw it under the bus is the exact way they throw#all southern folks under the bus for the fact that they think we’re all backwards and bigoted#and I’m just. I know I’m not articulating this well but like#country music is an art form as much as any other genre and throwing on a cowboy hat and butchering an accent you’ve never heard irl#is just hollow and comes across so strongly as one big joke where the punchline is ‘some people sing like this unironically!!#and those idiots actually like it!!’#and I’m not even much of a country fan but it’s so clearly malicious towards southern and rural cultures that it’s just#come on. be better than this. be better than them.#personal
18 notes
·
View notes
Text
seeing a bunch of white twitter blue check literatis bitch about how a litmag tweeting not to submit to them if you don’t support palestine is bringing around the death of all art and literature is like…oh we are not escaping liberalism ever are we
#and trying to defend it by a) refusing to name the thing in which the litmag is support because they know they’ll catch a lot more shit if#they do that and b) saying everyone submitting is too busy with life and children to READ THE NEWS??? to form an opinion about an ongoing#genocide is. tone deaf at the BEST. but i don’t feel like being generous sooo#<- and all of this is of course ignoring the fact that the litmag had a genocidal story submitted to them which sparked the original tweet.#so like. let’s not pretend this is about homogenizing the litmag space and suffocating the culture of diverse thought#if there’s anything killing art in the litmag space it’s universities and companies like amazon who have vested interest in milquetoast#bullshit coming from middle class white mouths about fucking english professors cheating on their wives#but sure let’s pretend it’s being pro-palestinian that’s killing art#give me a fucking break#if you feel the rage seeping out of this post…yes. i’m angry all the time
4 notes
·
View notes
Text

My usual methods did not agree with me today so I threw in a little creature for flair POW 💥 also I forgot to make a blue daily this week so instead we've got a reddish brown because the most important thing is to keep in order of colour. so my folder looks nice
#bael#demon#monsters#monster art#artists on tumblr#dailybeast 21#did you know bael's form has sometimes been described as made of “diverse shapes”?#i did not wanna draw that today
5 notes
·
View notes
Text
Enjoying Different Types and Styles of Art
This is the third post in a series about learning about other styles of art and how to see and enjoy them. Everyone is not the same, so it is natural that there should be so many styles of art available to enjoy. Maybe you don’t like abstract but love pointillism. Maybe impressionism speaks to you. It is wonderful that we can find what we enjoy in various types and styles of art. Our…

View On WordPress
#Art#art appreciation#art classes#art exhibitions#art forms#art gallery#art genres#art movements#art museums#art workshops#artistic diversity#artistic exploration#artistic expression#artistic journey#creativity#enjoy#explore#styles of art#types of art#visual arts
4 notes
·
View notes
Text
finally watched red white & royal blue and it’s a prime (no pun) example of how something can be both gay and homophobic at the same time. made me wish u could rate sth zero stars on letterboxd.
#we need john waters to come back and remind us all what queer cinema looks like#i mean i hated the book so idk what i expected#also it looked so… cheap? so many amazon originals look cheap? what’s with that?#people saying that it’s just a silly rom com can fuck off too like if the author chooses to set their book in that political context then i#think it’s 100% fair game to point out the romanticisation of the british monarchy AND the completely deranged depiction of the democrats as#such a diverse flag-waving kumbaya-singing group#the way that all the female characters exist to ship the two gay men soooo hard is also. embarrassing.#it’s fanfiction! that’s literally what it is!#and that may be fine in an alternate universe where cinema as an art form wasn’t dying a slow painful death u know#i haven’t been this angry about a film since the whale and even the whale was better than this#;txt
5 notes
·
View notes
Text
i know twitter going down in flames is hilarious and i want to point at the muskrat and laugh but guys i'm so fucking sad i'm so sad. the loss to modern society is going to be unprecedented
#we're losing so much#the most diverse set of news sources humanity has ever seen#the communities that would not have formed elsewhere#the art#the communication#we're gonna be okay but we are losing a whole generation of knowledge#twitterpocalypse
5 notes
·
View notes
Note
how about 7 and 14 for the weirdly specific artist asks?
[ask game]
Thank you for the ask!! <3
7. A medium of art you don't work in but appreciate
Oh god so so many. Pottery, miniature sculping (specially miniature environments <3), woodworking, photography, sewing & fashion design, everything involved in cosplay and fursuit making, embroidery, lace making, those doll makeovers (idk what it's called properly), graffiti and street art, smithing, silver/gold smithing, glassblowing, whatever it's called to make mosaiks (stained glass or otherwise), fricking sculpting with chocolate..... the list goes on and on and on
14. Any favorite motifs
Hmmm good question.... idk if i have a fave per se but i do love elemental and celestial motifs
#i am so in awe of any and all forms of art#humans can do so many creative and diverse things its amazing#and there are SO many forms of art if its music or performance or culinary or science or so many other things there is an art to all of it#and i think thats amazing#sorry for getting so rambly tho x'D ty again for the ask! <3#ask game/ my answers
3 notes
·
View notes
Text
Arts and Cafts Classes in Gundagai
Unleash your creativity with our Arts and Crafts Classes in Australia. From painting to pottery, Kiya Learning courses celebrate artistic expression in all its forms. Discover new techniques, explore diverse mediums.

#Unleash your creativity with our Arts and Crafts Classes in Australia. From painting to pottery#Kiya Learning courses celebrate artistic expression in all its forms. Discover new techniques#explore diverse mediums.
0 notes
Text
Zero-shot adaptive prompting of large language models
New Post has been published on https://thedigitalinsider.com/zero-shot-adaptive-prompting-of-large-language-models/
Zero-shot adaptive prompting of large language models
Posted by Xingchen Wan, Student Researcher, and Ruoxi Sun, Research Scientist, Cloud AI Team
Recent advances in large language models (LLMs) are very promising as reflected in their capability for general problem-solving in few-shot and zero-shot setups, even without explicit training on these tasks. This is impressive because in the few-shot setup, LLMs are presented with only a few question-answer demonstrations prior to being given a test question. Even more challenging is the zero-shot setup, where the LLM is directly prompted with the test question only.
Even though the few-shot setup has dramatically reduced the amount of data required to adapt a model for a specific use-case, there are still cases where generating sample prompts can be challenging. For example, handcrafting even a small number of demos for the broad range of tasks covered by general-purpose models can be difficult or, for unseen tasks, impossible. For example, for tasks like summarization of long articles or those that require domain knowledge (e.g., medical question answering), it can be challenging to generate sample answers. In such situations, models with high zero-shot performance are useful since no manual prompt generation is required. However, zero-shot performance is typically weaker as the LLM is not presented with guidance and thus is prone to spurious output.
In “Better Zero-shot Reasoning with Self-Adaptive Prompting”, published at ACL 2023, we propose Consistency-Based Self-Adaptive Prompting (COSP) to address this dilemma. COSP is a zero-shot automatic prompting method for reasoning problems that carefully selects and constructs pseudo-demonstrations for LLMs using only unlabeled samples (that are typically easy to obtain) and the models’ own predictions. With COSP, we largely close the performance gap between zero-shot and few-shot while retaining the desirable generality of zero-shot prompting. We follow this with “Universal Self-Adaptive Prompting“ (USP), accepted at EMNLP 2023, in which we extend the idea to a wide range of general natural language understanding (NLU) and natural language generation (NLG) tasks and demonstrate its effectiveness.
Prompting LLMs with their own outputs
Knowing that LLMs benefit from demonstrations and have at least some zero-shot abilities, we wondered whether the model’s zero-shot outputs could serve as demonstrations for the model to prompt itself. The challenge is that zero-shot solutions are imperfect, and we risk giving LLMs poor quality demonstrations, which could be worse than no demonstrations at all. Indeed, the figure below shows that adding a correct demonstration to a question can lead to a correct solution of the test question (Demo1 with question), whereas adding an incorrect demonstration (Demo 2 + questions, Demo 3 with questions) leads to incorrect answers. Therefore, we need to select reliable self-generated demonstrations.
Example inputs & outputs for reasoning tasks, which illustrates the need for carefully designed selection procedure for in-context demonstrations (MultiArith dataset & PaLM-62B model): (1) zero-shot chain-of-thought with no demo: correct logic but wrong answer; (2) correct demo (Demo1) and correct answer; (3) correct but repetitive demo (Demo2) leads to repetitive outputs; (4) erroneous demo (Demo3) leads to a wrong answer; but (5) combining Demo3 and Demo1 again leads to a correct answer.
COSP leverages a key observation of LLMs: that confident and consistent predictions are more likely correct. This observation, of course, depends on how good the uncertainty estimate of the LLM is. Luckily, in large models, previous works suggest that the uncertainty estimates are robust. Since measuring confidence requires only model predictions, not labels, we propose to use this as a zero-shot proxy of correctness. The high-confidence outputs and their inputs are then used as pseudo-demonstrations.
With this as our starting premise, we estimate the model’s confidence in its output based on its self-consistency and use this measure to select robust self-generated demonstrations. We ask LLMs the same question multiple times with zero-shot chain-of-thought (CoT) prompting. To guide the model to generate a range of possible rationales and final answers, we include randomness controlled by a “temperature” hyperparameter. In an extreme case, if the model is 100% certain, it should output identical final answers each time. We then compute the entropy of the answers to gauge the uncertainty — the answers that have high self-consistency and for which the LLM is more certain, are likely to be correct and will be selected.
Assuming that we are presented with a collection of unlabeled questions, the COSP method is:
Input each unlabeled question into an LLM, obtaining multiple rationales and answers by sampling the model multiple times. The most frequent answers are highlighted, followed by a score that measures consistency of answers across multiple sampled outputs (higher is better). In addition to favoring more consistent answers, we also penalize repetition within a response (i.e., with repeated words or phrases) and encourage diversity of selected demonstrations. We encode the preference towards consistent, un-repetitive and diverse outputs in the form of a scoring function that consists of a weighted sum of the three scores for selection of the self-generated pseudo-demonstrations.
We concatenate the pseudo-demonstrations into test questions, feed them to the LLM, and obtain a final predicted answer.
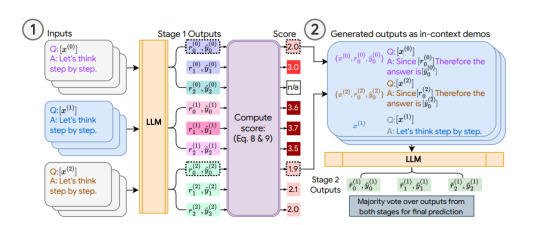
Illustration of COSP: In Stage 1 (left), we run zero-shot CoT multiple times to generate a pool of demonstrations (each consisting of the question, generated rationale and prediction) and assign a score. In Stage 2 (right), we augment the current test question with pseudo-demos (blue boxes) and query the LLM again. A majority vote over outputs from both stages forms the final prediction.
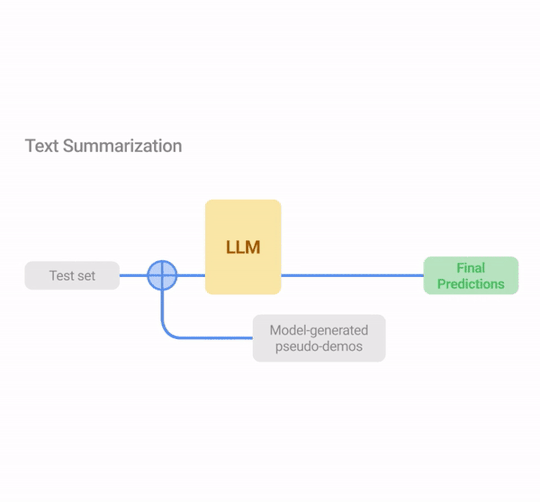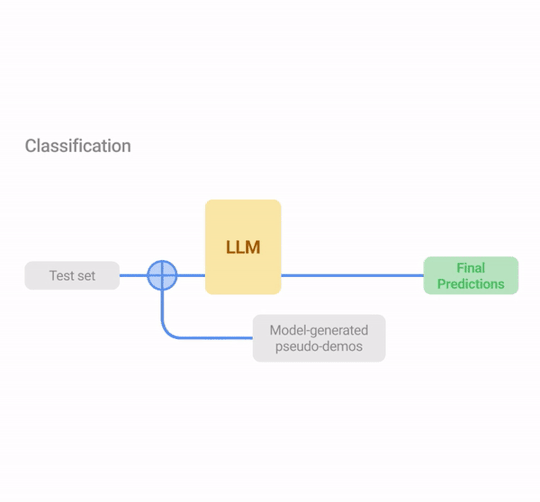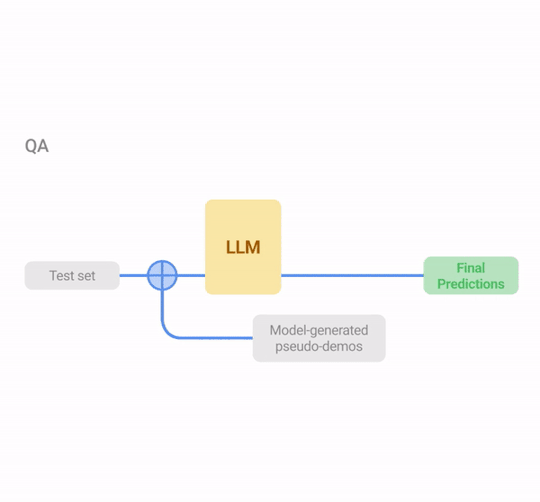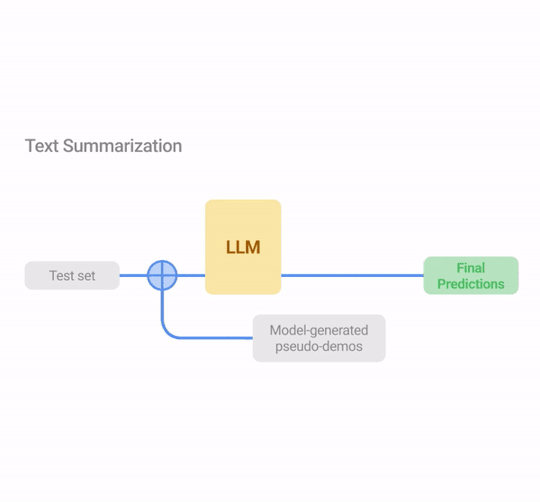
COSP focuses on question-answering tasks with CoT prompting for which it is easy to measure self-consistency since the questions have unique correct answers. But this can be difficult for other tasks, such as open-ended question-answering or generative tasks that don’t have unique answers (e.g., text summarization). To address this limitation, we introduce USP in which we generalize our approach to other general NLP tasks:
Classification (CLS): Problems where we can compute the probability of each class using the neural network output logits of each class. In this way, we can measure the uncertainty without multiple sampling by computing the entropy of the logit distribution.
Short-form generation (SFG): Problems like question answering where we can use the same procedure mentioned above for COSP, but, if necessary, without the rationale-generating step.
Long-form generation (LFG): Problems like summarization and translation, where the questions are often open-ended and the outputs are unlikely to be identical, even if the LLM is certain. In this case, we use an overlap metric in which we compute the average of the pairwise ROUGE score between the different outputs to the same query.

Illustration of USP in exemplary tasks (classification, QA and text summarization). Similar to COSP, the LLM first generates predictions on an unlabeled dataset whose outputs are scored with logit entropy, consistency or alignment, depending on the task type, and pseudo-demonstrations are selected from these input-output pairs. In Stage 2, the test instances are augmented with pseudo-demos for prediction.
We compute the relevant confidence scores depending on the type of task on the aforementioned set of unlabeled test samples. After scoring, similar to COSP, we pick the confident, diverse and less repetitive answers to form a model-generated pseudo-demonstration set. We finally query the LLM again in a few-shot format with these pseudo-demonstrations to obtain the final predictions on the entire test set.
Key Results
For COSP, we focus on a set of six arithmetic and commonsense reasoning problems, and we compare against 0-shot-CoT (i.e., “Let’s think step by step“ only). We use self-consistency in all baselines so that they use roughly the same amount of computational resources as COSP. Compared across three LLMs, we see that zero-shot COSP significantly outperforms the standard zero-shot baseline.
USP improves significantly on 0-shot performance. “CLS” is an average of 15 classification tasks; “SFG” is the average of five short-form generation tasks; “LFG” is the average of two summarization tasks. “SFG (BBH)” is an average of all BIG-Bench Hard tasks, where each question is in SFG format.
For USP, we expand our analysis to a much wider range of tasks, including more than 25 classifications, short-form generation, and long-form generation tasks. Using the state-of-the-art PaLM 2 models, we also test against the BIG-Bench Hard suite of tasks where LLMs have previously underperformed compared to people. We show that in all cases, USP again outperforms the baselines and is competitive to prompting with golden examples.
Accuracy on BIG-Bench Hard tasks with PaLM 2-M (each line represents a task of the suite). The gain/loss of USP (green stars) over standard 0-shot (green triangles) is shown in percentages. “Human” refers to average human performance; “AutoCoT” and “Random demo” are baselines we compared against in the paper; and “3-shot” is the few-shot performance for three handcrafted demos in CoT format.
We also analyze the working mechanism of USP by validating the key observation above on the relation between confidence and correctness, and we found that in an overwhelming majority of the cases, USP picks confident predictions that are more likely better in all task types considered, as shown in the figure below.
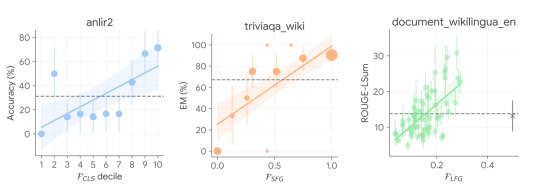
USP picks confident predictions that are more likely better. Ground-truth performance metrics against USP confidence scores in selected tasks in various task types (blue: CLS, orange: SFG, green: LFG) with PaLM-540B.
Conclusion
Zero-shot inference is a highly sought-after capability of modern LLMs, yet the success in which poses unique challenges. We propose COSP and USP, a family of versatile, zero-shot automatic prompting techniques applicable to a wide range of tasks. We show large improvement over the state-of-the-art baselines over numerous task and model combinations.
Acknowledgements
This work was conducted by Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan Ö. Arık, and Tomas Pfister. We would like to thank Jinsung Yoon Xuezhi Wang for providing helpful reviews, and other colleagues at Google Cloud AI Research for their discussion and feedback.
#2023#ai#amp#Analysis#approach#Art#Articles#Blue#challenge#Cloud#computing#course#data#diversity#easy#form#Forms#gap#generative#Giving#Google#google cloud#green#how#human#illustration#indeed#inference#it#labels
0 notes
Text

Alex Coal Sisswap
"Unveiling Creativity: Exploring the World of Alex Coal's Sisswap."
#Artistic Exploration#Alex Coal's Sisswap Creations#Innovative Expression#Creative Visionary#Unique Artistry#Boundless Imagination#Diverse Art Forms#Sisswap Art Showcase#Multifaceted Creations#Expressive Craftsmanship#pretty girl#beautiful women#pretty woman
1 note
·
View note
Text
@baytal.fann
"Did you know that the art of stained glass originated in the Muslim world?
In the eighth century, skilled glassmakers in Egypt made a groundbreaking discovery—the technique of painting glass with metallic stain. This innovation led to the creation of transparent stains, colored with copper (producing red or brown) and silver (resulting in yellow), which became distinctive features of early Islamic glassware in Egypt and the Near East.
Fast forward to the 13th century, when decorators in the Syrian region achieved a significant milestone by applying enamels on glass on a large scale. Over the following two centuries, Syrian and Egyptian craftsmen crafted a diverse array of glass objects in various shapes and sizes, adorned with brilliant polychrome ornamentation. These items served practical purposes such as hanging lamps for illuminating mosque interiors, as well as functional vessels and other useful items, along with awe-inspiring display pieces.
In the later Middle Ages, European admiration for Islamic luxury glasses soared due to their exotic aesthetics and advanced technical craftsmanship. Some even believed these objects to be relics from the Holy Land. Fragments of Islamic glass, often adorned with gilding and enameling, have been discovered in archaeological excavations across Europe, while intact pieces grace cathedral treasuries. Notably, excavations have unveiled evidence of the exportation of Islamic glass vessels to China, highlighting the widespread influence and global trade connections of this innovative art form."
4K notes
·
View notes
Text
i think it's sad how narrow of a view of drag people end up getting when they only see it through ru paul and other hyper commercialized avenues. drag is not only for conventionally attractive, thin, toned, or muscular people. it's not just for people assigned male at birth. it's not just for gay men. drag does not lean heavily white. drag does not have to be feminine.
drag is everything but that. drag is full of fat and chubby performers, performers of color, disabled performers, drag kings, male impersonators, men performing as men, women performing as women, people who perform as multiple genders, people who perform as no gender, people who perform as nonhumans, trans, men women and nonbinary people, lesbians, bisexuals, and whoever else you can think of.
drag is diverse as hell and it's best served hot, so checking out your local drag scenes is crucial to enjoying a taste of what it really has to offer as an art form.
#drag#drag performer#drag queen#drag king#lgbtqia#lgbtq#lgbt#lgbtqa#gay#transgender#trans#lesbian#bisexual#pansexual#bigender#multigender#genderfluid#nonbinary#genderqueer#enby#transfem#transfemme#transfeminine#transmasc#transmasculine#ftm#mtf#trans man#our writing
6K notes
·
View notes
Text
"Pieces Of Paper We Hold" (HuskerDust) is live on AO3!
hey hazbin fandom!! you might want to check out my complex and multi-layered fic for these two losers!! it explores the nuances of morality, sin, and redemption, as well as cool kink and some light BDSM between the ultimate otp.
read "Pieces Of Paper We Hold", a Hazbin Hotel post-season 1 HuskerDust fanfiction here: https://archiveofourown.org/works/53795893/chapters/136163467.
before you proceed, find all trigger warnings, as well as the rep, below the cut.
featured below is commissioned art by @mothmanadjacent (MothMommyy on Twitter)!

"PIECES OF PAPER WE HOLD" WILL BE AVAILABLE AS A LIMITED PAPERBACK SOON!
THE BOOK, AND SOME MERCH, WILL BE SOLD IN A CHARITY SALE FOR A LIMITED TIME
100% of the profit will go to a non-profit that helps SA survivors and victims of human trafficking. The sale will be handled by myself, and I will be keeping and providing receipts of ALL donations going to the right place.
You can find all the information about the charity sale here:


If you're interested, please fill out the interest form HERE.
TRIGGER WARNING LIST
Addiction
Alcoholism, alcohol abuse, drinking
Anxiety attacks
BDSM**
Emotional abuse*
Explicit sexual content**
Intimate partner violence*
Gambling
Gaslighting*
Gun violence
Loss of a child
Non-con sex as a punishment*
Physical violence
Post-traumatic stress disorder
Survivor's guilt
Swearing
Withdrawal from drugs
* = Challenged, not between the MCs (Angel and Husk)
** = Explicit scenes are cis-MLM, and they are clearly signalled with dividers so that readers who might be uncomfortable reading them may skip them
REPRESENTATION & DIVERSITY
Ethnicities and race
Black character with vitiligo
Body diversity
Fat character
Developmental disabilities
ADHD - Attention Deficit and Hyperactivity Disorder
Cri du chat syndrome
Dyslexia
Intellectual disability
Gender diversity
Non-binary characters
Sexual diversity
BDSM and kink positivity
Bisexuality
Bondage/shibari
Gay male MC
Pansexual male MC
Sex work positivity
#gee's archive#hazbin hotel#angel dust#huskerdust#hazbin hotel husk#angel dust x husk#fanfic#fanfiction#my writing#not my art
1K notes
·
View notes
Last Seen Blogs

wedding-photographer-josephine
Josephine Gray Photography

internerdionality
Filthy and Wholesome

jeremie-lortic
Les photos de Jeremie Lortic

doberart
Dobermutt

halsiin
is there a word for “bad miracle”?